Scalable Machine Learning - or what to do with all that Big Data infrastructure
|
|
|
- Duane Summers
- 10 years ago
- Views:
Transcription
1 - or what to do with all that Big Data infrastructure TU Berlin blog.mikiobraun.de Strata+Hadoop World London,

2 Complex Data Analysis at Scale Click-through prediction Personalized Spam Detection Image Classification Recommendation... 2

3 Click Through Prediction 3

4 Personalized Spam Detection 4

5 Supervised Learning in a Nutshell 5
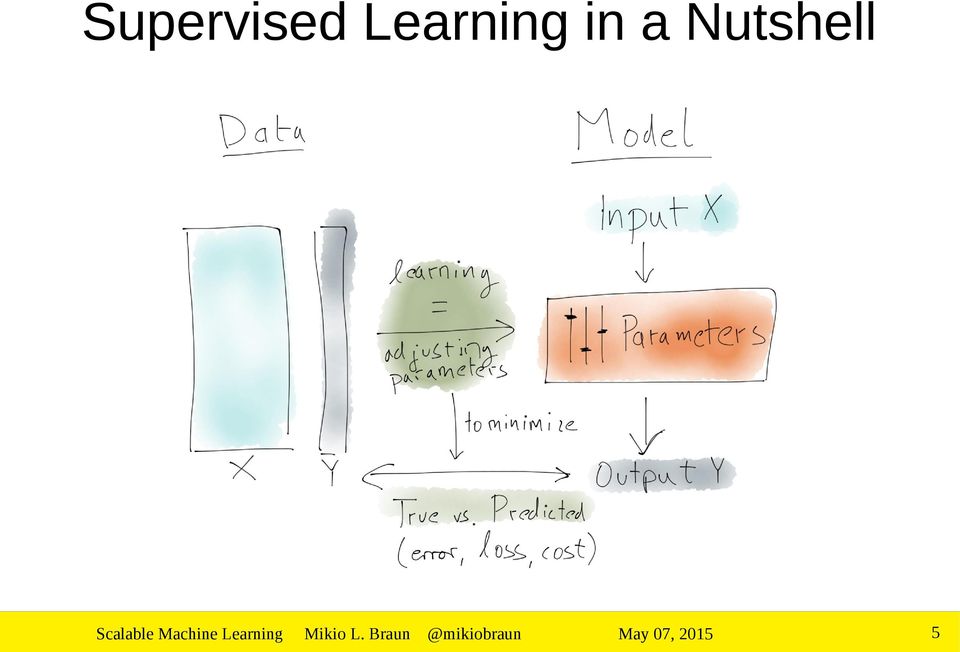
6 Large Scale Learning 100 millions of examples Millions of (potential) features Linear models: Learn one weight per feature Deep learning: Complex models with several stages of processing 6

7 ML Pipeline 7

8 Easily parallelized Data preparation, exactraction, normalization Parallel runs of ML pipelines for evaluation Mass application of data sets 8

9 What about the training step? Optimization problems Sometimes closed-form solutions ( matrix computations) Most often not, or it is slow 9
 Most often not, or")
10 Gradient Descent Very generic way to optimize functions Update parameters along line of steepest descent of cost function e.g. logistic regression 10

11 Gradient Descent in Parallel 11

12 Stochastic Gradient Descent #1 workhorse for large scale learning Gradient Descent = Error on whole data set Stochastic Gradient Descent = consider one point at a time 1. predict on one point 2. compute gradient for that one point 3. update parameters 12

13 Why can we do this? Learning is about prediction performance on future data Lots of freedom to find alternative algorithms 13

14 Ad Click Prediction at Google SIGKDD '13 Variant of SGD With tons of hacks: 16-bit fixed point, sharing memory, etc. No parallelization! 14

15 SGD is hard to parallelize 15

16 Parameter Servers Dean et al. Large Scale Distributed Deep Networks, NIPS 2012 Li et al. Communication Efficient Distributed Machine Learning with the Parameter Server, NIPS

17 Parallelized vs. Distributed Search Faster optimization by parallel searches Randomized updates lead to overall better performance 17

18 Approximation is key Goal is good predictions on future data You can solve an easier problem instead not just for the learning algorithms! 18

19 Approximating Features with Hashing Millions of features, but often very sparse Use random projections to compress feature space Attenberg et al. Collaborative -Spam Filtering with the Hashing-Trick CEAS

20 Counting: Count Min-Sketch update: hash value, increase counters query: hash value, take minimum Cormode, Muthukrishnan, "An Improved Data Stream Summary: The Count-Min Sketch and its Applications". J. Algorithms

21 Clustering with Count Min-Sketches Aggarwal et al. A Framework for Clustering Massive-Domain Data Streams, ICDE
22 Scalable ML is... NOT: learning algorithms + parallelization INSTEAD: faster learning algorithms approximative optimization feature hashing approximative counting asynchronous distributed search AND parallelization 24
23 So where are we with Spark and friends Original MR paper: Focus on simple stuff Distributed Collections & Dataflow the right abstraction? Distributed Matrices? Who tells us what the right approximation is? New mode of asynchronous, distributed, approximative computation? OR go with something which is slower but easier to parallelize? 25
24 Summary Large scale data sets: billions of examples, millions of features A lot of the ML pipeline (feature extraction, data preparation, evaluation) is parallelizable and should be! Large scale learning algorithms are harder to parallelize Approximation, asynchronous distributed computing, etc. 26
25 Thank you! 27
Big Data at Spotify. Anders Arpteg, Ph D Analytics Machine Learning, Spotify
 Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
Big-data Analytics: Challenges and Opportunities
 Big-data Analytics: Challenges and Opportunities Chih-Jen Lin Department of Computer Science National Taiwan University Talk at 台 灣 資 料 科 學 愛 好 者 年 會, August 30, 2014 Chih-Jen Lin (National Taiwan Univ.)
Big-data Analytics: Challenges and Opportunities Chih-Jen Lin Department of Computer Science National Taiwan University Talk at 台 灣 資 料 科 學 愛 好 者 年 會, August 30, 2014 Chih-Jen Lin (National Taiwan Univ.)
Parallel Data Mining. Team 2 Flash Coders Team Research Investigation Presentation 2. Foundations of Parallel Computing Oct 2014
 Parallel Data Mining Team 2 Flash Coders Team Research Investigation Presentation 2 Foundations of Parallel Computing Oct 2014 Agenda Overview of topic Analysis of research papers Software design Overview
Parallel Data Mining Team 2 Flash Coders Team Research Investigation Presentation 2 Foundations of Parallel Computing Oct 2014 Agenda Overview of topic Analysis of research papers Software design Overview
L3: Statistical Modeling with Hadoop
 L3: Statistical Modeling with Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 10, 2014 Today we are going to learn...
L3: Statistical Modeling with Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 10, 2014 Today we are going to learn...
Parallel & Distributed Optimization. Based on Mark Schmidt s slides
 Parallel & Distributed Optimization Based on Mark Schmidt s slides Motivation behind using parallel & Distributed optimization Performance Computational throughput have increased exponentially in linear
Parallel & Distributed Optimization Based on Mark Schmidt s slides Motivation behind using parallel & Distributed optimization Performance Computational throughput have increased exponentially in linear
Mammoth Scale Machine Learning!
 Mammoth Scale Machine Learning! Speaker: Robin Anil, Apache Mahout PMC Member! OSCON"10! Portland, OR! July 2010! Quick Show of Hands!# Are you fascinated about ML?!# Have you used ML?!# Do you have Gigabytes
Mammoth Scale Machine Learning! Speaker: Robin Anil, Apache Mahout PMC Member! OSCON"10! Portland, OR! July 2010! Quick Show of Hands!# Are you fascinated about ML?!# Have you used ML?!# Do you have Gigabytes
The Impact of Big Data on Classic Machine Learning Algorithms. Thomas Jensen, Senior Business Analyst @ Expedia
 The Impact of Big Data on Classic Machine Learning Algorithms Thomas Jensen, Senior Business Analyst @ Expedia Who am I? Senior Business Analyst @ Expedia Working within the competitive intelligence unit
The Impact of Big Data on Classic Machine Learning Algorithms Thomas Jensen, Senior Business Analyst @ Expedia Who am I? Senior Business Analyst @ Expedia Working within the competitive intelligence unit
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
CS 688 Pattern Recognition Lecture 4. Linear Models for Classification
 CS 688 Pattern Recognition Lecture 4 Linear Models for Classification Probabilistic generative models Probabilistic discriminative models 1 Generative Approach ( x ) p C k p( C k ) Ck p ( ) ( x Ck ) p(
CS 688 Pattern Recognition Lecture 4 Linear Models for Classification Probabilistic generative models Probabilistic discriminative models 1 Generative Approach ( x ) p C k p( C k ) Ck p ( ) ( x Ck ) p(
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Bayesian Machine Learning (ML): Modeling And Inference in Big Data. Zhuhua Cai Google, Rice University [email protected]
: Modeling And Inference in Big Data. Zhuhua Cai Google, Rice University caizhua@gmail.com") Bayesian Machine Learning (ML): Modeling And Inference in Big Data Zhuhua Cai Google Rice University [email protected] 1 Syllabus Bayesian ML Concepts (Today) Bayesian ML on MapReduce (Next morning) Bayesian
Bayesian Machine Learning (ML): Modeling And Inference in Big Data Zhuhua Cai Google Rice University [email protected] 1 Syllabus Bayesian ML Concepts (Today) Bayesian ML on MapReduce (Next morning) Bayesian
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Big Data Optimization: Randomized lock-free methods for minimizing partially separable convex functions
 Big Data Optimization: Randomized lock-free methods for minimizing partially separable convex functions Peter Richtárik School of Mathematics The University of Edinburgh Joint work with Martin Takáč (Edinburgh)
Big Data Optimization: Randomized lock-free methods for minimizing partially separable convex functions Peter Richtárik School of Mathematics The University of Edinburgh Joint work with Martin Takáč (Edinburgh)
Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect
 Matteo Migliavacca (mm53@kent) School of Computing Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect Simple past - Traditional
Matteo Migliavacca (mm53@kent) School of Computing Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect Simple past - Traditional
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 36 Outline
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 36 Outline
Monitis Project Proposals for AUA. September 2014, Yerevan, Armenia
 Monitis Project Proposals for AUA September 2014, Yerevan, Armenia Distributed Log Collecting and Analysing Platform Project Specifications Category: Big Data and NoSQL Software Requirements: Apache Hadoop
Monitis Project Proposals for AUA September 2014, Yerevan, Armenia Distributed Log Collecting and Analysing Platform Project Specifications Category: Big Data and NoSQL Software Requirements: Apache Hadoop
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Big Data by the numbers
 COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Towards a Thriving Data Economy: Open Data, Big Data, and Data Ecosystems
 Towards a Thriving Data Economy: Open Data, Big Data, and Data Ecosystems Volker Markl [email protected] dima.tu-berlin.de dfki.de/web/research/iam/ bbdc.berlin Based on my 2014 Vision Paper On
Towards a Thriving Data Economy: Open Data, Big Data, and Data Ecosystems Volker Markl [email protected] dima.tu-berlin.de dfki.de/web/research/iam/ bbdc.berlin Based on my 2014 Vision Paper On
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Jubatus: An Open Source Platform for Distributed Online Machine Learning
 Jubatus: An Open Source Platform for Distributed Online Machine Learning Shohei Hido Seiya Tokui Preferred Infrastructure Inc. Tokyo, Japan {hido, tokui}@preferred.jp Satoshi Oda NTT Software Innovation
Jubatus: An Open Source Platform for Distributed Online Machine Learning Shohei Hido Seiya Tokui Preferred Infrastructure Inc. Tokyo, Japan {hido, tokui}@preferred.jp Satoshi Oda NTT Software Innovation
Weekly Sales Forecasting
 Weekly Sales Forecasting! San Diego Data Science and R Users Group June 2014 Kevin Davenport! http://kldavenport.com [email protected] @KevinLDavenport Thank you to our sponsors: The competition
Weekly Sales Forecasting! San Diego Data Science and R Users Group June 2014 Kevin Davenport! http://kldavenport.com [email protected] @KevinLDavenport Thank you to our sponsors: The competition
Journée Thématique Big Data 13/03/2015
 Journée Thématique Big Data 13/03/2015 1 Agenda About Flaminem What Do We Want To Predict? What Is The Machine Learning Theory Behind It? How Does It Work In Practice? What Is Happening When Data Gets
Journée Thématique Big Data 13/03/2015 1 Agenda About Flaminem What Do We Want To Predict? What Is The Machine Learning Theory Behind It? How Does It Work In Practice? What Is Happening When Data Gets
MapReduce/Bigtable for Distributed Optimization
 MapReduce/Bigtable for Distributed Optimization Keith B. Hall Google Inc. [email protected] Scott Gilpin Google Inc. [email protected] Gideon Mann Google Inc. [email protected] Abstract With large data
MapReduce/Bigtable for Distributed Optimization Keith B. Hall Google Inc. [email protected] Scott Gilpin Google Inc. [email protected] Gideon Mann Google Inc. [email protected] Abstract With large data
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
MADlib. An open source library for in-database analytics. Hitoshi Harada PGCon 2012, May 17th
 MADlib An open source library for in-database analytics Hitoshi Harada PGCon 2012, May 17th 1 Myself Window functions in 8.4 and 9.0 Help wcte work in 9.1 PL/v8 Other modules like twitter_fdw, tinyint
MADlib An open source library for in-database analytics Hitoshi Harada PGCon 2012, May 17th 1 Myself Window functions in 8.4 and 9.0 Help wcte work in 9.1 PL/v8 Other modules like twitter_fdw, tinyint
The Stratosphere Big Data Analytics Platform
 The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science [email protected] June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science [email protected] June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
Maximize Revenues on your Customer Loyalty Program using Predictive Analytics
 Maximize Revenues on your Customer Loyalty Program using Predictive Analytics 27 th Feb 14 Free Webinar by Before we begin... www Q & A? Your Speakers @parikh_shachi Technical Analyst @tatvic Loves js
Maximize Revenues on your Customer Loyalty Program using Predictive Analytics 27 th Feb 14 Free Webinar by Before we begin... www Q & A? Your Speakers @parikh_shachi Technical Analyst @tatvic Loves js
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R
 Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Spark: Cluster Computing with Working Sets
 Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Parallel Programming Map-Reduce. Needless to Say, We Need Machine Learning for Big Data
 Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
How To Test The Performance Of An Ass 9.4 And Sas 7.4 On A Test On A Powerpoint Powerpoint 9.2 (Powerpoint) On A Microsoft Powerpoint 8.4 (Powerprobe) (
 On A Microsoft Powerpoint 8.4 (Powerprobe) (") White Paper Revolution R Enterprise: Faster Than SAS Benchmarking Results by Thomas W. Dinsmore and Derek McCrae Norton In analytics, speed matters. How much? We asked the director of analytics from a
White Paper Revolution R Enterprise: Faster Than SAS Benchmarking Results by Thomas W. Dinsmore and Derek McCrae Norton In analytics, speed matters. How much? We asked the director of analytics from a
Machine Learning over Big Data
 Machine Learning over Big Presented by Fuhao Zou [email protected] Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Machine Learning over Big Presented by Fuhao Zou [email protected] Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Steven C.H. Hoi School of Information Systems Singapore Management University Email: [email protected]
 Steven C.H. Hoi School of Information Systems Singapore Management University Email: [email protected] Introduction http://stevenhoi.org/ Finance Recommender Systems Cyber Security Machine Learning Visual
Steven C.H. Hoi School of Information Systems Singapore Management University Email: [email protected] Introduction http://stevenhoi.org/ Finance Recommender Systems Cyber Security Machine Learning Visual
Large Scale Learning to Rank
 Large Scale Learning to Rank D. Sculley Google, Inc. [email protected] Abstract Pairwise learning to rank methods such as RankSVM give good performance, but suffer from the computational burden of optimizing
Large Scale Learning to Rank D. Sculley Google, Inc. [email protected] Abstract Pairwise learning to rank methods such as RankSVM give good performance, but suffer from the computational burden of optimizing
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Big Data Research in Berlin BBDC and Apache Flink
 Big Data Research in Berlin BBDC and Apache Flink Tilmann Rabl [email protected] dima.tu-berlin.de bbdc.berlin 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2015 Agenda About Data Management,
Big Data Research in Berlin BBDC and Apache Flink Tilmann Rabl [email protected] dima.tu-berlin.de bbdc.berlin 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2015 Agenda About Data Management,
Intelligent Heuristic Construction with Active Learning
 Intelligent Heuristic Construction with Active Learning William F. Ogilvie, Pavlos Petoumenos, Zheng Wang, Hugh Leather E H U N I V E R S I T Y T O H F G R E D I N B U Space is BIG! Hubble Ultra-Deep Field
Intelligent Heuristic Construction with Active Learning William F. Ogilvie, Pavlos Petoumenos, Zheng Wang, Hugh Leather E H U N I V E R S I T Y T O H F G R E D I N B U Space is BIG! Hubble Ultra-Deep Field
Sibyl: a system for large scale machine learning
 Sibyl: a system for large scale machine learning Tushar Chandra, Eugene Ie, Kenneth Goldman, Tomas Lloret Llinares, Jim McFadden, Fernando Pereira, Joshua Redstone, Tal Shaked, Yoram Singer Machine Learning
Sibyl: a system for large scale machine learning Tushar Chandra, Eugene Ie, Kenneth Goldman, Tomas Lloret Llinares, Jim McFadden, Fernando Pereira, Joshua Redstone, Tal Shaked, Yoram Singer Machine Learning
Algorithmic Aspects of Big Data. Nikhil Bansal (TU Eindhoven)
") Algorithmic Aspects of Big Data Nikhil Bansal (TU Eindhoven) Algorithm design Algorithm: Set of steps to solve a problem (by a computer) Studied since 1950 s. Given a problem: Find (i) best solution (ii)
Algorithmic Aspects of Big Data Nikhil Bansal (TU Eindhoven) Algorithm design Algorithm: Set of steps to solve a problem (by a computer) Studied since 1950 s. Given a problem: Find (i) best solution (ii)
Prerequisites. Course Outline
 MS-55040: Data Mining, Predictive Analytics with Microsoft Analysis Services and Excel PowerPivot Description This three-day instructor-led course will introduce the students to the concepts of data mining,
MS-55040: Data Mining, Predictive Analytics with Microsoft Analysis Services and Excel PowerPivot Description This three-day instructor-led course will introduce the students to the concepts of data mining,
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics
 E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
Massive scale analytics with Stratosphere using R
 Massive scale analytics with Stratosphere using R Jose Luis Lopez Pino [email protected] Database Systems and Information Management Technische Universität Berlin Supervised by Volker Markl Advised
Massive scale analytics with Stratosphere using R Jose Luis Lopez Pino [email protected] Database Systems and Information Management Technische Universität Berlin Supervised by Volker Markl Advised
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Going For Large Scale Going For Large Scale 1
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Going For Large Scale Going For Large Scale 1
Summary Data Structures for Massive Data
 Summary Data Structures for Massive Data Graham Cormode Department of Computer Science, University of Warwick [email protected] Abstract. Prompted by the need to compute holistic properties of increasingly
Summary Data Structures for Massive Data Graham Cormode Department of Computer Science, University of Warwick [email protected] Abstract. Prompted by the need to compute holistic properties of increasingly
The Need for Training in Big Data: Experiences and Case Studies
 The Need for Training in Big Data: Experiences and Case Studies Guy Lebanon Amazon Background and Disclaimer All opinions are mine; other perspectives are legitimate. Based on my experience as a professor
The Need for Training in Big Data: Experiences and Case Studies Guy Lebanon Amazon Background and Disclaimer All opinions are mine; other perspectives are legitimate. Based on my experience as a professor
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Enabling Multi-pipeline Data Transfer in HDFS for Big Data Applications
 Enabling Multi-pipeline Data Transfer in HDFS for Big Data Applications Liqiang (Eric) Wang, Hong Zhang University of Wyoming Hai Huang IBM T.J. Watson Research Center Background Hadoop: Apache Hadoop
Enabling Multi-pipeline Data Transfer in HDFS for Big Data Applications Liqiang (Eric) Wang, Hong Zhang University of Wyoming Hai Huang IBM T.J. Watson Research Center Background Hadoop: Apache Hadoop
Apache Mahout's new DSL for Distributed Machine Learning. Sebastian Schelter GOTO Berlin 11/06/2014
 Apache Mahout's new DSL for Distributed Machine Learning Sebastian Schelter GOO Berlin /6/24 Overview Apache Mahout: Past & Future A DSL for Machine Learning Example Under the covers Distributed computation
Apache Mahout's new DSL for Distributed Machine Learning Sebastian Schelter GOO Berlin /6/24 Overview Apache Mahout: Past & Future A DSL for Machine Learning Example Under the covers Distributed computation
An Oracle White Paper November 2010. Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics
 An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
HIGH PERFORMANCE BIG DATA ANALYTICS
 HIGH PERFORMANCE BIG DATA ANALYTICS Kunle Olukotun Electrical Engineering and Computer Science Stanford University June 2, 2014 Explosion of Data Sources Sensors DoD is swimming in sensors and drowning
HIGH PERFORMANCE BIG DATA ANALYTICS Kunle Olukotun Electrical Engineering and Computer Science Stanford University June 2, 2014 Explosion of Data Sources Sensors DoD is swimming in sensors and drowning
Steven C.H. Hoi. School of Computer Engineering Nanyang Technological University Singapore
 Steven C.H. Hoi School of Computer Engineering Nanyang Technological University Singapore Acknowledgments: Peilin Zhao, Jialei Wang, Hao Xia, Jing Lu, Rong Jin, Pengcheng Wu, Dayong Wang, etc. 2 Agenda
Steven C.H. Hoi School of Computer Engineering Nanyang Technological University Singapore Acknowledgments: Peilin Zhao, Jialei Wang, Hao Xia, Jing Lu, Rong Jin, Pengcheng Wu, Dayong Wang, etc. 2 Agenda
CAS CS 565, Data Mining
 CAS CS 565, Data Mining Course logistics Course webpage: http://www.cs.bu.edu/~evimaria/cs565-10.html Schedule: Mon Wed, 4-5:30 Instructor: Evimaria Terzi, [email protected] Office hours: Mon 2:30-4pm,
CAS CS 565, Data Mining Course logistics Course webpage: http://www.cs.bu.edu/~evimaria/cs565-10.html Schedule: Mon Wed, 4-5:30 Instructor: Evimaria Terzi, [email protected] Office hours: Mon 2:30-4pm,
Similarity Search in a Very Large Scale Using Hadoop and HBase
 Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
APPM4720/5720: Fast algorithms for big data. Gunnar Martinsson The University of Colorado at Boulder
 APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
Advanced In-Database Analytics
 Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Collaborative Filtering. Radek Pelánek
 Collaborative Filtering Radek Pelánek 2015 Collaborative Filtering assumption: users with similar taste in past will have similar taste in future requires only matrix of ratings applicable in many domains
Collaborative Filtering Radek Pelánek 2015 Collaborative Filtering assumption: users with similar taste in past will have similar taste in future requires only matrix of ratings applicable in many domains
Fast Analytics on Big Data with H20
 Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
MLlib: Scalable Machine Learning on Spark
 MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
BIOINF 585 Fall 2015 Machine Learning for Systems Biology & Clinical Informatics http://www.ccmb.med.umich.edu/node/1376
 Course Director: Dr. Kayvan Najarian (DCM&B, [email protected]) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
Course Director: Dr. Kayvan Najarian (DCM&B, [email protected]) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University](/thumbs/26/8135278.jpg "CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Adapting scientific computing problems to cloud computing frameworks Ph.D. Thesis. Pelle Jakovits
 Adapting scientific computing problems to cloud computing frameworks Ph.D. Thesis Pelle Jakovits Outline Problem statement State of the art Approach Solutions and contributions Current work Conclusions
Adapting scientific computing problems to cloud computing frameworks Ph.D. Thesis Pelle Jakovits Outline Problem statement State of the art Approach Solutions and contributions Current work Conclusions
FEATURE 1. HASHING-TRICK
 FEATURE COLLABORATIVE SPAM FILTERING WITH THE HASHING TRICK Josh Attenberg Polytechnic Institute of NYU, USA Kilian Weinberger, Alex Smola, Anirban Dasgupta, Martin Zinkevich Yahoo! Research, USA User
FEATURE COLLABORATIVE SPAM FILTERING WITH THE HASHING TRICK Josh Attenberg Polytechnic Institute of NYU, USA Kilian Weinberger, Alex Smola, Anirban Dasgupta, Martin Zinkevich Yahoo! Research, USA User
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Scalable Data Analysis in R. Lee E. Edlefsen Chief Scientist UserR! 2011
 Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
How to use Big Data in Industry 4.0 implementations. LAURI ILISON, PhD Head of Big Data and Machine Learning
 How to use Big Data in Industry 4.0 implementations LAURI ILISON, PhD Head of Big Data and Machine Learning Big Data definition? Big Data is about structured vs unstructured data Big Data is about Volume
How to use Big Data in Industry 4.0 implementations LAURI ILISON, PhD Head of Big Data and Machine Learning Big Data definition? Big Data is about structured vs unstructured data Big Data is about Volume
Real Time Analytics for Big Data. NtiSh Nati Shalom @natishalom
 Real Time Analytics for Big Data A Twitter Inspired Case Study NtiSh Nati Shalom @natishalom Big Data Predictions Overthe next few years we'll see the adoption of scalable frameworks and platforms for
Real Time Analytics for Big Data A Twitter Inspired Case Study NtiSh Nati Shalom @natishalom Big Data Predictions Overthe next few years we'll see the adoption of scalable frameworks and platforms for
Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs
 1.1 Introduction Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs For brevity, the Lavastorm Analytics Library (LAL) Predictive and Statistical Analytics Node Pack will be
1.1 Introduction Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs For brevity, the Lavastorm Analytics Library (LAL) Predictive and Statistical Analytics Node Pack will be
AN EFFICIENT SELECTIVE DATA MINING ALGORITHM FOR BIG DATA ANALYTICS THROUGH HADOOP
 AN EFFICIENT SELECTIVE DATA MINING ALGORITHM FOR BIG DATA ANALYTICS THROUGH HADOOP Asst.Prof Mr. M.I Peter Shiyam,M.E * Department of Computer Science and Engineering, DMI Engineering college, Aralvaimozhi.
AN EFFICIENT SELECTIVE DATA MINING ALGORITHM FOR BIG DATA ANALYTICS THROUGH HADOOP Asst.Prof Mr. M.I Peter Shiyam,M.E * Department of Computer Science and Engineering, DMI Engineering college, Aralvaimozhi.
Large-Scale Test Mining
 Large-Scale Test Mining SIAM Conference on Data Mining Text Mining 2010 Alan Ratner Northrop Grumman Information Systems NORTHROP GRUMMAN PRIVATE / PROPRIETARY LEVEL I Aim Identify topic and language/script/coding
Large-Scale Test Mining SIAM Conference on Data Mining Text Mining 2010 Alan Ratner Northrop Grumman Information Systems NORTHROP GRUMMAN PRIVATE / PROPRIETARY LEVEL I Aim Identify topic and language/script/coding
SQL Server 2005 Features Comparison
 Page 1 of 10 Quick Links Home Worldwide Search Microsoft.com for: Go : Home Product Information How to Buy Editions Learning Downloads Support Partners Technologies Solutions Community Previous Versions
Page 1 of 10 Quick Links Home Worldwide Search Microsoft.com for: Go : Home Product Information How to Buy Editions Learning Downloads Support Partners Technologies Solutions Community Previous Versions
Big Data Analytics - Accelerated. stream-horizon.com
 Big Data Analytics - Accelerated stream-horizon.com StreamHorizon & Big Data Integrates into your Data Processing Pipeline Seamlessly integrates at any point of your your data processing pipeline Implements
Big Data Analytics - Accelerated stream-horizon.com StreamHorizon & Big Data Integrates into your Data Processing Pipeline Seamlessly integrates at any point of your your data processing pipeline Implements
Classification using Logistic Regression
 Classification using Logistic Regression Ingmar Schuster Patrick Jähnichen using slides by Andrew Ng Institut für Informatik This lecture covers Logistic regression hypothesis Decision Boundary Cost function
Classification using Logistic Regression Ingmar Schuster Patrick Jähnichen using slides by Andrew Ng Institut für Informatik This lecture covers Logistic regression hypothesis Decision Boundary Cost function
Probabilistic Models for Big Data. Alex Davies and Roger Frigola University of Cambridge 13th February 2014
 Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC)
") large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
B669 Sublinear Algorithms for Big Data
 B669 Sublinear Algorithms for Big Data Qin Zhang 1-1 Now about the Big Data Big data is everywhere : over 2.5 petabytes of sales transactions : an index of over 19 billion web pages : over 40 billion of
B669 Sublinear Algorithms for Big Data Qin Zhang 1-1 Now about the Big Data Big data is everywhere : over 2.5 petabytes of sales transactions : an index of over 19 billion web pages : over 40 billion of
Data De-duplication Methodologies: Comparing ExaGrid s Byte-level Data De-duplication To Block Level Data De-duplication
 Data De-duplication Methodologies: Comparing ExaGrid s Byte-level Data De-duplication To Block Level Data De-duplication Table of Contents Introduction... 3 Shortest Possible Backup Window... 3 Instant
Data De-duplication Methodologies: Comparing ExaGrid s Byte-level Data De-duplication To Block Level Data De-duplication Table of Contents Introduction... 3 Shortest Possible Backup Window... 3 Instant
Learning at scale on Hadoop
 Learning at scale on Hadoop Olivier Toromanoff, Software engineer Berlin Buzzwords, 2015-06-01 Copyright 2014 Criteo Prediction @ Criteo Learning on Hadoop Limits are lower than the sky From Experimentation
Learning at scale on Hadoop Olivier Toromanoff, Software engineer Berlin Buzzwords, 2015-06-01 Copyright 2014 Criteo Prediction @ Criteo Learning on Hadoop Limits are lower than the sky From Experimentation
Genome Analysis in a Dynamically Scaled Hybrid Cloud
 Genome Analysis in a Dynamically Scaled Hybrid Cloud Chris Smowton*, Georgiana Copil**, Hong- Linh Truong**, Crispin Miller* and Wei Xing* * CRUK Manchester ** TU Vienna In a Nutshell Users want to run
Genome Analysis in a Dynamically Scaled Hybrid Cloud Chris Smowton*, Georgiana Copil**, Hong- Linh Truong**, Crispin Miller* and Wei Xing* * CRUK Manchester ** TU Vienna In a Nutshell Users want to run
Introduction to Machine Learning Using Python. Vikram Kamath
 Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Big Data and Data Science: Behind the Buzz Words
 Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials