Tutorial for Assignment 2.0
|
|
|
- Lambert Whitehead
- 10 years ago
- Views:
Transcription
1 Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1

2 Review and Motivation Agenda Assignment Information Introduction to Hadoop and MapReduce Example MapReduce Application Setup pitfalls and hints 2

3 Review What you should have learned so far Network analysis and operations Such as degree distribution Clustering Coefficient Google s PageRank Network Evolution Computed for very small networks 3

4 Motivation So far these analyses do NOT scale What about networks with a huge amount of nodes and edges or GB/TB of data? Computation would take quite a long time How can we process large amounts of data? Hadoop 4

5 Provided Data You are given a subset of a large delicious data set which was gathered by Arkaitz Zubiaga Compressed 2.7GB [8.3GB] entries on the top tags minimum number of 3 tags per entry Tab separated: An entry represents a delicious bookmark: url tags[] 5

6 Co-occurrence According to wikipedia co-occurence is... the above-chance frequent occurrence of two terms from a text corpus alongside each other in a certain order [3] Example Given: [dog, cat, animal] [cat, lion, animal] [cat, lion, zoo] Result: animal cat 2 dog 1 lion 1 cat animal 2 dog 1 lion 2 zoo 1 dog animal 1 cat 1 lion animal 1 cat 2 zoo 1 zoo cat 1 lion 1 6
![in a certain order [3] Example Given: [dog, cat, animal] [cat, lion, animal] [cat, lion,](/docs-images/42/2746837/images/page_6.jpg "zoo] Result: animal cat 2 dog 1 lion 1 cat animal 2 dog 1 lion 2 zoo 1 dog animal 1 cat 1")
7 The Assignment Team up in groups of 5 students Nominate group captain Create Subversion repository (ADD ALL TUTORS AS READERS) Implement co-occurrence calculation for the given dataset and compute it You do not have to solve it in one step just explain it in the readme.txt file Hand in your source code, a co-occurrence adjacency list of 10 tags and visualize them! See assignment document for further details 7

8 Hand In 1/2 Create a Subversion repository on the TUG server Name: WSWT12_<GROUPNAME> Group members as members Teaching assistents as readers 8

9 Structure of the repository Hand In 2/2 report.pdf (short approx. 1 page) bash scripts (optional) python/ mapper_1.py reducer_1.py readme.txt results/ co-occurences.txt (adjacency list of 5 given tags + 5 of own choice) tag_cloud_*.png (tag cloud visualization of the 10 tags) 9
 tag_cloud_*.")
10 IMPORTANT NOW: Team up in groups of 5 Assignment is due: Monday June 11, :00 (noon) soft deadline 24:00 hard deadline Abgabegespräche will be on Tuesday June 12, 2012 Every team member has to attend As always: Plagiarism will not be tolerated!!!!! 10

11 Apache Hadoop One solution of the scaling problem Using the MapReduce paradigm Written in Java (but also other programming languages are possible) Used by Yahoo, Amazon etc. 11
 Used by Yahoo,")
 http://www.h-online.")
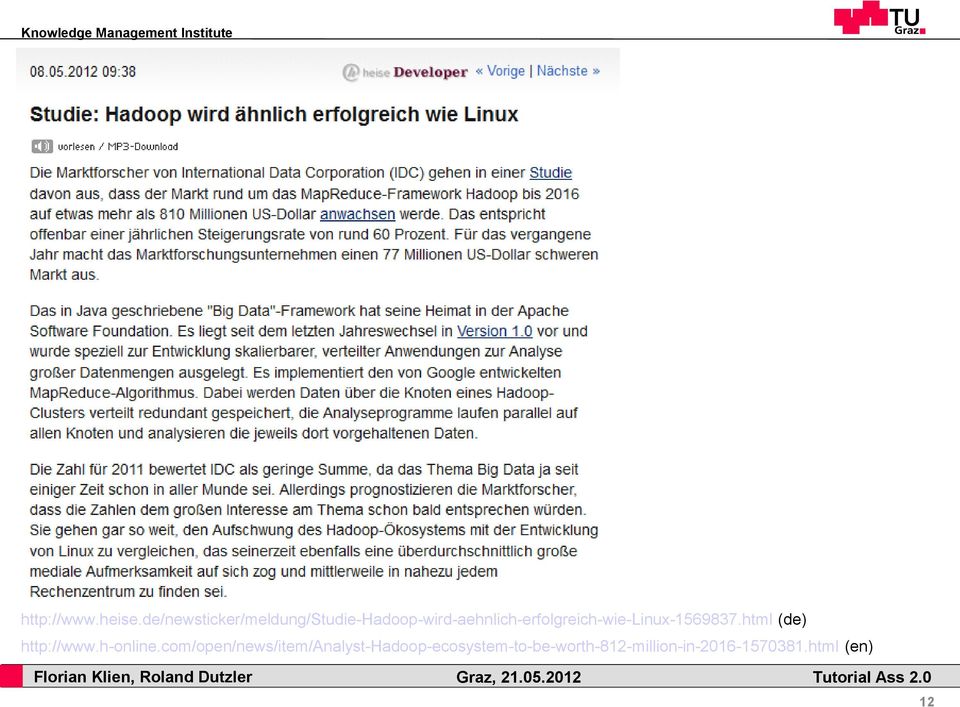
12 (de) (en) 12
13 MapReduce 1/2 Framework to support distributed computing of large data sets on clusters Developed by Google Inc. Used for data-intensive information processing Large Files/Lots of computation 13

14 MapReduce 2/2 Abstract view: Master splits problem in smaller parts Mapper solve sub-problem Reducer combines results from Mappers 14

15 15

16 Distributed File System (DFS) Hadoop comes with a distributed file system Highly fault tolerant Splits data in blocks of 64mb (default configuration) 16

17 Example of a MapReduce Application 1/4 Word Count Counting occurrences of words on lots of documents To keep things simple we will use the example from Michael G. Noll's tutorial [1] uses Python reads from StdIn writes to StdOut 17


18 Example of MapReduce Application 2/4 Mapper 18


19 Example of MapReduce Application 3/4 Reducer 19

20 Example of MapReduce Application 4/4 It is always recommended to test the code you have written on a small sample subset Think through with pen & paper and compare results Example: cat subset.txt python mapper.py sort python reducer.py Run the code on the cluster by issuing: bin/hadoop jar contrib/streaming/hadoop-streaming jar -file /home/hadoop/mapper.py -mapper / home/hadoop/mapper.py -file /home/hadoop/reducer.py -reducer /home/hadoop/reducer.py -input $input -output $output 20

21 Important The presented information has been tested on the following operating systems Ubuntu Linux Debian Linux The installation on Windows machines will not be supported by us in the newsgroup and is highly not recommended We also cannot support Mac OS X (although the setup should work fine) 21
22 Hadoop Setup 1/2 Use a native Linux (~ GB free space) Do the Multi-Node-Cluster Setup For runtime reasons As described in the tutorial by Michael G. Noll [1]: Create new user hadoop on your system Use functioning DNS or /etc/hosts file for client/master lookup Download current Hadoop distribution from Unpack distribution in a directory (e.g. /usr/local/hadoop) 22
23 Hadoop Setup 2/2 conf/hadoop-env.sh - holds environment variables and java installation conf/core-site.xml - names the host the default file system & temp data conf/mapred-site.xml - specifies the job tracker conf/masters - names the masters conf/slaves (only on master necessary) - names the slaves conf/hdfs-site.xml - specifies replication value Format DFS bin/hadoop namenode -format 23
24 Starting the Hadoop Cluster bin/start-dfs.sh starts HDFS daemons bin/start-mapred.sh - starts Map/Reduce daemons alternative: start-all.sh stopper scripts also available 24
25 Pitfalls for the Setup of Hadoop Use machines of approximately the same speed / setup Use the same directory structure for all installations of your machines Ensure that password-less ssh login is possible for all machines Avoid the term localhost and the ip at all cost use fixed IPs or functioning DNS for your experiments Read the Log files of the Hadoop installation Use the web interface of your cluster 25
26 Further hints Check if enough free space is available on your harddisk partition (~ GB are needed) Virtual Machines (DO NOT DO IT!) Same as above: give the machine enough space Give the machine a good amount of memory (~1024MB) For local networks: Use bridging (no NAT!!!) Read the tutorials carefully! [1] Post your problems to the newsgroup Read the logfiles (hadoop/logs/) Often google offers you a solution/hint to your problem 26
27 Thanks for your attention! Are there any questions? 27
28 References [1] Michael G. Noll's Hadoop Tutorial: Single Node Cluster Node_Cluster%29 Multi Node Cluster %29 Writing Map/Reduce Program in Python [2] H. Kwak, C. Lee, H. Park, and S. Moon. What istwitter, a social network or a news media? In WWW 10: Proceedings of the 19th international conference on World wide web, pages , New York, NY, USA, ACM. [3] 28
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Setup Hadoop On Ubuntu Linux. ---Multi-Node Cluster
 Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM
 IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM Sugandha Agarwal 1, Pragya Jain 2 1,2 Department of Computer Science & Engineering ASET, Amity University, Noida,
IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM Sugandha Agarwal 1, Pragya Jain 2 1,2 Department of Computer Science & Engineering ASET, Amity University, Noida,
Data Analytics. CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL. All rights reserved.
 2011, Parallel Systems Architecture Lab, EPFL. All rights reserved.") Data Analytics CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL All rights reserved. The data analytics benchmark relies on using the Hadoop MapReduce framework
Data Analytics CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL All rights reserved. The data analytics benchmark relies on using the Hadoop MapReduce framework
Running Hadoop On Ubuntu Linux (Multi-Node Cluster) - Michael G...
 - Michael G...") Go Home About Contact Blog Code Publications DMOZ100k06 Photography Running Hadoop On Ubuntu Linux (Multi-Node Cluster) From Michael G. Noll Contents 1 What we want to do 2 Tutorial approach and structure
Go Home About Contact Blog Code Publications DMOZ100k06 Photography Running Hadoop On Ubuntu Linux (Multi-Node Cluster) From Michael G. Noll Contents 1 What we want to do 2 Tutorial approach and structure
Single Node Setup. Table of contents
 Table of contents 1 Purpose... 2 2 Prerequisites...2 2.1 Supported Platforms...2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster... 3 5 Standalone
Table of contents 1 Purpose... 2 2 Prerequisites...2 2.1 Supported Platforms...2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster... 3 5 Standalone
2.1 Hadoop a. Hadoop Installation & Configuration
 2. Implementation 2.1 Hadoop a. Hadoop Installation & Configuration First of all, we need to install Java Sun 6, and it is preferred to be version 6 not 7 for running Hadoop. Type the following commands
2. Implementation 2.1 Hadoop a. Hadoop Installation & Configuration First of all, we need to install Java Sun 6, and it is preferred to be version 6 not 7 for running Hadoop. Type the following commands
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Single Node Hadoop Cluster Setup
 Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment
 CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
Installation and Configuration Documentation
 Installation and Configuration Documentation Release 1.0.1 Oshin Prem October 08, 2015 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE
Installation and Configuration Documentation Release 1.0.1 Oshin Prem October 08, 2015 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE
Integration Of Virtualization With Hadoop Tools
 Integration Of Virtualization With Hadoop Tools Aparna Raj K [email protected] Kamaldeep Kaur [email protected] Uddipan Dutta [email protected] V Venkat Sandeep [email protected] Technical
Integration Of Virtualization With Hadoop Tools Aparna Raj K [email protected] Kamaldeep Kaur [email protected] Uddipan Dutta [email protected] V Venkat Sandeep [email protected] Technical
TP1: Getting Started with Hadoop
 TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
Open Cloud System. (Integration of Eucalyptus, Hadoop and AppScale into deployment of University Private Cloud)
") Open Cloud System (Integration of Eucalyptus, Hadoop and into deployment of University Private Cloud) Thinn Thu Naing University of Computer Studies, Yangon 25 th October 2011 Open Cloud System University
Open Cloud System (Integration of Eucalyptus, Hadoop and into deployment of University Private Cloud) Thinn Thu Naing University of Computer Studies, Yangon 25 th October 2011 Open Cloud System University
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
MapReduce, Hadoop and Amazon AWS
 MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
1. GridGain In-Memory Accelerator For Hadoop. 2. Hadoop Installation. 2.1 Hadoop 1.x Installation
 1. GridGain In-Memory Accelerator For Hadoop GridGain's In-Memory Accelerator For Hadoop edition is based on the industry's first high-performance dual-mode in-memory file system that is 100% compatible
1. GridGain In-Memory Accelerator For Hadoop GridGain's In-Memory Accelerator For Hadoop edition is based on the industry's first high-performance dual-mode in-memory file system that is 100% compatible
Running Kmeans Mapreduce code on Amazon AWS
 Running Kmeans Mapreduce code on Amazon AWS Pseudo Code Input: Dataset D, Number of clusters k Output: Data points with cluster memberships Step 1: for iteration = 1 to MaxIterations do Step 2: Mapper:
Running Kmeans Mapreduce code on Amazon AWS Pseudo Code Input: Dataset D, Number of clusters k Output: Data points with cluster memberships Step 1: for iteration = 1 to MaxIterations do Step 2: Mapper:
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup)
") How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup) Author : Vignesh Prajapati Categories : Hadoop Date : February 22, 2015 Since you have reached on this blogpost of Setting up Multinode Hadoop
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup) Author : Vignesh Prajapati Categories : Hadoop Date : February 22, 2015 Since you have reached on this blogpost of Setting up Multinode Hadoop
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node/cluster setup)
") How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node/cluster setup) Author : Vignesh Prajapati Categories : Hadoop Tagged as : bigdata, Hadoop Date : April 20, 2015 As you have reached on this blogpost
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node/cluster setup) Author : Vignesh Prajapati Categories : Hadoop Tagged as : bigdata, Hadoop Date : April 20, 2015 As you have reached on this blogpost
Cloud Computing. Chapter 8. 8.1 Hadoop
 Chapter 8 Cloud Computing In cloud computing, the idea is that a large corporation that has many computers could sell time on them, for example to make profitable use of excess capacity. The typical customer
Chapter 8 Cloud Computing In cloud computing, the idea is that a large corporation that has many computers could sell time on them, for example to make profitable use of excess capacity. The typical customer
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Hadoop MapReduce Tutorial - Reduce Comp variability in Data Stamps
 Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
Hadoop Setup. 1 Cluster
 In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms
 Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Extreme computing lab exercises Session one
 Extreme computing lab exercises Session one Michail Basios ([email protected]) Stratis Viglas ([email protected]) 1 Getting started First you need to access the machine where you will be doing all
Extreme computing lab exercises Session one Michail Basios ([email protected]) Stratis Viglas ([email protected]) 1 Getting started First you need to access the machine where you will be doing all
研 發 專 案 原 始 程 式 碼 安 裝 及 操 作 手 冊. Version 0.1
 102 年 度 國 科 會 雲 端 計 算 與 資 訊 安 全 技 術 研 發 專 案 原 始 程 式 碼 安 裝 及 操 作 手 冊 Version 0.1 總 計 畫 名 稱 : 行 動 雲 端 環 境 動 態 群 組 服 務 研 究 與 創 新 應 用 子 計 畫 一 : 行 動 雲 端 群 組 服 務 架 構 與 動 態 群 組 管 理 (NSC 102-2218-E-259-003) 計
102 年 度 國 科 會 雲 端 計 算 與 資 訊 安 全 技 術 研 發 專 案 原 始 程 式 碼 安 裝 及 操 作 手 冊 Version 0.1 總 計 畫 名 稱 : 行 動 雲 端 環 境 動 態 群 組 服 務 研 究 與 創 新 應 用 子 計 畫 一 : 行 動 雲 端 群 組 服 務 架 構 與 動 態 群 組 管 理 (NSC 102-2218-E-259-003) 計
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop 2.2.0 MultiNode Cluster Setup
 Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay
 Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay Dipojjwal Ray Sandeep Prasad 1 Introduction In installation manual we listed out the steps for hadoop-1.0.3 and hadoop-
Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay Dipojjwal Ray Sandeep Prasad 1 Introduction In installation manual we listed out the steps for hadoop-1.0.3 and hadoop-
Set JAVA PATH in Linux Environment. Edit.bashrc and add below 2 lines $vi.bashrc export JAVA_HOME=/usr/lib/jvm/java-7-oracle/
 Download the Hadoop tar. Download the Java from Oracle - Unpack the Comparisons -- $tar -zxvf hadoop-2.6.0.tar.gz $tar -zxf jdk1.7.0_60.tar.gz Set JAVA PATH in Linux Environment. Edit.bashrc and add below
Download the Hadoop tar. Download the Java from Oracle - Unpack the Comparisons -- $tar -zxvf hadoop-2.6.0.tar.gz $tar -zxf jdk1.7.0_60.tar.gz Set JAVA PATH in Linux Environment. Edit.bashrc and add below
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
The objective of this lab is to learn how to set up an environment for running distributed Hadoop applications.
 Lab 9: Hadoop Development The objective of this lab is to learn how to set up an environment for running distributed Hadoop applications. Introduction Hadoop can be run in one of three modes: Standalone
Lab 9: Hadoop Development The objective of this lab is to learn how to set up an environment for running distributed Hadoop applications. Introduction Hadoop can be run in one of three modes: Standalone
An Experimental Approach Towards Big Data for Analyzing Memory Utilization on a Hadoop cluster using HDFS and MapReduce.
 An Experimental Approach Towards Big Data for Analyzing Memory Utilization on a Hadoop cluster using HDFS and MapReduce. Amrit Pal Stdt, Dept of Computer Engineering and Application, National Institute
An Experimental Approach Towards Big Data for Analyzing Memory Utilization on a Hadoop cluster using HDFS and MapReduce. Amrit Pal Stdt, Dept of Computer Engineering and Application, National Institute
MapReduce and Hadoop Distributed File System V I J A Y R A O
 MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
IDS 561 Big data analytics Assignment 1
 IDS 561 Big data analytics Assignment 1 Due Midnight, October 4th, 2015 General Instructions The purpose of this tutorial is (1) to get you started with Hadoop and (2) to get you acquainted with the code
IDS 561 Big data analytics Assignment 1 Due Midnight, October 4th, 2015 General Instructions The purpose of this tutorial is (1) to get you started with Hadoop and (2) to get you acquainted with the code
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Amazon-style shopping cart analysis using MapReduce on a Hadoop cluster. Dan Şerban
 Amazon-style shopping cart analysis using MapReduce on a Hadoop cluster Dan Şerban Agenda :: Introduction - Real-world uses of MapReduce - The origins of Hadoop - Hadoop facts and architecture :: Part
Amazon-style shopping cart analysis using MapReduce on a Hadoop cluster Dan Şerban Agenda :: Introduction - Real-world uses of MapReduce - The origins of Hadoop - Hadoop facts and architecture :: Part
Extreme computing lab exercises Session one
 Extreme computing lab exercises Session one Miles Osborne (original: Sasa Petrovic) October 23, 2012 1 Getting started First you need to access the machine where you will be doing all the work. Do this
Extreme computing lab exercises Session one Miles Osborne (original: Sasa Petrovic) October 23, 2012 1 Getting started First you need to access the machine where you will be doing all the work. Do this
Hadoop Installation. Sandeep Prasad
 Hadoop Installation Sandeep Prasad 1 Introduction Hadoop is a system to manage large quantity of data. For this report hadoop- 1.0.3 (Released, May 2012) is used and tested on Ubuntu-12.04. The system
Hadoop Installation Sandeep Prasad 1 Introduction Hadoop is a system to manage large quantity of data. For this report hadoop- 1.0.3 (Released, May 2012) is used and tested on Ubuntu-12.04. The system
Cloudera Distributed Hadoop (CDH) Installation and Configuration on Virtual Box
 Installation and Configuration on Virtual Box") Cloudera Distributed Hadoop (CDH) Installation and Configuration on Virtual Box By Kavya Mugadur W1014808 1 Table of contents 1.What is CDH? 2. Hadoop Basics 3. Ways to install CDH 4. Installation and
Cloudera Distributed Hadoop (CDH) Installation and Configuration on Virtual Box By Kavya Mugadur W1014808 1 Table of contents 1.What is CDH? 2. Hadoop Basics 3. Ways to install CDH 4. Installation and
How To Install Hadoop 1.2.1.1 From Apa Hadoop 1.3.2 To 1.4.2 (Hadoop)
") Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
IMPLEMENTATION OF P-PIC ALGORITHM IN MAP REDUCE TO HANDLE BIG DATA
 IMPLEMENTATION OF P-PIC ALGORITHM IN MAP REDUCE TO HANDLE BIG DATA Jayalatchumy D 1, Thambidurai. P 2 Abstract Clustering is a process of grouping objects that are similar among themselves but dissimilar
IMPLEMENTATION OF P-PIC ALGORITHM IN MAP REDUCE TO HANDLE BIG DATA Jayalatchumy D 1, Thambidurai. P 2 Abstract Clustering is a process of grouping objects that are similar among themselves but dissimilar
Installing Hadoop. You need a *nix system (Linux, Mac OS X, ) with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.
 with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.") Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco ([email protected]) Prerequisites You
Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco ([email protected]) Prerequisites You
A. Aiken & K. Olukotun PA3
 Programming Assignment #3 Hadoop N-Gram Due Tue, Feb 18, 11:59PM In this programming assignment you will use Hadoop s implementation of MapReduce to search Wikipedia. This is not a course in search, so
Programming Assignment #3 Hadoop N-Gram Due Tue, Feb 18, 11:59PM In this programming assignment you will use Hadoop s implementation of MapReduce to search Wikipedia. This is not a course in search, so
HDFS. Hadoop Distributed File System
 HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang
 Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang Independent Study Advanced Case-Based Reasoning Department of Computer Science
Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang Independent Study Advanced Case-Based Reasoning Department of Computer Science
Hadoop Tutorial. General Instructions
 CS246: Mining Massive Datasets Winter 2016 Hadoop Tutorial Due 11:59pm January 12, 2016 General Instructions The purpose of this tutorial is (1) to get you started with Hadoop and (2) to get you acquainted
CS246: Mining Massive Datasets Winter 2016 Hadoop Tutorial Due 11:59pm January 12, 2016 General Instructions The purpose of this tutorial is (1) to get you started with Hadoop and (2) to get you acquainted
EXPERIMENTATION. HARRISON CARRANZA School of Computer Science and Mathematics
 BIG DATA WITH HADOOP EXPERIMENTATION HARRISON CARRANZA Marist College APARICIO CARRANZA NYC College of Technology CUNY ECC Conference 2016 Poughkeepsie, NY, June 12-14, 2016 Marist College AGENDA Contents
BIG DATA WITH HADOOP EXPERIMENTATION HARRISON CARRANZA Marist College APARICIO CARRANZA NYC College of Technology CUNY ECC Conference 2016 Poughkeepsie, NY, June 12-14, 2016 Marist College AGENDA Contents
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney") Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Gluster Filesystem 3.3 Beta 2 Hadoop Compatible Storage
 Gluster Filesystem 3.3 Beta 2 Hadoop Compatible Storage Release: August 2011 Copyright Copyright 2011 Gluster, Inc. This is a preliminary document and may be changed substantially prior to final commercial
Gluster Filesystem 3.3 Beta 2 Hadoop Compatible Storage Release: August 2011 Copyright Copyright 2011 Gluster, Inc. This is a preliminary document and may be changed substantially prior to final commercial
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
A Study of Data Management Technology for Handling Big Data
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 9, September 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 9, September 2014,
Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.
 EDUREKA Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.0 Cluster edureka! 11/12/2013 A guide to Install and Configure
EDUREKA Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.0 Cluster edureka! 11/12/2013 A guide to Install and Configure
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
10605 BigML Assignment 4(a): Naive Bayes using Hadoop Streaming
: Naive Bayes using Hadoop Streaming") 10605 BigML Assignment 4(a): Naive Bayes using Hadoop Streaming Due: Friday, Feb. 21, 2014 23:59 EST via Autolab Late submission with 50% credit: Sunday, Feb. 23, 2014 23:59 EST via Autolab Policy on Collaboration
10605 BigML Assignment 4(a): Naive Bayes using Hadoop Streaming Due: Friday, Feb. 21, 2014 23:59 EST via Autolab Late submission with 50% credit: Sunday, Feb. 23, 2014 23:59 EST via Autolab Policy on Collaboration
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
Hadoop. Bioinformatics Big Data
 Hadoop Bioinformatics Big Data Paolo D Onorio De Meo Mattia D Antonio [email protected] [email protected] Big Data Too much information! Big Data Explosive data growth proliferation of data capture
Hadoop Bioinformatics Big Data Paolo D Onorio De Meo Mattia D Antonio [email protected] [email protected] Big Data Too much information! Big Data Explosive data growth proliferation of data capture
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Deploying Cloudera CDH (Cloudera Distribution Including Apache Hadoop) with Emulex OneConnect OCe14000 Network Adapters
 with Emulex OneConnect OCe14000 Network Adapters") Deploying Cloudera CDH (Cloudera Distribution Including Apache Hadoop) with Emulex OneConnect OCe14000 Network Adapters Table of Contents Introduction... Hardware requirements... Recommended Hadoop cluster
Deploying Cloudera CDH (Cloudera Distribution Including Apache Hadoop) with Emulex OneConnect OCe14000 Network Adapters Table of Contents Introduction... Hardware requirements... Recommended Hadoop cluster
MAP/REDUCE DESIGN AND IMPLEMENTATION OF APRIORIALGORITHM FOR HANDLING VOLUMINOUS DATA-SETS
 MAP/REDUCE DESIGN AND IMPLEMENTATION OF APRIORIALGORITHM FOR HANDLING VOLUMINOUS DATA-SETS Anjan K Koundinya 1,Srinath N K 1,K A K Sharma 1, Kiran Kumar 1, Madhu M N 1 and Kiran U Shanbag 1 1 Department
MAP/REDUCE DESIGN AND IMPLEMENTATION OF APRIORIALGORITHM FOR HANDLING VOLUMINOUS DATA-SETS Anjan K Koundinya 1,Srinath N K 1,K A K Sharma 1, Kiran Kumar 1, Madhu M N 1 and Kiran U Shanbag 1 1 Department
Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud
 Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud Aditya Jadhav, Mahesh Kukreja E-mail: [email protected] & [email protected] Abstract : In the information industry,
Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud Aditya Jadhav, Mahesh Kukreja E-mail: [email protected] & [email protected] Abstract : In the information industry,
Developing a MapReduce Application
 TIE 12206 - Apache Hadoop Tampere University of Technology, Finland November, 2014 Outline 1 MapReduce Paradigm 2 Hadoop Default Ports 3 Outline 1 MapReduce Paradigm 2 Hadoop Default Ports 3 MapReduce
TIE 12206 - Apache Hadoop Tampere University of Technology, Finland November, 2014 Outline 1 MapReduce Paradigm 2 Hadoop Default Ports 3 Outline 1 MapReduce Paradigm 2 Hadoop Default Ports 3 MapReduce
Integrating SAP BusinessObjects with Hadoop. Using a multi-node Hadoop Cluster
 Integrating SAP BusinessObjects with Hadoop Using a multi-node Hadoop Cluster May 17, 2013 SAP BO HADOOP INTEGRATION Contents 1. Installing a Single Node Hadoop Server... 2 2. Configuring a Multi-Node
Integrating SAP BusinessObjects with Hadoop Using a multi-node Hadoop Cluster May 17, 2013 SAP BO HADOOP INTEGRATION Contents 1. Installing a Single Node Hadoop Server... 2 2. Configuring a Multi-Node
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
HADOOP - MULTI NODE CLUSTER
 HADOOP - MULTI NODE CLUSTER http://www.tutorialspoint.com/hadoop/hadoop_multi_node_cluster.htm Copyright tutorialspoint.com This chapter explains the setup of the Hadoop Multi-Node cluster on a distributed
HADOOP - MULTI NODE CLUSTER http://www.tutorialspoint.com/hadoop/hadoop_multi_node_cluster.htm Copyright tutorialspoint.com This chapter explains the setup of the Hadoop Multi-Node cluster on a distributed
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop (pseudo-distributed) installation and configuration
 installation and configuration") Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Analysing Large Web Log Files in a Hadoop Distributed Cluster Environment
 Analysing Large Files in a Hadoop Distributed Cluster Environment S Saravanan, B Uma Maheswari Department of Computer Science and Engineering, Amrita School of Engineering, Amrita Vishwa Vidyapeetham,
Analysing Large Files in a Hadoop Distributed Cluster Environment S Saravanan, B Uma Maheswari Department of Computer Science and Engineering, Amrita School of Engineering, Amrita Vishwa Vidyapeetham,
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Hadoop Distributed File System Propagation Adapter for Nimbus
 University of Victoria Faculty of Engineering Coop Workterm Report Hadoop Distributed File System Propagation Adapter for Nimbus Department of Physics University of Victoria Victoria, BC Matthew Vliet
University of Victoria Faculty of Engineering Coop Workterm Report Hadoop Distributed File System Propagation Adapter for Nimbus Department of Physics University of Victoria Victoria, BC Matthew Vliet
Hadoop Installation MapReduce Examples Jake Karnes
 Big Data Management Hadoop Installation MapReduce Examples Jake Karnes These slides are based on materials / slides from Cloudera.com Amazon.com Prof. P. Zadrozny's Slides Prerequistes You must have an
Big Data Management Hadoop Installation MapReduce Examples Jake Karnes These slides are based on materials / slides from Cloudera.com Amazon.com Prof. P. Zadrozny's Slides Prerequistes You must have an
L1: Introduction to Hadoop
 L1: Introduction to Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
L1: Introduction to Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
Hadoop Basics with InfoSphere BigInsights
 An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Unit 4: Hadoop Administration An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government Users Restricted
An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Unit 4: Hadoop Administration An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government Users Restricted
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
CDH installation & Application Test Report
 CDH installation & Application Test Report He Shouchun (SCUID: 00001008350, Email: [email protected]) Chapter 1. Prepare the virtual machine... 2 1.1 Download virtual machine software... 2 1.2 Plan the guest
CDH installation & Application Test Report He Shouchun (SCUID: 00001008350, Email: [email protected]) Chapter 1. Prepare the virtual machine... 2 1.1 Download virtual machine software... 2 1.2 Plan the guest
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Tutorial- Counting Words in File(s) using MapReduce
 using MapReduce") Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
Deploying MongoDB and Hadoop to Amazon Web Services
 SGT WHITE PAPER Deploying MongoDB and Hadoop to Amazon Web Services HCCP Big Data Lab 2015 SGT, Inc. All Rights Reserved 7701 Greenbelt Road, Suite 400, Greenbelt, MD 20770 Tel: (301) 614-8600 Fax: (301)
SGT WHITE PAPER Deploying MongoDB and Hadoop to Amazon Web Services HCCP Big Data Lab 2015 SGT, Inc. All Rights Reserved 7701 Greenbelt Road, Suite 400, Greenbelt, MD 20770 Tel: (301) 614-8600 Fax: (301)
Introduction to Hadoop on the SDSC Gordon Data Intensive Cluster"
 Introduction to Hadoop on the SDSC Gordon Data Intensive Cluster" Mahidhar Tatineni SDSC Summer Institute August 06, 2013 Overview "" Hadoop framework extensively used for scalable distributed processing
Introduction to Hadoop on the SDSC Gordon Data Intensive Cluster" Mahidhar Tatineni SDSC Summer Institute August 06, 2013 Overview "" Hadoop framework extensively used for scalable distributed processing
CS242 PROJECT. Presented by Moloud Shahbazi Spring 2015
 CS242 PROJECT Presented by Moloud Shahbazi Spring 2015 AGENDA Project Overview Data Collection Indexing Big Data Processing PROJECT- PART1 1.1 Data Collection: 5G < data size < 10G Deliverables: Document
CS242 PROJECT Presented by Moloud Shahbazi Spring 2015 AGENDA Project Overview Data Collection Indexing Big Data Processing PROJECT- PART1 1.1 Data Collection: 5G < data size < 10G Deliverables: Document
Document Similarity Measurement Using Ferret Algorithm and Map Reduce Programming Model
 Document Similarity Measurement Using Ferret Algorithm and Map Reduce Programming Model Condro Wibawa, Irwan Bastian, Metty Mustikasari Department of Information Systems, Faculty of Computer Science and
Document Similarity Measurement Using Ferret Algorithm and Map Reduce Programming Model Condro Wibawa, Irwan Bastian, Metty Mustikasari Department of Information Systems, Faculty of Computer Science and
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely