Preliminaries: Problem Definition Agent model, POMDP, Bayesian RL
|
|
|
- Camilla Kelly
- 9 years ago
- Views:
Transcription
1 POMDP Tutorial

2 Preliminaries: Problem Definition Agent model, POMDP, Bayesian RL Observation Belief ACTOR Transition Dynamics WORLD b Policy π Action Markov Decision Process -X: set of states [x s,x r ] state component reward component --A: set of actions -T=P(x x,a): transition and reward probabilities -O: Observation function -b: Belief and info. state -π: Policy
![states [x s,x r ] state component reward component --A: set of actions -T=P(x x,a):](/docs-images/46/21190915/images/page_2.jpg "transition and reward probabilities -O: Observation function -b: Belief and info.")
3

4 Sequential decision making with uncertainty in a changing world Dynamics- The world and agent change over time. The agent may have a model of this change process Observation- Both world state and goal achievement are accessed through indirect measurements (sensations of state and reward) Beliefs - Understanding of world state with uncertainty Goals- encoded by rewards! => Find a policy that can maximize total reward over some duration Value Function- Measure of goodness of being in a belief state Policy- a function that describes how to select actions in each belief state.

5 Markov Decision Processes (MDPs) In RL, the environment is a modeled as an MDP, defined by S set of states of the environment A(s) set of actions possible in state s within S P(s,s',a) probability of transition from s to s' given a R(s,s',a) expected reward on transition s to s' given a g discount rate for delayed reward discrete time, t = 0, 1, 2, s t a t r t +1 s t +1 a t +1 r t +2 s t +2 t +2 a r t +3 st a t +3

6 MDP Model Agent State Reward Action Environment Process: Observe state s t in S Choose action at in A t Receive immediate reward r t State changes to s t+1 a s 0 0 r 0 s1 a1 r1 s2 a2 r2 s3 MDP Model <S, A, T, R>

7 The Objective is to Maximize Long-term Total Discounted Reward Find a policy π : s S a A(s) (could be stochastic) that maximizes the value (expected future reward) of each s : π V (s) = E {r + γ r + γ 2 r +... s =s, π } t +1 t +2 t +3 t and each s,a pair: rewards π 2 Q (s,a) = E {r + γ r + γ r +... s =s, a =a, π } t +1 t +2 t +3 t t These are called value functions - cf. evaluation functions

8 Policy & Value Function Which action, a, should the agent take? In MDPs: Policy is a mapping from state to action, π: S A Value Function V π,t (S) given a policy π The expected sum of reward gained from starting in state s executing non-stationary policy π for t steps. Relation Value function is evaluation for policy based on the long-run value that agent expects to gain from executing the policy.

9 Optimal Value Functions and Policies There exist optimal value functions: V * (s) = max! V! (s) Q * (s, a) = max! Q! (s,a) And corresponding optimal policies:! * (s) = argmaxq * (s, a) a π* is the greedy policy with respect to Q*
 = argmaxq * (s, a) a π* is the greedy policy with")
10 Optimization (MDPs) Recursively calculate expected long-term reward for each state/belief: $ % V * ( ) ( ) ( ) * t s = max R s, a! T s, a, s ' Vt " 1( s ') a & + * ' ( s' # S ) Find the action that maximizes the expected reward: % &! t *( s) = arg max ' R( s, a) + " + T ( s, a, s ') Vt # 1 *( s ')( a ) s' $ S *

11 Policies are not actions There is an important difference between policies and action choices A Policy is a (possibly stochastic) mapping between states and actions (where states can be beliefs or information vectors). Thus a policy is a strategy, a decision rule that can encode action contingencies on context, etc.

12 Example of Value Functions

13 4Grid Example
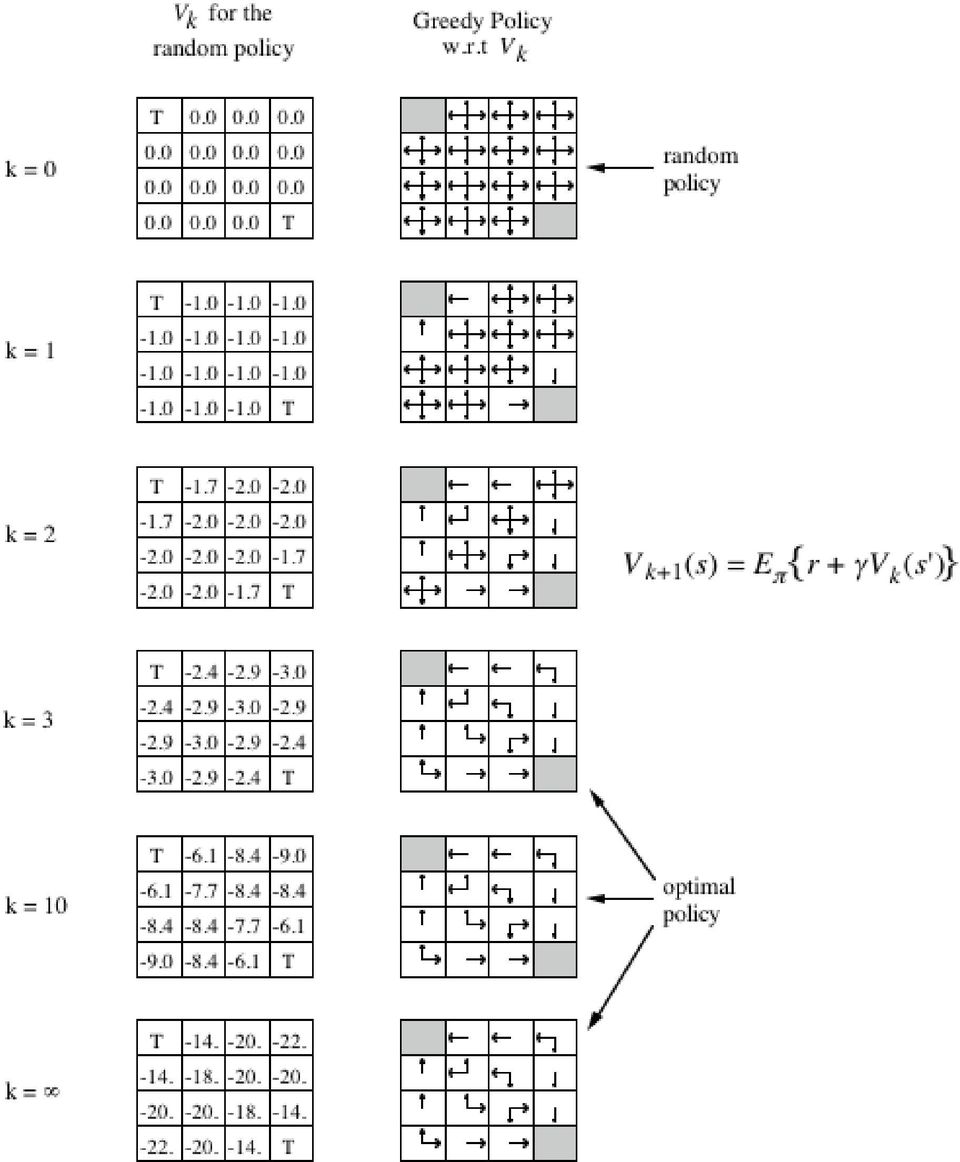
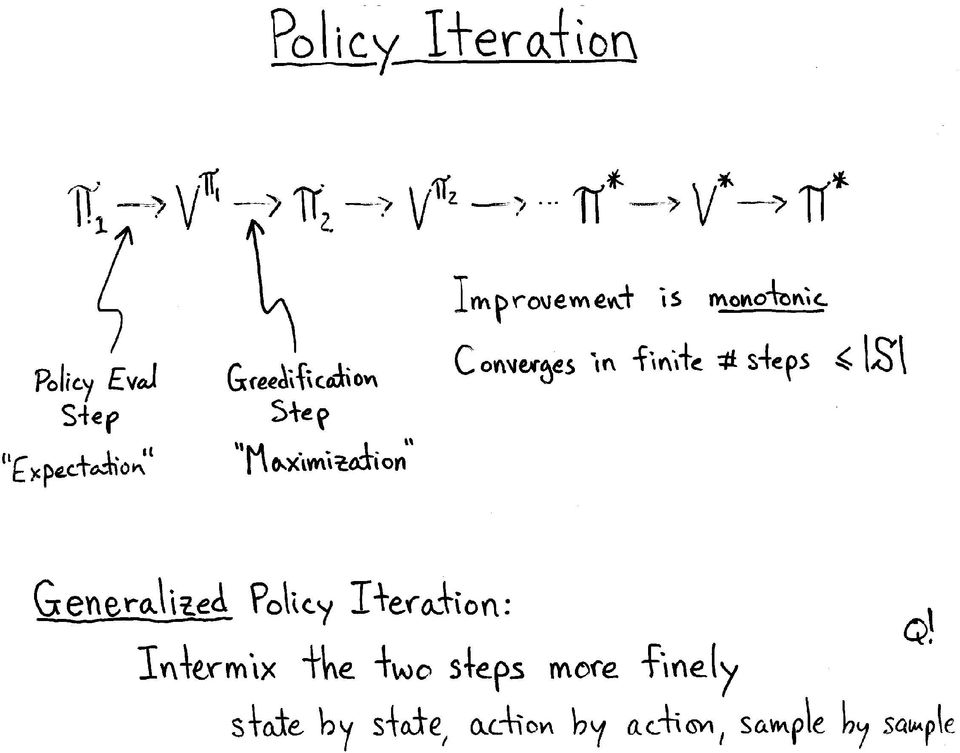
14 Policy Iteration
15 Classic Example: Car on the hill Goal: Top of the hill, final velocity =0 in minimum time Optimal Value function Optimal Trajec.

16 Ball-Balancing RL applied to a real physical system-illustrates online learning An easy problem...but learns as you watch

17 Smarts Demo Rewards? Environment state space? Action state space? Role of perception? Policy?

18 1-Step Model-free Q-Learning A model of the environment is not necessary to learn to act in a stationary domain On each state transition: s t a t r t +1 s t +1 Update: [ ] Q(s t,a t )! Q(s t,a t ) + " r t+1 + # maxq(s t +1,a) $ Q(s t,a t ) a table entry a TD Error lim t! " Q(s, a)! Q * (s,a) lim t! " # t! # * Optimal behavior found without a model of the environment! (Watkins, 1989) Assumes finite MDP
 lim t! \" # t! # * Optimal behavior found without a model of the environment!")
19 RL Theory: Generalized Policy Iteration Policy! policy evaluation value learning policy improvement greedification Value Function V, Q! * V *, Q *

20 Rooms Example ROOM HALLWAYS 4 rooms 4 hallways 4 unreliable primitive actions up left right Fail 33% of the time O 1 down O 2 G? G? 8 multi-step options (to each room's 2 hallways) Given goal location, quickly plan shortest route Goal states are given All rewards zero a terminal value of 1 γ =.9

21 Action representation matters: Value functions learned faster for macro-actions with primitive actions (cell-to-cell) V(goal )=1 Iteration #1 Iteration #2 Iteration #3 with behaviors (room-to-room) V(goal )=1 Iteration #1 Iteration #2 Iteration #3
22 MDP Model Agent State Reward Action Environment Process: Observe state s t in S Choose action at in A t Receive immediate reward r t State changes to s t+1 a s 0 0 r 0 s1 a1 r1 s2 a2 r2 s3 MDP Model <S, A, T, R>
23 POMDP: UNCERTAINTY Case #1: Uncertainty about the action outcome Case #2: Uncertainty about the world state due to imperfect (partial) information
24 A broad perspective Belief state OBSERVATIONS AGENT STATE WORLD + AGENT ACTIONS GOAL = Selecting appropriate actions
25 What are POMDPs? S1 Pr(o1)=0.5 Pr(o2)= a 2 a S2 Pr(o1)=0.9 Pr(o2)=0.1 S3 Pr(o1)=0.2 Pr(o2)=0.8 Components: Set of states: s S Set of actions: a A Set of observations: o Ω POMDP parameters: Initial belief: b 0 (s)=pr(s=s) Belief state updating: b (s )=Pr(s o, a, b) Observation probabilities: O(s,a,o)=Pr(o s,a) Transition probabilities: T(s,a,s )=Pr(s s,a) Rewards: R(s,a) MDP
26 Belief state Observation World b SE! Agent Action Probability distributions over states of the underlying MDP The agent keeps an internal belief state, b, that summarizes its experience. The agent uses a state estimator, SE, for updating the belief state b based on the last action a t-1, the current observation o t, and the previous belief state b. Belief state is a sufficient statistic (it satisfies the Markov proerty)
27 1D belief space for a 2 state POMDP with 3 possible observations Z i = Observations ( j) ( j ) b ' s = P s o, a, b = ( j, )" ( j i, ) ( i ) i " P( o s j, a) " P( s j si, a) b( si ) j! P o s a P s s a b s s! S s S s! S i
28 A POMDP example: The tiger problem S0 tiger-left Pr(o=TL S0, listen)=0.85 Pr(o=TR S1, listen)=0.15 S1 tiger-right Pr(o=TL S0, listen)=0.15 Pr(o=TR S1, listen)=0.85 Actions={ 0: listen, 1: open-left, 2: open-right} Reward Function - Penalty for wrong opening: Reward for correct opening: Cost for listening action: -1 Observations - to hear the tiger on the left (TL) - to hear the tiger on the right(tr)
29 POMDP Continuous-Space Belief MDP a POMDP can be seen as a continuous-space belief MDP, as the agent s belief is encoded through a continuous belief state. A 1 A 2 A 3 S 0 S 1 S 2 S 3 O 1 O 2 O 3 We may solve this belief MDP like before using value iteration algorithm to find the optimal policy in a continuous space. However, some adaptations for this algorithm are needed.
30 Belief MDP The policy of a POMDP maps the current belief state into an action. As the belief state holds all relevant information about the past, the optimal policy of the POMDP is the the solution of (continuous-space) belief MDP. A belief MDP is a tuple <B, A, ρ, P>: B = infinite set of belief states A = finite set of actions ρ(b, a) = b( s) R( s, a) " s! S (reward function) P(b b, a) = " o! O P( b' b, a, o) P( o a, b) (transition function) Where P(b b, a, o) = 1 if SE(b, a, o) = b, P(b b, a, o) = 0 otherwise;
31 A POMDP example: The tiger problem S0 tiger-left Pr(o=TL S0, listen)=0.85 Pr(o=TR S1, listen)=0.15 S1 tiger-right Pr(o=TL S0, listen)=0.15 Pr(o=TR S1, listen)=0.85 Actions={ 0: listen, 1: open-left, 2: open-right} Reward Function - Penalty for wrong opening: Reward for correct opening: Cost for listening action: -1 Observations - to hear the tiger on the left (TL) - to hear the tiger on the right(tr)
32 Tiger Problem (Transition Probabilities) Prob. (LISTEN) Tiger: left Tiger: right Doesn t change Tiger: left Tiger location Tiger: right Prob. (LEFT) Tiger: left Tiger: right Tiger: left Problem reset Tiger: right Prob. (RIGHT) Tiger: left Tiger: right Tiger: left Tiger: right
33 Tiger Problem (Observation Probabilities) Prob. (LISTEN) O: TL O: TR Tiger: left Tiger: right Prob. (LEFT) O: TL O: TR Any observation Tiger: left Without the listen action Tiger: right Is uninformative Prob. (LEFT) O: TL O: TR Tiger: left Tiger: right
34 Tiger Problem (Immediate Rewards) Reward (LISTEN) Tiger: left Tiger: right -1-1 Reward (LEFT) Tiger: left Tiger: right Reward (RIGHT) Tiger: left Tiger: right
35 The tiger problem: State tracking b 0 Belief vector S1 tiger-left S2 tiger-right Belief
36 The tiger problem: State tracking b 0 Belief vector S1 tiger-left S2 tiger-right obs=hear-tiger-left Belief action=listen
37 The tiger problem: State tracking b 1 b 0 b 1 ( s ) i = P ( o si, a)! P( si s j, a) b0( s j) s " S j P ( o a, b) Belief vector S1 tiger-left S2 tiger-right obs=growl-left Belief action=listen
38 Tiger Example Optimal Policy t=1 Optimal Policy for t=1 α 0 (1)=(-100.0, 10.0) α 1 (1)=(-1.0, -1.0) α 0 (1)=(10.0, ) left listen right [0.00, 0.10] [0.10, 0.90] [0.90, 1.00] Optimal policy: open-left listen open-right Belief Space: S1 tiger-left S2 tiger-right
39 Tiger Example Optimal Policy for t=2 For t=2 [0.00, 0.02] [0.02, 0.39] [0.39, 0.61] [0.61, 0.98] [0.98, 1.00] listen listen listen listen listen TL/TR TR TL TL/TR TR TL TL/TR left listen right
40 Can we solving this Belief MDP? The Bellman equation for this belief MDP is # $ % & ' ( a ( ) = max ) ( ) (, ) +! ) Pr (, ) ( o ) * * V b b s R s a o b a V b a" A s" S o" O In general case: Very Hard to solve continuous space MDPs. Unfortunately, DP updates cannot be carried out because there are uncountably many of belief states. One cannot enumerate every equation of value function. To conduct DP steps implicitly, we need to discuss the properties of value functions. Some special properties can be exploited first to simplify this problem Policy Tree Piecewise linear and convex property And then find an approximation algorithm to construct the optimal t-step discounted value function over belief space using value iteration
41 Policy Tree With one step remaining, the agent must take a single action. With 2 steps to go, it takes an action, make an observation, and makes the final action. In general, an agent t-step policy can be represented as a policy tree. A O 1 O O k 2 A A A T steps to go T-1 steps to go A O 1 O O k 2 A A A 2 steps to go (T=2) 1 step to go (T=1)
42 Value Function for policy tree p If p is one-step policy tree, then the value of executing that action in state s is Vp(s) = R(s, a(p)). More generally, if p is a t-step policy tree, then Vp(s) = R(s, a(p)) + r (Expected value of the future) = R(s, a(p)) + r s'! S o!" ( ) ( ) ( ) ( ) ( ) T ( s ' s, a p, s ') T s ', a p, o V s ' Thus, Vp(s) can be thought as a vector associated with the policy trees p since its dimension is the same as the number of states. We often use notation αp to refer to this vectors.! = # # V s, V s,..., V s ( ) ( ) ( ) p p 1 p 2 p n i i o p i
43 Value Function Over Belief Space As the exact world cannot be observed, the agent must compute an expectation over world states of executing policy tree p from belief state b: Vp(b) = " s! S ( ) ( s) b s V If we let! = V s, V s,..., V s, then p ( ) ( ) ( ) p p 1 p 2 p n p ( ) V b = b! p To construct an optimal t-step policy, we must maximize over all t-step policy trees P: t ( ) = max V b b! p" P As Vp(b) is linear in b for each p P, Vt(b) is the upper surface of those functions. That is, Vt(b) is piecewise linear and convex. p
44 Illustration: Piecewise Linear Value Function Let V p1 V p2 and V p3 be the value functions induced by policy trees p1, p2, and p3. Each of these value functions are the form Which is a multi-linear function of b. Thus, for each value function can be shown as a line, plane, or hyperplane, depending on the number of states, and the optimal t-step value p i ( ) V b = b! t ( ) = max pi V b b! p " P Example in the case of two states (b(s1) = 1- b(s2)) be illustrated as the upper surface in two dimensions: i p i
45 Picture: Optimal t-step Value Function V p1 Vp3 V p2 Belief 0 1 S=S 0 B(s 0 ) S=S 1
46 Optimal t-step Policy The optimal t-step policy is determined by projecting the optimal value function back down onto the belief space. V p1 V p3 V p2 0 A(p 1 ) A(p 2 ) A(p 3 ) Belief B(s 0 ) The projection of the optimal t-step value function yields a partition into regions, within each of which there is a single policy tree, p, such that is maximal over the entire region. The optimal action in that region a(p), the action in the root of the policy tree p. 1
47 First Step of Value Iteration One-step policy trees are just actions: a 0 a 1 To do a DP backup, we evaluate every possible 2-step policy tree a 0 a 0 a 0 O 0 O 1 O 0 O 1 O 0 O 1 a 0 O 0 O 1 a 0 a 0 a 0 a 1 a 1 a 0 a 1 a 1 a 1 a 1 O 0 O 1 O 0 O 1 a 1 a 1 O 0 O 1 O 0 O 1 a 0 a 0 a 0 a 1 a 1 a 0 a 1 a 1
48 Pruning Some policy trees are dominated and are never useful V p1 V p3 V p2 0 Belief B(s 0 ) They are pruned and not considered on the next step. The key idea is to prune before evaluating (Witness and Incremental Pruning do this) 1
49 Value Iteration (Belief MDP) Keep doing backups until the value function doesn t change much anymore In the worst case, you end up considering every possible policy tree But hopefully you will converge before this happens
50 More General POMDP: Model uncertainty Belief state b=p(θ) meta-level state Choose action to maximize long term reward r s b actions a s b actions s b +a rewards a s b +a rewards r s b Meta-level MDP decision a outcome r, s, b decision a outcome r, s, b Meta-level Model P(r,s b s b,a) Meta-level Model P(r,s b s b,a ) Tree required to compute optimal solution grows exponentially
51 Multi-armed Bandit Problem Bandit arms m 1 m 2 m 3 (unknown reward probabilities) Most complex problem for which optimal solution fully specified - Gittins index -More general than it looks - Projects with separable state spaces -Projects only change when worked on. -Key Properties of Solution -Each project s value can be separately computed -Optimal policy permanantly retires projects less valuable projects
52 Learning in a 2- armed bandit Arm1 Arm2
53 Problem difficulty Policies must specify actions For all possible information states Action dependent tree of Beta sufficient statistics
54 Value Function Optimal value function for learning while acting for k step look-ahead The reason information is valuable is the ability to use the information to follow the optimal policy: By distinguishing the arms, future best actions have higher expected payoffs.
55 More reading Planning and acting in partially Observable stochastic domains Leslie P. Kaelbling Optimal Policies for partially Observable Markov Decision Processes Anthony R.Cassandra 1995 Hierarchical Methods for Planning under Uncertainty Joelle Pineau POMDP s tutorial in Tony's POMDP Page
An Introduction to Markov Decision Processes. MDP Tutorial - 1
 An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
Reinforcement Learning
 Reinforcement Learning LU 2 - Markov Decision Problems and Dynamic Programming Dr. Martin Lauer AG Maschinelles Lernen und Natürlichsprachliche Systeme Albert-Ludwigs-Universität Freiburg [email protected]
Reinforcement Learning LU 2 - Markov Decision Problems and Dynamic Programming Dr. Martin Lauer AG Maschinelles Lernen und Natürlichsprachliche Systeme Albert-Ludwigs-Universität Freiburg [email protected]
Motivation. Motivation. Can a software agent learn to play Backgammon by itself? Machine Learning. Reinforcement Learning
 Motivation Machine Learning Can a software agent learn to play Backgammon by itself? Reinforcement Learning Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut
Motivation Machine Learning Can a software agent learn to play Backgammon by itself? Reinforcement Learning Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut
Reinforcement Learning
 Reinforcement Learning LU 2 - Markov Decision Problems and Dynamic Programming Dr. Joschka Bödecker AG Maschinelles Lernen und Natürlichsprachliche Systeme Albert-Ludwigs-Universität Freiburg [email protected]
Reinforcement Learning LU 2 - Markov Decision Problems and Dynamic Programming Dr. Joschka Bödecker AG Maschinelles Lernen und Natürlichsprachliche Systeme Albert-Ludwigs-Universität Freiburg [email protected]
Using Markov Decision Processes to Solve a Portfolio Allocation Problem
 Using Markov Decision Processes to Solve a Portfolio Allocation Problem Daniel Bookstaber April 26, 2005 Contents 1 Introduction 3 2 Defining the Model 4 2.1 The Stochastic Model for a Single Asset.........................
Using Markov Decision Processes to Solve a Portfolio Allocation Problem Daniel Bookstaber April 26, 2005 Contents 1 Introduction 3 2 Defining the Model 4 2.1 The Stochastic Model for a Single Asset.........................
A survey of point-based POMDP solvers
 DOI 10.1007/s10458-012-9200-2 A survey of point-based POMDP solvers Guy Shani Joelle Pineau Robert Kaplow The Author(s) 2012 Abstract The past decade has seen a significant breakthrough in research on
DOI 10.1007/s10458-012-9200-2 A survey of point-based POMDP solvers Guy Shani Joelle Pineau Robert Kaplow The Author(s) 2012 Abstract The past decade has seen a significant breakthrough in research on
Stochastic Models for Inventory Management at Service Facilities
 Stochastic Models for Inventory Management at Service Facilities O. Berman, E. Kim Presented by F. Zoghalchi University of Toronto Rotman School of Management Dec, 2012 Agenda 1 Problem description Deterministic
Stochastic Models for Inventory Management at Service Facilities O. Berman, E. Kim Presented by F. Zoghalchi University of Toronto Rotman School of Management Dec, 2012 Agenda 1 Problem description Deterministic
Lecture 5: Model-Free Control
 Lecture 5: Model-Free Control David Silver Outline 1 Introduction 2 On-Policy Monte-Carlo Control 3 On-Policy Temporal-Difference Learning 4 Off-Policy Learning 5 Summary Introduction Model-Free Reinforcement
Lecture 5: Model-Free Control David Silver Outline 1 Introduction 2 On-Policy Monte-Carlo Control 3 On-Policy Temporal-Difference Learning 4 Off-Policy Learning 5 Summary Introduction Model-Free Reinforcement
Numerical Methods for Option Pricing
 Chapter 9 Numerical Methods for Option Pricing Equation (8.26) provides a way to evaluate option prices. For some simple options, such as the European call and put options, one can integrate (8.26) directly
Chapter 9 Numerical Methods for Option Pricing Equation (8.26) provides a way to evaluate option prices. For some simple options, such as the European call and put options, one can integrate (8.26) directly
The MultiAgent Decision Process toolbox: software for decision-theoretic planning in multiagent systems
 The MultiAgent Decision Process toolbox: software for decision-theoretic planning in multiagent systems Matthijs T.J. Spaan Institute for Systems and Robotics Instituto Superior Técnico Lisbon, Portugal
The MultiAgent Decision Process toolbox: software for decision-theoretic planning in multiagent systems Matthijs T.J. Spaan Institute for Systems and Robotics Instituto Superior Técnico Lisbon, Portugal
Online Planning Algorithms for POMDPs
 Journal of Artificial Intelligence Research 32 (2008) 663-704 Submitted 03/08; published 07/08 Online Planning Algorithms for POMDPs Stéphane Ross Joelle Pineau School of Computer Science McGill University,
Journal of Artificial Intelligence Research 32 (2008) 663-704 Submitted 03/08; published 07/08 Online Planning Algorithms for POMDPs Stéphane Ross Joelle Pineau School of Computer Science McGill University,
Mathematical finance and linear programming (optimization)
") Mathematical finance and linear programming (optimization) Geir Dahl September 15, 2009 1 Introduction The purpose of this short note is to explain how linear programming (LP) (=linear optimization) may
Mathematical finance and linear programming (optimization) Geir Dahl September 15, 2009 1 Introduction The purpose of this short note is to explain how linear programming (LP) (=linear optimization) may
A Sarsa based Autonomous Stock Trading Agent
 A Sarsa based Autonomous Stock Trading Agent Achal Augustine The University of Texas at Austin Department of Computer Science Austin, TX 78712 USA [email protected] Abstract This paper describes an autonomous
A Sarsa based Autonomous Stock Trading Agent Achal Augustine The University of Texas at Austin Department of Computer Science Austin, TX 78712 USA [email protected] Abstract This paper describes an autonomous
Numerical methods for American options
 Lecture 9 Numerical methods for American options Lecture Notes by Andrzej Palczewski Computational Finance p. 1 American options The holder of an American option has the right to exercise it at any moment
Lecture 9 Numerical methods for American options Lecture Notes by Andrzej Palczewski Computational Finance p. 1 American options The holder of an American option has the right to exercise it at any moment
Inductive QoS Packet Scheduling for Adaptive Dynamic Networks
 Inductive QoS Packet Scheduling for Adaptive Dynamic Networks Malika BOURENANE Dept of Computer Science University of Es-Senia Algeria [email protected] Abdelhamid MELLOUK LISSI Laboratory University
Inductive QoS Packet Scheduling for Adaptive Dynamic Networks Malika BOURENANE Dept of Computer Science University of Es-Senia Algeria [email protected] Abdelhamid MELLOUK LISSI Laboratory University
Measuring the Performance of an Agent
 25 Measuring the Performance of an Agent The rational agent that we are aiming at should be successful in the task it is performing To assess the success we need to have a performance measure What is rational
25 Measuring the Performance of an Agent The rational agent that we are aiming at should be successful in the task it is performing To assess the success we need to have a performance measure What is rational
CHAPTER 2 Estimating Probabilities
 CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2016. Tom M. Mitchell. All rights reserved. *DRAFT OF January 24, 2016* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is a
CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2016. Tom M. Mitchell. All rights reserved. *DRAFT OF January 24, 2016* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is a
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Neuro-Dynamic Programming An Overview
 1 Neuro-Dynamic Programming An Overview Dimitri Bertsekas Dept. of Electrical Engineering and Computer Science M.I.T. September 2006 2 BELLMAN AND THE DUAL CURSES Dynamic Programming (DP) is very broadly
1 Neuro-Dynamic Programming An Overview Dimitri Bertsekas Dept. of Electrical Engineering and Computer Science M.I.T. September 2006 2 BELLMAN AND THE DUAL CURSES Dynamic Programming (DP) is very broadly
Lecture notes: single-agent dynamics 1
 Lecture notes: single-agent dynamics 1 Single-agent dynamic optimization models In these lecture notes we consider specification and estimation of dynamic optimization models. Focus on single-agent models.
Lecture notes: single-agent dynamics 1 Single-agent dynamic optimization models In these lecture notes we consider specification and estimation of dynamic optimization models. Focus on single-agent models.
Section 5.0 : Horn Physics. By Martin J. King, 6/29/08 Copyright 2008 by Martin J. King. All Rights Reserved.
 Section 5. : Horn Physics Section 5. : Horn Physics By Martin J. King, 6/29/8 Copyright 28 by Martin J. King. All Rights Reserved. Before discussing the design of a horn loaded loudspeaker system, it is
Section 5. : Horn Physics Section 5. : Horn Physics By Martin J. King, 6/29/8 Copyright 28 by Martin J. King. All Rights Reserved. Before discussing the design of a horn loaded loudspeaker system, it is
Largest Fixed-Aspect, Axis-Aligned Rectangle
 Largest Fixed-Aspect, Axis-Aligned Rectangle David Eberly Geometric Tools, LLC http://www.geometrictools.com/ Copyright c 1998-2016. All Rights Reserved. Created: February 21, 2004 Last Modified: February
Largest Fixed-Aspect, Axis-Aligned Rectangle David Eberly Geometric Tools, LLC http://www.geometrictools.com/ Copyright c 1998-2016. All Rights Reserved. Created: February 21, 2004 Last Modified: February
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
POMPDs Make Better Hackers: Accounting for Uncertainty in Penetration Testing. By: Chris Abbott
 POMPDs Make Better Hackers: Accounting for Uncertainty in Penetration Testing By: Chris Abbott Introduction What is penetration testing? Methodology for assessing network security, by generating and executing
POMPDs Make Better Hackers: Accounting for Uncertainty in Penetration Testing By: Chris Abbott Introduction What is penetration testing? Methodology for assessing network security, by generating and executing
Learning the Structure of Factored Markov Decision Processes in Reinforcement Learning Problems
 Learning the Structure of Factored Markov Decision Processes in Reinforcement Learning Problems Thomas Degris [email protected] Olivier Sigaud [email protected] Pierre-Henri Wuillemin [email protected]
Learning the Structure of Factored Markov Decision Processes in Reinforcement Learning Problems Thomas Degris [email protected] Olivier Sigaud [email protected] Pierre-Henri Wuillemin [email protected]
Lecture 3: Linear methods for classification
 Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Eligibility Traces. Suggested reading: Contents: Chapter 7 in R. S. Sutton, A. G. Barto: Reinforcement Learning: An Introduction MIT Press, 1998.
 Eligibility Traces 0 Eligibility Traces Suggested reading: Chapter 7 in R. S. Sutton, A. G. Barto: Reinforcement Learning: An Introduction MIT Press, 1998. Eligibility Traces Eligibility Traces 1 Contents:
Eligibility Traces 0 Eligibility Traces Suggested reading: Chapter 7 in R. S. Sutton, A. G. Barto: Reinforcement Learning: An Introduction MIT Press, 1998. Eligibility Traces Eligibility Traces 1 Contents:
An Application of Inverse Reinforcement Learning to Medical Records of Diabetes Treatment
 An Application of Inverse Reinforcement Learning to Medical Records of Diabetes Treatment Hideki Asoh 1, Masanori Shiro 1 Shotaro Akaho 1, Toshihiro Kamishima 1, Koiti Hasida 1, Eiji Aramaki 2, and Takahide
An Application of Inverse Reinforcement Learning to Medical Records of Diabetes Treatment Hideki Asoh 1, Masanori Shiro 1 Shotaro Akaho 1, Toshihiro Kamishima 1, Koiti Hasida 1, Eiji Aramaki 2, and Takahide
Creating a NL Texas Hold em Bot
 Creating a NL Texas Hold em Bot Introduction Poker is an easy game to learn by very tough to master. One of the things that is hard to do is controlling emotions. Due to frustration, many have made the
Creating a NL Texas Hold em Bot Introduction Poker is an easy game to learn by very tough to master. One of the things that is hard to do is controlling emotions. Due to frustration, many have made the
Single item inventory control under periodic review and a minimum order quantity
 Single item inventory control under periodic review and a minimum order quantity G. P. Kiesmüller, A.G. de Kok, S. Dabia Faculty of Technology Management, Technische Universiteit Eindhoven, P.O. Box 513,
Single item inventory control under periodic review and a minimum order quantity G. P. Kiesmüller, A.G. de Kok, S. Dabia Faculty of Technology Management, Technische Universiteit Eindhoven, P.O. Box 513,
Lecture 1: Introduction to Reinforcement Learning
 Lecture 1: Introduction to Reinforcement Learning David Silver Outline 1 Admin 2 About Reinforcement Learning 3 The Reinforcement Learning Problem 4 Inside An RL Agent 5 Problems within Reinforcement Learning
Lecture 1: Introduction to Reinforcement Learning David Silver Outline 1 Admin 2 About Reinforcement Learning 3 The Reinforcement Learning Problem 4 Inside An RL Agent 5 Problems within Reinforcement Learning
Two-Stage Stochastic Linear Programs
 Two-Stage Stochastic Linear Programs Operations Research Anthony Papavasiliou 1 / 27 Two-Stage Stochastic Linear Programs 1 Short Reviews Probability Spaces and Random Variables Convex Analysis 2 Deterministic
Two-Stage Stochastic Linear Programs Operations Research Anthony Papavasiliou 1 / 27 Two-Stage Stochastic Linear Programs 1 Short Reviews Probability Spaces and Random Variables Convex Analysis 2 Deterministic
Computing Near Optimal Strategies for Stochastic Investment Planning Problems
 Computing Near Optimal Strategies for Stochastic Investment Planning Problems Milos Hauskrecfat 1, Gopal Pandurangan 1,2 and Eli Upfal 1,2 Computer Science Department, Box 1910 Brown University Providence,
Computing Near Optimal Strategies for Stochastic Investment Planning Problems Milos Hauskrecfat 1, Gopal Pandurangan 1,2 and Eli Upfal 1,2 Computer Science Department, Box 1910 Brown University Providence,
TD(0) Leads to Better Policies than Approximate Value Iteration
 Leads to Better Policies than Approximate Value Iteration") TD(0) Leads to Better Policies than Approximate Value Iteration Benjamin Van Roy Management Science and Engineering and Electrical Engineering Stanford University Stanford, CA 94305 [email protected] Abstract
TD(0) Leads to Better Policies than Approximate Value Iteration Benjamin Van Roy Management Science and Engineering and Electrical Engineering Stanford University Stanford, CA 94305 [email protected] Abstract
Chapter 2: Binomial Methods and the Black-Scholes Formula
 Chapter 2: Binomial Methods and the Black-Scholes Formula 2.1 Binomial Trees We consider a financial market consisting of a bond B t = B(t), a stock S t = S(t), and a call-option C t = C(t), where the
Chapter 2: Binomial Methods and the Black-Scholes Formula 2.1 Binomial Trees We consider a financial market consisting of a bond B t = B(t), a stock S t = S(t), and a call-option C t = C(t), where the
Compact Representations and Approximations for Compuation in Games
 Compact Representations and Approximations for Compuation in Games Kevin Swersky April 23, 2008 Abstract Compact representations have recently been developed as a way of both encoding the strategic interactions
Compact Representations and Approximations for Compuation in Games Kevin Swersky April 23, 2008 Abstract Compact representations have recently been developed as a way of both encoding the strategic interactions
Scheduling Algorithms for Downlink Services in Wireless Networks: A Markov Decision Process Approach
 Scheduling Algorithms for Downlink Services in Wireless Networks: A Markov Decision Process Approach William A. Massey ORFE Department Engineering Quadrangle, Princeton University Princeton, NJ 08544 K.
Scheduling Algorithms for Downlink Services in Wireless Networks: A Markov Decision Process Approach William A. Massey ORFE Department Engineering Quadrangle, Princeton University Princeton, NJ 08544 K.
Best-response play in partially observable card games
 Best-response play in partially observable card games Frans Oliehoek Matthijs T. J. Spaan Nikos Vlassis Informatics Institute, Faculty of Science, University of Amsterdam, Kruislaan 43, 98 SJ Amsterdam,
Best-response play in partially observable card games Frans Oliehoek Matthijs T. J. Spaan Nikos Vlassis Informatics Institute, Faculty of Science, University of Amsterdam, Kruislaan 43, 98 SJ Amsterdam,
Lecture 10: Regression Trees
 Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
10.2 Series and Convergence
 10.2 Series and Convergence Write sums using sigma notation Find the partial sums of series and determine convergence or divergence of infinite series Find the N th partial sums of geometric series and
10.2 Series and Convergence Write sums using sigma notation Find the partial sums of series and determine convergence or divergence of infinite series Find the N th partial sums of geometric series and
LARGE CLASSES OF EXPERTS
 LARGE CLASSES OF EXPERTS Csaba Szepesvári University of Alberta CMPUT 654 E-mail: [email protected] UofA, October 31, 2006 OUTLINE 1 TRACKING THE BEST EXPERT 2 FIXED SHARE FORECASTER 3 VARIABLE-SHARE
LARGE CLASSES OF EXPERTS Csaba Szepesvári University of Alberta CMPUT 654 E-mail: [email protected] UofA, October 31, 2006 OUTLINE 1 TRACKING THE BEST EXPERT 2 FIXED SHARE FORECASTER 3 VARIABLE-SHARE
Reinforcement Learning for Resource Allocation and Time Series Tools for Mobility Prediction
 Reinforcement Learning for Resource Allocation and Time Series Tools for Mobility Prediction Baptiste Lefebvre 1,2, Stephane Senecal 2 and Jean-Marc Kelif 2 1 École Normale Supérieure (ENS), Paris, France,
Reinforcement Learning for Resource Allocation and Time Series Tools for Mobility Prediction Baptiste Lefebvre 1,2, Stephane Senecal 2 and Jean-Marc Kelif 2 1 École Normale Supérieure (ENS), Paris, France,
Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning
 Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning Richard S. Sutton a, Doina Precup b, and Satinder Singh a a AT&T Labs Research, 180 Park Avenue, Florham Park,
Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning Richard S. Sutton a, Doina Precup b, and Satinder Singh a a AT&T Labs Research, 180 Park Avenue, Florham Park,
The Effects of Start Prices on the Performance of the Certainty Equivalent Pricing Policy
 BMI Paper The Effects of Start Prices on the Performance of the Certainty Equivalent Pricing Policy Faculty of Sciences VU University Amsterdam De Boelelaan 1081 1081 HV Amsterdam Netherlands Author: R.D.R.
BMI Paper The Effects of Start Prices on the Performance of the Certainty Equivalent Pricing Policy Faculty of Sciences VU University Amsterdam De Boelelaan 1081 1081 HV Amsterdam Netherlands Author: R.D.R.
Persuasion by Cheap Talk - Online Appendix
 Persuasion by Cheap Talk - Online Appendix By ARCHISHMAN CHAKRABORTY AND RICK HARBAUGH Online appendix to Persuasion by Cheap Talk, American Economic Review Our results in the main text concern the case
Persuasion by Cheap Talk - Online Appendix By ARCHISHMAN CHAKRABORTY AND RICK HARBAUGH Online appendix to Persuasion by Cheap Talk, American Economic Review Our results in the main text concern the case
Course: Model, Learning, and Inference: Lecture 5
 Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 [email protected] Abstract Probability distributions on structured representation.
Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 [email protected] Abstract Probability distributions on structured representation.
10-601. Machine Learning. http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
 10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
Finite Differences Schemes for Pricing of European and American Options
 Finite Differences Schemes for Pricing of European and American Options Margarida Mirador Fernandes IST Technical University of Lisbon Lisbon, Portugal November 009 Abstract Starting with the Black-Scholes
Finite Differences Schemes for Pricing of European and American Options Margarida Mirador Fernandes IST Technical University of Lisbon Lisbon, Portugal November 009 Abstract Starting with the Black-Scholes
Penetration Testing == POMDP Solving?
 Penetration Testing == POMDP Solving? Carlos Sarraute Core Security Technologies & ITBA Buenos Aires, Argentina [email protected] Olivier Buffet and Jörg Hoffmann INRIA Nancy, France {olivier.buffet,joerg.hoffmann}@loria.fr
Penetration Testing == POMDP Solving? Carlos Sarraute Core Security Technologies & ITBA Buenos Aires, Argentina [email protected] Olivier Buffet and Jörg Hoffmann INRIA Nancy, France {olivier.buffet,joerg.hoffmann}@loria.fr
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh
 Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Introduction to Markov Chain Monte Carlo
 Introduction to Markov Chain Monte Carlo Monte Carlo: sample from a distribution to estimate the distribution to compute max, mean Markov Chain Monte Carlo: sampling using local information Generic problem
Introduction to Markov Chain Monte Carlo Monte Carlo: sample from a distribution to estimate the distribution to compute max, mean Markov Chain Monte Carlo: sampling using local information Generic problem
Learning Agents: Introduction
 Learning Agents: Introduction S Luz [email protected] October 22, 2013 Learning in agent architectures Performance standard representation Critic Agent perception rewards/ instruction Perception Learner Goals
Learning Agents: Introduction S Luz [email protected] October 22, 2013 Learning in agent architectures Performance standard representation Critic Agent perception rewards/ instruction Perception Learner Goals
2. Information Economics
 2. Information Economics In General Equilibrium Theory all agents had full information regarding any variable of interest (prices, commodities, state of nature, cost function, preferences, etc.) In many
2. Information Economics In General Equilibrium Theory all agents had full information regarding any variable of interest (prices, commodities, state of nature, cost function, preferences, etc.) In many
More details on the inputs, functionality, and output can be found below.
 Overview: The SMEEACT (Software for More Efficient, Ethical, and Affordable Clinical Trials) web interface (http://research.mdacc.tmc.edu/smeeactweb) implements a single analysis of a two-armed trial comparing
Overview: The SMEEACT (Software for More Efficient, Ethical, and Affordable Clinical Trials) web interface (http://research.mdacc.tmc.edu/smeeactweb) implements a single analysis of a two-armed trial comparing
6.254 : Game Theory with Engineering Applications Lecture 2: Strategic Form Games
 6.254 : Game Theory with Engineering Applications Lecture 2: Strategic Form Games Asu Ozdaglar MIT February 4, 2009 1 Introduction Outline Decisions, utility maximization Strategic form games Best responses
6.254 : Game Theory with Engineering Applications Lecture 2: Strategic Form Games Asu Ozdaglar MIT February 4, 2009 1 Introduction Outline Decisions, utility maximization Strategic form games Best responses
Continued Fractions and the Euclidean Algorithm
 Continued Fractions and the Euclidean Algorithm Lecture notes prepared for MATH 326, Spring 997 Department of Mathematics and Statistics University at Albany William F Hammond Table of Contents Introduction
Continued Fractions and the Euclidean Algorithm Lecture notes prepared for MATH 326, Spring 997 Department of Mathematics and Statistics University at Albany William F Hammond Table of Contents Introduction
Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay
 Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay Lecture - 17 Shannon-Fano-Elias Coding and Introduction to Arithmetic Coding
Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay Lecture - 17 Shannon-Fano-Elias Coding and Introduction to Arithmetic Coding
Temporal Difference Learning in the Tetris Game
 Temporal Difference Learning in the Tetris Game Hans Pirnay, Slava Arabagi February 6, 2009 1 Introduction Learning to play the game Tetris has been a common challenge on a few past machine learning competitions.
Temporal Difference Learning in the Tetris Game Hans Pirnay, Slava Arabagi February 6, 2009 1 Introduction Learning to play the game Tetris has been a common challenge on a few past machine learning competitions.
A Multi-agent Q-learning Framework for Optimizing Stock Trading Systems
 A Multi-agent Q-learning Framework for Optimizing Stock Trading Systems Jae Won Lee 1 and Jangmin O 2 1 School of Computer Science and Engineering, Sungshin Women s University, Seoul, Korea 136-742 [email protected]
A Multi-agent Q-learning Framework for Optimizing Stock Trading Systems Jae Won Lee 1 and Jangmin O 2 1 School of Computer Science and Engineering, Sungshin Women s University, Seoul, Korea 136-742 [email protected]
Analysis of Algorithms I: Optimal Binary Search Trees
 Analysis of Algorithms I: Optimal Binary Search Trees Xi Chen Columbia University Given a set of n keys K = {k 1,..., k n } in sorted order: k 1 < k 2 < < k n we wish to build an optimal binary search
Analysis of Algorithms I: Optimal Binary Search Trees Xi Chen Columbia University Given a set of n keys K = {k 1,..., k n } in sorted order: k 1 < k 2 < < k n we wish to build an optimal binary search
Cyber-Security Analysis of State Estimators in Power Systems
 Cyber-Security Analysis of State Estimators in Electric Power Systems André Teixeira 1, Saurabh Amin 2, Henrik Sandberg 1, Karl H. Johansson 1, and Shankar Sastry 2 ACCESS Linnaeus Centre, KTH-Royal Institute
Cyber-Security Analysis of State Estimators in Electric Power Systems André Teixeira 1, Saurabh Amin 2, Henrik Sandberg 1, Karl H. Johansson 1, and Shankar Sastry 2 ACCESS Linnaeus Centre, KTH-Royal Institute
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
STRATEGIC CAPACITY PLANNING USING STOCK CONTROL MODEL
 Session 6. Applications of Mathematical Methods to Logistics and Business Proceedings of the 9th International Conference Reliability and Statistics in Transportation and Communication (RelStat 09), 21
Session 6. Applications of Mathematical Methods to Logistics and Business Proceedings of the 9th International Conference Reliability and Statistics in Transportation and Communication (RelStat 09), 21
Decision Making under Uncertainty
 6.825 Techniques in Artificial Intelligence Decision Making under Uncertainty How to make one decision in the face of uncertainty Lecture 19 1 In the next two lectures, we ll look at the question of how
6.825 Techniques in Artificial Intelligence Decision Making under Uncertainty How to make one decision in the face of uncertainty Lecture 19 1 In the next two lectures, we ll look at the question of how
1 Representation of Games. Kerschbamer: Commitment and Information in Games
 1 epresentation of Games Kerschbamer: Commitment and Information in Games Game-Theoretic Description of Interactive Decision Situations This lecture deals with the process of translating an informal description
1 epresentation of Games Kerschbamer: Commitment and Information in Games Game-Theoretic Description of Interactive Decision Situations This lecture deals with the process of translating an informal description
Supply planning for two-level assembly systems with stochastic component delivery times: trade-off between holding cost and service level
 Supply planning for two-level assembly systems with stochastic component delivery times: trade-off between holding cost and service level Faicel Hnaien, Xavier Delorme 2, and Alexandre Dolgui 2 LIMOS,
Supply planning for two-level assembly systems with stochastic component delivery times: trade-off between holding cost and service level Faicel Hnaien, Xavier Delorme 2, and Alexandre Dolgui 2 LIMOS,
Assignment #1. Example: tetris state: board configuration + shape of the falling piece ~2 200 states! Recap RL so far. Page 1
 Generalization and function approximation CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Represent
Generalization and function approximation CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Represent
HETEROGENEOUS AGENTS AND AGGREGATE UNCERTAINTY. Daniel Harenberg [email protected]. University of Mannheim. Econ 714, 28.11.
 COMPUTING EQUILIBRIUM WITH HETEROGENEOUS AGENTS AND AGGREGATE UNCERTAINTY (BASED ON KRUEGER AND KUBLER, 2004) Daniel Harenberg [email protected] University of Mannheim Econ 714, 28.11.06 Daniel Harenberg
COMPUTING EQUILIBRIUM WITH HETEROGENEOUS AGENTS AND AGGREGATE UNCERTAINTY (BASED ON KRUEGER AND KUBLER, 2004) Daniel Harenberg [email protected] University of Mannheim Econ 714, 28.11.06 Daniel Harenberg
The Ergodic Theorem and randomness
 The Ergodic Theorem and randomness Peter Gács Department of Computer Science Boston University March 19, 2008 Peter Gács (Boston University) Ergodic theorem March 19, 2008 1 / 27 Introduction Introduction
The Ergodic Theorem and randomness Peter Gács Department of Computer Science Boston University March 19, 2008 Peter Gács (Boston University) Ergodic theorem March 19, 2008 1 / 27 Introduction Introduction
NEURAL NETWORKS AND REINFORCEMENT LEARNING. Abhijit Gosavi
 NEURAL NETWORKS AND REINFORCEMENT LEARNING Abhijit Gosavi Department of Engineering Management and Systems Engineering Missouri University of Science and Technology Rolla, MO 65409 1 Outline A Quick Introduction
NEURAL NETWORKS AND REINFORCEMENT LEARNING Abhijit Gosavi Department of Engineering Management and Systems Engineering Missouri University of Science and Technology Rolla, MO 65409 1 Outline A Quick Introduction
G(s) = Y (s)/u(s) In this representation, the output is always the Transfer function times the input. Y (s) = G(s)U(s).
 = Y (s)/u(s) In this representation, the output is always the Transfer function times the input. Y (s) = G(s)U(s).") Transfer Functions The transfer function of a linear system is the ratio of the Laplace Transform of the output to the Laplace Transform of the input, i.e., Y (s)/u(s). Denoting this ratio by G(s), i.e.,
Transfer Functions The transfer function of a linear system is the ratio of the Laplace Transform of the output to the Laplace Transform of the input, i.e., Y (s)/u(s). Denoting this ratio by G(s), i.e.,
Finitely Additive Dynamic Programming and Stochastic Games. Bill Sudderth University of Minnesota
 Finitely Additive Dynamic Programming and Stochastic Games Bill Sudderth University of Minnesota 1 Discounted Dynamic Programming Five ingredients: S, A, r, q, β. S - state space A - set of actions q(
Finitely Additive Dynamic Programming and Stochastic Games Bill Sudderth University of Minnesota 1 Discounted Dynamic Programming Five ingredients: S, A, r, q, β. S - state space A - set of actions q(
Influences in low-degree polynomials
 Influences in low-degree polynomials Artūrs Bačkurs December 12, 2012 1 Introduction In 3] it is conjectured that every bounded real polynomial has a highly influential variable The conjecture is known
Influences in low-degree polynomials Artūrs Bačkurs December 12, 2012 1 Introduction In 3] it is conjectured that every bounded real polynomial has a highly influential variable The conjecture is known
Higher Education Math Placement
 Higher Education Math Placement Placement Assessment Problem Types 1. Whole Numbers, Fractions, and Decimals 1.1 Operations with Whole Numbers Addition with carry Subtraction with borrowing Multiplication
Higher Education Math Placement Placement Assessment Problem Types 1. Whole Numbers, Fractions, and Decimals 1.1 Operations with Whole Numbers Addition with carry Subtraction with borrowing Multiplication
Statistical Machine Translation: IBM Models 1 and 2
 Statistical Machine Translation: IBM Models 1 and 2 Michael Collins 1 Introduction The next few lectures of the course will be focused on machine translation, and in particular on statistical machine translation
Statistical Machine Translation: IBM Models 1 and 2 Michael Collins 1 Introduction The next few lectures of the course will be focused on machine translation, and in particular on statistical machine translation
Language Modeling. Chapter 1. 1.1 Introduction
 Chapter 1 Language Modeling (Course notes for NLP by Michael Collins, Columbia University) 1.1 Introduction In this chapter we will consider the the problem of constructing a language model from a set
Chapter 1 Language Modeling (Course notes for NLP by Michael Collins, Columbia University) 1.1 Introduction In this chapter we will consider the the problem of constructing a language model from a set
Nonparametric adaptive age replacement with a one-cycle criterion
 Nonparametric adaptive age replacement with a one-cycle criterion P. Coolen-Schrijner, F.P.A. Coolen Department of Mathematical Sciences University of Durham, Durham, DH1 3LE, UK e-mail: [email protected]
Nonparametric adaptive age replacement with a one-cycle criterion P. Coolen-Schrijner, F.P.A. Coolen Department of Mathematical Sciences University of Durham, Durham, DH1 3LE, UK e-mail: [email protected]
Choice under Uncertainty
 Choice under Uncertainty Part 1: Expected Utility Function, Attitudes towards Risk, Demand for Insurance Slide 1 Choice under Uncertainty We ll analyze the underlying assumptions of expected utility theory
Choice under Uncertainty Part 1: Expected Utility Function, Attitudes towards Risk, Demand for Insurance Slide 1 Choice under Uncertainty We ll analyze the underlying assumptions of expected utility theory
THE NUMBER OF REPRESENTATIONS OF n OF THE FORM n = x 2 2 y, x > 0, y 0
 THE NUMBER OF REPRESENTATIONS OF n OF THE FORM n = x 2 2 y, x > 0, y 0 RICHARD J. MATHAR Abstract. We count solutions to the Ramanujan-Nagell equation 2 y +n = x 2 for fixed positive n. The computational
THE NUMBER OF REPRESENTATIONS OF n OF THE FORM n = x 2 2 y, x > 0, y 0 RICHARD J. MATHAR Abstract. We count solutions to the Ramanujan-Nagell equation 2 y +n = x 2 for fixed positive n. The computational
Analysis of Bayesian Dynamic Linear Models
 Analysis of Bayesian Dynamic Linear Models Emily M. Casleton December 17, 2010 1 Introduction The main purpose of this project is to explore the Bayesian analysis of Dynamic Linear Models (DLMs). The main
Analysis of Bayesian Dynamic Linear Models Emily M. Casleton December 17, 2010 1 Introduction The main purpose of this project is to explore the Bayesian analysis of Dynamic Linear Models (DLMs). The main
Predictive Representations of State
 Predictive Representations of State Michael L. Littman Richard S. Sutton AT&T Labs Research, Florham Park, New Jersey {sutton,mlittman}@research.att.com Satinder Singh Syntek Capital, New York, New York
Predictive Representations of State Michael L. Littman Richard S. Sutton AT&T Labs Research, Florham Park, New Jersey {sutton,mlittman}@research.att.com Satinder Singh Syntek Capital, New York, New York
Markov Decision Processes for Ad Network Optimization
 Markov Decision Processes for Ad Network Optimization Flávio Sales Truzzi 1, Valdinei Freire da Silva 2, Anna Helena Reali Costa 1, Fabio Gagliardi Cozman 3 1 Laboratório de Técnicas Inteligentes (LTI)
Markov Decision Processes for Ad Network Optimization Flávio Sales Truzzi 1, Valdinei Freire da Silva 2, Anna Helena Reali Costa 1, Fabio Gagliardi Cozman 3 1 Laboratório de Técnicas Inteligentes (LTI)
A Novel Binary Particle Swarm Optimization
 Proceedings of the 5th Mediterranean Conference on T33- A Novel Binary Particle Swarm Optimization Motaba Ahmadieh Khanesar, Member, IEEE, Mohammad Teshnehlab and Mahdi Aliyari Shoorehdeli K. N. Toosi
Proceedings of the 5th Mediterranean Conference on T33- A Novel Binary Particle Swarm Optimization Motaba Ahmadieh Khanesar, Member, IEEE, Mohammad Teshnehlab and Mahdi Aliyari Shoorehdeli K. N. Toosi
AI: A Modern Approach, Chpts. 3-4 Russell and Norvig
 AI: A Modern Approach, Chpts. 3-4 Russell and Norvig Sequential Decision Making in Robotics CS 599 Geoffrey Hollinger and Gaurav Sukhatme (Some slide content from Stuart Russell and HweeTou Ng) Spring,
AI: A Modern Approach, Chpts. 3-4 Russell and Norvig Sequential Decision Making in Robotics CS 599 Geoffrey Hollinger and Gaurav Sukhatme (Some slide content from Stuart Russell and HweeTou Ng) Spring,