arxiv: v1 [cs.cv] 25 Nov 2019
|
|
|
- Hester Henderson
- 4 years ago
- Views:
Transcription

![cv] 25 Nov 2019 Training Phase Testing Phase Single views only Input 3D reconstruction Textured Re-lighting Figure 1: Unsupervised learning of 3D deformable objects from in-the-wild images.](/docs-images/105/167895420/images/1-4.jpg "Left: Training uses only single views of the object category with no additional supervision at all (i.e. no ground-truth 3D information, multiple views, or any prior model of the object).")





 is available.")
1 Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild Shangzhe Wu Christian Rupprecht Andrea Vedaldi Visual Geometry Group, University of Oxford {szwu, chrisr, arxiv: v1 [cs.cv] 25 Nov 2019 Training Phase Testing Phase Single views only Input 3D reconstruction Textured Re-lighting Figure 1: Unsupervised learning of 3D deformable objects from in-the-wild images. Left: Training uses only single views of the object category with no additional supervision at all (i.e. no ground-truth 3D information, multiple views, or any prior model of the object). Right: Once trained, our model reconstructs the 3D pose, shape, albedo and illumination of a deformable object instance from a single image with excellent fidelity. Abstract We propose a method to learn 3D deformable object categories from raw single-view images, without external supervision. The method is based on an autoencoder that factors each input image into depth, albedo, viewpoint and illumination. In order to disentangle these components without supervision, we use the fact that many object categories have, at least in principle, a symmetric structure. We show that reasoning about illumination allows us to exploit the underlying object symmetry even if the appearance is not symmetric due to shading. Furthermore, we model objects that are probably, but not certainly, symmetric by predicting a symmetry probability map, learned end-to-end with the other components of the model. Our experiments show that this method can recover very accurately the 3D shape of human faces, cat faces and cars from single-view images, without any supervision or a prior shape model. On benchmarks, we demonstrate superior accuracy compared to another method that uses supervision at the level of 2D image correspondences. 1. Introduction Understanding the 3D structure of images is key in many computer vision applications. Futhermore, while many deep networks appear to understand images as 2D textures [16], 3D modelling can explain away much of the variability of natural images and potentially improve image understanding in general. Motivated by these facts, we consider the problem of learning 3D models for deformable object categories. We study this problem under two challenging conditions. The first condition is that no 2D or 3D ground truth information (such as keypoints, segmentation, depth maps, or prior knowledge of a 3D model) is available. Learning without external supervisions removes the bottleneck of collecting image annotations, which is often a major obstacle to deploying deep learning for new applications. The second condition is that the algorithm must use an unconstrained collection of single-view images in particular, it should not require multiple views of the same instance. Learning from single-view images is useful because in many applications, and especially for deformable objects, we only have a source of still images to work with. Consequently, our learning algorithm ingests a number of single-view images of a deformable object category and produces as output a deep network that can estimate the 3D shape of any instance given a single image of it (Fig. 1). We formulate this as an autoencoder that internally decomposes the image into albedo, depth, illumination and viewpoint, without direct supervision for any of these factors. 1
2 However, without further assumptions, decomposing images into these four factors is ill-posed. In search of minimal assumptions to achieve this, we note that many object categories are symmetric (e.g. almost all animals and many handcrafted objects). Assuming an object is perfectly symmetric, one can obtain a virtual second view of it by simply mirroring the image. In fact, if correspondences between the pair of mirrored images were available, 3D reconstruction could be achieved by stereo reconstruction [41, 12, 60, 54, 14]. Motivated by this, we seek to leverage symmetry as a geometric cue to constrain the decomposition. However, specific object instances are in practice never fully symmetric, neither in shape nor appearance. Shape is non-symmetric due to variations in pose or other details (e.g. hair style or expressions on a human face), and albedo can also be non-symmetric (e.g. asymmetric texture of cat faces). Even when both shape and albedo are symmetric, the appearance may still not be, due to asymmetric illumination. We address this issue in two ways. First, we explicitly model illumination to exploit the underlying symmetry. Furthermore, we show that, by doing so, the model can exploit illumination as an additional cue for recovering the shape. Second, we augment the model to reason about potential lack of symmetry in the objects. To do this, the model predicts, along with the other factors, a probability map that each given pixel has a symmetric counterpart in the image. We combine these elements in an end-to-end learning formulation, where all components, including the confidence maps, are learned from raw RGB data only. We also show that symmetry can be enforced by flipping internal representations, which is particularly useful for reasoning about symmetries probabilistically. We demonstrate the quality of our method in several datasets, including human faces, cat faces and cars. We provide a thorough ablation study using a synthetic face dataset to obtain the necessary 3D ground truth. On real images, we achieve higher fidelity reconstruction results compared to other methods [49, 56] that do not rely on 2D or 3D ground truth information, nor prior knowledge of a 3D model of the instance or class. In addition, we also outperform a recent state-of-the-art method [40] that uses keypoint supervision for 3D reconstruction on real faces, while our method uses no external supervision at all. Finally, we demonstrate that our trained face model generalizes to non-natural images such as face paintings and cartoon drawings without fine-tuning. 2. Related Work In order to assess our contribution in relation to the vast literature on image-based 3D reconstruction, it is important to consider three aspects of each approach: which information is used, which assumptions are made, and what the output is. Below and in Table 1 we compare our contribution to prior works based on these factors. Paper Supervision Goals Data [47] 3D scans 3DMM Face [66] 3DV, I Prior on 3DV, predict from I ShapeNet, Ikea [1] 3DP Prior on 3DP ShapeNet [48] 3DM Prior on 3DM Face [17] 3DMM, 2DKP, I Refine 3DMM fit to I Face [15] 3DMM, 2DKP, I Fit 3DMM to I+2DKP Face [18] 3DMM Fit 3DMM to 3D scans Face [27] 3DMM, 2DKP Pred. 3DMM from I Humans [51] 3DMM, 2DS+KP Pred. N, A, L from I Face [64] 3DMM, I Pred. 3DM, VP, T, E from I Face [50] 3DMM, 2DKP, I Fit 3DMM to I Face [13] 2DS Prior on 3DV, pred. from I Model/ScanNet [29] I, 2DS, VP Prior on 3DV ScanNet, PAS3D [28] I, 2DS+KP Pred. 3DM, T, VP from I Birds [7] I, 2DS Pred. 3DM, T, L, VP from I ShapeNet, Birds [22] I, 2DS Pred. 3DV, VP from I ShapeNet, others [56] I Prior on 3DM, T, I Face [49] I Pred. 3DM, VP, T from I Face [21] I Pred. V, L, VP from I ShapeNet Ours I Pred. D, L, A, VP from I Face, others Table 1: Comparison with selected prior work: supervision, goals, and data. I: image, 3DMM: 3D morphable model, 2DKP: 2D keypoints, 2DS: 2D silhouette, 3DP: 3D points, VP: viewpoint, E: expression, 3DM: 3D mesh, 3DV: 3D volume, D: depth, N: normals, A: albedo, T: texture, L: light. can also recover A and L in post-processing. Our method uses single-view images of an object category as training data, assumes that the objects belong to a specific class (e.g. human faces) which is weakly symmetric, and outputs a monocular predictor capable of decomposing any image of the category into shape, albedo, illumination, viewpoint and symmetry probability. Structure from Motion. Traditional methods such as Structure from Motion (SfM) [11] can reconstruct the 3D structure of individual rigid scenes given as input multiple views of each scene and 2D keypoint matches between the views. This can be extended in two ways. First, monocular reconstruction methods can perform dense 3D reconstruction from a single image without 2D keypoints [74, 62, 19]. However, they require multiple views [19] or videos of rigid scenes for training [74]. Second, Non-Rigid SfM (NRSfM) approaches [4, 44] can learn to reconstruct deformable objects by allowing 3D points to deform in a limited manner between views, but require supervision in terms of annotated 2D keypoints for both training and testing. Hence, neither family of SfM approaches can learn to reconstruct deformable objects from raw pixels of a single view. Shape from X. Many other monocular cues have been used as alternatives or supplements to SfM for recovering shape from images, such as shading [24, 71], silhouettes [32], texture [65], symmetry [41, 12] etc. In particular, our work is 2
3 inspired from shape from symmetry and shape from shading. Shape from symmetry [41, 12, 60, 54] reconstructs symmetric objects from a single image by using the mirrored image as a virtual second view, provided that symmetric correspondences are available. [54] also shows that it is possible to detect symmetries and correspondences using descriptors. Shape from shading [24, 71] assumes a shading model such as Lambertian reflectance, and reconstructs the surface by exploiting the non-uniform illumination. Category-specific reconstruction. Learning-based methods have recently been leveraged to reconstruct objects from a single view, either in the form of a raw image or 2D keypoints (see also Table 1). While this task is ill-posed, it has been shown to be solvable by learning a suitable object prior from the training data [47, 66, 1, 48]. A variety of supervisory signals have been proposed to learn such priors. Besides using 3D ground truth directly, authors have considered using videos [2, 74, 43, 63] and stereo pairs [19, 38]. Other approaches have used single views with 2D keypoint annotations [33, 28, 40, 55, 6] or object masks [28, 7]. For objects such as human bodies and human faces, some methods [27, 18, 64, 15] have learned reconstructions from raw images, but starting from the knowledge of a predefined shape model such as SMPL [36] or Basel [47]. These prior models are constructed using specialized hardware and/or other forms of supervision, which are often difficult to obtain for deformable objects in the wild, such as animals, and also limited in details of the shape. Only recently have authors attempted to learn the geometry of object categories from raw, monocular views only. Thewlis et al. [58, 59] uses equivariance to learn dense landmarks, which recovers the 2D geometry of the objects. DAE [52] learns to predict a deformation field through heavily constraining an autoencoder with a small bottleneck embedding and lift that to 3D in [49] in post processing, they further decompose the reconstruction in albedo and shading, obtaining an output similar to ours. Adversarial learning has been proposed as a way of hallucinating new views of an object. Some of these methods start from 3D representations [66, 1, 75, 48]. Kato et al. [29] trains a discriminator on raw images but uses viewpoint as addition supervision. HoloGAN [42] only uses raw images but does not obtain an explicit 3D reconstruction. Szabo et al. [56] uses adversarial training to reconstruct 3D meshes of the object, but does not assess their results quantitatively. Henzler et al. [22] also learns from raw images, but only experiments with images that contain the object on a white background, which is akin to supervision with 2D silhouettes. In Section 4.3, we compare to [49, 56] and demonstrate superior reconstruction results with much higher fidelity. Since our model generates images from an internal 3D representation, one component of the model is a differentiable renderer. However, with a traditional rendering Reconstruction Loss reconstruction መI input I conf. σ encoder decoder Photo-geometric Autoencoding encoder encoder decoder Renderer encoder shading encoder decoder conf. σ view w depth d depth d light l albedo a albedo a flip switch : horizontal flip canonical view J Figure 2: Photo-geometric autoencoding. Our network Φ decomposes an input image I into depth, albedo, viewpoint and lighting, together with a pair of confidence maps. It is trained to reconstruct the input without external supervision. pipeline, gradients across occlusions and boundaries are not defined. Several soft relaxations have thus been proposed [37, 30, 34]. Here, we use an implementation 1 of [30]. 3. Method Given an unconstrained collection of images of an object category, such as human faces, our goal is to learn a model Φ that receives as input an image of an object instance and produces as output a decomposition of it into 3D shape, albedo, illumination and viewpoint, as illustrated in Fig. 2. As we have only raw images to learn from, the learning objective is reconstructive: namely, the model is trained so that the combination of the four factors gives back the input image. This results in an autoencoding pipeline where the factors have, due to the way they are recomposed, an explicit photo-geometric meaning. In order to learn such a decomposition without supervision for any of the components, we use the fact that many object categories are bilaterally symmetric. However, the appearance of object instances is never perfectly symmetric. Asymmetries arise from shape deformation, asymmetric albedo and asymmetric illumination. We take two measures to account for these asymmetries. First, we explicitly model asymmetric illumination. Second, our model also estimates, for each pixel in the input image, a confidence score that explains the probability of the pixel having a symmetric counterpart in the image (see conf σ, σ in Fig. 2). The following sections describe how this is done, looking first at the photo-geometric autoencoder (Section 3.1), then at how symmetries are modelled (Section 3.2), followed by details of the image formation (Section 3.3) and the supplementary perceptual loss (Section 3.4)
4 3.1. Photo-geometric autoencoding An image I is a function Ω R 3 defined on a grid Ω = {0,..., W 1} {0,..., H 1}, or, equivalently, a tensor in R 3 W H. We assume that the image is roughly centered on an instance of the object of interest. The goal is to learn a function Φ, implemented as a neural network, that maps the image I to four factors (d, a, w, l) comprising a depth map d : Ω R +, an albedo image a : Ω R 3, a global light direction l S 2, and a viewpoint w R 6 so that the image can be reconstructed from them. The image I is reconstructed from the four factors in two steps, lighting Λ and reprojection Π, as follows: Î = Π (Λ(a, d, l), d, w). (1) The lighting function Λ generates a version of the object based on the depth map d, the light direction l and the albedo a as seen from a canonical viewpoint w = 0. The viewpoint w represents the transformation between the canonical view and the viewpoint of the actual input image I. Then, the reprojection function Π simulates the effect of a viewpoint change and generates the image Î given the canonical depth d and the shaded canonical image Λ(a, d, l). Learning uses a reconstruction loss which encourages I Î (Section 3.2). Discussion. The effect of lighting could be incorporated in the albedo a by interpreting the latter as a texture rather than as the object s albedo. However, there are two good reasons to avoid this. First, the albedo a is often symmetric even if the illumination causes the corresponding appearance to look asymmetric. Separating them allows us to more effectively incorporate the symmetry constraint described below. Second, shading provides an additional cue on the underlying 3D shape [23, 3]. In particular, unlike the recent work of [52] where a shading map is predicted independently from shape, our model computes the shading based on the predicted depth, mutually constraining each other Probably symmetric objects Leveraging symmetry for 3D reconstruction requires identifying symmetric object points in an image. Here we do so implicitly, assuming that depth and albedo, which are reconstructed in a canonical frame, are symmetric about a fixed vertical plane. An important beneficial side effect of this choice is that it helps the model discover a canonical view for the object, which is important for reconstruction [44]. To do this, we consider the operator that flips a map a R C W H along the horizontal axis 2 : [flip a] c,u,v = a c,w 1 u,v. We then require d flip d and a flip a. While these constraints could be enforced by adding corresponding loss terms to the learning objective, they would be difficult to balance. Instead, we achieve the same effect 2 The choice of axis is arbitrary as long as it is fixed. indirectly, by obtaining a second reconstruction Î from the flipped depth and albedo: Î = Π (Λ(a, d, l), d, w), a = flip a, d = flip d. (2) Then, we consider two reconstruction losses encouraging I Î and I Î. Since the two losses are commensurate, they are easy to balance and train jointly. Most importantly, this approach allows us to easily reason about symmetry probabilistically, as explained next. The source image I and the reconstruction Î are compared via the loss: 1 L(Î, I, σ) = Ω ln uv Ω 1 2l1,uv exp, (3) 2σuv σ uv where l 1,uv = Îuv I uv is the L 1 distance between the intensity of pixels at location uv, and σ R W + H is a confidence map, also estimated by the network Φ from the image I, which expresses the aleatoric uncertainty of the model. The loss can be interpreted as the negative log-likelihood of a factorized Laplacian distribution on the reconstruction residuals. Optimizing likelihood causes the model to selfcalibrate, learning a meaningful confidence map [31]. Modelling uncertainty is generally useful, but in our case is particularly important when we consider the symmetric reconstruction Î, for which we use the same loss L(Î, I, σ ). Crucially, we use the network to estimate, also from the same input image I, a second confidence map σ. This confidence map allows the model to learn which portions of the input image might not be symmetric. For instance, in some cases hair on a human face is not symmetric as shown in Fig. 2, and σ can assign a higher reconstruction uncertainty to the hair region where the symmetry assumption is not satisfied. Note that this depends on the specific instance under consideration, and is learned by the model itself. Overall, the learning objective is given by the combination of the two reconstruction errors: E(Φ; I) = L(Î, I, σ) + λ fl(î, I, σ ), (4) where λ f = 0.5 is a weighing factor, (d, a, w, l, σ, σ ) = Φ(I) is the output of the neural network, and Î and Î are obtained according to Eqs. (1) and (2) Image formation model We now describe the functions Π and Λ in Eq. (1) in more detail. The image is formed by a camera looking at a 3D object. If we denote with P = (P x, P y, P z ) R 3 a 3D point expressed in the reference frame of the camera, this is mapped to pixel p = (u, v, 1) by the following projection: c u = W 1 2, p KP, K = f 0 c u 0 f c v, c v = H 1 f = 2, W 1 2 tan θ FOV 2. (5) 4
5 This model assumes a perspective camera with field of view (FOV) θ FOV. We assume a nominal distance of the object from the camera at about 1m. Given that the images are cropped around a particular object, we assume a relatively narrow FOV of θ FOV 10. The depth map d : Ω R + associates a depth value d uv to each pixel (u, v) Ω in the canonical view. By inverting the camera model (5), we find that this corresponds to the 3D point P = d uv K 1 p. The viewpoint w R 6 represents an Euclidean transformation (R, T ) SE(3), where w 1:3 and w 4:6 are rotation angles and translations in x, y and z axes respectively. The map (R, T ) transforms 3D points from the canonical view to the actual view. Thus a pixel (u, v) in the canonical view is mapped to the pixel (u, v ) in the actual view by the warping function η d,w : (u, v) (u, v ) given by: p K(d uv RK 1 p + T ), (6) where p = (u, v, 1). Finally, the reprojection function Π takes as input the depth d and the viewpoint change w and applies the resulting warp to the canonical image J to obtain the actual image Î = Π(J, d, w) as Î u v = J uv, where (u, v) = η 1 d,w (u, v ). 3 The canonical image J = Λ(a, d, l) is in turn generated as a combination of albedo, normal map and light direction. To do so, given the depth map d, we derive the normal map n : Ω S 2 by associating to each pixel (u, v) a vector normal to the underlying 3D surface. In order to find this vector, we compute the vectors t u uv and t v uv tangent to the surface along the u and v directions. For example, the first one is: t u uv = d u+1,v K 1 (p + e x ) d u 1,v K 1 (p e x ) where p is defined above and e x = (1, 0, 0). Then the normal is obtained by taking the vector product n uv t u uv t v uv. The normal n uv is multiplied by the light direction l to obtain a value for the directional illumination and the latter is added to the ambient light. Finally, the result is multiplied by the albedo to obtain the illuminated texture, as follows: J uv = (k s + k d max{0, l, n uv }) a uv. Here k s and k d are the scalar coefficients weighting the ambient and diffuse terms, and are predicted by the model with range between 0 and 1 via rescaling a tanh output. The light direction l = (l x, l y, 1) T /(lx 2 + ly 2 + 1) 0.5 is modeled as a spherical sector by predicting l x and l y with tanh Perceptual loss The L 1 loss function Eq. (3) is sensitive to small geometric imperfections and tends to result in blurry reconstructions. We add a perceptual loss term to mitigate this problem. The k-th layer of an off-the-shelf image encoder e (VGG16 in our case [53]) predicts a representation e (k) (I) R C k W k H k where Ω k = {0,..., W k 1} {0,..., H k 1} is the 3 Note that this requires to compute the inverse of the warp η d,w, which is detailed in Section 6.1. corresponding spatial domain. Similar to Eq. (3), assuming a Gaussian distribution, the perceptual loss is given by: L (k) p (Î, I, σ(k) ) = 1 1 (l (k) uv ) 2 ln exp Ω k uv Ω k 2π(σ uv (k) ) 2 2(σ uv (k) ), 2 (7) where l (k) uv = e (k) uv (Î) e(k) uv (I) for each pixel index uv in the k-th layer. We also compute the loss for Î using σ (k). σ (k) and σ (k) are additional confidence maps predicted by our model. In practice, we found it is good enough for our purpose to use the features from only one layer relu3 3 of VGG16. We therefore shorten the notation of perceptual loss to L p. With this, the loss function L in Eq. (4) is replaced by L + λ p L p with λ p = Experiments We summarize the key experimental results here, and provide more qualitative evaluations in Section 6.3 and the supplementary video. We will release the code, trained models and the synthetic dataset Setup Datasets. We test our method on three human face datasets: CelebA [35], 3DFAW [20, 26, 73, 69] and BFM [47]. CelebA is a large scale human face dataset, consisting of over 200k images of real human faces in the wild annotated with bounding boxes. 3DFAW contains 23k images with 66 3D keypoint annotations, which we use to evaluate our 3D predictions in Section 4.3. We roughly crop the images around the head region and use the official train/val/test splits. BFM (Basel Face Model) is a synthetic face model, which we use to assess the quality of the 3D reconstructions (since the in-the-wild datasets lack groundtruth). We follow the protocol of [51] to generate a dataset, sampling shapes, poses, textures, and illumination randomly. We use images from SUN Database [68] as background and save ground truth depth maps for evaluation. We also test our method on cat faces and synthetic cars. We use two cat datasets [72, 46]. The first one has 10k cat images with nine keypoint annotations, and the second one is a collection of dog and cat images, containing 1.2k cat images with bounding box annotations. We combine the two datasets, crop the images around the cat heads, and split them by 8:1:1 into train, validation and test sets. For cars, we render 35k images of synthetic cars from ShapeNet [5] with random viewpoints and illumination, and randomly split them by 8:1:1 into train, validation and test sets. Metrics. Since the scale of 3D reconstruction from projective cameras is inherently ambiguous [11], we discount it in the evaluation. Specifically, given the depth map d predicted by our model in the canonical view, we warp it to a depth map d in the actual view using the predicted 5
6 No Baseline SIDE ( 10 2 ) MAD (deg.) (1) Supervised ± ±1.01 (2) Const. null depth ± ±2.25 (3) Average g.t. depth ± ±2.85 (4) Ours (unsupervised) ± ±1.56 Table 2: Comparison with baselines. SIDE and MAD errors for 3D reconstruction in the BFM dataset of our unsupervised reconstruction method against a fully-supervised and trivial baselines. viewpoint and compare the latter to the ground-truth depth map d using the scale-invariant depth error (SIDE) [10] E SIDE ( d, d ) = ( 1 W H uv 2 uv ( 1 W H uv uv) 2 ) 1 2 where uv = log d uv log d uv. We compare only valid depth pixel and erode the foreground mask by one pixel to discount rendering artefacts at object boundaries. Additionally, we report the mean angle deviation (MAD) between normals computed from ground truth depth and from the predicted depth, measuring how well the surface is captured by the prediction. Implementation details. The function (d, a, w, l, σ) = Φ(I) that extracts depth, albedo, viewpoint, lighting, and confidence maps from the single image I of the object is implemented using different neural networks. The depth and albedo are generated by encoder-decoder networks, while viewpoint and lighting are regressed using simple encoder networks. The encoder-decoders do not use skip connections because input and output images are not spatially aligned (since the output is in the canonical object space). All four confidence maps are predicted using the same network, using different decoding layers for the photometric and perceptual losses since these are computed at different resolutions. The final activation function is tanh for depth, albedo, viewpoint and lighting and softplus for the confidence maps. The depth prediction is centered on the mean before tanh, as the overall distance is estimated as part of the viewpoint. We do not use any special initialization for all predictions, except that 2 border pixels of the depth maps on both the left and the right are clamped at a maximal depth to avoid boundary issues. We train using Adam over batches of 64 input images, resized to pixels. The size of the output depth and albedo is also We train for approximately 50k iterations. For visualization, depth maps are upsampled to 256. We include more details in Section Results Comparison with baselines. Table 2 uses the BFM dataset to compare the depth reconstruction quality obtained by our method, a fully-supervised baseline and two baselines. No Method SIDE ( 10 2 ) MAD (deg.) (1) Ours full ± ±1.56 (2) w/o albedo flip ± ±1.80 (3) w/o depth flip ± ±2.33 (4) w/o light ± ±8.48 (5) w/o perc. loss ± ±2.31 (6) w/o confidence ± ±2.12 Table 3: Ablation study. Refer to Section 4.2 for details. SIDE ( 10 2 ) MAD (deg.) No perturb, no conf ± ±2.12 No perturb, conf ± ±1.56 Perturb, no conf ± ±5.39 Perturb, conf ± ±1.90 Table 4: Asymmetry objects. We add asymmetric perturbations to BFM and show that confidence maps allow the model to reject such noise, while the vanilla model without confidence maps breaks. Depth Corr. Ground truth 66 AIGN [61] (supervised, from [40]) DepthNetGAN [40] (supervised, from [40]) MOFA [57] (model-based, from [40]) DepthNet [40] (from [40]) DepthNet [40] (from GitHub) Ours Ours (w/ CelebA pre-training) Table 5: 3DFAW keypoint depth evaluation. Depth correlation between ground truth and prediction evaluated at 66 facial keypoint locations. The supervised baseline is a version of our model trained to regress the ground-truth depth maps using an L 1 loss. The trivial baseline predicts a constant uniform depth map, which provides a performance lower-bound. The third baseline is a constant depth map obtained by averaging all ground-truth depth maps in the test set. Our method largely outperforms the two constant baselines and approaches the results of supervised training. Improving over the third baseline (which has access to GT information) confirms that the model learns an instance specific 3D representation. Ablation. To understand the influence of the individual parts of the model, we remove them one at a time and evaluate the performance of the ablated model in Table 3. In the table, row (1) shows the performance of the full model (the same as in Table 2). Row (2) does not flip the albedo. Thus, the albedo is not encouraged to be symmetric in the canonical space, which fails to canonicalize the view- 6



 predicts a shading map instead of computing it from depth and light direction.")


 and (7) to the basic L 1 and L 2 losses,")
, as faces in")













7 perturbed dataset conf σ conf σ input recon w/ conf recon w/o conf Figure 3: Reconstruction on asymmetrically-perturbed images. Top: examples of the perturbed dataset. Bottom: example of the reconstruction with and without confidence maps. With confidence enabled, the model correctly reconstructs the 3D shape with the asymmetric texture. point of the object and to use cues from symmetry to recover shape. The performance is as low as the trivial baseline in Table 2. Row (3) does not flip the depth, with a similar effect to row (2). Row (4) predicts a shading map instead of computing it from depth and light direction. This also harms performance significantly because shading cannot be used as a cue to recover shape. Row (5) switches off the perceptual loss, which leads to degraded image quality and hence degraded reconstruction results. Finally, row (6) switches off the confidence maps, using a fixed and uniform value for the confidence this reduces losses (3) and (7) to the basic L 1 and L 2 losses, respectively. The reconstruction accuracy decreases slightly (its variance increases more), as faces in BFM are highly symmetric (e.g. do not have hair). To better understand the effect of the confidence maps, we specifically evaluate on partially asymmetric faces using perturbations. Asymmetric perturbation. In order to demonstrate that our uncertainty modelling allows the model to handle asymmetry, we add asymmetric perturbations to BFM. Specifically, we generate random rectangular color patches with 20% to 50% of the image size and blend them onto the images with α-values ranging from 0.5 to 1, as shown in Fig. 3. We then train our model with and without confidence on these perturbed images, and report the results in Table 4. Without the confidence maps, the model always predicts a symmetric albedo and geometry reconstruction often fails. With our confidence estimates, the model is able to reconstruct the asymmetric faces correctly, with very little loss in accuracy compared to the unperturbed case. Qualitative results. In Fig. 4 we show reconstruction results of human faces from CelebA and 3DFAW, cat faces from [72, 46] and synthetic cars from ShapeNet. The 3D shapes are recovered with high fidelity. The reconstructed 3D face, for instance, contain fine details of the nose, eyes and mouth even in the presence of extreme facial expression. To further test generalization, we collected a number of paintings and cartoon drawings of faces from [9] and the Internet, and tested them with our model trained on input reconstruction Figure 4: Reconstruction of faces, cats and cars. input reconstruction Figure 5: Reconstruction of faces in paintings. (a) symmetry plane (b) asymmetry visualization Figure 6: Symmetry plane and asymmetry detection. (a): our model can reconstruct the intrinsic symmetry plane of an in-the-wild object even though the appearance is highly asymmetric. (b): asymmetries (highlighted in red) are detected and visualized using confidence map σ. the CelebA dataset. As shown in Fig. 5, our method still works well even though it has never seen such images during training. Please see Section 6.3 for more qualitative results. Symmetry and asymmetry detection. Since our model predicts a canonical view of the objects that is symmetric about the vertical center-line of the image, we can easily visualize the symmetry plane, which is otherwise non-trivial to detect from in-the-wild images. In Fig. 6, we render the center-line of the canonical image and warp it to the input viewpoint. The symmetry planes detected by our method are accurate despite the presence of extreme asymmetric texture and lighting effects. We also overlay the predicted confidence map σ onto the image, confirming that the model 7

![[56] ours Figure 7: Qualitative comparison to SOTA.](/docs-images/105/167895420/images/8-1.jpg "Our method recovers much higher quality shapes compared to [49, 56].")



![reconstructs in-the-wild faces but does not report any quantitative results, and [49]](/docs-images/105/167895420/images/8-5.jpg "reports quantitative results only on the detection of 2D keypoints, but not on the 3D")


![papers [49, 56] and compare our results with theirs (Fig. 7).](/docs-images/105/167895420/images/8-9.jpg "Our method produces much higher quality reconstructions than both methods, with fine")
![details of the facial expression, whereas [49] recovers 3D shapes poorly and [56]](/docs-images/105/167895420/images/8-10.jpg "generates unnatural shapes.")
![Note that [56] uses an unconditional GAN that generates high resolution 3D faces from](/docs-images/105/167895420/images/8-11.jpg "random noise, and cannot recover 3D shapes from images.")
![The input images for [56] in Fig. 7 were generated by their method.](/docs-images/105/167895420/images/8-12.jpg "3D keypoint depth evaluation. Next, we compare to the DepthNet model of [40].")


![We also compare to the baselines MOFA [57] and AIGN [61] reported in [40].](/docs-images/105/167895420/images/8-15.jpg "For a fair comparison, we use their public code which computes the depth correlation")











8 a: extreme lighting b: noisy texture c: extreme pose Figure 8: Failure cases. See Section 4.4 for details. input LAE [49] ours input Szabó et al. [56] ours Figure 7: Qualitative comparison to SOTA. Our method recovers much higher quality shapes compared to [49, 56]. assigns low confidence to asymmetric regions in a samplespecific way Comparison with the state of the art As shown in Table 1, most reconstruction methods in the literature require either image annotations, a prior 3D model of the object, or both. When these assumptions are dropped, the task becomes considerably harder, and there is little prior work that is directly comparable. Of these, [21] only uses synthetic, texture-less objects from ShapeNet, [56] reconstructs in-the-wild faces but does not report any quantitative results, and [49] reports quantitative results only on the detection of 2D keypoints, but not on the 3D reconstruction quality. We were not able to obtain code or trained models from [49, 56] for a direct quantitative comparison and thus compare qualitatively. Qualitative comparison. In order to establish a side-byside comparison, we cropped the examples reported in the papers [49, 56] and compare our results with theirs (Fig. 7). Our method produces much higher quality reconstructions than both methods, with fine details of the facial expression, whereas [49] recovers 3D shapes poorly and [56] generates unnatural shapes. Note that [56] uses an unconditional GAN that generates high resolution 3D faces from random noise, and cannot recover 3D shapes from images. The input images for [56] in Fig. 7 were generated by their method. 3D keypoint depth evaluation. Next, we compare to the DepthNet model of [40]. This method predicts depth for selected facial keypoints, but uses 2D keypoint annotations as input a much easier setup than the one we consider here. Still, we compare the quality of the reconstruction of these sparse point obtained by DepthNet and our method. We also compare to the baselines MOFA [57] and AIGN [61] reported in [40]. For a fair comparison, we use their public code which computes the depth correlation score (between 0 and 66) on the frontal faces. We use the 2D keypoint locations to sample our predicted depth and then evaluate the same metric. The set of test images from 3DFAW and the preprocessing are identical to [40]. Since 3DFAW is a small dataset with limited variation, we also report results with CelebA pre-training. In Table 5 we report the results from their paper and the slightly improved results we obtained from their publiclyavailable implementation. The paper also evaluates a supervised model using a GAN discriminator trained with ground-truth depth information. While our method does not use any supervision, it still outperforms DepthNet and reaches close-to-supervised performance Limitations While our method is robust in many challenging scenarios (e.g., extreme facial expression, abstract drawing), we do observe failure cases as shown in Fig. 8. During training, we assume a simple Lambertian shading model, ignoring shadows and specularity, which leads to inaccurate reconstructions under extreme lighting conditions (Fig. 8a) or highly non-lambertian surfaces. Disentangling noisy dark textures and shading (Fig. 8b) is often difficult. The reconstruction quality is lower for extreme poses (Fig. 8c), partly due to poor supervisory signal from the reconstruction loss of side images. This may be improved by imposing constraints from accurate reconstructions of frontal poses. 5. Conclusions We have presented a method that can learn a 3D model of a deformable object category from an unconstrained collection of single-view images of the object category. The model is able to obtain high-fidelity monocular 3D reconstructions of individual object instances. This is trained based on a reconstruction loss without any supervision, resembling an autoencoder. We have shown that symmetry and illumination are strong cues for shape and help the model to converge to a meaningful reconstruction. Our model outperforms a current state-of-the-art 3D reconstruction method that uses 2D keypoint supervision. As for future work, the model currently represents 3D shape from a canonical viewpoint using a depth map, which is sufficient for objects such as faces that have a roughly convex shape and a natural canonical viewpoint. For more complex objects, it may be possible to extend the model to use either multiple canonical views or a different 3D representation, such as a mesh or a voxel map. 8
9 Acknowledgement We would like to thank Soumyadip Sengupta for sharing with us the code to generate synthetic face datasets, and Mihir Sahasrabudhe for sending us the reconstruction results of Lifting AutoEncoders. We are also indebted to the members of Visual Geometry Group for insightful discussions and comments. This work is jointly supported by Facebook Research and ERC Horizon 2020 Research and Innovation Programme IDIU References [1] Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. Learning representations and generative models for 3D point clouds. In Proc. ICML, , 3 [2] Pulkit Agrawal, Joao Carreira, and Jitendra Malik. Learning to see by moving. In Proc. ICCV, [3] Peter N. Belhumeur, David J. Kriegman, and Alan L. Yuille. The bas-relief ambiguity. IJCV, [4] Christoph Bregler, Aaron Hertzmann, and Henning Biermann. Recovering non-rigid 3D shape from image streams. In Proc. CVPR, [5] Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. Shapenet: An information-rich 3d model repository. arxiv, abs/ , [6] Ching-Hang Chen, Ambrish Tyagi, Amit Agrawal, Dylan Drover, Rohith MV, Stefan Stojanov, and James M. Rehg. Unsupervised 3d pose estimation with geometric selfsupervision. In Proc. CVPR, [7] Wenzheng Chen, Huan Ling, Jun Gao, Edward Smith, Jaako Lehtinen, Alec Jacobson, and Sanja Fidler. Learning to predict 3d objects with an interpolation-based differentiable renderer. In NeurIPS, , 3 [8] Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. VoxCeleb2: Deep speaker recognition. In INTERSPEECH, [9] Elliot J. Crowley, Omkar M. Parkhi, and Andrew Zisserman. Face painting: querying art with photos. In Proc. BMVC, , 12 [10] David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network. In NeurIPS, [11] Olivier Faugeras and Quang-Tuan Luong. The Geometry of Multiple Images. MIT Press, , 5 [12] Alexandre R. J. François, Gérard G. Medioni, and Roman Waupotitsch. Mirror symmetry 2-view stereo geometry. Image and Vision Computing, , 3 [13] Matheus Gadelha, Subhransu Maji, and Rui Wang. 3D shape induction from 2D views of multiple objects. In 3DV, [14] Yuan Gao and Alan L. Yuille. Exploiting symmetry and/or manhattan properties for 3d object structure estimation from single and multiple images. In Proc. CVPR, [15] Baris Gecer, Stylianos Ploumpis, Irene Kotsia, and Stefanos Zafeiriou. GANFIT: Generative adversarial network fitting for high fidelity 3D face reconstruction. In Proc. CVPR, , 3 [16] Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. Imagenet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In Proc. ICML, [17] Zhenglin Geng, Chen Cao, and Sergey Tulyakov. 3D guided fine-grained face manipulation. In Proc. CVPR, [18] Thomas Gerig, Andreas Morel-Forster, Clemens Blumer, Bernhard Egger, Marcel Lüthi, Sandro Schönborn, and Thomas Vetter. Morphable face models - an open framework. In Proc. Int. Conf. Autom. Face and Gesture Recog., , 3 [19] Clément Godard, Oisin Mac Aodha, and Gabriel J. Brostow. Unsupervised monocular depth estimation with left-right consistency. In Proc. CVPR, , 3 [20] Ralph Gross, Iain Matthews, Jeffrey Cohn, Takeo Kanade, and Simon Baker. Multi-pie. Image and Vision Computing, [21] Paul Henderson and Vittorio Ferrari. Learning single-image 3D reconstruction by generative modelling of shape, pose and shading. IJCV, , 8 [22] Philipp Henzler, Niloy Mitra, and Tobias Ritschel. Escaping plato s cave using adversarial training: 3d shape from unstructured 2d image collections. In Proc. ICCV, , 3 [23] Berthold Horn. Obtaining shape from shading information. In The Psychology of Computer Vision, [24] Berthold K. P. Horn and Michael J. Brooks. Shape from Shading. MIT Press, Cambridge Massachusetts, , 3 [25] Max Jaderberg, Karen Simonyan, Andrew Zisserman, and Koray Kavukcuoglu. Spatial transformer networks. In NeurIPS, [26] László A. Jeni, Jeffrey F. Cohn, and Takeo Kanade. Dense 3d face alignment from 2d videos in real-time. In Proc. Int. Conf. Autom. Face and Gesture Recog., [27] Angjoo Kanazawa, Michael J. Black, David W. Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. In Proc. CVPR, , 3 [28] Angjoo Kanazawa, Shubham Tulsiani, Alexei A. Efros, and Jitendra Malik. Learning category-specific mesh reconstruction from image collections. In Proc. ECCV, , 3 [29] Hiroharu Kato and Tatsuya Harada. Learning view priors for single-view 3d reconstruction. In Proc. CVPR, , 3 [30] Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. Neural 3d mesh renderer. In Proc. CVPR, , 11 [31] Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? In NeurIPS, [32] Jan J Koenderink. What does the occluding contour tell us about solid shape? Perception, [33] Yasunori Kudo, Keisuke Ogaki, Yusuke Matsui, and Yuri Odagiri. Unsupervised adversarial learning of 3d human pose from 2d joint locations. arxiv, abs/ , [34] Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proc. ICCV,
10 [35] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proc. ICCV, [36] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. SMPL: A skinned multiperson linear model. ACM transactions on graphics (TOG), 34(6):248, [37] Matthew M. Loper and Michael J. Black. OpenDR: An approximate differentiable renderer. In Proc. ECCV, [38] Yue Luo, Jimmy Ren, Mude Lin, Jiahao Pang, Wenxiu Sun, Hongsheng Li, and Liang Lin. Single view stereo matching. In Proc. CVPR, [39] Andrew L. Maas, Awni Y. Hannun, and Andrew Y. Ng. Rectifier nonlinearities improve neural network acoustic models. In Proc. ICML, [40] Joel Ruben Antony Moniz, Christopher Beckham, Simon Rajotte, Sina Honari, and Christopher Pal. Unsupervised depth estimation, 3d face rotation and replacement. In NeurIPS, , 3, 6, 8 [41] Dipti P. Mukherjee, Andrew Zisserman, and J. Michael Brady. Shape from symmetry detecting and exploiting symmetry in affine images. Philosophical Transactions of the Royal Society of London, 351:77 106, , 3 [42] Thu Nguyen-Phuoc, Chuan Li, Lucas Theis, Christian Richardt, and Yong-Liang Yang. Hologan: Unsupervised learning of 3d representations from natural images. In Proc. ICCV, [43] David Novotny, Diane Larlus, and Andrea Vedaldi. Learning 3d object categories by looking around them. In Proc. ICCV, [44] David Novotny, Nikhila Ravi, Benjamin Graham, Natalia Neverova, and Andrea Vedaldi. C3DPO: Canonical 3d pose networks for non-rigid structure from motion. In Proc. ICCV, , 4 [45] Augustus Odena, Vincent Dumoulin, and Chris Olah. Deconvolution and checkerboard artifacts. Distill, [46] Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. Cats and dogs. In Proc. CVPR, , 7, 12 [47] Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami Romdhani, and Thomas Vetter. A 3D face model for pose and illumination invariant face recognition. In Advanced video and signal based surveillance, , 3, 5 [48] Anurag Ranjan, Timo Bolkart, Soubhik Sanyal, and Michael J. Black. Generating 3D faces using convolutional mesh autoencoders. In Proc. ECCV, , 3 [49] Mihir Sahasrabudhe, Zhixin Shu, Edward Bartrum, Riza Alp Guler, Dimitris Samaras, and Iasonas Kokkinos. Lifting autoencoders: Unsupervised learning of a fully-disentangled 3d morphable model using deep non-rigid structure from motion. In ICCV Workshop on Geometry Meets Deep Learning, , 3, 8 [50] Soubhik Sanyal, Timo Bolkart, Haiwen Feng, and Michael J. Black. Learning to regress 3D face shape and expression from an image without 3D supervision. In Proc. CVPR, [51] Soumyadip Sengupta, Angjoo Kanazawa, Carlos D. Castillo, and David Jacobs. SfSNet: Learning shape, refectance and illuminance of faces in the wild. In Proc. CVPR, , 5 [52] Zhixin Shu, Mihir Sahasrabudhe, Alp Guler, Dimitris Samaras, Nikos Paragios, and Iasonas Kokkinos. Deforming autoencoders: Unsupervised disentangling of shape and appearance. In Proc. ECCV, , 4 [53] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In Proc. ICLR, [54] Sudipta N. Sinha, Krishnan Ramnath, and Richard Szeliski. Detecting and reconstructing 3d mirror symmetric objects. In Proc. ECCV, , 3 [55] Supasorn Suwajanakorn, Noah Snavely, Jonathan Tompson, and Mohammad Norouzi. Discovery of latent 3d keypoints via end-to-end geometric reasoning. In NeurIPS, [56] Attila Szabó, Givi Meishvili, and Paolo Favaro. Unsupervised generative 3d shape learning from natural images. arxiv, abs/ , , 3, 8 [57] Ayush Tewari, Michael Zollhöfer, Hyeongwoo Kim, Pablo Garrido, Florian Bernard, Patrick Pérez, and Christian Theobalt. MoFA: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In Proc. ICCV, , 8 [58] James Thewlis, Hakan Bilen, and Andrea Vedaldi. Unsupervised learning of object frames by dense equivariant image labelling. In NeurIPS, [59] James Thewlis, Hakan Bilen, and Andrea Vedaldi. Modelling and unsupervised learning of symmetric deformable object categories. In NeurIPS, [60] Sebastian Thrun and Ben Wegbreit. Shape from symmetry. In Proc. ICCV, , 3 [61] Hsiao-Yu Fish Tung, Adam W. Harley, William Seto, and Katerina Fragkiadaki. Adversarial inverse graphics networks: Learning 2d-to-3d lifting and image-to-image translation from unpaired supervision. In Proc. ICCV, , 8 [62] Benjamin Ummenhofer, Huizhong Zhou, Jonas Uhrig, Nikolaus Mayer, Eddy Ilg, Alexey Dosovitskiy, and Thomas Brox. Demon: Depth and motion network for learning monocular stereo. In Proc. CVPR, [63] Chaoyang Wang, Jose Miguel Buenaposada, Rui Zhu, and Simon Lucey. Learning depth from monocular videos using direct methods. In Proc. CVPR, [64] Mengjiao Wang, Zhixin Shu, Shiyang Cheng, Yannis Panagakis, Dimitris Samaras, and Stefanos Zafeiriou. An adversarial neuro-tensorial approach for learning disentangled representations. IJCV, , 3 [65] Andrew P. Witkin. Recovering surface shape and orientation from texture. Artificial Intelligence, [66] Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, and Joshua B. Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In NeurIPS, , 3 [67] Yuxin Wu and Kaiming He. Group normalization. In Proc. ECCV, [68] Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In Proc. CVPR, [69] Lijun Yin, Xiaochen Chen, Yi Sun, Tony Worm, and Michael Reale. A high-resolution 3d dynamic facial expression 10
11 database. In Proc. Int. Conf. Autom. Face and Gesture Recog., [70] Matthew D. Zeiler, Graham W. Taylor, and Rob Fergus. Adaptive deconvolutional networks for mid and high level feature learning. In Proc. ICCV, [71] Ruo Zhang, Ping-Sing Tsai, James Edwin Cryer, and Mubarak Shah. Shape-from-shading: a survey. IEEE PAMI, , 3 [72] Weiwei Zhang, Jian Sun, and Xiaoou Tang. Cat head detection - how to effectively exploit shape and texture features. In Proc. ECCV, , 7, 12 [73] Xing Zhang, Lijun Yin, Jeffrey F. Cohn, Shaun Canavan, Michael Reale, Andy Horowitz, Peng Liu, and Jeffrey M. Girard. Bp4d-spontaneous: a high-resolution spontaneous 3d dynamic facial expression database. Image and Vision Computing, 32(10): , [74] Tinghui Zhou, Matthew Brown, Noah Snavely, and David G. Lowe. Unsupervised learning of depth and ego-motion from video. In Proc. CVPR, , 3 [75] Jun-Yan Zhu, Zhoutong Zhang, Chengkai Zhang, Jiajun Wu, Antonio Torralba, Joshua B. Tenenbaum, and William T. Freeman. Visual object networks: Image generation with disentangled 3D representations. In NeurIPS, Supplementary Material 6.1. Differentiable rendering layer As noted in Section 3.3, the reprojection function Π warps the canonical image J to generate the actual image I. In CNNs, image warping is usually regarded as a simple operation that can be implemented efficiently using a bilinear resampling layer [25]. However, this is true only if we can easily send pixels (u, v ) in the warped image I back to pixels (u, v) in the source image J, a process also known as backward warping. Unfortunately, in our case the function η d,w obtained by Eq. (6) in the paper sends pixels in the opposite way. Implementing a forward warping layer is surprisingly delicate. One way of approaching the problem is to regard this task as a special case of rendering a textured mesh. The Neural Mesh Renderer (NMR) of [30] is a differentiable renderer of this type. In our case, the mesh has one vertex per pixel and each group of 2 2 adjacent pixels is tessellated by two triangles. Empirically, we found the quality of the texture gradients of NMR to be poor in this case, likely caused by high frequency content in the texture image J. We solve the problem as follows. First, we use NMR to warp only the depth map d, obtaining a version d of the depth map as seen from the input viewpoint. This has two advantages: backpropagation through NMR is faster and secondly, the gradients are more stable, probably also due to the comparatively smooth nature of the depth map d compared to the texture image J. Given the depth map d, we then use the inverse of Eq. (6) in the paper to find the warp field from the observed viewpoint to the canonical viewpoint, and bilinearly resample the canonical image J to obtain the reconstruction Training details We report the training details in Table 6 including all hyper-parameter settings, and detailed network architectures in Tables 7 to 9. We use standard encoder networks for both viewpoint and lighting predictions, and encoder-decoder networks for depth, albedo and confidence predictions. In order to mitigate checkerboard artifacts [45] in the predicted depth and albedo, we add a convolution layer after each deconvolution layer and replace the last deconvolotion layer with nearest-neighbor upsampling, followed by 3 convolution layers. Abbreviations of the operators are defined as follows: Conv(c in, c out, k, s, p): convolution with c in input channels, c out output channels, kernel size k, stride s and padding p. Deconv(c in, c out, k, s, p): deconvolution [70] with c in input channels, c out output channels, kernel size k, stride s and padding p. 11
12 Parameter Value/Range Optimizer Adam Learning rate Number of epochs 30 Batch size 64 Loss weight λ f 0.5 Loss weight λ p 1 Input image size Output image size Depth map (0.9, 1.1) Albedo (0, 1) Light coefficient k s (0, 1) Light coefficient k d (0, 1) Light direction l x, l y ( 1, 1) Viewpoint rotation w 1:3 ( 60, 60 ) Viewpoint translation w 4:6 ( 0.1, 0.1) Field of view (FOV) 10 Table 6: Training details and hyper-parameter settings. Upsample(s): nearest-neighbor upsampling with a scale factor of s. GN(n): group normalization [67] with n groups. LReLU(α): leaky ReLU [39] with a negative slope of α More qualitative results We provide more qualitative results in the following. Animations of the rotated 3D reconstructions are included in the supplementary video. Fig. 9 shows reconstruction results on human faces from CelebA and 3DFAW. We also show more results on face paintings (Fig. 10) and abstract drawings (Fig. 11) from [9] and the Internet. In Figs. 12 and 13, we show mroe examples on cat faces from [72, 46] and synthetic cars rendered using ShapeNet. Re-lighting. Since our model predicts the intrinsic components of an image, separating the albedo and illumination, we can easily re-light the objects with different lighting conditions. In Fig. 14, we demonstrate results of the intrinsic decomposition and the re-lit faces in the canonical view. Testing on videos. To further assess our model, we apply the model trained on CelebA faces to VoxCeleb [8] videos frame by frame and include the results in the supplementary video. Our trained model works surprisingly well, producing consistent, smooth reconstructions across different frames and recovering the details of the facial motions accurately. Encoder Output size Conv(3, 32, 4, 2, 1) + ReLU 32 Conv(32, 64, 4, 2, 1) + ReLU 16 Conv(64, 128, 4, 2, 1) + ReLU 8 Conv(128, 256, 4, 2, 1) + ReLU 4 Conv(256, 256, 4, 1, 0) + ReLU 1 Conv(256, c out, 1, 1, 0) + Tanh output 1 Table 7: Network architecture for viewpoint and lighting. The output channel size c out is 6 for viewpoint, corresponding to rotation angles and translation in x, y and z axes, and 4 for lighting, corresponding to k s, k d, l x and l y. Encoder Output size Conv(3, 64, 4, 2, 1) + GN(16) + LReLU(0.2) 32 Conv(64, 128, 4, 2, 1) + GN(32) + LReLU(0.2) 16 Conv(128, 256, 4, 2, 1) + GN(64) + LReLU(0.2) 8 Conv(256, 512, 4, 2, 1) + LReLU(0.2) 4 Conv(512, 256, 4, 1, 0) + ReLU 1 Decoder Output size Deconv(256, 512, 4, 1, 0) + ReLU 4 Conv(512, 512, 3, 1, 1) + ReLU 4 Deconv(512, 256, 4, 2, 1) + GN(64) + ReLU 8 Conv(256, 256, 3, 1, 1) + GN(64) + ReLU 8 Deconv(256, 128, 4, 2, 1) + GN(32) + ReLU 16 Conv(128, 128, 3, 1, 1) + GN(32) + ReLU 16 Deconv(128, 64, 4, 2, 1) + GN(16) + ReLU 32 Conv(64, 64, 3, 1, 1) + GN(16) + ReLU 32 Upsample(2) 64 Conv(64, 64, 3, 1, 1) + GN(16) + ReLU 64 Conv(64, 64, 5, 1, 2) + GN(16) + ReLU 64 Conv(64, c out, 5, 1, 2) + Tanh output 64 Table 8: Network architecture for depth and albedo. The output channel size c out is 1 for depth and 3 for albedo. Encoder Output size Conv(3, 64, 4, 2, 1) + GN(16) + LReLU(0.2) 32 Conv(64, 128, 4, 2, 1) + GN(32) + LReLU(0.2) 16 Conv(128, 256, 4, 2, 1) + GN(64) + LReLU(0.2) 8 Conv(256, 512, 4, 2, 1) + LReLU(0.2) 4 Conv(512, 128, 4, 1, 0) + ReLU 1 Decoder Output size Deconv(128, 512, 4, 1, 0) + ReLU 4 Deconv(512, 256, 4, 2, 1) + GN(64) + ReLU 8 Deconv(256, 128, 4, 2, 1) + GN(32) + ReLU 16 Conv(128, 2, 3, 1, 1) + GN(32) + SoftPlus output 16 Deconv(128, 64, 4, 2, 1) + GN(16) + ReLU 32 Deconv(64, 64, 4, 2, 1) + GN(16) + ReLU 64 Conv(64, 2, 5, 1, 2) + SoftPlus output 64 Table 9: Network architecture for confidence maps. The network outputs two pairs of confidence maps at different spatial resolutions for photometric and perceptual losses. 12




















































13 Input Reconstruction Figure 9: Reconstruction on human faces. 13
















































14 Input Reconstruction Figure 10: Reconstruction on realistic face paintings. 14

























































15 Input Reconstruction Figure 11: Reconstruction on abstract face drawings. 15

























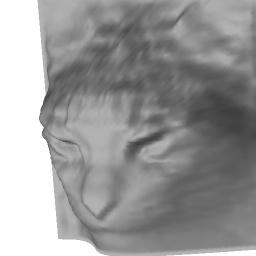
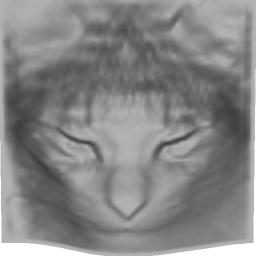





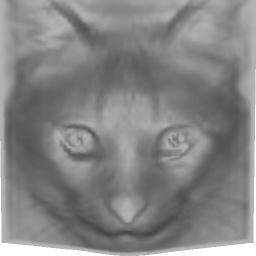

























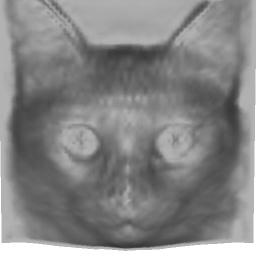


















16 Input Reconstruction Figure 12: Reconstruction on abstract face drawings. 16
























17 Input Reconstruction Figure 13: Reconstruction on synthetic cars. Input Albedo Original light Re-lit Figure 14: Re-lighting effects. 17
3D Model based Object Class Detection in An Arbitrary View
 3D Model based Object Class Detection in An Arbitrary View Pingkun Yan, Saad M. Khan, Mubarak Shah School of Electrical Engineering and Computer Science University of Central Florida http://www.eecs.ucf.edu/
3D Model based Object Class Detection in An Arbitrary View Pingkun Yan, Saad M. Khan, Mubarak Shah School of Electrical Engineering and Computer Science University of Central Florida http://www.eecs.ucf.edu/
Convolutional Feature Maps
 Convolutional Feature Maps Elements of efficient (and accurate) CNN-based object detection Kaiming He Microsoft Research Asia (MSRA) ICCV 2015 Tutorial on Tools for Efficient Object Detection Overview
Convolutional Feature Maps Elements of efficient (and accurate) CNN-based object detection Kaiming He Microsoft Research Asia (MSRA) ICCV 2015 Tutorial on Tools for Efficient Object Detection Overview
Optical Flow. Shenlong Wang CSC2541 Course Presentation Feb 2, 2016
 Optical Flow Shenlong Wang CSC2541 Course Presentation Feb 2, 2016 Outline Introduction Variation Models Feature Matching Methods End-to-end Learning based Methods Discussion Optical Flow Goal: Pixel motion
Optical Flow Shenlong Wang CSC2541 Course Presentation Feb 2, 2016 Outline Introduction Variation Models Feature Matching Methods End-to-end Learning based Methods Discussion Optical Flow Goal: Pixel motion
Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection
 CSED703R: Deep Learning for Visual Recognition (206S) Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 3 Object detection
CSED703R: Deep Learning for Visual Recognition (206S) Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 3 Object detection
Recognizing Cats and Dogs with Shape and Appearance based Models. Group Member: Chu Wang, Landu Jiang
 Recognizing Cats and Dogs with Shape and Appearance based Models Group Member: Chu Wang, Landu Jiang Abstract Recognizing cats and dogs from images is a challenging competition raised by Kaggle platform
Recognizing Cats and Dogs with Shape and Appearance based Models Group Member: Chu Wang, Landu Jiang Abstract Recognizing cats and dogs from images is a challenging competition raised by Kaggle platform
Taking Inverse Graphics Seriously
 CSC2535: 2013 Advanced Machine Learning Taking Inverse Graphics Seriously Geoffrey Hinton Department of Computer Science University of Toronto The representation used by the neural nets that work best
CSC2535: 2013 Advanced Machine Learning Taking Inverse Graphics Seriously Geoffrey Hinton Department of Computer Science University of Toronto The representation used by the neural nets that work best
Classifying Manipulation Primitives from Visual Data
 Classifying Manipulation Primitives from Visual Data Sandy Huang and Dylan Hadfield-Menell Abstract One approach to learning from demonstrations in robotics is to make use of a classifier to predict if
Classifying Manipulation Primitives from Visual Data Sandy Huang and Dylan Hadfield-Menell Abstract One approach to learning from demonstrations in robotics is to make use of a classifier to predict if
Template-based Eye and Mouth Detection for 3D Video Conferencing
 Template-based Eye and Mouth Detection for 3D Video Conferencing Jürgen Rurainsky and Peter Eisert Fraunhofer Institute for Telecommunications - Heinrich-Hertz-Institute, Image Processing Department, Einsteinufer
Template-based Eye and Mouth Detection for 3D Video Conferencing Jürgen Rurainsky and Peter Eisert Fraunhofer Institute for Telecommunications - Heinrich-Hertz-Institute, Image Processing Department, Einsteinufer
Module 5. Deep Convnets for Local Recognition Joost van de Weijer 4 April 2016
 Module 5 Deep Convnets for Local Recognition Joost van de Weijer 4 April 2016 Previously, end-to-end.. Dog Slide credit: Jose M 2 Previously, end-to-end.. Dog Learned Representation Slide credit: Jose
Module 5 Deep Convnets for Local Recognition Joost van de Weijer 4 April 2016 Previously, end-to-end.. Dog Slide credit: Jose M 2 Previously, end-to-end.. Dog Learned Representation Slide credit: Jose
Mean-Shift Tracking with Random Sampling
 1 Mean-Shift Tracking with Random Sampling Alex Po Leung, Shaogang Gong Department of Computer Science Queen Mary, University of London, London, E1 4NS Abstract In this work, boosting the efficiency of
1 Mean-Shift Tracking with Random Sampling Alex Po Leung, Shaogang Gong Department of Computer Science Queen Mary, University of London, London, E1 4NS Abstract In this work, boosting the efficiency of
Compacting ConvNets for end to end Learning
 Compacting ConvNets for end to end Learning Jose M. Alvarez Joint work with Lars Pertersson, Hao Zhou, Fatih Porikli. Success of CNN Image Classification Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,
Compacting ConvNets for end to end Learning Jose M. Alvarez Joint work with Lars Pertersson, Hao Zhou, Fatih Porikli. Success of CNN Image Classification Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,
Feature Tracking and Optical Flow
 02/09/12 Feature Tracking and Optical Flow Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Many slides adapted from Lana Lazebnik, Silvio Saverse, who in turn adapted slides from Steve
02/09/12 Feature Tracking and Optical Flow Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Many slides adapted from Lana Lazebnik, Silvio Saverse, who in turn adapted slides from Steve
Naive-Deep Face Recognition: Touching the Limit of LFW Benchmark or Not?
 Naive-Deep Face Recognition: Touching the Limit of LFW Benchmark or Not? Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com Qi Yin yq@megvii.com Abstract Face recognition performance improves rapidly
Naive-Deep Face Recognition: Touching the Limit of LFW Benchmark or Not? Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com Qi Yin yq@megvii.com Abstract Face recognition performance improves rapidly
Subspace Analysis and Optimization for AAM Based Face Alignment
 Subspace Analysis and Optimization for AAM Based Face Alignment Ming Zhao Chun Chen College of Computer Science Zhejiang University Hangzhou, 310027, P.R.China zhaoming1999@zju.edu.cn Stan Z. Li Microsoft
Subspace Analysis and Optimization for AAM Based Face Alignment Ming Zhao Chun Chen College of Computer Science Zhejiang University Hangzhou, 310027, P.R.China zhaoming1999@zju.edu.cn Stan Z. Li Microsoft
Colorado School of Mines Computer Vision Professor William Hoff
 Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ 1 Introduction to 2 What is? A process that produces from images of the external world a description
Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ 1 Introduction to 2 What is? A process that produces from images of the external world a description
Pedestrian Detection with RCNN
 Pedestrian Detection with RCNN Matthew Chen Department of Computer Science Stanford University mcc17@stanford.edu Abstract In this paper we evaluate the effectiveness of using a Region-based Convolutional
Pedestrian Detection with RCNN Matthew Chen Department of Computer Science Stanford University mcc17@stanford.edu Abstract In this paper we evaluate the effectiveness of using a Region-based Convolutional
Face Model Fitting on Low Resolution Images
 Face Model Fitting on Low Resolution Images Xiaoming Liu Peter H. Tu Frederick W. Wheeler Visualization and Computer Vision Lab General Electric Global Research Center Niskayuna, NY, 1239, USA {liux,tu,wheeler}@research.ge.com
Face Model Fitting on Low Resolution Images Xiaoming Liu Peter H. Tu Frederick W. Wheeler Visualization and Computer Vision Lab General Electric Global Research Center Niskayuna, NY, 1239, USA {liux,tu,wheeler}@research.ge.com
Image and Video Understanding
 Image and Video Understanding 2VO 710.095 WS Christoph Feichtenhofer, Axel Pinz Slide credits: Many thanks to all the great computer vision researchers on which this presentation relies on. Most material
Image and Video Understanding 2VO 710.095 WS Christoph Feichtenhofer, Axel Pinz Slide credits: Many thanks to all the great computer vision researchers on which this presentation relies on. Most material
Visualization and Feature Extraction, FLOW Spring School 2016 Prof. Dr. Tino Weinkauf. Flow Visualization. Image-Based Methods (integration-based)
") Visualization and Feature Extraction, FLOW Spring School 2016 Prof. Dr. Tino Weinkauf Flow Visualization Image-Based Methods (integration-based) Spot Noise (Jarke van Wijk, Siggraph 1991) Flow Visualization:
Visualization and Feature Extraction, FLOW Spring School 2016 Prof. Dr. Tino Weinkauf Flow Visualization Image-Based Methods (integration-based) Spot Noise (Jarke van Wijk, Siggraph 1991) Flow Visualization:
A Learning Based Method for Super-Resolution of Low Resolution Images
 A Learning Based Method for Super-Resolution of Low Resolution Images Emre Ugur June 1, 2004 emre.ugur@ceng.metu.edu.tr Abstract The main objective of this project is the study of a learning based method
A Learning Based Method for Super-Resolution of Low Resolution Images Emre Ugur June 1, 2004 emre.ugur@ceng.metu.edu.tr Abstract The main objective of this project is the study of a learning based method
Color Segmentation Based Depth Image Filtering
 Color Segmentation Based Depth Image Filtering Michael Schmeing and Xiaoyi Jiang Department of Computer Science, University of Münster Einsteinstraße 62, 48149 Münster, Germany, {m.schmeing xjiang}@uni-muenster.de
Color Segmentation Based Depth Image Filtering Michael Schmeing and Xiaoyi Jiang Department of Computer Science, University of Münster Einsteinstraße 62, 48149 Münster, Germany, {m.schmeing xjiang}@uni-muenster.de
Image Classification for Dogs and Cats
 Image Classification for Dogs and Cats Bang Liu, Yan Liu Department of Electrical and Computer Engineering {bang3,yan10}@ualberta.ca Kai Zhou Department of Computing Science kzhou3@ualberta.ca Abstract
Image Classification for Dogs and Cats Bang Liu, Yan Liu Department of Electrical and Computer Engineering {bang3,yan10}@ualberta.ca Kai Zhou Department of Computing Science kzhou3@ualberta.ca Abstract
The Visual Internet of Things System Based on Depth Camera
 The Visual Internet of Things System Based on Depth Camera Xucong Zhang 1, Xiaoyun Wang and Yingmin Jia Abstract The Visual Internet of Things is an important part of information technology. It is proposed
The Visual Internet of Things System Based on Depth Camera Xucong Zhang 1, Xiaoyun Wang and Yingmin Jia Abstract The Visual Internet of Things is an important part of information technology. It is proposed
Probabilistic Latent Semantic Analysis (plsa)
") Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org} References
Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org} References
Object class recognition using unsupervised scale-invariant learning
 Object class recognition using unsupervised scale-invariant learning Rob Fergus Pietro Perona Andrew Zisserman Oxford University California Institute of Technology Goal Recognition of object categories
Object class recognition using unsupervised scale-invariant learning Rob Fergus Pietro Perona Andrew Zisserman Oxford University California Institute of Technology Goal Recognition of object categories
Practical Tour of Visual tracking. David Fleet and Allan Jepson January, 2006
 Practical Tour of Visual tracking David Fleet and Allan Jepson January, 2006 Designing a Visual Tracker: What is the state? pose and motion (position, velocity, acceleration, ) shape (size, deformation,
Practical Tour of Visual tracking David Fleet and Allan Jepson January, 2006 Designing a Visual Tracker: What is the state? pose and motion (position, velocity, acceleration, ) shape (size, deformation,
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Bayesian Image Super-Resolution
 Bayesian Image Super-Resolution Michael E. Tipping and Christopher M. Bishop Microsoft Research, Cambridge, U.K..................................................................... Published as: Bayesian
Bayesian Image Super-Resolution Michael E. Tipping and Christopher M. Bishop Microsoft Research, Cambridge, U.K..................................................................... Published as: Bayesian
Automatic Labeling of Lane Markings for Autonomous Vehicles
 Automatic Labeling of Lane Markings for Autonomous Vehicles Jeffrey Kiske Stanford University 450 Serra Mall, Stanford, CA 94305 jkiske@stanford.edu 1. Introduction As autonomous vehicles become more popular,
Automatic Labeling of Lane Markings for Autonomous Vehicles Jeffrey Kiske Stanford University 450 Serra Mall, Stanford, CA 94305 jkiske@stanford.edu 1. Introduction As autonomous vehicles become more popular,
Assessment. Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall
 Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Wii Remote Calibration Using the Sensor Bar
 Wii Remote Calibration Using the Sensor Bar Alparslan Yildiz Abdullah Akay Yusuf Sinan Akgul GIT Vision Lab - http://vision.gyte.edu.tr Gebze Institute of Technology Kocaeli, Turkey {yildiz, akay, akgul}@bilmuh.gyte.edu.tr
Wii Remote Calibration Using the Sensor Bar Alparslan Yildiz Abdullah Akay Yusuf Sinan Akgul GIT Vision Lab - http://vision.gyte.edu.tr Gebze Institute of Technology Kocaeli, Turkey {yildiz, akay, akgul}@bilmuh.gyte.edu.tr
PHYSIOLOGICALLY-BASED DETECTION OF COMPUTER GENERATED FACES IN VIDEO
 PHYSIOLOGICALLY-BASED DETECTION OF COMPUTER GENERATED FACES IN VIDEO V. Conotter, E. Bodnari, G. Boato H. Farid Department of Information Engineering and Computer Science University of Trento, Trento (ITALY)
PHYSIOLOGICALLY-BASED DETECTION OF COMPUTER GENERATED FACES IN VIDEO V. Conotter, E. Bodnari, G. Boato H. Farid Department of Information Engineering and Computer Science University of Trento, Trento (ITALY)
Character Image Patterns as Big Data
 22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
Epipolar Geometry. Readings: See Sections 10.1 and 15.6 of Forsyth and Ponce. Right Image. Left Image. e(p ) Epipolar Lines. e(q ) q R.
 Epipolar Lines. e(q ) q R.") Epipolar Geometry We consider two perspective images of a scene as taken from a stereo pair of cameras (or equivalently, assume the scene is rigid and imaged with a single camera from two different locations).
Epipolar Geometry We consider two perspective images of a scene as taken from a stereo pair of cameras (or equivalently, assume the scene is rigid and imaged with a single camera from two different locations).
A NEW SUPER RESOLUTION TECHNIQUE FOR RANGE DATA. Valeria Garro, Pietro Zanuttigh, Guido M. Cortelazzo. University of Padova, Italy
 A NEW SUPER RESOLUTION TECHNIQUE FOR RANGE DATA Valeria Garro, Pietro Zanuttigh, Guido M. Cortelazzo University of Padova, Italy ABSTRACT Current Time-of-Flight matrix sensors allow for the acquisition
A NEW SUPER RESOLUTION TECHNIQUE FOR RANGE DATA Valeria Garro, Pietro Zanuttigh, Guido M. Cortelazzo University of Padova, Italy ABSTRACT Current Time-of-Flight matrix sensors allow for the acquisition
Segmentation of building models from dense 3D point-clouds
 Segmentation of building models from dense 3D point-clouds Joachim Bauer, Konrad Karner, Konrad Schindler, Andreas Klaus, Christopher Zach VRVis Research Center for Virtual Reality and Visualization, Institute
Segmentation of building models from dense 3D point-clouds Joachim Bauer, Konrad Karner, Konrad Schindler, Andreas Klaus, Christopher Zach VRVis Research Center for Virtual Reality and Visualization, Institute
Bert Huang Department of Computer Science Virginia Tech
 This paper was submitted as a final project report for CS6424/ECE6424 Probabilistic Graphical Models and Structured Prediction in the spring semester of 2016. The work presented here is done by students
This paper was submitted as a final project report for CS6424/ECE6424 Probabilistic Graphical Models and Structured Prediction in the spring semester of 2016. The work presented here is done by students
Image Segmentation and Registration
 Image Segmentation and Registration Dr. Christine Tanner (tanner@vision.ee.ethz.ch) Computer Vision Laboratory, ETH Zürich Dr. Verena Kaynig, Machine Learning Laboratory, ETH Zürich Outline Segmentation
Image Segmentation and Registration Dr. Christine Tanner (tanner@vision.ee.ethz.ch) Computer Vision Laboratory, ETH Zürich Dr. Verena Kaynig, Machine Learning Laboratory, ETH Zürich Outline Segmentation
Vision based Vehicle Tracking using a high angle camera
 Vision based Vehicle Tracking using a high angle camera Raúl Ignacio Ramos García Dule Shu gramos@clemson.edu dshu@clemson.edu Abstract A vehicle tracking and grouping algorithm is presented in this work
Vision based Vehicle Tracking using a high angle camera Raúl Ignacio Ramos García Dule Shu gramos@clemson.edu dshu@clemson.edu Abstract A vehicle tracking and grouping algorithm is presented in this work
arxiv:1312.6034v2 [cs.cv] 19 Apr 2014
![arxiv:1312.6034v2 [cs.cv] 19 Apr 2014](/thumbs/39/19892728.jpg "arxiv:1312.6034v2 [cs.cv] 19 Apr 2014") Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps arxiv:1312.6034v2 [cs.cv] 19 Apr 2014 Karen Simonyan Andrea Vedaldi Andrew Zisserman Visual Geometry Group,
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps arxiv:1312.6034v2 [cs.cv] 19 Apr 2014 Karen Simonyan Andrea Vedaldi Andrew Zisserman Visual Geometry Group,
Single Depth Image Super Resolution and Denoising Using Coupled Dictionary Learning with Local Constraints and Shock Filtering
 Single Depth Image Super Resolution and Denoising Using Coupled Dictionary Learning with Local Constraints and Shock Filtering Jun Xie 1, Cheng-Chuan Chou 2, Rogerio Feris 3, Ming-Ting Sun 1 1 University
Single Depth Image Super Resolution and Denoising Using Coupled Dictionary Learning with Local Constraints and Shock Filtering Jun Xie 1, Cheng-Chuan Chou 2, Rogerio Feris 3, Ming-Ting Sun 1 1 University
Tracking performance evaluation on PETS 2015 Challenge datasets
 Tracking performance evaluation on PETS 2015 Challenge datasets Tahir Nawaz, Jonathan Boyle, Longzhen Li and James Ferryman Computational Vision Group, School of Systems Engineering University of Reading,
Tracking performance evaluation on PETS 2015 Challenge datasets Tahir Nawaz, Jonathan Boyle, Longzhen Li and James Ferryman Computational Vision Group, School of Systems Engineering University of Reading,
Lighting Estimation in Indoor Environments from Low-Quality Images
 Lighting Estimation in Indoor Environments from Low-Quality Images Natalia Neverova, Damien Muselet, Alain Trémeau Laboratoire Hubert Curien UMR CNRS 5516, University Jean Monnet, Rue du Professeur Benoît
Lighting Estimation in Indoor Environments from Low-Quality Images Natalia Neverova, Damien Muselet, Alain Trémeau Laboratoire Hubert Curien UMR CNRS 5516, University Jean Monnet, Rue du Professeur Benoît
CS 534: Computer Vision 3D Model-based recognition
 CS 534: Computer Vision 3D Model-based recognition Ahmed Elgammal Dept of Computer Science CS 534 3D Model-based Vision - 1 High Level Vision Object Recognition: What it means? Two main recognition tasks:!
CS 534: Computer Vision 3D Model-based recognition Ahmed Elgammal Dept of Computer Science CS 534 3D Model-based Vision - 1 High Level Vision Object Recognition: What it means? Two main recognition tasks:!
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Expression Invariant 3D Face Recognition with a Morphable Model
 Expression Invariant 3D Face Recognition with a Morphable Model Brian Amberg brian.amberg@unibas.ch Reinhard Knothe reinhard.knothe@unibas.ch Thomas Vetter thomas.vetter@unibas.ch Abstract We present an
Expression Invariant 3D Face Recognition with a Morphable Model Brian Amberg brian.amberg@unibas.ch Reinhard Knothe reinhard.knothe@unibas.ch Thomas Vetter thomas.vetter@unibas.ch Abstract We present an
Deep Convolutional Inverse Graphics Network
 Deep Convolutional Inverse Graphics Network Tejas D. Kulkarni* 1, William F. Whitney* 2, Pushmeet Kohli 3, Joshua B. Tenenbaum 4 1,2,4 Massachusetts Institute of Technology, Cambridge, USA 3 Microsoft
Deep Convolutional Inverse Graphics Network Tejas D. Kulkarni* 1, William F. Whitney* 2, Pushmeet Kohli 3, Joshua B. Tenenbaum 4 1,2,4 Massachusetts Institute of Technology, Cambridge, USA 3 Microsoft
INTRODUCTION TO RENDERING TECHNIQUES
 INTRODUCTION TO RENDERING TECHNIQUES 22 Mar. 212 Yanir Kleiman What is 3D Graphics? Why 3D? Draw one frame at a time Model only once X 24 frames per second Color / texture only once 15, frames for a feature
INTRODUCTION TO RENDERING TECHNIQUES 22 Mar. 212 Yanir Kleiman What is 3D Graphics? Why 3D? Draw one frame at a time Model only once X 24 frames per second Color / texture only once 15, frames for a feature
VEHICLE LOCALISATION AND CLASSIFICATION IN URBAN CCTV STREAMS
 VEHICLE LOCALISATION AND CLASSIFICATION IN URBAN CCTV STREAMS Norbert Buch 1, Mark Cracknell 2, James Orwell 1 and Sergio A. Velastin 1 1. Kingston University, Penrhyn Road, Kingston upon Thames, KT1 2EE,
VEHICLE LOCALISATION AND CLASSIFICATION IN URBAN CCTV STREAMS Norbert Buch 1, Mark Cracknell 2, James Orwell 1 and Sergio A. Velastin 1 1. Kingston University, Penrhyn Road, Kingston upon Thames, KT1 2EE,
Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 269 Class Project Report
 Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 69 Class Project Report Junhua Mao and Lunbo Xu University of California, Los Angeles mjhustc@ucla.edu and lunbo
Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 69 Class Project Report Junhua Mao and Lunbo Xu University of California, Los Angeles mjhustc@ucla.edu and lunbo
Build Panoramas on Android Phones
 Build Panoramas on Android Phones Tao Chu, Bowen Meng, Zixuan Wang Stanford University, Stanford CA Abstract The purpose of this work is to implement panorama stitching from a sequence of photos taken
Build Panoramas on Android Phones Tao Chu, Bowen Meng, Zixuan Wang Stanford University, Stanford CA Abstract The purpose of this work is to implement panorama stitching from a sequence of photos taken
Determining optimal window size for texture feature extraction methods
 IX Spanish Symposium on Pattern Recognition and Image Analysis, Castellon, Spain, May 2001, vol.2, 237-242, ISBN: 84-8021-351-5. Determining optimal window size for texture feature extraction methods Domènec
IX Spanish Symposium on Pattern Recognition and Image Analysis, Castellon, Spain, May 2001, vol.2, 237-242, ISBN: 84-8021-351-5. Determining optimal window size for texture feature extraction methods Domènec
Semantic Recognition: Object Detection and Scene Segmentation
 Semantic Recognition: Object Detection and Scene Segmentation Xuming He xuming.he@nicta.com.au Computer Vision Research Group NICTA Robotic Vision Summer School 2015 Acknowledgement: Slides from Fei-Fei
Semantic Recognition: Object Detection and Scene Segmentation Xuming He xuming.he@nicta.com.au Computer Vision Research Group NICTA Robotic Vision Summer School 2015 Acknowledgement: Slides from Fei-Fei
Unsupervised Joint Alignment of Complex Images
 Unsupervised Joint Alignment of Complex Images Gary B. Huang Vidit Jain University of Massachusetts Amherst Amherst, MA {gbhuang,vidit,elm}@cs.umass.edu Erik Learned-Miller Abstract Many recognition algorithms
Unsupervised Joint Alignment of Complex Images Gary B. Huang Vidit Jain University of Massachusetts Amherst Amherst, MA {gbhuang,vidit,elm}@cs.umass.edu Erik Learned-Miller Abstract Many recognition algorithms
Steven C.H. Hoi School of Information Systems Singapore Management University Email: chhoi@smu.edu.sg
 Steven C.H. Hoi School of Information Systems Singapore Management University Email: chhoi@smu.edu.sg Introduction http://stevenhoi.org/ Finance Recommender Systems Cyber Security Machine Learning Visual
Steven C.H. Hoi School of Information Systems Singapore Management University Email: chhoi@smu.edu.sg Introduction http://stevenhoi.org/ Finance Recommender Systems Cyber Security Machine Learning Visual
Efficient online learning of a non-negative sparse autoencoder
 and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
The Delicate Art of Flower Classification
 The Delicate Art of Flower Classification Paul Vicol Simon Fraser University University Burnaby, BC pvicol@sfu.ca Note: The following is my contribution to a group project for a graduate machine learning
The Delicate Art of Flower Classification Paul Vicol Simon Fraser University University Burnaby, BC pvicol@sfu.ca Note: The following is my contribution to a group project for a graduate machine learning
Announcements. Active stereo with structured light. Project structured light patterns onto the object
 Announcements Active stereo with structured light Project 3 extension: Wednesday at noon Final project proposal extension: Friday at noon > consult with Steve, Rick, and/or Ian now! Project 2 artifact
Announcements Active stereo with structured light Project 3 extension: Wednesday at noon Final project proposal extension: Friday at noon > consult with Steve, Rick, and/or Ian now! Project 2 artifact
Interactive person re-identification in TV series
 Interactive person re-identification in TV series Mika Fischer Hazım Kemal Ekenel Rainer Stiefelhagen CV:HCI lab, Karlsruhe Institute of Technology Adenauerring 2, 76131 Karlsruhe, Germany E-mail: {mika.fischer,ekenel,rainer.stiefelhagen}@kit.edu
Interactive person re-identification in TV series Mika Fischer Hazım Kemal Ekenel Rainer Stiefelhagen CV:HCI lab, Karlsruhe Institute of Technology Adenauerring 2, 76131 Karlsruhe, Germany E-mail: {mika.fischer,ekenel,rainer.stiefelhagen}@kit.edu
Potential of face area data for predicting sharpness of natural images
 Potential of face area data for predicting sharpness of natural images Mikko Nuutinen a, Olli Orenius b, Timo Säämänen b, Pirkko Oittinen a a Dept. of Media Technology, Aalto University School of Science
Potential of face area data for predicting sharpness of natural images Mikko Nuutinen a, Olli Orenius b, Timo Säämänen b, Pirkko Oittinen a a Dept. of Media Technology, Aalto University School of Science
Part-Based Recognition
 Part-Based Recognition Benedict Brown CS597D, Fall 2003 Princeton University CS 597D, Part-Based Recognition p. 1/32 Introduction Many objects are made up of parts It s presumably easier to identify simple
Part-Based Recognition Benedict Brown CS597D, Fall 2003 Princeton University CS 597D, Part-Based Recognition p. 1/32 Introduction Many objects are made up of parts It s presumably easier to identify simple
Canny Edge Detection
 Canny Edge Detection 09gr820 March 23, 2009 1 Introduction The purpose of edge detection in general is to significantly reduce the amount of data in an image, while preserving the structural properties
Canny Edge Detection 09gr820 March 23, 2009 1 Introduction The purpose of edge detection in general is to significantly reduce the amount of data in an image, while preserving the structural properties
Extracting a Good Quality Frontal Face Images from Low Resolution Video Sequences
 Extracting a Good Quality Frontal Face Images from Low Resolution Video Sequences Pritam P. Patil 1, Prof. M.V. Phatak 2 1 ME.Comp, 2 Asst.Professor, MIT, Pune Abstract The face is one of the important
Extracting a Good Quality Frontal Face Images from Low Resolution Video Sequences Pritam P. Patil 1, Prof. M.V. Phatak 2 1 ME.Comp, 2 Asst.Professor, MIT, Pune Abstract The face is one of the important
ROBUST VEHICLE TRACKING IN VIDEO IMAGES BEING TAKEN FROM A HELICOPTER
 ROBUST VEHICLE TRACKING IN VIDEO IMAGES BEING TAKEN FROM A HELICOPTER Fatemeh Karimi Nejadasl, Ben G.H. Gorte, and Serge P. Hoogendoorn Institute of Earth Observation and Space System, Delft University
ROBUST VEHICLE TRACKING IN VIDEO IMAGES BEING TAKEN FROM A HELICOPTER Fatemeh Karimi Nejadasl, Ben G.H. Gorte, and Serge P. Hoogendoorn Institute of Earth Observation and Space System, Delft University
An Energy-Based Vehicle Tracking System using Principal Component Analysis and Unsupervised ART Network
 Proceedings of the 8th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING & DATA BASES (AIKED '9) ISSN: 179-519 435 ISBN: 978-96-474-51-2 An Energy-Based Vehicle Tracking System using Principal
Proceedings of the 8th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING & DATA BASES (AIKED '9) ISSN: 179-519 435 ISBN: 978-96-474-51-2 An Energy-Based Vehicle Tracking System using Principal
siftservice.com - Turning a Computer Vision algorithm into a World Wide Web Service
 siftservice.com - Turning a Computer Vision algorithm into a World Wide Web Service Ahmad Pahlavan Tafti 1, Hamid Hassannia 2, and Zeyun Yu 1 1 Department of Computer Science, University of Wisconsin -Milwaukee,
siftservice.com - Turning a Computer Vision algorithm into a World Wide Web Service Ahmad Pahlavan Tafti 1, Hamid Hassannia 2, and Zeyun Yu 1 1 Department of Computer Science, University of Wisconsin -Milwaukee,
Keywords: Image Generation and Manipulation, Video Processing, Video Factorization, Face Morphing
 TENSORIAL FACTORIZATION METHODS FOR MANIPULATION OF FACE VIDEOS S. Manikandan, Ranjeeth Kumar, C.V. Jawahar Center for Visual Information Technology International Institute of Information Technology, Hyderabad
TENSORIAL FACTORIZATION METHODS FOR MANIPULATION OF FACE VIDEOS S. Manikandan, Ranjeeth Kumar, C.V. Jawahar Center for Visual Information Technology International Institute of Information Technology, Hyderabad
Accurate and robust image superresolution by neural processing of local image representations
 Accurate and robust image superresolution by neural processing of local image representations Carlos Miravet 1,2 and Francisco B. Rodríguez 1 1 Grupo de Neurocomputación Biológica (GNB), Escuela Politécnica
Accurate and robust image superresolution by neural processing of local image representations Carlos Miravet 1,2 and Francisco B. Rodríguez 1 1 Grupo de Neurocomputación Biológica (GNB), Escuela Politécnica
Local features and matching. Image classification & object localization
 Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
More Local Structure Information for Make-Model Recognition
 More Local Structure Information for Make-Model Recognition David Anthony Torres Dept. of Computer Science The University of California at San Diego La Jolla, CA 9093 Abstract An object classification
More Local Structure Information for Make-Model Recognition David Anthony Torres Dept. of Computer Science The University of California at San Diego La Jolla, CA 9093 Abstract An object classification
Character Animation from 2D Pictures and 3D Motion Data ALEXANDER HORNUNG, ELLEN DEKKERS, and LEIF KOBBELT RWTH-Aachen University
 Character Animation from 2D Pictures and 3D Motion Data ALEXANDER HORNUNG, ELLEN DEKKERS, and LEIF KOBBELT RWTH-Aachen University Presented by: Harish CS-525 First presentation Abstract This article presents
Character Animation from 2D Pictures and 3D Motion Data ALEXANDER HORNUNG, ELLEN DEKKERS, and LEIF KOBBELT RWTH-Aachen University Presented by: Harish CS-525 First presentation Abstract This article presents
Edge tracking for motion segmentation and depth ordering
 Edge tracking for motion segmentation and depth ordering P. Smith, T. Drummond and R. Cipolla Department of Engineering University of Cambridge Cambridge CB2 1PZ,UK {pas1001 twd20 cipolla}@eng.cam.ac.uk
Edge tracking for motion segmentation and depth ordering P. Smith, T. Drummond and R. Cipolla Department of Engineering University of Cambridge Cambridge CB2 1PZ,UK {pas1001 twd20 cipolla}@eng.cam.ac.uk
A Short Introduction to Computer Graphics
 A Short Introduction to Computer Graphics Frédo Durand MIT Laboratory for Computer Science 1 Introduction Chapter I: Basics Although computer graphics is a vast field that encompasses almost any graphical
A Short Introduction to Computer Graphics Frédo Durand MIT Laboratory for Computer Science 1 Introduction Chapter I: Basics Although computer graphics is a vast field that encompasses almost any graphical
Circle Object Recognition Based on Monocular Vision for Home Security Robot
 Journal of Applied Science and Engineering, Vol. 16, No. 3, pp. 261 268 (2013) DOI: 10.6180/jase.2013.16.3.05 Circle Object Recognition Based on Monocular Vision for Home Security Robot Shih-An Li, Ching-Chang
Journal of Applied Science and Engineering, Vol. 16, No. 3, pp. 261 268 (2013) DOI: 10.6180/jase.2013.16.3.05 Circle Object Recognition Based on Monocular Vision for Home Security Robot Shih-An Li, Ching-Chang
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus
 Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Spatio-Temporally Coherent 3D Animation Reconstruction from Multi-view RGB-D Images using Landmark Sampling
 , March 13-15, 2013, Hong Kong Spatio-Temporally Coherent 3D Animation Reconstruction from Multi-view RGB-D Images using Landmark Sampling Naveed Ahmed Abstract We present a system for spatio-temporally
, March 13-15, 2013, Hong Kong Spatio-Temporally Coherent 3D Animation Reconstruction from Multi-view RGB-D Images using Landmark Sampling Naveed Ahmed Abstract We present a system for spatio-temporally
MetropoGIS: A City Modeling System DI Dr. Konrad KARNER, DI Andreas KLAUS, DI Joachim BAUER, DI Christopher ZACH
 MetropoGIS: A City Modeling System DI Dr. Konrad KARNER, DI Andreas KLAUS, DI Joachim BAUER, DI Christopher ZACH VRVis Research Center for Virtual Reality and Visualization, Virtual Habitat, Inffeldgasse
MetropoGIS: A City Modeling System DI Dr. Konrad KARNER, DI Andreas KLAUS, DI Joachim BAUER, DI Christopher ZACH VRVis Research Center for Virtual Reality and Visualization, Virtual Habitat, Inffeldgasse
A Prototype For Eye-Gaze Corrected
 A Prototype For Eye-Gaze Corrected Video Chat on Graphics Hardware Maarten Dumont, Steven Maesen, Sammy Rogmans and Philippe Bekaert Introduction Traditional webcam video chat: No eye contact. No extensive
A Prototype For Eye-Gaze Corrected Video Chat on Graphics Hardware Maarten Dumont, Steven Maesen, Sammy Rogmans and Philippe Bekaert Introduction Traditional webcam video chat: No eye contact. No extensive
Perception-based Design for Tele-presence
 Perception-based Design for Tele-presence Santanu Chaudhury 1, Shantanu Ghosh 1,2, Amrita Basu 3, Brejesh Lall 1, Sumantra Dutta Roy 1, Lopamudra Choudhury 3, Prashanth R 1, Ashish Singh 1, and Amit Maniyar
Perception-based Design for Tele-presence Santanu Chaudhury 1, Shantanu Ghosh 1,2, Amrita Basu 3, Brejesh Lall 1, Sumantra Dutta Roy 1, Lopamudra Choudhury 3, Prashanth R 1, Ashish Singh 1, and Amit Maniyar
3D Scanner using Line Laser. 1. Introduction. 2. Theory
 . Introduction 3D Scanner using Line Laser Di Lu Electrical, Computer, and Systems Engineering Rensselaer Polytechnic Institute The goal of 3D reconstruction is to recover the 3D properties of a geometric
. Introduction 3D Scanner using Line Laser Di Lu Electrical, Computer, and Systems Engineering Rensselaer Polytechnic Institute The goal of 3D reconstruction is to recover the 3D properties of a geometric
3D Face Modeling. Vuong Le. IFP group, Beckman Institute University of Illinois ECE417 Spring 2013
 3D Face Modeling Vuong Le IFP group, Beckman Institute University of Illinois ECE417 Spring 2013 Contents Motivation 3D facial geometry modeling 3D facial geometry acquisition 3D facial deformation modeling
3D Face Modeling Vuong Le IFP group, Beckman Institute University of Illinois ECE417 Spring 2013 Contents Motivation 3D facial geometry modeling 3D facial geometry acquisition 3D facial deformation modeling
CUBE-MAP DATA STRUCTURE FOR INTERACTIVE GLOBAL ILLUMINATION COMPUTATION IN DYNAMIC DIFFUSE ENVIRONMENTS
 ICCVG 2002 Zakopane, 25-29 Sept. 2002 Rafal Mantiuk (1,2), Sumanta Pattanaik (1), Karol Myszkowski (3) (1) University of Central Florida, USA, (2) Technical University of Szczecin, Poland, (3) Max- Planck-Institut
ICCVG 2002 Zakopane, 25-29 Sept. 2002 Rafal Mantiuk (1,2), Sumanta Pattanaik (1), Karol Myszkowski (3) (1) University of Central Florida, USA, (2) Technical University of Szczecin, Poland, (3) Max- Planck-Institut
Lecture 6: Classification & Localization. boris. ginzburg@intel.com
 Lecture 6: Classification & Localization boris. ginzburg@intel.com 1 Agenda ILSVRC 2014 Overfeat: integrated classification, localization, and detection Classification with Localization Detection. 2 ILSVRC-2014
Lecture 6: Classification & Localization boris. ginzburg@intel.com 1 Agenda ILSVRC 2014 Overfeat: integrated classification, localization, and detection Classification with Localization Detection. 2 ILSVRC-2014
Learning Motion Categories using both Semantic and Structural Information
 Learning Motion Categories using both Semantic and Structural Information Shu-Fai Wong, Tae-Kyun Kim and Roberto Cipolla Department of Engineering, University of Cambridge, Cambridge, CB2 1PZ, UK {sfw26,
Learning Motion Categories using both Semantic and Structural Information Shu-Fai Wong, Tae-Kyun Kim and Roberto Cipolla Department of Engineering, University of Cambridge, Cambridge, CB2 1PZ, UK {sfw26,
Image Normalization for Illumination Compensation in Facial Images
 Image Normalization for Illumination Compensation in Facial Images by Martin D. Levine, Maulin R. Gandhi, Jisnu Bhattacharyya Department of Electrical & Computer Engineering & Center for Intelligent Machines
Image Normalization for Illumination Compensation in Facial Images by Martin D. Levine, Maulin R. Gandhi, Jisnu Bhattacharyya Department of Electrical & Computer Engineering & Center for Intelligent Machines
A technical overview of the Fuel3D system.
 A technical overview of the Fuel3D system. Contents Introduction 3 How does Fuel3D actually work? 4 Photometric imaging for high-resolution surface detail 4 Optical localization to track movement during
A technical overview of the Fuel3D system. Contents Introduction 3 How does Fuel3D actually work? 4 Photometric imaging for high-resolution surface detail 4 Optical localization to track movement during
LOCAL SURFACE PATCH BASED TIME ATTENDANCE SYSTEM USING FACE. indhubatchvsa@gmail.com
 LOCAL SURFACE PATCH BASED TIME ATTENDANCE SYSTEM USING FACE 1 S.Manikandan, 2 S.Abirami, 2 R.Indumathi, 2 R.Nandhini, 2 T.Nanthini 1 Assistant Professor, VSA group of institution, Salem. 2 BE(ECE), VSA
LOCAL SURFACE PATCH BASED TIME ATTENDANCE SYSTEM USING FACE 1 S.Manikandan, 2 S.Abirami, 2 R.Indumathi, 2 R.Nandhini, 2 T.Nanthini 1 Assistant Professor, VSA group of institution, Salem. 2 BE(ECE), VSA
Supporting Online Material for
 www.sciencemag.org/cgi/content/full/313/5786/504/dc1 Supporting Online Material for Reducing the Dimensionality of Data with Neural Networks G. E. Hinton* and R. R. Salakhutdinov *To whom correspondence
www.sciencemag.org/cgi/content/full/313/5786/504/dc1 Supporting Online Material for Reducing the Dimensionality of Data with Neural Networks G. E. Hinton* and R. R. Salakhutdinov *To whom correspondence
Segmentation & Clustering
 EECS 442 Computer vision Segmentation & Clustering Segmentation in human vision K-mean clustering Mean-shift Graph-cut Reading: Chapters 14 [FP] Some slides of this lectures are courtesy of prof F. Li,
EECS 442 Computer vision Segmentation & Clustering Segmentation in human vision K-mean clustering Mean-shift Graph-cut Reading: Chapters 14 [FP] Some slides of this lectures are courtesy of prof F. Li,
Image Processing and Computer Graphics. Rendering Pipeline. Matthias Teschner. Computer Science Department University of Freiburg
 Image Processing and Computer Graphics Rendering Pipeline Matthias Teschner Computer Science Department University of Freiburg Outline introduction rendering pipeline vertex processing primitive processing
Image Processing and Computer Graphics Rendering Pipeline Matthias Teschner Computer Science Department University of Freiburg Outline introduction rendering pipeline vertex processing primitive processing
Tracking in flussi video 3D. Ing. Samuele Salti
 Seminari XXIII ciclo Tracking in flussi video 3D Ing. Tutors: Prof. Tullio Salmon Cinotti Prof. Luigi Di Stefano The Tracking problem Detection Object model, Track initiation, Track termination, Tracking
Seminari XXIII ciclo Tracking in flussi video 3D Ing. Tutors: Prof. Tullio Salmon Cinotti Prof. Luigi Di Stefano The Tracking problem Detection Object model, Track initiation, Track termination, Tracking
Transform-based Domain Adaptation for Big Data
 Transform-based Domain Adaptation for Big Data Erik Rodner University of Jena Judy Hoffman Jeff Donahue Trevor Darrell Kate Saenko UMass Lowell Abstract Images seen during test time are often not from
Transform-based Domain Adaptation for Big Data Erik Rodner University of Jena Judy Hoffman Jeff Donahue Trevor Darrell Kate Saenko UMass Lowell Abstract Images seen during test time are often not from
Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite
 Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite Philip Lenz 1 Andreas Geiger 2 Christoph Stiller 1 Raquel Urtasun 3 1 KARLSRUHE INSTITUTE OF TECHNOLOGY 2 MAX-PLANCK-INSTITUTE IS 3
Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite Philip Lenz 1 Andreas Geiger 2 Christoph Stiller 1 Raquel Urtasun 3 1 KARLSRUHE INSTITUTE OF TECHNOLOGY 2 MAX-PLANCK-INSTITUTE IS 3
A General Framework for Tracking Objects in a Multi-Camera Environment
 A General Framework for Tracking Objects in a Multi-Camera Environment Karlene Nguyen, Gavin Yeung, Soheil Ghiasi, Majid Sarrafzadeh {karlene, gavin, soheil, majid}@cs.ucla.edu Abstract We present a framework
A General Framework for Tracking Objects in a Multi-Camera Environment Karlene Nguyen, Gavin Yeung, Soheil Ghiasi, Majid Sarrafzadeh {karlene, gavin, soheil, majid}@cs.ucla.edu Abstract We present a framework
Deformable Part Models with CNN Features
 Deformable Part Models with CNN Features Pierre-André Savalle 1, Stavros Tsogkas 1,2, George Papandreou 3, Iasonas Kokkinos 1,2 1 Ecole Centrale Paris, 2 INRIA, 3 TTI-Chicago Abstract. In this work we
Deformable Part Models with CNN Features Pierre-André Savalle 1, Stavros Tsogkas 1,2, George Papandreou 3, Iasonas Kokkinos 1,2 1 Ecole Centrale Paris, 2 INRIA, 3 TTI-Chicago Abstract. In this work we
Bernice E. Rogowitz and Holly E. Rushmeier IBM TJ Watson Research Center, P.O. Box 704, Yorktown Heights, NY USA
 Are Image Quality Metrics Adequate to Evaluate the Quality of Geometric Objects? Bernice E. Rogowitz and Holly E. Rushmeier IBM TJ Watson Research Center, P.O. Box 704, Yorktown Heights, NY USA ABSTRACT
Are Image Quality Metrics Adequate to Evaluate the Quality of Geometric Objects? Bernice E. Rogowitz and Holly E. Rushmeier IBM TJ Watson Research Center, P.O. Box 704, Yorktown Heights, NY USA ABSTRACT
Robert Collins CSE598G. More on Mean-shift. R.Collins, CSE, PSU CSE598G Spring 2006
 More on Mean-shift R.Collins, CSE, PSU Spring 2006 Recall: Kernel Density Estimation Given a set of data samples x i ; i=1...n Convolve with a kernel function H to generate a smooth function f(x) Equivalent
More on Mean-shift R.Collins, CSE, PSU Spring 2006 Recall: Kernel Density Estimation Given a set of data samples x i ; i=1...n Convolve with a kernel function H to generate a smooth function f(x) Equivalent
DYNAMIC RANGE IMPROVEMENT THROUGH MULTIPLE EXPOSURES. Mark A. Robertson, Sean Borman, and Robert L. Stevenson
 c 1999 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or
c 1999 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or
3D Model-Based Face Recognition in Video
 The 2 nd International Conference on Biometrics, eoul, Korea, 2007 3D Model-Based Face Recognition in Video Unsang Park and Anil K. Jain Department of Computer cience and Engineering Michigan tate University
The 2 nd International Conference on Biometrics, eoul, Korea, 2007 3D Model-Based Face Recognition in Video Unsang Park and Anil K. Jain Department of Computer cience and Engineering Michigan tate University
Analecta Vol. 8, No. 2 ISSN 2064-7964
 EXPERIMENTAL APPLICATIONS OF ARTIFICIAL NEURAL NETWORKS IN ENGINEERING PROCESSING SYSTEM S. Dadvandipour Institute of Information Engineering, University of Miskolc, Egyetemváros, 3515, Miskolc, Hungary,
EXPERIMENTAL APPLICATIONS OF ARTIFICIAL NEURAL NETWORKS IN ENGINEERING PROCESSING SYSTEM S. Dadvandipour Institute of Information Engineering, University of Miskolc, Egyetemváros, 3515, Miskolc, Hungary,