Scheduling Algorithms in MapReduce Distributed Mind
|
|
|
- Clarence Farmer
- 10 years ago
- Views:
Transcription
1 Scheduling Algorithms in MapReduce Distributed Mind Karthik Kotian, Jason A Smith, Ye Zhang

2 Schedule Overview of topic (review) Hypothesis Research paper 1 Research paper 2 Research paper 3 Project software design

3 Overview of topic MapReduce Process a large set of data in parallel across a distributed cluster of computers Maximize the speed at which a task is completed Scheduling Splits a task into smaller jobs and distributes work to the nodes in the cluster Utilize the cluster's resources to its maximum capacity

4 Simulating schedulers FIFO Oldest job first. Fair-sharing Every task gets equal share of resources. Capacity Built over fairness for large cluster size. Queues Priorities

5 Hypothesis FIFO Least average execution time of jobs, compared to other two algorithms, when # of tasks < cluster size. Fairness Least average execution time of jobs, compared to other two algorithms, when cluster size < # of tasks. Capacity Least average execution time of jobs, compared to other two algorithms, when cluster size > 100.

6 Approach to test hypothesis Simulate MapReduce with each scheduler. Change the: Size of the cluster. Number of tasks. Complexity of the tasks. Compare schedulers based on average task completion time.

7 Research Paper 1 An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems Problem: Hadoop scheduling algorithm assumes homogeneous clusters and tasks Claim: "To the best of our knowledge, there is no Hadoop scheduling algorithm which simultaneously considers job and resource heterogeneity"

8 Hadoop System Model The users submit jobs to the system, where each job consists of some tasks. Each task is either a map task or a reduce task. The Hadoop system has a cluster. The cluster consists of a set of resources, where each resource has a computation unit, and a data storage unit

9 Hadoop System Model Typical scheduler receives two main messages New job arrival message from a user Heartbeat message from a free resource

10 Testing Environment Performance metrics for Hadoop systems Locality Fairness Satisfying the minimum share of the users Mean completion time of jobs Compare against two common schedulers FIFO Fair-sharing

11 Novel Contributions Adaptive scheduler based on: fairness and dissatisfaction minimum share requirements heterogeneity of jobs and resources Reducing communication costs by not necessarily maximizing a task s distribution Reducing search overhead for matching jobs and resources Increasing locality


12 Comparison Results

13 Results - Dissatisfaction

14 Results - Dissatisfaction
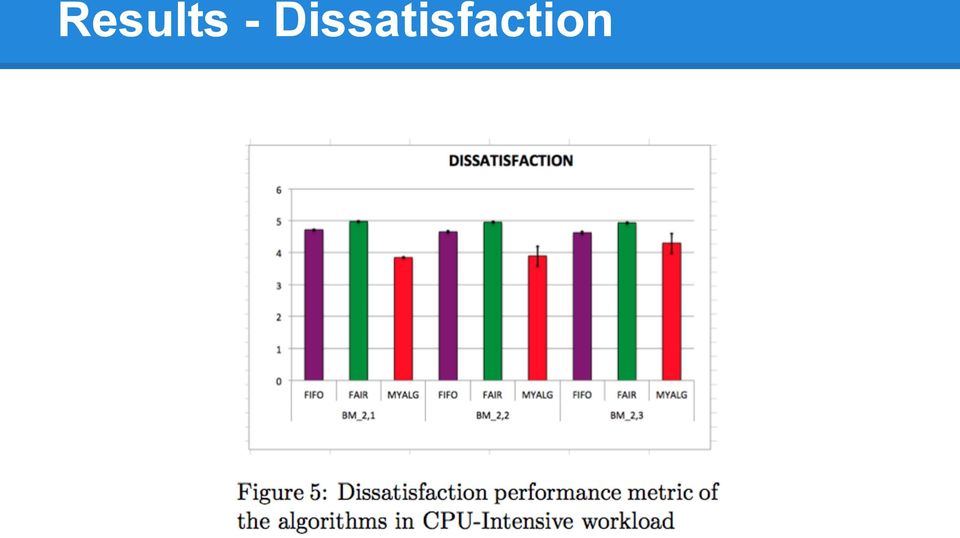

15 Results - Dissatisfaction

16 Results - Mean Completion Time
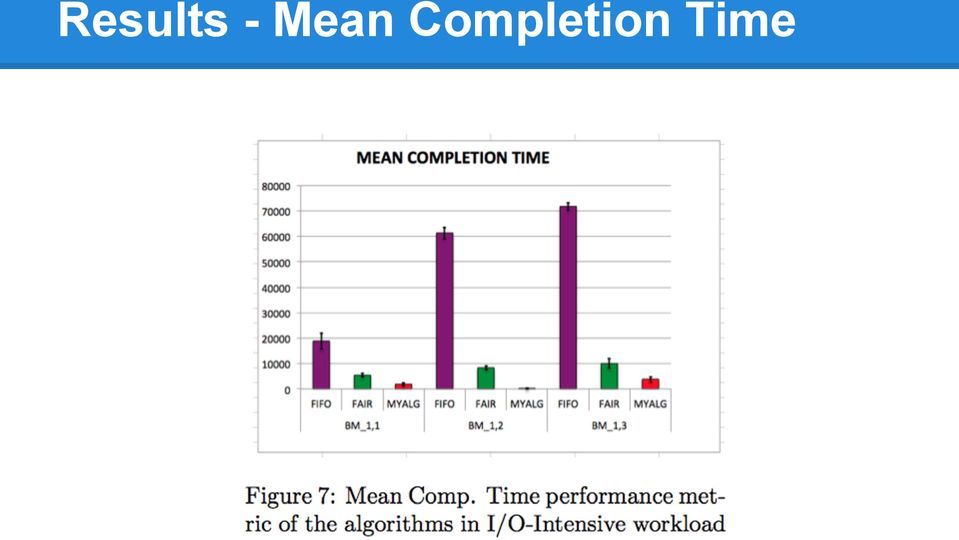
17 Results - Mean Completion Time


18 Results - Mean Completion Time

19 Usefulness Described FIFO and fair-sharing schedulers Comparison of a new scheduling algorithm to existing algorithms Average completion time as a comparison Modeling the MapReduce system

20 Research Paper 2 Investigation of Data Locality and Fairness in MapReduce. Zhenhua Guo, Geoffrey Fox, Mo Zhou Indiana University, Bloomingtom, IL MapReduce 2012 Proceeding of third international workshop on MapReduce and its application date. pdf

21 Data Locality[2] When a node reports that it has idle slots, the master scans the queue to find the task that can achieve the best data locality. Master searches for a task whose input data are located on that node. If the search fails, it searches for a task whose input data are located on the same rack as the node. If the search fails again, it randomly assigns a task. #2 - Research Paper #2
22 Problems Addressed[2] Fairness and Data Locality conflict with each other when used together. Strict Fairness degrades data locality. Pure Data Locality results in unfairness of resource usage. In a shared cluster, avoid scenario where small number of users overwhelm the resources of whole cluster. #2 - Research Paper #2
23 Novel Contribution[2] The paper investigates the tradeoff between data locality and fairness cost. Proposes algorithm lsap-sched gives optimal data locality by utilizing the well-known problem LSAP. In addition, it integrates fairness with lsapsched scheduler.this scheduler is called as lsap-fair-sched. #2 - Research Paper #2
24 lsap-fair-sched Algorithm[2] Input : α - DLC scaling factor for non data local tasks. β - FC scaling factor for tasks that are beyond its group allocation Output: assignment of tasks to idle map slots Functions: find the set of nodes with idle slots. find the set of tasks whose input data are stored on nodes with idle slots. calculate sto of all groups. #2 - Research Paper #2
25 lsap-fair-sched contd.[2] calculate task Fairness Cost matrix (FC). calculate Data Locality Cost matrix (DLC). C = FC + DLC. If C is not a square matrix then expand it to one. lsap algorithm is used to find the optimal assignment which is subsequently filtered and returned. Fault: Some tasks with bad data locality may be queued indefinitely. If the task have been waiting for a long time, reduce FC and DLC so that they could be scheduled at the subsequent scheduling points. #2 - Research Paper #2
26 Results[2] Reduces Data Locality Cost by 70-90% compared to Hadoop's dl-sched. #2 - Research Paper #2 Figure : Tradeoff between Fairness and Data Locality
27 Usefulness[2] We chose this paper to understand and investigate data locality scheduler in detail. Although we will not be implementing lsapfair-sched for our simulation because of its complexity, its comparison with Fairness and Hadoop's Data Locality Scheduler gave us valuable insights about Fairness Scheduler (which we are using for our simulation) and its limitations. #2 - Research Paper #2
28 Research Paper 3 Improving MapReduce Performance in Heterogeneous Environments Hadoop is an open-source implementation of MapReduce. Hadoop's performance is closely tied to its task scheduler. In practice, the homogeneity assumptions do not always hold. Hadoop's scheduler can cause severe performance degradation in heterogeneous environments. Longest Approximate Time to End (LATE) is highly robust to heterogeneity.
29 Scheduling in Hadoop
30 Assumptions in Hadoop's Scheduler 1. Nodes can perform work at roughly the same rate. 2. Tasks progress at a constant rate throughout time. 3. There is no cost to launching a speculative task on a node that would otherwise have an idle slot. 4. A task's progress score is representative of fraction of its total work that it has done. Specifically, in a reduce task, the copy, sort and reduce phases each take about 1/3 of the total time. 5. Tasks tend to finish in waves, so a task with a low progress score is likely a straggler. 6. Tasks in the same category (map or reduce) require roughly the same amount of work.
31 How the Assumptions Break Down 1. Nodes can perform work at roughly the same rate. 2. Tasks progress at a constant rate throughout time. Heterogeneity: Hadoop assumes that any detectably slow node is faulty. However, nodes can be slow for other reasons.
32 How the Assumptions Break Down 3. There is no cost to launching a speculative task on a node that would otherwise have an idle slot. It will be break down when resources are shared 4. A task's progress score is representative of fraction of its total work that it has done. Specifically, in a reduce task, the copy, sort and reduce phases each take about 1/3 of the total time. This may cause incorrect speculation of reducers. 5. Tasks tend to finish in waves, so a task with a low progress score is likely a straggler. Even in a homogeneous environment, these waves get more spread out over time due to variance adding up, so in a long enough job, tasks from different generations will be running concurrently.
33 The LATE Scheduler (Longest Approximation Time to End) Strategy: Always speculatively execute the task that we think will finish farthest into the future.
34 The LATE Scheduler 1. Previous progress score: For a map, the progress score is the fraction of input data read. For a reduce task, the execution is divided into three phases, each of which accounts for 1/3 of the score. (copy, sort, reduce) 2. Current progress rate: Use progress rate to decide which one is slower. It equals to: progress score / T T is the amount of time the task has been running for. estimation of time to completion: (1 - PS) / PR
35 Example In a typical MapReduce job, it contains three phases: copy, sort, reduce. The copy phase of reduce tasks is the slowest, because it involves all-pairs communication over the network. Tasks quickly complete the other two phases once they have all map output.
36 Example-continue Previous progress score: 30% reducers finish the average progress is: 0.3* *(1/3) it is around 53% current estimation = [(1-progress score) / progress score]t When 30% reducers finish their job. 70% reducers may have progress score 1/3. But, they have different T, which could be used to estimate which ones slower.
37 Advantages of LATE 1. It is robust to node heterogeneity, because it will relaunch only the slowest tasks, and only a small number of tasks. 2. LATE takes into account node heterogeneity when deciding where to run speculative tasks. 3. By focusing on estimated time left rather than progress rate, LATE speculatively executes only tasks that will improve job response time, rather than any slow tasks.
38 Results
39 Results
40 Results
41 Usefulness In reality, most assumptions that we mentioned previously, could not be ensured all the time. This paper help us understand what issue we may face when we implement the scheduler we selected before. For the reason of complexity and lack of data, we may not implement it. But, it offer a good reference for us to evaluate the scheduler that we will implement in our project.
42 Progress since previous report Replaced a research paper with a more relevant paper Better aligns with hypothesis Heterogeneous vs. homogeneous Software structure design for implementation
43 Software design Java SE 6 and Parallel Java Library Application: MasterNode Class WorkerNode Class Job Class Scheduler Class Input: Complexity of job (how long it takes to process) Size of the cluster. Size of the queue. Output : Average time to execute all jobs.
44 Software design
45 Software design
46 Software design
47 Software design
48 Software design java MapRedSim <T> <J> <N> <S> <seed> T: number of trials J: number of jobs N: size of cluster S: scheduler seed: random seed
49 Questions?
Improving MapReduce Performance in Heterogeneous Environments
 Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony D. Joseph, Randy Katz, Ion Stoica University of California, Berkeley {matei,andyk,adj,randy,stoica}@cs.berkeley.edu
Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony D. Joseph, Randy Katz, Ion Stoica University of California, Berkeley {matei,andyk,adj,randy,stoica}@cs.berkeley.edu
Job Scheduling for MapReduce
 UC Berkeley Job Scheduling for MapReduce Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Scott Shenker, Ion Stoica RAD Lab, * Facebook Inc 1 Motivation Hadoop was designed for large batch jobs
UC Berkeley Job Scheduling for MapReduce Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Scott Shenker, Ion Stoica RAD Lab, * Facebook Inc 1 Motivation Hadoop was designed for large batch jobs
A REAL TIME MEMORY SLOT UTILIZATION DESIGN FOR MAPREDUCE MEMORY CLUSTERS
 A REAL TIME MEMORY SLOT UTILIZATION DESIGN FOR MAPREDUCE MEMORY CLUSTERS Suma R 1, Vinay T R 2, Byre Gowda B K 3 1 Post graduate Student, CSE, SVCE, Bangalore 2 Assistant Professor, CSE, SVCE, Bangalore
A REAL TIME MEMORY SLOT UTILIZATION DESIGN FOR MAPREDUCE MEMORY CLUSTERS Suma R 1, Vinay T R 2, Byre Gowda B K 3 1 Post graduate Student, CSE, SVCE, Bangalore 2 Assistant Professor, CSE, SVCE, Bangalore
Improving MapReduce Performance in Heterogeneous Environments
 UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
Survey on Job Schedulers in Hadoop Cluster
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 1 (Sep. - Oct. 2013), PP 46-50 Bincy P Andrews 1, Binu A 2 1 (Rajagiri School of Engineering and Technology,
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 1 (Sep. - Oct. 2013), PP 46-50 Bincy P Andrews 1, Binu A 2 1 (Rajagiri School of Engineering and Technology,
Task Scheduling in Hadoop
 Task Scheduling in Hadoop Sagar Mamdapure Munira Ginwala Neha Papat SAE,Kondhwa SAE,Kondhwa SAE,Kondhwa Abstract Hadoop is widely used for storing large datasets and processing them efficiently under distributed
Task Scheduling in Hadoop Sagar Mamdapure Munira Ginwala Neha Papat SAE,Kondhwa SAE,Kondhwa SAE,Kondhwa Abstract Hadoop is widely used for storing large datasets and processing them efficiently under distributed
An improved task assignment scheme for Hadoop running in the clouds
 Dai and Bassiouni Journal of Cloud Computing: Advances, Systems and Applications 2013, 2:23 RESEARCH An improved task assignment scheme for Hadoop running in the clouds Wei Dai * and Mostafa Bassiouni
Dai and Bassiouni Journal of Cloud Computing: Advances, Systems and Applications 2013, 2:23 RESEARCH An improved task assignment scheme for Hadoop running in the clouds Wei Dai * and Mostafa Bassiouni
Research on Job Scheduling Algorithm in Hadoop
 Journal of Computational Information Systems 7: 6 () 5769-5775 Available at http://www.jofcis.com Research on Job Scheduling Algorithm in Hadoop Yang XIA, Lei WANG, Qiang ZHAO, Gongxuan ZHANG School of
Journal of Computational Information Systems 7: 6 () 5769-5775 Available at http://www.jofcis.com Research on Job Scheduling Algorithm in Hadoop Yang XIA, Lei WANG, Qiang ZHAO, Gongxuan ZHANG School of
Survey on Scheduling Algorithm in MapReduce Framework
 Survey on Scheduling Algorithm in MapReduce Framework Pravin P. Nimbalkar 1, Devendra P.Gadekar 2 1,2 Department of Computer Engineering, JSPM s Imperial College of Engineering and Research, Pune, India
Survey on Scheduling Algorithm in MapReduce Framework Pravin P. Nimbalkar 1, Devendra P.Gadekar 2 1,2 Department of Computer Engineering, JSPM s Imperial College of Engineering and Research, Pune, India
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE
 IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
Delay Scheduling. A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling
 Delay Scheduling A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Khaled Elmeleegy +, Scott Shenker, Ion Stoica UC Berkeley,
Delay Scheduling A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Khaled Elmeleegy +, Scott Shenker, Ion Stoica UC Berkeley,
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Shareability and Locality Aware Scheduling Algorithm in Hadoop for Mobile Cloud Computing
 Shareability and Locality Aware Scheduling Algorithm in Hadoop for Mobile Cloud Computing Hsin-Wen Wei 1,2, Che-Wei Hsu 2, Tin-Yu Wu 3, Wei-Tsong Lee 1 1 Department of Electrical Engineering, Tamkang University
Shareability and Locality Aware Scheduling Algorithm in Hadoop for Mobile Cloud Computing Hsin-Wen Wei 1,2, Che-Wei Hsu 2, Tin-Yu Wu 3, Wei-Tsong Lee 1 1 Department of Electrical Engineering, Tamkang University
MAPREDUCE [1] is proposed by Google in 2004 and
![MAPREDUCE [1] is proposed by Google in 2004 and](/thumbs/27/12216765.jpg "MAPREDUCE [1] is proposed by Google in 2004 and") IEEE TRANSACTIONS ON COMPUTERS 1 Improving MapReduce Performance Using Smart Speculative Execution Strategy Qi Chen, Cheng Liu, and Zhen Xiao, Senior Member, IEEE Abstract MapReduce is a widely used parallel
IEEE TRANSACTIONS ON COMPUTERS 1 Improving MapReduce Performance Using Smart Speculative Execution Strategy Qi Chen, Cheng Liu, and Zhen Xiao, Senior Member, IEEE Abstract MapReduce is a widely used parallel
Enabling Multi-pipeline Data Transfer in HDFS for Big Data Applications
 Enabling Multi-pipeline Data Transfer in HDFS for Big Data Applications Liqiang (Eric) Wang, Hong Zhang University of Wyoming Hai Huang IBM T.J. Watson Research Center Background Hadoop: Apache Hadoop
Enabling Multi-pipeline Data Transfer in HDFS for Big Data Applications Liqiang (Eric) Wang, Hong Zhang University of Wyoming Hai Huang IBM T.J. Watson Research Center Background Hadoop: Apache Hadoop
Analysis of Information Management and Scheduling Technology in Hadoop
 Analysis of Information Management and Scheduling Technology in Hadoop Ma Weihua, Zhang Hong, Li Qianmu, Xia Bin School of Computer Science and Technology Nanjing University of Science and Engineering
Analysis of Information Management and Scheduling Technology in Hadoop Ma Weihua, Zhang Hong, Li Qianmu, Xia Bin School of Computer Science and Technology Nanjing University of Science and Engineering
An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems
 An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems Aysan Rasooli, Douglas G. Down Department of Computing and Software McMaster University {rasooa, downd}@mcmaster.ca Abstract The
An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems Aysan Rasooli, Douglas G. Down Department of Computing and Software McMaster University {rasooa, downd}@mcmaster.ca Abstract The
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
COSHH: A Classification and Optimization based Scheduler for Heterogeneous Hadoop Systems
 COSHH: A Classification and Optimization based Scheduler for Heterogeneous Hadoop Systems Aysan Rasooli a, Douglas G. Down a a Department of Computing and Software, McMaster University, L8S 4K1, Canada
COSHH: A Classification and Optimization based Scheduler for Heterogeneous Hadoop Systems Aysan Rasooli a, Douglas G. Down a a Department of Computing and Software, McMaster University, L8S 4K1, Canada
6. How MapReduce Works. Jari-Pekka Voutilainen
 6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
Matchmaking: A New MapReduce Scheduling Technique
 Matchmaking: A New MapReduce Scheduling Technique Chen He Ying Lu David Swanson Department of Computer Science and Engineering University of Nebraska-Lincoln Lincoln, U.S. {che,ylu,dswanson}@cse.unl.edu
Matchmaking: A New MapReduce Scheduling Technique Chen He Ying Lu David Swanson Department of Computer Science and Engineering University of Nebraska-Lincoln Lincoln, U.S. {che,ylu,dswanson}@cse.unl.edu
1. Simulation of load balancing in a cloud computing environment using OMNET
 Cloud Computing Cloud computing is a rapidly growing technology that allows users to share computer resources according to their need. It is expected that cloud computing will generate close to 13.8 million
Cloud Computing Cloud computing is a rapidly growing technology that allows users to share computer resources according to their need. It is expected that cloud computing will generate close to 13.8 million
Fair Scheduler. Table of contents
 Table of contents 1 Purpose... 2 2 Introduction... 2 3 Installation... 3 4 Configuration...3 4.1 Scheduler Parameters in mapred-site.xml...4 4.2 Allocation File (fair-scheduler.xml)... 6 4.3 Access Control
Table of contents 1 Purpose... 2 2 Introduction... 2 3 Installation... 3 4 Configuration...3 4.1 Scheduler Parameters in mapred-site.xml...4 4.2 Allocation File (fair-scheduler.xml)... 6 4.3 Access Control
Daniel J. Adabi. Workshop presentation by Lukas Probst
 Daniel J. Adabi Workshop presentation by Lukas Probst 3 characteristics of a cloud computing environment: 1. Compute power is elastic, but only if workload is parallelizable 2. Data is stored at an untrusted
Daniel J. Adabi Workshop presentation by Lukas Probst 3 characteristics of a cloud computing environment: 1. Compute power is elastic, but only if workload is parallelizable 2. Data is stored at an untrusted
Characterizing Task Usage Shapes in Google s Compute Clusters
 Characterizing Task Usage Shapes in Google s Compute Clusters Qi Zhang 1, Joseph L. Hellerstein 2, Raouf Boutaba 1 1 University of Waterloo, 2 Google Inc. Introduction Cloud computing is becoming a key
Characterizing Task Usage Shapes in Google s Compute Clusters Qi Zhang 1, Joseph L. Hellerstein 2, Raouf Boutaba 1 1 University of Waterloo, 2 Google Inc. Introduction Cloud computing is becoming a key
Data Management in the Cloud
 Data Management in the Cloud Ryan Stern [email protected] : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
Data Management in the Cloud Ryan Stern [email protected] : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
The Improved Job Scheduling Algorithm of Hadoop Platform
 The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: [email protected]
The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: [email protected]
Extending Hadoop beyond MapReduce
 Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
AutoPig - Improving the Big Data user experience
 Imperial College London Department of Computing AutoPig - Improving the Big Data user experience Benjamin Jakobus Submitted in partial fulfilment of the requirements for the MSc degree in Advanced Computing
Imperial College London Department of Computing AutoPig - Improving the Big Data user experience Benjamin Jakobus Submitted in partial fulfilment of the requirements for the MSc degree in Advanced Computing
Energy Efficient MapReduce
 Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
A Locality Enhanced Scheduling Method for Multiple MapReduce Jobs In a Workflow Application
 2012 International Conference on Information and Computer Applications (ICICA 2012) IPCSIT vol. 24 (2012) (2012) IACSIT Press, Singapore A Locality Enhanced Scheduling Method for Multiple MapReduce Jobs
2012 International Conference on Information and Computer Applications (ICICA 2012) IPCSIT vol. 24 (2012) (2012) IACSIT Press, Singapore A Locality Enhanced Scheduling Method for Multiple MapReduce Jobs
Lifetime Management of Cache Memory using Hadoop Snehal Deshmukh 1 Computer, PGMCOE, Wagholi, Pune, India
 Volume 3, Issue 1, January 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at: www.ijarcsms.com ISSN:
Volume 3, Issue 1, January 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at: www.ijarcsms.com ISSN:
Hadoop. MPDL-Frühstück 9. Dezember 2013 MPDL INTERN
 Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
GraySort on Apache Spark by Databricks
 GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
CapacityScheduler Guide
 Table of contents 1 Purpose... 2 2 Overview... 2 3 Features...2 4 Installation... 3 5 Configuration...4 5.1 Using the CapacityScheduler...4 5.2 Setting up queues...4 5.3 Queue properties... 4 5.4 Resource
Table of contents 1 Purpose... 2 2 Overview... 2 3 Features...2 4 Installation... 3 5 Configuration...4 5.1 Using the CapacityScheduler...4 5.2 Setting up queues...4 5.3 Queue properties... 4 5.4 Resource
Chapter 2: Getting Started
 Chapter 2: Getting Started Once Partek Flow is installed, Chapter 2 will take the user to the next stage and describes the user interface and, of note, defines a number of terms required to understand
Chapter 2: Getting Started Once Partek Flow is installed, Chapter 2 will take the user to the next stage and describes the user interface and, of note, defines a number of terms required to understand
Supplement to Call Centers with Delay Information: Models and Insights
 Supplement to Call Centers with Delay Information: Models and Insights Oualid Jouini 1 Zeynep Akşin 2 Yves Dallery 1 1 Laboratoire Genie Industriel, Ecole Centrale Paris, Grande Voie des Vignes, 92290
Supplement to Call Centers with Delay Information: Models and Insights Oualid Jouini 1 Zeynep Akşin 2 Yves Dallery 1 1 Laboratoire Genie Industriel, Ecole Centrale Paris, Grande Voie des Vignes, 92290
Computing Load Aware and Long-View Load Balancing for Cluster Storage Systems
 215 IEEE International Conference on Big Data (Big Data) Computing Load Aware and Long-View Load Balancing for Cluster Storage Systems Guoxin Liu and Haiying Shen and Haoyu Wang Department of Electrical
215 IEEE International Conference on Big Data (Big Data) Computing Load Aware and Long-View Load Balancing for Cluster Storage Systems Guoxin Liu and Haiying Shen and Haoyu Wang Department of Electrical
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Apache Hama Design Document v0.6
 Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Joint Optimization of Overlapping Phases in MapReduce
 Joint Optimization of Overlapping Phases in MapReduce Minghong Lin, Li Zhang, Adam Wierman, Jian Tan Abstract MapReduce is a scalable parallel computing framework for big data processing. It exhibits multiple
Joint Optimization of Overlapping Phases in MapReduce Minghong Lin, Li Zhang, Adam Wierman, Jian Tan Abstract MapReduce is a scalable parallel computing framework for big data processing. It exhibits multiple
Keywords: Big Data, HDFS, Map Reduce, Hadoop
 Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing
 A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
Windows Server Performance Monitoring
 Spot server problems before they are noticed The system s really slow today! How often have you heard that? Finding the solution isn t so easy. The obvious questions to ask are why is it running slowly
Spot server problems before they are noticed The system s really slow today! How often have you heard that? Finding the solution isn t so easy. The obvious questions to ask are why is it running slowly
Cloud Computing using MapReduce, Hadoop, Spark
 Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman [email protected] Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman [email protected] Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Introduction to Parallel Programming and MapReduce
 Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
An efficient Mapreduce scheduling algorithm in hadoop R.Thangaselvi 1, S.Ananthbabu 2, R.Aruna 3
 An efficient Mapreduce scheduling algorithm in hadoop R.Thangaselvi 1, S.Ananthbabu 2, R.Aruna 3 1 M.E: Department of Computer Science, VV College of Engineering, Tirunelveli, India 2 Assistant Professor,
An efficient Mapreduce scheduling algorithm in hadoop R.Thangaselvi 1, S.Ananthbabu 2, R.Aruna 3 1 M.E: Department of Computer Science, VV College of Engineering, Tirunelveli, India 2 Assistant Professor,
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
MAPREDUCE Programming Model
 CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
Hadoop Scheduler w i t h Deadline Constraint
 Hadoop Scheduler w i t h Deadline Constraint Geetha J 1, N UdayBhaskar 2, P ChennaReddy 3,Neha Sniha 4 1,4 Department of Computer Science and Engineering, M S Ramaiah Institute of Technology, Bangalore,
Hadoop Scheduler w i t h Deadline Constraint Geetha J 1, N UdayBhaskar 2, P ChennaReddy 3,Neha Sniha 4 1,4 Department of Computer Science and Engineering, M S Ramaiah Institute of Technology, Bangalore,
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Similarity Search in a Very Large Scale Using Hadoop and HBase
 Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
DynamicMR: A Dynamic Slot Allocation Optimization Framework for MapReduce Clusters
 IEEE TRANSACTIONS ON CLOUD COMPUTING 1 DynamicMR: A Dynamic Slot Allocation Optimization Framework for MapReduce Clusters Shanjiang Tang, Bu-Sung Lee, Bingsheng He Abstract MapReduce is a popular computing
IEEE TRANSACTIONS ON CLOUD COMPUTING 1 DynamicMR: A Dynamic Slot Allocation Optimization Framework for MapReduce Clusters Shanjiang Tang, Bu-Sung Lee, Bingsheng He Abstract MapReduce is a popular computing
Discrete-Event Simulation
 Discrete-Event Simulation Prateek Sharma Abstract: Simulation can be regarded as the emulation of the behavior of a real-world system over an interval of time. The process of simulation relies upon the
Discrete-Event Simulation Prateek Sharma Abstract: Simulation can be regarded as the emulation of the behavior of a real-world system over an interval of time. The process of simulation relies upon the
Map-Parallel Scheduling (mps) using Hadoop environment for job scheduler and time span for Multicore Processors
 using Hadoop environment for job scheduler and time span for Multicore Processors") Map-Parallel Scheduling (mps) using Hadoop environment for job scheduler and time span for Sudarsanam P Abstract G. Singaravel Parallel computing is an base mechanism for data process with scheduling task,
Map-Parallel Scheduling (mps) using Hadoop environment for job scheduler and time span for Sudarsanam P Abstract G. Singaravel Parallel computing is an base mechanism for data process with scheduling task,
Resource Scalability for Efficient Parallel Processing in Cloud
 Resource Scalability for Efficient Parallel Processing in Cloud ABSTRACT Govinda.K #1, Abirami.M #2, Divya Mercy Silva.J #3 #1 SCSE, VIT University #2 SITE, VIT University #3 SITE, VIT University In the
Resource Scalability for Efficient Parallel Processing in Cloud ABSTRACT Govinda.K #1, Abirami.M #2, Divya Mercy Silva.J #3 #1 SCSE, VIT University #2 SITE, VIT University #3 SITE, VIT University In the
Advanced Big Data Analytics with R and Hadoop
 REVOLUTION ANALYTICS WHITE PAPER Advanced Big Data Analytics with R and Hadoop 'Big Data' Analytics as a Competitive Advantage Big Analytics delivers competitive advantage in two ways compared to the traditional
REVOLUTION ANALYTICS WHITE PAPER Advanced Big Data Analytics with R and Hadoop 'Big Data' Analytics as a Competitive Advantage Big Analytics delivers competitive advantage in two ways compared to the traditional
Optimization and analysis of large scale data sorting algorithm based on Hadoop
 Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
The primary goal of this thesis was to understand how the spatial dependence of
 5 General discussion 5.1 Introduction The primary goal of this thesis was to understand how the spatial dependence of consumer attitudes can be modeled, what additional benefits the recovering of spatial
5 General discussion 5.1 Introduction The primary goal of this thesis was to understand how the spatial dependence of consumer attitudes can be modeled, what additional benefits the recovering of spatial
Evaluating Task Scheduling in Hadoop-based Cloud Systems
 2013 IEEE International Conference on Big Data Evaluating Task Scheduling in Hadoop-based Cloud Systems Shengyuan Liu, Jungang Xu College of Computer and Control Engineering University of Chinese Academy
2013 IEEE International Conference on Big Data Evaluating Task Scheduling in Hadoop-based Cloud Systems Shengyuan Liu, Jungang Xu College of Computer and Control Engineering University of Chinese Academy
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Hadoop Fair Scheduler Design Document
 Hadoop Fair Scheduler Design Document October 18, 2010 Contents 1 Introduction 2 2 Fair Scheduler Goals 2 3 Scheduler Features 2 3.1 Pools........................................ 2 3.2 Minimum Shares.................................
Hadoop Fair Scheduler Design Document October 18, 2010 Contents 1 Introduction 2 2 Fair Scheduler Goals 2 3 Scheduler Features 2 3.1 Pools........................................ 2 3.2 Minimum Shares.................................
How To Test For Elulla
 EQUELLA Whitepaper Performance Testing Carl Hoffmann Senior Technical Consultant Contents 1 EQUELLA Performance Testing 3 1.1 Introduction 3 1.2 Overview of performance testing 3 2 Why do performance testing?
EQUELLA Whitepaper Performance Testing Carl Hoffmann Senior Technical Consultant Contents 1 EQUELLA Performance Testing 3 1.1 Introduction 3 1.2 Overview of performance testing 3 2 Why do performance testing?
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Lecture Outline Overview of real-time scheduling algorithms Outline relative strengths, weaknesses
 Overview of Real-Time Scheduling Embedded Real-Time Software Lecture 3 Lecture Outline Overview of real-time scheduling algorithms Clock-driven Weighted round-robin Priority-driven Dynamic vs. static Deadline
Overview of Real-Time Scheduling Embedded Real-Time Software Lecture 3 Lecture Outline Overview of real-time scheduling algorithms Clock-driven Weighted round-robin Priority-driven Dynamic vs. static Deadline
A Comprehensive View of Hadoop MapReduce Scheduling Algorithms
 International Journal of Computer Networks and Communications Security VOL. 2, NO. 9, SEPTEMBER 2014, 308 317 Available online at: www.ijcncs.org ISSN 23089830 C N C S A Comprehensive View of Hadoop MapReduce
International Journal of Computer Networks and Communications Security VOL. 2, NO. 9, SEPTEMBER 2014, 308 317 Available online at: www.ijcncs.org ISSN 23089830 C N C S A Comprehensive View of Hadoop MapReduce
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
A Load Balancing Algorithm based on the Variation Trend of Entropy in Homogeneous Cluster
 , pp.11-20 http://dx.doi.org/10.14257/ ijgdc.2014.7.2.02 A Load Balancing Algorithm based on the Variation Trend of Entropy in Homogeneous Cluster Kehe Wu 1, Long Chen 2, Shichao Ye 2 and Yi Li 2 1 Beijing
, pp.11-20 http://dx.doi.org/10.14257/ ijgdc.2014.7.2.02 A Load Balancing Algorithm based on the Variation Trend of Entropy in Homogeneous Cluster Kehe Wu 1, Long Chen 2, Shichao Ye 2 and Yi Li 2 1 Beijing
Batch Systems. provide a mechanism for submitting, launching, and tracking jobs on a shared resource
 PBS INTERNALS PBS & TORQUE PBS (Portable Batch System)-software system for managing system resources on workstations, SMP systems, MPPs and vector computers. It was based on Network Queuing System (NQS)
PBS INTERNALS PBS & TORQUE PBS (Portable Batch System)-software system for managing system resources on workstations, SMP systems, MPPs and vector computers. It was based on Network Queuing System (NQS)
Application of Predictive Analytics for Better Alignment of Business and IT
 Application of Predictive Analytics for Better Alignment of Business and IT Boris Zibitsker, PhD [email protected] July 25, 2014 Big Data Summit - Riga, Latvia About the Presenter Boris Zibitsker
Application of Predictive Analytics for Better Alignment of Business and IT Boris Zibitsker, PhD [email protected] July 25, 2014 Big Data Summit - Riga, Latvia About the Presenter Boris Zibitsker
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
HPC ABDS: The Case for an Integrating Apache Big Data Stack
 HPC ABDS: The Case for an Integrating Apache Big Data Stack with HPC 1st JTC 1 SGBD Meeting SDSC San Diego March 19 2014 Judy Qiu Shantenu Jha (Rutgers) Geoffrey Fox [email protected] http://www.infomall.org
HPC ABDS: The Case for an Integrating Apache Big Data Stack with HPC 1st JTC 1 SGBD Meeting SDSC San Diego March 19 2014 Judy Qiu Shantenu Jha (Rutgers) Geoffrey Fox [email protected] http://www.infomall.org
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
The Impact of Big Data on Classic Machine Learning Algorithms. Thomas Jensen, Senior Business Analyst @ Expedia
 The Impact of Big Data on Classic Machine Learning Algorithms Thomas Jensen, Senior Business Analyst @ Expedia Who am I? Senior Business Analyst @ Expedia Working within the competitive intelligence unit
The Impact of Big Data on Classic Machine Learning Algorithms Thomas Jensen, Senior Business Analyst @ Expedia Who am I? Senior Business Analyst @ Expedia Working within the competitive intelligence unit
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
HBase Schema Design. NoSQL Ma4ers, Cologne, April 2013. Lars George Director EMEA Services
 HBase Schema Design NoSQL Ma4ers, Cologne, April 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera ConsulFng on Hadoop projects (everywhere) Apache Commi4er HBase and Whirr
HBase Schema Design NoSQL Ma4ers, Cologne, April 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera ConsulFng on Hadoop projects (everywhere) Apache Commi4er HBase and Whirr
Hadoop. History and Introduction. Explained By Vaibhav Agarwal
 Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
An Oracle White Paper November 2010. Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics
 An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
Towards a Resource Aware Scheduler in Hadoop
 Towards a Resource Aware Scheduler in Hadoop Mark Yong, Nitin Garegrat, Shiwali Mohan Computer Science and Engineering, University of Michigan, Ann Arbor December 21, 2009 Abstract Hadoop-MapReduce is
Towards a Resource Aware Scheduler in Hadoop Mark Yong, Nitin Garegrat, Shiwali Mohan Computer Science and Engineering, University of Michigan, Ann Arbor December 21, 2009 Abstract Hadoop-MapReduce is
Hadoop Cluster Applications
 Hadoop Overview Data analytics has become a key element of the business decision process over the last decade. Classic reporting on a dataset stored in a database was sufficient until recently, but yesterday
Hadoop Overview Data analytics has become a key element of the business decision process over the last decade. Classic reporting on a dataset stored in a database was sufficient until recently, but yesterday
Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling
 Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling Matei Zaharia University of California, Berkeley [email protected] Khaled Elmeleegy Yahoo! Research [email protected]
Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling Matei Zaharia University of California, Berkeley [email protected] Khaled Elmeleegy Yahoo! Research [email protected]