Hadoop. History and Introduction. Explained By Vaibhav Agarwal
|
|
|
- Prudence Andrews
- 8 years ago
- Views:
Transcription
1 Hadoop History and Introduction Explained By Vaibhav Agarwal

2 Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2

3 Hadoop Architecture

4 HADOOP (HDFS) Data Flow
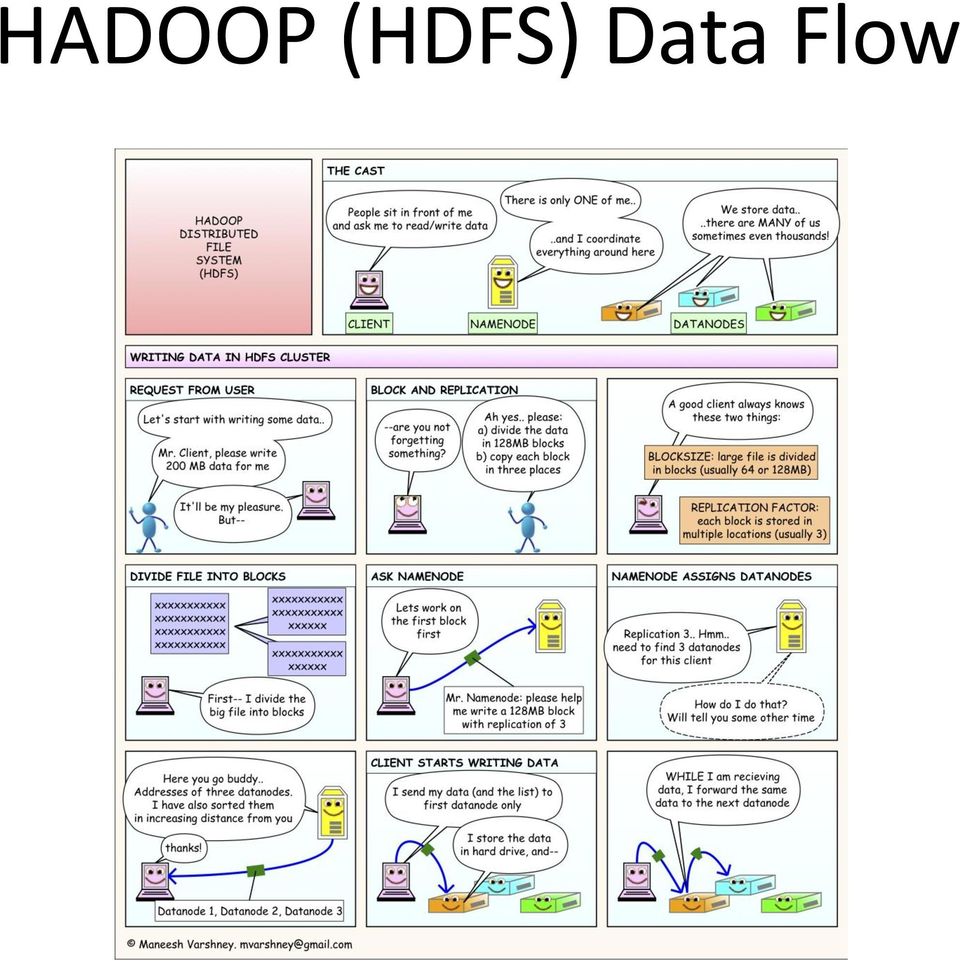
5 Reading from HDFS


6 Writing to HDFS

7

8 HADOOP (Map Reduce) Data Flow

9 External Client i.e. user Clients get all the files prepared Training/Input Data, input parameters, config file, jar file i.e. code which specifies InputFormat Defines InputSplits i.e. how to split the input Provides factory for RecordReader i.e. how to convert InputSplit to Record, Value pairs. output directory Copy these files to HDFS Training/Input Data is to be copied dfs.replication (Default 3) times. Other data i.e. User Code, config file, input parameters, etc are to be copied once as of now. JobClient copies it to HDFS later. Requests to start job and specifies HDFS address where files are stored. Compressed input files are not splitable (without patches)
")
10

11 JobClient() Ask JobTracker for a new Job Id. Checks if input and output specification of job is correct ie directories are correctly specified, etc. Splits the input into logical InputSplit instances. Sorts the InputSplits in descending order of size. Creates a new directory in HDFS named after job ID and copies with replication factor mapred.submit.replication job JAR file configuration file computed input splits Informs JobTracker that Job with Job Id is ready. Optionally polls JobTracker to get the status.

12 Job Tracker Only one JobTracker process run on any Hadoop cluster. It runs in its own JVM process. Puts job in an internal queue from where JobScheduler picks and initializes. Once a job is selected, Task Assignment is done by the JobTracker. JobTracker talks to NameNode to determine the location of data. It locates the TaskTracker nodes with available slots at or near the data. It submits work to the chosen task tracker nodes. If a task is completed Updates its status. Client polls for status. Makes a note of map output and task tracker in the Job object Identifies the next task to be executed on the TaskTracker. Takes care of speculative execution. Replies Reducer Task with map output locations it noted earlier.

13 Task Tracker (Generic) First localizes the JAR, config file and one copy of input split. Job jar and config file are copied from shared filesystem to task tracker s filesystem. Copies any file needed from distributed cache to the local disk. Creates local working directory for task and unjars the contents of JAR into this directory. Executes TaskRunner() by launching a new JVM To run each task separately Any bugs in mapper/reducer doesn t affect the TaskTracker Older launched JVMs may be reused Updates parent process its progress every few seconds until task is complete If a task reports progress it sets a flag which is tested every 3 seconds by a separate thread. If flag is set, status is reported to task tracker. The task tracker heartbeat is a different loop which is sent every 5 seconds and is directly proportional and dependent on the size of cluster. The heartbeat comprises of: Number of available mapper and reducer slots status of mapper/reducer jobs already running Status of RAM and Virtual Memory on the node ids of blocks possessed (HDFS heartbeat) detail of I/O threads currently working (HDFS heartbeat)

14 Task Tracker (Mapper) Fetches Input split if not locally present Fetches JAR code and config files if not locally present RecordReader converts InputSplit into key, value pairs Once all the input available has been converted, executes user defined map() method. On task completion notify tasktracker of status update goes to commit pending state ie renames output file and performs clean up. Task Tracker writes the outputs on HDFS and gets them replicated. The mapper outputs are deleted when Job Tracker instructs to do so Status for map task is identified by the proportion of input that has been processed. A flag is set if the task progresses. Every 3 seconds a separate thread runs to test if the flag is set. On it being set, task reports status to task tracker.

15 Task Tracker (Reducer) Fetches Outputs from ALL the mappers even if they have not completed. Keeps on updating the input as mapper execution proceeds. Periodically asks Job Tracker for map output locations until it has retrieved them all. Starts execution only when all the input from all the mappers has been received. Status of reduce phase being more complex is identified as (1/3 each for copy, sort and reduction). A flag is set if the task progresses. Every 3 seconds a separate thread runs to test if the flag is set. On it being set, task reports status to task tracker. Once all input has been received and merged, user defined reduce() method executes.
. A flag is set if the task progresses.")
16

17 Hadoop Versions

18 Brief History of Hadoop Versions

19 Hadoop 0.23 features Released on November 15, 2011 Federated HDFS Introduction of YARN or MRv2 or NextGen Map Reduce Same as Hadoop v2.0 alpha

20 Hadoop 2.x features 1. Name Node federation (Multiple Namespaces are permitted as opposed to earlier 1 NS) Old Name Node Mechanism New Name Node Mechanism
 Old Name Node Mechanism")
21 2. A big change in architecture Why? Under utilization Hard partition of resources into map and reduce slots Many a times either only mapper or reducer tasks run Scalability Max Cluster size nodes Max Concurrent tasks Coarse Synchronization in Job Tracker Single Point of Failure Failure killed all queued and running jobs Lacks support for alternate paradigms Necessity of client and cluster to be of same version
22 Requirements Reliability Availability Cluster Utilization Wire Compatibility Agility and Evolution Ability for customers to control Hadoop software stack trace. Scalability - Clusters of ,000 (16 core) m/c 100,000+ concurrent tasks 10,000+ concurrent jobs Support for other Programming Paradigms OpenMPI, Spark is Hive-on-Spark Storm (Real time data processing by Twitter), Apache S4 Graph Processing Apache Giraph Support for short lived services Predictable Latency Map Reduce Reduce will be done in future
23 Next Gen Map-Reduce Design Center Split up the two major functions of Job Tracker Cluster resource management Application life-cycle management Map-Reduce becomes user-land library

24 Architecture
25 Components Resource Manager Global resource scheduler Hierarchical queues Node Manager Per-machine agent Manages the life-cycle of container Container resource monitoring Application Master Per-application Manages application scheduling and task execution Eg. Map-Reduce Application Master

26 RM Architecture
27 RM Architecture ASM Responsible for launching/managing Application Master Monitors the AM for liveness Scheduler Responsible for scheduling containers to applications Schedules on heart beats from NM s Returns scheduled containers to AM s on heartbeats Resource Tracker Responsible for managing Node Managers Monitors liveness of NM s Maintains data structures for containers running on particular NM
28 Map Reduce Application JobClient Uses ClientRMProtocol to submit to RM ApplicationMaster Uses AMRMProtocol to get containers Uses ContainerManager to launch containers Task Same task as in JT world Talk to AM over TaskUmbilicalProtocol
29 Application Master: Component Event Flow
30 Thankyou
31
32 Input Split Represents data to be processed by an individual Mapper Comprises of total split length (in bytes) Locations ie list of hostnames where the input split is located. Upper bound: dfs.block.size, Lower bound: mapred.min.split.size In HDFS terms: Split = physical data block Location = set of machines where block is located (set size = replication factor) In HBase terms: Split = set of table keys belonging to a table region Location = machine where a region server is running Data Locality can be defined by implementing custom InputFormat by overriding getsplits() method.
33 Default Scenario FileInputFormat is TextInputFormat i.e. input is Text File InputSplit is FileSplit which sets map.input.file to the path of the input file for the logical split. RecordReader is LineRecordReader i.e. key is offset and value is every line Size of input split = size of one HDFS block = mapred.min.split.size
34 Hadoop 0.19 features Released on 24 Nov, 2008 Hadoop Core NOW needs Java 6 Filesystem checksum changed Thrift interface was added to include languages other than Java
35
Extending Hadoop beyond MapReduce
 Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
How MapReduce Works 資碩一 戴睿宸
 How MapReduce Works MapReduce Entities four independent entities: The client The jobtracker The tasktrackers The distributed filesystem Steps 1. Asks the jobtracker for a new job ID 2. Checks the output
How MapReduce Works MapReduce Entities four independent entities: The client The jobtracker The tasktrackers The distributed filesystem Steps 1. Asks the jobtracker for a new job ID 2. Checks the output
Data-intensive computing systems
 Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
6. How MapReduce Works. Jari-Pekka Voutilainen
 6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
Lecture 3 Hadoop Technical Introduction CSE 490H
 Lecture 3 Hadoop Technical Introduction CSE 490H Announcements My office hours: M 2:30 3:30 in CSE 212 Cluster is operational; instructions in assignment 1 heavily rewritten Eclipse plugin is deprecated
Lecture 3 Hadoop Technical Introduction CSE 490H Announcements My office hours: M 2:30 3:30 in CSE 212 Cluster is operational; instructions in assignment 1 heavily rewritten Eclipse plugin is deprecated
MapReduce, Hadoop and Amazon AWS
 MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing
 YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
YARN Apache Hadoop Next Generation Compute Platform
 YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Hadoop 2.6 Configuration and More Examples
 Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
MapReduce Job Processing
 April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
Getting to know Apache Hadoop
 Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Sujee Maniyam, ElephantScale
 Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Istanbul Şehir University Big Data Camp 14. Hadoop Map Reduce. Aslan Bakirov Kevser Nur Çoğalmış
 Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
HADOOP PERFORMANCE TUNING
 PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney") Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Working With Hadoop. Important Terminology. Important Terminology. Anatomy of MapReduce Job Run. Important Terminology
 Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Apache Hama Design Document v0.6
 Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Architecture of Next Generation Apache Hadoop MapReduce Framework
 Architecture of Next Generation Apache Hadoop MapReduce Framework Authors: Arun C. Murthy, Chris Douglas, Mahadev Konar, Owen O Malley, Sanjay Radia, Sharad Agarwal, Vinod K V BACKGROUND The Apache Hadoop
Architecture of Next Generation Apache Hadoop MapReduce Framework Authors: Arun C. Murthy, Chris Douglas, Mahadev Konar, Owen O Malley, Sanjay Radia, Sharad Agarwal, Vinod K V BACKGROUND The Apache Hadoop
Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200
 CCD-410, CCA-410 and CCB-400 and DS-200") Hadoop Learning Resources 1 Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200 Author: Hadoop Learning Resource Hadoop Training in Just $60/3000INR
Hadoop Learning Resources 1 Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200 Author: Hadoop Learning Resource Hadoop Training in Just $60/3000INR
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
University of Maryland. Tuesday, February 2, 2010
 Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013
 Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
Hadoop Distributed Filesystem. Spring 2015, X. Zhang Fordham Univ.
 Hadoop Distributed Filesystem Spring 2015, X. Zhang Fordham Univ. MapReduce Programming Model Split Shuffle Input: a set of [key,value] pairs intermediate [key,value] pairs [k1,v11,v12, ] [k2,v21,v22,
Hadoop Distributed Filesystem Spring 2015, X. Zhang Fordham Univ. MapReduce Programming Model Split Shuffle Input: a set of [key,value] pairs intermediate [key,value] pairs [k1,v11,v12, ] [k2,v21,v22,
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
THE ANATOMY OF MAPREDUCE JOBS, SCHEDULING, AND PERFORMANCE CHALLENGES
 THE ANATOMY OF MAPREDUCE JOBS, SCHEDULING, AND PERFORMANCE CHALLENGES SHOUVIK BARDHAN DANIEL A. MENASCÉ DEPT. OF COMPUTER SCIENCE, MS 4A5 VOLGENAU SCHOOL OF ENGINEERING GEORGE MASON UNIVERSITY FAIRFAX,
THE ANATOMY OF MAPREDUCE JOBS, SCHEDULING, AND PERFORMANCE CHALLENGES SHOUVIK BARDHAN DANIEL A. MENASCÉ DEPT. OF COMPUTER SCIENCE, MS 4A5 VOLGENAU SCHOOL OF ENGINEERING GEORGE MASON UNIVERSITY FAIRFAX,
CS 378 Big Data Programming. Lecture 5 Summariza9on Pa:erns
 CS 378 Big Data Programming Lecture 5 Summariza9on Pa:erns Review Assignment 2 Ques9ons? If you d like to use guava (Google collec9ons classes) pom.xml available for assignment 2 Includes dependency for
CS 378 Big Data Programming Lecture 5 Summariza9on Pa:erns Review Assignment 2 Ques9ons? If you d like to use guava (Google collec9ons classes) pom.xml available for assignment 2 Includes dependency for
Hadoop MapReduce: Review. Spring 2015, X. Zhang Fordham Univ.
 Hadoop MapReduce: Review Spring 2015, X. Zhang Fordham Univ. Outline 1.Review of how map reduce works: the HDFS, Yarn sorting and shuffling advanced topics: partial sort, total sort, join, chained mapper/reducer,
Hadoop MapReduce: Review Spring 2015, X. Zhang Fordham Univ. Outline 1.Review of how map reduce works: the HDFS, Yarn sorting and shuffling advanced topics: partial sort, total sort, join, chained mapper/reducer,
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Data-Intensive Computing with Hadoop. Thanks to: Milind Bhandarkar <milindb@yahoo-inc.com> Yahoo! Inc.
 Data-Intensive Computing with Hadoop Thanks to: Milind Bhandarkar Yahoo! Inc. Agenda Hadoop Overview HDFS Programming Hadoop Architecture Examples Hadoop Streaming Performance Tuning
Data-Intensive Computing with Hadoop Thanks to: Milind Bhandarkar Yahoo! Inc. Agenda Hadoop Overview HDFS Programming Hadoop Architecture Examples Hadoop Streaming Performance Tuning
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Big Data Storage Options for Hadoop Sam Fineberg, HP Storage
 Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
HDFS Federation. Sanjay Radia Founder and Architect @ Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Hadoop Streaming. Table of contents
 Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
How To Write A Map Reduce In Hadoop Hadooper 2.5.2.2 (Ahemos)
") Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
HDFS: Hadoop Distributed File System
 Istanbul Şehir University Big Data Camp 14 HDFS: Hadoop Distributed File System Aslan Bakirov Kevser Nur Çoğalmış Agenda Distributed File System HDFS Concepts HDFS Interfaces HDFS Full Picture Read Operation
Istanbul Şehir University Big Data Camp 14 HDFS: Hadoop Distributed File System Aslan Bakirov Kevser Nur Çoğalmış Agenda Distributed File System HDFS Concepts HDFS Interfaces HDFS Full Picture Read Operation
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Design and k-means Clustering
 Hadoop Design and k-means Clustering Kenneth Heafield Google Inc January 15, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise
Hadoop Design and k-means Clustering Kenneth Heafield Google Inc January 15, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise
International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
YARN and how MapReduce works in Hadoop By Alex Holmes
 YARN and how MapReduce works in Hadoop By Alex Holmes YARN was created so that Hadoop clusters could run any type of work. This meant MapReduce had to become a YARN application and required the Hadoop
YARN and how MapReduce works in Hadoop By Alex Holmes YARN was created so that Hadoop clusters could run any type of work. This meant MapReduce had to become a YARN application and required the Hadoop
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
The Improved Job Scheduling Algorithm of Hadoop Platform
 The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: wulinzhi1001@163.com
The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: wulinzhi1001@163.com
Distributed Image Processing using Hadoop MapReduce framework. Binoy A Fernandez (200950006) Sameer Kumar (200950031)
 Sameer Kumar (200950031)") using Hadoop MapReduce framework Binoy A Fernandez (200950006) Sameer Kumar (200950031) Objective To demonstrate how the hadoop mapreduce framework can be extended to work with image data for distributed
using Hadoop MapReduce framework Binoy A Fernandez (200950006) Sameer Kumar (200950031) Objective To demonstrate how the hadoop mapreduce framework can be extended to work with image data for distributed
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Survey on Scheduling Algorithm in MapReduce Framework
 Survey on Scheduling Algorithm in MapReduce Framework Pravin P. Nimbalkar 1, Devendra P.Gadekar 2 1,2 Department of Computer Engineering, JSPM s Imperial College of Engineering and Research, Pune, India
Survey on Scheduling Algorithm in MapReduce Framework Pravin P. Nimbalkar 1, Devendra P.Gadekar 2 1,2 Department of Computer Engineering, JSPM s Imperial College of Engineering and Research, Pune, India
Hadoop. Dawid Weiss. Institute of Computing Science Poznań University of Technology
 Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
CloudCom 2012 Taipei, Taiwan December 5, 2012 viraj@yahoo-inc.com
 Hadoop 23 - dotnext CloudCom 2012 Taipei, Taiwan December 5, 2012 viraj@yahoo-inc.com About Me Principal Engg in the Yahoo! Grid Team since May 2008 PhD from Rutgers University, NJ Specialization in Data
Hadoop 23 - dotnext CloudCom 2012 Taipei, Taiwan December 5, 2012 viraj@yahoo-inc.com About Me Principal Engg in the Yahoo! Grid Team since May 2008 PhD from Rutgers University, NJ Specialization in Data
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE
 IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS
 A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
Apache Hadoop YARN: The Nextgeneration Distributed Operating. System. Zhijie Shen & Jian He @ Hortonworks
 Apache Hadoop YARN: The Nextgeneration Distributed Operating System Zhijie Shen & Jian He @ Hortonworks About Us Software Engineer @ Hortonworks, Inc. Hadoop Committer @ The Apache Foundation We re doing
Apache Hadoop YARN: The Nextgeneration Distributed Operating System Zhijie Shen & Jian He @ Hortonworks About Us Software Engineer @ Hortonworks, Inc. Hadoop Committer @ The Apache Foundation We re doing
CURSO: ADMINISTRADOR PARA APACHE HADOOP
 CURSO: ADMINISTRADOR PARA APACHE HADOOP TEST DE EJEMPLO DEL EXÁMEN DE CERTIFICACIÓN www.formacionhadoop.com 1 Question: 1 A developer has submitted a long running MapReduce job with wrong data sets. You
CURSO: ADMINISTRADOR PARA APACHE HADOOP TEST DE EJEMPLO DEL EXÁMEN DE CERTIFICACIÓN www.formacionhadoop.com 1 Question: 1 A developer has submitted a long running MapReduce job with wrong data sets. You
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Big Data and Hadoop. Sreedhar C, Dr. D. Kavitha, K. Asha Rani
 Big Data and Hadoop Sreedhar C, Dr. D. Kavitha, K. Asha Rani Abstract Big data has become a buzzword in the recent years. Big data is used to describe a massive volume of both structured and unstructured
Big Data and Hadoop Sreedhar C, Dr. D. Kavitha, K. Asha Rani Abstract Big data has become a buzzword in the recent years. Big data is used to describe a massive volume of both structured and unstructured
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
HowTo Hadoop. Devaraj Das
 HowTo Hadoop Devaraj Das Hadoop http://hadoop.apache.org/core/ Hadoop Distributed File System Fault tolerant, scalable, distributed storage system Designed to reliably store very large files across machines
HowTo Hadoop Devaraj Das Hadoop http://hadoop.apache.org/core/ Hadoop Distributed File System Fault tolerant, scalable, distributed storage system Designed to reliably store very large files across machines
Performance Comparison of Intel Enterprise Edition for Lustre* software and HDFS for MapReduce Applications
 Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Using Lustre with Apache Hadoop
 Using Lustre with Apache Hadoop Table of Contents Overview and Issues with Hadoop+HDFS...2 MapReduce and Hadoop overview...2 Challenges of Hadoop + HDFS...4 Some useful suggestions...5 Hadoop over Lustre...5
Using Lustre with Apache Hadoop Table of Contents Overview and Issues with Hadoop+HDFS...2 MapReduce and Hadoop overview...2 Challenges of Hadoop + HDFS...4 Some useful suggestions...5 Hadoop over Lustre...5
MapReduce. Tushar B. Kute, http://tusharkute.com
 MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
The Hadoop Distributed File System
 The Hadoop Distributed File System The Hadoop Distributed File System, Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, Yahoo, 2010 Agenda Topic 1: Introduction Topic 2: Architecture
The Hadoop Distributed File System The Hadoop Distributed File System, Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, Yahoo, 2010 Agenda Topic 1: Introduction Topic 2: Architecture
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Intro to Map/Reduce a.k.a. Hadoop
 Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
H2O on Hadoop. September 30, 2014. www.0xdata.com
 H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
Capacity Scheduler Guide
 Table of contents 1 Purpose...2 2 Features... 2 3 Picking a task to run...2 4 Installation...3 5 Configuration... 3 5.1 Using the Capacity Scheduler... 3 5.2 Setting up queues...3 5.3 Configuring properties
Table of contents 1 Purpose...2 2 Features... 2 3 Picking a task to run...2 4 Installation...3 5 Configuration... 3 5.1 Using the Capacity Scheduler... 3 5.2 Setting up queues...3 5.3 Configuring properties
Tutorial: MapReduce. Theory and Practice of Data-intensive Applications. Pietro Michiardi. Eurecom
 Tutorial: MapReduce Theory and Practice of Data-intensive Applications Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Tutorial: MapReduce 1 / 132 Introduction Introduction Pietro Michiardi (Eurecom)
Tutorial: MapReduce Theory and Practice of Data-intensive Applications Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Tutorial: MapReduce 1 / 132 Introduction Introduction Pietro Michiardi (Eurecom)
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data