Parallel Databases vs. Hadoop
|
|
|
- Alexandrina Sparks
- 10 years ago
- Views:
Transcription
1 Parallel Databases vs. Hadoop Juliana Freire New York University Some slides from J. Lin, C. Olston et al.

2 The Debate Starts
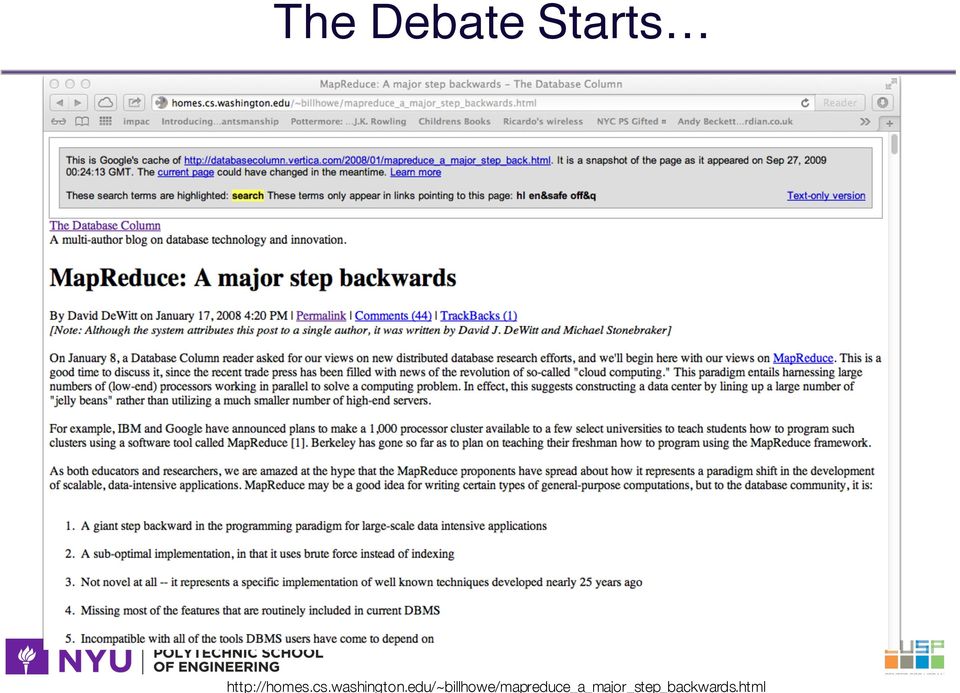
3 The Debate Continues A comparison of approaches to large-scale data analysis. Pavlo et al., SIGMOD 2009 Parallel DBMS beats MapReduce by a lot! Many were outraged by the comparison MapReduce: A Flexible Data Processing Tool. Dean and Ghemawat, CACM 2010 Pointed out inconsistencies and mistakes in the comparison MapReduce and Parallel DBMSs: Friends or Foes? Stonebraker et al., CACM 2010 Toned down claims

4 Why use Database Systems? Declarative query languages Data independence Efficient access through optimization Data integrity and security Safeguarding data from failures and malicious access Concurrent access Reduced application development time Uniform data administration

5 Parallel DBMSs Old and mature technology --- late 80 s: Gamma, Grace Aim to improve performance by executing operations in parallel Benefit: easy and cheap to scale Add more nodes, get higher speed Reduce the time to run queries Higher transaction rates Ability to process more data Challenge: minimize overheads and efficiently deal with contention docs.oracle.com Speedup Scaleup

6 or not physical data partitioning is used as a foundation and therefore a static pre-requisite for parallelizing the work. Different Architectures These fundamental approaches are known as shared everything architecture and shared nothing architecture respectively. In a shared nothing system, the system is divided into individual parallel processing units. Each processing unit has its own processing power (cores) and its own storage component (disk) and its CPU cores are solely responsible for its individual data set on its own disks. The only way to
 and its own storage component (disk) and its CPU cores are solely responsible")
7 Linear vs. Non-Linear Speedup Linear v.s. Non-linear Speedup Speedup Dan Suciu -- CSEP544 Fall 2011 # processors (=P) 7

8 Achieving Linear Speedup: Challenges Start-up cost: starting an operation on many processors Contention for resources between processors Data transfer Slowest processor becomes the bottleneck Data skew à load balancing Shared-nothing: Most scalable architecture Minimizes resource sharing across processors Can use commodity hardware Hard to program and manage Any feeling of déjà vu?

9 What to Parallelize? Inter-query parallelism Each query runs on one processor Inter-operator parallelism A query runs on multiple processors an Inter-operator runs on one parallelism processor Intra-operator parallelism An operator runs on multiple processors Taxonomy for Parallel Query Evaluation Inter-query parallelism Each query runs on one processor A query runs on multiple processors An operator runs on one processor Intra-operator parallelism An operator runs on multiple processors Purchase pid=pid cid=cid Customer Product Product Purchase pid=pid cid=cid Customer Purchase e study only intra-operator Dan Suciu -- CSEP544 parallelism: Fall 2011 most scalable 13 Product pid=pid cid=cid Product pid=pid cid=cid Purchase Product Customer pid=pid cid=cid Purchase Customer Customer

10 Partitioning Data Query Evaluation From: Greenplum Database Whitepaper

11 Partitioning a Relation across Disks If a relation contains only a few tuples which will fit into a single disk block, then assign the relation to a single disk Large relations are preferably partitioned across all the available disks The distribution of tuples to disks may be skewed that is, some disks have many tuples, while others may have fewer tuples Ideal: partitioning should be balanced

12 Horizontal Data Partitioning Relation R split into P chunks R 0,..., R P-1, stored at the P nodes Round robin: tuple T i to chunk (i mod P) Hash-based partitioning on attribute A: Tuple t to chunk h(t.a) mod P Range-based partitioning on attribute A: Tuple t to chunk i if v i-1 <t.a<v i E.g., with a partitioning vector [5,11], a tuple with partitioning attribute value of 2 will go to disk 0, a tuple with value 8 will go to disk 1, while a tuple with value 20 will go to disk 2. Partitioning in Oracle: Partitioning in DB2:

13 Range Partitioning in DBMSs CREATE TABLE sales_range (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date) ( PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','DD/MM/YYYY')), PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','DD/MM/YYYY')), PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','DD/MM/YYYY')), PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','DD/MM/YYYY')) ); CREATE TABLE sales_hash (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2)) PARTITION BY HASH(salesman_id) PARTITIONS 4 STORE IN (data1, data2, data3, data4);
) ); CREATE TABLE sales_hash (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2)) PARTITION")
14 Parallel Selection Compute SELECT * FROM R SELECT * FROM R WHERE R.A < v1 AND R.A>v2 What is the cost of these operations on a conventional database? Cost = B(R) SELECT * FROM R WHERE R.A =v What is the cost of these operations on a parallel database with P processors?
 SELECT * FROM R WHERE R.")
15 Parallel Selection: Round Robin tuple T i to chunk (i mod P) (1) SELECT * FROM R (2) SELECT * FROM R WHERE R.A = v (3) SELECT * FROM R WHERE R.A < v1 AND R.A>v2 Best suited for sequential scan of entire relation on each query. Why? All disks have almost an equal number of tuples; retrieval work is thus well balanced between disks Range queries are difficult to process --- tuples are scattered across all disks

16 Parallel Selection: Hash Partitioning CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT ' ', separated DATE NOT NULL DEFAULT ' ', job_code INT, store_id INT ) PARTITION BY HASH(store_id) PARTITIONS 4;
 PARTITIONS 4; http://docs.oracle.com/cd/e17952_01/refman-5.")
17 Parallel Selection: Hash Partitioning (1) SELECT * FROM R (2) SELECT * FROM R WHERE R.A = v (3) SELECT * FROM R WHERE R.A < v1 AND R.A>v2 Good for sequential access Assuming hash function is good, and partitioning attributes form a key, tuples will be equally distributed between disks Retrieval work is then well balanced between disks Good for point queries on partitioning attribute Can lookup single disk, leaving others available for answering other queries. Index on partitioning attribute can be local to disk, making lookup and update more efficient No clustering, so difficult to answer range queries

18 Parallel Selection: Range Partitioning CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT ' ', job_code INT NOT NULL, store_id INT NOT NULL ) PARTITION BY RANGE (store_id) ( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION p2 VALUES LESS THAN (16), PARTITION p3 VALUES LESS THAN (21) );
, PARTITION p3 VALUES LESS THAN (21) ); http://docs.oracle.com/cd/e17952_01/refman-5.")
19 Parallel Selection: Range Partitioning (1) SELECT * FROM R (2) SELECT * FROM R (3) SELECT * FROM R WHERE R.A < v1 AND R.A>v2 WHERE R.A = v Provides data clustering by partitioning attribute value Good for sequential access Good for point queries on partitioning attribute: only one disk needs to be accessed. For range queries on partitioning attribute, one to a few disks may need to be accessed Remaining disks are available for other queries Caveat: badly chosen partition vector may assign too many tuples to some partitions and too few to others

20 Parallel Join The join operation requires pairs of tuples to be tested to see if they satisfy the join condition, and if they do, the pair is added to the join output. Parallel join algorithms attempt to split the pairs to be tested over several processors. Each processor then computes part of the join locally. In a final step, the results from each processor can be collected together to produce the final result. How would you implement a join in MapReduce?

21 Partitioned Join For equi-joins and natural joins, it is possible to partition the two input relations across the processors, and compute the join locally at each processor Let r and s be the input relations, and we want to compute r r.a=s.b s. r and s each are partitioned into n partitions, denoted r 0, r 1,..., r n-1 and s 0, s 1,..., s n-1. Can use either range partitioning or hash partitioning. r and s must be partitioned on their join attributes r.a and s.b, using the same range-partitioning vector or hash function. Partitions r i and s i are sent to processor P i, Each processor P i locally computes r i standard join methods can be used. ri.a=si.b s i. Any of the
22 Partitioned Join (Cont.)
23 Pipelined Parallelism Consider a join of four relations r 1 r 2 r 3 r 4 Set up a pipeline that computes the three joins in parallel Let P1 be assigned the computation of temp1 = r 1 r 2 And P2 be assigned the computation of temp2 = temp1 r 3 And P3 be assigned the computation of temp2 r 4 Each of these operations can execute in parallel, sending result tuples it computes to the next operation even as it is computing further results Provided a pipelineable join evaluation algorithm (e.g., indexed nested loops join) is used
24 Pipelined Parallelism Can we implement pipelined joins in MapReduce?
25 Factors Limiting Utility of Pipeline Parallelism Pipeline parallelism is useful since it avoids writing intermediate results to disk Cannot pipeline operators which do not produce output until all inputs have been accessed (e.g., blocking operations such as aggregate and sort)
26 MapReduce: A Step Backwards
27 Dewitt and Stonebraker Views We are amazed at the hype that the MapReduce proponents have spread about how it represents a paradigm shift in the development of scalable, data-intensive applications 1. A giant step backward in the programming paradigm for large-scale data intensive applications 2. A sub-optimal implementation, in that it uses brute force instead of indexing 3. Not novel at all -- it represents a specific implementation of well known techniques developed nearly 25 years ago 4. Missing most of the features that are routinely included in current DBMS 5. Incompatible with all of the tools DBMS users have come to depend on
28 Dewitt and Stonebraker Views (cont.) The database community has learned the following three lessons over the past 40 years Schemas are good. Separation of the schema from the application is good. High-level access languages are good MapReduce has learned none of these lessons MapReduce is a poor implementation MapReduce advocates have overlooked the issue of skew Skew is a huge impediment to achieving successful scale-up in parallel query systems When there is wide variance in the distribution of records with the same key lead some reduce instances to take much longer to run than others à execution time for the computation is the running time of the slowest reduce instance.
29 Dewitt and Stonebraker Views (cont.) I/O bottleneck: N map instances produces M output files If N is 1,000 and M is 500, the map phase produces 500,000 local files. When the reduce phase starts, each of the 500 reduce instances needs to read its 1,000 input files and must use a protocol like FTP to "pull" each of its input files from the nodes on which the map instances were run In contrast, Parallel Databases do not materialize their split files
30 Case for Parallel Databases Pavlo et al., SIGMOD 2009
31 MapReduce vs. Parallel Databases [Pavlo et al., SIGMOD 2009] compared the performance of Hadoop against Vertica and a Parallel DBMS Why use MapReduce when parallel databases are so efficient and effective? Point of view from the perspective of database researchers Compare the different approaches and perform an experimental evaluation
32 Architectural Elements: ParDB vs. MR Schema support: Relational paradigm: rigid structure of rows and columns Flexible structure, but need to write parsers and challenging to share results Indexing B-trees to speed up access No built-in indexes --- programmers must code indexes Programming model Declarative, high-level language Imperative, write programs Data distribution Use knowledge of data distribution to automatically optimize queries Programmer must optimize the access
33 Architectural Elements: ParDB vs. MR Execution strategy and fault tolerance: Pipeline operators (push), failures dealt with at the transaction level Write intermediate files (pull), provide fault tolerance
34 Architectural Elements Parallel DBMS MapReduce Schema Support ü Not out of the box Indexing ü Not out of the box Programming Model Optimizations (Compression, Query Optimization) Declarative (SQL) ü Imperative (C/C++, Java, ) Extensions through Pig and Hive Not out of the box Flexibility Not out of the box ü Fault Tolerance Coarse grained techniques ü [Pavlo et al., SIGMOD 2009, Stonebraker et al., CACM 2010, ]
35 Experimental Evaluation 5 tasks --- including task from original MapReduce paper Compared: Hadoop, DBMS-X, Vertica 100-node cluster Test speedup using clusters of size 1, 10, 25, 50, 100 nodes Fix the size of data in each node to 535MB (match MapReduce paper) Evenly divide data among the different nodes We will look at the Grep task --- see paper for details on the other tasks
36 Load Time seconds seconds seconds Nodes 10 Nodes 25 Nodes 50 Nodes 100 Nodes Nodes 50 Nodes 100 Nodes 1000 Vertica Hadoop Vertica Hadoop Figure 1: Load Times Grep Task Data Set (535MB/node) Figure 2: Load Times Grep Task Data Set (1TB/cluster) Figur Since Hadoop needs outperforms a total of 3TB of both disk space Vertica in order and to store DBMS-X ferent node based on the ha loaded, the columns are au cording to the physical desi three replicas of each block in HDFS, we were limited to running this benchmark only on 25, 50, and 100 nodes (at fewer than 25 nodes, there is not enough available disk space to store 3TB) Data Loading We now describe the procedures used to load the data from the nodes local files into each system s internal storage representation. Results & Discussion: The and 1TB/cluster data sets ar For DBMS-X, we separate which are shown as a stac
37 Grep Task Scan through a data set of 100-byte records looking for a threecharacter pattern. Each record consists of a unique key in the first 10 bytes, followed by a 90-byte random value. SELECT * FROM Data WHERE field LIKE %XYZ%
38 Grep Task: Analysis Fig 4: Little data is processed in each node --- start-up costs for Hadoop dominate that takes seconds before all Map tasks have been started and are running at full speed across the nodes in the cluster execution time of the additional MR job to combine the output into a single file seconds Nodes 10 Nodes 25 Nodes 50 Nodes 100 Nodes Vertica Hadoop Figure 4: Grep Task Results 535MB/node Data Set two figures. In Figure 4, the two parallel databases perform about the same, more than a factor of two faster in Hadoop. But in Figure 5, both DBMS-X and Hadoop perform more than a factor of two slower than Vertica. The reason is that the amount of data processing varies substantially from the two experiments. For the results in Figure 4, very little data is being processed (535MB/node). Thiscauses Hadoop snon-insignificant start-upcoststobecome the limiting factor in its performance. As will be described in Section 5.1.2, for short-running queries (i.e., queries that take less than a minute), Hadoop s start-up costs can dominate the execution time. In our observations, we found that takes seconds before all
39 Grep Task: Analysis 70 Fig 5: Hadoop s start-up costs are 60 ammortized --- more data 50 processed in each node 40 Vertica s superior performance is 30 due to aggressive compression seconds seconds Nodes 10 Nodes 25 Nodes 50 Nodes 100 Nodes 0 25 Nodes 50 Nodes 100 Nodes Vertica Hadoop Vertica Hadoop Figure 4: Grep Task Results 535MB/node Data Set two figures. In Figure 4, the two parallel databases perform about the same, more than a factor of two faster in Hadoop. But in Figure 5, both DBMS-X and Hadoop perform more than a factor of two slower than Vertica. The reason is that the amount of data processing varies substantially from the two experiments. For the results in Figure 4, very little data is being processed (535MB/node). Thiscauses Hadoop snon-insignificant start-upcoststobecome the limiting factor in its performance. As will be described in Section 5.1.2, for short-running queries (i.e., queries that take less than a minute), Hadoop s start-up costs can dominate the execution time. In our observations, we found that takes seconds before all Map tasks have been started and are running at full speed across the nodes in the cluster. Furthermore, as the total number of allocated Figure 5: Grep Task Results 1TB/cluster Data Set 600,000 unique HTML documents, each with a unique URL. In each document, we randomly generate links to other pages set using a Zipfian distribution. We also generated two additional data sets meant to model log files of HTTP server traffic. These data sets consist of values derived from the HTML documents as well as several randomly generated attributes. The schema of these three tables is as follows: CREATE TABLE Documents ( url VARCHAR(100) PRIMARY KEY, contents TEXT ); CREATE TABLE Rankings ( pageurl VARCHAR(100) PRIMARY KEY, CREATE TABLE UserVisits ( sourceip VARCHAR(16), desturl VARCHAR(100), visitdate DATE, adrevenue FLOAT, useragent VARCHAR(64), countrycode VARCHAR(3), languagecode VARCHAR(6),
40 Discussion Installation, configuration and use: Hadoop is easy and free DBMS-X is very hard --- lots of tuning required; and very expensive Task start-up is an issue with Hadoop Compression is helpful and supported by DBMS-X and Vertica Loading is much faster on Hadoop x faster than DBMS-X If data will be processed only a few times, it might not be worth it to use a parallel DBMS
41 Case for MapReduce By Dean and Ghemawat, CACM 2010
42 MapReduce vs. Parallel Databases [Dean and Ghemawat, CACM 2010] criticize the comparison by Pavlo et al. Point of view from the creators of MapReduce Discuss misconceptions in Pavlo et al. MapReduce cannot use indices Inputs and outputs are always simple files in a file system Require inefficient data formats MapReduce provides storage independence and fine-grained fault tolerance Supports complex transformations
43 Heterogeneous Systems Production environments use a plethora of storage systems: files, RDBMS, Bigtable, column stores MapReduce can be extended to support different storage backends --- it can be used to combine data from different sources Parallel databases require all data to be loaded Would you use a ParDB to load Web pages retrieved by a crawler and build an inverted index?
44 An Aside: BigTable BigTable is a distributed storage system for managing structured data. Designed to scale to a very large size Petabytes of data across thousands of servers Used for many Google projects Web indexing, Personalized Search, Google Earth, Google Analytics, Google Finance, Flexible, high-performance solution for Google s products [Chang et al., OSDI 2006]
45 BigTable: Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank, Per-user data: User preference settings, recent queries/search results, Geographic locations: Physical entities (shops, restaurants, etc.), roads, satellite image data, user annotations, Scale is large Billions of URLs, many versions/page (~20K/version) Hundreds of millions of users, thousands or q/sec 100TB+ of satellite image data
46 Why not just use commercial DB? Scale is too large for most commercial databases Even if it weren t, cost would be very high Building internally means system can be applied across many projects for low incremental cost Low-level storage optimizations help performance significantly Much harder to do when running on top of a database layer
47 Goals Want asynchronous processes to be continuously updating different pieces of data Want access to most current data at any time Need to support: Very high read/write rates (millions of ops per second) Efficient scans over all or interesting subsets of data Efficient joins of large one-to-one and one-to-many datasets Often want to examine data changes over time E.g., Contents of a web page over multiple crawls
48 Distributed multi-level map Fault-tolerant, persistent Scalable Thousands of servers Terabytes of in-memory data Petabyte of disk-based data BigTable Millions of reads/writes per second, efficient scans Self-managing Servers can be added/removed dynamically Servers adjust to load imbalance
49 Data model: a big map <Row, Column, Timestamp> à string triple for key - lookup, insert, and delete API Arbitrary columns on a row-by-row basis Column-oriented physical store- rows are sparse! Does not support a relational model No table-wide integrity constraints No multirow transactions: read/write row is atomic 51 of 19
50 Indices Techniques used by DBMSs can also be applied to MapReduce For example, HadoopDB gives Hadoop access to multiple single-node DBMS servers (e.g., PostgreSQL or MySQL) deployed across the cluster It pushes as much as possible data processing into the database engine by issuing SQL queries (usually most of the Map/Combine phase logic is expressible in SQL) Indexing can also be obtained through appropriate partitioning of the data, e.g., range partitioning Log files are partitioned based on date ranges
51 Complex Functions MapReduce was designed for complex tasks that manipulate diverse data: Extract links from Web pages and aggregating them by target document Generate inverted index files to support efficient search queries Process all road segments in the world and rendering map images These data do not fit well in the relational paradigm Remember: SQL is not Turing-complete! RDMS supports UDF, but these have limitations Buggy in DBMS-X and missing in Vertica
52 Structured Data and Schemas Schemas are helpful to share data Google s MapReduce implementation supports the Protocol Buffer format A high-level language is used to describe the input and output types Compiler-generated code hides the details of encoding/decoding data Use optimized binary representation --- compact and faster to encode/decode; huge performance gains 80x for example in paper!
53 Protocol Buffer format
54 Hadoop Alternatives Avro: Thrift:
55 Fault Tolerance Pull model is necessary to provide fault tolerance It may lead to the creation of many small files Use implementation tricks to mitigate these costs Keep this in mind when writing your MapReduce programs!
56 Conclusions It doesn t make much sense to compare MapReduce and Parallel DBMS: they were designed for different purposes! You can do anything in MapReduce it may not be easy, but it is possible MapReduce is free, Parallel DB are expensive Growing ecosystem around MapReduce is making it more similar to PDBMSs
57 Conclusions (cont.) There is a lot of ongoing work on adding DB features to the Cloud environment Spark: support streaming Shark: large-scale data warehouse system for Spark SQL API Now HadoopDB: hybrid of DBMS and MapReduce technologies that targets analytical workloads ElasTraS: An elastic, scalable, and self-managing transactional database for the cloud Twister: enhanced runtime that supports iterative MapReduce computations efficiently
58 Conclusions (cont.) Apache Hbase: random, real-time read/write access to Big Data Apache Accumulo ( distributed key/value store similar to BigTable High-level languages Pig and Hive MongoDB ( document database Hive ( data warehouse that supports querying and managing large data residing in distributed storage
59 Questions
60
61
Hadoop vs. Parallel Databases. Juliana Freire!
 Hadoop vs. Parallel Databases Juliana Freire! The Debate Starts The Debate Continues A comparison of approaches to large-scale data analysis. Pavlo et al., SIGMOD 2009! o Parallel DBMS beats MapReduce
Hadoop vs. Parallel Databases Juliana Freire! The Debate Starts The Debate Continues A comparison of approaches to large-scale data analysis. Pavlo et al., SIGMOD 2009! o Parallel DBMS beats MapReduce
Big Data Data-intensive Computing Methods, Tools, and Applications (CMSC 34900)
") Big Data Data-intensive Computing Methods, Tools, and Applications (CMSC 34900) Ian Foster Computation Institute Argonne National Lab & University of Chicago 2 3 SQL Overview Structured Query Language
Big Data Data-intensive Computing Methods, Tools, and Applications (CMSC 34900) Ian Foster Computation Institute Argonne National Lab & University of Chicago 2 3 SQL Overview Structured Query Language
A Comparison of Approaches to Large-Scale Data Analysis
 A Comparison of Approaches to Large-Scale Data Analysis Sam Madden MIT CSAIL with Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, and Michael Stonebraker In SIGMOD 2009 MapReduce
A Comparison of Approaches to Large-Scale Data Analysis Sam Madden MIT CSAIL with Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, and Michael Stonebraker In SIGMOD 2009 MapReduce
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Big Table A Distributed Storage System For Data
 Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
A Comparison of Approaches to Large-Scale Data Analysis
 A Comparison of Approaches to Large-Scale Data Analysis Andrew Pavlo Erik Paulson Alexander Rasin Brown University University of Wisconsin Brown University [email protected] [email protected] [email protected]
A Comparison of Approaches to Large-Scale Data Analysis Andrew Pavlo Erik Paulson Alexander Rasin Brown University University of Wisconsin Brown University [email protected] [email protected] [email protected]
YANG, Lin COMP 6311 Spring 2012 CSE HKUST
 YANG, Lin COMP 6311 Spring 2012 CSE HKUST 1 Outline Background Overview of Big Data Management Comparison btw PDB and MR DB Solution on MapReduce Conclusion 2 Data-driven World Science Data bases from
YANG, Lin COMP 6311 Spring 2012 CSE HKUST 1 Outline Background Overview of Big Data Management Comparison btw PDB and MR DB Solution on MapReduce Conclusion 2 Data-driven World Science Data bases from
Data Management in the Cloud MAP/REDUCE. Map/Reduce. Programming model Examples Execution model Criticism Iterative map/reduce
 Data Management in the Cloud MAP/REDUCE 117 Programming model Examples Execution model Criticism Iterative map/reduce Map/Reduce 118 Motivation Background and Requirements computations are conceptually
Data Management in the Cloud MAP/REDUCE 117 Programming model Examples Execution model Criticism Iterative map/reduce Map/Reduce 118 Motivation Background and Requirements computations are conceptually
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
The Performance of MapReduce: An In-depth Study
 The Performance of MapReduce: An In-depth Study Dawei Jiang Beng Chin Ooi Lei Shi Sai Wu School of Computing National University of Singapore {jiangdw, ooibc, shilei, wusai}@comp.nus.edu.sg ABSTRACT MapReduce
The Performance of MapReduce: An In-depth Study Dawei Jiang Beng Chin Ooi Lei Shi Sai Wu School of Computing National University of Singapore {jiangdw, ooibc, shilei, wusai}@comp.nus.edu.sg ABSTRACT MapReduce
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
How To Handle Big Data With A Data Scientist
 III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
SQL VS. NO-SQL. Adapted Slides from Dr. Jennifer Widom from Stanford
 SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Hadoop s Entry into the Traditional Analytical DBMS Market. Daniel Abadi Yale University August 3 rd, 2010
 Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
MapReduce: A Flexible Data Processing Tool
 DOI:10.1145/1629175.1629198 MapReduce advantages over parallel databases include storage-system independence and fine-grain fault tolerance for large jobs. BY JEFFREY DEAN AND SANJAY GHEMAWAT MapReduce:
DOI:10.1145/1629175.1629198 MapReduce advantages over parallel databases include storage-system independence and fine-grain fault tolerance for large jobs. BY JEFFREY DEAN AND SANJAY GHEMAWAT MapReduce:
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
MapReduce Jeffrey Dean and Sanjay Ghemawat. Background context
 MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
Can the Elephants Handle the NoSQL Onslaught?
 Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Data Management in the Cloud -
 Data Management in the Cloud - current issues and research directions Patrick Valduriez Esther Pacitti DNAC Congress, Paris, nov. 2010 http://www.med-hoc-net-2010.org SOPHIA ANTIPOLIS - MÉDITERRANÉE Is
Data Management in the Cloud - current issues and research directions Patrick Valduriez Esther Pacitti DNAC Congress, Paris, nov. 2010 http://www.med-hoc-net-2010.org SOPHIA ANTIPOLIS - MÉDITERRANÉE Is
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Benchmarking Cassandra on Violin
 Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
MapReduce. MapReduce and SQL Injections. CS 3200 Final Lecture. Introduction. MapReduce. Programming Model. Example
 MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Advanced Data Management Technologies
 ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Overview of Databases On MacOS. Karl Kuehn Automation Engineer RethinkDB
 Overview of Databases On MacOS Karl Kuehn Automation Engineer RethinkDB Session Goals Introduce Database concepts Show example players Not Goals: Cover non-macos systems (Oracle) Teach you SQL Answer what
Overview of Databases On MacOS Karl Kuehn Automation Engineer RethinkDB Session Goals Introduce Database concepts Show example players Not Goals: Cover non-macos systems (Oracle) Teach you SQL Answer what
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads
 HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid 1, Kamil Bajda-Pawlikowski 1, Daniel Abadi 1, Avi Silberschatz 1, Alexander Rasin 2 1 Yale University,
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid 1, Kamil Bajda-Pawlikowski 1, Daniel Abadi 1, Avi Silberschatz 1, Alexander Rasin 2 1 Yale University,
Similarity Search in a Very Large Scale Using Hadoop and HBase
 Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
NoSQL Data Base Basics
 NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Constructing a Data Lake: Hadoop and Oracle Database United!
 Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Parquet. Columnar storage for the people
 Parquet Columnar storage for the people Julien Le Dem @J_ Processing tools lead, analytics infrastructure at Twitter Nong Li [email protected] Software engineer, Cloudera Impala Outline Context from various
Parquet Columnar storage for the people Julien Le Dem @J_ Processing tools lead, analytics infrastructure at Twitter Nong Li [email protected] Software engineer, Cloudera Impala Outline Context from various
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Big Data Primer. 1 Why Big Data? Alex Sverdlov [email protected]
 Big Data Primer Alex Sverdlov [email protected] 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Data Primer Alex Sverdlov [email protected] 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
IN-MEMORY DATABASE SYSTEMS. Prof. Dr. Uta Störl Big Data Technologies: In-Memory DBMS - SoSe 2015 1
 IN-MEMORY DATABASE SYSTEMS Prof. Dr. Uta Störl Big Data Technologies: In-Memory DBMS - SoSe 2015 1 Analytical Processing Today Separation of OLTP and OLAP Motivation Online Transaction Processing (OLTP)
IN-MEMORY DATABASE SYSTEMS Prof. Dr. Uta Störl Big Data Technologies: In-Memory DBMS - SoSe 2015 1 Analytical Processing Today Separation of OLTP and OLAP Motivation Online Transaction Processing (OLTP)
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5
 Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 [email protected], 2 [email protected],
Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 [email protected], 2 [email protected],
The Hadoop Framework
 The Hadoop Framework Nils Braden University of Applied Sciences Gießen-Friedberg Wiesenstraße 14 35390 Gießen [email protected] Abstract. The Hadoop Framework offers an approach to large-scale
The Hadoop Framework Nils Braden University of Applied Sciences Gießen-Friedberg Wiesenstraße 14 35390 Gießen [email protected] Abstract. The Hadoop Framework offers an approach to large-scale
How to Choose Between Hadoop, NoSQL and RDBMS
 How to Choose Between Hadoop, NoSQL and RDBMS Keywords: Jean-Pierre Dijcks Oracle Redwood City, CA, USA Big Data, Hadoop, NoSQL Database, Relational Database, SQL, Security, Performance Introduction A
How to Choose Between Hadoop, NoSQL and RDBMS Keywords: Jean-Pierre Dijcks Oracle Redwood City, CA, USA Big Data, Hadoop, NoSQL Database, Relational Database, SQL, Security, Performance Introduction A
HBase A Comprehensive Introduction. James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367
 CIT 367") HBase A Comprehensive Introduction James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367 Overview Overview: History Began as project by Powerset to process massive
HBase A Comprehensive Introduction James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367 Overview Overview: History Began as project by Powerset to process massive
I/O Considerations in Big Data Analytics
 Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
CitusDB Architecture for Real-Time Big Data
 CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
Replicating to everything
 Replicating to everything Featuring Tungsten Replicator A Giuseppe Maxia, QA Architect Vmware About me Giuseppe Maxia, a.k.a. "The Data Charmer" QA Architect at VMware Previously at AB / Sun / 3 times
Replicating to everything Featuring Tungsten Replicator A Giuseppe Maxia, QA Architect Vmware About me Giuseppe Maxia, a.k.a. "The Data Charmer" QA Architect at VMware Previously at AB / Sun / 3 times
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
Sector vs. Hadoop. A Brief Comparison Between the Two Systems
 Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Big Data. Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich
 Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
Analytics in the Cloud. Peter Sirota, GM Elastic MapReduce
 Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
A survey of big data architectures for handling massive data
 CSIT 6910 Independent Project A survey of big data architectures for handling massive data Jordy Domingos - [email protected] Supervisor : Dr David Rossiter Content Table 1 - Introduction a - Context
CSIT 6910 Independent Project A survey of big data architectures for handling massive data Jordy Domingos - [email protected] Supervisor : Dr David Rossiter Content Table 1 - Introduction a - Context