Yu Xu Pekka Kostamaa Like Gao. Presented By: Sushma Ajjampur Jagadeesh
|
|
|
- Walter Cain
- 8 years ago
- Views:
Transcription
1 Yu Xu Pekka Kostamaa Like Gao Presented By: Sushma Ajjampur Jagadeesh

2 Introduction Teradata s parallel DBMS can hold data sets ranging from few terabytes to multiple petabytes. Due to explosive data volume increase in recent years at some customer sites some data such as web logs and sensor data are not managed by Teradata EDW (Enterprise Data Warehouse). Expensive to load large volume of data such as web logs and sensor data onto Teradata EDW. Google s MapReduce and open source implementation of Hadoop is gaining momentum to perform large scale data analysis. Teradata customers have seen increasing needs to perform BI (Business Intelligence) over both data stored in Hadoop and data in Teradata EDW.

3 Parallel DBMS v/s HDFS Slow to load very high volume data into an RDBMS Fast execution of queries HDFS has reliability and quick load time 2-3 times slower in execution of queries Easy to write SQL for complex BI analysis Difficult to write MapReduce programs Expensive Low Cost

4 Solution Efficiently transferring data between Hadoop and Teradata EDW is the important first step for integrated BI over Hadoop and Teradata EDW. A straightforward approach is to use Hadoop and Teradata s current load and export utilities. One common thing between Hadoop and Teradata EDW is that data in both systems are partitioned across multiple nodes for parallel computing, which creates integration optimization opportunities not possible for DBMSs running on a single node. Three efforts towards tight and efficient integration of Hadoop and Teradata EDW.

5 Methods of Integration Direct Load - Load Hadoop data into EDW TeradataInputFormat - Retrieve EDW data from MapReduce programs Table UDF - Access Hadoop data as a table

6 Parallel Loading of Hadoop Data to Teradata EDW FastLoad Approach FastLoad utility/protocol is widely in production use for loading data to a Teradata EDW table. A FastLoad client connects to a Gateway process residing at one node in the Teradata EDW system and establishes many sessions. Each node in a Teradata EDW system is configured to run multiple virtual parallel units called AMPs (Access Module Processors). AMP is responsible for doing scans, joins and other data management tasks on the data it manages. FastLoad client sends a batch of rows in a round-robin fashion over one session at a time to the connected Gateway process. The Gateway forwards the rows to a receiving AMP. The receiving AMP computes the row-hash value of each row. The value determines which AMP should manage the row. The receiving AMP sends the rows it receives to the right final AMPs which will store the rows in Teradata EDW.

7 DirectLoad Approach Remove the two hops in the current FastLoad approach. Hadoop file is divided into many portions. Decide which portion of a Hadoop file each AMP should receive. Start as many DirectLoad jobs as the number of AMPs in Teradata EDW. Each DirectLoad job connects to a Teradata Gateway process and reads the designated portion of a Hadoop file using Hadoop s API. Forwards the data to its connected Gateway which sends Hadoop data only to a unique local AMP on the same Teradata node. Each receiving AMP acts as the final AMP managing the rows the AMP has received. No row-hash computation is needed and the second hop in the FastLoad approach is removed.

8 Retrieving EDW Data from MapReduce Programs Straightforward approach for a MapReduce program to access relational data: Export the results of SQL queries to a local file Load the local file to Hadoop More convenient and productive to directly access relational data from their MapReduce programs without the external steps of exporting data from a DBMS Based on the DBInputFormat new approach called TeradataInputFormat is developed. This enables MapReduce programs to directly read Teradata EDW data via JDBC drivers without any external steps.

9 DBInputFormat MapReduce programmer provides a SQL query via the DBInputFormat class. The DBInputFormat implementation first generates a query SELECT count(*) from T where C and sends to the DBMS to get the number of rows (R) in the table T. At runtime, the DBInputFormat implementation knows the number of Mappers (M) started by Hadoop. Each Mapper sends a query through a standard JDBC driver to DBMS. Select P From T Where C Order By O Limit L Offset X (Q)
 started by Hadoop.")
10 DBInputFormat (cont d) Drawbacks: Each Mapper sends the same SQL query to the DBMS but with different LIMIT and OFFSET. Performance issues are serious for a parallel DBMS which have higher number of concurrent queries and larger datasets.

11 TeradataInputFormat Teradata connector for Hadoop named TeradataInputFormat sends the SQL query only once to Teradata EDW. TeradataInputFormat class sends the following query P to Teradata EDW based on the query Q provided by the MapReduce program. CREATE TABLE T AS (Q) WITH DATA PRIMARY INDEX ( c1 ) PARTITION BY (c2 MOD M) + 1 (P) Q is executed only once and the results are stored in a PPI (Partitioned Primary Index) table T. After the query Q is evaluated and the table T is created, each AMP has M partitions numbered from 1 to M. Each Mapper from Hadoop sends a new query Q i which just asks for all rows in the i-th partition on every AMP. SELECT * FROM T WHERE PARTITION = i (Q i ) After all Mappers retrieve their data, the table T is deleted.

12 TeradataInputFormat (cont d) Drawbacks: Currently a PPI table in Teradata EDW must have a primary index column. The data retrieved by a MapReduce program are not stored in Hadoop.

13 Accessing Hadoop Data from SQL via Table UDF A table UDF (User Defined Function) named HDFSUDF pulls data from Hadoop to Teradata EDW using SQL queries. INSERT INTO Tab1 SELECT * FROM TABLE ( HDFSUDF ( mydfsfile.txt ) ) AS T1; Typically an instance of HDFSUDF is run on every AMP in a Teradata system to retrieve a portion of Hadoop file. When a UDF instance is invoked on an AMP, the table UDF instance communicates with the NameNode in Hadoop which manages the metadata about mydfsfile.txt. Each UDF instance talks to the NameNode and finds the total size S of mydfsfile.txt. The table UDF then inquires Teradata EDW to discover its own numeric AMP identity and the number of AMPs. Each UDF instance identifies the offset into mydfsfile.txt and starts reading data from Hadoop.

14 Continued
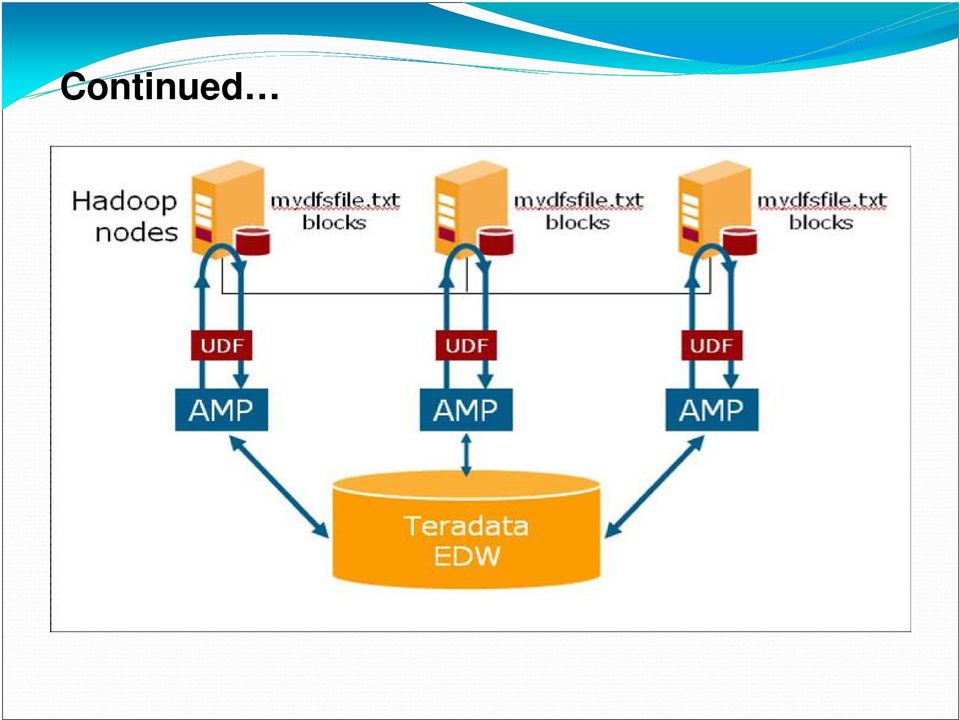
15 Conclusion Teradata Customers are increasingly seeing the need to perform integrated BI over both data stored in Hadoop and Teradata EDW. DirectLoad approach: Fast parallel loading of Hadoop data to Teradata EDW. TeradataInputFormat: Allows MapReduce programs efficient and direct parallel access to Teradata EDW data without external steps. Table UDF SQL: Directly access and join Hadoop data with Teradata EDW data from SQL queries via user defined table functions. Future work: Push more computation from Hadoop to Teradata EDW or from Teradata EDW to Hadoop.

16 Thank You

Integrating Hadoop and Parallel DBMS
 Integrating Hadoop and Parallel DBMS Yu Xu Pekka Kostamaa Like Gao Teradata San Diego, CA, USA and El Segundo, CA, USA {yu.xu,pekka.kostamaa,like.gao}@teradata.com ABSTRACT Teradata s parallel DBMS has
Integrating Hadoop and Parallel DBMS Yu Xu Pekka Kostamaa Like Gao Teradata San Diego, CA, USA and El Segundo, CA, USA {yu.xu,pekka.kostamaa,like.gao}@teradata.com ABSTRACT Teradata s parallel DBMS has
Native Connectivity to Big Data Sources in MSTR 10
 Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
IBM BigInsights Has Potential If It Lives Up To Its Promise. InfoSphere BigInsights A Closer Look
 IBM BigInsights Has Potential If It Lives Up To Its Promise By Prakash Sukumar, Principal Consultant at iolap, Inc. IBM released Hadoop-based InfoSphere BigInsights in May 2013. There are already Hadoop-based
IBM BigInsights Has Potential If It Lives Up To Its Promise By Prakash Sukumar, Principal Consultant at iolap, Inc. IBM released Hadoop-based InfoSphere BigInsights in May 2013. There are already Hadoop-based
ITG Software Engineering
 Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
CERULIUM TERADATA COURSE CATALOG
 CERULIUM TERADATA COURSE CATALOG Cerulium Corporation has provided quality Teradata education and consulting expertise for over seven years. We offer customized solutions to maximize your warehouse. Prepared
CERULIUM TERADATA COURSE CATALOG Cerulium Corporation has provided quality Teradata education and consulting expertise for over seven years. We offer customized solutions to maximize your warehouse. Prepared
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Hadoop and Relational Database The Best of Both Worlds for Analytics Greg Battas Hewlett Packard
 Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Introduction to NoSQL Databases and MapReduce. Tore Risch Information Technology Uppsala University 2014-05-12
 Introduction to NoSQL Databases and MapReduce Tore Risch Information Technology Uppsala University 2014-05-12 What is a NoSQL Database? 1. A key/value store Basic index manager, no complete query language
Introduction to NoSQL Databases and MapReduce Tore Risch Information Technology Uppsala University 2014-05-12 What is a NoSQL Database? 1. A key/value store Basic index manager, no complete query language
Qsoft Inc www.qsoft-inc.com
 Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Tap into Hadoop and Other No SQL Sources
 Tap into Hadoop and Other No SQL Sources Presented by: Trishla Maru What is Big Data really? The Three Vs of Big Data According to Gartner Volume Volume Orders of magnitude bigger than conventional data
Tap into Hadoop and Other No SQL Sources Presented by: Trishla Maru What is Big Data really? The Three Vs of Big Data According to Gartner Volume Volume Orders of magnitude bigger than conventional data
Mr. Apichon Witayangkurn apichon@iis.u-tokyo.ac.jp Department of Civil Engineering The University of Tokyo
 Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn apichon@iis.u-tokyo.ac.jp Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn apichon@iis.u-tokyo.ac.jp Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Big Telco, Bigger DW Demands: Moving Towards SQL-on-Hadoop
 Big Telco, Bigger DW Demands: Moving Towards SQL-on-Hadoop Keuntae Park IT Manager of SK Telecom, South Korea s largest wireless communications provider Work on commercial products (~ 12) T-FS: Distributed
Big Telco, Bigger DW Demands: Moving Towards SQL-on-Hadoop Keuntae Park IT Manager of SK Telecom, South Korea s largest wireless communications provider Work on commercial products (~ 12) T-FS: Distributed
Presented By Smit Ambalia
 Presented By Smit Ambalia Map Reduce Background In-Database Map-Reduce Why Previous initiatives and Limitation Oracle In-Database HADOOP Integration with Oracle s Big-Data Solution Conclusion Avoid bringing
Presented By Smit Ambalia Map Reduce Background In-Database Map-Reduce Why Previous initiatives and Limitation Oracle In-Database HADOOP Integration with Oracle s Big-Data Solution Conclusion Avoid bringing
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Discovering Business Insights in Big Data Using SQL-MapReduce
 Discovering Business Insights in Big Data Using SQL-MapReduce A Technical Whitepaper Rick F. van der Lans Independent Business Intelligence Analyst R20/Consultancy July 2013 Sponsored by Copyright 2013
Discovering Business Insights in Big Data Using SQL-MapReduce A Technical Whitepaper Rick F. van der Lans Independent Business Intelligence Analyst R20/Consultancy July 2013 Sponsored by Copyright 2013
Oracle BI EE Implementation on Netezza. Prepared by SureShot Strategies, Inc.
 Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
HadoopRDF : A Scalable RDF Data Analysis System
 HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
AGENDA. What is BIG DATA? What is Hadoop? Why Microsoft? The Microsoft BIG DATA story. Our BIG DATA Roadmap. Hadoop PDW
 AGENDA What is BIG DATA? What is Hadoop? Why Microsoft? The Microsoft BIG DATA story Hadoop PDW Our BIG DATA Roadmap BIG DATA? Volume 59% growth in annual WW information 1.2M Zetabytes (10 21 bytes) this
AGENDA What is BIG DATA? What is Hadoop? Why Microsoft? The Microsoft BIG DATA story Hadoop PDW Our BIG DATA Roadmap BIG DATA? Volume 59% growth in annual WW information 1.2M Zetabytes (10 21 bytes) this
Delivering Intelligence to Publishers Through Big Data
 Delivering Intelligence to Publishers Through Big Data 2015-05- 21 Jonathan Sharley Team Lead, Data Operations www.sovrn.com Who is Sovrn? Ø An advertising network with direct relationships to 20,000+
Delivering Intelligence to Publishers Through Big Data 2015-05- 21 Jonathan Sharley Team Lead, Data Operations www.sovrn.com Who is Sovrn? Ø An advertising network with direct relationships to 20,000+
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
W H I T E P A P E R. Deriving Intelligence from Large Data Using Hadoop and Applying Analytics. Abstract
 W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
DATA MINING OVER LARGE DATASETS USING HADOOP IN CLOUD ENVIRONMENT
 DATA MINING VER LARGE DATASETS USING HADP IN CLUD ENVIRNMENT V.Nappinna lakshmi 1, N. Revathi 2* 1 PG Scholar, 2 Assistant Professor Department of Information Technology, Sri Venkateswara College of Engineering,
DATA MINING VER LARGE DATASETS USING HADP IN CLUD ENVIRNMENT V.Nappinna lakshmi 1, N. Revathi 2* 1 PG Scholar, 2 Assistant Professor Department of Information Technology, Sri Venkateswara College of Engineering,
iservdb The database closest to you IDEAS Institute
 iservdb The database closest to you IDEAS Institute 1 Overview 2 Long-term Anticipation iservdb is a relational database SQL compliance and a general purpose database Data is reliable and consistency iservdb
iservdb The database closest to you IDEAS Institute 1 Overview 2 Long-term Anticipation iservdb is a relational database SQL compliance and a general purpose database Data is reliable and consistency iservdb
Integrated Big Data: Hadoop + DBMS + Discovery for SAS High Performance Analytics
 Paper 1828-2014 Integrated Big Data: Hadoop + DBMS + Discovery for SAS High Performance Analytics John Cunningham, Teradata Corporation, Danville, CA ABSTRACT SAS High Performance Analytics (HPA) is a
Paper 1828-2014 Integrated Big Data: Hadoop + DBMS + Discovery for SAS High Performance Analytics John Cunningham, Teradata Corporation, Danville, CA ABSTRACT SAS High Performance Analytics (HPA) is a
MySQL and Hadoop. Percona Live 2014 Chris Schneider
 MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
An Oracle White Paper November 2010. Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics
 An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
CitusDB Architecture for Real-Time Big Data
 CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
Hadoop s Entry into the Traditional Analytical DBMS Market. Daniel Abadi Yale University August 3 rd, 2010
 Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
Certified Big Data and Apache Hadoop Developer VS-1221
 Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS)
") Use Data from a Hadoop Cluster with Oracle Database Hands-On Lab Lab Structure Acronyms: OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS) All files are
Use Data from a Hadoop Cluster with Oracle Database Hands-On Lab Lab Structure Acronyms: OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS) All files are
Analytics in the Cloud. Peter Sirota, GM Elastic MapReduce
 Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
Apache Kylin Introduction Dec 8, 2014 @ApacheKylin
 Apache Kylin Introduction Dec 8, 2014 @ApacheKylin Luke Han Sr. Product Manager lukhan@ebay.com @lukehq Yang Li Architect & Tech Leader yangli9@ebay.com Agenda What s Apache Kylin? Tech Highlights Performance
Apache Kylin Introduction Dec 8, 2014 @ApacheKylin Luke Han Sr. Product Manager lukhan@ebay.com @lukehq Yang Li Architect & Tech Leader yangli9@ebay.com Agenda What s Apache Kylin? Tech Highlights Performance
#mstrworld. Tapping into Hadoop and NoSQL Data Sources in MicroStrategy. Presented by: Trishla Maru. #mstrworld
 Tapping into Hadoop and NoSQL Data Sources in MicroStrategy Presented by: Trishla Maru Agenda Big Data Overview All About Hadoop What is Hadoop? How does MicroStrategy connects to Hadoop? Customer Case
Tapping into Hadoop and NoSQL Data Sources in MicroStrategy Presented by: Trishla Maru Agenda Big Data Overview All About Hadoop What is Hadoop? How does MicroStrategy connects to Hadoop? Customer Case
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
SAP Business Objects Business Intelligence platform Document Version: 4.1 Support Package 7 2015-11-24. Data Federation Administration Tool Guide
 SAP Business Objects Business Intelligence platform Document Version: 4.1 Support Package 7 2015-11-24 Data Federation Administration Tool Guide Content 1 What's new in the.... 5 2 Introduction to administration
SAP Business Objects Business Intelligence platform Document Version: 4.1 Support Package 7 2015-11-24 Data Federation Administration Tool Guide Content 1 What's new in the.... 5 2 Introduction to administration
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Decoding the Big Data Deluge a Virtual Approach. Dan Luongo, Global Lead, Field Solution Engineering Data Virtualization Business Unit, Cisco
 Decoding the Big Data Deluge a Virtual Approach Dan Luongo, Global Lead, Field Solution Engineering Data Virtualization Business Unit, Cisco High-volume, velocity and variety information assets that demand
Decoding the Big Data Deluge a Virtual Approach Dan Luongo, Global Lead, Field Solution Engineering Data Virtualization Business Unit, Cisco High-volume, velocity and variety information assets that demand
An Oracle White Paper June 2012. High Performance Connectors for Load and Access of Data from Hadoop to Oracle Database
 An Oracle White Paper June 2012 High Performance Connectors for Load and Access of Data from Hadoop to Oracle Database Executive Overview... 1 Introduction... 1 Oracle Loader for Hadoop... 2 Oracle Direct
An Oracle White Paper June 2012 High Performance Connectors for Load and Access of Data from Hadoop to Oracle Database Executive Overview... 1 Introduction... 1 Oracle Loader for Hadoop... 2 Oracle Direct
www.intelligentbusiness.biz mferguson@intelligentbusiness.biz Twitter: @mikeferguson1
 Welcome to Today s Web Seminar! March 15, 2011 12:00PM ET Sponsored by: Hosted by: Eric Kavanagh is the host of DM Radio and Information Management's Webcasts. He is a veteran journalist and consultant
Welcome to Today s Web Seminar! March 15, 2011 12:00PM ET Sponsored by: Hosted by: Eric Kavanagh is the host of DM Radio and Information Management's Webcasts. He is a veteran journalist and consultant
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Hadoop for MySQL DBAs. Copyright 2011 Cloudera. All rights reserved. Not to be reproduced without prior written consent.
 Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years sarah@cloudera.com 2 What is Hadoop? An open-source
Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years sarah@cloudera.com 2 What is Hadoop? An open-source
Using SAS as a Relational Database
 Using SAS as a Relational Database Yves DeGuire Statistics Canada Come out of the desert of ignorance to the OASUS of knowledge Introduction Overview of relational database concepts Why using SAS as a
Using SAS as a Relational Database Yves DeGuire Statistics Canada Come out of the desert of ignorance to the OASUS of knowledge Introduction Overview of relational database concepts Why using SAS as a
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Move Data from Oracle to Hadoop and Gain New Business Insights
 Move Data from Oracle to Hadoop and Gain New Business Insights Written by Lenka Vanek, senior director of engineering, Dell Software Abstract Today, the majority of data for transaction processing resides
Move Data from Oracle to Hadoop and Gain New Business Insights Written by Lenka Vanek, senior director of engineering, Dell Software Abstract Today, the majority of data for transaction processing resides
Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com
 REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
A Next-Generation Analytics Ecosystem for Big Data. Colin White, BI Research September 2012 Sponsored by ParAccel
 A Next-Generation Analytics Ecosystem for Big Data Colin White, BI Research September 2012 Sponsored by ParAccel BIG DATA IS BIG NEWS The value of big data lies in the business analytics that can be generated
A Next-Generation Analytics Ecosystem for Big Data Colin White, BI Research September 2012 Sponsored by ParAccel BIG DATA IS BIG NEWS The value of big data lies in the business analytics that can be generated
Creating a universe on Hive with Hortonworks HDP 2.0
 Creating a universe on Hive with Hortonworks HDP 2.0 Learn how to create an SAP BusinessObjects Universe on top of Apache Hive 2 using the Hortonworks HDP 2.0 distribution Author(s): Company: Ajay Singh
Creating a universe on Hive with Hortonworks HDP 2.0 Learn how to create an SAP BusinessObjects Universe on top of Apache Hive 2 using the Hortonworks HDP 2.0 distribution Author(s): Company: Ajay Singh
Manifest for Big Data Pig, Hive & Jaql
 Manifest for Big Data Pig, Hive & Jaql Ajay Chotrani, Priyanka Punjabi, Prachi Ratnani, Rupali Hande Final Year Student, Dept. of Computer Engineering, V.E.S.I.T, Mumbai, India Faculty, Computer Engineering,
Manifest for Big Data Pig, Hive & Jaql Ajay Chotrani, Priyanka Punjabi, Prachi Ratnani, Rupali Hande Final Year Student, Dept. of Computer Engineering, V.E.S.I.T, Mumbai, India Faculty, Computer Engineering,
Information Architecture
 The Bloor Group Actian and The Big Data Information Architecture WHITE PAPER The Actian Big Data Information Architecture Actian and The Big Data Information Architecture Originally founded in 2005 to
The Bloor Group Actian and The Big Data Information Architecture WHITE PAPER The Actian Big Data Information Architecture Actian and The Big Data Information Architecture Originally founded in 2005 to
Using an In-Memory Data Grid for Near Real-Time Data Analysis
 SCALEOUT SOFTWARE Using an In-Memory Data Grid for Near Real-Time Data Analysis by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 IN today s competitive world, businesses
SCALEOUT SOFTWARE Using an In-Memory Data Grid for Near Real-Time Data Analysis by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 IN today s competitive world, businesses
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Using RDBMS, NoSQL or Hadoop?
 Using RDBMS, NoSQL or Hadoop? DOAG Conference 2015 Jean- Pierre Dijcks Big Data Product Management Server Technologies Copyright 2014 Oracle and/or its affiliates. All rights reserved. Data Ingest 2 Ingest
Using RDBMS, NoSQL or Hadoop? DOAG Conference 2015 Jean- Pierre Dijcks Big Data Product Management Server Technologies Copyright 2014 Oracle and/or its affiliates. All rights reserved. Data Ingest 2 Ingest
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
PLATFORA INTERACTIVE, IN-MEMORY BUSINESS INTELLIGENCE FOR HADOOP
 PLATFORA INTERACTIVE, IN-MEMORY BUSINESS INTELLIGENCE FOR HADOOP Your business is swimming in data, and your business analysts want to use it to answer the questions of today and tomorrow. YOU LOOK TO
PLATFORA INTERACTIVE, IN-MEMORY BUSINESS INTELLIGENCE FOR HADOOP Your business is swimming in data, and your business analysts want to use it to answer the questions of today and tomorrow. YOU LOOK TO
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems CLOUD COMPUTING GROUP - LITAO DENG
 1 RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems CLOUD COMPUTING GROUP - LITAO DENG Background 2 Hive is a data warehouse system for Hadoop that facilitates
1 RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems CLOUD COMPUTING GROUP - LITAO DENG Background 2 Hive is a data warehouse system for Hadoop that facilitates
SQL Server 2016 New Features!
 SQL Server 2016 New Features! Improvements on Always On Availability Groups: Standard Edition will come with AGs support with one db per group synchronous or asynchronous, not readable (HA/DR only). Improved
SQL Server 2016 New Features! Improvements on Always On Availability Groups: Standard Edition will come with AGs support with one db per group synchronous or asynchronous, not readable (HA/DR only). Improved
Alternatives to HIVE SQL in Hadoop File Structure
 Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Connecting Hadoop with Oracle Database
 Connecting Hadoop with Oracle Database Sharon Stephen Senior Curriculum Developer Server Technologies Curriculum The following is intended to outline our general product direction.
Connecting Hadoop with Oracle Database Sharon Stephen Senior Curriculum Developer Server Technologies Curriculum The following is intended to outline our general product direction.
Native Connectivity to Big Data Sources in MicroStrategy 10. Presented by: Raja Ganapathy
 Native Connectivity to Big Data Sources in MicroStrategy 10 Presented by: Raja Ganapathy Agenda MicroStrategy supports several data sources, including Hadoop Why Hadoop? How does MicroStrategy Analytics
Native Connectivity to Big Data Sources in MicroStrategy 10 Presented by: Raja Ganapathy Agenda MicroStrategy supports several data sources, including Hadoop Why Hadoop? How does MicroStrategy Analytics
Trafodion Operational SQL-on-Hadoop
 Trafodion Operational SQL-on-Hadoop SophiaConf 2015 Pierre Baudelle, HP EMEA TSC July 6 th, 2015 Hadoop workload profiles Operational Interactive Non-interactive Batch Real-time analytics Operational SQL
Trafodion Operational SQL-on-Hadoop SophiaConf 2015 Pierre Baudelle, HP EMEA TSC July 6 th, 2015 Hadoop workload profiles Operational Interactive Non-interactive Batch Real-time analytics Operational SQL
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Data Warehouse as a Service. Lot 2 - Platform as a Service. Version: 1.1, Issue Date: 05/02/2014. Classification: Open
 Data Warehouse as a Service Version: 1.1, Issue Date: 05/02/2014 Classification: Open Classification: Open ii MDS Technologies Ltd 2014. Other than for the sole purpose of evaluating this Response, no
Data Warehouse as a Service Version: 1.1, Issue Date: 05/02/2014 Classification: Open Classification: Open ii MDS Technologies Ltd 2014. Other than for the sole purpose of evaluating this Response, no
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
Applied research on data mining platform for weather forecast based on cloud storage
 Applied research on data mining platform for weather forecast based on cloud storage Haiyan Song¹, Leixiao Li 2* and Yuhong Fan 3* 1 Department of Software Engineering t, Inner Mongolia Electronic Information
Applied research on data mining platform for weather forecast based on cloud storage Haiyan Song¹, Leixiao Li 2* and Yuhong Fan 3* 1 Department of Software Engineering t, Inner Mongolia Electronic Information
Actian Vector in Hadoop
 Actian Vector in Hadoop Industrialized, High-Performance SQL in Hadoop A Technical Overview Contents Introduction...3 Actian Vector in Hadoop - Uniquely Fast...5 Exploiting the CPU...5 Exploiting Single
Actian Vector in Hadoop Industrialized, High-Performance SQL in Hadoop A Technical Overview Contents Introduction...3 Actian Vector in Hadoop - Uniquely Fast...5 Exploiting the CPU...5 Exploiting Single
MySQL and Hadoop: Big Data Integration. Shubhangi Garg & Neha Kumari MySQL Engineering
 MySQL and Hadoop: Big Data Integration Shubhangi Garg & Neha Kumari MySQL Engineering 1Copyright 2013, Oracle and/or its affiliates. All rights reserved. Agenda Design rationale Implementation Installation
MySQL and Hadoop: Big Data Integration Shubhangi Garg & Neha Kumari MySQL Engineering 1Copyright 2013, Oracle and/or its affiliates. All rights reserved. Agenda Design rationale Implementation Installation
E6893 Big Data Analytics Lecture 2: Big Data Analytics Platforms
 E6893 Big Data Analytics Lecture 2: Big Data Analytics Platforms Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big Data
E6893 Big Data Analytics Lecture 2: Big Data Analytics Platforms Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big Data
BIG DATA: FROM HYPE TO REALITY. Leandro Ruiz Presales Partner for C&LA Teradata
 BIG DATA: FROM HYPE TO REALITY Leandro Ruiz Presales Partner for C&LA Teradata Evolution in The Use of Information Action s ACTIVATING MAKE it happen! Insights OPERATIONALIZING WHAT IS happening now? PREDICTING
BIG DATA: FROM HYPE TO REALITY Leandro Ruiz Presales Partner for C&LA Teradata Evolution in The Use of Information Action s ACTIVATING MAKE it happen! Insights OPERATIONALIZING WHAT IS happening now? PREDICTING
Teradata Connector for Hadoop Tutorial
 Teradata Connector for Hadoop Tutorial Version: 1.0 April 2013 Page 1 Teradata Connector for Hadoop Tutorial v1.0 Copyright 2013 Teradata All rights reserved Table of Contents 1 Introduction... 5 1.1 Overview...
Teradata Connector for Hadoop Tutorial Version: 1.0 April 2013 Page 1 Teradata Connector for Hadoop Tutorial v1.0 Copyright 2013 Teradata All rights reserved Table of Contents 1 Introduction... 5 1.1 Overview...
Hadoop Introduction. Olivier Renault Solution Engineer - Hortonworks
 Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop and its Usage at Facebook. Dhruba Borthakur dhruba@apache.org, June 22 rd, 2009
 Hadoop and its Usage at Facebook Dhruba Borthakur dhruba@apache.org, June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Hadoop and its Usage at Facebook Dhruba Borthakur dhruba@apache.org, June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Oracle s Big Data solutions. Roger Wullschleger. <Insert Picture Here>
 s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
NoSQL for SQL Professionals William McKnight
 NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
Next Gen Hadoop Gather around the campfire and I will tell you a good YARN
 Next Gen Hadoop Gather around the campfire and I will tell you a good YARN Akmal B. Chaudhri* Hortonworks *about.me/akmalchaudhri My background ~25 years experience in IT Developer (Reuters) Academic (City
Next Gen Hadoop Gather around the campfire and I will tell you a good YARN Akmal B. Chaudhri* Hortonworks *about.me/akmalchaudhri My background ~25 years experience in IT Developer (Reuters) Academic (City