Hadoop Configuration and First Examples
|
|
|
- Barnard Higgins
- 10 years ago
- Views:
Transcription
1 Hadoop Configuration and First Examples Big Data 2015

2 Hadoop Configuration In the bash_profile export all needed environment variables

3 Hadoop Configuration Allow remote login
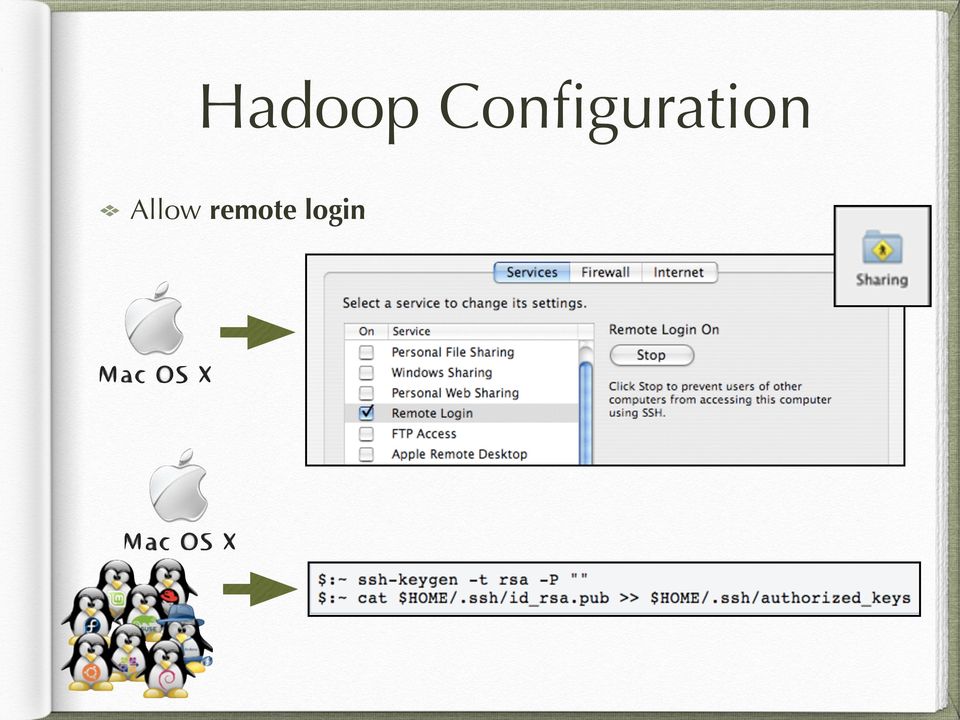
4 Hadoop Configuration Download the binary release of apache hadoop: hadoop bin.tar

5 Hadoop Configuration In the conf directory of the hadoop-home directory, set the following files core-site.xml hadoop-env.sh hdfs-site.xml mapred-site.xml

6 Hadoop Configuration In the hadoop-env.sh file you have to edit the following

7 Hadoop Configuration core-site.xml hdfs-site.xml mapred-site.xml

8 Hadoop Configuration & Running Final configuration: Running hadoop:

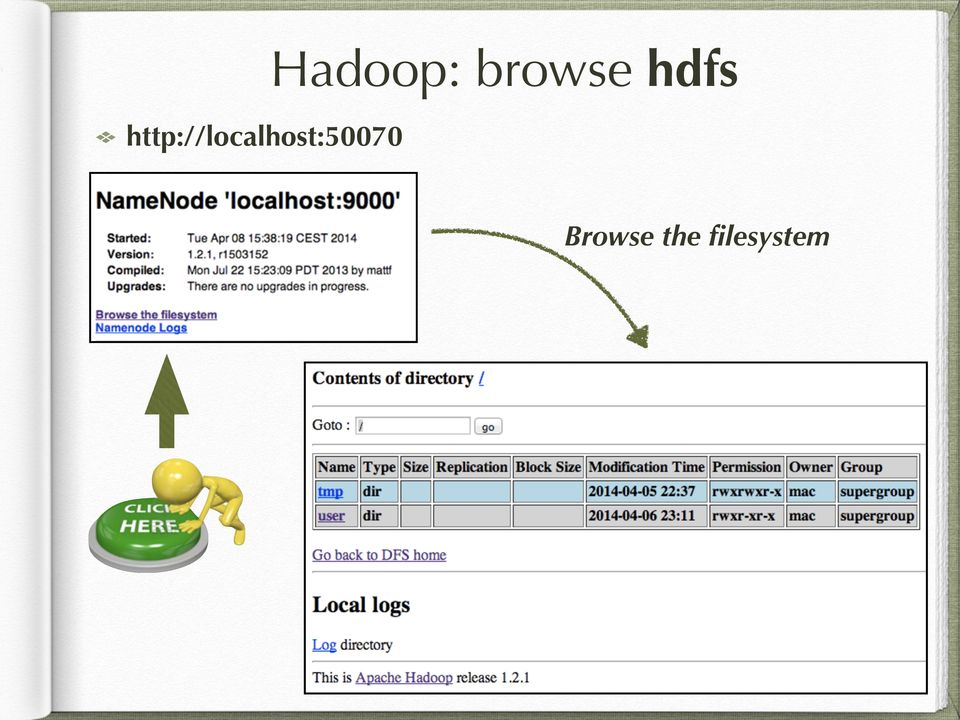
9 Hadoop: browse hdfs Browse the filesystem
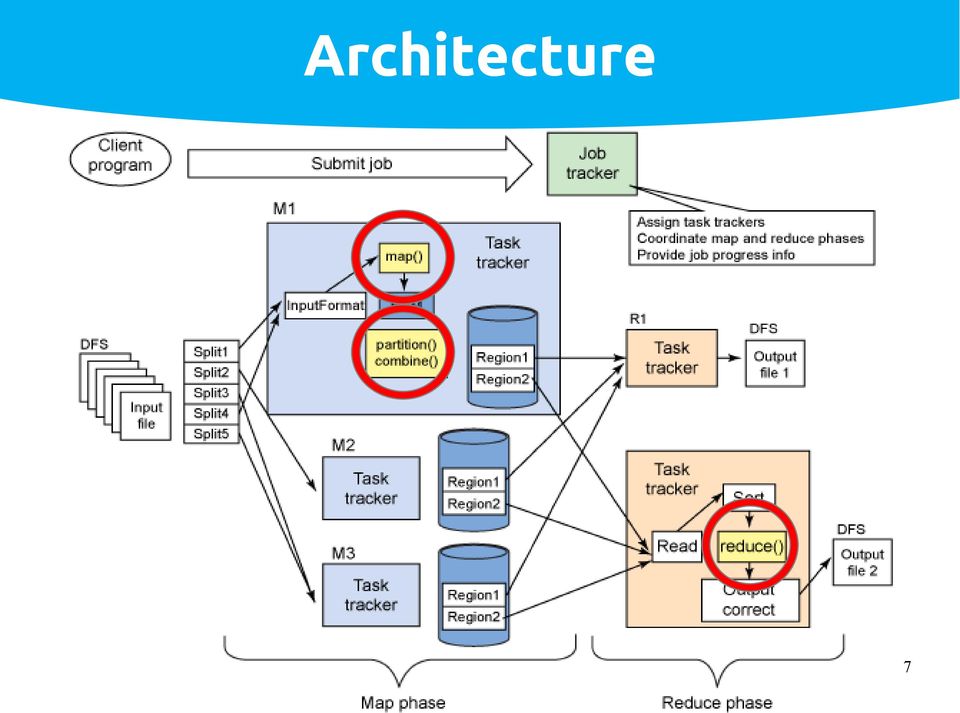
10 Architecture 6

11 Architecture 7
12 Hadoop Configuration & Running Check all running daemons in Hadoop using the command jps $:~ jps JobTracker TaskTracker SecondaryNameNode DataNode NameNode Jps

13 Hadoop: commands on hdfs $:~hadoop-*/bin/hadoop dfs <command> <parameters> create a directory in hdfs! $:~hadoop-*/bin/hadoop dfs -mkdir input copy a local file in hdfs! $:~hadoop-*/bin/hadoop dfs -copyfromlocal /tmp/example.txt input delete a directory in hdfs $:~hadoop-*/bin/hadoop dfs -rmr input

14 Hadoop: execute MR application $:~hadoop-*/bin/hadoop jar <path-jar> <jar-mainclass> <jar-parameters> Example: Word Count in MapReduce $:~hadoop-*/bin/hadoop dfs -mkdir input $:~hadoop-*/bin/hadoop dfs -mkdir output $:~hadoop-*/bin/hadoop dfs -copyfromlocal /tmp/parole.txt input $:~hadoop-*/bin/hadoop jar /tmp/word.jar WordCount input/parole.txt output/result { { path on hdfs to reach the file path on hdfs of the directory to generate to store the result

15 Let s start with some examples!

16 Install Pseudo-Distributed Mode Good luck! 4

17 Example: Temperature We collected information from (National Climatic Data Center) about the atmosphere. For each year (starting from 1763), for each month, for each day, for each hours, for each existing meteorogical stations in the world we have an entry in a file that specifies: data, time, id, air temperature, pressure, elevation, latitude, longitude... 9

18 Example: Temperature What if we want to know the max temperature in each year? 10

19 Example: Temperature What if we want to know the max temperature in each year? 11

20 Example: Temperature What if we want to know the max temperature in each year? 12

21 Temperature - data format File entries example: FM V N CN N FM V N CN N FM V N CN N Year Degrees Celsius x10 13
22 Temperature logical data flow INPUT MAP (0, ) (106, ) (212, ) (318, ) (424, ) (1950, 0) (1950, 22) (1950, -11) (1949, 111) (1949, 78) (1950, 0) (1950, 22) (1950, -11) (1949, 111) (1949, 78) SHUFFLE & SORT (1949, [111, 78]) (1950, [0, 22, -11]) REDUCE (1949, 111) (1950, 22) 14
23 Temperature Mapper map (k1, v1) [(k2, v2)] import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; public class MaxTemperatureMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { privatestatic final int MISSING = 9999; public void map(longwritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { Stringline = value.tostring(); String year = line.substring(15, 19); int airtemperature; if (line.charat(87) == '+') { map (k1, v1) [(k2, v2)] 15
24 Temperature Reducer (1) import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; reduce (k2, [v2]) [(k3, v3)] publicclass MaxTemperatureReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, DoubleWritable> { publicvoid reduce(text key, Iterator<IntWritable> values, OutputCollector<Text, DoubleWritable> output, Reporter reporter) throws IOException { intmaxvalue = Integer.MIN_VALUE; while (values.hasnext()) { maxvalue = Math.max(maxValue, values.next().get()); output.collect(key, new DoubleWritable(((double)maxValue)/10)); 16
25 Temperature Reducer (2) import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; reduce (k2, [v2]) [(k3, v3)] publicclass MaxTemperatureReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, DoubleWritable> { public void reduce(text key, Iterator<IntWritable> values, OutputCollector<Text, DoubleWritable> output, Reporter reporter) throws IOException { intmaxvalue = Integer.MIN_VALUE; while (values.hasnext()) { maxvalue = Math.max(maxValue, values.next().get()); output.collect(key, new DoubleWritable(((double)maxValue)/10)); 17
26 Temperature - Job publicclassmaxtemperature { publicstatic void main(string[]args) throws IOException { JobConf conf = newjobconf(maxtemperature.class); conf.setjobname("max temperature"); FileInputFormat.addInputPath(conf, new Path("temperature.txt")); FileOutputFormat.setOutputPath(conf, new Path("output")); conf.setmapperclass(maxtemperaturemapper.class); conf.setreducerclass(maxtemperaturereducer.class); conf.setmapoutputkeyclass(text.class); conf.setmapoutputvalueclass(intwritable.class); conf.setoutputkeyclass(text.class); conf.setoutputvalueclass(doublewritable.class); JobClient.runJob(conf); 18
27 Hadoop: execute MaxTemperature application $:~hadoop-*/bin/hadoop jar <path-jar> <jar-mainclass> <jar-parameters> Example: MaxTemperature in MapReduce $:~hadoop-*/bin/hadoop dfs -mkdir input $:~hadoop-*/bin/hadoop dfs -mkdir output $:~hadoop-*/bin/hadoop dfs -copyfromlocal /example_data/temperature.txt input $:~hadoop-*/bin/hadoop jar /example_jar/bg-example1-1.jar temperature/maxtemperature input/temperature.txt output/result_temperature { { path on hdfs to reach the file path on hdfs of the directory to generate to store the result
28 Hadoop: clean MaxTemperature application $:~hadoop-*/bin/hadoop jar <path-jar> <jar-mainclass> <jar-parameters> Example: MaxTemperature in MapReduce $:~hadoop-*/bin/hadoop dfs -rmr input $:~hadoop-*/bin/hadoop dfs -rmr output
29 Word Count logical data flow sopra la panca la capra campa, sotto la panca la capra crepa INPUT (0, sopra) (6, la) (9, panca) (15, la) (18, capra) (24, campa,) MAP (sopra, 1) (la, 1) (panca, 1) (la,1) (capra, 1) (campa, 1) SHUFFLE & SORT REDUCE (sopra, 1) (la, 1) (panca, 1) (la,1) (capra, 1) (campa, 1) (campa,, [1]) (capra, [1,1]) (crepa, [1]) (la, [1,1,1,1]) (campa,, 1) (capra, 2) (crepa, 1) (la, 4) 20
30 Word Count Mapper (1) import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.mapper; publicclass WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); publicvoid map(longwritable key, Text value, Context context) throws IOException, InterruptedException { Stringline = value.tostring(); StringTokenizer tokenizer = newstringtokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 21
31 Word Count Mapper (2) import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.mapper; publicclass WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); publicvoid map(longwritable key, Text value, Context context) throws IOException, InterruptedException { Stringline = value.tostring(); StringTokenizer tokenizer = newstringtokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 22
32 Word Count Reducer (1) import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.reducer; publicclass WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); context.write(key, new IntWritable(sum)); 23
33 Word Count Reducer (2) import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.reducer; publicclass WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); context.write(key, new IntWritable(sum)); 24
34 Word Count Job import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.*; publicclass WordCount { publicstatic void main(string[]args) throws Exception { Job job = newjob(newconfiguration(), "WordCount"); job.setjarbyclass(wordcount.class); job.setmapperclass(wordcountmapper.class); job.setreducerclass(wordcountreducer.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.waitforcompletion(true); 25
35 Hadoop: execute WordCount application $:~hadoop-*/bin/hadoop jar <path-jar> <jar-mainclass> <jar-parameters> Example: WordCount in MapReduce $:~hadoop-*/bin/hadoop dfs -mkdir input $:~hadoop-*/bin/hadoop dfs -mkdir output $:~hadoop-*/bin/hadoop dfs -copyfromlocal /example_data/words.txt input $:~hadoop-*/bin/hadoop jar /example_jar/bg-example1-1.jar wordcount/wordcount input/words.txt output/result_words { { path on hdfs to reach the file path on hdfs of the directory to generate to store the result
36 Hadoop: clean WordCount application $:~hadoop-*/bin/hadoop jar <path-jar> <jar-mainclass> <jar-parameters> Example: WordCount in MapReduce $:~hadoop-*/bin/hadoop dfs -rmr input $:~hadoop-*/bin/hadoop dfs -rmr output
37 Word Count: Without Combiner MAP OUTPUT (worda,1) (worda,1) (wordb,1) (wordb,1) (wordb,1) (worda,1) (worda,1) (worda,1) (wordb,1) (wordc,1) REDUCER INPUT (worda, [1,1,1,1,1]) (wordb, [1,1,1]) (wordc, [1]) OUTPUT (worda, 5) (wordb, 3) (wordc, 1) 27
38 Word Count: With Combiner MAP OUTPUT (worda,1) (worda,1) (wordb,1) (wordb,1) (wordb,1) (worda,1) (worda,1) (worda,1) (wordb,1) (wordc,1) (worda, 2) (wordb, 3) (worda, 3) (wordb, 1) (wordc, 1) REDUCER INPUT (worda, [2,3]) (wordb, [3,1]) (wordc, [1]) OUTPUT (worda, 5) (wordb, 3) (wordc, 1) COMBINER OUTPUT 28
39 Combiner In the job configuration: job.setmapperclass(wordcountmapper.class); job.setcombinerclass(wordcountreducer.class); job.setreducerclass(wordcountreducer.class); Watch for types! 29
40 Bigram Count A bigram is a couple of two consecutive words In this sentence there are 8 bigrams: A bigram bigram is is a a couple... 31
41 Bigram Count Example: sopra la panca la capra campa, sotto la panca la capra crepa campa, sotto 1 capra campa, 1 capra crepa 1 la capra 2 la panca 2 panca la 2 sopra la 1 sotto la 1 To represent a Bigram we want to use a custom Writable type (BigramWritable) 32
42 Bigram Count import org.apache.hadoop.io.*; publicclass BigramWritable implements WritableComparable<BigramWritable> { private Text leftbigram; private Text rightbigram; public BigramWritable(Text left, Text right){ this.leftbigram = left; this.rightbigram = publicvoid readfields(datainput in) throws IOException { leftbigram = newtext(in.readutf()); rightbigram = publicvoid write(dataoutput out) throws IOException { out.writeutf(leftbigram.tostring()); out.writeutf(rightbigram.tostring()); 33
43 Bigram Count public void set(text prev, Text cur) { leftbigram = prev; rightbigram = public int hashcode() { return leftbigram.hashcode() + public boolean equals(object o) { if (o instanceof BigramWritable) { BigramWritable bigram = (BigramWritable) o; return leftbigram.equals(bigram.leftbigram) && rightbigram.equals(bigram.rightbigram); return false; 34
44 Bigram public int compareto(bigramwritable tp) { intcmp = leftbigram.compareto(tp.leftbigram); if (cmp!= 0) { return cmp; return rightbigram.compareto(tp.rightbigram); 35
45 Bigram Count - Mapper publicclass BigramCountMapper extends Mapper<LongWritable, Text, BigramWritable, IntWritable> { private static final IntWritable ONE = new IntWritable(1); private static final BigramWritable BIGRAM = new publicvoid map(longwritable key, Text value, Context context) throws IOException, InterruptedException { Stringline = value.tostring(); String prev = null; StringTokenizer itr = newstringtokenizer(line); while (itr.hasmoretokens()) { Stringcur = itr.nexttoken(); if (prev!= null) { BIGRAM.set( new Text(prev), new Text(cur) ); context.write(bigram, ONE); prev = cur; 36
46 Bigram Count - Reducer import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.reducer; public class BigramCountReducer extends Reducer<BigramWritable,IntWritable,Text, IntWritable> { private final static IntWritable SUM = new publicvoid reduce(bigramwritablekey, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; Iterator<IntWritable> iter = values.iterator(); while (iter.hasnext()) { sum += iter.next().get(); SUM.set(sum); context.write(new Text( key.tostring() ), SUM); 37
47 Bigram Count - Job import org.apache.hadoop.conf.configured; import org.apache.hadoop.util.toolrunner; import org.apache.hadoop.util.tool; publicclass BigramCount extends Configured implements Tool { private BigramCount() { publicint run(string[] args) throws Exception { Job job = newjob(getconf()); job.setjobname(bigramcount.class.getsimplename()); job.setjarbyclass(bigramcount.class); job.waitforcompletion(true); publicstatic void main(string[]args) throws Exception { ToolRunner.run(new BigramCount(), args); 38
48 Hadoop: execute BigramCount application $:~hadoop-*/bin/hadoop jar <path-jar> <jar-mainclass> <jar-parameters> Example: BigramCount in MapReduce $:~hadoop-*/bin/hadoop dfs -mkdir input $:~hadoop-*/bin/hadoop dfs -mkdir output $:~hadoop-*/bin/hadoop dfs -copyfromlocal /example_data/words.txt input $:~hadoop-*/bin/hadoop jar /example_jar/bg-example1-1.jar bigram/bigramcount -input input/words.txt -numreducers 1 -output output/result_bigram
49 Hadoop: clean BigramCount application $:~hadoop-*/bin/hadoop jar <path-jar> <jar-mainclass> <jar-parameters> Example: BigramCount in MapReduce $:~hadoop-*/bin/hadoop dfs -rmr input $:~hadoop-*/bin/hadoop dfs -rmr output
50 Stopping the Hadoop DFS Stop hadoop: That's all! Happy Map Reducing!
51 Resources
52 Hadoop Configuration and First Examples Big Data 2015
Working With Hadoop. Important Terminology. Important Terminology. Anatomy of MapReduce Job Run. Important Terminology
 Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Word Count Code using MR2 Classes and API
 EDUREKA Word Count Code using MR2 Classes and API A Guide to Understand the Execution of Word Count edureka! A guide to understand the execution and flow of word count WRITE YOU FIRST MRV2 PROGRAM AND
EDUREKA Word Count Code using MR2 Classes and API A Guide to Understand the Execution of Word Count edureka! A guide to understand the execution and flow of word count WRITE YOU FIRST MRV2 PROGRAM AND
Hadoop Lab Notes. Nicola Tonellotto November 15, 2010
 Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
Hadoop WordCount Explained! IT332 Distributed Systems
 Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Istanbul Şehir University Big Data Camp 14. Hadoop Map Reduce. Aslan Bakirov Kevser Nur Çoğalmış
 Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Word count example Abdalrahman Alsaedi
 Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Tutorial- Counting Words in File(s) using MapReduce
 using MapReduce") Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
Hadoop 2.6 Configuration and More Examples
 Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网. Information Management. Information Management IBM CDL Lab
 IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
How To Write A Mapreduce Program In Java.Io 4.4.4 (Orchestra)
") MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
Hadoop Framework. technology basics for data scientists. Spring - 2014. Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN
 Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
Introduction To Hadoop
 Introduction To Hadoop Kenneth Heafield Google Inc January 14, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise noted, the
Introduction To Hadoop Kenneth Heafield Google Inc January 14, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise noted, the
Zebra and MapReduce. Table of contents. 1 Overview...2 2 Hadoop MapReduce APIs...2 3 Zebra MapReduce APIs...2 4 Zebra MapReduce Examples...
 Table of contents 1 Overview...2 2 Hadoop MapReduce APIs...2 3 Zebra MapReduce APIs...2 4 Zebra MapReduce Examples... 2 1. Overview MapReduce allows you to take full advantage of Zebra's capabilities.
Table of contents 1 Overview...2 2 Hadoop MapReduce APIs...2 3 Zebra MapReduce APIs...2 4 Zebra MapReduce Examples... 2 1. Overview MapReduce allows you to take full advantage of Zebra's capabilities.
MR-(Mapreduce Programming Language)
") MR-(Mapreduce Programming Language) Siyang Dai Zhi Zhang Shuai Yuan Zeyang Yu Jinxiong Tan sd2694 zz2219 sy2420 zy2156 jt2649 Objective of MR MapReduce is a software framework introduced by Google, aiming
MR-(Mapreduce Programming Language) Siyang Dai Zhi Zhang Shuai Yuan Zeyang Yu Jinxiong Tan sd2694 zz2219 sy2420 zy2156 jt2649 Objective of MR MapReduce is a software framework introduced by Google, aiming
Introduc)on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan [email protected]
on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan sriram@sdsc.edu") Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan [email protected] Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan [email protected] Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
Hadoop & Pig. Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship
 Hadoop & Pig Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship Outline Introduction (Setup) Hadoop, HDFS and MapReduce Pig Introduction What is Hadoop and where did it come from? Big Data
Hadoop & Pig Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship Outline Introduction (Setup) Hadoop, HDFS and MapReduce Pig Introduction What is Hadoop and where did it come from? Big Data
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Distributed Systems + Middleware Hadoop
 Distributed Systems + Middleware Hadoop Alessandro Sivieri Dipartimento di Elettronica, Informazione e Bioingegneria Politecnico, Italy [email protected] http://corsi.dei.polimi.it/distsys Contents
Distributed Systems + Middleware Hadoop Alessandro Sivieri Dipartimento di Elettronica, Informazione e Bioingegneria Politecnico, Italy [email protected] http://corsi.dei.polimi.it/distsys Contents
Hadoop. Dawid Weiss. Institute of Computing Science Poznań University of Technology
 Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Mrs: MapReduce for Scientific Computing in Python
 Mrs: for Scientific Computing in Python Andrew McNabb, Jeff Lund, and Kevin Seppi Brigham Young University November 16, 2012 Large scale problems require parallel processing Communication in parallel processing
Mrs: for Scientific Computing in Python Andrew McNabb, Jeff Lund, and Kevin Seppi Brigham Young University November 16, 2012 Large scale problems require parallel processing Communication in parallel processing
Step 4: Configure a new Hadoop server This perspective will add a new snap-in to your bottom pane (along with Problems and Tasks), like so:
, like so:") Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
Hadoop: Understanding the Big Data Processing Method
 Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
Hadoop MapReduce Tutorial - Reduce Comp variability in Data Stamps
 Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
BIG DATA APPLICATIONS
 BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
Download and install Download virtual machine Import virtual machine in Virtualbox
 Hadoop/Pig Install Download and install Virtualbox www.virtualbox.org Virtualbox Extension Pack Download virtual machine link in schedule (https://rmacchpcsymposium2015.sched.org/? iframe=no) Import virtual
Hadoop/Pig Install Download and install Virtualbox www.virtualbox.org Virtualbox Extension Pack Download virtual machine link in schedule (https://rmacchpcsymposium2015.sched.org/? iframe=no) Import virtual
Hadoop Basics with InfoSphere BigInsights
 An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Unit 2: Using MapReduce An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government Users Restricted Rights
An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Unit 2: Using MapReduce An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government Users Restricted Rights
Big Data 2012 Hadoop Tutorial
 Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
HPCHadoop: MapReduce on Cray X-series
 HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
Getting to know Apache Hadoop
 Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Lambda Architecture. CSCI 5828: Foundations of Software Engineering Lecture 29 12/09/2014
 Lambda Architecture CSCI 5828: Foundations of Software Engineering Lecture 29 12/09/2014 1 Goals Cover the material in Chapter 8 of the Concurrency Textbook The Lambda Architecture Batch Layer MapReduce
Lambda Architecture CSCI 5828: Foundations of Software Engineering Lecture 29 12/09/2014 1 Goals Cover the material in Chapter 8 of the Concurrency Textbook The Lambda Architecture Batch Layer MapReduce
Data Science in the Wild
 Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
CS54100: Database Systems
 CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
How To Install Hadoop 1.2.1.1 From Apa Hadoop 1.3.2 To 1.4.2 (Hadoop)
") Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Copy the.jar file into the plugins/ subfolder of your Eclipse installation. (e.g., C:\Program Files\Eclipse\plugins)
") Beijing Codelab 1 Introduction to the Hadoop Environment Spinnaker Labs, Inc. Contains materials Copyright 2007 University of Washington, licensed under the Creative Commons Attribution 3.0 License --
Beijing Codelab 1 Introduction to the Hadoop Environment Spinnaker Labs, Inc. Contains materials Copyright 2007 University of Washington, licensed under the Creative Commons Attribution 3.0 License --
Introduction to Big Data Science. Wuhui Chen
 Introduction to Big Data Science Wuhui Chen What is Big data? Volume Variety Velocity Outline What are people doing with Big data? Classic examples Two basic technologies for Big data management: Data
Introduction to Big Data Science Wuhui Chen What is Big data? Volume Variety Velocity Outline What are people doing with Big data? Classic examples Two basic technologies for Big data management: Data
Data Science Analytics & Research Centre
 Data Science Analytics & Research Centre Data Science Analytics & Research Centre 1 Big Data Big Data Overview Characteristics Applications & Use Case HDFS Hadoop Distributed File System (HDFS) Overview
Data Science Analytics & Research Centre Data Science Analytics & Research Centre 1 Big Data Big Data Overview Characteristics Applications & Use Case HDFS Hadoop Distributed File System (HDFS) Overview
19 Putting into Practice: Large-Scale Data Management with HADOOP
 19 Putting into Practice: Large-Scale Data Management with HADOOP The chapter proposes an introduction to HADOOP and suggests some exercises to initiate a practical experience of the system. The following
19 Putting into Practice: Large-Scale Data Management with HADOOP The chapter proposes an introduction to HADOOP and suggests some exercises to initiate a practical experience of the system. The following
Elastic Map Reduce. Shadi Khalifa Database Systems Laboratory (DSL) [email protected]
 khalifa@cs.queensu.ca") Elastic Map Reduce Shadi Khalifa Database Systems Laboratory (DSL) [email protected] The Amazon Web Services Universe Cross Service Features Management Interface Platform Services Infrastructure Services
Elastic Map Reduce Shadi Khalifa Database Systems Laboratory (DSL) [email protected] The Amazon Web Services Universe Cross Service Features Management Interface Platform Services Infrastructure Services
Hadoop and Eclipse. Eclipse Hawaii User s Group May 26th, 2009. Seth Ladd http://sethladd.com
 Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang
 Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang Independent Study Advanced Case-Based Reasoning Department of Computer Science
Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang Independent Study Advanced Case-Based Reasoning Department of Computer Science
and HDFS for Big Data Applications Serge Blazhievsky Nice Systems
 Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Hadoop Streaming. 2012 coreservlets.com and Dima May. 2012 coreservlets.com and Dima May
 2012 coreservlets.com and Dima May Hadoop Streaming Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training courses (onsite
2012 coreservlets.com and Dima May Hadoop Streaming Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training courses (onsite
Introduc)on to Map- Reduce. Vincent Leroy
on to Map- Reduce. Vincent Leroy") Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Hadoop 2.2.0 MultiNode Cluster Setup
 Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
How To Write A Mapreduce Program On An Ipad Or Ipad (For Free)
") Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro
 Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro CELEBRATING 10 YEARS OF JAVA.NET Apache Hadoop.NET-based MapReducers Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro
Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro CELEBRATING 10 YEARS OF JAVA.NET Apache Hadoop.NET-based MapReducers Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro
Running Hadoop on Windows CCNP Server
 Running Hadoop at Stirling Kevin Swingler Summary The Hadoopserver in CS @ Stirling A quick intoduction to Unix commands Getting files in and out Compliing your Java Submit a HadoopJob Monitor your jobs
Running Hadoop at Stirling Kevin Swingler Summary The Hadoopserver in CS @ Stirling A quick intoduction to Unix commands Getting files in and out Compliing your Java Submit a HadoopJob Monitor your jobs
By Hrudaya nath K Cloud Computing
 Processing Big Data with Map Reduce and HDFS By Hrudaya nath K Cloud Computing Some MapReduce Terminology Job A full program - an execution of a Mapper and Reducer across a data set Task An execution of
Processing Big Data with Map Reduce and HDFS By Hrudaya nath K Cloud Computing Some MapReduce Terminology Job A full program - an execution of a Mapper and Reducer across a data set Task An execution of
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Programming Hadoop Map-Reduce Programming, Tuning & Debugging. Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008
 Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Hadoop (pseudo-distributed) installation and configuration
 installation and configuration") Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Programming in Hadoop Programming, Tuning & Debugging
 Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
How To Write A Map Reduce In Hadoop Hadooper 2.5.2.2 (Ahemos)
") Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
INTRODUCTION TO HADOOP
 Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2
 USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2 (Using HDFS on Discovery Cluster for Discovery Cluster Users email [email protected] if you have questions or need more clarifications. Nilay
USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2 (Using HDFS on Discovery Cluster for Discovery Cluster Users email [email protected] if you have questions or need more clarifications. Nilay
Parallel Programming Map-Reduce. Needless to Say, We Need Machine Learning for Big Data
 Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Tutorial. Christopher M. Judd
 Tutorial Christopher M. Judd Christopher M. Judd CTO and Partner at leader Columbus Developer User Group (CIDUG) Marc Peabody @marcpeabody Introduction http://hadoop.apache.org/ Scale up Scale up
Tutorial Christopher M. Judd Christopher M. Judd CTO and Partner at leader Columbus Developer User Group (CIDUG) Marc Peabody @marcpeabody Introduction http://hadoop.apache.org/ Scale up Scale up
How To Write A Map In Java (Java) On A Microsoft Powerbook 2.5 (Ahem) On An Ipa (Aeso) Or Ipa 2.4 (Aseo) On Your Computer Or Your Computer
 On A Microsoft Powerbook 2.5 (Ahem) On An Ipa (Aeso) Or Ipa 2.4 (Aseo) On Your Computer Or Your Computer") Lab 0 - Introduction to Hadoop/Eclipse/Map/Reduce CSE 490h - Winter 2007 To Do 1. Eclipse plug in introduction Dennis Quan, IBM 2. Read this hand out. 3. Get Eclipse set up on your machine. 4. Load the
Lab 0 - Introduction to Hadoop/Eclipse/Map/Reduce CSE 490h - Winter 2007 To Do 1. Eclipse plug in introduction Dennis Quan, IBM 2. Read this hand out. 3. Get Eclipse set up on your machine. 4. Load the
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected]
 Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Connecting Hadoop with Oracle Database
 Connecting Hadoop with Oracle Database Sharon Stephen Senior Curriculum Developer Server Technologies Curriculum The following is intended to outline our general product direction.
Connecting Hadoop with Oracle Database Sharon Stephen Senior Curriculum Developer Server Technologies Curriculum The following is intended to outline our general product direction.
Three Approaches to Data Analysis with Hadoop
 Three Approaches to Data Analysis with Hadoop A Dell Technical White Paper Dave Jaffe, Ph.D. Solution Architect Dell Solution Centers Executive Summary This white paper demonstrates analysis of large datasets
Three Approaches to Data Analysis with Hadoop A Dell Technical White Paper Dave Jaffe, Ph.D. Solution Architect Dell Solution Centers Executive Summary This white paper demonstrates analysis of large datasets
Hadoop Integration Guide
 HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 2/20/2015 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
HP Vertica Analytic Database Software Version: 7.0.x Document Release Date: 2/20/2015 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.
 EDUREKA Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.0 Cluster edureka! 11/12/2013 A guide to Install and Configure
EDUREKA Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.0 Cluster edureka! 11/12/2013 A guide to Install and Configure
Report Vertiefung, Spring 2013 Constant Interval Extraction using Hadoop
 Report Vertiefung, Spring 2013 Constant Interval Extraction using Hadoop Thomas Brenner, 08-928-434 1 Introduction+and+Task+ Temporal databases are databases expanded with a time dimension in order to
Report Vertiefung, Spring 2013 Constant Interval Extraction using Hadoop Thomas Brenner, 08-928-434 1 Introduction+and+Task+ Temporal databases are databases expanded with a time dimension in order to
BIG DATA, MAPREDUCE & HADOOP
 BIG, MAPREDUCE & HADOOP LARGE SCALE DISTRIBUTED SYSTEMS By Jean-Pierre Lozi A tutorial for the LSDS class LARGE SCALE DISTRIBUTED SYSTEMS BIG, MAPREDUCE & HADOOP 1 OBJECTIVES OF THIS LAB SESSION The LSDS
BIG, MAPREDUCE & HADOOP LARGE SCALE DISTRIBUTED SYSTEMS By Jean-Pierre Lozi A tutorial for the LSDS class LARGE SCALE DISTRIBUTED SYSTEMS BIG, MAPREDUCE & HADOOP 1 OBJECTIVES OF THIS LAB SESSION The LSDS
5 HDFS - Hadoop Distributed System
 5 HDFS - Hadoop Distributed System 5.1 Definition and Remarks HDFS is a file system designed for storing very large files with streaming data access patterns running on clusters of commoditive hardware.
5 HDFS - Hadoop Distributed System 5.1 Definition and Remarks HDFS is a file system designed for storing very large files with streaming data access patterns running on clusters of commoditive hardware.
How to program a MapReduce cluster
 How to program a MapReduce cluster TF-IDF step by step Ján Súkeník [email protected] [email protected] TF-IDF potrebujeme pre každý dokument počet slov frekvenciu každého slova pre každé
How to program a MapReduce cluster TF-IDF step by step Ján Súkeník [email protected] [email protected] TF-IDF potrebujeme pre každý dokument počet slov frekvenciu každého slova pre každé
School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014. Hadoop for HPC. Instructor: Ekpe Okorafor
 School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Hadoop for HPC Instructor: Ekpe Okorafor Outline Hadoop Basics Hadoop Infrastructure HDFS MapReduce Hadoop & HPC Hadoop
School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Hadoop for HPC Instructor: Ekpe Okorafor Outline Hadoop Basics Hadoop Infrastructure HDFS MapReduce Hadoop & HPC Hadoop
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Hadoop Integration Guide
 HP Vertica Analytic Database Software Version: 7.1.x Document Release Date: 12/9/2015 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
HP Vertica Analytic Database Software Version: 7.1.x Document Release Date: 12/9/2015 Legal Notices Warranty The only warranties for HP products and services are set forth in the express warranty statements
Big Data Management. Big Data Management. (BDM) Autumn 2013. Povl Koch November 11, 2013 10-11-2013 1
 Autumn 2013. Povl Koch November 11, 2013 10-11-2013 1") Big Data Management Big Data Management (BDM) Autumn 2013 Povl Koch November 11, 2013 10-11-2013 1 Overview Today s program 1. Little more practical details about this course 2. Recap from last time (Google
Big Data Management Big Data Management (BDM) Autumn 2013 Povl Koch November 11, 2013 10-11-2013 1 Overview Today s program 1. Little more practical details about this course 2. Recap from last time (Google
HDInsight Essentials. Rajesh Nadipalli. Chapter No. 1 "Hadoop and HDInsight in a Heartbeat"
 HDInsight Essentials Rajesh Nadipalli Chapter No. 1 "Hadoop and HDInsight in a Heartbeat" In this package, you will find: A Biography of the author of the book A preview chapter from the book, Chapter
HDInsight Essentials Rajesh Nadipalli Chapter No. 1 "Hadoop and HDInsight in a Heartbeat" In this package, you will find: A Biography of the author of the book A preview chapter from the book, Chapter
LANGUAGES FOR HADOOP: PIG & HIVE
 Friday, September 27, 13 1 LANGUAGES FOR HADOOP: PIG & HIVE Michail Michailidis & Patrick Maiden Friday, September 27, 13 2 Motivation Native MapReduce Gives fine-grained control over how program interacts
Friday, September 27, 13 1 LANGUAGES FOR HADOOP: PIG & HIVE Michail Michailidis & Patrick Maiden Friday, September 27, 13 2 Motivation Native MapReduce Gives fine-grained control over how program interacts
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
Enterprise Data Storage and Analysis on Tim Barr
 Enterprise Data Storage and Analysis on Tim Barr January 15, 2015 Agenda Challenges in Big Data Analytics Why many Hadoop deployments under deliver What is Apache Spark Spark Core, SQL, Streaming, MLlib,
Enterprise Data Storage and Analysis on Tim Barr January 15, 2015 Agenda Challenges in Big Data Analytics Why many Hadoop deployments under deliver What is Apache Spark Spark Core, SQL, Streaming, MLlib,
An Implementation of Sawzall on Hadoop
 1 An Implementation of Sawzall on Hadoop Hidemoto Nakada, Tatsuhiko Inoue and Tomohiro Kudoh, 1-1-1 National Institute of Advanced Industrial Science and Technology, Umezono, Tsukuba, Ibaraki 35-8568,
1 An Implementation of Sawzall on Hadoop Hidemoto Nakada, Tatsuhiko Inoue and Tomohiro Kudoh, 1-1-1 National Institute of Advanced Industrial Science and Technology, Umezono, Tsukuba, Ibaraki 35-8568,
Installing Hadoop. You need a *nix system (Linux, Mac OS X, ) with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.
 with a working installation of Java 1.7, either OpenJDK or the Oracle JDK. See, e.g.") Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco ([email protected]) Prerequisites You
Big Data Computing Instructor: Prof. Irene Finocchi Master's Degree in Computer Science Academic Year 2013-2014, spring semester Installing Hadoop Emanuele Fusco ([email protected]) Prerequisites You
Installation Guide Setting Up and Testing Hadoop on Mac By Ryan Tabora, Think Big Analytics
 Installation Guide Setting Up and Testing Hadoop on Mac By Ryan Tabora, Think Big Analytics www.thinkbiganalytics.com 520 San Antonio Rd, Suite 210 Mt. View, CA 94040 (650) 949-2350 Table of Contents OVERVIEW
Installation Guide Setting Up and Testing Hadoop on Mac By Ryan Tabora, Think Big Analytics www.thinkbiganalytics.com 520 San Antonio Rd, Suite 210 Mt. View, CA 94040 (650) 949-2350 Table of Contents OVERVIEW
Hadoop and Big Data. Keijo Heljanko. Department of Information and Computer Science School of Science Aalto University keijo.heljanko@aalto.
 Keijo Heljanko Department of Information and Computer Science School of Science Aalto University [email protected] 1/77 Business Drivers of Cloud Computing Large data centers allow for economics
Keijo Heljanko Department of Information and Computer Science School of Science Aalto University [email protected] 1/77 Business Drivers of Cloud Computing Large data centers allow for economics
Setup Hadoop On Ubuntu Linux. ---Multi-Node Cluster
 Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Introduction to Map/Reduce & Hadoop
 Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES Department of Computer Science University of Crete 1 What is MapReduce? MapReduce: programming model and associated implementation for batch processing
Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES Department of Computer Science University of Crete 1 What is MapReduce? MapReduce: programming model and associated implementation for batch processing
Cloud Computing Era. Trend Micro
 Cloud Computing Era Trend Micro Three Major Trends to Chang the World Cloud Computing Big Data Mobile 什 麼 是 雲 端 運 算? 美 國 國 家 標 準 技 術 研 究 所 (NIST) 的 定 義 : Essential Characteristics Service Models Deployment
Cloud Computing Era Trend Micro Three Major Trends to Chang the World Cloud Computing Big Data Mobile 什 麼 是 雲 端 運 算? 美 國 國 家 標 準 技 術 研 究 所 (NIST) 的 定 義 : Essential Characteristics Service Models Deployment