Introduc)on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan
|
|
|
- Aubrey Mitchell
- 8 years ago
- Views:
Transcription
1 Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan

2 Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs. The MapReduce library expresses the computa)on as two func)ons Map and Reduce All data resides in files e.g. in the Google File System (GFS)

3 Func)on Prototype map (k1,v1) list(k2,v2) The map func)on takes a key/value pair and generates a list of new key/value pairs reduce (k2,list(v2)) list(v2) The reduce func)on takes a key/list pair and generates a list of resul)ng values
on takes a key/list pair and generates a list of")
4 Example: Word Count map(string key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); reduce(string key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); The map func)on emits a word and an associated count The reduce func)on sums together all counts emiyed for a par)cular word
on emits a word and an associated count The reduce func)on sums together all counts emiyed for a")
5 Example: Word Count Input File 1 Hello World Bye World Input File 2 Hello Hadoop Goodbye Hadoop First Combiner < Bye, 1> < Hello, 1> < World, 2> Second Combiner < Goodbye, 1> < Hadoop, 2> < Hello, 1> 1. Map Phase 2. Combiner Phase 3. Reduce Phase First Map < Hello, 1> < World, 1> < Bye, 1> < World, 1> Second Map < Hello, 1> < Hadoop, 1> < Goodbye, 1> < Hadoop, 1> Reducer < Bye, 1> < Goodbye, 1> < Hadoop, 2> < Hello, 2> < World, 2>

6 Implementa)on Details The Map invoca)ons are distributed across mul)ple machines by automa)cally par))oning the input data into a set of M splits Reduce invoca)ons are distributed by par))oning the intermediate key space into R pieces using a par))oning func)on (e.g., hash(key) mod R). The number of par))ons (R) and the par))oning func)on may be specified by the user
on (e.g., hash(key) mod R).")
7 Execu)on Overview

8 Advantages Scalable and conducive to data intensive and data parallel applica)ons Fault tolerant by design workers can be restarted on failures Ability to run on non specialized commodity hardware

9 Common Complaints Need to write code to get an applica)on to conform to the MapReduce programming model Need to be able to script queries at run )me Need a higher level SQL like abstrac)on Hard to write complicated SQL type queries Too simplis)c The onus on op)miza)on falls on the programmer, not the database engine
c The onus on op)miza)on falls on the programmer, not the database")
10 Apache Hadoop Hadoop provides an Open Source implementa)on of MapReduce Uses the Hadoop Distributed File System (HDFS), which is a GFS clone Has been demonstrated on clusters with 2000 nodes

11 HDFS A distributed file system designed to run on commodity hardware Many similari)es with exis)ng distributed file systems Highly fault tolerant and is designed to be deployed on low cost hardware Provides high throughput access to applica)on data and is suitable for applica)ons that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data.

12 HDFS
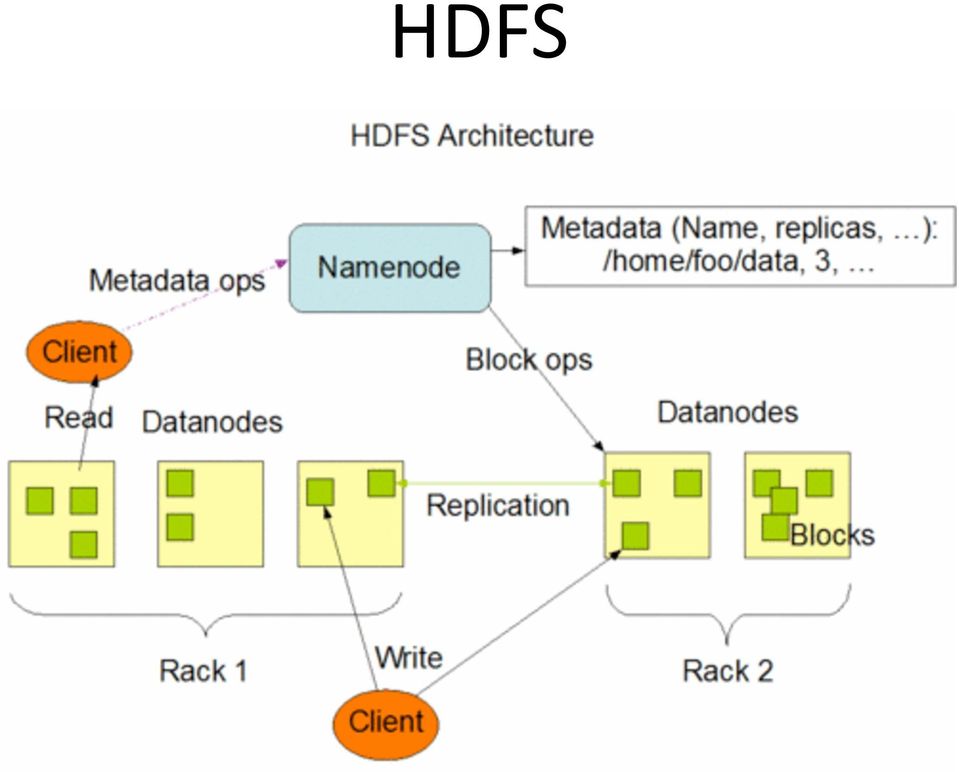
13 Hadoop: Modes of Opera)on Stand alone By default, Hadoop is configured to run in a non distributed mode, as a single Java process. Mostly useful for debugging Pseudo distributed Hadoop can also be run on a single node in a pseudo distributed mode where each Hadoop daemon runs in a separate Java process Fully distributed Typically involves unpacking the sokware on all the machines in the cluster One machine in the cluster is designated as the NameNode and another machine the as JobTracker, exclusively. These are the masters. The rest of the machines in the cluster act as both DataNode and TaskTracker. These are the slaves.

14 Hadoop Code: Word Count 12. public class WordCount { public sta)c class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { 15. private final sta)c IntWritable one = new IntWritable(1); 16. private Text word = new Text(); public void map(longwritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOExcep)on { 19. String line = value.tostring(); 20. StringTokenizer tokenizer = new StringTokenizer(line); 21. while (tokenizer.hasmoretokens()) { 22. word.set(tokenizer.nexttoken()); 23. output.collect(word, one); 24. } 25. } 26. } public sta)c class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { 29. public void reduce(text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOExcep)on { 30. int sum = 0; 31. while (values.hasnext()) { 32. sum += values.next().get(); 33. } 34. output.collect(key, new IntWritable(sum)); 35. } 36. } Map Func)on Reduce Func)on
; 21. while (tokenizer.hasmoretokens()) { 22. word.set(tokenizer.nexttoken()); 23. output.collect(word, one); 24. } 25. } 26. } 27. 28.")
15 Hadoop Code: Contd public sta)c void main(string[] args) throws Excep)on { 39. JobConf conf = new JobConf(WordCount.class); 40. conf.setjobname("wordcount"); conf.setoutputkeyclass(text.class); 43. conf.setoutputvalueclass(intwritable.class); conf.setmapperclass(map.class); 46. conf.setcombinerclass(reduce.class); 47. conf.setreducerclass(reduce.class); conf.setinputformat(textinputformat.class); 50. conf.setoutputformat(textoutputformat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); 53. FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); 57. } 58. } 59. Job setup and launch
); 53. FileOutputFormat.setOutputPath(conf, new Path(args[1])); 54. 55. JobClient.runJob(conf); 57. } 58. } 59.")
16 References MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean & Sanjay Ghemawat. In proceedings of OSDI 2004 The Google File System, Sanjay Ghemawat, Howard Gobioff, and Shun Tak Leung. In proceedings of SOSP'03 Apache Hadoop: hyp://hadoop.apache.org/ HDFS: hyp://hadoop.apache.org/core/docs/current/hdfs_design.html

Hadoop WordCount Explained! IT332 Distributed Systems
 Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Istanbul Şehir University Big Data Camp 14. Hadoop Map Reduce. Aslan Bakirov Kevser Nur Çoğalmış
 Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Word count example Abdalrahman Alsaedi
 Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Hadoop Framework. technology basics for data scientists. Spring - 2014. Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN
 Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
How To Write A Mapreduce Program In Java.Io 4.4.4 (Orchestra)
") MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
Data Science in the Wild
 Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
CS54100: Database Systems
 CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
Biomap Jobs and the Big Picture
 Lots of Data, Little Money. A Last.fm perspective Martin Dittus, martind@last.fm London Geek Nights, 2009-04-23 Big Data Little Money You have lots of data You want to process it For your product (Last.fm:
Lots of Data, Little Money. A Last.fm perspective Martin Dittus, martind@last.fm London Geek Nights, 2009-04-23 Big Data Little Money You have lots of data You want to process it For your product (Last.fm:
How To Write A Mapreduce Program On An Ipad Or Ipad (For Free)
") Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Hadoop: Understanding the Big Data Processing Method
 Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
HPCHadoop: MapReduce on Cray X-series
 HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
MR-(Mapreduce Programming Language)
") MR-(Mapreduce Programming Language) Siyang Dai Zhi Zhang Shuai Yuan Zeyang Yu Jinxiong Tan sd2694 zz2219 sy2420 zy2156 jt2649 Objective of MR MapReduce is a software framework introduced by Google, aiming
MR-(Mapreduce Programming Language) Siyang Dai Zhi Zhang Shuai Yuan Zeyang Yu Jinxiong Tan sd2694 zz2219 sy2420 zy2156 jt2649 Objective of MR MapReduce is a software framework introduced by Google, aiming
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Hadoop and Eclipse. Eclipse Hawaii User s Group May 26th, 2009. Seth Ladd http://sethladd.com
 Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Introduction To Hadoop
 Introduction To Hadoop Kenneth Heafield Google Inc January 14, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise noted, the
Introduction To Hadoop Kenneth Heafield Google Inc January 14, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise noted, the
Hadoop. Dawid Weiss. Institute of Computing Science Poznań University of Technology
 Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Sriram Krishnan, Ph.D. sriram@sdsc.edu
 Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang
 Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang Independent Study Advanced Case-Based Reasoning Department of Computer Science
Case-Based Reasoning Implementation on Hadoop and MapReduce Frameworks Done By: Soufiane Berouel Supervised By: Dr Lily Liang Independent Study Advanced Case-Based Reasoning Department of Computer Science
Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro
 Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro CELEBRATING 10 YEARS OF JAVA.NET Apache Hadoop.NET-based MapReducers Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro
Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro CELEBRATING 10 YEARS OF JAVA.NET Apache Hadoop.NET-based MapReducers Creating.NET-based Mappers and Reducers for Hadoop with JNBridgePro
Hadoop & Pig. Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship
 Hadoop & Pig Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship Outline Introduction (Setup) Hadoop, HDFS and MapReduce Pig Introduction What is Hadoop and where did it come from? Big Data
Hadoop & Pig Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship Outline Introduction (Setup) Hadoop, HDFS and MapReduce Pig Introduction What is Hadoop and where did it come from? Big Data
Step 4: Configure a new Hadoop server This perspective will add a new snap-in to your bottom pane (along with Problems and Tasks), like so:
, like so:") Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
By Hrudaya nath K Cloud Computing
 Processing Big Data with Map Reduce and HDFS By Hrudaya nath K Cloud Computing Some MapReduce Terminology Job A full program - an execution of a Mapper and Reducer across a data set Task An execution of
Processing Big Data with Map Reduce and HDFS By Hrudaya nath K Cloud Computing Some MapReduce Terminology Job A full program - an execution of a Mapper and Reducer across a data set Task An execution of
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
MapReduce (in the cloud)
") MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
How To Write A Map Reduce In Hadoop Hadooper 2.5.2.2 (Ahemos)
") Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
Implementations of iterative algorithms in Hadoop and Spark
 Implementations of iterative algorithms in Hadoop and Spark by Junyu Lai A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Master of Mathematics
Implementations of iterative algorithms in Hadoop and Spark by Junyu Lai A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Master of Mathematics
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Word Count Code using MR2 Classes and API
 EDUREKA Word Count Code using MR2 Classes and API A Guide to Understand the Execution of Word Count edureka! A guide to understand the execution and flow of word count WRITE YOU FIRST MRV2 PROGRAM AND
EDUREKA Word Count Code using MR2 Classes and API A Guide to Understand the Execution of Word Count edureka! A guide to understand the execution and flow of word count WRITE YOU FIRST MRV2 PROGRAM AND
Getting to know Apache Hadoop
 Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Hadoop Configuration and First Examples
 Hadoop Configuration and First Examples Big Data 2015 Hadoop Configuration In the bash_profile export all needed environment variables Hadoop Configuration Allow remote login Hadoop Configuration Download
Hadoop Configuration and First Examples Big Data 2015 Hadoop Configuration In the bash_profile export all needed environment variables Hadoop Configuration Allow remote login Hadoop Configuration Download
marlabs driving digital agility WHITEPAPER Big Data and Hadoop
 marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
Programming in Hadoop Programming, Tuning & Debugging
 Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
Download and install Download virtual machine Import virtual machine in Virtualbox
 Hadoop/Pig Install Download and install Virtualbox www.virtualbox.org Virtualbox Extension Pack Download virtual machine link in schedule (https://rmacchpcsymposium2015.sched.org/? iframe=no) Import virtual
Hadoop/Pig Install Download and install Virtualbox www.virtualbox.org Virtualbox Extension Pack Download virtual machine link in schedule (https://rmacchpcsymposium2015.sched.org/? iframe=no) Import virtual
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Hadoop. Scalable Distributed Computing. Claire Jaja, Julian Chan October 8, 2013
 Hadoop Scalable Distributed Computing Claire Jaja, Julian Chan October 8, 2013 What is Hadoop? A general-purpose storage and data-analysis platform Open source Apache software, implemented in Java Enables
Hadoop Scalable Distributed Computing Claire Jaja, Julian Chan October 8, 2013 What is Hadoop? A general-purpose storage and data-analysis platform Open source Apache software, implemented in Java Enables
Introduc)on to Map- Reduce. Vincent Leroy
on to Map- Reduce. Vincent Leroy") Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Programming Hadoop Map-Reduce Programming, Tuning & Debugging. Arun C Murthy Yahoo! CCDI acm@yahoo-inc.com ApacheCon US 2008
 Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI acm@yahoo-inc.com ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI acm@yahoo-inc.com ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Introduc8on to Apache Spark
 Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Building a distributed search system with Apache Hadoop and Lucene. Mirko Calvaresi
 Building a distributed search system with Apache Hadoop and Lucene Mirko Calvaresi a Barbara, Leonardo e Vittoria 2 Index Preface... 5 1 Introduction: the Big Data Problem... 6 1.1 Big data: handling the
Building a distributed search system with Apache Hadoop and Lucene Mirko Calvaresi a Barbara, Leonardo e Vittoria 2 Index Preface... 5 1 Introduction: the Big Data Problem... 6 1.1 Big data: handling the
Introduction to Cloud Computing
 Introduction to Cloud Computing MapReduce and Hadoop 15 319, spring 2010 17 th Lecture, Mar 16 th Majd F. Sakr Lecture Goals Transition to MapReduce from Functional Programming Understand the origins of
Introduction to Cloud Computing MapReduce and Hadoop 15 319, spring 2010 17 th Lecture, Mar 16 th Majd F. Sakr Lecture Goals Transition to MapReduce from Functional Programming Understand the origins of
and HDFS for Big Data Applications Serge Blazhievsky Nice Systems
 Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
White Paper. Big Data and Hadoop. Abhishek S, Java COE. Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP
 White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014. Hadoop for HPC. Instructor: Ekpe Okorafor
 School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Hadoop for HPC Instructor: Ekpe Okorafor Outline Hadoop Basics Hadoop Infrastructure HDFS MapReduce Hadoop & HPC Hadoop
School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Hadoop for HPC Instructor: Ekpe Okorafor Outline Hadoop Basics Hadoop Infrastructure HDFS MapReduce Hadoop & HPC Hadoop
Data Science Analytics & Research Centre
 Data Science Analytics & Research Centre Data Science Analytics & Research Centre 1 Big Data Big Data Overview Characteristics Applications & Use Case HDFS Hadoop Distributed File System (HDFS) Overview
Data Science Analytics & Research Centre Data Science Analytics & Research Centre 1 Big Data Big Data Overview Characteristics Applications & Use Case HDFS Hadoop Distributed File System (HDFS) Overview
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data Analytics* Outline. Issues. Big Data
 Outline Big Data Analytics* Big Data Data Analytics: Challenges and Issues Misconceptions Big Data Infrastructure Scalable Distributed Computing: Hadoop Programming in Hadoop: MapReduce Paradigm Example
Outline Big Data Analytics* Big Data Data Analytics: Challenges and Issues Misconceptions Big Data Infrastructure Scalable Distributed Computing: Hadoop Programming in Hadoop: MapReduce Paradigm Example
BIG DATA ANALYTICS HADOOP PERFORMANCE ANALYSIS. A Thesis. Presented to the. Faculty of. San Diego State University. In Partial Fulfillment
 BIG DATA ANALYTICS HADOOP PERFORMANCE ANALYSIS A Thesis Presented to the Faculty of San Diego State University In Partial Fulfillment of the Requirements for the Degree Master of Science in Computer Science
BIG DATA ANALYTICS HADOOP PERFORMANCE ANALYSIS A Thesis Presented to the Faculty of San Diego State University In Partial Fulfillment of the Requirements for the Degree Master of Science in Computer Science
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Big Data Management. Big Data Management. (BDM) Autumn 2013. Povl Koch November 11, 2013 10-11-2013 1
 Autumn 2013. Povl Koch November 11, 2013 10-11-2013 1") Big Data Management Big Data Management (BDM) Autumn 2013 Povl Koch November 11, 2013 10-11-2013 1 Overview Today s program 1. Little more practical details about this course 2. Recap from last time (Google
Big Data Management Big Data Management (BDM) Autumn 2013 Povl Koch November 11, 2013 10-11-2013 1 Overview Today s program 1. Little more practical details about this course 2. Recap from last time (Google
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com
 Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
MAPREDUCE Programming Model
 CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
Parallel Programming Map-Reduce. Needless to Say, We Need Machine Learning for Big Data
 Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
The MapReduce Framework
 The MapReduce Framework Luke Tierney Department of Statistics & Actuarial Science University of Iowa November 8, 2007 Luke Tierney (U. of Iowa) The MapReduce Framework November 8, 2007 1 / 16 Background
The MapReduce Framework Luke Tierney Department of Statistics & Actuarial Science University of Iowa November 8, 2007 Luke Tierney (U. of Iowa) The MapReduce Framework November 8, 2007 1 / 16 Background
MapReduce Job Processing
 April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
Hadoop, Hive & Spark Tutorial
 Hadoop, Hive & Spark Tutorial 1 Introduction This tutorial will cover the basic principles of Hadoop MapReduce, Apache Hive and Apache Spark for the processing of structured datasets. For more information
Hadoop, Hive & Spark Tutorial 1 Introduction This tutorial will cover the basic principles of Hadoop MapReduce, Apache Hive and Apache Spark for the processing of structured datasets. For more information
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网. Information Management. Information Management IBM CDL Lab
 IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
Hadoop MapReduce Tutorial - Reduce Comp variability in Data Stamps
 Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
BIG DATA, MAPREDUCE & HADOOP
 BIG, MAPREDUCE & HADOOP LARGE SCALE DISTRIBUTED SYSTEMS By Jean-Pierre Lozi A tutorial for the LSDS class LARGE SCALE DISTRIBUTED SYSTEMS BIG, MAPREDUCE & HADOOP 1 OBJECTIVES OF THIS LAB SESSION The LSDS
BIG, MAPREDUCE & HADOOP LARGE SCALE DISTRIBUTED SYSTEMS By Jean-Pierre Lozi A tutorial for the LSDS class LARGE SCALE DISTRIBUTED SYSTEMS BIG, MAPREDUCE & HADOOP 1 OBJECTIVES OF THIS LAB SESSION The LSDS
Tes$ng Hadoop Applica$ons. Tom Wheeler
 Tes$ng Hadoop Applica$ons Tom Wheeler About The Presenter Tom Wheeler Software Engineer, etc.! Greater St. Louis Area Information Technology and Services! Current:! Past:! Senior Curriculum Developer at
Tes$ng Hadoop Applica$ons Tom Wheeler About The Presenter Tom Wheeler Software Engineer, etc.! Greater St. Louis Area Information Technology and Services! Current:! Past:! Senior Curriculum Developer at
Lecture 10 - Functional programming: Hadoop and MapReduce
 Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Copy the.jar file into the plugins/ subfolder of your Eclipse installation. (e.g., C:\Program Files\Eclipse\plugins)
") Beijing Codelab 1 Introduction to the Hadoop Environment Spinnaker Labs, Inc. Contains materials Copyright 2007 University of Washington, licensed under the Creative Commons Attribution 3.0 License --
Beijing Codelab 1 Introduction to the Hadoop Environment Spinnaker Labs, Inc. Contains materials Copyright 2007 University of Washington, licensed under the Creative Commons Attribution 3.0 License --
Introduction to MapReduce and Hadoop
 UC Berkeley Introduction to MapReduce and Hadoop Matei Zaharia UC Berkeley RAD Lab matei@eecs.berkeley.edu What is MapReduce? Data-parallel programming model for clusters of commodity machines Pioneered
UC Berkeley Introduction to MapReduce and Hadoop Matei Zaharia UC Berkeley RAD Lab matei@eecs.berkeley.edu What is MapReduce? Data-parallel programming model for clusters of commodity machines Pioneered
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
INTRODUCTION TO HADOOP
 Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
Hadoop + Clojure. Hadoop World NYC Friday, October 2, 2009. Stuart Sierra, AltLaw.org
 Hadoop + Clojure Hadoop World NYC Friday, October 2, 2009 Stuart Sierra, AltLaw.org JVM Languages Functional Object Oriented Native to the JVM Clojure Scala Groovy Ported to the JVM Armed Bear CL Kawa
Hadoop + Clojure Hadoop World NYC Friday, October 2, 2009 Stuart Sierra, AltLaw.org JVM Languages Functional Object Oriented Native to the JVM Clojure Scala Groovy Ported to the JVM Armed Bear CL Kawa
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Big Data 2012 Hadoop Tutorial
 Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
Mrs: MapReduce for Scientific Computing in Python
 Mrs: for Scientific Computing in Python Andrew McNabb, Jeff Lund, and Kevin Seppi Brigham Young University November 16, 2012 Large scale problems require parallel processing Communication in parallel processing
Mrs: for Scientific Computing in Python Andrew McNabb, Jeff Lund, and Kevin Seppi Brigham Young University November 16, 2012 Large scale problems require parallel processing Communication in parallel processing
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Working With Hadoop. Important Terminology. Important Terminology. Anatomy of MapReduce Job Run. Important Terminology
 Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Introduction to Parallel Programming and MapReduce
 Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5
 Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 uskenbaevar@gmail.com, 2 abu.kuandykov@gmail.com,
Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 uskenbaevar@gmail.com, 2 abu.kuandykov@gmail.com,
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Hadoop Lab Notes. Nicola Tonellotto November 15, 2010
 Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Map Reduce a Programming Model for Cloud Computing Based On Hadoop Ecosystem
 Map Reduce a Programming Model for Cloud Computing Based On Hadoop Ecosystem Santhosh voruganti Asst.Prof CSE Dept,CBIT, Hyderabad,India Abstract Cloud Computing is emerging as a new computational paradigm
Map Reduce a Programming Model for Cloud Computing Based On Hadoop Ecosystem Santhosh voruganti Asst.Prof CSE Dept,CBIT, Hyderabad,India Abstract Cloud Computing is emerging as a new computational paradigm
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 Lecture XI: MapReduce & Hadoop The new world of Big Data (programming model) Big Data Buzzword for challenges occurring
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 Lecture XI: MapReduce & Hadoop The new world of Big Data (programming model) Big Data Buzzword for challenges occurring
Cloud Computing using MapReduce, Hadoop, Spark
 Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman benh@cs.berkeley.edu Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman benh@cs.berkeley.edu Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Elastic Map Reduce. Shadi Khalifa Database Systems Laboratory (DSL) khalifa@cs.queensu.ca
 khalifa@cs.queensu.ca") Elastic Map Reduce Shadi Khalifa Database Systems Laboratory (DSL) khalifa@cs.queensu.ca The Amazon Web Services Universe Cross Service Features Management Interface Platform Services Infrastructure Services
Elastic Map Reduce Shadi Khalifa Database Systems Laboratory (DSL) khalifa@cs.queensu.ca The Amazon Web Services Universe Cross Service Features Management Interface Platform Services Infrastructure Services
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Advanced Data Management Technologies
 ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information