Building Big Data Pipelines using OSS. Costin Leau Staff Engineer
|
|
|
- Morgan Campbell
- 10 years ago
- Views:
Transcription
1

2 Building Big Data Pipelines using OSS Costin Leau Staff Engineer

3 Costin Leau Speaker Bio Spring committer since 2006 Spring Framework cache abstraction) Spring OSGi/Dynamic Modules, OSGi Blueprint spec Spring Data (GemFire, Redis, Hadoop) 3

4 Data Landscape



5 Data Trends
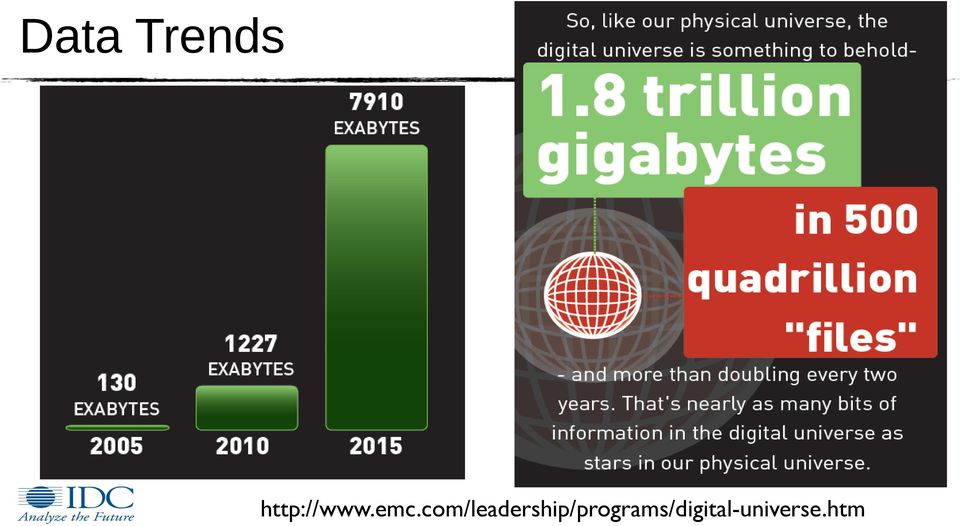
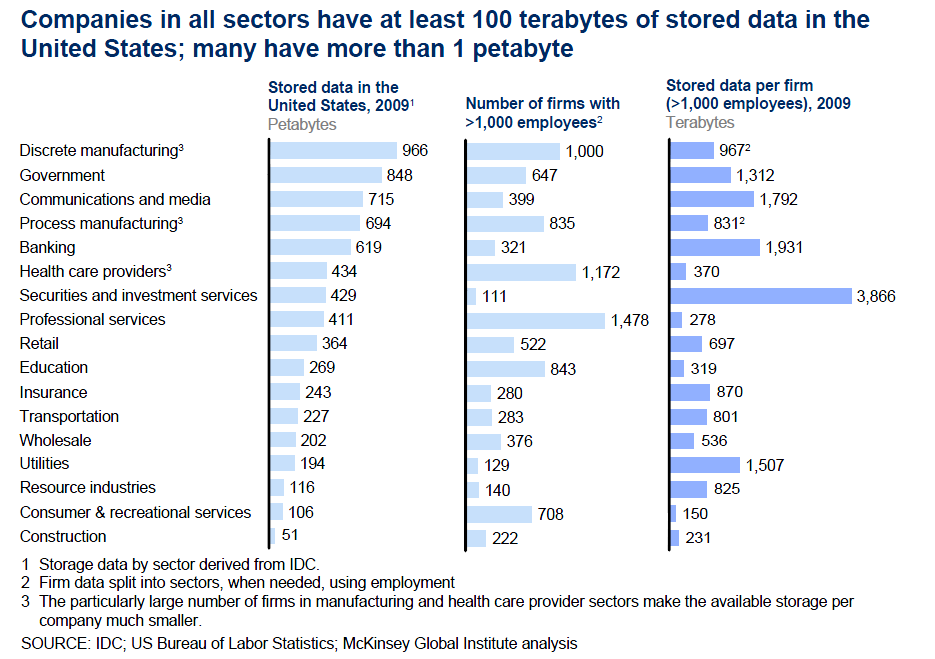

6 Enterprise Data Trends
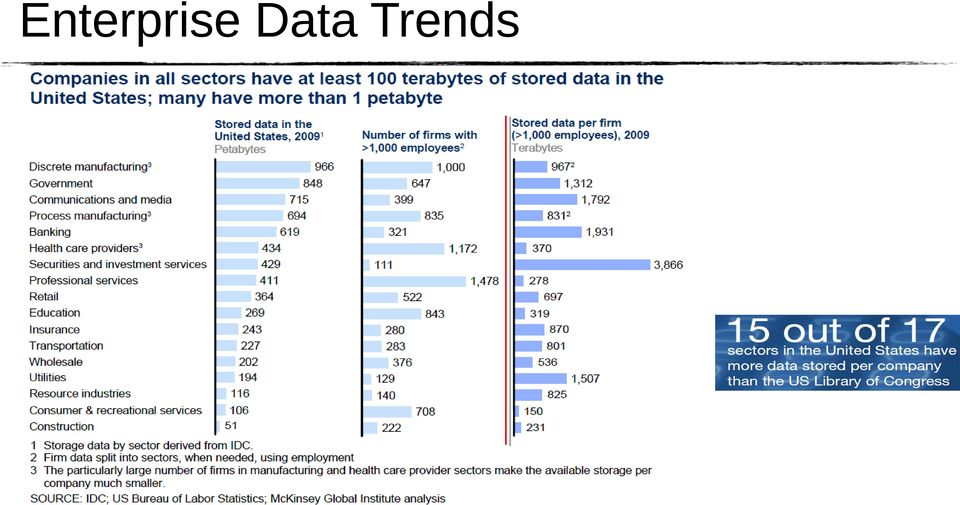

7 Enterprise Data Trends Unstructured data No predefined model Often doesn t fit well in RDBMS Pre-Aggregated Data Computed during data collection Counters Running Averages



8 Cost Trends Big Iron: $40k/CPU ardware cost halving every 18 months Commodity Cluster: $1k/CPU


 AppleWebKit/418.")
9 The Value of Data Value from Data Exceeds Hardware & Software costs Value in connecting data sets Grouping e-commerce users by user agent Mozilla/5.0 (Macintosh; U; Intel Mac OS X; en) AppleWebKit/418.9 (KHTML, like Gecko) Safari/419.3
 AppleWebKit/418.")
10 Big Data Big data refers to datasets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyze A subjective and moving target Big data in many sectors today range from 10 s of TB to multiple PB

11 (Big) Data Pipelines

12 A Holistic View of a Big Data System ETL Real Time Streams Real-Time Processing (s4, storm) Real Time Structured Database (hbase, Gemfre, Cassandra) Analytics Big SQL (Greenplum, AsterData, Etc ) Unstructured Data (HDFS) Batch Processing
 Unstructured Data (HDFS) Batch")
13 Big Data probls == Integration probls Collect Transform RT Analysis Ingest Batch Analysis Distribute Use Real world big data solutions require workflow across systems Workflow for big data processing is an integration problem Share core components of a classic integration workflow Big data solutions need to integrate with existing data and apps Event-driven vs Batch workflows No silver bullet Michael Stonebraker: One Size Fits All, An Idea Whose Time Has Come And Pass

14 Big Data probls == Integration probls Collect Transform RT Analysis Ingest Batch Analysis Distribute Use Real world big data solutions require workflow across systems Workflow for big data processing is an integration problem Share core components of a classic integration workflow Big data solutions need to integrate with existing data and apps Event-driven vs Batch workflows No silver bullet Michael Stonebraker: One Size Fits All, An Idea Whose Time Has Come And Pass Spring projects can provide the foundation for Big Data workflows

15 Taming Big Data

16 Hadoop as a Big Data Platform Map Reduce Framework (MapRed) Hadoop Distributed File System (HDFS)

17 Spring for Hadoop - Goals Hadoop has a poor out of the box programming model Spring simplifies developing Hadoop applications By providing a familiar and consistent Applications are generally a collection of scripts calling command line apps programming and configuration mode Across a wide range of use cases HDFS usage Data Analysis (MR/Pig/Hive/Cascading) Workflow Event Streams Integration Allowing to start small and grow
 Workflow Event Streams Integration Allowing to start small and")
18 Relationship with other Spring projects Spring Batch On and Off Hadoop workflows Spring Integration Event-driven applications, Enterprise Integration Patterns Spring Data Redis, MongoDB, Neo4j, Gemfire Spring Framework Web, Messaging Applications Spring for Apache Hadoop Simplify Hadoop programming

19 Capabilities: Spring + Hadoop Declarative configuration Create, configure, and parameterize Hadoop connectivity and all job types Environment profiles easily move from dev to qa to prod Developer productivity Create well-formed applications, not spaghetti script applications Simplify HDFS and FsShell API with support for JVM scripting Runner classes for MR/Pig/Hive/Cascading for small workflows Helper Template classes for Pig/Hive/HBase

20 Core Hadoop

21 Core Map Reduce idea
22 Counting Words M/R public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); Text word = new Text(); public void map(object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasmoretokens()) { word.set(itr.nexttoken());context.write(word, one); }}} public class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
23 Counting Words Configuring M/R Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true);
24 Running Hadoop Jars (WordCount 1.0) Vanilla Hadoop bin/hadoop jar hadoop-examples.jar wordcount /wc/input /wc/output SHDP <hdp:configuration /> <hdp:jar-runner id= wordcount jar="hadoop-examples.jar> <hdp:arg value= wordcount /> <hdp:arg value= /wc/input /> <hdp:arg value= /wc/output /> </hdp:jar-runner>
25 Running Hadoop Tools (WordCount 2.0) Vanilla Hadoop bin/hadoop jar conf myhadoop-site.xml D ignorecase=true wordcount.jar org.myorg.wordcount /wc/input /wc/output SHDP <hdp:configuration resources= myhadoop-site.xml /> <hdp:tool-runner id="wc jar= wordcount.jar > <hdp:arg value= /wc/input /> <hdp:arg value= /wc/output /> ignorecase=true </hdp:tool-runner>
26 Configuring Hadoop <context:property-placeholder location="hadoop-dev.properties"/> <hdp:configuration> fs.default.name=${hd.fs} </hdp:configuration> <hdp:job id="word-count-job" applicationcontext.xml input-path= ${input.path}" output-path="${output.path} jar= myjob.jar mapper="org.apache.hadoop.examples.wordcount.tokenizermapper reducer="org.apache.hadoop.examples.wordcount.intsumreducer"/> <hdp:job-runner id= runner job-ref="word-count-job run-at-startup= true /> input.path=/wc/input/ output.path=/wc/word/ hd.fs=hdfs://localhost:9000 hadoop-dev.properties
27 Running a Streaming Job bin/hadoop jar hadoop-streaming.jar \ input /wc/input output /wc/output \ -mapper /bin/cat reducer /bin/wc \ -files stopwords.txt <context:property-placeholder location="hadoop-${env}.properties"/> <hdp:streaming id= wc input-path= ${input} output-path= ${output} mapper= ${cat} reducer= ${wc} files= classpath:stopwords.txt > </hdp:streaming> hadoop-dev.properties input.path=/wc/input/ output.path=/wc/word/ hd.fs=hdfs://localhost:9000 env=dev java jar SpringLauncher.jar applicationcontext.xml
28 Running a Streaming Job bin/hadoop jar hadoop-streaming.jar \ input /wc/input output /wc/output \ -mapper /bin/cat reducer /bin/wc \ -files stopwords.txt <context:property-placeholder location="hadoop-${env}.properties"/> <hdp:streaming id= wc input-path= ${input} output-path= ${output} mapper= ${cat} reducer= ${wc} files= classpath:stopwords.txt > </hdp:streaming> hadoop-dev.properties input.path=/wc/input/ output.path=/wc/word/ hd.fs=hdfs://localhost:9000 hadoop-qa.properties input.path=/gutenberg/input/ output.path=/gutenberg/word/ hd.fs=hdfs://darwin:9000 env=qa java jar SpringLauncher.jar applicationcontext.xml
29 Word Count Injecting Jobs Use Dependency Injection to obtain reference to Hadoop Job additional runtime Perform public class WordService { configuration and private Job mapreducejob; public void processwords() { mapreducejob.submit(); } }
30 HDFS and Hadoop Shell as APIs Has all bin/hadoop fs commands through FsShell chmod, test class { FsShell void init() { String outputdir = "/data/output"; if (fsshell.test(outputdir)) { fsshell.rmr(outputdir); } }}
31 HDFS and FsShell as APIs Excellent for JVM scripting init-files.groovy // use the shell (made available under variable fsh) if (!fsh.test(inputdir)) { fsh.mkdir(inputdir); fsh.copyfromlocal(sourcefile, inputdir); fsh.chmod(700, inputdir) } if (fsh.test(outputdir)) { fsh.rmr(outputdir) }
32 HDFS and FsShell as APIs appctx.xml <hdp:script id= init-script language= groovy > <hdp:property name= inputdir value= ${input} /> <hdp:property name= outputdir value= ${output} /> <hdp:property name= sourcefile value= ${source} /> // use the shell (made available under variable fsh) if (!fsh.test(inputdir)) { fsh.mkdir(inputdir); fsh.copyfromlocal(sourcefile, inputdir); fsh.chmod(700, inputdir) } if (fsh.test(outputdir)) { fsh.rmr(outputdir) } </hdp:script>
33 Counting Words - Pig input_lines = LOAD '/tmp/books' AS (line:chararray); -- Extract words from each line and put them into a pig bag words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word; -- filter out any words that are just white spaces filtered_ words = FILTER words BY word MATCHES '\\w+'; -- create a group for each word word_groups = GROUP filtered_words BY word; -- count the entries in each group word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word; ordered_word_count = ORDER word_count BY count DESC; STORE ordered_word_count INTO '/tmp/number-of-words';
34 Pig Vanilla Pig pig x mapreduce wordcount.pig pig wordcount.pig P pig.properties p pig.exec.nocombiner=true SHDP Creates a PigServer Executes script on startup (optional) <pig-factory job-name= wc properties-location= pig.properties"> pig.exec.nocombiner=true <script location= wordcount.pig"> <arguments>ignorecase=true</arguments> </script> </pig-factory>
35 PigRunner A small pig * *? ) public void process() { pigrunner.call(); }
36 PigTemplate - Configuration
37 PigTemplate Programmatic Use public class PigPasswordRepository implements PasswordRepository { private PigTemplate pigtemplate; private String pigscript = "classpath:password-analysis.pig"; public void processpasswordfile(string inputfile) { String outputdir = baseoutputdir + File.separator + counter.incrementandget(); Properties scriptparameters = new Properties(); scriptparameters.put("inputdir", inputfile); scriptparameters.put("outputdir", outputdir); pigtemplate.executescript(pigscript, scriptparameters); } //... }
38 Counting Words Hive -- import the file as lines CREATE EXTERNAL TABLE lines(line string) LOAD DATA INPATH books OVERWRITE INTO TABLE lines; -- create a virtual view that splits the lines SELECT word, count(*) FROM lines LATERAL VIEW explode(split(text, )) ltable as word GROUP BY word;

39 Vanilla Hive Command-line JDBC based
40 Hive w/ SHDP Create Hive JDBC Client and use with Spring JdbcTemplate <bean id="hive-driver" class="org.apache.hadoop.hive.jdbc.hivedriver"/> <bean id="hive-ds" class="org.springframework.jdbc.datasource.simpledriverdatasource" c:driver-ref="hive-driver" c:url="${hive.url}"/> <bean id="template" class="org.springframework.jdbc.core.jdbctemplate" c:data-source-ref="hive-ds"/>
41 Hive w/ SHDP Create Hive JDBC Client and use with Spring JdbcTemplate <bean id="hive-driver" class="org.apache.hadoop.hive.jdbc.hivedriver"/> <bean id="hive-ds" class="org.springframework.jdbc.datasource.simpledriverdatasource" c:driver-ref="hive-driver" c:url="${hive.url}"/> <bean id="template" class="org.springframework.jdbc.core.jdbctemplate" c:data-source-ref="hive-ds"/> Reuse Spring s Rich ResultSet to POJO Mapping Features public long count() { return jdbctemplate.queryforlong("select count(*) from " + tablename); } List<Password> result = jdbctemplate.query( select * from passwords", new ResultSetExtractor<List<Password>() { public String extractdata(resultset rs) throws SQLException { // extract data from result set }});
42 Vanilla Hive - Thrift HiveClient is not thread-safe, throws checked exceptions public long count() { HiveClient hiveclient = createhiveclient(); try { hiveclient.execute("select count(*) from " + tablename); return Long.parseLong(hiveClient.fetchOne()); // checked exceptions } catch (HiveServerException ex) { throw translateexcpetion(ex); } catch (org.apache.thrift.texception tex) { throw translateexcpetion(tex); } finally { try { hiveclient.shutdown(); } catch (org.apache.thrift.texception tex) { logger.debug("unexpected exception on shutting down HiveClient", tex); }}} protected HiveClient createhiveclient() { TSocket transport = new TSocket(host, port, timeout); HiveClient hive = new HiveClient(new TBinaryProtocol(transport)); try { transport.open(); } catch (TTransportException e) { throw translateexcpetion(e); } return hive; }
43 SHDP Hive Easy client confguration <hive-client-factory host="${hive.host}" port="${hive.port}"/> <hive-template id="hivetemplate"/> Can create an embedded Hive server instance <hive-server auto-startup="true" port="${hive.port}"/> Declarative Usage <hive-runner run-at-startup="true > <hdp:script> DROP TABLE IF EXISTS ${wc.table}; </hdp:script> <hdp:script location= word-count.q /> </hive-runner>
44 SHDP - HiveTemplate (Thrift) One-liners to execute public class HiveTemplatePasswordRepository implements PasswordRepository { String tablename; HiveOperations public Long count() { return hivetemplate.queryforlong("select count(*) from " + tablename); } } One-lines for executing scripts Properties scriptparameters = new Properties(); scriptparameters.put("inputdir", inputfile); scriptparameters.put("outputdir", outputdir); hivetemplate.query( classpath:hive-analysis.q", scriptparameters);
45 Cascading Counting Words Scheme sourcescheme = new TextLine(new Fields("line")); Tap source = new Hfs(sourceScheme, inputpath); Scheme sinkscheme = new TextLine(new Fields("word", "count")); Tap sink = new Hfs(sinkScheme, outputpath, SinkMode.REPLACE); Pipe assembly = new Pipe("wordcount"); String regex = "(?<!\\pl)(?=\\pl)[^ ]*(?<=\\pl)(?!\\pl)"; Function function = new RegexGenerator(new Fields("word"), regex); assembly = new Each(assembly, new Fields("line ), function ); assembly = new GroupBy(assembly, new Fields("word ) ); Aggregator count = new Count(new Fields("count )); assembly = new Every(assembly, count);

46 Cascading Based on Spring s type <bean class= wordcount.cascading.cascadingconfig "/> <bean id="cascade" class="org.springframework.data.hadoop.cascading.hadoopflowfactorybean" p:configuration-ref="hadoopconfiguration" p:tails-ref= countpipe" /> <hdp:configuration />
47 HBase Bootstrap HBase confguration from Hadoop Confguration <hdp:configuration/> <hdp:hbase-configuration delete-connection="true /> <bean id="hbasetemplate class="org.springframework.data.hadoop.hbase.hbasetemplate p:configuration-ref="hbaseconfiguration /> Template usage public List<User> findall() { return hbasetemplate.find(tablename, "cfinfo", new RowMapper<User>() public User maprow(result result, int rownum) throws Exception { return new User(Bytes.toString(result.getValue(CF_INFO, quser)), Bytes.toString(result.getValue(CF_INFO, q )), Bytes.toString(result.getValue(CF_INFO, qpassword))); } });}
48 Batch Workflows

49 On Hadoop Workflows Reuse same infrastructure for Hadoop based workflows HDFS PIG MR Step can any Hadoop job Hive HDFS
50 Capabilities: Spring + Hadoop + Batch Collect Transform RT Analysis Ingest Batch Analysis Spring Batch for File/DB/NoSQL driven applications Collect: Process local files Transform: Scripting or Java code to transform and enrich RT Analysis: N/A Ingest: (batch/aggregate) write to HDFS or split/filtering Batch Analysis: Orchestrate Hadoop steps in a workflow Distribute: Copy data out of HDFS to structured storage JMX enabled along with REST interface for job control Distribute Use
51 Spring Batch Configuration <job id="job1"> <step id="import" next="wordcount"> <tasklet ref= import-tasklet"/> </step> <step id= wc" next="pig"> <tasklet ref="wordcount-tasklet"/> </step> <step id="pig"> <tasklet ref="pig-tasklet ></step> <split id="parallel" next="hdfs"> <flow><step id="mrstep"> <tasklet ref="mr-tasklet"/> </step></flow> <flow><step id="hive"> <tasklet ref="hive-tasklet"/> </step></flow> </split> <step id="hdfs"> <tasklet ref="hdfs-tasklet"/></step> </job>
52 Spring Batch Configuration Additional configuration behind the graph Reuse previous Hadoop job definitions
53 Spring Batch Admin
54 Event Driven Applications
55 Capabilities: Spring + Hadoop + EAI Collect Transform RT Analysis Ingest Batch Analysis Distribute Big data solutions need to integrate with existing data and apps Share core components of a classic integration workflow Spring Integration for Event driven applications Collect: Single node or distributed data collection (tcp/jms/rabbit) Transform: Scripting or Java code to transform and enrich RT Analysis: Connectivity to multiple analysis techniques Ingest: Write to HDFS, Split/Filter data stream to other stores JMX enabled + control bus for starting/stopping individual components Use
56 Spring Integration Polling Log File Poll a directory for files, files are rolled over every 10 min Copy files to staging area Copy files to HDFS Use an aggregator to wait for 10 files in 20 minute interval to launch MR job
57 Spring Integration Syslog to HDFS Use tcp/udp Syslog adapter Transformer categorizes messages Route to specific channels based on category One route leads to HDFS write and filtered data stored in Redis
58 Spring Integration Multi-node Syslog Spread log collection across multiple machines Use TCP Adapters to forward events across machines Can use other middleware Reusable flows, creak the flow at a channel boundary and insert inbound/outbound adapter pair
59 Resources Prepping for GA feedback welcome Project Page: springsource.org/spring-data/hadoop Source Code: github.com/springsource/spring-hadoop Books
60
Big Data for the JVM developer. Costin Leau, Elasticsearch @costinl
 Big Data for the JVM developer Costin Leau, Elasticsearch @costinl Agenda Data Trends Data Pipelines JVM and Big Data Tool Eco-system Data Landscape Data Trends http://www.emc.com/leadership/programs/digital-universe.htm
Big Data for the JVM developer Costin Leau, Elasticsearch @costinl Agenda Data Trends Data Pipelines JVM and Big Data Tool Eco-system Data Landscape Data Trends http://www.emc.com/leadership/programs/digital-universe.htm
Word Count Code using MR2 Classes and API
 EDUREKA Word Count Code using MR2 Classes and API A Guide to Understand the Execution of Word Count edureka! A guide to understand the execution and flow of word count WRITE YOU FIRST MRV2 PROGRAM AND
EDUREKA Word Count Code using MR2 Classes and API A Guide to Understand the Execution of Word Count edureka! A guide to understand the execution and flow of word count WRITE YOU FIRST MRV2 PROGRAM AND
Hadoop Lab Notes. Nicola Tonellotto November 15, 2010
 Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
BIG DATA APPLICATIONS
 BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
Tutorial- Counting Words in File(s) using MapReduce
 using MapReduce") Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
How To Write A Nosql Database In Spring Data Project
 Spring Data Modern Data Access for Enterprise Java Mark Pollack, Oliver Gierke, Thomas Risberg, Jon Brisbin, and Michael Hunger O'REILLY* Beijing Cambridge Farnham Koln Sebastopol Tokyo Table of Contents
Spring Data Modern Data Access for Enterprise Java Mark Pollack, Oliver Gierke, Thomas Risberg, Jon Brisbin, and Michael Hunger O'REILLY* Beijing Cambridge Farnham Koln Sebastopol Tokyo Table of Contents
LANGUAGES FOR HADOOP: PIG & HIVE
 Friday, September 27, 13 1 LANGUAGES FOR HADOOP: PIG & HIVE Michail Michailidis & Patrick Maiden Friday, September 27, 13 2 Motivation Native MapReduce Gives fine-grained control over how program interacts
Friday, September 27, 13 1 LANGUAGES FOR HADOOP: PIG & HIVE Michail Michailidis & Patrick Maiden Friday, September 27, 13 2 Motivation Native MapReduce Gives fine-grained control over how program interacts
Getting to know Apache Hadoop
 Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Lambda Architecture. CSCI 5828: Foundations of Software Engineering Lecture 29 12/09/2014
 Lambda Architecture CSCI 5828: Foundations of Software Engineering Lecture 29 12/09/2014 1 Goals Cover the material in Chapter 8 of the Concurrency Textbook The Lambda Architecture Batch Layer MapReduce
Lambda Architecture CSCI 5828: Foundations of Software Engineering Lecture 29 12/09/2014 1 Goals Cover the material in Chapter 8 of the Concurrency Textbook The Lambda Architecture Batch Layer MapReduce
Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网. Information Management. Information Management IBM CDL Lab
 IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
ITG Software Engineering
 Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Big Data 2012 Hadoop Tutorial
 Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
Cloud Computing Era. Trend Micro
 Cloud Computing Era Trend Micro Three Major Trends to Chang the World Cloud Computing Big Data Mobile 什 麼 是 雲 端 運 算? 美 國 國 家 標 準 技 術 研 究 所 (NIST) 的 定 義 : Essential Characteristics Service Models Deployment
Cloud Computing Era Trend Micro Three Major Trends to Chang the World Cloud Computing Big Data Mobile 什 麼 是 雲 端 運 算? 美 國 國 家 標 準 技 術 研 究 所 (NIST) 的 定 義 : Essential Characteristics Service Models Deployment
Hadoop and Eclipse. Eclipse Hawaii User s Group May 26th, 2009. Seth Ladd http://sethladd.com
 Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Introduc)on to Map- Reduce. Vincent Leroy
on to Map- Reduce. Vincent Leroy") Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Enterprise Data Storage and Analysis on Tim Barr
 Enterprise Data Storage and Analysis on Tim Barr January 15, 2015 Agenda Challenges in Big Data Analytics Why many Hadoop deployments under deliver What is Apache Spark Spark Core, SQL, Streaming, MLlib,
Enterprise Data Storage and Analysis on Tim Barr January 15, 2015 Agenda Challenges in Big Data Analytics Why many Hadoop deployments under deliver What is Apache Spark Spark Core, SQL, Streaming, MLlib,
Mrs: MapReduce for Scientific Computing in Python
 Mrs: for Scientific Computing in Python Andrew McNabb, Jeff Lund, and Kevin Seppi Brigham Young University November 16, 2012 Large scale problems require parallel processing Communication in parallel processing
Mrs: for Scientific Computing in Python Andrew McNabb, Jeff Lund, and Kevin Seppi Brigham Young University November 16, 2012 Large scale problems require parallel processing Communication in parallel processing
Connecting Hadoop with Oracle Database
 Connecting Hadoop with Oracle Database Sharon Stephen Senior Curriculum Developer Server Technologies Curriculum The following is intended to outline our general product direction.
Connecting Hadoop with Oracle Database Sharon Stephen Senior Curriculum Developer Server Technologies Curriculum The following is intended to outline our general product direction.
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
HDInsight Essentials. Rajesh Nadipalli. Chapter No. 1 "Hadoop and HDInsight in a Heartbeat"
 HDInsight Essentials Rajesh Nadipalli Chapter No. 1 "Hadoop and HDInsight in a Heartbeat" In this package, you will find: A Biography of the author of the book A preview chapter from the book, Chapter
HDInsight Essentials Rajesh Nadipalli Chapter No. 1 "Hadoop and HDInsight in a Heartbeat" In this package, you will find: A Biography of the author of the book A preview chapter from the book, Chapter
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
The Cloud Computing Era and Ecosystem. Phoenix Liau, Technical Manager
 The Cloud Computing Era and Ecosystem Phoenix Liau, Technical Manager Three Major Trends to Chang the World Cloud Computing Big Data Mobile Mobility and Personal Cloud My World! My Way! What is Personal
The Cloud Computing Era and Ecosystem Phoenix Liau, Technical Manager Three Major Trends to Chang the World Cloud Computing Big Data Mobile Mobility and Personal Cloud My World! My Way! What is Personal
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Hadoop Basics with InfoSphere BigInsights
 An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Unit 2: Using MapReduce An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government Users Restricted Rights
An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Unit 2: Using MapReduce An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government Users Restricted Rights
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected]
 Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Working With Hadoop. Important Terminology. Important Terminology. Anatomy of MapReduce Job Run. Important Terminology
 Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Hadoop Streaming. 2012 coreservlets.com and Dima May. 2012 coreservlets.com and Dima May
 2012 coreservlets.com and Dima May Hadoop Streaming Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training courses (onsite
2012 coreservlets.com and Dima May Hadoop Streaming Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training courses (onsite
Programming Hadoop Map-Reduce Programming, Tuning & Debugging. Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008
 Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Creating Big Data Applications with Spring XD
 Creating Big Data Applications with Spring XD Thomas Darimont @thomasdarimont THE FASTEST PATH TO NEW BUSINESS VALUE Journey Introduction Concepts Applications Outlook 3 Unless otherwise indicated, these
Creating Big Data Applications with Spring XD Thomas Darimont @thomasdarimont THE FASTEST PATH TO NEW BUSINESS VALUE Journey Introduction Concepts Applications Outlook 3 Unless otherwise indicated, these
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Unified Batch & Stream Processing Platform
 Unified Batch & Stream Processing Platform Himanshu Bari Director Product Management Most Big Data Use Cases Are About Improving/Re-write EXISTING solutions To KNOWN problems Current Solutions Were Built
Unified Batch & Stream Processing Platform Himanshu Bari Director Product Management Most Big Data Use Cases Are About Improving/Re-write EXISTING solutions To KNOWN problems Current Solutions Were Built
CS54100: Database Systems
 CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
IBM Big Data Platform
 Mike Winer IBM Information Management IBM Big Data Platform The big data opportunity Extracting insight from an immense volume, variety and velocity of data, in a timely and cost-effective manner. Variety:
Mike Winer IBM Information Management IBM Big Data Platform The big data opportunity Extracting insight from an immense volume, variety and velocity of data, in a timely and cost-effective manner. Variety:
USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2
 USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2 (Using HDFS on Discovery Cluster for Discovery Cluster Users email [email protected] if you have questions or need more clarifications. Nilay
USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2 (Using HDFS on Discovery Cluster for Discovery Cluster Users email [email protected] if you have questions or need more clarifications. Nilay
Yahoo! Grid Services Where Grid Computing at Yahoo! is Today
 Yahoo! Grid Services Where Grid Computing at Yahoo! is Today Marco Nicosia Grid Services Operations [email protected] What is Apache Hadoop? Distributed File System and Map-Reduce programming platform
Yahoo! Grid Services Where Grid Computing at Yahoo! is Today Marco Nicosia Grid Services Operations [email protected] What is Apache Hadoop? Distributed File System and Map-Reduce programming platform
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Hadoop Configuration and First Examples
 Hadoop Configuration and First Examples Big Data 2015 Hadoop Configuration In the bash_profile export all needed environment variables Hadoop Configuration Allow remote login Hadoop Configuration Download
Hadoop Configuration and First Examples Big Data 2015 Hadoop Configuration In the bash_profile export all needed environment variables Hadoop Configuration Allow remote login Hadoop Configuration Download
Hadoop Streaming. Table of contents
 Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
ITG Software Engineering
 Introduction to Cloudera Course ID: Page 1 Last Updated 12/15/2014 Introduction to Cloudera Course : This 5 day course introduces the student to the Hadoop architecture, file system, and the Hadoop Ecosystem.
Introduction to Cloudera Course ID: Page 1 Last Updated 12/15/2014 Introduction to Cloudera Course : This 5 day course introduces the student to the Hadoop architecture, file system, and the Hadoop Ecosystem.
HPCHadoop: MapReduce on Cray X-series
 HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1
 How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
Hadoop Framework. technology basics for data scientists. Spring - 2014. Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN
 Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
How To Write A Mapreduce Program On An Ipad Or Ipad (For Free)
") Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Map-Reduce and Hadoop
 Map-Reduce and Hadoop 1 Introduction to Map-Reduce 2 3 Map Reduce operations Input data are (key, value) pairs 2 operations available : map and reduce Map Takes a (key, value) and generates other (key,
Map-Reduce and Hadoop 1 Introduction to Map-Reduce 2 3 Map Reduce operations Input data are (key, value) pairs 2 operations available : map and reduce Map Takes a (key, value) and generates other (key,
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
COSC 6397 Big Data Analytics. 2 nd homework assignment Pig and Hive. Edgar Gabriel Spring 2015
 COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Hadoop: Understanding the Big Data Processing Method
 Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
Federated SQL on Hadoop and Beyond: Leveraging Apache Geode to Build a Poor Man's SAP HANA. by Christian Tzolov @christzolov
 Federated SQL on Hadoop and Beyond: Leveraging Apache Geode to Build a Poor Man's SAP HANA by Christian Tzolov @christzolov Whoami Christian Tzolov Technical Architect at Pivotal, BigData, Hadoop, SpringXD,
Federated SQL on Hadoop and Beyond: Leveraging Apache Geode to Build a Poor Man's SAP HANA by Christian Tzolov @christzolov Whoami Christian Tzolov Technical Architect at Pivotal, BigData, Hadoop, SpringXD,
Istanbul Şehir University Big Data Camp 14. Hadoop Map Reduce. Aslan Bakirov Kevser Nur Çoğalmış
 Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
http://glennengstrand.info/analytics/fp
 Functional Programming and Big Data by Glenn Engstrand (September 2014) http://glennengstrand.info/analytics/fp What is Functional Programming? It is a style of programming that emphasizes immutable state,
Functional Programming and Big Data by Glenn Engstrand (September 2014) http://glennengstrand.info/analytics/fp What is Functional Programming? It is a style of programming that emphasizes immutable state,
Big Data and Data Science Grows Up. Ron Bodkin Founder & CEO Think Big Analy8cs [email protected]
 Big Data and Data Science Grows Up Ron Bodkin Founder & CEO Think Big Analy8cs [email protected] 1 Source IDC 2 Hadoop Open Source Distributed Cluster SoGware Distributed file system Java-
Big Data and Data Science Grows Up Ron Bodkin Founder & CEO Think Big Analy8cs [email protected] 1 Source IDC 2 Hadoop Open Source Distributed Cluster SoGware Distributed file system Java-
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Hadoop WordCount Explained! IT332 Distributed Systems
 Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Qsoft Inc www.qsoft-inc.com
 Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Spring for Apache Hadoop - Reference Documentation
 Spring for Apache Hadoop - Reference Documentation 2.1.0.RELEASE Costin Leau Elasticsearch, Thomas Risberg Pivotal, Janne Valkealahti Pivotal Copyright 2011-2015 Pivotal Software, Inc. Copies of this document
Spring for Apache Hadoop - Reference Documentation 2.1.0.RELEASE Costin Leau Elasticsearch, Thomas Risberg Pivotal, Janne Valkealahti Pivotal Copyright 2011-2015 Pivotal Software, Inc. Copies of this document
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us
 DATA INTELLIGENCE FOR ALL Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us Christopher Nguyen, PhD Co-Founder & CEO Agenda 1. Challenges & Motivation 2. DDF Overview 3. DDF Design
DATA INTELLIGENCE FOR ALL Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us Christopher Nguyen, PhD Co-Founder & CEO Agenda 1. Challenges & Motivation 2. DDF Overview 3. DDF Design
Certified Big Data and Apache Hadoop Developer VS-1221
 Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Running Hadoop on Windows CCNP Server
 Running Hadoop at Stirling Kevin Swingler Summary The Hadoopserver in CS @ Stirling A quick intoduction to Unix commands Getting files in and out Compliing your Java Submit a HadoopJob Monitor your jobs
Running Hadoop at Stirling Kevin Swingler Summary The Hadoopserver in CS @ Stirling A quick intoduction to Unix commands Getting files in and out Compliing your Java Submit a HadoopJob Monitor your jobs
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Upcoming Announcements
 Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC [email protected] Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC [email protected] Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Programming in Hadoop Programming, Tuning & Debugging
 Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Important Notice. (c) 2010-2013 Cloudera, Inc. All rights reserved.
 2010-2013 Cloudera, Inc. All rights reserved.") Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Word count example Abdalrahman Alsaedi
 Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Introduc8on to Apache Spark
 Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
How To Write A Mapreduce Program In Java.Io 4.4.4 (Orchestra)
") MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
BIG DATA - HADOOP PROFESSIONAL amron
 0 Training Details Course Duration: 30-35 hours training + assignments + actual project based case studies Training Materials: All attendees will receive: Assignment after each module, video recording
0 Training Details Course Duration: 30-35 hours training + assignments + actual project based case studies Training Materials: All attendees will receive: Assignment after each module, video recording
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment
 CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop
 Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Automated Data Ingestion. Bernhard Disselhoff Enterprise Sales Engineer
 Automated Data Ingestion Bernhard Disselhoff Enterprise Sales Engineer Agenda Pentaho Overview Templated dynamic ETL workflows Pentaho Data Integration (PDI) Use Cases Pentaho Overview Overview What we
Automated Data Ingestion Bernhard Disselhoff Enterprise Sales Engineer Agenda Pentaho Overview Templated dynamic ETL workflows Pentaho Data Integration (PDI) Use Cases Pentaho Overview Overview What we
Real World Big Data Architecture - Splunk, Hadoop, RDBMS
 Copyright 2015 Splunk Inc. Real World Big Data Architecture - Splunk, Hadoop, RDBMS Raanan Dagan, Big Data Specialist, Splunk Disclaimer During the course of this presentagon, we may make forward looking
Copyright 2015 Splunk Inc. Real World Big Data Architecture - Splunk, Hadoop, RDBMS Raanan Dagan, Big Data Specialist, Splunk Disclaimer During the course of this presentagon, we may make forward looking
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and