Big Data Analytics - Accelerated. stream-horizon.com
|
|
|
- Elmer Ball
- 10 years ago
- Views:
Transcription

1 Big Data Analytics - Accelerated stream-horizon.com
2 StreamHorizon & Big Data Integrates into your Data Processing Pipeline Seamlessly integrates at any point of your your data processing pipeline Implements generic input/output connectivity. Enables you to implement your own, customised input/output connectivity. Ability to process data from heterogeneous sources like: Spark Kafka Storm Netty Accelerates your clients TCP Streams Local File System Any Other Reduces Network data congestion Improves latency of, or any other Massively Parallel Processing S Query Engine. HBase Any Other And more Portable Across Heterogeneous Hardware and Software Platforms Portable from one platform to another

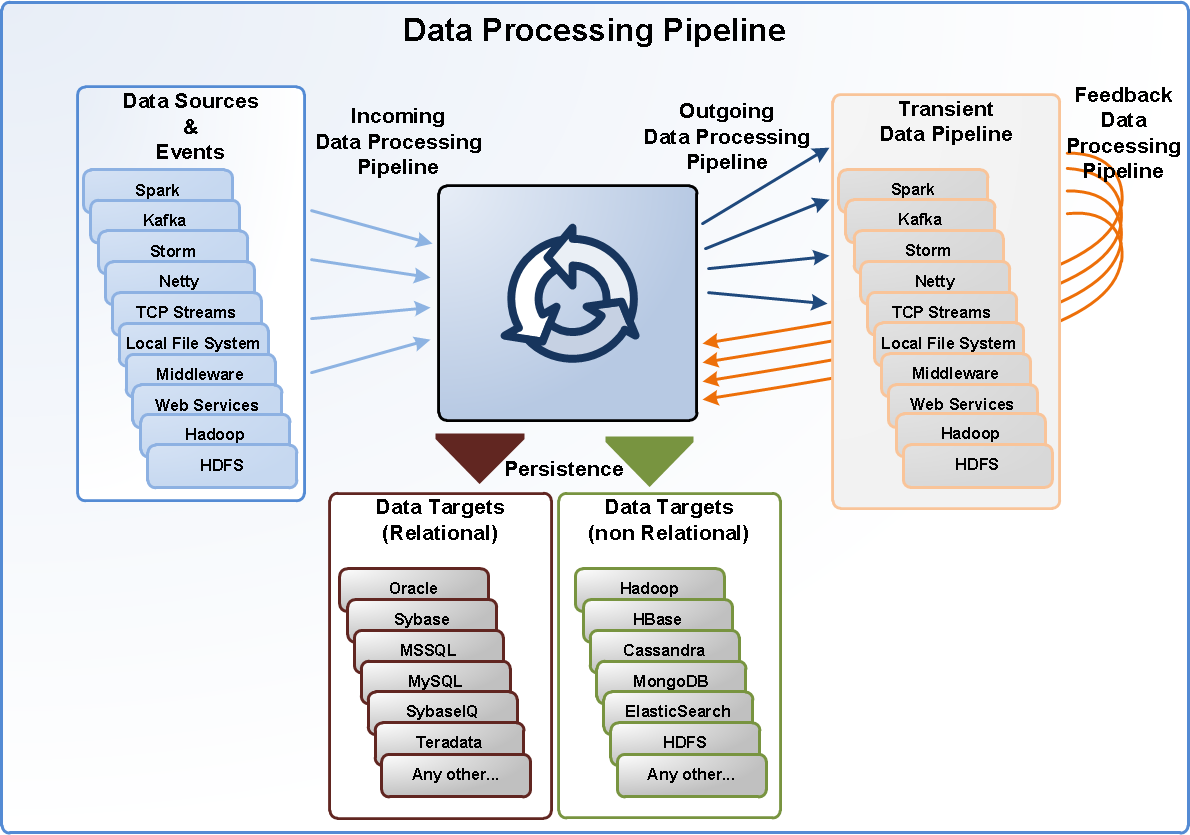
3 StreamHorizon Big Data Processing Pipeline
4 StreamHorizon - Flavours Big Data Processing Storm - Reactive, Fast, Real Time Processing Guaranteed data processing Guarantees no data loss Real-time processing Horizontal scalability Fault-tolerance Stateless nodes Open Source Seamless Integration Hadoop Big Batch Oriented Processing Batch processing Jobs runs to completion Stateful nodes Scalable Guarantees no data loss Open Source Kafka Designed for processing of real time activity stream data (metrics, KPI's, collections, social media streams) A distributed Publish-Subscribe messaging system for Big Data Acts as Producer, Broker, Consumer of message topics Persists messages (has ability to rewind) Initially developed by LinkedIn (current ownership of Apache)
5 NameNode Big Data & StreamHorizon Data Persistence (Example: Finance Industry) Data Calculation, Data Processing & Persistence Data Processing Tasks Big Data DataNode Cluster - Data Source (Quant Library Instance) - StreamHorizon instance (daemon)
6 HDSF vs. Tier 2 Storage Performance Benchmark Big Data () vs. Commodity Tier 2 Storage Benchmarks Non - filesystem filesystem Single Server Single DataNode Cluster of 10 DataNodes File to File 0.95 million records/sec 1.1 million records/sec per node 11 million records/sec per node Stream to File 1.04 million records/sec 1.2million records/sec per node 12million records/sec per node
7 StreamHorizon & Big Data Advanced Concepts Streaming Data Aggregations SDA SDA are integral part of all StreamHorizon instances (daemons) StreamHorizon SDA processes & aggregates data as it is processed (on the fly) Aggregated data is directly persisted to (or any alternative Data Target)
8 StreamHorizon Accelerator Method - persisting your Big Data (faster) Accelerate Hadoop or/and persistence by writing less: StreamHorizon enables you to persist only transactional data (traditionally known as Fact table data ) and omit persisting repetitive dimensional data (low cardinality data) to DataNodes across your Big Data cluster Client front end tool (or any end user application like Excel) simply merges Dimensional data with Fact (transactional data) brought from your Big Data cluster. Reduced Client & Network footprint StreamHorizon Accelerator Method reduces Network traffic between your clients & Big Data cluster to ~10% of nominal size (due to avoidance of shipping of low cardinality data (dimensional data) via network)
9 NameNode NameNode Big Data & StreamHorizon Data Retrieval (Example: Finance Industry) Nominal Network Congestion User Groups Network Congestion StreamHorizon Accelerator Method User Groups Dimensional Data (Low cardinality) Dimensional And Fact Data Fact Data (High Cardinality)
10 StreamHorizon beneficial to Big Data filesystem () StreamHorizon Accelerates Hadoop processing - MapReduce has two main disadvantages (processing is slow & inconvenient to use) + StreamHorizon SDA outperforms ( based reporting stack usually has higher query latency compared to stack. This is significantly improved with StreamHorizon) Due to aggregation, single file contains even more of your business data. Benefits are: queries are more effective Reduces number of I/O requests Single I/O request executes as sequential read in comparison to default I/O footprint Reduces replication latency Move via Network only high cardinality (Fact) rather than low cardinality (Dimensional) data. Achieve reduction of network traffic down to 10% of it s nominal value. StreamHorizon SDA accelerates heavy data operations like joins etc.
11 Client Queries - accelerated by StreamHorizon StreamHorizon accelerates ad-hoc queries for, or any other MPP S Query Engine. This is can be achieved with: StreamHorizon SDA (Streaming Data Aggregations) StreamHorizon Accelerated Method data topology StreamHorizon reduces memory pressure for (or any other memory dependent data access component) StreamHorizon reduces MapReduce processing latency for (when utilizing StreamHorizon SDA) query latency reduced by order of magnitude (function of data volume reduction of your StreamHorizon SDA aggregations)
12 Streaming Data Aggregations impact on Big Data Query Latency Out of the Box With Streaming Data Aggregations Query Latency Medium-Low Medium-High Low Medium-Low Memory Footprint High Nominal Medium - Low Nominal - Low Processing Footprint Medium-Low High Low Low Space Consumption Medium High Low Low
13 Q&A stream-horizon.com
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Big Data Analytics - Accelerated. stream-horizon.com
 Big Data Analytics - Accelerated stream-horizon.com Legacy ETL platforms & conventional Data Integration approach Unable to meet latency & data throughput demands of Big Data integration challenges Based
Big Data Analytics - Accelerated stream-horizon.com Legacy ETL platforms & conventional Data Integration approach Unable to meet latency & data throughput demands of Big Data integration challenges Based
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Enabling High performance Big Data platform with RDMA
 Enabling High performance Big Data platform with RDMA Tong Liu HPC Advisory Council Oct 7 th, 2014 Shortcomings of Hadoop Administration tooling Performance Reliability SQL support Backup and recovery
Enabling High performance Big Data platform with RDMA Tong Liu HPC Advisory Council Oct 7 th, 2014 Shortcomings of Hadoop Administration tooling Performance Reliability SQL support Backup and recovery
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Building Scalable Big Data Infrastructure Using Open Source Software. Sam William sampd@stumbleupon.
 Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
[Hadoop, Storm and Couchbase: Faster Big Data]
![[Hadoop, Storm and Couchbase: Faster Big Data]](/thumbs/24/3894711.jpg "[Hadoop, Storm and Couchbase: Faster Big Data]") [Hadoop, Storm and Couchbase: Faster Big Data] With over 8,500 clients, LivePerson is the global leader in intelligent online customer engagement. With an increasing amount of agent/customer engagements,
[Hadoop, Storm and Couchbase: Faster Big Data] With over 8,500 clients, LivePerson is the global leader in intelligent online customer engagement. With an increasing amount of agent/customer engagements,
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Big Data Technology Core Hadoop: HDFS-YARN Internals
 Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
From Spark to Ignition:
 From Spark to Ignition: Fueling Your Business on Real-Time Analytics Eric Frenkiel, MemSQL CEO June 29, 2015 San Francisco, CA What s in Store For This Presentation? 1. MemSQL: A real-time database for
From Spark to Ignition: Fueling Your Business on Real-Time Analytics Eric Frenkiel, MemSQL CEO June 29, 2015 San Francisco, CA What s in Store For This Presentation? 1. MemSQL: A real-time database for
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM
 Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Realtime Apache Hadoop at Facebook. Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens
 Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo
 Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
BIG DATA. Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management. Author: Sandesh Deshmane
 BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Virtualizing Apache Hadoop. June, 2012
 June, 2012 Table of Contents EXECUTIVE SUMMARY... 3 INTRODUCTION... 3 VIRTUALIZING APACHE HADOOP... 4 INTRODUCTION TO VSPHERE TM... 4 USE CASES AND ADVANTAGES OF VIRTUALIZING HADOOP... 4 MYTHS ABOUT RUNNING
June, 2012 Table of Contents EXECUTIVE SUMMARY... 3 INTRODUCTION... 3 VIRTUALIZING APACHE HADOOP... 4 INTRODUCTION TO VSPHERE TM... 4 USE CASES AND ADVANTAGES OF VIRTUALIZING HADOOP... 4 MYTHS ABOUT RUNNING
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
HDMQ :Towards In-Order and Exactly-Once Delivery using Hierarchical Distributed Message Queues. Dharmit Patel Faraj Khasib Shiva Srivastava
 HDMQ :Towards In-Order and Exactly-Once Delivery using Hierarchical Distributed Message Queues Dharmit Patel Faraj Khasib Shiva Srivastava Outline What is Distributed Queue Service? Major Queue Service
HDMQ :Towards In-Order and Exactly-Once Delivery using Hierarchical Distributed Message Queues Dharmit Patel Faraj Khasib Shiva Srivastava Outline What is Distributed Queue Service? Major Queue Service
I/O Considerations in Big Data Analytics
 Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
NoSQL Data Base Basics
 NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
Big Data Introduction
 Big Data Introduction Ralf Lange Global ISV & OEM Sales 1 Copyright 2012, Oracle and/or its affiliates. All rights Conventional infrastructure 2 Copyright 2012, Oracle and/or its affiliates. All rights
Big Data Introduction Ralf Lange Global ISV & OEM Sales 1 Copyright 2012, Oracle and/or its affiliates. All rights Conventional infrastructure 2 Copyright 2012, Oracle and/or its affiliates. All rights
Big Data: A Storage Systems Perspective Muthukumar Murugan Ph.D. HP Storage Division
 Big Data: A Storage Systems Perspective Muthukumar Murugan Ph.D. HP Storage Division In this talk Big data storage: Current trends Issues with current storage options Evolution of storage to support big
Big Data: A Storage Systems Perspective Muthukumar Murugan Ph.D. HP Storage Division In this talk Big data storage: Current trends Issues with current storage options Evolution of storage to support big
Putting Apache Kafka to Use!
 Putting Apache Kafka to Use! Building a Real-time Data Platform for Event Streams! JAY KREPS, CONFLUENT! A Couple of Themes! Theme 1: Rise of Events! Theme 2: Immutability Everywhere! Level! Example! Immutable
Putting Apache Kafka to Use! Building a Real-time Data Platform for Event Streams! JAY KREPS, CONFLUENT! A Couple of Themes! Theme 1: Rise of Events! Theme 2: Immutability Everywhere! Level! Example! Immutable
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Hadoop Distributed File System (HDFS) Overview
 Overview") 2012 coreservlets.com and Dima May Hadoop Distributed File System (HDFS) Overview Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized
2012 coreservlets.com and Dima May Hadoop Distributed File System (HDFS) Overview Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Driving IBM BigInsights Performance Over GPFS Using InfiniBand+RDMA
 WHITE PAPER April 2014 Driving IBM BigInsights Performance Over GPFS Using InfiniBand+RDMA Executive Summary...1 Background...2 File Systems Architecture...2 Network Architecture...3 IBM BigInsights...5
WHITE PAPER April 2014 Driving IBM BigInsights Performance Over GPFS Using InfiniBand+RDMA Executive Summary...1 Background...2 File Systems Architecture...2 Network Architecture...3 IBM BigInsights...5
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Alternatives to HIVE SQL in Hadoop File Structure
 Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Dell* In-Memory Appliance for Cloudera* Enterprise
 Built with Intel Dell* In-Memory Appliance for Cloudera* Enterprise Find out what faster big data analytics can do for your business The need for speed in all things related to big data is an enormous
Built with Intel Dell* In-Memory Appliance for Cloudera* Enterprise Find out what faster big data analytics can do for your business The need for speed in all things related to big data is an enormous
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Luncheon Webinar Series May 13, 2013
 Luncheon Webinar Series May 13, 2013 InfoSphere DataStage is Big Data Integration Sponsored By: Presented by : Tony Curcio, InfoSphere Product Management 0 InfoSphere DataStage is Big Data Integration
Luncheon Webinar Series May 13, 2013 InfoSphere DataStage is Big Data Integration Sponsored By: Presented by : Tony Curcio, InfoSphere Product Management 0 InfoSphere DataStage is Big Data Integration
Architectures for massive data management
 Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
Kafka & Redis for Big Data Solutions
 Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Massive Cloud Auditing using Data Mining on Hadoop
 Massive Cloud Auditing using Data Mining on Hadoop Prof. Sachin Shetty CyberBAT Team, AFRL/RIGD AFRL VFRP Tennessee State University Outline Massive Cloud Auditing Traffic Characterization Distributed
Massive Cloud Auditing using Data Mining on Hadoop Prof. Sachin Shetty CyberBAT Team, AFRL/RIGD AFRL VFRP Tennessee State University Outline Massive Cloud Auditing Traffic Characterization Distributed
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
The 3 questions to ask yourself about BIG DATA
 The 3 questions to ask yourself about BIG DATA Do you have a big data problem? Companies looking to tackle big data problems are embarking on a journey that is full of hype, buzz, confusion, and misinformation.
The 3 questions to ask yourself about BIG DATA Do you have a big data problem? Companies looking to tackle big data problems are embarking on a journey that is full of hype, buzz, confusion, and misinformation.
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert [email protected]/
Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert [email protected]/
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
HYPER-CONVERGED INFRASTRUCTURE STRATEGIES
 1 HYPER-CONVERGED INFRASTRUCTURE STRATEGIES MYTH BUSTING & THE FUTURE OF WEB SCALE IT 2 ROADMAP INFORMATION DISCLAIMER EMC makes no representation and undertakes no obligations with regard to product planning
1 HYPER-CONVERGED INFRASTRUCTURE STRATEGIES MYTH BUSTING & THE FUTURE OF WEB SCALE IT 2 ROADMAP INFORMATION DISCLAIMER EMC makes no representation and undertakes no obligations with regard to product planning
Big Fast Data Hadoop acceleration with Flash. June 2013
 Big Fast Data Hadoop acceleration with Flash June 2013 Agenda The Big Data Problem What is Hadoop Hadoop and Flash The Nytro Solution Test Results The Big Data Problem Big Data Output Facebook Traditional
Big Fast Data Hadoop acceleration with Flash June 2013 Agenda The Big Data Problem What is Hadoop Hadoop and Flash The Nytro Solution Test Results The Big Data Problem Big Data Output Facebook Traditional
Real Time Fraud Detection With Sequence Mining on Big Data Platform. Pranab Ghosh Big Data Consultant IEEE CNSV meeting, May 6 2014 Santa Clara, CA
 Real Time Fraud Detection With Sequence Mining on Big Data Platform Pranab Ghosh Big Data Consultant IEEE CNSV meeting, May 6 2014 Santa Clara, CA Open Source Big Data Eco System Query (NOSQL) : Cassandra,
Real Time Fraud Detection With Sequence Mining on Big Data Platform Pranab Ghosh Big Data Consultant IEEE CNSV meeting, May 6 2014 Santa Clara, CA Open Source Big Data Eco System Query (NOSQL) : Cassandra,
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
Traditional BI vs. Business Data Lake A comparison
 Traditional BI vs. Business Data Lake A comparison The need for new thinking around data storage and analysis Traditional Business Intelligence (BI) systems provide various levels and kinds of analyses
Traditional BI vs. Business Data Lake A comparison The need for new thinking around data storage and analysis Traditional Business Intelligence (BI) systems provide various levels and kinds of analyses
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Powerful Duo: MapR Big Data Analytics with Cisco ACI Network Switches
 Powerful Duo: MapR Big Data Analytics with Cisco ACI Network Switches Introduction For companies that want to quickly gain insights into or opportunities from big data - the dramatic volume growth in corporate
Powerful Duo: MapR Big Data Analytics with Cisco ACI Network Switches Introduction For companies that want to quickly gain insights into or opportunities from big data - the dramatic volume growth in corporate
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Big Data Analytics. with EMC Greenplum and Hadoop. Big Data Analytics. Ofir Manor Pre Sales Technical Architect EMC Greenplum
 Big Data Analytics with EMC Greenplum and Hadoop Big Data Analytics with EMC Greenplum and Hadoop Ofir Manor Pre Sales Technical Architect EMC Greenplum 1 Big Data and the Data Warehouse Potential All
Big Data Analytics with EMC Greenplum and Hadoop Big Data Analytics with EMC Greenplum and Hadoop Ofir Manor Pre Sales Technical Architect EMC Greenplum 1 Big Data and the Data Warehouse Potential All
Scalable Cloud Computing Solutions for Next Generation Sequencing Data
 Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Hadoop. MPDL-Frühstück 9. Dezember 2013 MPDL INTERN
 Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Big Data Testbed for Research and Education Networks Analysis. SomkiatDontongdang, PanjaiTantatsanawong, andajchariyasaeung
 Big Data Testbed for Research and Education Networks Analysis SomkiatDontongdang, PanjaiTantatsanawong, andajchariyasaeung Research and Education Networks ThaiREN is a specialized Internet Service Provider
Big Data Testbed for Research and Education Networks Analysis SomkiatDontongdang, PanjaiTantatsanawong, andajchariyasaeung Research and Education Networks ThaiREN is a specialized Internet Service Provider
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Apache Hadoop FileSystem Internals
 Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
WHITE PAPER. Reference Guide for Deploying and Configuring Apache Kafka
 WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
Building & Optimizing Enterprise-class Hadoop with Open Architectures Prem Jain NetApp
 Building & Optimizing Enterprise-class Hadoop with Open Architectures Prem Jain NetApp Introduction to Hadoop Comes from Internet companies Emerging big data storage and analytics platform HDFS and MapReduce
Building & Optimizing Enterprise-class Hadoop with Open Architectures Prem Jain NetApp Introduction to Hadoop Comes from Internet companies Emerging big data storage and analytics platform HDFS and MapReduce
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ. Cloudera World Japan November 2014
 Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
NOT IN KANSAS ANY MORE
 NOT IN KANSAS ANY MORE How we moved into Big Data Dan Taylor - JDSU Dan Taylor Dan Taylor: An Engineering Manager, Software Developer, data enthusiast and advocate of all things Agile. I m currently lucky
NOT IN KANSAS ANY MORE How we moved into Big Data Dan Taylor - JDSU Dan Taylor Dan Taylor: An Engineering Manager, Software Developer, data enthusiast and advocate of all things Agile. I m currently lucky
Pulsar Realtime Analytics At Scale. Tony Ng April 14, 2015
 Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA TOOLS. Top 10 open source technologies for Big Data
 BIG DATA TOOLS Top 10 open source technologies for Big Data We are in an ever expanding marketplace!!! With shorter product lifecycles, evolving customer behavior and an economy that travels at the speed
BIG DATA TOOLS Top 10 open source technologies for Big Data We are in an ever expanding marketplace!!! With shorter product lifecycles, evolving customer behavior and an economy that travels at the speed
Converged, Real-time Analytics Enabling Faster Decision Making and New Business Opportunities
 Technology Insight Paper Converged, Real-time Analytics Enabling Faster Decision Making and New Business Opportunities By John Webster February 2015 Enabling you to make the best technology decisions Enabling
Technology Insight Paper Converged, Real-time Analytics Enabling Faster Decision Making and New Business Opportunities By John Webster February 2015 Enabling you to make the best technology decisions Enabling
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: [email protected] Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Big Data & QlikView. Democratizing Big Data Analytics. David Freriks Principal Solution Architect
 Big Data & QlikView Democratizing Big Data Analytics David Freriks Principal Solution Architect TDWI Vancouver Agenda What really is Big Data? How do we separate hype from reality? How does that relate
Big Data & QlikView Democratizing Big Data Analytics David Freriks Principal Solution Architect TDWI Vancouver Agenda What really is Big Data? How do we separate hype from reality? How does that relate
Agenda. Some Examples from Yahoo! Hadoop. Some Examples from Yahoo! Crawling. Cloud (data) management Ahmed Ali-Eldin. First part: Second part:
 management Ahmed Ali-Eldin. First part: Second part:") Cloud (data) management Ahmed Ali-Eldin First part: ZooKeeper (Yahoo!) Agenda A highly available, scalable, distributed, configuration, consensus, group membership, leader election, naming, and coordination
Cloud (data) management Ahmed Ali-Eldin First part: ZooKeeper (Yahoo!) Agenda A highly available, scalable, distributed, configuration, consensus, group membership, leader election, naming, and coordination
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming. by Dibyendu Bhattacharya
 Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Intro to Map/Reduce a.k.a. Hadoop
 Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
BASHO DATA PLATFORM SIMPLIFIES BIG DATA, IOT, AND HYBRID CLOUD APPS
 WHITEPAPER BASHO DATA PLATFORM BASHO DATA PLATFORM SIMPLIFIES BIG DATA, IOT, AND HYBRID CLOUD APPS INTRODUCTION Big Data applications and the Internet of Things (IoT) are changing and often improving our
WHITEPAPER BASHO DATA PLATFORM BASHO DATA PLATFORM SIMPLIFIES BIG DATA, IOT, AND HYBRID CLOUD APPS INTRODUCTION Big Data applications and the Internet of Things (IoT) are changing and often improving our
ANALYSIS OF BILL OF MATERIAL DATA USING KAFKA AND SPARK
 44 ANALYSIS OF BILL OF MATERIAL DATA USING KAFKA AND SPARK Ashwitha Jain *, Dr. Venkatramana Bhat P ** * Student, Department of Computer Science & Engineering, Mangalore Institute of Technology & Engineering
44 ANALYSIS OF BILL OF MATERIAL DATA USING KAFKA AND SPARK Ashwitha Jain *, Dr. Venkatramana Bhat P ** * Student, Department of Computer Science & Engineering, Mangalore Institute of Technology & Engineering
Accelerating and Simplifying Apache
 Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly