Improving our Evaluation of Transport Protocols. Sally Floyd Hamilton Institute July 29, 2005
|
|
|
- Madlyn Lester
- 8 years ago
- Views:
Transcription
1 Improving our Evaluation of Transport Protocols Sally Floyd Hamilton Institute July 29, 2005

2 Computer System Performance Modeling and Durable Nonsense A disconcertingly large portion of the literature on modeling the performance of complex systems, such as computer networks, satisfies Rosanoff's definition of durable nonsense.

3 "THE FIRST PRINCIPLE OF NONSENSE: For every durable item of nonsense, there exists an irrelevant frame of reference in which the item is sensible. "THE SECOND PRINCIPLE OF NONSENSE: Rigorous argument from inapplicable assumptions produces the world's most durable nonsense. "THE THIRD PRINCIPLE OF NONSENSE: The roots of most nonsense are found in the fact that people are more specialized than problems"

4 The quote is 25 years old! John Spragins, "Computer System Performance Modeling and Durable Nonsense", January R. A. Rosanoff, "A Survey of Modern Nonsense as Applied to Matrix Computations", April 1969.

5 Outline of Talk: Metrics for evaluating congestion control. Models for use in simulations, experiments, and analysis. Examples: HighSpeed TCP Quick-Start Congestion control for VoIP

6 Metrics for evaluating congestion control: throughput, delay, and drop rates Throughput: Router-based metric: link throughput. User-based metrics: per-connection throughput or file transfer times. Throughput after a sudden change in the app s demand (e.g., for voice and video). Fast startup. Delay: Router-based metric: queueing delay User-based metrics: per-packet delay (average or worst-case?) Drop rates.

7 Throughput, delay, and drop rates: Tradeoffs between throughput, delay, and drop rates. The space of possibilities depends on: the traffic mix; the range of RTTs; the traffic on the reverse path; the queue management at routers;

8 Metrics for evaluating congestion control: response times and minimizing oscillations. Response to sudden congestion: from other traffic; from routing or bandwidth changes. Concern: slowly-responding congestion control: Tradeoffs between responsiveness, smoothness, and aggressiveness. Minimizing oscillations in aggregate delay or throughput: Of particular interest to control theorists. Tradeoffs between responsiveness and minimizing oscillations.

9 Metrics for evaluating congestion control: fairness and convergence Fairness between flows using the same protocol: Which fairness metric? Fairness between flows with different RTTs? Fairness between flows with different packet sizes? Fairness with TCP Convergence times: Of particular concern with high bandwidth flows.

10 Robustness to failures and misbehavior: Within a connection: Receivers that lie to senders. Senders that lie to routers. Between connections: Flows that don t obey congestion control. Ease of diagnosing failures.

11 Metrics for evaluating congestion control: robustness for specific environments Robustness to: Corruption-based losses; Variable bandwidth; Packet reordering; Asymmetric routing; Route changes; Metric: energy consumption for mobile nodes Metric: goodput over wireless links Other metrics?

12 Metrics for evaluating congestion control: metrics for special classes of transport Below best-effort traffic. QoS-enabled traffic Metrics for evaluating congestion control: Deployability Is it deployable in the Internet?

13 Internet research needs better models! What models do we use for evaluating transport protocols? In simulations, experiments, and analysis. The simpliest model sufficient, but no simplier! A simple topology with one-way traffic of long-lived flows all with the same RTT? A complex topology aiming for full realism of the global Internet? Or something in between

14 Simulation with Two Long-lived Flows:
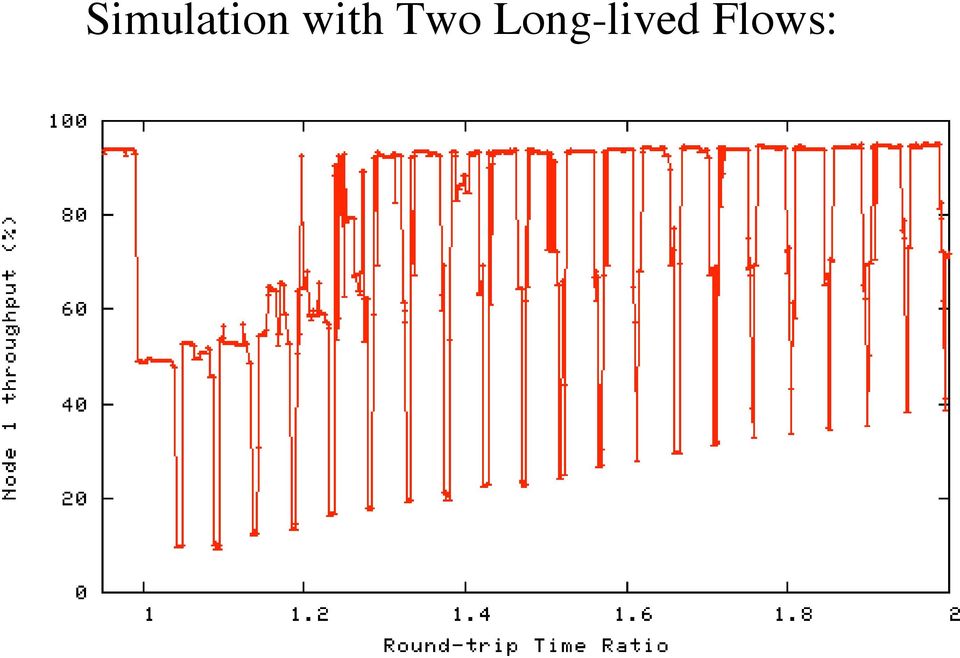
15 Two Long-lived Flows, with Telnet and Reverse-path Traffic:

16 Use a range of scenarios! A range of: Link bandwidths; Levels of congestion; Levels of statistical multiplexing Look for weaknesses as well as strengths! Look for the space of possible tradeoffs.

17 Characterizing scenarios: The distribution of RTTs: Measured by per-packet RTTs. Affects throughput, delay, etc. The distribution of connection sizes: Measured by packet sequence numbers. Affects throughput, delay, much else. Medium-sized flows slow-starting.

18 Distribution of Flow Sizes Distributions of packet numbers on the congested link over the second half of two simulations, with data measured on the Internet for comparison.

19 Distribution of RTTs Distributions of packet round-trip times on the congested link of two simulations, with data measured on the Internet for comparison.

20 Characterizing scenarios, continued. The degree of synchronization between flows: Measured by synchronization between flow pairs. Affects convergence times. The effect of burstiness: Measured by congestion response to bursts within flows. Affects throughput, delay, etc. Other characterizations?

21 Example: HighSpeed TCP The problem with standard TCP:: achieving 10 Gbps requires a window of 83,000 packets, and at most one loss every 1 2/3 hours, for 1500-byte packets,100 ms RTT The answer: more aggressive forms of TCP HighSpeed TCP (HSTCP), Scalable TCP, HTCP, FAST TCP, BIC TCP, XCP, etc. HighSpeed TCP: With higher congestion windows, increase faster than one packet per RTT, decrease less than halving the window.
22
23 Concerns raised by HighSpeed TCP: Two key metrics: Fairness with standard TCP. Convergence times. Different models give different convergence times! Model #1: DropTail queues, global synchronization for loss events. Model #2: Drop Tail queues, some synchronization, (depending on traffic mix). Model #3: RED queues, some synchronization, (depending on traffic mix). Model #4: RED queues, no synchronization Which model is the best fit for the current and future Internet?
24 Synchronization for HighSpeed TCP: What to we know about synchronization on high-bandwidth paths? Has it been measured? Is there a rich traffic mix at the congested router? Do the congested routers use AQM? Are future high-bandwidth paths likely to be similar to current ones?
25 Example: Quick-Start Quick-Start (QS): A proposal for end nodes to ask permission from routers to send at a high rate. Uses an IP option. Routers approve request by decrementing a counter. Approval only by underutilized routers. Metrics for evaluation? Effective use of bandwidth in underutilized paths? Incremental deployment? Robustness against competition and attacks?
26 Evaluation of QuickStart: Possible problems: Senders asking for too much QuickStart bandwidth. QuickStart requests denied downstream. Malicious QuickStart requests. The result: No QuickStart bandwidth available for others. The partial fix: Routers keeping history of sender s behaviors.
27 Evaluation of QuickStart, continued: Lessons: Each mechanism has its own strengths and weaknesses, that need to be discovered and explored. For evaluating QuickStart: Knowing behavior in the current Internet doesn t help. Evaluation is about understanding possible behavior in the future Internet. This is hard.
28 Example: congestion control for VoIP TFRC (TCP-Friendly Rate Control): The same average sending rate, in packets per RTT, as a TCP flow with the same loss event rate. More slowly-responding than TCP - Doesn t halve the sending rate in response to a single loss. The mechanism: The receiver calculates the loss event rate. The sender calculates the allowed sending rate for that loss event rate.
29 VoIP TFRC: A variant of TFRC for flows with small packets: Sending at most 100 packets per second. The goal: The same sending rate in bytes per second as TCP flows with large packets and the same packet drop rate. The problem: Works fine when flows with small packets receive a similar packet drop rate as flows with large packets
30 VoIP TFRC, Queue in Packets:
31 VoIP TFRC, Queue in Packets:
32 VoIP TFRC, Queue in Bytes:
33 VoIP TFRC, Queue in Bytes:
34 VoIP TFRC: What are queues like in congested routers in the Internet today and tomorrow? Queue in packets, bytes, or K-byte buffers? Cisco routers have pools of fixed-size buffers, e.g., of 1500B, 600B, and 80B. What is the effect on packet-dropping? DropTail or AQM (Active Queue Management)? If AQM: Are all packets dropped with the same probability (e.g.,cisco)? All bytes dropped with the same probability? Should transport be changed to accommodate small-packet flows, or should routers be changed?
35 Conclusions: Questions How do our models affect our results? How do our models affect the relevance of our results to the current or future Internet? What kinds of tools do we need to improve our understanding of models?
36 References: Metrics for the Evaluation of Congestion Control Mechanisms, S. Floyd, internet-draft draft-floyd-transportmodels-00.txt, Internet Research Needs Better Models, Sally Floyd and Eddie Kohler, Hotnets-I, On Traffic Phase Effects in Packet-Switched Gateways, S. Floyd and V. Jacobson, Internetworking: Research and Experience, HighSpeed TCP for Large Congestion Windows, S. Floyd, RFC 3649, 2003.
37 References, continued: Evaluating Quick-Start for TCP. Pasi Sarolahti, Mark Allman, and Sally Floyd. February TCP Friendly Rate Control (TFRC) for Voice: VoIP Variant, Sally Floyd, internet-draft draftietf-dccp-tfrc-voip-02.txt, work in progress, July 2005.
Requirements for Simulation and Modeling Tools. Sally Floyd NSF Workshop August 2005
 Requirements for Simulation and Modeling Tools Sally Floyd NSF Workshop August 2005 Outline for talk: Requested topic: the requirements for simulation and modeling tools that allow one to study, design,
Requirements for Simulation and Modeling Tools Sally Floyd NSF Workshop August 2005 Outline for talk: Requested topic: the requirements for simulation and modeling tools that allow one to study, design,
Adaptive RED: An Algorithm for Increasing the Robustness of RED s Active Queue Management. by Ramakrishna Gummadi.
 Adaptive RED: An Algorithm for Increasing the Robustness of RED s Active Queue Management by Ramakrishna Gummadi Research Project Submitted to the Department of Electrical Engineering and Computer Sciences,
Adaptive RED: An Algorithm for Increasing the Robustness of RED s Active Queue Management by Ramakrishna Gummadi Research Project Submitted to the Department of Electrical Engineering and Computer Sciences,
17: Queue Management. Queuing. Mark Handley
 17: Queue Management Mark Handley Queuing The primary purpose of a queue in an IP router is to smooth out bursty arrivals, so that the network utilization can be high. But queues add delay and cause jitter.
17: Queue Management Mark Handley Queuing The primary purpose of a queue in an IP router is to smooth out bursty arrivals, so that the network utilization can be high. But queues add delay and cause jitter.
Assessing the Impact of Multiple Active Queue Management Routers
 Assessing the Impact of Multiple Active Queue Management Routers Michele C. Weigle Department of Computer Science Old Dominion University Norfolk, VA 23529 mweigle@cs.odu.edu Deepak Vembar and Zhidian
Assessing the Impact of Multiple Active Queue Management Routers Michele C. Weigle Department of Computer Science Old Dominion University Norfolk, VA 23529 mweigle@cs.odu.edu Deepak Vembar and Zhidian
Adaptive RED: An Algorithm for Increasing the Robustness of RED s Active Queue Management
 Adaptive RED: An Algorithm for Increasing the Robustness of RED s Active Queue Management Sally Floyd, Ramakrishna Gummadi, and Scott Shenker AT&T Center for Internet Research at ICSI August 1, 21, under
Adaptive RED: An Algorithm for Increasing the Robustness of RED s Active Queue Management Sally Floyd, Ramakrishna Gummadi, and Scott Shenker AT&T Center for Internet Research at ICSI August 1, 21, under
Research Topics Typical Models Supporting Measurements AQM, scheduling, differentiated services. A dumbbell topology, with aggregate traffic.
 Internet Research Needs Better Models Sally Floyd Eddie Kohler ICSI Center for Internet Research, Berkeley, California {floyd, kohler}@icir.org 1 INTRODUCTION Networking researchers work from mental models
Internet Research Needs Better Models Sally Floyd Eddie Kohler ICSI Center for Internet Research, Berkeley, California {floyd, kohler}@icir.org 1 INTRODUCTION Networking researchers work from mental models
3 Experimental Design
 A Step toward Realistic Performance Evaluation of High-Speed TCP Variants (Extended Abstract) Sangtae Ha, Yusung Kim, Long Le, Injong Rhee Lisong Xu Department of Computer Science Department of Computer
A Step toward Realistic Performance Evaluation of High-Speed TCP Variants (Extended Abstract) Sangtae Ha, Yusung Kim, Long Le, Injong Rhee Lisong Xu Department of Computer Science Department of Computer
Delay-Based Early Congestion Detection and Adaptation in TCP: Impact on web performance
 1 Delay-Based Early Congestion Detection and Adaptation in TCP: Impact on web performance Michele C. Weigle Clemson University Clemson, SC 29634-196 Email: mweigle@cs.clemson.edu Kevin Jeffay and F. Donelson
1 Delay-Based Early Congestion Detection and Adaptation in TCP: Impact on web performance Michele C. Weigle Clemson University Clemson, SC 29634-196 Email: mweigle@cs.clemson.edu Kevin Jeffay and F. Donelson
SHIV SHAKTI International Journal of in Multidisciplinary and Academic Research (SSIJMAR) Vol. 4, No. 3, June 2015 (ISSN 2278 5973)
 Vol. 4, No. 3, June 2015 (ISSN 2278 5973)") SHIV SHAKTI International Journal of in Multidisciplinary and Academic Research (SSIJMAR) Vol. 4, No. 3, June 2015 (ISSN 2278 5973) RED Routing Algorithm in Active Queue Management for Transmission Congesstion
SHIV SHAKTI International Journal of in Multidisciplinary and Academic Research (SSIJMAR) Vol. 4, No. 3, June 2015 (ISSN 2278 5973) RED Routing Algorithm in Active Queue Management for Transmission Congesstion
4 High-speed Transmission and Interoperability
 4 High-speed Transmission and Interoperability Technology 4-1 Transport Protocols for Fast Long-Distance Networks: Comparison of Their Performances in JGN KUMAZOE Kazumi, KOUYAMA Katsushi, HORI Yoshiaki,
4 High-speed Transmission and Interoperability Technology 4-1 Transport Protocols for Fast Long-Distance Networks: Comparison of Their Performances in JGN KUMAZOE Kazumi, KOUYAMA Katsushi, HORI Yoshiaki,
Internet Congestion Control for Future High Bandwidth-Delay Product Environments
 Internet Congestion Control for Future High Bandwidth-Delay Product Environments Dina Katabi Mark Handley Charlie Rohrs MIT-LCS ICSI Tellabs dk@mit.edu mjh@icsi.berkeley.edu crhors@mit.edu Abstract Theory
Internet Congestion Control for Future High Bandwidth-Delay Product Environments Dina Katabi Mark Handley Charlie Rohrs MIT-LCS ICSI Tellabs dk@mit.edu mjh@icsi.berkeley.edu crhors@mit.edu Abstract Theory
15-441: Computer Networks Homework 2 Solution
 5-44: omputer Networks Homework 2 Solution Assigned: September 25, 2002. Due: October 7, 2002 in class. In this homework you will test your understanding of the TP concepts taught in class including flow
5-44: omputer Networks Homework 2 Solution Assigned: September 25, 2002. Due: October 7, 2002 in class. In this homework you will test your understanding of the TP concepts taught in class including flow
Performance Analysis of AQM Schemes in Wired and Wireless Networks based on TCP flow
 International Journal of Soft Computing and Engineering (IJSCE) Performance Analysis of AQM Schemes in Wired and Wireless Networks based on TCP flow Abdullah Al Masud, Hossain Md. Shamim, Amina Akhter
International Journal of Soft Computing and Engineering (IJSCE) Performance Analysis of AQM Schemes in Wired and Wireless Networks based on TCP flow Abdullah Al Masud, Hossain Md. Shamim, Amina Akhter
High-Speed TCP Performance Characterization under Various Operating Systems
 High-Speed TCP Performance Characterization under Various Operating Systems Y. Iwanaga, K. Kumazoe, D. Cavendish, M.Tsuru and Y. Oie Kyushu Institute of Technology 68-4, Kawazu, Iizuka-shi, Fukuoka, 82-852,
High-Speed TCP Performance Characterization under Various Operating Systems Y. Iwanaga, K. Kumazoe, D. Cavendish, M.Tsuru and Y. Oie Kyushu Institute of Technology 68-4, Kawazu, Iizuka-shi, Fukuoka, 82-852,
XCP-i : explicit Control Protocol for heterogeneous inter-networking of high-speed networks
 : explicit Control Protocol for heterogeneous inter-networking of high-speed networks D. M. Lopez-Pacheco INRIA RESO/LIP, France Email: dmlopezp@ens-lyon.fr C. Pham, Member, IEEE LIUPPA, University of
: explicit Control Protocol for heterogeneous inter-networking of high-speed networks D. M. Lopez-Pacheco INRIA RESO/LIP, France Email: dmlopezp@ens-lyon.fr C. Pham, Member, IEEE LIUPPA, University of
Sizing Internet Router Buffers, Active Queue Management, and the Lur e Problem
 Sizing Internet Router Buffers, Active Queue Management, and the Lur e Problem Christopher M. Kellett, Robert N. Shorten, and Douglas J. Leith Abstract Recent work in sizing Internet router buffers has
Sizing Internet Router Buffers, Active Queue Management, and the Lur e Problem Christopher M. Kellett, Robert N. Shorten, and Douglas J. Leith Abstract Recent work in sizing Internet router buffers has
International Journal of Scientific & Engineering Research, Volume 6, Issue 7, July-2015 1169 ISSN 2229-5518
 International Journal of Scientific & Engineering Research, Volume 6, Issue 7, July-2015 1169 Comparison of TCP I-Vegas with TCP Vegas in Wired-cum-Wireless Network Nitin Jain & Dr. Neelam Srivastava Abstract
International Journal of Scientific & Engineering Research, Volume 6, Issue 7, July-2015 1169 Comparison of TCP I-Vegas with TCP Vegas in Wired-cum-Wireless Network Nitin Jain & Dr. Neelam Srivastava Abstract
Analyzing Marking Mod RED Active Queue Management Scheme on TCP Applications
 212 International Conference on Information and Network Technology (ICINT 212) IPCSIT vol. 7 (212) (212) IACSIT Press, Singapore Analyzing Marking Active Queue Management Scheme on TCP Applications G.A.
212 International Conference on Information and Network Technology (ICINT 212) IPCSIT vol. 7 (212) (212) IACSIT Press, Singapore Analyzing Marking Active Queue Management Scheme on TCP Applications G.A.
Lecture 15: Congestion Control. CSE 123: Computer Networks Stefan Savage
 Lecture 15: Congestion Control CSE 123: Computer Networks Stefan Savage Overview Yesterday: TCP & UDP overview Connection setup Flow control: resource exhaustion at end node Today: Congestion control Resource
Lecture 15: Congestion Control CSE 123: Computer Networks Stefan Savage Overview Yesterday: TCP & UDP overview Connection setup Flow control: resource exhaustion at end node Today: Congestion control Resource
Improving Quality of Service
 Improving Quality of Service Using Dell PowerConnect 6024/6024F Switches Quality of service (QoS) mechanisms classify and prioritize network traffic to improve throughput. This article explains the basic
Improving Quality of Service Using Dell PowerConnect 6024/6024F Switches Quality of service (QoS) mechanisms classify and prioritize network traffic to improve throughput. This article explains the basic
Performance of VoIP using DCCP over a DVB-RCS Satellite Network
 Performance of VoIP using DCCP over a DVB-RCS Satellite Network Arjuna Sathiaseelan Gorry Fairhurst Department of Engineering, Electronics Research Group, University of Aberdeen, United Kingdom Email:
Performance of VoIP using DCCP over a DVB-RCS Satellite Network Arjuna Sathiaseelan Gorry Fairhurst Department of Engineering, Electronics Research Group, University of Aberdeen, United Kingdom Email:
Comparative Analysis of Congestion Control Algorithms Using ns-2
 www.ijcsi.org 89 Comparative Analysis of Congestion Control Algorithms Using ns-2 Sanjeev Patel 1, P. K. Gupta 2, Arjun Garg 3, Prateek Mehrotra 4 and Manish Chhabra 5 1 Deptt. of Computer Sc. & Engg,
www.ijcsi.org 89 Comparative Analysis of Congestion Control Algorithms Using ns-2 Sanjeev Patel 1, P. K. Gupta 2, Arjun Garg 3, Prateek Mehrotra 4 and Manish Chhabra 5 1 Deptt. of Computer Sc. & Engg,
Lecture Objectives. Lecture 07 Mobile Networks: TCP in Wireless Networks. Agenda. TCP Flow Control. Flow Control Can Limit Throughput (1)
") Lecture Objectives Wireless and Mobile Systems Design Lecture 07 Mobile Networks: TCP in Wireless Networks Describe TCP s flow control mechanism Describe operation of TCP Reno and TCP Vegas, including
Lecture Objectives Wireless and Mobile Systems Design Lecture 07 Mobile Networks: TCP in Wireless Networks Describe TCP s flow control mechanism Describe operation of TCP Reno and TCP Vegas, including
GREEN: Proactive Queue Management over a Best-Effort Network
 IEEE GlobeCom (GLOBECOM ), Taipei, Taiwan, November. LA-UR -4 : Proactive Queue Management over a Best-Effort Network Wu-chun Feng, Apu Kapadia, Sunil Thulasidasan feng@lanl.gov, akapadia@uiuc.edu, sunil@lanl.gov
IEEE GlobeCom (GLOBECOM ), Taipei, Taiwan, November. LA-UR -4 : Proactive Queue Management over a Best-Effort Network Wu-chun Feng, Apu Kapadia, Sunil Thulasidasan feng@lanl.gov, akapadia@uiuc.edu, sunil@lanl.gov
LRU-RED: An active queue management scheme to contain high bandwidth flows at congested routers
 LRU-RED: An active queue management scheme to contain high bandwidth flows at congested routers Smitha A. L. Narasimha Reddy Dept. of Elec. Engg., Texas A & M University, College Station, TX 77843-3128,
LRU-RED: An active queue management scheme to contain high bandwidth flows at congested routers Smitha A. L. Narasimha Reddy Dept. of Elec. Engg., Texas A & M University, College Station, TX 77843-3128,
Performance Evaluation of AODV, OLSR Routing Protocol in VOIP Over Ad Hoc
 (International Journal of Computer Science & Management Studies) Vol. 17, Issue 01 Performance Evaluation of AODV, OLSR Routing Protocol in VOIP Over Ad Hoc Dr. Khalid Hamid Bilal Khartoum, Sudan dr.khalidbilal@hotmail.com
(International Journal of Computer Science & Management Studies) Vol. 17, Issue 01 Performance Evaluation of AODV, OLSR Routing Protocol in VOIP Over Ad Hoc Dr. Khalid Hamid Bilal Khartoum, Sudan dr.khalidbilal@hotmail.com
Congestion Control for High Bandwidth-Delay Product Networks
 Congestion Control for High Bandwidth-Delay Product Networks Dina Katabi Mark Handley Charlie Rohrs Ý MIT-LCS ICSI Tellabs dk@mit.edu mjh@icsi.berkeley.edu crhors@mit.edu ABSTRACT Theory and experiments
Congestion Control for High Bandwidth-Delay Product Networks Dina Katabi Mark Handley Charlie Rohrs Ý MIT-LCS ICSI Tellabs dk@mit.edu mjh@icsi.berkeley.edu crhors@mit.edu ABSTRACT Theory and experiments
Adaptive Virtual Buffer(AVB)-An Active Queue Management Scheme for Internet Quality of Service
-An Active Queue Management Scheme for Internet Quality of Service") Adaptive Virtual Buffer(AVB)-An Active Queue Management Scheme for Internet Quality of Service Xidong Deng, George esidis, Chita Das Department of Computer Science and Engineering The Pennsylvania State
Adaptive Virtual Buffer(AVB)-An Active Queue Management Scheme for Internet Quality of Service Xidong Deng, George esidis, Chita Das Department of Computer Science and Engineering The Pennsylvania State
Outline. TCP connection setup/data transfer. 15-441 Computer Networking. TCP Reliability. Congestion sources and collapse. Congestion control basics
 Outline 15-441 Computer Networking Lecture 8 TCP & Congestion Control TCP connection setup/data transfer TCP Reliability Congestion sources and collapse Congestion control basics Lecture 8: 09-23-2002
Outline 15-441 Computer Networking Lecture 8 TCP & Congestion Control TCP connection setup/data transfer TCP Reliability Congestion sources and collapse Congestion control basics Lecture 8: 09-23-2002
A Spectrum of TCP-Friendly Window-Based Congestion Control Algorithms
 IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 11, NO. 3, JUNE 2003 341 A Spectrum of TCP-Friendly Window-Based Congestion Control Algorithms Shudong Jin, Liang Guo, Student Member, IEEE, Ibrahim Matta, Member,
IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 11, NO. 3, JUNE 2003 341 A Spectrum of TCP-Friendly Window-Based Congestion Control Algorithms Shudong Jin, Liang Guo, Student Member, IEEE, Ibrahim Matta, Member,
Random Early Detection Gateways for Congestion Avoidance
 Random Early Detection Gateways for Congestion Avoidance Sally Floyd and Van Jacobson Lawrence Berkeley Laboratory University of California floyd@eelblgov van@eelblgov To appear in the August 1993 IEEE/ACM
Random Early Detection Gateways for Congestion Avoidance Sally Floyd and Van Jacobson Lawrence Berkeley Laboratory University of California floyd@eelblgov van@eelblgov To appear in the August 1993 IEEE/ACM
Improving the Performance of TCP Using Window Adjustment Procedure and Bandwidth Estimation
 Improving the Performance of TCP Using Window Adjustment Procedure and Bandwidth Estimation R.Navaneethakrishnan Assistant Professor (SG) Bharathiyar College of Engineering and Technology, Karaikal, India.
Improving the Performance of TCP Using Window Adjustment Procedure and Bandwidth Estimation R.Navaneethakrishnan Assistant Professor (SG) Bharathiyar College of Engineering and Technology, Karaikal, India.
Network management and QoS provisioning - QoS in the Internet
 QoS in the Internet Inernet approach is based on datagram service (best effort), so provide QoS was not a purpose for developers. Mainly problems are:. recognizing flows;. manage the issue that packets
QoS in the Internet Inernet approach is based on datagram service (best effort), so provide QoS was not a purpose for developers. Mainly problems are:. recognizing flows;. manage the issue that packets
MMPTCP: A Novel Transport Protocol for Data Centre Networks
 MMPTCP: A Novel Transport Protocol for Data Centre Networks Morteza Kheirkhah FoSS, Department of Informatics, University of Sussex Modern Data Centre Networks FatTree It provides full bisection bandwidth
MMPTCP: A Novel Transport Protocol for Data Centre Networks Morteza Kheirkhah FoSS, Department of Informatics, University of Sussex Modern Data Centre Networks FatTree It provides full bisection bandwidth
Passive Queue Management
 , 2013 Performance Evaluation of Computer Networks Objectives Explain the role of active queue management in performance optimization of TCP/IP networks Learn a range of active queue management algorithms
, 2013 Performance Evaluation of Computer Networks Objectives Explain the role of active queue management in performance optimization of TCP/IP networks Learn a range of active queue management algorithms
Equation-Based Congestion Control for Unicast Applications
 Equation-Based Congestion Control for Unicast Applications Sally Floyd, Mark Handley ATT Center for Internet Research at ICSI (ACIRI) Jitendra Padhye University of Massachusetts at Amherst Jörg Widmer
Equation-Based Congestion Control for Unicast Applications Sally Floyd, Mark Handley ATT Center for Internet Research at ICSI (ACIRI) Jitendra Padhye University of Massachusetts at Amherst Jörg Widmer
Robustness to Packet Reordering in High-speed Networks
 13 Robustness to Packet Reordering in High-speed Networks Sumitha Bhandarkar and A. L. Narasimha Reddy Dept. of Electrical and Computer Engineering Texas A & M University sumitha,reddy @ee.tamu.edu Abstract
13 Robustness to Packet Reordering in High-speed Networks Sumitha Bhandarkar and A. L. Narasimha Reddy Dept. of Electrical and Computer Engineering Texas A & M University sumitha,reddy @ee.tamu.edu Abstract
Murari Sridharan Windows TCP/IP Networking, Microsoft Corp. (Collaborators: Kun Tan, Jingmin Song, MSRA & Qian Zhang, HKUST)
") Murari Sridharan Windows TCP/IP Networking, Microsoft Corp. (Collaborators: Kun Tan, Jingmin Song, MSRA & Qian Zhang, HKUST) Design goals Efficiency Improve throughput by efficiently using the spare capacity
Murari Sridharan Windows TCP/IP Networking, Microsoft Corp. (Collaborators: Kun Tan, Jingmin Song, MSRA & Qian Zhang, HKUST) Design goals Efficiency Improve throughput by efficiently using the spare capacity
Requirements of Voice in an IP Internetwork
 Requirements of Voice in an IP Internetwork Real-Time Voice in a Best-Effort IP Internetwork This topic lists problems associated with implementation of real-time voice traffic in a best-effort IP internetwork.
Requirements of Voice in an IP Internetwork Real-Time Voice in a Best-Effort IP Internetwork This topic lists problems associated with implementation of real-time voice traffic in a best-effort IP internetwork.
Sync & Sense Enabled Adaptive Packetization VoIP
 Sync & Sense Enabled Adaptive Packetization VoIP by Boonchai Ngamwongwattana B.Eng., King Mongkut s Institute of Technology, Ladkrabang, Thailand, 1994 M.S., Telecommunications, University of Pittsburgh,
Sync & Sense Enabled Adaptive Packetization VoIP by Boonchai Ngamwongwattana B.Eng., King Mongkut s Institute of Technology, Ladkrabang, Thailand, 1994 M.S., Telecommunications, University of Pittsburgh,
Robust Router Congestion Control Using Acceptance and Departure Rate Measures
 Robust Router Congestion Control Using Acceptance and Departure Rate Measures Ganesh Gopalakrishnan a, Sneha Kasera b, Catherine Loader c, and Xin Wang b a {ganeshg@microsoft.com}, Microsoft Corporation,
Robust Router Congestion Control Using Acceptance and Departure Rate Measures Ganesh Gopalakrishnan a, Sneha Kasera b, Catherine Loader c, and Xin Wang b a {ganeshg@microsoft.com}, Microsoft Corporation,
Chapter 4. VoIP Metric based Traffic Engineering to Support the Service Quality over the Internet (Inter-domain IP network)
") Chapter 4 VoIP Metric based Traffic Engineering to Support the Service Quality over the Internet (Inter-domain IP network) 4.1 Introduction Traffic Engineering can be defined as a task of mapping traffic
Chapter 4 VoIP Metric based Traffic Engineering to Support the Service Quality over the Internet (Inter-domain IP network) 4.1 Introduction Traffic Engineering can be defined as a task of mapping traffic
Protagonist International Journal of Management And Technology (PIJMT) Online ISSN- 2394-3742. Vol 2 No 3 (May-2015) Active Queue Management
 Online ISSN- 2394-3742. Vol 2 No 3 (May-2015) Active Queue Management") Protagonist International Journal of Management And Technology (PIJMT) Online ISSN- 2394-3742 Vol 2 No 3 (May-2015) Active Queue Management For Transmission Congestion control Manu Yadav M.Tech Student
Protagonist International Journal of Management And Technology (PIJMT) Online ISSN- 2394-3742 Vol 2 No 3 (May-2015) Active Queue Management For Transmission Congestion control Manu Yadav M.Tech Student
TCP in Wireless Mobile Networks
 TCP in Wireless Mobile Networks 1 Outline Introduction to transport layer Introduction to TCP (Internet) congestion control Congestion control in wireless networks 2 Transport Layer v.s. Network Layer
TCP in Wireless Mobile Networks 1 Outline Introduction to transport layer Introduction to TCP (Internet) congestion control Congestion control in wireless networks 2 Transport Layer v.s. Network Layer
Quality of Service. Traditional Nonconverged Network. Traditional data traffic characteristics:
 Quality of Service 1 Traditional Nonconverged Network Traditional data traffic characteristics: Bursty data flow FIFO access Not overly time-sensitive; delays OK Brief outages are survivable 2 1 Converged
Quality of Service 1 Traditional Nonconverged Network Traditional data traffic characteristics: Bursty data flow FIFO access Not overly time-sensitive; delays OK Brief outages are survivable 2 1 Converged
Quality of Service using Traffic Engineering over MPLS: An Analysis. Praveen Bhaniramka, Wei Sun, Raj Jain
 Praveen Bhaniramka, Wei Sun, Raj Jain Department of Computer and Information Science The Ohio State University 201 Neil Ave, DL39 Columbus, OH 43210 USA Telephone Number: +1 614-292-3989 FAX number: +1
Praveen Bhaniramka, Wei Sun, Raj Jain Department of Computer and Information Science The Ohio State University 201 Neil Ave, DL39 Columbus, OH 43210 USA Telephone Number: +1 614-292-3989 FAX number: +1
Optimization of Communication Systems Lecture 6: Internet TCP Congestion Control
 Optimization of Communication Systems Lecture 6: Internet TCP Congestion Control Professor M. Chiang Electrical Engineering Department, Princeton University ELE539A February 21, 2007 Lecture Outline TCP
Optimization of Communication Systems Lecture 6: Internet TCP Congestion Control Professor M. Chiang Electrical Engineering Department, Princeton University ELE539A February 21, 2007 Lecture Outline TCP
Applications. Network Application Performance Analysis. Laboratory. Objective. Overview
 Laboratory 12 Applications Network Application Performance Analysis Objective The objective of this lab is to analyze the performance of an Internet application protocol and its relation to the underlying
Laboratory 12 Applications Network Application Performance Analysis Objective The objective of this lab is to analyze the performance of an Internet application protocol and its relation to the underlying
Performance improvement of active queue management with per-flow scheduling
 Performance improvement of active queue management with per-flow scheduling Masayoshi Nabeshima, Kouji Yata NTT Cyber Solutions Laboratories, NTT Corporation 1-1 Hikari-no-oka Yokosuka-shi Kanagawa 239
Performance improvement of active queue management with per-flow scheduling Masayoshi Nabeshima, Kouji Yata NTT Cyber Solutions Laboratories, NTT Corporation 1-1 Hikari-no-oka Yokosuka-shi Kanagawa 239
Active Queue Management
 Active Queue Management TELCOM2321 CS2520 Wide Area Networks Dr. Walter Cerroni University of Bologna Italy Visiting Assistant Professor at SIS, Telecom Program Slides partly based on Dr. Znati s material
Active Queue Management TELCOM2321 CS2520 Wide Area Networks Dr. Walter Cerroni University of Bologna Italy Visiting Assistant Professor at SIS, Telecom Program Slides partly based on Dr. Znati s material
CSE 123: Computer Networks
 CSE 123: Computer Networks Homework 4 Solutions Out: 12/03 Due: 12/10 1. Routers and QoS Packet # Size Flow 1 100 1 2 110 1 3 50 1 4 160 2 5 80 2 6 240 2 7 90 3 8 180 3 Suppose a router has three input
CSE 123: Computer Networks Homework 4 Solutions Out: 12/03 Due: 12/10 1. Routers and QoS Packet # Size Flow 1 100 1 2 110 1 3 50 1 4 160 2 5 80 2 6 240 2 7 90 3 8 180 3 Suppose a router has three input
THE end-to-end congestion control mechanisms of TCP
 458 IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 7, NO. 4, AUGUST 1999 Promoting the Use of End-to-End Congestion Control in the Internet Sally Floyd, Senior Member, IEEE, and Kevin Fall Abstract This paper
458 IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 7, NO. 4, AUGUST 1999 Promoting the Use of End-to-End Congestion Control in the Internet Sally Floyd, Senior Member, IEEE, and Kevin Fall Abstract This paper
Adaptive Coding and Packet Rates for TCP-Friendly VoIP Flows
 Adaptive Coding and Packet Rates for TCP-Friendly VoIP Flows C. Mahlo, C. Hoene, A. Rostami, A. Wolisz Technical University of Berlin, TKN, Sekr. FT 5-2 Einsteinufer 25, 10587 Berlin, Germany. Emails:
Adaptive Coding and Packet Rates for TCP-Friendly VoIP Flows C. Mahlo, C. Hoene, A. Rostami, A. Wolisz Technical University of Berlin, TKN, Sekr. FT 5-2 Einsteinufer 25, 10587 Berlin, Germany. Emails:
Congestion Control Review. 15-441 Computer Networking. Resource Management Approaches. Traffic and Resource Management. What is congestion control?
 Congestion Control Review What is congestion control? 15-441 Computer Networking What is the principle of TCP? Lecture 22 Queue Management and QoS 2 Traffic and Resource Management Resource Management
Congestion Control Review What is congestion control? 15-441 Computer Networking What is the principle of TCP? Lecture 22 Queue Management and QoS 2 Traffic and Resource Management Resource Management
STANDPOINT FOR QUALITY-OF-SERVICE MEASUREMENT
 STANDPOINT FOR QUALITY-OF-SERVICE MEASUREMENT 1. TIMING ACCURACY The accurate multi-point measurements require accurate synchronization of clocks of the measurement devices. If for example time stamps
STANDPOINT FOR QUALITY-OF-SERVICE MEASUREMENT 1. TIMING ACCURACY The accurate multi-point measurements require accurate synchronization of clocks of the measurement devices. If for example time stamps
Traffic Engineering & Network Planning Tool for MPLS Networks
 Traffic Engineering & Network Planning Tool for MPLS Networks Dr. Associate Professor, Department of Electrical Engineering Indian Institute of Technology Bombay, Powai, Mumbai 76 Founder & Director, Vegayan
Traffic Engineering & Network Planning Tool for MPLS Networks Dr. Associate Professor, Department of Electrical Engineering Indian Institute of Technology Bombay, Powai, Mumbai 76 Founder & Director, Vegayan
Quality of Service versus Fairness. Inelastic Applications. QoS Analogy: Surface Mail. How to Provide QoS?
 18-345: Introduction to Telecommunication Networks Lectures 20: Quality of Service Peter Steenkiste Spring 2015 www.cs.cmu.edu/~prs/nets-ece Overview What is QoS? Queuing discipline and scheduling Traffic
18-345: Introduction to Telecommunication Networks Lectures 20: Quality of Service Peter Steenkiste Spring 2015 www.cs.cmu.edu/~prs/nets-ece Overview What is QoS? Queuing discipline and scheduling Traffic
Internet Flow Control - Improving on TCP
 Internet Flow Control - Improving on TCP Glynn Rogers The Team - Jonathan Chan, Fariza Sabrina, and Darwin Agahari CSIRO ICT Centre Why Bother? - Isn t TCP About as Good as It Gets?! Well, TCP is a very
Internet Flow Control - Improving on TCP Glynn Rogers The Team - Jonathan Chan, Fariza Sabrina, and Darwin Agahari CSIRO ICT Centre Why Bother? - Isn t TCP About as Good as It Gets?! Well, TCP is a very
TCP, Active Queue Management and QoS
 TCP, Active Queue Management and QoS Don Towsley UMass Amherst towsley@cs.umass.edu Collaborators: W. Gong, C. Hollot, V. Misra Outline motivation TCP friendliness/fairness bottleneck invariant principle
TCP, Active Queue Management and QoS Don Towsley UMass Amherst towsley@cs.umass.edu Collaborators: W. Gong, C. Hollot, V. Misra Outline motivation TCP friendliness/fairness bottleneck invariant principle
Cisco Application Networking for Citrix Presentation Server
 Cisco Application Networking for Citrix Presentation Server Faster Site Navigation, Less Bandwidth and Server Processing, and Greater Availability for Global Deployments What You Will Learn To address
Cisco Application Networking for Citrix Presentation Server Faster Site Navigation, Less Bandwidth and Server Processing, and Greater Availability for Global Deployments What You Will Learn To address
Enabling Cloud Architecture for Globally Distributed Applications
 The increasingly on demand nature of enterprise and consumer services is driving more companies to execute business processes in real-time and give users information in a more realtime, self-service manner.
The increasingly on demand nature of enterprise and consumer services is driving more companies to execute business processes in real-time and give users information in a more realtime, self-service manner.
() XCP-i: explicit Control Protocol for heterogeneous inter-networking November 28th, of high-speed 2006 1 networks / 15
 XCP-i: explicit Control Protocol for heterogeneous inter-networking November 28th, of high-speed 2006 1 networks / 15") XCP-i: explicit Control Protocol for heterogeneous inter-networking of high-speed networks Dino LOPEZ 1 C. PHAM 2 L. LEFEVRE 3 November 28th, 2006 1 INRIA RESO/LIP, France dmlopezp@ens-lyon.fr 2 LIUPPA,
XCP-i: explicit Control Protocol for heterogeneous inter-networking of high-speed networks Dino LOPEZ 1 C. PHAM 2 L. LEFEVRE 3 November 28th, 2006 1 INRIA RESO/LIP, France dmlopezp@ens-lyon.fr 2 LIUPPA,
A Survey: High Speed TCP Variants in Wireless Networks
 ISSN: 2321-7782 (Online) Volume 1, Issue 7, December 2013 International Journal of Advance Research in Computer Science and Management Studies Research Paper Available online at: www.ijarcsms.com A Survey:
ISSN: 2321-7782 (Online) Volume 1, Issue 7, December 2013 International Journal of Advance Research in Computer Science and Management Studies Research Paper Available online at: www.ijarcsms.com A Survey:
AN IMPROVED SNOOP FOR TCP RENO AND TCP SACK IN WIRED-CUM- WIRELESS NETWORKS
 AN IMPROVED SNOOP FOR TCP RENO AND TCP SACK IN WIRED-CUM- WIRELESS NETWORKS Srikanth Tiyyagura Department of Computer Science and Engineering JNTUA College of Engg., pulivendula, Andhra Pradesh, India.
AN IMPROVED SNOOP FOR TCP RENO AND TCP SACK IN WIRED-CUM- WIRELESS NETWORKS Srikanth Tiyyagura Department of Computer Science and Engineering JNTUA College of Engg., pulivendula, Andhra Pradesh, India.
SJBIT, Bangalore, KARNATAKA
 A Comparison of the TCP Variants Performance over different Routing Protocols on Mobile Ad Hoc Networks S. R. Biradar 1, Subir Kumar Sarkar 2, Puttamadappa C 3 1 Sikkim Manipal Institute of Technology,
A Comparison of the TCP Variants Performance over different Routing Protocols on Mobile Ad Hoc Networks S. R. Biradar 1, Subir Kumar Sarkar 2, Puttamadappa C 3 1 Sikkim Manipal Institute of Technology,
Optimizing Converged Cisco Networks (ONT)
") Optimizing Converged Cisco Networks (ONT) Module 3: Introduction to IP QoS Introducing QoS Objectives Explain why converged networks require QoS. Identify the major quality issues with converged networks.
Optimizing Converged Cisco Networks (ONT) Module 3: Introduction to IP QoS Introducing QoS Objectives Explain why converged networks require QoS. Identify the major quality issues with converged networks.
Applying Router-Assisted Congestion Control to Wireless Networks: Challenges and Solutions 1
 Applying Router-Assisted Congestion Control to Wireless Networks: Challenges and Solutions Jian Pu and Mounir Hamdi Department of Computer Science and Engineering, HKUST, Hong Kong {pujian, hamdi}@cse.ust.hk
Applying Router-Assisted Congestion Control to Wireless Networks: Challenges and Solutions Jian Pu and Mounir Hamdi Department of Computer Science and Engineering, HKUST, Hong Kong {pujian, hamdi}@cse.ust.hk
Survey on AQM Congestion Control Algorithms
 Survey on AQM Congestion Control Algorithms B. Kiruthiga 1, Dr. E. George Dharma Prakash Raj 2 1 School of Computer Science and Engineering, Bharathidasan University, Trichy, India 2 School of Computer
Survey on AQM Congestion Control Algorithms B. Kiruthiga 1, Dr. E. George Dharma Prakash Raj 2 1 School of Computer Science and Engineering, Bharathidasan University, Trichy, India 2 School of Computer
TCP/IP Optimization for Wide Area Storage Networks. Dr. Joseph L White Juniper Networks
 TCP/IP Optimization for Wide Area Storage Networks Dr. Joseph L White Juniper Networks SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individuals
TCP/IP Optimization for Wide Area Storage Networks Dr. Joseph L White Juniper Networks SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individuals
A Congestion Control Algorithm for Data Center Area Communications
 A Congestion Control Algorithm for Data Center Area Communications Hideyuki Shimonishi, Junichi Higuchi, Takashi Yoshikawa, and Atsushi Iwata System Platforms Research Laboratories, NEC Corporation 1753
A Congestion Control Algorithm for Data Center Area Communications Hideyuki Shimonishi, Junichi Higuchi, Takashi Yoshikawa, and Atsushi Iwata System Platforms Research Laboratories, NEC Corporation 1753
Chapter 1 Reading Organizer
 Chapter 1 Reading Organizer After completion of this chapter, you should be able to: Describe convergence of data, voice and video in the context of switched networks Describe a switched network in a small
Chapter 1 Reading Organizer After completion of this chapter, you should be able to: Describe convergence of data, voice and video in the context of switched networks Describe a switched network in a small
WITH THE universal adoption of the Internet as a global
 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 7, NO. 2, APRIL 2005 339 Performance Analysis of TCP-Friendly AIMD Algorithms for Multimedia Applications Lin Cai, Student Member, IEEE, Xuemin Shen, Senior Member,
IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 7, NO. 2, APRIL 2005 339 Performance Analysis of TCP-Friendly AIMD Algorithms for Multimedia Applications Lin Cai, Student Member, IEEE, Xuemin Shen, Senior Member,
IAB CONCERNS ABOUT CONGESTION CONTROL. Iffat Hasnian 1832659
 IAB CONCERNS ABOUT CONGESTION CONTROL Iffat Hasnian 1832659 IAB CONCERNS Outline 1- Introduction 2- Persistent High Drop rate Problem 3- Current Efforts in the IETF 3.1 RTP 3.2 TFRC 3.3 DCCP 3.4 Audio
IAB CONCERNS ABOUT CONGESTION CONTROL Iffat Hasnian 1832659 IAB CONCERNS Outline 1- Introduction 2- Persistent High Drop rate Problem 3- Current Efforts in the IETF 3.1 RTP 3.2 TFRC 3.3 DCCP 3.4 Audio
Data Networks Summer 2007 Homework #3
 Data Networks Summer Homework # Assigned June 8, Due June in class Name: Email: Student ID: Problem Total Points Problem ( points) Host A is transferring a file of size L to host B using a TCP connection.
Data Networks Summer Homework # Assigned June 8, Due June in class Name: Email: Student ID: Problem Total Points Problem ( points) Host A is transferring a file of size L to host B using a TCP connection.
Analysis of IP Network for different Quality of Service
 2009 International Symposium on Computing, Communication, and Control (ISCCC 2009) Proc.of CSIT vol.1 (2011) (2011) IACSIT Press, Singapore Analysis of IP Network for different Quality of Service Ajith
2009 International Symposium on Computing, Communication, and Control (ISCCC 2009) Proc.of CSIT vol.1 (2011) (2011) IACSIT Press, Singapore Analysis of IP Network for different Quality of Service Ajith
Strategies. Addressing and Routing
 Strategies Circuit switching: carry bit streams original telephone network Packet switching: store-and-forward messages Internet Spring 2007 CSE 30264 14 Addressing and Routing Address: byte-string that
Strategies Circuit switching: carry bit streams original telephone network Packet switching: store-and-forward messages Internet Spring 2007 CSE 30264 14 Addressing and Routing Address: byte-string that
Performance of Cisco IPS 4500 and 4300 Series Sensors
 White Paper Performance of Cisco IPS 4500 and 4300 Series Sensors White Paper September 2012 2012 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public Information. Page 1 of
White Paper Performance of Cisco IPS 4500 and 4300 Series Sensors White Paper September 2012 2012 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public Information. Page 1 of
VoIP Network Dimensioning using Delay and Loss Bounds for Voice and Data Applications
 VoIP Network Dimensioning using Delay and Loss Bounds for Voice and Data Applications Veselin Rakocevic School of Engineering and Mathematical Sciences City University, London, UK V.Rakocevic@city.ac.uk
VoIP Network Dimensioning using Delay and Loss Bounds for Voice and Data Applications Veselin Rakocevic School of Engineering and Mathematical Sciences City University, London, UK V.Rakocevic@city.ac.uk
Design and Modeling of Internet Protocols. Dmitri Loguinov March 1, 2005
 Design and Modeling of Internet Protocols Dmitri Loguinov March 1, 2005 1 Agenda What is protocol scalability Why TCP does not scale Future high-speed applications AQM congestion control Other work at
Design and Modeling of Internet Protocols Dmitri Loguinov March 1, 2005 1 Agenda What is protocol scalability Why TCP does not scale Future high-speed applications AQM congestion control Other work at
How To Provide Qos Based Routing In The Internet
 CHAPTER 2 QoS ROUTING AND ITS ROLE IN QOS PARADIGM 22 QoS ROUTING AND ITS ROLE IN QOS PARADIGM 2.1 INTRODUCTION As the main emphasis of the present research work is on achieving QoS in routing, hence this
CHAPTER 2 QoS ROUTING AND ITS ROLE IN QOS PARADIGM 22 QoS ROUTING AND ITS ROLE IN QOS PARADIGM 2.1 INTRODUCTION As the main emphasis of the present research work is on achieving QoS in routing, hence this
Exhibit n.2: The layers of a hierarchical network
 3. Advanced Secure Network Design 3.1 Introduction You already know that routers are probably the most critical equipment piece in today s networking. Without routers, internetwork communication would
3. Advanced Secure Network Design 3.1 Introduction You already know that routers are probably the most critical equipment piece in today s networking. Without routers, internetwork communication would
QoS issues in Voice over IP
 COMP9333 Advance Computer Networks Mini Conference QoS issues in Voice over IP Student ID: 3058224 Student ID: 3043237 Student ID: 3036281 Student ID: 3025715 QoS issues in Voice over IP Abstract: This
COMP9333 Advance Computer Networks Mini Conference QoS issues in Voice over IP Student ID: 3058224 Student ID: 3043237 Student ID: 3036281 Student ID: 3025715 QoS issues in Voice over IP Abstract: This
Per-Flow Queuing Allot's Approach to Bandwidth Management
 White Paper Per-Flow Queuing Allot's Approach to Bandwidth Management Allot Communications, July 2006. All Rights Reserved. Table of Contents Executive Overview... 3 Understanding TCP/IP... 4 What is Bandwidth
White Paper Per-Flow Queuing Allot's Approach to Bandwidth Management Allot Communications, July 2006. All Rights Reserved. Table of Contents Executive Overview... 3 Understanding TCP/IP... 4 What is Bandwidth
Parallel TCP Data Transfers: A Practical Model and its Application
 D r a g a n a D a m j a n o v i ć Parallel TCP Data Transfers: A Practical Model and its Application s u b m i t t e d t o the Faculty of Mathematics, Computer Science and Physics, the University of Innsbruck
D r a g a n a D a m j a n o v i ć Parallel TCP Data Transfers: A Practical Model and its Application s u b m i t t e d t o the Faculty of Mathematics, Computer Science and Physics, the University of Innsbruck
Network Virtualization
 Network Virtualization Jennifer Rexford Advanced Computer Networks http://www.cs.princeton.edu/courses/archive/fall08/cos561/ Tuesdays/Thursdays 1:30pm-2:50pm Introduction Motivation for network virtualization
Network Virtualization Jennifer Rexford Advanced Computer Networks http://www.cs.princeton.edu/courses/archive/fall08/cos561/ Tuesdays/Thursdays 1:30pm-2:50pm Introduction Motivation for network virtualization
The Effect of Packet Reordering in a Backbone Link on Application Throughput Michael Laor and Lior Gendel, Cisco Systems, Inc.
 The Effect of Packet Reordering in a Backbone Link on Application Throughput Michael Laor and Lior Gendel, Cisco Systems, Inc. Abstract Packet reordering in the Internet is a well-known phenomenon. As
The Effect of Packet Reordering in a Backbone Link on Application Throughput Michael Laor and Lior Gendel, Cisco Systems, Inc. Abstract Packet reordering in the Internet is a well-known phenomenon. As
A Preferred Service Architecture for Payload Data Flows. Ray Gilstrap, Thom Stone, Ken Freeman
 A Preferred Service Architecture for Payload Data Flows Ray Gilstrap, Thom Stone, Ken Freeman NASA Research and Engineering Network NASA Advanced Supercomputing Division NASA Ames Research Center Outline
A Preferred Service Architecture for Payload Data Flows Ray Gilstrap, Thom Stone, Ken Freeman NASA Research and Engineering Network NASA Advanced Supercomputing Division NASA Ames Research Center Outline
Binary Increase Congestion Control for Fast, Long Distance Networks
 Abstract High-speed networks with large delays present a unique environment where TCP may have a problem utilizing the full bandwidth. Several congestion control proposals have been suggested to remedy
Abstract High-speed networks with large delays present a unique environment where TCP may have a problem utilizing the full bandwidth. Several congestion control proposals have been suggested to remedy
IP SLAs Overview. Finding Feature Information. Information About IP SLAs. IP SLAs Technology Overview
 This module describes IP Service Level Agreements (SLAs). IP SLAs allows Cisco customers to analyze IP service levels for IP applications and services, to increase productivity, to lower operational costs,
This module describes IP Service Level Agreements (SLAs). IP SLAs allows Cisco customers to analyze IP service levels for IP applications and services, to increase productivity, to lower operational costs,
Active Queue Management and Wireless Networks
 Active Queue Management and Wireless Networks Vikas Paliwal November 13, 2003 1 Introduction Considerable research has been done on internet dynamics and it has been shown that TCP s congestion avoidance
Active Queue Management and Wireless Networks Vikas Paliwal November 13, 2003 1 Introduction Considerable research has been done on internet dynamics and it has been shown that TCP s congestion avoidance
TCP over Multi-hop Wireless Networks * Overview of Transmission Control Protocol / Internet Protocol (TCP/IP) Internet Protocol (IP)
 Internet Protocol (IP)") TCP over Multi-hop Wireless Networks * Overview of Transmission Control Protocol / Internet Protocol (TCP/IP) *Slides adapted from a talk given by Nitin Vaidya. Wireless Computing and Network Systems Page
TCP over Multi-hop Wireless Networks * Overview of Transmission Control Protocol / Internet Protocol (TCP/IP) *Slides adapted from a talk given by Nitin Vaidya. Wireless Computing and Network Systems Page
An Improved TCP Congestion Control Algorithm for Wireless Networks
 An Improved TCP Congestion Control Algorithm for Wireless Networks Ahmed Khurshid Department of Computer Science University of Illinois at Urbana-Champaign Illinois, USA khurshi1@illinois.edu Md. Humayun
An Improved TCP Congestion Control Algorithm for Wireless Networks Ahmed Khurshid Department of Computer Science University of Illinois at Urbana-Champaign Illinois, USA khurshi1@illinois.edu Md. Humayun
CSE 473 Introduction to Computer Networks. Exam 2 Solutions. Your name: 10/31/2013
 CSE 473 Introduction to Computer Networks Jon Turner Exam Solutions Your name: 0/3/03. (0 points). Consider a circular DHT with 7 nodes numbered 0,,...,6, where the nodes cache key-values pairs for 60
CSE 473 Introduction to Computer Networks Jon Turner Exam Solutions Your name: 0/3/03. (0 points). Consider a circular DHT with 7 nodes numbered 0,,...,6, where the nodes cache key-values pairs for 60
Using TrueSpeed VNF to Test TCP Throughput in a Call Center Environment
 Using TrueSpeed VNF to Test TCP Throughput in a Call Center Environment TrueSpeed VNF provides network operators and enterprise users with repeatable, standards-based testing to resolve complaints about
Using TrueSpeed VNF to Test TCP Throughput in a Call Center Environment TrueSpeed VNF provides network operators and enterprise users with repeatable, standards-based testing to resolve complaints about
Using Fuzzy Logic Control to Provide Intelligent Traffic Management Service for High-Speed Networks ABSTRACT:
 Using Fuzzy Logic Control to Provide Intelligent Traffic Management Service for High-Speed Networks ABSTRACT: In view of the fast-growing Internet traffic, this paper propose a distributed traffic management
Using Fuzzy Logic Control to Provide Intelligent Traffic Management Service for High-Speed Networks ABSTRACT: In view of the fast-growing Internet traffic, this paper propose a distributed traffic management
Transport for Enterprise VoIP Services
 Transport for Enterprise VoIP Services Introduction Many carriers are looking to advanced packet services as an opportunity to generate new revenue or lower costs. These services, which include VoIP, IP
Transport for Enterprise VoIP Services Introduction Many carriers are looking to advanced packet services as an opportunity to generate new revenue or lower costs. These services, which include VoIP, IP
CHAPTER 6. VOICE COMMUNICATION OVER HYBRID MANETs
 CHAPTER 6 VOICE COMMUNICATION OVER HYBRID MANETs Multimedia real-time session services such as voice and videoconferencing with Quality of Service support is challenging task on Mobile Ad hoc Network (MANETs).
CHAPTER 6 VOICE COMMUNICATION OVER HYBRID MANETs Multimedia real-time session services such as voice and videoconferencing with Quality of Service support is challenging task on Mobile Ad hoc Network (MANETs).
Advanced Computer Networks IN2097. 1 Dec 2015
 Chair for Network Architectures and Services Technische Universität München Advanced Computer Networks IN2097 1 Dec 2015 Prof. Dr.-Ing. Georg Carle Chair for Network Architectures and Services Department
Chair for Network Architectures and Services Technische Universität München Advanced Computer Networks IN2097 1 Dec 2015 Prof. Dr.-Ing. Georg Carle Chair for Network Architectures and Services Department
Introduction to LAN/WAN. Network Layer
 Introduction to LAN/WAN Network Layer Topics Introduction (5-5.1) Routing (5.2) (The core) Internetworking (5.5) Congestion Control (5.3) Network Layer Design Isues Store-and-Forward Packet Switching Services
Introduction to LAN/WAN Network Layer Topics Introduction (5-5.1) Routing (5.2) (The core) Internetworking (5.5) Congestion Control (5.3) Network Layer Design Isues Store-and-Forward Packet Switching Services
Reordering of IP Packets in Internet
 Reordering of IP Packets in Internet Xiaoming Zhou and Piet Van Mieghem Delft University of Technology Faculty of Electrical Engineering, Mathematics, and Computer Science P.O. Box 5031, 2600 GA Delft,
Reordering of IP Packets in Internet Xiaoming Zhou and Piet Van Mieghem Delft University of Technology Faculty of Electrical Engineering, Mathematics, and Computer Science P.O. Box 5031, 2600 GA Delft,