Production HPC on Commodity Linux Clusters: The Role of Infrastructural Software
|
|
|
- Maud Copeland
- 8 years ago
- Views:
Transcription
1 Production HPC on Commodity Linux Clusters: The Role of Infrastructural Software Ian Lumb 11 th ECMWF Workshop Use of HPC in Meteorology Reading, UK October 28, 2004

2 Outline Introduction Real-World Examples Topology Awareness Task Geometry Summary 2

3 Introduction

4 IA-32/64 CPUs Low-latency, high-bandwidth interconnects Potential for progress on Grand Challenge problems MPI 4

5 5

6 Infrastructural Software 6
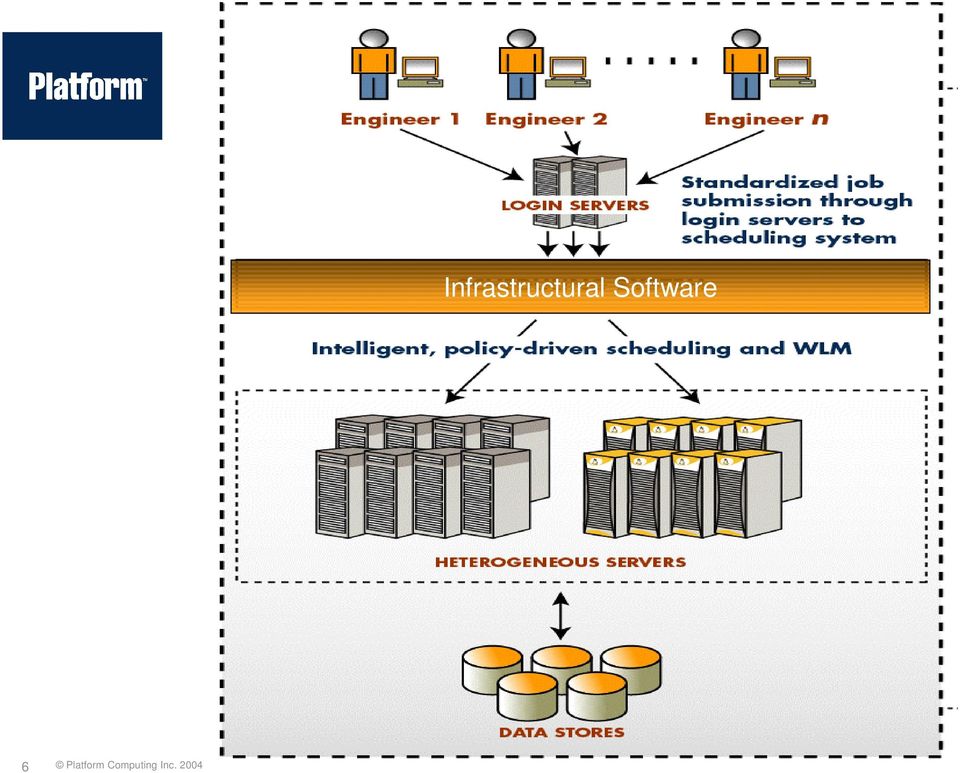
7 Infrastructural Software 7
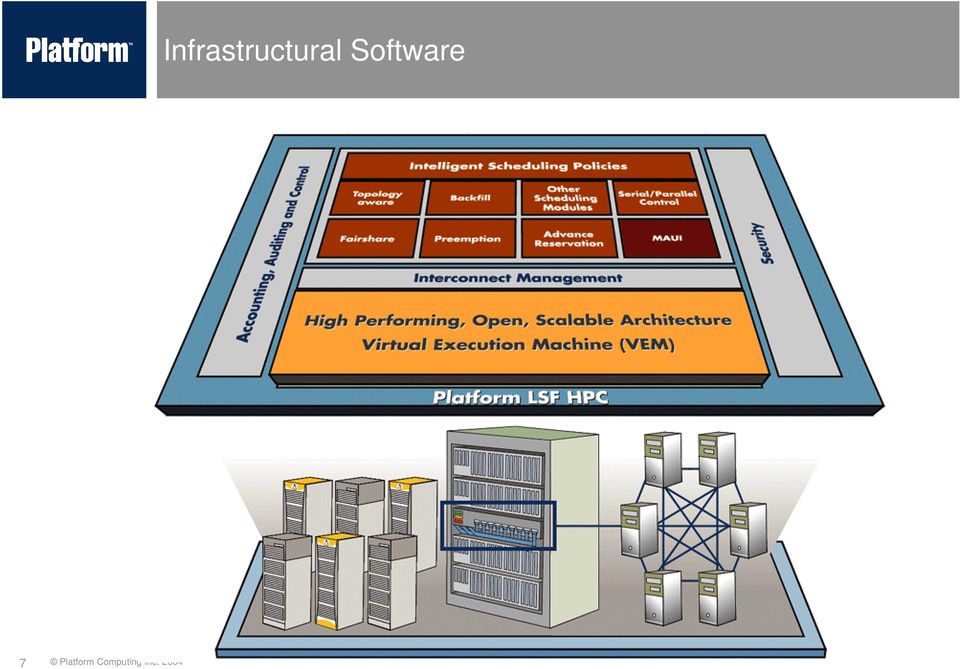
8 Infrastructural Software Platform LSF MultiCluster Globus Toolkit + CSF User Space Kernel Space cpuset Platform LSF HPC RMS Other Linux i.e., an ecosystem of resource management 8

9 Topology-Aware Scheduling

10 Topology-Aware, Bound-Processor Scheduling on Linux/NUMA Web Application Topology Master Host User Job Submission API SBD 1 6 MBD 4 MBSCHD Backfill MAUI Serial/Parallel Control Job Starvation Fairshare Preemption Advance Reservation Other Scheduler Modules 5 Altix cpuset 2 Execution Host Task PAM Accounting, auditing and control information 3 LIM 10

11 Topology-Aware, Bound-Processor Scheduling on Linux/NUMA bsub <bsub options> -n <number of processors> -R -ext "SGI_CPUSET[cpuset_options]" pam -mpi -auto_place a.out CPUSET_TYPE=static; CPUSET_NAME=<static cpuset name> or CPUSET_TYPE=dynamic; [MAX_RADIUS=<radius>;] [RESUME_OPTION=ORIG_CPUS]; [CPU_LIST=<cpu_ID_list>;] [CPUSET_OPTIONS=<SGI cpuset option>;] [MAX_CPU_PER_NODE=max_num_cpus] or 11 CPUSET_TYPE=none RSL = Resource Specification Language
![out CPUSET_TYPE=static; CPUSET_NAME=<static cpuset name> or CPUSET_TYPE=dynamic; [MAX_RADIUS=<radius>;]](/docs-images/44/13841823/images/page_11.jpg "[RESUME_OPTION=ORIG_CPUS]; [CPU_LIST=<cpu_ID_list>;] [CPUSET_OPTIONS=<SGI cpuset option>;]")
12 Topology-Aware Scheduling on Linux/RMS bsub n # -ext "alloc_type[; nodes=# \ ptile=cpus_per_node base=base_node_name] \ [; rails=# railmask=bitmask]" where alloc_type is: RMS_SNODE sorted node order as returned by RMS, gaps are allowed in the allocation RMS_MCONT contiguous allocation from left to right taking into consideration RMS ordering, no gaps are allowed in the allocation RMS_SLOAD sorted node order as returned by LSF, gaps are allowed in the allocation 12

13 Task Geometry
14 Task Geometry (TG) Addresses the locality of related tasks Job submission requires some effort but the rest is transparent to the end user Step 1 Set LSB_PJL_TASK_GEOMETRY environment variables Step 2 Use bsub -n and -R "span[ptile=]" to make sure LSF selects appropriate hosts to run the job 14

15 Task Geometry: Step 1 Set LSB_PJL_TASK_GEOMETRY environment variables e.g., LSB_PJL_TASK_GEOMETRY="{(2,5,7)(0,6)(1,3)(4)}" This job spawns 8 tasks and span 4 nodes Tasks 2,5, and 7 will run on the same node the first node Tasks 0 and 6 will run on the same node the second node Tasks 1 and 3 will run on the same node the third node Task 4 will run on one node alone the fourth node 15

16 Task Geometry: Step 2 Use bsub -n and -R "span[ptile=]" to make sure LSF selects appropriate hosts to run the job This functionality guarantees the geometry but not the host order Job submission directives must ensure each host selected by LSF can run any group of tasks specified in LSB_PJL_TASK_GEOMETRY Over-book CPUs to achieve this bsub -n x -R "span[ptile=y]" a mpich_gm myjob x = y * (the # of nodes) y = the maxinum # of tasks in one group in LSB_PJL_TASK_GEOMETRY e.g., bsub -n 12 -R "span[ptile=3]" a mpich_gm myjob 16
![run any group of tasks specified in LSB_PJL_TASK_GEOMETRY Over-book CPUs to achieve this bsub -n x -R "span[ptile=y]" a mpich_gm](/docs-images/44/13841823/images/page_16.jpg "myjob x = y * (the # of nodes) y = the maxinum # of tasks in one group in LSB_PJL_TASK_GEOMETRY e.g., bsub -n 12 -R \"span[ptile=3]\" a mpich_gm myjob 16")
17 TG Example: Community Climate System Model (CCSM) Multiple Process, Multiple Data i.e., MPMD application: OpenMP + MPI 17

18 Summary

19 Summary Infrastructural software enables production HPC Infrastructure needs to be factored into HPC productivity assessments Use economic measures Skill in assimilation and reanalysis efforts Evaluate time-to-production Increase parallel computing ROI Abstract complexity via RSL, programming language or some combination Comply with standards/certifications Linux Standards Base Common Criteria Certification The Open Grid Services Architecture October 2004 issue dedicated to HPC

20 Thank you.

21
The ENEA-EGEE site: Access to non-standard platforms
 V INFNGrid Workshop Padova, Italy December 18-20 2006 The ENEA-EGEE site: Access to non-standard platforms C. Sciò**, G. Bracco, P. D'Angelo, L. Giammarino*, S.Migliori, A. Quintiliani, F. Simoni, S. Podda
V INFNGrid Workshop Padova, Italy December 18-20 2006 The ENEA-EGEE site: Access to non-standard platforms C. Sciò**, G. Bracco, P. D'Angelo, L. Giammarino*, S.Migliori, A. Quintiliani, F. Simoni, S. Podda
Scheduling and Resource Management in Computational Mini-Grids
 Scheduling and Resource Management in Computational Mini-Grids July 1, 2002 Project Description The concept of grid computing is becoming a more and more important one in the high performance computing
Scheduling and Resource Management in Computational Mini-Grids July 1, 2002 Project Description The concept of grid computing is becoming a more and more important one in the high performance computing
SAS Grid: Grid Scheduling Policy and Resource Allocation Adam H. Diaz, IBM Platform Computing, Research Triangle Park, NC
 Paper BI222012 SAS Grid: Grid Scheduling Policy and Resource Allocation Adam H. Diaz, IBM Platform Computing, Research Triangle Park, NC ABSTRACT This paper will discuss at a high level some of the options
Paper BI222012 SAS Grid: Grid Scheduling Policy and Resource Allocation Adam H. Diaz, IBM Platform Computing, Research Triangle Park, NC ABSTRACT This paper will discuss at a high level some of the options
The RWTH Compute Cluster Environment
 The RWTH Compute Cluster Environment Tim Cramer 11.03.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) How to login Frontends cluster.rz.rwth-aachen.de cluster-x.rz.rwth-aachen.de
The RWTH Compute Cluster Environment Tim Cramer 11.03.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) How to login Frontends cluster.rz.rwth-aachen.de cluster-x.rz.rwth-aachen.de
Cloud Computing for HPC
 Cloud Computing for HPC Extending Clusters to Clouds Solution Briefing TORONTO 10/25/2011 Company Background 2 Platform Computing, Inc. Platform Clusters, Grids, Clouds Computing The leader in cluster,
Cloud Computing for HPC Extending Clusters to Clouds Solution Briefing TORONTO 10/25/2011 Company Background 2 Platform Computing, Inc. Platform Clusters, Grids, Clouds Computing The leader in cluster,
Program Grid and HPC5+ workshop
 Program Grid and HPC5+ workshop 24-30, Bahman 1391 Tuesday Wednesday 9.00-9.45 9.45-10.30 Break 11.00-11.45 11.45-12.30 Lunch 14.00-17.00 Workshop Rouhani Karimi MosalmanTabar Karimi G+MMT+K Opening IPM_Grid
Program Grid and HPC5+ workshop 24-30, Bahman 1391 Tuesday Wednesday 9.00-9.45 9.45-10.30 Break 11.00-11.45 11.45-12.30 Lunch 14.00-17.00 Workshop Rouhani Karimi MosalmanTabar Karimi G+MMT+K Opening IPM_Grid
159.735. Final Report. Cluster Scheduling. Submitted by: Priti Lohani 04244354
 159.735 Final Report Cluster Scheduling Submitted by: Priti Lohani 04244354 1 Table of contents: 159.735... 1 Final Report... 1 Cluster Scheduling... 1 Table of contents:... 2 1. Introduction:... 3 1.1
159.735 Final Report Cluster Scheduling Submitted by: Priti Lohani 04244354 1 Table of contents: 159.735... 1 Final Report... 1 Cluster Scheduling... 1 Table of contents:... 2 1. Introduction:... 3 1.1
Provisioning and Resource Management at Large Scale (Kadeploy and OAR)
") Provisioning and Resource Management at Large Scale (Kadeploy and OAR) Olivier Richard Laboratoire d Informatique de Grenoble (LIG) Projet INRIA Mescal 31 octobre 2007 Olivier Richard ( Laboratoire d Informatique
Provisioning and Resource Management at Large Scale (Kadeploy and OAR) Olivier Richard Laboratoire d Informatique de Grenoble (LIG) Projet INRIA Mescal 31 octobre 2007 Olivier Richard ( Laboratoire d Informatique
Microsoft HPC. V 1.0 José M. Cámara (checam@ubu.es)
") Microsoft HPC V 1.0 José M. Cámara (checam@ubu.es) Introduction Microsoft High Performance Computing Package addresses computing power from a rather different approach. It is mainly focused on commodity
Microsoft HPC V 1.0 José M. Cámara (checam@ubu.es) Introduction Microsoft High Performance Computing Package addresses computing power from a rather different approach. It is mainly focused on commodity
National Facility Job Management System
 National Facility Job Management System 1. Summary This document describes the job management system used by the NCI National Facility (NF) on their current systems. The system is based on a modified version
National Facility Job Management System 1. Summary This document describes the job management system used by the NCI National Facility (NF) on their current systems. The system is based on a modified version
A High Performance Computing Scheduling and Resource Management Primer
 LLNL-TR-652476 A High Performance Computing Scheduling and Resource Management Primer D. H. Ahn, J. E. Garlick, M. A. Grondona, D. A. Lipari, R. R. Springmeyer March 31, 2014 Disclaimer This document was
LLNL-TR-652476 A High Performance Computing Scheduling and Resource Management Primer D. H. Ahn, J. E. Garlick, M. A. Grondona, D. A. Lipari, R. R. Springmeyer March 31, 2014 Disclaimer This document was
The Lattice Project: A Multi-Model Grid Computing System. Center for Bioinformatics and Computational Biology University of Maryland
 The Lattice Project: A Multi-Model Grid Computing System Center for Bioinformatics and Computational Biology University of Maryland Parallel Computing PARALLEL COMPUTING a form of computation in which
The Lattice Project: A Multi-Model Grid Computing System Center for Bioinformatics and Computational Biology University of Maryland Parallel Computing PARALLEL COMPUTING a form of computation in which
supercomputing. simplified.
 supercomputing. simplified. INTRODUCING WINDOWS HPC SERVER 2008 R2 SUITE Windows HPC Server 2008 R2, Microsoft s third-generation HPC solution, provides a comprehensive and costeffective solution for harnessing
supercomputing. simplified. INTRODUCING WINDOWS HPC SERVER 2008 R2 SUITE Windows HPC Server 2008 R2, Microsoft s third-generation HPC solution, provides a comprehensive and costeffective solution for harnessing
Job Management System Extension To Support SLAAC-1V Reconfigurable Hardware
 Job Management System Extension To Support SLAAC-1V Reconfigurable Hardware Mohamed Taher 1, Kris Gaj 2, Tarek El-Ghazawi 1, and Nikitas Alexandridis 1 1 The George Washington University 2 George Mason
Job Management System Extension To Support SLAAC-1V Reconfigurable Hardware Mohamed Taher 1, Kris Gaj 2, Tarek El-Ghazawi 1, and Nikitas Alexandridis 1 1 The George Washington University 2 George Mason
Storage Virtualization from clusters to grid
 Seanodes presents Storage Virtualization from clusters to grid Rennes 4th october 2007 Agenda Seanodes Presentation Overview of storage virtualization in clusters Seanodes cluster virtualization, with
Seanodes presents Storage Virtualization from clusters to grid Rennes 4th october 2007 Agenda Seanodes Presentation Overview of storage virtualization in clusters Seanodes cluster virtualization, with
A Taxonomy and Survey of Grid Resource Planning and Reservation Systems for Grid Enabled Analysis Environment
 A Taxonomy and Survey of Grid Resource Planning and Reservation Systems for Grid Enabled Analysis Environment Arshad Ali 3, Ashiq Anjum 3, Atif Mehmood 3, Richard McClatchey 2, Ian Willers 2, Julian Bunn
A Taxonomy and Survey of Grid Resource Planning and Reservation Systems for Grid Enabled Analysis Environment Arshad Ali 3, Ashiq Anjum 3, Atif Mehmood 3, Richard McClatchey 2, Ian Willers 2, Julian Bunn
Optimizing Shared Resource Contention in HPC Clusters
 Optimizing Shared Resource Contention in HPC Clusters Sergey Blagodurov Simon Fraser University Alexandra Fedorova Simon Fraser University Abstract Contention for shared resources in HPC clusters occurs
Optimizing Shared Resource Contention in HPC Clusters Sergey Blagodurov Simon Fraser University Alexandra Fedorova Simon Fraser University Abstract Contention for shared resources in HPC clusters occurs
System Software for High Performance Computing. Joe Izraelevitz
 System Software for High Performance Computing Joe Izraelevitz Agenda Overview of Supercomputers Blue Gene/Q System LoadLeveler Job Scheduler General Parallel File System HPC at UR What is a Supercomputer?
System Software for High Performance Computing Joe Izraelevitz Agenda Overview of Supercomputers Blue Gene/Q System LoadLeveler Job Scheduler General Parallel File System HPC at UR What is a Supercomputer?
benchmarking Amazon EC2 for high-performance scientific computing
 Edward Walker benchmarking Amazon EC2 for high-performance scientific computing Edward Walker is a Research Scientist with the Texas Advanced Computing Center at the University of Texas at Austin. He received
Edward Walker benchmarking Amazon EC2 for high-performance scientific computing Edward Walker is a Research Scientist with the Texas Advanced Computing Center at the University of Texas at Austin. He received
HPC and Grid Concepts
 HPC and Grid Concepts Divya MG (divyam@cdac.in) CDAC Knowledge Park, Bangalore 16 th Feb 2012 GBC@PRL Ahmedabad 1 Presentation Overview What is HPC Need for HPC HPC Tools Grid Concepts GARUDA Overview
HPC and Grid Concepts Divya MG (divyam@cdac.in) CDAC Knowledge Park, Bangalore 16 th Feb 2012 GBC@PRL Ahmedabad 1 Presentation Overview What is HPC Need for HPC HPC Tools Grid Concepts GARUDA Overview
The Top Six Advantages of CUDA-Ready Clusters. Ian Lumb Bright Evangelist
 The Top Six Advantages of CUDA-Ready Clusters Ian Lumb Bright Evangelist GTC Express Webinar January 21, 2015 We scientists are time-constrained, said Dr. Yamanaka. Our priority is our research, not managing
The Top Six Advantages of CUDA-Ready Clusters Ian Lumb Bright Evangelist GTC Express Webinar January 21, 2015 We scientists are time-constrained, said Dr. Yamanaka. Our priority is our research, not managing
Windows HPC Server 2008 R2 Service Pack 3 (V3 SP3)
") Windows HPC Server 2008 R2 Service Pack 3 (V3 SP3) Greg Burgess, Principal Development Manager Windows Azure High Performance Computing Microsoft Corporation HPC Server Components Job Scheduler Distributed
Windows HPC Server 2008 R2 Service Pack 3 (V3 SP3) Greg Burgess, Principal Development Manager Windows Azure High Performance Computing Microsoft Corporation HPC Server Components Job Scheduler Distributed
Using WestGrid. Patrick Mann, Manager, Technical Operations Jan.15, 2014
 Using WestGrid Patrick Mann, Manager, Technical Operations Jan.15, 2014 Winter 2014 Seminar Series Date Speaker Topic 5 February Gino DiLabio Molecular Modelling Using HPC and Gaussian 26 February Jonathan
Using WestGrid Patrick Mann, Manager, Technical Operations Jan.15, 2014 Winter 2014 Seminar Series Date Speaker Topic 5 February Gino DiLabio Molecular Modelling Using HPC and Gaussian 26 February Jonathan
enanos: Coordinated Scheduling in Grid Environments
 John von Neumann Institute for Computing enanos: Coordinated Scheduling in Grid Environments I. Rodero, F. Guim, J. Corbalán, J. Labarta published in Parallel Computing: Current & Future Issues of High-End
John von Neumann Institute for Computing enanos: Coordinated Scheduling in Grid Environments I. Rodero, F. Guim, J. Corbalán, J. Labarta published in Parallel Computing: Current & Future Issues of High-End
IBM Platform Computing Cloud Service Ready to use Platform LSF & Symphony clusters in the SoftLayer cloud
 IBM Platform Computing Cloud Service Ready to use Platform LSF & Symphony clusters in the SoftLayer cloud February 25, 2014 1 Agenda v Mapping clients needs to cloud technologies v Addressing your pain
IBM Platform Computing Cloud Service Ready to use Platform LSF & Symphony clusters in the SoftLayer cloud February 25, 2014 1 Agenda v Mapping clients needs to cloud technologies v Addressing your pain
The ENEA gateway approach providing EGEE/gLite access to unsupported platforms and operating systems
 EU-IndiaGrid Workshop Taipei, November 2nd 2007 The ENEA gateway approach providing EGEE/gLite access to unsupported platforms and operating systems G. Bracco, S.Migliori, A. Quintiliani, A. Santoro, C.
EU-IndiaGrid Workshop Taipei, November 2nd 2007 The ENEA gateway approach providing EGEE/gLite access to unsupported platforms and operating systems G. Bracco, S.Migliori, A. Quintiliani, A. Santoro, C.
"Charting the Course...... to Your Success!" MOC 50290 A Understanding and Administering Windows HPC Server 2008. Course Summary
 Description Course Summary This course provides students with the knowledge and skills to manage and deploy Microsoft HPC Server 2008 clusters. Objectives At the end of this course, students will be Plan
Description Course Summary This course provides students with the knowledge and skills to manage and deploy Microsoft HPC Server 2008 clusters. Objectives At the end of this course, students will be Plan
Microsoft Compute Clusters in High Performance Technical Computing. Björn Tromsdorf, HPC Product Manager, Microsoft Corporation
 Microsoft Compute Clusters in High Performance Technical Computing Björn Tromsdorf, HPC Product Manager, Microsoft Corporation Flexible and efficient job scheduling via Windows CCS has allowed more of
Microsoft Compute Clusters in High Performance Technical Computing Björn Tromsdorf, HPC Product Manager, Microsoft Corporation Flexible and efficient job scheduling via Windows CCS has allowed more of
HPC performance applications on Virtual Clusters
 Panagiotis Kritikakos EPCC, School of Physics & Astronomy, University of Edinburgh, Scotland - UK pkritika@epcc.ed.ac.uk 4 th IC-SCCE, Athens 7 th July 2010 This work investigates the performance of (Java)
Panagiotis Kritikakos EPCC, School of Physics & Astronomy, University of Edinburgh, Scotland - UK pkritika@epcc.ed.ac.uk 4 th IC-SCCE, Athens 7 th July 2010 This work investigates the performance of (Java)
Ten Reasons to Switch from Maui Cluster Scheduler to Moab HPC Suite Comparison Brief
 TM Ten Reasons to Switch from Maui Cluster Scheduler to Moab HPC Suite Comparison Brief Many Maui users make the switch to Moab each year for key scalability, capability and support advantages that help
TM Ten Reasons to Switch from Maui Cluster Scheduler to Moab HPC Suite Comparison Brief Many Maui users make the switch to Moab each year for key scalability, capability and support advantages that help
Benchmark Report: Univa Grid Engine, Nextflow, and Docker for running Genomic Analysis Workflows
 PRBB / Ferran Mateo Benchmark Report: Univa Grid Engine, Nextflow, and Docker for running Genomic Analysis Workflows Summary of testing by the Centre for Genomic Regulation (CRG) utilizing new virtualization
PRBB / Ferran Mateo Benchmark Report: Univa Grid Engine, Nextflow, and Docker for running Genomic Analysis Workflows Summary of testing by the Centre for Genomic Regulation (CRG) utilizing new virtualization
SRNWP Workshop. HP Solutions and Activities in Climate & Weather Research. Michael Riedmann European Performance Center
 SRNWP Workshop HP Solutions and Activities in Climate & Weather Research Michael Riedmann European Performance Center Agenda A bit of marketing: HP Solutions for HPC A few words about recent Met deals
SRNWP Workshop HP Solutions and Activities in Climate & Weather Research Michael Riedmann European Performance Center Agenda A bit of marketing: HP Solutions for HPC A few words about recent Met deals
Cluster, Grid, Cloud Concepts
 Cluster, Grid, Cloud Concepts Kalaiselvan.K Contents Section 1: Cluster Section 2: Grid Section 3: Cloud Cluster An Overview Need for a Cluster Cluster categorizations A computer cluster is a group of
Cluster, Grid, Cloud Concepts Kalaiselvan.K Contents Section 1: Cluster Section 2: Grid Section 3: Cloud Cluster An Overview Need for a Cluster Cluster categorizations A computer cluster is a group of
Resource Models: Batch Scheduling
 Resource Models: Batch Scheduling Last Time» Cycle Stealing Resource Model Large Reach, Mass Heterogeneity, complex resource behavior Asynchronous Revocation, independent, idempotent tasks» Resource Sharing
Resource Models: Batch Scheduling Last Time» Cycle Stealing Resource Model Large Reach, Mass Heterogeneity, complex resource behavior Asynchronous Revocation, independent, idempotent tasks» Resource Sharing
Grid Engine Administration. Overview
 Grid Engine Administration Overview This module covers Grid Problem Types How it works Distributed Resource Management Grid Engine 6 Variants Grid Engine Scheduling Grid Engine 6 Architecture Grid Problem
Grid Engine Administration Overview This module covers Grid Problem Types How it works Distributed Resource Management Grid Engine 6 Variants Grid Engine Scheduling Grid Engine 6 Architecture Grid Problem
CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensive Computing. University of Florida, CISE Department Prof.
 CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensie Computing Uniersity of Florida, CISE Department Prof. Daisy Zhe Wang Map/Reduce: Simplified Data Processing on Large Clusters Parallel/Distributed
CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensie Computing Uniersity of Florida, CISE Department Prof. Daisy Zhe Wang Map/Reduce: Simplified Data Processing on Large Clusters Parallel/Distributed
Job Scheduling on a Large UV 1000. Chad Vizino SGI User Group Conference May 2011. 2011 Pittsburgh Supercomputing Center
 Job Scheduling on a Large UV 1000 Chad Vizino SGI User Group Conference May 2011 Overview About PSC s UV 1000 Simon UV Distinctives UV Operational issues Conclusion PSC s UV 1000 - Blacklight Blacklight
Job Scheduling on a Large UV 1000 Chad Vizino SGI User Group Conference May 2011 Overview About PSC s UV 1000 Simon UV Distinctives UV Operational issues Conclusion PSC s UV 1000 - Blacklight Blacklight
Interoperability between Sun Grid Engine and the Windows Compute Cluster
 Interoperability between Sun Grid Engine and the Windows Compute Cluster Steven Newhouse Program Manager, Windows HPC Team steven.newhouse@microsoft.com 1 Computer Cluster Roadmap Mainstream HPC Mainstream
Interoperability between Sun Grid Engine and the Windows Compute Cluster Steven Newhouse Program Manager, Windows HPC Team steven.newhouse@microsoft.com 1 Computer Cluster Roadmap Mainstream HPC Mainstream
Cloud Computing through Virtualization and HPC technologies
 Cloud Computing through Virtualization and HPC technologies William Lu, Ph.D. 1 Agenda Cloud Computing & HPC A Case of HPC Implementation Application Performance in VM Summary 2 Cloud Computing & HPC HPC
Cloud Computing through Virtualization and HPC technologies William Lu, Ph.D. 1 Agenda Cloud Computing & HPC A Case of HPC Implementation Application Performance in VM Summary 2 Cloud Computing & HPC HPC
Installing and running COMSOL on a Linux cluster
 Installing and running COMSOL on a Linux cluster Introduction This quick guide explains how to install and operate COMSOL Multiphysics 5.0 on a Linux cluster. It is a complement to the COMSOL Installation
Installing and running COMSOL on a Linux cluster Introduction This quick guide explains how to install and operate COMSOL Multiphysics 5.0 on a Linux cluster. It is a complement to the COMSOL Installation
Parallel Processing using the LOTUS cluster
 Parallel Processing using the LOTUS cluster Alison Pamment / Cristina del Cano Novales JASMIN/CEMS Workshop February 2015 Overview Parallelising data analysis LOTUS HPC Cluster Job submission on LOTUS
Parallel Processing using the LOTUS cluster Alison Pamment / Cristina del Cano Novales JASMIN/CEMS Workshop February 2015 Overview Parallelising data analysis LOTUS HPC Cluster Job submission on LOTUS
HPC Wales Skills Academy Course Catalogue 2015
 HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
Supercomputing on Windows. Microsoft (Thailand) Limited
 Limited") Supercomputing on Windows Microsoft (Thailand) Limited W hat D efines S upercom puting A lso called High Performance Computing (HPC) Technical Computing Cutting edge problems in science, engineering and
Supercomputing on Windows Microsoft (Thailand) Limited W hat D efines S upercom puting A lso called High Performance Computing (HPC) Technical Computing Cutting edge problems in science, engineering and
OpenMP Programming on ScaleMP
 OpenMP Programming on ScaleMP Dirk Schmidl schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
OpenMP Programming on ScaleMP Dirk Schmidl schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
Cobalt: An Open Source Platform for HPC System Software Research
 Cobalt: An Open Source Platform for HPC System Software Research Edinburgh BG/L System Software Workshop Narayan Desai Mathematics and Computer Science Division Argonne National Laboratory October 6, 2005
Cobalt: An Open Source Platform for HPC System Software Research Edinburgh BG/L System Software Workshop Narayan Desai Mathematics and Computer Science Division Argonne National Laboratory October 6, 2005
Building a Linux Cluster
 Building a Linux Cluster CUG Conference May 21-25, 2001 by Cary Whitney Clwhitney@lbl.gov Outline What is PDSF and a little about its history. Growth problems and solutions. Storage Network Hardware Administration
Building a Linux Cluster CUG Conference May 21-25, 2001 by Cary Whitney Clwhitney@lbl.gov Outline What is PDSF and a little about its history. Growth problems and solutions. Storage Network Hardware Administration
Technical Computing Suite Job Management Software
 Technical Computing Suite Job Management Software Toshiaki Mikamo Fujitsu Limited Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Outline System Configuration and Software Stack Features The major functions
Technical Computing Suite Job Management Software Toshiaki Mikamo Fujitsu Limited Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Outline System Configuration and Software Stack Features The major functions
Parallel Computing using MATLAB Distributed Compute Server ZORRO HPC
 Parallel Computing using MATLAB Distributed Compute Server ZORRO HPC Goals of the session Overview of parallel MATLAB Why parallel MATLAB? Multiprocessing in MATLAB Parallel MATLAB using the Parallel Computing
Parallel Computing using MATLAB Distributed Compute Server ZORRO HPC Goals of the session Overview of parallel MATLAB Why parallel MATLAB? Multiprocessing in MATLAB Parallel MATLAB using the Parallel Computing
Grid Scheduling Architectures with Globus GridWay and Sun Grid Engine
 Grid Scheduling Architectures with and Sun Grid Engine Sun Grid Engine Workshop 2007 Regensburg, Germany September 11, 2007 Ignacio Martin Llorente Javier Fontán Muiños Distributed Systems Architecture
Grid Scheduling Architectures with and Sun Grid Engine Sun Grid Engine Workshop 2007 Regensburg, Germany September 11, 2007 Ignacio Martin Llorente Javier Fontán Muiños Distributed Systems Architecture
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
GRID Computing and Networks
 A Member of the ExperTeam Group GRID Computing and Networks Karl Solchenbach Global IPv6 Summit Madrid, May 14, 2003 Pallas GmbH Hermülheimer Straße 10 D-50321 Brühl, Germany info@pallas.de http://www.pallas.com
A Member of the ExperTeam Group GRID Computing and Networks Karl Solchenbach Global IPv6 Summit Madrid, May 14, 2003 Pallas GmbH Hermülheimer Straße 10 D-50321 Brühl, Germany info@pallas.de http://www.pallas.com
Integrated Communication Systems
 Integrated Communication Systems Courses, Research, and Thesis Topics Prof. Paul Müller University of Kaiserslautern Department of Computer Science Integrated Communication Systems ICSY http://www.icsy.de
Integrated Communication Systems Courses, Research, and Thesis Topics Prof. Paul Müller University of Kaiserslautern Department of Computer Science Integrated Communication Systems ICSY http://www.icsy.de
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
GC3: Grid Computing Competence Center Cluster computing, I Batch-queueing systems
 GC3: Grid Computing Competence Center Cluster computing, I Batch-queueing systems Riccardo Murri, Sergio Maffioletti Grid Computing Competence Center, Organisch-Chemisches Institut, University of Zurich
GC3: Grid Computing Competence Center Cluster computing, I Batch-queueing systems Riccardo Murri, Sergio Maffioletti Grid Computing Competence Center, Organisch-Chemisches Institut, University of Zurich
On-Demand Supercomputing Multiplies the Possibilities
 Microsoft Windows Compute Cluster Server 2003 Partner Solution Brief Image courtesy of Wolfram Research, Inc. On-Demand Supercomputing Multiplies the Possibilities Microsoft Windows Compute Cluster Server
Microsoft Windows Compute Cluster Server 2003 Partner Solution Brief Image courtesy of Wolfram Research, Inc. On-Demand Supercomputing Multiplies the Possibilities Microsoft Windows Compute Cluster Server
MPI / ClusterTools Update and Plans
 HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
Cluster Implementation and Management; Scheduling
 Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
So#ware Tools and Techniques for HPC, Clouds, and Server- Class SoCs Ron Brightwell
 So#ware Tools and Techniques for HPC, Clouds, and Server- Class SoCs Ron Brightwell R&D Manager, Scalable System So#ware Department Sandia National Laboratories is a multi-program laboratory managed and
So#ware Tools and Techniques for HPC, Clouds, and Server- Class SoCs Ron Brightwell R&D Manager, Scalable System So#ware Department Sandia National Laboratories is a multi-program laboratory managed and
Altix Usage and Application Programming. Welcome and Introduction
 Zentrum für Informationsdienste und Hochleistungsrechnen Altix Usage and Application Programming Welcome and Introduction Zellescher Weg 12 Tel. +49 351-463 - 35450 Dresden, November 30th 2005 Wolfgang
Zentrum für Informationsdienste und Hochleistungsrechnen Altix Usage and Application Programming Welcome and Introduction Zellescher Weg 12 Tel. +49 351-463 - 35450 Dresden, November 30th 2005 Wolfgang
24/08/2004. Introductory User Guide
 24/08/2004 Introductory User Guide CSAR Introductory User Guide Introduction This material is designed to provide new users with all the information they need to access and use the SGI systems provided
24/08/2004 Introductory User Guide CSAR Introductory User Guide Introduction This material is designed to provide new users with all the information they need to access and use the SGI systems provided
High Performance Computing
 High Performance Computing Trey Breckenridge Computing Systems Manager Engineering Research Center Mississippi State University What is High Performance Computing? HPC is ill defined and context dependent.
High Performance Computing Trey Breckenridge Computing Systems Manager Engineering Research Center Mississippi State University What is High Performance Computing? HPC is ill defined and context dependent.
Logically a Linux cluster looks something like the following: Compute Nodes. user Head node. network
 A typical Linux cluster consists of a group of compute nodes for executing parallel jobs and a head node to which users connect to build and launch their jobs. Often the compute nodes are connected to
A typical Linux cluster consists of a group of compute nodes for executing parallel jobs and a head node to which users connect to build and launch their jobs. Often the compute nodes are connected to
LSKA 2010 Survey Report Job Scheduler
 LSKA 2010 Survey Report Job Scheduler Graduate Institute of Communication Engineering {r98942067, r98942112}@ntu.edu.tw March 31, 2010 1. Motivation Recently, the computing becomes much more complex. However,
LSKA 2010 Survey Report Job Scheduler Graduate Institute of Communication Engineering {r98942067, r98942112}@ntu.edu.tw March 31, 2010 1. Motivation Recently, the computing becomes much more complex. However,
BLM 413E - Parallel Programming Lecture 3
 BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
Installing on UNIX and Linux
 Platform LSF Version 9 Release 1.1 Installing on UNIX and Linux SC27-5314-01 Platform LSF Version 9 Release 1.1 Installing on UNIX and Linux SC27-5314-01 Note Before using this information and the product
Platform LSF Version 9 Release 1.1 Installing on UNIX and Linux SC27-5314-01 Platform LSF Version 9 Release 1.1 Installing on UNIX and Linux SC27-5314-01 Note Before using this information and the product
General Overview. Slurm Training15. Alfred Gil & Jordi Blasco (HPCNow!)
") Slurm Training15 Agenda 1 2 3 About Slurm Key Features of Slurm Extending Slurm Resource Management Daemons Job/step allocation 4 5 SMP MPI Parametric Job monitoring Accounting Scheduling Administration
Slurm Training15 Agenda 1 2 3 About Slurm Key Features of Slurm Extending Slurm Resource Management Daemons Job/step allocation 4 5 SMP MPI Parametric Job monitoring Accounting Scheduling Administration
Architecting Low Latency Cloud Networks
 Architecting Low Latency Cloud Networks Introduction: Application Response Time is Critical in Cloud Environments As data centers transition to next generation virtualized & elastic cloud architectures,
Architecting Low Latency Cloud Networks Introduction: Application Response Time is Critical in Cloud Environments As data centers transition to next generation virtualized & elastic cloud architectures,
Seminarbeschreibung. Windows Server 2008 Developing High-performance Applications using Microsoft Windows HPC Server 2008.
 Seminarbeschreibung Windows Server 2008 Developing High-performance Applications using Microsoft Windows HPC Server 2008 Einleitung: In dieser Schulung lernen die Entwickler - High-Performance Computing
Seminarbeschreibung Windows Server 2008 Developing High-performance Applications using Microsoft Windows HPC Server 2008 Einleitung: In dieser Schulung lernen die Entwickler - High-Performance Computing
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Technical Guide to ULGrid
 Technical Guide to ULGrid Ian C. Smith Computing Services Department September 4, 2007 1 Introduction This document follows on from the User s Guide to Running Jobs on ULGrid using Condor-G [1] and gives
Technical Guide to ULGrid Ian C. Smith Computing Services Department September 4, 2007 1 Introduction This document follows on from the User s Guide to Running Jobs on ULGrid using Condor-G [1] and gives
1 Bull, 2011 Bull Extreme Computing
 1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
High Performance Computing (HPC)
") High Performance Computing (HPC) High Performance Computing (HPC) White Paper Attn: Name, Title Phone: xxx.xxx.xxxx Fax: xxx.xxx.xxxx 1.0 OVERVIEW When heterogeneous enterprise environments are involved,
High Performance Computing (HPC) High Performance Computing (HPC) White Paper Attn: Name, Title Phone: xxx.xxx.xxxx Fax: xxx.xxx.xxxx 1.0 OVERVIEW When heterogeneous enterprise environments are involved,
www.xenon.com.au STORAGE HIGH SPEED INTERCONNECTS HIGH PERFORMANCE COMPUTING VISUALISATION GPU COMPUTING
 www.xenon.com.au STORAGE HIGH SPEED INTERCONNECTS HIGH PERFORMANCE COMPUTING GPU COMPUTING VISUALISATION XENON Accelerating Exploration Mineral, oil and gas exploration is an expensive and challenging
www.xenon.com.au STORAGE HIGH SPEED INTERCONNECTS HIGH PERFORMANCE COMPUTING GPU COMPUTING VISUALISATION XENON Accelerating Exploration Mineral, oil and gas exploration is an expensive and challenging
Cloud Computing with Red Hat Solutions. Sivaram Shunmugam Red Hat Asia Pacific Pte Ltd. sivaram@redhat.com
 Cloud Computing with Red Hat Solutions Sivaram Shunmugam Red Hat Asia Pacific Pte Ltd sivaram@redhat.com Linux Automation Details Red Hat's Linux Automation strategy for next-generation IT infrastructure
Cloud Computing with Red Hat Solutions Sivaram Shunmugam Red Hat Asia Pacific Pte Ltd sivaram@redhat.com Linux Automation Details Red Hat's Linux Automation strategy for next-generation IT infrastructure
A Case Study - Scaling Legacy Code on Next Generation Platforms
 Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Cluster Grid Interconects. Tony Kay Chief Architect Enterprise Grid and Networking
 Cluster Grid Interconects Tony Kay Chief Architect Enterprise Grid and Networking Agenda Cluster Grid Interconnects The Upstart - Infiniband The Empire Strikes Back - Myricom Return of the King 10G Gigabit
Cluster Grid Interconects Tony Kay Chief Architect Enterprise Grid and Networking Agenda Cluster Grid Interconnects The Upstart - Infiniband The Empire Strikes Back - Myricom Return of the King 10G Gigabit
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
Building an energy dashboard. Energy measurement and visualization in current HPC systems
 Building an energy dashboard Energy measurement and visualization in current HPC systems Thomas Geenen 1/58 thomas.geenen@surfsara.nl SURFsara The Dutch national HPC center 2H 2014 > 1PFlop GPGPU accelerators
Building an energy dashboard Energy measurement and visualization in current HPC systems Thomas Geenen 1/58 thomas.geenen@surfsara.nl SURFsara The Dutch national HPC center 2H 2014 > 1PFlop GPGPU accelerators
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
New Issues and New Capabilities in HPC Scheduling with the Maui Scheduler
 New Issues and New Capabilities in HPC Scheduling with the Maui Scheduler I.Introduction David B Jackson Center for High Performance Computing, University of Utah Much has changed in a few short years.
New Issues and New Capabilities in HPC Scheduling with the Maui Scheduler I.Introduction David B Jackson Center for High Performance Computing, University of Utah Much has changed in a few short years.
Alternative Deployment Models for Cloud Computing in HPC Applications. Society of HPC Professionals November 9, 2011 Steve Hebert, Nimbix
 Alternative Deployment Models for Cloud Computing in HPC Applications Society of HPC Professionals November 9, 2011 Steve Hebert, Nimbix The case for Cloud in HPC Build it in house Assemble in the cloud?
Alternative Deployment Models for Cloud Computing in HPC Applications Society of HPC Professionals November 9, 2011 Steve Hebert, Nimbix The case for Cloud in HPC Build it in house Assemble in the cloud?
About the Author About the Technical Contributors About the Technical Reviewers Acknowledgments. How to Use This Book
 About the Author p. xv About the Technical Contributors p. xvi About the Technical Reviewers p. xvi Acknowledgments p. xix Preface p. xxiii About This Book p. xxiii How to Use This Book p. xxiv Appendices
About the Author p. xv About the Technical Contributors p. xvi About the Technical Reviewers p. xvi Acknowledgments p. xix Preface p. xxiii About This Book p. xxiii How to Use This Book p. xxiv Appendices
Red Hat Enterprprise Linux - Renewals DETAILS SUPPORTED ARCHITECTURE
 Red Hat Enterprprise Linux - Renewals PRODUCT CODE DESCRIPTION 1 Year DETAILS SUPPORTED ARCHITECTURE Red Hat Enterprise Linux Advanced Platform Red Hat Enterprise Linux Advanced Platform, (unlimited Red
Red Hat Enterprprise Linux - Renewals PRODUCT CODE DESCRIPTION 1 Year DETAILS SUPPORTED ARCHITECTURE Red Hat Enterprise Linux Advanced Platform Red Hat Enterprise Linux Advanced Platform, (unlimited Red
Auto-Tunning of Data Communication on Heterogeneous Systems
 1 Auto-Tunning of Data Communication on Heterogeneous Systems Marc Jordà 1, Ivan Tanasic 1, Javier Cabezas 1, Lluís Vilanova 1, Isaac Gelado 1, and Nacho Navarro 1, 2 1 Barcelona Supercomputing Center
1 Auto-Tunning of Data Communication on Heterogeneous Systems Marc Jordà 1, Ivan Tanasic 1, Javier Cabezas 1, Lluís Vilanova 1, Isaac Gelado 1, and Nacho Navarro 1, 2 1 Barcelona Supercomputing Center
HPC-Nutzer Informationsaustausch. The Workload Management System LSF
 HPC-Nutzer Informationsaustausch The Workload Management System LSF Content Cluster facts Job submission esub messages Scheduling strategies Tools and security Future plans 2 von 10 Some facts about the
HPC-Nutzer Informationsaustausch The Workload Management System LSF Content Cluster facts Job submission esub messages Scheduling strategies Tools and security Future plans 2 von 10 Some facts about the
Bibliography. University of Applied Sciences Fulda, Prof. Dr. S. Groß
 Slide III Bibliography 1) Abbas, A.: Grid Computing - A Practical Guide to Technology and Applications. Charles River Media, 2004. http://www.charlesriver.com/titles/gridcomputing.html 2) Berman, F.; et
Slide III Bibliography 1) Abbas, A.: Grid Computing - A Practical Guide to Technology and Applications. Charles River Media, 2004. http://www.charlesriver.com/titles/gridcomputing.html 2) Berman, F.; et
Batch System Deployment on a Production Terascale Cluster
 Batch System Deployment on a Production Terascale Cluster Karl W. Schulz, Kent Milfeld, Chona S. Guiang, Avijit Purkayastha, Tommy Minyard, John R. Boisseau, and John Casu Texas Advanced Computing Center
Batch System Deployment on a Production Terascale Cluster Karl W. Schulz, Kent Milfeld, Chona S. Guiang, Avijit Purkayastha, Tommy Minyard, John R. Boisseau, and John Casu Texas Advanced Computing Center
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
LoadLeveler Overview. January 30-31, 2012. IBM Storage & Technology Group. IBM HPC Developer Education @ TIFR, Mumbai
 IBM HPC Developer Education @ TIFR, Mumbai IBM Storage & Technology Group LoadLeveler Overview January 30-31, 2012 Pidad D'Souza (pidsouza@in.ibm.com) IBM, System & Technology Group 2009 IBM Corporation
IBM HPC Developer Education @ TIFR, Mumbai IBM Storage & Technology Group LoadLeveler Overview January 30-31, 2012 Pidad D'Souza (pidsouza@in.ibm.com) IBM, System & Technology Group 2009 IBM Corporation
Cisco Unified Data Center Solutions for MapR: Deliver Automated, High-Performance Hadoop Workloads
 Solution Overview Cisco Unified Data Center Solutions for MapR: Deliver Automated, High-Performance Hadoop Workloads What You Will Learn MapR Hadoop clusters on Cisco Unified Computing System (Cisco UCS
Solution Overview Cisco Unified Data Center Solutions for MapR: Deliver Automated, High-Performance Hadoop Workloads What You Will Learn MapR Hadoop clusters on Cisco Unified Computing System (Cisco UCS
HPC Software Requirements to Support an HPC Cluster Supercomputer
 HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
Comparative Study of Distributed Resource Management Systems SGE, LSF, PBS Pro, and LoadLeveler
 Comparative Study of Distributed Resource Management Systems SGE, LSF, PBS Pro, and LoadLeveler Yonghong Yan, Barbara Chapman {yanyh,chapman}@cs.uh.edu Department of Computer Science University of Houston
Comparative Study of Distributed Resource Management Systems SGE, LSF, PBS Pro, and LoadLeveler Yonghong Yan, Barbara Chapman {yanyh,chapman}@cs.uh.edu Department of Computer Science University of Houston
Scaling Across the Supercomputer Performance Spectrum
 Scaling Across the Supercomputer Performance Spectrum Cray s XC40 system leverages the combined advantages of next-generation Aries interconnect and Dragonfly network topology, Intel Xeon processors, integrated
Scaling Across the Supercomputer Performance Spectrum Cray s XC40 system leverages the combined advantages of next-generation Aries interconnect and Dragonfly network topology, Intel Xeon processors, integrated
Denis Caromel, CEO Ac.veEon. Orchestrate and Accelerate Applica.ons. Open Source Cloud Solu.ons Hybrid Cloud: Private with Burst Capacity
 Cloud computing et Virtualisation : applications au domaine de la Finance Denis Caromel, CEO Ac.veEon Orchestrate and Accelerate Applica.ons Open Source Cloud Solu.ons Hybrid Cloud: Private with Burst
Cloud computing et Virtualisation : applications au domaine de la Finance Denis Caromel, CEO Ac.veEon Orchestrate and Accelerate Applica.ons Open Source Cloud Solu.ons Hybrid Cloud: Private with Burst
Distributed Operating Systems. Cluster Systems
 Distributed Operating Systems Cluster Systems Ewa Niewiadomska-Szynkiewicz ens@ia.pw.edu.pl Institute of Control and Computation Engineering Warsaw University of Technology E&IT Department, WUT 1 1. Cluster
Distributed Operating Systems Cluster Systems Ewa Niewiadomska-Szynkiewicz ens@ia.pw.edu.pl Institute of Control and Computation Engineering Warsaw University of Technology E&IT Department, WUT 1 1. Cluster
Sun Grid Engine, a new scheduler for EGEE middleware
 Sun Grid Engine, a new scheduler for EGEE middleware G. Borges 1, M. David 1, J. Gomes 1, J. Lopez 2, P. Rey 2, A. Simon 2, C. Fernandez 2, D. Kant 3, K. M. Sephton 4 1 Laboratório de Instrumentação em
Sun Grid Engine, a new scheduler for EGEE middleware G. Borges 1, M. David 1, J. Gomes 1, J. Lopez 2, P. Rey 2, A. Simon 2, C. Fernandez 2, D. Kant 3, K. M. Sephton 4 1 Laboratório de Instrumentação em
PERFORMANCE CONSIDERATIONS FOR NETWORK SWITCH FABRICS ON LINUX CLUSTERS
 PERFORMANCE CONSIDERATIONS FOR NETWORK SWITCH FABRICS ON LINUX CLUSTERS Philip J. Sokolowski Department of Electrical and Computer Engineering Wayne State University 55 Anthony Wayne Dr. Detroit, MI 822
PERFORMANCE CONSIDERATIONS FOR NETWORK SWITCH FABRICS ON LINUX CLUSTERS Philip J. Sokolowski Department of Electrical and Computer Engineering Wayne State University 55 Anthony Wayne Dr. Detroit, MI 822
A Performance Data Storage and Analysis Tool
 A Performance Data Storage and Analysis Tool Steps for Using 1. Gather Machine Data 2. Build Application 3. Execute Application 4. Load Data 5. Analyze Data 105% Faster! 72% Slower Build Application Execute
A Performance Data Storage and Analysis Tool Steps for Using 1. Gather Machine Data 2. Build Application 3. Execute Application 4. Load Data 5. Analyze Data 105% Faster! 72% Slower Build Application Execute