Application of Grid-Enabled Technologies for Solving Optimization Problems in Data Driven Reservoir Systems
|
|
|
- Stanley Charles
- 8 years ago
- Views:
Transcription
1 Application of Grid-Enabled Technologies for Solving Optimization Problems in Data Driven Reservoir Systems M. Parashar, H. Klie, U. Catalyurek, T. Kurc, V. Matossian, J. Saltz, M.F. Wheeler

2 ITR Collaborators University of Chicago CS: Stevens, Papka University of Maryland CS: Sussman MIT Ohio State CS: Saltz, Kurc, Catalyurek Rutgers ECE: Parashar Univ. Chicago OSU Rutgers MIT Engineering: Haines UT Austin Wheeler, Dawson, Peszynska, Klie, Bangerth (Computaional and Applied math); Sen, Stoffa, Seifoullaev (UTIG), Torres-Verdin (CPGE) UMD UT Austin
; Sen, Stoffa, Seifoullaev (UTIG), Torres-Verdin")
3 The Instrumented Oil Field Detect and track changes in data during production Invert data for reservoir properties Detect and track reservoir changes Assimilate data & reservoir properties into the evolving reservoir model Use simulation and optimization to guide future production, future data acquisition strategy

4 Assumptions: Production of oil and gas will take advantage of permanently installed geophysical sensors and down hole instrumentation that will monitor the reservoir s state as fluids are extracted. Knowledge of the reservoir s state during production will result in better engineering decisions to modify production techniques that optimize goals while maintaining safe operating conditions in environmentally complex and difficult areas.

5 Data Driven Model Optimization Management decision Dynamic Decision System Optimize Economic revenue Environmental hazard Based on the present subsurface knowledge and numerical model Update knowledge of model Subsurface characterization Dynamic Data- Driven Assimilation Improve knowledge of subsurface to reduce uncertainty Acquire remote sensing data Data assimilation Improve numerical model Experimental design START Plan optimal data acquisition Processing Middleware Autonomic Grid Middleware Grid Data Management

6 D V D D V D D V D D V D D V D D V D MetaData Servers DDDSF Requires Multi-petabyte Virtual Data Archive Ohio Supercomputing Center Mass Storage Testbed (2) 890 MB/s Throughput SAN Volume Controller (4 servers) (2) (2) 890 MB/s throughput (2) (4) 772 MB/s throughput (16-4 per server) 890 MB/s throughput (2) (2) Cisco Directors 9509 (4) 772 MB/s throughput (4) 772 MB/s throughput FAStT900 (4) (2) (4) 772 MB/s throughput Core Storage Pool (35/50 TB) with SAN.FS (2) (40-2 per xseries) 10 GB/s (40-2 per T600) 384 MB/s throughput (4) LinTel boxes (PvFS/ Active Disk Archive) (20) FAStT600 Turbo (20) Scratch / Archive Storage Pool (310/420 TB) Backup Storage 3584 Tape 1 L32 2 D32 Actual: GB for a total of 128 TB 4 drives max drive data rate is 35 MB/s IBM s Storage Tank technology combined with TFN connections will allow large data sets to be seamlessly moved throughout the state with increased redundancy and seamless delivery. 50 TB of performance storage home directories, project storage space, and longterm frequently accessed files. 420 TB of performance/capacity storage Active Disk Cache - compute jobs that require directly connected storage parallel file systems, and scratch space. Large temporary holding area 128 TB tape library Backups and long-term "offline" storage
 (40-2 per xseries) 10 GB/s (40-2 per T600) 384 MB/s throughput (4) LinTel boxes (PvFS/ Active Disk Archive) (20) FAStT600 Turbo (20) Scratch / Archive Storage Pool (310/420 TB) Backup Storage")
7 A new generation of IPARS Optimizing oil production on the Grid Static data Clients Visualization Data manag./ assimilation Steering Monitoring Dynamic data Objective function Collaboration

8 Optimization with a Known Oil Reservoir Model f: Objective function α: Control variables in feasibility set A c: Model data

9 Interplay between Data Acquisition, Data Assimilation and Optimization Model c as stochastic E: expectation for PDF of c A posteriori PDF computed to describe current subsurface knowledge Optimization seeks best production strategy Control variables α parameterize production and data acquisition strategy Good choice of α optimizes production and improves model certainty

10 Parallel/Grid Computing Tools The Multiblock Adaptive Computational Engine (MACE) for solving heterogeneous domain applications Adaptive grid blocks Automatic and transparent scheduling, load balancing Distributed Shared Objects: distributed dynamic arrays Datacutter/STORM: Middleware for On-Demand Data Product Generation for Large Archival Scientific Datasets in a Grid Environment Exploration and analysis of scientific datasets in distributed and heterogeneous environments Represents components of a data-intensive application as a set of filters Data virtualization for heterogeneous collections of data formats, storage systems Discover: Grid Computational Collaboratory enabling seamless and secure access to and interactions between users, applications, services, data and resources P2P Grid Middleware: services, autonomic composition, secure access Collaborative Portals

11 Scalability of IPARS and geomechanical coupling 1.2 Parallel efficiency Number of processors Domain by by 1059 feet 513 by 513 by 45 mesh points 282 nodes of dual-processor Dell PowerEdge GHz computer interconnected by a Myrinet 2000 with a point-to-point bandwidth of 2Gb/sec. Each node has a 2GB of memory.

12 Data Middleware Services Filter-stream based distributed execution middleware (DataCutter, STORM) Grid based data virtualization, data management, query, on demand data product generation (STORM, Active ProxyG, Mako) Distributed metadata management (Mobius Global Model Exchange) Track metadata associated with workflows, input image datasets, checkpointed intermediate results
 Track metadata associated with workflows, input image datasets, checkpointed")
13 Processing Remotely-Sensed Data NOAA Tiros-N w/ AVHRR sensor Data Middleware Services and Very Large Scale Distributed Data Applications AVHRR Level 1 Data As the TIROS-N satellite orbits, the Advanced Very High Resolution Radiometer (AVHRR) sensor scans perpendicular to the satellite s track. At regular intervals along a scan line measurements are gathered to form an instantaneous field of view (IFOV). Scan lines are aggregated into Level 1 data sets. A single file of Global Area Coverage (GAC) data represents: ~one full earth orbit. ~110 minutes. ~40 megabytes. ~15,000 scan lines. One scan line is 409 IFOV s Satellite Data Processing Digital Pathology Managing Oilfields, Contaminant Transport DCE-MRI Analysis Derivation of macroscopic materials properties from MD simulations
 data represents: ~one full earth orbit. ~110 minutes. ~40 megabytes. ~15,000 scan lines.")
14 DataCutter Flow control between components Schedulers place filters on grid processors (scheduler API) Parallel stream based communication Data aggregation implemented as a component Filters placed near data sources NPACkage, NMI host1 Combined Data/Task Parallelism R 0 R 1 E K+1 R 2 host2 Cluster 1 E 0 E K host1 E N Ra 0 host3 Ra 1 M host4 host1 Ra 2 host2 host5 Cluster 2 Cluster 3 9/11/2002 DataCutter 19

15 Automatic Data Virtualization Scientific and engineering applications require interactive exploration and analysis of datasets. Applications developers generally prefer storing data in files Support high level queries on multi-dimensional distributed datasets Many possible data abstractions, query interfaces Grid virtualized object relational database or XML database Grid virtualized objects with user defined methods invoked to access and process data A virtual relational table view Data Service Large distributed scientific datasets Data Virtualization

16 Our Approach Automatic data virtualization Friendly front-end Support a basic SQL Select query with a virtual relational table view or a virtual XML database view A lightweight layer on top of datasets STORM runtime middleware STORM carries out query execution, query planning Compiler front end customizes runtime support Automatic customization and configuration of runtime query support middleware

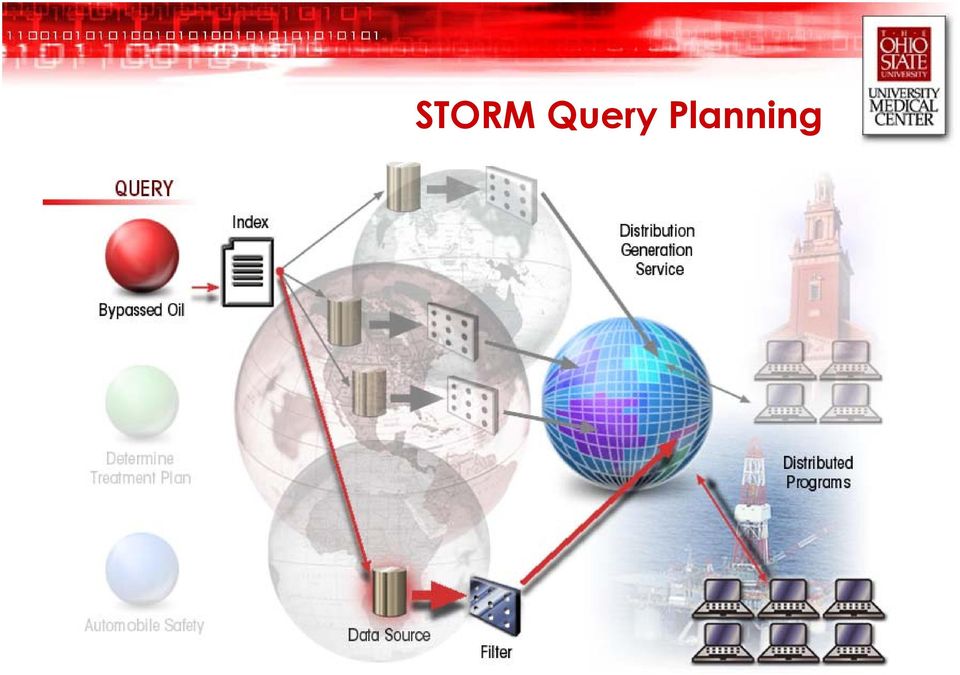
17 STORM Query Planning
18 STORM Query Execution

19 Compiler Customization support for Select query SELECT < Data Elements > SELECT * FROM < Dataset Name > FROM IPARS WHERE < Expression > WHERE REL in (0,6,26,27) AND TIME>1000 AND Filer( < Data Element> ); AND TIME<1100 AND SOIL>0.7 AND SPEED(OILVX, OILVY,OILVZ)<30.0;
; AND TIME<1100 AND SOIL>0.")
20 Analysis of Oil Reservoir Simulation Data Prototype Implementation Evaluate geologic uncertainty and production strategies simultaneously Multiple realizations of multiple geostatistical models Multiple production strategies (number, location of wells) Dataset Size = ~5TB 500 simulations, selected from several Geostatistics models and well patterns Each simulation is ~10GB 2,000 time steps, 65K grid elements, 8 scalars + 3 vectors = 17 variables Stored at SDSC: HPSS and 30TB Storage Area Network System UMD: 9TB disks on 50 nodes: PIII-650, 128MB, Switched Ethernet OSU: 7.2TB disks on 24 nodes: PIII-900, 512MB, Switched Ethernet Data Analysis Economic model assessment Bypassed oil regions Representative Realization Selection for more simulations

21 Survey # Seismic Data Analysis STORM: On Demand Processing of 1.5 TB Seismic Dataset Line # Sp (or CDP) # & source position Traces Array # Receiver group # & receiver group position Component #
22 DISCOVER: A Grid Computational Collaboratory enabling seamless and secure access to and interactions between users, applications, services, data and resources CPU's, Storage, Instruments,... P2P Grid Middleware (PAWN, DISCOVER-COG) Peer services (discovery, routing, message publication, notification, event), context-aware access control, p2p deductive engines. Autonomic and Interactive Components (DIOS, AUTOMATE) Components encapsulate sensors, actuators, policies and rules. Distributed control network connects sensors, actuators and interaction agents. P2P deductive shell, control network, rules and polices enable autonomic composition, configuration, interaction, protection, optimization and adaptation. Collaborative Portals Pervasive (secure) access, monitoring, interaction and control User Scientist Laptop Computer PDA Discovery Points Resources P2P Grid Middleware Data Archive & Sensors Discovery Points Applications & Services Application Service DISCOVER Portals Data Archives Sensors, Non- Traditional Data Sources
23 Autonomic Oil Well Placement (UT-CSM, UT-IG) Optimization services: VFSA (Very Fast Simulated Annealing) SPSA (Simultaneous Perturbation Stochastic Optimization) IPARS delivers fast-forward model (guess->objective function value) post-processing Formulate a parameter space well position and pressure (y,z,p) Formulate an objective function: maximize economic value Eval(y,z,P)(T)
24 Autonomic Oil Reservoir Optimization using Decentralized Services
25 Components of the AORO Application IPARS : Integrated Parallel Accurate Reservoir Simulator Parallel reservoir simulation framework IPARS Factory Configures instances of IPARS simulations Deploys them on resources on the Grid Manages their execution VFSA/SPSA Optimization Services Optimizes the placement of wells and the inputs (pressure, temperature) to IPARS simulations. Economic Modeling Service Uses IPARS simulations outputs and current market parameters (oil prices, costs, etc.) to compute estimated revenues for a particular reservoir configuration. DISCOVER Computational Collaboratory Interaction & Collaboration Distributed Interactive Object Substrate (DIOS) Collaborative Portals
26 Autonomic Oil Well Placement (VFSA)
27 Autonomic Oil Well Placement (SPSA) Permeability field showing the positioning of current wells. The symbols * and + indicate injection and producer wells, respectively. Search space response surface: Expected revenue - f(p) for all possible well locations p. White marks indicate optimal well locations found by SPSA for 7 different starting points of the algorithm.
28 The Future Scaling up: High resolution IPARS simulations Multi-petabyte distributed archives of model data Exploitation of OSC and Teragrid resources (large teragrid allocation approved) Large scale demonstration of Discover/STORM/DataCutter integration Experimental testbeds EPA/INEEL collaboration live sensor data from superfund site NSF Center for Subsurface Sensing and Imaging Systems Data from industrial affiliates New numerical methods Next generation accurate, multi-scale coupled chemical, fluid, geomechanical and geophysical simulator Large scale global optimization module to drive decision making
Servicing Seismic and Oil Reservoir Simulation Data through Grid Data Services
 Servicing Seismic and Oil Reservoir Simulation Data through Grid Data Services Sivaramakrishnan Narayanan, Tahsin Kurc, Umit Catalyurek and Joel Saltz Multiscale Computing Lab Biomedical Informatics Department
Servicing Seismic and Oil Reservoir Simulation Data through Grid Data Services Sivaramakrishnan Narayanan, Tahsin Kurc, Umit Catalyurek and Joel Saltz Multiscale Computing Lab Biomedical Informatics Department
Towards Dynamic Data-Driven Management of the Ruby Gulch Waste Repository
 Towards Dynamic Data-Driven Management of the Ruby Gulch Waste Repository Manish Parashar 1, Vincent Matossian 1, Hector Klie 2, Sunil G. Thomas 2, Mary F. Wheeler 2,TahsinKurc 3,JoelSaltz 3, and Roelof
Towards Dynamic Data-Driven Management of the Ruby Gulch Waste Repository Manish Parashar 1, Vincent Matossian 1, Hector Klie 2, Sunil G. Thomas 2, Mary F. Wheeler 2,TahsinKurc 3,JoelSaltz 3, and Roelof
Agenda. HPC Software Stack. HPC Post-Processing Visualization. Case Study National Scientific Center. European HPC Benchmark Center Montpellier PSSC
 HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
A simulation and data analysis system for large-scale, data-driven oil reservoir simulation studies
 CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2005; 17:1441 1467 Published online in Wiley InterScience (www.interscience.wiley.com). DOI: 10.1002/cpe.898 A
CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2005; 17:1441 1467 Published online in Wiley InterScience (www.interscience.wiley.com). DOI: 10.1002/cpe.898 A
Building Platform as a Service for Scientific Applications
 Building Platform as a Service for Scientific Applications Moustafa AbdelBaky moustafa@cac.rutgers.edu Rutgers Discovery Informa=cs Ins=tute (RDI 2 ) The NSF Cloud and Autonomic Compu=ng Center Department
Building Platform as a Service for Scientific Applications Moustafa AbdelBaky moustafa@cac.rutgers.edu Rutgers Discovery Informa=cs Ins=tute (RDI 2 ) The NSF Cloud and Autonomic Compu=ng Center Department
Dell High-Performance Computing Clusters and Reservoir Simulation Research at UT Austin. http://www.dell.com/clustering
 Dell High-Performance Computing Clusters and Reservoir Simulation Research at UT Austin Reza Rooholamini, Ph.D. Director Enterprise Solutions Dell Computer Corp. Reza_Rooholamini@dell.com http://www.dell.com/clustering
Dell High-Performance Computing Clusters and Reservoir Simulation Research at UT Austin Reza Rooholamini, Ph.D. Director Enterprise Solutions Dell Computer Corp. Reza_Rooholamini@dell.com http://www.dell.com/clustering
Middleware support for the Internet of Things
 Middleware support for the Internet of Things Karl Aberer, Manfred Hauswirth, Ali Salehi School of Computer and Communication Sciences Ecole Polytechnique Fédérale de Lausanne (EPFL) CH-1015 Lausanne,
Middleware support for the Internet of Things Karl Aberer, Manfred Hauswirth, Ali Salehi School of Computer and Communication Sciences Ecole Polytechnique Fédérale de Lausanne (EPFL) CH-1015 Lausanne,
Scala Storage Scale-Out Clustered Storage White Paper
 White Paper Scala Storage Scale-Out Clustered Storage White Paper Chapter 1 Introduction... 3 Capacity - Explosive Growth of Unstructured Data... 3 Performance - Cluster Computing... 3 Chapter 2 Current
White Paper Scala Storage Scale-Out Clustered Storage White Paper Chapter 1 Introduction... 3 Capacity - Explosive Growth of Unstructured Data... 3 Performance - Cluster Computing... 3 Chapter 2 Current
Managing Large Imagery Databases via the Web
 'Photogrammetric Week 01' D. Fritsch & R. Spiller, Eds. Wichmann Verlag, Heidelberg 2001. Meyer 309 Managing Large Imagery Databases via the Web UWE MEYER, Dortmund ABSTRACT The terramapserver system is
'Photogrammetric Week 01' D. Fritsch & R. Spiller, Eds. Wichmann Verlag, Heidelberg 2001. Meyer 309 Managing Large Imagery Databases via the Web UWE MEYER, Dortmund ABSTRACT The terramapserver system is
Data Management in an International Data Grid Project. Timur Chabuk 04/09/2007
 Data Management in an International Data Grid Project Timur Chabuk 04/09/2007 Intro LHC opened in 2005 several Petabytes of data per year data created at CERN distributed to Regional Centers all over the
Data Management in an International Data Grid Project Timur Chabuk 04/09/2007 Intro LHC opened in 2005 several Petabytes of data per year data created at CERN distributed to Regional Centers all over the
The Data Grid: Towards an Architecture for Distributed Management and Analysis of Large Scientific Datasets
 The Data Grid: Towards an Architecture for Distributed Management and Analysis of Large Scientific Datasets!! Large data collections appear in many scientific domains like climate studies.!! Users and
The Data Grid: Towards an Architecture for Distributed Management and Analysis of Large Scientific Datasets!! Large data collections appear in many scientific domains like climate studies.!! Users and
Database Support for Data-driven Scientific Applications in the Grid
 Database Support for Data-driven Scientific Applications in the Grid Sivaramakrishnan Narayanan, Tahsin Kurc, Umit Catalyurek, Joel Saltz Dept. of Biomedical Informatics The Ohio State University Columbus,
Database Support for Data-driven Scientific Applications in the Grid Sivaramakrishnan Narayanan, Tahsin Kurc, Umit Catalyurek, Joel Saltz Dept. of Biomedical Informatics The Ohio State University Columbus,
Data Mining for Data Cloud and Compute Cloud
 Data Mining for Data Cloud and Compute Cloud Prof. Uzma Ali 1, Prof. Punam Khandar 2 Assistant Professor, Dept. Of Computer Application, SRCOEM, Nagpur, India 1 Assistant Professor, Dept. Of Computer Application,
Data Mining for Data Cloud and Compute Cloud Prof. Uzma Ali 1, Prof. Punam Khandar 2 Assistant Professor, Dept. Of Computer Application, SRCOEM, Nagpur, India 1 Assistant Professor, Dept. Of Computer Application,
THE EXPAND PARALLEL FILE SYSTEM A FILE SYSTEM FOR CLUSTER AND GRID COMPUTING. José Daniel García Sánchez ARCOS Group University Carlos III of Madrid
 THE EXPAND PARALLEL FILE SYSTEM A FILE SYSTEM FOR CLUSTER AND GRID COMPUTING José Daniel García Sánchez ARCOS Group University Carlos III of Madrid Contents 2 The ARCOS Group. Expand motivation. Expand
THE EXPAND PARALLEL FILE SYSTEM A FILE SYSTEM FOR CLUSTER AND GRID COMPUTING José Daniel García Sánchez ARCOS Group University Carlos III of Madrid Contents 2 The ARCOS Group. Expand motivation. Expand
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
HPC and Big Data. EPCC The University of Edinburgh. Adrian Jackson Technical Architect a.jackson@epcc.ed.ac.uk
 HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect a.jackson@epcc.ed.ac.uk EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect a.jackson@epcc.ed.ac.uk EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
Data Management/Visualization on the Grid at PPPL. Scott A. Klasky Stephane Ethier Ravi Samtaney
 Data Management/Visualization on the Grid at PPPL Scott A. Klasky Stephane Ethier Ravi Samtaney The Problem Simulations at NERSC generate GB s TB s of data. The transfer time for practical visualization
Data Management/Visualization on the Grid at PPPL Scott A. Klasky Stephane Ethier Ravi Samtaney The Problem Simulations at NERSC generate GB s TB s of data. The transfer time for practical visualization
Reference Architecture. EMC Global Solutions. 42 South Street Hopkinton MA 01748-9103 1.508.435.1000 www.emc.com
 EMC Backup and Recovery for SAP with IBM DB2 on IBM AIX Enabled by EMC Symmetrix DMX-4, EMC CLARiiON CX3, EMC Replication Manager, IBM Tivoli Storage Manager, and EMC NetWorker Reference Architecture EMC
EMC Backup and Recovery for SAP with IBM DB2 on IBM AIX Enabled by EMC Symmetrix DMX-4, EMC CLARiiON CX3, EMC Replication Manager, IBM Tivoli Storage Manager, and EMC NetWorker Reference Architecture EMC
Cluster Scalability of ANSYS FLUENT 12 for a Large Aerodynamics Case on the Darwin Supercomputer
 Cluster Scalability of ANSYS FLUENT 12 for a Large Aerodynamics Case on the Darwin Supercomputer Stan Posey, MSc and Bill Loewe, PhD Panasas Inc., Fremont, CA, USA Paul Calleja, PhD University of Cambridge,
Cluster Scalability of ANSYS FLUENT 12 for a Large Aerodynamics Case on the Darwin Supercomputer Stan Posey, MSc and Bill Loewe, PhD Panasas Inc., Fremont, CA, USA Paul Calleja, PhD University of Cambridge,
Workload Characterization and Analysis of Storage and Bandwidth Needs of LEAD Workspace
 Workload Characterization and Analysis of Storage and Bandwidth Needs of LEAD Workspace Beth Plale Indiana University plale@cs.indiana.edu LEAD TR 001, V3.0 V3.0 dated January 24, 2007 V2.0 dated August
Workload Characterization and Analysis of Storage and Bandwidth Needs of LEAD Workspace Beth Plale Indiana University plale@cs.indiana.edu LEAD TR 001, V3.0 V3.0 dated January 24, 2007 V2.0 dated August
Bringing Big Data Modelling into the Hands of Domain Experts
 Bringing Big Data Modelling into the Hands of Domain Experts David Willingham Senior Application Engineer MathWorks david.willingham@mathworks.com.au 2015 The MathWorks, Inc. 1 Data is the sword of the
Bringing Big Data Modelling into the Hands of Domain Experts David Willingham Senior Application Engineer MathWorks david.willingham@mathworks.com.au 2015 The MathWorks, Inc. 1 Data is the sword of the
High Performance Applications over the Cloud: Gains and Losses
 High Performance Applications over the Cloud: Gains and Losses Dr. Leila Ismail Faculty of Information Technology United Arab Emirates University leila@uaeu.ac.ae http://citweb.uaeu.ac.ae/citweb/profile/leila
High Performance Applications over the Cloud: Gains and Losses Dr. Leila Ismail Faculty of Information Technology United Arab Emirates University leila@uaeu.ac.ae http://citweb.uaeu.ac.ae/citweb/profile/leila
IBM Deep Computing Visualization Offering
 P - 271 IBM Deep Computing Visualization Offering Parijat Sharma, Infrastructure Solution Architect, IBM India Pvt Ltd. email: parijatsharma@in.ibm.com Summary Deep Computing Visualization in Oil & Gas
P - 271 IBM Deep Computing Visualization Offering Parijat Sharma, Infrastructure Solution Architect, IBM India Pvt Ltd. email: parijatsharma@in.ibm.com Summary Deep Computing Visualization in Oil & Gas
News and trends in Data Warehouse Automation, Big Data and BI. Johan Hendrickx & Dirk Vermeiren
 News and trends in Data Warehouse Automation, Big Data and BI Johan Hendrickx & Dirk Vermeiren Extreme Agility from Source to Analysis DWH Appliances & DWH Automation Typical Architecture 3 What Business
News and trends in Data Warehouse Automation, Big Data and BI Johan Hendrickx & Dirk Vermeiren Extreme Agility from Source to Analysis DWH Appliances & DWH Automation Typical Architecture 3 What Business
Microsoft SQL Server 2005 on Windows Server 2003
 EMC Backup and Recovery for SAP Microsoft SQL Server 2005 on Windows Server 2003 Enabled by EMC CLARiiON CX3, EMC Disk Library, EMC Replication Manager, EMC NetWorker, and Symantec Veritas NetBackup Reference
EMC Backup and Recovery for SAP Microsoft SQL Server 2005 on Windows Server 2003 Enabled by EMC CLARiiON CX3, EMC Disk Library, EMC Replication Manager, EMC NetWorker, and Symantec Veritas NetBackup Reference
Scheduling and Resource Management in Computational Mini-Grids
 Scheduling and Resource Management in Computational Mini-Grids July 1, 2002 Project Description The concept of grid computing is becoming a more and more important one in the high performance computing
Scheduling and Resource Management in Computational Mini-Grids July 1, 2002 Project Description The concept of grid computing is becoming a more and more important one in the high performance computing
A Survey Study on Monitoring Service for Grid
 A Survey Study on Monitoring Service for Grid Erkang You erkyou@indiana.edu ABSTRACT Grid is a distributed system that integrates heterogeneous systems into a single transparent computer, aiming to provide
A Survey Study on Monitoring Service for Grid Erkang You erkyou@indiana.edu ABSTRACT Grid is a distributed system that integrates heterogeneous systems into a single transparent computer, aiming to provide
Storage Switzerland White Paper Storage Infrastructures for Big Data Workflows
 Storage Switzerland White Paper Storage Infrastructures for Big Data Workflows Sponsored by: Prepared by: Eric Slack, Sr. Analyst May 2012 Storage Infrastructures for Big Data Workflows Introduction Big
Storage Switzerland White Paper Storage Infrastructures for Big Data Workflows Sponsored by: Prepared by: Eric Slack, Sr. Analyst May 2012 Storage Infrastructures for Big Data Workflows Introduction Big
NVIDIA IndeX Enabling Interactive and Scalable Visualization for Large Data Marc Nienhaus, NVIDIA IndeX Engineering Manager and Chief Architect
 SIGGRAPH 2013 Shaping the Future of Visual Computing NVIDIA IndeX Enabling Interactive and Scalable Visualization for Large Data Marc Nienhaus, NVIDIA IndeX Engineering Manager and Chief Architect NVIDIA
SIGGRAPH 2013 Shaping the Future of Visual Computing NVIDIA IndeX Enabling Interactive and Scalable Visualization for Large Data Marc Nienhaus, NVIDIA IndeX Engineering Manager and Chief Architect NVIDIA
Globus Striped GridFTP Framework and Server. Raj Kettimuthu, ANL and U. Chicago
 Globus Striped GridFTP Framework and Server Raj Kettimuthu, ANL and U. Chicago Outline Introduction Features Motivation Architecture Globus XIO Experimental Results 3 August 2005 The Ohio State University
Globus Striped GridFTP Framework and Server Raj Kettimuthu, ANL and U. Chicago Outline Introduction Features Motivation Architecture Globus XIO Experimental Results 3 August 2005 The Ohio State University
The Lattice Project: A Multi-Model Grid Computing System. Center for Bioinformatics and Computational Biology University of Maryland
 The Lattice Project: A Multi-Model Grid Computing System Center for Bioinformatics and Computational Biology University of Maryland Parallel Computing PARALLEL COMPUTING a form of computation in which
The Lattice Project: A Multi-Model Grid Computing System Center for Bioinformatics and Computational Biology University of Maryland Parallel Computing PARALLEL COMPUTING a form of computation in which
DELL s Oracle Database Advisor
 DELL s Oracle Database Advisor Underlying Methodology A Dell Technical White Paper Database Solutions Engineering By Roger Lopez Phani MV Dell Product Group January 2010 THIS WHITE PAPER IS FOR INFORMATIONAL
DELL s Oracle Database Advisor Underlying Methodology A Dell Technical White Paper Database Solutions Engineering By Roger Lopez Phani MV Dell Product Group January 2010 THIS WHITE PAPER IS FOR INFORMATIONAL
Hadoop on the Gordon Data Intensive Cluster
 Hadoop on the Gordon Data Intensive Cluster Amit Majumdar, Scientific Computing Applications Mahidhar Tatineni, HPC User Services San Diego Supercomputer Center University of California San Diego Dec 18,
Hadoop on the Gordon Data Intensive Cluster Amit Majumdar, Scientific Computing Applications Mahidhar Tatineni, HPC User Services San Diego Supercomputer Center University of California San Diego Dec 18,
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications. Jürgen Primsch, SAP AG July 2011
 SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
Clusters: Mainstream Technology for CAE
 Clusters: Mainstream Technology for CAE Alanna Dwyer HPC Division, HP Linux and Clusters Sparked a Revolution in High Performance Computing! Supercomputing performance now affordable and accessible Linux
Clusters: Mainstream Technology for CAE Alanna Dwyer HPC Division, HP Linux and Clusters Sparked a Revolution in High Performance Computing! Supercomputing performance now affordable and accessible Linux
Grid on Blades. Basil Smith 7/2/2005. 2003 IBM Corporation
 Grid on Blades Basil Smith 7/2/2005 2003 IBM Corporation What is the problem? Inefficient utilization of resources (MIPS, Memory, Storage, Bandwidth) Fundamentally resources are being wasted due to wide
Grid on Blades Basil Smith 7/2/2005 2003 IBM Corporation What is the problem? Inefficient utilization of resources (MIPS, Memory, Storage, Bandwidth) Fundamentally resources are being wasted due to wide
Big Data and Cloud Computing for GHRSST
 Big Data and Cloud Computing for GHRSST Jean-Francois Piollé (jfpiolle@ifremer.fr) Frédéric Paul, Olivier Archer CERSAT / Institut Français de Recherche pour l Exploitation de la Mer Facing data deluge
Big Data and Cloud Computing for GHRSST Jean-Francois Piollé (jfpiolle@ifremer.fr) Frédéric Paul, Olivier Archer CERSAT / Institut Français de Recherche pour l Exploitation de la Mer Facing data deluge
Big Data Mining Services and Knowledge Discovery Applications on Clouds
 Big Data Mining Services and Knowledge Discovery Applications on Clouds Domenico Talia DIMES, Università della Calabria & DtoK Lab Italy talia@dimes.unical.it Data Availability or Data Deluge? Some decades
Big Data Mining Services and Knowledge Discovery Applications on Clouds Domenico Talia DIMES, Università della Calabria & DtoK Lab Italy talia@dimes.unical.it Data Availability or Data Deluge? Some decades
Administration GUIDE. SharePoint Server idataagent. Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 201
 Administration GUIDE SharePoint Server idataagent Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 201 Getting Started - SharePoint Server idataagent Overview Deployment Configuration Decision Table
Administration GUIDE SharePoint Server idataagent Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 201 Getting Started - SharePoint Server idataagent Overview Deployment Configuration Decision Table
A Flexible Cluster Infrastructure for Systems Research and Software Development
 Award Number: CNS-551555 Title: CRI: Acquisition of an InfiniBand Cluster with SMP Nodes Institution: Florida State University PIs: Xin Yuan, Robert van Engelen, Kartik Gopalan A Flexible Cluster Infrastructure
Award Number: CNS-551555 Title: CRI: Acquisition of an InfiniBand Cluster with SMP Nodes Institution: Florida State University PIs: Xin Yuan, Robert van Engelen, Kartik Gopalan A Flexible Cluster Infrastructure
High Performance Computing. Course Notes 2007-2008. HPC Fundamentals
 High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
Cluster Implementation and Management; Scheduling
 Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
Nexus. Reservoir Simulation Software DATA SHEET
 DATA SHEET Nexus Reservoir Simulation Software OVERVIEW KEY VALUE Compute surface and subsurface fluid flow simultaneously for increased accuracy and stability Build multi-reservoir models by combining
DATA SHEET Nexus Reservoir Simulation Software OVERVIEW KEY VALUE Compute surface and subsurface fluid flow simultaneously for increased accuracy and stability Build multi-reservoir models by combining
Dr. Raju Namburu Computational Sciences Campaign U.S. Army Research Laboratory. The Nation s Premier Laboratory for Land Forces UNCLASSIFIED
 Dr. Raju Namburu Computational Sciences Campaign U.S. Army Research Laboratory 21 st Century Research Continuum Theory Theory embodied in computation Hypotheses tested through experiment SCIENTIFIC METHODS
Dr. Raju Namburu Computational Sciences Campaign U.S. Army Research Laboratory 21 st Century Research Continuum Theory Theory embodied in computation Hypotheses tested through experiment SCIENTIFIC METHODS
Data Requirements from NERSC Requirements Reviews
 Data Requirements from NERSC Requirements Reviews Richard Gerber and Katherine Yelick Lawrence Berkeley National Laboratory Summary Department of Energy Scientists represented by the NERSC user community
Data Requirements from NERSC Requirements Reviews Richard Gerber and Katherine Yelick Lawrence Berkeley National Laboratory Summary Department of Energy Scientists represented by the NERSC user community
for my computation? Stefano Cozzini Which infrastructure Which infrastructure Democrito and SISSA/eLAB - Trieste
 Which infrastructure Which infrastructure for my computation? Stefano Cozzini Democrito and SISSA/eLAB - Trieste Agenda Introduction:! E-infrastructure and computing infrastructures! What is available
Which infrastructure Which infrastructure for my computation? Stefano Cozzini Democrito and SISSA/eLAB - Trieste Agenda Introduction:! E-infrastructure and computing infrastructures! What is available
An approach to grid scheduling by using Condor-G Matchmaking mechanism
 An approach to grid scheduling by using Condor-G Matchmaking mechanism E. Imamagic, B. Radic, D. Dobrenic University Computing Centre, University of Zagreb, Croatia {emir.imamagic, branimir.radic, dobrisa.dobrenic}@srce.hr
An approach to grid scheduling by using Condor-G Matchmaking mechanism E. Imamagic, B. Radic, D. Dobrenic University Computing Centre, University of Zagreb, Croatia {emir.imamagic, branimir.radic, dobrisa.dobrenic}@srce.hr
BlueArc unified network storage systems 7th TF-Storage Meeting. Scale Bigger, Store Smarter, Accelerate Everything
 BlueArc unified network storage systems 7th TF-Storage Meeting Scale Bigger, Store Smarter, Accelerate Everything BlueArc s Heritage Private Company, founded in 1998 Headquarters in San Jose, CA Highest
BlueArc unified network storage systems 7th TF-Storage Meeting Scale Bigger, Store Smarter, Accelerate Everything BlueArc s Heritage Private Company, founded in 1998 Headquarters in San Jose, CA Highest
Cloud computing. Intelligent Services for Energy-Efficient Design and Life Cycle Simulation. as used by the ISES project
 Intelligent Services for Energy-Efficient Design and Life Cycle Simulation Project number: 288819 Call identifier: FP7-ICT-2011-7 Project coordinator: Technische Universität Dresden, Germany Website: ises.eu-project.info
Intelligent Services for Energy-Efficient Design and Life Cycle Simulation Project number: 288819 Call identifier: FP7-ICT-2011-7 Project coordinator: Technische Universität Dresden, Germany Website: ises.eu-project.info
THE EMC ISILON STORY. Big Data In The Enterprise. Copyright 2012 EMC Corporation. All rights reserved.
 THE EMC ISILON STORY Big Data In The Enterprise 2012 1 Big Data In The Enterprise Isilon Overview Isilon Technology Summary 2 What is Big Data? 3 The Big Data Challenge File Shares 90 and Archives 80 Bioinformatics
THE EMC ISILON STORY Big Data In The Enterprise 2012 1 Big Data In The Enterprise Isilon Overview Isilon Technology Summary 2 What is Big Data? 3 The Big Data Challenge File Shares 90 and Archives 80 Bioinformatics
Cluster, Grid, Cloud Concepts
 Cluster, Grid, Cloud Concepts Kalaiselvan.K Contents Section 1: Cluster Section 2: Grid Section 3: Cloud Cluster An Overview Need for a Cluster Cluster categorizations A computer cluster is a group of
Cluster, Grid, Cloud Concepts Kalaiselvan.K Contents Section 1: Cluster Section 2: Grid Section 3: Cloud Cluster An Overview Need for a Cluster Cluster categorizations A computer cluster is a group of
Grid Scheduling Architectures with Globus GridWay and Sun Grid Engine
 Grid Scheduling Architectures with and Sun Grid Engine Sun Grid Engine Workshop 2007 Regensburg, Germany September 11, 2007 Ignacio Martin Llorente Javier Fontán Muiños Distributed Systems Architecture
Grid Scheduling Architectures with and Sun Grid Engine Sun Grid Engine Workshop 2007 Regensburg, Germany September 11, 2007 Ignacio Martin Llorente Javier Fontán Muiños Distributed Systems Architecture
Oracle BI EE Implementation on Netezza. Prepared by SureShot Strategies, Inc.
 Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Private cloud computing advances
 Building robust private cloud services infrastructures By Brian Gautreau and Gong Wang Private clouds optimize utilization and management of IT resources to heighten availability. Microsoft Private Cloud
Building robust private cloud services infrastructures By Brian Gautreau and Gong Wang Private clouds optimize utilization and management of IT resources to heighten availability. Microsoft Private Cloud
Computer System. Chapter 1. 1.1 Introduction
 Chapter 1 Computer System 1.1 Introduction The Japan Meteorological Agency (JMA) installed its first-generation computer (IBM 704) to run an operational numerical weather prediction model in March 1959.
Chapter 1 Computer System 1.1 Introduction The Japan Meteorological Agency (JMA) installed its first-generation computer (IBM 704) to run an operational numerical weather prediction model in March 1959.
A Service for Data-Intensive Computations on Virtual Clusters
 A Service for Data-Intensive Computations on Virtual Clusters Executing Preservation Strategies at Scale Rainer Schmidt, Christian Sadilek, and Ross King rainer.schmidt@arcs.ac.at Planets Project Permanent
A Service for Data-Intensive Computations on Virtual Clusters Executing Preservation Strategies at Scale Rainer Schmidt, Christian Sadilek, and Ross King rainer.schmidt@arcs.ac.at Planets Project Permanent
Cloud Computing Where ISR Data Will Go for Exploitation
 Cloud Computing Where ISR Data Will Go for Exploitation 22 September 2009 Albert Reuther, Jeremy Kepner, Peter Michaleas, William Smith This work is sponsored by the Department of the Air Force under Air
Cloud Computing Where ISR Data Will Go for Exploitation 22 September 2009 Albert Reuther, Jeremy Kepner, Peter Michaleas, William Smith This work is sponsored by the Department of the Air Force under Air
Digital Preservation Lifecycle Management
 Digital Preservation Lifecycle Management Building a demonstration prototype for the preservation of large-scale multi-media collections Arcot Rajasekar San Diego Supercomputer Center, University of California,
Digital Preservation Lifecycle Management Building a demonstration prototype for the preservation of large-scale multi-media collections Arcot Rajasekar San Diego Supercomputer Center, University of California,
Big data management with IBM General Parallel File System
 Big data management with IBM General Parallel File System Optimize storage management and boost your return on investment Highlights Handles the explosive growth of structured and unstructured data Offers
Big data management with IBM General Parallel File System Optimize storage management and boost your return on investment Highlights Handles the explosive growth of structured and unstructured data Offers
Cray DVS: Data Virtualization Service
 Cray : Data Virtualization Service Stephen Sugiyama and David Wallace, Cray Inc. ABSTRACT: Cray, the Cray Data Virtualization Service, is a new capability being added to the XT software environment with
Cray : Data Virtualization Service Stephen Sugiyama and David Wallace, Cray Inc. ABSTRACT: Cray, the Cray Data Virtualization Service, is a new capability being added to the XT software environment with
The PHI solution. Fujitsu Industry Ready Intel XEON-PHI based solution. SC2013 - Denver
 1 The PHI solution Fujitsu Industry Ready Intel XEON-PHI based solution SC2013 - Denver Industrial Application Challenges Most of existing scientific and technical applications Are written for legacy execution
1 The PHI solution Fujitsu Industry Ready Intel XEON-PHI based solution SC2013 - Denver Industrial Application Challenges Most of existing scientific and technical applications Are written for legacy execution
Implementing Network Attached Storage. Ken Fallon Bill Bullers Impactdata
 Implementing Network Attached Storage Ken Fallon Bill Bullers Impactdata Abstract The Network Peripheral Adapter (NPA) is an intelligent controller and optimized file server that enables network-attached
Implementing Network Attached Storage Ken Fallon Bill Bullers Impactdata Abstract The Network Peripheral Adapter (NPA) is an intelligent controller and optimized file server that enables network-attached
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
XML Database Support for Distributed Execution of Data-intensive Scientific Workflows
 XML Database Support for Distributed Execution of Data-intensive Scientific Workflows Shannon Hastings, Matheus Ribeiro, Stephen Langella, Scott Oster, Umit Catalyurek, Tony Pan, Kun Huang, Renato Ferreira,
XML Database Support for Distributed Execution of Data-intensive Scientific Workflows Shannon Hastings, Matheus Ribeiro, Stephen Langella, Scott Oster, Umit Catalyurek, Tony Pan, Kun Huang, Renato Ferreira,
CMS Tier-3 cluster at NISER. Dr. Tania Moulik
 CMS Tier-3 cluster at NISER Dr. Tania Moulik What and why? Grid computing is a term referring to the combination of computer resources from multiple administrative domains to reach common goal. Grids tend
CMS Tier-3 cluster at NISER Dr. Tania Moulik What and why? Grid computing is a term referring to the combination of computer resources from multiple administrative domains to reach common goal. Grids tend
Data Centric Systems (DCS)
") Data Centric Systems (DCS) Architecture and Solutions for High Performance Computing, Big Data and High Performance Analytics High Performance Computing with Data Centric Systems 1 Data Centric Systems
Data Centric Systems (DCS) Architecture and Solutions for High Performance Computing, Big Data and High Performance Analytics High Performance Computing with Data Centric Systems 1 Data Centric Systems
Performance and scalability of a large OLTP workload
 Performance and scalability of a large OLTP workload ii Performance and scalability of a large OLTP workload Contents Performance and scalability of a large OLTP workload with DB2 9 for System z on Linux..............
Performance and scalability of a large OLTP workload ii Performance and scalability of a large OLTP workload Contents Performance and scalability of a large OLTP workload with DB2 9 for System z on Linux..............
Concepts and Architecture of Grid Computing. Advanced Topics Spring 2008 Prof. Robert van Engelen
 Concepts and Architecture of Grid Computing Advanced Topics Spring 2008 Prof. Robert van Engelen Overview Grid users: who are they? Concept of the Grid Challenges for the Grid Evolution of Grid systems
Concepts and Architecture of Grid Computing Advanced Topics Spring 2008 Prof. Robert van Engelen Overview Grid users: who are they? Concept of the Grid Challenges for the Grid Evolution of Grid systems
Collaborative & Integrated Network & Systems Management: Management Using Grid Technologies
 2011 International Conference on Computer Communication and Management Proc.of CSIT vol.5 (2011) (2011) IACSIT Press, Singapore Collaborative & Integrated Network & Systems Management: Management Using
2011 International Conference on Computer Communication and Management Proc.of CSIT vol.5 (2011) (2011) IACSIT Press, Singapore Collaborative & Integrated Network & Systems Management: Management Using
System Models for Distributed and Cloud Computing
 System Models for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Classification of Distributed Computing Systems
System Models for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Classification of Distributed Computing Systems
Implementing Managed Services in the Data Center and Cloud Space
 Implementing Managed Services in the Data Center and Cloud Space 1 Managed Hosting Offerings 2 Managed Network Services Diverse 10Gbps backbone between data centers meshed with Windstream s nationwide
Implementing Managed Services in the Data Center and Cloud Space 1 Managed Hosting Offerings 2 Managed Network Services Diverse 10Gbps backbone between data centers meshed with Windstream s nationwide
IBM Solutions Grid for Business Partners Helping IBM Business Partners to Grid-enable applications for the next phase of e-business on demand
 PartnerWorld Developers IBM Solutions Grid for Business Partners Helping IBM Business Partners to Grid-enable applications for the next phase of e-business on demand 2 Introducing the IBM Solutions Grid
PartnerWorld Developers IBM Solutions Grid for Business Partners Helping IBM Business Partners to Grid-enable applications for the next phase of e-business on demand 2 Introducing the IBM Solutions Grid
High Availability Databases based on Oracle 10g RAC on Linux
 High Availability Databases based on Oracle 10g RAC on Linux WLCG Tier2 Tutorials, CERN, June 2006 Luca Canali, CERN IT Outline Goals Architecture of an HA DB Service Deployment at the CERN Physics Database
High Availability Databases based on Oracle 10g RAC on Linux WLCG Tier2 Tutorials, CERN, June 2006 Luca Canali, CERN IT Outline Goals Architecture of an HA DB Service Deployment at the CERN Physics Database
Neptune. A Domain Specific Language for Deploying HPC Software on Cloud Platforms. Chris Bunch Navraj Chohan Chandra Krintz Khawaja Shams
 Neptune A Domain Specific Language for Deploying HPC Software on Cloud Platforms Chris Bunch Navraj Chohan Chandra Krintz Khawaja Shams ScienceCloud 2011 @ San Jose, CA June 8, 2011 Cloud Computing Three
Neptune A Domain Specific Language for Deploying HPC Software on Cloud Platforms Chris Bunch Navraj Chohan Chandra Krintz Khawaja Shams ScienceCloud 2011 @ San Jose, CA June 8, 2011 Cloud Computing Three
The Methodology Behind the Dell SQL Server Advisor Tool
 The Methodology Behind the Dell SQL Server Advisor Tool Database Solutions Engineering By Phani MV Dell Product Group October 2009 Executive Summary The Dell SQL Server Advisor is intended to perform capacity
The Methodology Behind the Dell SQL Server Advisor Tool Database Solutions Engineering By Phani MV Dell Product Group October 2009 Executive Summary The Dell SQL Server Advisor is intended to perform capacity
SLA BASED SERVICE BROKERING IN INTERCLOUD ENVIRONMENTS
 SLA BASED SERVICE BROKERING IN INTERCLOUD ENVIRONMENTS Foued Jrad, Jie Tao and Achim Streit Steinbuch Centre for Computing, Karlsruhe Institute of Technology, Karlsruhe, Germany {foued.jrad, jie.tao, achim.streit}@kit.edu
SLA BASED SERVICE BROKERING IN INTERCLOUD ENVIRONMENTS Foued Jrad, Jie Tao and Achim Streit Steinbuch Centre for Computing, Karlsruhe Institute of Technology, Karlsruhe, Germany {foued.jrad, jie.tao, achim.streit}@kit.edu
The Trials and Tribulations and ultimate success of parallelisation using Hadoop within the SCAPE project
 The Trials and Tribulations and ultimate success of parallelisation using Hadoop within the SCAPE project Alastair Duncan STFC Pre Coffee talk STFC July 2014 SCAPE Scalable Preservation Environments The
The Trials and Tribulations and ultimate success of parallelisation using Hadoop within the SCAPE project Alastair Duncan STFC Pre Coffee talk STFC July 2014 SCAPE Scalable Preservation Environments The
VStore++: Virtual Storage Services for Mobile Devices
 VStore++: Virtual Storage Services for Mobile Devices Sudarsun Kannan, Karishma Babu, Ada Gavrilovska, and Karsten Schwan Center for Experimental Research in Computer Systems Georgia Institute of Technology
VStore++: Virtual Storage Services for Mobile Devices Sudarsun Kannan, Karishma Babu, Ada Gavrilovska, and Karsten Schwan Center for Experimental Research in Computer Systems Georgia Institute of Technology
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes. Anthony Kenisky, VP of North America Sales
 Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
Big Data and the Earth Observation and Climate Modelling Communities: JASMIN and CEMS
 Big Data and the Earth Observation and Climate Modelling Communities: JASMIN and CEMS Workshop on the Future of Big Data Management 27-28 June 2013 Philip Kershaw Centre for Environmental Data Archival
Big Data and the Earth Observation and Climate Modelling Communities: JASMIN and CEMS Workshop on the Future of Big Data Management 27-28 June 2013 Philip Kershaw Centre for Environmental Data Archival
Implementing a Digital Video Archive Based on XenData Software
 Based on XenData Software The Video Edition of XenData Archive Series software manages a digital tape library on a Windows Server 2003 platform to create a digital video archive that is ideal for the demanding
Based on XenData Software The Video Edition of XenData Archive Series software manages a digital tape library on a Windows Server 2003 platform to create a digital video archive that is ideal for the demanding
Application Frameworks for High Performance and Grid Computing
 Application Frameworks for High Performance and Grid Computing Gabrielle Allen Assistant Director for Computing Applications, Center for Computation & Technology Associate Professor, Department of Computer
Application Frameworks for High Performance and Grid Computing Gabrielle Allen Assistant Director for Computing Applications, Center for Computation & Technology Associate Professor, Department of Computer
Service and Resource Discovery in Smart Spaces Composed of Low Capacity Devices
 Service and Resource Discovery in Smart Spaces Composed of Low Capacity Devices Önder Uzun, Tanır Özçelebi, Johan Lukkien, Remi Bosman System Architecture and Networking Department of Mathematics and Computer
Service and Resource Discovery in Smart Spaces Composed of Low Capacity Devices Önder Uzun, Tanır Özçelebi, Johan Lukkien, Remi Bosman System Architecture and Networking Department of Mathematics and Computer
Implementing a Digital Video Archive Using XenData Software and a Spectra Logic Archive
 Using XenData Software and a Spectra Logic Archive With the Video Edition of XenData Archive Series software on a Windows server and a Spectra Logic T-Series digital archive, broadcast organizations have
Using XenData Software and a Spectra Logic Archive With the Video Edition of XenData Archive Series software on a Windows server and a Spectra Logic T-Series digital archive, broadcast organizations have
Business white paper. HP Process Automation. Version 7.0. Server performance
 Business white paper HP Process Automation Version 7.0 Server performance Table of contents 3 Summary of results 4 Benchmark profile 5 Benchmark environmant 6 Performance metrics 6 Process throughput 6
Business white paper HP Process Automation Version 7.0 Server performance Table of contents 3 Summary of results 4 Benchmark profile 5 Benchmark environmant 6 Performance metrics 6 Process throughput 6
Avid ISIS 7000. www.avid.com
 Avid ISIS 7000 www.avid.com Table of Contents Overview... 3 Avid ISIS Technology Overview... 6 ISIS Storage Blade... 6 ISIS Switch Blade... 7 ISIS System Director... 7 ISIS Client Software... 8 ISIS Redundant
Avid ISIS 7000 www.avid.com Table of Contents Overview... 3 Avid ISIS Technology Overview... 6 ISIS Storage Blade... 6 ISIS Switch Blade... 7 ISIS System Director... 7 ISIS Client Software... 8 ISIS Redundant
EOFS Workshop Paris Sept, 2011. Lustre at exascale. Eric Barton. CTO Whamcloud, Inc. eeb@whamcloud.com. 2011 Whamcloud, Inc.
 EOFS Workshop Paris Sept, 2011 Lustre at exascale Eric Barton CTO Whamcloud, Inc. eeb@whamcloud.com Agenda Forces at work in exascale I/O Technology drivers I/O requirements Software engineering issues
EOFS Workshop Paris Sept, 2011 Lustre at exascale Eric Barton CTO Whamcloud, Inc. eeb@whamcloud.com Agenda Forces at work in exascale I/O Technology drivers I/O requirements Software engineering issues
2009 Oracle Corporation 1
 The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material,
The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material,
Exploring Software Defined Federated Infrastructures for Science
 Exploring Software Defined Federated Infrastructures for Science Manish Parashar NSF Cloud and Autonomic Computing Center (CAC) Rutgers Discovery Informatics Institute (RDI 2 ) Rutgers, The State University
Exploring Software Defined Federated Infrastructures for Science Manish Parashar NSF Cloud and Autonomic Computing Center (CAC) Rutgers Discovery Informatics Institute (RDI 2 ) Rutgers, The State University
Silviu Panica, Marian Neagul, Daniela Zaharie and Dana Petcu (Romania)
") Silviu Panica, Marian Neagul, Daniela Zaharie and Dana Petcu (Romania) Outline Introduction EO challenges; EO and classical/cloud computing; EO Services The computing platform Cluster -> Grid -> Cloud
Silviu Panica, Marian Neagul, Daniela Zaharie and Dana Petcu (Romania) Outline Introduction EO challenges; EO and classical/cloud computing; EO Services The computing platform Cluster -> Grid -> Cloud
Enabling Large-Scale Testing of IaaS Cloud Platforms on the Grid 5000 Testbed
 Enabling Large-Scale Testing of IaaS Cloud Platforms on the Grid 5000 Testbed Sébastien Badia, Alexandra Carpen-Amarie, Adrien Lèbre, Lucas Nussbaum Grid 5000 S. Badia, A. Carpen-Amarie, A. Lèbre, L. Nussbaum
Enabling Large-Scale Testing of IaaS Cloud Platforms on the Grid 5000 Testbed Sébastien Badia, Alexandra Carpen-Amarie, Adrien Lèbre, Lucas Nussbaum Grid 5000 S. Badia, A. Carpen-Amarie, A. Lèbre, L. Nussbaum
Cisco UCS and Fusion- io take Big Data workloads to extreme performance in a small footprint: A case study with Oracle NoSQL database
 Cisco UCS and Fusion- io take Big Data workloads to extreme performance in a small footprint: A case study with Oracle NoSQL database Built up on Cisco s big data common platform architecture (CPA), a
Cisco UCS and Fusion- io take Big Data workloads to extreme performance in a small footprint: A case study with Oracle NoSQL database Built up on Cisco s big data common platform architecture (CPA), a
Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy?
 HPC2012 Workshop Cetraro, Italy Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy? Bill Blake CTO Cray, Inc. The Big Data Challenge Supercomputing minimizes data
HPC2012 Workshop Cetraro, Italy Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy? Bill Blake CTO Cray, Inc. The Big Data Challenge Supercomputing minimizes data
Pentaho High-Performance Big Data Reference Configurations using Cisco Unified Computing System
 Pentaho High-Performance Big Data Reference Configurations using Cisco Unified Computing System By Jake Cornelius Senior Vice President of Products Pentaho June 1, 2012 Pentaho Delivers High-Performance
Pentaho High-Performance Big Data Reference Configurations using Cisco Unified Computing System By Jake Cornelius Senior Vice President of Products Pentaho June 1, 2012 Pentaho Delivers High-Performance
Get More Scalability and Flexibility for Big Data
 Solution Overview LexisNexis High-Performance Computing Cluster Systems Platform Get More Scalability and Flexibility for What You Will Learn Modern enterprises are challenged with the need to store and
Solution Overview LexisNexis High-Performance Computing Cluster Systems Platform Get More Scalability and Flexibility for What You Will Learn Modern enterprises are challenged with the need to store and
Hue Streams. Seismic Compression Technology. Years of my life were wasted waiting for data loading and copying
 Hue Streams Seismic Compression Technology Hue Streams real-time seismic compression results in a massive reduction in storage utilization and significant time savings for all seismic-consuming workflows.
Hue Streams Seismic Compression Technology Hue Streams real-time seismic compression results in a massive reduction in storage utilization and significant time savings for all seismic-consuming workflows.
EMC NETWORKER AND DATADOMAIN
 EMC NETWORKER AND DATADOMAIN Capabilities, options and news Madis Pärn Senior Technology Consultant EMC madis.parn@emc.com 1 IT Pressures 2009 0.8 Zettabytes 2020 35.2 Zettabytes DATA DELUGE BUDGET DILEMMA
EMC NETWORKER AND DATADOMAIN Capabilities, options and news Madis Pärn Senior Technology Consultant EMC madis.parn@emc.com 1 IT Pressures 2009 0.8 Zettabytes 2020 35.2 Zettabytes DATA DELUGE BUDGET DILEMMA
Classic Grid Architecture
 Peer-to to-peer Grids Classic Grid Architecture Resources Database Database Netsolve Collaboration Composition Content Access Computing Security Middle Tier Brokers Service Providers Middle Tier becomes
Peer-to to-peer Grids Classic Grid Architecture Resources Database Database Netsolve Collaboration Composition Content Access Computing Security Middle Tier Brokers Service Providers Middle Tier becomes
Wrangler: A New Generation of Data-intensive Supercomputing. Christopher Jordan, Siva Kulasekaran, Niall Gaffney
 Wrangler: A New Generation of Data-intensive Supercomputing Christopher Jordan, Siva Kulasekaran, Niall Gaffney Project Partners Academic partners: TACC Primary system design, deployment, and operations
Wrangler: A New Generation of Data-intensive Supercomputing Christopher Jordan, Siva Kulasekaran, Niall Gaffney Project Partners Academic partners: TACC Primary system design, deployment, and operations
White Paper. How Streaming Data Analytics Enables Real-Time Decisions
 White Paper How Streaming Data Analytics Enables Real-Time Decisions Contents Introduction... 1 What Is Streaming Analytics?... 1 How Does SAS Event Stream Processing Work?... 2 Overview...2 Event Stream
White Paper How Streaming Data Analytics Enables Real-Time Decisions Contents Introduction... 1 What Is Streaming Analytics?... 1 How Does SAS Event Stream Processing Work?... 2 Overview...2 Event Stream