GiST. Amol Deshpande. March 8, University of Maryland, College Park. CMSC724: Access Methods; Indexes; GiST. Amol Deshpande.
|
|
|
- Shanon Hubbard
- 8 years ago
- Views:
Transcription
1 CMSC724: ; Indexes; : Generalized University of Maryland, College Park March 8, 2012

2 Outline : Generalized : Generalized

3 : Why? Most queries have predicates in them Accessing only the needed records key in performance How relations are stored? Heap files: sequential scans, very very fast Index structures: random accesses to the needed data Scan performance increasing much faster than seeks Must perform much better than Scan No point in building indexes on small relations Note the emphasis on queries Utility depends more on query workload than data Why not use in-memory indexes? Data exchange with disks in units of blocks : Generalized

4 Support iterator interface: open (possibly with selection condition) get_next, close, insert, delete, update_field Performance goals: Disk I/O (or time) for lookups, inserts, deletes cold vs hot lookups Compare to sequential (seek times improving much slower) : Generalized
 :")
5 At a high level: partition: partition a dataset or domain into buckets label: provide a label for each bucket Sometimes hierarchically (trees), sometimes not (hashing) Partitioning is critical for good performance In s, we take the sorted order as a given since natural For all other cases, unclear how to pack : Generalized

6 Outline : Generalized : Generalized
7 B+ Trees Balanced; Optimal for 1-d (O(log B n) search/update) (B = ) Utilization kept around 70% or so In practice, deletes do not result in merging of siblings : Generalized

8 B+ Tree Inserts : Generalized

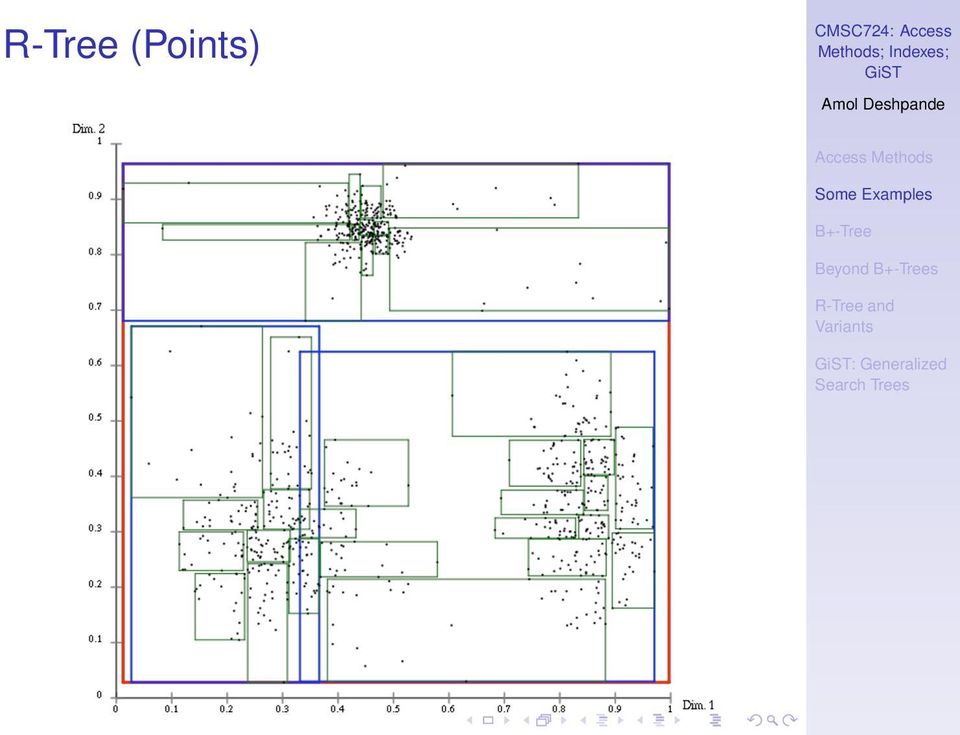
9 R-Tree (Points) : Generalized
10 Quad Tree : Generalized

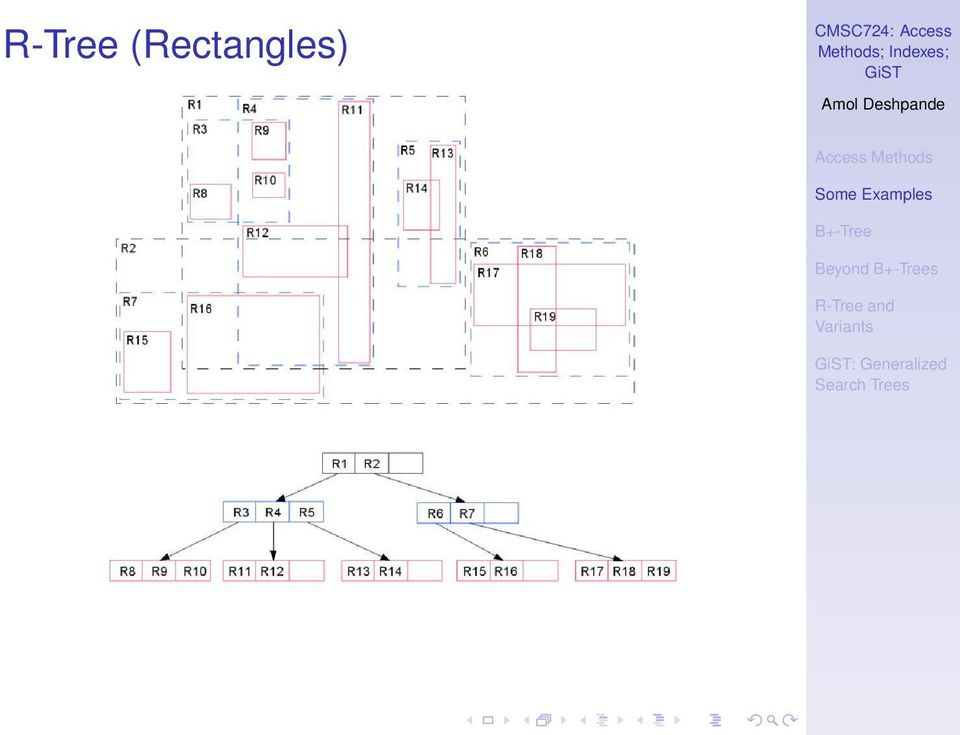
11 R-Tree (Rectangles) : Generalized
12 sented by two predicates: a centroid point (weighted center of mass) and a bounding sphere radius. 2 Each SS-Tree tree (a) (A) 2 1 (d) (c) (e) (B) (A) 3 (B) (b) (a) (b) (c) (d) (e) centroid query datum (record) (a) (b) Figure 1. Similarity search using an SS-tree. (a) Spatial coverage diagram. (b) Tree structure diagram. 2 Even though the SS-tree does center its bounding sphere on the centroid, the bounding sphere need not be the (unique) minimum boundbound well a bor. F that w to rem 3.2. I Th canno rithm tree b ond, u beyon : Generalized and upd cates. 3 is base here be
 minimum boundbound well")
13 Key Differentiating Factors Data (1-d vs 2-d vs n-d, points vs intervals vs spatial objects vs images etc...) Query types (equality, range, nearest-neighbor etc..) Balanced (B+-tre, R-Tree) vs Unbalanced (Quad-tree) Balanced predictable, uniform performance, but hard to guarantee Typically requires rearranging of labels, splits etc.. : Generalized

14 Key Differentiating Factors Data- vs Space-partitioning Data-partitioning: the buckets are disjoint, but the labels may not be May have to follow down the tree along multiple paths (e.g. R*-tree) Space-partitioniing: the labels are disjoint, buckets may not be e.g. Quad-trees, K-D-B trees May have to duplicate pointers to data items in the leaves (e.g. R+-tree) B+-trees: disjoint buckets and disjoint labels : Generalized
 Space-partitioniing:")
15 Imagine: The data is already stored on disk in some arbitrary order and you are not allowed to change it How would you best build a hierarchical index structure on top for equality queries? Use BloomFilters? No option is going to work well if the data is really arbitrary and you can t find something to order by But an interesting thought exercise E.g. you might discover the third byte is different across blocks, but same within a block Clustering of data is critical Obvious for 1-d data, not so clear otherwise Not academic question: Imagine building an index over a distributed Grid/P2P data : Generalized

16 Implementation Issues: Concurrency & recovery Very important issue Intertwined to a very complex degree Can t build access methods in vacuum for just querying Cost estimation Query optimizer needs this information Bulk loading Important have to be done very often : Generalized

17 Outline : Generalized : Generalized
18 Balanced, 50% utilization In practice, allow getting lower when doing deletes Inserts are more common, something will get inserted there soon O(log d (n)) search, update, delete costs d = order of the tree (number of keys per page) Optimizations Key compression Bulk loading algorithms Faster count queries Maintain counts of tuples in the subtrees at the inner nodes : Generalized

19 Concurrency: not 2PL - too slow Release locks on upper-level nodes as soon as possible Too many queries want to access them Tricky when doing inserts Higher-level pages may have to be split One Solution: Do preparatory splits when inserting We will talk about this in detail later B-Trees? The inner nodes store pointers to data all pointers to data are at the leaves s make many things significantly easier E.g. Can do a scan on the leaves for range queries : Generalized

20 Outline : Generalized : Generalized
21 Indexes B+-tree: Optimal for one-dimensional data (for range/equality queries) Linear hashing, extensible hashing: Only equality queries Multi-dimensional point data Range queries: (20 < age < 30) (10, 000 < salary) Space-filling curves: Impose a linear order on the multi-d data (limited applicability) Grid-files, Quad-trees, K-D-B trees etc... Nearest-Neighbor queries/similarity searches (very common) Many indexing structures designed, no real consensus Golden rule: Must beat sequential scans : Generalized
22 Indexes Multi-dimensional spatial data (regions, areas etc.) Queries: find all objects that contain this point, find objects that overlap this object variants Intervals (e.g. time periods associated with events) Queries: Find intervals containing this point, find overlapping intervals etc... Several optimality results exists (see work by Lars Arge, Jeff Vitter et al.) XML? Some work, but generally considered very hard : Generalized Search Tree : Generalized
23 Indexes: A Timeline Multidimensional ; Gaede, Gunther; ACM Surveys 1998 P-Tree (Jagadish 90c) Packed R-Tree (Roussopoulos et al.. 85) Cell Tree (Gunther 88) Cell Tree With Oversize Parallel R-tree Shelves (Gunther 91) (Kamel/Faloutsos 92) Sphere Tree TR*-Tree (Oosterom 90) (Schneider/Kriegel 91) X-tree (Berchtold et al. 96) B-Tree (Bayer et al. 72) R-Tree (Guttman 84) R+-Tree (Sellis et al. 87) R*-Tree (Beckmann et al. 90) TV-Tree (Lin et al. 94) Grid File (Nievergelt et al. 81) BANG File (Freeston 87) Hilbert R-tree P-Tree General Grid File (Schiwietz 93) (Kamel/Faloutsos 94) (Blanken et al. 90) Extendible Hashing (Fagin et al. 79) Linear (Larson 80, Litwin 80) Adaptive K-D-Tree (Bentley 79) Hashing EXCELL (Tamminen 82) Buddy Tree Two-Level Grid File (Seeger/Kriegel 90a) (Hinrichs 85) R-File Multi-Level Grid File Twin Grid File (Hutflesz et al. 90) (Whang/Krishnamurthy 85) (Hutflesz et al. 88b) Extended K-D-Tree (Matsuyama et al. 84) Multi-Layer Grid File (Six/Widmayer 88) Nested Interpolationbased Grid File MOLHPE (Kriegel/Seeger 86) (Ouksel/Mayer 92) Z-Hashing (Hutflesz et al. 88a) BV-Tree (Freeston 95) Filter Tree (Sevcik/Koudas 96) : Generalized K-D-Tree K-D-B-Tree (Robinson 81) Quantile Hashing (Kriegel/Seeger 87) Segment Indexes (Kolovson/Stonebraker 91) (Bentley 75) LSD-Tree lz-hashing Point Quadtree (Klinger 71) BSP-Tree (Fuchs et al. 80) SKD-Tree (Henrich et al. 89) (Hutflesz et a. 91) (Ooi et al. 87) KD2B-Tree (Oosterom 90) G-Tree BD-Tree PLOP-Hashing (Kumar 94a) Region Quadtree (Ohsawa/Sakauchi 83) (Kriegel/Seeger 88) GBD-Tree (Finkel/Bentley 74) (Ohsawa/Sakauchi 90) Space-Filling Curves (Morton 66) Z-Ordering (Orenstein/Merrett 84) Fieldtree Interpolation-Based hb-tree (Lomet/Salzberg 89) DOT hb! -Tree (Evangelidis et al. 95) (Frank 83) Grid File (Ouksel 85) (Faloutsos/Rong 91) Figure: A Timeline of Indexes (From Multidimensional Access Methods; Gaede, Gunther; ACM Surveys 1998)
24 Indexes Much work since then as well When reading these papers, ask yourself: Does it beat sequential scan sufficiently? Is the data/workload realistic? Are there other natural workloads on which it may not do well? Little rigor in this area Some theoretical work, but problems not easy Curse of Dimensionality : Generalized
25 Outline : Generalized : Generalized
26 R-Tree : Generalized Figure: R-Tree
27 R-Tree Multi-dimensional, spatial data (points, rectangles) Queries: point in polygon, polygon in polygon, overlaps polygon, contains polygon labels: bounding rectangles Bulk loading? Hard... Search: Follow all paths. Insert: Driven by minimizing area enlargement Split algorithms: exhaustive, quadratic, linear Delete: re-insert if too small (why?) : Generalized
28 R*-Tree R*-Tree: An improvement over R-Tree Analysis: four optimization metrics? Minimize area covered by a directory rectangle. Minimize overlap Minimize margin Maximize storage utilization Conflict with each other E.g., minimizing area covered conflicts with maximizing storage utilization. : Generalized
29 R*-Tree Changes: Insertion algorithm slightly different (minimizes overlap at leaf level) Aggressive re-insertion (30% entries re-inserted at the same level) Causes headaches with concurrency Lots of heuristics... backed by experimental analysis... Shown to outperform R-Trees in many experimental studies : Generalized
30 R+-Tree R+-Tree Space-partitioning version of R*-Tree Forces non-overlapping keys So same data item must be inserted into multiple leaf nodes BUT don t need to follow all paths down to the leaves : Generalized
31 Outline : Generalized : Generalized
32 Motivation: Extensibility New applications: GIS, multimedia (e.g. pictures), CAD, libraries, sequence datasets (Bioinformatics) etc... Object-relational systems allow defining new data types What about querying over them? Two proposed solutions: Option 1: Design new index structures Option 2: Try to use an existing index structure E.g. Can use space-filling curves and s to support querying multi-dimensional data Limited applicability (only equality/range queries) What if the app needs new type of query? Postgres paper had an initial discussion : Generalized
33 Heap B + -tree Heap B + -tree R-tree Query Processing Query Processing New AMs require custom CC&R code R-tree R*-tree SR-tree Storage, Buffer, Log,... Storage, Buffer, Log,... : Generalized (a) Standard ORDBMS (b) ORDBMS with Figure 1: Access method interfaces the database extender s perspective. Figure: From: High-Performance Extensible Indexing; ructure that is easily extensible in both the data types it n index and the query types itcan support. encapsutes core Kornacker; indexing functionality VLDB such1999 as search and update erations, concurrency and recovery. The interface, e the existing extensibility interfaces, defines a set of nctions for implementing an external AM. However, the ist interface raises the level of abstraction, only requiring e AM developer to implement the semantics of the data pe that is being indexed and those operational properties nal handler to catch segmentation violations and bus errors, 2 allocationofadditionalstack space, if necessary, and checking of parameters for NULL values. This makes a UDF call considerably more expensive than a regular function call. In Oracle and DB2, UDFs can be executed in a separate address space, which even adds to the cost. When dividing the full functionality of an AM between the database server and an external extension module, as does, UDF calls become inevitable, which can become a performance prob-
34 Generalized Search Tree Allows extending data types as well as queries A single data structure that can handle many different index structures So a single code-base How to use? Register six methods with the database system Start inserting/deleting/querying Allows indexing arbitrary types of data Question: Is it always a good idea to use a? No Some data and query workloads not amenable to indexing (scan preferred) Ideas later further developed in Theory of Indexability : Generalized
35 Key insight: An index structure partitions the input data hierarchically associates a predicate with each subtree, that is true for all data items in the subtree Predicates on a single path from root to a leaf may not agree with each other, but must agree with the leaf Nodes contain between 2 to M entries (except root) Leaf nodes: (p, ptr) ptr: pointer to actual record p: predicate satisfied by the record Non-leaf nodes: (p, ptr) ptr: pointer to another node p: predicate satisfied by all records in the subtree below : Generalized
36 Need to define 6 functions for a new search tree Consistent(E, q): given a E = (ptr, p), might q be satisfied by some tuple in the subtree below ptr search/querying (search also done when inserting) Union: Find new keys inserts (when add a new E to a page) Compress, Decompress: used for compressing the keys Required to implement common optimizations Penalty, PickSplit: Used for deciding where to insert a new object, and how to split a page if needed Very similar to R-Tree in many regards : Generalized
37 Algorithms Search: Query q Find all pairs E = (p, ptr) such that consistent(e, q) Follow down all the pointers Somewhat inefficient, can do better for linear orders Insert/Delete: Keep the tree balanced Use the methods Penalty, PickSplit etc, to decide where to insert/delete, how to rearrange Discussion of how to support R*-Tree illustrates the difficulties simulating an index precisely But as with all generalized/extensible approaches, you gain in simplicity what you sacrifice in performance : Generalized
38 : Analysis Why an index might perform poorly? Predicates at inner nodes not effective traverse down unnecessarily Reason 1: Too much overlap between the data items themselves (e.g. spatial data) Reason 2: Key compression not good, ie., the predicates can t approximate the subtree well (e.g. homework question) Predicates too large in size in number of bytes If predicates are allowed to be large, then search will be more efficient (fewer paths travelled) BUT large predicates tree height increases Trade-off between key compression and search effectiveness : Generalized
39 : Analysis; Why an index might perform poorly? Poor storage utilization (too much wasted space) Trade-off between this and above factors Better storage utilization increases key overlap Since we may have to force items together that shouldn t be BUT poor storage utilization tree height increases Complex trade-offs that can only be answered given a dataset and a query workload : Generalized
40 : Using Bloom Filters as Predicates The predicates are Bloom filters of the items in the subtree (as in homework) Only supports equality queries Consistent(E, q): Check if q the Bloom filter Union: Bit-wise union etc... Why bad? If the Bloom Filter size is small (say 10 bits): Too much key overlap All bits in the higher level nodes likely to be set to 1 Many predicates will satisy Consistent(E, q) If the Bloom Filter size large (say 1000 bits): Number of keys per page too low The height of the tree will be large Not sure if anybody has formally analyzed this : Generalized
41 : Other issues Much later work at Berkeley: Project Website Indexability theory Formalisms for analysis: different types of inefficiencies AmDB: A visual debugger and profiler Concurrency, recovery etc: Not addressed in this paper See High-Performance Extensible Indexing : Generalized
42 : How extensible is it? Generalizes many ideas, but some limitations Recall the discussion of R*-Trees in the paper From: Generalizing Search...; P. Aoki; ICDE 98 SS-Tree: Similarity search tree For nearest-neighbor queries Records organized in hierarchical clusters For each cluster: store centroid, bounding sphere radius Search: Traverse down the tree looking for the sphere closest to the query point Several Issues: e.g. Search is not depth-first Need a few modifications (see the paper above) : Generalized
Data Warehousing und Data Mining
 Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
R-trees. R-Trees: A Dynamic Index Structure For Spatial Searching. R-Tree. Invariants
 R-Trees: A Dynamic Index Structure For Spatial Searching A. Guttman R-trees Generalization of B+-trees to higher dimensions Disk-based index structure Occupancy guarantee Multiple search paths Insertions
R-Trees: A Dynamic Index Structure For Spatial Searching A. Guttman R-trees Generalization of B+-trees to higher dimensions Disk-based index structure Occupancy guarantee Multiple search paths Insertions
Generalizing Database Access Methods
 Generalizing Database Access Methods by Ming Zhou A thesis presented to the University of Waterloo in fulfilment of the thesis requirement for the degree of Master of Mathematics in Computer Science Waterloo,
Generalizing Database Access Methods by Ming Zhou A thesis presented to the University of Waterloo in fulfilment of the thesis requirement for the degree of Master of Mathematics in Computer Science Waterloo,
Physical Data Organization
 Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Comp 5311 Database Management Systems. 16. Review 2 (Physical Level)
") Comp 5311 Database Management Systems 16. Review 2 (Physical Level) 1 Main Topics Indexing Join Algorithms Query Processing and Optimization Transactions and Concurrency Control 2 Indexing Used for faster
Comp 5311 Database Management Systems 16. Review 2 (Physical Level) 1 Main Topics Indexing Join Algorithms Query Processing and Optimization Transactions and Concurrency Control 2 Indexing Used for faster
Previous Lectures. B-Trees. External storage. Two types of memory. B-trees. Main principles
 B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
CUBE INDEXING IMPLEMENTATION USING INTEGRATION OF SIDERA AND BERKELEY DB
 CUBE INDEXING IMPLEMENTATION USING INTEGRATION OF SIDERA AND BERKELEY DB Badal K. Kothari 1, Prof. Ashok R. Patel 2 1 Research Scholar, Mewar University, Chittorgadh, Rajasthan, India 2 Department of Computer
CUBE INDEXING IMPLEMENTATION USING INTEGRATION OF SIDERA AND BERKELEY DB Badal K. Kothari 1, Prof. Ashok R. Patel 2 1 Research Scholar, Mewar University, Chittorgadh, Rajasthan, India 2 Department of Computer
DATABASE DESIGN - 1DL400
 DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
Databases and Information Systems 1 Part 3: Storage Structures and Indices
 bases and Information Systems 1 Part 3: Storage Structures and Indices Prof. Dr. Stefan Böttcher Fakultät EIM, Institut für Informatik Universität Paderborn WS 2009 / 2010 Contents: - database buffer -
bases and Information Systems 1 Part 3: Storage Structures and Indices Prof. Dr. Stefan Böttcher Fakultät EIM, Institut für Informatik Universität Paderborn WS 2009 / 2010 Contents: - database buffer -
Large Databases. mjf@inesc-id.pt, jorgej@acm.org. Abstract. Many indexing approaches for high dimensional data points have evolved into very complex
 NB-Tree: An Indexing Structure for Content-Based Retrieval in Large Databases Manuel J. Fonseca, Joaquim A. Jorge Department of Information Systems and Computer Science INESC-ID/IST/Technical University
NB-Tree: An Indexing Structure for Content-Based Retrieval in Large Databases Manuel J. Fonseca, Joaquim A. Jorge Department of Information Systems and Computer Science INESC-ID/IST/Technical University
Lecture 1: Data Storage & Index
 Lecture 1: Data Storage & Index R&G Chapter 8-11 Concurrency control Query Execution and Optimization Relational Operators File & Access Methods Buffer Management Disk Space Management Recovery Manager
Lecture 1: Data Storage & Index R&G Chapter 8-11 Concurrency control Query Execution and Optimization Relational Operators File & Access Methods Buffer Management Disk Space Management Recovery Manager
External Memory Geometric Data Structures
 External Memory Geometric Data Structures Lars Arge Department of Computer Science University of Aarhus and Duke University Augues 24, 2005 1 Introduction Many modern applications store and process datasets
External Memory Geometric Data Structures Lars Arge Department of Computer Science University of Aarhus and Duke University Augues 24, 2005 1 Introduction Many modern applications store and process datasets
THE concept of Big Data refers to systems conveying
 EDIC RESEARCH PROPOSAL 1 High Dimensional Nearest Neighbors Techniques for Data Cleaning Anca-Elena Alexandrescu I&C, EPFL Abstract Organisations from all domains have been searching for increasingly more
EDIC RESEARCH PROPOSAL 1 High Dimensional Nearest Neighbors Techniques for Data Cleaning Anca-Elena Alexandrescu I&C, EPFL Abstract Organisations from all domains have been searching for increasingly more
TheHow and Why of Having a Successful Home Office
 Indexing in Spatial Databases Beng Chin Ooi Ron Sacks-Davis Jiawei Han Dept of Inf Sys and Comp Sci Collaborative Inf Tech Res Inst School of Computing National U of Singapore RMIT and The U of Melbourne
Indexing in Spatial Databases Beng Chin Ooi Ron Sacks-Davis Jiawei Han Dept of Inf Sys and Comp Sci Collaborative Inf Tech Res Inst School of Computing National U of Singapore RMIT and The U of Melbourne
Vector storage and access; algorithms in GIS. This is lecture 6
 Vector storage and access; algorithms in GIS This is lecture 6 Vector data storage and access Vectors are built from points, line and areas. (x,y) Surface: (x,y,z) Vector data access Access to vector
Vector storage and access; algorithms in GIS This is lecture 6 Vector data storage and access Vectors are built from points, line and areas. (x,y) Surface: (x,y,z) Vector data access Access to vector
QuickDB Yet YetAnother Database Management System?
 QuickDB Yet YetAnother Database Management System? Radim Bača, Peter Chovanec, Michal Krátký, and Petr Lukáš Radim Bača, Peter Chovanec, Michal Krátký, and Petr Lukáš Department of Computer Science, FEECS,
QuickDB Yet YetAnother Database Management System? Radim Bača, Peter Chovanec, Michal Krátký, and Petr Lukáš Radim Bača, Peter Chovanec, Michal Krátký, and Petr Lukáš Department of Computer Science, FEECS,
B-Trees. Algorithms and data structures for external memory as opposed to the main memory B-Trees. B -trees
 B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
File Management. Chapter 12
 Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Oracle8i Spatial: Experiences with Extensible Databases
 Oracle8i Spatial: Experiences with Extensible Databases Siva Ravada and Jayant Sharma Spatial Products Division Oracle Corporation One Oracle Drive Nashua NH-03062 {sravada,jsharma}@us.oracle.com 1 Introduction
Oracle8i Spatial: Experiences with Extensible Databases Siva Ravada and Jayant Sharma Spatial Products Division Oracle Corporation One Oracle Drive Nashua NH-03062 {sravada,jsharma}@us.oracle.com 1 Introduction
Data Structures for Moving Objects
 Data Structures for Moving Objects Pankaj K. Agarwal Department of Computer Science Duke University Geometric Data Structures S: Set of geometric objects Points, segments, polygons Ask several queries
Data Structures for Moving Objects Pankaj K. Agarwal Department of Computer Science Duke University Geometric Data Structures S: Set of geometric objects Points, segments, polygons Ask several queries
Chapter 13: Query Processing. Basic Steps in Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Indexing Techniques in Data Warehousing Environment The UB-Tree Algorithm
 Indexing Techniques in Data Warehousing Environment The UB-Tree Algorithm Prepared by: Yacine ghanjaoui Supervised by: Dr. Hachim Haddouti March 24, 2003 Abstract The indexing techniques in multidimensional
Indexing Techniques in Data Warehousing Environment The UB-Tree Algorithm Prepared by: Yacine ghanjaoui Supervised by: Dr. Hachim Haddouti March 24, 2003 Abstract The indexing techniques in multidimensional
Cluster Analysis for Optimal Indexing
 Proceedings of the Twenty-Sixth International Florida Artificial Intelligence Research Society Conference Cluster Analysis for Optimal Indexing Tim Wylie, Michael A. Schuh, John Sheppard, and Rafal A.
Proceedings of the Twenty-Sixth International Florida Artificial Intelligence Research Society Conference Cluster Analysis for Optimal Indexing Tim Wylie, Michael A. Schuh, John Sheppard, and Rafal A.
B+ Tree Properties B+ Tree Searching B+ Tree Insertion B+ Tree Deletion Static Hashing Extendable Hashing Questions in pass papers
 B+ Tree and Hashing B+ Tree Properties B+ Tree Searching B+ Tree Insertion B+ Tree Deletion Static Hashing Extendable Hashing Questions in pass papers B+ Tree Properties Balanced Tree Same height for paths
B+ Tree and Hashing B+ Tree Properties B+ Tree Searching B+ Tree Insertion B+ Tree Deletion Static Hashing Extendable Hashing Questions in pass papers B+ Tree Properties Balanced Tree Same height for paths
SQL Query Evaluation. Winter 2006-2007 Lecture 23
 SQL Query Evaluation Winter 2006-2007 Lecture 23 SQL Query Processing Databases go through three steps: Parse SQL into an execution plan Optimize the execution plan Evaluate the optimized plan Execution
SQL Query Evaluation Winter 2006-2007 Lecture 23 SQL Query Processing Databases go through three steps: Parse SQL into an execution plan Optimize the execution plan Evaluate the optimized plan Execution
Indexing and Processing Big Data
 Indexing and Processing Big Data Patrick Valduriez INRIA, Montpellier Why Big Data Today? Overwhelming amounts of data Generated by all kinds of devices, networks and programs E.g. sensors, mobile devices,
Indexing and Processing Big Data Patrick Valduriez INRIA, Montpellier Why Big Data Today? Overwhelming amounts of data Generated by all kinds of devices, networks and programs E.g. sensors, mobile devices,
BIRCH: An Efficient Data Clustering Method For Very Large Databases
 BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
High-Performance Extensible Indexing
 High-Performance Extensible Indexing Marcel Kornacker U. C. Berkeley marcel@cs.berkeley.edu Abstract Today s object-relational DBMSs (ORDBMSs) are designed to support novel application domains by providing
High-Performance Extensible Indexing Marcel Kornacker U. C. Berkeley marcel@cs.berkeley.edu Abstract Today s object-relational DBMSs (ORDBMSs) are designed to support novel application domains by providing
Overview of Storage and Indexing
 Overview of Storage and Indexing Chapter 8 How index-learning turns no student pale Yet holds the eel of science by the tail. -- Alexander Pope (1688-1744) Database Management Systems 3ed, R. Ramakrishnan
Overview of Storage and Indexing Chapter 8 How index-learning turns no student pale Yet holds the eel of science by the tail. -- Alexander Pope (1688-1744) Database Management Systems 3ed, R. Ramakrishnan
Database Design Patterns. Winter 2006-2007 Lecture 24
 Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
Data Mining. Cluster Analysis: Advanced Concepts and Algorithms
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
In-Memory Databases MemSQL
 IT4BI - Université Libre de Bruxelles In-Memory Databases MemSQL Gabby Nikolova Thao Ha Contents I. In-memory Databases...4 1. Concept:...4 2. Indexing:...4 a. b. c. d. AVL Tree:...4 B-Tree and B+ Tree:...5
IT4BI - Université Libre de Bruxelles In-Memory Databases MemSQL Gabby Nikolova Thao Ha Contents I. In-memory Databases...4 1. Concept:...4 2. Indexing:...4 a. b. c. d. AVL Tree:...4 B-Tree and B+ Tree:...5
Big Data and Scripting. Part 4: Memory Hierarchies
 1, Big Data and Scripting Part 4: Memory Hierarchies 2, Model and Definitions memory size: M machine words total storage (on disk) of N elements (N is very large) disk size unlimited (for our considerations)
1, Big Data and Scripting Part 4: Memory Hierarchies 2, Model and Definitions memory size: M machine words total storage (on disk) of N elements (N is very large) disk size unlimited (for our considerations)
Multi-dimensional index structures Part I: motivation
 Multi-dimensional index structures Part I: motivation 144 Motivation: Data Warehouse A definition A data warehouse is a repository of integrated enterprise data. A data warehouse is used specifically for
Multi-dimensional index structures Part I: motivation 144 Motivation: Data Warehouse A definition A data warehouse is a repository of integrated enterprise data. A data warehouse is used specifically for
Sorting revisited. Build the binary search tree: O(n^2) Traverse the binary tree: O(n) Total: O(n^2) + O(n) = O(n^2)
 Traverse the binary tree: O(n) Total: O(n^2) + O(n) = O(n^2)") Sorting revisited How did we use a binary search tree to sort an array of elements? Tree Sort Algorithm Given: An array of elements to sort 1. Build a binary search tree out of the elements 2. Traverse
Sorting revisited How did we use a binary search tree to sort an array of elements? Tree Sort Algorithm Given: An array of elements to sort 1. Build a binary search tree out of the elements 2. Traverse
ISSUES IN SPATIAL DATABASES AND GEOGRAPHIC INFORMATION SYSTEMS (GIS) HANAN SAMET
 HANAN SAMET") ISSUES IN SPATIAL DATABASES AND GEOGRAPHIC INFORMATION SYSTEMS (GIS) HANAN SAMET COMPUTER SCIENCE DEPARTMENT AND CENTER FOR AUTOMATION RESEARCH AND INSTITUTE FOR ADVANCED COMPUTER STUDIES UNIVERSITY OF
ISSUES IN SPATIAL DATABASES AND GEOGRAPHIC INFORMATION SYSTEMS (GIS) HANAN SAMET COMPUTER SCIENCE DEPARTMENT AND CENTER FOR AUTOMATION RESEARCH AND INSTITUTE FOR ADVANCED COMPUTER STUDIES UNIVERSITY OF
External Sorting. Chapter 13. Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1
 External Sorting Chapter 13 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Why Sort? A classic problem in computer science! Data requested in sorted order e.g., find students in increasing
External Sorting Chapter 13 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Why Sort? A classic problem in computer science! Data requested in sorted order e.g., find students in increasing
Data storage Tree indexes
 Data storage Tree indexes Rasmus Pagh February 7 lecture 1 Access paths For many database queries and updates, only a small fraction of the data needs to be accessed. Extreme examples are looking or updating
Data storage Tree indexes Rasmus Pagh February 7 lecture 1 Access paths For many database queries and updates, only a small fraction of the data needs to be accessed. Extreme examples are looking or updating
Performance of KDB-Trees with Query-Based Splitting*
 Performance of KDB-Trees with Query-Based Splitting* Yves Lépouchard Ratko Orlandic John L. Pfaltz Dept. of Computer Science Dept. of Computer Science Dept. of Computer Science University of Virginia Illinois
Performance of KDB-Trees with Query-Based Splitting* Yves Lépouchard Ratko Orlandic John L. Pfaltz Dept. of Computer Science Dept. of Computer Science Dept. of Computer Science University of Virginia Illinois
Database Systems. Session 8 Main Theme. Physical Database Design, Query Execution Concepts and Database Programming Techniques
 Database Systems Session 8 Main Theme Physical Database Design, Query Execution Concepts and Database Programming Techniques Dr. Jean-Claude Franchitti New York University Computer Science Department Courant
Database Systems Session 8 Main Theme Physical Database Design, Query Execution Concepts and Database Programming Techniques Dr. Jean-Claude Franchitti New York University Computer Science Department Courant
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Expanding the CASEsim Framework to Facilitate Load Balancing of Social Network Simulations
 Expanding the CASEsim Framework to Facilitate Load Balancing of Social Network Simulations Amara Keller, Martin Kelly, Aaron Todd 4 June 2010 Abstract This research has two components, both involving the
Expanding the CASEsim Framework to Facilitate Load Balancing of Social Network Simulations Amara Keller, Martin Kelly, Aaron Todd 4 June 2010 Abstract This research has two components, both involving the
Clustering & Visualization
 Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Overview of Storage and Indexing. Data on External Storage. Alternative File Organizations. Chapter 8
 Overview of Storage and Indexing Chapter 8 How index-learning turns no student pale Yet holds the eel of science by the tail. -- Alexander Pope (1688-1744) Database Management Systems 3ed, R. Ramakrishnan
Overview of Storage and Indexing Chapter 8 How index-learning turns no student pale Yet holds the eel of science by the tail. -- Alexander Pope (1688-1744) Database Management Systems 3ed, R. Ramakrishnan
10. Creating and Maintaining Geographic Databases. Learning objectives. Keywords and concepts. Overview. Definitions
 10. Creating and Maintaining Geographic Databases Geographic Information Systems and Science SECOND EDITION Paul A. Longley, Michael F. Goodchild, David J. Maguire, David W. Rhind 005 John Wiley and Sons,
10. Creating and Maintaining Geographic Databases Geographic Information Systems and Science SECOND EDITION Paul A. Longley, Michael F. Goodchild, David J. Maguire, David W. Rhind 005 John Wiley and Sons,
External Sorting. Why Sort? 2-Way Sort: Requires 3 Buffers. Chapter 13
 External Sorting Chapter 13 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Why Sort? A classic problem in computer science! Data requested in sorted order e.g., find students in increasing
External Sorting Chapter 13 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Why Sort? A classic problem in computer science! Data requested in sorted order e.g., find students in increasing
Symbol Tables. Introduction
 Symbol Tables Introduction A compiler needs to collect and use information about the names appearing in the source program. This information is entered into a data structure called a symbol table. The
Symbol Tables Introduction A compiler needs to collect and use information about the names appearing in the source program. This information is entered into a data structure called a symbol table. The
Partitioning and Divide and Conquer Strategies
 and Divide and Conquer Strategies Lecture 4 and Strategies Strategies Data partitioning aka domain decomposition Functional decomposition Lecture 4 and Strategies Quiz 4.1 For nuclear reactor simulation,
and Divide and Conquer Strategies Lecture 4 and Strategies Strategies Data partitioning aka domain decomposition Functional decomposition Lecture 4 and Strategies Quiz 4.1 For nuclear reactor simulation,
Sorting Hierarchical Data in External Memory for Archiving
 Sorting Hierarchical Data in External Memory for Archiving Ioannis Koltsidas School of Informatics University of Edinburgh i.koltsidas@sms.ed.ac.uk Heiko Müller School of Informatics University of Edinburgh
Sorting Hierarchical Data in External Memory for Archiving Ioannis Koltsidas School of Informatics University of Edinburgh i.koltsidas@sms.ed.ac.uk Heiko Müller School of Informatics University of Edinburgh
Challenges in Finding an Appropriate Multi-Dimensional Index Structure with Respect to Specific Use Cases
 Challenges in Finding an Appropriate Multi-Dimensional Index Structure with Respect to Specific Use Cases Alexander Grebhahn grebhahn@st.ovgu.de Reimar Schröter rschroet@st.ovgu.de David Broneske dbronesk@st.ovgu.de
Challenges in Finding an Appropriate Multi-Dimensional Index Structure with Respect to Specific Use Cases Alexander Grebhahn grebhahn@st.ovgu.de Reimar Schröter rschroet@st.ovgu.de David Broneske dbronesk@st.ovgu.de
The DC-Tree: A Fully Dynamic Index Structure for Data Warehouses
 Published in the Proceedings of 16th International Conference on Data Engineering (ICDE 2) The DC-Tree: A Fully Dynamic Index Structure for Data Warehouses Martin Ester, Jörn Kohlhammer, Hans-Peter Kriegel
Published in the Proceedings of 16th International Conference on Data Engineering (ICDE 2) The DC-Tree: A Fully Dynamic Index Structure for Data Warehouses Martin Ester, Jörn Kohlhammer, Hans-Peter Kriegel
Survey On: Nearest Neighbour Search With Keywords In Spatial Databases
 Survey On: Nearest Neighbour Search With Keywords In Spatial Databases SayaliBorse 1, Prof. P. M. Chawan 2, Prof. VishwanathChikaraddi 3, Prof. Manish Jansari 4 P.G. Student, Dept. of Computer Engineering&
Survey On: Nearest Neighbour Search With Keywords In Spatial Databases SayaliBorse 1, Prof. P. M. Chawan 2, Prof. VishwanathChikaraddi 3, Prof. Manish Jansari 4 P.G. Student, Dept. of Computer Engineering&
Index Internals Heikki Linnakangas / Pivotal
 Index Internals Heikki Linnakangas / Pivotal Index Access Methods in PostgreSQL 9.5 B-tree GiST GIN SP-GiST BRIN (Hash) but first, the Heap Heap Stores all tuples in table Unordered Copenhagen Amsterdam
Index Internals Heikki Linnakangas / Pivotal Index Access Methods in PostgreSQL 9.5 B-tree GiST GIN SP-GiST BRIN (Hash) but first, the Heap Heap Stores all tuples in table Unordered Copenhagen Amsterdam
Chapter 8: Structures for Files. Truong Quynh Chi tqchi@cse.hcmut.edu.vn. Spring- 2013
 Chapter 8: Data Storage, Indexing Structures for Files Truong Quynh Chi tqchi@cse.hcmut.edu.vn Spring- 2013 Overview of Database Design Process 2 Outline Data Storage Disk Storage Devices Files of Records
Chapter 8: Data Storage, Indexing Structures for Files Truong Quynh Chi tqchi@cse.hcmut.edu.vn Spring- 2013 Overview of Database Design Process 2 Outline Data Storage Disk Storage Devices Files of Records
A Novel Index Supporting High Volume Data Warehouse Insertions
 A Novel Index Supporting High Volume Data Warehouse Insertions Christopher Jermaine College of Computing Georgia Institute of Technology jermaine@cc.gatech.edu Anindya Datta DuPree College of Management
A Novel Index Supporting High Volume Data Warehouse Insertions Christopher Jermaine College of Computing Georgia Institute of Technology jermaine@cc.gatech.edu Anindya Datta DuPree College of Management
Operating Systems CSE 410, Spring 2004. File Management. Stephen Wagner Michigan State University
 Operating Systems CSE 410, Spring 2004 File Management Stephen Wagner Michigan State University File Management File management system has traditionally been considered part of the operating system. Applications
Operating Systems CSE 410, Spring 2004 File Management Stephen Wagner Michigan State University File Management File management system has traditionally been considered part of the operating system. Applications
Spatial Data Management over Flash Memory
 Spatial Data Management over Flash Memory Ioannis Koltsidas 1 and Stratis D. Viglas 2 1 IBM Research, Zurich, Switzerland iko@zurich.ibm.com 2 School of Informatics, University of Edinburgh, UK sviglas@inf.ed.ac.uk
Spatial Data Management over Flash Memory Ioannis Koltsidas 1 and Stratis D. Viglas 2 1 IBM Research, Zurich, Switzerland iko@zurich.ibm.com 2 School of Informatics, University of Edinburgh, UK sviglas@inf.ed.ac.uk
CSE 326, Data Structures. Sample Final Exam. Problem Max Points Score 1 14 (2x7) 2 18 (3x6) 3 4 4 7 5 9 6 16 7 8 8 4 9 8 10 4 Total 92.
 2 18 (3x6) 3 4 4 7 5 9 6 16 7 8 8 4 9 8 10 4 Total 92.") Name: Email ID: CSE 326, Data Structures Section: Sample Final Exam Instructions: The exam is closed book, closed notes. Unless otherwise stated, N denotes the number of elements in the data structure
Name: Email ID: CSE 326, Data Structures Section: Sample Final Exam Instructions: The exam is closed book, closed notes. Unless otherwise stated, N denotes the number of elements in the data structure
Storage and File Structure
 Storage and File Structure Chapter 10: Storage and File Structure Overview of Physical Storage Media Magnetic Disks RAID Tertiary Storage Storage Access File Organization Organization of Records in Files
Storage and File Structure Chapter 10: Storage and File Structure Overview of Physical Storage Media Magnetic Disks RAID Tertiary Storage Storage Access File Organization Organization of Records in Files
InfiniteGraph: The Distributed Graph Database
 A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
So today we shall continue our discussion on the search engines and web crawlers. (Refer Slide Time: 01:02)
") Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
MySQL Storage Engines
 MySQL Storage Engines Data in MySQL is stored in files (or memory) using a variety of different techniques. Each of these techniques employs different storage mechanisms, indexing facilities, locking levels
MySQL Storage Engines Data in MySQL is stored in files (or memory) using a variety of different techniques. Each of these techniques employs different storage mechanisms, indexing facilities, locking levels
PETASCALE DATA STORAGE INSTITUTE. SciDAC @ Petascale storage issues. 3 universities, 5 labs, G. Gibson, CMU, PI
 PETASCALE DATA STORAGE INSTITUTE 3 universities, 5 labs, G. Gibson, CMU, PI SciDAC @ Petascale storage issues www.pdsi-scidac.org Community building: ie. PDSW-SC07 (Sun 11th) APIs & standards: ie., Parallel
PETASCALE DATA STORAGE INSTITUTE 3 universities, 5 labs, G. Gibson, CMU, PI SciDAC @ Petascale storage issues www.pdsi-scidac.org Community building: ie. PDSW-SC07 (Sun 11th) APIs & standards: ie., Parallel
MIDAS: Multi-Attribute Indexing for Distributed Architecture Systems
 MIDAS: Multi-Attribute Indexing for Distributed Architecture Systems George Tsatsanifos (NTUA) Dimitris Sacharidis (R.C. Athena ) Timos Sellis (NTUA, R.C. Athena ) 12 th International Symposium on Spatial
MIDAS: Multi-Attribute Indexing for Distributed Architecture Systems George Tsatsanifos (NTUA) Dimitris Sacharidis (R.C. Athena ) Timos Sellis (NTUA, R.C. Athena ) 12 th International Symposium on Spatial
COS 318: Operating Systems. File Layout and Directories. Topics. File System Components. Steps to Open A File
 Topics COS 318: Operating Systems File Layout and Directories File system structure Disk allocation and i-nodes Directory and link implementations Physical layout for performance 2 File System Components
Topics COS 318: Operating Systems File Layout and Directories File system structure Disk allocation and i-nodes Directory and link implementations Physical layout for performance 2 File System Components
Quiz! Database Indexes. Index. Quiz! Disc and main memory. Quiz! How costly is this operation (naive solution)?
?") Database Indexes How costly is this operation (naive solution)? course per weekday hour room TDA356 2 VR Monday 13:15 TDA356 2 VR Thursday 08:00 TDA356 4 HB1 Tuesday 08:00 TDA356 4 HB1 Friday 13:15 TIN090
Database Indexes How costly is this operation (naive solution)? course per weekday hour room TDA356 2 VR Monday 13:15 TDA356 2 VR Thursday 08:00 TDA356 4 HB1 Tuesday 08:00 TDA356 4 HB1 Friday 13:15 TIN090
From Last Time: Remove (Delete) Operation
 Operation") CSE 32 Lecture : More on Search Trees Today s Topics: Lazy Operations Run Time Analysis of Binary Search Tree Operations Balanced Search Trees AVL Trees and Rotations Covered in Chapter of the text From
CSE 32 Lecture : More on Search Trees Today s Topics: Lazy Operations Run Time Analysis of Binary Search Tree Operations Balanced Search Trees AVL Trees and Rotations Covered in Chapter of the text From
CS 2112 Spring 2014. 0 Instructions. Assignment 3 Data Structures and Web Filtering. 0.1 Grading. 0.2 Partners. 0.3 Restrictions
 CS 2112 Spring 2014 Assignment 3 Data Structures and Web Filtering Due: March 4, 2014 11:59 PM Implementing spam blacklists and web filters requires matching candidate domain names and URLs very rapidly
CS 2112 Spring 2014 Assignment 3 Data Structures and Web Filtering Due: March 4, 2014 11:59 PM Implementing spam blacklists and web filters requires matching candidate domain names and URLs very rapidly
Accelerating network security services with fast packet classification
 Computer Communications 27 (2004) 1637 1646 www.elsevier.com/locate/comcom Accelerating network security services with fast packet classification Shiuhpyng Shieh 1, Fu-Yuan Lee 1, *, Ya-Wen Lin 1 Department
Computer Communications 27 (2004) 1637 1646 www.elsevier.com/locate/comcom Accelerating network security services with fast packet classification Shiuhpyng Shieh 1, Fu-Yuan Lee 1, *, Ya-Wen Lin 1 Department
File Management Chapters 10, 11, 12
 File Management Chapters 10, 11, 12 Requirements For long-term storage: possible to store large amount of info. info must survive termination of processes multiple processes must be able to access concurrently
File Management Chapters 10, 11, 12 Requirements For long-term storage: possible to store large amount of info. info must survive termination of processes multiple processes must be able to access concurrently
Graph Database Proof of Concept Report
 Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
low-level storage structures e.g. partitions underpinning the warehouse logical table structures
 DATA WAREHOUSE PHYSICAL DESIGN The physical design of a data warehouse specifies the: low-level storage structures e.g. partitions underpinning the warehouse logical table structures low-level structures
DATA WAREHOUSE PHYSICAL DESIGN The physical design of a data warehouse specifies the: low-level storage structures e.g. partitions underpinning the warehouse logical table structures low-level structures
EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES
 ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada tcossentine@gmail.com
ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada tcossentine@gmail.com
ICOM 6005 Database Management Systems Design. Dr. Manuel Rodríguez Martínez Electrical and Computer Engineering Department Lecture 2 August 23, 2001
 ICOM 6005 Database Management Systems Design Dr. Manuel Rodríguez Martínez Electrical and Computer Engineering Department Lecture 2 August 23, 2001 Readings Read Chapter 1 of text book ICOM 6005 Dr. Manuel
ICOM 6005 Database Management Systems Design Dr. Manuel Rodríguez Martínez Electrical and Computer Engineering Department Lecture 2 August 23, 2001 Readings Read Chapter 1 of text book ICOM 6005 Dr. Manuel
Concurrency Control. Chapter 17. Comp 521 Files and Databases Fall 2010 1
 Concurrency Control Chapter 17 Comp 521 Files and Databases Fall 2010 1 Conflict Serializable Schedules Recall conflicts (WR, RW, WW) were the cause of sequential inconsistency Two schedules are conflict
Concurrency Control Chapter 17 Comp 521 Files and Databases Fall 2010 1 Conflict Serializable Schedules Recall conflicts (WR, RW, WW) were the cause of sequential inconsistency Two schedules are conflict
Hypertable Architecture Overview
 WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
Chapter 13. Chapter Outline. Disk Storage, Basic File Structures, and Hashing
 Chapter 13 Disk Storage, Basic File Structures, and Hashing Copyright 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files
Chapter 13 Disk Storage, Basic File Structures, and Hashing Copyright 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files
Providing Diversity in K-Nearest Neighbor Query Results
 Providing Diversity in K-Nearest Neighbor Query Results Anoop Jain, Parag Sarda, and Jayant R. Haritsa Database Systems Lab, SERC/CSA Indian Institute of Science, Bangalore 560012, INDIA. Abstract. Given
Providing Diversity in K-Nearest Neighbor Query Results Anoop Jain, Parag Sarda, and Jayant R. Haritsa Database Systems Lab, SERC/CSA Indian Institute of Science, Bangalore 560012, INDIA. Abstract. Given
The DC-tree: A Fully Dynamic Index Structure for Data Warehouses
 The DC-tree: A Fully Dynamic Index Structure for Data Warehouses Martin Ester, Jörn Kohlhammer, Hans-Peter Kriegel Institute for Computer Science, University of Munich Oettingenstr. 67, D-80538 Munich,
The DC-tree: A Fully Dynamic Index Structure for Data Warehouses Martin Ester, Jörn Kohlhammer, Hans-Peter Kriegel Institute for Computer Science, University of Munich Oettingenstr. 67, D-80538 Munich,
Persistent Binary Search Trees
 Persistent Binary Search Trees Datastructures, UvA. May 30, 2008 0440949, Andreas van Cranenburgh Abstract A persistent binary tree allows access to all previous versions of the tree. This paper presents
Persistent Binary Search Trees Datastructures, UvA. May 30, 2008 0440949, Andreas van Cranenburgh Abstract A persistent binary tree allows access to all previous versions of the tree. This paper presents
The Classical Architecture. Storage 1 / 36
 1 / 36 The Problem Application Data? Filesystem Logical Drive Physical Drive 2 / 36 Requirements There are different classes of requirements: Data Independence application is shielded from physical storage
1 / 36 The Problem Application Data? Filesystem Logical Drive Physical Drive 2 / 36 Requirements There are different classes of requirements: Data Independence application is shielded from physical storage
Chapter 12 File Management
 Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 12 File Management Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Roadmap Overview File organisation and Access
Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 12 File Management Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Roadmap Overview File organisation and Access
Chapter 12 File Management. Roadmap
 Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 12 File Management Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Overview Roadmap File organisation and Access
Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 12 File Management Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Overview Roadmap File organisation and Access
Chapter 6: Physical Database Design and Performance. Database Development Process. Physical Design Process. Physical Database Design
 Chapter 6: Physical Database Design and Performance Modern Database Management 6 th Edition Jeffrey A. Hoffer, Mary B. Prescott, Fred R. McFadden Robert C. Nickerson ISYS 464 Spring 2003 Topic 23 Database
Chapter 6: Physical Database Design and Performance Modern Database Management 6 th Edition Jeffrey A. Hoffer, Mary B. Prescott, Fred R. McFadden Robert C. Nickerson ISYS 464 Spring 2003 Topic 23 Database
CIS 631 Database Management Systems Sample Final Exam
 CIS 631 Database Management Systems Sample Final Exam 1. (25 points) Match the items from the left column with those in the right and place the letters in the empty slots. k 1. Single-level index files
CIS 631 Database Management Systems Sample Final Exam 1. (25 points) Match the items from the left column with those in the right and place the letters in the empty slots. k 1. Single-level index files
Copyright 2007 Ramez Elmasri and Shamkant B. Navathe. Slide 13-1
 Slide 13-1 Chapter 13 Disk Storage, Basic File Structures, and Hashing Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files Hashed Files Dynamic and Extendible
Slide 13-1 Chapter 13 Disk Storage, Basic File Structures, and Hashing Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files Hashed Files Dynamic and Extendible
Facebook: Cassandra. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Data Structures for Databases
 60 Data Structures for Databases Joachim Hammer University of Florida Markus Schneider University of Florida 60.1 Overview of the Functionality of a Database Management System..................................
60 Data Structures for Databases Joachim Hammer University of Florida Markus Schneider University of Florida 60.1 Overview of the Functionality of a Database Management System..................................
A Comparison of Dictionary Implementations
 A Comparison of Dictionary Implementations Mark P Neyer April 10, 2009 1 Introduction A common problem in computer science is the representation of a mapping between two sets. A mapping f : A B is a function
A Comparison of Dictionary Implementations Mark P Neyer April 10, 2009 1 Introduction A common problem in computer science is the representation of a mapping between two sets. A mapping f : A B is a function
Elena Baralis, Silvia Chiusano Politecnico di Torino. Pag. 1. Physical Design. Phases of database design. Physical design: Inputs.
 Phases of database design Application requirements Conceptual design Database Management Systems Conceptual schema Logical design ER or UML Physical Design Relational tables Logical schema Physical design
Phases of database design Application requirements Conceptual design Database Management Systems Conceptual schema Logical design ER or UML Physical Design Relational tables Logical schema Physical design
Efficient Structure Oriented Storage of XML Documents Using ORDBMS
 Efficient Structure Oriented Storage of XML Documents Using ORDBMS Alexander Kuckelberg 1 and Ralph Krieger 2 1 Chair of Railway Studies and Transport Economics, RWTH Aachen Mies-van-der-Rohe-Str. 1, D-52056
Efficient Structure Oriented Storage of XML Documents Using ORDBMS Alexander Kuckelberg 1 and Ralph Krieger 2 1 Chair of Railway Studies and Transport Economics, RWTH Aachen Mies-van-der-Rohe-Str. 1, D-52056
Chapter 12 File Management
 Operating Systems: Internals and Design Principles Chapter 12 File Management Eighth Edition By William Stallings Files Data collections created by users The File System is one of the most important parts
Operating Systems: Internals and Design Principles Chapter 12 File Management Eighth Edition By William Stallings Files Data collections created by users The File System is one of the most important parts
Hierarchical Data Visualization. Ai Nakatani IAT 814 February 21, 2007
 Hierarchical Data Visualization Ai Nakatani IAT 814 February 21, 2007 Introduction Hierarchical Data Directory structure Genealogy trees Biological taxonomy Business structure Project structure Challenges
Hierarchical Data Visualization Ai Nakatani IAT 814 February 21, 2007 Introduction Hierarchical Data Directory structure Genealogy trees Biological taxonomy Business structure Project structure Challenges
Learning Outcomes. COMP202 Complexity of Algorithms. Binary Search Trees and Other Search Trees
 Learning Outcomes COMP202 Complexity of Algorithms Binary Search Trees and Other Search Trees [See relevant sections in chapters 2 and 3 in Goodrich and Tamassia.] At the conclusion of this set of lecture
Learning Outcomes COMP202 Complexity of Algorithms Binary Search Trees and Other Search Trees [See relevant sections in chapters 2 and 3 in Goodrich and Tamassia.] At the conclusion of this set of lecture
Cloud and Big Data Summer School, Stockholm, Aug., 2015 Jeffrey D. Ullman
 Cloud and Big Data Summer School, Stockholm, Aug., 2015 Jeffrey D. Ullman To motivate the Bloom-filter idea, consider a web crawler. It keeps, centrally, a list of all the URL s it has found so far. It
Cloud and Big Data Summer School, Stockholm, Aug., 2015 Jeffrey D. Ullman To motivate the Bloom-filter idea, consider a web crawler. It keeps, centrally, a list of all the URL s it has found so far. It
A Deduplication-based Data Archiving System
 2012 International Conference on Image, Vision and Computing (ICIVC 2012) IPCSIT vol. 50 (2012) (2012) IACSIT Press, Singapore DOI: 10.7763/IPCSIT.2012.V50.20 A Deduplication-based Data Archiving System
2012 International Conference on Image, Vision and Computing (ICIVC 2012) IPCSIT vol. 50 (2012) (2012) IACSIT Press, Singapore DOI: 10.7763/IPCSIT.2012.V50.20 A Deduplication-based Data Archiving System
Large-Scale Spatial Data Management on Modern Parallel and Distributed Platforms
 Large-Scale Spatial Data Management on Modern Parallel and Distributed Platforms Thesis Proposal Abstract Rapidly growing volume of spatial data has made it desirable to develop efficient techniques for
Large-Scale Spatial Data Management on Modern Parallel and Distributed Platforms Thesis Proposal Abstract Rapidly growing volume of spatial data has made it desirable to develop efficient techniques for
FAWN - a Fast Array of Wimpy Nodes
 University of Warsaw January 12, 2011 Outline Introduction 1 Introduction 2 3 4 5 Key issues Introduction Growing CPU vs. I/O gap Contemporary systems must serve millions of users Electricity consumed
University of Warsaw January 12, 2011 Outline Introduction 1 Introduction 2 3 4 5 Key issues Introduction Growing CPU vs. I/O gap Contemporary systems must serve millions of users Electricity consumed