FAWN - a Fast Array of Wimpy Nodes
|
|
|
- Cameron Jennings
- 9 years ago
- Views:
Transcription
1 University of Warsaw January 12, 2011

2 Outline Introduction 1 Introduction
3 Key issues Introduction Growing CPU vs. I/O gap Contemporary systems must serve millions of users Electricity consumed adds up to significant costs

4 Key issues Introduction Is there a way to exploit the CPU vs. I/O gap to the users advantage?

5 Observations Introduction Many industry problems exhibit massive data parallelism with relatively small computational demands A fair amount of real-life problems heavily depends on efficient, distributed key-value stores that span several gigabytes Such stores often contain millions of small items (on the order of kilobytes)

6 A motivating example Twitter A wonderfully popular service, Twitter has all the above-mentioned properties. Each tweet is limited to 140B. There is fairly little processing performed on the tweets, yet just the search system is stressed by an average of queries per second. There is a stream of over a thousand tweets per second entering the system. A high-performance key-value store is crucial to the operation. At the same time the cost of running a conventional cluster capable of meeting this demand is extremely high. Disclaimer To my knowledge, FAWN is not being used in Twitter. But it would probably make a lot of sense if it were. Thank you.

7 The problem, defined To engineer a fast, scalable key-value store for small (hundreds to thousands of bytes) items This store is expected to: respond to upwards from thousands of random queries per second (QPS) conserve power as much as possible meet service level agreements regarding latency scale well upwards as the system grows scale well downwards as demand fluctuates during operating hours

8 Possible solutions (1) A cluster of traditional servers with HDD as storage. Problems: very poor performance for random accesses, unless RAID or a similar disk array is used if RAID is to be used, both initial price and total cost of ownership skyrocket most of the power consumption is fixed not much power is conserved during low load periods

9 Possible solutions (2) A cluster of traditional servers with RAM as storage (think memcached) Problems: very high cost in terms of $/GB robustness is lost unless additional systems are employed power consumption is just as bad as before

10 Possible solutions (3) A cluster of traditional servers with SSD as storage Problems: while random reads are great, random writes are terrible (BerkleyDB running on SSD averages just 0.07MBps) power consumption is just as bad as before

11 Possible solutions (4) A combination of the above Problems: a combination of the above :)

12 Introducing FAWN A slightly different approach: Let s use energy-efficient, wimpy processors coupled with fast SSD storage. Design a custom key-value store exploiting the characteristics of flash storage. That way power consumption can be kept to a minimum while retaining high performance and robustness. The resulting system has a lower total cost of ownership and good scalability.

13 Outline Introduction 1 Introduction

14 Anatomy of a key-value data store A request can be either a get, put or delete Keys are 160-bit integers Values are small blobs (typically between 256B and 1KB) Each request pertains to a single key-value pair there is no relational overlay at this level

15 Overview Introduction
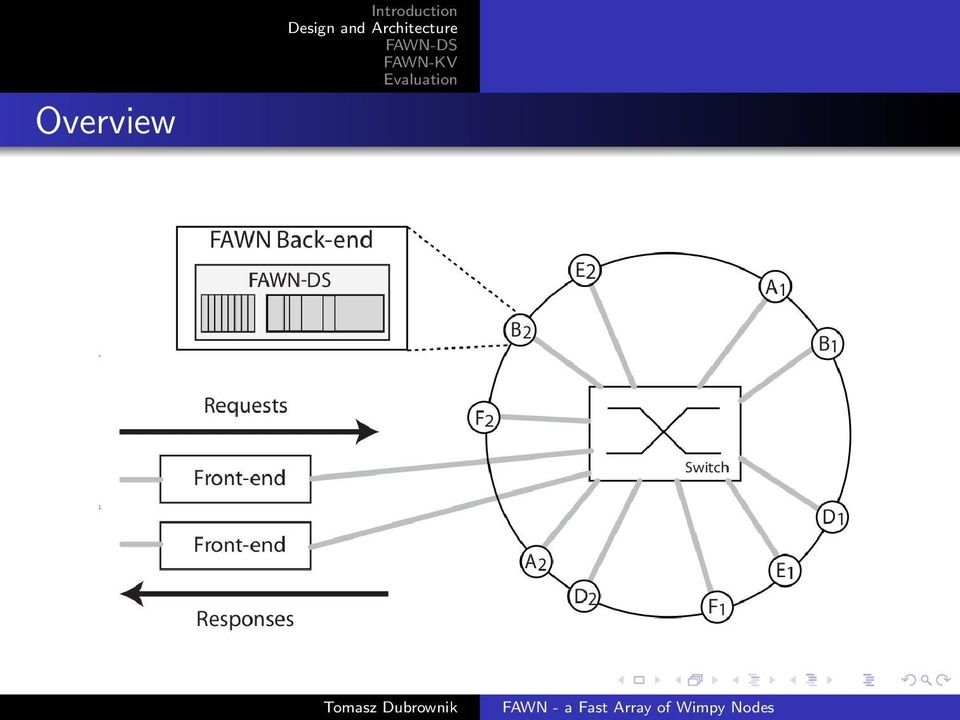
16 Overview Introduction The cluster is composed of Front-ends and Back-ends Front-ends forward requests to appropriate back-ends and return responses to clients The front-ends are responsible for maintaining order in the cluster Back-ends run the datastores (one per key-range) Together the machines form a single key-value store
 Together the machines form a")
17 Front-end Introduction Responsibilities: passing requests and responses keeping track of back-ends Virtual IDs and their mapping to key ranges managing joins and leaves. Example configuration used for evaluation: Intel Atom CPU (27 W)

18 Back-end Introduction A back-end runs one data store per key range. Each data store supports the basic key-value requests, as well as maintance operations (Split, Merge, Compact) Example configuration used for evaluation: AMD Geode LX CPU (500MHz) 256MB DDR SDRAM (400MHz) 100Mbps Ethernet Sandisk Extreme IV CompactFlash (4GB)
 256MB DDR SDRAM (400MHz) 100Mbps Ethernet Sandisk Extreme")
19 Back-ends, cont. Back-ends are organized in a logical ring which coincides with the key space (mod ) Each back-end is assigned a fixed number of Virtual IDs in hopes of maintaining balance Virtual IDs are the lowest keys a node handles This allows for a well-defined successor relation on keys and virtual nodes More on this later.

20 Outline Introduction 1 Introduction

21 Peculiarities of flash storage Flash media differ from traditional HDDs in a number of ways, some of which seriously impact persistent data store designs. Random reads are nearly as fast as sequential reads Random writes are very inefficient (owing to the fact that a whole page needs to be flashed) Sequential writes perform admirably On modern devices, semi-random writes (random appends to a small number of files) are nearly as fast as sequential writes These features can be exploited by using a log-structured data store.
22 Introduction To take advantage of the properties of flash storage, is structured as follows: The key-value mappings are stored in a Data Log on the flash medium. This store is append-only. To provide fast random access, a hash index map into the data log is kept in RAM. In order to reduce the memory footprint, keys are reduced, inflicting as a trade-off a (configurable) chance of necessitating more than one flash access. To reclaim unused storage space, a Compact operation is introduced. It is designed to be as efficient as possible on flash, using only bulk sequential writes. In order to facilitate reconstruction of the in-memory index, checkpointing is utilized.
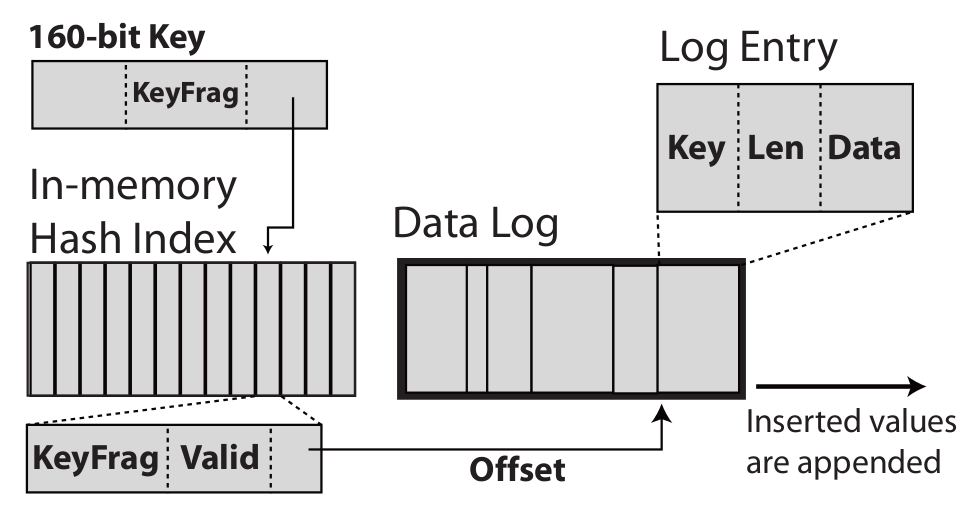
23 Lookup Introduction
24 Lookup cont. Introduction Two smaller numbers are extracted from the key: The index bits the lowest i bits key fragment the next lowest k bits The index bits serve as an index into the first in-memory hash index. If the bucket pointed to by the index bits is valid and the key fragments match, the data log entry is retrieved and the full keys compared. If keys match, the record is returned, otherwise the next bucket in the hash chain is examined as above. If nothing is found, an appropriate response is generated.
25 Lookup, now in pseudocode!
26 Store and Delete When a value is inserted into the store, it is simply appended to the data log and the corresponding bucket are changed to point to the new record. The valid bit is set to true. When a record is to be deleted, a delete entry is appended to the log (for fault-tolerance) and the valid bit in the corresponding bucket is set to false. Actual storage space is not reclaimed until a Compact is performed.
27 Maintenance operations Split is issued when the key range is divided as a new virtual node joins the ring. It scans the data log sequentially and writes out the appropriate entries into a new one. Merge is responsible for merging two data stores into one, encompassing the combined key range. It achieves this by copying entries from one log into the other. Compact copies the valid data store entries into a new log, skipping those that have been orphaned by puts and those that were actively deleted. Owing to the append-only design it is possible to perform these operations concurrently with normal requests, only locking to switch data stores while finalizing maintenance.
28 Outline Introduction 1 Introduction
29 In order to provide a robust, scalable service the back-ends running instances are joined together and managed by front-end nodes, which in turn in industry applications would be connected to a master node. Fault-tolerance is introduced via replication Each front-end is ideally responsible for some 80 back-ends and manages joins and leaves, exposing a simple put, get, delete interface Additionally, front-ends can route requests between themselves and cache responses, leaving the master node as an optimization and a convenience without leaving it a single point of failure
30 Life-cycle of a request
31 Life-cycle of a request, elaborated Each front-end is assigned a contiguous portion of the key space Upon receiving a request it either processes it using its managed back-ends or forwards it if the key belongs to a different front-end Front-ends maintain a list of virtual nodes and their corresponding addresses, and thus can instantly translate the request to the appropriate calls While the request is processed by back-ends, the front-end ensures replication is maintained
32 Replication in Chains
33 Replication in Chains, cont. Each key defines a chain in the virtual node ring A fixed number of nodes maintains copies of the mapping The nodes are obtained by iterating the successor function of the key The first node that contains a replica is the head of the chain The last node is the tail Every put request is issued to the head of the chain and waits for an acknowledgement from the tail. Every get is passed to the tail. This ensures consistency and proper ordering of changes throughout the change.
34 Replication of a put After receiving the put request, the head forwards the put along the chain and waits for an acknowledgement. If all goes well, the tail acknowledges both to the front-end and recursively to its predecessor.
35 How a join is handled When a (virtual) node joins the ring precisely one key range is split in two. To maintain replication the following happens: The current tail transmits its whole log to the new node (pre-copy) The front-end informs the nodes in the chain of the join via a chain membership message In response to said message, nodes flush updates received during pre-copy down the chain Please refer to the paper for details on how updates arriving during the flush are handled, as well as the special cases of joining as head or tail.
36 What happens when a node leaves When a node leaves the ring, each node that is supposed to take over the replicas in essence joins the replica chain at a different position in the key space, so the protocol is essentially the same as for a join. At this stage failure detection is achieved by a heartbeat. If a node misses a set number of heartbeat signals, the front-end initiates a leave and appropriate action is taken.
37 Outline Introduction 1 Introduction
38 Procedure description FAWN s performance was evaluated under a number of criteria: Single node efficiency (compared to baseline hardware capabilities) Cluster performance (tested on a 21 back-end/1 front-end system) Energy efficiency The results were then compared with a number of more traditional configurations.
39 Single node performance Baseline: Seq. read Rand. read Seq. write Rand. write 28.5 MBps 1424 QPS 24 MBps 110 QPS FAWN: Data size Rand read (1KB) Rand read (256B) 125MB QPS QPS 1GB 1595 QPS 1964 QPS 3.5GB 1150 QPS 1298 QPS
40 Gets vs Puts Introduction
41 Cluster performance and power consumption
42 Important points on power consumption The plot displayed does not take into account the front-end (further 27W) The networking hardware used takes 20W to operate (included in the plotted figure) Even factoring in the front-end, the system achieved 330 queries per Joule. A desktop computer can provide about 50 Q/J using SSD.
43 CDF of Query Latency
44 Comparison with alternative approaches (projected) Important point The FAWN entries in this table are expected performance measurements of systems built using state of the art components.

45 Solution space for system builders (projected)
46 Conclusions Introduction FAWN is demonstrated to be a viable approach to providing cost-efficient data stores Using wimpy processors in an array can reduce power consumption while retaining performance Barring breakthrough discoveries, FAWN-like technologies are expected to deliver the lowest TCO for a large portion of the problem space Larger scale testing is necessary to establish the correctness of these claims and to demonstrate scalability
47 References Introduction [FAWN] D. G. Andersen, J. Franklin, M. Kaminsky, A. Phanishayee, L. Tan, and V. Vasudevan FAWN: A Fast Array of Wimpy Nodes Proceedings ACM SOSP 2009, Big Sky, MT, USA, October All images are taken from the FAWN paper.
Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software
 WHITEPAPER Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software SanDisk ZetaScale software unlocks the full benefits of flash for In-Memory Compute and NoSQL applications
WHITEPAPER Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software SanDisk ZetaScale software unlocks the full benefits of flash for In-Memory Compute and NoSQL applications
Benchmarking Cassandra on Violin
 Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems Finding a needle in Haystack: Facebook
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems Finding a needle in Haystack: Facebook
Speeding Up Cloud/Server Applications Using Flash Memory
 Speeding Up Cloud/Server Applications Using Flash Memory Sudipta Sengupta Microsoft Research, Redmond, WA, USA Contains work that is joint with B. Debnath (Univ. of Minnesota) and J. Li (Microsoft Research,
Speeding Up Cloud/Server Applications Using Flash Memory Sudipta Sengupta Microsoft Research, Redmond, WA, USA Contains work that is joint with B. Debnath (Univ. of Minnesota) and J. Li (Microsoft Research,
How To Store Data On An Ocora Nosql Database On A Flash Memory Device On A Microsoft Flash Memory 2 (Iomemory)
") WHITE PAPER Oracle NoSQL Database and SanDisk Offer Cost-Effective Extreme Performance for Big Data 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Abstract... 3 What Is Big Data?...
WHITE PAPER Oracle NoSQL Database and SanDisk Offer Cost-Effective Extreme Performance for Big Data 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Abstract... 3 What Is Big Data?...
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION
 DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
Bigdata High Availability (HA) Architecture
 Architecture") Bigdata High Availability (HA) Architecture Introduction This whitepaper describes an HA architecture based on a shared nothing design. Each node uses commodity hardware and has its own local resources
Bigdata High Availability (HA) Architecture Introduction This whitepaper describes an HA architecture based on a shared nothing design. Each node uses commodity hardware and has its own local resources
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
WITH A FUSION POWERED SQL SERVER 2014 IN-MEMORY OLTP DATABASE
 WITH A FUSION POWERED SQL SERVER 2014 IN-MEMORY OLTP DATABASE 1 W W W. F U S I ON I O.COM Table of Contents Table of Contents... 2 Executive Summary... 3 Introduction: In-Memory Meets iomemory... 4 What
WITH A FUSION POWERED SQL SERVER 2014 IN-MEMORY OLTP DATABASE 1 W W W. F U S I ON I O.COM Table of Contents Table of Contents... 2 Executive Summary... 3 Introduction: In-Memory Meets iomemory... 4 What
G22.3250-001. Porcupine. Robert Grimm New York University
 G22.3250-001 Porcupine Robert Grimm New York University Altogether Now: The Three Questions! What is the problem?! What is new or different?! What are the contributions and limitations? Porcupine from
G22.3250-001 Porcupine Robert Grimm New York University Altogether Now: The Three Questions! What is the problem?! What is new or different?! What are the contributions and limitations? Porcupine from
Facebook: Cassandra. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
COSC 6374 Parallel Computation. Parallel I/O (I) I/O basics. Concept of a clusters
 I/O basics. Concept of a clusters") COSC 6374 Parallel Computation Parallel I/O (I) I/O basics Spring 2008 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network
COSC 6374 Parallel Computation Parallel I/O (I) I/O basics Spring 2008 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Cisco UCS and Fusion- io take Big Data workloads to extreme performance in a small footprint: A case study with Oracle NoSQL database
 Cisco UCS and Fusion- io take Big Data workloads to extreme performance in a small footprint: A case study with Oracle NoSQL database Built up on Cisco s big data common platform architecture (CPA), a
Cisco UCS and Fusion- io take Big Data workloads to extreme performance in a small footprint: A case study with Oracle NoSQL database Built up on Cisco s big data common platform architecture (CPA), a
Distributed File Systems
 Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
Virtuoso and Database Scalability
 Virtuoso and Database Scalability By Orri Erling Table of Contents Abstract Metrics Results Transaction Throughput Initializing 40 warehouses Serial Read Test Conditions Analysis Working Set Effect of
Virtuoso and Database Scalability By Orri Erling Table of Contents Abstract Metrics Results Transaction Throughput Initializing 40 warehouses Serial Read Test Conditions Analysis Working Set Effect of
Distributed File Systems
 Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Improve Business Productivity and User Experience with a SanDisk Powered SQL Server 2014 In-Memory OLTP Database
 WHITE PAPER Improve Business Productivity and User Experience with a SanDisk Powered SQL Server 2014 In-Memory OLTP Database 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive
WHITE PAPER Improve Business Productivity and User Experience with a SanDisk Powered SQL Server 2014 In-Memory OLTP Database 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive
Couchbase Server Under the Hood
 Couchbase Server Under the Hood An Architectural Overview Couchbase Server is an open-source distributed NoSQL document-oriented database for interactive applications, uniquely suited for those needing
Couchbase Server Under the Hood An Architectural Overview Couchbase Server is an open-source distributed NoSQL document-oriented database for interactive applications, uniquely suited for those needing
The Google File System
 The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
The Sierra Clustered Database Engine, the technology at the heart of
 A New Approach: Clustrix Sierra Database Engine The Sierra Clustered Database Engine, the technology at the heart of the Clustrix solution, is a shared-nothing environment that includes the Sierra Parallel
A New Approach: Clustrix Sierra Database Engine The Sierra Clustered Database Engine, the technology at the heart of the Clustrix solution, is a shared-nothing environment that includes the Sierra Parallel
Operating Systems CSE 410, Spring 2004. File Management. Stephen Wagner Michigan State University
 Operating Systems CSE 410, Spring 2004 File Management Stephen Wagner Michigan State University File Management File management system has traditionally been considered part of the operating system. Applications
Operating Systems CSE 410, Spring 2004 File Management Stephen Wagner Michigan State University File Management File management system has traditionally been considered part of the operating system. Applications
Cloud Storage. Parallels. Performance Benchmark Results. White Paper. www.parallels.com
 Parallels Cloud Storage White Paper Performance Benchmark Results www.parallels.com Table of Contents Executive Summary... 3 Architecture Overview... 3 Key Features... 4 No Special Hardware Requirements...
Parallels Cloud Storage White Paper Performance Benchmark Results www.parallels.com Table of Contents Executive Summary... 3 Architecture Overview... 3 Key Features... 4 No Special Hardware Requirements...
Google File System. Web and scalability
 Google File System Web and scalability The web: - How big is the Web right now? No one knows. - Number of pages that are crawled: o 100,000 pages in 1994 o 8 million pages in 2005 - Crawlable pages might
Google File System Web and scalability The web: - How big is the Web right now? No one knows. - Number of pages that are crawled: o 100,000 pages in 1994 o 8 million pages in 2005 - Crawlable pages might
Fusion iomemory iodrive PCIe Application Accelerator Performance Testing
 WHITE PAPER Fusion iomemory iodrive PCIe Application Accelerator Performance Testing SPAWAR Systems Center Atlantic Cary Humphries, Steven Tully and Karl Burkheimer 2/1/2011 Product testing of the Fusion
WHITE PAPER Fusion iomemory iodrive PCIe Application Accelerator Performance Testing SPAWAR Systems Center Atlantic Cary Humphries, Steven Tully and Karl Burkheimer 2/1/2011 Product testing of the Fusion
RAMCloud and the Low- Latency Datacenter. John Ousterhout Stanford University
 RAMCloud and the Low- Latency Datacenter John Ousterhout Stanford University Most important driver for innovation in computer systems: Rise of the datacenter Phase 1: large scale Phase 2: low latency Introduction
RAMCloud and the Low- Latency Datacenter John Ousterhout Stanford University Most important driver for innovation in computer systems: Rise of the datacenter Phase 1: large scale Phase 2: low latency Introduction
Hypertable Architecture Overview
 WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
The Bw-Tree Key-Value Store and Its Applications to Server/Cloud Data Management in Production
 The Bw-Tree Key-Value Store and Its Applications to Server/Cloud Data Management in Production Sudipta Sengupta Joint work with Justin Levandoski and David Lomet (Microsoft Research) And Microsoft Product
The Bw-Tree Key-Value Store and Its Applications to Server/Cloud Data Management in Production Sudipta Sengupta Joint work with Justin Levandoski and David Lomet (Microsoft Research) And Microsoft Product
COSC 6374 Parallel Computation. Parallel I/O (I) I/O basics. Concept of a clusters
 I/O basics. Concept of a clusters") COSC 6374 Parallel I/O (I) I/O basics Fall 2012 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network card 1 Network card
COSC 6374 Parallel I/O (I) I/O basics Fall 2012 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network card 1 Network card
Physical Data Organization
 Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Analyzing Big Data with Splunk A Cost Effective Storage Architecture and Solution
 Analyzing Big Data with Splunk A Cost Effective Storage Architecture and Solution Jonathan Halstuch, COO, RackTop Systems [email protected] Big Data Invasion We hear so much on Big Data and
Analyzing Big Data with Splunk A Cost Effective Storage Architecture and Solution Jonathan Halstuch, COO, RackTop Systems [email protected] Big Data Invasion We hear so much on Big Data and
Seeking Fast, Durable Data Management: A Database System and Persistent Storage Benchmark
 Seeking Fast, Durable Data Management: A Database System and Persistent Storage Benchmark In-memory database systems (IMDSs) eliminate much of the performance latency associated with traditional on-disk
Seeking Fast, Durable Data Management: A Database System and Persistent Storage Benchmark In-memory database systems (IMDSs) eliminate much of the performance latency associated with traditional on-disk
NoSQL Data Base Basics
 NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
Parallels Cloud Storage
 Parallels Cloud Storage White Paper Best Practices for Configuring a Parallels Cloud Storage Cluster www.parallels.com Table of Contents Introduction... 3 How Parallels Cloud Storage Works... 3 Deploying
Parallels Cloud Storage White Paper Best Practices for Configuring a Parallels Cloud Storage Cluster www.parallels.com Table of Contents Introduction... 3 How Parallels Cloud Storage Works... 3 Deploying
Accelerating Server Storage Performance on Lenovo ThinkServer
 Accelerating Server Storage Performance on Lenovo ThinkServer Lenovo Enterprise Product Group April 214 Copyright Lenovo 214 LENOVO PROVIDES THIS PUBLICATION AS IS WITHOUT WARRANTY OF ANY KIND, EITHER
Accelerating Server Storage Performance on Lenovo ThinkServer Lenovo Enterprise Product Group April 214 Copyright Lenovo 214 LENOVO PROVIDES THIS PUBLICATION AS IS WITHOUT WARRANTY OF ANY KIND, EITHER
The Data Placement Challenge
 The Data Placement Challenge Entire Dataset Applications Active Data Lowest $/IOP Highest throughput Lowest latency 10-20% Right Place Right Cost Right Time 100% 2 2 What s Driving the AST Discussion?
The Data Placement Challenge Entire Dataset Applications Active Data Lowest $/IOP Highest throughput Lowest latency 10-20% Right Place Right Cost Right Time 100% 2 2 What s Driving the AST Discussion?
Performance Characteristics of VMFS and RDM VMware ESX Server 3.0.1
 Performance Study Performance Characteristics of and RDM VMware ESX Server 3.0.1 VMware ESX Server offers three choices for managing disk access in a virtual machine VMware Virtual Machine File System
Performance Study Performance Characteristics of and RDM VMware ESX Server 3.0.1 VMware ESX Server offers three choices for managing disk access in a virtual machine VMware Virtual Machine File System
Using Synology SSD Technology to Enhance System Performance Synology Inc.
 Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
File Management. Chapter 12
 Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Secondary Storage. Any modern computer system will incorporate (at least) two levels of storage: magnetic disk/optical devices/tape systems
 two levels of storage: magnetic disk/optical devices/tape systems") 1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity
1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity
Parallels Cloud Server 6.0
 Parallels Cloud Server 6.0 Parallels Cloud Storage I/O Benchmarking Guide September 05, 2014 Copyright 1999-2014 Parallels IP Holdings GmbH and its affiliates. All rights reserved. Parallels IP Holdings
Parallels Cloud Server 6.0 Parallels Cloud Storage I/O Benchmarking Guide September 05, 2014 Copyright 1999-2014 Parallels IP Holdings GmbH and its affiliates. All rights reserved. Parallels IP Holdings
Best Practices for Deploying Citrix XenDesktop on NexentaStor Open Storage
 Best Practices for Deploying Citrix XenDesktop on NexentaStor Open Storage White Paper July, 2011 Deploying Citrix XenDesktop on NexentaStor Open Storage Table of Contents The Challenges of VDI Storage
Best Practices for Deploying Citrix XenDesktop on NexentaStor Open Storage White Paper July, 2011 Deploying Citrix XenDesktop on NexentaStor Open Storage Table of Contents The Challenges of VDI Storage
The What, Why and How of the Pure Storage Enterprise Flash Array
 The What, Why and How of the Pure Storage Enterprise Flash Array Ethan L. Miller (and a cast of dozens at Pure Storage) What is an enterprise storage array? Enterprise storage array: store data blocks
The What, Why and How of the Pure Storage Enterprise Flash Array Ethan L. Miller (and a cast of dozens at Pure Storage) What is an enterprise storage array? Enterprise storage array: store data blocks
Lecture 1: Data Storage & Index
 Lecture 1: Data Storage & Index R&G Chapter 8-11 Concurrency control Query Execution and Optimization Relational Operators File & Access Methods Buffer Management Disk Space Management Recovery Manager
Lecture 1: Data Storage & Index R&G Chapter 8-11 Concurrency control Query Execution and Optimization Relational Operators File & Access Methods Buffer Management Disk Space Management Recovery Manager
All-Flash Storage Solution for SAP HANA:
 All-Flash Storage Solution for SAP HANA: Storage Considerations using SanDisk Solid State Devices WHITE PAPER 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Preface 3 Why SanDisk?
All-Flash Storage Solution for SAP HANA: Storage Considerations using SanDisk Solid State Devices WHITE PAPER 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Preface 3 Why SanDisk?
MySQL Storage Engines
 MySQL Storage Engines Data in MySQL is stored in files (or memory) using a variety of different techniques. Each of these techniques employs different storage mechanisms, indexing facilities, locking levels
MySQL Storage Engines Data in MySQL is stored in files (or memory) using a variety of different techniques. Each of these techniques employs different storage mechanisms, indexing facilities, locking levels
IOmark- VDI. HP HP ConvergedSystem 242- HC StoreVirtual Test Report: VDI- HC- 150427- b Test Report Date: 27, April 2015. www.iomark.
 IOmark- VDI HP HP ConvergedSystem 242- HC StoreVirtual Test Report: VDI- HC- 150427- b Test Copyright 2010-2014 Evaluator Group, Inc. All rights reserved. IOmark- VDI, IOmark- VM, VDI- IOmark, and IOmark
IOmark- VDI HP HP ConvergedSystem 242- HC StoreVirtual Test Report: VDI- HC- 150427- b Test Copyright 2010-2014 Evaluator Group, Inc. All rights reserved. IOmark- VDI, IOmark- VM, VDI- IOmark, and IOmark
Chapter 13 Disk Storage, Basic File Structures, and Hashing.
 Chapter 13 Disk Storage, Basic File Structures, and Hashing. Copyright 2004 Pearson Education, Inc. Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files
Chapter 13 Disk Storage, Basic File Structures, and Hashing. Copyright 2004 Pearson Education, Inc. Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files
Distributed Data Stores
 Distributed Data Stores 1 Distributed Persistent State MapReduce addresses distributed processing of aggregation-based queries Persistent state across a large number of machines? Distributed DBMS High
Distributed Data Stores 1 Distributed Persistent State MapReduce addresses distributed processing of aggregation-based queries Persistent state across a large number of machines? Distributed DBMS High
VMware Virtual SAN Backup Using VMware vsphere Data Protection Advanced SEPTEMBER 2014
 VMware SAN Backup Using VMware vsphere Data Protection Advanced SEPTEMBER 2014 VMware SAN Backup Using VMware vsphere Table of Contents Introduction.... 3 vsphere Architectural Overview... 4 SAN Backup
VMware SAN Backup Using VMware vsphere Data Protection Advanced SEPTEMBER 2014 VMware SAN Backup Using VMware vsphere Table of Contents Introduction.... 3 vsphere Architectural Overview... 4 SAN Backup
Benchmarking Couchbase Server for Interactive Applications. By Alexey Diomin and Kirill Grigorchuk
 Benchmarking Couchbase Server for Interactive Applications By Alexey Diomin and Kirill Grigorchuk Contents 1. Introduction... 3 2. A brief overview of Cassandra, MongoDB, and Couchbase... 3 3. Key criteria
Benchmarking Couchbase Server for Interactive Applications By Alexey Diomin and Kirill Grigorchuk Contents 1. Introduction... 3 2. A brief overview of Cassandra, MongoDB, and Couchbase... 3 3. Key criteria
Virtualization of the MS Exchange Server Environment
 MS Exchange Server Acceleration Maximizing Users in a Virtualized Environment with Flash-Powered Consolidation Allon Cohen, PhD OCZ Technology Group Introduction Microsoft (MS) Exchange Server is one of
MS Exchange Server Acceleration Maximizing Users in a Virtualized Environment with Flash-Powered Consolidation Allon Cohen, PhD OCZ Technology Group Introduction Microsoft (MS) Exchange Server is one of
Evaluation of NoSQL databases for large-scale decentralized microblogging
 Evaluation of NoSQL databases for large-scale decentralized microblogging Cassandra & Couchbase Alexandre Fonseca, Anh Thu Vu, Peter Grman Decentralized Systems - 2nd semester 2012/2013 Universitat Politècnica
Evaluation of NoSQL databases for large-scale decentralized microblogging Cassandra & Couchbase Alexandre Fonseca, Anh Thu Vu, Peter Grman Decentralized Systems - 2nd semester 2012/2013 Universitat Politècnica
PIONEER RESEARCH & DEVELOPMENT GROUP
 SURVEY ON RAID Aishwarya Airen 1, Aarsh Pandit 2, Anshul Sogani 3 1,2,3 A.I.T.R, Indore. Abstract RAID stands for Redundant Array of Independent Disk that is a concept which provides an efficient way for
SURVEY ON RAID Aishwarya Airen 1, Aarsh Pandit 2, Anshul Sogani 3 1,2,3 A.I.T.R, Indore. Abstract RAID stands for Redundant Array of Independent Disk that is a concept which provides an efficient way for
Microsoft Exchange Server 2003 Deployment Considerations
 Microsoft Exchange Server 3 Deployment Considerations for Small and Medium Businesses A Dell PowerEdge server can provide an effective platform for Microsoft Exchange Server 3. A team of Dell engineers
Microsoft Exchange Server 3 Deployment Considerations for Small and Medium Businesses A Dell PowerEdge server can provide an effective platform for Microsoft Exchange Server 3. A team of Dell engineers
IOmark- VDI. Nimbus Data Gemini Test Report: VDI- 130906- a Test Report Date: 6, September 2013. www.iomark.org
 IOmark- VDI Nimbus Data Gemini Test Report: VDI- 130906- a Test Copyright 2010-2013 Evaluator Group, Inc. All rights reserved. IOmark- VDI, IOmark- VDI, VDI- IOmark, and IOmark are trademarks of Evaluator
IOmark- VDI Nimbus Data Gemini Test Report: VDI- 130906- a Test Copyright 2010-2013 Evaluator Group, Inc. All rights reserved. IOmark- VDI, IOmark- VDI, VDI- IOmark, and IOmark are trademarks of Evaluator
Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand
 Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand P. Balaji, K. Vaidyanathan, S. Narravula, K. Savitha, H. W. Jin D. K. Panda Network Based
Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand P. Balaji, K. Vaidyanathan, S. Narravula, K. Savitha, H. W. Jin D. K. Panda Network Based
MS Exchange Server Acceleration
 White Paper MS Exchange Server Acceleration Using virtualization to dramatically maximize user experience for Microsoft Exchange Server Allon Cohen, PhD Scott Harlin OCZ Storage Solutions, Inc. A Toshiba
White Paper MS Exchange Server Acceleration Using virtualization to dramatically maximize user experience for Microsoft Exchange Server Allon Cohen, PhD Scott Harlin OCZ Storage Solutions, Inc. A Toshiba
Understanding Data Locality in VMware Virtual SAN
 Understanding Data Locality in VMware Virtual SAN July 2014 Edition T E C H N I C A L M A R K E T I N G D O C U M E N T A T I O N Table of Contents Introduction... 2 Virtual SAN Design Goals... 3 Data
Understanding Data Locality in VMware Virtual SAN July 2014 Edition T E C H N I C A L M A R K E T I N G D O C U M E N T A T I O N Table of Contents Introduction... 2 Virtual SAN Design Goals... 3 Data
VDI Without Compromise with SimpliVity OmniStack and Citrix XenDesktop
 VDI Without Compromise with SimpliVity OmniStack and Citrix XenDesktop Page 1 of 11 Introduction Virtual Desktop Infrastructure (VDI) provides customers with a more consistent end-user experience and excellent
VDI Without Compromise with SimpliVity OmniStack and Citrix XenDesktop Page 1 of 11 Introduction Virtual Desktop Infrastructure (VDI) provides customers with a more consistent end-user experience and excellent
How To Scale Myroster With Flash Memory From Hgst On A Flash Flash Flash Memory On A Slave Server
 White Paper October 2014 Scaling MySQL Deployments Using HGST FlashMAX PCIe SSDs An HGST and Percona Collaborative Whitepaper Table of Contents Introduction The Challenge Read Workload Scaling...1 Write
White Paper October 2014 Scaling MySQL Deployments Using HGST FlashMAX PCIe SSDs An HGST and Percona Collaborative Whitepaper Table of Contents Introduction The Challenge Read Workload Scaling...1 Write
RevoScaleR Speed and Scalability
 EXECUTIVE WHITE PAPER RevoScaleR Speed and Scalability By Lee Edlefsen Ph.D., Chief Scientist, Revolution Analytics Abstract RevoScaleR, the Big Data predictive analytics library included with Revolution
EXECUTIVE WHITE PAPER RevoScaleR Speed and Scalability By Lee Edlefsen Ph.D., Chief Scientist, Revolution Analytics Abstract RevoScaleR, the Big Data predictive analytics library included with Revolution
Storage Systems Autumn 2009. Chapter 6: Distributed Hash Tables and their Applications André Brinkmann
 Storage Systems Autumn 2009 Chapter 6: Distributed Hash Tables and their Applications André Brinkmann Scaling RAID architectures Using traditional RAID architecture does not scale Adding news disk implies
Storage Systems Autumn 2009 Chapter 6: Distributed Hash Tables and their Applications André Brinkmann Scaling RAID architectures Using traditional RAID architecture does not scale Adding news disk implies
Virtualizing SQL Server 2008 Using EMC VNX Series and Microsoft Windows Server 2008 R2 Hyper-V. Reference Architecture
 Virtualizing SQL Server 2008 Using EMC VNX Series and Microsoft Windows Server 2008 R2 Hyper-V Copyright 2011 EMC Corporation. All rights reserved. Published February, 2011 EMC believes the information
Virtualizing SQL Server 2008 Using EMC VNX Series and Microsoft Windows Server 2008 R2 Hyper-V Copyright 2011 EMC Corporation. All rights reserved. Published February, 2011 EMC believes the information
A High-Throughput In-Memory Index, Durable on Flash-based SSD
 A High-Throughput In-Memory Index, Durable on Flash-based SSD Insights into the Winning Solution of the SIGMOD Programming Contest 2011 Thomas Kissinger, Benjamin Schlegel, Matthias Boehm, Dirk Habich,
A High-Throughput In-Memory Index, Durable on Flash-based SSD Insights into the Winning Solution of the SIGMOD Programming Contest 2011 Thomas Kissinger, Benjamin Schlegel, Matthias Boehm, Dirk Habich,
High-Performance SSD-Based RAID Storage. Madhukar Gunjan Chakhaiyar Product Test Architect
 High-Performance SSD-Based RAID Storage Madhukar Gunjan Chakhaiyar Product Test Architect 1 Agenda HDD based RAID Performance-HDD based RAID Storage Dynamics driving to SSD based RAID Storage Evolution
High-Performance SSD-Based RAID Storage Madhukar Gunjan Chakhaiyar Product Test Architect 1 Agenda HDD based RAID Performance-HDD based RAID Storage Dynamics driving to SSD based RAID Storage Evolution
Amazon Cloud Storage Options
 Amazon Cloud Storage Options Table of Contents 1. Overview of AWS Storage Options 02 2. Why you should use the AWS Storage 02 3. How to get Data into the AWS.03 4. Types of AWS Storage Options.03 5. Object
Amazon Cloud Storage Options Table of Contents 1. Overview of AWS Storage Options 02 2. Why you should use the AWS Storage 02 3. How to get Data into the AWS.03 4. Types of AWS Storage Options.03 5. Object
File System Management
 Lecture 7: Storage Management File System Management Contents Non volatile memory Tape, HDD, SSD Files & File System Interface Directories & their Organization File System Implementation Disk Space Allocation
Lecture 7: Storage Management File System Management Contents Non volatile memory Tape, HDD, SSD Files & File System Interface Directories & their Organization File System Implementation Disk Space Allocation
Upgrading Small Business Client and Server Infrastructure E-LEET Solutions. E-LEET Solutions is an information technology consulting firm
 Thank you for considering E-LEET Solutions! E-LEET Solutions is an information technology consulting firm that specializes in low-cost high-performance computing solutions. This document was written as
Thank you for considering E-LEET Solutions! E-LEET Solutions is an information technology consulting firm that specializes in low-cost high-performance computing solutions. This document was written as
SQL Server Virtualization
 The Essential Guide to SQL Server Virtualization S p o n s o r e d b y Virtualization in the Enterprise Today most organizations understand the importance of implementing virtualization. Virtualization
The Essential Guide to SQL Server Virtualization S p o n s o r e d b y Virtualization in the Enterprise Today most organizations understand the importance of implementing virtualization. Virtualization
Tableau Server Scalability Explained
 Tableau Server Scalability Explained Author: Neelesh Kamkolkar Tableau Software July 2013 p2 Executive Summary In March 2013, we ran scalability tests to understand the scalability of Tableau 8.0. We wanted
Tableau Server Scalability Explained Author: Neelesh Kamkolkar Tableau Software July 2013 p2 Executive Summary In March 2013, we ran scalability tests to understand the scalability of Tableau 8.0. We wanted
Sistemas Operativos: Input/Output Disks
 Sistemas Operativos: Input/Output Disks Pedro F. Souto ([email protected]) April 28, 2012 Topics Magnetic Disks RAID Solid State Disks Topics Magnetic Disks RAID Solid State Disks Magnetic Disk Construction
Sistemas Operativos: Input/Output Disks Pedro F. Souto ([email protected]) April 28, 2012 Topics Magnetic Disks RAID Solid State Disks Topics Magnetic Disks RAID Solid State Disks Magnetic Disk Construction
Copyright 2007 Ramez Elmasri and Shamkant B. Navathe. Slide 13-1
 Slide 13-1 Chapter 13 Disk Storage, Basic File Structures, and Hashing Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files Hashed Files Dynamic and Extendible
Slide 13-1 Chapter 13 Disk Storage, Basic File Structures, and Hashing Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files Hashed Files Dynamic and Extendible
Agenda. Some Examples from Yahoo! Hadoop. Some Examples from Yahoo! Crawling. Cloud (data) management Ahmed Ali-Eldin. First part: Second part:
 management Ahmed Ali-Eldin. First part: Second part:") Cloud (data) management Ahmed Ali-Eldin First part: ZooKeeper (Yahoo!) Agenda A highly available, scalable, distributed, configuration, consensus, group membership, leader election, naming, and coordination
Cloud (data) management Ahmed Ali-Eldin First part: ZooKeeper (Yahoo!) Agenda A highly available, scalable, distributed, configuration, consensus, group membership, leader election, naming, and coordination
Using Synology SSD Technology to Enhance System Performance. Based on DSM 5.2
 Using Synology SSD Technology to Enhance System Performance Based on DSM 5.2 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD Cache as Solution...
Using Synology SSD Technology to Enhance System Performance Based on DSM 5.2 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD Cache as Solution...
Chapter 18: Database System Architectures. Centralized Systems
 Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
The Hadoop Distributed File System
 The Hadoop Distributed File System The Hadoop Distributed File System, Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, Yahoo, 2010 Agenda Topic 1: Introduction Topic 2: Architecture
The Hadoop Distributed File System The Hadoop Distributed File System, Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, Yahoo, 2010 Agenda Topic 1: Introduction Topic 2: Architecture
Microsoft SQL Server 2000 Index Defragmentation Best Practices
 Microsoft SQL Server 2000 Index Defragmentation Best Practices Author: Mike Ruthruff Microsoft Corporation February 2003 Summary: As Microsoft SQL Server 2000 maintains indexes to reflect updates to their
Microsoft SQL Server 2000 Index Defragmentation Best Practices Author: Mike Ruthruff Microsoft Corporation February 2003 Summary: As Microsoft SQL Server 2000 maintains indexes to reflect updates to their
Chapter 13. Chapter Outline. Disk Storage, Basic File Structures, and Hashing
 Chapter 13 Disk Storage, Basic File Structures, and Hashing Copyright 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files
Chapter 13 Disk Storage, Basic File Structures, and Hashing Copyright 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files
Flash Memory Arrays Enabling the Virtualized Data Center. July 2010
 Flash Memory Arrays Enabling the Virtualized Data Center July 2010 2 Flash Memory Arrays Enabling the Virtualized Data Center This White Paper describes a new product category, the flash Memory Array,
Flash Memory Arrays Enabling the Virtualized Data Center July 2010 2 Flash Memory Arrays Enabling the Virtualized Data Center This White Paper describes a new product category, the flash Memory Array,
In-Memory Databases MemSQL
 IT4BI - Université Libre de Bruxelles In-Memory Databases MemSQL Gabby Nikolova Thao Ha Contents I. In-memory Databases...4 1. Concept:...4 2. Indexing:...4 a. b. c. d. AVL Tree:...4 B-Tree and B+ Tree:...5
IT4BI - Université Libre de Bruxelles In-Memory Databases MemSQL Gabby Nikolova Thao Ha Contents I. In-memory Databases...4 1. Concept:...4 2. Indexing:...4 a. b. c. d. AVL Tree:...4 B-Tree and B+ Tree:...5
SMALL INDEX LARGE INDEX (SILT)
") Wayne State University ECE 7650: Scalable and Secure Internet Services and Architecture SMALL INDEX LARGE INDEX (SILT) A Memory Efficient High Performance Key Value Store QA REPORT Instructor: Dr. Song
Wayne State University ECE 7650: Scalable and Secure Internet Services and Architecture SMALL INDEX LARGE INDEX (SILT) A Memory Efficient High Performance Key Value Store QA REPORT Instructor: Dr. Song
Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage
 White Paper Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage A Benchmark Report August 211 Background Objectivity/DB uses a powerful distributed processing architecture to manage
White Paper Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage A Benchmark Report August 211 Background Objectivity/DB uses a powerful distributed processing architecture to manage
SSDs: Practical Ways to Accelerate Virtual Servers
 SSDs: Practical Ways to Accelerate Virtual Servers Session B-101, Increasing Storage Performance Andy Mills CEO Enmotus Santa Clara, CA November 2012 1 Summary Market and Technology Trends Virtual Servers
SSDs: Practical Ways to Accelerate Virtual Servers Session B-101, Increasing Storage Performance Andy Mills CEO Enmotus Santa Clara, CA November 2012 1 Summary Market and Technology Trends Virtual Servers
6. Storage and File Structures
 ECS-165A WQ 11 110 6. Storage and File Structures Goals Understand the basic concepts underlying different storage media, buffer management, files structures, and organization of records in files. Contents
ECS-165A WQ 11 110 6. Storage and File Structures Goals Understand the basic concepts underlying different storage media, buffer management, files structures, and organization of records in files. Contents
Chapter 13. Disk Storage, Basic File Structures, and Hashing
 Chapter 13 Disk Storage, Basic File Structures, and Hashing Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files Hashed Files Dynamic and Extendible Hashing
Chapter 13 Disk Storage, Basic File Structures, and Hashing Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files Ordered Files Hashed Files Dynamic and Extendible Hashing
Understanding Disk Storage in Tivoli Storage Manager
 Understanding Disk Storage in Tivoli Storage Manager Dave Cannon Tivoli Storage Manager Architect Oxford University TSM Symposium September 2005 Disclaimer Unless otherwise noted, functions and behavior
Understanding Disk Storage in Tivoli Storage Manager Dave Cannon Tivoli Storage Manager Architect Oxford University TSM Symposium September 2005 Disclaimer Unless otherwise noted, functions and behavior
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications. Jürgen Primsch, SAP AG July 2011
 SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
Centralized Systems. A Centralized Computer System. Chapter 18: Database System Architectures
 Chapter 18: Database System Architectures Centralized Systems! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types! Run on a single computer system and do
Chapter 18: Database System Architectures Centralized Systems! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types! Run on a single computer system and do
SSDs: Practical Ways to Accelerate Virtual Servers
 SSDs: Practical Ways to Accelerate Virtual Servers Session B-101, Increasing Storage Performance Andy Mills CEO Enmotus Santa Clara, CA November 2012 1 Summary Market and Technology Trends Virtual Servers
SSDs: Practical Ways to Accelerate Virtual Servers Session B-101, Increasing Storage Performance Andy Mills CEO Enmotus Santa Clara, CA November 2012 1 Summary Market and Technology Trends Virtual Servers
Scaling Database Performance in Azure
 Scaling Database Performance in Azure Results of Microsoft-funded Testing Q1 2015 2015 2014 ScaleArc. All Rights Reserved. 1 Test Goals and Background Info Test Goals and Setup Test goals Microsoft commissioned
Scaling Database Performance in Azure Results of Microsoft-funded Testing Q1 2015 2015 2014 ScaleArc. All Rights Reserved. 1 Test Goals and Background Info Test Goals and Setup Test goals Microsoft commissioned
Hardware/Software Guidelines
 There are many things to consider when preparing for a TRAVERSE v11 installation. The number of users, application modules and transactional volume are only a few. Reliable performance of the system is
There are many things to consider when preparing for a TRAVERSE v11 installation. The number of users, application modules and transactional volume are only a few. Reliable performance of the system is
SALSA Flash-Optimized Software-Defined Storage
 Flash-Optimized Software-Defined Storage Nikolas Ioannou, Ioannis Koltsidas, Roman Pletka, Sasa Tomic,Thomas Weigold IBM Research Zurich 1 New Market Category of Big Data Flash Multiple workloads don t
Flash-Optimized Software-Defined Storage Nikolas Ioannou, Ioannis Koltsidas, Roman Pletka, Sasa Tomic,Thomas Weigold IBM Research Zurich 1 New Market Category of Big Data Flash Multiple workloads don t
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction