How MapReduce Works 資碩一 戴睿宸
|
|
|
- Alan Cole
- 10 years ago
- Views:
Transcription
1 How MapReduce Works

2 MapReduce Entities four independent entities: The client The jobtracker The tasktrackers The distributed filesystem

3
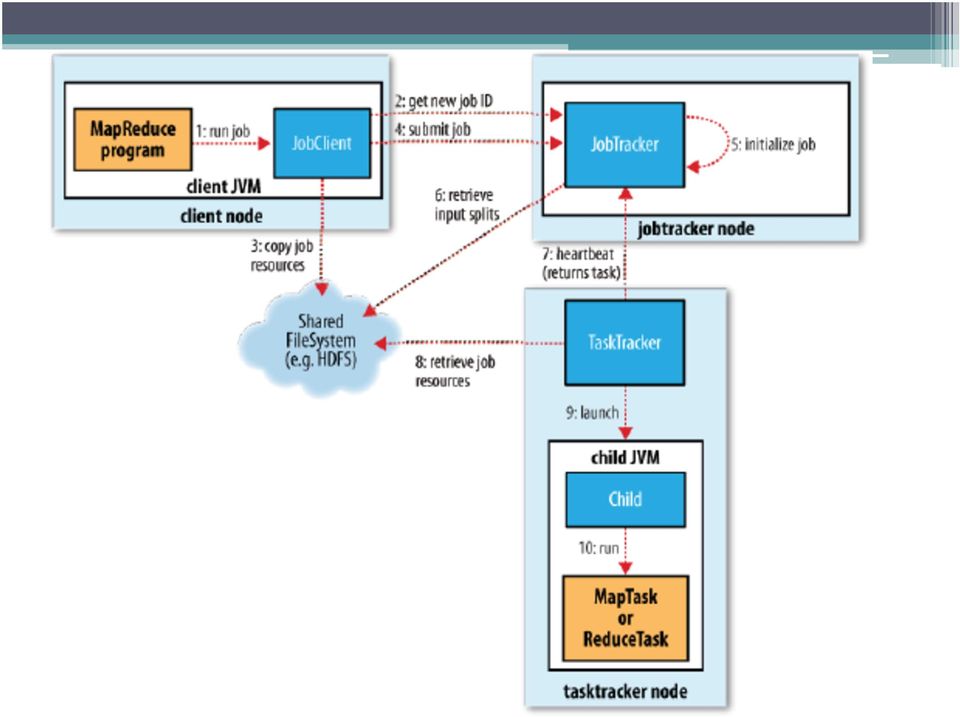
4 Steps 1. Asks the jobtracker for a new job ID 2. Checks the output specification of the job 3. Computes the input splits for the job 4. Copies the resources needed to run the job 5. Tells the jobtracker that the job is ready for execution

5 Job Submission polls the job s progress once a second reports the progress to the console if it has changed since the last report When the job is complete, if it was successful, the job counters are displayed.

6 Job Initialization job scheduler first retrieves the input splits computed by the JobClient from the shared filesystem It then creates one map task for each split. The number of reduce tasks is determined by the property Tasks are given IDs at this point

7 Task Assignment Tasktrackers run a simple loop that periodically sends heartbeat method calls to the jobtracker. As a part of the heartbeat, a tasktracker will indicate whether it is ready to run a new task, and if it is, the jobtracker will allocate it a task

8 Task Assignment In the optimal case, the task is data-local Alternatively, the task may be rack-local tasks are neither data-local nor rack-local and retrieve their data from a different rack from the one they are running on

9 Task Execution First, it localizes the job JAR by copying it from the shared filesystem Second, it creates a local working directory Third, it creates an instance of TaskRunner to run the task.rectory for the task TaskRunner launches a new Java Virtual Machine to run each task in

10 Task Execution progress When a task is running, it keeps track of its progress, that is, the proportion of the task completed. For map tasks, this is the proportion of the input that has been processed. For reduce tasks, it s the estimated proportion

11 Task Execution If a task reports progress, it sets a flag to indicate that the status change should be sent to the tasktracker. Meanwhile, the tasktracker is sending heartbeats to the jobtracker every five seconds

12 Job Completion jobtracker receives a notification that the last task for a job is complete, it changes the status for the job to successful. JobClient polls for status, it learns that the job has completed successfully, so it prints a message to tell the user, and then returns from the runjob() method.

13

14 Task Failure Wihle the child JVM reports the error back to its parent tasktracker, The tasktracker marks the task attempt as failed, freeing up a slot to run another task. The tasktracker notices that it hasn t received a progress update for a while, and proceeds to mark the task as failed. (normally 10 min)

15 Task Failure When the jobtracker is notified of a task attempt that has failed, it will reschedule execution of the task The jobtracker will try to avoid rescheduling the task on a tasktracker where it has previously failed By default, if any task fails more than four times, the whole job fails (editable)

16 Tasktracker Failure If a tasktracker fails by crashing, or running very slowly, it will stop sending heartbeats to the jobtracker The jobtracker arranges for map tasks that were run and completed successfully on that tasktracker to be rerun if they belong to incomplete jobs and reschedule.

17 Jobtracker Failure Hadoop has no mechanism for dealing with failure of the jobtracker It is possible that a future releaseof Hadoop will remove this limitation by running multiple jobtrackers, only one of which is the primary jobtracker at any time

18 Job Scheduling Basically FIFO setting a job s priority was enabled, which take one of the values VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW priorities do not support preemption

19 The Fair Scheduler For Multiuser The Fair Scheduler aims to give every user a fair share of the cluster capacity over time. If a single job is running, it gets all of the cluster It is also possible to define custom pools with guaranteed minimum capacities and to set weighting for each pool The Fair Scheduler supports preemption

20 Shuffle and Sort MapReduce makes the guarantee that the input to every reducer is sorted by key. Theprocess by which the system performs the sort and transfers the map outputs to thereducers as inputs is known as the shuffle.

21 The Map Side
22 The Map Side Spills are written in round-robin fashion to the directories specified by the mapred.local.dir property, in a job-specific subdirectory Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to. The background thread performs an in-memory sort by key
23 The Map Side The spill files are merged into a single partitioned and sorted output file It is often a good idea to compress the map output as it is written to disk
24 The Reduce Side
25 The Reduce Side The map outputs are copied to the reduce tasktracker s memory if they are small enough ;otherwise, they are copied to disk. When all the map outputs have been copied, the reduce task moves into the sort phase (merge phase) The merge saves a trip to disk by directly feeding the reduce function in what is the last phase: the reduce phase. This final merge can come from a mixture of in-memory and on-disk segments.
26
Istanbul Şehir University Big Data Camp 14. Hadoop Map Reduce. Aslan Bakirov Kevser Nur Çoğalmış
 Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
6. How MapReduce Works. Jari-Pekka Voutilainen
 6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
Hadoop. History and Introduction. Explained By Vaibhav Agarwal
 Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
Data-intensive computing systems
 Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
CS 378 Big Data Programming. Lecture 5 Summariza9on Pa:erns
 CS 378 Big Data Programming Lecture 5 Summariza9on Pa:erns Review Assignment 2 Ques9ons? If you d like to use guava (Google collec9ons classes) pom.xml available for assignment 2 Includes dependency for
CS 378 Big Data Programming Lecture 5 Summariza9on Pa:erns Review Assignment 2 Ques9ons? If you d like to use guava (Google collec9ons classes) pom.xml available for assignment 2 Includes dependency for
Working With Hadoop. Important Terminology. Important Terminology. Anatomy of MapReduce Job Run. Important Terminology
 Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
Working With Hadoop Now that we covered the basics of MapReduce, let s look at some Hadoop specifics. Mostly based on Tom White s book Hadoop: The Definitive Guide, 3 rd edition Note: We will use the new
HADOOP PERFORMANCE TUNING
 PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
Hadoop Fair Scheduler Design Document
 Hadoop Fair Scheduler Design Document October 18, 2010 Contents 1 Introduction 2 2 Fair Scheduler Goals 2 3 Scheduler Features 2 3.1 Pools........................................ 2 3.2 Minimum Shares.................................
Hadoop Fair Scheduler Design Document October 18, 2010 Contents 1 Introduction 2 2 Fair Scheduler Goals 2 3 Scheduler Features 2 3.1 Pools........................................ 2 3.2 Minimum Shares.................................
Lecture 3 Hadoop Technical Introduction CSE 490H
 Lecture 3 Hadoop Technical Introduction CSE 490H Announcements My office hours: M 2:30 3:30 in CSE 212 Cluster is operational; instructions in assignment 1 heavily rewritten Eclipse plugin is deprecated
Lecture 3 Hadoop Technical Introduction CSE 490H Announcements My office hours: M 2:30 3:30 in CSE 212 Cluster is operational; instructions in assignment 1 heavily rewritten Eclipse plugin is deprecated
MapReduce on YARN Job Execution
 2012 coreservlets.com and Dima May MapReduce on YARN Job Execution Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training
2012 coreservlets.com and Dima May MapReduce on YARN Job Execution Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop training
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Fair Scheduler. Table of contents
 Table of contents 1 Purpose... 2 2 Introduction... 2 3 Installation... 3 4 Configuration...3 4.1 Scheduler Parameters in mapred-site.xml...4 4.2 Allocation File (fair-scheduler.xml)... 6 4.3 Access Control
Table of contents 1 Purpose... 2 2 Introduction... 2 3 Installation... 3 4 Configuration...3 4.1 Scheduler Parameters in mapred-site.xml...4 4.2 Allocation File (fair-scheduler.xml)... 6 4.3 Access Control
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Apache Hama Design Document v0.6
 Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Keywords: Big Data, HDFS, Map Reduce, Hadoop
 Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
Cloud Computing. Lectures 10 and 11 Map Reduce: System Perspective 2014-2015
 Cloud Computing Lectures 10 and 11 Map Reduce: System Perspective 2014-2015 1 MapReduce in More Detail 2 Master (i) Execution is controlled by the master process: Input data are split into 64MB blocks.
Cloud Computing Lectures 10 and 11 Map Reduce: System Perspective 2014-2015 1 MapReduce in More Detail 2 Master (i) Execution is controlled by the master process: Input data are split into 64MB blocks.
Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay
 Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay Dipojjwal Ray Sandeep Prasad 1 Introduction In installation manual we listed out the steps for hadoop-1.0.3 and hadoop-
Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay Dipojjwal Ray Sandeep Prasad 1 Introduction In installation manual we listed out the steps for hadoop-1.0.3 and hadoop-
THE ANATOMY OF MAPREDUCE JOBS, SCHEDULING, AND PERFORMANCE CHALLENGES
 THE ANATOMY OF MAPREDUCE JOBS, SCHEDULING, AND PERFORMANCE CHALLENGES SHOUVIK BARDHAN DANIEL A. MENASCÉ DEPT. OF COMPUTER SCIENCE, MS 4A5 VOLGENAU SCHOOL OF ENGINEERING GEORGE MASON UNIVERSITY FAIRFAX,
THE ANATOMY OF MAPREDUCE JOBS, SCHEDULING, AND PERFORMANCE CHALLENGES SHOUVIK BARDHAN DANIEL A. MENASCÉ DEPT. OF COMPUTER SCIENCE, MS 4A5 VOLGENAU SCHOOL OF ENGINEERING GEORGE MASON UNIVERSITY FAIRFAX,
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Capacity Scheduler Guide
 Table of contents 1 Purpose...2 2 Features... 2 3 Picking a task to run...2 4 Installation...3 5 Configuration... 3 5.1 Using the Capacity Scheduler... 3 5.2 Setting up queues...3 5.3 Configuring properties
Table of contents 1 Purpose...2 2 Features... 2 3 Picking a task to run...2 4 Installation...3 5 Configuration... 3 5.1 Using the Capacity Scheduler... 3 5.2 Setting up queues...3 5.3 Configuring properties
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
University of Maryland. Tuesday, February 2, 2010
 Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013
 Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
Tutorial: MapReduce. Theory and Practice of Data-intensive Applications. Pietro Michiardi. Eurecom
 Tutorial: MapReduce Theory and Practice of Data-intensive Applications Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Tutorial: MapReduce 1 / 132 Introduction Introduction Pietro Michiardi (Eurecom)
Tutorial: MapReduce Theory and Practice of Data-intensive Applications Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Tutorial: MapReduce 1 / 132 Introduction Introduction Pietro Michiardi (Eurecom)
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Hadoop Scheduler w i t h Deadline Constraint
 Hadoop Scheduler w i t h Deadline Constraint Geetha J 1, N UdayBhaskar 2, P ChennaReddy 3,Neha Sniha 4 1,4 Department of Computer Science and Engineering, M S Ramaiah Institute of Technology, Bangalore,
Hadoop Scheduler w i t h Deadline Constraint Geetha J 1, N UdayBhaskar 2, P ChennaReddy 3,Neha Sniha 4 1,4 Department of Computer Science and Engineering, M S Ramaiah Institute of Technology, Bangalore,
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS
 A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Research on Job Scheduling Algorithm in Hadoop
 Journal of Computational Information Systems 7: 6 () 5769-5775 Available at http://www.jofcis.com Research on Job Scheduling Algorithm in Hadoop Yang XIA, Lei WANG, Qiang ZHAO, Gongxuan ZHANG School of
Journal of Computational Information Systems 7: 6 () 5769-5775 Available at http://www.jofcis.com Research on Job Scheduling Algorithm in Hadoop Yang XIA, Lei WANG, Qiang ZHAO, Gongxuan ZHANG School of
Big Data. Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich
 Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich First, an Announcement There will be a repetition exercise group on Wednesday this week. TAs will answer your questions on SQL, relational
Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich First, an Announcement There will be a repetition exercise group on Wednesday this week. TAs will answer your questions on SQL, relational
Survey on Scheduling Algorithm in MapReduce Framework
 Survey on Scheduling Algorithm in MapReduce Framework Pravin P. Nimbalkar 1, Devendra P.Gadekar 2 1,2 Department of Computer Engineering, JSPM s Imperial College of Engineering and Research, Pune, India
Survey on Scheduling Algorithm in MapReduce Framework Pravin P. Nimbalkar 1, Devendra P.Gadekar 2 1,2 Department of Computer Engineering, JSPM s Imperial College of Engineering and Research, Pune, India
The Improved Job Scheduling Algorithm of Hadoop Platform
 The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: [email protected]
The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: [email protected]
MapReduce Online. Tyson Condie, Neil Conway, Peter Alvaro, Joseph Hellerstein, Khaled Elmeleegy, Russell Sears. Neeraj Ganapathy
 MapReduce Online Tyson Condie, Neil Conway, Peter Alvaro, Joseph Hellerstein, Khaled Elmeleegy, Russell Sears Neeraj Ganapathy Outline Hadoop Architecture Pipelined MapReduce Online Aggregation Continuous
MapReduce Online Tyson Condie, Neil Conway, Peter Alvaro, Joseph Hellerstein, Khaled Elmeleegy, Russell Sears Neeraj Ganapathy Outline Hadoop Architecture Pipelined MapReduce Online Aggregation Continuous
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Big Data Storage Options for Hadoop Sam Fineberg, HP Storage
 Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
A Comparative Analysis of Join Algorithms Using the Hadoop Map/Reduce Framework
 A Comparative Analysis of Join Algorithms Using the Hadoop Map/Reduce Framework Konstantina Palla E H U N I V E R S I T Y T O H F G R E D I N B U Master of Science School of Informatics University of Edinburgh
A Comparative Analysis of Join Algorithms Using the Hadoop Map/Reduce Framework Konstantina Palla E H U N I V E R S I T Y T O H F G R E D I N B U Master of Science School of Informatics University of Edinburgh
Parameterizable benchmarking framework for designing a MapReduce performance model
 CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. (2014) Published online in Wiley Online Library (wileyonlinelibrary.com)..3229 SPECIAL ISSUE PAPER Parameterizable
CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. (2014) Published online in Wiley Online Library (wileyonlinelibrary.com)..3229 SPECIAL ISSUE PAPER Parameterizable
H2O on Hadoop. September 30, 2014. www.0xdata.com
 H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
USING HADOOP TO ACCELERATE THE ANALYSIS OF SEMICONDUCTOR-MANUFACTURING MONITORING DATA
 USING HADOOP TO ACCELERATE THE ANALYSIS OF SEMICONDUCTOR-MANUFACTURING MONITORING DATA By WENJIE ZHANG A THESIS PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE
USING HADOOP TO ACCELERATE THE ANALYSIS OF SEMICONDUCTOR-MANUFACTURING MONITORING DATA By WENJIE ZHANG A THESIS PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE
7 Deadly Hadoop Misconfigurations. Kathleen Ting February 2013
 7 Deadly Hadoop Misconfigurations Kathleen Ting February 2013 Who Am I? Kathleen Ting Apache Sqoop Committer, PMC Member Customer Operations Engineering Mgr, Cloudera @kate_ting, [email protected] 2
7 Deadly Hadoop Misconfigurations Kathleen Ting February 2013 Who Am I? Kathleen Ting Apache Sqoop Committer, PMC Member Customer Operations Engineering Mgr, Cloudera @kate_ting, [email protected] 2
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Analysis of Information Management and Scheduling Technology in Hadoop
 Analysis of Information Management and Scheduling Technology in Hadoop Ma Weihua, Zhang Hong, Li Qianmu, Xia Bin School of Computer Science and Technology Nanjing University of Science and Engineering
Analysis of Information Management and Scheduling Technology in Hadoop Ma Weihua, Zhang Hong, Li Qianmu, Xia Bin School of Computer Science and Technology Nanjing University of Science and Engineering
How to properly misuse Hadoop. Marcel Huntemann NERSC tutorial session 2/12/13
 How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
Record Setting Hadoop in the Cloud By M.C. Srivas, CTO, MapR Technologies
 Record Setting Hadoop in the Cloud By M.C. Srivas, CTO, MapR Technologies When MapR was invited to provide Hadoop on Google Compute Engine, we ran a lot of mini tests on the virtualized hardware to figure
Record Setting Hadoop in the Cloud By M.C. Srivas, CTO, MapR Technologies When MapR was invited to provide Hadoop on Google Compute Engine, we ran a lot of mini tests on the virtualized hardware to figure
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012
 Author: Motti Beck, Mellanox Technologies Date: March 27, 2012") Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012 1 Market Trends Big Data Growing technology deployments are creating an exponential increase in the volume
Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012 1 Market Trends Big Data Growing technology deployments are creating an exponential increase in the volume
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Architecture of Next Generation Apache Hadoop MapReduce Framework
 Architecture of Next Generation Apache Hadoop MapReduce Framework Authors: Arun C. Murthy, Chris Douglas, Mahadev Konar, Owen O Malley, Sanjay Radia, Sharad Agarwal, Vinod K V BACKGROUND The Apache Hadoop
Architecture of Next Generation Apache Hadoop MapReduce Framework Authors: Arun C. Murthy, Chris Douglas, Mahadev Konar, Owen O Malley, Sanjay Radia, Sharad Agarwal, Vinod K V BACKGROUND The Apache Hadoop
MapReduce, Hadoop and Amazon AWS
 MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
PaRFR : Parallel Random Forest Regression on Hadoop for Multivariate Quantitative Trait Loci Mapping. Version 1.0, Oct 2012
 PaRFR : Parallel Random Forest Regression on Hadoop for Multivariate Quantitative Trait Loci Mapping Version 1.0, Oct 2012 This document describes PaRFR, a Java package that implements a parallel random
PaRFR : Parallel Random Forest Regression on Hadoop for Multivariate Quantitative Trait Loci Mapping Version 1.0, Oct 2012 This document describes PaRFR, a Java package that implements a parallel random
CapacityScheduler Guide
 Table of contents 1 Purpose... 2 2 Overview... 2 3 Features...2 4 Installation... 3 5 Configuration...4 5.1 Using the CapacityScheduler...4 5.2 Setting up queues...4 5.3 Queue properties... 4 5.4 Resource
Table of contents 1 Purpose... 2 2 Overview... 2 3 Features...2 4 Installation... 3 5 Configuration...4 5.1 Using the CapacityScheduler...4 5.2 Setting up queues...4 5.3 Queue properties... 4 5.4 Resource
An improved task assignment scheme for Hadoop running in the clouds
 Dai and Bassiouni Journal of Cloud Computing: Advances, Systems and Applications 2013, 2:23 RESEARCH An improved task assignment scheme for Hadoop running in the clouds Wei Dai * and Mostafa Bassiouni
Dai and Bassiouni Journal of Cloud Computing: Advances, Systems and Applications 2013, 2:23 RESEARCH An improved task assignment scheme for Hadoop running in the clouds Wei Dai * and Mostafa Bassiouni
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
FP-Hadoop: Efficient Execution of Parallel Jobs Over Skewed Data
 FP-Hadoop: Efficient Execution of Parallel Jobs Over Skewed Data Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez To cite this version: Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez. FP-Hadoop:
FP-Hadoop: Efficient Execution of Parallel Jobs Over Skewed Data Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez To cite this version: Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez. FP-Hadoop:
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
Hands-on Exercises with Big Data
 Hands-on Exercises with Big Data Lab Sheet 1: Getting Started with MapReduce and Hadoop The aim of this exercise is to learn how to begin creating MapReduce programs using the Hadoop Java framework. In
Hands-on Exercises with Big Data Lab Sheet 1: Getting Started with MapReduce and Hadoop The aim of this exercise is to learn how to begin creating MapReduce programs using the Hadoop Java framework. In
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
GraySort on Apache Spark by Databricks
 GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
Hadoop Optimizations for BigData Analytics
 Hadoop Optimizations for BigData Analytics Weikuan Yu Auburn University Outline WBDB, Oct 2012 S-2 Background Network Levitated Merge JVM-Bypass Shuffling Fast Completion Scheduler WBDB, Oct 2012 S-3 Emerging
Hadoop Optimizations for BigData Analytics Weikuan Yu Auburn University Outline WBDB, Oct 2012 S-2 Background Network Levitated Merge JVM-Bypass Shuffling Fast Completion Scheduler WBDB, Oct 2012 S-3 Emerging
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
This exam contains 13 pages (including this cover page) and 18 questions. Check to see if any pages are missing.
 and 18 questions. Check to see if any pages are missing.") Big Data Processing 2013-2014 Q2 April 7, 2014 (Resit) Lecturer: Claudia Hauff Time Limit: 180 Minutes Name: Answer the questions in the spaces provided on this exam. If you run out of room for an answer,
Big Data Processing 2013-2014 Q2 April 7, 2014 (Resit) Lecturer: Claudia Hauff Time Limit: 180 Minutes Name: Answer the questions in the spaces provided on this exam. If you run out of room for an answer,
MapReduce. Tushar B. Kute, http://tusharkute.com
 MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网. Information Management. Information Management IBM CDL Lab
 IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200
 CCD-410, CCA-410 and CCB-400 and DS-200") Hadoop Learning Resources 1 Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200 Author: Hadoop Learning Resource Hadoop Training in Just $60/3000INR
Hadoop Learning Resources 1 Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200 Author: Hadoop Learning Resource Hadoop Training in Just $60/3000INR
Performance Comparison of Intel Enterprise Edition for Lustre* software and HDFS for MapReduce Applications
 Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Introduction to Apache YARN Schedulers & Queues
 Introduction to Apache YARN Schedulers & Queues In a nutshell, YARN was designed to address the many limitations (performance/scalability) embedded into Hadoop version 1 (MapReduce & HDFS). Some of the
Introduction to Apache YARN Schedulers & Queues In a nutshell, YARN was designed to address the many limitations (performance/scalability) embedded into Hadoop version 1 (MapReduce & HDFS). Some of the
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE
 IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Survey on Job Schedulers in Hadoop Cluster
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 1 (Sep. - Oct. 2013), PP 46-50 Bincy P Andrews 1, Binu A 2 1 (Rajagiri School of Engineering and Technology,
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 1 (Sep. - Oct. 2013), PP 46-50 Bincy P Andrews 1, Binu A 2 1 (Rajagiri School of Engineering and Technology,
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters