MapReduce, Hadoop and Amazon AWS
|
|
|
- Brandon Park
- 8 years ago
- Views:
Transcription
1 MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar February 2011

2 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables applications to work with thousands of nodes and petabytes of data. Hadoop was inspired by Google's MapReduce and Google File System (GFS). Hadoop is a top-level Apache project being built and used by a global community of contributors, using the Java programming language. Yahoo! has been the largest contributor to the project, and uses Hadoop extensively across its businesses.



3 Who uses Hadoop?

4 Who uses Hadoop? Yahoo! More than 100,000 CPUs in >36,000 computers. Facebook Used in reporting/analytics and machine learning and also as storage engine for logs. A 1100-machine cluster with 8800 cores and about 12 PB raw storage. A 300-machine cluster with 2400 cores and about 3 PB raw storage. Each (commodity) node has 8 cores and 12 TB of storage.

5 Very Large Storage Requirements Facebook has Hadoop clusters with 15 PB of raw storage (15,000,000 GB). No single storage can handle this amount of data. We need a large set of nodes each storing part of the data.

6 HDFS: Hadoop Distributed File System 1. filename, index Namenode Client 2. Datanodes, Blockid 3. Read data Data Nodes

7 Terabyte Sort Benchmark Task: Sorting 100TB of data and writing results on disk (10^12 records each 100 bytes). Yahoo s Hadoop Cluster is the current winner: 173 minutes 3452 nodes x (2 Quadcore Xeons, 8 GB RAM) This is the first time that a Java program has won this competition.

8 Counting Words by MapReduce Hello World Bye World Hello Hadoop Goodbye Hadoop Split Hello World Bye World Hello Hadoop Goodbye Hadoop


9 Counting Words by MapReduce Hello World Bye World Mapper Hello, <1> World, <1> Bye, <1> World, <1> Sort & Merge Bye, <1> Hello, <1> World, <1, 1> Combiner Bye, <1> Hello, <1> World, <2> Node 1

10 Counting Words by MapReduce Bye, <1> Hello, <1> World, <2> Goodbye, <1> Hadoop, <2> Hello, <1> Sort & Merge Bye, <1> Goodbye, <1> Hadoop, <2> Hello, <1, 1> World, <2> Split Bye, <1> Goodbye, <1> Hadoop, <2> Hello, <1, 1> World, <2>

11 Counting Words by MapReduce Node 1 Bye, <1> Goodbye, <1> Hadoop, <2> Reducer Bye, <1> Goodbye, <1> Hadoop, <2> part Bye 1 Goodbye 1 Hadoop 2 Node 2 Write on Disk part Hello, <1, 1> World, <2> Reducer Hello, <2> World, <2> Hello 2 World 2

12 Writing Word Count in Java Download hadoop core (version ): It would be something like: hadoop tar.gz Unzip the package and extract: hadoop core.jar Add this jar file to your project class path Warning! Most of the sample codes on web are for older versions of Hadoop.

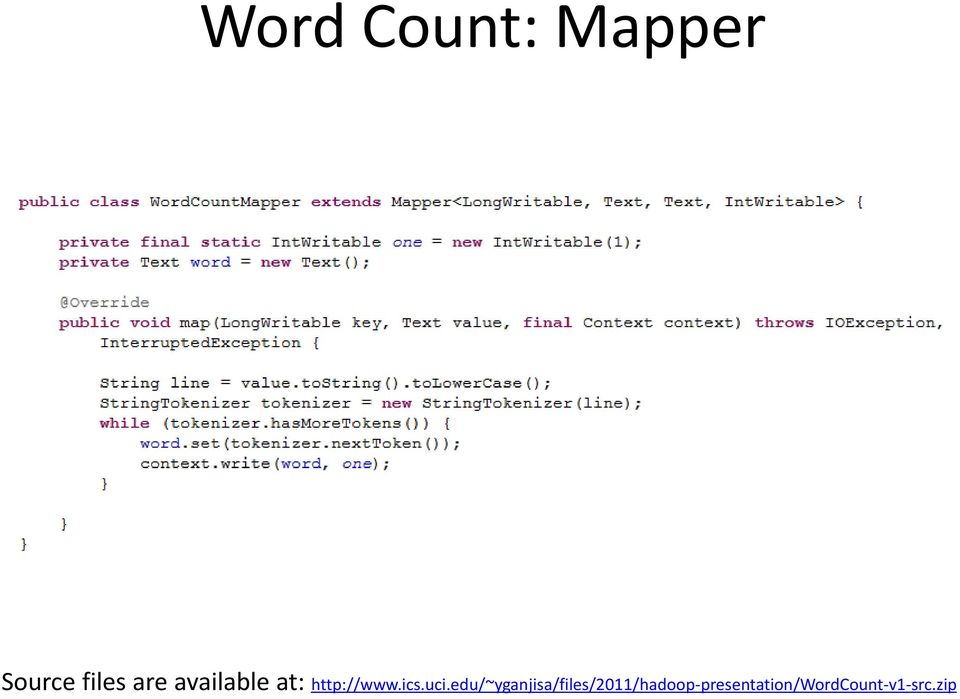
13 Word Count: Mapper Source files are available at:
14 Word Count: Reducer

15 Word Count: Main Class

16 My Small Test Cluster 3 nodes 1 master (ip address: ) 2 slaves Copy your jar file to master node: Linux: scp WordCount.jar john@ :wordcount.jar Windows (you need to download pscp.exe): pscp.exe WordCount.jar john@ :wordcount.jar Login to master node: ssh john@
: pscp.exe WordCount.jar john@50.17.65.29:wordcount.")
17 Counting words in U.S. Constitution! Download text version: wget Put input text file on HDFS: hadoop dfs -put const.txt const.txt Run the job: hadoop jar WordCount.jar edu.uci.hadoop.wordcount const.txt word-count-result

18 Counting words in U.S. Constitution! List my files on HDFS: Hadoop dfs -ls List files in word-count-result folder: Hadoop dfs -ls word-count-result/


19 Counting words in U.S. Constitution! Downloading results from HDFS: hadoop dfs -cat word-count-result/part-r > word-count.txt Sort and view results: sort -k2 -n -r word-count.txt more

20 Hadoop Map/Reduce - Terminology Running Word Count across 20 files is one job Job Tracker initiates some number of map tasks and some number of reduce tasks. For each map task at least one task attempt will be performed more if a task fails (e.g., machine crashes).

21 High Level Architecture of MapReduce Master Node Client Computer JobTracker TaskTracker TaskTracker TaskTracker Task Task Task Task Task Slave Node Slave Node Slave Node
22 High Level Architecture of Hadoop Master Node Slave Node Slave Node TaskTracker TaskTracker TaskTracker MapReduce layer JobTracker HDFS layer NameNode DataNode DataNode DataNode
23 Web based User interfaces JobTracker: NameNode:
24 Hadoop Job Scheduling FIFO queue matches incoming jobs to available nodes No notion of fairness Never switches out running job Warning! Start your job as soon as possible.
25 Reporting Progress If your tasks don t report anything in 10 minutes they would be killed by Hadoop! Source files are available at:
26 Distributed File Cache The Distributed Cache facility allows you to transfer files from the distributed file system to the local file system (for reading only) of all participating nodes before the beginning of a job.

27 TextInputFormat LineRecordReader <offset 1, line 1 > <offset 2, line 2 > <offset 3, line 3 > Split For more complex inputs, You should extend: InputSplit RecordReader InputFormat

28 Part 2: Amazon Web Services (AWS)
29 What is AWS? A collection of services that together make up a cloud computing platform: S3 (Simple Storage Service) EC2 (Elastic Compute Cloud) Elastic MapReduce Service SimpleDB Flexibile Payments Service

30 Case Study: yelp Yelp uses Amazon S3 to store daily logs and photos, generating around 100GB of logs per day. Features powered by Amazon Elastic MapReduce include: People Who Viewed this Also Viewed Review highlights Auto complete as you type on search Search spelling suggestions Top searches Ads Yelp runs approximately 200 Elastic MapReduce jobs per day, processing 3TB of data.
31 Amazon S3 Data Storage in Amazon Data Center Web Service interface 99.99% monthly uptime guarantee Storage cost: $0.15 per GB/Month S3 is reported to store more than 102 billion objects as of March 2010.
32 Amazon S3 You can think of S3 as a big HashMap where you store your files with a unique key: HashMap: key -> File
33 References Hadoop Project Page: Amazon Web Services:
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
MapReduce Job Processing
 April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Hadoop. History and Introduction. Explained By Vaibhav Agarwal
 Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Open Cloud System. (Integration of Eucalyptus, Hadoop and AppScale into deployment of University Private Cloud)
") Open Cloud System (Integration of Eucalyptus, Hadoop and into deployment of University Private Cloud) Thinn Thu Naing University of Computer Studies, Yangon 25 th October 2011 Open Cloud System University
Open Cloud System (Integration of Eucalyptus, Hadoop and into deployment of University Private Cloud) Thinn Thu Naing University of Computer Studies, Yangon 25 th October 2011 Open Cloud System University
MapReduce. Tushar B. Kute, http://tusharkute.com
 MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
University of Maryland. Tuesday, February 2, 2010
 Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
and HDFS for Big Data Applications Serge Blazhievsky Nice Systems
 Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
t] open source Hadoop Beginner's Guide ij$ data avalanche Garry Turkington Learn how to crunch big data to extract meaning from
![t] open source Hadoop Beginner's Guide ij$ data avalanche Garry Turkington Learn how to crunch big data to extract meaning from](/thumbs/26/7239192.jpg "t] open source Hadoop Beginner's Guide ij$ data avalanche Garry Turkington Learn how to crunch big data to extract meaning from") Hadoop Beginner's Guide Learn how to crunch big data to extract meaning from data avalanche Garry Turkington [ PUBLISHING t] open source I I community experience distilled ftu\ ij$ BIRMINGHAMMUMBAI ')
Hadoop Beginner's Guide Learn how to crunch big data to extract meaning from data avalanche Garry Turkington [ PUBLISHING t] open source I I community experience distilled ftu\ ij$ BIRMINGHAMMUMBAI ')
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Lecture 3 Hadoop Technical Introduction CSE 490H
 Lecture 3 Hadoop Technical Introduction CSE 490H Announcements My office hours: M 2:30 3:30 in CSE 212 Cluster is operational; instructions in assignment 1 heavily rewritten Eclipse plugin is deprecated
Lecture 3 Hadoop Technical Introduction CSE 490H Announcements My office hours: M 2:30 3:30 in CSE 212 Cluster is operational; instructions in assignment 1 heavily rewritten Eclipse plugin is deprecated
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Intro to Map/Reduce a.k.a. Hadoop
 Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the Cloud
 A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the Cloud Thuy D. Nguyen, Cynthia E. Irvine, Jean Khosalim Department of Computer Science Ground System Architectures Workshop
A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the Cloud Thuy D. Nguyen, Cynthia E. Irvine, Jean Khosalim Department of Computer Science Ground System Architectures Workshop
Hadoop Setup. 1 Cluster
 In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
Hadoop and its Usage at Facebook. Dhruba Borthakur dhruba@apache.org, June 22 rd, 2009
 Hadoop and its Usage at Facebook Dhruba Borthakur dhruba@apache.org, June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Hadoop and its Usage at Facebook Dhruba Borthakur dhruba@apache.org, June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
TP1: Getting Started with Hadoop
 TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment
 CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
CS54100: Database Systems
 CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
Hadoop (pseudo-distributed) installation and configuration
 installation and configuration") Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com
 Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
A Cost-Evaluation of MapReduce Applications in the Cloud
 1/23 A Cost-Evaluation of MapReduce Applications in the Cloud Diana Moise, Alexandra Carpen-Amarie Gabriel Antoniu, Luc Bougé KerData team 2/23 1 MapReduce applications - case study 2 3 4 5 3/23 MapReduce
1/23 A Cost-Evaluation of MapReduce Applications in the Cloud Diana Moise, Alexandra Carpen-Amarie Gabriel Antoniu, Luc Bougé KerData team 2/23 1 MapReduce applications - case study 2 3 4 5 3/23 MapReduce
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Using Hadoop for Webscale Computing. Ajay Anand Yahoo! aanand@yahoo-inc.com Usenix 2008
 Using Hadoop for Webscale Computing Ajay Anand Yahoo! aanand@yahoo-inc.com Agenda The Problem Solution Approach / Introduction to Hadoop HDFS File System Map Reduce Programming Pig Hadoop implementation
Using Hadoop for Webscale Computing Ajay Anand Yahoo! aanand@yahoo-inc.com Agenda The Problem Solution Approach / Introduction to Hadoop HDFS File System Map Reduce Programming Pig Hadoop implementation
How To Install Hadoop 1.2.1.1 From Apa Hadoop 1.3.2 To 1.4.2 (Hadoop)
") Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
How to properly misuse Hadoop. Marcel Huntemann NERSC tutorial session 2/12/13
 How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
Hadoop Installation MapReduce Examples Jake Karnes
 Big Data Management Hadoop Installation MapReduce Examples Jake Karnes These slides are based on materials / slides from Cloudera.com Amazon.com Prof. P. Zadrozny's Slides Prerequistes You must have an
Big Data Management Hadoop Installation MapReduce Examples Jake Karnes These slides are based on materials / slides from Cloudera.com Amazon.com Prof. P. Zadrozny's Slides Prerequistes You must have an
Sriram Krishnan, Ph.D. sriram@sdsc.edu
 Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2
 USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2 (Using HDFS on Discovery Cluster for Discovery Cluster Users email n.roy@neu.edu if you have questions or need more clarifications. Nilay
USING HDFS ON DISCOVERY CLUSTER TWO EXAMPLES - test1 and test2 (Using HDFS on Discovery Cluster for Discovery Cluster Users email n.roy@neu.edu if you have questions or need more clarifications. Nilay
Hadoop 2.6 Configuration and More Examples
 Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Data-intensive computing systems
 Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Hadoop. Dawid Weiss. Institute of Computing Science Poznań University of Technology
 Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
1. GridGain In-Memory Accelerator For Hadoop. 2. Hadoop Installation. 2.1 Hadoop 1.x Installation
 1. GridGain In-Memory Accelerator For Hadoop GridGain's In-Memory Accelerator For Hadoop edition is based on the industry's first high-performance dual-mode in-memory file system that is 100% compatible
1. GridGain In-Memory Accelerator For Hadoop GridGain's In-Memory Accelerator For Hadoop edition is based on the industry's first high-performance dual-mode in-memory file system that is 100% compatible
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Entering the Zettabyte Age Jeffrey Krone
 Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
MapReduce for Statistical NLP/Machine Learning
 MapReduce for Statistical NLP/Machine Learning Sameer Maskey Week 7, October 17, 2012 1 Topics for Today MapReduce Running MapReduce jobs in Amazon Hadoop MapReduce for Machine Learning Naïve Bayes, K-Means,
MapReduce for Statistical NLP/Machine Learning Sameer Maskey Week 7, October 17, 2012 1 Topics for Today MapReduce Running MapReduce jobs in Amazon Hadoop MapReduce for Machine Learning Naïve Bayes, K-Means,
PaRFR : Parallel Random Forest Regression on Hadoop for Multivariate Quantitative Trait Loci Mapping. Version 1.0, Oct 2012
 PaRFR : Parallel Random Forest Regression on Hadoop for Multivariate Quantitative Trait Loci Mapping Version 1.0, Oct 2012 This document describes PaRFR, a Java package that implements a parallel random
PaRFR : Parallel Random Forest Regression on Hadoop for Multivariate Quantitative Trait Loci Mapping Version 1.0, Oct 2012 This document describes PaRFR, a Java package that implements a parallel random
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Reduction of Data at Namenode in HDFS using harballing Technique
 Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu vgkorat@gmail.com swamy.uncis@gmail.com Abstract HDFS stands for the Hadoop Distributed File System.
Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu vgkorat@gmail.com swamy.uncis@gmail.com Abstract HDFS stands for the Hadoop Distributed File System.
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
EXPERIMENTATION. HARRISON CARRANZA School of Computer Science and Mathematics
 BIG DATA WITH HADOOP EXPERIMENTATION HARRISON CARRANZA Marist College APARICIO CARRANZA NYC College of Technology CUNY ECC Conference 2016 Poughkeepsie, NY, June 12-14, 2016 Marist College AGENDA Contents
BIG DATA WITH HADOOP EXPERIMENTATION HARRISON CARRANZA Marist College APARICIO CARRANZA NYC College of Technology CUNY ECC Conference 2016 Poughkeepsie, NY, June 12-14, 2016 Marist College AGENDA Contents
Jordan Boyd-Graber University of Maryland. Tuesday, February 10, 2011
 Data-Intensive Information Processing Applications! Session #2 Hadoop: Nuts and Bolts Jordan Boyd-Graber University of Maryland Tuesday, February 10, 2011 This work is licensed under a Creative Commons
Data-Intensive Information Processing Applications! Session #2 Hadoop: Nuts and Bolts Jordan Boyd-Graber University of Maryland Tuesday, February 10, 2011 This work is licensed under a Creative Commons
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
Comparative analysis of Google File System and Hadoop Distributed File System
 Comparative analysis of Google File System and Hadoop Distributed File System R.Vijayakumari, R.Kirankumar, K.Gangadhara Rao Dept. of Computer Science, Krishna University, Machilipatnam, India, vijayakumari28@gmail.com
Comparative analysis of Google File System and Hadoop Distributed File System R.Vijayakumari, R.Kirankumar, K.Gangadhara Rao Dept. of Computer Science, Krishna University, Machilipatnam, India, vijayakumari28@gmail.com
LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT
 LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT Samira Daneshyar 1 and Majid Razmjoo 2 1,2 School of Computer Science, Centre of Software Technology and Management (SOFTEM),
LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT Samira Daneshyar 1 and Majid Razmjoo 2 1,2 School of Computer Science, Centre of Software Technology and Management (SOFTEM),
MapReduce with Apache Hadoop Analysing Big Data
 MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
Setup Hadoop On Ubuntu Linux. ---Multi-Node Cluster
 Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Introduction to Cloud Computing
 Introduction to Cloud Computing Qloud Demonstration 15 319, spring 2010 3 rd Lecture, Jan 19 th Suhail Rehman Time to check out the Qloud! Enough Talk! Time for some Action! Finally you can have your own
Introduction to Cloud Computing Qloud Demonstration 15 319, spring 2010 3 rd Lecture, Jan 19 th Suhail Rehman Time to check out the Qloud! Enough Talk! Time for some Action! Finally you can have your own
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Four Orders of Magnitude: Running Large Scale Accumulo Clusters. Aaron Cordova Accumulo Summit, June 2014
 Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Hadoop Lab - Setting a 3 node Cluster. http://hadoop.apache.org/releases.html. Java - http://wiki.apache.org/hadoop/hadoopjavaversions
 Hadoop Lab - Setting a 3 node Cluster Packages Hadoop Packages can be downloaded from: http://hadoop.apache.org/releases.html Java - http://wiki.apache.org/hadoop/hadoopjavaversions Note: I have tested
Hadoop Lab - Setting a 3 node Cluster Packages Hadoop Packages can be downloaded from: http://hadoop.apache.org/releases.html Java - http://wiki.apache.org/hadoop/hadoopjavaversions Note: I have tested
Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster. A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech
 OIT/ART, Georgia Tech") Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster Fang (Cherry) Liu, PhD fang.liu@oit.gatech.edu A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech Targets
Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster Fang (Cherry) Liu, PhD fang.liu@oit.gatech.edu A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech Targets
Introduc)on to Map- Reduce. Vincent Leroy
on to Map- Reduce. Vincent Leroy") Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Introduc)on to Map- Reduce Vincent Leroy Sources Apache Hadoop Yahoo! Developer Network Hortonworks Cloudera Prac)cal Problem Solving with Hadoop and Pig Slides will be available at hgp://lig- membres.imag.fr/leroyv/
Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud
 Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud Aditya Jadhav, Mahesh Kukreja E-mail: aditya.jadhav27@gmail.com & mr_mahesh_in@yahoo.co.in Abstract : In the information industry,
Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud Aditya Jadhav, Mahesh Kukreja E-mail: aditya.jadhav27@gmail.com & mr_mahesh_in@yahoo.co.in Abstract : In the information industry,
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Single Node Hadoop Cluster Setup
 Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
The Performance Characteristics of MapReduce Applications on Scalable Clusters
 The Performance Characteristics of MapReduce Applications on Scalable Clusters Kenneth Wottrich Denison University Granville, OH 43023 wottri_k1@denison.edu ABSTRACT Many cluster owners and operators have
The Performance Characteristics of MapReduce Applications on Scalable Clusters Kenneth Wottrich Denison University Granville, OH 43023 wottri_k1@denison.edu ABSTRACT Many cluster owners and operators have
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Optimize the execution of local physics analysis workflows using Hadoop
 Optimize the execution of local physics analysis workflows using Hadoop INFN CCR - GARR Workshop 14-17 May Napoli Hassen Riahi Giacinto Donvito Livio Fano Massimiliano Fasi Andrea Valentini INFN-PERUGIA
Optimize the execution of local physics analysis workflows using Hadoop INFN CCR - GARR Workshop 14-17 May Napoli Hassen Riahi Giacinto Donvito Livio Fano Massimiliano Fasi Andrea Valentini INFN-PERUGIA
Research Laboratory. Java Web Crawler & Hadoop MapReduce Anri Morchiladze && Bachana Dolidze Supervisor Nodar Momtselidze
 Research Laboratory Java Web Crawler & Hadoop MapReduce Anri Morchiladze && Bachana Dolidze Supervisor Nodar Momtselidze 1. Java Web Crawler Description Java Code 2. MapReduce Overview Example of mapreduce
Research Laboratory Java Web Crawler & Hadoop MapReduce Anri Morchiladze && Bachana Dolidze Supervisor Nodar Momtselidze 1. Java Web Crawler Description Java Code 2. MapReduce Overview Example of mapreduce
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters