Cluster Computing in a College of Criminal Justice
|
|
|
- Piers Todd
- 10 years ago
- Views:
Transcription
1 Cluster Computing in a College of Criminal Justice Boris Bondarenko and Douglas E. Salane Mathematics & Computer Science Dept. John Jay College of Criminal Justice The City University of New York 2004 USENIX Annual Technical Conference Boston, MA July 2, 2004

2 Outline Importance of cluster computing (HPC) in a college whose focus is criminal justice and public administration Cluster computing projects in progress and planned (research and instruction) Issues that arise in building and managing clusters in organizations with limited resources and staff Cluster, Linux, and open source developments

3 Institutional Background John Jay College/CUNY College: Specialized Liberal Arts College within CUNY ( 13,000 students including 2000 graduate students). Degrees: Law and Police Science, Public Management, Fire Science, Security, Forensic Science, Computer Information Systems, M.S. in Forensic Computing (2004), Ph.D. in Criminal Justice. Mission: Advance the practice of criminal justice and public administration through research and by providing a professional workforce.
, Ph.D. in Criminal Justice.")
4 High Performance Computing at John Jay College I Fire standards and codes for buildings (Computational Fluid Dynamics - NIST Fire Dynamics Simulator and Smoke View) Latent Semantic Indexing (Principal Component Analysis Singular Value Decomposition) Toxicology (molecular modeling Gaussian) FBI s National Incident-Based Reporting System (NIBRS database analysis and data mining)
 FBI s National Incident-Based Reporting System (NIBRS database analysis and")
5 High Performance Computing at John Jay College II Aircraft control systems ( Parallel computation of Schur Form for rapid solution of Riccati Equation) Research and Instruction in mathematical software (ScaLAPACK, HPL Benchmark) Instruction in systems areas of computing, parallel algorithms, and distributed algorithms (NASA CIPA) Password Cracking (Teracrack SDSC)
 Password Cracking")
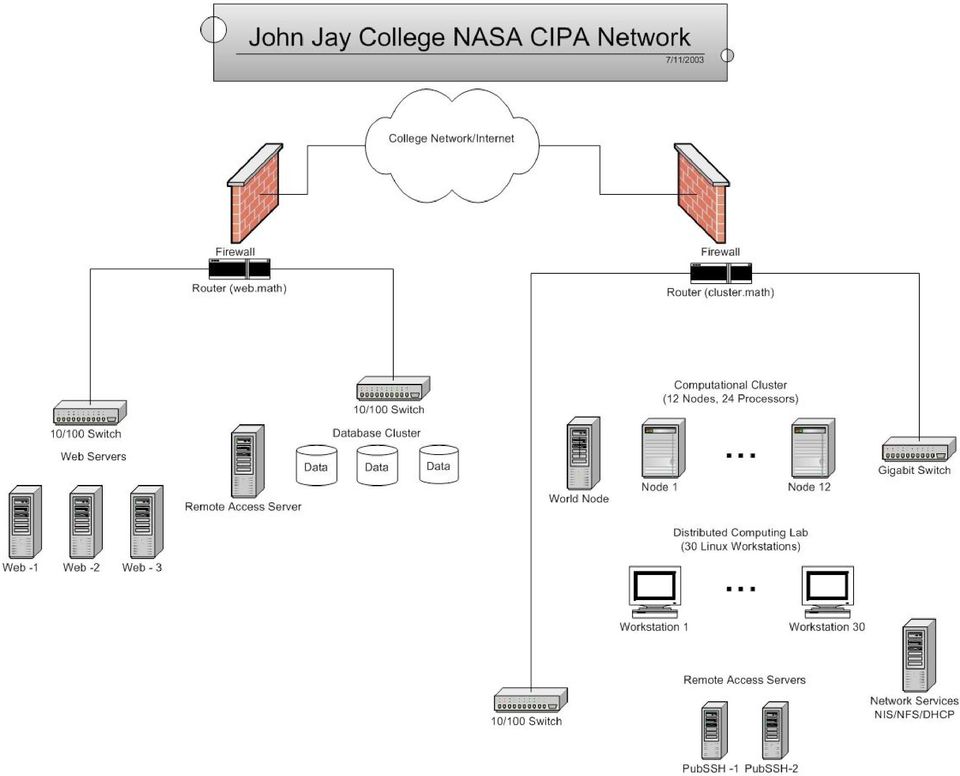
6 Cluster Computing Facilities Computational Cluster (Beowulf Cluster): worldnode, 12 compute nodes (24 Pentium IV XEON (1.8 and 2.4 GHz processors, 1 GB RAM, 512K L2 cache), 20 GB local disk, Gigabit Ethernet, MPICH over TCP/IP, NFS File server, Linux smp Database Cluster: 4 nodes - remote access server, web server, Microsoft SQL and Oracle 10g Distributed Computing Laboratory: Computing Laboratory with 30 Linux Workstations (partnership with Science Dept.)

7
8 Cluster Design Considerations I Architecture Vendor supported blade/rack system or pile of PCs Cluster Software cluster distribution software (OSCAR - ORNL, NPAIC ROCKS - SDSC, or Scyld Beowulf) vs. self-configuration (Kickstart+ shell scripts) File System NFS; Andrew; GFS Sistina Systems; Lustre CFS, Inc.; PVS ANL, GPFS - IBM
 File System NFS; Andrew; GFS")
9 Cluster Design Considerations II Interconnect Gigabit Ethernet, Myrinet, Quadrics, InfiniBand Message passing MPICH over TCP/IP Monitoring Ganglia UC Berkeley, Supermon - LANL, direct console access Testing Netpipe AMES Laboratory, BLACS, MPI Testers

10 ScaLAPACK Dense matrix computations in a distributed memory environment (clusters and MPP machines) Linear systems, least squares, eigenvalues, matrix decompositions (e.g., LU, QR, SVD) Reliable software with good error reporting facilities Not easy to use. User must write code to distribute the matrix over the process grid. User must set algorithmic parameters (e.g., block size, process array dimensions)
 Reliable software with good error reporting facilities Not easy to use.")
11

12 Basic Linear Algebra Communications Subroutines (BLACS) Setup/teardown process topologies (Array of processes most common) Point-to-point & broadcast send/receive of rectangular and trapezoidal matrices Miscellaneous routines (e.g., barrier, matrix element wise sum, max and min) Test routines to ensure reliable communications

13 Using BLACS to Detect Errors Broadcast testing routine: generates matrix on selected process, broadcasts it, receiving routines test for correct transmission. Process (0,1) reports errors, invalid element at A(12,16): Expected Received
 reports errors, invalid element at A(12,16): Expected")
14 Basic Linear Algebra Subroutines (BLAS) Perform scalar, matrix vector and matrix matrix operations. Block algorithms to take advantage of memory hierarchies. Must be optimized for a specific processor. Three versions: Intel Math Kernel Library (MKL), ATLAS Generated, and KGoto. Multithreaded and single threaded versions.
, ATLAS Generated, and KGoto.")
15 BLAS matrix multiply routine DGEMM C = alpha*ab + beta*c, alpha and beta are scalars, A,B and C are matrices Critical for performance of many ScaLAPACK routines and HPL (e.g. HPL benchmark on Livermore MCR Cluster raised from 5.69 to 7.63 TFLOPS) Best results on Pentium IV: KGoto BLAS (special coding to minimize cache and TLB misses)
 Best results on Pentium IV: KGoto BLAS (special coding to minimize cache")
16 Performance of DGEMM (SMP 1.8 Mhz P4, SSE2, 512k L2 cache) MFLOPS KGOTO_PT KGOTO ATLAS ATLAS_PT Matrix Size (A,B,C)

17 HPL Benchmark Results (from Top 500) R Site CPUs R max R peak Earth 1 Japan 5,120 35,860 40,960 Simulator MCR Linux 12 LLNL 2,304 7,634 11,060 Network X 2.4Ghz X HP Alpha 67 NASA ,164 2,784 Server GSFC E*Trade X 499 E*Trade Financial Ghz X 634 1,392 JJ Cluster John Jay & Ghx X R rank in Top 500 Super Computers list Rmax Linpack Benchmark (GFLOPS) Rpeak Theoretical Highest Performance (GFLOPS)

18 FBI National Incident Based Reporting System (NIBRS) Develop an Oracle database version of NIBRS and make it available to criminal justice research community Support online analysis and data mining through a web portal Provide mechanism for automatic updates Employ cluster/grid computing to provide high throughput and availability

19 NIBRS Data warehouse: Oracle 10G database on Linux Red Hat AS 3 Server 13 segments (flat files), 6 Main segments (administrative/incident, offense, property, victim, offender, arrestee), largest 3.2 million records, 100 to 200 bytes per record, 39 reference tables 2000/2001 data 1.29 Gbyte, expect about 10 Gbyte for 1995 to present

20 Cluster Developments Single System Image (cluster monitoring, OS version skew, single process space) Commodity low latency interconnect technology that provides unified I/O (Remote Direct Memory Access, InfiniBand?) Nodes that consume less power Cluster applications that provide error checking
 Nodes that consume less power Cluster applications that provide error")
21 Collaborators NIBRS Peter Shenkin, Raul Cabrera, Atiqual Mondal, and Samra Vlasnovec; Math and Computer Science Dept. Parallel Schur Decomposition Mythilli Mantharam, Math and Computer Science Dept. Fire and Smoke Simulation Glenn Corbet, Fire Science Dept. Molecular Modeling Ann Marie Sapse and Robert Rothchild, Science Dept.
22 Contact Information Douglas E. Salane NASA CIPA Cluster Computing Project web.math.jjay.cuny.edu Bibliography available
23 Credits NASA Curriculum Partnership Improvement Award Graduate Research and Technology Initiative of CUNY (01,02,03) Open Source and freely available software (Linux, GNU compilers and languages, Apache, PHP, Oracle Academic License)
The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation
 The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation Mark Baker, Garry Smith and Ahmad Hasaan SSE, University of Reading Paravirtualization A full assessment of paravirtualization
The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation Mark Baker, Garry Smith and Ahmad Hasaan SSE, University of Reading Paravirtualization A full assessment of paravirtualization
1 Bull, 2011 Bull Extreme Computing
 1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
Agenda. HPC Software Stack. HPC Post-Processing Visualization. Case Study National Scientific Center. European HPC Benchmark Center Montpellier PSSC
 HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
Building a Top500-class Supercomputing Cluster at LNS-BUAP
 Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Introduction to High Performance Cluster Computing. Cluster Training for UCL Part 1
 Introduction to High Performance Cluster Computing Cluster Training for UCL Part 1 What is HPC HPC = High Performance Computing Includes Supercomputing HPCC = High Performance Cluster Computing Note: these
Introduction to High Performance Cluster Computing Cluster Training for UCL Part 1 What is HPC HPC = High Performance Computing Includes Supercomputing HPCC = High Performance Cluster Computing Note: these
Cluster Computing at HRI
 Cluster Computing at HRI J.S.Bagla Harish-Chandra Research Institute, Chhatnag Road, Jhunsi, Allahabad 211019. E-mail: [email protected] 1 Introduction and some local history High performance computing
Cluster Computing at HRI J.S.Bagla Harish-Chandra Research Institute, Chhatnag Road, Jhunsi, Allahabad 211019. E-mail: [email protected] 1 Introduction and some local history High performance computing
PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN
 1 PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster Construction
1 PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster Construction
Performance Characteristics of a Cost-Effective Medium-Sized Beowulf Cluster Supercomputer
 Res. Lett. Inf. Math. Sci., 2003, Vol.5, pp 1-10 Available online at http://iims.massey.ac.nz/research/letters/ 1 Performance Characteristics of a Cost-Effective Medium-Sized Beowulf Cluster Supercomputer
Res. Lett. Inf. Math. Sci., 2003, Vol.5, pp 1-10 Available online at http://iims.massey.ac.nz/research/letters/ 1 Performance Characteristics of a Cost-Effective Medium-Sized Beowulf Cluster Supercomputer
BSC - Barcelona Supercomputer Center
 Objectives Research in Supercomputing and Computer Architecture Collaborate in R&D e-science projects with prestigious scientific teams Manage BSC supercomputers to accelerate relevant contributions to
Objectives Research in Supercomputing and Computer Architecture Collaborate in R&D e-science projects with prestigious scientific teams Manage BSC supercomputers to accelerate relevant contributions to
Linux Cluster Computing An Administrator s Perspective
 Linux Cluster Computing An Administrator s Perspective Robert Whitinger Traques LLC and High Performance Computing Center East Tennessee State University : http://lxer.com/pub/self2015_clusters.pdf 2015-Jun-14
Linux Cluster Computing An Administrator s Perspective Robert Whitinger Traques LLC and High Performance Computing Center East Tennessee State University : http://lxer.com/pub/self2015_clusters.pdf 2015-Jun-14
Linux clustering. Morris Law, IT Coordinator, Science Faculty, Hong Kong Baptist University
 Linux clustering Morris Law, IT Coordinator, Science Faculty, Hong Kong Baptist University PII 4-node clusters started in 1999 PIII 16 node cluster purchased in 2001. Plan for grid For test base HKBU -
Linux clustering Morris Law, IT Coordinator, Science Faculty, Hong Kong Baptist University PII 4-node clusters started in 1999 PIII 16 node cluster purchased in 2001. Plan for grid For test base HKBU -
High Performance Computing in CST STUDIO SUITE
 High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes. Anthony Kenisky, VP of North America Sales
 Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
MOSIX: High performance Linux farm
 MOSIX: High performance Linux farm Paolo Mastroserio [[email protected]] Francesco Maria Taurino [[email protected]] Gennaro Tortone [[email protected]] Napoli Index overview on Linux farm farm
MOSIX: High performance Linux farm Paolo Mastroserio [[email protected]] Francesco Maria Taurino [[email protected]] Gennaro Tortone [[email protected]] Napoli Index overview on Linux farm farm
SR-IOV: Performance Benefits for Virtualized Interconnects!
 SR-IOV: Performance Benefits for Virtualized Interconnects! Glenn K. Lockwood! Mahidhar Tatineni! Rick Wagner!! July 15, XSEDE14, Atlanta! Background! High Performance Computing (HPC) reaching beyond traditional
SR-IOV: Performance Benefits for Virtualized Interconnects! Glenn K. Lockwood! Mahidhar Tatineni! Rick Wagner!! July 15, XSEDE14, Atlanta! Background! High Performance Computing (HPC) reaching beyond traditional
The CNMS Computer Cluster
 The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
High Performance Computing. Course Notes 2007-2008. HPC Fundamentals
 High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
Overview of HPC systems and software available within
 Overview of HPC systems and software available within Overview Available HPC Systems Ba Cy-Tera Available Visualization Facilities Software Environments HPC System at Bibliotheca Alexandrina SUN cluster
Overview of HPC systems and software available within Overview Available HPC Systems Ba Cy-Tera Available Visualization Facilities Software Environments HPC System at Bibliotheca Alexandrina SUN cluster
Building an Inexpensive Parallel Computer
 Res. Lett. Inf. Math. Sci., (2000) 1, 113-118 Available online at http://www.massey.ac.nz/~wwiims/rlims/ Building an Inexpensive Parallel Computer Lutz Grosz and Andre Barczak I.I.M.S., Massey University
Res. Lett. Inf. Math. Sci., (2000) 1, 113-118 Available online at http://www.massey.ac.nz/~wwiims/rlims/ Building an Inexpensive Parallel Computer Lutz Grosz and Andre Barczak I.I.M.S., Massey University
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS
 AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS") A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 [email protected] THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 [email protected] THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
PERFORMANCE CONSIDERATIONS FOR NETWORK SWITCH FABRICS ON LINUX CLUSTERS
 PERFORMANCE CONSIDERATIONS FOR NETWORK SWITCH FABRICS ON LINUX CLUSTERS Philip J. Sokolowski Department of Electrical and Computer Engineering Wayne State University 55 Anthony Wayne Dr. Detroit, MI 822
PERFORMANCE CONSIDERATIONS FOR NETWORK SWITCH FABRICS ON LINUX CLUSTERS Philip J. Sokolowski Department of Electrical and Computer Engineering Wayne State University 55 Anthony Wayne Dr. Detroit, MI 822
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER
 CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
Building Clusters for Gromacs and other HPC applications
 Building Clusters for Gromacs and other HPC applications Erik Lindahl [email protected] CBR Outline: Clusters Clusters vs. small networks of machines Why do YOU need a cluster? Computer hardware Network
Building Clusters for Gromacs and other HPC applications Erik Lindahl [email protected] CBR Outline: Clusters Clusters vs. small networks of machines Why do YOU need a cluster? Computer hardware Network
64-Bit versus 32-Bit CPUs in Scientific Computing
 64-Bit versus 32-Bit CPUs in Scientific Computing Axel Kohlmeyer Lehrstuhl für Theoretische Chemie Ruhr-Universität Bochum March 2004 1/25 Outline 64-Bit and 32-Bit CPU Examples
64-Bit versus 32-Bit CPUs in Scientific Computing Axel Kohlmeyer Lehrstuhl für Theoretische Chemie Ruhr-Universität Bochum March 2004 1/25 Outline 64-Bit and 32-Bit CPU Examples
Trends in High-Performance Computing for Power Grid Applications
 Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
A Study on the Scalability of Hybrid LS-DYNA on Multicore Architectures
 11 th International LS-DYNA Users Conference Computing Technology A Study on the Scalability of Hybrid LS-DYNA on Multicore Architectures Yih-Yih Lin Hewlett-Packard Company Abstract In this paper, the
11 th International LS-DYNA Users Conference Computing Technology A Study on the Scalability of Hybrid LS-DYNA on Multicore Architectures Yih-Yih Lin Hewlett-Packard Company Abstract In this paper, the
Microsoft Windows Server 2003 with Internet Information Services (IIS) 6.0 vs. Linux Competitive Web Server Performance Comparison
 6.0 vs. Linux Competitive Web Server Performance Comparison") April 23 11 Aviation Parkway, Suite 4 Morrisville, NC 2756 919-38-28 Fax 919-38-2899 32 B Lakeside Drive Foster City, CA 9444 65-513-8 Fax 65-513-899 www.veritest.com [email protected] Microsoft Windows
April 23 11 Aviation Parkway, Suite 4 Morrisville, NC 2756 919-38-28 Fax 919-38-2899 32 B Lakeside Drive Foster City, CA 9444 65-513-8 Fax 65-513-899 www.veritest.com [email protected] Microsoft Windows
Mississippi State University High Performance Computing Collaboratory Brief Overview. Trey Breckenridge Director, HPC
 Mississippi State University High Performance Computing Collaboratory Brief Overview Trey Breckenridge Director, HPC Mississippi State University Public university (Land Grant) founded in 1878 Traditional
Mississippi State University High Performance Computing Collaboratory Brief Overview Trey Breckenridge Director, HPC Mississippi State University Public university (Land Grant) founded in 1878 Traditional
HPC Software Requirements to Support an HPC Cluster Supercomputer
 HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
Lecture 1: the anatomy of a supercomputer
 Where a calculator on the ENIAC is equipped with 18,000 vacuum tubes and weighs 30 tons, computers of the future may have only 1,000 vacuum tubes and perhaps weigh 1½ tons. Popular Mechanics, March 1949
Where a calculator on the ENIAC is equipped with 18,000 vacuum tubes and weighs 30 tons, computers of the future may have only 1,000 vacuum tubes and perhaps weigh 1½ tons. Popular Mechanics, March 1949
Parallel Computing. Introduction
 Parallel Computing Introduction Thorsten Grahs, 14. April 2014 Administration Lecturer Dr. Thorsten Grahs (that s me) [email protected] Institute of Scientific Computing Room RZ 120 Lecture Monday 11:30-13:00
Parallel Computing Introduction Thorsten Grahs, 14. April 2014 Administration Lecturer Dr. Thorsten Grahs (that s me) [email protected] Institute of Scientific Computing Room RZ 120 Lecture Monday 11:30-13:00
Performance Evaluation of Amazon EC2 for NASA HPC Applications!
 National Aeronautics and Space Administration Performance Evaluation of Amazon EC2 for NASA HPC Applications! Piyush Mehrotra!! J. Djomehri, S. Heistand, R. Hood, H. Jin, A. Lazanoff,! S. Saini, R. Biswas!
National Aeronautics and Space Administration Performance Evaluation of Amazon EC2 for NASA HPC Applications! Piyush Mehrotra!! J. Djomehri, S. Heistand, R. Hood, H. Jin, A. Lazanoff,! S. Saini, R. Biswas!
Supercomputing 2004 - Status und Trends (Conference Report) Peter Wegner
 Peter Wegner") (Conference Report) Peter Wegner SC2004 conference Top500 List BG/L Moors Law, problems of recent architectures Solutions Interconnects Software Lattice QCD machines DESY @SC2004 QCDOC Conclusions Technical
(Conference Report) Peter Wegner SC2004 conference Top500 List BG/L Moors Law, problems of recent architectures Solutions Interconnects Software Lattice QCD machines DESY @SC2004 QCDOC Conclusions Technical
OpenMP Programming on ScaleMP
 OpenMP Programming on ScaleMP Dirk Schmidl [email protected] Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
OpenMP Programming on ScaleMP Dirk Schmidl [email protected] Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
Toward a practical HPC Cloud : Performance tuning of a virtualized HPC cluster
 Toward a practical HPC Cloud : Performance tuning of a virtualized HPC cluster Ryousei Takano Information Technology Research Institute, National Institute of Advanced Industrial Science and Technology
Toward a practical HPC Cloud : Performance tuning of a virtualized HPC cluster Ryousei Takano Information Technology Research Institute, National Institute of Advanced Industrial Science and Technology
Shared Parallel File System
 Shared Parallel File System Fangbin Liu [email protected] System and Network Engineering University of Amsterdam Shared Parallel File System Introduction of the project The PVFS2 parallel file system
Shared Parallel File System Fangbin Liu [email protected] System and Network Engineering University of Amsterdam Shared Parallel File System Introduction of the project The PVFS2 parallel file system
Improved LS-DYNA Performance on Sun Servers
 8 th International LS-DYNA Users Conference Computing / Code Tech (2) Improved LS-DYNA Performance on Sun Servers Youn-Seo Roh, Ph.D. And Henry H. Fong Sun Microsystems, Inc. Abstract Current Sun platforms
8 th International LS-DYNA Users Conference Computing / Code Tech (2) Improved LS-DYNA Performance on Sun Servers Youn-Seo Roh, Ph.D. And Henry H. Fong Sun Microsystems, Inc. Abstract Current Sun platforms
Cluster Implementation and Management; Scheduling
 Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
System Requirements Table of contents
 Table of contents 1 Introduction... 2 2 Knoa Agent... 2 2.1 System Requirements...2 2.2 Environment Requirements...4 3 Knoa Server Architecture...4 3.1 Knoa Server Components... 4 3.2 Server Hardware Setup...5
Table of contents 1 Introduction... 2 2 Knoa Agent... 2 2.1 System Requirements...2 2.2 Environment Requirements...4 3 Knoa Server Architecture...4 3.1 Knoa Server Components... 4 3.2 Server Hardware Setup...5
ANALYSIS OF SUPERCOMPUTER DESIGN
 ANALYSIS OF SUPERCOMPUTER DESIGN CS/ECE 566 Parallel Processing Fall 2011 1 Anh Huy Bui Nilesh Malpekar Vishnu Gajendran AGENDA Brief introduction of supercomputer Supercomputer design concerns and analysis
ANALYSIS OF SUPERCOMPUTER DESIGN CS/ECE 566 Parallel Processing Fall 2011 1 Anh Huy Bui Nilesh Malpekar Vishnu Gajendran AGENDA Brief introduction of supercomputer Supercomputer design concerns and analysis
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
benchmarking Amazon EC2 for high-performance scientific computing
 Edward Walker benchmarking Amazon EC2 for high-performance scientific computing Edward Walker is a Research Scientist with the Texas Advanced Computing Center at the University of Texas at Austin. He received
Edward Walker benchmarking Amazon EC2 for high-performance scientific computing Edward Walker is a Research Scientist with the Texas Advanced Computing Center at the University of Texas at Austin. He received
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
SRNWP Workshop. HP Solutions and Activities in Climate & Weather Research. Michael Riedmann European Performance Center
 SRNWP Workshop HP Solutions and Activities in Climate & Weather Research Michael Riedmann European Performance Center Agenda A bit of marketing: HP Solutions for HPC A few words about recent Met deals
SRNWP Workshop HP Solutions and Activities in Climate & Weather Research Michael Riedmann European Performance Center Agenda A bit of marketing: HP Solutions for HPC A few words about recent Met deals
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Enabling Technologies for Distributed Computing
 Enabling Technologies for Distributed Computing Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF Multi-core CPUs and Multithreading Technologies
Enabling Technologies for Distributed Computing Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF Multi-core CPUs and Multithreading Technologies
JUROPA Linux Cluster An Overview. 19 May 2014 Ulrich Detert
 Mitglied der Helmholtz-Gemeinschaft JUROPA Linux Cluster An Overview 19 May 2014 Ulrich Detert JuRoPA JuRoPA Jülich Research on Petaflop Architectures Bull, Sun, ParTec, Intel, Mellanox, Novell, FZJ JUROPA
Mitglied der Helmholtz-Gemeinschaft JUROPA Linux Cluster An Overview 19 May 2014 Ulrich Detert JuRoPA JuRoPA Jülich Research on Petaflop Architectures Bull, Sun, ParTec, Intel, Mellanox, Novell, FZJ JUROPA
Dell High-Performance Computing Clusters and Reservoir Simulation Research at UT Austin. http://www.dell.com/clustering
 Dell High-Performance Computing Clusters and Reservoir Simulation Research at UT Austin Reza Rooholamini, Ph.D. Director Enterprise Solutions Dell Computer Corp. [email protected] http://www.dell.com/clustering
Dell High-Performance Computing Clusters and Reservoir Simulation Research at UT Austin Reza Rooholamini, Ph.D. Director Enterprise Solutions Dell Computer Corp. [email protected] http://www.dell.com/clustering
The Green Index: A Metric for Evaluating System-Wide Energy Efficiency in HPC Systems
 202 IEEE 202 26th IEEE International 26th International Parallel Parallel and Distributed and Distributed Processing Processing Symposium Symposium Workshops Workshops & PhD Forum The Green Index: A Metric
202 IEEE 202 26th IEEE International 26th International Parallel Parallel and Distributed and Distributed Processing Processing Symposium Symposium Workshops Workshops & PhD Forum The Green Index: A Metric
Overlapping Data Transfer With Application Execution on Clusters
 Overlapping Data Transfer With Application Execution on Clusters Karen L. Reid and Michael Stumm [email protected] [email protected] Department of Computer Science Department of Electrical and Computer
Overlapping Data Transfer With Application Execution on Clusters Karen L. Reid and Michael Stumm [email protected] [email protected] Department of Computer Science Department of Electrical and Computer
SERVER CLUSTERING TECHNOLOGY & CONCEPT
 SERVER CLUSTERING TECHNOLOGY & CONCEPT M00383937, Computer Network, Middlesex University, E mail: [email protected] Abstract Server Cluster is one of the clustering technologies; it is use for
SERVER CLUSTERING TECHNOLOGY & CONCEPT M00383937, Computer Network, Middlesex University, E mail: [email protected] Abstract Server Cluster is one of the clustering technologies; it is use for
Simplest Scalable Architecture
 Simplest Scalable Architecture NOW Network Of Workstations Many types of Clusters (form HP s Dr. Bruce J. Walker) High Performance Clusters Beowulf; 1000 nodes; parallel programs; MPI Load-leveling Clusters
Simplest Scalable Architecture NOW Network Of Workstations Many types of Clusters (form HP s Dr. Bruce J. Walker) High Performance Clusters Beowulf; 1000 nodes; parallel programs; MPI Load-leveling Clusters
Business white paper. HP Process Automation. Version 7.0. Server performance
 Business white paper HP Process Automation Version 7.0 Server performance Table of contents 3 Summary of results 4 Benchmark profile 5 Benchmark environmant 6 Performance metrics 6 Process throughput 6
Business white paper HP Process Automation Version 7.0 Server performance Table of contents 3 Summary of results 4 Benchmark profile 5 Benchmark environmant 6 Performance metrics 6 Process throughput 6
A Flexible Cluster Infrastructure for Systems Research and Software Development
 Award Number: CNS-551555 Title: CRI: Acquisition of an InfiniBand Cluster with SMP Nodes Institution: Florida State University PIs: Xin Yuan, Robert van Engelen, Kartik Gopalan A Flexible Cluster Infrastructure
Award Number: CNS-551555 Title: CRI: Acquisition of an InfiniBand Cluster with SMP Nodes Institution: Florida State University PIs: Xin Yuan, Robert van Engelen, Kartik Gopalan A Flexible Cluster Infrastructure
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
High Performance Computing, an Introduction to
 High Performance ing, an Introduction to Nicolas Renon, Ph. D, Research Engineer in Scientific ations CALMIP - DTSI Université Paul Sabatier University of Toulouse ([email protected]) Michel
High Performance ing, an Introduction to Nicolas Renon, Ph. D, Research Engineer in Scientific ations CALMIP - DTSI Université Paul Sabatier University of Toulouse ([email protected]) Michel
Client/Server and Distributed Computing
 Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Achieving Performance Isolation with Lightweight Co-Kernels
 Achieving Performance Isolation with Lightweight Co-Kernels Jiannan Ouyang, Brian Kocoloski, John Lange The Prognostic Lab @ University of Pittsburgh Kevin Pedretti Sandia National Laboratories HPDC 2015
Achieving Performance Isolation with Lightweight Co-Kernels Jiannan Ouyang, Brian Kocoloski, John Lange The Prognostic Lab @ University of Pittsburgh Kevin Pedretti Sandia National Laboratories HPDC 2015
Enabling Technologies for Distributed and Cloud Computing
 Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
- An Essential Building Block for Stable and Reliable Compute Clusters
 Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
Large Scale Simulation on Clusters using COMSOL 4.2
 Large Scale Simulation on Clusters using COMSOL 4.2 Darrell W. Pepper 1 Xiuling Wang 2 Steven Senator 3 Joseph Lombardo 4 David Carrington 5 with David Kan and Ed Fontes 6 1 DVP-USAFA-UNLV, 2 Purdue-Calumet,
Large Scale Simulation on Clusters using COMSOL 4.2 Darrell W. Pepper 1 Xiuling Wang 2 Steven Senator 3 Joseph Lombardo 4 David Carrington 5 with David Kan and Ed Fontes 6 1 DVP-USAFA-UNLV, 2 Purdue-Calumet,
Clusters: Mainstream Technology for CAE
 Clusters: Mainstream Technology for CAE Alanna Dwyer HPC Division, HP Linux and Clusters Sparked a Revolution in High Performance Computing! Supercomputing performance now affordable and accessible Linux
Clusters: Mainstream Technology for CAE Alanna Dwyer HPC Division, HP Linux and Clusters Sparked a Revolution in High Performance Computing! Supercomputing performance now affordable and accessible Linux
FLOW-3D Performance Benchmark and Profiling. September 2012
 FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
Current Trend of Supercomputer Architecture
 Current Trend of Supercomputer Architecture Haibei Zhang Department of Computer Science and Engineering [email protected] Abstract As computer technology evolves at an amazingly fast pace,
Current Trend of Supercomputer Architecture Haibei Zhang Department of Computer Science and Engineering [email protected] Abstract As computer technology evolves at an amazingly fast pace,
Main Memory Data Warehouses
 Main Memory Data Warehouses Robert Wrembel Poznan University of Technology Institute of Computing Science [email protected] www.cs.put.poznan.pl/rwrembel Lecture outline Teradata Data Warehouse
Main Memory Data Warehouses Robert Wrembel Poznan University of Technology Institute of Computing Science [email protected] www.cs.put.poznan.pl/rwrembel Lecture outline Teradata Data Warehouse
Cloud Computing through Virtualization and HPC technologies
 Cloud Computing through Virtualization and HPC technologies William Lu, Ph.D. 1 Agenda Cloud Computing & HPC A Case of HPC Implementation Application Performance in VM Summary 2 Cloud Computing & HPC HPC
Cloud Computing through Virtualization and HPC technologies William Lu, Ph.D. 1 Agenda Cloud Computing & HPC A Case of HPC Implementation Application Performance in VM Summary 2 Cloud Computing & HPC HPC
COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1)
") COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1) Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1) Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster
 Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster Gabriele Jost and Haoqiang Jin NAS Division, NASA Ames Research Center, Moffett Field, CA 94035-1000 {gjost,hjin}@nas.nasa.gov
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster Gabriele Jost and Haoqiang Jin NAS Division, NASA Ames Research Center, Moffett Field, CA 94035-1000 {gjost,hjin}@nas.nasa.gov
High Performance Computing
 High Performance Computing Trey Breckenridge Computing Systems Manager Engineering Research Center Mississippi State University What is High Performance Computing? HPC is ill defined and context dependent.
High Performance Computing Trey Breckenridge Computing Systems Manager Engineering Research Center Mississippi State University What is High Performance Computing? HPC is ill defined and context dependent.
CAS2K5. Jim Tuccillo [email protected] 912.576.5215
 CAS2K5 Jim Tuccillo [email protected] 912.576.5215 Agenda icorporate Overview isystem Architecture inode Design iprocessor Options iinterconnect Options ihigh Performance File Systems Lustre isystem Management
CAS2K5 Jim Tuccillo [email protected] 912.576.5215 Agenda icorporate Overview isystem Architecture inode Design iprocessor Options iinterconnect Options ihigh Performance File Systems Lustre isystem Management
Very Large Enterprise Network, Deployment, 25000+ Users
 Very Large Enterprise Network, Deployment, 25000+ Users Websense software can be deployed in different configurations, depending on the size and characteristics of the network, and the organization s filtering
Very Large Enterprise Network, Deployment, 25000+ Users Websense software can be deployed in different configurations, depending on the size and characteristics of the network, and the organization s filtering
Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand
 Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand P. Balaji, K. Vaidyanathan, S. Narravula, K. Savitha, H. W. Jin D. K. Panda Network Based
Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand P. Balaji, K. Vaidyanathan, S. Narravula, K. Savitha, H. W. Jin D. K. Panda Network Based
New Storage System Solutions
 New Storage System Solutions Craig Prescott Research Computing May 2, 2013 Outline } Existing storage systems } Requirements and Solutions } Lustre } /scratch/lfs } Questions? Existing Storage Systems
New Storage System Solutions Craig Prescott Research Computing May 2, 2013 Outline } Existing storage systems } Requirements and Solutions } Lustre } /scratch/lfs } Questions? Existing Storage Systems
Cluster performance, how to get the most out of Abel. Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013
 Cluster performance, how to get the most out of Abel Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013 Introduction Architecture x86-64 and NVIDIA Compilers MPI Interconnect Storage Batch queue
Cluster performance, how to get the most out of Abel Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013 Introduction Architecture x86-64 and NVIDIA Compilers MPI Interconnect Storage Batch queue
A Very Brief History of High-Performance Computing
 A Very Brief History of High-Performance Computing CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Very Brief History of High-Performance Computing Spring 2016 1
A Very Brief History of High-Performance Computing CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Very Brief History of High-Performance Computing Spring 2016 1
Network Performance in High Performance Linux Clusters
 Network Performance in High Performance Linux Clusters Ben Huang, Michael Bauer, Michael Katchabaw Department of Computer Science The University of Western Ontario London, Ontario, Canada N6A 5B7 (huang
Network Performance in High Performance Linux Clusters Ben Huang, Michael Bauer, Michael Katchabaw Department of Computer Science The University of Western Ontario London, Ontario, Canada N6A 5B7 (huang
Removing Performance Bottlenecks in Databases with Red Hat Enterprise Linux and Violin Memory Flash Storage Arrays. Red Hat Performance Engineering
 Removing Performance Bottlenecks in Databases with Red Hat Enterprise Linux and Violin Memory Flash Storage Arrays Red Hat Performance Engineering Version 1.0 August 2013 1801 Varsity Drive Raleigh NC
Removing Performance Bottlenecks in Databases with Red Hat Enterprise Linux and Violin Memory Flash Storage Arrays Red Hat Performance Engineering Version 1.0 August 2013 1801 Varsity Drive Raleigh NC
LS DYNA Performance Benchmarks and Profiling. January 2009
 LS DYNA Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center The
LS DYNA Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center The
High Performance Computing with Linux Clusters
 High Performance Computing with Linux Clusters Panduranga Rao MV Mtech, MISTE Lecturer, Dept of IS and Engg., JNNCE, Shimoga, Karnataka INDIA email: [email protected] URL: http://www.raomvp.bravepages.com/
High Performance Computing with Linux Clusters Panduranga Rao MV Mtech, MISTE Lecturer, Dept of IS and Engg., JNNCE, Shimoga, Karnataka INDIA email: [email protected] URL: http://www.raomvp.bravepages.com/
Mathematical Libraries and Application Software on JUROPA and JUQUEEN
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA and JUQUEEN JSC Training Course May 2014 I.Gutheil Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA and JUQUEEN JSC Training Course May 2014 I.Gutheil Outline General Informations Sequential Libraries Parallel
Kashif Iqbal - PhD [email protected]
 HPC/HTC vs. Cloud Benchmarking An empirical evalua.on of the performance and cost implica.ons Kashif Iqbal - PhD [email protected] ICHEC, NUI Galway, Ireland With acknowledgment to Michele MicheloDo
HPC/HTC vs. Cloud Benchmarking An empirical evalua.on of the performance and cost implica.ons Kashif Iqbal - PhD [email protected] ICHEC, NUI Galway, Ireland With acknowledgment to Michele MicheloDo
Fast Setup and Integration of ABAQUS on HPC Linux Cluster and the Study of Its Scalability
 Fast Setup and Integration of ABAQUS on HPC Linux Cluster and the Study of Its Scalability Betty Huang, Jeff Williams, Richard Xu Baker Hughes Incorporated Abstract: High-performance computing (HPC), the
Fast Setup and Integration of ABAQUS on HPC Linux Cluster and the Study of Its Scalability Betty Huang, Jeff Williams, Richard Xu Baker Hughes Incorporated Abstract: High-performance computing (HPC), the
Peter Senna Tschudin. Performance Overhead and Comparative Performance of 4 Virtualization Solutions. Version 1.29
 Peter Senna Tschudin Performance Overhead and Comparative Performance of 4 Virtualization Solutions Version 1.29 Table of Contents Project Description...4 Virtualization Concepts...4 Virtualization...4
Peter Senna Tschudin Performance Overhead and Comparative Performance of 4 Virtualization Solutions Version 1.29 Table of Contents Project Description...4 Virtualization Concepts...4 Virtualization...4
Performance Monitoring of Parallel Scientific Applications
 Performance Monitoring of Parallel Scientific Applications Abstract. David Skinner National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory This paper introduces an infrastructure
Performance Monitoring of Parallel Scientific Applications Abstract. David Skinner National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory This paper introduces an infrastructure
Performance of the Cloud-Based Commodity Cluster. School of Computer Science and Engineering, International University, Hochiminh City 70000, Vietnam
 Computer Technology and Application 4 (2013) 532-537 D DAVID PUBLISHING Performance of the Cloud-Based Commodity Cluster Van-Hau Pham, Duc-Cuong Nguyen and Tien-Dung Nguyen School of Computer Science and
Computer Technology and Application 4 (2013) 532-537 D DAVID PUBLISHING Performance of the Cloud-Based Commodity Cluster Van-Hau Pham, Duc-Cuong Nguyen and Tien-Dung Nguyen School of Computer Science and
Best Practices for Data Sharing in a Grid Distributed SAS Environment. Updated July 2010
 Best Practices for Data Sharing in a Grid Distributed SAS Environment Updated July 2010 B E S T P R A C T I C E D O C U M E N T Table of Contents 1 Abstract... 2 1.1 Storage performance is critical...
Best Practices for Data Sharing in a Grid Distributed SAS Environment Updated July 2010 B E S T P R A C T I C E D O C U M E N T Table of Contents 1 Abstract... 2 1.1 Storage performance is critical...
Cluster Scalability of ANSYS FLUENT 12 for a Large Aerodynamics Case on the Darwin Supercomputer
 Cluster Scalability of ANSYS FLUENT 12 for a Large Aerodynamics Case on the Darwin Supercomputer Stan Posey, MSc and Bill Loewe, PhD Panasas Inc., Fremont, CA, USA Paul Calleja, PhD University of Cambridge,
Cluster Scalability of ANSYS FLUENT 12 for a Large Aerodynamics Case on the Darwin Supercomputer Stan Posey, MSc and Bill Loewe, PhD Panasas Inc., Fremont, CA, USA Paul Calleja, PhD University of Cambridge,
Architecture of Hitachi SR-8000
 Architecture of Hitachi SR-8000 University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Most of the slides from Hitachi Slide 2 the problem modern computer are data
Architecture of Hitachi SR-8000 University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Most of the slides from Hitachi Slide 2 the problem modern computer are data