Introduction to Clustering
|
|
|
- Daisy Carroll
- 3 years ago
- Views:
From this document you will learn the answers to the following questions:
What is the k - nearest neighbour algorithm classify?
What does the k - nearest neighbour algorithm use to indicate label Y?
Transcription
1 1/57 Introduction to Clustering Mark Johnson Department of Computing Macquarie University

2 2/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary

3 3/57 Data for supervised and unsupervised learning In both supervised and unsupervised learning, goal is to map novel items to labels example 1: map names to their gender example 2: map documents to their topic example 3: maps words to their parts of speech The difference is the kind of training data used in supervised learning the training data contains the labels to be learnt example 1: input to supervised learner is [( Adam, male ), ( Eve, female ),...] in unsupervised learning the training data does not contain the labels to be learnt example 1: input to unsupervised learner is [ Adam, Eve,...]
,.")
4 4/57 Why is unsupervised learning important? Supervised learning requires labelled training data Manually labelling the training examples is often expensive and slow often labelled training data sets are very small Unsupervised learning uses unlabelled training data, which is often cheap and plentiful There are semi-supervised learning techniques which can take as input a labelled data set and an unlabelled data set usually the labelled data set is much smaller than the unlabelled data set these typically build on unsupervised learning techniques

5 5/57 The role of labels in unsupervised classification Training data for unsupervised classification does not contain labels Name-gender example: input is [ Adam, Eve, Ida,...] No way to learn the names of the labels (e.g., male, female ) but in e.g., document clustering, we can identify key words in documents in each cluster Use arbitrary identifiers as labels (e.g., integers) In name-gender example: output is [0, 1, 1,...] Since the unsupervised labels are arbitrary, all that matters is whether two data items have the same label or different labels
 In name-gender example: output is [0, 1, 1,.")
6 6/57 Unsupervised classification as clustering In unsupervised learning, the learner associates unlabelled items with labels from an arbitrary label set In name-gender example: input is [ Adam, Eve, Ida, Bill,...] and output is [0, 1, 1, 0,...] Since the labels are arbitrary, all they do is cluster items into groups To convert a labelling into a clustering, put all items with the same label into the same cluster items with label 0 form cluster Adam, Bill,... items with label 1 form cluster Eve, Ida,... Unsupervised classification is equivalent to clustering
![..] Since the labels are arbitrary, all they do is cluster items into groups To convert a labelling into a clustering, put all items with](/docs-images/49/17285090/images/page_6.jpg "the same label into the same cluster items with label 0 form cluster Adam, Bill,... items with label 1 form cluster Eve, Ida,.")
7 7/57 Truth in advertising about machine learning In supervised learning the labels in the training data tell the learner what to look for In unsupervised learning the learner tries to group items that look similiar the features and distance function are more important than in supervised learning Unsupervised learning often returns surprising results you might cluster names in the hope of automatically learning gender but the clusterer might group them by ethnicity instead! Supervised learning works faily reliably if you have good data usually most modern supervised classification algorithms have similiar performance too many features doesn t hurt (so long as there are some informative features) Unsupervised learning is much more uncertain different algorithms can produce very different results choice of features is extremely important

8 8/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary


9 Clustering news stories by topic 9/57
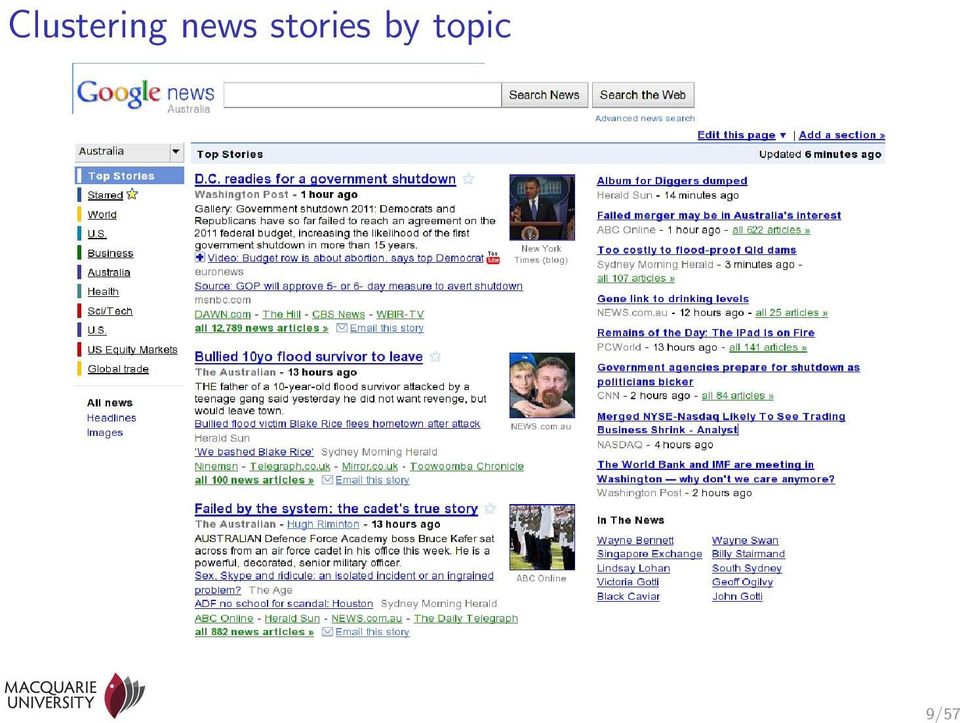
10 10/57 Document clustering and keyword identification Document clustering identifies thematically-similiar documents in a document collection news stories about the same topic in a collection of news stories tweets on related topics from a twitter feed scientific articles on related topics We can use key-word identification methods to identify the most characteristic words in each cluster treat each cluster as a giant meta-document (i.e., append all of the documents in a document cluster together) run Tf.Idf or similiar term-weighting program on the meta-documents to weight the words (and/or phrases) in the meta-documents identify the words and/or phrases with the highest scores in each meta-document use these high-scoring words and/or phrases as a label for the corresponding cluster
 in the meta-documents identify the words and/or phrases with the highest scores in each")
11 Clustering in search 11/57

12 12/57 Scatter-gather search Education Domestic Iraq Arts Sports Oil Germany Legal Scatter

13 12/57 Scatter-gather search Education Domestic Iraq Arts Sports Oil Germany Legal group of stories Gather

14 12/57 Scatter-gather search Education Domestic Iraq Arts Sports Oil Germany Legal group of stories ccupation Politics Germany Afghanistan Africa Markets Oil Pakistan Scatter

15 12/57 Scatter-gather search Education Domestic Iraq Arts Sports Oil Germany Legal group of stories ccupation Politics Germany Afghanistan Africa Markets Oil Pakistan smaller group of stories Gather

16 12/57 Scatter-gather search Education Domestic Iraq Arts Sports Oil Germany Legal group of stories ccupation Politics Germany Afghanistan Africa Markets Oil Pakistan smaller group of stories Trinidad W. Africa S. Africa Security Iraq Iran Nigeria Somalia Scatter

17 13/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary

18 14/57 Internal and external measures of clustering accuracy Internal measures: A clustering procedure should return a clustering where: all data items in the same cluster are very similiar (i.e., close to each other) if two data items come from different clusters, then the data items are different (i.e., distant from each other) External measures: Sometimes for evaluation we can obtain labels for (a subset of) the training data labels are not available to clustering program (i.e., clustering program is unsupervised) it s usually not reasonable to expect the clustering program to recover the labels but the labels define a clustering of the data items data items with the same label are assigned to the same cluster so all we can really do is compare the way that clustering program groups data items with the way the labels cluster data items

19 15/57 Confusion matrices Confusion matrices depict the relationship between two clusterings. Each cell shows the number of items in the cross product of the clusterings. They can sometimes help us understand just what a clustering has found. c1 c2 c3 c4 science romance politics news

20 16/57 Purity The purity of a clustering is the fraction of data items assigned to the majority label of each cluster. If n is the number of data items and C = (C 1,..., C m ) and C = (C 1,..., C m ) are two clusterings (partitions of the data items), then: c1 c2 c3 c4 science romance politics news purity(c, C ) = 1 n m max C j=1:m k C k=1 In this example, purity = 44/ j
 = 1 n m max C j=1:m k C k=1 In this example,")
21 17/57 The problem with purity Purity is the fraction of data items assigned to the majority label of each cluster If the clusters only contain a single data item, whatever label it happens to have will be the majority label of that cluster In one-item clusters, the data item in that cluster will have the majority label To produce a clustering algorithm that has perfect purity just assign each data item to its own cluster the number of clusters is the number of data items Purity is a useful measure if the number of clusters is fixed and much smaller than the number of data items
22 18/57 The Rand Index Developed by William Rand in 1971 to avoid problems with purity Central idea: given two data items x, x D, a clustering C either places them into the same cluster or places them into different clusters Given two clusterings C and C, the Rand Index R is the number of pairs x, x D that are classified the same way by C and C divided by the total number of pairs x, x D if a is the number of pairs x, x D that are in the same cluster in C and in the same cluster in C, and if b is the number of pairs x, x D that are in different clusters in C and in different clusters in C, and n = n(n 1)/2 is the number of pairs x, x D, then: R = a + b n
23 19/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary
24 20/57 Review: the k-nearest neighbour algorithm The k-nearest neighbour algorithm for supervised classification: To classify a data item x: item space X colour indicates label Y
25 20/57 Review: the k-nearest neighbour algorithm The k-nearest neighbour algorithm for supervised classification: To classify a data item x: item space X colour indicates label Y
26 20/57 Review: the k-nearest neighbour algorithm The k-nearest neighbour algorithm for supervised classification: To classify a data item x: set N to the k-nearest neighbours of x in D the k-nearest neighbours of x are the k training items in D with the smallest d(x, x ) values item space X colour indicates label Y
27 20/57 Review: the k-nearest neighbour algorithm The k-nearest neighbour algorithm for supervised classification: To classify a data item x: set N to the k-nearest neighbours of x in D the k-nearest neighbours of x are the k training items in D with the smallest d(x, x ) values count how often each label y appears in N item space X colour indicates label Y
28 20/57 Review: the k-nearest neighbour algorithm The k-nearest neighbour algorithm for supervised classification: To classify a data item x: set N to the k-nearest neighbours of x in D the k-nearest neighbours of x are the k training items in D with the smallest d(x, x ) values count how often each label y appears in N return the most frequent label y in the k-nearest neighbours N of x as the predicted label for x item space X colour indicates label Y
29 21/57 The k-nearest neighbour algorithm Let D be a labelled training data set: D = ((x 1, y 1 ),..., (x n, y n )) where each item x i X has label y i Y and let d be distance function, where d(x, x ) is the distance between two items x, x X Given a novel item x to label, the 1-nearest neighbour label ŷ(x ) is: ŷ(x) = argmin y Y min d(x, x ) x D y where for each y Y, D y is the multiset of the training data items labelled y, i.e., D y = {x : (x, y) D}
30 22/57 The difference between min and argmin The min of a set of values is the smallest value in a set If S = { Alpha, Beta, Gamma } and len(s) returns the length of string s then min len(s) = 4 s S The argmin of a function is the value that minimises that function argmin len(s) = Beta s S argmin can also be be used to find the location of the smallest value in a sequence If T = ( Alpha, Beta, Gamma ) then: argmin len(t i ) = 2 i 1:3 There are corresponding max and argmax functions as well
31 23/57 Python code for min and argmin Python has min and max functions: >>> xs = ( Alpha, Beta, Gamma ) >>> min(xs) Alpha with no arguments, min returns the smallest element in a sequence with respect to Python s default ordering Use comprehensions to compute more complex expressions >>> xs = ( Alpha, Beta, Gamma ) >>> min(len(x) for x in xs) 4 computes min s S len(s) where S = { Alpha, Beta, Gamma } Use the key argument to specify a function to compute argmin >>> xs = ( Alpha, Beta, Gamma ) >>> min(xs, key=len) Beta computes argmin s S len(s) where S = { Alpha, Beta, Gamma }
32 24/57 More fun with min and max To find the location or index of the smallest item in a sequence, use enumerate >>> xs = ( Gamma, Beta, Alpha ) >>> min(enumerate(xs), key=lambda ix: len(ix[1]))[0] 1 computes argmin i 0:n 1 len(x i ) where X = ( Gamma, Beta, Alpha )
33 25/57 Understanding argmin with enumerate enumerate generates pairs consisting of an index and an object >>> xs = ( Alpha, Beta, Gamma ) >>> enumerate(xs) <enumerate object at 0x7f536dd9d5f0> >>> list(enumerate(xs)) [(0, Alpha ), (1, Beta ), (2, Gamma )] lambda ix: len(ix[1]) maps a pair to the length of its second element >>> (lambda ix: len(ix[1]))( (1, Beta ) ) 4 min(enumerate(xs), key=lambda ix: ix[1]) returns the pair whose second element minimises the len function >>> min(enumerate(xs), key=lambda ix: len(ix[1])) (1, Beta )
34 26/57 Informal description of the k-means classification algorithm Note: this is not a serious classification algorithm. It is just a stepping stone to the k-means clustering algorithm. The k-means classification algorithm: At training time (i.e., when you have the training data D, but before you see any test data) Given training data D, let D y be subset of training data items with label y For each label y, let c y be the mean or centre of D y To classify a new test item x : for each cluster mean c y, compute d y = distance from c y to x return the y that minimises d y (i.e., the y such that x is closest to c y ) This classifier might not be too bad if the D y are well clustered
35 27/57 Graphical depiction of k-means classification algorithm At training time: item space X colour indicates label Y
36 27/57 Graphical depiction of k-means classification algorithm At training time: compute cluster means c y item space X colour indicates label Y
37 Graphical depiction of k-means classification algorithm At training time: compute cluster means c y At test time: To classify a new data item x : item space X colour indicates label Y 27/57
38 Graphical depiction of k-means classification algorithm At training time: compute cluster means c y At test time: To classify a new data item x : compute the distances d(c y, x ) from each cluster mean c y to x item space X colour indicates label Y 27/57
39 Graphical depiction of k-means classification algorithm At training time: compute cluster means c y At test time: To classify a new data item x : compute the distances d(c y, x ) from each cluster mean c y to x return the label y of the closest cluster mean c y to x item space X colour indicates label Y 27/57
40 28/57 The k-means classification algorithm Let D be a labelled training data set: D = ((x 1, y 1 ),..., (x n, y n )) where each item x i X has label y i Y and X is a real-valued vector space (i.e., the features have numeric values), and let d be a distance function as before For each y Y, let D y = {x : (x, y) D} For each y Y, let c y be the mean or centre of D y 1 c y = D y x D y x Given a novel item x X to label, the k-means classification algorithm returns: ŷ(x ) = argmin d(c y, x ) y Y
41 29/57 Review of set size and summation notation S is number of elements in the set S If S = {1, 3, 5, 7} then S = 4 If S = {v 1,..., v n } is a set (or a sequence) of elements v i that can be added then: v = v v n v S If S = {1, 3, 5, 7} then v S v = 16 If S = {(1, 2), (5, 4), (2, 2)} then v S v = (8, 8)
42 30/57 Set size and summation in Python len returns the size of a set sum returns the sum of the values of its arguments >>> S = set([1,5,10,20]) >>> S set([1, 10, 20, 5]) >>> len(s) 4 >>> sum(s) 36
43 31/57 Summing vectors in Python Python doesn t directly support vector arithmetic but specialised libraries like numpy do But it s easy to sum sequences of vectors >>> vectors = [(1,5), (2,7), (4,9)] >>> [sum(vector) for vector in zip(*vectors)] [7, 21] >>> zip(*vectors) [(1, 2, 4), (5, 7, 9)]
44 32/57 Using Python s Counter class to count >>> import collections >>> cntr = collections.counter([ a, b, r, a ]) >>> cntr Counter({ a : 2, r : 1, b : 1}) >>> cntr[ b ] 1 >>> cntr[ 0 ] += 1 >>> cntr Counter({ a : 2, 0 : 1, r : 1, b : 1}) >>> cntr.update([ E, E, N, I, E ]) >>> cntr Counter({ E : 3, a : 2, b : 1, I : 1, N : 1, 0 : 1, r : 1}) >>> cntr.most_common(2) [( E, 3), ( a, 2)]
45 33/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary
46 34/57 Informal description of k-means clustering The k-means clustering algorithm is an iterative algorithm that reassigns data items to clusters at each iteration
47 34/57 Informal description of k-means clustering The k-means clustering algorithm is an iterative algorithm that reassigns data items to clusters at each iteration initialise the k cluster centres c 1,..., c k somehow repeat until done: clear the clusters C 1,..., C k for each training data item x: find the closest cluster center c j to x add x to cluster C j for each cluster C j : set c j to the mean or centre of cluster C j
48 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data item space X colours show clusters
49 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data Initialise cluster centers somehow item space X colours show clusters
50 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data Initialise cluster centers somehow Move each data item into closest cluster item space X colours show clusters
51 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data Initialise cluster centers somehow Move each data item into closest cluster Move cluster centres to mean of data items in cluster item space X colours show clusters
52 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data Initialise cluster centers somehow Move each data item into closest cluster Move cluster centres to mean of data items in cluster Move each data item into closest cluster item space X colours show clusters
53 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data Initialise cluster centers somehow Move each data item into closest cluster Move cluster centres to mean of data items in cluster Move each data item into closest cluster Move cluster centres to mean of data items in cluster item space X colours show clusters
54 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data Initialise cluster centers somehow Move each data item into closest cluster Move cluster centres to mean of data items in cluster Move each data item into closest cluster Move cluster centres to mean of data items in cluster Move each data item into closest cluster item space X colours show clusters
55 35/57 Graphical depiction of k-means clustering algorithm Unlabelled training data Initialise cluster centers somehow Move each data item into closest cluster Move cluster centres to mean of data items in cluster Move each data item into closest cluster Move cluster centres to mean of data items in cluster Move each data item into closest cluster No data items moved clusters, so we re done item space X colours show clusters
56 36/57 The k-means clustering algorithm Input to k-means clustering algorithm: Unlabelled training data D = (x1,..., x n ), where each x i X a distance function d, where d(x, x ) is the distance between x, x X the number of clusters k K-means clustering algorithm: Initialise cluster centres c j, for j = 1,..., k while not converged: C j =, for j = 1,..., k for i = 1,..., n: j = argmin j 1,...,k d(c j, x i ) add x i to C j for j = 1,..., k: set c j = mean(c j )
57 37/57 Initialising the k-means algorithm How the initial cluster centres are chosen makes a big difference to the clusters produced by the k-means algorithm There are many different initialisation strategies A simple and commonly-used strategy: pick k different items from the training data at random initialise cluster centre c j to the j randomly-chosen item Random initialisation each run produces different clusters Simple initialisation strategies (like this) can result in isolated 1-item clusters Unfortunately even complicated initialisation strategies have draw-backs
58 38/57 Determining convergence of the k-means algorithm Tracing the the number of items moved from one cluster to another, and the intra-cluster distance S S = d(c i, x) i=1,...,k x C i is a good way to monitor convergence. these usually drops quickly with the first few iterations and change very slowly after that Often after enough iterations no data items are reassigned from one cluster to another further iterations will not change cluster assignments the algorithm has converged Unfortunately the k-means algorithm only converges to a local optimum, which in general is not the global optimum
59 39/57 Clustering as an optimisation problem The intra-cluster distance S (distance from data items to their cluster centres) measures how well the cluster centres describe the data S = d(c i, x) i=1,...,k x C i The clusters C i are determined by the cluster centers c i and the data D = (x 1,..., x n ) Goal of clustering: find cluster centres c = (c 1,..., c k ) that minimise the intra-cluster distance ĉ = argmin c = argmin c S i=1,...,k x C i d(c i, x) The k-means algorithm is a way of finding cluster centres c that approximately minimise the the intra-cluster distance S
60 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) z
61 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) local min. local min. z
62 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) global min. z
63 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) z
64 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) z
65 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) z
66 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) z
67 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) z
68 40/57 Global and local optima in optimisation problems Machine learning algorithms like k-means involve solving an optimisation problem these are usually multi-dimensional the graph here only shows 1 dimension There can be several local minima But only one global minimum Iterative optimisation algorithms often are attracted into the closest basin of attraction f (z) z
69 41/57 K-means clustering in Python class kmeans_clusters: def init (self, data, k, max_iterations, meanf, distf): self.data = data self.meanf = meanf self.distf = distf self.k = k self.initial_assignment_of_data_to_clusters() for iteration in xrange(max_iterations): self.compute_cluster_centres() nchanged = self.assign_data_to_closest_clusters() if nchanged == 0: break
70 42/57 Initialising k-means clustering in Python In class kmeans_clusters: def initial_assignment_of_data_to_clusters(self): self.cluster_centres = random.sample(self.data, self.k) self.cids = [self.closest_cluster(item) for item in self.data] def closest_cluster(self, item): distances = [self.distf(centre, item) for centre in self.cluster_centres] closest = min(xrange(self.k), key=lambda j:distances[j]) return closest self.cluster_centres is a list of the k cluster centers self.cids is a list of the cluster ids (integers that index into self.cluser_centres You ll also need an import random statement at the start of your code
71 43/57 Computing cluster centres in Python In class kmeans_clusters: def compute_cluster_centres(self): self.cluster_centres = [self.meanf([item for item,cid in zip(self.data,self.cids) if cid == id]) for id in xrange(self.k)] This uses the user-supplied function meanf to compute the mean or the centre of a set of data items
72 44/57 Updating the clusters in Python In class kmeans_clusters: def assign_data_to_closest_clusters(self): old_cids = self.cids self.cids = [] nchanged = 0 for i in xrange(len(self.data)): cid = self.closest_cluster(self.data[i]) self.cids.append(cid) if cid!= old_cids[i]: nchanged += 1 return nchanged
73 45/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary
74 46/57 Document clustering Input: a collection of documents we ll use all 500 documents in nltk.corpus.brown these are classified into news, popular fiction, etc. the k-means clusterer won t see these classes... but we ll use them to evaluate its output We need to provide: a distance function and a mean function that computes the centre of a document cluster We ll use a bag of words representation for each document each document is represented by a dictionary mapping words to their frequency counts for computational efficiency we ll only use a subset of the vocabulary
75 47/57 Finding the keywords import random, re import nltk, nltk.corpus word_rex = re.compile(r"^[a-za-z]+$") def compute_keywords(corpus, nwords): cntr = collections.counter(w.lower() for w in corpus.words() if word_rex.match(w)) return set(word for word,count in cntr.most_common(nwords)) The clusters that the algorithm finds depend on which features it uses compute_keywords(corpus, 1000) returns a set containing the the 1,000th most frequent words We ll use these words as features
76 48/57 Mapping fileids to word-frequencies def fileid_featurevalues(corpus, fileid, keywords): cntr = collections.counter(w.lower() for w in corpus.words(fileid) if word_rex.match(w) and w.lower() in keywords) return cntr This returns a dictionary mapping words to their frequencies in document specified by fileid This is a sparse representation of word frequencies words with zero frequency are not present in the dictionary
77 49/57 Distance between two word-frequency dictionaries def sparse_sum_squared_differences(key_val1, key_val2): keys = set(key_val1.iterkeys()) set(key_val2.iterkeys()) return sum(pow(key_val1.get(key,0) - key_val2.get(key,0), 2) for key in keys) key_val1 and key_val2 are two dictionaries mapping words to their frequencies they represent different documents keys is a set containing the union of their keys The result is the sum of the square of the differences in the frequencies
78 50/57 Calculating the cluster means def sparse_means(key_vals): keys = set() keys.update(*(key_val.iterkeys() for key_val in key_vals)) n = len(key_vals)+1e-100 key_meanval = {} for key in keys: key_meanval[key] = sum(key_val.get(key,0) for key_val in key_vals)/n return key_meanval key_vals is a list of word-frequency dictionaries keys is a set containing the union of the keys in key_vals n is the number of word-frequency dictionaries in key_vals key_meanval is a dictionary mapping each key to its mean value
79 51/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary
80 52/57 Numerical features in machine learning The k-means algorithms (and many other machine learning algorithms) require features to have numerical values In many applications, features naturally take categorical values in name-gender application, the suffix1 feature takes 1-letter values and the suffix2 feature takes 2-letter values gender features( Christiana ) = { suffix1 : a, suffix2 : na } We ll re-express these category-valued features as vectors of Boolean-valued features Boolean-valued features are numeric if we treat False = 0 and True = 1 A feature f can be viewed as a function from items X to feature values V (for Boolean features, V = {0, 1}) suffix1( Cynthia ) = a
81 53/57 Re-expressing a categorical feature using Boolean features Suppose a categorical feature f ranges over values V = {v 1,..., v m } Example: suffix1 ranges over { a,..., z } We re-express a categorical feature pair f with a vector b = (b 1,..., b m ) of m Boolean-valued features If x X is a data item then: f (x) = v j b j (x) = 1 Example: If suffix1 : e is a feature-value pair for an item then: b = ( 0,..., 0, 1, 0,..., 0 ) a d e f z This is called a one-hot encoding of the feature Question: how are the suffix2 features expressed as Boolean features?
82 54/57 Multiple categorical features as Boolean features Each categorical feature can be represented as a vector of Boolean features To represent several categorical features, concatenate the vectors of Boolean features that represent them Example: b = (0,..., 0, 1, 0,..., 0, 0,..., 0, 1, 0,..., 0) } {{ } } {{ } suffix1 suffix2
83 55/57 Representations for sparse numerical features A set of features is sparse if most features have value 0 when categorical features are converted to binary features, all but one binary feature has value 0 the resulting binary feature vectors are sparse Representing very sparse feature vectors as as standard arrays wastes space and time Idea: only store features whose value is non-zero Represent sparse feature vectors as a set of feature:value pairs for each feature that has a non-zero value if a feature is not represented, its value is zero Example: gender features( Christiana ) = { suffix1=a :1, suffix2=na :1}
84 56/57 Outline Supervised versus unsupervised learning Applications of clustering in text processing Evaluating clustering algorithms Background for the k-means algorithm The k-means clustering algorithm Document clustering with k-means clustering Numerical features in machine learning Summary
85 57/57 Summary Supervised versus unsupervised learning unsupervised learning is generally far more challenging Unsupervised learning as clustering The k-means clustering algorithm Confusion matrices as ways of comparing two clusterings Evaluating clustering is difficult cluster purity and its problems the Rand index The difference between local and global optima, and the problems this causes for unsupervised learning
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING)
 LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING)") ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING) Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Preliminaries Classification and Clustering Applications
ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING) Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Preliminaries Classification and Clustering Applications
K-Means Clustering Tutorial
 K-Means Clustering Tutorial By Kardi Teknomo,PhD Preferable reference for this tutorial is Teknomo, Kardi. K-Means Clustering Tutorials. http:\\people.revoledu.com\kardi\ tutorial\kmean\ Last Update: July
K-Means Clustering Tutorial By Kardi Teknomo,PhD Preferable reference for this tutorial is Teknomo, Kardi. K-Means Clustering Tutorials. http:\\people.revoledu.com\kardi\ tutorial\kmean\ Last Update: July
Classification algorithm in Data mining: An Overview
 Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Unsupervised learning: Clustering
 Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Introduction to Support Vector Machines. Colin Campbell, Bristol University
 Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization
 A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland
 State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland") Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
Cluster Analysis. Isabel M. Rodrigues. Lisboa, 2014. Instituto Superior Técnico
 Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Unsupervised Learning and Data Mining. Unsupervised Learning and Data Mining. Clustering. Supervised Learning. Supervised Learning
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS
 UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 dcmishra@iasri.res.in What is Learning? "Learning denotes changes in a system that enable
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 dcmishra@iasri.res.in What is Learning? "Learning denotes changes in a system that enable
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus
 Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Clustering UE 141 Spring 2013
 Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
An Introduction to Data Mining. Big Data World. Related Fields and Disciplines. What is Data Mining? 2/12/2015
 An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
MACHINE LEARNING IN HIGH ENERGY PHYSICS
 MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Text Clustering Using LucidWorks and Apache Mahout
 Text Clustering Using LucidWorks and Apache Mahout (Nov. 17, 2012) 1. Module name Text Clustering Using Lucidworks and Apache Mahout 2. Scope This module introduces algorithms and evaluation metrics for
Text Clustering Using LucidWorks and Apache Mahout (Nov. 17, 2012) 1. Module name Text Clustering Using Lucidworks and Apache Mahout 2. Scope This module introduces algorithms and evaluation metrics for
Performance Metrics for Graph Mining Tasks
 Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
dedupe Documentation Release 1.0.0 Forest Gregg, Derek Eder, and contributors
 dedupe Documentation Release 1.0.0 Forest Gregg, Derek Eder, and contributors January 04, 2016 Contents 1 Important links 3 2 Contents 5 2.1 API Documentation...........................................
dedupe Documentation Release 1.0.0 Forest Gregg, Derek Eder, and contributors January 04, 2016 Contents 1 Important links 3 2 Contents 5 2.1 API Documentation...........................................
Medical Information Management & Mining. You Chen Jan,15, 2013 You.chen@vanderbilt.edu
 Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
How To Solve The Cluster Algorithm
 Cluster Algorithms Adriano Cruz adriano@nce.ufrj.br 28 de outubro de 2013 Adriano Cruz adriano@nce.ufrj.br () Cluster Algorithms 28 de outubro de 2013 1 / 80 Summary 1 K-Means Adriano Cruz adriano@nce.ufrj.br
Cluster Algorithms Adriano Cruz adriano@nce.ufrj.br 28 de outubro de 2013 Adriano Cruz adriano@nce.ufrj.br () Cluster Algorithms 28 de outubro de 2013 1 / 80 Summary 1 K-Means Adriano Cruz adriano@nce.ufrj.br
There are a number of different methods that can be used to carry out a cluster analysis; these methods can be classified as follows:
 Statistics: Rosie Cornish. 2007. 3.1 Cluster Analysis 1 Introduction This handout is designed to provide only a brief introduction to cluster analysis and how it is done. Books giving further details are
Statistics: Rosie Cornish. 2007. 3.1 Cluster Analysis 1 Introduction This handout is designed to provide only a brief introduction to cluster analysis and how it is done. Books giving further details are
THREE DIMENSIONAL REPRESENTATION OF AMINO ACID CHARAC- TERISTICS
 THREE DIMENSIONAL REPRESENTATION OF AMINO ACID CHARAC- TERISTICS O.U. Sezerman 1, R. Islamaj 2, E. Alpaydin 2 1 Laborotory of Computational Biology, Sabancı University, Istanbul, Turkey. 2 Computer Engineering
THREE DIMENSIONAL REPRESENTATION OF AMINO ACID CHARAC- TERISTICS O.U. Sezerman 1, R. Islamaj 2, E. Alpaydin 2 1 Laborotory of Computational Biology, Sabancı University, Istanbul, Turkey. 2 Computer Engineering
Standardization and Its Effects on K-Means Clustering Algorithm
 Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
NLP Lab Session Week 3 Bigram Frequencies and Mutual Information Scores in NLTK September 16, 2015
 NLP Lab Session Week 3 Bigram Frequencies and Mutual Information Scores in NLTK September 16, 2015 Starting a Python and an NLTK Session Open a Python 2.7 IDLE (Python GUI) window or a Python interpreter
NLP Lab Session Week 3 Bigram Frequencies and Mutual Information Scores in NLTK September 16, 2015 Starting a Python and an NLTK Session Open a Python 2.7 IDLE (Python GUI) window or a Python interpreter
Python Loops and String Manipulation
 WEEK TWO Python Loops and String Manipulation Last week, we showed you some basic Python programming and gave you some intriguing problems to solve. But it is hard to do anything really exciting until
WEEK TWO Python Loops and String Manipulation Last week, we showed you some basic Python programming and gave you some intriguing problems to solve. But it is hard to do anything really exciting until
Course: Model, Learning, and Inference: Lecture 5
 Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 yuille@stat.ucla.edu Abstract Probability distributions on structured representation.
Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 yuille@stat.ucla.edu Abstract Probability distributions on structured representation.
Practical Graph Mining with R. 5. Link Analysis
 Practical Graph Mining with R 5. Link Analysis Outline Link Analysis Concepts Metrics for Analyzing Networks PageRank HITS Link Prediction 2 Link Analysis Concepts Link A relationship between two entities
Practical Graph Mining with R 5. Link Analysis Outline Link Analysis Concepts Metrics for Analyzing Networks PageRank HITS Link Prediction 2 Link Analysis Concepts Link A relationship between two entities
Categorical Data Visualization and Clustering Using Subjective Factors
 Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
How To Make A Credit Risk Model For A Bank Account
 TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző csaba.fozo@lloydsbanking.com 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző csaba.fozo@lloydsbanking.com 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
Machine Learning: Overview
 Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
Machine Learning. CUNY Graduate Center, Spring 2013. Professor Liang Huang. huang@cs.qc.cuny.edu
 Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
Data Mining Clustering (2) Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining
 Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining") Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining and Visualization
 Data Mining and Visualization Jeremy Walton NAG Ltd, Oxford Overview Data mining components Functionality Example application Quality control Visualization Use of 3D Example application Market research
Data Mining and Visualization Jeremy Walton NAG Ltd, Oxford Overview Data mining components Functionality Example application Quality control Visualization Use of 3D Example application Market research
Introduction to Machine Learning Using Python. Vikram Kamath
 Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Big Data & Scripting Part II Streaming Algorithms
 Big Data & Scripting Part II Streaming Algorithms 1, 2, a note on sampling and filtering sampling: (randomly) choose a representative subset filtering: given some criterion (e.g. membership in a set),
Big Data & Scripting Part II Streaming Algorithms 1, 2, a note on sampling and filtering sampling: (randomly) choose a representative subset filtering: given some criterion (e.g. membership in a set),
D-optimal plans in observational studies
 D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
Practical Introduction to Machine Learning and Optimization. Alessio Signorini <alessio.signorini@oneriot.com>
 Practical Introduction to Machine Learning and Optimization Alessio Signorini Everyday's Optimizations Although you may not know, everybody uses daily some sort of optimization
Practical Introduction to Machine Learning and Optimization Alessio Signorini Everyday's Optimizations Although you may not know, everybody uses daily some sort of optimization
Data, Measurements, Features
 Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Programming Using Python
 Introduction to Computation and Programming Using Python Revised and Expanded Edition John V. Guttag The MIT Press Cambridge, Massachusetts London, England CONTENTS PREFACE xiii ACKNOWLEDGMENTS xv 1 GETTING
Introduction to Computation and Programming Using Python Revised and Expanded Edition John V. Guttag The MIT Press Cambridge, Massachusetts London, England CONTENTS PREFACE xiii ACKNOWLEDGMENTS xv 1 GETTING
Distances between Clustering, Hierarchical Clustering
 Distances between Clustering, Hierarchical Clustering 36-350, Data Mining 14 September 2009 Contents 1 Distances Between Partitions 1 2 Hierarchical clustering 2 2.1 Ward s method............................
Distances between Clustering, Hierarchical Clustering 36-350, Data Mining 14 September 2009 Contents 1 Distances Between Partitions 1 2 Hierarchical clustering 2 2.1 Ward s method............................
Car Insurance. Jan Tomášek Štěpán Havránek Michal Pokorný
 Car Insurance Jan Tomášek Štěpán Havránek Michal Pokorný Competition details Jan Tomášek Official text As a customer shops an insurance policy, he/she will receive a number of quotes with different coverage
Car Insurance Jan Tomášek Štěpán Havránek Michal Pokorný Competition details Jan Tomášek Official text As a customer shops an insurance policy, he/she will receive a number of quotes with different coverage
Lecture 3: Linear methods for classification
 Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Programming Exercise 3: Multi-class Classification and Neural Networks
 Programming Exercise 3: Multi-class Classification and Neural Networks Machine Learning November 4, 2011 Introduction In this exercise, you will implement one-vs-all logistic regression and neural networks
Programming Exercise 3: Multi-class Classification and Neural Networks Machine Learning November 4, 2011 Introduction In this exercise, you will implement one-vs-all logistic regression and neural networks
Sibyl: a system for large scale machine learning
 Sibyl: a system for large scale machine learning Tushar Chandra, Eugene Ie, Kenneth Goldman, Tomas Lloret Llinares, Jim McFadden, Fernando Pereira, Joshua Redstone, Tal Shaked, Yoram Singer Machine Learning
Sibyl: a system for large scale machine learning Tushar Chandra, Eugene Ie, Kenneth Goldman, Tomas Lloret Llinares, Jim McFadden, Fernando Pereira, Joshua Redstone, Tal Shaked, Yoram Singer Machine Learning
Introduction to Learning & Decision Trees
 Artificial Intelligence: Representation and Problem Solving 5-38 April 0, 2007 Introduction to Learning & Decision Trees Learning and Decision Trees to learning What is learning? - more than just memorizing
Artificial Intelligence: Representation and Problem Solving 5-38 April 0, 2007 Introduction to Learning & Decision Trees Learning and Decision Trees to learning What is learning? - more than just memorizing
Machine Learning. Chapter 18, 21. Some material adopted from notes by Chuck Dyer
 Machine Learning Chapter 18, 21 Some material adopted from notes by Chuck Dyer What is learning? Learning denotes changes in a system that... enable a system to do the same task more efficiently the next
Machine Learning Chapter 18, 21 Some material adopted from notes by Chuck Dyer What is learning? Learning denotes changes in a system that... enable a system to do the same task more efficiently the next
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
F. Aiolli - Sistemi Informativi 2007/2008
 Text Categorization Text categorization (TC - aka text classification) is the task of buiding text classifiers, i.e. sofware systems that classify documents from a domain D into a given, fixed set C =
Text Categorization Text categorization (TC - aka text classification) is the task of buiding text classifiers, i.e. sofware systems that classify documents from a domain D into a given, fixed set C =
Why? A central concept in Computer Science. Algorithms are ubiquitous.
 Analysis of Algorithms: A Brief Introduction Why? A central concept in Computer Science. Algorithms are ubiquitous. Using the Internet (sending email, transferring files, use of search engines, online
Analysis of Algorithms: A Brief Introduction Why? A central concept in Computer Science. Algorithms are ubiquitous. Using the Internet (sending email, transferring files, use of search engines, online
Intro to scientific programming (with Python) Pietro Berkes, Brandeis University
 Pietro Berkes, Brandeis University") Intro to scientific programming (with Python) Pietro Berkes, Brandeis University Next 4 lessons: Outline Scientific programming: best practices Classical learning (Hoepfield network) Probabilistic learning
Intro to scientific programming (with Python) Pietro Berkes, Brandeis University Next 4 lessons: Outline Scientific programming: best practices Classical learning (Hoepfield network) Probabilistic learning
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Analytics on Big Data
 Analytics on Big Data Riccardo Torlone Università Roma Tre Credits: Mohamed Eltabakh (WPI) Analytics The discovery and communication of meaningful patterns in data (Wikipedia) It relies on data analysis
Analytics on Big Data Riccardo Torlone Università Roma Tre Credits: Mohamed Eltabakh (WPI) Analytics The discovery and communication of meaningful patterns in data (Wikipedia) It relies on data analysis
Data Mining Algorithms Part 1. Dejan Sarka
 Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Open Access Research on Application of Neural Network in Computer Network Security Evaluation. Shujuan Jin *
 Send Orders for Reprints to reprints@benthamscience.ae 766 The Open Electrical & Electronic Engineering Journal, 2014, 8, 766-771 Open Access Research on Application of Neural Network in Computer Network
Send Orders for Reprints to reprints@benthamscience.ae 766 The Open Electrical & Electronic Engineering Journal, 2014, 8, 766-771 Open Access Research on Application of Neural Network in Computer Network
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Example: Document Clustering. Clustering: Definition. Notion of a Cluster can be Ambiguous. Types of Clusterings. Hierarchical Clustering
 Overview Prognostic Models and Data Mining in Medicine, part I Cluster Analsis What is Cluster Analsis? K-Means Clustering Hierarchical Clustering Cluster Validit Eample: Microarra data analsis 6 Summar
Overview Prognostic Models and Data Mining in Medicine, part I Cluster Analsis What is Cluster Analsis? K-Means Clustering Hierarchical Clustering Cluster Validit Eample: Microarra data analsis 6 Summar
An Introduction to APGL
 An Introduction to APGL Charanpal Dhanjal February 2012 Abstract Another Python Graph Library (APGL) is a graph library written using pure Python, NumPy and SciPy. Users new to the library can gain an
An Introduction to APGL Charanpal Dhanjal February 2012 Abstract Another Python Graph Library (APGL) is a graph library written using pure Python, NumPy and SciPy. Users new to the library can gain an
Hadoop SNS. renren.com. Saturday, December 3, 11
 Hadoop SNS renren.com Saturday, December 3, 11 2.2 190 40 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December
Hadoop SNS renren.com Saturday, December 3, 11 2.2 190 40 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December
CHAPTER 2 Estimating Probabilities
 CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2016. Tom M. Mitchell. All rights reserved. *DRAFT OF January 24, 2016* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is a
CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2016. Tom M. Mitchell. All rights reserved. *DRAFT OF January 24, 2016* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is a
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 10 th, 2013 Wolf-Tilo Balke and Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 10 th, 2013 Wolf-Tilo Balke and Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig
Why is Internal Audit so Hard?
 Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
IBM SPSS Direct Marketing 23
 IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
Applied Algorithm Design Lecture 5
 Applied Algorithm Design Lecture 5 Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Applied Algorithm Design Lecture 5 1 / 86 Approximation Algorithms Pietro Michiardi (Eurecom) Applied Algorithm Design
Applied Algorithm Design Lecture 5 Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Applied Algorithm Design Lecture 5 1 / 86 Approximation Algorithms Pietro Michiardi (Eurecom) Applied Algorithm Design
Data Mining Individual Assignment report
 Björn Þór Jónsson bjrr@itu.dk Data Mining Individual Assignment report This report outlines the implementation and results gained from the Data Mining methods of preprocessing, supervised learning, frequent
Björn Þór Jónsson bjrr@itu.dk Data Mining Individual Assignment report This report outlines the implementation and results gained from the Data Mining methods of preprocessing, supervised learning, frequent
Classification Techniques (1)
") 10 10 Overview Classification Techniques (1) Today Classification Problem Classification based on Regression Distance-based Classification (KNN) Net Lecture Decision Trees Classification using Rules Quality
10 10 Overview Classification Techniques (1) Today Classification Problem Classification based on Regression Distance-based Classification (KNN) Net Lecture Decision Trees Classification using Rules Quality
How can we discover stocks that will
 Algorithmic Trading Strategy Based On Massive Data Mining Haoming Li, Zhijun Yang and Tianlun Li Stanford University Abstract We believe that there is useful information hiding behind the noisy and massive
Algorithmic Trading Strategy Based On Massive Data Mining Haoming Li, Zhijun Yang and Tianlun Li Stanford University Abstract We believe that there is useful information hiding behind the noisy and massive
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr
 Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Introduction to Clustering
 Introduction to Clustering Yumi Kondo Student Seminar LSK301 Sep 25, 2010 Yumi Kondo (University of British Columbia) Introduction to Clustering Sep 25, 2010 1 / 36 Microarray Example N=65 P=1756 Yumi
Introduction to Clustering Yumi Kondo Student Seminar LSK301 Sep 25, 2010 Yumi Kondo (University of British Columbia) Introduction to Clustering Sep 25, 2010 1 / 36 Microarray Example N=65 P=1756 Yumi
Engineering Problem Solving and Excel. EGN 1006 Introduction to Engineering
 Engineering Problem Solving and Excel EGN 1006 Introduction to Engineering Mathematical Solution Procedures Commonly Used in Engineering Analysis Data Analysis Techniques (Statistics) Curve Fitting techniques
Engineering Problem Solving and Excel EGN 1006 Introduction to Engineering Mathematical Solution Procedures Commonly Used in Engineering Analysis Data Analysis Techniques (Statistics) Curve Fitting techniques
Mining Social-Network Graphs
 342 Chapter 10 Mining Social-Network Graphs There is much information to be gained by analyzing the large-scale data that is derived from social networks. The best-known example of a social network is
342 Chapter 10 Mining Social-Network Graphs There is much information to be gained by analyzing the large-scale data that is derived from social networks. The best-known example of a social network is
Hadoop Design and k-means Clustering
 Hadoop Design and k-means Clustering Kenneth Heafield Google Inc January 15, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise
Hadoop Design and k-means Clustering Kenneth Heafield Google Inc January 15, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise
IBM SPSS Direct Marketing 22
 IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
Package HPdcluster. R topics documented: May 29, 2015
 Type Package Title Distributed Clustering for Big Data Version 1.1.0 Date 2015-04-17 Author HP Vertica Analytics Team Package HPdcluster May 29, 2015 Maintainer HP Vertica Analytics Team
Type Package Title Distributed Clustering for Big Data Version 1.1.0 Date 2015-04-17 Author HP Vertica Analytics Team Package HPdcluster May 29, 2015 Maintainer HP Vertica Analytics Team
Chapter 11. 11.1 Load Balancing. Approximation Algorithms. Load Balancing. Load Balancing on 2 Machines. Load Balancing: Greedy Scheduling
 Approximation Algorithms Chapter Approximation Algorithms Q. Suppose I need to solve an NP-hard problem. What should I do? A. Theory says you're unlikely to find a poly-time algorithm. Must sacrifice one
Approximation Algorithms Chapter Approximation Algorithms Q. Suppose I need to solve an NP-hard problem. What should I do? A. Theory says you're unlikely to find a poly-time algorithm. Must sacrifice one
Role of Neural network in data mining
 Role of Neural network in data mining Chitranjanjit kaur Associate Prof Guru Nanak College, Sukhchainana Phagwara,(GNDU) Punjab, India Pooja kapoor Associate Prof Swami Sarvanand Group Of Institutes Dinanagar(PTU)
Role of Neural network in data mining Chitranjanjit kaur Associate Prof Guru Nanak College, Sukhchainana Phagwara,(GNDU) Punjab, India Pooja kapoor Associate Prof Swami Sarvanand Group Of Institutes Dinanagar(PTU)
Self Organizing Maps: Fundamentals
 Self Organizing Maps: Fundamentals Introduction to Neural Networks : Lecture 16 John A. Bullinaria, 2004 1. What is a Self Organizing Map? 2. Topographic Maps 3. Setting up a Self Organizing Map 4. Kohonen
Self Organizing Maps: Fundamentals Introduction to Neural Networks : Lecture 16 John A. Bullinaria, 2004 1. What is a Self Organizing Map? 2. Topographic Maps 3. Setting up a Self Organizing Map 4. Kohonen
Data Intensive Computing Handout 6 Hadoop
 Data Intensive Computing Handout 6 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Data Intensive Computing Handout 6 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Lecture 10: Regression Trees
 Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Recognition. Sanja Fidler CSC420: Intro to Image Understanding 1 / 28
 Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING. ----Changsheng Liu 10-30-2014
 LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
Package dsmodellingclient
 Package dsmodellingclient Maintainer Author Version 4.1.0 License GPL-3 August 20, 2015 Title DataSHIELD client site functions for statistical modelling DataSHIELD
Package dsmodellingclient Maintainer Author Version 4.1.0 License GPL-3 August 20, 2015 Title DataSHIELD client site functions for statistical modelling DataSHIELD
Data Mining Essentials
 This chapter is from Social Media Mining: An Introduction. By Reza Zafarani, Mohammad Ali Abbasi, and Huan Liu. Cambridge University Press, 2014. Draft version: April 20, 2014. Complete Draft and Slides
This chapter is from Social Media Mining: An Introduction. By Reza Zafarani, Mohammad Ali Abbasi, and Huan Liu. Cambridge University Press, 2014. Draft version: April 20, 2014. Complete Draft and Slides
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
CI6227: Data Mining. Lesson 11b: Ensemble Learning. Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore.
 CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
Chapter 10: Network Flow Programming
 Chapter 10: Network Flow Programming Linear programming, that amazingly useful technique, is about to resurface: many network problems are actually just special forms of linear programs! This includes,
Chapter 10: Network Flow Programming Linear programming, that amazingly useful technique, is about to resurface: many network problems are actually just special forms of linear programs! This includes,
Monday Morning Data Mining
 Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik
Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik