A Crash course to (The) Bighouse
|
|
|
- Harold Blankenship
- 10 years ago
- Views:
Transcription
1 A Crash course to (The) Bighouse Brock Palen SVTI Users meeting Sep 20th

2 Outline 1 Resources Configuration Hardware 2 Architecture ccnuma Altix 4700 Brick 3 Software Packaged Software Compiled Code 4 PBS PBS Queues

3 Hardware: bighouse Bighouse bighouse is our Itanium SMP machine; Login: bighouse.engin.umich.edu Shares nyx s 6TB NFS file system Running SUsE Linux Enterprise Server 10 ProPack 5 from SGI

4 Bighouse Hardware Current Hardware 16 CPU, 32 core Intel Itanium II s Measured 5.5 Gflop/cpu running 4 way Gflop running 32 way 96 GB Ram Max 41 GB/s Aggregate Memory bandwidth

5 Bighouse Hardware Current Hardware 16 CPU, 32 core Intel Itanium II s Measured 5.5 Gflop/cpu running 4 way Gflop running 32 way 96 GB Ram Max 41 GB/s Aggregate Memory bandwidth

6 Bighouse Hardware Current Hardware 16 CPU, 32 core Intel Itanium II s Measured 5.5 Gflop/cpu running 4 way Gflop running 32 way 96 GB Ram Max 41 GB/s Aggregate Memory bandwidth

7 Bighouse Hardware Current Hardware 16 CPU, 32 core Intel Itanium II s Measured 5.5 Gflop/cpu running 4 way Gflop running 32 way 96 GB Ram Max 41 GB/s Aggregate Memory bandwidth

8 Bighouse Hardware Current Hardware 16 CPU, 32 core Intel Itanium II s Measured 5.5 Gflop/cpu running 4 way Gflop running 32 way 96 GB Ram Max 41 GB/s Aggregate Memory bandwidth


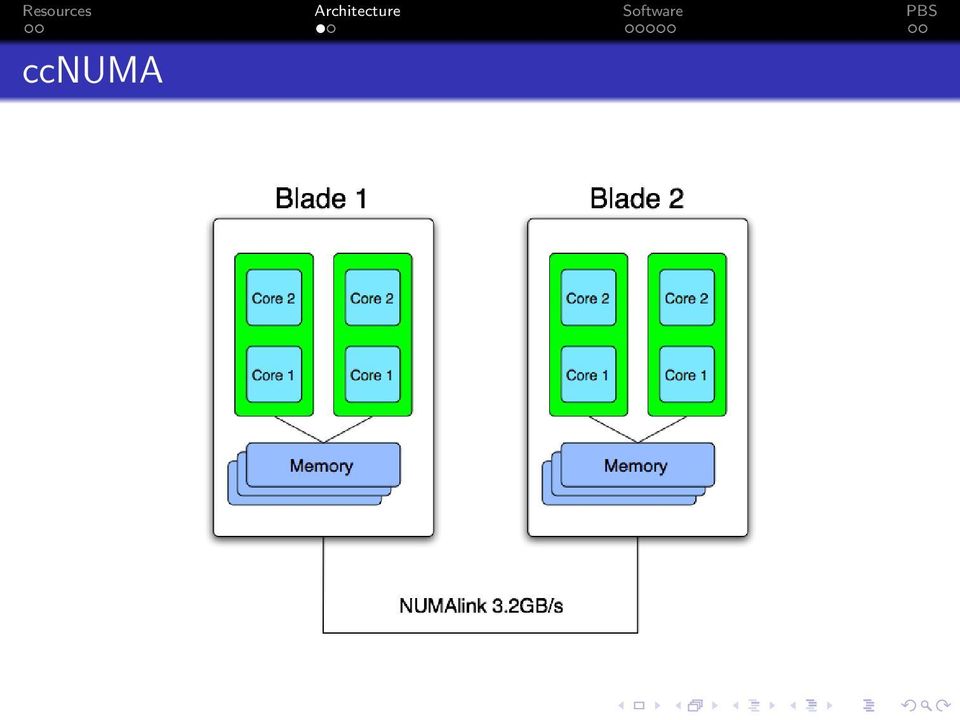
9 ccnuma

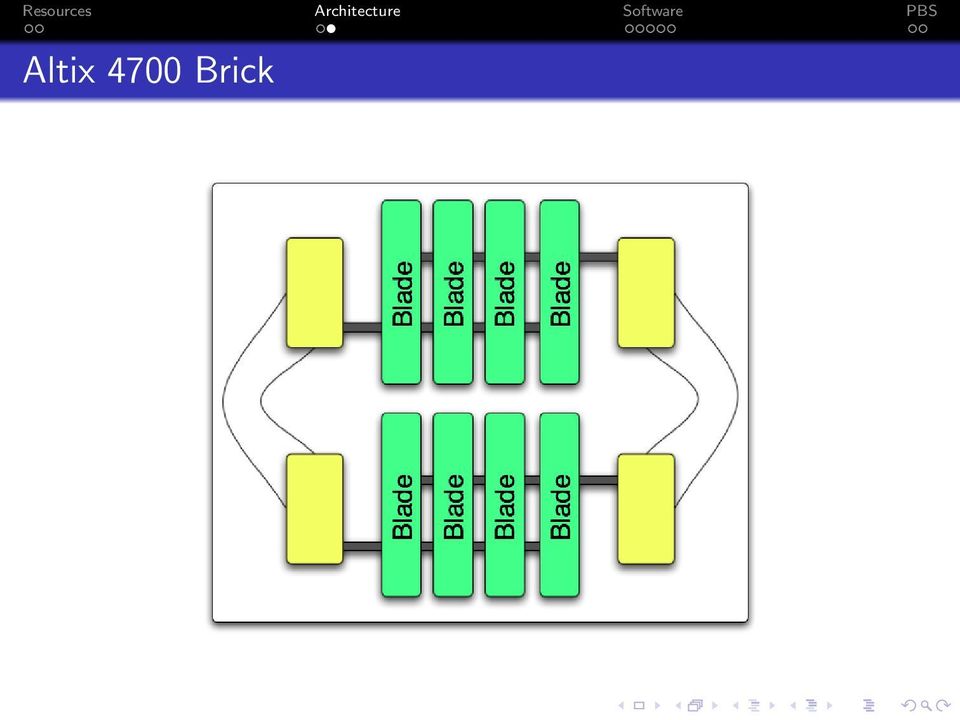
10 Altix 4700 Brick
11 Packaged Software Packaged Software Abaqus/6.6 abaqus v6.env standard memory policy=15000mb standard memory policy=maximum Nastran/2007r2 Gaussian/03 %nproc=8 %mem=20gb DO NOT SET $GAUSS SCR

12 Packaged Software Packaged Software Abaqus/6.6 abaqus v6.env standard memory policy=15000mb standard memory policy=maximum Nastran/2007r2 Gaussian/03 %nproc=8 %mem=20gb DO NOT SET $GAUSS SCR

13 Packaged Software Packaged Software Abaqus/6.6 abaqus v6.env standard memory policy=15000mb standard memory policy=maximum Nastran/2007r2 Gaussian/03 %nproc=8 %mem=20gb DO NOT SET $GAUSS SCR

14 Packaged Software Packaged Software Abaqus/6.6 abaqus v6.env standard memory policy=15000mb standard memory policy=maximum Nastran/2007r2 Gaussian/03 %nproc=8 %mem=20gb DO NOT SET $GAUSS SCR

15 Abaqus Abaqus Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. abaqus job=input scratch=/tmp interactive cpus=10 cp -fr * ~/ && rm -fr /tmp/$pbs JOBID

16 Abaqus Abaqus Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. abaqus job=input scratch=/tmp interactive cpus=10 cp -fr * ~/ && rm -fr /tmp/$pbs JOBID

17 Abaqus Abaqus Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. abaqus job=input scratch=/tmp interactive cpus=10 cp -fr * ~/ && rm -fr /tmp/$pbs JOBID

18 Abaqus Abaqus Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. abaqus job=input scratch=/tmp interactive cpus=10 cp -fr * ~/ && rm -fr /tmp/$pbs JOBID

19 Abaqus Abaqus Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. abaqus job=input scratch=/tmp interactive cpus=10 cp -fr * ~/ && rm -fr /tmp/$pbs JOBID

20 Abaqus Abaqus Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. abaqus job=input scratch=/tmp interactive cpus=10 cp -fr * ~/ && rm -fr /tmp/$pbs JOBID

21 Nastran Nastran Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. nastran batch=no hpmpi=yes dmp=10 input.dat cp -fr * ~/ && rm -fr /tmp/$pbs JOBID
22 Nastran Nastran Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. nastran batch=no hpmpi=yes dmp=10 input.dat cp -fr * ~/ && rm -fr /tmp/$pbs JOBID
23 Nastran Nastran Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. nastran batch=no hpmpi=yes dmp=10 input.dat cp -fr * ~/ && rm -fr /tmp/$pbs JOBID
24 Nastran Nastran Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. nastran batch=no hpmpi=yes dmp=10 input.dat cp -fr * ~/ && rm -fr /tmp/$pbs JOBID
25 Nastran Nastran Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. nastran batch=no hpmpi=yes dmp=10 input.dat cp -fr * ~/ && rm -fr /tmp/$pbs JOBID
26 Nastran Nastran Example mkdir /tmp/$pbs JOBID cd /tmp/$pbs JOBID cp ~/Input.inp. cp ~/abaqus v6.env. nastran batch=no hpmpi=yes dmp=10 input.dat cp -fr * ~/ && rm -fr /tmp/$pbs JOBID
27 Compilers Compilers ifort Fortran90/77 icc C icpc C++ GNU Compilers are available but not recommended Compiler Options -O2 General optimization -O3 -ipo -funroll-loops -ftz Better Optimization -openmp Enable OpenMP support
28 Compilers Compilers ifort Fortran90/77 icc C icpc C++ GNU Compilers are available but not recommended Compiler Options -O2 General optimization -O3 -ipo -funroll-loops -ftz Better Optimization -openmp Enable OpenMP support
29 Compilers Compilers ifort Fortran90/77 icc C icpc C++ GNU Compilers are available but not recommended Compiler Options -O2 General optimization -O3 -ipo -funroll-loops -ftz Better Optimization -openmp Enable OpenMP support
30 Libraries Libraries MPT MPI Library Optimized for Shared Memory ifort source.f90 -lmpi mpirun -np 10 a.out MKL Math Kernel Library Optimized Threaded Math Library Full Support for BLAS and LAPACK PRNG FFT s, and FFTW compatible DO Use, Contact us for support
31 Libraries Libraries MPT MPI Library Optimized for Shared Memory ifort source.f90 -lmpi mpirun -np 10 a.out MKL Math Kernel Library Optimized Threaded Math Library Full Support for BLAS and LAPACK PRNG FFT s, and FFTW compatible DO Use, Contact us for support
32 Libraries Libraries MPT MPI Library Optimized for Shared Memory ifort source.f90 -lmpi mpirun -np 10 a.out MKL Math Kernel Library Optimized Threaded Math Library Full Support for BLAS and LAPACK PRNG FFT s, and FFTW compatible DO Use, Contact us for support
33 PBS PBS Memory is Enforced Defaults to 1MB Use #PBS -l mem=100mb to request what you need Use route queue Only 30 cpus available for batch jobs 2 cpus for compiling sftp PBS etc Please clean up /tmp
34 Questions Questions? Questions?
Introduction to Linux and Cluster Basics for the CCR General Computing Cluster
 Introduction to Linux and Cluster Basics for the CCR General Computing Cluster Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY 14203 Phone: 716-881-8959
Introduction to Linux and Cluster Basics for the CCR General Computing Cluster Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY 14203 Phone: 716-881-8959
The CNMS Computer Cluster
 The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
JUROPA Linux Cluster An Overview. 19 May 2014 Ulrich Detert
 Mitglied der Helmholtz-Gemeinschaft JUROPA Linux Cluster An Overview 19 May 2014 Ulrich Detert JuRoPA JuRoPA Jülich Research on Petaflop Architectures Bull, Sun, ParTec, Intel, Mellanox, Novell, FZJ JUROPA
Mitglied der Helmholtz-Gemeinschaft JUROPA Linux Cluster An Overview 19 May 2014 Ulrich Detert JuRoPA JuRoPA Jülich Research on Petaflop Architectures Bull, Sun, ParTec, Intel, Mellanox, Novell, FZJ JUROPA
Altix Usage and Application Programming. Welcome and Introduction
 Zentrum für Informationsdienste und Hochleistungsrechnen Altix Usage and Application Programming Welcome and Introduction Zellescher Weg 12 Tel. +49 351-463 - 35450 Dresden, November 30th 2005 Wolfgang
Zentrum für Informationsdienste und Hochleistungsrechnen Altix Usage and Application Programming Welcome and Introduction Zellescher Weg 12 Tel. +49 351-463 - 35450 Dresden, November 30th 2005 Wolfgang
24/08/2004. Introductory User Guide
 24/08/2004 Introductory User Guide CSAR Introductory User Guide Introduction This material is designed to provide new users with all the information they need to access and use the SGI systems provided
24/08/2004 Introductory User Guide CSAR Introductory User Guide Introduction This material is designed to provide new users with all the information they need to access and use the SGI systems provided
1 Bull, 2011 Bull Extreme Computing
 1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Cluster performance, how to get the most out of Abel. Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013
 Cluster performance, how to get the most out of Abel Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013 Introduction Architecture x86-64 and NVIDIA Compilers MPI Interconnect Storage Batch queue
Cluster performance, how to get the most out of Abel Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013 Introduction Architecture x86-64 and NVIDIA Compilers MPI Interconnect Storage Batch queue
Getting Started with HPC
 Getting Started with HPC An Introduction to the Minerva High Performance Computing Resource 17 Sep 2013 Outline of Topics Introduction HPC Accounts Logging onto the HPC Clusters Common Linux Commands Storage
Getting Started with HPC An Introduction to the Minerva High Performance Computing Resource 17 Sep 2013 Outline of Topics Introduction HPC Accounts Logging onto the HPC Clusters Common Linux Commands Storage
Introduction to ACENET Accelerating Discovery with Computational Research May, 2015
 Introduction to ACENET Accelerating Discovery with Computational Research May, 2015 What is ACENET? What is ACENET? Shared regional resource for... high-performance computing (HPC) remote collaboration
Introduction to ACENET Accelerating Discovery with Computational Research May, 2015 What is ACENET? What is ACENET? Shared regional resource for... high-performance computing (HPC) remote collaboration
NEC HPC-Linux-Cluster
 NEC HPC-Linux-Cluster Hardware configuration: 4 Front-end servers: each with SandyBridge-EP processors: 16 cores per node 128 GB memory 134 compute nodes: 112 nodes with SandyBridge-EP processors (16 cores
NEC HPC-Linux-Cluster Hardware configuration: 4 Front-end servers: each with SandyBridge-EP processors: 16 cores per node 128 GB memory 134 compute nodes: 112 nodes with SandyBridge-EP processors (16 cores
Cluster Computing at HRI
 Cluster Computing at HRI J.S.Bagla Harish-Chandra Research Institute, Chhatnag Road, Jhunsi, Allahabad 211019. E-mail: [email protected] 1 Introduction and some local history High performance computing
Cluster Computing at HRI J.S.Bagla Harish-Chandra Research Institute, Chhatnag Road, Jhunsi, Allahabad 211019. E-mail: [email protected] 1 Introduction and some local history High performance computing
Introduction to Running Computations on the High Performance Clusters at the Center for Computational Research
 ! Introduction to Running Computations on the High Performance Clusters at the Center for Computational Research! Cynthia Cornelius! Center for Computational Research University at Buffalo, SUNY! cdc at
! Introduction to Running Computations on the High Performance Clusters at the Center for Computational Research! Cynthia Cornelius! Center for Computational Research University at Buffalo, SUNY! cdc at
Using WestGrid. Patrick Mann, Manager, Technical Operations Jan.15, 2014
 Using WestGrid Patrick Mann, Manager, Technical Operations Jan.15, 2014 Winter 2014 Seminar Series Date Speaker Topic 5 February Gino DiLabio Molecular Modelling Using HPC and Gaussian 26 February Jonathan
Using WestGrid Patrick Mann, Manager, Technical Operations Jan.15, 2014 Winter 2014 Seminar Series Date Speaker Topic 5 February Gino DiLabio Molecular Modelling Using HPC and Gaussian 26 February Jonathan
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
SUSE LINUX Enterprise Server for SGI Altix Systems
 SUSE LINUX Enterprise Server for SGI Altix Systems 007 4651 002 COPYRIGHT 2004, Silicon Graphics, Inc. All rights reserved; provided portions may be copyright in third parties, as indicated elsewhere herein.
SUSE LINUX Enterprise Server for SGI Altix Systems 007 4651 002 COPYRIGHT 2004, Silicon Graphics, Inc. All rights reserved; provided portions may be copyright in third parties, as indicated elsewhere herein.
PBS Tutorial. Fangrui Ma Universit of Nebraska-Lincoln. October 26th, 2007
 PBS Tutorial Fangrui Ma Universit of Nebraska-Lincoln October 26th, 2007 Abstract In this tutorial we gave a brief introduction to using PBS Pro. We gave examples on how to write control script, and submit
PBS Tutorial Fangrui Ma Universit of Nebraska-Lincoln October 26th, 2007 Abstract In this tutorial we gave a brief introduction to using PBS Pro. We gave examples on how to write control script, and submit
Cluster@WU User s Manual
 Cluster@WU User s Manual Stefan Theußl Martin Pacala September 29, 2014 1 Introduction and scope At the WU Wirtschaftsuniversität Wien the Research Institute for Computational Methods (Forschungsinstitut
Cluster@WU User s Manual Stefan Theußl Martin Pacala September 29, 2014 1 Introduction and scope At the WU Wirtschaftsuniversität Wien the Research Institute for Computational Methods (Forschungsinstitut
Performance Characteristics of Large SMP Machines
 Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller [email protected] Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller [email protected] Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
FileCruiser Backup & Restoring Guide
 FileCruiser Backup & Restoring Guide Version: 0.3 FileCruiser Model: VA2600/VR2600 with SR1 Date: JAN 27, 2015 1 Index Index... 2 Introduction... 3 Backup Requirements... 6 Backup Set up... 7 Backup the
FileCruiser Backup & Restoring Guide Version: 0.3 FileCruiser Model: VA2600/VR2600 with SR1 Date: JAN 27, 2015 1 Index Index... 2 Introduction... 3 Backup Requirements... 6 Backup Set up... 7 Backup the
Enabling Technologies for Distributed Computing
 Enabling Technologies for Distributed Computing Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF Multi-core CPUs and Multithreading Technologies
Enabling Technologies for Distributed Computing Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF Multi-core CPUs and Multithreading Technologies
OpenMP Programming on ScaleMP
 OpenMP Programming on ScaleMP Dirk Schmidl [email protected] Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
OpenMP Programming on ScaleMP Dirk Schmidl [email protected] Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
CNAG User s Guide. Barcelona Supercomputing Center Copyright c 2015 BSC-CNS December 18, 2015. 1 Introduction 2
 CNAG User s Guide Barcelona Supercomputing Center Copyright c 2015 BSC-CNS December 18, 2015 Contents 1 Introduction 2 2 System Overview 2 3 Connecting to CNAG cluster 2 3.1 Transferring files...................................
CNAG User s Guide Barcelona Supercomputing Center Copyright c 2015 BSC-CNS December 18, 2015 Contents 1 Introduction 2 2 System Overview 2 3 Connecting to CNAG cluster 2 3.1 Transferring files...................................
Streamline Computing Linux Cluster User Training. ( Nottingham University)
") 1 Streamline Computing Linux Cluster User Training ( Nottingham University) 3 User Training Agenda System Overview System Access Description of Cluster Environment Code Development Job Schedulers Running
1 Streamline Computing Linux Cluster User Training ( Nottingham University) 3 User Training Agenda System Overview System Access Description of Cluster Environment Code Development Job Schedulers Running
Job Scheduling on a Large UV 1000. Chad Vizino SGI User Group Conference May 2011. 2011 Pittsburgh Supercomputing Center
 Job Scheduling on a Large UV 1000 Chad Vizino SGI User Group Conference May 2011 Overview About PSC s UV 1000 Simon UV Distinctives UV Operational issues Conclusion PSC s UV 1000 - Blacklight Blacklight
Job Scheduling on a Large UV 1000 Chad Vizino SGI User Group Conference May 2011 Overview About PSC s UV 1000 Simon UV Distinctives UV Operational issues Conclusion PSC s UV 1000 - Blacklight Blacklight
Linux für bwgrid. Sabine Richling, Heinz Kredel. Universitätsrechenzentrum Heidelberg Rechenzentrum Universität Mannheim. 27.
 Linux für bwgrid Sabine Richling, Heinz Kredel Universitätsrechenzentrum Heidelberg Rechenzentrum Universität Mannheim 27. June 2011 Richling/Kredel (URZ/RUM) Linux für bwgrid FS 2011 1 / 33 Introduction
Linux für bwgrid Sabine Richling, Heinz Kredel Universitätsrechenzentrum Heidelberg Rechenzentrum Universität Mannheim 27. June 2011 Richling/Kredel (URZ/RUM) Linux für bwgrid FS 2011 1 / 33 Introduction
Cloud Computing through Virtualization and HPC technologies
 Cloud Computing through Virtualization and HPC technologies William Lu, Ph.D. 1 Agenda Cloud Computing & HPC A Case of HPC Implementation Application Performance in VM Summary 2 Cloud Computing & HPC HPC
Cloud Computing through Virtualization and HPC technologies William Lu, Ph.D. 1 Agenda Cloud Computing & HPC A Case of HPC Implementation Application Performance in VM Summary 2 Cloud Computing & HPC HPC
Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises
 Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises Pierre-Yves Taunay Research Computing and Cyberinfrastructure 224A Computer Building The Pennsylvania State University University
Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises Pierre-Yves Taunay Research Computing and Cyberinfrastructure 224A Computer Building The Pennsylvania State University University
Background and introduction Using the cluster Summary. The DMSC datacenter. Lars Melwyn Jensen. Niels Bohr Institute University of Copenhagen
 Niels Bohr Institute University of Copenhagen Who am I Theoretical physics (KU, NORDITA, TF, NSC) Computing non-standard superconductivity and superfluidity condensed matter / statistical physics several
Niels Bohr Institute University of Copenhagen Who am I Theoretical physics (KU, NORDITA, TF, NSC) Computing non-standard superconductivity and superfluidity condensed matter / statistical physics several
Agenda. Using HPC Wales 2
 Using HPC Wales Agenda Infrastructure : An Overview of our Infrastructure Logging in : Command Line Interface and File Transfer Linux Basics : Commands and Text Editors Using Modules : Managing Software
Using HPC Wales Agenda Infrastructure : An Overview of our Infrastructure Logging in : Command Line Interface and File Transfer Linux Basics : Commands and Text Editors Using Modules : Managing Software
System Requirements Table of contents
 Table of contents 1 Introduction... 2 2 Knoa Agent... 2 2.1 System Requirements...2 2.2 Environment Requirements...4 3 Knoa Server Architecture...4 3.1 Knoa Server Components... 4 3.2 Server Hardware Setup...5
Table of contents 1 Introduction... 2 2 Knoa Agent... 2 2.1 System Requirements...2 2.2 Environment Requirements...4 3 Knoa Server Architecture...4 3.1 Knoa Server Components... 4 3.2 Server Hardware Setup...5
Service Partition Specialized Linux nodes. Compute PE Login PE Network PE System PE I/O PE
 2 Service Partition Specialized Linux nodes Compute PE Login PE Network PE System PE I/O PE Microkernel on Compute PEs, full featured Linux on Service PEs. Service PEs specialize by function Software Architecture
2 Service Partition Specialized Linux nodes Compute PE Login PE Network PE System PE I/O PE Microkernel on Compute PEs, full featured Linux on Service PEs. Service PEs specialize by function Software Architecture
An Introduction to High Performance Computing in the Department
 An Introduction to High Performance Computing in the Department Ashley Ford & Chris Jewell Department of Statistics University of Warwick October 30, 2012 1 Some Background 2 How is Buster used? 3 Software
An Introduction to High Performance Computing in the Department Ashley Ford & Chris Jewell Department of Statistics University of Warwick October 30, 2012 1 Some Background 2 How is Buster used? 3 Software
Work Environment. David Tur HPC Expert. HPC Users Training September, 18th 2015
 Work Environment David Tur HPC Expert HPC Users Training September, 18th 2015 1. Atlas Cluster: Accessing and using resources 2. Software Overview 3. Job Scheduler 1. Accessing Resources DIPC technicians
Work Environment David Tur HPC Expert HPC Users Training September, 18th 2015 1. Atlas Cluster: Accessing and using resources 2. Software Overview 3. Job Scheduler 1. Accessing Resources DIPC technicians
Introduction to SDSC systems and data analytics software packages "
 Introduction to SDSC systems and data analytics software packages " Mahidhar Tatineni ([email protected]) SDSC Summer Institute August 05, 2013 Getting Started" System Access Logging in Linux/Mac Use available
Introduction to SDSC systems and data analytics software packages " Mahidhar Tatineni ([email protected]) SDSC Summer Institute August 05, 2013 Getting Started" System Access Logging in Linux/Mac Use available
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Enabling Technologies for Distributed and Cloud Computing
 Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Introductory Tutorial for Discover - NCCS s newest Linux Networx Cluster. Software Integration and Visualization Office (SIVO)
") Introductory Tutorial for Discover - NCCS s newest Linux Networx Cluster by Software Integration and Visualization Office (SIVO) Introduction to SIVO Who we are: Leadership in the development of advanced
Introductory Tutorial for Discover - NCCS s newest Linux Networx Cluster by Software Integration and Visualization Office (SIVO) Introduction to SIVO Who we are: Leadership in the development of advanced
The Foundation for Better Business Intelligence
 Product Brief Intel Xeon Processor E7-8800/4800/2800 v2 Product Families Data Center The Foundation for Big data is changing the way organizations make business decisions. To transform petabytes of data
Product Brief Intel Xeon Processor E7-8800/4800/2800 v2 Product Families Data Center The Foundation for Big data is changing the way organizations make business decisions. To transform petabytes of data
8/15/2014. Best Practices @OLCF (and more) General Information. Staying Informed. Staying Informed. Staying Informed-System Status
 General Information. Staying Informed. Staying Informed. Staying Informed-System Status") Best Practices @OLCF (and more) Bill Renaud OLCF User Support General Information This presentation covers some helpful information for users of OLCF Staying informed Aspects of system usage that may differ
Best Practices @OLCF (and more) Bill Renaud OLCF User Support General Information This presentation covers some helpful information for users of OLCF Staying informed Aspects of system usage that may differ
Parallel Debugging with DDT
 Parallel Debugging with DDT Nate Woody 3/10/2009 www.cac.cornell.edu 1 Debugging Debugging is a methodical process of finding and reducing the number of bugs, or defects, in a computer program or a piece
Parallel Debugging with DDT Nate Woody 3/10/2009 www.cac.cornell.edu 1 Debugging Debugging is a methodical process of finding and reducing the number of bugs, or defects, in a computer program or a piece
SGI High Performance Computing
 SGI High Performance Computing Accelerate time to discovery, innovation, and profitability 2014 SGI SGI Company Proprietary 1 Typical Use Cases for SGI HPC Products Large scale-out, distributed memory
SGI High Performance Computing Accelerate time to discovery, innovation, and profitability 2014 SGI SGI Company Proprietary 1 Typical Use Cases for SGI HPC Products Large scale-out, distributed memory
Computational Platforms for VASP
 Computational Platforms for VASP Robert LORENZ Institut für Materialphysik and Center for Computational Material Science Universität Wien, Strudlhofgasse 4, A-1090 Wien, Austria b-initio ienna ackage imulation
Computational Platforms for VASP Robert LORENZ Institut für Materialphysik and Center for Computational Material Science Universität Wien, Strudlhofgasse 4, A-1090 Wien, Austria b-initio ienna ackage imulation
OLCF Best Practices (and More) Bill Renaud OLCF User Assistance Group
 Bill Renaud OLCF User Assistance Group") OLCF Best Practices (and More) Bill Renaud OLCF User Assistance Group Overview This presentation covers some helpful information for users of OLCF Staying informed Some aspects of system usage that may
OLCF Best Practices (and More) Bill Renaud OLCF User Assistance Group Overview This presentation covers some helpful information for users of OLCF Staying informed Some aspects of system usage that may
ELEC 377. Operating Systems. Week 1 Class 3
 Operating Systems Week 1 Class 3 Last Class! Computer System Structure, Controllers! Interrupts & Traps! I/O structure and device queues.! Storage Structure & Caching! Hardware Protection! Dual Mode Operation
Operating Systems Week 1 Class 3 Last Class! Computer System Structure, Controllers! Interrupts & Traps! I/O structure and device queues.! Storage Structure & Caching! Hardware Protection! Dual Mode Operation
The RWTH Compute Cluster Environment
 The RWTH Compute Cluster Environment Tim Cramer 11.03.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) How to login Frontends cluster.rz.rwth-aachen.de cluster-x.rz.rwth-aachen.de
The RWTH Compute Cluster Environment Tim Cramer 11.03.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) How to login Frontends cluster.rz.rwth-aachen.de cluster-x.rz.rwth-aachen.de
Computational infrastructure for NGS data analysis. José Carbonell Caballero Pablo Escobar
 Computational infrastructure for NGS data analysis José Carbonell Caballero Pablo Escobar Computational infrastructure for NGS Cluster definition: A computer cluster is a group of linked computers, working
Computational infrastructure for NGS data analysis José Carbonell Caballero Pablo Escobar Computational infrastructure for NGS Cluster definition: A computer cluster is a group of linked computers, working
Parallel Processing using the LOTUS cluster
 Parallel Processing using the LOTUS cluster Alison Pamment / Cristina del Cano Novales JASMIN/CEMS Workshop February 2015 Overview Parallelising data analysis LOTUS HPC Cluster Job submission on LOTUS
Parallel Processing using the LOTUS cluster Alison Pamment / Cristina del Cano Novales JASMIN/CEMS Workshop February 2015 Overview Parallelising data analysis LOTUS HPC Cluster Job submission on LOTUS
Agenda. HPC Software Stack. HPC Post-Processing Visualization. Case Study National Scientific Center. European HPC Benchmark Center Montpellier PSSC
 HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Towards OpenMP Support in LLVM
 Towards OpenMP Support in LLVM Alexey Bataev, Andrey Bokhanko, James Cownie Intel 1 Agenda What is the OpenMP * language? Who Can Benefit from the OpenMP language? OpenMP Language Support Early / Late
Towards OpenMP Support in LLVM Alexey Bataev, Andrey Bokhanko, James Cownie Intel 1 Agenda What is the OpenMP * language? Who Can Benefit from the OpenMP language? OpenMP Language Support Early / Late
1 DCSC/AU: HUGE. DeIC Sekretariat 2013-03-12/RB. Bilag 1. DeIC (DCSC) Scientific Computing Installations
 Scientific Computing Installations") Bilag 1 2013-03-12/RB DeIC (DCSC) Scientific Computing Installations DeIC, previously DCSC, currently has a number of scientific computing installations, distributed at five regional operating centres.
Bilag 1 2013-03-12/RB DeIC (DCSC) Scientific Computing Installations DeIC, previously DCSC, currently has a number of scientific computing installations, distributed at five regional operating centres.
Parallel Computing using MATLAB Distributed Compute Server ZORRO HPC
 Parallel Computing using MATLAB Distributed Compute Server ZORRO HPC Goals of the session Overview of parallel MATLAB Why parallel MATLAB? Multiprocessing in MATLAB Parallel MATLAB using the Parallel Computing
Parallel Computing using MATLAB Distributed Compute Server ZORRO HPC Goals of the session Overview of parallel MATLAB Why parallel MATLAB? Multiprocessing in MATLAB Parallel MATLAB using the Parallel Computing
An introduction to compute resources in Biostatistics. Chris Scheller [email protected]
 An introduction to compute resources in Biostatistics Chris Scheller [email protected] 1. Resources 1. Hardware 2. Account Allocation 3. Storage 4. Software 2. Usage 1. Environment Modules 2. Tools 3.
An introduction to compute resources in Biostatistics Chris Scheller [email protected] 1. Resources 1. Hardware 2. Account Allocation 3. Storage 4. Software 2. Usage 1. Environment Modules 2. Tools 3.
Building a Top500-class Supercomputing Cluster at LNS-BUAP
 Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
The Asterope compute cluster
 The Asterope compute cluster ÅA has a small cluster named asterope.abo.fi with 8 compute nodes Each node has 2 Intel Xeon X5650 processors (6-core) with a total of 24 GB RAM 2 NVIDIA Tesla M2050 GPGPU
The Asterope compute cluster ÅA has a small cluster named asterope.abo.fi with 8 compute nodes Each node has 2 Intel Xeon X5650 processors (6-core) with a total of 24 GB RAM 2 NVIDIA Tesla M2050 GPGPU
Cray XT3 Supercomputer Scalable by Design CRAY XT3 DATASHEET
 CRAY XT3 DATASHEET Cray XT3 Supercomputer Scalable by Design The Cray XT3 system offers a new level of scalable computing where: a single powerful computing system handles the most complex problems every
CRAY XT3 DATASHEET Cray XT3 Supercomputer Scalable by Design The Cray XT3 system offers a new level of scalable computing where: a single powerful computing system handles the most complex problems every
OLCF Best Practices. Bill Renaud OLCF User Assistance Group
 OLCF Best Practices Bill Renaud OLCF User Assistance Group Overview This presentation covers some helpful information for users of OLCF Staying informed Some aspects of system usage that may differ from
OLCF Best Practices Bill Renaud OLCF User Assistance Group Overview This presentation covers some helpful information for users of OLCF Staying informed Some aspects of system usage that may differ from
Mathematical Libraries and Application Software on JUROPA and JUQUEEN
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA and JUQUEEN JSC Training Course May 2014 I.Gutheil Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA and JUQUEEN JSC Training Course May 2014 I.Gutheil Outline General Informations Sequential Libraries Parallel
Grid Engine Users Guide. 2011.11p1 Edition
 Grid Engine Users Guide 2011.11p1 Edition Grid Engine Users Guide : 2011.11p1 Edition Published Nov 01 2012 Copyright 2012 University of California and Scalable Systems This document is subject to the
Grid Engine Users Guide 2011.11p1 Edition Grid Engine Users Guide : 2011.11p1 Edition Published Nov 01 2012 Copyright 2012 University of California and Scalable Systems This document is subject to the
Integration of Virtualized Workernodes in Batch Queueing Systems The ViBatch Concept
 Integration of Virtualized Workernodes in Batch Queueing Systems, Dr. Armin Scheurer, Oliver Oberst, Prof. Günter Quast INSTITUT FÜR EXPERIMENTELLE KERNPHYSIK FAKULTÄT FÜR PHYSIK KIT University of the
Integration of Virtualized Workernodes in Batch Queueing Systems, Dr. Armin Scheurer, Oliver Oberst, Prof. Günter Quast INSTITUT FÜR EXPERIMENTELLE KERNPHYSIK FAKULTÄT FÜR PHYSIK KIT University of the
Multi-core Programming System Overview
 Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
SR-IOV: Performance Benefits for Virtualized Interconnects!
 SR-IOV: Performance Benefits for Virtualized Interconnects! Glenn K. Lockwood! Mahidhar Tatineni! Rick Wagner!! July 15, XSEDE14, Atlanta! Background! High Performance Computing (HPC) reaching beyond traditional
SR-IOV: Performance Benefits for Virtualized Interconnects! Glenn K. Lockwood! Mahidhar Tatineni! Rick Wagner!! July 15, XSEDE14, Atlanta! Background! High Performance Computing (HPC) reaching beyond traditional
FOR SERVERS 2.2: FEATURE matrix
 RED hat ENTERPRISE VIRTUALIZATION FOR SERVERS 2.2: FEATURE matrix Red hat enterprise virtualization for servers Server virtualization offers tremendous benefits for enterprise IT organizations server consolidation,
RED hat ENTERPRISE VIRTUALIZATION FOR SERVERS 2.2: FEATURE matrix Red hat enterprise virtualization for servers Server virtualization offers tremendous benefits for enterprise IT organizations server consolidation,
CAS2K5. Jim Tuccillo [email protected] 912.576.5215
 CAS2K5 Jim Tuccillo [email protected] 912.576.5215 Agenda icorporate Overview isystem Architecture inode Design iprocessor Options iinterconnect Options ihigh Performance File Systems Lustre isystem Management
CAS2K5 Jim Tuccillo [email protected] 912.576.5215 Agenda icorporate Overview isystem Architecture inode Design iprocessor Options iinterconnect Options ihigh Performance File Systems Lustre isystem Management
Trends in High-Performance Computing for Power Grid Applications
 Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Running Native Lustre* Client inside Intel Xeon Phi coprocessor
 Running Native Lustre* Client inside Intel Xeon Phi coprocessor Dmitry Eremin, Zhiqi Tao and Gabriele Paciucci 08 April 2014 * Some names and brands may be claimed as the property of others. What is the
Running Native Lustre* Client inside Intel Xeon Phi coprocessor Dmitry Eremin, Zhiqi Tao and Gabriele Paciucci 08 April 2014 * Some names and brands may be claimed as the property of others. What is the
INF-110. GPFS Installation
 INF-110 GPFS Installation Overview Plan the installation Before installing any software, it is important to plan the GPFS installation by choosing the hardware, deciding which kind of disk connectivity
INF-110 GPFS Installation Overview Plan the installation Before installing any software, it is important to plan the GPFS installation by choosing the hardware, deciding which kind of disk connectivity
Windows HPC 2008 Cluster Launch
 Windows HPC 2008 Cluster Launch Regionales Rechenzentrum Erlangen (RRZE) Johannes Habich [email protected] Launch overview Small presentation and basic introduction Questions and answers Hands-On
Windows HPC 2008 Cluster Launch Regionales Rechenzentrum Erlangen (RRZE) Johannes Habich [email protected] Launch overview Small presentation and basic introduction Questions and answers Hands-On
Configuration Maximums VMware Infrastructure 3
 Technical Note Configuration s VMware Infrastructure 3 When you are selecting and configuring your virtual and physical equipment, you must stay at or below the maximums supported by VMware Infrastructure
Technical Note Configuration s VMware Infrastructure 3 When you are selecting and configuring your virtual and physical equipment, you must stay at or below the maximums supported by VMware Infrastructure
MOSIX: High performance Linux farm
 MOSIX: High performance Linux farm Paolo Mastroserio [[email protected]] Francesco Maria Taurino [[email protected]] Gennaro Tortone [[email protected]] Napoli Index overview on Linux farm farm
MOSIX: High performance Linux farm Paolo Mastroserio [[email protected]] Francesco Maria Taurino [[email protected]] Gennaro Tortone [[email protected]] Napoli Index overview on Linux farm farm
INTEL PARALLEL STUDIO XE EVALUATION GUIDE
 Introduction This guide will illustrate how you use Intel Parallel Studio XE to find the hotspots (areas that are taking a lot of time) in your application and then recompiling those parts to improve overall
Introduction This guide will illustrate how you use Intel Parallel Studio XE to find the hotspots (areas that are taking a lot of time) in your application and then recompiling those parts to improve overall
Sage Grant Management System Requirements
 Sage Grant Management System Requirements You should meet or exceed the following system requirements: One Server - Database/Web Server The following system requirements are for Sage Grant Management to
Sage Grant Management System Requirements You should meet or exceed the following system requirements: One Server - Database/Web Server The following system requirements are for Sage Grant Management to
Running applications on the Cray XC30 4/12/2015
 Running applications on the Cray XC30 4/12/2015 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch jobs on compute nodes
Running applications on the Cray XC30 4/12/2015 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch jobs on compute nodes
Three Paths to Faster Simulations Using ANSYS Mechanical 16.0 and Intel Architecture
 White Paper Intel Xeon processor E5 v3 family Intel Xeon Phi coprocessor family Digital Design and Engineering Three Paths to Faster Simulations Using ANSYS Mechanical 16.0 and Intel Architecture Executive
White Paper Intel Xeon processor E5 v3 family Intel Xeon Phi coprocessor family Digital Design and Engineering Three Paths to Faster Simulations Using ANSYS Mechanical 16.0 and Intel Architecture Executive
BLM 413E - Parallel Programming Lecture 3
 BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
Using NeSI HPC Resources. NeSI Computational Science Team ([email protected])
") NeSI Computational Science Team ([email protected]) Outline 1 About Us About NeSI Our Facilities 2 Using the Cluster Suitable Work What to expect Parallel speedup Data Getting to the Login Node 3 Submitting
NeSI Computational Science Team ([email protected]) Outline 1 About Us About NeSI Our Facilities 2 Using the Cluster Suitable Work What to expect Parallel speedup Data Getting to the Login Node 3 Submitting
Biowulf2 Training Session
 Biowulf2 Training Session 9 July 2015 Slides at: h,p://hpc.nih.gov/docs/b2training.pdf HPC@NIH website: h,p://hpc.nih.gov System hardware overview What s new/different The batch system & subminng jobs
Biowulf2 Training Session 9 July 2015 Slides at: h,p://hpc.nih.gov/docs/b2training.pdf HPC@NIH website: h,p://hpc.nih.gov System hardware overview What s new/different The batch system & subminng jobs
Performance Evaluation of Amazon EC2 for NASA HPC Applications!
 National Aeronautics and Space Administration Performance Evaluation of Amazon EC2 for NASA HPC Applications! Piyush Mehrotra!! J. Djomehri, S. Heistand, R. Hood, H. Jin, A. Lazanoff,! S. Saini, R. Biswas!
National Aeronautics and Space Administration Performance Evaluation of Amazon EC2 for NASA HPC Applications! Piyush Mehrotra!! J. Djomehri, S. Heistand, R. Hood, H. Jin, A. Lazanoff,! S. Saini, R. Biswas!
Intel Xeon Phi Basic Tutorial
 Intel Xeon Phi Basic Tutorial Evan Bollig and Brent Swartz 1pm, 12/19/2013 Overview Intro to MSI Intro to the MIC Architecture Targeting the Xeon Phi Examples Automatic Offload Offload Mode Native Mode
Intel Xeon Phi Basic Tutorial Evan Bollig and Brent Swartz 1pm, 12/19/2013 Overview Intro to MSI Intro to the MIC Architecture Targeting the Xeon Phi Examples Automatic Offload Offload Mode Native Mode
MPI / ClusterTools Update and Plans
 HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
22S:295 Seminar in Applied Statistics High Performance Computing in Statistics
 22S:295 Seminar in Applied Statistics High Performance Computing in Statistics Luke Tierney Department of Statistics & Actuarial Science University of Iowa August 30, 2007 Luke Tierney (U. of Iowa) HPC
22S:295 Seminar in Applied Statistics High Performance Computing in Statistics Luke Tierney Department of Statistics & Actuarial Science University of Iowa August 30, 2007 Luke Tierney (U. of Iowa) HPC
Improved LS-DYNA Performance on Sun Servers
 8 th International LS-DYNA Users Conference Computing / Code Tech (2) Improved LS-DYNA Performance on Sun Servers Youn-Seo Roh, Ph.D. And Henry H. Fong Sun Microsystems, Inc. Abstract Current Sun platforms
8 th International LS-DYNA Users Conference Computing / Code Tech (2) Improved LS-DYNA Performance on Sun Servers Youn-Seo Roh, Ph.D. And Henry H. Fong Sun Microsystems, Inc. Abstract Current Sun platforms
Grant Management. System Requirements
 January 26, 2014 This is a publication of Abila, Inc. Version 2014.x 2013 Abila, Inc. and its affiliated entities. All rights reserved. Abila, the Abila logos, and the Abila product and service names mentioned
January 26, 2014 This is a publication of Abila, Inc. Version 2014.x 2013 Abila, Inc. and its affiliated entities. All rights reserved. Abila, the Abila logos, and the Abila product and service names mentioned
Introduction to Running Hadoop on the High Performance Clusters at the Center for Computational Research
 Introduction to Running Hadoop on the High Performance Clusters at the Center for Computational Research Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St
Introduction to Running Hadoop on the High Performance Clusters at the Center for Computational Research Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St
Performance Application Programming Interface
 /************************************************************************************ ** Notes on Performance Application Programming Interface ** ** Intended audience: Those who would like to learn more
/************************************************************************************ ** Notes on Performance Application Programming Interface ** ** Intended audience: Those who would like to learn more
OBSERVEIT DEPLOYMENT SIZING GUIDE
 OBSERVEIT DEPLOYMENT SIZING GUIDE The most important number that drives the sizing of an ObserveIT deployment is the number of Concurrent Connected Users (CCUs) you plan to monitor. This document provides
OBSERVEIT DEPLOYMENT SIZING GUIDE The most important number that drives the sizing of an ObserveIT deployment is the number of Concurrent Connected Users (CCUs) you plan to monitor. This document provides
Introduction to HPC Workshop. Center for e-research ([email protected])
") Center for e-research ([email protected]) Outline 1 About Us About CER and NeSI The CS Team Our Facilities 2 Key Concepts What is a Cluster Parallel Programming Shared Memory Distributed Memory 3 Using
Center for e-research ([email protected]) Outline 1 About Us About CER and NeSI The CS Team Our Facilities 2 Key Concepts What is a Cluster Parallel Programming Shared Memory Distributed Memory 3 Using
CHEOPS Cologne High Efficient Operating Platform for Science Brief Instructions
 CHEOPS Cologne High Efficient Operating Platform for Science Brief Instructions (Version: 07.10.2013) Foto: Thomas Josek/JosekDesign Viktor Achter Dr. Stefan Borowski Lech Nieroda Dr. Lars Packschies Volker
CHEOPS Cologne High Efficient Operating Platform for Science Brief Instructions (Version: 07.10.2013) Foto: Thomas Josek/JosekDesign Viktor Achter Dr. Stefan Borowski Lech Nieroda Dr. Lars Packschies Volker
Adonis Technical Requirements
 Information Sheet Adonis Technical Requirements CONTENTS Contents... 1 Adonis Project Implementation... 1 Host Installation / Onboard Installation Full replication (LARGER Vessels):... 1 Onboard installation
Information Sheet Adonis Technical Requirements CONTENTS Contents... 1 Adonis Project Implementation... 1 Host Installation / Onboard Installation Full replication (LARGER Vessels):... 1 Onboard installation