Automatic Text Processing: Cross-Lingual. Text Categorization
|
|
|
- Dustin Ramsey
- 10 years ago
- Views:
Transcription
1 Automatic Text Processing: Cross-Lingual Text Categorization Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena Dottorato di Ricerca in Ingegneria dell Informazone XVII ciclo Candidate: Leonardo Rigutini Advisor: Prof. Marco Maggini

2 Outlines Introduction to Cross Lingual Text Categorization: Realtionships with Cross Lingual Information Retrieval Possible approaches Text Categorization Multinomial Naive Bayes models Distance distribution and term filtering Learning with labeled and unlabeled data The algorithm The basic solution The modified algorithm Experimental results and conclusions

3 Cross Lingual Text Categorization The problem arose in the last years due to the large amount of documents in many different languages Many industries would categorize the new documents according to the existing class structure without building a different text management system for each language The CLTC is highly close to the Cross-Lingual Information Retrieval (CLIR): Many works in the literature deal with CLIR Very little work about CLTC
: Many works in the literature deal with CLIR Very little work about")
4 Cross Lingual Information Retrieval a) Poly-Lingual Data composed by documents in different languages Dictionary contains terms from different dictionaries A wide learning set containing sufficient documents for each languages is needed An unique classifier is trained b) Cross-Lingual: The language is identified and translated into a different one A new classifier is trained for each language

5 a) Poly-Lingual Drawbacks: Requires many documents for the learning set for each language High dimensionality of the dictionary: n vocabularies Many terms shared between two languages Difficult feature selection due to the coexistence of many different languages Advantages: Conceptually simple method An unique classifier is used Quite good performances

6 b) Cross-Lingual Drawbacks: Use of a translation step: Very low performances Named Entity Recognition (NER) Time consuming In some approaches experts for each language are needed Advantages: It does not need experts for each language Three different approaches: 1. Training set translation 2. Test set translation 3. Esperanto

7 1. Training set translation The classifier is trained with documents in language L 2 translated from the L 1 learning set: L 2 is the language of the unlabeled data The learning set is highly noisy and the classifier could show poor performances The system works on the L 2 language documents Number of translations lower than the test set translation approach Notmuchusedin CLIR

8 2. Test set translation The model is trained using documents in language L 1 without translation: Training using data not corrupted by noise The unlabeled documents in language L 2 are translated into the language L 1 : The translation step is highly time consuming It has very low performances and it introduces much noise A filtering phase on the test data after the translation is needed The translated documents are categorized by the classifier trained in the language L 1 : Possible inconsistency between training and unlabeled data

9 3. Esperanto All documents in each languages are translated into a new universal language, Esperanto (L E ) The new language should maintain all the semantic features of each language Very difficult to design High amount of knowledge for each language is needed The system works in this new universal language It needs the translation of the training set and of the test set Very time consuming Few used in CLIR

10 From CLIR to CLTC Following the CLIR: a) Poly-Lingual approach n mono-lingual text categorization problems, one for each language It requires a test set for each language: experts that labels the documents for each language b) Cross-lingual 1. Test set translation: It requires the tet set translation time consuming 2. Esperanto: It is very time consuming and requires a large amount of knowledge for each language 3. Training set translation: No proposals using this thecnique

11 CLTC problem formulation Given a predefined category organization for documents in the language L 1 the task is to classify documents in language L 2 according to that organization without having to manually label the data in L 2 since it requires experts in that language and this is expensive. The Poly-Lingual approach translation is not usable in this case, since it requires a learning set in the unknown language L 2 Even the esperanto approach is not possible, since it needs knowledge about all the languages Only the training and test set approach can be used in this type of problem

12 Outlines Introduction to Cross Lingual Text Categorization: Realtionships with Cross Lingual Information Retrieval Possible approaches Text Categorization Multinomial Naive Bayes models Distance distribution and term filtering Learning with labeled and unlabeled data The algorithm The basic solution The modified algorithm Experimental results and conclusions

13 Naive Bayes classifier The two most successful techniques for text categorization: NaiveBayes SVM Naive Bayes A document d i belongs to class C j such that: C = argmaxp( C Using bayes rule the probability j P( C r d i C r ) = P( C r d i ) P( C r di r ) P( d P( d ) i i ) C can be expressed as: r )
 = P( C r d i ) P( C r di r ) P( d P( d ) i i ) C can be expressed")
14 Multinomial Naive Bayes Since is a common factor, it can be negleted P C ( r ) P ( d i ) can be easily estimated from the document distribution in the training set or otherwise it can be considered constant The naive assumption is that the presence of each word in a document is an independent event and does not depend on the others. It allows to write: N ( wt, di ) P( d C ) = P( w C ) where N w t, d document d i. ( i ) i r w d t is the number of occurrences of word w t in the i t r
 P( d C ) = P( w C ) where N w t, d document d i.")
15 Multinomial Naive Bayes Assuming that each document is drawn from a multinomial distribution of words, the probability of w t in class C r can be estimated as: P( w t C r ) This method is very simple and it is one of the most used in text categorization = Despite the strong naive assumption, it yelds good performances in most cases w s d C i d C i j N( w, d ) j t N( w s i, d i )
 j t N( w s i,")
16 Smoothing techniques A typical problem in probailistic models are the zero values: If a feature was never observed in training process, its estimated probability is 0. When it is observed during the classification process, the 0 value can not be used, since it makes null the likelihood The two main methods to avoid the zero are Additive smoothing (add-one or Laplace): Good-Turing smoothing: Pˆ( w # w(1 ) C P( w(0)) = # w C j t C j j ) = 1+ (# w V t C + (# w C j ) j )
: Good-Turing smoothing:")
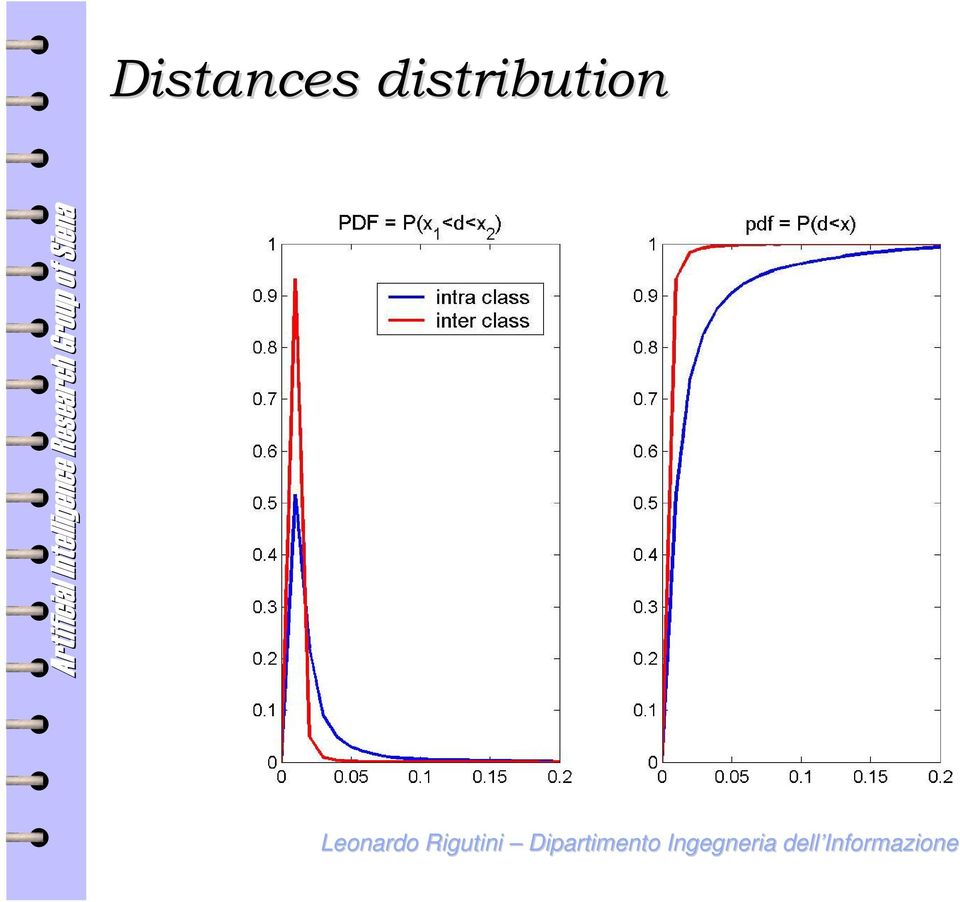
17 Distance distribution The distribution of documents in the space is uniform and does not form clouds The distances between two similar documents and between two different documents are very close It depends on: High number of dimensions High number of not discriminative words that overcome the others in the evaluation of the distances

18 Distances distribution
19 Information Gain Term filtering: Stopword list Luhn reduction Information gain Information gain: IG( w, C i IG( w ) i k ) = = C k = c 1 { C C } k { w w }, w, k IG( w i, C i k ) i P( w, c)log 2 P( w, c) P( w) P( c)
 i P( w, c)log 2 P( w, c) P( w) P( c)")
20 Learning from labeled and unlabeled data New research area in Automatic Text Processing: Usually having a large labeled dataset is a time consuming task and much expensive Learning from labeled and unlabeled examples: Use a small initial labeled dataset Extract information from a large unlabeled dataset The idea is: Use the labeled data to initialize a labeling process on the unlabeled data Use the new labeled data to build the classifier

21 Learning from labeled and unlabeled data EM algorithm E step: data are labeled using the current parameter configuration M step: model is updated assuming the labeled to be correct The model is initialized using the small labeled dataset
22 Outlines Introduction to Cross Lingual Text Categorization: Realtionships with Cross Lingual Information Retrieval Possible approaches Text Categorization Multinomial Naive Bayes models Distance distribution and term filtering Learning with labeled and unlabeled data The algorithm The basic solution The modified algorithm Experimental results and Conclusions
23 Cross Lingual Text Categorization The problem can be stated as: We have a small labeled dataset in language L 1 We want to categorize a large unlabeled dataset in language L 2 We do not want to use experts for the language L 2 The idea is: We can translate the training set into the language L 2 We can initialize an EM algorithm with these very noisy data We can reinforce the behavior of the classifier using the unlabeled data in language L 2
24 Notation With L 1, L 2 and L 1 2 we indicate the languages 1,2 and L 1 translated into L 2 We use these pedices for training set Tr, test set Ts and classifier C: C 1 2 indicates the classifier trained with Tr 1 2,, that is the training set Tr 1 translated into language L 2
25 The basic algorithm Tr 1 Translation 1 2 Tr 1 2 C 2 1 M step Ts 2 E step results E(t) start EM iterations
26 The basic algorithm Once the classifier is trained, it can be used to label a larger dataset This algortihm can start with small initial dataset and it is an advantage since our initial dataset is very noisy Problems Data Translation Algorithm
27 Data Temporal dependency: Documents regarding same topic in different times, deal with different themes Geographical dependency: Documents regarding the same topics in different places, deal with different persons, facts etc Find the discriminative terms for each topic independent of time and place
28 Translation The translator performs very poorly expecially when the text is badly written : Named Entity Recognition (NER): words that should not be translated different words referring to the same entity Word-sense disambiguation: In translation it is a fundamental problem
29 Algorithm EM algorithm has some important limitations: The trivial solution is a good solution: all documents in a single cluster all the others clusters empty Usually it tends to form few large central clusters and many small peripheral clusters: It depends on the starting point and on the noise on the data added at the cluster at each EM step
30 Improved algorithm by using IG Tr 1 2 start IG k 1 C 2 1 M step Ts 2 IG k 2 E step results E(t) EM iterations
31 The filter k 1 Highly selective since the data are composed by translated text and they are very noisy Initialize the EM process by selecting the most informative words in the data Ts 2 Tr 1 2 IG k 1 results
32 The filter k 2 It performs a regularization effect on the EM algorithm it selects the most discriminative words at each EM iteration The not significative words do not influence the updating of the centroid in EM iterations The parameter should be higher than the previous: It works on the original data C 2 1 M step Ts 2 IG k 2 E step results E(t)
33 Outlines Introduction to Cross Lingual Text Categorization: Realtionships with Cross Lingual Information Retrieval Possible approaches Text Categorization Multinomial Naive Bayes models Distance distribution and term filtering Learning with labeled and unlabeled data The algorithm The basic solution The modified algorithm Experimental results and Conclusions
34 Previous works Nuria et al. used ILO corpus and two language (E,S) to test three different approaches to CLTC: Polylingual Test set translation Profile-based translation They used the Winnow (ANN) and Rocchio algorithm They compared the results with the monolingual test Low performances: 70%-75%
35 Multi-lingual lingual Dataset Very few multi-lingual data sets available: No one with Italian language We built the data set by crawling the Newsgroups Newsgroups: Availability of the same groups in different languages Large number of available messages Different levels of each topic
36 Multi-lingual lingual Dataset Multi lingual dataset compostion Two languages: Italian (L I ) and English (L E ) Three groups: auto, hardware and sport Tr I Auto Hw Sports total TRAIN TEST Tr E Ts I
37 Multi-lingual lingual Dataset Drawbacks: Short messages Informal documents: Slang terms Badly written words Often transversal topics advertising, spam, other actual topics (elections) Temporal dependency: same topic in two different moments deals with different problems Geographical dependency: same topic in two different places deals with different persons, facts etc
38 Monolingual test No traslation Training set and test set in the Italian language Auto Hw Sports total Ts I test set Recall Tr I 94,01 ± 1,03% 96,21 ± 0,93% 92,89 ± 1,12% 94,43 ± 0,90% Ts I C I Precision 93,76 ± 1,09% 93,01 ± 0,45% 96,74 ± 1,24% 94,43 ± 0,90% results Results are averaged on a ten-fold cross-validation
39 Baseline multilingual test total Tr E Translation from English to Italian Ts I test set Auto Hw Sports Translation E I Recall Tr E I 69,56 ± 5,34% 87,24 ± 2,02% 50,95 ± 6,28% 69,26 ± 4,22% Ts I C E I Precision 66,56 ± 4,76% 63,35 ± 3,72% 88,22 ± 4,36% 69,26 ± 4,22% results Results are averaged on a ten-fold cross-validation
40 Simple EM Algorithm Translation from English to Italian Auto Hw Sports total Ts I test set Tr E Translation E I Recall Tr E I start 71,32 ± 1,05% 98,04 ± 1,01% 0,73 ± 0,41% 56,32 ± 1,10% C E I Ts I EM iterations E step M step Results are averaged on a ten-fold cross-validation Precision results E(t) 51,40 ± 1,00% 61,55 ± 0,98% 65,41 ± 0,05% 56,32 ± 1,10%
41 Filtered EM algorithm k 1 = 300 k 2 = 1000 Translation from English to Italian Auto Hw Sports total Ts I test set Tr E I Recall IG k 1 start 92,59 ± 1,05% 87,88 ± 0,98% 91,01 ± 1,03% 90,64 ± 0,96% C E I Ts I IG k 2 M step E step Results are averaged on a ten-fold cross-validation results E(t) EM iterations Precision 87,07 ± 1,02% 92,78 ± 0,88% 92,28 ± 0,90% 90,64 ± 0,96%
42 Conclusions The filtered EM algorithm performs better than other algorithms existing in literature It does not needs an initial labeled dataset in the desired language: No other algorithms have been proposed having such feature It achieves good results starting with few translated documents: It does not require much time for translation
Bayes and Naïve Bayes. cs534-machine Learning
 Bayes and aïve Bayes cs534-machine Learning Bayes Classifier Generative model learns Prediction is made by and where This is often referred to as the Bayes Classifier, because of the use of the Bayes rule
Bayes and aïve Bayes cs534-machine Learning Bayes Classifier Generative model learns Prediction is made by and where This is often referred to as the Bayes Classifier, because of the use of the Bayes rule
Exploiting Comparable Corpora and Bilingual Dictionaries. the Cross Language Text Categorization
 Exploiting Comparable Corpora and Bilingual Dictionaries for Cross-Language Text Categorization Alfio Gliozzo and Carlo Strapparava ITC-Irst via Sommarive, I-38050, Trento, ITALY {gliozzo,strappa}@itc.it
Exploiting Comparable Corpora and Bilingual Dictionaries for Cross-Language Text Categorization Alfio Gliozzo and Carlo Strapparava ITC-Irst via Sommarive, I-38050, Trento, ITALY {gliozzo,strappa}@itc.it
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier. Santosh Tirunagari : 245577
 T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Sentiment analysis using emoticons
 Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
Logistic Regression for Spam Filtering
 Logistic Regression for Spam Filtering Nikhila Arkalgud February 14, 28 Abstract The goal of the spam filtering problem is to identify an email as a spam or not spam. One of the classic techniques used
Logistic Regression for Spam Filtering Nikhila Arkalgud February 14, 28 Abstract The goal of the spam filtering problem is to identify an email as a spam or not spam. One of the classic techniques used
Machine Learning Final Project Spam Email Filtering
 Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
How To Use Neural Networks In Data Mining
 International Journal of Electronics and Computer Science Engineering 1449 Available Online at www.ijecse.org ISSN- 2277-1956 Neural Networks in Data Mining Priyanka Gaur Department of Information and
International Journal of Electronics and Computer Science Engineering 1449 Available Online at www.ijecse.org ISSN- 2277-1956 Neural Networks in Data Mining Priyanka Gaur Department of Information and
Content-Based Recommendation
 Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
CIRGIRDISCO at RepLab2014 Reputation Dimension Task: Using Wikipedia Graph Structure for Classifying the Reputation Dimension of a Tweet
 CIRGIRDISCO at RepLab2014 Reputation Dimension Task: Using Wikipedia Graph Structure for Classifying the Reputation Dimension of a Tweet Muhammad Atif Qureshi 1,2, Arjumand Younus 1,2, Colm O Riordan 1,
CIRGIRDISCO at RepLab2014 Reputation Dimension Task: Using Wikipedia Graph Structure for Classifying the Reputation Dimension of a Tweet Muhammad Atif Qureshi 1,2, Arjumand Younus 1,2, Colm O Riordan 1,
CSE 473: Artificial Intelligence Autumn 2010
 CSE 473: Artificial Intelligence Autumn 2010 Machine Learning: Naive Bayes and Perceptron Luke Zettlemoyer Many slides over the course adapted from Dan Klein. 1 Outline Learning: Naive Bayes and Perceptron
CSE 473: Artificial Intelligence Autumn 2010 Machine Learning: Naive Bayes and Perceptron Luke Zettlemoyer Many slides over the course adapted from Dan Klein. 1 Outline Learning: Naive Bayes and Perceptron
DISIT Lab, competence and project idea on bigdata. reasoning
 DISIT Lab, competence and project idea on bigdata knowledge modeling, OD/LD and reasoning Paolo Nesi Dipartimento di Ingegneria dell Informazione, DINFO Università degli Studi di Firenze Via S. Marta 3,
DISIT Lab, competence and project idea on bigdata knowledge modeling, OD/LD and reasoning Paolo Nesi Dipartimento di Ingegneria dell Informazione, DINFO Università degli Studi di Firenze Via S. Marta 3,
1 Maximum likelihood estimation
 COS 424: Interacting with Data Lecturer: David Blei Lecture #4 Scribes: Wei Ho, Michael Ye February 14, 2008 1 Maximum likelihood estimation 1.1 MLE of a Bernoulli random variable (coin flips) Given N
COS 424: Interacting with Data Lecturer: David Blei Lecture #4 Scribes: Wei Ho, Michael Ye February 14, 2008 1 Maximum likelihood estimation 1.1 MLE of a Bernoulli random variable (coin flips) Given N
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Statistical Feature Selection Techniques for Arabic Text Categorization
 Statistical Feature Selection Techniques for Arabic Text Categorization Rehab M. Duwairi Department of Computer Information Systems Jordan University of Science and Technology Irbid 22110 Jordan Tel. +962-2-7201000
Statistical Feature Selection Techniques for Arabic Text Categorization Rehab M. Duwairi Department of Computer Information Systems Jordan University of Science and Technology Irbid 22110 Jordan Tel. +962-2-7201000
Web based English-Chinese OOV term translation using Adaptive rules and Recursive feature selection
 Web based English-Chinese OOV term translation using Adaptive rules and Recursive feature selection Jian Qu, Nguyen Le Minh, Akira Shimazu School of Information Science, JAIST Ishikawa, Japan 923-1292
Web based English-Chinese OOV term translation using Adaptive rules and Recursive feature selection Jian Qu, Nguyen Le Minh, Akira Shimazu School of Information Science, JAIST Ishikawa, Japan 923-1292
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering
 A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
Bagged Ensemble Classifiers for Sentiment Classification of Movie Reviews
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 3 Issue 2 February, 2014 Page No. 3951-3961 Bagged Ensemble Classifiers for Sentiment Classification of Movie
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 3 Issue 2 February, 2014 Page No. 3951-3961 Bagged Ensemble Classifiers for Sentiment Classification of Movie
Web Mining. Margherita Berardi LACAM. Dipartimento di Informatica Università degli Studi di Bari [email protected]
 Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari [email protected] Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari [email protected] Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
Classification algorithm in Data mining: An Overview
 Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
CENG 734 Advanced Topics in Bioinformatics
 CENG 734 Advanced Topics in Bioinformatics Week 9 Text Mining for Bioinformatics: BioCreative II.5 Fall 2010-2011 Quiz #7 1. Draw the decompressed graph for the following graph summary 2. Describe the
CENG 734 Advanced Topics in Bioinformatics Week 9 Text Mining for Bioinformatics: BioCreative II.5 Fall 2010-2011 Quiz #7 1. Draw the decompressed graph for the following graph summary 2. Describe the
Email Spam Detection A Machine Learning Approach
 Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Segmentation and Classification of Online Chats
 Segmentation and Classification of Online Chats Justin Weisz Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 [email protected] Abstract One method for analyzing textual chat
Segmentation and Classification of Online Chats Justin Weisz Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 [email protected] Abstract One method for analyzing textual chat
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j
 Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Emoticon Smoothed Language Models for Twitter Sentiment Analysis
 Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence Emoticon Smoothed Language Models for Twitter Sentiment Analysis Kun-Lin Liu, Wu-Jun Li, Minyi Guo Shanghai Key Laboratory of
Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence Emoticon Smoothed Language Models for Twitter Sentiment Analysis Kun-Lin Liu, Wu-Jun Li, Minyi Guo Shanghai Key Laboratory of
Machine Learning CS 6830. Lecture 01. Razvan C. Bunescu School of Electrical Engineering and Computer Science [email protected]
 Machine Learning CS 6830 Razvan C. Bunescu School of Electrical Engineering and Computer Science [email protected] What is Learning? Merriam-Webster: learn = to acquire knowledge, understanding, or skill
Machine Learning CS 6830 Razvan C. Bunescu School of Electrical Engineering and Computer Science [email protected] What is Learning? Merriam-Webster: learn = to acquire knowledge, understanding, or skill
Spam Filtering using Naïve Bayesian Classification
 Spam Filtering using Naïve Bayesian Classification Presented by: Samer Younes Outline What is spam anyway? Some statistics Why is Spam a Problem Major Techniques for Classifying Spam Transport Level Filtering
Spam Filtering using Naïve Bayesian Classification Presented by: Samer Younes Outline What is spam anyway? Some statistics Why is Spam a Problem Major Techniques for Classifying Spam Transport Level Filtering
Clustering Technique in Data Mining for Text Documents
 Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Introduction to Machine Learning Using Python. Vikram Kamath
 Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Wikipedia and Web document based Query Translation and Expansion for Cross-language IR
 Wikipedia and Web document based Query Translation and Expansion for Cross-language IR Ling-Xiang Tang 1, Andrew Trotman 2, Shlomo Geva 1, Yue Xu 1 1Faculty of Science and Technology, Queensland University
Wikipedia and Web document based Query Translation and Expansion for Cross-language IR Ling-Xiang Tang 1, Andrew Trotman 2, Shlomo Geva 1, Yue Xu 1 1Faculty of Science and Technology, Queensland University
Categorical Data Visualization and Clustering Using Subjective Factors
 Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Towards better accuracy for Spam predictions
 Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 [email protected] Abstract Spam identification is crucial
Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 [email protected] Abstract Spam identification is crucial
Tracking and Recognition in Sports Videos
 Tracking and Recognition in Sports Videos Mustafa Teke a, Masoud Sattari b a Graduate School of Informatics, Middle East Technical University, Ankara, Turkey [email protected] b Department of Computer
Tracking and Recognition in Sports Videos Mustafa Teke a, Masoud Sattari b a Graduate School of Informatics, Middle East Technical University, Ankara, Turkey [email protected] b Department of Computer
An Overview of Knowledge Discovery Database and Data mining Techniques
 An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Final Project Report
 CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus
 Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Predict Influencers in the Social Network
 Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, [email protected] Department of Electrical Engineering, Stanford University Abstract Given two persons
Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, [email protected] Department of Electrical Engineering, Stanford University Abstract Given two persons
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts
 MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts Julio Villena-Román 1,3, Sara Lana-Serrano 2,3 1 Universidad Carlos III de Madrid 2 Universidad Politécnica de Madrid 3 DAEDALUS
MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts Julio Villena-Román 1,3, Sara Lana-Serrano 2,3 1 Universidad Carlos III de Madrid 2 Universidad Politécnica de Madrid 3 DAEDALUS
CINDOR Conceptual Interlingua Document Retrieval: TREC-8 Evaluation.
 CINDOR Conceptual Interlingua Document Retrieval: TREC-8 Evaluation. Miguel Ruiz, Anne Diekema, Páraic Sheridan MNIS-TextWise Labs Dey Centennial Plaza 401 South Salina Street Syracuse, NY 13202 Abstract:
CINDOR Conceptual Interlingua Document Retrieval: TREC-8 Evaluation. Miguel Ruiz, Anne Diekema, Páraic Sheridan MNIS-TextWise Labs Dey Centennial Plaza 401 South Salina Street Syracuse, NY 13202 Abstract:
A Content based Spam Filtering Using Optical Back Propagation Technique
 A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT
A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT
How To Create A Text Classification System For Spam Filtering
 Term Discrimination Based Robust Text Classification with Application to Email Spam Filtering PhD Thesis Khurum Nazir Junejo 2004-03-0018 Advisor: Dr. Asim Karim Department of Computer Science Syed Babar
Term Discrimination Based Robust Text Classification with Application to Email Spam Filtering PhD Thesis Khurum Nazir Junejo 2004-03-0018 Advisor: Dr. Asim Karim Department of Computer Science Syed Babar
Question 2 Naïve Bayes (16 points)
") Question 2 Naïve Bayes (16 points) About 2/3 of your email is spam so you downloaded an open source spam filter based on word occurrences that uses the Naive Bayes classifier. Assume you collected the
Question 2 Naïve Bayes (16 points) About 2/3 of your email is spam so you downloaded an open source spam filter based on word occurrences that uses the Naive Bayes classifier. Assume you collected the
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks
 A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
Université de Montpellier 2 Hugo Alatrista-Salas : [email protected]
 Université de Montpellier 2 Hugo Alatrista-Salas : [email protected] WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : [email protected] WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Employer Health Insurance Premium Prediction Elliott Lui
 Employer Health Insurance Premium Prediction Elliott Lui 1 Introduction The US spends 15.2% of its GDP on health care, more than any other country, and the cost of health insurance is rising faster than
Employer Health Insurance Premium Prediction Elliott Lui 1 Introduction The US spends 15.2% of its GDP on health care, more than any other country, and the cost of health insurance is rising faster than
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Social Business Intelligence Framework. Copyright 2012 Deloitte Development LLC. All rights reserved.
 Social Business Intelligence Framework Key Insight / Takeaways Business Outcomes Insightful Brand Analysis Improved Customer Experience Benchmarked Performance Revelation of Market Trends/Opportunities
Social Business Intelligence Framework Key Insight / Takeaways Business Outcomes Insightful Brand Analysis Improved Customer Experience Benchmarked Performance Revelation of Market Trends/Opportunities
Data Quality Mining: Employing Classifiers for Assuring consistent Datasets
 Data Quality Mining: Employing Classifiers for Assuring consistent Datasets Fabian Grüning Carl von Ossietzky Universität Oldenburg, Germany, [email protected] Abstract: Independent
Data Quality Mining: Employing Classifiers for Assuring consistent Datasets Fabian Grüning Carl von Ossietzky Universität Oldenburg, Germany, [email protected] Abstract: Independent
Research on Sentiment Classification of Chinese Micro Blog Based on
 Research on Sentiment Classification of Chinese Micro Blog Based on Machine Learning School of Economics and Management, Shenyang Ligong University, Shenyang, 110159, China E-mail: [email protected] Abstract
Research on Sentiment Classification of Chinese Micro Blog Based on Machine Learning School of Economics and Management, Shenyang Ligong University, Shenyang, 110159, China E-mail: [email protected] Abstract
Approaches of Using a Word-Image Ontology and an Annotated Image Corpus as Intermedia for Cross-Language Image Retrieval
 Approaches of Using a Word-Image Ontology and an Annotated Image Corpus as Intermedia for Cross-Language Image Retrieval Yih-Chen Chang and Hsin-Hsi Chen Department of Computer Science and Information
Approaches of Using a Word-Image Ontology and an Annotated Image Corpus as Intermedia for Cross-Language Image Retrieval Yih-Chen Chang and Hsin-Hsi Chen Department of Computer Science and Information
OPINION MINING IN PRODUCT REVIEW SYSTEM USING BIG DATA TECHNOLOGY HADOOP
 OPINION MINING IN PRODUCT REVIEW SYSTEM USING BIG DATA TECHNOLOGY HADOOP 1 KALYANKUMAR B WADDAR, 2 K SRINIVASA 1 P G Student, S.I.T Tumkur, 2 Assistant Professor S.I.T Tumkur Abstract- Product Review System
OPINION MINING IN PRODUCT REVIEW SYSTEM USING BIG DATA TECHNOLOGY HADOOP 1 KALYANKUMAR B WADDAR, 2 K SRINIVASA 1 P G Student, S.I.T Tumkur, 2 Assistant Professor S.I.T Tumkur Abstract- Product Review System
Simple Language Models for Spam Detection
 Simple Language Models for Spam Detection Egidio Terra Faculty of Informatics PUC/RS - Brazil Abstract For this year s Spam track we used classifiers based on language models. These models are used to
Simple Language Models for Spam Detection Egidio Terra Faculty of Informatics PUC/RS - Brazil Abstract For this year s Spam track we used classifiers based on language models. These models are used to
Three types of messages: A, B, C. Assume A is the oldest type, and C is the most recent type.
 Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
How To Solve The Kd Cup 2010 Challenge
 A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China [email protected] [email protected]
A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China [email protected] [email protected]
UNDERSTANDING THE EFFECTIVENESS OF BANK DIRECT MARKETING Tarun Gupta, Tong Xia and Diana Lee
 UNDERSTANDING THE EFFECTIVENESS OF BANK DIRECT MARKETING Tarun Gupta, Tong Xia and Diana Lee 1. Introduction There are two main approaches for companies to promote their products / services: through mass
UNDERSTANDING THE EFFECTIVENESS OF BANK DIRECT MARKETING Tarun Gupta, Tong Xia and Diana Lee 1. Introduction There are two main approaches for companies to promote their products / services: through mass
Using News Articles to Predict Stock Price Movements
 Using News Articles to Predict Stock Price Movements Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 9237 [email protected] 21, June 15,
Using News Articles to Predict Stock Price Movements Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 9237 [email protected] 21, June 15,
diagnosis through Random
 Convegno Calcolo ad Alte Prestazioni "Biocomputing" Bio-molecular diagnosis through Random Subspace Ensembles of Learning Machines Alberto Bertoni, Raffaella Folgieri, Giorgio Valentini DSI Dipartimento
Convegno Calcolo ad Alte Prestazioni "Biocomputing" Bio-molecular diagnosis through Random Subspace Ensembles of Learning Machines Alberto Bertoni, Raffaella Folgieri, Giorgio Valentini DSI Dipartimento
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization
 A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca [email protected] Spain Manuel Martín-Merino Universidad
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca [email protected] Spain Manuel Martín-Merino Universidad
Principles of Data Mining by Hand&Mannila&Smyth
 Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Clustering Connectionist and Statistical Language Processing
 Clustering Connectionist and Statistical Language Processing Frank Keller [email protected] Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Clustering Connectionist and Statistical Language Processing Frank Keller [email protected] Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Using LSI for Implementing Document Management Systems Turning unstructured data from a liability to an asset.
 White Paper Using LSI for Implementing Document Management Systems Turning unstructured data from a liability to an asset. Using LSI for Implementing Document Management Systems By Mike Harrison, Director,
White Paper Using LSI for Implementing Document Management Systems Turning unstructured data from a liability to an asset. Using LSI for Implementing Document Management Systems By Mike Harrison, Director,
W6.B.1. FAQs CS535 BIG DATA W6.B.3. 4. If the distance of the point is additionally less than the tight distance T 2, remove it from the original set
 http://wwwcscolostateedu/~cs535 W6B W6B2 CS535 BIG DAA FAQs Please prepare for the last minute rush Store your output files safely Partial score will be given for the output from less than 50GB input Computer
http://wwwcscolostateedu/~cs535 W6B W6B2 CS535 BIG DAA FAQs Please prepare for the last minute rush Store your output files safely Partial score will be given for the output from less than 50GB input Computer
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
A MACHINE LEARNING APPROACH TO FILTER UNWANTED MESSAGES FROM ONLINE SOCIAL NETWORKS
 A MACHINE LEARNING APPROACH TO FILTER UNWANTED MESSAGES FROM ONLINE SOCIAL NETWORKS Charanma.P 1, P. Ganesh Kumar 2, 1 PG Scholar, 2 Assistant Professor,Department of Information Technology, Anna University
A MACHINE LEARNING APPROACH TO FILTER UNWANTED MESSAGES FROM ONLINE SOCIAL NETWORKS Charanma.P 1, P. Ganesh Kumar 2, 1 PG Scholar, 2 Assistant Professor,Department of Information Technology, Anna University
A Survey on Product Aspect Ranking
 A Survey on Product Aspect Ranking Charushila Patil 1, Prof. P. M. Chawan 2, Priyamvada Chauhan 3, Sonali Wankhede 4 M. Tech Student, Department of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra,
A Survey on Product Aspect Ranking Charushila Patil 1, Prof. P. M. Chawan 2, Priyamvada Chauhan 3, Sonali Wankhede 4 M. Tech Student, Department of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra,
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Semantic Sentiment Analysis of Twitter
 Semantic Sentiment Analysis of Twitter Hassan Saif, Yulan He & Harith Alani Knowledge Media Institute, The Open University, Milton Keynes, United Kingdom The 11 th International Semantic Web Conference
Semantic Sentiment Analysis of Twitter Hassan Saif, Yulan He & Harith Alani Knowledge Media Institute, The Open University, Milton Keynes, United Kingdom The 11 th International Semantic Web Conference
Experiments in Web Page Classification for Semantic Web
 Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
Spam Filtering based on Naive Bayes Classification. Tianhao Sun
 Spam Filtering based on Naive Bayes Classification Tianhao Sun May 1, 2009 Abstract This project discusses about the popular statistical spam filtering process: naive Bayes classification. A fairly famous
Spam Filtering based on Naive Bayes Classification Tianhao Sun May 1, 2009 Abstract This project discusses about the popular statistical spam filtering process: naive Bayes classification. A fairly famous
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
The Enron Corpus: A New Dataset for Email Classification Research
 The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
Facilitating Business Process Discovery using Email Analysis
 Facilitating Business Process Discovery using Email Analysis Matin Mavaddat [email protected] Stewart Green Stewart.Green Ian Beeson Ian.Beeson Jin Sa Jin.Sa Abstract Extracting business process
Facilitating Business Process Discovery using Email Analysis Matin Mavaddat [email protected] Stewart Green Stewart.Green Ian Beeson Ian.Beeson Jin Sa Jin.Sa Abstract Extracting business process
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Personalized Hierarchical Clustering
 Personalized Hierarchical Clustering Korinna Bade, Andreas Nürnberger Faculty of Computer Science, Otto-von-Guericke-University Magdeburg, D-39106 Magdeburg, Germany {kbade,nuernb}@iws.cs.uni-magdeburg.de
Personalized Hierarchical Clustering Korinna Bade, Andreas Nürnberger Faculty of Computer Science, Otto-von-Guericke-University Magdeburg, D-39106 Magdeburg, Germany {kbade,nuernb}@iws.cs.uni-magdeburg.de
Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project
 Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project Ahmet Suerdem Istanbul Bilgi University; LSE Methodology Dept. Science in the media project is funded
Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project Ahmet Suerdem Istanbul Bilgi University; LSE Methodology Dept. Science in the media project is funded
Automated News Item Categorization
 Automated News Item Categorization Hrvoje Bacan, Igor S. Pandzic* Department of Telecommunications, Faculty of Electrical Engineering and Computing, University of Zagreb, Croatia {Hrvoje.Bacan,Igor.Pandzic}@fer.hr
Automated News Item Categorization Hrvoje Bacan, Igor S. Pandzic* Department of Telecommunications, Faculty of Electrical Engineering and Computing, University of Zagreb, Croatia {Hrvoje.Bacan,Igor.Pandzic}@fer.hr
Assessment. Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall
 Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
PSSF: A Novel Statistical Approach for Personalized Service-side Spam Filtering
 2007 IEEE/WIC/ACM International Conference on Web Intelligence PSSF: A Novel Statistical Approach for Personalized Service-side Spam Filtering Khurum Nazir Juneo Dept. of Computer Science Lahore University
2007 IEEE/WIC/ACM International Conference on Web Intelligence PSSF: A Novel Statistical Approach for Personalized Service-side Spam Filtering Khurum Nazir Juneo Dept. of Computer Science Lahore University
TS3: an Improved Version of the Bilingual Concordancer TransSearch
 TS3: an Improved Version of the Bilingual Concordancer TransSearch Stéphane HUET, Julien BOURDAILLET and Philippe LANGLAIS EAMT 2009 - Barcelona June 14, 2009 Computer assisted translation Preferred by
TS3: an Improved Version of the Bilingual Concordancer TransSearch Stéphane HUET, Julien BOURDAILLET and Philippe LANGLAIS EAMT 2009 - Barcelona June 14, 2009 Computer assisted translation Preferred by
Defending Networks with Incomplete Information: A Machine Learning Approach. Alexandre Pinto [email protected] @alexcpsec @MLSecProject
 Defending Networks with Incomplete Information: A Machine Learning Approach Alexandre Pinto [email protected] @alexcpsec @MLSecProject Agenda Security Monitoring: We are doing it wrong Machine Learning
Defending Networks with Incomplete Information: A Machine Learning Approach Alexandre Pinto [email protected] @alexcpsec @MLSecProject Agenda Security Monitoring: We are doing it wrong Machine Learning
Predicting Student Performance by Using Data Mining Methods for Classification
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 13, No 1 Sofia 2013 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.2478/cait-2013-0006 Predicting Student Performance
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 13, No 1 Sofia 2013 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.2478/cait-2013-0006 Predicting Student Performance
Detecting E-mail Spam Using Spam Word Associations
 Detecting E-mail Spam Using Spam Word Associations N.S. Kumar 1, D.P. Rana 2, R.G.Mehta 3 Sardar Vallabhbhai National Institute of Technology, Surat, India 1 [email protected] 2 [email protected]
Detecting E-mail Spam Using Spam Word Associations N.S. Kumar 1, D.P. Rana 2, R.G.Mehta 3 Sardar Vallabhbhai National Institute of Technology, Surat, India 1 [email protected] 2 [email protected]
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
Machine Learning. CS 188: Artificial Intelligence Naïve Bayes. Example: Digit Recognition. Other Classification Tasks
 CS 188: Artificial Intelligence Naïve Bayes Machine Learning Up until now: how use a model to make optimal decisions Machine learning: how to acquire a model from data / experience Learning parameters
CS 188: Artificial Intelligence Naïve Bayes Machine Learning Up until now: how use a model to make optimal decisions Machine learning: how to acquire a model from data / experience Learning parameters
Large-scale Data Mining: MapReduce and Beyond Part 2: Algorithms. Spiros Papadimitriou, IBM Research Jimeng Sun, IBM Research Rong Yan, Facebook
 Large-scale Data Mining: MapReduce and Beyond Part 2: Algorithms Spiros Papadimitriou, IBM Research Jimeng Sun, IBM Research Rong Yan, Facebook Part 2:Mining using MapReduce Mining algorithms using MapReduce
Large-scale Data Mining: MapReduce and Beyond Part 2: Algorithms Spiros Papadimitriou, IBM Research Jimeng Sun, IBM Research Rong Yan, Facebook Part 2:Mining using MapReduce Mining algorithms using MapReduce