Data Warehouse and Hive. Presented By: Shalva Gelenidze Supervisor: Nodar Momtselidze
|
|
|
- Spencer Boone
- 10 years ago
- Views:
Transcription
1 Data Warehouse and Hive Presented By: Shalva Gelenidze Supervisor: Nodar Momtselidze

2 Decision support systems Decision Support Systems allowed managers, supervisors, and executives to once again see the clipboard with all its information. By 1992, Windows 3.1 was in the stores and Ralph Kimball and Bill Inmon were figuring out how to gather data from two business areas and figuring out how to warehouse the data of an enterprise.

3 Data warehouse philosophy A data warehouse is an asset of an enterprise and exists for the benefit of an entire enterprise. It does not exist for the benefit of a single entity (e.g., business unit, individual customer, etc.) to the exclusion of all others in the enterprise. As such, data in a data warehouse does not conform specifically to the preferences of any single enterprise entity. Instead, a data warehouse is intended to provide data to the entire enterprise in such a way that all members can use the data in the warehouse throughout its lifespan. In the 1990s, Kimball and Inmon created and documented the concepts and principles of data warehouses, which today are the foundation of all data warehouses.

4 Decision Support Systems allowed managers, supervisors, and executives to once again see the clipboard with all its information Principles: Subject Orientation: Data will be grouped by subject, rather than author, department, or physical location. Data Integration: Even though data comes from separate applications, departments, etc., differences should be smoothed out so they have the same look and feel. Nonvolatility: Unlike the data in operational applications, which is discarded once the company is finished using it, the data in a data warehouse will remain in the warehouse. Time Variant: All data has a context at a moment in time. A data warehouse will keep that context. So, all data from 1995 will retain its context within One Version of the truth: The proliferation of data in the 1980s and 1990s yielded many copies of the same data. Only the one, true gold, standard copy of each data element would be included in a data warehouse. Long-Term Investment: A data warehouse should be flexible enough to absorb changes in the company and the world, and scalable enough to grow with the company. By doing so, a data warehouse can add value to the company for a long time.

5 Ralph Kimball & Bill Inmon Ralph Kimball was a co-creator of the Xerox Star Workstation, the world s first commercially viable GUI application. Ralph was the founder and CEO of Red Brick Systems, the group which created an extremely fast RDBMS targeted specifically for data warehousing. When he authored The Data Warehouse Lifecycle Toolkit, Ralph introduced the Dimension-al Data Model. Bill Inmon was the creator of the Corporate Information Factory and Government Information Factory. In so doing, Bill also established many of the principles of Data Warehousing.

6 DW principles Ralph Kimball & Bill Inmon Working separately arrived at a common set of guidelines and principles: Subject Orientation - Data will be grouped by subject, rather than author, department, or physical location. So, all manufacturing data goes together, and the sales data, and the promotions data, etc., regardless of where it came from. Data Integration - Even though data comes from separate applications, departments, etc., differences should be smoothed out so they have the same look and feel. Form: When two data elements have different layouts, for eg. Telephone. One should be imposed on both of them. Function: When two data elements identify the same thing with different names, it should be changed into one name Grain: When two data elements apply different hierarchies (e.g., region and district) to the same thing, or different levels of detail (e.g., miles and feet), the two data elements will be resolved to the same level of hierarchy or detail.

7 DW principles Nonvolatility: Unlike the data in operational applications, which is discarded once the company is finished using it, the data in a data warehouse will remain in the warehouse. Time Variant: All data has a context at a moment in time. A data warehouse will keep that context. So, all data from 1995 will retain its context within One Version of the Truth: The proliferation of data in the 1980s and 1990s yielded many copies of the same data. Only the one, true gold, standard copy of each data element would be included in a data warehouse. Long-Term Investment: A data warehouse should be flexible enough to absorb changes in the company and the world, and scalable enough to grow with the company. By doing so, a data warehouse can add value to the company for a long time.

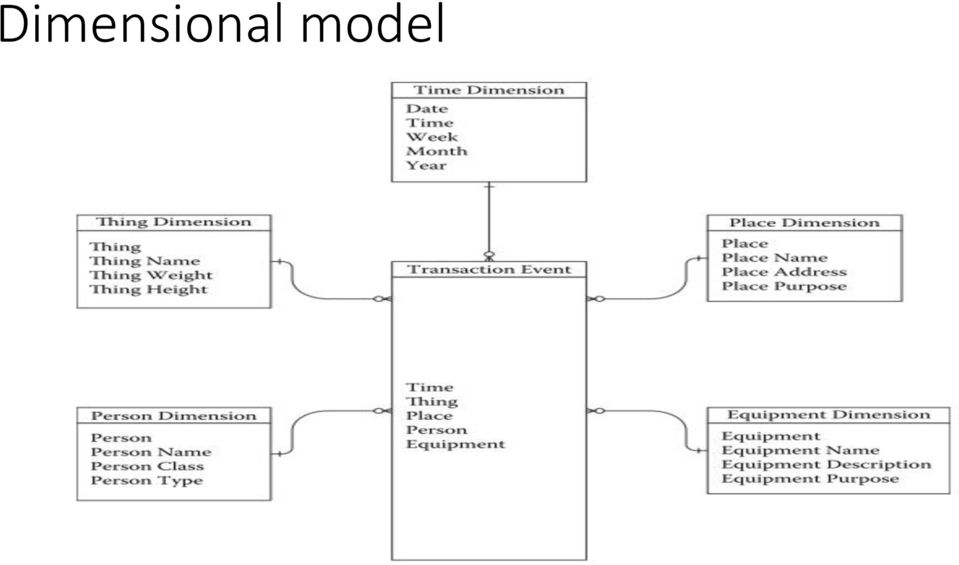
8 Dimensional and Third Normal Form Data Models Kimball and Inmon arrived at the same set of principles, yet each used completely different designs. Kimball created the Dimensional Data Model also known as a Star Schema because it looks like star. In the middle is a Fact table surrounding tables are dimensional tables Bill Inmon Created the Third Normal Form Data Model Within the data warehousing community, a debate emerged. Which was better, the Dimensional Data Model or the Third Normal Form data model? By the twenty-first century, the answer was clear both. Both designs had their strengths and their weaknesses. Rather than apply a one size fits all mindset, data warehouse designers learned to apply the strengths and avoid the weaknesses of both in each situation.

9 Dimensional model
10 Third normal form data model

11 EDW model
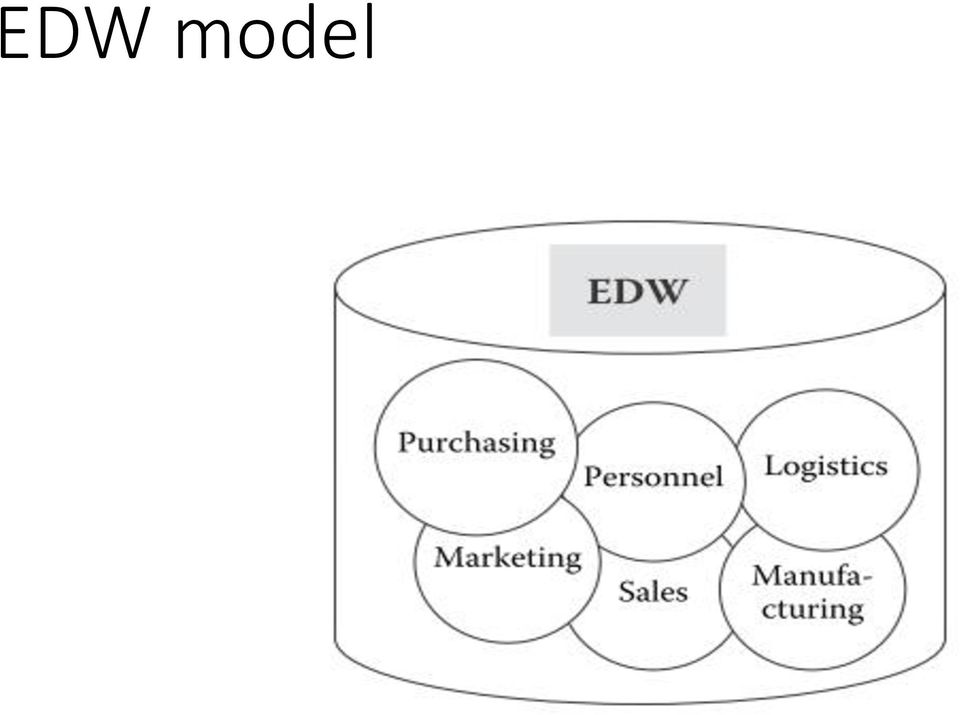
12 EDW and Data Marts

13 Data Warehouse Data warehouse (DW or DWH), also known as an enterprise data warehouse (EDW), is a system used for reporting and data analysis DWs are central repositories of integrated data from one or more disparate sources. They store current and historical data and are used for creating trending reports for senior management reporting such as annual and quarterly comparisons. The data stored in the warehouse is uploaded from the operational systems The data may pass through an operational data store for additional operations before it is used in the DW for reporting. Source: Wikipedia

14 Data Mart A data mart is a simple form of a data warehouse that is focused on a single subject (or functional area), such as sales, finance or marketing. Data marts are often built and controlled by a single department within an organization. Given their single-subject focus, data marts usually draw data from only a few sources. The sources could be internal operational systems, a central data warehouse, or external data. Source: wikipedia

15 Data Warehouse and Hadoop Identify all possible enterprise data assets Select those that have actionable content and can accessed Bring assets into logically centralized data warehouse Expose data warehouse for decision making most effectively

16 RDBS Pros Places data in well defined structure SQL language Cons Not capable of handling unstructured data Can handle an data in MBs and GBs, performance goes down when data increases RDBS cannot be scaled out (if data size increases you cannot add extra database server)

17 Big data Big Data is a term applied to data sets whose size is beyond the ability of commonly used software tools to capture, manage, and process within a tolerable elapsed time. Big Data sizes are a constantly moving target currently ranging from a few dozen terabytes to many petabytes in a single data set. Examples include Web logs; RFID; sensor networks; social networks; Internet text and documents; Internet search indexing; call detail records; astronomy, atmospheric science, biological, genomics, biochemical, medical records; scientific research; military surveillance; photography archives; video archives; and large scale ecommerce

18 Types of big data Structured data Data is organized into entities that have a defined format, they conform to a particular schema. Semi structured data Unstructured data

19 Nosql summary 32bit MongoDB handles only 2GB of data and has 12 node limitations.

20 Is Hadoop a Data Warehouse??? Mapreduce Hive Environment Distributed file system

21 Can we create data warehouse on Hadoop?? Generating data Capture data Store data Analyze data Present results
22 Hive s Architecture
23 Metastore Hive s architecture consists of a Relational Metastore which store data about (table definitions, location of data, data type info, how tables are partitioned ) it is relational database, by default hive installs derby database however it has limitations and that s why hives metastore is installed in sql db.
24 Hive Query Language Interacts with Driver responsible for Query processing, compiling, optimizing So hive is just an interface which allows you to write SQL like queries which hive than translates to mapreduce jobs and executes them. Hive interpreter sits on user s machine and compiles HiveQL into MapReduce jobs then submits to the Hadoop cluster. You can access hive using command line interface or any other interfaces as JDBC or ODBC, you can also use a web UI which provide web interface for hiveql
25 Hive Principles
26 Hive Principles In HDFS data is unstructured and hive adds some structure to it but this is assign when the data is read not as its written.
27 Hive warehouse Consists of Meta data about all the objects known to Hive, persisted in meta store. Data consists of: Databases Tables Partitions (tables are split into) based on the value of the column which determines where the data is actually stored. Helps to officially query the tables. Buckets/ Clusters, partitions are divided into, based on the value of the hash function of column or set of columns. They have performance benefits. Local Hive warehouse hive defines a location in HDFS which is marked as local Hive Warehouse, this is how hive distinguishes between locally managed tables and unmanaged external tables. Managed by hive Dropping the table will drop table as well as meta data External Tables Hive manages the meta data only Hive can create tables and make some changes in it, but it does not assume the ownership of external tables. Dropping the table will drop only a table definition the data remains in untouched.
28 HiveQL SELECT Select exp1, exp2, exp3 FROM table WHETE condition LIMIT limitation SELECT DISTINCT col1, col2,col3 FROM table; SELECT col1 + col2 AS col3 FROM table; SELECT (ID NAME)?+.+ FROM table ; - not regular java regex FROM table Select exp1, exp2, exp3 WHETE condition; interchangeable select Interchangeable constructs Hive is not case sensitive Needs semicolon at the end of each expression Select col (select cola + colb as col from some_table ) subq;
29 HiveQL Hive lets as look at the data stored on hdfs as table perspective. Database in Hive is simple an abstraction to group tables together. /hive/warehouse here is placed data if we define table and load data into it. /hive/warehouse/marketing.db database is just metadata that defines a logical unit and it is another directory under hive directory. With same name of database, and.db extension suffix to database name to differentiate that it is a database. /somewhere/on/hdfs if you don t want to save files in default location you can save them anywhere under hdfs folder.
30 HiveQL Create Database CREATE (DATABASE SCHEMA) [IF NOT EXISTS] database_name [COMMENT some_comment] [LOCATION some_location] [WITH DBPROPERTIES (property_name = property_value)]; USE db_name; DROP (DATABASE SCHEMA) [IF EXISTS] database_name; CREATE [EXTERNAL] TABLE (IF NOT EXISTS) [db_name] table_name [(col_name data type]
31 Hive Create table CREATE [EXTERNAL] TABLE (IF NOT EXISTS) [db_name]table_name [(col_name data type [COMMENT col_comment+, )+ [PARTITIONED BY (col_name data type [COMMENT col_comment+, )+ [ROW FORMAT row_format][stored AS file_format] [LOCATION hdfs_location] [TBLPROPERTIES (property_name = property_value, )+;
32 Tables - How they are stored
33 Primitive data types Numeric TINYINT, SMALLING, INT, BIGINT FLOAT DOUBLE DECIMAL DATE/TIME TIMESTAMP YYYY-MM-DD HH:MM:SS.FFFFFFFF DATE MISC BOOLEAN STRING BINARY
34 COMPLEX DATA TYPES ARRAY ARRAY <DATA_TYPE> MAPS MAP <PRIMITIVE_TYPE, DATA_TYPE> STRUCT STRUCT <COL_NAEM:DATA_TYPE*COMMENT COL_COMMENT+, > UNION TYPE UNIONTYPE <DATA_TYPE, DATA_TYPE>
35 Thank you!
Spring,2015. Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE
 Spring,2015 Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE Contents: Briefly About Big Data Management What is hive? Hive Architecture Working
Spring,2015 Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE Contents: Briefly About Big Data Management What is hive? Hive Architecture Working
11/18/15 CS 6030. q Hadoop was not designed to migrate data from traditional relational databases to its HDFS. q This is where Hive comes in.
 by shatha muhi CS 6030 1 q Big Data: collections of large datasets (huge volume, high velocity, and variety of data). q Apache Hadoop framework emerged to solve big data management and processing challenges.
by shatha muhi CS 6030 1 q Big Data: collections of large datasets (huge volume, high velocity, and variety of data). q Apache Hadoop framework emerged to solve big data management and processing challenges.
BIG DATA CAN DRIVE THE BUSINESS AND IT TO EVOLVE AND ADAPT RALPH KIMBALL BUSSUM 2014
 BIG DATA CAN DRIVE THE BUSINESS AND IT TO EVOLVE AND ADAPT RALPH KIMBALL BUSSUM 2014 Ralph Kimball Associates 2014 The Data Warehouse Mission Identify all possible enterprise data assets Select those assets
BIG DATA CAN DRIVE THE BUSINESS AND IT TO EVOLVE AND ADAPT RALPH KIMBALL BUSSUM 2014 Ralph Kimball Associates 2014 The Data Warehouse Mission Identify all possible enterprise data assets Select those assets
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Integration of Apache Hive and HBase
 Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 About Me User and committer of Hadoop since 2007 Contributor to Apache Hadoop, HBase, Hive and Gora Joined
Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 About Me User and committer of Hadoop since 2007 Contributor to Apache Hadoop, HBase, Hive and Gora Joined
COSC 6397 Big Data Analytics. 2 nd homework assignment Pig and Hive. Edgar Gabriel Spring 2015
 COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
So What s the Big Deal?
 So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
+,-./012345<ya") }w!"#$%&'()+,-./012345
}w!"#$%&'()+,-./012345 Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
WINDOWS AZURE DATA MANAGEMENT AND BUSINESS ANALYTICS
 WINDOWS AZURE DATA MANAGEMENT AND BUSINESS ANALYTICS Managing and analyzing data in the cloud is just as important as it is anywhere else. To let you do this, Windows Azure provides a range of technologies
WINDOWS AZURE DATA MANAGEMENT AND BUSINESS ANALYTICS Managing and analyzing data in the cloud is just as important as it is anywhere else. To let you do this, Windows Azure provides a range of technologies
Hadoop Distributed File System. -Kishan Patel ID#2618621
 Hadoop Distributed File System -Kishan Patel ID#2618621 Emirates Airlines Schedule Schedule of Emirates airlines was downloaded from official website of Emirates. Originally schedule was in pdf format.
Hadoop Distributed File System -Kishan Patel ID#2618621 Emirates Airlines Schedule Schedule of Emirates airlines was downloaded from official website of Emirates. Originally schedule was in pdf format.
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Hadoop and Hive Development at Facebook. Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009
 Hadoop and Hive Development at Facebook Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009 Hadoop @ Facebook Who generates this data? Lots of data
Hadoop and Hive Development at Facebook Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009 Hadoop @ Facebook Who generates this data? Lots of data
Microsoft Azure Data Technologies: An Overview
 David Chappell Microsoft Azure Data Technologies: An Overview Sponsored by Microsoft Corporation Copyright 2014 Chappell & Associates Contents Blobs... 3 Running a DBMS in a Virtual Machine... 4 SQL Database...
David Chappell Microsoft Azure Data Technologies: An Overview Sponsored by Microsoft Corporation Copyright 2014 Chappell & Associates Contents Blobs... 3 Running a DBMS in a Virtual Machine... 4 SQL Database...
Bringing Big Data into the Enterprise
 Bringing Big Data into the Enterprise Overview When evaluating Big Data applications in enterprise computing, one often-asked question is how does Big Data compare to the Enterprise Data Warehouse (EDW)?
Bringing Big Data into the Enterprise Overview When evaluating Big Data applications in enterprise computing, one often-asked question is how does Big Data compare to the Enterprise Data Warehouse (EDW)?
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Oracle BI EE Implementation on Netezza. Prepared by SureShot Strategies, Inc.
 Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Replicating to everything
 Replicating to everything Featuring Tungsten Replicator A Giuseppe Maxia, QA Architect Vmware About me Giuseppe Maxia, a.k.a. "The Data Charmer" QA Architect at VMware Previously at AB / Sun / 3 times
Replicating to everything Featuring Tungsten Replicator A Giuseppe Maxia, QA Architect Vmware About me Giuseppe Maxia, a.k.a. "The Data Charmer" QA Architect at VMware Previously at AB / Sun / 3 times
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Integrating Hadoop. Into Business Intelligence & Data Warehousing. Philip Russom TDWI Research Director for Data Management, April 9 2013
 Integrating Hadoop Into Business Intelligence & Data Warehousing Philip Russom TDWI Research Director for Data Management, April 9 2013 TDWI would like to thank the following companies for sponsoring the
Integrating Hadoop Into Business Intelligence & Data Warehousing Philip Russom TDWI Research Director for Data Management, April 9 2013 TDWI would like to thank the following companies for sponsoring the
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect
 Huibert Aalbers Senior Certified Executive IT Architect") The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
Architecting the Future of Big Data
 Hive ODBC Driver User Guide Revised: July 22, 2013 2012-2013 Hortonworks Inc. All Rights Reserved. Parts of this Program and Documentation include proprietary software and content that is copyrighted and
Hive ODBC Driver User Guide Revised: July 22, 2013 2012-2013 Hortonworks Inc. All Rights Reserved. Parts of this Program and Documentation include proprietary software and content that is copyrighted and
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop
 Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
American International Journal of Research in Science, Technology, Engineering & Mathematics
 American International Journal of Research in Science, Technology, Engineering & Mathematics Available online at http://www.iasir.net ISSN (Print): 2328-3491, ISSN (Online): 2328-3580, ISSN (CD-ROM): 2328-3629
American International Journal of Research in Science, Technology, Engineering & Mathematics Available online at http://www.iasir.net ISSN (Print): 2328-3491, ISSN (Online): 2328-3580, ISSN (CD-ROM): 2328-3629
Architecting for Big Data Analytics and Beyond: A New Framework for Business Intelligence and Data Warehousing
 Architecting for Big Data Analytics and Beyond: A New Framework for Business Intelligence and Data Warehousing Wayne W. Eckerson Director of Research, TechTarget Founder, BI Leadership Forum Business Analytics
Architecting for Big Data Analytics and Beyond: A New Framework for Business Intelligence and Data Warehousing Wayne W. Eckerson Director of Research, TechTarget Founder, BI Leadership Forum Business Analytics
Microsoft SQL Server Connector for Apache Hadoop Version 1.0. User Guide
 Microsoft SQL Server Connector for Apache Hadoop Version 1.0 User Guide October 3, 2011 Contents Legal Notice... 3 Introduction... 4 What is SQL Server-Hadoop Connector?... 4 What is Sqoop?... 4 Supported
Microsoft SQL Server Connector for Apache Hadoop Version 1.0 User Guide October 3, 2011 Contents Legal Notice... 3 Introduction... 4 What is SQL Server-Hadoop Connector?... 4 What is Sqoop?... 4 Supported
Architecting the Future of Big Data
 Hive ODBC Driver User Guide Revised: October 1, 2012 2012 Hortonworks Inc. All Rights Reserved. Parts of this Program and Documentation include proprietary software and content that is copyrighted and
Hive ODBC Driver User Guide Revised: October 1, 2012 2012 Hortonworks Inc. All Rights Reserved. Parts of this Program and Documentation include proprietary software and content that is copyrighted and
Alternatives to HIVE SQL in Hadoop File Structure
 Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Data Domain Profiling and Data Masking for Hadoop
 Data Domain Profiling and Data Masking for Hadoop 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or
Data Domain Profiling and Data Masking for Hadoop 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
About the Tutorial. Audience. Prerequisites. Disclaimer & Copyright. Apache Hive
 i About the Tutorial Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarize Big Data, and makes querying and analyzing easy. This is
i About the Tutorial Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarize Big Data, and makes querying and analyzing easy. This is
Real World Big Data Architecture - Splunk, Hadoop, RDBMS
 Copyright 2015 Splunk Inc. Real World Big Data Architecture - Splunk, Hadoop, RDBMS Raanan Dagan, Big Data Specialist, Splunk Disclaimer During the course of this presentagon, we may make forward looking
Copyright 2015 Splunk Inc. Real World Big Data Architecture - Splunk, Hadoop, RDBMS Raanan Dagan, Big Data Specialist, Splunk Disclaimer During the course of this presentagon, we may make forward looking
Tap into Hadoop and Other No SQL Sources
 Tap into Hadoop and Other No SQL Sources Presented by: Trishla Maru What is Big Data really? The Three Vs of Big Data According to Gartner Volume Volume Orders of magnitude bigger than conventional data
Tap into Hadoop and Other No SQL Sources Presented by: Trishla Maru What is Big Data really? The Three Vs of Big Data According to Gartner Volume Volume Orders of magnitude bigger than conventional data
A Scalable Data Transformation Framework using the Hadoop Ecosystem
 A Scalable Data Transformation Framework using the Hadoop Ecosystem Raj Nair Director Data Platform Kiru Pakkirisamy CTO AGENDA About Penton and Serendio Inc Data Processing at Penton PoC Use Case Functional
A Scalable Data Transformation Framework using the Hadoop Ecosystem Raj Nair Director Data Platform Kiru Pakkirisamy CTO AGENDA About Penton and Serendio Inc Data Processing at Penton PoC Use Case Functional
Data Warehouse design
 Data Warehouse design Design of Enterprise Systems University of Pavia 11/11/2013-1- Data Warehouse design DATA MODELLING - 2- Data Modelling Important premise Data warehouses typically reside on a RDBMS
Data Warehouse design Design of Enterprise Systems University of Pavia 11/11/2013-1- Data Warehouse design DATA MODELLING - 2- Data Modelling Important premise Data warehouses typically reside on a RDBMS
Introduction to NoSQL Databases and MapReduce. Tore Risch Information Technology Uppsala University 2014-05-12
 Introduction to NoSQL Databases and MapReduce Tore Risch Information Technology Uppsala University 2014-05-12 What is a NoSQL Database? 1. A key/value store Basic index manager, no complete query language
Introduction to NoSQL Databases and MapReduce Tore Risch Information Technology Uppsala University 2014-05-12 What is a NoSQL Database? 1. A key/value store Basic index manager, no complete query language
Spectrum Technology Platform. Version 9.0. Enterprise Data Integration Guide
 Spectrum Technology Platform Version 9.0 Enterprise Data Integration Guide Contents Chapter 1: Introduction...7 Enterprise Data Management Architecture...8 The Star Schema Data Warehouse Design...10 Advantages
Spectrum Technology Platform Version 9.0 Enterprise Data Integration Guide Contents Chapter 1: Introduction...7 Enterprise Data Management Architecture...8 The Star Schema Data Warehouse Design...10 Advantages
ISSN: 2321-7782 (Online) Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies
 Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
ISSN: 2321-7782 (Online) Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Agenda. ! Strengths of PostgreSQL. ! Strengths of Hadoop. ! Hadoop Community. ! Use Cases
 Postgres & Hadoop Agenda! Strengths of PostgreSQL! Strengths of Hadoop! Hadoop Community! Use Cases Best of Both World Postgres Hadoop World s most advanced open source database solution Enterprise class
Postgres & Hadoop Agenda! Strengths of PostgreSQL! Strengths of Hadoop! Hadoop Community! Use Cases Best of Both World Postgres Hadoop World s most advanced open source database solution Enterprise class
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Data storing and data access
 Data storing and data access Plan Basic Java API for HBase demo Bulk data loading Hands-on Distributed storage for user files SQL on nosql Summary Basic Java API for HBase import org.apache.hadoop.hbase.*
Data storing and data access Plan Basic Java API for HBase demo Bulk data loading Hands-on Distributed storage for user files SQL on nosql Summary Basic Java API for HBase import org.apache.hadoop.hbase.*
Big Data Can Drive the Business and IT to Evolve and Adapt
 Big Data Can Drive the Business and IT to Evolve and Adapt Ralph Kimball Associates 2013 Ralph Kimball Brussels 2013 Big Data Itself is Being Monetized Executives see the short path from data insights
Big Data Can Drive the Business and IT to Evolve and Adapt Ralph Kimball Associates 2013 Ralph Kimball Brussels 2013 Big Data Itself is Being Monetized Executives see the short path from data insights
Can the Elephants Handle the NoSQL Onslaught?
 Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
How, What, and Where of Data Warehouses for MySQL
 How, What, and Where of Data Warehouses for MySQL Robert Hodges CEO, Continuent. Introducing Continuent The leading provider of clustering and replication for open source DBMS Our Product: Continuent Tungsten
How, What, and Where of Data Warehouses for MySQL Robert Hodges CEO, Continuent. Introducing Continuent The leading provider of clustering and replication for open source DBMS Our Product: Continuent Tungsten
Native Connectivity to Big Data Sources in MSTR 10
 Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
INDEX-BASED JOIN OPERATIONS IN HIVE
 INDEX-BASED JOIN OPERATIONS IN HIVE MAHSA MOFIDPOOR A THESIS in THE DEPARTMENT of COMPUTER SCIENCE AND SOFTWARE ENGINEERING PRESENTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER
INDEX-BASED JOIN OPERATIONS IN HIVE MAHSA MOFIDPOOR A THESIS in THE DEPARTMENT of COMPUTER SCIENCE AND SOFTWARE ENGINEERING PRESENTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
Big Data. Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich
 Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
Understanding NoSQL on Microsoft Azure
 David Chappell Understanding NoSQL on Microsoft Azure Sponsored by Microsoft Corporation Copyright 2014 Chappell & Associates Contents Data on Azure: The Big Picture... 3 Relational Technology: A Quick
David Chappell Understanding NoSQL on Microsoft Azure Sponsored by Microsoft Corporation Copyright 2014 Chappell & Associates Contents Data on Azure: The Big Picture... 3 Relational Technology: A Quick
Set Up Hortonworks Hadoop with SQL Anywhere
 Set Up Hortonworks Hadoop with SQL Anywhere TABLE OF CONTENTS 1 INTRODUCTION... 3 2 INSTALL HADOOP ENVIRONMENT... 3 3 SET UP WINDOWS ENVIRONMENT... 5 3.1 Install Hortonworks ODBC Driver... 5 3.2 ODBC Driver
Set Up Hortonworks Hadoop with SQL Anywhere TABLE OF CONTENTS 1 INTRODUCTION... 3 2 INSTALL HADOOP ENVIRONMENT... 3 3 SET UP WINDOWS ENVIRONMENT... 5 3.1 Install Hortonworks ODBC Driver... 5 3.2 ODBC Driver
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
ETL-EXTRACT, TRANSFORM & LOAD TESTING
 ETL-EXTRACT, TRANSFORM & LOAD TESTING Rajesh Popli Manager (Quality), Nagarro Software Pvt. Ltd., Gurgaon, INDIA [email protected] ABSTRACT Data is most important part in any organization. Data
ETL-EXTRACT, TRANSFORM & LOAD TESTING Rajesh Popli Manager (Quality), Nagarro Software Pvt. Ltd., Gurgaon, INDIA [email protected] ABSTRACT Data is most important part in any organization. Data
Open Source Technologies on Microsoft Azure
 Open Source Technologies on Microsoft Azure A Survey @DChappellAssoc Copyright 2014 Chappell & Associates The Main Idea i Open source technologies are a fundamental part of Microsoft Azure The Big Questions
Open Source Technologies on Microsoft Azure A Survey @DChappellAssoc Copyright 2014 Chappell & Associates The Main Idea i Open source technologies are a fundamental part of Microsoft Azure The Big Questions
Data Warehousing Systems: Foundations and Architectures
 Data Warehousing Systems: Foundations and Architectures Il-Yeol Song Drexel University, http://www.ischool.drexel.edu/faculty/song/ SYNONYMS None DEFINITION A data warehouse (DW) is an integrated repository
Data Warehousing Systems: Foundations and Architectures Il-Yeol Song Drexel University, http://www.ischool.drexel.edu/faculty/song/ SYNONYMS None DEFINITION A data warehouse (DW) is an integrated repository
Creating a universe on Hive with Hortonworks HDP 2.0
 Creating a universe on Hive with Hortonworks HDP 2.0 Learn how to create an SAP BusinessObjects Universe on top of Apache Hive 2 using the Hortonworks HDP 2.0 distribution Author(s): Company: Ajay Singh
Creating a universe on Hive with Hortonworks HDP 2.0 Learn how to create an SAP BusinessObjects Universe on top of Apache Hive 2 using the Hortonworks HDP 2.0 distribution Author(s): Company: Ajay Singh
Parallel Data Warehouse
 MICROSOFT S ANALYTICS SOLUTIONS WITH PARALLEL DATA WAREHOUSE Parallel Data Warehouse Stefan Cronjaeger Microsoft May 2013 AGENDA PDW overview Columnstore and Big Data Business Intellignece Project Ability
MICROSOFT S ANALYTICS SOLUTIONS WITH PARALLEL DATA WAREHOUSE Parallel Data Warehouse Stefan Cronjaeger Microsoft May 2013 AGENDA PDW overview Columnstore and Big Data Business Intellignece Project Ability
NoSQL - What we ve learned with mongodb. Paul Pedersen, Deputy CTO [email protected] DAMA SF December 15, 2011
 NoSQL - What we ve learned with mongodb Paul Pedersen, Deputy CTO [email protected] DAMA SF December 15, 2011 DW2.0 and NoSQL management decision support intgrated access - local v. global - structured v.
NoSQL - What we ve learned with mongodb Paul Pedersen, Deputy CTO [email protected] DAMA SF December 15, 2011 DW2.0 and NoSQL management decision support intgrated access - local v. global - structured v.
BIRT in the World of Big Data
 BIRT in the World of Big Data David Rosenbacher VP Sales Engineering Actuate Corporation 2013 Actuate Customer Days Today s Agenda and Goals Introduction to Big Data Compare with Regular Data Common Approaches
BIRT in the World of Big Data David Rosenbacher VP Sales Engineering Actuate Corporation 2013 Actuate Customer Days Today s Agenda and Goals Introduction to Big Data Compare with Regular Data Common Approaches
MySQL and Hadoop: Big Data Integration. Shubhangi Garg & Neha Kumari MySQL Engineering
 MySQL and Hadoop: Big Data Integration Shubhangi Garg & Neha Kumari MySQL Engineering 1Copyright 2013, Oracle and/or its affiliates. All rights reserved. Agenda Design rationale Implementation Installation
MySQL and Hadoop: Big Data Integration Shubhangi Garg & Neha Kumari MySQL Engineering 1Copyright 2013, Oracle and/or its affiliates. All rights reserved. Agenda Design rationale Implementation Installation
Hive Interview Questions
 HADOOPEXAM LEARNING RESOURCES Hive Interview Questions www.hadoopexam.com Please visit www.hadoopexam.com for various resources for BigData/Hadoop/Cassandra/MongoDB/Node.js/Scala etc. 1 Professional Training
HADOOPEXAM LEARNING RESOURCES Hive Interview Questions www.hadoopexam.com Please visit www.hadoopexam.com for various resources for BigData/Hadoop/Cassandra/MongoDB/Node.js/Scala etc. 1 Professional Training
Hadoop and Relational Database The Best of Both Worlds for Analytics Greg Battas Hewlett Packard
 Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Big Data Analytics Platform @ Nokia
 Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Harnessing the Potential Raj Nair
 Linking Structured and Unstructured Data Harnessing the Potential Raj Nair AGENDA Structured and Unstructured Data What s the distinction? The rise of Unstructured Data What s driving this? Big Data Use
Linking Structured and Unstructured Data Harnessing the Potential Raj Nair AGENDA Structured and Unstructured Data What s the distinction? The rise of Unstructured Data What s driving this? Big Data Use
Cloud Scale Distributed Data Storage. Jürmo Mehine
 Cloud Scale Distributed Data Storage Jürmo Mehine 2014 Outline Background Relational model Database scaling Keys, values and aggregates The NoSQL landscape Non-relational data models Key-value Document-oriented
Cloud Scale Distributed Data Storage Jürmo Mehine 2014 Outline Background Relational model Database scaling Keys, values and aggregates The NoSQL landscape Non-relational data models Key-value Document-oriented
Introduction to Apache Hive
 Introduction to Apache Hive Pelle Jakovits 14 Oct, 2015, Tartu Outline What is Hive Why Hive over MapReduce or Pig? Advantages and disadvantages Running Hive HiveQL language User Defined Functions Hive
Introduction to Apache Hive Pelle Jakovits 14 Oct, 2015, Tartu Outline What is Hive Why Hive over MapReduce or Pig? Advantages and disadvantages Running Hive HiveQL language User Defined Functions Hive
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,[email protected]
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Constructing a Data Lake: Hadoop and Oracle Database United!
 Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Big Data Weather Analytics Using Hadoop
 Big Data Weather Analytics Using Hadoop Veershetty Dagade #1 Mahesh Lagali #2 Supriya Avadhani #3 Priya Kalekar #4 Professor, Computer science and Engineering Department, Jain College of Engineering, Belgaum,
Big Data Weather Analytics Using Hadoop Veershetty Dagade #1 Mahesh Lagali #2 Supriya Avadhani #3 Priya Kalekar #4 Professor, Computer science and Engineering Department, Jain College of Engineering, Belgaum,
Luncheon Webinar Series May 13, 2013
 Luncheon Webinar Series May 13, 2013 InfoSphere DataStage is Big Data Integration Sponsored By: Presented by : Tony Curcio, InfoSphere Product Management 0 InfoSphere DataStage is Big Data Integration
Luncheon Webinar Series May 13, 2013 InfoSphere DataStage is Big Data Integration Sponsored By: Presented by : Tony Curcio, InfoSphere Product Management 0 InfoSphere DataStage is Big Data Integration
Decoding the Big Data Deluge a Virtual Approach. Dan Luongo, Global Lead, Field Solution Engineering Data Virtualization Business Unit, Cisco
 Decoding the Big Data Deluge a Virtual Approach Dan Luongo, Global Lead, Field Solution Engineering Data Virtualization Business Unit, Cisco High-volume, velocity and variety information assets that demand
Decoding the Big Data Deluge a Virtual Approach Dan Luongo, Global Lead, Field Solution Engineering Data Virtualization Business Unit, Cisco High-volume, velocity and variety information assets that demand
Hadoop. for Oracle database professionals. Alex Gorbachev Calgary, AB September 2013
 Hadoop for Oracle database professionals Alex Gorbachev Calgary, AB September 2013 Alex Gorbachev Chief Technology Officer at Pythian Blogger Cloudera Champion of Big Data OakTable Network member Oracle
Hadoop for Oracle database professionals Alex Gorbachev Calgary, AB September 2013 Alex Gorbachev Chief Technology Officer at Pythian Blogger Cloudera Champion of Big Data OakTable Network member Oracle
Big Data: Tools and Technologies in Big Data
 Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
#mstrworld. Tapping into Hadoop and NoSQL Data Sources in MicroStrategy. Presented by: Trishla Maru. #mstrworld
 Tapping into Hadoop and NoSQL Data Sources in MicroStrategy Presented by: Trishla Maru Agenda Big Data Overview All About Hadoop What is Hadoop? How does MicroStrategy connects to Hadoop? Customer Case
Tapping into Hadoop and NoSQL Data Sources in MicroStrategy Presented by: Trishla Maru Agenda Big Data Overview All About Hadoop What is Hadoop? How does MicroStrategy connects to Hadoop? Customer Case
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
How To Create A Large Data Storage System
 UT DALLAS Erik Jonsson School of Engineering & Computer Science Secure Data Storage and Retrieval in the Cloud Agenda Motivating Example Current work in related areas Our approach Contributions of this
UT DALLAS Erik Jonsson School of Engineering & Computer Science Secure Data Storage and Retrieval in the Cloud Agenda Motivating Example Current work in related areas Our approach Contributions of this
Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo
 Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
A survey of big data architectures for handling massive data
 CSIT 6910 Independent Project A survey of big data architectures for handling massive data Jordy Domingos - [email protected] Supervisor : Dr David Rossiter Content Table 1 - Introduction a - Context
CSIT 6910 Independent Project A survey of big data architectures for handling massive data Jordy Domingos - [email protected] Supervisor : Dr David Rossiter Content Table 1 - Introduction a - Context
Introduction to Apache Hive
 Introduction to Apache Hive Pelle Jakovits 1. Oct, 2013, Tartu Outline What is Hive Why Hive over MapReduce or Pig? Advantages and disadvantages Running Hive HiveQL language Examples Internals Hive vs
Introduction to Apache Hive Pelle Jakovits 1. Oct, 2013, Tartu Outline What is Hive Why Hive over MapReduce or Pig? Advantages and disadvantages Running Hive HiveQL language Examples Internals Hive vs
Data Warehousing. Jens Teubner, TU Dortmund [email protected]. Winter 2015/16. Jens Teubner Data Warehousing Winter 2015/16 1
 Jens Teubner Data Warehousing Winter 2015/16 1 Data Warehousing Jens Teubner, TU Dortmund [email protected] Winter 2015/16 Jens Teubner Data Warehousing Winter 2015/16 13 Part II Overview
Jens Teubner Data Warehousing Winter 2015/16 1 Data Warehousing Jens Teubner, TU Dortmund [email protected] Winter 2015/16 Jens Teubner Data Warehousing Winter 2015/16 13 Part II Overview
Oracle s Big Data solutions. Roger Wullschleger. <Insert Picture Here>
 s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig
 BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig Contents Acknowledgements... 1 Introduction to Hive and Pig... 2 Setup... 2 Exercise 1 Load Avro data into HDFS... 2 Exercise 2 Define an
BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig Contents Acknowledgements... 1 Introduction to Hive and Pig... 2 Setup... 2 Exercise 1 Load Avro data into HDFS... 2 Exercise 2 Define an
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Datenverwaltung im Wandel - Building an Enterprise Data Hub with
 Datenverwaltung im Wandel - Building an Enterprise Data Hub with Cloudera Bernard Doering Regional Director, Central EMEA, Cloudera Cloudera Your Hadoop Experts Founded 2008, by former employees of Employees
Datenverwaltung im Wandel - Building an Enterprise Data Hub with Cloudera Bernard Doering Regional Director, Central EMEA, Cloudera Cloudera Your Hadoop Experts Founded 2008, by former employees of Employees
ODBC Client Driver Help. 2015 Kepware, Inc.
 2015 Kepware, Inc. 2 Table of Contents Table of Contents 2 4 Overview 4 External Dependencies 4 Driver Setup 5 Data Source Settings 5 Data Source Setup 6 Data Source Access Methods 13 Fixed Table 14 Table
2015 Kepware, Inc. 2 Table of Contents Table of Contents 2 4 Overview 4 External Dependencies 4 Driver Setup 5 Data Source Settings 5 Data Source Setup 6 Data Source Access Methods 13 Fixed Table 14 Table
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Cloudera Impala: A Modern SQL Engine for Hadoop Headline Goes Here
 Cloudera Impala: A Modern SQL Engine for Hadoop Headline Goes Here JusIn Erickson Senior Product Manager, Cloudera Speaker Name or Subhead Goes Here May 2013 DO NOT USE PUBLICLY PRIOR TO 10/23/12 Agenda
Cloudera Impala: A Modern SQL Engine for Hadoop Headline Goes Here JusIn Erickson Senior Product Manager, Cloudera Speaker Name or Subhead Goes Here May 2013 DO NOT USE PUBLICLY PRIOR TO 10/23/12 Agenda
Stinger Initiative: Introduction
 Stinger Initiative: Introduction Interactive Query on Hadoop Chris Harris E-Mail : [email protected] Twitter : cj_harris5 Page 1 The World of Data is Changing Data Explosion 1 Zettabyte (ZB) = 1
Stinger Initiative: Introduction Interactive Query on Hadoop Chris Harris E-Mail : [email protected] Twitter : cj_harris5 Page 1 The World of Data is Changing Data Explosion 1 Zettabyte (ZB) = 1
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Fact Sheet In-Memory Analysis
 Fact Sheet In-Memory Analysis 1 Copyright Yellowfin International 2010 Contents In Memory Overview...3 Benefits...3 Agile development & rapid delivery...3 Data types supported by the In-Memory Database...4
Fact Sheet In-Memory Analysis 1 Copyright Yellowfin International 2010 Contents In Memory Overview...3 Benefits...3 Agile development & rapid delivery...3 Data types supported by the In-Memory Database...4