Common Patterns and Pitfalls for Implementing Algorithms in Spark. Hossein
|
|
|
- Reginald Stanley Wade
- 10 years ago
- Views:
Transcription
1 Common Patterns and Pitfalls for Implementing Algorithms in Spark Hossein

2 Challenges of numerical computation over big data When applying any algorithm to big data watch for 1. Correctness 2. Performance 3. Trade-off between accuracy and performance 2

3 Three Practical Examples Point estimation (Variance) Approximate estimation (Cardinality) Matrix operations (PageRank) We use these examples to demonstrate Spark internals, data flow, and challenges of implementing algorithms for Big Data. 3

4 1. Big Data Variance > The plain variance formula requires two passes over data Second pass Var(X) = 1 N N i=1 (x i µ) 2 4 First pass
 = 1 N N i=1 (x i µ) 2 4")
5 Fast but inaccurate solution Var(X) = E[X 2 ] E[X] 2 = x 2 N x N 2 Can be performed in a single pass, but Subtracts two very close and large numbers! 5

6 Accumulator Pattern An object that incrementally tracks the variance Class RunningVar { var variance: Double = 0.0! // Compute initial variance for numbers def this(numbers: Iterator[Double]) { numbers.foreach(this.add(_)) }! // Update variance for a single value def add(value: Double) {... } } 6
 { numbers.foreach(this.add(_)) }!")
7 Parallelize for performance Distribute adding values in map phase Merge partial results in reduce phase Class RunningVar {... // Merge another RunningVar object // and update variance def merge(other: RunningVar) = {... } } 7

8 Computing Variance in Spark Use the RunningVar in Spark doublerdd.mappartitions(v => Iterator(new RunningVar(v))).reduce((a, b) => a.merge(b)) Or simply use the Spark API doublerdd.variance() 8
 => a.")
9 2. Approximate Estimations Often an approximate estimate is good enough especially if it can be computed faster or cheaper 1. Trade accuracy with memory 2. Trade accuracy with running time We really like the cases where there is a bound on error that can be controlled 9

10 Cardinality Problem Example: Count number of unique words in Shakespeare s work. Using a HashSet requires ~10GB of memory This can be much worse in many real world applications involving large strings, such as counting web visitors 10

11 count mln v m Linear Probabilistic Counting 1. Allocate a bitmap of size m and initialize to zero. A. Hash each value to a position in the bitmap B. Set corresponding bit to 1 2. Count number of empty bit entries: v 11

12 The Spark API Use the LogLinearCounter in Spark rdd.mappartitions(v => Iterator(new LPCounter(v))).reduce((a, b) => a.merge(b)).getcardinality Or simply use the Spark API myrdd.countapproxdistinct(0.01) 12

13 3. Google PageRank Popular algorithm originally introduced by Google 13

14 PageRank Algorithm PageRank Algorithm Start each page with a rank of 1 On each iteration: A. contrib = currank neighbors B. currank = neighbors contrib i 14

15 PageRank Example
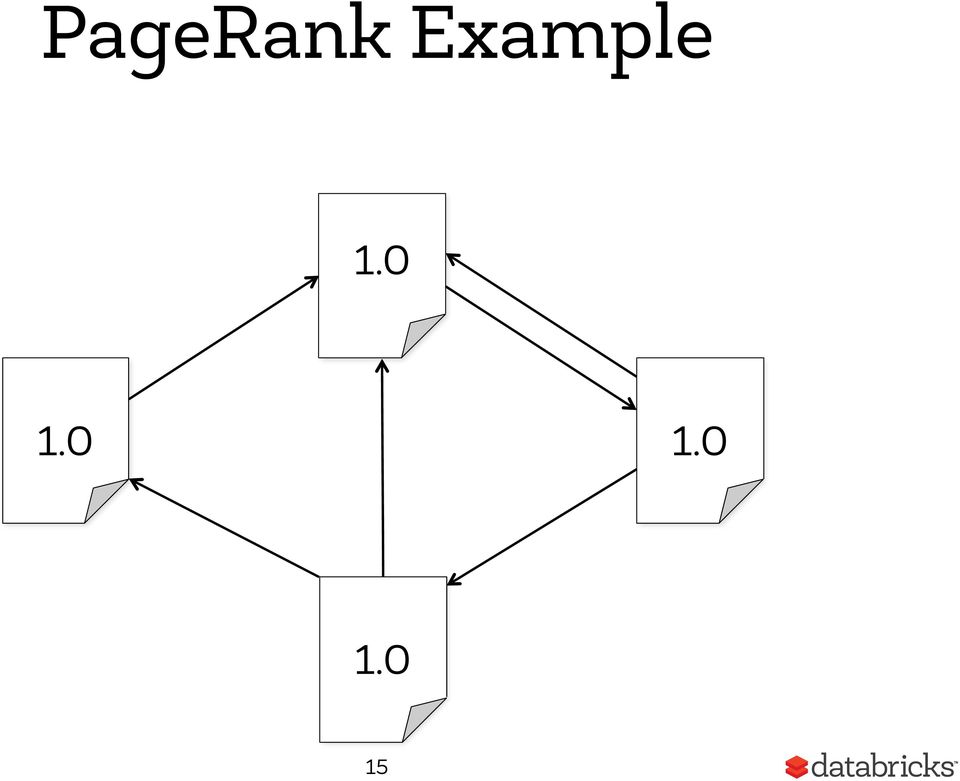
16 PageRank Example

17 PageRank Example

18 PageRank Example

19 PageRank Example

20 PageRank Example Eventually

21 PageRank as Matrix Multiplication Rank of each page is the probability of landing on that page for a random surfer on the web Probability of visiting all pages after k steps is V k = A k V t V: the initial rank vector A: the link structure (sparse matrix) 21
22 Data Representation in Spark Each page is identified by its unique URL rather than an index Ranks vectors (V): RDD[(URL, Double)] Links matrix (A): RDD[(URL, List(URL))] 22
23 Spark Implementation val links = // load RDD of (url, neighbors) pairs var ranks = // load RDD of (url, rank) pairs! for (i <- 1 to ITERATIONS) { val contribs = links.join(ranks).flatmap { case (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) } ranks = contribs.reducebykey(_ + _).mapvalues( * _) } ranks.saveastextfile(...) 23
24 Matrix Multiplication Repeatedly multiply sparse matrix and vector Same file read over and over Links (url, neighbors) Ranks (url, rank) iteration 1 iteration 2 iteration 3 24
25 Spark can do much better Using cache(), keep neighbors in memory Do not write intermediate results on disk Grouping same RDD over and over Links (url, neighbors) Ranks (url, rank) join 25 join join
26 Spark can do much better Do not partition neighbors every time partitionby Links (url, neighbors) Same node Ranks (url, rank) join 26 join join
27 Spark Implementation val links = // load RDD of (url, neighbors) pairs var ranks = // load RDD of (url, rank) pairs! links.partitionby(hashfunction).cache()! for (i <- 1 to ITERATIONS) { val contribs = links.join(ranks).flatmap { case (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) } ranks = contribs.reducebykey(_ + _).mapvalues( * _) } ranks.saveastextfile(...) 27
28 Conclusions When applying any algorithm to big data watch for 1. Correctness 2. Performance Cache RDDs to avoid I/O Avoid unnecessary computation 3. Trade-off between accuracy and performance 28
29
Writing Standalone Spark Programs
 Writing Standalone Spark Programs Matei Zaharia UC Berkeley www.spark- project.org UC BERKELEY Outline Setting up for Spark development Example: PageRank PageRank in Java Testing and debugging Building
Writing Standalone Spark Programs Matei Zaharia UC Berkeley www.spark- project.org UC BERKELEY Outline Setting up for Spark development Example: PageRank PageRank in Java Testing and debugging Building
MapReduce: Simplified Data Processing on Large Clusters. Jeff Dean, Sanjay Ghemawat Google, Inc.
 MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
Using Apache Spark Pat McDonough - Databricks
 Using Apache Spark Pat McDonough - Databricks Apache Spark spark.incubator.apache.org github.com/apache/incubator-spark [email protected] The Spark Community +You! INTRODUCTION TO APACHE
Using Apache Spark Pat McDonough - Databricks Apache Spark spark.incubator.apache.org github.com/apache/incubator-spark [email protected] The Spark Community +You! INTRODUCTION TO APACHE
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Unified Big Data Analytics Pipeline. 连 城 [email protected]
 Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark: Cluster Computing with Working Sets
 Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Spark and Shark: High-speed In-memory Analytics over Hadoop Data
 Spark and Shark: High-speed In-memory Analytics over Hadoop Data May 14, 2013 @ Oracle Reynold Xin, AMPLab, UC Berkeley The Big Data Problem Data is growing faster than computation speeds Accelerating
Spark and Shark: High-speed In-memory Analytics over Hadoop Data May 14, 2013 @ Oracle Reynold Xin, AMPLab, UC Berkeley The Big Data Problem Data is growing faster than computation speeds Accelerating
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
Spark Application Carousel. Spark Summit East 2015
 Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect
 Matteo Migliavacca (mm53@kent) School of Computing Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect Simple past - Traditional
Matteo Migliavacca (mm53@kent) School of Computing Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect Simple past - Traditional
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
DATA ANALYSIS II. Matrix Algorithms
 DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
Big Graph Processing: Some Background
 Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
The PageRank Citation Ranking: Bring Order to the Web
 The PageRank Citation Ranking: Bring Order to the Web presented by: Xiaoxi Pang 25.Nov 2010 1 / 20 Outline Introduction A ranking for every page on the Web Implementation Convergence Properties Personalized
The PageRank Citation Ranking: Bring Order to the Web presented by: Xiaoxi Pang 25.Nov 2010 1 / 20 Outline Introduction A ranking for every page on the Web Implementation Convergence Properties Personalized
Asking Hard Graph Questions. Paul Burkhardt. February 3, 2014
 Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
Big Data looks Tiny from the Stratosphere
 Volker Markl http://www.user.tu-berlin.de/marklv [email protected] Big Data looks Tiny from the Stratosphere Data and analyses are becoming increasingly complex! Size Freshness Format/Media Type
Volker Markl http://www.user.tu-berlin.de/marklv [email protected] Big Data looks Tiny from the Stratosphere Data and analyses are becoming increasingly complex! Size Freshness Format/Media Type
Big Data and Scripting Systems beyond Hadoop
 Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Scalable Data Analysis in R. Lee E. Edlefsen Chief Scientist UserR! 2011
 Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
Presto/Blockus: Towards Scalable R Data Analysis
 /Blockus: Towards Scalable R Data Analysis Andrew A. Chien University of Chicago and Argonne ational Laboratory IRIA-UIUC-AL Joint Institute Potential Collaboration ovember 19, 2012 ovember 19, 2012 Andrew
/Blockus: Towards Scalable R Data Analysis Andrew A. Chien University of Chicago and Argonne ational Laboratory IRIA-UIUC-AL Joint Institute Potential Collaboration ovember 19, 2012 ovember 19, 2012 Andrew
Introduction to Big Data with Apache Spark UC BERKELEY
 Introduction to Big Data with Apache Spark UC BERKELEY This Lecture Programming Spark Resilient Distributed Datasets (RDDs) Creating an RDD Spark Transformations and Actions Spark Programming Model Python
Introduction to Big Data with Apache Spark UC BERKELEY This Lecture Programming Spark Resilient Distributed Datasets (RDDs) Creating an RDD Spark Transformations and Actions Spark Programming Model Python
Kafka & Redis for Big Data Solutions
 Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Graph Mining on Big Data System. Presented by Hefu Chai, Rui Zhang, Jian Fang
 Graph Mining on Big Data System Presented by Hefu Chai, Rui Zhang, Jian Fang Outline * Overview * Approaches & Environment * Results * Observations * Notes * Conclusion Overview * What we have done? *
Graph Mining on Big Data System Presented by Hefu Chai, Rui Zhang, Jian Fang Outline * Overview * Approaches & Environment * Results * Observations * Notes * Conclusion Overview * What we have done? *
Spark and Shark. High- Speed In- Memory Analytics over Hadoop and Hive Data
 Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
PDQCollections*: A Data-Parallel Programming Model and Library for Associative Containers
 PDQCollections*: A Data-Parallel Programming Model and Library for Associative Containers Maneesh Varshney Vishwa Goudar Christophe Beaumont Jan, 2013 * PDQ could stand for Pretty Darn Quick or Processes
PDQCollections*: A Data-Parallel Programming Model and Library for Associative Containers Maneesh Varshney Vishwa Goudar Christophe Beaumont Jan, 2013 * PDQ could stand for Pretty Darn Quick or Processes
Spark ΕΡΓΑΣΤΗΡΙΟ 10. Prepared by George Nikolaides 4/19/2015 1
 Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
APPM4720/5720: Fast algorithms for big data. Gunnar Martinsson The University of Colorado at Boulder
 APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
Nimble Algorithms for Cloud Computing. Ravi Kannan, Santosh Vempala and David Woodruff
 Nimble Algorithms for Cloud Computing Ravi Kannan, Santosh Vempala and David Woodruff Cloud computing Data is distributed arbitrarily on many servers Parallel algorithms: time Streaming algorithms: sublinear
Nimble Algorithms for Cloud Computing Ravi Kannan, Santosh Vempala and David Woodruff Cloud computing Data is distributed arbitrarily on many servers Parallel algorithms: time Streaming algorithms: sublinear
Chapter 13: Query Processing. Basic Steps in Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Hadoop SNS. renren.com. Saturday, December 3, 11
 Hadoop SNS renren.com Saturday, December 3, 11 2.2 190 40 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December
Hadoop SNS renren.com Saturday, December 3, 11 2.2 190 40 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Apache Flink Next-gen data analysis. Kostas Tzoumas [email protected] @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Parallelism and Cloud Computing
 Parallelism and Cloud Computing Kai Shen Parallel Computing Parallel computing: Process sub tasks simultaneously so that work can be completed faster. For instances: divide the work of matrix multiplication
Parallelism and Cloud Computing Kai Shen Parallel Computing Parallel computing: Process sub tasks simultaneously so that work can be completed faster. For instances: divide the work of matrix multiplication
Overview on Graph Datastores and Graph Computing Systems. -- Litao Deng (Cloud Computing Group) 06-08-2012
 06-08-2012") Overview on Graph Datastores and Graph Computing Systems -- Litao Deng (Cloud Computing Group) 06-08-2012 Graph - Everywhere 1: Friendship Graph 2: Food Graph 3: Internet Graph Most of the relationships
Overview on Graph Datastores and Graph Computing Systems -- Litao Deng (Cloud Computing Group) 06-08-2012 Graph - Everywhere 1: Friendship Graph 2: Food Graph 3: Internet Graph Most of the relationships
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Juwei Shi, Yunjie Qiu, Umar Farooq Minhas, Limei Jiao, Chen Wang, Berthold Reinwald, and Fatma Özcan IBM Research China IBM Almaden
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Juwei Shi, Yunjie Qiu, Umar Farooq Minhas, Limei Jiao, Chen Wang, Berthold Reinwald, and Fatma Özcan IBM Research China IBM Almaden
Distance Degree Sequences for Network Analysis
 Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
MapReduce and the New Software Stack
 20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
Search Engines. Stephen Shaw <[email protected]> 18th of February, 2014. Netsoc
 Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Beyond Hadoop with Apache Spark and BDAS
 Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Apache Spark and Distributed Programming
 Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
Data Science in the Wild
 Data Science in the Wild Lecture 4 59 Apache Spark 60 1 What is Spark? Not a modified version of Hadoop Separate, fast, MapReduce-like engine In-memory data storage for very fast iterative queries General
Data Science in the Wild Lecture 4 59 Apache Spark 60 1 What is Spark? Not a modified version of Hadoop Separate, fast, MapReduce-like engine In-memory data storage for very fast iterative queries General
Introduction to Spark
 Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
The Stratosphere Big Data Analytics Platform
 The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science [email protected] June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science [email protected] June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
High Throughput Computing on P2P Networks. Carlos Pérez Miguel [email protected]
 High Throughput Computing on P2P Networks Carlos Pérez Miguel [email protected] Overview High Throughput Computing Motivation All things distributed: Peer-to-peer Non structured overlays Structured
High Throughput Computing on P2P Networks Carlos Pérez Miguel [email protected] Overview High Throughput Computing Motivation All things distributed: Peer-to-peer Non structured overlays Structured
Enhancing the Ranking of a Web Page in the Ocean of Data
 Database Systems Journal vol. IV, no. 3/2013 3 Enhancing the Ranking of a Web Page in the Ocean of Data Hitesh KUMAR SHARMA University of Petroleum and Energy Studies, India [email protected] In today
Database Systems Journal vol. IV, no. 3/2013 3 Enhancing the Ranking of a Web Page in the Ocean of Data Hitesh KUMAR SHARMA University of Petroleum and Energy Studies, India [email protected] In today
Big Data Primer. 1 Why Big Data? Alex Sverdlov [email protected]
 Big Data Primer Alex Sverdlov [email protected] 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Data Primer Alex Sverdlov [email protected] 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Data Processing. Patrick Wendell Databricks
 Big Data Processing Patrick Wendell Databricks About me Committer and PMC member of Apache Spark Former PhD student at Berkeley Left Berkeley to help found Databricks Now managing open source work at Databricks
Big Data Processing Patrick Wendell Databricks About me Committer and PMC member of Apache Spark Former PhD student at Berkeley Left Berkeley to help found Databricks Now managing open source work at Databricks
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
ENHANCEMENTS TO SQL SERVER COLUMN STORES. Anuhya Mallempati #2610771
 ENHANCEMENTS TO SQL SERVER COLUMN STORES Anuhya Mallempati #2610771 CONTENTS Abstract Introduction Column store indexes Batch mode processing Other Enhancements Conclusion ABSTRACT SQL server introduced
ENHANCEMENTS TO SQL SERVER COLUMN STORES Anuhya Mallempati #2610771 CONTENTS Abstract Introduction Column store indexes Batch mode processing Other Enhancements Conclusion ABSTRACT SQL server introduced
Fast and Expressive Big Data Analytics with Python. Matei Zaharia UC BERKELEY
 Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Fast Iterative Graph Computation with Resource Aware Graph Parallel Abstraction
 Human connectome. Gerhard et al., Frontiers in Neuroinformatics 5(3), 2011 2 NA = 6.022 1023 mol 1 Paul Burkhardt, Chris Waring An NSA Big Graph experiment Fast Iterative Graph Computation with Resource
Human connectome. Gerhard et al., Frontiers in Neuroinformatics 5(3), 2011 2 NA = 6.022 1023 mol 1 Paul Burkhardt, Chris Waring An NSA Big Graph experiment Fast Iterative Graph Computation with Resource
MLlib: Scalable Machine Learning on Spark
 MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming. by Dibyendu Bhattacharya
 Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
ProTrack: A Simple Provenance-tracking Filesystem
 ProTrack: A Simple Provenance-tracking Filesystem Somak Das Department of Electrical Engineering and Computer Science Massachusetts Institute of Technology [email protected] Abstract Provenance describes a file
ProTrack: A Simple Provenance-tracking Filesystem Somak Das Department of Electrical Engineering and Computer Science Massachusetts Institute of Technology [email protected] Abstract Provenance describes a file
Clustering Big Data. Efficient Data Mining Technologies. J Singh and Teresa Brooks. June 4, 2015
 Clustering Big Data Efficient Data Mining Technologies J Singh and Teresa Brooks June 4, 2015 Hello Bulgaria (http://hello.bg/) A website with thousands of pages... Some pages identical to other pages
Clustering Big Data Efficient Data Mining Technologies J Singh and Teresa Brooks June 4, 2015 Hello Bulgaria (http://hello.bg/) A website with thousands of pages... Some pages identical to other pages
HiBench Introduction. Carson Wang ([email protected]) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
Integrating Apache Spark with an Enterprise Data Warehouse
 Integrating Apache Spark with an Enterprise Warehouse Dr. Michael Wurst, IBM Corporation Architect Spark/R/Python base Integration, In-base Analytics Dr. Toni Bollinger, IBM Corporation Senior Software
Integrating Apache Spark with an Enterprise Warehouse Dr. Michael Wurst, IBM Corporation Architect Spark/R/Python base Integration, In-base Analytics Dr. Toni Bollinger, IBM Corporation Senior Software
Big Data & Scripting Part II Streaming Algorithms
 Big Data & Scripting Part II Streaming Algorithms 1, Counting Distinct Elements 2, 3, counting distinct elements problem formalization input: stream of elements o from some universe U e.g. ids from a set
Big Data & Scripting Part II Streaming Algorithms 1, Counting Distinct Elements 2, 3, counting distinct elements problem formalization input: stream of elements o from some universe U e.g. ids from a set
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Data Algorithms. Mahmoud Parsian. Tokyo O'REILLY. Beijing. Boston Farnham Sebastopol
 Data Algorithms Mahmoud Parsian Beijing Boston Farnham Sebastopol Tokyo O'REILLY Table of Contents Foreword xix Preface xxi 1. Secondary Sort: Introduction 1 Solutions to the Secondary Sort Problem 3 Implementation
Data Algorithms Mahmoud Parsian Beijing Boston Farnham Sebastopol Tokyo O'REILLY Table of Contents Foreword xix Preface xxi 1. Secondary Sort: Introduction 1 Solutions to the Secondary Sort Problem 3 Implementation
 Zihang Yin Introduction R is commonly used as an open share statistical software platform that enables analysts to do complex statistical analysis with limited computing knowledge. Frequently these analytical
Zihang Yin Introduction R is commonly used as an open share statistical software platform that enables analysts to do complex statistical analysis with limited computing knowledge. Frequently these analytical
Machine Learning Big Data using Map Reduce
 Machine Learning Big Data using Map Reduce By Michael Bowles, PhD Where Does Big Data Come From? -Web data (web logs, click histories) -e-commerce applications (purchase histories) -Retail purchase histories
Machine Learning Big Data using Map Reduce By Michael Bowles, PhD Where Does Big Data Come From? -Web data (web logs, click histories) -e-commerce applications (purchase histories) -Retail purchase histories
Data Warehousing und Data Mining
 Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
Storage Management for Files of Dynamic Records
 Storage Management for Files of Dynamic Records Justin Zobel Department of Computer Science, RMIT, GPO Box 2476V, Melbourne 3001, Australia. [email protected] Alistair Moffat Department of Computer Science
Storage Management for Files of Dynamic Records Justin Zobel Department of Computer Science, RMIT, GPO Box 2476V, Melbourne 3001, Australia. [email protected] Alistair Moffat Department of Computer Science
Apache Mahout's new DSL for Distributed Machine Learning. Sebastian Schelter GOTO Berlin 11/06/2014
 Apache Mahout's new DSL for Distributed Machine Learning Sebastian Schelter GOO Berlin /6/24 Overview Apache Mahout: Past & Future A DSL for Machine Learning Example Under the covers Distributed computation
Apache Mahout's new DSL for Distributed Machine Learning Sebastian Schelter GOO Berlin /6/24 Overview Apache Mahout: Past & Future A DSL for Machine Learning Example Under the covers Distributed computation
Probabilistic Models for Big Data. Alex Davies and Roger Frigola University of Cambridge 13th February 2014
 Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Spark: Making Big Data Interactive & Real-Time
 Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
5. Binary objects labeling
 Image Processing - Laboratory 5: Binary objects labeling 1 5. Binary objects labeling 5.1. Introduction In this laboratory an object labeling algorithm which allows you to label distinct objects from a
Image Processing - Laboratory 5: Binary objects labeling 1 5. Binary objects labeling 5.1. Introduction In this laboratory an object labeling algorithm which allows you to label distinct objects from a
SOLVING LINEAR SYSTEMS
 SOLVING LINEAR SYSTEMS Linear systems Ax = b occur widely in applied mathematics They occur as direct formulations of real world problems; but more often, they occur as a part of the numerical analysis
SOLVING LINEAR SYSTEMS Linear systems Ax = b occur widely in applied mathematics They occur as direct formulations of real world problems; but more often, they occur as a part of the numerical analysis
Storing Measurement Data
 Storing Measurement Data File I/O records or reads data in a file. A typical file I/O operation involves the following process. 1. Create or open a file. Indicate where an existing file resides or where
Storing Measurement Data File I/O records or reads data in a file. A typical file I/O operation involves the following process. 1. Create or open a file. Indicate where an existing file resides or where
Hierarchical Bloom Filters: Accelerating Flow Queries and Analysis
 Hierarchical Bloom Filters: Accelerating Flow Queries and Analysis January 8, 2008 FloCon 2008 Chris Roblee, P. O. Box 808, Livermore, CA 94551 This work performed under the auspices of the U.S. Department
Hierarchical Bloom Filters: Accelerating Flow Queries and Analysis January 8, 2008 FloCon 2008 Chris Roblee, P. O. Box 808, Livermore, CA 94551 This work performed under the auspices of the U.S. Department
Quantifind s story: Building custom interactive data analytics infrastructure
 Quantifind s story: Building custom interactive data analytics infrastructure Ryan LeCompte @ryanlecompte Scala Days 2015 Background Software Engineer at Quantifind @ryanlecompte [email protected] http://github.com/ryanlecompte
Quantifind s story: Building custom interactive data analytics infrastructure Ryan LeCompte @ryanlecompte Scala Days 2015 Background Software Engineer at Quantifind @ryanlecompte [email protected] http://github.com/ryanlecompte
Algorithmic Techniques for Big Data Analysis. Barna Saha AT&T Lab-Research
 Algorithmic Techniques for Big Data Analysis Barna Saha AT&T Lab-Research Challenges of Big Data VOLUME Large amount of data VELOCITY Needs to be analyzed quickly VARIETY Different types of structured
Algorithmic Techniques for Big Data Analysis Barna Saha AT&T Lab-Research Challenges of Big Data VOLUME Large amount of data VELOCITY Needs to be analyzed quickly VARIETY Different types of structured
Fast Analytics on Big Data with H20
 Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Scalable Machine Learning - or what to do with all that Big Data infrastructure
 - or what to do with all that Big Data infrastructure TU Berlin blog.mikiobraun.de Strata+Hadoop World London, 2015 1 Complex Data Analysis at Scale Click-through prediction Personalized Spam Detection
- or what to do with all that Big Data infrastructure TU Berlin blog.mikiobraun.de Strata+Hadoop World London, 2015 1 Complex Data Analysis at Scale Click-through prediction Personalized Spam Detection
Search Engine Architecture
 Search Engine Architecture 1. Introduction This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Search Engine Architecture 1. Introduction This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Big Data Systems CS 5965/6965 FALL 2015
 Big Data Systems CS 5965/6965 FALL 2015 Today General course overview Expectations from this course Q&A Introduction to Big Data Assignment #1 General Course Information Course Web Page http://www.cs.utah.edu/~hari/teaching/fall2015.html
Big Data Systems CS 5965/6965 FALL 2015 Today General course overview Expectations from this course Q&A Introduction to Big Data Assignment #1 General Course Information Course Web Page http://www.cs.utah.edu/~hari/teaching/fall2015.html
Apache Flink. Fast and Reliable Large-Scale Data Processing
 Apache Flink Fast and Reliable Large-Scale Data Processing Fabian Hueske @fhueske 1 What is Apache Flink? Distributed Data Flow Processing System Focused on large-scale data analytics Real-time stream
Apache Flink Fast and Reliable Large-Scale Data Processing Fabian Hueske @fhueske 1 What is Apache Flink? Distributed Data Flow Processing System Focused on large-scale data analytics Real-time stream
File Management. Chapter 12
 Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Streamdrill: Analyzing Big Data Streams in Realtime
 Streamdrill: Analyzing Big Data Streams in Realtime Mikio L. Braun [email protected] @mikiobraun th 6 Realtime Big Data: Sources Finance Gaming Monitoring Advertisment Sensor Networks Social Media
Streamdrill: Analyzing Big Data Streams in Realtime Mikio L. Braun [email protected] @mikiobraun th 6 Realtime Big Data: Sources Finance Gaming Monitoring Advertisment Sensor Networks Social Media
File Systems Management and Examples
 File Systems Management and Examples Today! Efficiency, performance, recovery! Examples Next! Distributed systems Disk space management! Once decided to store a file as sequence of blocks What s the size
File Systems Management and Examples Today! Efficiency, performance, recovery! Examples Next! Distributed systems Disk space management! Once decided to store a file as sequence of blocks What s the size
Estimating PageRank Values of Wikipedia Articles using MapReduce
 Estimating PageRank Values of Wikipedia Articles using MapReduce Due: Sept. 30 Wednesday 5:00PM Submission: via Canvas, individual submission Instructor: Sangmi Pallickara Web page: http://www.cs.colostate.edu/~cs535/assignments.html
Estimating PageRank Values of Wikipedia Articles using MapReduce Due: Sept. 30 Wednesday 5:00PM Submission: via Canvas, individual submission Instructor: Sangmi Pallickara Web page: http://www.cs.colostate.edu/~cs535/assignments.html
Optimization and analysis of large scale data sorting algorithm based on Hadoop
 Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
DB2 for i5/os: Tuning for Performance
 DB2 for i5/os: Tuning for Performance Jackie Jansen Senior Consulting IT Specialist [email protected] August 2007 Agenda Query Optimization Index Design Materialized Query Tables Parallel Processing Optimization
DB2 for i5/os: Tuning for Performance Jackie Jansen Senior Consulting IT Specialist [email protected] August 2007 Agenda Query Optimization Index Design Materialized Query Tables Parallel Processing Optimization
Big Data Analytics with Spark and Oscar BAO. Tamas Jambor, Lead Data Scientist at Massive Analytic
 Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the