Text Classification and Naïve Bayes. The Task of Text Classifica1on
|
|
|
- Jeffry Sharp
- 10 years ago
- Views:
Transcription
1 Text Classification and Naïve Bayes The Task of Text Classifica1on

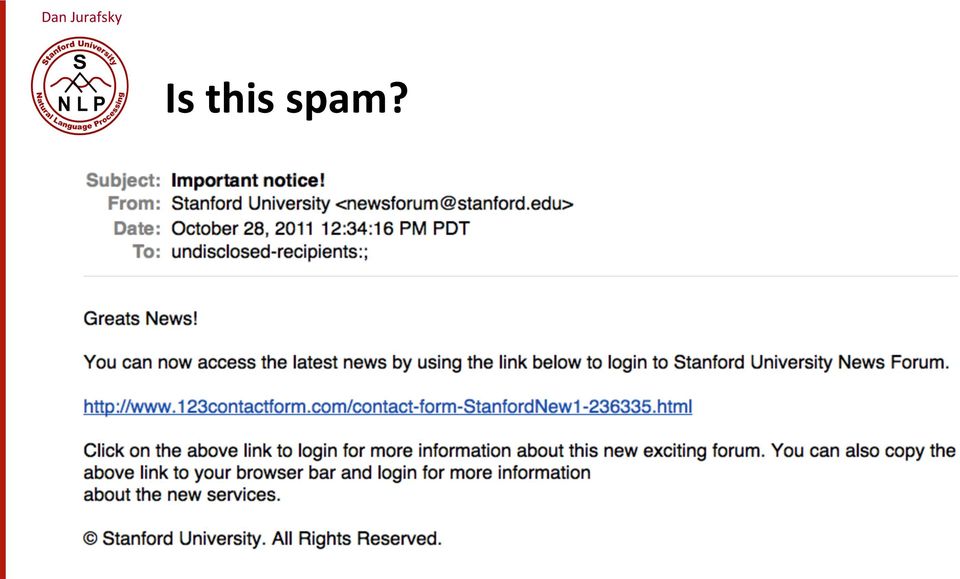
2 Is this spam?
3 Who wrote which Federalist papers? : anonymous essays try to convince New York to ra1fy U.S Cons1tu1on: Jay, Madison, Hamilton. Authorship of 12 of the lelers in dispute 1963: solved by Mosteller and Wallace using Bayesian methods James Madison Alexander Hamilton

4 Male or female author? 1. By 1925 present- day Vietnam was divided into three parts under French colonial rule. The southern region embracing Saigon and the Mekong delta was the colony of Cochin- China; the central area with its imperial capital at Hue was the protectorate of Annam 2. Clara never failed to be astonished by the extraordinary felicity of her own name. She found it hard to trust herself to the mercy of fate, which had managed over the years to convert her greatest shame into one of her greatest assets S. Argamon, M. Koppel, J. Fine, A. R. Shimoni, Gender, Genre, and Wri1ng Style in Formal WriLen Texts, Text, volume 23, number 3, pp

5 Posi8ve or nega8ve movie review? unbelievably disappoin1ng Full of zany characters and richly applied sa1re, and some great plot twists this is the greatest screwball comedy ever filmed It was pathe1c. The worst part about it was the boxing scenes. 5

6 What is the subject of this ar8cle? 6 MEDLINE Article? MeSH Subject Category Hierarchy Antogonists and Inhibitors Blood Supply Chemistry Drug Therapy Embryology Epidemiology

7 Text Classifica8on Assigning subject categories, topics, or genres Spam detec1on Authorship iden1fica1on Age/gender iden1fica1on Language Iden1fica1on Sen1ment analysis

8 Text Classifica8on: defini8on Input: a document d a fixed set of classes C = {c 1, c 2,, c J } Output: a predicted class c C

9 Classifica8on Methods: Hand- coded rules Rules based on combina1ons of words or other features spam: black- list- address OR ( dollars AND have been selected ) Accuracy can be high If rules carefully refined by expert But building and maintaining these rules is expensive

10 Classifica8on Methods: Supervised Machine Learning Input: a document d a fixed set of classes C = {c 1, c 2,, c J } A training set of m hand- labeled documents (d 1,c 1 ),...,(d m,c m ) Output: a learned classifier γ:d! c 10
,.")
11 Classifica8on Methods: Supervised Machine Learning Any kind of classifier Naïve Bayes Logis1c regression Support- vector machines k- Nearest Neighbors

12 Text Classification and Naïve Bayes The Task of Text Classifica1on

13 Text Classification and Naïve Bayes Naïve Bayes (I)

14 Naïve Bayes Intui8on Simple ( naïve ) classifica1on method based on Bayes rule Relies on very simple representa1on of document Bag of words

15 The bag of words representa8on I love this movie! It's sweet, but with satirical humor. The dialogue is great and the adventure scenes are fun It manages to be whimsical and romantic while laughing at the conventions of the fairy tale genre. I would recommend it to just about anyone. I've seen it several times, and I'm always happy to see it again whenever I have a friend who hasn't seen it yet.! γ( )=c

16 The bag of words representa8on I love this movie! It's sweet, but with satirical humor. The dialogue is great and the adventure scenes are fun It manages to be whimsical and romantic while laughing at the conventions of the fairy tale genre. I would recommend it to just about anyone. I've seen it several times, and I'm always happy to see it again whenever I have a friend who hasn't seen it yet.! γ( )=c

17 The bag of words representa8on: using a subset of words x love xxxxxxxxxxxxxxxx sweet xxxxxxx satirical xxxxxxxxxx xxxxxxxxxxx great xxxxxxx xxxxxxxxxxxxxxxxxxx fun xxxx xxxxxxxxxxxxx whimsical xxxx romantic xxxx laughing xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxx recommend xxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xx several xxxxxxxxxxxxxxxxx xxxxx happy xxxxxxxxx again xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxx! γ( )=c

18 The bag of words representa8on great! 2! love! 2! γ( )=c recommend! 1! laugh! 1! happy! 1!...!...!
=c recommend! 1!")
19 Bag of words for document classifica8on Test document parser! language! label! translation!! Machine Learning! learning! training! algorithm! shrinkage! network...! NLP! parser! tag! training! translation! language...!? Garbage! Collection! garbage! collection! memory! optimization! region...! Planning! planning! temporal! reasoning! plan! language...! GUI!...!

20 Text Classification and Naïve Bayes Naïve Bayes (I)

21 Text Classification and Naïve Bayes Formalizing the Naïve Bayes Classifier
22 Bayes Rule Applied to Documents and Classes For a document d and a class c P(c d) = P(d c)p(c) P(d)
23 Naïve Bayes Classifier (I) c MAP = argmax c C = argmax c C = argmax c C P(c d) P(d c)p(c) P(d) P(d c)p(c) MAP is maximum a posteriori = most likely class Bayes Rule Dropping the denominator
24 Naïve Bayes Classifier (II) c MAP = argmax c C P(d c)p(c) = argmax c C P(x 1, x 2,, x n c)p(c) Document d represented as features x1..xn
25 Naïve Bayes Classifier (IV) c MAP = argmax c C P(x 1, x 2,, x n c)p(c) O( X n C ) parameters Could only be es1mated if a very, very large number of training examples was available. How often does this class occur? We can just count the relative frequencies in a corpus
26 Mul8nomial Naïve Bayes Independence Assump8ons P(x 1, x 2,, x n c) Bag of Words assump8on: Assume posi1on doesn t maler Condi8onal Independence: Assume the feature probabili1es P(x i c j ) are independent given the class c. P(x 1,, x n c) = P(x 1 c) P(x 2 c) P(x 3 c)... P(x n c)
27 Mul8nomial Naïve Bayes Classifier c MAP = argmax c C c NB = argmax c C P(x 1, x 2,, x n c)p(c) x X P(c j ) P(x c)
28 Applying Mul8nomial Naive Bayes Classifiers to Text Classifica8on positions all word posi1ons in test document c NB = argmax c j C i positions P(c j ) P(x i c j )
29 Text Classification and Naïve Bayes Formalizing the Naïve Bayes Classifier
30 Text Classification and Naïve Bayes Naïve Bayes: Learning
31 Sec.13.3 Learning the Mul8nomial Naïve Bayes Model First alempt: maximum likelihood es1mates simply use the frequencies in the data ˆP(c j ) = doccount(c = c j ) N doc ˆP(w i c j ) = count(w i,c j ) count(w,c j ) w V
32 Parameter es8ma8on ˆP(w i c j ) = count(w i,c j ) count(w, c j ) w V frac1on of 1mes word w i appears among all words in documents of topic c j Create mega- document for topic j by concatena1ng all docs in this topic Use frequency of w in mega- document
33 Sec.13.3 Problem with Maximum Likelihood What if we have seen no training documents with the word fantas&c and classified in the topic posi8ve (thumbs- up)? ˆP("fantastic" positive) = count("fantastic", positive) count(w, positive) Zero probabili1es cannot be condi1oned away, no maler the other evidence! w V c MAP = argmax c ˆP(c) ˆP(xi c) i = 0
34 Laplace (add- 1) smoothing for Naïve Bayes ˆP(w i c) = = w V # % $ count(w i, c)+1 count(w, c) +1 ( ) ) count(w i, c)+1 & count(w, c) ( + V ' w V
35 Mul8nomial Naïve Bayes: Learning From training corpus, extract Vocabulary Calculate P(c j ) terms For each c j in C do docs j all docs with class =c j docs P(c j ) j total # documents Calculate P(w k c j ) terms Text j single doc containing all docs j For each word w k in Vocabulary n k # of occurrences of w k in Text j n P(w k c j ) k +α n +α Vocabulary
36 Text Classification and Naïve Bayes Naïve Bayes: Learning
37 Text Classification and Naïve Bayes Naïve Bayes: Rela1onship to Language Modeling
38 Genera8ve Model for Mul8nomial Naïve Bayes c=china X 1 =Shanghai X 2 =and X 3 =Shenzhen X 4 =issue X 5 =bonds 38
39 Naïve Bayes and Language Modeling Naïve bayes classifiers can use any sort of feature URL, address, dic1onaries, network features But if, as in the previous slides We use only word features we use all of the words in the text (not a subset) Then 39 Naïve bayes has an important similarity to language modeling.
40 Sec Each class = a unigram language model Assigning each word: P(word c) Assigning each sentence: P(s c)=π P(word c) Class pos 0.1 I 0.1 love 0.01 this 0.05 fun 0.1 film I love this fun film P(s pos) =
41 Sec Naïve Bayes as a Language Model Which class assigns the higher probability to s? Model pos Model neg 0.1 I 0.1 love 0.01 this 0.2 I love 0.01 this I love this fun film fun 0.1 film fun 0.1 film P(s pos) > P(s neg)
42 Text Classification and Naïve Bayes Naïve Bayes: Rela1onship to Language Modeling
43 Text Classification and Naïve Bayes Mul1nomial Naïve Bayes: A Worked Example
44 ˆP(w c) = count(w,c)+1 count(c)+ V 44 Priors: P(c)= P(j)= 4 ˆP(c) = N c N Condi8onal Probabili8es: P(Chinese c) = P(Tokyo c) = (5+1) / (8+6) = 6/14 = 3/7 (0+1) / (8+6) = 1/14 P(Japan c) = (0+1) / (8+6) = 1/14 P(Chinese j) = (1+1) / (3+6) = 2/9 P(Tokyo j) = (1+1) / (3+6) = 2/9 P(Japan j) = (1+1) / (3+6) = 2/9 Doc Words Class Training 1 Chinese Beijing Chinese c 2 Chinese Chinese Shanghai c 3 Chinese Macao c 4 Tokyo Japan Chinese j Test 5 Chinese Chinese Chinese Tokyo Japan? Choosing a class: P(c d5) 3/4 * (3/7) 3 * 1/14 * 1/ P(j d5) 1/4 * (2/9) 3 * 2/9 * 2/
45 Naïve Bayes in Spam Filtering SpamAssassin Features: Men1ons Generic Viagra Online Pharmacy Men1ons millions of (dollar) ((dollar) NN,NNN,NNN.NN) Phrase: impress... girl From: starts with many numbers Subject is all capitals HTML has a low ra1o of text to image area One hundred percent guaranteed Claims you can be removed from the list 'Pres1gious Non- Accredited Universi1es' hlp://spamassassin.apache.org/tests_3_3_x.html
46 Summary: Naive Bayes is Not So Naive Very Fast, low storage requirements Robust to Irrelevant Features Irrelevant Features cancel each other without affec1ng results Very good in domains with many equally important features Decision Trees suffer from fragmentagon in such cases especially if lille data Op1mal if the independence assump1ons hold: If assumed independence is correct, then it is the Bayes Op1mal Classifier for problem A good dependable baseline for text classifica1on But we will see other classifiers that give bewer accuracy
47 Text Classification and Naïve Bayes Mul1nomial Naïve Bayes: A Worked Example
48 Text Classification and Naïve Bayes Precision, Recall, and the F measure
49 The 2- by- 2 con8ngency table correct not correct selected tp fp not selected fn tn
50 Precision and recall Precision: % of selected items that are correct Recall: % of correct items that are selected correct not correct selected tp fp not selected fn tn
51 A combined measure: F A combined measure that assesses the P/R tradeoff is F measure (weighted harmonic mean): F 2 1 ( β + 1) PR = = α + (1 α) β P + R P R The harmonic mean is a very conserva1ve average; see IIR 8.3 People usually use balanced F1 measure i.e., with β = 1 (that is, α = ½): F = 2PR/(P+R)
52 Text Classification and Naïve Bayes Precision, Recall, and the F measure
53 Text Classification and Naïve Bayes Text Classifica1on: Evalua1on
54 More Than Two Classes: Sets of binary classifiers Sec.14.5 Dealing with any- of or mul1value classifica1on A document can belong to 0, 1, or >1 classes. For each class c C Build a classifier γ c to dis1nguish c from all other classes c C Given test doc d, Evaluate it for membership in each class using each γ c d belongs to any class for which γ c returns true 54
55 More Than Two Classes: Sets of binary classifiers Sec.14.5 One- of or mul1nomial classifica1on Classes are mutually exclusive: each document in exactly one class For each class c C Build a classifier γ c to dis1nguish c from all other classes c C Given test doc d, Evaluate it for membership in each class using each γ c d belongs to the one class with maximum score 55
56 56 Evalua8on: Classic Reuters Data Set Most (over)used data set, 21,578 docs (each 90 types, 200 toknens) 9603 training, 3299 test ar1cles (ModApte/Lewis split) 118 categories An ar1cle can be in more than one category Learn 118 binary category dis1nc1ons Average document (with at least one category) has 1.24 classes Only about 10 out of 118 categories are large Common categories (#train, #test) Earn (2877, 1087) Acquisitions (1650, 179) Money-fx (538, 179) Grain (433, 149) Crude (389, 189) Trade (369,119) Interest (347, 131) Ship (197, 89) Wheat (212, 71) Corn (182, 56) Sec
57 Reuters Text Categoriza8on data set (Reuters ) document Sec <REUTERS TOPICS="YES" LEWISSPLIT="TRAIN" CGISPLIT="TRAINING-SET" OLDID="12981" NEWID="798"> <DATE> 2-MAR :51:43.42</DATE> <TOPICS><D>livestock</D><D>hog</D></TOPICS> <TITLE>AMERICAN PORK CONGRESS KICKS OFF TOMORROW</TITLE> <DATELINE> CHICAGO, March 2 - </DATELINE><BODY>The American Pork Congress kicks off tomorrow, March 3, in Indianapolis with 160 of the nations pork producers from 44 member states determining industry positions on a number of issues, according to the National Pork Producers Council, NPPC. Delegates to the three day Congress will be considering 26 resolutions concerning various issues, including the future direction of farm policy and the tax law as it applies to the agriculture sector. The delegates will also debate whether to endorse concepts of a national PRV (pseudorabies virus) control and eradication program, the NPPC said. A large trade show, in conjunction with the congress, will feature the latest in technology in all areas of the industry, the NPPC added. Reuter 57 </BODY></TEXT></REUTERS>
58 Confusion matrix c For each pair of classes <c 1,c 2 > how many documents from c 1 were incorrectly assigned to c 2? c 3,2 : 90 wheat documents incorrectly assigned to poultry Docs in test set Assigned UK Assigned poultry Assigned wheat Assigned coffee Assigned interest True UK True poultry True wheat True coffee True interest Assigned trade 58 True trade
59 Sec Per class evalua8on measures Recall: Frac1on of docs in class i classified correctly: j c ii c ij 59 Precision: Frac1on of docs assigned class i that are actually about class i: Accuracy: (1 - error rate) Frac1on of docs classified correctly: j i i c ii j c ii c ji c ij
60 Sec Micro- vs. Macro- Averaging If we have more than one class, how do we combine mul1ple performance measures into one quan1ty? Macroaveraging: Compute performance for each class, then average. Microaveraging: Collect decisions for all classes, compute con1ngency table, evaluate. 60
61 Sec Micro- vs. Macro- Averaging: Example Class 1 Class 2 Micro Ave. Table Truth: yes Classifier: yes Truth: no Classifier: no Truth: yes Classifier: yes Truth: no Classifier: no Truth: yes Classifier: yes Truth: no Classifier: no Macroaveraged precision: ( )/2 = 0.7 Microaveraged precision: 100/120 =.83 Microaveraged score is dominated by score on common classes 61
62 Development Test Sets and Cross- valida8on Training set Development Test Set Test Set Metric: P/R/F1 or Accuracy Unseen test set avoid overfiƒng ( tuning to the test set ) more conserva1ve es1mate of performance Cross- valida1on over mul1ple splits Handle sampling errors from different datasets Pool results over each split Compute pooled dev set performance Training Set Training Set Dev Test Dev Test Dev Test Training Set Test Set
63 Text Classification and Naïve Bayes Text Classifica1on: Evalua1on
64 Text Classification and Naïve Bayes Text Classifica1on: Prac1cal Issues
65 Sec The Real World Gee, I m building a text classifier for real, now! What should I do? 65
66 No training data? Manually written rules Sec If (wheat or grain) and not (whole or bread) then Categorize as grain Need careful cra ing Human tuning on development data Time- consuming: 2 days per class 66
67 Sec Very little data? Use Naïve Bayes Naïve Bayes is a high- bias algorithm (Ng and Jordan 2002 NIPS) Get more labeled data Find clever ways to get humans to label data for you Try semi- supervised training methods: Bootstrapping, EM over unlabeled documents, 67
68 Sec A reasonable amount of data? Perfect for all the clever classifiers SVM Regularized Logis1c Regression You can even use user- interpretable decision trees Users like to hack Management likes quick fixes 68
69 Sec A huge amount of data? Can achieve high accuracy! At a cost: SVMs (train 1me) or knn (test 1me) can be too slow Regularized logis1c regression can be somewhat beler So Naïve Bayes can come back into its own again! 69
70 Sec Accuracy as a function of data size With enough data Classifier may not maler 70 Brill and Banko on spelling correc1on
71 Real- world systems generally combine: Automa1c classifica1on Manual review of uncertain/difficult/"new cases 71
72 Underflow Preven8on: log space Mul1plying lots of probabili1es can result in floa1ng- point underflow. Since log(xy) = log(x) + log(y) BeLer to sum logs of probabili1es instead of mul1plying probabili1es. Class with highest un- normalized log probability score is s1ll most probable. c NB = argmax c j C Model is now just max of sum of weights i positions log P(c j )+ log P(x i c j )
73 Sec How to tweak performance Domain- specific features and weights: very important in real performance Some1mes need to collapse terms: 73 Part numbers, chemical formulas, But stemming generally doesn t help Upweigh1ng: Coun1ng a word as if it occurred twice: 1tle words (Cohen & Singer 1996) first sentence of each paragraph (Murata, 1999) In sentences that contain 1tle words (Ko et al, 2002)
74 Text Classification and Naïve Bayes Text Classifica1on: Prac1cal Issues
Projektgruppe. Categorization of text documents via classification
 Projektgruppe Steffen Beringer Categorization of text documents via classification 4. Juni 2010 Content Motivation Text categorization Classification in the machine learning Document indexing Construction
Projektgruppe Steffen Beringer Categorization of text documents via classification 4. Juni 2010 Content Motivation Text categorization Classification in the machine learning Document indexing Construction
Introduction to Bayesian Classification (A Practical Discussion) Todd Holloway Lecture for B551 Nov. 27, 2007
 Todd Holloway Lecture for B551 Nov. 27, 2007") Introduction to Bayesian Classification (A Practical Discussion) Todd Holloway Lecture for B551 Nov. 27, 2007 Naïve Bayes Components ML vs. MAP Benefits Feature Preparation Filtering Decay Extended Examples
Introduction to Bayesian Classification (A Practical Discussion) Todd Holloway Lecture for B551 Nov. 27, 2007 Naïve Bayes Components ML vs. MAP Benefits Feature Preparation Filtering Decay Extended Examples
Data Mining. Supervised Methods. Ciro Donalek [email protected]. Ay/Bi 199ab: Methods of Computa@onal Sciences hcp://esci101.blogspot.
 Data Mining Supervised Methods Ciro Donalek [email protected] Supervised Methods Summary Ar@ficial Neural Networks Mul@layer Perceptron Support Vector Machines SoLwares Supervised Models: Supervised
Data Mining Supervised Methods Ciro Donalek [email protected] Supervised Methods Summary Ar@ficial Neural Networks Mul@layer Perceptron Support Vector Machines SoLwares Supervised Models: Supervised
Machine Learning in Spam Filtering
 Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov [email protected] Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov [email protected] Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
1 Maximum likelihood estimation
 COS 424: Interacting with Data Lecturer: David Blei Lecture #4 Scribes: Wei Ho, Michael Ye February 14, 2008 1 Maximum likelihood estimation 1.1 MLE of a Bernoulli random variable (coin flips) Given N
COS 424: Interacting with Data Lecturer: David Blei Lecture #4 Scribes: Wei Ho, Michael Ye February 14, 2008 1 Maximum likelihood estimation 1.1 MLE of a Bernoulli random variable (coin flips) Given N
Sentiment analysis using emoticons
 Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
Pa8ern Recogni6on. and Machine Learning. Chapter 4: Linear Models for Classifica6on
 Pa8ern Recogni6on and Machine Learning Chapter 4: Linear Models for Classifica6on Represen'ng the target values for classifica'on If there are only two classes, we typically use a single real valued output
Pa8ern Recogni6on and Machine Learning Chapter 4: Linear Models for Classifica6on Represen'ng the target values for classifica'on If there are only two classes, we typically use a single real valued output
Semi-Supervised Learning for Blog Classification
 Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008) Semi-Supervised Learning for Blog Classification Daisuke Ikeda Department of Computational Intelligence and Systems Science,
Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008) Semi-Supervised Learning for Blog Classification Daisuke Ikeda Department of Computational Intelligence and Systems Science,
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier. Santosh Tirunagari : 245577
 T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
Machine Learning Final Project Spam Email Filtering
 Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
CSE 473: Artificial Intelligence Autumn 2010
 CSE 473: Artificial Intelligence Autumn 2010 Machine Learning: Naive Bayes and Perceptron Luke Zettlemoyer Many slides over the course adapted from Dan Klein. 1 Outline Learning: Naive Bayes and Perceptron
CSE 473: Artificial Intelligence Autumn 2010 Machine Learning: Naive Bayes and Perceptron Luke Zettlemoyer Many slides over the course adapted from Dan Klein. 1 Outline Learning: Naive Bayes and Perceptron
Author Gender Identification of English Novels
 Author Gender Identification of English Novels Joseph Baena and Catherine Chen December 13, 2013 1 Introduction Machine learning algorithms have long been used in studies of authorship, particularly in
Author Gender Identification of English Novels Joseph Baena and Catherine Chen December 13, 2013 1 Introduction Machine learning algorithms have long been used in studies of authorship, particularly in
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering
 A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Bayesian Spam Filtering
 Bayesian Spam Filtering Ahmed Obied Department of Computer Science University of Calgary [email protected] http://www.cpsc.ucalgary.ca/~amaobied Abstract. With the enormous amount of spam messages propagating
Bayesian Spam Filtering Ahmed Obied Department of Computer Science University of Calgary [email protected] http://www.cpsc.ucalgary.ca/~amaobied Abstract. With the enormous amount of spam messages propagating
Simple Language Models for Spam Detection
 Simple Language Models for Spam Detection Egidio Terra Faculty of Informatics PUC/RS - Brazil Abstract For this year s Spam track we used classifiers based on language models. These models are used to
Simple Language Models for Spam Detection Egidio Terra Faculty of Informatics PUC/RS - Brazil Abstract For this year s Spam track we used classifiers based on language models. These models are used to
Search and Information Retrieval
 Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification
 Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification Tina R. Patil, Mrs. S. S. Sherekar Sant Gadgebaba Amravati University, Amravati [email protected], [email protected]
Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification Tina R. Patil, Mrs. S. S. Sherekar Sant Gadgebaba Amravati University, Amravati [email protected], [email protected]
Data Mining Algorithms Part 1. Dejan Sarka
 Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka ([email protected]) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka ([email protected]) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Chapter 6. The stacking ensemble approach
 82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
Part III: Machine Learning. CS 188: Artificial Intelligence. Machine Learning This Set of Slides. Parameter Estimation. Estimation: Smoothing
 CS 188: Artificial Intelligence Lecture 20: Dynamic Bayes Nets, Naïve Bayes Pieter Abbeel UC Berkeley Slides adapted from Dan Klein. Part III: Machine Learning Up until now: how to reason in a model and
CS 188: Artificial Intelligence Lecture 20: Dynamic Bayes Nets, Naïve Bayes Pieter Abbeel UC Berkeley Slides adapted from Dan Klein. Part III: Machine Learning Up until now: how to reason in a model and
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Anti-Spam Filter Based on Naïve Bayes, SVM, and KNN model
 AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing and Developing E-mail Classifier
 International Journal of Recent Technology and Engineering (IJRTE) ISSN: 2277-3878, Volume-1, Issue-6, January 2013 Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing
International Journal of Recent Technology and Engineering (IJRTE) ISSN: 2277-3878, Volume-1, Issue-6, January 2013 Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Feature Subset Selection in E-mail Spam Detection
 Feature Subset Selection in E-mail Spam Detection Amir Rajabi Behjat, Universiti Technology MARA, Malaysia IT Security for the Next Generation Asia Pacific & MEA Cup, Hong Kong 14-16 March, 2012 Feature
Feature Subset Selection in E-mail Spam Detection Amir Rajabi Behjat, Universiti Technology MARA, Malaysia IT Security for the Next Generation Asia Pacific & MEA Cup, Hong Kong 14-16 March, 2012 Feature
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
A Content based Spam Filtering Using Optical Back Propagation Technique
 A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT
A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT
Tweaking Naïve Bayes classifier for intelligent spam detection
 682 Tweaking Naïve Bayes classifier for intelligent spam detection Ankita Raturi 1 and Sunil Pranit Lal 2 1 University of California, Irvine, CA 92697, USA. [email protected] 2 School of Computing, Information
682 Tweaking Naïve Bayes classifier for intelligent spam detection Ankita Raturi 1 and Sunil Pranit Lal 2 1 University of California, Irvine, CA 92697, USA. [email protected] 2 School of Computing, Information
Overview. Evaluation Connectionist and Statistical Language Processing. Test and Validation Set. Training and Test Set
 Overview Evaluation Connectionist and Statistical Language Processing Frank Keller [email protected] Computerlinguistik Universität des Saarlandes training set, validation set, test set holdout, stratification
Overview Evaluation Connectionist and Statistical Language Processing Frank Keller [email protected] Computerlinguistik Universität des Saarlandes training set, validation set, test set holdout, stratification
CI6227: Data Mining. Lesson 11b: Ensemble Learning. Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore.
 CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
Predicting the Stock Market with News Articles
 Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Experiments in Web Page Classification for Semantic Web
 Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
Mining the Software Change Repository of a Legacy Telephony System
 Mining the Software Change Repository of a Legacy Telephony System Jelber Sayyad Shirabad, Timothy C. Lethbridge, Stan Matwin School of Information Technology and Engineering University of Ottawa, Ottawa,
Mining the Software Change Repository of a Legacy Telephony System Jelber Sayyad Shirabad, Timothy C. Lethbridge, Stan Matwin School of Information Technology and Engineering University of Ottawa, Ottawa,
The Enron Corpus: A New Dataset for Email Classification Research
 The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Statistical Validation and Data Analytics in ediscovery. Jesse Kornblum
 Statistical Validation and Data Analytics in ediscovery Jesse Kornblum Administrivia Silence your mobile Interactive talk Please ask questions 2 Outline Introduction Big Questions What Makes Things Similar?
Statistical Validation and Data Analytics in ediscovery Jesse Kornblum Administrivia Silence your mobile Interactive talk Please ask questions 2 Outline Introduction Big Questions What Makes Things Similar?
Email Spam Detection A Machine Learning Approach
 Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Example: Credit card default, we may be more interested in predicting the probabilty of a default than classifying individuals as default or not.
 Statistical Learning: Chapter 4 Classification 4.1 Introduction Supervised learning with a categorical (Qualitative) response Notation: - Feature vector X, - qualitative response Y, taking values in C
Statistical Learning: Chapter 4 Classification 4.1 Introduction Supervised learning with a categorical (Qualitative) response Notation: - Feature vector X, - qualitative response Y, taking values in C
Towards better accuracy for Spam predictions
 Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 [email protected] Abstract Spam identification is crucial
Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 [email protected] Abstract Spam identification is crucial
ANALYTICAL TECHNIQUES FOR DATA VISUALIZATION
 ANALYTICAL TECHNIQUES FOR DATA VISUALIZATION CSE 537 Ar@ficial Intelligence Professor Anita Wasilewska GROUP 2 TEAM MEMBERS: SAEED BOOR BOOR - 110564337 SHIH- YU TSAI - 110385129 HAN LI 110168054 SOURCES
ANALYTICAL TECHNIQUES FOR DATA VISUALIZATION CSE 537 Ar@ficial Intelligence Professor Anita Wasilewska GROUP 2 TEAM MEMBERS: SAEED BOOR BOOR - 110564337 SHIH- YU TSAI - 110385129 HAN LI 110168054 SOURCES
Micro blogs Oriented Word Segmentation System
 Micro blogs Oriented Word Segmentation System Yijia Liu, Meishan Zhang, Wanxiang Che, Ting Liu, Yihe Deng Research Center for Social Computing and Information Retrieval Harbin Institute of Technology,
Micro blogs Oriented Word Segmentation System Yijia Liu, Meishan Zhang, Wanxiang Che, Ting Liu, Yihe Deng Research Center for Social Computing and Information Retrieval Harbin Institute of Technology,
Machine Learning. CS 188: Artificial Intelligence Naïve Bayes. Example: Digit Recognition. Other Classification Tasks
 CS 188: Artificial Intelligence Naïve Bayes Machine Learning Up until now: how use a model to make optimal decisions Machine learning: how to acquire a model from data / experience Learning parameters
CS 188: Artificial Intelligence Naïve Bayes Machine Learning Up until now: how use a model to make optimal decisions Machine learning: how to acquire a model from data / experience Learning parameters
Data Mining as a tool to Predict the Churn Behaviour among Indian bank customers
 Data Mining as a tool to Predict the Churn Behaviour among Indian bank customers Manjit Kaur Department of Computer Science Punjabi University Patiala, India [email protected] Dr. Kawaljeet Singh University
Data Mining as a tool to Predict the Churn Behaviour among Indian bank customers Manjit Kaur Department of Computer Science Punjabi University Patiala, India [email protected] Dr. Kawaljeet Singh University
Ensemble Methods. Adapted from slides by Todd Holloway h8p://abeau<fulwww.com/2007/11/23/ ensemble- machine- learning- tutorial/
 Ensemble Methods Adapted from slides by Todd Holloway h8p://abeau
Ensemble Methods Adapted from slides by Todd Holloway h8p://abeau
Data Mining Yelp Data - Predicting rating stars from review text
 Data Mining Yelp Data - Predicting rating stars from review text Rakesh Chada Stony Brook University [email protected] Chetan Naik Stony Brook University [email protected] ABSTRACT The majority
Data Mining Yelp Data - Predicting rating stars from review text Rakesh Chada Stony Brook University [email protected] Chetan Naik Stony Brook University [email protected] ABSTRACT The majority
Building a Question Classifier for a TREC-Style Question Answering System
 Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Machine Learning Capacity and Performance Analysis and R
 Machine Learning and R May 3, 11 30 25 15 10 5 25 15 10 5 30 25 15 10 5 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 100 80 60 40 100 80 60 40 100 80 60 40 30 25 15 10 5 25 15 10
Machine Learning and R May 3, 11 30 25 15 10 5 25 15 10 5 30 25 15 10 5 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 100 80 60 40 100 80 60 40 100 80 60 40 30 25 15 10 5 25 15 10
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
A semi-supervised Spam mail detector
 A semi-supervised Spam mail detector Bernhard Pfahringer Department of Computer Science, University of Waikato, Hamilton, New Zealand Abstract. This document describes a novel semi-supervised approach
A semi-supervised Spam mail detector Bernhard Pfahringer Department of Computer Science, University of Waikato, Hamilton, New Zealand Abstract. This document describes a novel semi-supervised approach
MACHINE LEARNING IN HIGH ENERGY PHYSICS
 MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
ISSN: 2321-7782 (Online) Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
ISSN: 2321-7782 (Online) Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Homework 4 Statistics W4240: Data Mining Columbia University Due Tuesday, October 29 in Class
 Problem 1. (10 Points) James 6.1 Problem 2. (10 Points) James 6.3 Problem 3. (10 Points) James 6.5 Problem 4. (15 Points) James 6.7 Problem 5. (15 Points) James 6.10 Homework 4 Statistics W4240: Data Mining
Problem 1. (10 Points) James 6.1 Problem 2. (10 Points) James 6.3 Problem 3. (10 Points) James 6.5 Problem 4. (15 Points) James 6.7 Problem 5. (15 Points) James 6.10 Homework 4 Statistics W4240: Data Mining
Cross-Validation. Synonyms Rotation estimation
 Comp. by: BVijayalakshmiGalleys0000875816 Date:6/11/08 Time:19:52:53 Stage:First Proof C PAYAM REFAEILZADEH, LEI TANG, HUAN LIU Arizona State University Synonyms Rotation estimation Definition is a statistical
Comp. by: BVijayalakshmiGalleys0000875816 Date:6/11/08 Time:19:52:53 Stage:First Proof C PAYAM REFAEILZADEH, LEI TANG, HUAN LIU Arizona State University Synonyms Rotation estimation Definition is a statistical
Challenges of Cloud Scale Natural Language Processing
 Challenges of Cloud Scale Natural Language Processing Mark Dredze Johns Hopkins University My Interests? Information Expressed in Human Language Machine Learning Natural Language Processing Intelligent
Challenges of Cloud Scale Natural Language Processing Mark Dredze Johns Hopkins University My Interests? Information Expressed in Human Language Machine Learning Natural Language Processing Intelligent
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
An Approach to Detect Spam Emails by Using Majority Voting
 An Approach to Detect Spam Emails by Using Majority Voting Roohi Hussain Department of Computer Engineering, National University of Science and Technology, H-12 Islamabad, Pakistan Usman Qamar Faculty,
An Approach to Detect Spam Emails by Using Majority Voting Roohi Hussain Department of Computer Engineering, National University of Science and Technology, H-12 Islamabad, Pakistan Usman Qamar Faculty,
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j
 Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Attribution. Modified from Stuart Russell s slides (Berkeley) Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley)
 Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley)") Machine Learning 1 Attribution Modified from Stuart Russell s slides (Berkeley) Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley) 2 Outline Inductive learning Decision
Machine Learning 1 Attribution Modified from Stuart Russell s slides (Berkeley) Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley) 2 Outline Inductive learning Decision
Chapter 7. Language models. Statistical Machine Translation
 Chapter 7 Language models Statistical Machine Translation Language models Language models answer the question: How likely is a string of English words good English? Help with reordering p lm (the house
Chapter 7 Language models Statistical Machine Translation Language models Language models answer the question: How likely is a string of English words good English? Help with reordering p lm (the house
ECBDL 14: Evolu/onary Computa/on for Big Data and Big Learning Workshop July 13 th, 2014 Big Data Compe//on
 ECBDL 14: Evolu/onary Computa/on for Big Data and Big Learning Workshop July 13 th, 2014 Big Data Compe//on Jaume Bacardit [email protected] The Interdisciplinary Compu/ng and Complex BioSystems
ECBDL 14: Evolu/onary Computa/on for Big Data and Big Learning Workshop July 13 th, 2014 Big Data Compe//on Jaume Bacardit [email protected] The Interdisciplinary Compu/ng and Complex BioSystems
Combining Global and Personal Anti-Spam Filtering
 Combining Global and Personal Anti-Spam Filtering Richard Segal IBM Research Hawthorne, NY 10532 Abstract Many of the first successful applications of statistical learning to anti-spam filtering were personalized
Combining Global and Personal Anti-Spam Filtering Richard Segal IBM Research Hawthorne, NY 10532 Abstract Many of the first successful applications of statistical learning to anti-spam filtering were personalized
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
How To Make A Credit Risk Model For A Bank Account
 TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző [email protected] 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző [email protected] 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
Sentiment analysis of Twitter microblogging posts. Jasmina Smailović Jožef Stefan Institute Department of Knowledge Technologies
 Sentiment analysis of Twitter microblogging posts Jasmina Smailović Jožef Stefan Institute Department of Knowledge Technologies Introduction Popularity of microblogging services Twitter microblogging posts
Sentiment analysis of Twitter microblogging posts Jasmina Smailović Jožef Stefan Institute Department of Knowledge Technologies Introduction Popularity of microblogging services Twitter microblogging posts
Customer Classification And Prediction Based On Data Mining Technique
 Customer Classification And Prediction Based On Data Mining Technique Ms. Neethu Baby 1, Mrs. Priyanka L.T 2 1 M.E CSE, Sri Shakthi Institute of Engineering and Technology, Coimbatore 2 Assistant Professor
Customer Classification And Prediction Based On Data Mining Technique Ms. Neethu Baby 1, Mrs. Priyanka L.T 2 1 M.E CSE, Sri Shakthi Institute of Engineering and Technology, Coimbatore 2 Assistant Professor
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Evaluation & Validation: Credibility: Evaluating what has been learned
 Evaluation & Validation: Credibility: Evaluating what has been learned How predictive is a learned model? How can we evaluate a model Test the model Statistical tests Considerations in evaluating a Model
Evaluation & Validation: Credibility: Evaluating what has been learned How predictive is a learned model? How can we evaluate a model Test the model Statistical tests Considerations in evaluating a Model
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
8. Machine Learning Applied Artificial Intelligence
 8. Machine Learning Applied Artificial Intelligence Prof. Dr. Bernhard Humm Faculty of Computer Science Hochschule Darmstadt University of Applied Sciences 1 Retrospective Natural Language Processing Name
8. Machine Learning Applied Artificial Intelligence Prof. Dr. Bernhard Humm Faculty of Computer Science Hochschule Darmstadt University of Applied Sciences 1 Retrospective Natural Language Processing Name
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Predicting Flight Delays
 Predicting Flight Delays Dieterich Lawson [email protected] William Castillo [email protected] Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Predicting Flight Delays Dieterich Lawson [email protected] William Castillo [email protected] Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Learning from Data: Naive Bayes
 Semester 1 http://www.anc.ed.ac.uk/ amos/lfd/ Naive Bayes Typical example: Bayesian Spam Filter. Naive means naive. Bayesian methods can be much more sophisticated. Basic assumption: conditional independence.
Semester 1 http://www.anc.ed.ac.uk/ amos/lfd/ Naive Bayes Typical example: Bayesian Spam Filter. Naive means naive. Bayesian methods can be much more sophisticated. Basic assumption: conditional independence.
Chapter 5. Phrase-based models. Statistical Machine Translation
 Chapter 5 Phrase-based models Statistical Machine Translation Motivation Word-Based Models translate words as atomic units Phrase-Based Models translate phrases as atomic units Advantages: many-to-many
Chapter 5 Phrase-based models Statistical Machine Translation Motivation Word-Based Models translate words as atomic units Phrase-Based Models translate phrases as atomic units Advantages: many-to-many
Comparing the Results of Support Vector Machines with Traditional Data Mining Algorithms
 Comparing the Results of Support Vector Machines with Traditional Data Mining Algorithms Scott Pion and Lutz Hamel Abstract This paper presents the results of a series of analyses performed on direct mail
Comparing the Results of Support Vector Machines with Traditional Data Mining Algorithms Scott Pion and Lutz Hamel Abstract This paper presents the results of a series of analyses performed on direct mail
Applying Machine Learning to Network Security Monitoring. Alex Pinto Chief Data Scien2st MLSec Project @alexcpsec @MLSecProject!
 Applying Machine Learning to Network Security Monitoring Alex Pinto Chief Data Scien2st MLSec Project @alexcpsec @MLSecProject! whoami Almost 15 years in Informa2on Security, done a licle bit of everything.
Applying Machine Learning to Network Security Monitoring Alex Pinto Chief Data Scien2st MLSec Project @alexcpsec @MLSecProject! whoami Almost 15 years in Informa2on Security, done a licle bit of everything.
Knowledge Discovery from patents using KMX Text Analytics
 Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs [email protected] Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs [email protected] Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Chapter 7. Feature Selection. 7.1 Introduction
 Chapter 7 Feature Selection Feature selection is not used in the system classification experiments, which will be discussed in Chapter 8 and 9. However, as an autonomous system, OMEGA includes feature
Chapter 7 Feature Selection Feature selection is not used in the system classification experiments, which will be discussed in Chapter 8 and 9. However, as an autonomous system, OMEGA includes feature
Bagged Ensemble Classifiers for Sentiment Classification of Movie Reviews
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 3 Issue 2 February, 2014 Page No. 3951-3961 Bagged Ensemble Classifiers for Sentiment Classification of Movie
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 3 Issue 2 February, 2014 Page No. 3951-3961 Bagged Ensemble Classifiers for Sentiment Classification of Movie
Natural Language Processing. Today. Logistic Regression Models. Lecture 13 10/6/2015. Jim Martin. Multinomial Logistic Regression
 Natural Language Processing Lecture 13 10/6/2015 Jim Martin Today Multinomial Logistic Regression Aka log-linear models or maximum entropy (maxent) Components of the model Learning the parameters 10/1/15
Natural Language Processing Lecture 13 10/6/2015 Jim Martin Today Multinomial Logistic Regression Aka log-linear models or maximum entropy (maxent) Components of the model Learning the parameters 10/1/15
Applying Machine Learning to Stock Market Trading Bryce Taylor
 Applying Machine Learning to Stock Market Trading Bryce Taylor Abstract: In an effort to emulate human investors who read publicly available materials in order to make decisions about their investments,
Applying Machine Learning to Stock Market Trading Bryce Taylor Abstract: In an effort to emulate human investors who read publicly available materials in order to make decisions about their investments,
Spam Filtering based on Naive Bayes Classification. Tianhao Sun
 Spam Filtering based on Naive Bayes Classification Tianhao Sun May 1, 2009 Abstract This project discusses about the popular statistical spam filtering process: naive Bayes classification. A fairly famous
Spam Filtering based on Naive Bayes Classification Tianhao Sun May 1, 2009 Abstract This project discusses about the popular statistical spam filtering process: naive Bayes classification. A fairly famous
Université de Montpellier 2 Hugo Alatrista-Salas : [email protected]
 Université de Montpellier 2 Hugo Alatrista-Salas : [email protected] WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : [email protected] WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Forecasting stock markets with Twitter
 Forecasting stock markets with Twitter Argimiro Arratia [email protected] Joint work with Marta Arias and Ramón Xuriguera To appear in: ACM Transactions on Intelligent Systems and Technology, 2013,
Forecasting stock markets with Twitter Argimiro Arratia [email protected] Joint work with Marta Arias and Ramón Xuriguera To appear in: ACM Transactions on Intelligent Systems and Technology, 2013,
Sentiment Analysis of Movie Reviews and Twitter Statuses. Introduction
 Sentiment Analysis of Movie Reviews and Twitter Statuses Introduction Sentiment analysis is the task of identifying whether the opinion expressed in a text is positive or negative in general, or about
Sentiment Analysis of Movie Reviews and Twitter Statuses Introduction Sentiment analysis is the task of identifying whether the opinion expressed in a text is positive or negative in general, or about
Automatic Text Processing: Cross-Lingual. Text Categorization
 Automatic Text Processing: Cross-Lingual Text Categorization Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena Dottorato di Ricerca in Ingegneria dell Informazone XVII ciclo
Automatic Text Processing: Cross-Lingual Text Categorization Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena Dottorato di Ricerca in Ingegneria dell Informazone XVII ciclo
Microsoft Azure Machine learning Algorithms
 Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql [email protected] http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql [email protected] http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
On the Effectiveness of Obfuscation Techniques in Online Social Networks
 On the Effectiveness of Obfuscation Techniques in Online Social Networks Terence Chen 1,2, Roksana Boreli 1,2, Mohamed-Ali Kaafar 1,3, and Arik Friedman 1,2 1 NICTA, Australia 2 UNSW, Australia 3 INRIA,
On the Effectiveness of Obfuscation Techniques in Online Social Networks Terence Chen 1,2, Roksana Boreli 1,2, Mohamed-Ali Kaafar 1,3, and Arik Friedman 1,2 1 NICTA, Australia 2 UNSW, Australia 3 INRIA,
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Application of Data Mining based Malicious Code Detection Techniques for Detecting new Spyware
 Application of Data Mining based Malicious Code Detection Techniques for Detecting new Spyware Cumhur Doruk Bozagac Bilkent University, Computer Science and Engineering Department, 06532 Ankara, Turkey
Application of Data Mining based Malicious Code Detection Techniques for Detecting new Spyware Cumhur Doruk Bozagac Bilkent University, Computer Science and Engineering Department, 06532 Ankara, Turkey
Search and Data Mining: Techniques. Text Mining Anya Yarygina Boris Novikov
 Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or