Intro Systems. Big Data Pot Pourri. Olivier Curé. Université Paris-Est Marne la Vallée, LIGM UMR CNRS 8049, France.
|
|
|
- Jody Stanley
- 8 years ago
- Views:
Transcription
1 Big Data Pot Pourri Université Paris-Est Marne la Vallée, LIGM UMR CNRS 8049, France January 7, 2014
2 Bon anniversaire Pierre
3
4
5 Wikipedia definition Big data usually includes data sets with sizes beyond the ability of commonly-used software tools to capture, curate, manage, and process the data within a tolerable elapsed time.
6 Meaning of big evolves 2008: Google processes 20 PB a day 2009: Facebook has 2.5 PB user data + 15 TB/day 2009: ebay has 6.5 PB user data + 50 TB/day 2011: Yahoo! has PB of data 2012: Facebook ingests 500 TB/day
7

8
9 3 Vs of big data Big Velocity: ranging from batch processing to real-time Uses cases: electronic trading, real-time ad placement on the Web, mobile socail networking, etc. Big Variety: ranging from structured to unstructured Data sources: xls, html, xml, rdbms, rdf, csv, etc. Tools: ETL (Extract Transform Load), Big volumes: ranging To to Po and more
10 more Vs Veracity : data quality many companies starting to address this area Trifacta, Data Tamer Vocabulary : Semantics Ontologies Venue : location
11
12 Hype cycle 2013
13
14 Why big data Increase of storage capacities Increase of processing power Availability of data The Web

15 Storage capacity

16 Computation capacity $5 million vs $400: price of fastest supercomputer in 1975 and iphone4 with equal performance
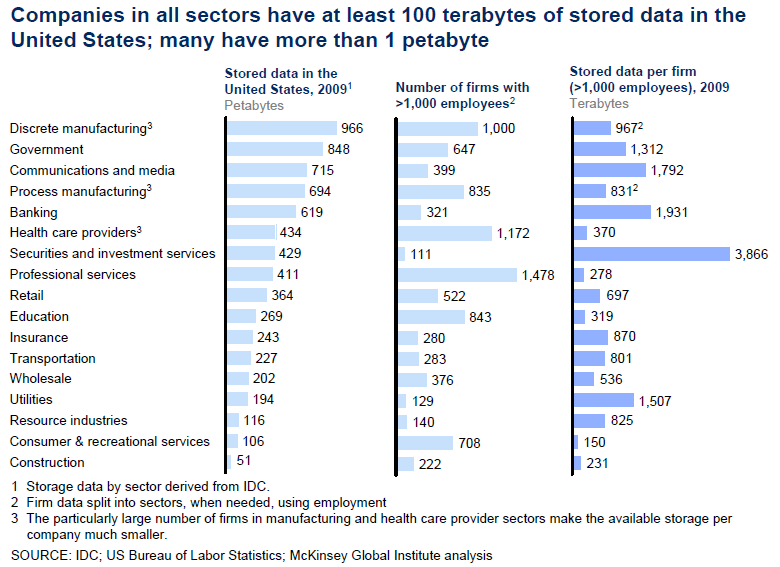
17 Data availability

18 Type of available data

19 Data available from Internet of Things

20 Growth of IoT

21 Lack of talent for big data
22 2 forms of Big volumes 1 small analytics : SQL on very large data sets. Using aggregate ops of SQL big analytics : Data clustering, regressions, machine learning. Using statistical tools: R, SPSS (Statistical Product and Service Solutions - IBM), SAS. 1
23 Making sense at scale Machines: cloud computing Algorithms: machine learning and analytics People: crowdsourcing and human computation
24 Crowdsourcing and Human computation Crowdsourcing first coined in 2006 in Wired magazine: a task of taking a job traditionally performed by a designated agent and outsourcing it to an undefined, generally large group of people in the form of an open call. Human computation 2 :... a paradigm for utilizing human processing power to solve problems that computers cannot yet solve. Global Brain 3 : people and computers to constitute a global brain. Ask for new programming metaphors to program it. 2 van Ahn Bernstein, CACM12
25 Machine Learning (aka data mining, predictive analytics) Machine learning systems automatically learn programs from data. Different types of ML: supervised (e.g. decision trees, rules, Bayesian techniques, Neural networks, SVM) and unsupervised learning (e.g. Clustering, Dimensionality reduction). Use cases: Spam filtering, Clickstream mining, Recommendation, etc..
26 Machines Two main solutions to process big data: MR and high compression approches Using them together will be more and more frequent in future systems. For instance by distributing compressed data over a cluster of machines.

27 Related tools
28 Tools using Hadoop Hive: data warehouse infrastructure that provides data summarization and ad hoc querying (HiveQL) Pig: high-level data-flow language and execution framework for parallel computation (Pig Latin) Mahout: Scalable machine learning and data mining library Flume: Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data Many more: Cascading, Cascalog, mrjob, MapR, Azkaban, Oozie,...
29 @ Twitter Others Graph oriented systems Dremel 4 Scalable, interactive, ad-hoc query system for analysis of read-only nested data Combines multi level exec trees and columnar data layout Operates on in-situ nested data Provides high level, SQL, like language to express queries Executes queries natively without translating them to MR not a replacement for MR, used in conjunction with MR to analyze MR pipelines outputs and prototype larger computations. Data model is ColumnIO Uses a columnar storage approach 4 VLDB 2010
30 Tenzing 5 Twitter Others Graph oriented systems SQL query execution built on top of Map Reduce SQL features: projection, filtering, aggregation, joins, OLAP extensions (cube, rollup), set operations, nested queries, views, analytic functions (rank, sum, min, max) Optimzation and indexes to speed up query execution Not adapted to nested-repeated structures provides better optimization built-in than Pig Latin and Sawzall FlumeJava and DryadLinq are geared for programmers for simple ETL tasks Hive, Scope, Hadapt are competitors of Tenzing. Greenplum, Teradata, Paraccel, Vertica are parallel DB that are embedding MR 5 VLDB 2011
31 @ Twitter Others Graph oriented systems Sawzall Tenzing Dremel Latency High Medium Low Scalability High High Medium SQL None High Medium Power High Medium Low
32 @ Twitter Others Graph oriented systems Google s Megastore 6 Storage system that mixes the scalability of NoSQL and convenience of RDBLS. Strong consistency, high availability ACID semantics with fine-grained partitions of data. Synchronously-replication DB across data centers Layered on top of BigTable, hence high communication costs. 6 CIDR 2011
33 @ Twitter Others Graph oriented systems Google s Spanner 7 Scalable Globally-distributed Synchronously-replicated DB across data centers Higher performance than Megastore. 7 OSDI 2012
34 @ Twitter Others Graph oriented systems Facebook Company s largest cluster is more than 100Po Hive queries/day Datawarehouse has grown 2.500x in 4 years. That forced them to design a better way to process bi data at web scale: Corona
35 @ Twitter Others Graph oriented systems Facebook s Corona A new system for scheduling Hadoop jobs that makes better use of a cluster s resources and also makes it more amenable to multitenant environments. Hadoop s jobtracker node is responsible for both the cluster management and job-scheduling. Thus it is slow. Hadoop s job scheduling involves an inherent delay: problematic for small jobs that require fast exec. Corona creates individual job trackers for each job and a cluster manager that handles tracking nodes and available resources. Apache Yarn and Apache Mesos (used at Twitter) are Corona s competitors.
36 @ Twitter Others Graph oriented systems Netflix in numbers (2012) an American provider of on-demand Internet streaming media Netflix consumes 32.7 percent of the Internet s peak downstream traffic in North America 25 million users 30 million plays per day (tracks user s rewind, foward, pause) more than 2 billion hours of streaming video for the last quarter of million ratings/day 3 million searches/day Geo-location data, device info, Social media data from Facebook and Twitter
37 @ Twitter Others Graph oriented systems Netflix s recommendation system 75% of users selections based on the company s recommendations Main goal: predict what you will watch next and propose it if available on Netflix. Ultimate goal: predict what customers will view to completion Aims to consider volume, colors, scenery configs

38 @ Twitter Others Graph oriented systems
39 @ Twitter Others Graph oriented systems Netflix 8 Considered the king of computing in the cloud Runs almost entirely in AWS platform Uses Hadoop (Elastic Map Reduce, Amazon s MR on AWS) as storage and processing for almost everything. Genie is Netflix s homemade Hadoop Platform as a Service (Paas) : submit jobs via a REST-API Uses both S3 and HDFS as the storage layer: S3 to share the same data among clusters, HDFS to speed up computation process. 8
40 @ Twitter Others Graph oriented systems Twitter Over 140M active user Over 400M visitors 400M tweets/day (peak 25K/sec) Types of data: text, social graph, time series, interest graph What do they do with data: search, recommendations, ads, anti-spam
41 @ Twitter Others Graph oriented systems Twitter (2) When a write a tweet: the tweet enters the WriteAPI which calls the Fanout module to send it to all followers, i.e. stored in a user array of tweets (in Redis) In the Redis cluster, all users s timelines are stored (not persisted, everything in RAM, duplicated 3 times). In case of failover, it can be reconstructed. They keep the last 800 tweets for each user in RAM. Fanout asks the Social Graph service to know who is following who. In redis, data model is tweetid (8bytes), UserID (8bytes), bits (4bytes) plus retweet (tweetid) Timeline service, provides the Redis server where your home timeline is stored.
42 @ Twitter Others Graph oriented systems Twitter (3) The WriteAPI also sends tweets to the Search Ingester then it stores it in a modified Lucene index (named Earlybird). Index is in-memory. Blender is the service that enables to access Earlybird. Twitter also a a pull solution (pulls tweets to users). WriteAPI sends tweets to HTTP Push which contains Hosebird which searches to how to sends that tweet. A similar service exists for mobile devices, named Mobile Push. WriteAPI also sends all tweets to HDFS to run MR jobs.
43 @ Twitter Others Graph oriented systems Spark Fast, MR-like engine In-memory storage for fast iterative queries (in Resilient Distributed Datasets-RDD) vs disk in MR Not restricted to Map and Reduce but has sample, join, group-by ops Up to 100x faster than hadoop (2-10x for on-disk data) Compatible with Hadoop s storage APIs: access HDFS, HBase, S3, SequenceFiles
44 @ Twitter Others Graph oriented systems Spark - Resilient Distributed Datasets-RDD A collection of Java objects Can be partitioned/distributed and shuffled/distributed across a cluster Need not to be in-memory at once At the moment, RDD expire at the end of a job
45 @ Twitter Others Graph oriented systems Shark Port of Apache Hive to run on Spark Compatible with Hive data, queries (HiveQL, UDFs) Up to 100x faster Who uses Spark/Shark: Yahoo!, Foursquare, AirBnb, etc.
46 @ Twitter Others Graph oriented systems Graph processing Hadoop is great at many apps but everything Graph processing is better handled by systems like Google Pregel, Apache Giraph or iterative modeling (MPI).
47 @ Twitter Others Graph oriented systems Bulk Synchronous Parallel (BSP) model 9 An abstract computer to design parallel algorithms. A BSP computer: a set of connected processors. Each processor has local memory and may follow different threads of computation. A BSP computation proceeds in a series of global supersteps. A superstep has 3 components: Concurrent computation on every participating processor. Each process uses values stored in its local memory. Computations execute asynchronously of each others. Communication: processes exchange data via 1-sided put and get calls rather than 2-sided send and receive calls. Barrier synchronization: A point when a process waits for all other processes to finish their comunication actions. It concludes a superstep. Computation and commnunication actions are necessarily timely ordered. 9 L. Valiant, CACM 1990
48 @ Twitter Others Graph oriented systems Bulk Synchronous Parallel (BSP) model (2) Processes are randmoly assigned to processors The problem to solve is splitted into more logical processes than there is physical processors. One-sided communication prevents from deadlocks (no circular dependencies), permits fault tolerance. Apache Hama is pure BSP computing framework on top of HDFS. Pregel and Giraph both follow this model.
49 @ Twitter Others Graph oriented systems Pregel and Giraph programs are expressed as a sequence of iterations In each iteration, a vertex can, independently of other vertices, receive messages sent to it in the previous iteration, send messages to other vertices, modify its own and its outgoing edges states, and mutate the graph s topology
50 @ Twitter Others Graph oriented systems Haloop 10 a modified version of Hadoop MR framework to support iterative programs. Task scheduler is loop-aware. Adds various caching mechanisms. 10 VLDB 2010
51 @ Twitter Others Graph oriented systems Message Passing Interface (MPI) a language-independent communications protocol used to program parallel computers. Point to point and collective communication are supported Goals: high performance, scalability and portability.
52 @ Twitter Others Graph oriented systems Polyglot persistence Term coined after Neal Frod s Polygot programming, asking to write programs with a mix prog. languages. Polyglot persistence aims to use different different data stores in your applications. Imagine a e-commerce application. What would you use for the shopping cart, the completed orders and session data?
53 @ Twitter Others Graph oriented systems The shopping cart and the session data can be efficiently stored in a Key-Value store. Respectively, their keys are userid and sessionid. Once an order is completed, that data can be stored in an RDBMS or a Document store. What if we want to add a product recommendation service? Thing Collaborative Filtering, those who bought that product also like that product or your friends bought.. What about inventory and item prices?
54 @ Twitter Others Graph oriented systems A graph database corresponds to storing recommendation data. Inventory and item prices fit nicely in an RDBMS. If we have a lot of text, we can index that text using a store like Solr (part of the Lucene project). With Polyglot Persistence, one has to be careful with deployment complexity: all databases are needed in production at the same time. It may be a got solution to design services on these databases. It reduces the impact of data storage choices.
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani
 A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Large-Scale Data Processing
 Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
BIG DATA ANALYTICS REFERENCE ARCHITECTURES AND CASE STUDIES
 BIG DATA ANALYTICS REFERENCE ARCHITECTURES AND CASE STUDIES Relational vs. Non-Relational Architecture Relational Non-Relational Rational Predictable Traditional Agile Flexible Modern 2 Agenda Big Data
BIG DATA ANALYTICS REFERENCE ARCHITECTURES AND CASE STUDIES Relational vs. Non-Relational Architecture Relational Non-Relational Rational Predictable Traditional Agile Flexible Modern 2 Agenda Big Data
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Play with Big Data on the Shoulders of Open Source
 OW2 Open Source Corporate Network Meeting Play with Big Data on the Shoulders of Open Source Liu Jie Technology Center of Software Engineering Institute of Software, Chinese Academy of Sciences 2012-10-19
OW2 Open Source Corporate Network Meeting Play with Big Data on the Shoulders of Open Source Liu Jie Technology Center of Software Engineering Institute of Software, Chinese Academy of Sciences 2012-10-19
Real Time Big Data Processing
 Real Time Big Data Processing Cloud Expo 2014 Ian Meyers Amazon Web Services Global Infrastructure Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Real Time Big Data Processing Cloud Expo 2014 Ian Meyers Amazon Web Services Global Infrastructure Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
The Internet of Things and Big Data: Intro
 The Internet of Things and Big Data: Intro John Berns, Solutions Architect, APAC - MapR Technologies April 22 nd, 2014 1 What This Is; What This Is Not It s not specific to IoT It s not about any specific
The Internet of Things and Big Data: Intro John Berns, Solutions Architect, APAC - MapR Technologies April 22 nd, 2014 1 What This Is; What This Is Not It s not specific to IoT It s not about any specific
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
Big Data Approaches. Making Sense of Big Data. Ian Crosland. Jan 2016
 Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
Big Data, Why All the Buzz? (Abridged) Anita Luthra, February 20, 2014
 Anita Luthra, February 20, 2014") Big Data, Why All the Buzz? (Abridged) Anita Luthra, February 20, 2014 Defining Big Not Just Massive Data Big data refers to data sets whose size is beyond the ability of typical database software tools
Big Data, Why All the Buzz? (Abridged) Anita Luthra, February 20, 2014 Defining Big Not Just Massive Data Big data refers to data sets whose size is beyond the ability of typical database software tools
Apache Flink Next-gen data analysis. Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Analytics on Spark & Shark @Yahoo
 Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
Analysis of Web Archives. Vinay Goel Senior Data Engineer
 Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Google Cloud Data Platform & Services. Gregor Hohpe
 Google Cloud Data Platform & Services Gregor Hohpe All About Data We Have More of It Internet data more easily available Logs user & system behavior Cheap Storage keep more of it 3 Beyond just Relational
Google Cloud Data Platform & Services Gregor Hohpe All About Data We Have More of It Internet data more easily available Logs user & system behavior Cheap Storage keep more of it 3 Beyond just Relational
Big Data and Data Science: Behind the Buzz Words
 Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Chukwa, Hadoop subproject, 37, 131 Cloud enabled big data, 4 Codd s 12 rules, 1 Column-oriented databases, 18, 52 Compression pattern, 83 84
 Index A Amazon Web Services (AWS), 50, 58 Analytics engine, 21 22 Apache Kafka, 38, 131 Apache S4, 38, 131 Apache Sqoop, 37, 131 Appliance pattern, 104 105 Application architecture, big data analytics
Index A Amazon Web Services (AWS), 50, 58 Analytics engine, 21 22 Apache Kafka, 38, 131 Apache S4, 38, 131 Apache Sqoop, 37, 131 Appliance pattern, 104 105 Application architecture, big data analytics
Beyond Hadoop with Apache Spark and BDAS
 Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Tap into Hadoop and Other No SQL Sources
 Tap into Hadoop and Other No SQL Sources Presented by: Trishla Maru What is Big Data really? The Three Vs of Big Data According to Gartner Volume Volume Orders of magnitude bigger than conventional data
Tap into Hadoop and Other No SQL Sources Presented by: Trishla Maru What is Big Data really? The Three Vs of Big Data According to Gartner Volume Volume Orders of magnitude bigger than conventional data
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing
 YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
Pulsar Realtime Analytics At Scale. Tony Ng April 14, 2015
 Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Apache Hadoop Ecosystem
 Apache Hadoop Ecosystem Rim Moussa ZENITH Team Inria Sophia Antipolis DataScale project rim.moussa@inria.fr Context *large scale systems Response time (RIUD ops: one hit, OLTP) Time Processing (analytics:
Apache Hadoop Ecosystem Rim Moussa ZENITH Team Inria Sophia Antipolis DataScale project rim.moussa@inria.fr Context *large scale systems Response time (RIUD ops: one hit, OLTP) Time Processing (analytics:
Unified Big Data Analytics Pipeline. 连 城 lian@databricks.com
 Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
TRAINING PROGRAM ON BIGDATA/HADOOP
 Course: Training on Bigdata/Hadoop with Hands-on Course Duration / Dates / Time: 4 Days / 24th - 27th June 2015 / 9:30-17:30 Hrs Venue: Eagle Photonics Pvt Ltd First Floor, Plot No 31, Sector 19C, Vashi,
Course: Training on Bigdata/Hadoop with Hands-on Course Duration / Dates / Time: 4 Days / 24th - 27th June 2015 / 9:30-17:30 Hrs Venue: Eagle Photonics Pvt Ltd First Floor, Plot No 31, Sector 19C, Vashi,
How to Hadoop Without the Worry: Protecting Big Data at Scale
 How to Hadoop Without the Worry: Protecting Big Data at Scale SESSION ID: CDS-W06 Davi Ottenheimer Senior Director of Trust EMC Corporation @daviottenheimer Big Data Trust. Redefined Transparency Relevance
How to Hadoop Without the Worry: Protecting Big Data at Scale SESSION ID: CDS-W06 Davi Ottenheimer Senior Director of Trust EMC Corporation @daviottenheimer Big Data Trust. Redefined Transparency Relevance
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source
 - In- Memory Data Fabric Fast Data Meets Open Source") Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Hadoop and Relational Database The Best of Both Worlds for Analytics Greg Battas Hewlett Packard
 Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
YARN Apache Hadoop Next Generation Compute Platform
 YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
Apache Hama Design Document v0.6
 Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Pro Apache Hadoop. Second Edition. Sameer Wadkar. Madhu Siddalingaiah
 Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Building Scalable Big Data Infrastructure Using Open Source Software. Sam William sampd@stumbleupon.
 Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu
 Yabo (Arber) Xu") Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Native Connectivity to Big Data Sources in MSTR 10
 Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Big Data Explained. An introduction to Big Data Science.
 Big Data Explained An introduction to Big Data Science. 1 Presentation Agenda What is Big Data Why learn Big Data Who is it for How to start learning Big Data When to learn it Objective and Benefits of
Big Data Explained An introduction to Big Data Science. 1 Presentation Agenda What is Big Data Why learn Big Data Who is it for How to start learning Big Data When to learn it Objective and Benefits of
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
Spark: Making Big Data Interactive & Real-Time
 Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Information Builders Mission & Value Proposition
 Value 10/06/2015 2015 MapR Technologies 2015 MapR Technologies 1 Information Builders Mission & Value Proposition Economies of Scale & Increasing Returns (Note: Not to be confused with diminishing returns
Value 10/06/2015 2015 MapR Technologies 2015 MapR Technologies 1 Information Builders Mission & Value Proposition Economies of Scale & Increasing Returns (Note: Not to be confused with diminishing returns
Introduction to NOSQL
 Introduction to NOSQL Université Paris-Est Marne la Vallée, LIGM UMR CNRS 8049, France January 31, 2014 Motivations NOSQL stands for Not Only SQL Motivations Exponential growth of data set size (161Eo
Introduction to NOSQL Université Paris-Est Marne la Vallée, LIGM UMR CNRS 8049, France January 31, 2014 Motivations NOSQL stands for Not Only SQL Motivations Exponential growth of data set size (161Eo
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics
 Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at spoozhikala@stratapps.com.
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at spoozhikala@stratapps.com.
HDP Hadoop From concept to deployment.
 HDP Hadoop From concept to deployment. Ankur Gupta Senior Solutions Engineer Rackspace: Page 41 27 th Jan 2015 Where are you in your Hadoop Journey? A. Researching our options B. Currently evaluating some
HDP Hadoop From concept to deployment. Ankur Gupta Senior Solutions Engineer Rackspace: Page 41 27 th Jan 2015 Where are you in your Hadoop Journey? A. Researching our options B. Currently evaluating some
Putting Apache Kafka to Use!
 Putting Apache Kafka to Use! Building a Real-time Data Platform for Event Streams! JAY KREPS, CONFLUENT! A Couple of Themes! Theme 1: Rise of Events! Theme 2: Immutability Everywhere! Level! Example! Immutable
Putting Apache Kafka to Use! Building a Real-time Data Platform for Event Streams! JAY KREPS, CONFLUENT! A Couple of Themes! Theme 1: Rise of Events! Theme 2: Immutability Everywhere! Level! Example! Immutable
The Big Data Ecosystem at LinkedIn. Presented by Zhongfang Zhuang
 The Big Data Ecosystem at LinkedIn Presented by Zhongfang Zhuang Based on the paper The Big Data Ecosystem at LinkedIn, written by Roshan Sumbaly, Jay Kreps, and Sam Shah. The Ecosystems Hadoop Ecosystem
The Big Data Ecosystem at LinkedIn Presented by Zhongfang Zhuang Based on the paper The Big Data Ecosystem at LinkedIn, written by Roshan Sumbaly, Jay Kreps, and Sam Shah. The Ecosystems Hadoop Ecosystem
Kafka & Redis for Big Data Solutions
 Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
Big Data and Industrial Internet
 Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University keijo.heljanko@aalto.fi 16.6-2015
Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University keijo.heljanko@aalto.fi 16.6-2015
TE's Analytics on Hadoop and SAP HANA Using SAP Vora
 TE's Analytics on Hadoop and SAP HANA Using SAP Vora Naveen Narra Senior Manager TE Connectivity Santha Kumar Rajendran Enterprise Data Architect TE Balaji Krishna - Director, SAP HANA Product Mgmt. -
TE's Analytics on Hadoop and SAP HANA Using SAP Vora Naveen Narra Senior Manager TE Connectivity Santha Kumar Rajendran Enterprise Data Architect TE Balaji Krishna - Director, SAP HANA Product Mgmt. -
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Pla7orms for Big Data Management and Analysis. Michael J. Carey Informa(on Systems Group UCI CS Department
 Pla7orms for Big Data Management and Analysis Michael J. Carey Informa(on Systems Group UCI CS Department Outline Big Data Pla6orm Space The Big Data Era Brief History of Data Pla6orms Dominant Pla6orms
Pla7orms for Big Data Management and Analysis Michael J. Carey Informa(on Systems Group UCI CS Department Outline Big Data Pla6orm Space The Big Data Era Brief History of Data Pla6orms Dominant Pla6orms
Big Data Buzzwords From A to Z. By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012
 Big Data Buzzwords From A to Z By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012 Big Data Buzzwords Big data is one of the, well, biggest trends in IT today, and it has spawned a whole new generation
Big Data Buzzwords From A to Z By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012 Big Data Buzzwords Big data is one of the, well, biggest trends in IT today, and it has spawned a whole new generation
Big Data: Tools and Technologies in Big Data
 Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Big Data, Cloud Computing, Spatial Databases Steven Hagan Vice President Server Technologies
 Big Data, Cloud Computing, Spatial Databases Steven Hagan Vice President Server Technologies Big Data: Global Digital Data Growth Growing leaps and bounds by 40+% Year over Year! 2009 =.8 Zetabytes =.08
Big Data, Cloud Computing, Spatial Databases Steven Hagan Vice President Server Technologies Big Data: Global Digital Data Growth Growing leaps and bounds by 40+% Year over Year! 2009 =.8 Zetabytes =.08
Big Data Analytics Platform @ Nokia
 Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 PART 2 PART 3 BIG DATA PATTERNS...253 PART 4 BEYOND MAPREDUCE...385
 brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 1 Hadoop in a heartbeat 3 2 Introduction to YARN 22 PART 2 DATA LOGISTICS...59 3 Data serialization working with text and beyond 61 4 Organizing and
brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 1 Hadoop in a heartbeat 3 2 Introduction to YARN 22 PART 2 DATA LOGISTICS...59 3 Data serialization working with text and beyond 61 4 Organizing and
Architecting for Big Data Analytics and Beyond: A New Framework for Business Intelligence and Data Warehousing
 Architecting for Big Data Analytics and Beyond: A New Framework for Business Intelligence and Data Warehousing Wayne W. Eckerson Director of Research, TechTarget Founder, BI Leadership Forum Business Analytics
Architecting for Big Data Analytics and Beyond: A New Framework for Business Intelligence and Data Warehousing Wayne W. Eckerson Director of Research, TechTarget Founder, BI Leadership Forum Business Analytics
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP. Eva Andreasson Cloudera
 PROBLEMS USING HADOOP. Eva Andreasson Cloudera") SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
Transforming the Telecoms Business using Big Data and Analytics
 Transforming the Telecoms Business using Big Data and Analytics Event: ICT Forum for HR Professionals Venue: Meikles Hotel, Harare, Zimbabwe Date: 19 th 21 st August 2015 AFRALTI 1 Objectives Describe
Transforming the Telecoms Business using Big Data and Analytics Event: ICT Forum for HR Professionals Venue: Meikles Hotel, Harare, Zimbabwe Date: 19 th 21 st August 2015 AFRALTI 1 Objectives Describe
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
COMP9321 Web Application Engineering
 COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411
COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
We are building the next generation of Big Data and Analytics solutions!
 We are building the next generation of Big Data and Analytics solutions! Background 26 years Experience IT Industry 12 Years Solutions Architect - International Profile Passionate about Technology Genuine
We are building the next generation of Big Data and Analytics solutions! Background 26 years Experience IT Industry 12 Years Solutions Architect - International Profile Passionate about Technology Genuine
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
SQL on NoSQL (and all of the data) With Apache Drill
 With Apache Drill") SQL on NoSQL (and all of the data) With Apache Drill Richard Shaw Solutions Architect @aggress Who What Where NoSQL DB Very Nice People Open Source Distributed Storage & Compute Platform (up to 1000s of
SQL on NoSQL (and all of the data) With Apache Drill Richard Shaw Solutions Architect @aggress Who What Where NoSQL DB Very Nice People Open Source Distributed Storage & Compute Platform (up to 1000s of
#mstrworld. Tapping into Hadoop and NoSQL Data Sources in MicroStrategy. Presented by: Trishla Maru. #mstrworld
 Tapping into Hadoop and NoSQL Data Sources in MicroStrategy Presented by: Trishla Maru Agenda Big Data Overview All About Hadoop What is Hadoop? How does MicroStrategy connects to Hadoop? Customer Case
Tapping into Hadoop and NoSQL Data Sources in MicroStrategy Presented by: Trishla Maru Agenda Big Data Overview All About Hadoop What is Hadoop? How does MicroStrategy connects to Hadoop? Customer Case
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Collaborative Big Data Analytics. Copyright 2012 EMC Corporation. All rights reserved.
 Collaborative Big Data Analytics 1 Big Data Is Less About Size, And More About Freedom TechCrunch!!!!!!!!! Total data: bigger than big data 451 Group Findings: Big Data Is More Extreme Than Volume Gartner!!!!!!!!!!!!!!!
Collaborative Big Data Analytics 1 Big Data Is Less About Size, And More About Freedom TechCrunch!!!!!!!!! Total data: bigger than big data 451 Group Findings: Big Data Is More Extreme Than Volume Gartner!!!!!!!!!!!!!!!
Big Data and Analytics: Challenges and Opportunities
 Big Data and Analytics: Challenges and Opportunities Dr. Amin Beheshti Lecturer and Senior Research Associate University of New South Wales, Australia (Service Oriented Computing Group, CSE) Talk: Sharif
Big Data and Analytics: Challenges and Opportunities Dr. Amin Beheshti Lecturer and Senior Research Associate University of New South Wales, Australia (Service Oriented Computing Group, CSE) Talk: Sharif
EMC Federation Big Data Solutions. Copyright 2015 EMC Corporation. All rights reserved.
 EMC Federation Big Data Solutions 1 Introduction to data analytics Federation offering 2 Traditional Analytics! Traditional type of data analysis, sometimes called Business Intelligence! Type of analytics
EMC Federation Big Data Solutions 1 Introduction to data analytics Federation offering 2 Traditional Analytics! Traditional type of data analysis, sometimes called Business Intelligence! Type of analytics
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: bdg@qburst.com Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...