PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5)
|
|
|
- Dorthy Newman
- 7 years ago
- Views:
Transcription
1 PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5) Rob van Nieuwpoort Vrije Universiteit Amsterdam & Astron, the Netherlands Institute for Radio Astronomy

2 Why Radio? Credit: NASA/IPAC

3 Centaurus A, visible light and radio


4 The Dwingeloo telescope Dwingeloo telescope, 's 25m dish, largest turnable telescope in the world Hydrogen line (21cm), galaxies Dwingeloo I & II Now a national monument

5 Westerbork synthesis radio telescope 14 25m dishes, 3 km Combined in hardware Built in 1970, upgraded in MHz GHz

6 Software radio telescopes (1) 6 Software radio telescopes We cannot keep on building larger dishes Replace dishes with thousands of small antennas Combine signals in software
7 Software radio telescopes (2) Software telescopes are being built now LOFAR: LOw Frequency Array (Netherlands, Europe) ASKAP: Australian Square Kilometre Array Pathfinder MeerKAT: Karoo Array Telescope (South Africa) 2020: SKA, Square Kilometre Array Exa-scale! (10 18 :giga, tera, peta, exa)
8 LOFAR 8 Largest telescope in the world omni-directional antennas Hundreds of gbit/s 14x LHC Hundreds of teraflops MHz 100x more sensitive


9 LOFAR overview Hierarchical Receiver Tile Station Telescope Central processing Groningen IBM BG/P Dedicated fibers


10 LOFAR low-band antennas 10





11 LOFAR high-band antennas 11
")
12 Station (150m)

13

14 2x3 km

15 Station cabinet


16 Station processing Special-purpose hardware, FPGAs 200 MHz ADC, filtering Send to BG/P Dedicated fiber UDP



17 LOFAR science 17 Imaging Epoch of re-ionization Cosmic rays Extragalactic surveys Transients Pulsars

18 A LOFAR observation Cas A Supernova remnant MHz 12 stations
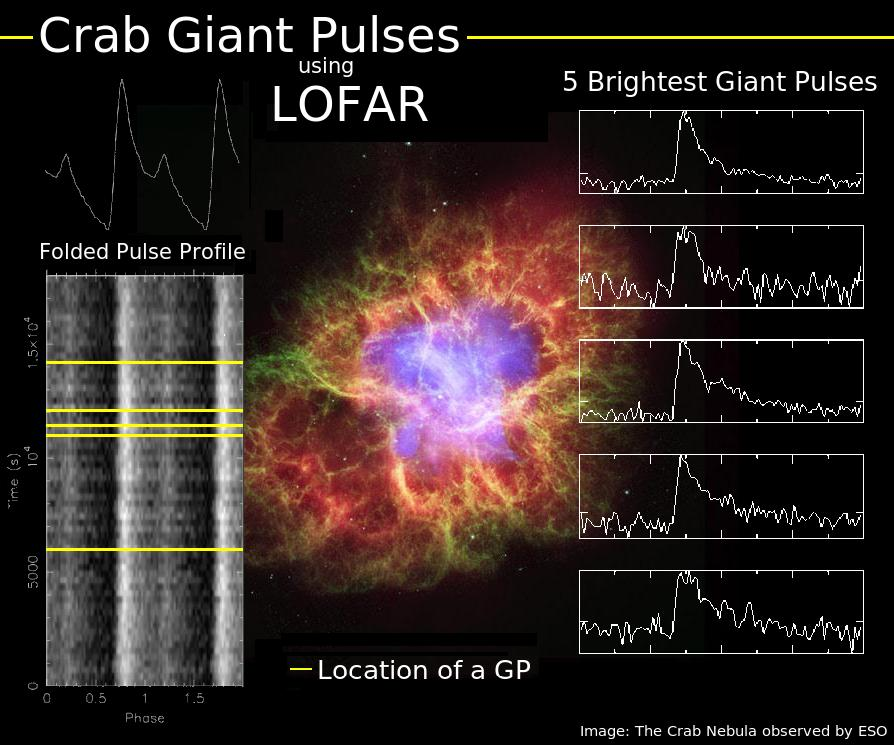
19
20 Processing pipeline real time offline astronomy pipelines 10 terabit/s 265 DVDs /s 200 gigabit/s 5 DVDs /s 50 gigabit/s 1.3 DVD/s Data volume
21 Processing pipeline real time offline astronomy pipelines 10 terabit/s 265 DVDs /s 200 gigabit/s 5 DVDs /s 50 gigabit/s 1.3 DVD/s Data volume Flexibility
22 Processing pipeline real time offline astronomy pipelines 10 terabit/s 265 DVDs /s 200 gigabit/s 5 DVDs /s 50 gigabit/s 1.3 DVD/s Data volume Flexibility Data intensiveness

23 Processing overview 23

24 Online pipelines

25 Stella, the IBM Blue Gene/P 25 Was #2, now # MHz PowerPC Designed for energy efficiency Complex numbers 3-D torus, collective, barrier, 10 GbE, JTAG networks 2½ racks = 10,880 cores = 37 TFLOP/s + 160*10 Gb/s
26 Optimizations We need high bandwidth, high performance, real-time behavior Use assembly for performance-critical code [SPAA'06] Avoid resource contention by smart scheduling [PPoPP'10] Run part of application on I/O node [PPoPP'08] Use optimized network protocol [PDPTA'09] Modify OS to avoid software TLB miss handler [IJHPC'10] Use real-time scheduler [PPoPP'10] Drop data if running behind [PPoPP'10] Use asynchronous I/O [PPoPP'10]
 achieve 96% of the theoretical")
27 BG/P performance 27 Correlator is O(n 2 ) achieve 96% of the theoretical peak

28 frequency Correlator output 28 time
29 Problem: processing is challenging Special-purpose hardware Inflexible Expensive to design Long time from design to production Supercomputer Flexible Expensive to purchase Expensive maintenance Expensive due to electrical power costs For SKA, we need orders of magnitude more!
30 Many-core advantages 30 Fast and cheap Latest ATI HD 6990 has 3072 cores, 5.1 tflops Costs only 575 euro! Comparison: entire 72-node DAS-4 VU cluster has 4.4 tflops Potentially more power efficient Example: In theory, ATI 4870 GPU is 15 times more power efficient than BG/P Many-cores are becoming more general CPUs are incorporating many-core techniques
31 Research questions Architectural problems: Which part of the theoretical performance can be achieved in practice? Can we get the data into the accelerators fast enough? Performance consistent enough for real-time use? Which architectural properties are essential?
32 Many-cores Intel core i7 quad core + hyperthreading + SSE Sony/Toshiba/IBM Cell/B.E. QS21 blade GPUs: NVIDIA Tesla C1060/GTX280, ATI 4870 Compare with production code on BG/P Compare architectures: Implemented everything in assembly Reader: Rob V. van Nieuwpoort and John W. Romein, Correlating Radio Astronomy Signals with Many-Core Hardware,
33 Essential many-core properties architecture Intel core i7 IBM BG/P ATI 4870 NVIDIA C1060 STI Cell cores x FPUs per core = total FPUs 4 x 4 = 16 4 x 2 = x 5 = x 8 = x 4 = 32 gflops registers/core x width (floats) device RAM bandwidth (GB/s) host RAM bandwidth (GB/s) per operation bandwidth slowdown compared to BG/P 16 x x x x x n.a n.a n.a (host: 150) (host: 117)
34 Correlator algorithm 34 For all channels (63488) For all combinations of two stations (2080) For the combinations of polarizations (4) Complex float sum = 0; For the time integration interval (768 samples) Sum += sample1 * sample2 (complex multiplication) Store sum in memory
35 Correlator optimization 35 Overlap data transfers and computations Exploit caches / shared memory / local store Loop unrolling Tiling Scheduling SIMD operations...
36 Correlator: Arithmetic Intensity 36 Correlator inner loop: for (time = 0; time < integrationtime; time++) { sum += samples[ch][station1][time][pol1] * samples[ch][station2][time][pol2]; } complex multiply-add: 8 flops sample: real + complex float (2 * 4 bytes)
37 Correlator: Arithmetic Intensity 37 Correlator inner loop: for (time = 0; time < integrationtime; time++) { sum += samples[ch][station1][time][pol1] * samples[ch][station2][time][pol2]; } complex multiply-add: 8 flops sample: real + complex float: 8 bytes AI: 8 FLOPS, 2 samples: 8 / 16 = 0.5


38 Correlator AI optimization 38 Combine polarizations complex multiply-add: 8 flops 2 polarizations: X, Y calculate XX, XY, YX, YY 32 flops per square XY-sample: 16 bytes (x2) 1 flop/byte Tiling 1 flop/byte 2.4 flops/byte but, we need registers 1x1 already needs 16!
39 Tuning the tile size tile size floating point operations memory loads (bytes) arithmetic intensity 1 x x x x x x x Minimum # Registers (floats)
40 Correlator implementation Intel Core i7 CPU The Cell Broadband Engine ATI & NVIDIA GPUs
41 Implementation strategy on CPU 41 Partition frequencies over the cores Independent Multithreading Each core computes its own correlation triangle Use tiling: 2x2 Vectorize with SSE Unroll time loop; compute 4 time steps in parallel
42 Implementation strategy on the Cell/BE 42 Partition frequencies over the SPEs Independent Each SPE computes its own correlation triangle Use tiling: 4x4 (128 registers!) Keep a strip of tiles in the local store: more reuse Use double buffering from memory to local store Overlap communication and computation Vectorize Different vector elements compute different polarizations
43 Implementation strategy on GPUs 43 Partition frequencies over the streaming multiprocessors Independent Double buffering between GPU and host Exploit data reuse as much as possible Each streaming multiprocessor computes a correlation triangle Threads/cores within a SM cooperate on a single triangle Load samples into shared memory Use tiling (4x3 on ATI, 3x2 on NVIDIA)
44 44 Evaluation

45 How to cheat with speedups, part 2 45 How can this be? Core I7 CPU has 154 GFLOPs NVIDIA GTX 580 GPU has 1581 GFLOPs (10.3 X more)
46 How to cheat with speedups, part 2 46 Heavily Optimize GPU version Coalescing, Shared memory Tiling, Loop unrolling Do not optimize CPU version 1 core only No SSE Cache unaware No loop unrolling and tiling, Result: very high speedups! Exception: kernels that do interpolations (texturing hardware) Solution Optimize CPU version Use efficiencies: % of peak performance, Roofline
47 Theoretical performance bounds 47 Distinguish between global and local (host vs device) Local AI = Depends on tile size, and # registers Max performance = AI * memory bandwidth ATI (4x3): 3.43 * = 395 gflops Peak of 1200 needs AI of 10.4 or 350 GB/s bandwidth NVIDIA (3x2): 2.40 * = 245 gflops Peak of 996 needs AI of 9.8 or 415 GB/s bandwidth Can we achieve more than this?
48 Theoretical performance bounds 48 Global AI = #stations + 1 (LOFAR: 65) Max performance = AI * memory bandwidth Max performance GPUs, with AI global: ATI: 65 * 4.6 = 300 gflops need 19 GB/s for peak NVIDIA: 65 * 5.6 = 363 gflops need 15 GB/s for peak


49 Correlator performance 49
 still are less power efficient than BG/P (90 nm)")

50 Measured power efficiency 50 Current CPUs (even at 45 nm) still are less power efficient than BG/P (90 nm) GPUs are not 15, but only 2-3x more power efficient than BG/P 65 nm Cell is 4x more power efficient than the BG/P
51 gflops Scalability on NVIDIA GTX number of stations
52 Weak and strong points 52 Intel Core i7 IBM BG/P ATI 4870 NVIDIA Tesla C well-known toolchain - few registers - limited shuffling + L2 prefetch unit + high memory bandwidth - double precision only - expensive + largest # cores + shuffling support - low PCI-e bandwidth (4.6 GB/s) - transfer slows down kernel - CAL is low-level - bad Brook+ performance - not well documented STI Cell + Cuda is high-level + explicit cache (LS) + shuffle capabilities + power efficiency - low PCI-e bandwidth (5.6 GB/s) - multiple parallelism Levels (6!) - no increment in odd pipeline
53 Conclusions Software telescopes are the future, extremely challenging Software provides the required flexibility Many-core architectures show great potential (28x) PCI-e is a bottleneck Compared to the BG/P or CPUs, the many-cores have low memory bandwidth per operation This is OK if the architecture allows efficient data reuse Optimal use of registers (tile size + SIMD strategy) Exploit caches / local memories / shared memories The Cell has 8 times lower memory bandwidth per operation, but still works thanks to explicit cache control and large number of registers
54 Backup slides
55 Vectorizing the correlator 55 How do we efficiently use the vectors? for (pol1 = 0; pol1 < nrpolarizations; pol1++) { for (pol2 = 0; pol2 < nrpolarizations; pol2++) { float sum = 0.0; for (time = 0; time < integrationtime; time++) { sum += samples[ch][station1][time][pol1] * samples[ch][station2][time][pol2]; } } }
56 Vectorizing the correlator 56 Option 1: vectorize over time Unroll time loop 4 times for (pol1 = 0; pol1 < nrpolarizations; pol1++) { for (pol2 = 0; pol2 < nrpolarizations; pol2++) { float sum = 0.0; for (time = 0; time < integrationtime; time += 4) { sum += samples[ch][station1][time+0][pol1] * samples[ch][station2][time+0][pol2]; sum += samples[ch][station1][time+1][pol1] * samples[ch][station2][time+1][pol2]; sum += samples[ch][station1][time+2][pol1] * samples[ch][station2][time+2][pol2]; sum += samples[ch][station1][time+3][pol1] * samples[ch][station2][time+3][pol2]; } } }
57 Vectorizing the correlator 57 for (pol1 = 0; pol1 < nrpolarizations; pol1++) { for (pol2 = 0; pol2 < nrpolarizations; pol2++) { vector float sum = {0.0, 0.0, 0.0, 0.0}; for (time = 0; time < integrationtime; time += 4) { vector float s1 = { samples[ch][station1][time+0][pol1], samples[ch][station1][time+1][pol1], samples[ch][station1][time+2][pol1], samples[ch][station1][time+3][pol1], }; vector float s2 = { samples[ch][station2][time+0][pol2], samples[ch][station2][time+1][pol2], samples[ch][station2][time+2][pol2], samples[ch][station2][time+3][pol2], }; sum = spu_madd(s1, s2, sum); // sum = sum + s1 * s2 } result = sum.x + sum.y + sum.z + sum.w; } }
58 Vectorizing the correlator 58 Option 2: vectorize over polarization for (pol1 = 0; pol1 < nrpolarizations; pol1++) { for (pol2 = 0; pol2 < nrpolarizations; pol2++) { float sum = 0.0; for (time = 0; time < integrationtime; time++) { sum += samples[ch][station1][time][pol1] * samples[ch][station2][time][pol2]; } } }
59 Vectorizing the correlator 59 Option 2: vectorize over polarization Remove polarization loops (4 combinations) float sum = 0.0; for (time = 0; time < integrationtime; time++) { sum += samples[ch][station1][time][0] * samples[ch][station2][time][0]; // XX sum += samples[ch][station1][time][0] * samples[ch][station2][time][1]; // XY sum += samples[ch][station1][time][1] * samples[ch][station2][time][0]; // YX sum += samples[ch][station1][time][1] * samples[ch][station2][time][1]; // YY }
60 Vectorizing the correlator 60 vector float sum = {0.0, 0.0, 0.0, 0.0}; for (time = 0; time < integrationtime; time++) { vector float s1 = { samples[ch][station1][time][0], samples[ch][station1][time][0], samples[ch][station1][time][1], samples[ch][station1][time][1], }; vector float s2 = { samples[ch][station2][time][0], samples[ch][station2][time][1], samples[ch][station2][time][0], samples[ch][station2][time][1], }; sum = spu_madd(s1, s2, sum); // sum = sum + s1 * s2 // sum now contains {XX, XY, YX, YY} }

61 Delay Compensation
62 It's all about the memory feature Cell/B.E. GPUs access times uniform non-uniform cache sharing level single thread (SPE) all threads in a multiprocessor access to off-chip memory not possible, only through DMA memory access overlapping asynchronous DMA supported Hardware-managed thread preemption (tens of thousands of threads) communication communication between SPEs through EIB independent thread blocks + shared memory within a block 62
Using Many-Core Hardware to Correlate Radio Astronomy Signals
 Using Many-Core Hardware to Correlate Radio Astronomy Signals Rob V. van Nieuwpoort ASTRON, Netherlands Institute for Radio Astronomy Dwingeloo, The Netherlands nieuwpoort@astron.nl Categories and Subject
Using Many-Core Hardware to Correlate Radio Astronomy Signals Rob V. van Nieuwpoort ASTRON, Netherlands Institute for Radio Astronomy Dwingeloo, The Netherlands nieuwpoort@astron.nl Categories and Subject
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Introduction to GPGPU. Tiziano Diamanti t.diamanti@cineca.it
 t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
Introduction to GP-GPUs. Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1
 Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Ionospheric Research with the LOFAR Telescope
 Ionospheric Research with the LOFAR Telescope Leszek P. Błaszkiewicz Faculty of Mathematics and Computer Science, UWM Olsztyn LOFAR - The LOw Frequency ARray The LOFAR interferometer consist of a large
Ionospheric Research with the LOFAR Telescope Leszek P. Błaszkiewicz Faculty of Mathematics and Computer Science, UWM Olsztyn LOFAR - The LOw Frequency ARray The LOFAR interferometer consist of a large
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR
 LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
Architecture of Hitachi SR-8000
 Architecture of Hitachi SR-8000 University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Most of the slides from Hitachi Slide 2 the problem modern computer are data
Architecture of Hitachi SR-8000 University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Most of the slides from Hitachi Slide 2 the problem modern computer are data
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
GPGPU Computing. Yong Cao
 GPGPU Computing Yong Cao Why Graphics Card? It s powerful! A quiet trend Copyright 2009 by Yong Cao Why Graphics Card? It s powerful! Processor Processing Units FLOPs per Unit Clock Speed Processing Power
GPGPU Computing Yong Cao Why Graphics Card? It s powerful! A quiet trend Copyright 2009 by Yong Cao Why Graphics Card? It s powerful! Processor Processing Units FLOPs per Unit Clock Speed Processing Power
Trends in High-Performance Computing for Power Grid Applications
 Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Hardware-Aware Analysis and. Presentation Date: Sep 15 th 2009 Chrissie C. Cui
 Hardware-Aware Analysis and Optimization of Stable Fluids Presentation Date: Sep 15 th 2009 Chrissie C. Cui Outline Introduction Highlights Flop and Bandwidth Analysis Mehrstellen Schemes Advection Caching
Hardware-Aware Analysis and Optimization of Stable Fluids Presentation Date: Sep 15 th 2009 Chrissie C. Cui Outline Introduction Highlights Flop and Bandwidth Analysis Mehrstellen Schemes Advection Caching
Unleashing the Performance Potential of GPUs for Atmospheric Dynamic Solvers
 Unleashing the Performance Potential of GPUs for Atmospheric Dynamic Solvers Haohuan Fu haohuan@tsinghua.edu.cn High Performance Geo-Computing (HPGC) Group Center for Earth System Science Tsinghua University
Unleashing the Performance Potential of GPUs for Atmospheric Dynamic Solvers Haohuan Fu haohuan@tsinghua.edu.cn High Performance Geo-Computing (HPGC) Group Center for Earth System Science Tsinghua University
Introduction to GPU Architecture
 Introduction to GPU Architecture Ofer Rosenberg, PMTS SW, OpenCL Dev. Team AMD Based on From Shader Code to a Teraflop: How GPU Shader Cores Work, By Kayvon Fatahalian, Stanford University Content 1. Three
Introduction to GPU Architecture Ofer Rosenberg, PMTS SW, OpenCL Dev. Team AMD Based on From Shader Code to a Teraflop: How GPU Shader Cores Work, By Kayvon Fatahalian, Stanford University Content 1. Three
The Evolution of Computer Graphics. SVP, Content & Technology, NVIDIA
 The Evolution of Computer Graphics Tony Tamasi SVP, Content & Technology, NVIDIA Graphics Make great images intricate shapes complex optical effects seamless motion Make them fast invent clever techniques
The Evolution of Computer Graphics Tony Tamasi SVP, Content & Technology, NVIDIA Graphics Make great images intricate shapes complex optical effects seamless motion Make them fast invent clever techniques
 Introduction History Design Blue Gene/Q Job Scheduler Filesystem Power usage Performance Summary Sequoia is a petascale Blue Gene/Q supercomputer Being constructed by IBM for the National Nuclear Security
Introduction History Design Blue Gene/Q Job Scheduler Filesystem Power usage Performance Summary Sequoia is a petascale Blue Gene/Q supercomputer Being constructed by IBM for the National Nuclear Security
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Home Exam 3: Distributed Video Encoding using Dolphin PCI Express Networks. October 20 th 2015
 INF5063: Programming heterogeneous multi-core processors because the OS-course is just to easy! Home Exam 3: Distributed Video Encoding using Dolphin PCI Express Networks October 20 th 2015 Håkon Kvale
INF5063: Programming heterogeneous multi-core processors because the OS-course is just to easy! Home Exam 3: Distributed Video Encoding using Dolphin PCI Express Networks October 20 th 2015 Håkon Kvale
Evaluation of CUDA Fortran for the CFD code Strukti
 Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
L20: GPU Architecture and Models
 L20: GPU Architecture and Models scribe(s): Abdul Khalifa 20.1 Overview GPUs (Graphics Processing Units) are large parallel structure of processing cores capable of rendering graphics efficiently on displays.
L20: GPU Architecture and Models scribe(s): Abdul Khalifa 20.1 Overview GPUs (Graphics Processing Units) are large parallel structure of processing cores capable of rendering graphics efficiently on displays.
Uniboard based digital receiver
 Uniboard based digital receiver G. Comoretto 1, A. Russo 1, G. Knittel 2 1- INAF Osservatorio di Arcetri 2- MPIfR Bonn Plus many others at Jive, Astron, Bordeaux, Bonn Summary Not really VLBI Pulsar timing:
Uniboard based digital receiver G. Comoretto 1, A. Russo 1, G. Knittel 2 1- INAF Osservatorio di Arcetri 2- MPIfR Bonn Plus many others at Jive, Astron, Bordeaux, Bonn Summary Not really VLBI Pulsar timing:
Ray Tracing on Graphics Hardware
 Ray Tracing on Graphics Hardware Toshiya Hachisuka University of California, San Diego Abstract Ray tracing is one of the important elements in photo-realistic image synthesis. Since ray tracing is computationally
Ray Tracing on Graphics Hardware Toshiya Hachisuka University of California, San Diego Abstract Ray tracing is one of the important elements in photo-realistic image synthesis. Since ray tracing is computationally
ultra fast SOM using CUDA
 ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Cell-SWat: Modeling and Scheduling Wavefront Computations on the Cell Broadband Engine
 Cell-SWat: Modeling and Scheduling Wavefront Computations on the Cell Broadband Engine Ashwin Aji, Wu Feng, Filip Blagojevic and Dimitris Nikolopoulos Forecast Efficient mapping of wavefront algorithms
Cell-SWat: Modeling and Scheduling Wavefront Computations on the Cell Broadband Engine Ashwin Aji, Wu Feng, Filip Blagojevic and Dimitris Nikolopoulos Forecast Efficient mapping of wavefront algorithms
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs
 Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Optimizing Code for Accelerators: The Long Road to High Performance
 Optimizing Code for Accelerators: The Long Road to High Performance Hans Vandierendonck Mons GPU Day November 9 th, 2010 The Age of Accelerators 2 Accelerators in Real Life 3 Latency (ps/inst) Why Accelerators?
Optimizing Code for Accelerators: The Long Road to High Performance Hans Vandierendonck Mons GPU Day November 9 th, 2010 The Age of Accelerators 2 Accelerators in Real Life 3 Latency (ps/inst) Why Accelerators?
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
GPU Computing with CUDA Lecture 4 - Optimizations. Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile
 GPU Computing with CUDA Lecture 4 - Optimizations Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 3 Control flow Coalescing Latency hiding
GPU Computing with CUDA Lecture 4 - Optimizations Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 3 Control flow Coalescing Latency hiding
Advancements in Beamformer and Correlator Optical Backplane. Dr. Grant Hampson 11 th January 2013 URSI Boulder
 Advancements in Beamformer and Correlator Optical Backplane Technology Dr. Grant Hampson 11 th January 2013 URSI Boulder CSIROASTRONOMY AND SPACE SCIENCE Australian Square Kilometre Array Pathfinder Sensitive
Advancements in Beamformer and Correlator Optical Backplane Technology Dr. Grant Hampson 11 th January 2013 URSI Boulder CSIROASTRONOMY AND SPACE SCIENCE Australian Square Kilometre Array Pathfinder Sensitive
Computer Graphics Hardware An Overview
 Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
GPU Computing with CUDA Lecture 2 - CUDA Memories. Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile
 GPU Computing with CUDA Lecture 2 - CUDA Memories Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 1 Warp scheduling CUDA Memory hierarchy
GPU Computing with CUDA Lecture 2 - CUDA Memories Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 1 Warp scheduling CUDA Memory hierarchy
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
ST810 Advanced Computing
 ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
Next Generation GPU Architecture Code-named Fermi
 Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
Performance monitoring at CERN openlab. July 20 th 2012 Andrzej Nowak, CERN openlab
 Performance monitoring at CERN openlab July 20 th 2012 Andrzej Nowak, CERN openlab Data flow Reconstruction Selection and reconstruction Online triggering and filtering in detectors Raw Data (100%) Event
Performance monitoring at CERN openlab July 20 th 2012 Andrzej Nowak, CERN openlab Data flow Reconstruction Selection and reconstruction Online triggering and filtering in detectors Raw Data (100%) Event
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU
 Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Lecture 1. Course Introduction
 Lecture 1 Course Introduction Welcome to CSE 262! Your instructor is Scott B. Baden Office hours (week 1) Tues/Thurs 3.30 to 4.30 Room 3244 EBU3B 2010 Scott B. Baden / CSE 262 /Spring 2011 2 Content Our
Lecture 1 Course Introduction Welcome to CSE 262! Your instructor is Scott B. Baden Office hours (week 1) Tues/Thurs 3.30 to 4.30 Room 3244 EBU3B 2010 Scott B. Baden / CSE 262 /Spring 2011 2 Content Our
High Performance. CAEA elearning Series. Jonathan G. Dudley, Ph.D. 06/09/2015. 2015 CAE Associates
 High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
Implementation of Canny Edge Detector of color images on CELL/B.E. Architecture.
 Implementation of Canny Edge Detector of color images on CELL/B.E. Architecture. Chirag Gupta,Sumod Mohan K cgupta@clemson.edu, sumodm@clemson.edu Abstract In this project we propose a method to improve
Implementation of Canny Edge Detector of color images on CELL/B.E. Architecture. Chirag Gupta,Sumod Mohan K cgupta@clemson.edu, sumodm@clemson.edu Abstract In this project we propose a method to improve
Data Parallel Computing on Graphics Hardware. Ian Buck Stanford University
 Data Parallel Computing on Graphics Hardware Ian Buck Stanford University Brook General purpose Streaming language DARPA Polymorphous Computing Architectures Stanford - Smart Memories UT Austin - TRIPS
Data Parallel Computing on Graphics Hardware Ian Buck Stanford University Brook General purpose Streaming language DARPA Polymorphous Computing Architectures Stanford - Smart Memories UT Austin - TRIPS
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1)
") COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1) Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1) Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
YALES2 porting on the Xeon- Phi Early results
 YALES2 porting on the Xeon- Phi Early results Othman Bouizi Ghislain Lartigue Innovation and Pathfinding Architecture Group in Europe, Exascale Lab. Paris CRIHAN - Demi-journée calcul intensif, 16 juin
YALES2 porting on the Xeon- Phi Early results Othman Bouizi Ghislain Lartigue Innovation and Pathfinding Architecture Group in Europe, Exascale Lab. Paris CRIHAN - Demi-journée calcul intensif, 16 juin
Radeon GPU Architecture and the Radeon 4800 series. Michael Doggett Graphics Architecture Group June 27, 2008
 Radeon GPU Architecture and the series Michael Doggett Graphics Architecture Group June 27, 2008 Graphics Processing Units Introduction GPU research 2 GPU Evolution GPU started as a triangle rasterizer
Radeon GPU Architecture and the series Michael Doggett Graphics Architecture Group June 27, 2008 Graphics Processing Units Introduction GPU research 2 GPU Evolution GPU started as a triangle rasterizer
SPARC64 VIIIfx: CPU for the K computer
 SPARC64 VIIIfx: CPU for the K computer Toshio Yoshida Mikio Hondo Ryuji Kan Go Sugizaki SPARC64 VIIIfx, which was developed as a processor for the K computer, uses Fujitsu Semiconductor Ltd. s 45-nm CMOS
SPARC64 VIIIfx: CPU for the K computer Toshio Yoshida Mikio Hondo Ryuji Kan Go Sugizaki SPARC64 VIIIfx, which was developed as a processor for the K computer, uses Fujitsu Semiconductor Ltd. s 45-nm CMOS
Energy efficient computing on Embedded and Mobile devices. Nikola Rajovic, Nikola Puzovic, Lluis Vilanova, Carlos Villavieja, Alex Ramirez
 Energy efficient computing on Embedded and Mobile devices Nikola Rajovic, Nikola Puzovic, Lluis Vilanova, Carlos Villavieja, Alex Ramirez A brief look at the (outdated) Top500 list Most systems are built
Energy efficient computing on Embedded and Mobile devices Nikola Rajovic, Nikola Puzovic, Lluis Vilanova, Carlos Villavieja, Alex Ramirez A brief look at the (outdated) Top500 list Most systems are built
FPGA-based Multithreading for In-Memory Hash Joins
 FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
High-Performance Modular Multiplication on the Cell Processor
 High-Performance Modular Multiplication on the Cell Processor Joppe W. Bos Laboratory for Cryptologic Algorithms EPFL, Lausanne, Switzerland joppe.bos@epfl.ch 1 / 19 Outline Motivation and previous work
High-Performance Modular Multiplication on the Cell Processor Joppe W. Bos Laboratory for Cryptologic Algorithms EPFL, Lausanne, Switzerland joppe.bos@epfl.ch 1 / 19 Outline Motivation and previous work
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS
 AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS") A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
Mixing Multi-Core CPUs and GPUs for Scientific Simulation Software
 SUBMITTED TO IEEE TRANS. ON PARALLEL AND DISTRIBUTED SYSTEMS 1 Mixing Multi-Core CPUs and GPUs for Scientific Simulation Software K.A. Hawick, Member, IEEE, A. Leist, and D.P. Playne Abstract Recent technological
SUBMITTED TO IEEE TRANS. ON PARALLEL AND DISTRIBUTED SYSTEMS 1 Mixing Multi-Core CPUs and GPUs for Scientific Simulation Software K.A. Hawick, Member, IEEE, A. Leist, and D.P. Playne Abstract Recent technological
SPEEDUP - optimization and porting of path integral MC Code to new computing architectures
 SPEEDUP - optimization and porting of path integral MC Code to new computing architectures V. Slavnić, A. Balaž, D. Stojiljković, A. Belić, A. Bogojević Scientific Computing Laboratory, Institute of Physics
SPEEDUP - optimization and porting of path integral MC Code to new computing architectures V. Slavnić, A. Balaž, D. Stojiljković, A. Belić, A. Bogojević Scientific Computing Laboratory, Institute of Physics
Design and Optimization of OpenFOAM-based CFD Applications for Hybrid and Heterogeneous HPC Platforms
 Design and Optimization of OpenFOAM-based CFD Applications for Hybrid and Heterogeneous HPC Platforms Amani AlOnazi, David E. Keyes, Alexey Lastovetsky, Vladimir Rychkov Extreme Computing Research Center,
Design and Optimization of OpenFOAM-based CFD Applications for Hybrid and Heterogeneous HPC Platforms Amani AlOnazi, David E. Keyes, Alexey Lastovetsky, Vladimir Rychkov Extreme Computing Research Center,
Systems and Networks for Astronomy. Marco de Vos ASTRON Director of R&D (devos@astron.nl)
") Systems and Networks for Astronomy Marco de Vos ASTRON Director of R&D (devos@astron.nl) ASTRON NWO Knowledge Institute for Astronomical Instrumentation Our mission: Making astronomical discoveries happen,
Systems and Networks for Astronomy Marco de Vos ASTRON Director of R&D (devos@astron.nl) ASTRON NWO Knowledge Institute for Astronomical Instrumentation Our mission: Making astronomical discoveries happen,
QCD as a Video Game?
 QCD as a Video Game? Sándor D. Katz Eötvös University Budapest in collaboration with Győző Egri, Zoltán Fodor, Christian Hoelbling Dániel Nógrádi, Kálmán Szabó Outline 1. Introduction 2. GPU architecture
QCD as a Video Game? Sándor D. Katz Eötvös University Budapest in collaboration with Győző Egri, Zoltán Fodor, Christian Hoelbling Dániel Nógrádi, Kálmán Szabó Outline 1. Introduction 2. GPU architecture
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Parallel Computing with MATLAB
 Parallel Computing with MATLAB Scott Benway Senior Account Manager Jiro Doke, Ph.D. Senior Application Engineer 2013 The MathWorks, Inc. 1 Acceleration Strategies Applied in MATLAB Approach Options Best
Parallel Computing with MATLAB Scott Benway Senior Account Manager Jiro Doke, Ph.D. Senior Application Engineer 2013 The MathWorks, Inc. 1 Acceleration Strategies Applied in MATLAB Approach Options Best
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC
 OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Router Architectures
 Router Architectures An overview of router architectures. Introduction What is a Packet Switch? Basic Architectural Components Some Example Packet Switches The Evolution of IP Routers 2 1 Router Components
Router Architectures An overview of router architectures. Introduction What is a Packet Switch? Basic Architectural Components Some Example Packet Switches The Evolution of IP Routers 2 1 Router Components
GPU File System Encryption Kartik Kulkarni and Eugene Linkov
 GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
GPU Architectures. A CPU Perspective. Data Parallelism: What is it, and how to exploit it? Workload characteristics
 GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
Real-time Process Network Sonar Beamformer
 Real-time Process Network Sonar Gregory E. Allen Applied Research Laboratories gallen@arlut.utexas.edu Brian L. Evans Dept. Electrical and Computer Engineering bevans@ece.utexas.edu The University of Texas
Real-time Process Network Sonar Gregory E. Allen Applied Research Laboratories gallen@arlut.utexas.edu Brian L. Evans Dept. Electrical and Computer Engineering bevans@ece.utexas.edu The University of Texas
By studying the Big Questions of Physics Donkere Energie / Donkere Massa We face Major Challenges of Technology! Antennas. Chips.
 Netherlands Institute for Radio Astronomy Credits: Albert-Jan Boonstra, Program manager ASTRON- project ASTRON is part of the Netherlands Organisation for Scientific Research (NWO) 1 Origins By studying
Netherlands Institute for Radio Astronomy Credits: Albert-Jan Boonstra, Program manager ASTRON- project ASTRON is part of the Netherlands Organisation for Scientific Research (NWO) 1 Origins By studying
Main Memory Data Warehouses
 Main Memory Data Warehouses Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Lecture outline Teradata Data Warehouse
Main Memory Data Warehouses Robert Wrembel Poznan University of Technology Institute of Computing Science Robert.Wrembel@cs.put.poznan.pl www.cs.put.poznan.pl/rwrembel Lecture outline Teradata Data Warehouse
Binary search tree with SIMD bandwidth optimization using SSE
 Binary search tree with SIMD bandwidth optimization using SSE Bowen Zhang, Xinwei Li 1.ABSTRACT In-memory tree structured index search is a fundamental database operation. Modern processors provide tremendous
Binary search tree with SIMD bandwidth optimization using SSE Bowen Zhang, Xinwei Li 1.ABSTRACT In-memory tree structured index search is a fundamental database operation. Modern processors provide tremendous
September 25, 2007. Maya Gokhale Georgia Institute of Technology
 NAND Flash Storage for High Performance Computing Craig Ulmer cdulmer@sandia.gov September 25, 2007 Craig Ulmer Maya Gokhale Greg Diamos Michael Rewak SNL/CA, LLNL Georgia Institute of Technology University
NAND Flash Storage for High Performance Computing Craig Ulmer cdulmer@sandia.gov September 25, 2007 Craig Ulmer Maya Gokhale Greg Diamos Michael Rewak SNL/CA, LLNL Georgia Institute of Technology University
HPC and Big Data. EPCC The University of Edinburgh. Adrian Jackson Technical Architect a.jackson@epcc.ed.ac.uk
 HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect a.jackson@epcc.ed.ac.uk EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect a.jackson@epcc.ed.ac.uk EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
AUDIO ON THE GPU: REAL-TIME TIME DOMAIN CONVOLUTION ON GRAPHICS CARDS. A Thesis by ANDREW KEITH LACHANCE May 2011
 AUDIO ON THE GPU: REAL-TIME TIME DOMAIN CONVOLUTION ON GRAPHICS CARDS A Thesis by ANDREW KEITH LACHANCE May 2011 Submitted to the Graduate School Appalachian State University in partial fulfillment of
AUDIO ON THE GPU: REAL-TIME TIME DOMAIN CONVOLUTION ON GRAPHICS CARDS A Thesis by ANDREW KEITH LACHANCE May 2011 Submitted to the Graduate School Appalachian State University in partial fulfillment of
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age
 Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
GPU Architecture. Michael Doggett ATI
 GPU Architecture Michael Doggett ATI GPU Architecture RADEON X1800/X1900 Microsoft s XBOX360 Xenos GPU GPU research areas ATI - Driving the Visual Experience Everywhere Products from cell phones to super
GPU Architecture Michael Doggett ATI GPU Architecture RADEON X1800/X1900 Microsoft s XBOX360 Xenos GPU GPU research areas ATI - Driving the Visual Experience Everywhere Products from cell phones to super
Introduction to GPU Computing
 Matthis Hauschild Universität Hamburg Fakultät für Mathematik, Informatik und Naturwissenschaften Technische Aspekte Multimodaler Systeme December 4, 2014 M. Hauschild - 1 Table of Contents 1. Architecture
Matthis Hauschild Universität Hamburg Fakultät für Mathematik, Informatik und Naturwissenschaften Technische Aspekte Multimodaler Systeme December 4, 2014 M. Hauschild - 1 Table of Contents 1. Architecture
Design Patterns for Packet Processing Applications on Multi-core Intel Architecture Processors
 White Paper Cristian F. Dumitrescu Software Engineer Intel Corporation Design Patterns for Packet Processing Applications on Multi-core Intel Architecture Processors December 2008 321058 Executive Summary
White Paper Cristian F. Dumitrescu Software Engineer Intel Corporation Design Patterns for Packet Processing Applications on Multi-core Intel Architecture Processors December 2008 321058 Executive Summary
Lecture 1: the anatomy of a supercomputer
 Where a calculator on the ENIAC is equipped with 18,000 vacuum tubes and weighs 30 tons, computers of the future may have only 1,000 vacuum tubes and perhaps weigh 1½ tons. Popular Mechanics, March 1949
Where a calculator on the ENIAC is equipped with 18,000 vacuum tubes and weighs 30 tons, computers of the future may have only 1,000 vacuum tubes and perhaps weigh 1½ tons. Popular Mechanics, March 1949
IBM CELL CELL INTRODUCTION. Project made by: Origgi Alessandro matr. 682197 Teruzzi Roberto matr. 682552 IBM CELL. Politecnico di Milano Como Campus
 Project made by: Origgi Alessandro matr. 682197 Teruzzi Roberto matr. 682552 CELL INTRODUCTION 2 1 CELL SYNERGY Cell is not a collection of different processors, but a synergistic whole Operation paradigms,
Project made by: Origgi Alessandro matr. 682197 Teruzzi Roberto matr. 682552 CELL INTRODUCTION 2 1 CELL SYNERGY Cell is not a collection of different processors, but a synergistic whole Operation paradigms,
This Unit: Putting It All Together. CIS 501 Computer Architecture. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
NVIDIA GeForce GTX 580 GPU Datasheet
 NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
Clustering Billions of Data Points Using GPUs
 Clustering Billions of Data Points Using GPUs Ren Wu ren.wu@hp.com Bin Zhang bin.zhang2@hp.com Meichun Hsu meichun.hsu@hp.com ABSTRACT In this paper, we report our research on using GPUs to accelerate
Clustering Billions of Data Points Using GPUs Ren Wu ren.wu@hp.com Bin Zhang bin.zhang2@hp.com Meichun Hsu meichun.hsu@hp.com ABSTRACT In this paper, we report our research on using GPUs to accelerate
Building a Top500-class Supercomputing Cluster at LNS-BUAP
 Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
 WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
Acceleration of Spiking Neural Networks in Emerging Multi-core and GPU Architectures
 Acceleration of Spiking Neural Networks in Emerging Multi-core and GPU Architectures Mohammad A. Bhuiyan, Vivek K. Pallipuram and Melissa C. Smith Department of Electrical and Computer Engineering, Clemson
Acceleration of Spiking Neural Networks in Emerging Multi-core and GPU Architectures Mohammad A. Bhuiyan, Vivek K. Pallipuram and Melissa C. Smith Department of Electrical and Computer Engineering, Clemson
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging
 Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
E6895 Advanced Big Data Analytics Lecture 14:! NVIDIA GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
Stream Processing on GPUs Using Distributed Multimedia Middleware
 Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Reduced Precision Hardware for Ray Tracing. Sean Keely University of Texas, Austin
 Reduced Precision Hardware for Ray Tracing Sean Keely University of Texas, Austin Question Why don t GPU s accelerate ray tracing? Real time ray tracing needs very high ray rate Example Scene: 3 area lights
Reduced Precision Hardware for Ray Tracing Sean Keely University of Texas, Austin Question Why don t GPU s accelerate ray tracing? Real time ray tracing needs very high ray rate Example Scene: 3 area lights
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
The Orca Chip... Heart of IBM s RISC System/6000 Value Servers
 The Orca Chip... Heart of IBM s RISC System/6000 Value Servers Ravi Arimilli IBM RISC System/6000 Division 1 Agenda. Server Background. Cache Heirarchy Performance Study. RS/6000 Value Server System Structure.
The Orca Chip... Heart of IBM s RISC System/6000 Value Servers Ravi Arimilli IBM RISC System/6000 Division 1 Agenda. Server Background. Cache Heirarchy Performance Study. RS/6000 Value Server System Structure.
GPU Hardware Performance. Fall 2015
 Fall 2015 Atomic operations performs read-modify-write operations on shared or global memory no interference with other threads for 32-bit and 64-bit integers (c. c. 1.2), float addition (c. c. 2.0) using
Fall 2015 Atomic operations performs read-modify-write operations on shared or global memory no interference with other threads for 32-bit and 64-bit integers (c. c. 1.2), float addition (c. c. 2.0) using
Big Data Visualization on the MIC
 Big Data Visualization on the MIC Tim Dykes School of Creative Technologies University of Portsmouth timothy.dykes@port.ac.uk Many-Core Seminar Series 26/02/14 Splotch Team Tim Dykes, University of Portsmouth
Big Data Visualization on the MIC Tim Dykes School of Creative Technologies University of Portsmouth timothy.dykes@port.ac.uk Many-Core Seminar Series 26/02/14 Splotch Team Tim Dykes, University of Portsmouth
Fast Implementations of AES on Various Platforms
 Fast Implementations of AES on Various Platforms Joppe W. Bos 1 Dag Arne Osvik 1 Deian Stefan 2 1 EPFL IC IIF LACAL, Station 14, CH-1015 Lausanne, Switzerland {joppe.bos, dagarne.osvik}@epfl.ch 2 Dept.
Fast Implementations of AES on Various Platforms Joppe W. Bos 1 Dag Arne Osvik 1 Deian Stefan 2 1 EPFL IC IIF LACAL, Station 14, CH-1015 Lausanne, Switzerland {joppe.bos, dagarne.osvik}@epfl.ch 2 Dept.
Radeon HD 2900 and Geometry Generation. Michael Doggett
 Radeon HD 2900 and Geometry Generation Michael Doggett September 11, 2007 Overview Introduction to 3D Graphics Radeon 2900 Starting Point Requirements Top level Pipeline Blocks from top to bottom Command
Radeon HD 2900 and Geometry Generation Michael Doggett September 11, 2007 Overview Introduction to 3D Graphics Radeon 2900 Starting Point Requirements Top level Pipeline Blocks from top to bottom Command
Interactive Level-Set Deformation On the GPU
 Interactive Level-Set Deformation On the GPU Institute for Data Analysis and Visualization University of California, Davis Problem Statement Goal Interactive system for deformable surface manipulation
Interactive Level-Set Deformation On the GPU Institute for Data Analysis and Visualization University of California, Davis Problem Statement Goal Interactive system for deformable surface manipulation
Embedded Systems: map to FPGA, GPU, CPU?
 Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
MIDeA: A Multi-Parallel Intrusion Detection Architecture
 MIDeA: A Multi-Parallel Intrusion Detection Architecture Giorgos Vasiliadis, FORTH-ICS, Greece Michalis Polychronakis, Columbia U., USA Sotiris Ioannidis, FORTH-ICS, Greece CCS 2011, 19 October 2011 Network
MIDeA: A Multi-Parallel Intrusion Detection Architecture Giorgos Vasiliadis, FORTH-ICS, Greece Michalis Polychronakis, Columbia U., USA Sotiris Ioannidis, FORTH-ICS, Greece CCS 2011, 19 October 2011 Network
A New, High-Performance, Low-Power, Floating-Point Embedded Processor for Scientific Computing and DSP Applications
 1 A New, High-Performance, Low-Power, Floating-Point Embedded Processor for Scientific Computing and DSP Applications Simon McIntosh-Smith Director of Architecture 2 Multi-Threaded Array Processing Architecture
1 A New, High-Performance, Low-Power, Floating-Point Embedded Processor for Scientific Computing and DSP Applications Simon McIntosh-Smith Director of Architecture 2 Multi-Threaded Array Processing Architecture