Parallel Computing and OpenMP Tutorial
|
|
|
- Asher Booker
- 7 years ago
- Views:
Transcription
1 Parallel Computing and OpenMP Tutorial Shao-Ching Huang IDRE High Performance Computing Workshop
2 Overview Part I: Parallel Computing Basic Concepts Memory models Data parallelism Part II: OpenMP Tutorial Important features Examples & programming tips 2
3 Part I : Basic Concepts
4 Why Parallel Computing? Bigger data High-res simulation Single machine too small to hold/process all data Utilize all resources to solve one problem All new computers are parallel computers Multi-core phones, laptops, desktops Multi-node clusters, supercomputers 4
5 Memory models Parallel computing is about data processing. In practice, memory models determine how we write parallel programs. Two types: Shared memory model Distributed memory model
6 Shared Memory All CPUs have access to the (shared) memory (e.g. Your laptop/desktop computer) 6
7 Distributed Memory Each CPU has its own (local) memory, invisible to other CPUs High speed networking (e.g. Infiniband) for good performance 7
8 Hybrid Model Shared-memory style within a node Distributed-memory style across nodes For example, this is one node of Hoffman2 cluster 8
9 Parallel Scalability Strong scaling fixed the global problem size local size decreases as N is increased ideal case: T*N=const (linear decay) Weak scaling fixed the local problem size (per processor) global size increases as N increases ideal case: T=const. T T Real code ideal N Real code ideal T(N) = wall clock run time N = number of processors N 9
10 Identify Data Parallelism some typical examples High-throughput calculations Many independent jobs Mesh-based problems Structured or unstructured mesh Mesh viewed as a graph partition the graph For structured mesh one can simply partition along coord. axes Particle-based problems Short-range interaction Group particles in cells partition the cells Long-range interaction Parallel fast multipole method partition the tree 10
11 Portal parallel programming OpenMP example OpenMP Compiler support Works on ONE multi-core computer Compile (with openmp support): $ ifort openmp foo.f90 Run with 8 threads : $ export OMP_NUM_THREADS=8 $./a.out Typically you will see CPU utilization over 100% (because the program is utilizing multiple CPUs) 11
12 Portal parallel programming MPI example Works on any computers Compile with MPI compiler wrapper: $ mpicc foo.c Run on 32 CPUs across 4 physical computers: $ mpirun n 32 machinefile mach./foo 'mach' is a file listing the computers the program will run on, e.g. n25 slots=8 n32 slots=8 n48 slots=8 n50 slots=8 The exact format of machine file may vary slightly in each MPI implementation. More on this in MPI class... 12
13 Part II : OpenMP Tutorial (thread programming) 14
14 What is OpenMP? API for shared-memory parallel programming compiler directives + functions Supported by mainstream compilers portable code Fortran 77/9x/20xx C and C++ Has a long history, standard defined by a consortium Version 1.0, released in 1997 Version 2.5, released in 2005 Version 3.0, released in 2008 Version 3.1, released in
15 Elements of Shared-memory Programming Fork/join threads Synchronization barrier mutual exclusive (mutex) Assign/distribute work to threads work share task queue Run time control query/request available resources interaction with OS, compiler, etc. 16
16 OpenMP Execution Model We get speedup by running multiple threads simultaneously. Source: wikipedia.org
17 saxpy operation (C) Sequential code const int n = 10000; float x[n], y[n], a; int i; for (i=0; i<n; i++) y[i] = a * x[i] + y[i]; OpenMP code const int n = 10000; float x[n], y[n], a; int i; #pragma omp parallel for for (i=0; i<n; i++) y[i] = a * x[i] + y[i]; gcc saxpy.c gcc saxpy.c -fopenmp Enable OpenMP support 18
18 19 saxpy operation (Fortran) Sequential Code integer, paramter :: n=10000 real :: x(n), y(n), a Integer :: i do i=1,n y(i) = a*x(i) + y(i) end do OpenMP code integer, paramter :: n=10000 real :: x(n), y(n), a integer :: i!$omp parallel do do i=1,n y(i) = a*x(i) + y(i) end do gfortran saxpy.f90 gfortran saxpy.f90 -fopenmp Enable OpenMP support
19 Private vs. shared threads' point of view Loop index i is private each thread maintains its own i value and range private variable i becomes undefined after parallel for Everything else is shared all threads update y, but at different memory locations a,n,x are read-only (ok to share) const int n = 10000; float x[n], y[n], a = 0.5; int i; #pragma omp parallel for for (i=0; i<n; i++) y[i] = a * x[i] + y[i];
20 Nested loop outer loop is parallelized #pragma omp parallel for for (j=0; j<n; j++) for (i=0; i<n; i++) // do some work here // i-loop // j-loop!$omp parallel do do j=1,n do i=1,n! do some work here end do end do By default, only j (the outer loop) is private But we want both i and j to be private, i.e. Solution (overriding the OpenMP default): #pragma omp parallel for private(i)!$omp parallel do private(i) j is already private by default 21
21 OpenMP General Syntax Header file #include <omp.h> Parallel region: Clauses specifies the precise behavior of the parallel region C/C++ #pragma omp construct_name [clauses ] // do some work here // end of parallel region/block Fortran!$omp construct_name [clauses ]! do some work here!$omp end construct_name Environment variables and functions (discussed later) 23
22 Parallel Region To fork a team of N threads, numbered 0,1,..,N-1 Probably the most important construct in OpenMP Implicit barrier C/C++ //sequential code here (master thread) #pragma omp parallel [clauses] // parallel computing here // // sequential code here (master thread) Fortran!sequential code here (master thread)!$omp parallel [clauses]! parallel computing here!!$omp end parallel! sequential code here (master thread) 24
23 Clauses for Parallel Construct C/C++ Fortran #pragma omp parallel clauses, clauses,!$omp parallel clauses, clauses, Some commonly-used clauses: shared nowait if reduction copyin private firstprivate num_threads default 25
24 Clause Private The values of private data are undefined upon entry to and exit from the specific construct To ensure the last value is accessible after the construct, consider using lastprivate To pre-initialize private variables with values available prior to the region, consider using firstprivate Loop iteration variable is private by default 26
25 Clause Shared Shared among the team of threads executing the region Each thread can read or modify shared variables Data corruption is possible when multiple threads attempt to update the same memory location Data race condition Memory store operation not necessarily atomic Code correctness is user s responsibility 27
26 nowait C/C++ #pragma omp for nowait // for loop here #pragma omp for nowait... Fortran!$omp do! do-loop here!$omp end do nowait!$omp do! some other code In a big parallel region This is useful inside a big parallel region allows threads that finish earlier to proceed without waiting More flexibility for scheduling threads (i.e. less synchronization may improve performance) 28
27 If clause if (integer expression) determine if the region should run in parallel useful option when data is too small (or too large) Example C/C++ #pragma omp parallel if (n>100) // some stuff Fortran!$omp parallel if (n>100) // some stuff!$omp end parallel 29
28 Work Sharing We have not yet discussed how work is distributed among threads... Without specifying how to share work, all threads will redundantly execute all the work (i.e. no speedup!) The choice of work-share method is important for performance OpenMP work-sharing constructs loop ( for in C/C++; do in Fortran) sections single 33
29 Loop Construct (work sharing) Clauses: private firstprivate lastprivate reduction ordered schedule nowait #pragma omp parallel shared(n,a,b) private(i) #pragma omp for for (i=0; i<n; i++) a[i]=i; #pragma omp for for (i=0; i<n; i++) b[i] = 2 * a[i];!$omp parallel shared(n,a,b) private(i)!$omp do do i=1,n a(i)=i end do!$omp end do... 34
30 Parallel Loop (C/C++) Style 1 Style 2 #pragma omp parallel // #pragma omp for for (i=0; i<n; i++) // end of for // end of parallel #pragma omp parallel for for (i=0; i<n; i++) // end of for 35
31 Parallel Loop (Fortran) Style 1 Style 2 $!omp parallel!... $!omp do do i=1,n... end do $!omp end do $!omp end parallel $!omp parallel do do i=1,n... end do $!omp end parallel do 36
32 Loop Scheduling #pragma omp parallel for for (i=0; i<1000; i++) foo(i); How is the loop divided into separate threads? Scheduling types: static: each thread is assigned a fixed-size chunk (default) dynamic: work is assigned as a thread request it guided: big chunks first and smaller and smaller chunks later runtime: use environment variable to control scheduling 37
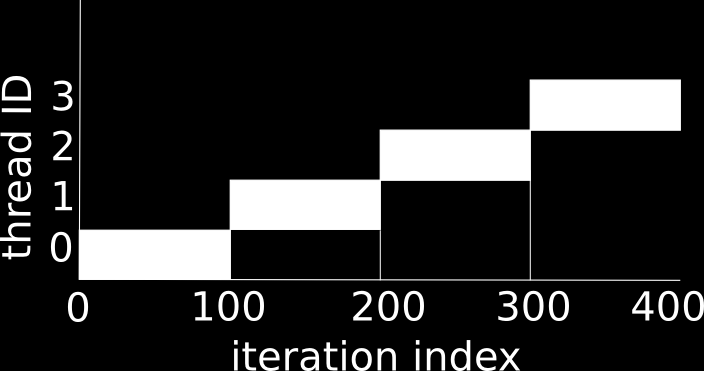
33 Static scheduling

34 Dynamic scheduling
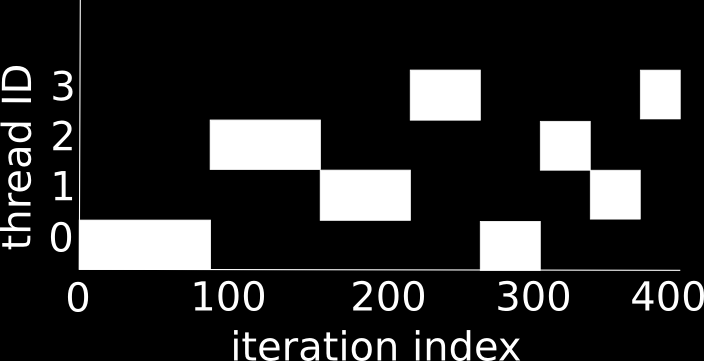
35 Guided scheduling
36 Loop Schedule Example #pragma omp parallel for schedule(dynamic,5) \ shared(n) private(i,j) for (i=0; i<n; i++) for (j=0; j<i; j++) foo(i,j); // j-loop // i-loop // end of parallel for dynamic is useful when the amount of work in foo(i,j) depends on i and j. 41
37 Sections One thread executes one section If too many sections, some threads execute more than one section (round-robin) If too few sections, some threads are idle We don t know in advance which thread will execute which section Each section is executed exactly once C/C++ #pragma omp sections #pragma omp section foo(); #pragma omp section bar(); #pragma omp section beer(); // end of sections Fortran $!omp sections $!omp section call foo() $!omp end section $!omp section call bar $!omp end section $!omp end sections 42
38 Single A single block is executed by one thread Useful for initializing shared variables We don t know exactly which thread will execute the block Only one thread executes the single region; others bypass it. C/C++ #pragma omp single a = 10; #pragma omp for for (i=0; i<n; i++) b[i] = a; Fortran $!omp single a = 10; $!omp end single $!omp parallel do do i=1,n b(i) = a end do $!omp end parallel do 43
39 Computing the Sum We want to compute the sum of a[0] and a[n-1]: C/C++ sum = 0; for (i=0; i<n; i++) sum += a[i]; Fortran sum = 0; do i=1,n sum = sum + a(i) end do A naive OpenMP implementation (incorrect): C/C++ sum = 0; #pragma omp parallel for for (i=0; i<n; i++) sum += a[i]; Race condition! Fortran sum = 0; $!omp parallel do do i=1,n sum = sum + a(i) end do $!omp end parallel do 44
40 Critical C/C++ #pragma omp critical //...some stuff Fortran $!omp critical!...some stuff $!omp end critical One thread at a time ALL threads will execute the region eventually Note the difference between single and critical Mutual exclusive 45
41 Computing the sum The correct OpenMP-way: sum = 0; #pragma omp parallel shared(n,a,sum) private(sum_local) sum_local = 0; #pragma omp for for (i=0; i<n; i++) sum_local += a[i]; // form per-thread local sum #pragma omp critical sum += sum_local; // form global sum 46
42 Reduction operation sum example from previous slide: sum = 0; #pragma omp parallel \ shared(...) private(...) sum_local = 0; #pragma omp for for (i=0; i<n; i++) sum_local += a[i]; #pragma omp critical sum += sum_local; A cleaner solution: sum = 0; #pragma omp parallel for \ shared(...) private(...) \ reduction(+:sum) for (i=0; i<n; i++) sum += a[i]; Reduction operations of +,*,-,&, ^, &&, are supported. 47
43 48 Barrier int x = 2; #pragma omp parallel shared(x) int tid = omp_get_thread_num(); if (tid == 0) x = 5; else printf("[1] thread %2d: x = %d\n",tid,x); #pragma omp barrier printf("[2] thread %2d: x = %d\n",tid,x); some threads may still have x=2 here cache flush + thread synchronization all threads have x=5 here
44 Resource Query Functions Max number of threads omp_get_max_threads() Number of processors omp_get_num_procs() Number of threads (inside a parallel region) omp_get_num_threads() Get thread ID omp_get_thread_num() See OpenMP specification for more functions. 49
45 Query function example: #include <omp.h> int main() float *array = new float[10000]; foo(array,10000); void bar(float *x, int istart, int ipts) for (int i=0; i<ipts; i++) x[istart+i] = ; void foo(float *x, int npts) int tid,ntids,ipts,istart; #pragma omp parallel private(tid,ntids,ipts,istart) tid = omp_get_thread_num(); // thread ID ntids = omp_get_num_threads(); // total number of threads ipts = npts / ntids; istart = tid * ipts; if (tid == ntids-1) ipts = npts - istart; bar(x,istart,ipts); // each thread calls bar 50
46 Control the Number of Threads Parallel region #pragma omp parallel num_threads(integer) Run-time function omp_set_num_threads() Environment variable export OMP_NUM_THREADS=n higher priority High-priority ones override low-priority ones. 51
47 Which OpenMP version do I have? GNU compiler on my desktop: $ g++ --version g++ (Ubuntu/Linaro ubuntu5) $ g++ version.cpp fopenmp $ a.out version : Intel compiler on Hoffman2: $ icpc --version icpc (ICC) #include <iostream> using namespace std; int main() cout << "version : " << _OPENMP << endl; $ icpc version.cpp -openmp $ a.out version : Version Date 3.0 May May March
48 OpenMP Environment Variables OMP_SCHEDULE Loop scheduling policy OMP_NUM_THREADS number of threads OMP_STACKSIZE See OpenMP specification for many others. 53
49 Parallel Region in Subroutines Main program is sequential subroutines/functions are parallelized int main() foo(); void foo() #pragma omp parallel // some fancy stuff here 54
50 Parallel Region in main Program Main program is sequential subroutines/functions are parallelized void main() #pragma omp parallel i = some_index; foo(i); void foo(int i) // sequential code 55
51 Nested Parallel Regions Need available hardware resources (e.g. CPUs) to gain performance void main() #pragma omp parallel i = some_index; foo(i); void foo() #pragma omp parallel // some fancy stuff here Each thread from main fork a team of threads. 56
52 Conditional Compilation Check _OPENMP to see if OpenMP is supported by the compiler #include <omp.h> #include <iostream> using namespace std; int main() #ifdef _OPENMP cout << "Have OpenMP support\n"; #else cout << "No OpenMP support\n"; #endif return 0; $ g++ check_openmp.cpp -fopenmp $ a.out Have OpenMP support $ g++ check_openmp.cpp $ a.out No OpenMP support 57
53 Single Source Code Use _OPENMP to separate sequential and parallel code within the same source file Redefine runtime library functions to avoid linking errors #ifdef _OPENMP #include <omp.h> #else #define omp_get_max_threads() 1 #define omp_get_thread_num() 0 #endif To simulate a single-thread run 58
54 Good Things about OpenMP Simplicity In many cases, the right way to do it is clean and simple Incremental parallelization possible Can incrementally parallelize a sequential code, one block at a time Great for debugging & validation Leave thread management to the compiler It is directly supported by the compiler No need to install additional libraries (unlike MPI) 59
55 Other things about OpenMP Data race condition can be hard to detect/debug The code may run correctly with a small number of threads! True for all thread programming, not only OpenMP Some tools may help It may take some work to get parallel performance right In some cases, the performance is limited by memory bandwidth (i.e. a hardware issue) 60
56 Other types of parallel programming MPI works on both shared- and distributed memory systems relatively low level (i.e. lots of details) in the form of a library PGAS languages Partitioned Global Address Space native compiler support for parallelization UPC, Co-array Fortran and several others 61
57 Summary Identify compute-intensive, data parallel parts of your code Use OpenMP constructs to parallelize your code Spawn threads (parallel regions) In parallel regions, distinguish shared variables from the private ones Assign work to individual threads loop, schedule, etc. Watch out variable initialization before/after parallel region Single thread required? (single/critical) Experiment and improve performance 62
58 Thank you. 63
Parallel Computing. Shared memory parallel programming with OpenMP
 Parallel Computing Shared memory parallel programming with OpenMP Thorsten Grahs, 27.04.2015 Table of contents Introduction Directives Scope of data Synchronization 27.04.2015 Thorsten Grahs Parallel Computing
Parallel Computing Shared memory parallel programming with OpenMP Thorsten Grahs, 27.04.2015 Table of contents Introduction Directives Scope of data Synchronization 27.04.2015 Thorsten Grahs Parallel Computing
Parallel Computing. Parallel shared memory computing with OpenMP
 Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
OpenMP & MPI CISC 879. Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware
 OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
To copy all examples and exercises to your local scratch directory type: /g/public/training/openmp/setup.sh
 OpenMP by Example To copy all examples and exercises to your local scratch directory type: /g/public/training/openmp/setup.sh To build one of the examples, type make (where is the
OpenMP by Example To copy all examples and exercises to your local scratch directory type: /g/public/training/openmp/setup.sh To build one of the examples, type make (where is the
#pragma omp critical x = x + 1; !$OMP CRITICAL X = X + 1!$OMP END CRITICAL. (Very inefficiant) example using critical instead of reduction:
 example using critical instead of reduction:") omp critical The code inside a CRITICAL region is executed by only one thread at a time. The order is not specified. This means that if a thread is currently executing inside a CRITICAL region and another
omp critical The code inside a CRITICAL region is executed by only one thread at a time. The order is not specified. This means that if a thread is currently executing inside a CRITICAL region and another
High Performance Computing
 High Performance Computing Oliver Rheinbach oliver.rheinbach@math.tu-freiberg.de http://www.mathe.tu-freiberg.de/nmo/ Vorlesung Introduction to High Performance Computing Hörergruppen Woche Tag Zeit Raum
High Performance Computing Oliver Rheinbach oliver.rheinbach@math.tu-freiberg.de http://www.mathe.tu-freiberg.de/nmo/ Vorlesung Introduction to High Performance Computing Hörergruppen Woche Tag Zeit Raum
OpenMP C and C++ Application Program Interface
 OpenMP C and C++ Application Program Interface Version.0 March 00 Copyright 1-00 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP
OpenMP C and C++ Application Program Interface Version.0 March 00 Copyright 1-00 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP
Objectives. Overview of OpenMP. Structured blocks. Variable scope, work-sharing. Scheduling, synchronization
 OpenMP Objectives Overview of OpenMP Structured blocks Variable scope, work-sharing Scheduling, synchronization 1 Overview of OpenMP OpenMP is a collection of compiler directives and library functions
OpenMP Objectives Overview of OpenMP Structured blocks Variable scope, work-sharing Scheduling, synchronization 1 Overview of OpenMP OpenMP is a collection of compiler directives and library functions
COMP/CS 605: Introduction to Parallel Computing Lecture 21: Shared Memory Programming with OpenMP
 COMP/CS 605: Introduction to Parallel Computing Lecture 21: Shared Memory Programming with OpenMP Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State
COMP/CS 605: Introduction to Parallel Computing Lecture 21: Shared Memory Programming with OpenMP Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State
An Introduction to Parallel Programming with OpenMP
 An Introduction to Parallel Programming with OpenMP by Alina Kiessling E U N I V E R S I H T T Y O H F G R E D I N B U A Pedagogical Seminar April 2009 ii Contents 1 Parallel Programming with OpenMP 1
An Introduction to Parallel Programming with OpenMP by Alina Kiessling E U N I V E R S I H T T Y O H F G R E D I N B U A Pedagogical Seminar April 2009 ii Contents 1 Parallel Programming with OpenMP 1
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Introduction to OpenMP Programming. NERSC Staff
 Introduction to OpenMP Programming NERSC Staff Agenda Basic informa,on An selec(ve introduc(on to the programming model. Direc(ves for work paralleliza(on and synchroniza(on. Some hints on usage Hands-
Introduction to OpenMP Programming NERSC Staff Agenda Basic informa,on An selec(ve introduc(on to the programming model. Direc(ves for work paralleliza(on and synchroniza(on. Some hints on usage Hands-
OpenMP 1. OpenMP. Jalel Chergui Pierre-François Lavallée. Multithreaded Parallelization for Shared-Memory Machines. <Prénom.Nom@idris.
 OpenMP 1 OpenMP Multithreaded Parallelization for Shared-Memory Machines Jalel Chergui Pierre-François Lavallée Reproduction Rights 2 Copyright c 2001-2012 CNRS/IDRIS OpenMP : plan
OpenMP 1 OpenMP Multithreaded Parallelization for Shared-Memory Machines Jalel Chergui Pierre-François Lavallée Reproduction Rights 2 Copyright c 2001-2012 CNRS/IDRIS OpenMP : plan
OpenMP* 4.0 for HPC in a Nutshell
 OpenMP* 4.0 for HPC in a Nutshell Dr.-Ing. Michael Klemm Senior Application Engineer Software and Services Group (michael.klemm@intel.com) *Other brands and names are the property of their respective owners.
OpenMP* 4.0 for HPC in a Nutshell Dr.-Ing. Michael Klemm Senior Application Engineer Software and Services Group (michael.klemm@intel.com) *Other brands and names are the property of their respective owners.
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
A Comparison Of Shared Memory Parallel Programming Models. Jace A Mogill David Haglin
 A Comparison Of Shared Memory Parallel Programming Models Jace A Mogill David Haglin 1 Parallel Programming Gap Not many innovations... Memory semantics unchanged for over 50 years 2010 Multi-Core x86
A Comparison Of Shared Memory Parallel Programming Models Jace A Mogill David Haglin 1 Parallel Programming Gap Not many innovations... Memory semantics unchanged for over 50 years 2010 Multi-Core x86
What is Multi Core Architecture?
 What is Multi Core Architecture? When a processor has more than one core to execute all the necessary functions of a computer, it s processor is known to be a multi core architecture. In other words, a
What is Multi Core Architecture? When a processor has more than one core to execute all the necessary functions of a computer, it s processor is known to be a multi core architecture. In other words, a
Towards OpenMP Support in LLVM
 Towards OpenMP Support in LLVM Alexey Bataev, Andrey Bokhanko, James Cownie Intel 1 Agenda What is the OpenMP * language? Who Can Benefit from the OpenMP language? OpenMP Language Support Early / Late
Towards OpenMP Support in LLVM Alexey Bataev, Andrey Bokhanko, James Cownie Intel 1 Agenda What is the OpenMP * language? Who Can Benefit from the OpenMP language? OpenMP Language Support Early / Late
OpenMP Application Program Interface
 OpenMP Application Program Interface Version.1 July 0 Copyright 1-0 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
OpenMP Application Program Interface Version.1 July 0 Copyright 1-0 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
OpenMP Application Program Interface
 OpenMP Application Program Interface Version.0 - July 01 Copyright 1-01 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
OpenMP Application Program Interface Version.0 - July 01 Copyright 1-01 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
Workshare Process of Thread Programming and MPI Model on Multicore Architecture
 Vol., No. 7, 011 Workshare Process of Thread Programming and MPI Model on Multicore Architecture R. Refianti 1, A.B. Mutiara, D.T Hasta 3 Faculty of Computer Science and Information Technology, Gunadarma
Vol., No. 7, 011 Workshare Process of Thread Programming and MPI Model on Multicore Architecture R. Refianti 1, A.B. Mutiara, D.T Hasta 3 Faculty of Computer Science and Information Technology, Gunadarma
Getting OpenMP Up To Speed
 1 Getting OpenMP Up To Speed Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline The
1 Getting OpenMP Up To Speed Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline The
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
University of Amsterdam - SURFsara. High Performance Computing and Big Data Course
 University of Amsterdam - SURFsara High Performance Computing and Big Data Course Workshop 7: OpenMP and MPI Assignments Clemens Grelck C.Grelck@uva.nl Roy Bakker R.Bakker@uva.nl Adam Belloum A.S.Z.Belloum@uva.nl
University of Amsterdam - SURFsara High Performance Computing and Big Data Course Workshop 7: OpenMP and MPI Assignments Clemens Grelck C.Grelck@uva.nl Roy Bakker R.Bakker@uva.nl Adam Belloum A.S.Z.Belloum@uva.nl
Programação pelo modelo partilhada de memória
 Programação pelo modelo partilhada de memória PDP Parallel Programming in C with MPI and OpenMP Michael J. Quinn Introdução OpenMP Ciclos for paralelos Blocos paralelos Variáveis privadas Secções criticas
Programação pelo modelo partilhada de memória PDP Parallel Programming in C with MPI and OpenMP Michael J. Quinn Introdução OpenMP Ciclos for paralelos Blocos paralelos Variáveis privadas Secções criticas
How to Run Parallel Jobs Efficiently
 How to Run Parallel Jobs Efficiently Shao-Ching Huang High Performance Computing Group UCLA Institute for Digital Research and Education May 9, 2013 1 The big picture: running parallel jobs on Hoffman2
How to Run Parallel Jobs Efficiently Shao-Ching Huang High Performance Computing Group UCLA Institute for Digital Research and Education May 9, 2013 1 The big picture: running parallel jobs on Hoffman2
Basic Concepts in Parallelization
 1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
OpenACC 2.0 and the PGI Accelerator Compilers
 OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group michael.wolfe@pgroup.com This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group michael.wolfe@pgroup.com This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
Programming the Intel Xeon Phi Coprocessor
 Programming the Intel Xeon Phi Coprocessor Tim Cramer cramer@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Motivation Many Integrated Core (MIC) Architecture Programming Models Native
Programming the Intel Xeon Phi Coprocessor Tim Cramer cramer@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Motivation Many Integrated Core (MIC) Architecture Programming Models Native
Practical Introduction to
 1 Practical Introduction to http://tinyurl.com/cq-intro-openmp-20151006 By: Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@calculquebec.ca, Bart.Oldeman@mcgill.ca Partners and Sponsors 2 3 Outline
1 Practical Introduction to http://tinyurl.com/cq-intro-openmp-20151006 By: Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@calculquebec.ca, Bart.Oldeman@mcgill.ca Partners and Sponsors 2 3 Outline
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems
 David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
OpenACC Basics Directive-based GPGPU Programming
 OpenACC Basics Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum (RZ) PPCES,
OpenACC Basics Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum (RZ) PPCES,
An Incomplete C++ Primer. University of Wyoming MA 5310
 An Incomplete C++ Primer University of Wyoming MA 5310 Professor Craig C. Douglas http://www.mgnet.org/~douglas/classes/na-sc/notes/c++primer.pdf C++ is a legacy programming language, as is other languages
An Incomplete C++ Primer University of Wyoming MA 5310 Professor Craig C. Douglas http://www.mgnet.org/~douglas/classes/na-sc/notes/c++primer.pdf C++ is a legacy programming language, as is other languages
MPI and Hybrid Programming Models. William Gropp www.cs.illinois.edu/~wgropp
 MPI and Hybrid Programming Models William Gropp www.cs.illinois.edu/~wgropp 2 What is a Hybrid Model? Combination of several parallel programming models in the same program May be mixed in the same source
MPI and Hybrid Programming Models William Gropp www.cs.illinois.edu/~wgropp 2 What is a Hybrid Model? Combination of several parallel programming models in the same program May be mixed in the same source
HPC Wales Skills Academy Course Catalogue 2015
 HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
Scalability evaluation of barrier algorithms for OpenMP
 Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
BLM 413E - Parallel Programming Lecture 3
 BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
Debugging with TotalView
 Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises
 Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises Pierre-Yves Taunay Research Computing and Cyberinfrastructure 224A Computer Building The Pennsylvania State University University
Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises Pierre-Yves Taunay Research Computing and Cyberinfrastructure 224A Computer Building The Pennsylvania State University University
PROACTIVE BOTTLENECK PERFORMANCE ANALYSIS IN PARALLEL COMPUTING USING OPENMP
 PROACTIVE BOTTLENECK PERFORMANCE ANALYSIS IN PARALLEL COMPUTING USING OPENMP Vibha Rajput Computer Science and Engineering M.Tech.2 nd Sem (CSE) Indraprastha Engineering College. M. T.U Noida, U.P., India
PROACTIVE BOTTLENECK PERFORMANCE ANALYSIS IN PARALLEL COMPUTING USING OPENMP Vibha Rajput Computer Science and Engineering M.Tech.2 nd Sem (CSE) Indraprastha Engineering College. M. T.U Noida, U.P., India
IUmd. Performance Analysis of a Molecular Dynamics Code. Thomas William. Dresden, 5/27/13
 Center for Information Services and High Performance Computing (ZIH) IUmd Performance Analysis of a Molecular Dynamics Code Thomas William Dresden, 5/27/13 Overview IUmd Introduction First Look with Vampir
Center for Information Services and High Performance Computing (ZIH) IUmd Performance Analysis of a Molecular Dynamics Code Thomas William Dresden, 5/27/13 Overview IUmd Introduction First Look with Vampir
An Introduction to Parallel Computing/ Programming
 An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
Running applications on the Cray XC30 4/12/2015
 Running applications on the Cray XC30 4/12/2015 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch jobs on compute nodes
Running applications on the Cray XC30 4/12/2015 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch jobs on compute nodes
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
<Insert Picture Here> An Experimental Model to Analyze OpenMP Applications for System Utilization
 An Experimental Model to Analyze OpenMP Applications for System Utilization Mark Woodyard Principal Software Engineer 1 The following is an overview of a research project. It is intended
An Experimental Model to Analyze OpenMP Applications for System Utilization Mark Woodyard Principal Software Engineer 1 The following is an overview of a research project. It is intended
A Pattern-Based Comparison of OpenACC & OpenMP for Accelerators
 A Pattern-Based Comparison of OpenACC & OpenMP for Accelerators Sandra Wienke 1,2, Christian Terboven 1,2, James C. Beyer 3, Matthias S. Müller 1,2 1 IT Center, RWTH Aachen University 2 JARA-HPC, Aachen
A Pattern-Based Comparison of OpenACC & OpenMP for Accelerators Sandra Wienke 1,2, Christian Terboven 1,2, James C. Beyer 3, Matthias S. Müller 1,2 1 IT Center, RWTH Aachen University 2 JARA-HPC, Aachen
A Performance Monitoring Interface for OpenMP
 A Performance Monitoring Interface for OpenMP Bernd Mohr, Allen D. Malony, Hans-Christian Hoppe, Frank Schlimbach, Grant Haab, Jay Hoeflinger, and Sanjiv Shah Research Centre Jülich, ZAM Jülich, Germany
A Performance Monitoring Interface for OpenMP Bernd Mohr, Allen D. Malony, Hans-Christian Hoppe, Frank Schlimbach, Grant Haab, Jay Hoeflinger, and Sanjiv Shah Research Centre Jülich, ZAM Jülich, Germany
Embedded Systems. Review of ANSI C Topics. A Review of ANSI C and Considerations for Embedded C Programming. Basic features of C
 Embedded Systems A Review of ANSI C and Considerations for Embedded C Programming Dr. Jeff Jackson Lecture 2-1 Review of ANSI C Topics Basic features of C C fundamentals Basic data types Expressions Selection
Embedded Systems A Review of ANSI C and Considerations for Embedded C Programming Dr. Jeff Jackson Lecture 2-1 Review of ANSI C Topics Basic features of C C fundamentals Basic data types Expressions Selection
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Application Performance Analysis Tools and Techniques
 Mitglied der Helmholtz-Gemeinschaft Application Performance Analysis Tools and Techniques 2012-06-27 Christian Rössel Jülich Supercomputing Centre c.roessel@fz-juelich.de EU-US HPC Summer School Dublin
Mitglied der Helmholtz-Gemeinschaft Application Performance Analysis Tools and Techniques 2012-06-27 Christian Rössel Jülich Supercomputing Centre c.roessel@fz-juelich.de EU-US HPC Summer School Dublin
Chapter 2 Parallel Architecture, Software And Performance
 Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
An introduction to Fyrkat
 Cluster Computing May 25, 2011 How to get an account https://fyrkat.grid.aau.dk/useraccount How to get help https://fyrkat.grid.aau.dk/wiki What is a Cluster Anyway It is NOT something that does any of
Cluster Computing May 25, 2011 How to get an account https://fyrkat.grid.aau.dk/useraccount How to get help https://fyrkat.grid.aau.dk/wiki What is a Cluster Anyway It is NOT something that does any of
OpenACC Programming on GPUs
 OpenACC Programming on GPUs Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum
OpenACC Programming on GPUs Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum
Multi-core CPUs, Clusters, and Grid Computing: a Tutorial
 Multi-core CPUs, Clusters, and Grid Computing: a Tutorial Michael Creel Department of Economics and Economic History Edifici B, Universitat Autònoma de Barcelona 08193 Bellaterra (Barcelona) Spain michael.creel@uab.es
Multi-core CPUs, Clusters, and Grid Computing: a Tutorial Michael Creel Department of Economics and Economic History Edifici B, Universitat Autònoma de Barcelona 08193 Bellaterra (Barcelona) Spain michael.creel@uab.es
Common Mistakes in OpenMP and How To Avoid Them
 Common Mistakes in OpenMP and How To Avoid Them A Collection of Best Practices Michael Süß and Claudia Leopold University of Kassel, Research Group Programming Languages / Methodologies, Wilhelmshöher
Common Mistakes in OpenMP and How To Avoid Them A Collection of Best Practices Michael Süß and Claudia Leopold University of Kassel, Research Group Programming Languages / Methodologies, Wilhelmshöher
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Shared Address Space Computing: Programming
 Shared Address Space Computing: Programming Alistair Rendell See Chapter 6 or Lin and Synder, Chapter 7 of Grama, Gupta, Karypis and Kumar, and Chapter 8 of Wilkinson and Allen Fork/Join Programming Model
Shared Address Space Computing: Programming Alistair Rendell See Chapter 6 or Lin and Synder, Chapter 7 of Grama, Gupta, Karypis and Kumar, and Chapter 8 of Wilkinson and Allen Fork/Join Programming Model
Parallelization of video compressing with FFmpeg and OpenMP in supercomputing environment
 Proceedings of the 9 th International Conference on Applied Informatics Eger, Hungary, January 29 February 1, 2014. Vol. 1. pp. 231 237 doi: 10.14794/ICAI.9.2014.1.231 Parallelization of video compressing
Proceedings of the 9 th International Conference on Applied Informatics Eger, Hungary, January 29 February 1, 2014. Vol. 1. pp. 231 237 doi: 10.14794/ICAI.9.2014.1.231 Parallelization of video compressing
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Performance analysis with Periscope
 Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München September 2010 Outline Motivation Periscope architecture Periscope performance analysis
Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München September 2010 Outline Motivation Periscope architecture Periscope performance analysis
Introduction to Hybrid Programming
 Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
OMPT and OMPD: OpenMP Tools Application Programming Interfaces for Performance Analysis and Debugging
 OMPT and OMPD: OpenMP Tools Application Programming Interfaces for Performance Analysis and Debugging Alexandre Eichenberger, John Mellor-Crummey, Martin Schulz, Nawal Copty, John DelSignore, Robert Dietrich,
OMPT and OMPD: OpenMP Tools Application Programming Interfaces for Performance Analysis and Debugging Alexandre Eichenberger, John Mellor-Crummey, Martin Schulz, Nawal Copty, John DelSignore, Robert Dietrich,
OpenACC Programming and Best Practices Guide
 OpenACC Programming and Best Practices Guide June 2015 2015 openacc-standard.org. All Rights Reserved. Contents 1 Introduction 3 Writing Portable Code........................................... 3 What
OpenACC Programming and Best Practices Guide June 2015 2015 openacc-standard.org. All Rights Reserved. Contents 1 Introduction 3 Writing Portable Code........................................... 3 What
Debugging. Common Semantic Errors ESE112. Java Library. It is highly unlikely that you will write code that will work on the first go
 Debugging ESE112 Java Programming: API, Psuedo-Code, Scope It is highly unlikely that you will write code that will work on the first go Bugs or errors Syntax Fixable if you learn to read compiler error
Debugging ESE112 Java Programming: API, Psuedo-Code, Scope It is highly unlikely that you will write code that will work on the first go Bugs or errors Syntax Fixable if you learn to read compiler error
LS-DYNA Scalability on Cray Supercomputers. Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp.
 LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters
 The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
A Case Study - Scaling Legacy Code on Next Generation Platforms
 Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Petascale Software Challenges. William Gropp www.cs.illinois.edu/~wgropp
 Petascale Software Challenges William Gropp www.cs.illinois.edu/~wgropp Petascale Software Challenges Why should you care? What are they? Which are different from non-petascale? What has changed since
Petascale Software Challenges William Gropp www.cs.illinois.edu/~wgropp Petascale Software Challenges Why should you care? What are they? Which are different from non-petascale? What has changed since
OpenMP and Performance
 Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Tuning Cycle Performance Tuning aims to improve the runtime of an
Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Tuning Cycle Performance Tuning aims to improve the runtime of an
Parallel Programming with MPI on the Odyssey Cluster
 Parallel Programming with MPI on the Odyssey Cluster Plamen Krastev Office: Oxford 38, Room 204 Email: plamenkrastev@fas.harvard.edu FAS Research Computing Harvard University Objectives: To introduce you
Parallel Programming with MPI on the Odyssey Cluster Plamen Krastev Office: Oxford 38, Room 204 Email: plamenkrastev@fas.harvard.edu FAS Research Computing Harvard University Objectives: To introduce you
BIG CPU, BIG DATA. Solving the World s Toughest Computational Problems with Parallel Computing. Alan Kaminsky
 Solving the World s Toughest Computational Problems with Parallel Computing Alan Kaminsky Solving the World s Toughest Computational Problems with Parallel Computing Alan Kaminsky Department of Computer
Solving the World s Toughest Computational Problems with Parallel Computing Alan Kaminsky Solving the World s Toughest Computational Problems with Parallel Computing Alan Kaminsky Department of Computer
Parallelization: Binary Tree Traversal
 By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
Introduction to Linux and Cluster Basics for the CCR General Computing Cluster
 Introduction to Linux and Cluster Basics for the CCR General Computing Cluster Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY 14203 Phone: 716-881-8959
Introduction to Linux and Cluster Basics for the CCR General Computing Cluster Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY 14203 Phone: 716-881-8959
GPU Hardware and Programming Models. Jeremy Appleyard, September 2015
 GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
Course Development of Programming for General-Purpose Multicore Processors
 Course Development of Programming for General-Purpose Multicore Processors Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University Richmond, VA 23284 wzhang4@vcu.edu
Course Development of Programming for General-Purpose Multicore Processors Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University Richmond, VA 23284 wzhang4@vcu.edu
Supporting OpenMP on Cell
 Supporting OpenMP on Cell Kevin O Brien, Kathryn O Brien, Zehra Sura, Tong Chen and Tao Zhang IBM T. J Watson Research Abstract. The Cell processor is a heterogeneous multi-core processor with one Power
Supporting OpenMP on Cell Kevin O Brien, Kathryn O Brien, Zehra Sura, Tong Chen and Tao Zhang IBM T. J Watson Research Abstract. The Cell processor is a heterogeneous multi-core processor with one Power
SWARM: A Parallel Programming Framework for Multicore Processors. David A. Bader, Varun N. Kanade and Kamesh Madduri
 SWARM: A Parallel Programming Framework for Multicore Processors David A. Bader, Varun N. Kanade and Kamesh Madduri Our Contributions SWARM: SoftWare and Algorithms for Running on Multicore, a portable
SWARM: A Parallel Programming Framework for Multicore Processors David A. Bader, Varun N. Kanade and Kamesh Madduri Our Contributions SWARM: SoftWare and Algorithms for Running on Multicore, a portable
The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud.
 White Paper 021313-3 Page 1 : A Software Framework for Parallel Programming* The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud. ABSTRACT Programming for Multicore,
White Paper 021313-3 Page 1 : A Software Framework for Parallel Programming* The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud. ABSTRACT Programming for Multicore,
Sources: On the Web: Slides will be available on:
 C programming Introduction The basics of algorithms Structure of a C code, compilation step Constant, variable type, variable scope Expression and operators: assignment, arithmetic operators, comparison,
C programming Introduction The basics of algorithms Structure of a C code, compilation step Constant, variable type, variable scope Expression and operators: assignment, arithmetic operators, comparison,
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Advanced MPI. Hybrid programming, profiling and debugging of MPI applications. Hristo Iliev RZ. Rechen- und Kommunikationszentrum (RZ)
") Advanced MPI Hybrid programming, profiling and debugging of MPI applications Hristo Iliev RZ Rechen- und Kommunikationszentrum (RZ) Agenda Halos (ghost cells) Hybrid programming Profiling of MPI applications
Advanced MPI Hybrid programming, profiling and debugging of MPI applications Hristo Iliev RZ Rechen- und Kommunikationszentrum (RZ) Agenda Halos (ghost cells) Hybrid programming Profiling of MPI applications
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Scheduling Task Parallelism" on Multi-Socket Multicore Systems"
 Scheduling Task Parallelism" on Multi-Socket Multicore Systems" Stephen Olivier, UNC Chapel Hill Allan Porterfield, RENCI Kyle Wheeler, Sandia National Labs Jan Prins, UNC Chapel Hill Outline" Introduction
Scheduling Task Parallelism" on Multi-Socket Multicore Systems" Stephen Olivier, UNC Chapel Hill Allan Porterfield, RENCI Kyle Wheeler, Sandia National Labs Jan Prins, UNC Chapel Hill Outline" Introduction
Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002. sack@stud.ntnu.no www.stud.ntnu.
 Paul Sack 20 September, 2002. sack@stud.ntnu.no www.stud.ntnu.") Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002 sack@stud.ntnu.no www.stud.ntnu.no/ sack/ Outline Background information Work on clusters Profiling tools
Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002 sack@stud.ntnu.no www.stud.ntnu.no/ sack/ Outline Background information Work on clusters Profiling tools
Scalable Data Analysis in R. Lee E. Edlefsen Chief Scientist UserR! 2011
 Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
Hybrid Programming with MPI and OpenMP
 Hybrid Programming with and OpenMP Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2015/2016 R. Rocha and F. Silva (DCC-FCUP) Programming
Hybrid Programming with and OpenMP Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2015/2016 R. Rocha and F. Silva (DCC-FCUP) Programming
Introduction. Reading. Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF. CMSC 818Z - S99 (lect 5)
") Introduction Reading Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF 1 Programming Assignment Notes Assume that memory is limited don t replicate the board on all nodes Need to provide load
Introduction Reading Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF 1 Programming Assignment Notes Assume that memory is limited don t replicate the board on all nodes Need to provide load
SYCL for OpenCL. Andrew Richards, CEO Codeplay & Chair SYCL Working group GDC, March 2014. Copyright Khronos Group 2014 - Page 1
 SYCL for OpenCL Andrew Richards, CEO Codeplay & Chair SYCL Working group GDC, March 2014 Copyright Khronos Group 2014 - Page 1 Where is OpenCL today? OpenCL: supported by a very wide range of platforms
SYCL for OpenCL Andrew Richards, CEO Codeplay & Chair SYCL Working group GDC, March 2014 Copyright Khronos Group 2014 - Page 1 Where is OpenCL today? OpenCL: supported by a very wide range of platforms
OMPT: OpenMP Tools Application Programming Interfaces for Performance Analysis
 OMPT: OpenMP Tools Application Programming Interfaces for Performance Analysis Alexandre Eichenberger, John Mellor-Crummey, Martin Schulz, Michael Wong, Nawal Copty, John DelSignore, Robert Dietrich, Xu
OMPT: OpenMP Tools Application Programming Interfaces for Performance Analysis Alexandre Eichenberger, John Mellor-Crummey, Martin Schulz, Michael Wong, Nawal Copty, John DelSignore, Robert Dietrich, Xu
An Easier Way for Cross-Platform Data Acquisition Application Development
 An Easier Way for Cross-Platform Data Acquisition Application Development For industrial automation and measurement system developers, software technology continues making rapid progress. Software engineers
An Easier Way for Cross-Platform Data Acquisition Application Development For industrial automation and measurement system developers, software technology continues making rapid progress. Software engineers
OpenCL for programming shared memory multicore CPUs
 Akhtar Ali, Usman Dastgeer and Christoph Kessler. OpenCL on shared memory multicore CPUs. Proc. MULTIPROG-212 Workshop at HiPEAC-212, Paris, Jan. 212. OpenCL for programming shared memory multicore CPUs
Akhtar Ali, Usman Dastgeer and Christoph Kessler. OpenCL on shared memory multicore CPUs. Proc. MULTIPROG-212 Workshop at HiPEAC-212, Paris, Jan. 212. OpenCL for programming shared memory multicore CPUs
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
WinBioinfTools: Bioinformatics Tools for Windows Cluster. Done By: Hisham Adel Mohamed
 WinBioinfTools: Bioinformatics Tools for Windows Cluster Done By: Hisham Adel Mohamed Objective Implement and Modify Bioinformatics Tools To run under Windows Cluster Project : Research Project between
WinBioinfTools: Bioinformatics Tools for Windows Cluster Done By: Hisham Adel Mohamed Objective Implement and Modify Bioinformatics Tools To run under Windows Cluster Project : Research Project between
How To Write A Multi Threaded Software On A Single Core (Or Multi Threaded) System
 System") Multicore Systems Challenges for the Real-Time Software Developer Dr. Fridtjof Siebert aicas GmbH Haid-und-Neu-Str. 18 76131 Karlsruhe, Germany siebert@aicas.com Abstract Multicore systems have become
Multicore Systems Challenges for the Real-Time Software Developer Dr. Fridtjof Siebert aicas GmbH Haid-und-Neu-Str. 18 76131 Karlsruhe, Germany siebert@aicas.com Abstract Multicore systems have become
reduction critical_section
 A comparison of OpenMP and MPI for the parallel CFD test case Michael Resch, Bjíorn Sander and Isabel Loebich High Performance Computing Center Stuttgart èhlrsè Allmandring 3, D-755 Stuttgart Germany resch@hlrs.de
A comparison of OpenMP and MPI for the parallel CFD test case Michael Resch, Bjíorn Sander and Isabel Loebich High Performance Computing Center Stuttgart èhlrsè Allmandring 3, D-755 Stuttgart Germany resch@hlrs.de
INTEL PARALLEL STUDIO EVALUATION GUIDE. Intel Cilk Plus: A Simple Path to Parallelism
 Intel Cilk Plus: A Simple Path to Parallelism Compiler extensions to simplify task and data parallelism Intel Cilk Plus adds simple language extensions to express data and task parallelism to the C and
Intel Cilk Plus: A Simple Path to Parallelism Compiler extensions to simplify task and data parallelism Intel Cilk Plus adds simple language extensions to express data and task parallelism to the C and
The SpiceC Parallel Programming System of Computer Systems
 UNIVERSITY OF CALIFORNIA RIVERSIDE The SpiceC Parallel Programming System A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science
UNIVERSITY OF CALIFORNIA RIVERSIDE The SpiceC Parallel Programming System A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research