and its Applications and Lowd & Meek (2005) Presented by Tianyu Cao
|
|
|
- Nelson Flowers
- 7 years ago
- Views:
Transcription
1 On the Inverse Classification Problem and its Applications Based on Aggarwal, Chen & Han (2006) and Lowd & Meek (2005) Presented by Tianyu Cao
 Presented by")
2 Outline Section 1 Application i Background Problem Definition Gini Index and Support Threshold Inverted List & Inverse Classification Algorithm Experimental Results Conclusions & Discussions Section 2 A Naive Idea for Inverse Classification Section 3 Implications for Security Issues on Machine learning 2

3 Section 1 Based on the paper On the Inverse Classification and its Application. 3

4 Application Background Action driven applications in which the features can be used to define certain actions. How to select feature values to drive the decision support system towards a desired end result? Example. Mass marketing MilS Mail Spammer Possible attacks to a general classification system 4

5 Problem Definition Given a training data set D that contains N records, X 1, X 2, X 3, X n. The test dataset contains M records, Y 1, Y 2, Y 3, Y m. Each record Y i is not completely defined. Each record Y i is associated with a desired class label C i. The inverse classification is defined as how to fill the unknown feature f j for each record Y i such that the probability of Y i being classified in to C i is maximized. 5

6 Example Customer ID Decision variable 1 Decision variable ?? Yes 0002?? Yes Yes?? Yes Response How to fill the missing values such that the customer will most likely to respond to the mailer? 6

7 Ways to fill the unknown features Assume the missing features are i 1, i 2, i 3, i q. Suppose the number of possible values for these features are v i1, v i2, v i3, v iq. The number of ways to fill the missing value is as follows. q j= 1 v i j 7

8 How to Search Efficiently in this Space Some feature value combinations are not good and thus should beprunedout. Two prune strategies. Gini index Support threshold Use Gini index to rank the candidate combinations. 8

9 Gini Index Some notations. L(i,q) be the set of points in the training set such that the value of the ith feature is the qth possible value of the ith feature. F(i,q,s) be the fraction of points in the set L(i,q) such that the class label is s. 9

10 Gini Index Gini index is defined as follows. G( L( i, q)) = k s = 1 f ( i, q, s) The least discriminative case. Each f(i,q,s)=1/k. The most discriminative case. Only one f(i,q,s) is 1, all the other f(i,q,s) is

11 Example Customer ID Decision Decision Decision Response variable 1 variable 2 variable No Yes No Yes No No No Yes 11

12 Example L(1,1) is {0001,0002,0003,0004}. Therefore the gini index of L(1,1) 1) is (1/2)^2+(1/2)^2=1/2 2+(1/2) 2=1/2, which is the least discriminative case. Consider the combination of feature 1 is 1 and feature 3 is 1. The set of points are {0002,0004}. The gini index is 1^2+0=1, which is the most discriminative case. 12

13 Support Threshold The number of points in the set L(i,q) must be greater than the support threshold. In the previous example, if the support threshold is 4. Even though the combination of feature 1 is 1 and feature 3 is 1 satisfies the gini index requirement, it does not satisfy the support threshold. 13

14 Inverted List An efficient data structure that can be used to calculate gini index and support for a given combination of feature values. Similar to inverted index in information retrieval. 14

15 Inverted List Feature Value

16 Calculate Combination of L(i,q) To calculate the set of points that satisfy feature 1 is 1 and feature 2 is 0, we simply merge the inverted list L(1,1) and L(2,0). This corresponds to L(1,1) L(2,0). For the convenience of calculating Gini index, the class label is also stored. 16

17 The Inverse Classification Algorithm Step 1. Compute all possible singleton sets L1 for test example T with support at least s and gini index at least a and prune out those L1 that dominant class is not the target class. Set k=1. Step 2. Join Lk and L1 to form Ck+1; Prune Ck+1 according to gini index and support threshold. Assume theremaining is Ck+1 Step 3 Let Lk+1=Ck+1, if Lk+1 is not empty. Go to step 2 17

18 The Inverse Classification Algorithm Step 4 Let LF be the union of all Lk. Step 5 While there are missing values in T, go to step 6 otherwise terminate. Step 6 Pick the feature value combination H with highest gini index from LF. Add the missing value in T using the corresponding values in H. Remove any sets in LF which are inconsistent i twith the filled value in T. Go to step 5. 18

19 Experimental Considerations and Settings No benchmark datasets for this problem. Used UCI dataset by dividing the dataset into three parts. Two parts are used as training and the remaining part are used as testing. Set some feature in the testing set to be missing. Try to use the inverse classification algorithm to fill the missing value. In this case the desired class label is the test instance s actual class label. 19

20 Experimental Results 20
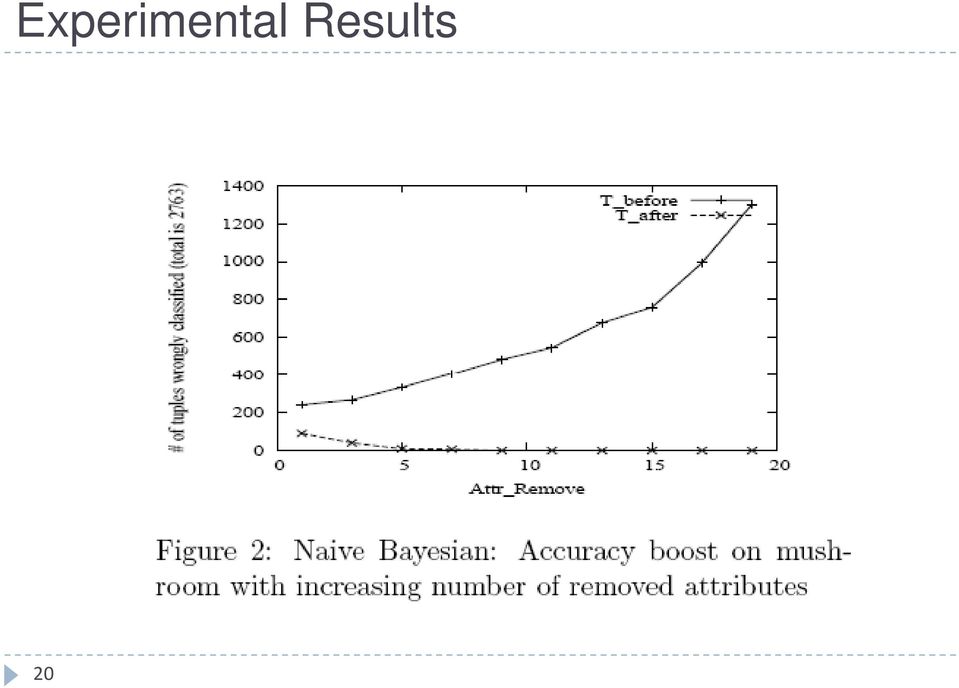
21 Experimental Results 21
22 Experimental Results 22
23 Experimental Results 23
24 Experimental Results 24
25 Experimental Results 25
26 Experimental Results 26
27 Summary of Section 1 The accuracy before substitution of the missing attributes reduces with increasing numberof missing attributes. The accuracy of the classifier showed a considerable boost over original dataset. In general the default gini index in training set served an effective default value. The threshold value could be defined well by the average number of data points per nominal attributes. The algorithm is scalable to the dataset size and the number of missing attributes. 27
28 Discussions The inverse classification problem algorithm does not make useof any classification models. Why not? Relaxation to the problem itself. The inverse classification is defined as how to fill the unknown feature f j for each record Y i such that the probability of Y i being classified in to C i is maximized. 28
29 Discussions Sometimes it is enough to fill the missing value so that the data point Y i is likely to be classified into the target class C i. It means that the probability of data point Y i being classified in to C i is reasonably high. Combining these two ideas we can get a somewhat naive solution to the inverse classification problem. 29
30 Section 2 Based on the presenter s thoughts. 30
31 A Naive Idea Step1 Sep Build uda cass classifier C from the training gdata. a Step2 Consider the missing attributes of a test instance T as a subspace, uniformly random sample a point Pi from this subspace. Step3 Fill Pi into the missing attributes of the testing instance T and send the test tinstance to the classifier C. If C classifies T in to the desired class Ci. The process ends. Otherwise goto step 2. 31
32 A Naive Idea As long as the classifier C fits to the training data set reasonably well, we should expect that the instance T with missing value filled is likely to be classified to the target class by any classifier that fits the training data reasonably well. 32
33 A Naive Idea Second Problem. How many points do we need to sample in order to find one that will be classified into the target class by the classifer C? It turns out we only need to sample a few points. 33
34 A Naive Idea Assume we sample n points in this subspace, we want a blue point. The probability that we can get a blue point is as follows. 1 (P ) red n This probability approaches to 1 exponentially fast as long as the fraction of blue points is not 0. Consider an extreme case, the fraction of blue points is 1% and the fraction of red points is 99%. Even with such an extreme case, the probability that you can get a blue point of sampling 500 points is actually 34higher that 99%.
35 A Naive Idea There are problems with the naive solution even for the relaxed inverse classification problem. It is not always able to find a classifier to fit well to the training data. How to justify the point that you find is likely to be classified to the desired target class. (You cannot use the same classifier for testing ti this. ) 35
36 Section 3 Based on the slides from Good Word Attacks on Statistical Spam Filters. 36
37 Implications for Security Issues As such problem arises, this poses a potential threat to machinelearning system. Adversarial learning deals with such issues. Consider a Content Based Spam Filtering System. The success of inverse classification implies that the spammer can manipulate the spam mail so that it can pass the Spam Filter. 37
38 Content-based Spam Filtering 1. From: Cheap mortgage now!!! Feature Weights 2. cheap = mortgage = Total score = 2.5 > 1.0 (threshold) Spam 38
39 Content-based Spam Filtering 1. From: Cheap mortgage now!!! Corvallis Corvallis OSU Feature Weights 2. cheap = mortgage = 1.5 Corvallis = 1.0 OSU = Total score = 0.5 < 1.0 (threshold) 39 OK
40 Implications for Security Issues It is generally difficult because the spammer does not know thefeature thespam filter uses. Thespammer does not have the necessary training data. But assume the spammer does somehow both of these, how well can he do? 40
41 Good Word Attacks Practice: good word attacks Passive attacks Active attacks Experimental results 41
42 Attacking Spam Filters Can we efficiently find a list of good words? Types of attacks Passive attacks no filter access Active attacks test s allowed Metrics Expected number of words required dto get median (blocked) spam past the filter Numberof querymessages sent 42
43 Filter Configuration Models used Naïve Bayes: generative Maximum Entropy (Maxent): discriminative Training 500,000 messages from Hotmail feedback loop 276,000 features Maxent let 30% less spam through 43
44 Passive Attacks Heuristics Select random dictionary words (Dictionary) Select most frequent English words (Freq. Word) Select highest ratio: English freq./spam freq. (Freq. Ratio) Spam corpus: spamarchive.org English corpora: Reuters news articles Written English Spoken English 1992 USENET 44
45 Passive Attack Results 45
46 Active Attacks Learn which words are best by sending test messages (queries) through the filter First N: Find n good words using as few queries as possible Best N: Find the best n words 46
47 First-N Attack Step 1: Find a Barely spam message Original legit. Barely legit. Barely spam Original spam Hi, mom! now!!! mortgage gg Cheap mortgage gg now!!! now!!! Legitimate Spam Threshold 47
48 First-N Attack Step 2: Test each word Good words Barely spam message Legitimate Spam Less good words Threshold 48
49 Best-N Attack Legitimate Better Worse Spam Threshold Key idea: use spammy words to sort the good words. 49
50 Active Attack Results (n = 100) Best N twice as effective as First N Maxent more vulnerable to active attacks Active attacks much more effective than passive attacks 50
51 References 1. Charu C. Aggarwal, Chen Chen, Jiawei Han. On the Inverse Classification Problem and its Applications. ICDE Daniel Lowd, Christopher Meek. Good Word Attacks on Statistical Spam Filters. In Proceedings of the 2nd Conference on and Anti Spam,
52 Thanks 52
On Attacking Statistical Spam Filters
 On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Paper review by Deepak Chinavle
On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Paper review by Deepak Chinavle
Good Word Attacks on Statistical Spam Filters
 Good Word Attacks on Statistical Spam Filters Daniel Lowd Dept. of Computer Science and Engineering University of Washington Seattle, WA 98195-2350 lowd@cs.washington.edu Christopher Meek Microsoft Research
Good Word Attacks on Statistical Spam Filters Daniel Lowd Dept. of Computer Science and Engineering University of Washington Seattle, WA 98195-2350 lowd@cs.washington.edu Christopher Meek Microsoft Research
COMP3420: Advanced Databases and Data Mining. Classification and prediction: Introduction and Decision Tree Induction
 COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
Spam Filtering using Naïve Bayesian Classification
 Spam Filtering using Naïve Bayesian Classification Presented by: Samer Younes Outline What is spam anyway? Some statistics Why is Spam a Problem Major Techniques for Classifying Spam Transport Level Filtering
Spam Filtering using Naïve Bayesian Classification Presented by: Samer Younes Outline What is spam anyway? Some statistics Why is Spam a Problem Major Techniques for Classifying Spam Transport Level Filtering
eprism Email Security Appliance 6.0 Intercept Anti-Spam Quick Start Guide
 eprism Email Security Appliance 6.0 Intercept Anti-Spam Quick Start Guide This guide is designed to help the administrator configure the eprism Intercept Anti-Spam engine to provide a strong spam protection
eprism Email Security Appliance 6.0 Intercept Anti-Spam Quick Start Guide This guide is designed to help the administrator configure the eprism Intercept Anti-Spam engine to provide a strong spam protection
Volume 4, Issue 1, January 2016 International Journal of Advance Research in Computer Science and Management Studies
 Volume 4, Issue 1, January 2016 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at: www.ijarcsms.com Spam
Volume 4, Issue 1, January 2016 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at: www.ijarcsms.com Spam
Conclusions and Future Directions
 Chapter 9 This chapter summarizes the thesis with discussion of (a) the findings and the contributions to the state-of-the-art in the disciplines covered by this work, and (b) future work, those directions
Chapter 9 This chapter summarizes the thesis with discussion of (a) the findings and the contributions to the state-of-the-art in the disciplines covered by this work, and (b) future work, those directions
Classification and Prediction
 Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
OIS. Update on the anti spam system at CERN. Pawel Grzywaczewski, CERN IT/OIS HEPIX fall 2010
 OIS Update on the anti spam system at CERN Pawel Grzywaczewski, CERN IT/OIS HEPIX fall 2010 OIS Current mail infrastructure Mail service in numbers: ~18 000 mailboxes ~ 18 000 mailing lists (e-groups)
OIS Update on the anti spam system at CERN Pawel Grzywaczewski, CERN IT/OIS HEPIX fall 2010 OIS Current mail infrastructure Mail service in numbers: ~18 000 mailboxes ~ 18 000 mailing lists (e-groups)
Intercept Anti-Spam Quick Start Guide
 Intercept Anti-Spam Quick Start Guide Software Version: 6.5.2 Date: 5/24/07 PREFACE...3 PRODUCT DOCUMENTATION...3 CONVENTIONS...3 CONTACTING TECHNICAL SUPPORT...4 COPYRIGHT INFORMATION...4 OVERVIEW...5
Intercept Anti-Spam Quick Start Guide Software Version: 6.5.2 Date: 5/24/07 PREFACE...3 PRODUCT DOCUMENTATION...3 CONVENTIONS...3 CONTACTING TECHNICAL SUPPORT...4 COPYRIGHT INFORMATION...4 OVERVIEW...5
Email Deliverability Demystified:
 Email Deliverability Demystified: Papilia s Commitment to Optimizing Results A Whitepaper by Mark DiMaio Deliverability Expert SM Email Deliverability Demystified: Papilia s Commitment to Optimizing Results
Email Deliverability Demystified: Papilia s Commitment to Optimizing Results A Whitepaper by Mark DiMaio Deliverability Expert SM Email Deliverability Demystified: Papilia s Commitment to Optimizing Results
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Data Mining Classification: Decision Trees
 Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Introduction. How does email filtering work? What is the Quarantine? What is an End User Digest?
 Introduction The purpose of this memo is to explain how the email that originates from outside this organization is processed, and to describe the tools that you can use to manage your personal spam quarantine.
Introduction The purpose of this memo is to explain how the email that originates from outside this organization is processed, and to describe the tools that you can use to manage your personal spam quarantine.
Data Mining for Knowledge Management. Classification
 1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
Personalized Spam Filtering for Gray Mail
 Personalized Spam Filtering for Gray Mail Ming-wei Chang Computer Science Dept. University of Illinois Urbana, IL, USA mchang21@uiuc.edu Wen-tau Yih Microsoft Research One Microsoft Way Redmond, WA, USA
Personalized Spam Filtering for Gray Mail Ming-wei Chang Computer Science Dept. University of Illinois Urbana, IL, USA mchang21@uiuc.edu Wen-tau Yih Microsoft Research One Microsoft Way Redmond, WA, USA
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
1 Introductory Comments. 2 Bayesian Probability
 Introductory Comments First, I would like to point out that I got this material from two sources: The first was a page from Paul Graham s website at www.paulgraham.com/ffb.html, and the second was a paper
Introductory Comments First, I would like to point out that I got this material from two sources: The first was a page from Paul Graham s website at www.paulgraham.com/ffb.html, and the second was a paper
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering
 A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
Gerry Hobbs, Department of Statistics, West Virginia University
 Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Spam Filtering based on Naive Bayes Classification. Tianhao Sun
 Spam Filtering based on Naive Bayes Classification Tianhao Sun May 1, 2009 Abstract This project discusses about the popular statistical spam filtering process: naive Bayes classification. A fairly famous
Spam Filtering based on Naive Bayes Classification Tianhao Sun May 1, 2009 Abstract This project discusses about the popular statistical spam filtering process: naive Bayes classification. A fairly famous
Predicting borrowers chance of defaulting on credit loans
 Predicting borrowers chance of defaulting on credit loans Junjie Liang (junjie87@stanford.edu) Abstract Credit score prediction is of great interests to banks as the outcome of the prediction algorithm
Predicting borrowers chance of defaulting on credit loans Junjie Liang (junjie87@stanford.edu) Abstract Credit score prediction is of great interests to banks as the outcome of the prediction algorithm
Email Spam Detection A Machine Learning Approach
 Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Detecting client-side e-banking fraud using a heuristic model
 Detecting client-side e-banking fraud using a heuristic model Tim Timmermans tim.timmermans@os3.nl Jurgen Kloosterman jurgen.kloosterman@os3.nl University of Amsterdam July 4, 2013 Tim Timmermans, Jurgen
Detecting client-side e-banking fraud using a heuristic model Tim Timmermans tim.timmermans@os3.nl Jurgen Kloosterman jurgen.kloosterman@os3.nl University of Amsterdam July 4, 2013 Tim Timmermans, Jurgen
Tightening the Net: A Review of Current and Next Generation Spam Filtering Tools
 Tightening the Net: A Review of Current and Next Generation Spam Filtering Tools Spam Track Wednesday 1 March, 2006 APRICOT Perth, Australia James Carpinter & Ray Hunt Dept. of Computer Science and Software
Tightening the Net: A Review of Current and Next Generation Spam Filtering Tools Spam Track Wednesday 1 March, 2006 APRICOT Perth, Australia James Carpinter & Ray Hunt Dept. of Computer Science and Software
Manual Prepared by GalaxyVisions Customer Care Team
 Toll Free: 1.866-GVHOST1 (484-6781) 882 3rd Ave, 8th Floor, Brooklyn, Ny 11232 Manual Prepared by GalaxyVisions Customer Care Team Topics Covered The problem How to prevent spammers from using my server
Toll Free: 1.866-GVHOST1 (484-6781) 882 3rd Ave, 8th Floor, Brooklyn, Ny 11232 Manual Prepared by GalaxyVisions Customer Care Team Topics Covered The problem How to prevent spammers from using my server
The Enron Corpus: A New Dataset for Email Classification Research
 The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Less naive Bayes spam detection
 Less naive Bayes spam detection Hongming Yang Eindhoven University of Technology Dept. EE, Rm PT 3.27, P.O.Box 53, 5600MB Eindhoven The Netherlands. E-mail:h.m.yang@tue.nl also CoSiNe Connectivity Systems
Less naive Bayes spam detection Hongming Yang Eindhoven University of Technology Dept. EE, Rm PT 3.27, P.O.Box 53, 5600MB Eindhoven The Netherlands. E-mail:h.m.yang@tue.nl also CoSiNe Connectivity Systems
Categorical Data Visualization and Clustering Using Subjective Factors
 Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Sentiment analysis using emoticons
 Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
A Procedure for Classifying New Respondents into Existing Segments Using Maximum Difference Scaling
 A Procedure for Classifying New Respondents into Existing Segments Using Maximum Difference Scaling Background Bryan Orme and Rich Johnson, Sawtooth Software March, 2009 Market segmentation is pervasive
A Procedure for Classifying New Respondents into Existing Segments Using Maximum Difference Scaling Background Bryan Orme and Rich Johnson, Sawtooth Software March, 2009 Market segmentation is pervasive
Spam Detection and Pattern Recognition
 International Journal of Signal Processing, Image Processing and Pattern Recognition 31 Learning to Detect Spam: Naive-Euclidean Approach Tony Y.T. Chan, Jie Ji, and Qiangfu Zhao The University of Akureyri,
International Journal of Signal Processing, Image Processing and Pattern Recognition 31 Learning to Detect Spam: Naive-Euclidean Approach Tony Y.T. Chan, Jie Ji, and Qiangfu Zhao The University of Akureyri,
Anti Spamming Techniques
 Anti Spamming Techniques Written by Sumit Siddharth In this article will we first look at some of the existing methods to identify an email as a spam? We look at the pros and cons of the existing methods
Anti Spamming Techniques Written by Sumit Siddharth In this article will we first look at some of the existing methods to identify an email as a spam? We look at the pros and cons of the existing methods
On Attacking Statistical Spam Filters
 On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Abstract. The efforts of anti-spammers
On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Abstract. The efforts of anti-spammers
Machine Learning in Spam Filtering
 Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov kt@ut.ee Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov kt@ut.ee Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Task Scheduling in Hadoop
 Task Scheduling in Hadoop Sagar Mamdapure Munira Ginwala Neha Papat SAE,Kondhwa SAE,Kondhwa SAE,Kondhwa Abstract Hadoop is widely used for storing large datasets and processing them efficiently under distributed
Task Scheduling in Hadoop Sagar Mamdapure Munira Ginwala Neha Papat SAE,Kondhwa SAE,Kondhwa SAE,Kondhwa Abstract Hadoop is widely used for storing large datasets and processing them efficiently under distributed
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S
 e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Chapter 20: Data Analysis
 Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Search and Information Retrieval
 Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Solutions to Math 51 First Exam January 29, 2015
 Solutions to Math 5 First Exam January 29, 25. ( points) (a) Complete the following sentence: A set of vectors {v,..., v k } is defined to be linearly dependent if (2 points) there exist c,... c k R, not
Solutions to Math 5 First Exam January 29, 25. ( points) (a) Complete the following sentence: A set of vectors {v,..., v k } is defined to be linearly dependent if (2 points) there exist c,... c k R, not
Combining Global and Personal Anti-Spam Filtering
 Combining Global and Personal Anti-Spam Filtering Richard Segal IBM Research Hawthorne, NY 10532 Abstract Many of the first successful applications of statistical learning to anti-spam filtering were personalized
Combining Global and Personal Anti-Spam Filtering Richard Segal IBM Research Hawthorne, NY 10532 Abstract Many of the first successful applications of statistical learning to anti-spam filtering were personalized
Learning Example. Machine learning and our focus. Another Example. An example: data (loan application) The data and the goal
 The data and the goal") Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
The versatile solution of anti-spam, personal email backup and recovery, easy email security policy management and enforcement.
 Anti-Spam Expert The versatile solution of anti-spam, personal email backup and recovery, easy email security policy management and enforcement. Effectively filter spam mails by cocktailed N-Tier filter
Anti-Spam Expert The versatile solution of anti-spam, personal email backup and recovery, easy email security policy management and enforcement. Effectively filter spam mails by cocktailed N-Tier filter
ECON 459 Game Theory. Lecture Notes Auctions. Luca Anderlini Spring 2015
 ECON 459 Game Theory Lecture Notes Auctions Luca Anderlini Spring 2015 These notes have been used before. If you can still spot any errors or have any suggestions for improvement, please let me know. 1
ECON 459 Game Theory Lecture Notes Auctions Luca Anderlini Spring 2015 These notes have been used before. If you can still spot any errors or have any suggestions for improvement, please let me know. 1
Research on Clustering Analysis of Big Data Yuan Yuanming 1, 2, a, Wu Chanle 1, 2
 Advanced Engineering Forum Vols. 6-7 (2012) pp 82-87 Online: 2012-09-26 (2012) Trans Tech Publications, Switzerland doi:10.4028/www.scientific.net/aef.6-7.82 Research on Clustering Analysis of Big Data
Advanced Engineering Forum Vols. 6-7 (2012) pp 82-87 Online: 2012-09-26 (2012) Trans Tech Publications, Switzerland doi:10.4028/www.scientific.net/aef.6-7.82 Research on Clustering Analysis of Big Data
PROOFPOINT - EMAIL SPAM FILTER
 416 Morrill Hall of Agriculture Hall Michigan State University 517-355-3776 http://support.anr.msu.edu support@anr.msu.edu PROOFPOINT - EMAIL SPAM FILTER Contents PROOFPOINT - EMAIL SPAM FILTER... 1 INTRODUCTION...
416 Morrill Hall of Agriculture Hall Michigan State University 517-355-3776 http://support.anr.msu.edu support@anr.msu.edu PROOFPOINT - EMAIL SPAM FILTER Contents PROOFPOINT - EMAIL SPAM FILTER... 1 INTRODUCTION...
Feature Subset Selection in E-mail Spam Detection
 Feature Subset Selection in E-mail Spam Detection Amir Rajabi Behjat, Universiti Technology MARA, Malaysia IT Security for the Next Generation Asia Pacific & MEA Cup, Hong Kong 14-16 March, 2012 Feature
Feature Subset Selection in E-mail Spam Detection Amir Rajabi Behjat, Universiti Technology MARA, Malaysia IT Security for the Next Generation Asia Pacific & MEA Cup, Hong Kong 14-16 March, 2012 Feature
Learn How to Defend Your Online Marketplace from Unwanted Traffic
 Learn How to Defend Your Online Marketplace from Unwanted Traffic Speakers Rami Essaid CEO & Co-founder Distil in Classifieds The Basics of Bots A Bot is an automated program that runs on the internet
Learn How to Defend Your Online Marketplace from Unwanted Traffic Speakers Rami Essaid CEO & Co-founder Distil in Classifieds The Basics of Bots A Bot is an automated program that runs on the internet
Bayesian Spam Detection
 Scholarly Horizons: University of Minnesota, Morris Undergraduate Journal Volume 2 Issue 1 Article 2 2015 Bayesian Spam Detection Jeremy J. Eberhardt University or Minnesota, Morris Follow this and additional
Scholarly Horizons: University of Minnesota, Morris Undergraduate Journal Volume 2 Issue 1 Article 2 2015 Bayesian Spam Detection Jeremy J. Eberhardt University or Minnesota, Morris Follow this and additional
Supervised and unsupervised learning - 1
 Chapter 3 Supervised and unsupervised learning - 1 3.1 Introduction The science of learning plays a key role in the field of statistics, data mining, artificial intelligence, intersecting with areas in
Chapter 3 Supervised and unsupervised learning - 1 3.1 Introduction The science of learning plays a key role in the field of statistics, data mining, artificial intelligence, intersecting with areas in
Machine Learning for Naive Bayesian Spam Filter Tokenization
 Machine Learning for Naive Bayesian Spam Filter Tokenization Michael Bevilacqua-Linn December 20, 2003 Abstract Background Traditional client level spam filters rely on rule based heuristics. While these
Machine Learning for Naive Bayesian Spam Filter Tokenization Michael Bevilacqua-Linn December 20, 2003 Abstract Background Traditional client level spam filters rely on rule based heuristics. While these
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier. Santosh Tirunagari : 245577
 T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
Anti-Spam Filter Based on Naïve Bayes, SVM, and KNN model
 AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
Active Learning with Boosting for Spam Detection
 Active Learning with Boosting for Spam Detection Nikhila Arkalgud Last update: March 22, 2008 Active Learning with Boosting for Spam Detection Last update: March 22, 2008 1 / 38 Outline 1 Spam Filters
Active Learning with Boosting for Spam Detection Nikhila Arkalgud Last update: March 22, 2008 Active Learning with Boosting for Spam Detection Last update: March 22, 2008 1 / 38 Outline 1 Spam Filters
Adaption of Statistical Email Filtering Techniques
 Adaption of Statistical Email Filtering Techniques David Kohlbrenner IT.com Thomas Jefferson High School for Science and Technology January 25, 2007 Abstract With the rise of the levels of spam, new techniques
Adaption of Statistical Email Filtering Techniques David Kohlbrenner IT.com Thomas Jefferson High School for Science and Technology January 25, 2007 Abstract With the rise of the levels of spam, new techniques
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus
 Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Commtouch RPD Technology. Network Based Protection Against Email-Borne Threats
 Network Based Protection Against Email-Borne Threats Fighting Spam, Phishing and Malware Spam, phishing and email-borne malware such as viruses and worms are most often released in large quantities in
Network Based Protection Against Email-Borne Threats Fighting Spam, Phishing and Malware Spam, phishing and email-borne malware such as viruses and worms are most often released in large quantities in
Professor Anita Wasilewska. Classification Lecture Notes
 Professor Anita Wasilewska Classification Lecture Notes Classification (Data Mining Book Chapters 5 and 7) PART ONE: Supervised learning and Classification Data format: training and test data Concept,
Professor Anita Wasilewska Classification Lecture Notes Classification (Data Mining Book Chapters 5 and 7) PART ONE: Supervised learning and Classification Data format: training and test data Concept,
KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS
 ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,
ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree
 Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Globally Optimal Crowdsourcing Quality Management
 Globally Optimal Crowdsourcing Quality Management Akash Das Sarma Stanford University akashds@stanford.edu Aditya G. Parameswaran University of Illinois (UIUC) adityagp@illinois.edu Jennifer Widom Stanford
Globally Optimal Crowdsourcing Quality Management Akash Das Sarma Stanford University akashds@stanford.edu Aditya G. Parameswaran University of Illinois (UIUC) adityagp@illinois.edu Jennifer Widom Stanford
Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach
 Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach Alex Hai Wang College of Information Sciences and Technology, The Pennsylvania State University, Dunmore, PA 18512, USA
Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach Alex Hai Wang College of Information Sciences and Technology, The Pennsylvania State University, Dunmore, PA 18512, USA
SVM-Based Spam Filter with Active and Online Learning
 SVM-Based Spam Filter with Active and Online Learning Qiang Wang Yi Guan Xiaolong Wang School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China Email:{qwang, guanyi,
SVM-Based Spam Filter with Active and Online Learning Qiang Wang Yi Guan Xiaolong Wang School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China Email:{qwang, guanyi,
Analysis of Algorithms I: Optimal Binary Search Trees
 Analysis of Algorithms I: Optimal Binary Search Trees Xi Chen Columbia University Given a set of n keys K = {k 1,..., k n } in sorted order: k 1 < k 2 < < k n we wish to build an optimal binary search
Analysis of Algorithms I: Optimal Binary Search Trees Xi Chen Columbia University Given a set of n keys K = {k 1,..., k n } in sorted order: k 1 < k 2 < < k n we wish to build an optimal binary search
Detecting Corporate Fraud: An Application of Machine Learning
 Detecting Corporate Fraud: An Application of Machine Learning Ophir Gottlieb, Curt Salisbury, Howard Shek, Vishal Vaidyanathan December 15, 2006 ABSTRACT This paper explores the application of several
Detecting Corporate Fraud: An Application of Machine Learning Ophir Gottlieb, Curt Salisbury, Howard Shek, Vishal Vaidyanathan December 15, 2006 ABSTRACT This paper explores the application of several
Math 202-0 Quizzes Winter 2009
 Quiz : Basic Probability Ten Scrabble tiles are placed in a bag Four of the tiles have the letter printed on them, and there are two tiles each with the letters B, C and D on them (a) Suppose one tile
Quiz : Basic Probability Ten Scrabble tiles are placed in a bag Four of the tiles have the letter printed on them, and there are two tiles each with the letters B, C and D on them (a) Suppose one tile
Industrial Challenges for Content-Based Image Retrieval
 Title Slide Industrial Challenges for Content-Based Image Retrieval Chahab Nastar, CEO Vienna, 20 September 2005 www.ltutech.com LTU technologies Page 1 Agenda CBIR what is it good for? Technological challenges
Title Slide Industrial Challenges for Content-Based Image Retrieval Chahab Nastar, CEO Vienna, 20 September 2005 www.ltutech.com LTU technologies Page 1 Agenda CBIR what is it good for? Technological challenges
Protein Protein Interaction Networks
 Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Chapter 4. Probability and Probability Distributions
 Chapter 4. robability and robability Distributions Importance of Knowing robability To know whether a sample is not identical to the population from which it was selected, it is necessary to assess the
Chapter 4. robability and robability Distributions Importance of Knowing robability To know whether a sample is not identical to the population from which it was selected, it is necessary to assess the
Removing Web Spam Links from Search Engine Results
 Removing Web Spam Links from Search Engine Results Manuel EGELE pizzaman@iseclab.org, 1 Overview Search Engine Optimization and definition of web spam Motivation Approach Inferring importance of features
Removing Web Spam Links from Search Engine Results Manuel EGELE pizzaman@iseclab.org, 1 Overview Search Engine Optimization and definition of web spam Motivation Approach Inferring importance of features
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC)
") large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
Index Terms Domain name, Firewall, Packet, Phishing, URL.
 BDD for Implementation of Packet Filter Firewall and Detecting Phishing Websites Naresh Shende Vidyalankar Institute of Technology Prof. S. K. Shinde Lokmanya Tilak College of Engineering Abstract Packet
BDD for Implementation of Packet Filter Firewall and Detecting Phishing Websites Naresh Shende Vidyalankar Institute of Technology Prof. S. K. Shinde Lokmanya Tilak College of Engineering Abstract Packet
A Practical Attack to De Anonymize Social Network Users
 A Practical Attack to De Anonymize Social Network Users Gilbert Wondracek () Thorsten Holz () Engin Kirda (Institute Eurecom) Christopher Kruegel (UC Santa Barbara) http://iseclab.org 1 Attack Overview
A Practical Attack to De Anonymize Social Network Users Gilbert Wondracek () Thorsten Holz () Engin Kirda (Institute Eurecom) Christopher Kruegel (UC Santa Barbara) http://iseclab.org 1 Attack Overview
Comparing Industry-Leading Anti-Spam Services
 Comparing Industry-Leading Anti-Spam Services Results from Twelve Months of Testing Joel Snyder Opus One April, 2016 INTRODUCTION The following analysis summarizes the spam catch and false positive rates
Comparing Industry-Leading Anti-Spam Services Results from Twelve Months of Testing Joel Snyder Opus One April, 2016 INTRODUCTION The following analysis summarizes the spam catch and false positive rates
Personal Spam Solution Overview
 Personal Spam Solution Overview Please logon to https://mailstop.dickinson.edu using your network logon and password. This is an overview of what you can do with this system. Common Terms used in this
Personal Spam Solution Overview Please logon to https://mailstop.dickinson.edu using your network logon and password. This is an overview of what you can do with this system. Common Terms used in this
Semi-Supervised and Unsupervised Machine Learning. Novel Strategies
 Brochure More information from http://www.researchandmarkets.com/reports/2179190/ Semi-Supervised and Unsupervised Machine Learning. Novel Strategies Description: This book provides a detailed and up to
Brochure More information from http://www.researchandmarkets.com/reports/2179190/ Semi-Supervised and Unsupervised Machine Learning. Novel Strategies Description: This book provides a detailed and up to
IBM SPSS Direct Marketing 23
 IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
A Multiple Instance Learning Strategy for Combating Good Word Attacks on Spam Filters
 Journal of Machine Learning Research 8 (2008) 1115-1146 Submitted 9/07; Revised 2/08; Published 6/08 A Multiple Instance Learning Strategy for Combating Good Word Attacks on Spam Filters Zach Jorgensen
Journal of Machine Learning Research 8 (2008) 1115-1146 Submitted 9/07; Revised 2/08; Published 6/08 A Multiple Instance Learning Strategy for Combating Good Word Attacks on Spam Filters Zach Jorgensen
IBM SPSS Direct Marketing 22
 IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
Learning to Recognize Missing E-mail Attachments
 Learning to Recognize Missing E-mail Attachments Technical Report TUD KE 2009-05 Marco Ghiglieri, Johannes Fürnkranz Knowledge Engineering Group, Technische Universität Darmstadt Knowledge Engineering
Learning to Recognize Missing E-mail Attachments Technical Report TUD KE 2009-05 Marco Ghiglieri, Johannes Fürnkranz Knowledge Engineering Group, Technische Universität Darmstadt Knowledge Engineering
Homework 4 Statistics W4240: Data Mining Columbia University Due Tuesday, October 29 in Class
 Problem 1. (10 Points) James 6.1 Problem 2. (10 Points) James 6.3 Problem 3. (10 Points) James 6.5 Problem 4. (15 Points) James 6.7 Problem 5. (15 Points) James 6.10 Homework 4 Statistics W4240: Data Mining
Problem 1. (10 Points) James 6.1 Problem 2. (10 Points) James 6.3 Problem 3. (10 Points) James 6.5 Problem 4. (15 Points) James 6.7 Problem 5. (15 Points) James 6.10 Homework 4 Statistics W4240: Data Mining
Anti Spam Best Practices
 53 Anti Spam Best Practices Anti Spam LIVE Service: Zero-Hour Protection An IceWarp White Paper October 2008 www.icewarp.com 54 Background As discussed in the IceWarp white paper entitled, Anti Spam Engine:
53 Anti Spam Best Practices Anti Spam LIVE Service: Zero-Hour Protection An IceWarp White Paper October 2008 www.icewarp.com 54 Background As discussed in the IceWarp white paper entitled, Anti Spam Engine:
Assessment. Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall
 Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Three types of messages: A, B, C. Assume A is the oldest type, and C is the most recent type.
 Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
Automatic Text Processing: Cross-Lingual. Text Categorization
 Automatic Text Processing: Cross-Lingual Text Categorization Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena Dottorato di Ricerca in Ingegneria dell Informazone XVII ciclo
Automatic Text Processing: Cross-Lingual Text Categorization Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena Dottorato di Ricerca in Ingegneria dell Informazone XVII ciclo
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information
 Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
COS 116 The Computational Universe Laboratory 11: Machine Learning
 COS 116 The Computational Universe Laboratory 11: Machine Learning In last Tuesday s lecture, we surveyed many machine learning algorithms and their applications. In this lab, you will explore algorithms
COS 116 The Computational Universe Laboratory 11: Machine Learning In last Tuesday s lecture, we surveyed many machine learning algorithms and their applications. In this lab, you will explore algorithms
6367(Print), ISSN 0976 6375(Online) & TECHNOLOGY Volume 4, Issue 1, (IJCET) January- February (2013), IAEME
, ISSN 0976 6375(Online) & TECHNOLOGY Volume 4, Issue 1, (IJCET) January- February (2013), IAEME") INTERNATIONAL International Journal of Computer JOURNAL Engineering OF COMPUTER and Technology ENGINEERING (IJCET), ISSN 0976-6367(Print), ISSN 0976 6375(Online) & TECHNOLOGY Volume 4, Issue 1, (IJCET)
INTERNATIONAL International Journal of Computer JOURNAL Engineering OF COMPUTER and Technology ENGINEERING (IJCET), ISSN 0976-6367(Print), ISSN 0976 6375(Online) & TECHNOLOGY Volume 4, Issue 1, (IJCET)
CHAPTER-12. Analytical Characterization : Analysis of Attribute Relevance
 CHAPTER-12 Analytical Characterization : Analysis of Attribute Relevance 12.1 Introduction 12.2 Methods of Attribute Relevance Analysis 12.3 Review Questions 12.4 References 12. Analytical Characterization
CHAPTER-12 Analytical Characterization : Analysis of Attribute Relevance 12.1 Introduction 12.2 Methods of Attribute Relevance Analysis 12.3 Review Questions 12.4 References 12. Analytical Characterization
1 Sufficient statistics
 1 Sufficient statistics A statistic is a function T = rx 1, X 2,, X n of the random sample X 1, X 2,, X n. Examples are X n = 1 n s 2 = = X i, 1 n 1 the sample mean X i X n 2, the sample variance T 1 =
1 Sufficient statistics A statistic is a function T = rx 1, X 2,, X n of the random sample X 1, X 2,, X n. Examples are X n = 1 n s 2 = = X i, 1 n 1 the sample mean X i X n 2, the sample variance T 1 =
Text Analytics Illustrated with a Simple Data Set
 CSC 594 Text Mining More on SAS Enterprise Miner Text Analytics Illustrated with a Simple Data Set This demonstration illustrates some text analytic results using a simple data set that is designed to
CSC 594 Text Mining More on SAS Enterprise Miner Text Analytics Illustrated with a Simple Data Set This demonstration illustrates some text analytic results using a simple data set that is designed to
Bayesian spam filtering
 Bayesian spam filtering Keith Briggs Keith.Briggs@bt.com more.btexact.com/people/briggsk2 Pervasive ICT seminar 2004 Apr 29 1500 bayes-2004apr29.tex typeset 2004 May 6 10:48 in pdflatex on a linux system
Bayesian spam filtering Keith Briggs Keith.Briggs@bt.com more.btexact.com/people/briggsk2 Pervasive ICT seminar 2004 Apr 29 1500 bayes-2004apr29.tex typeset 2004 May 6 10:48 in pdflatex on a linux system
Procedia Computer Science 00 (2012) 1 21. Trieu Minh Nhut Le, Jinli Cao, and Zhen He. trieule@sgu.edu.vn, j.cao@latrobe.edu.au, z.he@latrobe.edu.
 1 21. Trieu Minh Nhut Le, Jinli Cao, and Zhen He. trieule@sgu.edu.vn, j.cao@latrobe.edu.au, z.he@latrobe.edu.") Procedia Computer Science 00 (2012) 1 21 Procedia Computer Science Top-k best probability queries and semantics ranking properties on probabilistic databases Trieu Minh Nhut Le, Jinli Cao, and Zhen He
Procedia Computer Science 00 (2012) 1 21 Procedia Computer Science Top-k best probability queries and semantics ranking properties on probabilistic databases Trieu Minh Nhut Le, Jinli Cao, and Zhen He
Sender Identity and Reputation Management
 Dec 4 th 2008 IT IS 3100 Sender Identity and Reputation Management Guest Lecture by: Gautam Singaraju College of Information Technology University i of North Carolina at Charlotte Accountability on the
Dec 4 th 2008 IT IS 3100 Sender Identity and Reputation Management Guest Lecture by: Gautam Singaraju College of Information Technology University i of North Carolina at Charlotte Accountability on the
Email Spam Detection Using Customized SimHash Function
 International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 1, Issue 8, December 2014, PP 35-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Email
International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 1, Issue 8, December 2014, PP 35-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Email