Feature Selection vs. Extraction
|
|
|
- Elijah Townsend
- 7 years ago
- Views:
Transcription
1 Feature Selection In many applications, we often encounter a very large number of potential features that can be used Which subset of features should be used for the best classification? Need for a small number of discriminative features To avoid curse of dimensionality To reduce feature measurement cost To reduce computational burden Given an n x d pattern matrix (n patterns in d- dimensional space), generate an n x m pattern matrix, where m << d

2 Feature Selection vs. Extraction Both are collectively known as dimensionality reduction Selection: choose the best subset of size m from the available d features Extraction: given d features (set Y), extract m new features (set X) by linear or non-linear combination of all the d features Linear feature extraction: X = TY, where T is a m x d matrix Non-linear feature extraction: X = f(y) New extracted features may not have physical interpretation or meaning Examples of linear feature extraction PCA (unsupervised); LDA (supervised) Goals for feature selection & extraction: simplify classifier complexity and improve the classification accuracy,
 New extracted features may not have physical interpretation or meaning Examples of linear feature extraction PCA")
3 Feature Selection How to find the best subset of size m? Recall, best means a classifier based on these m features has the lowest probability of error Simplest approach an exhaustive search: (i) select a criterion fn., (ii) evaluate ALL possible subsets Computationally prohibitive For d=24 and m=12, there are about 2.7 million possible feature subsets! Cover & Van Campenhout (IEEE SMC, 1977) showed that to guarantee the best subset of size m from the available set of size d, one must examine all possible subsets of size m Heuristics have been used to avoid exhaustive search How to evaluate the subsets? Error rate; but then which classifier should be used? Distance measure; Mahalanobis, divergence, Feature selection is an optimization problem
 showed that to guarantee the best subset of size m from the available set of size d, one must examine all possible subsets of size m Heuristics")
4 Feature Selection: Evaluation, Application, and Small Sample Performance (Jain & Zongker, IEEE Trans. PAMI, Feb 1997) Feature selection enables combining features from different data models Potential difficulties in feature selection (i) small sample size, (ii) what criterion function to use Let Y be the original set of features and X is the selected subset Feature selection criterion for the set X is J(X); large value of J indicates a better feature subset; problem is to find subset X such that 3
; large value of J indicates a better feature subset;")
5 Taxonomy of Feature Selection Algorithms

: begin with an empty set & add features Top-down (backward method): begin with a full set & delete features These greedy methods do not examine all possible subsets, so no")
6 Deterministic Single-Solution Methods Begin with a single solution (feature subset) & iteratively add or remove features until some termination criterion is met Also known as sequential methods Bottom up (forward method): begin with an empty set & add features Top-down (backward method): begin with a full set & delete features These greedy methods do not examine all possible subsets, so no guarantee of finding the optimal subset Pudil introduced two floating selection methods: SFFS, SFBS 15 feature selection methods listed in Table 1 were evaluated 5

7 Naiive Method Sort the given d features in order of their prob. of correct recognition Select the top m features from this sorted list Disadvantage: Feature correlation is not considered; best pair of features may not even contain the best individual feature

8 Sequential Forward Selection (SFS) Start with the empty set, X=0 Repeatedly add the most significant feature with respect to X Disadvantage: Once a feature is retained, it cannot be discarded; nesting problem

9 Sequential Backward Selection (SBS) Start with the full set, X=Y Repeatedly delete the least significant feature in X Disadvantage: SBS requires more computation than SFS; Nesting problem

10 Generalized Sequential Forward Selection (GSFS(m)) Start with the empty set, X=0 Repeatedly add the most significant m- subset of (Y - X) (found through exhaustive search)
 (found through")
11 Generalized Sequential Backward Selection (GSBS(m)) Start with the full set, X=Y Repeatedly delete the least significant m- subset of X (found through exhaustive search)

12 Sequential Forward Floating Search (SFFS) Step 1: Inclusion. Use the basic SFS method to select the most significant feature with respect to X and include it in X. Stop if d features have been selected, otherwise go to step 2. Step 2: Conditional exclusion. Find the least significant feature k in X. If it is the feature just added, then keep it and return to step 1. Otherwise, exclude the feature k. Note that X is now better than it was before step 1. Continue to step 3. Step 3: Continuation of conditional exclusion. Again find the least significant feature in X. If its removal will (a) leave X with at least 2 features, and (b) the value of J(X) is greater than the criterion value of the best feature subset of that size found so far, then remove it and repeat step 3. When these two conditions cease to be satisfied, return to step 1.

13 Experimental Results 20-dimensional 2-class Gaussian data with a common covariance matrix Goodness of features (criterion function) is measured by the Mahalanobis distance; recall that in the common covariance matrix case, the prob. of error is inversely proportional to the Mahalanobis distance Forward search methods are faster than backward methods Performance of floating method (SFFS) is comparable to branch & bound methods, but SFFS is significantly faster Nesting problem: The optimal three feature subset is not contained in the optimal four feature subset! Feature selection is an off-line process, so large cost during training can be afforded 12

14 Experimental Results 13
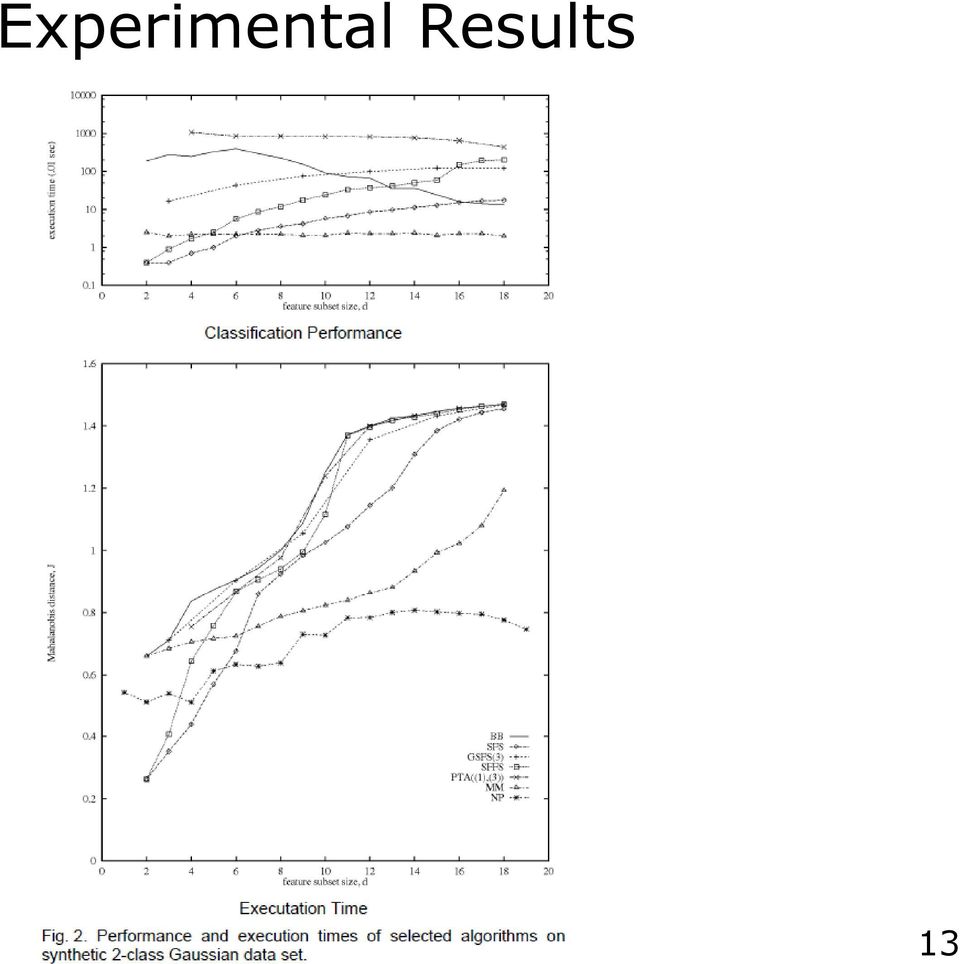
 from 5 classes; equally split for training/test Can the classification error be reduced by feature")
15 Selection of Texture Features Selection of texture features for classifying Synthetic Aperture Radar (SAR) images A total of 18 different features/pixel from 4 different models Can classification error be reduced by feature selection 22,000 samples (pixels) from 5 classes; equally split for training/test Can the classification error be reduced by feature selection? 14


16 Performance of SFFS on Texture Features Best individual texture model for this data is the MAR model Pooling features from different models and then applying feature selection results in an accuracy of 89.3% by the 1NN method Selected subset has representative feature from every model; 5- feature subset selected contains features from 3 different models 15

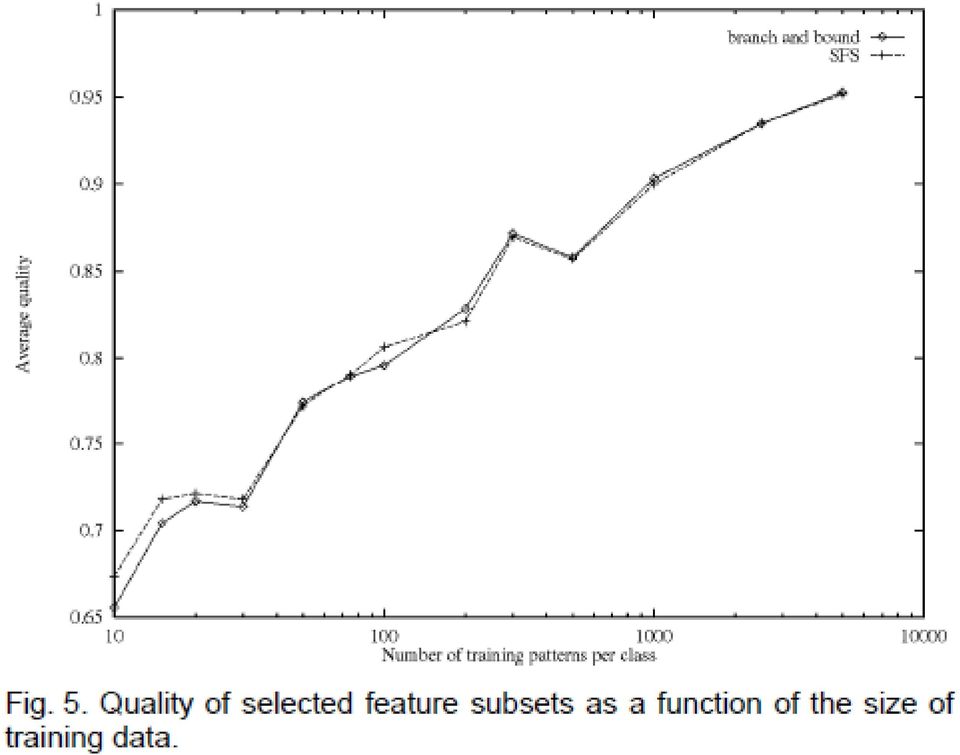
17 Effect of Training Set Size on Feature Selection How reliable are the feature selection results in small sample size situations? Would the error is estimating covariance (for Mahalanobis distance) affect the feature selection performance? Feature selection on the Trunk data with varying sample size 20-dim data from distributions below; n in [10, 5000] Feature selection quality: no. of common features in the subset selected by SFFS and by the optimal method For n = 20, B&B selected the subset {1,2,4,7,9,12,13,14,15,18}; optimal subset is {1,2,3,4,5,6,7,8,9,10} 16
![Feature selection on the Trunk data with varying sample size 20-dim data from distributions below; n in [10, 5000] Feature selection quality:](/docs-images/46/21293123/images/page_17.jpg "no. of common features in the subset selected by SFFS and by the optimal method For n = 20, B&B selected the subset")
18
Supervised Feature Selection & Unsupervised Dimensionality Reduction
 Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j
 Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Biometric Authentication using Online Signatures
 Biometric Authentication using Online Signatures Alisher Kholmatov and Berrin Yanikoglu alisher@su.sabanciuniv.edu, berrin@sabanciuniv.edu http://fens.sabanciuniv.edu Sabanci University, Tuzla, Istanbul,
Biometric Authentication using Online Signatures Alisher Kholmatov and Berrin Yanikoglu alisher@su.sabanciuniv.edu, berrin@sabanciuniv.edu http://fens.sabanciuniv.edu Sabanci University, Tuzla, Istanbul,
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Distance Metric Learning in Data Mining (Part I) Fei Wang and Jimeng Sun IBM TJ Watson Research Center
 Fei Wang and Jimeng Sun IBM TJ Watson Research Center") Distance Metric Learning in Data Mining (Part I) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Distance Metric Learning in Data Mining (Part I) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Clustering Big Data. Anil K. Jain. (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012
 Department of Computer Science Michigan State University November 29, 2012") Clustering Big Data Anil K. Jain (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012 Outline Big Data How to extract information? Data clustering
Clustering Big Data Anil K. Jain (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012 Outline Big Data How to extract information? Data clustering
Hyperspectral Data Analysis and Supervised Feature Reduction Via Projection Pursuit
 Hyperspectral Data Analysis and Supervised Feature Reduction Via Projection Pursuit Medical Image Analysis Luis O. Jimenez and David A. Landgrebe Ion Marqués, Grupo de Inteligencia Computacional, UPV/EHU
Hyperspectral Data Analysis and Supervised Feature Reduction Via Projection Pursuit Medical Image Analysis Luis O. Jimenez and David A. Landgrebe Ion Marqués, Grupo de Inteligencia Computacional, UPV/EHU
Unsupervised and supervised dimension reduction: Algorithms and connections
 Unsupervised and supervised dimension reduction: Algorithms and connections Jieping Ye Department of Computer Science and Engineering Evolutionary Functional Genomics Center The Biodesign Institute Arizona
Unsupervised and supervised dimension reduction: Algorithms and connections Jieping Ye Department of Computer Science and Engineering Evolutionary Functional Genomics Center The Biodesign Institute Arizona
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set
 EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Similarity-Based Unsupervised Band Selection for Hyperspectral Image Analysis
 564 IEEE GEOSCIENCE AND REMOTE SENSING LETTERS, VOL. 5, NO. 4, OCTOBER 2008 Similarity-Based Unsupervised Band Selection for Hyperspectral Image Analysis Qian Du, Senior Member, IEEE, and He Yang, Student
564 IEEE GEOSCIENCE AND REMOTE SENSING LETTERS, VOL. 5, NO. 4, OCTOBER 2008 Similarity-Based Unsupervised Band Selection for Hyperspectral Image Analysis Qian Du, Senior Member, IEEE, and He Yang, Student
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES
 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
Component Ordering in Independent Component Analysis Based on Data Power
 Component Ordering in Independent Component Analysis Based on Data Power Anne Hendrikse Raymond Veldhuis University of Twente University of Twente Fac. EEMCS, Signals and Systems Group Fac. EEMCS, Signals
Component Ordering in Independent Component Analysis Based on Data Power Anne Hendrikse Raymond Veldhuis University of Twente University of Twente Fac. EEMCS, Signals and Systems Group Fac. EEMCS, Signals
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Medical Information Management & Mining. You Chen Jan,15, 2013 You.chen@vanderbilt.edu
 Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Sub-class Error-Correcting Output Codes
 Sub-class Error-Correcting Output Codes Sergio Escalera, Oriol Pujol and Petia Radeva Computer Vision Center, Campus UAB, Edifici O, 08193, Bellaterra, Spain. Dept. Matemàtica Aplicada i Anàlisi, Universitat
Sub-class Error-Correcting Output Codes Sergio Escalera, Oriol Pujol and Petia Radeva Computer Vision Center, Campus UAB, Edifici O, 08193, Bellaterra, Spain. Dept. Matemàtica Aplicada i Anàlisi, Universitat
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization
 A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
Adaptive Face Recognition System from Myanmar NRC Card
 Adaptive Face Recognition System from Myanmar NRC Card Ei Phyo Wai University of Computer Studies, Yangon, Myanmar Myint Myint Sein University of Computer Studies, Yangon, Myanmar ABSTRACT Biometrics is
Adaptive Face Recognition System from Myanmar NRC Card Ei Phyo Wai University of Computer Studies, Yangon, Myanmar Myint Myint Sein University of Computer Studies, Yangon, Myanmar ABSTRACT Biometrics is
ADVANCED MACHINE LEARNING. Introduction
 1 1 Introduction Lecturer: Prof. Aude Billard (aude.billard@epfl.ch) Teaching Assistants: Guillaume de Chambrier, Nadia Figueroa, Denys Lamotte, Nicola Sommer 2 2 Course Format Alternate between: Lectures
1 1 Introduction Lecturer: Prof. Aude Billard (aude.billard@epfl.ch) Teaching Assistants: Guillaume de Chambrier, Nadia Figueroa, Denys Lamotte, Nicola Sommer 2 2 Course Format Alternate between: Lectures
A Survey on Pre-processing and Post-processing Techniques in Data Mining
 , pp. 99-128 http://dx.doi.org/10.14257/ijdta.2014.7.4.09 A Survey on Pre-processing and Post-processing Techniques in Data Mining Divya Tomar and Sonali Agarwal Indian Institute of Information Technology,
, pp. 99-128 http://dx.doi.org/10.14257/ijdta.2014.7.4.09 A Survey on Pre-processing and Post-processing Techniques in Data Mining Divya Tomar and Sonali Agarwal Indian Institute of Information Technology,
An Introduction to Data Mining. Big Data World. Related Fields and Disciplines. What is Data Mining? 2/12/2015
 An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Using multiple models: Bagging, Boosting, Ensembles, Forests
 Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Example: Credit card default, we may be more interested in predicting the probabilty of a default than classifying individuals as default or not.
 Statistical Learning: Chapter 4 Classification 4.1 Introduction Supervised learning with a categorical (Qualitative) response Notation: - Feature vector X, - qualitative response Y, taking values in C
Statistical Learning: Chapter 4 Classification 4.1 Introduction Supervised learning with a categorical (Qualitative) response Notation: - Feature vector X, - qualitative response Y, taking values in C
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches
 Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Determining optimal window size for texture feature extraction methods
 IX Spanish Symposium on Pattern Recognition and Image Analysis, Castellon, Spain, May 2001, vol.2, 237-242, ISBN: 84-8021-351-5. Determining optimal window size for texture feature extraction methods Domènec
IX Spanish Symposium on Pattern Recognition and Image Analysis, Castellon, Spain, May 2001, vol.2, 237-242, ISBN: 84-8021-351-5. Determining optimal window size for texture feature extraction methods Domènec
D-optimal plans in observational studies
 D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
Machine Learning and Pattern Recognition Logistic Regression
 Machine Learning and Pattern Recognition Logistic Regression Course Lecturer:Amos J Storkey Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh Crichton Street,
Machine Learning and Pattern Recognition Logistic Regression Course Lecturer:Amos J Storkey Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh Crichton Street,
Predictive Modeling Techniques in Insurance
 Predictive Modeling Techniques in Insurance Tuesday May 5, 2015 JF. Breton Application Engineer 2014 The MathWorks, Inc. 1 Opening Presenter: JF. Breton: 13 years of experience in predictive analytics
Predictive Modeling Techniques in Insurance Tuesday May 5, 2015 JF. Breton Application Engineer 2014 The MathWorks, Inc. 1 Opening Presenter: JF. Breton: 13 years of experience in predictive analytics
CITY UNIVERSITY OF HONG KONG 香 港 城 市 大 學. Self-Organizing Map: Visualization and Data Handling 自 組 織 神 經 網 絡 : 可 視 化 和 數 據 處 理
 CITY UNIVERSITY OF HONG KONG 香 港 城 市 大 學 Self-Organizing Map: Visualization and Data Handling 自 組 織 神 經 網 絡 : 可 視 化 和 數 據 處 理 Submitted to Department of Electronic Engineering 電 子 工 程 學 系 in Partial Fulfillment
CITY UNIVERSITY OF HONG KONG 香 港 城 市 大 學 Self-Organizing Map: Visualization and Data Handling 自 組 織 神 經 網 絡 : 可 視 化 和 數 據 處 理 Submitted to Department of Electronic Engineering 電 子 工 程 學 系 in Partial Fulfillment
High-Dimensional Data Visualization by PCA and LDA
 High-Dimensional Data Visualization by PCA and LDA Chaur-Chin Chen Department of Computer Science, National Tsing Hua University, Hsinchu, Taiwan Abbie Hsu Institute of Information Systems & Applications,
High-Dimensional Data Visualization by PCA and LDA Chaur-Chin Chen Department of Computer Science, National Tsing Hua University, Hsinchu, Taiwan Abbie Hsu Institute of Information Systems & Applications,
The Artificial Prediction Market
 The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC)
") large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING
 AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
CROP CLASSIFICATION WITH HYPERSPECTRAL DATA OF THE HYMAP SENSOR USING DIFFERENT FEATURE EXTRACTION TECHNIQUES
 Proceedings of the 2 nd Workshop of the EARSeL SIG on Land Use and Land Cover CROP CLASSIFICATION WITH HYPERSPECTRAL DATA OF THE HYMAP SENSOR USING DIFFERENT FEATURE EXTRACTION TECHNIQUES Sebastian Mader
Proceedings of the 2 nd Workshop of the EARSeL SIG on Land Use and Land Cover CROP CLASSIFICATION WITH HYPERSPECTRAL DATA OF THE HYMAP SENSOR USING DIFFERENT FEATURE EXTRACTION TECHNIQUES Sebastian Mader
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Email Spam Detection A Machine Learning Approach
 Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Email Spam Detection A Machine Learning Approach Ge Song, Lauren Steimle ABSTRACT Machine learning is a branch of artificial intelligence concerned with the creation and study of systems that can learn
Accurate and robust image superresolution by neural processing of local image representations
 Accurate and robust image superresolution by neural processing of local image representations Carlos Miravet 1,2 and Francisco B. Rodríguez 1 1 Grupo de Neurocomputación Biológica (GNB), Escuela Politécnica
Accurate and robust image superresolution by neural processing of local image representations Carlos Miravet 1,2 and Francisco B. Rodríguez 1 1 Grupo de Neurocomputación Biológica (GNB), Escuela Politécnica
Data Preprocessing. Week 2
 Data Preprocessing Week 2 Topics Data Types Data Repositories Data Preprocessing Present homework assignment #1 Team Homework Assignment #2 Read pp. 227 240, pp. 250 250, and pp. 259 263 the text book.
Data Preprocessing Week 2 Topics Data Types Data Repositories Data Preprocessing Present homework assignment #1 Team Homework Assignment #2 Read pp. 227 240, pp. 250 250, and pp. 259 263 the text book.
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
NAVIGATING SCIENTIFIC LITERATURE A HOLISTIC PERSPECTIVE. Venu Govindaraju
 NAVIGATING SCIENTIFIC LITERATURE A HOLISTIC PERSPECTIVE Venu Govindaraju BIOMETRICS DOCUMENT ANALYSIS PATTERN RECOGNITION 8/24/2015 ICDAR- 2015 2 Towards a Globally Optimal Approach for Learning Deep Unsupervised
NAVIGATING SCIENTIFIC LITERATURE A HOLISTIC PERSPECTIVE Venu Govindaraju BIOMETRICS DOCUMENT ANALYSIS PATTERN RECOGNITION 8/24/2015 ICDAR- 2015 2 Towards a Globally Optimal Approach for Learning Deep Unsupervised
Unsupervised learning: Clustering
 Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
Learning Example. Machine learning and our focus. Another Example. An example: data (loan application) The data and the goal
 The data and the goal") Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Mathematical Models of Supervised Learning and their Application to Medical Diagnosis
 Genomic, Proteomic and Transcriptomic Lab High Performance Computing and Networking Institute National Research Council, Italy Mathematical Models of Supervised Learning and their Application to Medical
Genomic, Proteomic and Transcriptomic Lab High Performance Computing and Networking Institute National Research Council, Italy Mathematical Models of Supervised Learning and their Application to Medical
Final Project Report
 CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
Visualization by Linear Projections as Information Retrieval
 Visualization by Linear Projections as Information Retrieval Jaakko Peltonen Helsinki University of Technology, Department of Information and Computer Science, P. O. Box 5400, FI-0015 TKK, Finland jaakko.peltonen@tkk.fi
Visualization by Linear Projections as Information Retrieval Jaakko Peltonen Helsinki University of Technology, Department of Information and Computer Science, P. O. Box 5400, FI-0015 TKK, Finland jaakko.peltonen@tkk.fi
TOWARD BIG DATA ANALYSIS WORKSHOP
 TOWARD BIG DATA ANALYSIS WORKSHOP 邁 向 巨 量 資 料 分 析 研 討 會 摘 要 集 2015.06.05-06 巨 量 資 料 之 矩 陣 視 覺 化 陳 君 厚 中 央 研 究 院 統 計 科 學 研 究 所 摘 要 視 覺 化 (Visualization) 與 探 索 式 資 料 分 析 (Exploratory Data Analysis, EDA)
TOWARD BIG DATA ANALYSIS WORKSHOP 邁 向 巨 量 資 料 分 析 研 討 會 摘 要 集 2015.06.05-06 巨 量 資 料 之 矩 陣 視 覺 化 陳 君 厚 中 央 研 究 院 統 計 科 學 研 究 所 摘 要 視 覺 化 (Visualization) 與 探 索 式 資 料 分 析 (Exploratory Data Analysis, EDA)
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Machine Learning for Data Science (CS4786) Lecture 1
 Lecture 1") Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
Neural Networks Lesson 5 - Cluster Analysis
 Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm michele.scarpiniti@uniroma1.it Rome, 29
Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm michele.scarpiniti@uniroma1.it Rome, 29
A Review of Missing Data Treatment Methods
 A Review of Missing Data Treatment Methods Liu Peng, Lei Lei Department of Information Systems, Shanghai University of Finance and Economics, Shanghai, 200433, P.R. China ABSTRACT Missing data is a common
A Review of Missing Data Treatment Methods Liu Peng, Lei Lei Department of Information Systems, Shanghai University of Finance and Economics, Shanghai, 200433, P.R. China ABSTRACT Missing data is a common
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
A Content based Spam Filtering Using Optical Back Propagation Technique
 A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT
A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT
AdaBoost for Learning Binary and Multiclass Discriminations. (set to the music of Perl scripts) Avinash Kak Purdue University. June 8, 2015 12:20 Noon
 Avinash Kak Purdue University. June 8, 2015 12:20 Noon") AdaBoost for Learning Binary and Multiclass Discriminations (set to the music of Perl scripts) Avinash Kak Purdue University June 8, 2015 12:20 Noon An RVL Tutorial Presentation Originally presented in
AdaBoost for Learning Binary and Multiclass Discriminations (set to the music of Perl scripts) Avinash Kak Purdue University June 8, 2015 12:20 Noon An RVL Tutorial Presentation Originally presented in
. Learn the number of classes and the structure of each class using similarity between unlabeled training patterns
 Outline Part 1: of data clustering Non-Supervised Learning and Clustering : Problem formulation cluster analysis : Taxonomies of Clustering Techniques : Data types and Proximity Measures : Difficulties
Outline Part 1: of data clustering Non-Supervised Learning and Clustering : Problem formulation cluster analysis : Taxonomies of Clustering Techniques : Data types and Proximity Measures : Difficulties
Chapter ML:XI (continued)
") Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Face detection is a process of localizing and extracting the face region from the
 Chapter 4 FACE NORMALIZATION 4.1 INTRODUCTION Face detection is a process of localizing and extracting the face region from the background. The detected face varies in rotation, brightness, size, etc.
Chapter 4 FACE NORMALIZATION 4.1 INTRODUCTION Face detection is a process of localizing and extracting the face region from the background. The detected face varies in rotation, brightness, size, etc.
Tracking and Recognition in Sports Videos
 Tracking and Recognition in Sports Videos Mustafa Teke a, Masoud Sattari b a Graduate School of Informatics, Middle East Technical University, Ankara, Turkey mustafa.teke@gmail.com b Department of Computer
Tracking and Recognition in Sports Videos Mustafa Teke a, Masoud Sattari b a Graduate School of Informatics, Middle East Technical University, Ankara, Turkey mustafa.teke@gmail.com b Department of Computer
Predict Influencers in the Social Network
 Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, lyzhou@stanford.edu Department of Electrical Engineering, Stanford University Abstract Given two persons
Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, lyzhou@stanford.edu Department of Electrical Engineering, Stanford University Abstract Given two persons
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier. Santosh Tirunagari : 245577
 T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
Handling missing data in large data sets. Agostino Di Ciaccio Dept. of Statistics University of Rome La Sapienza
 Handling missing data in large data sets Agostino Di Ciaccio Dept. of Statistics University of Rome La Sapienza The problem Often in official statistics we have large data sets with many variables and
Handling missing data in large data sets Agostino Di Ciaccio Dept. of Statistics University of Rome La Sapienza The problem Often in official statistics we have large data sets with many variables and
Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams
 Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams Pramod D. Patil Research Scholar Department of Computer Engineering College of Engg. Pune, University of Pune Parag
Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams Pramod D. Patil Research Scholar Department of Computer Engineering College of Engg. Pune, University of Pune Parag
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Synthetic Aperture Radar: Principles and Applications of AI in Automatic Target Recognition
 Synthetic Aperture Radar: Principles and Applications of AI in Automatic Target Recognition Paulo Marques 1 Instituto Superior de Engenharia de Lisboa / Instituto de Telecomunicações R. Conselheiro Emídio
Synthetic Aperture Radar: Principles and Applications of AI in Automatic Target Recognition Paulo Marques 1 Instituto Superior de Engenharia de Lisboa / Instituto de Telecomunicações R. Conselheiro Emídio
Evaluation & Validation: Credibility: Evaluating what has been learned
 Evaluation & Validation: Credibility: Evaluating what has been learned How predictive is a learned model? How can we evaluate a model Test the model Statistical tests Considerations in evaluating a Model
Evaluation & Validation: Credibility: Evaluating what has been learned How predictive is a learned model? How can we evaluate a model Test the model Statistical tests Considerations in evaluating a Model
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning
 in Semi-supervised Learning Reducing Dimension and Maintaining Meaning") Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
Machine Learning and Data Analysis overview. Department of Cybernetics, Czech Technical University in Prague. http://ida.felk.cvut.
 Machine Learning and Data Analysis overview Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz psyllabus Lecture Lecturer Content 1. J. Kléma Introduction,
Machine Learning and Data Analysis overview Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz psyllabus Lecture Lecturer Content 1. J. Kléma Introduction,
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING
 EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
STATISTICA Formula Guide: Logistic Regression. Table of Contents
 : Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
: Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
Categorical Data Visualization and Clustering Using Subjective Factors
 Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Data, Measurements, Features
 Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
Dimensionality Reduction: Principal Components Analysis
 Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
COMPARISON OF OBJECT BASED AND PIXEL BASED CLASSIFICATION OF HIGH RESOLUTION SATELLITE IMAGES USING ARTIFICIAL NEURAL NETWORKS
 COMPARISON OF OBJECT BASED AND PIXEL BASED CLASSIFICATION OF HIGH RESOLUTION SATELLITE IMAGES USING ARTIFICIAL NEURAL NETWORKS B.K. Mohan and S. N. Ladha Centre for Studies in Resources Engineering IIT
COMPARISON OF OBJECT BASED AND PIXEL BASED CLASSIFICATION OF HIGH RESOLUTION SATELLITE IMAGES USING ARTIFICIAL NEURAL NETWORKS B.K. Mohan and S. N. Ladha Centre for Studies in Resources Engineering IIT
Data quality in Accounting Information Systems
 Data quality in Accounting Information Systems Comparing Several Data Mining Techniques Erjon Zoto Department of Statistics and Applied Informatics Faculty of Economy, University of Tirana Tirana, Albania
Data quality in Accounting Information Systems Comparing Several Data Mining Techniques Erjon Zoto Department of Statistics and Applied Informatics Faculty of Economy, University of Tirana Tirana, Albania
Distance Metric Learning for Large Margin Nearest Neighbor Classification
 Journal of Machine Learning Research 10 (2009) 207-244 Submitted 12/07; Revised 9/08; Published 2/09 Distance Metric Learning for Large Margin Nearest Neighbor Classification Kilian Q. Weinberger Yahoo!
Journal of Machine Learning Research 10 (2009) 207-244 Submitted 12/07; Revised 9/08; Published 2/09 Distance Metric Learning for Large Margin Nearest Neighbor Classification Kilian Q. Weinberger Yahoo!
Chapter 12 Discovering New Knowledge Data Mining
 Chapter 12 Discovering New Knowledge Data Mining Becerra-Fernandez, et al. -- Knowledge Management 1/e -- 2004 Prentice Hall Additional material 2007 Dekai Wu Chapter Objectives Introduce the student to
Chapter 12 Discovering New Knowledge Data Mining Becerra-Fernandez, et al. -- Knowledge Management 1/e -- 2004 Prentice Hall Additional material 2007 Dekai Wu Chapter Objectives Introduce the student to
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Towards better accuracy for Spam predictions
 Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 czhao@cs.toronto.edu Abstract Spam identification is crucial
Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 czhao@cs.toronto.edu Abstract Spam identification is crucial
Classification Techniques for Remote Sensing
 Classification Techniques for Remote Sensing Selim Aksoy Department of Computer Engineering Bilkent University Bilkent, 06800, Ankara saksoy@cs.bilkent.edu.tr http://www.cs.bilkent.edu.tr/ saksoy/courses/cs551
Classification Techniques for Remote Sensing Selim Aksoy Department of Computer Engineering Bilkent University Bilkent, 06800, Ankara saksoy@cs.bilkent.edu.tr http://www.cs.bilkent.edu.tr/ saksoy/courses/cs551
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING. ----Changsheng Liu 10-30-2014
 LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10
![131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10](/thumbs/25/4963058.jpg "131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10") 1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
Binary Logistic Regression
 Binary Logistic Regression Main Effects Model Logistic regression will accept quantitative, binary or categorical predictors and will code the latter two in various ways. Here s a simple model including
Binary Logistic Regression Main Effects Model Logistic regression will accept quantitative, binary or categorical predictors and will code the latter two in various ways. Here s a simple model including
Mahalanobis Distance Map Approach for Anomaly Detection
 Edith Cowan University Research Online Australian Information Security Management Conference Security Research Institute Conferences 2010 Mahalanobis Distance Map Approach for Anomaly Detection Aruna Jamdagnil
Edith Cowan University Research Online Australian Information Security Management Conference Security Research Institute Conferences 2010 Mahalanobis Distance Map Approach for Anomaly Detection Aruna Jamdagnil
Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods
 Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods Jerzy B laszczyński 1, Krzysztof Dembczyński 1, Wojciech Kot lowski 1, and Mariusz Paw lowski 2 1 Institute of Computing
Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods Jerzy B laszczyński 1, Krzysztof Dembczyński 1, Wojciech Kot lowski 1, and Mariusz Paw lowski 2 1 Institute of Computing
1816 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 7, JULY 2006. Principal Components Null Space Analysis for Image and Video Classification
 1816 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 7, JULY 2006 Principal Components Null Space Analysis for Image and Video Classification Namrata Vaswani, Member, IEEE, and Rama Chellappa, Fellow,
1816 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 7, JULY 2006 Principal Components Null Space Analysis for Image and Video Classification Namrata Vaswani, Member, IEEE, and Rama Chellappa, Fellow,
Independent component ordering in ICA time series analysis
 Neurocomputing 41 (2001) 145}152 Independent component ordering in ICA time series analysis Yiu-ming Cheung*, Lei Xu Department of Computer Science and Engineering, The Chinese University of Hong Kong,
Neurocomputing 41 (2001) 145}152 Independent component ordering in ICA time series analysis Yiu-ming Cheung*, Lei Xu Department of Computer Science and Engineering, The Chinese University of Hong Kong,
Character Image Patterns as Big Data
 22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
Feature Selection for Stock Market Analysis
 Feature Selection for Stock Market Analysis Yuqinq He, Kamaladdin Fataliyev, and Lipo Wang School of Electrical and Electronic Engineering Nanyang Technological University Singapore Abstract. The analysis
Feature Selection for Stock Market Analysis Yuqinq He, Kamaladdin Fataliyev, and Lipo Wang School of Electrical and Electronic Engineering Nanyang Technological University Singapore Abstract. The analysis
Why do statisticians "hate" us?
 Why do statisticians "hate" us? David Hand, Heikki Mannila, Padhraic Smyth "Data mining is the analysis of (often large) observational data sets to find unsuspected relationships and to summarize the data
Why do statisticians "hate" us? David Hand, Heikki Mannila, Padhraic Smyth "Data mining is the analysis of (often large) observational data sets to find unsuspected relationships and to summarize the data
Data Mining Algorithms Part 1. Dejan Sarka
 Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Data Visualization and Feature Selection: New Algorithms for Nongaussian Data
 Data Visualization and Feature Selection: New Algorithms for Nongaussian Data Howard Hua Yang and John Moody Oregon Graduate nstitute of Science and Technology NW, Walker Rd., Beaverton, OR976, USA hyang@ece.ogi.edu,
Data Visualization and Feature Selection: New Algorithms for Nongaussian Data Howard Hua Yang and John Moody Oregon Graduate nstitute of Science and Technology NW, Walker Rd., Beaverton, OR976, USA hyang@ece.ogi.edu,