A quick tutorial on Intel's Xeon Phi Coprocessor
|
|
|
- Mildred Gardner
- 7 years ago
- Views:
Transcription
1 A quick tutorial on Intel's Xeon Phi Coprocessor Architecture Setup Programming

2 The beginning of wisdom is the definition of terms. * Name Is a... As opposed to... Just like... Xeon Phi Product series Xeon Tesla, Quadro, GeForce MIC Microprocessor architecture Itanium, Nehalem, Sandy-Bridge, Atom Tesla, Fermi, Kepler Shippable product (SKU) 3110D, 3110P, or E C1060, C2075, M2090 Chip code name Nehalem, Westmere, Sandy-Bridge, Ivy-Bridge Lincroft, Cedarview GF110, GK110 Set of software (drivers, kernel modules, etc.) N.A. CUDA toolkit Many Integrated Core Architecture 5110P Knights Corner MPSS Manycore Platform Software Stack Visual * Socrates ( B.C.)
 N.A.")
3 60-cores Architecture

4 Xeon Phi core Architecture and core definition 1 to 1.3 GHz Xeon Phi core 1 SPU 1 double op/cycle In-order architecture x86 + mic extensions 4 hardware threads 1 VPU 32 float op/cycle 16 double op/cycle Supports fused mult-add Supports transcendentals 4 clock latency 4 hardware threads nvidia Kepler SMX 735 to 745 MHz 192 SP CUDA cores 2 double op/cycle Supports fused mult-add CUDA core 64 DPUnits 2 double op/cycle Supports fused mult-add 32 SFU units 1 double op/cycle Supports transcendentals

5 Xeon Phi core Architecture and core definition 1 to 1.3 GHz 1 SPU 1 double op/cycle In-order architecture x86 + mic extensions 4 hardware threads Xeon Phi core A Xeon Phi core is much more complex than a CUDA core 1 VPU 32 float op/cycle 16 double op/cycle Supports fused mult-add Supports transcendentals 4 clock latency 4 hardware threads nvidia Kepler SMX 735 to 745 MHz 192 SP CUDA cores 2 double op/cycle Supports fused mult-add CUDA core 64 DPUnits 2 double op/cycle Supports fused mult-add 32 SFU units 1 double op/cycle Supports transcendentals

6 Architecture and core definition Nehalem core



7 Architecture and core definition Nehalem core But still far less complex than a Xeon core

8 Architecture and core definition Two specificities: (1) In-Order architecture with hardware multithreading --> need multithreaded/multiprocessed code (2) Huge vector processing unit --> need vectorized code
 Huge vector")
9 When working with them: Think multithreading Think Vectorization

10 Setup

11 Accelerator mode vs Cluster mode * GbE GbE** PCIe 0 br PCIe /dev/ttymic0 * Host must route packets from Xeon Phi /dev/ttymic0 ** Or Infiniband with RDMA (OFED)

12 Accelerator mode vs Cluster mode * GbE PCIe /dev/ttymic0 * Host must route packets from Xeon Phi GbE** Our Xeon phi is installed in node mback40 of 0 clusterbrmanneback in 'accelerator mode' PCIe /dev/ttymic0 ** Or Infiniband with RDMA (OFED)

13 Slurm integration
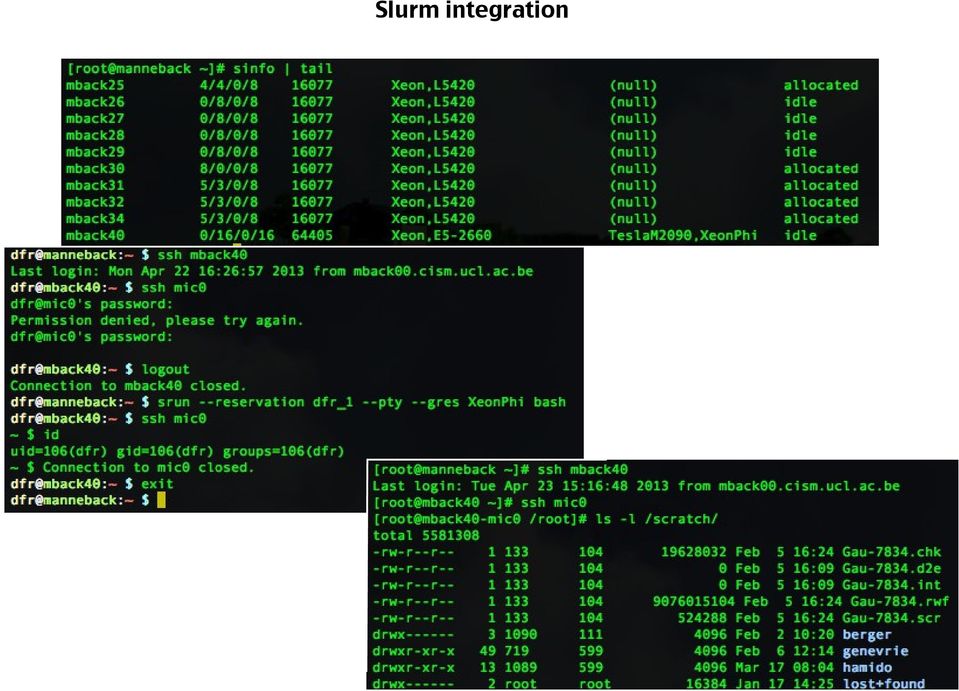
14 Slurm integration As a so-called 'generic resource' Within a job allocation, users have ssh access to the Xeon Phi Mback40's scratch space is available from the Xeon Phi

15 Slurm integration You need to have a pair of corresponding SSH keys As a so-called 'generic resource' id_rsa / id_rsa.pub in your.ssh directory for this to work. The public key is copied to the Xeon Phi upon job startup Within a job allocation, users have ssh access to the Xeon Phi Mback40's scratch space is available from the Xeon Phi

16 Programming

17 Intel: First optimize on Xeon then port to Xeon Phi

18 Execution models OpenCL Offload OpenMP Offload MPI MKL Offload mode Intel MPI Native OpenMP Native Intel MPI

19 Execution models CUDA OpenCL CuBLAS Intel MPI Native OpenMP Native Intel MPI


20 4 Programming models

21 (symmetric) Execution models Offload Hybrid Native Programming models OpenMP MPI MKL OpenCL Easy Bit more complex Truly complex Impossible
22 Native OpenMP
23 Native OpenMP Simple OpenMP Hello world program
24 Native OpenMP Classical compilation for Xeon Compilation for Xeon Phi Code transfer through micnativeloadex Code transfer through SSH Compile on the host, run on the Xeon Phi
25 Offload OpenMP
26 Offload OpenMP Same program with offload pragmas
27 Offload OpenMP Classical compilation Offloaded sections run on the Xeon Phi Same code runs on Xeon flawlessly when no Xeon Phi is available Compile on the host, launch on the host, offload to Xeon Phi
28 Hybrid OpenMP
29 Hybrid OpenMP This section will run on the host...
30 Hybrid OpenMP... in parallel with that section which will run on the Xeon Phi
31 Hybrid OpenMP You get some threads on the host and some others on the Phi Compile on the host, run some on the host, offload some to Phi
32 Native intel MPI
33 Native intel MPI Simple MPI hello world program
34 Native intel MPI Compile on the host, run on Xeon Phi
35 Hybrid intel MPI
36 Hybrid intel MPI Same MPI hello world program
37 Hybrid intel MPI Compile once for the host and once for the XeonPhi Add the Xeon Phi to the machine file You get 2 processes on the host and 2 other on the Phi Compile on the host, run some on the host, offload some to Phi
38 Offload intel MPI Hybrid OpenMP/MPI hello world program with offload sections
39 Offload intel MPI You get 2 MPI processes on the host, each offloading 4 OMP threads to the Xeon Phi
40 Native MKL
41 Native MKL Simple SGEMM usage (remaining of the code not shown... handles parameter parsing, matrix creation, initialization, etc.)
42 Native MKL Compile on the host, run on Xeon Phi
43 Automatic offload MKL
44 Automatic offload MKL Same Simple SGEMM usage (no change)
45 Automatic offload MKL Allow MKL to use the Xeon Phi and be verbose about offloading Half the work done by the host, the other half by the Phi Compile on the host, run some on the host, offload some to Phi
46 Automatic offload MKL When data are too small, the Xeon Phi is not used (transfers would cost proportionally too much)
47 When working with them: Porting should be easy Hybrid is doable
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
GPU Hardware CS 380P. Paul A. Navrá7l Manager Scalable Visualiza7on Technologies Texas Advanced Compu7ng Center
 GPU Hardware CS 380P Paul A. Navrá7l Manager Scalable Visualiza7on Technologies Texas Advanced Compu7ng Center with thanks to Don Fussell for slides 15-28 and Bill Barth for slides 36-55 CPU vs. GPU characteris7cs
GPU Hardware CS 380P Paul A. Navrá7l Manager Scalable Visualiza7on Technologies Texas Advanced Compu7ng Center with thanks to Don Fussell for slides 15-28 and Bill Barth for slides 36-55 CPU vs. GPU characteris7cs
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Introduction to GP-GPUs. Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1
 Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Using the Intel Xeon Phi (with the Stampede Supercomputer) ISC 13 Tutorial
 ISC 13 Tutorial") Using the Intel Xeon Phi (with the Stampede Supercomputer) ISC 13 Tutorial Bill Barth, Kent Milfeld, Dan Stanzione Tommy Minyard Texas Advanced Computing Center Jim Jeffers, Intel June 2013, Leipzig, Germany
Using the Intel Xeon Phi (with the Stampede Supercomputer) ISC 13 Tutorial Bill Barth, Kent Milfeld, Dan Stanzione Tommy Minyard Texas Advanced Computing Center Jim Jeffers, Intel June 2013, Leipzig, Germany
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
RWTH GPU Cluster. Sandra Wienke wienke@rz.rwth-aachen.de November 2012. Rechen- und Kommunikationszentrum (RZ) Fotos: Christian Iwainsky
 Fotos: Christian Iwainsky") RWTH GPU Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de November 2012 Rechen- und Kommunikationszentrum (RZ) The RWTH GPU Cluster GPU Cluster: 57 Nvidia Quadro 6000 (Fermi) innovative
RWTH GPU Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de November 2012 Rechen- und Kommunikationszentrum (RZ) The RWTH GPU Cluster GPU Cluster: 57 Nvidia Quadro 6000 (Fermi) innovative
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing
 Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
Big Data Visualization on the MIC
 Big Data Visualization on the MIC Tim Dykes School of Creative Technologies University of Portsmouth timothy.dykes@port.ac.uk Many-Core Seminar Series 26/02/14 Splotch Team Tim Dykes, University of Portsmouth
Big Data Visualization on the MIC Tim Dykes School of Creative Technologies University of Portsmouth timothy.dykes@port.ac.uk Many-Core Seminar Series 26/02/14 Splotch Team Tim Dykes, University of Portsmouth
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Running Native Lustre* Client inside Intel Xeon Phi coprocessor
 Running Native Lustre* Client inside Intel Xeon Phi coprocessor Dmitry Eremin, Zhiqi Tao and Gabriele Paciucci 08 April 2014 * Some names and brands may be claimed as the property of others. What is the
Running Native Lustre* Client inside Intel Xeon Phi coprocessor Dmitry Eremin, Zhiqi Tao and Gabriele Paciucci 08 April 2014 * Some names and brands may be claimed as the property of others. What is the
Kashif Iqbal - PhD Kashif.iqbal@ichec.ie
 HPC/HTC vs. Cloud Benchmarking An empirical evalua.on of the performance and cost implica.ons Kashif Iqbal - PhD Kashif.iqbal@ichec.ie ICHEC, NUI Galway, Ireland With acknowledgment to Michele MicheloDo
HPC/HTC vs. Cloud Benchmarking An empirical evalua.on of the performance and cost implica.ons Kashif Iqbal - PhD Kashif.iqbal@ichec.ie ICHEC, NUI Galway, Ireland With acknowledgment to Michele MicheloDo
Case Study on Productivity and Performance of GPGPUs
 Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Exascale Challenges and General Purpose Processors. Avinash Sodani, Ph.D. Chief Architect, Knights Landing Processor Intel Corporation
 Exascale Challenges and General Purpose Processors Avinash Sodani, Ph.D. Chief Architect, Knights Landing Processor Intel Corporation Jun-93 Aug-94 Oct-95 Dec-96 Feb-98 Apr-99 Jun-00 Aug-01 Oct-02 Dec-03
Exascale Challenges and General Purpose Processors Avinash Sodani, Ph.D. Chief Architect, Knights Landing Processor Intel Corporation Jun-93 Aug-94 Oct-95 Dec-96 Feb-98 Apr-99 Jun-00 Aug-01 Oct-02 Dec-03
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Overview of HPC Resources at Vanderbilt
 Overview of HPC Resources at Vanderbilt Will French Senior Application Developer and Research Computing Liaison Advanced Computing Center for Research and Education June 10, 2015 2 Computing Resources
Overview of HPC Resources at Vanderbilt Will French Senior Application Developer and Research Computing Liaison Advanced Computing Center for Research and Education June 10, 2015 2 Computing Resources
White Paper. Intel Xeon Phi Coprocessor DEVELOPER S QUICK START GUIDE. Version 1.5
 White Paper Intel Xeon Phi Coprocessor DEVELOPER S QUICK START GUIDE Version 1.5 Contents Introduction... 4 Goals... 4 This document does:... 4 This document does not:... 4 Terminology... 4 System Configuration...
White Paper Intel Xeon Phi Coprocessor DEVELOPER S QUICK START GUIDE Version 1.5 Contents Introduction... 4 Goals... 4 This document does:... 4 This document does not:... 4 Terminology... 4 System Configuration...
Retargeting PLAPACK to Clusters with Hardware Accelerators
 Retargeting PLAPACK to Clusters with Hardware Accelerators Manuel Fogué 1 Francisco Igual 1 Enrique S. Quintana-Ortí 1 Robert van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores.
Retargeting PLAPACK to Clusters with Hardware Accelerators Manuel Fogué 1 Francisco Igual 1 Enrique S. Quintana-Ortí 1 Robert van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores.
The PHI solution. Fujitsu Industry Ready Intel XEON-PHI based solution. SC2013 - Denver
 1 The PHI solution Fujitsu Industry Ready Intel XEON-PHI based solution SC2013 - Denver Industrial Application Challenges Most of existing scientific and technical applications Are written for legacy execution
1 The PHI solution Fujitsu Industry Ready Intel XEON-PHI based solution SC2013 - Denver Industrial Application Challenges Most of existing scientific and technical applications Are written for legacy execution
Experiences on using GPU accelerators for data analysis in ROOT/RooFit
 Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Pedraforca: ARM + GPU prototype
 www.bsc.es Pedraforca: ARM + GPU prototype Filippo Mantovani Workshop on exascale and PRACE prototypes Barcelona, 20 May 2014 Overview Goals: Test the performance, scalability, and energy efficiency of
www.bsc.es Pedraforca: ARM + GPU prototype Filippo Mantovani Workshop on exascale and PRACE prototypes Barcelona, 20 May 2014 Overview Goals: Test the performance, scalability, and energy efficiency of
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
Programming the Intel Xeon Phi Coprocessor
 Programming the Intel Xeon Phi Coprocessor Tim Cramer cramer@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Motivation Many Integrated Core (MIC) Architecture Programming Models Native
Programming the Intel Xeon Phi Coprocessor Tim Cramer cramer@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Motivation Many Integrated Core (MIC) Architecture Programming Models Native
CFD Implementation with In-Socket FPGA Accelerators
 CFD Implementation with In-Socket FPGA Accelerators Ivan Gonzalez UAM Team at DOVRES FuSim-E Programme Symposium: CFD on Future Architectures C 2 A 2 S 2 E DLR Braunschweig 14 th -15 th October 2009 Outline
CFD Implementation with In-Socket FPGA Accelerators Ivan Gonzalez UAM Team at DOVRES FuSim-E Programme Symposium: CFD on Future Architectures C 2 A 2 S 2 E DLR Braunschweig 14 th -15 th October 2009 Outline
Resource Scheduling Best Practice in Hybrid Clusters
 Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Resource Scheduling Best Practice in Hybrid Clusters C. Cavazzoni a, A. Federico b, D. Galetti a, G. Morelli b, A. Pieretti
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Resource Scheduling Best Practice in Hybrid Clusters C. Cavazzoni a, A. Federico b, D. Galetti a, G. Morelli b, A. Pieretti
Introduction to Linux and Cluster Basics for the CCR General Computing Cluster
 Introduction to Linux and Cluster Basics for the CCR General Computing Cluster Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY 14203 Phone: 716-881-8959
Introduction to Linux and Cluster Basics for the CCR General Computing Cluster Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY 14203 Phone: 716-881-8959
Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com
 mzahran@cs.nyu.edu http://www.mzahran.com") CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
A Case Study - Scaling Legacy Code on Next Generation Platforms
 Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age
 Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
 WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
ST810 Advanced Computing
 ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
Debugging in Heterogeneous Environments with TotalView. ECMWF HPC Workshop 30 th October 2014
 Debugging in Heterogeneous Environments with TotalView ECMWF HPC Workshop 30 th October 2014 Agenda Introduction Challenges TotalView overview Advanced features Current work and future plans 2014 Rogue
Debugging in Heterogeneous Environments with TotalView ECMWF HPC Workshop 30 th October 2014 Agenda Introduction Challenges TotalView overview Advanced features Current work and future plans 2014 Rogue
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Programming Techniques for Supercomputers: Multicore processors. There is no way back Modern multi-/manycore chips Basic Compute Node Architecture
 Programming Techniques for Supercomputers: Multicore processors There is no way back Modern multi-/manycore chips Basic ompute Node Architecture SimultaneousMultiThreading (SMT) Prof. Dr. G. Wellein (a,b),
Programming Techniques for Supercomputers: Multicore processors There is no way back Modern multi-/manycore chips Basic ompute Node Architecture SimultaneousMultiThreading (SMT) Prof. Dr. G. Wellein (a,b),
Cluster performance, how to get the most out of Abel. Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013
 Cluster performance, how to get the most out of Abel Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013 Introduction Architecture x86-64 and NVIDIA Compilers MPI Interconnect Storage Batch queue
Cluster performance, how to get the most out of Abel Ole W. Saastad, Dr.Scient USIT / UAV / FI April 18 th 2013 Introduction Architecture x86-64 and NVIDIA Compilers MPI Interconnect Storage Batch queue
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
OpenCL Optimization. San Jose 10/2/2009 Peng Wang, NVIDIA
 OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
Intel Xeon Phi Basic Tutorial
 Intel Xeon Phi Basic Tutorial Evan Bollig and Brent Swartz 1pm, 12/19/2013 Overview Intro to MSI Intro to the MIC Architecture Targeting the Xeon Phi Examples Automatic Offload Offload Mode Native Mode
Intel Xeon Phi Basic Tutorial Evan Bollig and Brent Swartz 1pm, 12/19/2013 Overview Intro to MSI Intro to the MIC Architecture Targeting the Xeon Phi Examples Automatic Offload Offload Mode Native Mode
Programming models for heterogeneous computing. Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga
 Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Intel Many Integrated Core Architecture: An Overview and Programming Models
 Intel Many Integrated Core Architecture: An Overview and Programming Models Jim Jeffers SW Product Application Engineer Technical Computing Group Agenda An Overview of Intel Many Integrated Core Architecture
Intel Many Integrated Core Architecture: An Overview and Programming Models Jim Jeffers SW Product Application Engineer Technical Computing Group Agenda An Overview of Intel Many Integrated Core Architecture
HIGH PERFORMANCE CONSULTING COURSE OFFERINGS
 Performance 1(6) HIGH PERFORMANCE CONSULTING COURSE OFFERINGS LEARN TO TAKE ADVANTAGE OF POWERFUL GPU BASED ACCELERATOR TECHNOLOGY TODAY 2006 2013 Nvidia GPUs Intel CPUs CONTENTS Acronyms and Terminology...
Performance 1(6) HIGH PERFORMANCE CONSULTING COURSE OFFERINGS LEARN TO TAKE ADVANTAGE OF POWERFUL GPU BASED ACCELERATOR TECHNOLOGY TODAY 2006 2013 Nvidia GPUs Intel CPUs CONTENTS Acronyms and Terminology...
Next Generation GPU Architecture Code-named Fermi
 Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs
 Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
GPU File System Encryption Kartik Kulkarni and Eugene Linkov
 GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
FLOW-3D Performance Benchmark and Profiling. September 2012
 FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
Introduction to Running Computations on the High Performance Clusters at the Center for Computational Research
 ! Introduction to Running Computations on the High Performance Clusters at the Center for Computational Research! Cynthia Cornelius! Center for Computational Research University at Buffalo, SUNY! cdc at
! Introduction to Running Computations on the High Performance Clusters at the Center for Computational Research! Cynthia Cornelius! Center for Computational Research University at Buffalo, SUNY! cdc at
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
High Performance. CAEA elearning Series. Jonathan G. Dudley, Ph.D. 06/09/2015. 2015 CAE Associates
 High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
The Fastest, Most Efficient HPC Architecture Ever Built
 Whitepaper NVIDIA s Next Generation TM CUDA Compute Architecture: TM Kepler GK110 The Fastest, Most Efficient HPC Architecture Ever Built V1.0 Table of Contents Kepler GK110 The Next Generation GPU Computing
Whitepaper NVIDIA s Next Generation TM CUDA Compute Architecture: TM Kepler GK110 The Fastest, Most Efficient HPC Architecture Ever Built V1.0 Table of Contents Kepler GK110 The Next Generation GPU Computing
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
Kalray MPPA Massively Parallel Processing Array
 Kalray MPPA Massively Parallel Processing Array Next-Generation Accelerated Computing February 2015 2015 Kalray, Inc. All Rights Reserved February 2015 1 Accelerated Computing 2015 Kalray, Inc. All Rights
Kalray MPPA Massively Parallel Processing Array Next-Generation Accelerated Computing February 2015 2015 Kalray, Inc. All Rights Reserved February 2015 1 Accelerated Computing 2015 Kalray, Inc. All Rights
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
Introduction to Hybrid Programming
 Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC
 OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
Using NeSI HPC Resources. NeSI Computational Science Team (support@nesi.org.nz)
") NeSI Computational Science Team (support@nesi.org.nz) Outline 1 About Us About NeSI Our Facilities 2 Using the Cluster Suitable Work What to expect Parallel speedup Data Getting to the Login Node 3 Submitting
NeSI Computational Science Team (support@nesi.org.nz) Outline 1 About Us About NeSI Our Facilities 2 Using the Cluster Suitable Work What to expect Parallel speedup Data Getting to the Login Node 3 Submitting
The Asterope compute cluster
 The Asterope compute cluster ÅA has a small cluster named asterope.abo.fi with 8 compute nodes Each node has 2 Intel Xeon X5650 processors (6-core) with a total of 24 GB RAM 2 NVIDIA Tesla M2050 GPGPU
The Asterope compute cluster ÅA has a small cluster named asterope.abo.fi with 8 compute nodes Each node has 2 Intel Xeon X5650 processors (6-core) with a total of 24 GB RAM 2 NVIDIA Tesla M2050 GPGPU
1 Bull, 2011 Bull Extreme Computing
 1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
HPC Software Requirements to Support an HPC Cluster Supercomputer
 HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
Home Exam 3: Distributed Video Encoding using Dolphin PCI Express Networks. October 20 th 2015
 INF5063: Programming heterogeneous multi-core processors because the OS-course is just to easy! Home Exam 3: Distributed Video Encoding using Dolphin PCI Express Networks October 20 th 2015 Håkon Kvale
INF5063: Programming heterogeneous multi-core processors because the OS-course is just to easy! Home Exam 3: Distributed Video Encoding using Dolphin PCI Express Networks October 20 th 2015 Håkon Kvale
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
An Overview of Programming for Intel Xeon processors and Intel Xeon Phi coprocessors
 An Overview of Programming for Intel Xeon processors and Intel Xeon Phi coprocessors James Reinders, Intel Introduction Intel Xeon Phi coprocessors are designed to extend the reach of applications that
An Overview of Programming for Intel Xeon processors and Intel Xeon Phi coprocessors James Reinders, Intel Introduction Intel Xeon Phi coprocessors are designed to extend the reach of applications that
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER
 CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Turbomachinery CFD on many-core platforms experiences and strategies
 Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Evaluation of CUDA Fortran for the CFD code Strukti
 Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
Three Paths to Faster Simulations Using ANSYS Mechanical 16.0 and Intel Architecture
 White Paper Intel Xeon processor E5 v3 family Intel Xeon Phi coprocessor family Digital Design and Engineering Three Paths to Faster Simulations Using ANSYS Mechanical 16.0 and Intel Architecture Executive
White Paper Intel Xeon processor E5 v3 family Intel Xeon Phi coprocessor family Digital Design and Engineering Three Paths to Faster Simulations Using ANSYS Mechanical 16.0 and Intel Architecture Executive
Design and Optimization of a Portable Lattice Boltzmann Code for Heterogeneous Architectures
 Design and Optimization of a Portable Lattice Boltzmann Code for Heterogeneous Architectures E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy Perspectives of GPU Computing in Physics
Design and Optimization of a Portable Lattice Boltzmann Code for Heterogeneous Architectures E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy Perspectives of GPU Computing in Physics
How To Build A Supermicro Computer With A 32 Core Power Core (Powerpc) And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (
 And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
CERN openlab III. Major Review Platform CC. Sverre Jarp Alfio Lazzaro Julien Leduc Andrzej Nowak
 CERN openlab III Major Review Platform CC Sverre Jarp Alfio Lazzaro Julien Leduc Andrzej Nowak Teaching (1) 3 workshops already held this year: Computer Architecture and Performance Tuning: 17/18 February
CERN openlab III Major Review Platform CC Sverre Jarp Alfio Lazzaro Julien Leduc Andrzej Nowak Teaching (1) 3 workshops already held this year: Computer Architecture and Performance Tuning: 17/18 February
Building a Top500-class Supercomputing Cluster at LNS-BUAP
 Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Windows IB. Introduction to Windows 2003 Compute Cluster Edition. Eric Lantz Microsoft elantz@microsoft.com
 Datacenter Fabric Workshop Windows IB Introduction to Windows 2003 Compute Cluster Edition Eric Lantz Microsoft elantz@microsoft.com August 22, 2005 What this talk is not about High Availability, Fail-over
Datacenter Fabric Workshop Windows IB Introduction to Windows 2003 Compute Cluster Edition Eric Lantz Microsoft elantz@microsoft.com August 22, 2005 What this talk is not about High Availability, Fail-over
High Performance Computing in CST STUDIO SUITE
 High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
Debugging with TotalView
 Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
GPU Usage. Requirements
 GPU Usage Use the GPU Usage tool in the Performance and Diagnostics Hub to better understand the high-level hardware utilization of your Direct3D app. You can use it to determine whether the performance
GPU Usage Use the GPU Usage tool in the Performance and Diagnostics Hub to better understand the high-level hardware utilization of your Direct3D app. You can use it to determine whether the performance
Xeon Phi Application Development on Windows OS
 Chapter 12 Xeon Phi Application Development on Windows OS So far we have looked at application development on the Linux OS for the Xeon Phi coprocessor. This chapter looks at what types of support are
Chapter 12 Xeon Phi Application Development on Windows OS So far we have looked at application development on the Linux OS for the Xeon Phi coprocessor. This chapter looks at what types of support are
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU
 Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Deep Learning GPU-Based Hardware Platform
 Deep Learning GPU-Based Hardware Platform Hardware and Software Criteria and Selection Mourad Bouache Yahoo! Performance Engineering Group Sunnyvale, CA +1.408.784.1446 bouache@yahoo-inc.com John Glover
Deep Learning GPU-Based Hardware Platform Hardware and Software Criteria and Selection Mourad Bouache Yahoo! Performance Engineering Group Sunnyvale, CA +1.408.784.1446 bouache@yahoo-inc.com John Glover
Auto-Tuning TRSM with an Asynchronous Task Assignment Model on Multicore, GPU and Coprocessor Systems
 Auto-Tuning TRSM with an Asynchronous Task Assignment Model on Multicore, GPU and Coprocessor Systems Murilo Boratto Núcleo de Arquitetura de Computadores e Sistemas Operacionais, Universidade do Estado
Auto-Tuning TRSM with an Asynchronous Task Assignment Model on Multicore, GPU and Coprocessor Systems Murilo Boratto Núcleo de Arquitetura de Computadores e Sistemas Operacionais, Universidade do Estado
Assessing the Performance of OpenMP Programs on the Intel Xeon Phi
 Assessing the Performance of OpenMP Programs on the Intel Xeon Phi Dirk Schmidl, Tim Cramer, Sandra Wienke, Christian Terboven, and Matthias S. Müller schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum
Assessing the Performance of OpenMP Programs on the Intel Xeon Phi Dirk Schmidl, Tim Cramer, Sandra Wienke, Christian Terboven, and Matthias S. Müller schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum
Introduction to HPC Workshop. Center for e-research (eresearch@nesi.org.nz)
") Center for e-research (eresearch@nesi.org.nz) Outline 1 About Us About CER and NeSI The CS Team Our Facilities 2 Key Concepts What is a Cluster Parallel Programming Shared Memory Distributed Memory 3 Using
Center for e-research (eresearch@nesi.org.nz) Outline 1 About Us About CER and NeSI The CS Team Our Facilities 2 Key Concepts What is a Cluster Parallel Programming Shared Memory Distributed Memory 3 Using
Keys to node-level performance analysis and threading in HPC applications
 Keys to node-level performance analysis and threading in HPC applications Thomas GUILLET (Intel; Exascale Computing Research) IFERC seminar, 18 March 2015 Legal Disclaimer & Optimization Notice INFORMATION
Keys to node-level performance analysis and threading in HPC applications Thomas GUILLET (Intel; Exascale Computing Research) IFERC seminar, 18 March 2015 Legal Disclaimer & Optimization Notice INFORMATION
HP ProLiant SL270s Gen8 Server. Evaluation Report
 HP ProLiant SL270s Gen8 Server Evaluation Report Thomas Schoenemeyer, Hussein Harake and Daniel Peter Swiss National Supercomputing Centre (CSCS), Lugano Institute of Geophysics, ETH Zürich schoenemeyer@cscs.ch
HP ProLiant SL270s Gen8 Server Evaluation Report Thomas Schoenemeyer, Hussein Harake and Daniel Peter Swiss National Supercomputing Centre (CSCS), Lugano Institute of Geophysics, ETH Zürich schoenemeyer@cscs.ch
SLURM Workload Manager
 SLURM Workload Manager What is SLURM? SLURM (Simple Linux Utility for Resource Management) is the native scheduler software that runs on ASTI's HPC cluster. Free and open-source job scheduler for the Linux
SLURM Workload Manager What is SLURM? SLURM (Simple Linux Utility for Resource Management) is the native scheduler software that runs on ASTI's HPC cluster. Free and open-source job scheduler for the Linux
Introduction to GPGPU. Tiziano Diamanti t.diamanti@cineca.it
 t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS
 AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS") A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
SR-IOV In High Performance Computing
 SR-IOV In High Performance Computing Hoot Thompson & Dan Duffy NASA Goddard Space Flight Center Greenbelt, MD 20771 hoot@ptpnow.com daniel.q.duffy@nasa.gov www.nccs.nasa.gov Focus on the research side
SR-IOV In High Performance Computing Hoot Thompson & Dan Duffy NASA Goddard Space Flight Center Greenbelt, MD 20771 hoot@ptpnow.com daniel.q.duffy@nasa.gov www.nccs.nasa.gov Focus on the research side
Performance Characteristics of Large SMP Machines
 Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
NVIDIA CUDA GETTING STARTED GUIDE FOR MICROSOFT WINDOWS
 NVIDIA CUDA GETTING STARTED GUIDE FOR MICROSOFT WINDOWS DU-05349-001_v6.0 February 2014 Installation and Verification on TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2.
NVIDIA CUDA GETTING STARTED GUIDE FOR MICROSOFT WINDOWS DU-05349-001_v6.0 February 2014 Installation and Verification on TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2.
Enhancing Cloud-based Servers by GPU/CPU Virtualization Management
 Enhancing Cloud-based Servers by GPU/CPU Virtualiz Management Tin-Yu Wu 1, Wei-Tsong Lee 2, Chien-Yu Duan 2 Department of Computer Science and Inform Engineering, Nal Ilan University, Taiwan, ROC 1 Department
Enhancing Cloud-based Servers by GPU/CPU Virtualiz Management Tin-Yu Wu 1, Wei-Tsong Lee 2, Chien-Yu Duan 2 Department of Computer Science and Inform Engineering, Nal Ilan University, Taiwan, ROC 1 Department
Xeon+FPGA Platform for the Data Center
 Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
CPU Session 1. Praktikum Parallele Rechnerarchtitekturen. Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1
 CPU Session 1 Praktikum Parallele Rechnerarchtitekturen Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1 Overview Types of Parallelism in Modern Multi-Core CPUs o Multicore
CPU Session 1 Praktikum Parallele Rechnerarchtitekturen Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1 Overview Types of Parallelism in Modern Multi-Core CPUs o Multicore
REMOTE VISUALIZATION ON SERVER-CLASS TESLA GPUS
 REMOTE VISUALIZATION ON SERVER-CLASS TESLA GPUS WP-07313-001_v01 June 2014 White Paper TABLE OF CONTENTS Introduction... 4 Challenges in Remote and In-Situ Visualization... 5 GPU-Accelerated Remote Visualization
REMOTE VISUALIZATION ON SERVER-CLASS TESLA GPUS WP-07313-001_v01 June 2014 White Paper TABLE OF CONTENTS Introduction... 4 Challenges in Remote and In-Situ Visualization... 5 GPU-Accelerated Remote Visualization
Performance monitoring at CERN openlab. July 20 th 2012 Andrzej Nowak, CERN openlab
 Performance monitoring at CERN openlab July 20 th 2012 Andrzej Nowak, CERN openlab Data flow Reconstruction Selection and reconstruction Online triggering and filtering in detectors Raw Data (100%) Event
Performance monitoring at CERN openlab July 20 th 2012 Andrzej Nowak, CERN openlab Data flow Reconstruction Selection and reconstruction Online triggering and filtering in detectors Raw Data (100%) Event
Intel Xeon +FPGA Platform for the Data Center
 Intel Xeon +FPGA Platform for the Data Center FPL 15 Workshop on Reconfigurable Computing for the Masses PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA
Intel Xeon +FPGA Platform for the Data Center FPL 15 Workshop on Reconfigurable Computing for the Masses PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA
PCI Express IO Virtualization Overview
 Ron Emerick, Oracle Corporation Author: Ron Emerick, Oracle Corporation SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and
Ron Emerick, Oracle Corporation Author: Ron Emerick, Oracle Corporation SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and
GPU Computing. The GPU Advantage. To ExaScale and Beyond. The GPU is the Computer
 GU Computing 1 2 3 The GU Advantage To ExaScale and Beyond The GU is the Computer The GU Advantage The GU Advantage A Tale of Two Machines Tianhe-1A at NSC Tianjin Tianhe-1A at NSC Tianjin The World s
GU Computing 1 2 3 The GU Advantage To ExaScale and Beyond The GU is the Computer The GU Advantage The GU Advantage A Tale of Two Machines Tianhe-1A at NSC Tianjin Tianhe-1A at NSC Tianjin The World s