KNIME TUTORIAL. Anna Monreale KDD-Lab, University of Pisa
|
|
|
- Audra Esther Doyle
- 8 years ago
- Views:
Transcription
1 KNIME TUTORIAL Anna Monreale KDD-Lab, University of Pisa

2 Outline Introduction on KNIME KNIME components Exercise: Market Basket Analysis Exercise: Customer Segmentation Exercise: Churn Analysis Exercise: Social Network Analysis

3 What is KNIME? KNIME = Konstanz Information Miner Developed at University of Konstanz in Germany Desktop version available free of charge (Open Source) Modular platform for building and executing workflows using predefined components, called nodes Functionality available for tasks such as standard data mining, data analysis and data manipulation Extra features and functionalities available in KNIME by extensions Written in Java based on the Eclipse SDK platform

4 KNIME resources Web pages containing documentation - tech.knime.org tech.knime.org installation-0 Downloads knime.org/download-desktop Community forum tech.knime.org/forum Books and white papers knime.org/node/33079

5 What can you do with KNIME? Data manipulation and analysis File & database I/O, filtering, grouping, joining,. Data mining / machine learning WEKA, R, Interactive plotting Scripting Integration R, Perl, Python, Matlab Much more Bioinformatics, text mining and network analysis

6 Installation and updates Download and unzip KNIME No further setup required Additional nodes after first launch New software (nodes) from update sites realease Workflows and data are stored in a workspace

7
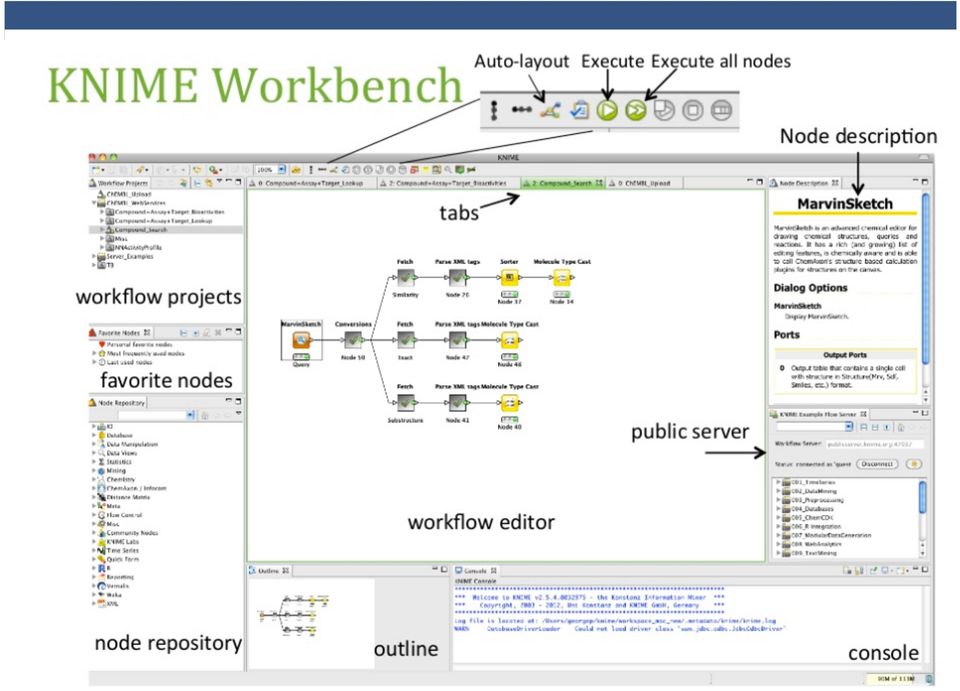
8 KNIME nodes: Overview
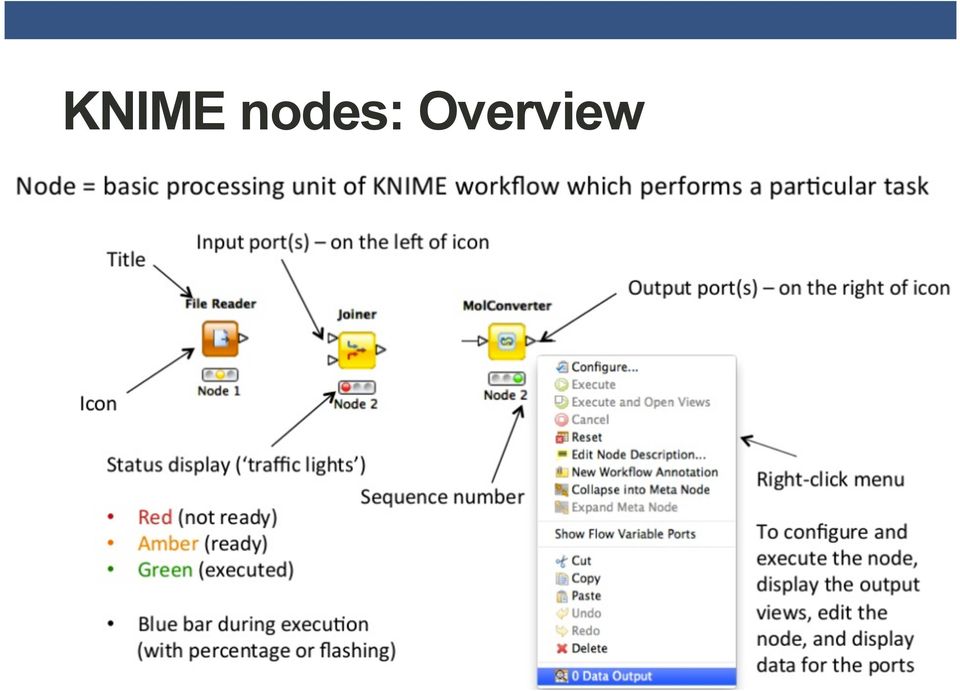
9 KNIME nodes: Dialogs

10 An example of workflow

11 CSV Reader

12 CSV Writer

13 Statistics node For all numeric columns computes statistics such as minimum, maximum, mean, standard deviation, variance, median, overall sum, number of missing values and row counts For all nominal values counts them together with their occurrences.

14 Correlation Analysis Linear Correlation node computes for each pair of selected columns a correlation coefficient, i.e. a measure of the correlation of the two variables Pearson Correlation Coefficient Correlation Filtering node uses the model as generated by a Correlation node to determine which columns are redundant (i.e. correlated) and filters them out. The output table will contain the reduced set of columns.
 and filters them out.")
15 Data Views Box Plots Histograms,Pie Charts, Scatter plots, Scatter Matrix

16 Data Manipulation Three main sections Columns: binning, replace, filters, normalizer, missing values, Rows: filtering, sampling, partitioning, Matrix: Transpose

17 Mining Algorithms Clustering Hierarchical K-means Fuzzy c-means Decision Tree Item sets / Association Rules Borgelt s Algorithms Weka

18 EXERCISES Anna Monreale KDD-Lab, University of Pisa

19 Exercises and Final Exams 3 Exercises Market Basket Analysis Customer segmentation with k-means Churn analysis with decision trees Final Exam A report describing the three analysis and your findings

20 MARKET BASKET ANALYSIS Anna Monreale KDD-Lab, University of Pisa

21 Market Basket Analysis Problem: given a database of transactions of customers of a supermarket, find the set of frequent items copurchased and analyze the association rules that is possible to derive from the frequent patterns. Provide a short document (max three pages in pdf, excluding figures/plots) which illustrates the input dataset, the adopted frequent pattern algorithm and the association rule analysis.
22 DATA DESCRIPTION A sample of transaction data from a Supermarket 15 days of May 2010 About 35,200 transactions Two versions of the transaction dataset 1. Each transaction (row) has the list of product_id purchased by a client (File: TDB_product.csv) 2. Each transaction (row) has the list of segment_id of the product purchased by a client (File: TDB_segment.csv) Segment_id is an aggregation of articles Performing the analysis on both and compare the results Additional Files contain the description of each code Description_mkts.csv and Description_product.csv
23 Frequent Patterns and AR in KNIME Use the nodes implementing the Borgelt s Algorithms: Item Set Finder node provides different algorithms: Apriori (Agrawal et al. 1993) FPgrowth (frequent pattern growth, Han et al 2000) RElim (recursive elimination) SaM (Split and Merge) JIM (Jaccard Item Set Mining) AR Learner uses Apriori Algorithm
24 Search for description of items Suppose that the rule is [343,587] à [1027] Use the workflow for the product description to find the meaning of the products
25 Search for description of items Configure Row Filter with a regular expression capturing all the records containing one of the 3 code products
26 .. the output table
27 Filter out an item from output itemset/ AR Suppose that you want to filter out all item sets containing the item (shopper bag). Configure Row Filter with the following regular expression
28 Write the itemsets in a file Given the output of the Item set Finder node some time you cannot see all the components of the itemset so we need to transform it in a string and then we can also write the result in a file
29 Write the itemsets in a file First we need to split the collection
30 Write the itemsets in a file Second we combine the columns that have to compose the itemset (string)
31 Write the itemsets in a file The combiner does not eliminate the missing values? The combined itemsets contain a lot of? We use the replace operation to eliminate them
32 Write the itemsets in a file Before writing in a file eliminate the split columns
33 .. The output table that will write Now you can see all the items in a set!!!
34 Write the itemsets in a file Now we can complete the workflow with the CSV Writer
35 CUSTOMER SEGMENTATION Anna Monreale KDD-Lab, University of Pisa
36 Customer Segmentation Problem: given the dataset of RFM (Recency, Frequency and Monetary value) measurements of a set of customers of a supermarket, find a high-quality clustering using K-means and discuss the profile of each found cluster (in terms of the purchasing behavior of the customers of each cluster). Applying also the Hierarchical clustering and compare the results Provide a short document (max three pages in pdf, excluding figures/plots) which illustrates the input dataset, the adopted clustering methodology and the cluster interpretation.
37 DATA Dataset filename: rfm_data.csv. Dataset legend: for each customer, the dataset contains date_first_purchase: integer that indicates the date of the first purchase of the customer date_last_purchase: integer that indicates the date of the last purchase of the customer Number of purchases: number of different purchases in terms of receipts Amount: total money spent by the customer Need to vompute the columns for Recency: no. of days since last purchase Frequency: no. of visits (shopping in the supermarket) in the observation period Monetary value: total amount spent in purchases during the observation period.
38 Clustering in KNIME Data normalization Min-max normalization Z-score normalization Compare the clustering results before and after this operation and discuss the comparison
39 K-Means Two options K-means in Mining section of Knime K-means in Weka section of Knime The second one allows the SSE computation useful for finding the best k value
40 Hierarchical Clustering The node is in Mining section Allow to generate the dendogram Various Distances
41 CHURN ANALYSIS Anna Monreale KDD-Lab, University of Pisa
42 Churn Analysis Problem: Problem: given a dataset of measurements over a set of customers of an e-commenrce site, find a high-quality classifier, using decision trees, which predicts whether each customers will place only one or more orders to the shop. Provide a short document (max three pages in pdf, excluding figures/plots) which illustrates the input dataset, the adopted clustering methodology and the cluster interpretation.
43 Data Filename: OneShotCustomersEX.csv Contains transactions from 15,000 online customers In the web page of the course you can download the attribute description The class of the data is Customer Typology that can be one shot = only 1 purchase loyal = more than one purchase
44 Decision Trees in Knime For Classification by decision trees Partitioning of the data in training and test set On the training set applying the learner On the test set applying the predictor
45 Evaluation of our classification model
Didacticiel Études de cas. Association Rules mining with Tanagra, R (arules package), Orange, RapidMiner, Knime and Weka.
, Orange, RapidMiner, Knime and Weka.") 1 Subject Association Rules mining with Tanagra, R (arules package), Orange, RapidMiner, Knime and Weka. This document extends a previous tutorial dedicated to the comparison of various implementations
1 Subject Association Rules mining with Tanagra, R (arules package), Orange, RapidMiner, Knime and Weka. This document extends a previous tutorial dedicated to the comparison of various implementations
Medical Information Management & Mining. You Chen Jan,15, 2013 You.chen@vanderbilt.edu
 Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
2 Decision tree + Cross-validation with R (package rpart)
") 1 Subject Using cross-validation for the performance evaluation of decision trees with R, KNIME and RAPIDMINER. This paper takes one of our old study on the implementation of cross-validation for assessing
1 Subject Using cross-validation for the performance evaluation of decision trees with R, KNIME and RAPIDMINER. This paper takes one of our old study on the implementation of cross-validation for assessing
Ensembles and PMML in KNIME
 Ensembles and PMML in KNIME Alexander Fillbrunn 1, Iris Adä 1, Thomas R. Gabriel 2 and Michael R. Berthold 1,2 1 Department of Computer and Information Science Universität Konstanz Konstanz, Germany First.Last@Uni-Konstanz.De
Ensembles and PMML in KNIME Alexander Fillbrunn 1, Iris Adä 1, Thomas R. Gabriel 2 and Michael R. Berthold 1,2 1 Department of Computer and Information Science Universität Konstanz Konstanz, Germany First.Last@Uni-Konstanz.De
Clustering UE 141 Spring 2013
 Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Introduction Predictive Analytics Tools: Weka
 Introduction Predictive Analytics Tools: Weka Predictive Analytics Center of Excellence San Diego Supercomputer Center University of California, San Diego Tools Landscape Considerations Scale User Interface
Introduction Predictive Analytics Tools: Weka Predictive Analytics Center of Excellence San Diego Supercomputer Center University of California, San Diego Tools Landscape Considerations Scale User Interface
Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs
 1.1 Introduction Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs For brevity, the Lavastorm Analytics Library (LAL) Predictive and Statistical Analytics Node Pack will be
1.1 Introduction Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs For brevity, the Lavastorm Analytics Library (LAL) Predictive and Statistical Analytics Node Pack will be
IBM SPSS Direct Marketing 23
 IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
In this tutorial, we try to build a roc curve from a logistic regression.
 Subject In this tutorial, we try to build a roc curve from a logistic regression. Regardless the software we used, even for commercial software, we have to prepare the following steps when we want build
Subject In this tutorial, we try to build a roc curve from a logistic regression. Regardless the software we used, even for commercial software, we have to prepare the following steps when we want build
IBM SPSS Direct Marketing 22
 IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
TIBCO Spotfire Business Author Essentials Quick Reference Guide. Table of contents:
 Table of contents: Access Data for Analysis Data file types Format assumptions Data from Excel Information links Add multiple data tables Create & Interpret Visualizations Table Pie Chart Cross Table Treemap
Table of contents: Access Data for Analysis Data file types Format assumptions Data from Excel Information links Add multiple data tables Create & Interpret Visualizations Table Pie Chart Cross Table Treemap
Technical Report. The KNIME Text Processing Feature:
 Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
Easily Identify Your Best Customers
 IBM SPSS Statistics Easily Identify Your Best Customers Use IBM SPSS predictive analytics software to gain insight from your customer database Contents: 1 Introduction 2 Exploring customer data Where do
IBM SPSS Statistics Easily Identify Your Best Customers Use IBM SPSS predictive analytics software to gain insight from your customer database Contents: 1 Introduction 2 Exploring customer data Where do
WebFOCUS RStat. RStat. Predict the Future and Make Effective Decisions Today. WebFOCUS RStat
 Information Builders enables agile information solutions with business intelligence (BI) and integration technologies. WebFOCUS the most widely utilized business intelligence platform connects to any enterprise
Information Builders enables agile information solutions with business intelligence (BI) and integration technologies. WebFOCUS the most widely utilized business intelligence platform connects to any enterprise
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr
 Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Big Data and Scripting map/reduce in Hadoop
 Big Data and Scripting map/reduce in Hadoop 1, 2, parts of a Hadoop map/reduce implementation core framework provides customization via indivudual map and reduce functions e.g. implementation in mongodb
Big Data and Scripting map/reduce in Hadoop 1, 2, parts of a Hadoop map/reduce implementation core framework provides customization via indivudual map and reduce functions e.g. implementation in mongodb
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R
 Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Tutorial Segmentation and Classification
 MARKETING ENGINEERING FOR EXCEL TUTORIAL VERSION 1.0.8 Tutorial Segmentation and Classification Marketing Engineering for Excel is a Microsoft Excel add-in. The software runs from within Microsoft Excel
MARKETING ENGINEERING FOR EXCEL TUTORIAL VERSION 1.0.8 Tutorial Segmentation and Classification Marketing Engineering for Excel is a Microsoft Excel add-in. The software runs from within Microsoft Excel
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
An Introduction to WEKA. As presented by PACE
 An Introduction to WEKA As presented by PACE Download and Install WEKA Website: http://www.cs.waikato.ac.nz/~ml/weka/index.html 2 Content Intro and background Exploring WEKA Data Preparation Creating Models/
An Introduction to WEKA As presented by PACE Download and Install WEKA Website: http://www.cs.waikato.ac.nz/~ml/weka/index.html 2 Content Intro and background Exploring WEKA Data Preparation Creating Models/
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
IT services for analyses of various data samples
 IT services for analyses of various data samples Ján Paralič, František Babič, Martin Sarnovský, Peter Butka, Cecília Havrilová, Miroslava Muchová, Michal Puheim, Martin Mikula, Gabriel Tutoky Technical
IT services for analyses of various data samples Ján Paralič, František Babič, Martin Sarnovský, Peter Butka, Cecília Havrilová, Miroslava Muchová, Michal Puheim, Martin Mikula, Gabriel Tutoky Technical
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP
 Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Data Analysis in E-Learning System of Gunadarma University by Using Knime
 Data Analysis in E-Learning System of Gunadarma University by Using Knime Dian Kusuma Ningtyas tyaz tyaz tyaz@student.gunadarma.ac.id Prasetiyo prasetiyo@student.gunadarma.ac.id Farah Virnawati virtha
Data Analysis in E-Learning System of Gunadarma University by Using Knime Dian Kusuma Ningtyas tyaz tyaz tyaz@student.gunadarma.ac.id Prasetiyo prasetiyo@student.gunadarma.ac.id Farah Virnawati virtha
Chapter 1. Introduction
 Chapter 1. Introduction 1.1. Purpose and structure of this book We live in the age of data! Traditionally every purchase we make is dutifully recorded; every money transaction is carefully registered;
Chapter 1. Introduction 1.1. Purpose and structure of this book We live in the age of data! Traditionally every purchase we make is dutifully recorded; every money transaction is carefully registered;
Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features
 Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features Charlie Berger, MS Eng, MBA Sr. Director Product Management, Data Mining and Advanced Analytics charlie.berger@oracle.com www.twitter.com/charliedatamine
Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features Charlie Berger, MS Eng, MBA Sr. Director Product Management, Data Mining and Advanced Analytics charlie.berger@oracle.com www.twitter.com/charliedatamine
Clustering on Large Numeric Data Sets Using Hierarchical Approach Birch
 Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Statistical Distributions in Astronomy
 Data Mining In Modern Astronomy Sky Surveys: Statistical Distributions in Astronomy Ching-Wa Yip cwyip@pha.jhu.edu; Bloomberg 518 From Data to Information We don t just want data. We want information from
Data Mining In Modern Astronomy Sky Surveys: Statistical Distributions in Astronomy Ching-Wa Yip cwyip@pha.jhu.edu; Bloomberg 518 From Data to Information We don t just want data. We want information from
Customer Analytics. Turn Big Data into Big Value
 Turn Big Data into Big Value All Your Data Integrated in Just One Place BIRT Analytics lets you capture the value of Big Data that speeds right by most enterprises. It analyzes massive volumes of data
Turn Big Data into Big Value All Your Data Integrated in Just One Place BIRT Analytics lets you capture the value of Big Data that speeds right by most enterprises. It analyzes massive volumes of data
A Comparative study of Techniques in Data Mining
 A Comparative study of Techniques in Data Mining Manika Verma 1, Dr. Devarshi Mehta 2 1 Asst. Professor, Department of Computer Science, Kadi Sarva Vishwavidyalaya, Gandhinagar, India 2 Associate Professor
A Comparative study of Techniques in Data Mining Manika Verma 1, Dr. Devarshi Mehta 2 1 Asst. Professor, Department of Computer Science, Kadi Sarva Vishwavidyalaya, Gandhinagar, India 2 Associate Professor
DATA MINING TOOL FOR INTEGRATED COMPLAINT MANAGEMENT SYSTEM WEKA 3.6.7
 DATA MINING TOOL FOR INTEGRATED COMPLAINT MANAGEMENT SYSTEM WEKA 3.6.7 UNDER THE GUIDANCE Dr. N.P. DHAVALE, DGM, INFINET Department SUBMITTED TO INSTITUTE FOR DEVELOPMENT AND RESEARCH IN BANKING TECHNOLOGY
DATA MINING TOOL FOR INTEGRATED COMPLAINT MANAGEMENT SYSTEM WEKA 3.6.7 UNDER THE GUIDANCE Dr. N.P. DHAVALE, DGM, INFINET Department SUBMITTED TO INSTITUTE FOR DEVELOPMENT AND RESEARCH IN BANKING TECHNOLOGY
Data Mining. SPSS Clementine 12.0. 1. Clementine Overview. Spring 2010 Instructor: Dr. Masoud Yaghini. Clementine
 Data Mining SPSS 12.0 1. Overview Spring 2010 Instructor: Dr. Masoud Yaghini Introduction Types of Models Interface Projects References Outline Introduction Introduction Three of the common data mining
Data Mining SPSS 12.0 1. Overview Spring 2010 Instructor: Dr. Masoud Yaghini Introduction Types of Models Interface Projects References Outline Introduction Introduction Three of the common data mining
CUSTOMER Presentation of SAP Predictive Analytics
 SAP Predictive Analytics 2.0 2015-02-09 CUSTOMER Presentation of SAP Predictive Analytics Content 1 SAP Predictive Analytics Overview....3 2 Deployment Configurations....4 3 SAP Predictive Analytics Desktop
SAP Predictive Analytics 2.0 2015-02-09 CUSTOMER Presentation of SAP Predictive Analytics Content 1 SAP Predictive Analytics Overview....3 2 Deployment Configurations....4 3 SAP Predictive Analytics Desktop
STATISTICA. Clustering Techniques. Case Study: Defining Clusters of Shopping Center Patrons. and
 Clustering Techniques and STATISTICA Case Study: Defining Clusters of Shopping Center Patrons STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table
Clustering Techniques and STATISTICA Case Study: Defining Clusters of Shopping Center Patrons STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table
Data Mining Individual Assignment report
 Björn Þór Jónsson bjrr@itu.dk Data Mining Individual Assignment report This report outlines the implementation and results gained from the Data Mining methods of preprocessing, supervised learning, frequent
Björn Þór Jónsson bjrr@itu.dk Data Mining Individual Assignment report This report outlines the implementation and results gained from the Data Mining methods of preprocessing, supervised learning, frequent
Easily Identify the Right Customers
 PASW Direct Marketing 18 Specifications Easily Identify the Right Customers You want your marketing programs to be as profitable as possible, and gaining insight into the information contained in your
PASW Direct Marketing 18 Specifications Easily Identify the Right Customers You want your marketing programs to be as profitable as possible, and gaining insight into the information contained in your
Data exploration with Microsoft Excel: analysing more than one variable
 Data exploration with Microsoft Excel: analysing more than one variable Contents 1 Introduction... 1 2 Comparing different groups or different variables... 2 3 Exploring the association between categorical
Data exploration with Microsoft Excel: analysing more than one variable Contents 1 Introduction... 1 2 Comparing different groups or different variables... 2 3 Exploring the association between categorical
COC131 Data Mining - Clustering
 COC131 Data Mining - Clustering Martin D. Sykora m.d.sykora@lboro.ac.uk Tutorial 05, Friday 20th March 2009 1. Fire up Weka (Waikako Environment for Knowledge Analysis) software, launch the explorer window
COC131 Data Mining - Clustering Martin D. Sykora m.d.sykora@lboro.ac.uk Tutorial 05, Friday 20th March 2009 1. Fire up Weka (Waikako Environment for Knowledge Analysis) software, launch the explorer window
PSG College of Technology, Coimbatore-641 004 Department of Computer & Information Sciences BSc (CT) G1 & G2 Sixth Semester PROJECT DETAILS.
 G1 & G2 Sixth Semester PROJECT DETAILS.") PSG College of Technology, Coimbatore-641 004 Department of Computer & Information Sciences BSc (CT) G1 & G2 Sixth Semester PROJECT DETAILS Project Project Title Area of Abstract No Specialization 1. Software
PSG College of Technology, Coimbatore-641 004 Department of Computer & Information Sciences BSc (CT) G1 & G2 Sixth Semester PROJECT DETAILS Project Project Title Area of Abstract No Specialization 1. Software
Structural Health Monitoring Tools (SHMTools)
") Structural Health Monitoring Tools (SHMTools) Getting Started LANL/UCSD Engineering Institute LA-CC-14-046 c Copyright 2014, Los Alamos National Security, LLC All rights reserved. May 30, 2014 Contents
Structural Health Monitoring Tools (SHMTools) Getting Started LANL/UCSD Engineering Institute LA-CC-14-046 c Copyright 2014, Los Alamos National Security, LLC All rights reserved. May 30, 2014 Contents
IT462 Lab 5: Clustering with MS SQL Server
 IT462 Lab 5: Clustering with MS SQL Server This lab should give you the chance to practice some of the data mining techniques you've learned in class. Preliminaries: For this lab, you will use the SQL
IT462 Lab 5: Clustering with MS SQL Server This lab should give you the chance to practice some of the data mining techniques you've learned in class. Preliminaries: For this lab, you will use the SQL
Advanced analytics at your hands
 2.3 Advanced analytics at your hands Neural Designer is the most powerful predictive analytics software. It uses innovative neural networks techniques to provide data scientists with results in a way previously
2.3 Advanced analytics at your hands Neural Designer is the most powerful predictive analytics software. It uses innovative neural networks techniques to provide data scientists with results in a way previously
Instructions for SPSS 21
 1 Instructions for SPSS 21 1 Introduction... 2 1.1 Opening the SPSS program... 2 1.2 General... 2 2 Data inputting and processing... 2 2.1 Manual input and data processing... 2 2.2 Saving data... 3 2.3
1 Instructions for SPSS 21 1 Introduction... 2 1.1 Opening the SPSS program... 2 1.2 General... 2 2 Data inputting and processing... 2 2.1 Manual input and data processing... 2 2.2 Saving data... 3 2.3
Analytics on Big Data
 Analytics on Big Data Riccardo Torlone Università Roma Tre Credits: Mohamed Eltabakh (WPI) Analytics The discovery and communication of meaningful patterns in data (Wikipedia) It relies on data analysis
Analytics on Big Data Riccardo Torlone Università Roma Tre Credits: Mohamed Eltabakh (WPI) Analytics The discovery and communication of meaningful patterns in data (Wikipedia) It relies on data analysis
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS
 UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 dcmishra@iasri.res.in What is Learning? "Learning denotes changes in a system that enable
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 dcmishra@iasri.res.in What is Learning? "Learning denotes changes in a system that enable
Anomaly Detection in Predictive Maintenance Time Alignment and Visualization
 Anomaly Detection in Predictive Maintenance Time Alignment and Visualization Phil Winters Rosaria Silipo Phil.Winters@knime.com Rosaria.Silipo@knime.com Copyright 2015 by KNIME.com AG all rights reserved
Anomaly Detection in Predictive Maintenance Time Alignment and Visualization Phil Winters Rosaria Silipo Phil.Winters@knime.com Rosaria.Silipo@knime.com Copyright 2015 by KNIME.com AG all rights reserved
Pentaho Data Mining Last Modified on January 22, 2007
 Pentaho Data Mining Copyright 2007 Pentaho Corporation. Redistribution permitted. All trademarks are the property of their respective owners. For the latest information, please visit our web site at www.pentaho.org
Pentaho Data Mining Copyright 2007 Pentaho Corporation. Redistribution permitted. All trademarks are the property of their respective owners. For the latest information, please visit our web site at www.pentaho.org
Prof. Pietro Ducange Students Tutor and Practical Classes Course of Business Intelligence 2014 http://www.iet.unipi.it/p.ducange/esercitazionibi/
 Prof. Pietro Ducange Students Tutor and Practical Classes Course of Business Intelligence 2014 http://www.iet.unipi.it/p.ducange/esercitazionibi/ Email: p.ducange@iet.unipi.it Office: Dipartimento di Ingegneria
Prof. Pietro Ducange Students Tutor and Practical Classes Course of Business Intelligence 2014 http://www.iet.unipi.it/p.ducange/esercitazionibi/ Email: p.ducange@iet.unipi.it Office: Dipartimento di Ingegneria
IBM SPSS Direct Marketing 19
 IBM SPSS Direct Marketing 19 Note: Before using this information and the product it supports, read the general information under Notices on p. 105. This document contains proprietary information of SPSS
IBM SPSS Direct Marketing 19 Note: Before using this information and the product it supports, read the general information under Notices on p. 105. This document contains proprietary information of SPSS
Didacticiel Études de cas
 1 Theme Data Mining with R The rattle package. R (http://www.r project.org/) is one of the most exciting free data mining software projects of these last years. Its popularity is completely justified (see
1 Theme Data Mining with R The rattle package. R (http://www.r project.org/) is one of the most exciting free data mining software projects of these last years. Its popularity is completely justified (see
Today's Topics. COMP 388/441: Human-Computer Interaction. simple 2D plotting. 1D techniques. Ancient plotting techniques. Data Visualization:
 COMP 388/441: Human-Computer Interaction Today's Topics Overview of visualization techniques 1D charts, 2D plots, 3D+ techniques, maps A few guidelines for scientific visualization methods, guidelines,
COMP 388/441: Human-Computer Interaction Today's Topics Overview of visualization techniques 1D charts, 2D plots, 3D+ techniques, maps A few guidelines for scientific visualization methods, guidelines,
IBM SPSS Direct Marketing 20
 IBM SPSS Direct Marketing 20 Note: Before using this information and the product it supports, read the general information under Notices on p. 105. This edition applies to IBM SPSS Statistics 20 and to
IBM SPSS Direct Marketing 20 Note: Before using this information and the product it supports, read the general information under Notices on p. 105. This edition applies to IBM SPSS Statistics 20 and to
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analsis: Basic Concepts and Algorithms What does it mean clustering? Applications Tpes of clustering K-means Intuition Algorithm Choosing initial centroids Bisecting K-means Post-processing Strengths
Cluster Analsis: Basic Concepts and Algorithms What does it mean clustering? Applications Tpes of clustering K-means Intuition Algorithm Choosing initial centroids Bisecting K-means Post-processing Strengths
IBM SPSS Direct Marketing
 IBM Software IBM SPSS Statistics 19 IBM SPSS Direct Marketing Understand your customers and improve marketing campaigns Highlights With IBM SPSS Direct Marketing, you can: Understand your customers in
IBM Software IBM SPSS Statistics 19 IBM SPSS Direct Marketing Understand your customers and improve marketing campaigns Highlights With IBM SPSS Direct Marketing, you can: Understand your customers in
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
CONTENTS PREFACE 1 INTRODUCTION 1 2 DATA VISUALIZATION 19
 PREFACE xi 1 INTRODUCTION 1 1.1 Overview 1 1.2 Definition 1 1.3 Preparation 2 1.3.1 Overview 2 1.3.2 Accessing Tabular Data 3 1.3.3 Accessing Unstructured Data 3 1.3.4 Understanding the Variables and Observations
PREFACE xi 1 INTRODUCTION 1 1.1 Overview 1 1.2 Definition 1 1.3 Preparation 2 1.3.1 Overview 2 1.3.2 Accessing Tabular Data 3 1.3.3 Accessing Unstructured Data 3 1.3.4 Understanding the Variables and Observations
Analyzing the Web from Start to Finish Knowledge Extraction from a Web Forum using KNIME
 Analyzing the Web from Start to Finish Knowledge Extraction from a Web Forum using KNIME Bernd Wiswedel Tobias Kötter Rosaria Silipo Bernd.Wiswedel@knime.com Tobias.Koetter@uni-konstanz.de Rosaria.Silipo@knime.com
Analyzing the Web from Start to Finish Knowledge Extraction from a Web Forum using KNIME Bernd Wiswedel Tobias Kötter Rosaria Silipo Bernd.Wiswedel@knime.com Tobias.Koetter@uni-konstanz.de Rosaria.Silipo@knime.com
Actian Analytics Platform Express Hadoop SQL Edition 2.0
 Actian Analytics Platform Express Hadoop SQL Edition 2.0 Tutorial AH-2-TU-05 This Documentation is for the end user's informational purposes only and may be subject to change or withdrawal by Actian Corporation
Actian Analytics Platform Express Hadoop SQL Edition 2.0 Tutorial AH-2-TU-05 This Documentation is for the end user's informational purposes only and may be subject to change or withdrawal by Actian Corporation
Hierarchical Clustering Analysis
 Hierarchical Clustering Analysis What is Hierarchical Clustering? Hierarchical clustering is used to group similar objects into clusters. In the beginning, each row and/or column is considered a cluster.
Hierarchical Clustering Analysis What is Hierarchical Clustering? Hierarchical clustering is used to group similar objects into clusters. In the beginning, each row and/or column is considered a cluster.
Chapter 20: Data Analysis
 Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Chapter ML:XI (continued)
") Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Oracle Data Mining Hands On Lab
 Oracle Data Mining Hands On Lab Material provided by Oracle Corporation Vlamis Software Solutions is one of the most respected training organizations in the Oracle Business Intelligence community because
Oracle Data Mining Hands On Lab Material provided by Oracle Corporation Vlamis Software Solutions is one of the most respected training organizations in the Oracle Business Intelligence community because
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Enhanced Boosted Trees Technique for Customer Churn Prediction Model
 IOSR Journal of Engineering (IOSRJEN) ISSN (e): 2250-3021, ISSN (p): 2278-8719 Vol. 04, Issue 03 (March. 2014), V5 PP 41-45 www.iosrjen.org Enhanced Boosted Trees Technique for Customer Churn Prediction
IOSR Journal of Engineering (IOSRJEN) ISSN (e): 2250-3021, ISSN (p): 2278-8719 Vol. 04, Issue 03 (March. 2014), V5 PP 41-45 www.iosrjen.org Enhanced Boosted Trees Technique for Customer Churn Prediction
Data Mining and Visualization
 Data Mining and Visualization Jeremy Walton NAG Ltd, Oxford Overview Data mining components Functionality Example application Quality control Visualization Use of 3D Example application Market research
Data Mining and Visualization Jeremy Walton NAG Ltd, Oxford Overview Data mining components Functionality Example application Quality control Visualization Use of 3D Example application Market research
Data Algorithms. Mahmoud Parsian. Tokyo O'REILLY. Beijing. Boston Farnham Sebastopol
 Data Algorithms Mahmoud Parsian Beijing Boston Farnham Sebastopol Tokyo O'REILLY Table of Contents Foreword xix Preface xxi 1. Secondary Sort: Introduction 1 Solutions to the Secondary Sort Problem 3 Implementation
Data Algorithms Mahmoud Parsian Beijing Boston Farnham Sebastopol Tokyo O'REILLY Table of Contents Foreword xix Preface xxi 1. Secondary Sort: Introduction 1 Solutions to the Secondary Sort Problem 3 Implementation
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Mining an Online Auctions Data Warehouse
 Proceedings of MASPLAS'02 The Mid-Atlantic Student Workshop on Programming Languages and Systems Pace University, April 19, 2002 Mining an Online Auctions Data Warehouse David Ulmer Under the guidance
Proceedings of MASPLAS'02 The Mid-Atlantic Student Workshop on Programming Languages and Systems Pace University, April 19, 2002 Mining an Online Auctions Data Warehouse David Ulmer Under the guidance
Anomaly Detection and Predictive Maintenance
 Anomaly Detection and Predictive Maintenance Rosaria Silipo Iris Adae Christian Dietz Phil Winters Rosaria.Silipo@knime.com Iris.Adae@uni-konstanz.de Christian.Dietz@uni-konstanz.de Phil.Winters@knime.com
Anomaly Detection and Predictive Maintenance Rosaria Silipo Iris Adae Christian Dietz Phil Winters Rosaria.Silipo@knime.com Iris.Adae@uni-konstanz.de Christian.Dietz@uni-konstanz.de Phil.Winters@knime.com
Chapter 12 Discovering New Knowledge Data Mining
 Chapter 12 Discovering New Knowledge Data Mining Becerra-Fernandez, et al. -- Knowledge Management 1/e -- 2004 Prentice Hall Additional material 2007 Dekai Wu Chapter Objectives Introduce the student to
Chapter 12 Discovering New Knowledge Data Mining Becerra-Fernandez, et al. -- Knowledge Management 1/e -- 2004 Prentice Hall Additional material 2007 Dekai Wu Chapter Objectives Introduce the student to
Oracle Data Miner (Extension of SQL Developer 4.0)
") An Oracle White Paper October 2013 Oracle Data Miner (Extension of SQL Developer 4.0) Generate a PL/SQL script for workflow deployment Denny Wong Oracle Data Mining Technologies 10 Van de Graff Drive Burlington,
An Oracle White Paper October 2013 Oracle Data Miner (Extension of SQL Developer 4.0) Generate a PL/SQL script for workflow deployment Denny Wong Oracle Data Mining Technologies 10 Van de Graff Drive Burlington,
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Directions for using SPSS
 Directions for using SPSS Table of Contents Connecting and Working with Files 1. Accessing SPSS... 2 2. Transferring Files to N:\drive or your computer... 3 3. Importing Data from Another File Format...
Directions for using SPSS Table of Contents Connecting and Working with Files 1. Accessing SPSS... 2 2. Transferring Files to N:\drive or your computer... 3 3. Importing Data from Another File Format...
Comparative Study in Building of Associations Rules from Commercial Transactions through Data Mining Techniques
 Third International Conference Modelling and Development of Intelligent Systems October 10-12, 2013 Lucian Blaga University Sibiu - Romania Comparative Study in Building of Associations Rules from Commercial
Third International Conference Modelling and Development of Intelligent Systems October 10-12, 2013 Lucian Blaga University Sibiu - Romania Comparative Study in Building of Associations Rules from Commercial
Monday Morning Data Mining
 Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik
Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik
BIDM Project. Predicting the contract type for IT/ITES outsourcing contracts
 BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
Dimensionality Reduction: Principal Components Analysis
 Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
How to Get More Value from Your Survey Data
 Technical report How to Get More Value from Your Survey Data Discover four advanced analysis techniques that make survey research more effective Table of contents Introduction..............................................................2
Technical report How to Get More Value from Your Survey Data Discover four advanced analysis techniques that make survey research more effective Table of contents Introduction..............................................................2
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Predictive Analytics: Extracts from Red Olive foundational course
 Predictive Analytics: Extracts from Red Olive foundational course For more details or to speak about a tailored course for your organisation please contact: Jefferson Lynch: jefferson.lynch@red-olive.co.uk
Predictive Analytics: Extracts from Red Olive foundational course For more details or to speak about a tailored course for your organisation please contact: Jefferson Lynch: jefferson.lynch@red-olive.co.uk
Mammoth Scale Machine Learning!
 Mammoth Scale Machine Learning! Speaker: Robin Anil, Apache Mahout PMC Member! OSCON"10! Portland, OR! July 2010! Quick Show of Hands!# Are you fascinated about ML?!# Have you used ML?!# Do you have Gigabytes
Mammoth Scale Machine Learning! Speaker: Robin Anil, Apache Mahout PMC Member! OSCON"10! Portland, OR! July 2010! Quick Show of Hands!# Are you fascinated about ML?!# Have you used ML?!# Do you have Gigabytes
Summary Data Mining & Process Mining (1BM46) Content. Made by S.P.T. Ariesen
 Content. Made by S.P.T. Ariesen") Summary Data Mining & Process Mining (1BM46) Made by S.P.T. Ariesen Content Data Mining part... 2 Lecture 1... 2 Lecture 2:... 4 Lecture 3... 7 Lecture 4... 9 Process mining part... 13 Lecture 5... 13
Summary Data Mining & Process Mining (1BM46) Made by S.P.T. Ariesen Content Data Mining part... 2 Lecture 1... 2 Lecture 2:... 4 Lecture 3... 7 Lecture 4... 9 Process mining part... 13 Lecture 5... 13
New Work Item for ISO 3534-5 Predictive Analytics (Initial Notes and Thoughts) Introduction
 Introduction") Introduction New Work Item for ISO 3534-5 Predictive Analytics (Initial Notes and Thoughts) Predictive analytics encompasses the body of statistical knowledge supporting the analysis of massive data sets.
Introduction New Work Item for ISO 3534-5 Predictive Analytics (Initial Notes and Thoughts) Predictive analytics encompasses the body of statistical knowledge supporting the analysis of massive data sets.
COMP3420: Advanced Databases and Data Mining. Classification and prediction: Introduction and Decision Tree Induction
 COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
An Overview and Evaluation of Decision Tree Methodology
 An Overview and Evaluation of Decision Tree Methodology ASA Quality and Productivity Conference Terri Moore Motorola Austin, TX terri.moore@motorola.com Carole Jesse Cargill, Inc. Wayzata, MN carole_jesse@cargill.com
An Overview and Evaluation of Decision Tree Methodology ASA Quality and Productivity Conference Terri Moore Motorola Austin, TX terri.moore@motorola.com Carole Jesse Cargill, Inc. Wayzata, MN carole_jesse@cargill.com
<no narration for this slide>
 1 2 The standard narration text is : After completing this lesson, you will be able to: < > SAP Visual Intelligence is our latest innovation
1 2 The standard narration text is : After completing this lesson, you will be able to: < > SAP Visual Intelligence is our latest innovation
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Data Mining: A Preprocessing Engine
 Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Data Mining - The Next Mining Boom?
 Howard Ong Principal Consultant Aurora Consulting Pty Ltd Abstract This paper introduces Data Mining to its audience by explaining Data Mining in the context of Corporate and Business Intelligence Reporting.
Howard Ong Principal Consultant Aurora Consulting Pty Ltd Abstract This paper introduces Data Mining to its audience by explaining Data Mining in the context of Corporate and Business Intelligence Reporting.
Consumption of OData Services of Open Items Analytics Dashboard using SAP Predictive Analysis
 Consumption of OData Services of Open Items Analytics Dashboard using SAP Predictive Analysis (Version 1.17) For validation Document version 0.1 7/7/2014 Contents What is SAP Predictive Analytics?... 3
Consumption of OData Services of Open Items Analytics Dashboard using SAP Predictive Analysis (Version 1.17) For validation Document version 0.1 7/7/2014 Contents What is SAP Predictive Analytics?... 3
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
PASW Direct Marketing 18
 i PASW Direct Marketing 18 For more information about SPSS Inc. software products, please visit our Web site at http://www.spss.com or contact SPSS Inc. 233 South Wacker Drive, 11th Floor Chicago, IL 60606-6412
i PASW Direct Marketing 18 For more information about SPSS Inc. software products, please visit our Web site at http://www.spss.com or contact SPSS Inc. 233 South Wacker Drive, 11th Floor Chicago, IL 60606-6412
Overview. Introduction. Recommender Systems & Slope One Recommender. Distributed Slope One on Mahout and Hadoop. Experimental Setup and Analyses
 Slope One Recommender on Hadoop YONG ZHENG Center for Web Intelligence DePaul University Nov 15, 2012 Overview Introduction Recommender Systems & Slope One Recommender Distributed Slope One on Mahout and
Slope One Recommender on Hadoop YONG ZHENG Center for Web Intelligence DePaul University Nov 15, 2012 Overview Introduction Recommender Systems & Slope One Recommender Distributed Slope One on Mahout and
New Matrix Approach to Improve Apriori Algorithm
 New Matrix Approach to Improve Apriori Algorithm A. Rehab H. Alwa, B. Anasuya V Patil Associate Prof., IT Faculty, Majan College-University College Muscat, Oman, rehab.alwan@majancolleg.edu.om Associate
New Matrix Approach to Improve Apriori Algorithm A. Rehab H. Alwa, B. Anasuya V Patil Associate Prof., IT Faculty, Majan College-University College Muscat, Oman, rehab.alwan@majancolleg.edu.om Associate
Cluster Analysis. Alison Merikangas Data Analysis Seminar 18 November 2009
 Cluster Analysis Alison Merikangas Data Analysis Seminar 18 November 2009 Overview What is cluster analysis? Types of cluster Distance functions Clustering methods Agglomerative K-means Density-based Interpretation
Cluster Analysis Alison Merikangas Data Analysis Seminar 18 November 2009 Overview What is cluster analysis? Types of cluster Distance functions Clustering methods Agglomerative K-means Density-based Interpretation
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14