How To Learn From Perspective
|
|
|
- Lee Gordon
- 5 years ago
- Views:
Transcription

1 Pulling Things out of Perspective L ubor Ladický ETH Zürich, Switzerland [email protected] Jianbo Shi University of Pennsylvania, USA [email protected] Marc Pollefeys ETH Zürich, Switzerland [email protected] Abstract The limitations of current state-of-the-art methods for single-view depth estimation and semantic segmentations are closely tied to the property of perspective geometry, that the perceived size of the objects scales inversely with the distance. In this paper, we show that we can use this property to reduce the learning of a pixel-wise depth classifier to a much simpler classifier predicting only the likelihood of a pixel being at an arbitrarily fixed canonical depth. The likelihoods for any other depths can be obtained by applying the same classifier after appropriate image manipulations. Such transformation of the problem to the canonical depth removes the training data bias towards certain depths and the effect of perspective. The approach can be straight-forwardly generalized to multiple semantic classes, improving both depth estimation and semantic segmentation performance by directly targeting the weaknesses of independent approaches. Conditioning the semantic label on the depth provides a way to align the data to their physical scale, allowing to learn a more discriminative classifier. Conditioning depth on the semantic class helps the classifier to distinguish between ambiguities of the otherwise ill-posed problem. We tested our algorithm on the KITTI road scene dataset and NYU2 indoor dataset and obtained obtained results that significantly outperform current state-of-the-art in both single-view depth and semantic segmentation domain. 1. Introduction Depth estimation from a single RGB image has not been an exhaustively studied problem in computer vision, mainly due to its difficulty, lack of data and apparent ill-posedness of the problem in general. However, humans can still perform this task with ease, suggesting, that the pixel-wise depth is encoded in the observed features and can be learnt directly from the data [20, 1, 10, 16]. Such approaches typically predict the depth, the orientation, or fit the plane for the super-pixels using standard object recognition pipeline, Figure 1. Schematic description of the training of our semantic depth classifier. Positive training samples for each semantic class, projected to the canonical depth d c using the ground truth depth, are trained against other semantic classes and against samples of the same class projected to other than the canonical depth. Such a classifier is able to predict a semantic class and any depth by applying appropriate image transformations. consisting of the calculation of dense or sparse features, building rich feature representations, such as bag-of-words, and application of a trained classifier or regressor on them. The responses of a classifier or a regressor are combined in a probabilistic framework, and under very strong geometric priors the most probable scene layout is estimated. This process is completely data-driven and does not exploit known properties of the perspective geometry, most importantly, that the perceived size of the objects scales with an inverse distance (depth) from the centre of projection. This leads to severe biases towards the distributions of depths in the training set; it is impossible to estimate the depth of an object if a similar object has not been seen at the same depth during the training stage. These short-comings of the algorithm can be partially resolved by jittering or very careful weighting of the data samples, however, the trained classi-
2 fier would still not be intrinsically unbiased. A typical argument against the data-driven depth estimation is, that to successful perform this task, we need to be able to recognize and understand the scene. Thus one should wait, until sufficiently good recognition approaches are developed. For some recognition tasks this is already the case. Recent progress in computer vision and machine learning led to the development of algorithms [15, 27, 29, 28], that are able to successfully categorize images into hundreds [4] or even thousands [3] of different object classes. Further investigation reveals, that the success of these methods lies in how the problem is constrained; the objects of interest are typically scaled to the size of an image and under this setting carefully designed feature representations become much more discriminative. Based on this observation it is apparent, that the devil that limits the performance of algorithms for computer vision tasks, lies in the scale misalignment of the data due to the perspective geometry. Standard semantic classifiers are trained to be discriminative between semantic classes, but robust to the change of scale. Such dissonance between the desired properties makes learning unnecessarily hard. For an object detection problem [2, 5, 27] the varying 2D scale of an object is typically handled by scaling the content of bounding boxes tightly surrounding the objects to the same size, and building a feature vector for each individual bounding box after this transformation. Without this crucial step, the performance of the detection methods decreases dramatically. In case geometry of the scene is known, or it could be reliably estimated, the location of bounding boxes can be constrained to be on the specific location, such as on the ground plane [11]. However, these approaches can be used only for foreground objects with specific spatial extent, shape and size, "things". For semantic segmentation task with background classes, "stuff", such as a road, a building, grass or a tree, such an approach is not suitable. Scaling bounding boxes surrounding lawns of grass to the same size does not make the feature representations more discriminative. However, there still exists a concept of scale for stuff classes tied to their real-world physical size. The physical size of a blade of grass, a window of a building or a leaf of a tree varies much less than the size of a lawn, of a building or of a tree. Consequently, the most suitable alignment, applicable to both things and stuff, is the normalization to the same physical size. This has been recognized in the scenarios with the Kinect camera, where the depth is known. The classifier using features normalized with respect to the measured depth [22] typically perform significantly better. The mutual dependencies of visual appearance of a semantic class and its geometrical depth suggest that the problems of semantic segmentation and depth estimation should be solved jointly. It has been shown in [16] that conditioning depth on the semantic segmentation in a two-stage algorithm leads to a significant performance improvement. For stereo and multi-view images, [14, 9] have demonstrated that joint semantic segmentation and 3D reconstruction leads to a better result than performing each task in isolation. In these approaches, the rather weak source of mutual information utilized is the distribution of height [14] or surface normals [9] of different semantic classes. In this paper we show, that using the properties of the perspective geometry we can reduce the learning of a pixelwise depth classifier to a much simpler classifier predicting only the likelihood of a pixel being at an arbitrarily fixed canonical depth. The likelihoods for any other depths can be obtained by applying the same classifier after appropriate image manipulations. Such transformation of the problem to the canonical depth removes the training data bias towards certain depths and the effect of perspective. The approach can be straight-forwardly generalized to multiple semantic classes, improving both depth estimation and semantic segmentation performance by directly targeting the weaknesses of independent approaches. Conditioning the semantic label on the depth provides the way to align the data to their physical size, and conditioning depth on the semantic class helps the classifier to distinguish between ambiguities of the otherwise ill-posed problem. We perform experiments on the very constrained streetscene KITTI data set [6] and the very challenging NYU2 indoor dataset [25], where no assumptions about the layout of the scene can be made. Our algorithm significantly outperforms independent depth estimation and semantic segmentation approaches, and obtains comparable results in the semantic segmentation domain with methods, that use full RGB-D data. Our pixel-wise classifier can be directly placed into any competing recognition or depth estimation frameworks to further improve the results; either as a unary potential for CRF recognition approaches [13] or as predictions for fitting the planes to the super-pixels [20]. 2. An unbiased depth classifier First, we define the notation. Let I be an image and α I an image I geometrically scaled by a factor α. Let W w,h (I,x) be the (sub-)window of an image I of the size w h, centered at given point x. Any translation-invariant classifier H d (x), predicting the likelihood of pixel x being at the depth d D has to be a function of the arbitrarily large fixed size w h sub-window centered at the point x: H d (x) := H d (W w,h (I,x)). (1) The perspective geometry is characterized by the feature that objects are scaled with their inverse distance from the observer s centre of projection. Thus, for any unbiased depth classifier H d (x) the likelihood of the depth d of any
3 pixelx I should be the same as the likelihood of the depth d/α of the corresponding pixel of the scaled imageα I: H d (W w,h (I,x)) = H d/α (W w,h (α I,αx)). (2) This property is crucial to keep the classifier robust to the fluctuations in the training data, which are always present for small and average-sized data sets. It seems straightforward, but it has not been used in any previous data-driven depth estimation approach [20, 1, 16]. This property implies, that the depth classification can be reduced to a much simpler prediction of whether the pixel x I is at any arbitrarily fixed canonical depth d c. The response for any other depthd can be obtained by applying the same classifierh dc to the appropriately scaled image by a factord/d c as: H d (W w,h (I,x)) = H dc (W w,h ( d d c I, d d c x)). (3) Thus, the problem of depth estimation is converted into the estimation of which transformation (scaling) would project the pixel into the canonical depth. The special form of the classifier directly implies how it should be learnt. In the training stage, a classifier should learn to distinguish the training samples transformed to the canonical depth from the training samples transformed to the depths other than the canonical depth. The details largely depend on the framework chosen; e.g. in the classification framework the problem is treated as a standard 2-label positives vs negatives problem, in the ranking framework the response for a training sample transformed to the canonical depth should be larger (by a sufficient margin if appropriate) than the response for a sample transformed to any other than the canonical depth. Our classifier has several advantages over the direct learning of the depth from the feature representations of pixels. First, to predict a certain object (for example a car) at a certain depth d does not require a similar object to be seen at the same depth during the training stage. Second, our classifier does not have a problem with unbalanced training data, which is always present for a multi-class classifier or regressor. Intuitively, closer objects consist of more points and some object may have appeared at certain depth in the training data more often just by chance. These problems of a multi-class classifier or regressor could partially be resolved by jittering the data, using suitable sampling or reweighting of the training points; however, a direct enforcement of the property (2) is bound to be a better and more principled solution. 3. Semantic depth classifier Single-view depth estimation is in general an ill-posed problem. Several ambiguities could be potentially resolved if the depth classifier was conditioned on the semantic label. Training a classifier, which should be on one hand discriminative between semantic classes, but on the other robust to the change of scale, is unnecessarily hard. The problem would be much easier if the training samples were scale-aligned. The most suitable alignment, applicable to both things and stuff, is the normalization according to the physical size, and that is exactly, what the projection to the canonical depth (4) does. The generalization of the depth classifier to multiple semantic classes can be done straight-forwardly by learning a joint classifier H (l,dc)(w w,h (I,x)), predicting whether a pixel x takes a semantic label l L and is at the canonical depthd c. By applying (4), the response of the classifier for any other depth d is: H (l,d) (W w,h (I,x)) = H (l,dc)(w w,h ( d d c I, d d c x)). (4) The advantage of our classifier being unbiased towards certain depths is now more apparent. An alternative approach of learning a D L -class classifier or a L depth regressors would require a very large amount of training data, sufficient to represent a distribution for each label in a cross product of semantic and depth labels. In the training stage, our classifier should learn to distinguish the training samples of each class transformed to the canonical depth from the training samples of other classes and samples transformed to the depths other than the canonical depth. The transformation to the canonical depth is not applied for the sky class (for outdoor scenes) and the depth during test time is automatically assigned to. 4. Implementation details Transforming the window around each training sample to the canonical distance independently with a consequent calculation of features is computationally infeasible in practice. Thus, we discretize the problem of depth estimation during test stage into a discrete set of labelsd i D. The error of a prediction based on the scale of objects is expected to grow linearly with the distance, suggesting that the neighbouring depths d i and d i+1 should have a fixed ratio di+1 d i, chosen depending on the desired accuracy. This allows us to transform the problem into a classification over a pyramid of imagesα i I = di d c I for each training or test imagei. For pixels at the depth α i d c, the scaling of an image by α i corresponds to the transformation to the canonical depth. Thus in the training stage, a point of the image pyramid x i j (α i I) is used as a positive or negative sample based on how close is the ground truth depth of the corresponding pixel in the original non-scaled imaged x i j = d (xj/α i) to the depthα i d c. If their ratio is close to1, e.g. max( d x i j α i d c, α id c d x i j ) < δ POS, (5)
4 the pixel x j is used as a positive for a corresponding semantic class and negative for all other classes. If they are sufficiently different, e.g. max( d x i j α i d c, α id c d x i j ) > δ NEG, (6) the scaling by α i does not transform the sample to the canonical depth d c and thus is used as a negative for all semantic classes. In the training stage each object of the same real-world size and shape should have the same influence on the learnt classifier, no matter how far they are. Thus, the samples are sampled from α i I with the same subsampling for all α i, and are used as positives or negatives if they satisfy corresponding constraints (5) or (6) respectively. Transforming the problem into the canonical depth aligns the data based on their real-world physical size, which could be significantly different for different semantic classes. Thus, the most suitable classifiers are context-based with an automatically learnt context size, such as [24, 23, 13]. Following the methodology of the multi-feature [13] extension of TextonBoost [24], the dense features, namely texton [18], SIFT [17], local quantized ternary patters [12] and self-similarity features [21], are extracted for each pixel in each image in a pyramid α I. Each feature is clustered into 512 visual words using k-means clustering and for each pixel a soft weighting for 8 nearest neighbours is calculated using distance-based weighting [7] with an exponential kernel. The feature representation for a window W w,h (α i I,x i j ) consists of a concatenation of the softweighted bag-of-words representations over its fixed random set of 200 sub-windows as in [24]. The multi-class boosted classifier [26] is learnt as a sum of decision stumps, comparing one dimension of the feature representation to a threshold θ T. Unlike in [24], the set of thresholds T is found independently for each particular dimension by uniformly splitting its range in the training set. Long feature vectors ( for each feature) for each pixel can not be kept in memory, but have to be calculated on fly using integral images [24] for each image in the pyramid and each visual word of a feature. We implement several heuristics to decrease the resulting memory requirements. The soft weights from (0, 1) are approximated using 1-byte. The integral images are built only for a sub-window of an image, that covers all the features of given visual word, using an integer type (1 8 bytes) based on the required range for each individual visual word for each image. The multiple features are, unlike in [13], fused using late fusion, e.g. the classifiers for each feature are trained independently and eventually averaged. Thanks to these heuristics, the requirements for memory dropped approximately 40 for the NYU2 dataset [25] to below 32GB. An approximately 10 drop was due to the integral image updates and 4 due to the late fusion. 5. Experiments We tested our algorithm on KITTI [6] and NYU2 [25] datasets. The KITTI dataset was chosen to demonstrate the ability of our classifier to learn depth for semantic classes with a relatively small number of training samples. The NYU2 dataset was used to show that depth can be predicted for an unconstraint problem with no assumptions about the layout of the scene. Furthermore, we show that for both datasets learning of the problem jointly leads to an improvement of the performance KITTI data set The KITTI data set [6] consists of a large number of outdoor street scene images of the resolution , out of which 194 images contain sparse disparity maps obtained by Velodyne laser scanner. We labelled the semantic segmentation ground truth for the 60 images with ground truth depth and split them into 30 training and 30 test images. The label set consists of 12 semantic class labels (see Table 3). Three semantic classes (bicycle, person and sign) with high variations were ignored in the evaluation due to the insufficient training data (only 2 instances in the training set). We aimed to recognize depth in the range of2 50 meters with a maximum relative error δ = max( dgt d res, dres d gt ) < 1.25, where d res is the estimated depth and d gt the ground truth depth. Thus, we set δ POS = Visual recognition of depth with higher precision is very hard for human also. The canonical depth was set to 20 meters. Training samples were taken as negatives if their error exceeded δ NEG = 2.5. Training samples with error between δ POS and δ NEG were ignored. Quantitative comparison to the state-of-the-art class-only unary classifier [13] is given in the table 3. Quantitative comparison of the Make3D [20], trained with the same data, with our depth-only and joint depth semantic classifier is given in the table 2. Our joint classifier significantly outperformed competing algorithms in both domains. Qualitative results are given in the figure 3. Qualitative comparison of depth-only and joint classifier is given in figure 4. The distribution of relative errors of estimated depth is given in figure NYU2 data set The NYU2 data set [25] consist of1449 indoor images of the resolution , containing ground truth for semantic segmentation with 894 semantic classes and pixel-wise depth obtained by a Kinect sensor. For the experiments we used the subset of 40 semantic classes as in [19, 25, 8]. The images were split into 725 training and 724 test images. We aimed to recognize depth in the range meters with a maximum relative error δ = max( dgt d res, dres d gt ) <
![1.25. The canonical depth was set to 6.9 meters. Training samples were taken as positives if their error was below δ POS = 1.25, as negatives if their error exceeded δ NEG = 2.5. Quantitative comparison to the class-only unary classifier [13] and state-of-the-art algorithms using both RGB and depth during test time is given in the table 1.](/docs-images/17/168581/images/5-0.png "Our classifier performance was comparable to these methods even in these unfair conditions. Quantitative results in the depth domain can be found in the table 2.")
5 1.25. The canonical depth was set to 6.9 meters. Training samples were taken as positives if their error was below δ POS = 1.25, as negatives if their error exceeded δ NEG = 2.5. Quantitative comparison to the class-only unary classifier [13] and state-of-the-art algorithms using both RGB and depth during test time is given in the table 1. Our classifier performance was comparable to these methods even in these unfair conditions. Quantitative results in the depth domain can be found in the table 2. There was no other classifier we could have compared to; all other methods are constrained only to very specific scenes with strong layout constraints, such as road scenes. The performance was higher than for the KITTI dataset mainly due to the significantly more narrow range of depths. 6. Discussion and conclusions In this paper we proposed a new pixel-wise classifier, that can jointly predict a semantic class and a depth label from a single image. In general, the obtained results look very promising. In the depth domain the reduction of the problem into classification of one depth only turned up to be very powerful due to its intrinsic dealing with the dataset biases. In the semantic segmentation domain we showed the importance of proper alignment, leading to quantitatively better results. The main weaknesses of the method are the inability to deal with low resolution images, very large requirements in terms of hardware and apparent inability to locate the objects more precisely for semantic classes with high variance. Obtained results suggest future work in three directions: further alignment of orientation using estimated normals, estimation of depth as a latent variable during training for the datasets with small amount of images (or none) with ground truth depth, and development of different forms of regularizations suitable for the problem. The naïve use of standard Potts model pairwise potentials did not lead to an improvement, because this form of regularization typically removed all the small distant objects, and thus we omitted these results in the paper. However, our joint depth/semantic classifier has the potential to enable richer pairwise potentials representing expected spatial relations between objects of different classes. Acknowledgements We gratefully acknowledge the support of the 4DVideo ERC Starting Grant Nr References [1] O. Barinova, V. Konushin, A. Yakubenko, K. Lee, H. Lim, and A. Konushin. Fast automatic single-view 3-d reconstruction of urban scenes. In European Conference on Computer Vision, [2] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Conference on Computer Vision and Pattern Recognition, RGB methods RGB-D methods Class-only [13] Joint classifier [19] [25] [8] Table 1. Quantitative comparison in the frequency-weighted intersection vs union measure on the 40-class NYU2 dataset. Our pixel-wise method outperformed the baseline non-scale-adaptive method using the same features and obtained comparable results to the methods that use full RGB-D data during test time. KITTI NYU2 Make3D Depth-only Joint Depth-only Joint δ < % 43.83% 47.00% 44.35% 54.22% δ < % 68.01% 72.09% 70.82% 82.90% δ < % 82.19% 85.35% 85.90% 94.09% Table 2. Quantitative comparison of Make3D [20], our depth-only classifier and joint classifier on the KITTI and NYU2 dataset in the ratio of pixels correctly labelled, depending on the maximum allowed relative error δ = max( dgt d res, dres d gt ), where d res is the estimated depth andd gt the ground truth depth. Figure 2. The distribution of the relative errors of an estimated depth given a semantic label for the KITTI dataset in the log space with the base 1.25 for each semantic class. Average distribution is calculated excluding the sky label. Green and red line below the x-axis indicates, in which interval the training samples were used as positives and negatives respectively. [3] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei- Fei. Imagenet: A large-scale hierarchical image database [4] L. Fei-Fei, R. Fergus, and P. Perona. Learning generative visual models from few training examples an incremental bayesian approach tested on 101 object categories. In Workshop on GMBS, [5] P. F. Felzenszwalb, D. McAllester, and D. Ramanan. A discriminatively trained, multiscale, deformable part model. In Conference on Computer Vision and Pattern Recognition, [6] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Con-




![class-only baseline classifier [13] using the same](/docs-images/17/168581/images/6-4.jpg "features.")


![2012. [7] J. C. V. Gemert, J. Geusebroek, C. J. Veenman, and A.](/docs-images/17/168581/images/6-7.png "W. M. Smeulders.")

![[8] S. Gupta, P. Arbelaez, and J. Malik.](/docs-images/17/168581/images/6-9.png "Perceptual organization and recognition of indoor")
![scenes from RGB-D images. Con 2013. [9] C. Hane, C.](/docs-images/17/168581/images/6-10.png "Zach, A. Cohen, R. Angst, and M. Pollefeys.")


![[11] D. Hoiem, A. A. Efros, and M. Hebert.](/docs-images/17/168581/images/6-13.jpg "Putting objects in perspective. In Con 2006. [12] S.")






















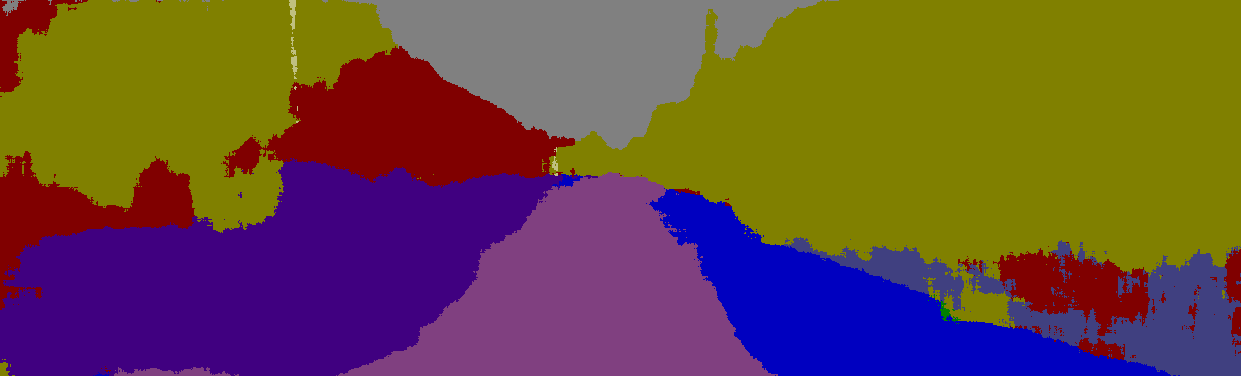



6 Global Average Building Tree Class-only classifier [13] Joint classifier Sky Sidewalk Fence Road Grass Column Car Table 3. Quantitative results in the recall measure for the Kitti data set. Our scale adjusting classifier outperformed the class-only baseline classifier [13] using the same features. Most improvement was obtained on the rare classes and on the pixels belonging to objects far from the camera. ference on Computer Vision and Pattern Recognition, [7] J. C. V. Gemert, J. Geusebroek, C. J. Veenman, and A. W. M. Smeulders. Kernel codebooks for scene categorization. In European Conference on Computer Vision, [8] S. Gupta, P. Arbelaez, and J. Malik. Perceptual organization and recognition of indoor scenes from RGB-D images. Conference on Computer Vision and Pattern Recognition, [9] C. Hane, C. Zach, A. Cohen, R. Angst, and M. Pollefeys. Joint 3D scene reconstruction and class segmentation. In Conference on Computer Vision and Pattern Recognition, [10] D. Hoiem, A. Efros, and M. Hebert. Geometric context from a single image. In International Conference on Computer Vision, [11] D. Hoiem, A. A. Efros, and M. Hebert. Putting objects in perspective. In Conference on Computer Vision and Pattern Recognition, [12] S. u. Hussain and B. Triggs. Visual recognition using local quantized patterns. In European Conference on Computer Vision, [13] L. Ladicky, C. Russell, P. Kohli, and P. H. S. Torr. Associative hierarchical CRFs for object class image segmentation. In International Conference on Computer Vision, [14] L. Ladicky, P. Sturgess, C. Russell, S. Sengupta, Y. Bastanlar, W. Clocksin, and P. H. S. Torr. Joint Optimization for Object Class Segmentation and Dense Stereo Reconstruction. International Journal of Computer Vision, [15] S. Lazebnik, C. Schmid, and J. Ponce. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Conference on Computer Vision and Pattern Recognition, [16] B. Liu, S. Gould, and D. Koller. Single image depth estimation from predicted semantic labels. In Conference on Computer Vision and Pattern Recognition, [17] D. G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, [18] J. Malik, S. Belongie, T. Leung, and J. Shi. Contour and texture analysis for image segmentation. International Journal of Computer Vision, [19] X. Ren, L. Bo, and D. Fox. RGB-(D) scene labeling: Features and algorithms. In Conference on Computer Vision and Pattern Recognition, [20] A. Saxena, S. H. Chung, and A. Y. Ng. Learning depth from single monocular images. In Advances in Neural Information Processing Systems, [21] E. Shechtman and M. Irani. Matching local self-similarities across images and videos. In Conference on Computer Vision and Pattern Recognition, [22] J. Shotton, A. Fitzgibbon, M. Cook, and A. Blake. Real-time human pose recognition in parts from single depth images [23] J. Shotton, M. Johnson, and R. Cipolla. Semantic texton forests for image categorization and segmentation. In Conference on Computer Vision and Pattern Recognition, [24] J. Shotton, J. Winn, C. Rother, and A. Criminisi. Texton- Boost: Joint appearance, shape and context modeling for multi-class object recognition and segmentation. In European Conference on Computer Vision, [25] N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor segmentation and support inference from RGBD images. In European Conference on Computer Vision, [26] A. Torralba, K. Murphy, and W. Freeman. Sharing features: efficient boosting procedures for multiclass object detection [27] A. Vedaldi, V. Gulshan, M. Varma, and A. Zisserman. Multiple kernels for object detection. In International Conference on Computer Vision, [28] J. Wang, J. Yang, K. Yu, F. Lv, T. S. Huang, and Y. Gong. Locality-constrained linear coding for image classification [29] K. Yu, T. Zhang, and Y. Gong. Nonlinear learning using local coordinate coding. In Advances in Neural Information Processing Systems, 2009.
Local features and matching. Image classification & object localization
 Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
3D Model based Object Class Detection in An Arbitrary View
 3D Model based Object Class Detection in An Arbitrary View Pingkun Yan, Saad M. Khan, Mubarak Shah School of Electrical Engineering and Computer Science University of Central Florida http://www.eecs.ucf.edu/
3D Model based Object Class Detection in An Arbitrary View Pingkun Yan, Saad M. Khan, Mubarak Shah School of Electrical Engineering and Computer Science University of Central Florida http://www.eecs.ucf.edu/
Recognizing Cats and Dogs with Shape and Appearance based Models. Group Member: Chu Wang, Landu Jiang
 Recognizing Cats and Dogs with Shape and Appearance based Models Group Member: Chu Wang, Landu Jiang Abstract Recognizing cats and dogs from images is a challenging competition raised by Kaggle platform
Recognizing Cats and Dogs with Shape and Appearance based Models Group Member: Chu Wang, Landu Jiang Abstract Recognizing cats and dogs from images is a challenging competition raised by Kaggle platform
Object Recognition. Selim Aksoy. Bilkent University [email protected]
 Image Classification and Object Recognition Selim Aksoy Department of Computer Engineering Bilkent University [email protected] Image classification Image (scene) classification is a fundamental
Image Classification and Object Recognition Selim Aksoy Department of Computer Engineering Bilkent University [email protected] Image classification Image (scene) classification is a fundamental
Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 269 Class Project Report
 Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 69 Class Project Report Junhua Mao and Lunbo Xu University of California, Los Angeles [email protected] and lunbo
Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 69 Class Project Report Junhua Mao and Lunbo Xu University of California, Los Angeles [email protected] and lunbo
The Delicate Art of Flower Classification
 The Delicate Art of Flower Classification Paul Vicol Simon Fraser University University Burnaby, BC [email protected] Note: The following is my contribution to a group project for a graduate machine learning
The Delicate Art of Flower Classification Paul Vicol Simon Fraser University University Burnaby, BC [email protected] Note: The following is my contribution to a group project for a graduate machine learning
Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite
 Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite Philip Lenz 1 Andreas Geiger 2 Christoph Stiller 1 Raquel Urtasun 3 1 KARLSRUHE INSTITUTE OF TECHNOLOGY 2 MAX-PLANCK-INSTITUTE IS 3
Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite Philip Lenz 1 Andreas Geiger 2 Christoph Stiller 1 Raquel Urtasun 3 1 KARLSRUHE INSTITUTE OF TECHNOLOGY 2 MAX-PLANCK-INSTITUTE IS 3
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Recognition. Sanja Fidler CSC420: Intro to Image Understanding 1 / 28
 Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Object Categorization using Co-Occurrence, Location and Appearance
 Object Categorization using Co-Occurrence, Location and Appearance Carolina Galleguillos Andrew Rabinovich Serge Belongie Department of Computer Science and Engineering University of California, San Diego
Object Categorization using Co-Occurrence, Location and Appearance Carolina Galleguillos Andrew Rabinovich Serge Belongie Department of Computer Science and Engineering University of California, San Diego
What, Where & How Many? Combining Object Detectors and CRFs
 What, Where & How Many? Combining Object Detectors and CRFs L ubor Ladický, Paul Sturgess, Karteek Alahari, Chris Russell, and Philip H.S. Torr Oxford Brookes University http://cms.brookes.ac.uk/research/visiongroup
What, Where & How Many? Combining Object Detectors and CRFs L ubor Ladický, Paul Sturgess, Karteek Alahari, Chris Russell, and Philip H.S. Torr Oxford Brookes University http://cms.brookes.ac.uk/research/visiongroup
Semantic Recognition: Object Detection and Scene Segmentation
 Semantic Recognition: Object Detection and Scene Segmentation Xuming He [email protected] Computer Vision Research Group NICTA Robotic Vision Summer School 2015 Acknowledgement: Slides from Fei-Fei
Semantic Recognition: Object Detection and Scene Segmentation Xuming He [email protected] Computer Vision Research Group NICTA Robotic Vision Summer School 2015 Acknowledgement: Slides from Fei-Fei
Character Image Patterns as Big Data
 22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
Human Pose Estimation from RGB Input Using Synthetic Training Data
 Human Pose Estimation from RGB Input Using Synthetic Training Data Oscar Danielsson and Omid Aghazadeh School of Computer Science and Communication KTH, Stockholm, Sweden {osda02, omida}@kth.se arxiv:1405.1213v2
Human Pose Estimation from RGB Input Using Synthetic Training Data Oscar Danielsson and Omid Aghazadeh School of Computer Science and Communication KTH, Stockholm, Sweden {osda02, omida}@kth.se arxiv:1405.1213v2
How does the Kinect work? John MacCormick
 How does the Kinect work? John MacCormick Xbox demo Laptop demo The Kinect uses structured light and machine learning Inferring body position is a two-stage process: first compute a depth map (using structured
How does the Kinect work? John MacCormick Xbox demo Laptop demo The Kinect uses structured light and machine learning Inferring body position is a two-stage process: first compute a depth map (using structured
IMPLICIT SHAPE MODELS FOR OBJECT DETECTION IN 3D POINT CLOUDS
 IMPLICIT SHAPE MODELS FOR OBJECT DETECTION IN 3D POINT CLOUDS Alexander Velizhev 1 (presenter) Roman Shapovalov 2 Konrad Schindler 3 1 Hexagon Technology Center, Heerbrugg, Switzerland 2 Graphics & Media
IMPLICIT SHAPE MODELS FOR OBJECT DETECTION IN 3D POINT CLOUDS Alexander Velizhev 1 (presenter) Roman Shapovalov 2 Konrad Schindler 3 1 Hexagon Technology Center, Heerbrugg, Switzerland 2 Graphics & Media
Cees Snoek. Machine. Humans. Multimedia Archives. Euvision Technologies The Netherlands. University of Amsterdam The Netherlands. Tree.
 Visual search: what's next? Cees Snoek University of Amsterdam The Netherlands Euvision Technologies The Netherlands Problem statement US flag Tree Aircraft Humans Dog Smoking Building Basketball Table
Visual search: what's next? Cees Snoek University of Amsterdam The Netherlands Euvision Technologies The Netherlands Problem statement US flag Tree Aircraft Humans Dog Smoking Building Basketball Table
The Visual Internet of Things System Based on Depth Camera
 The Visual Internet of Things System Based on Depth Camera Xucong Zhang 1, Xiaoyun Wang and Yingmin Jia Abstract The Visual Internet of Things is an important part of information technology. It is proposed
The Visual Internet of Things System Based on Depth Camera Xucong Zhang 1, Xiaoyun Wang and Yingmin Jia Abstract The Visual Internet of Things is an important part of information technology. It is proposed
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Fast Matching of Binary Features
 Fast Matching of Binary Features Marius Muja and David G. Lowe Laboratory for Computational Intelligence University of British Columbia, Vancouver, Canada {mariusm,lowe}@cs.ubc.ca Abstract There has been
Fast Matching of Binary Features Marius Muja and David G. Lowe Laboratory for Computational Intelligence University of British Columbia, Vancouver, Canada {mariusm,lowe}@cs.ubc.ca Abstract There has been
Fast Semantic Segmentation of 3D Point Clouds using a Dense CRF with Learned Parameters
 Fast Semantic Segmentation of 3D Point Clouds using a Dense CRF with Learned Parameters Daniel Wolf, Johann Prankl and Markus Vincze Abstract In this paper, we present an efficient semantic segmentation
Fast Semantic Segmentation of 3D Point Clouds using a Dense CRF with Learned Parameters Daniel Wolf, Johann Prankl and Markus Vincze Abstract In this paper, we present an efficient semantic segmentation
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Scalable Object Detection by Filter Compression with Regularized Sparse Coding
 Scalable Object Detection by Filter Compression with Regularized Sparse Coding Ting-Hsuan Chao, Yen-Liang Lin, Yin-Hsi Kuo, and Winston H Hsu National Taiwan University, Taipei, Taiwan Abstract For practical
Scalable Object Detection by Filter Compression with Regularized Sparse Coding Ting-Hsuan Chao, Yen-Liang Lin, Yin-Hsi Kuo, and Winston H Hsu National Taiwan University, Taipei, Taiwan Abstract For practical
Image Classification for Dogs and Cats
 Image Classification for Dogs and Cats Bang Liu, Yan Liu Department of Electrical and Computer Engineering {bang3,yan10}@ualberta.ca Kai Zhou Department of Computing Science [email protected] Abstract
Image Classification for Dogs and Cats Bang Liu, Yan Liu Department of Electrical and Computer Engineering {bang3,yan10}@ualberta.ca Kai Zhou Department of Computing Science [email protected] Abstract
Assessment. Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall
 Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Improving Spatial Support for Objects via Multiple Segmentations
 Improving Spatial Support for Objects via Multiple Segmentations Tomasz Malisiewicz and Alexei A. Efros Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 Abstract Sliding window scanning
Improving Spatial Support for Objects via Multiple Segmentations Tomasz Malisiewicz and Alexei A. Efros Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 Abstract Sliding window scanning
Edge Boxes: Locating Object Proposals from Edges
 Edge Boxes: Locating Object Proposals from Edges C. Lawrence Zitnick and Piotr Dollár Microsoft Research Abstract. The use of object proposals is an effective recent approach for increasing the computational
Edge Boxes: Locating Object Proposals from Edges C. Lawrence Zitnick and Piotr Dollár Microsoft Research Abstract. The use of object proposals is an effective recent approach for increasing the computational
Machine Learning for Medical Image Analysis. A. Criminisi & the InnerEye team @ MSRC
 Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
A Genetic Algorithm-Evolved 3D Point Cloud Descriptor
 A Genetic Algorithm-Evolved 3D Point Cloud Descriptor Dominik Wȩgrzyn and Luís A. Alexandre IT - Instituto de Telecomunicações Dept. of Computer Science, Univ. Beira Interior, 6200-001 Covilhã, Portugal
A Genetic Algorithm-Evolved 3D Point Cloud Descriptor Dominik Wȩgrzyn and Luís A. Alexandre IT - Instituto de Telecomunicações Dept. of Computer Science, Univ. Beira Interior, 6200-001 Covilhã, Portugal
Probabilistic Latent Semantic Analysis (plsa)
") Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg [email protected] www.multimedia-computing.{de,org} References
Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg [email protected] www.multimedia-computing.{de,org} References
Semantic Image Segmentation and Web-Supervised Visual Learning
 Semantic Image Segmentation and Web-Supervised Visual Learning Florian Schroff Andrew Zisserman University of Oxford, UK Antonio Criminisi Microsoft Research Ltd, Cambridge, UK Outline Part I: Semantic
Semantic Image Segmentation and Web-Supervised Visual Learning Florian Schroff Andrew Zisserman University of Oxford, UK Antonio Criminisi Microsoft Research Ltd, Cambridge, UK Outline Part I: Semantic
Part-Based Recognition
 Part-Based Recognition Benedict Brown CS597D, Fall 2003 Princeton University CS 597D, Part-Based Recognition p. 1/32 Introduction Many objects are made up of parts It s presumably easier to identify simple
Part-Based Recognition Benedict Brown CS597D, Fall 2003 Princeton University CS 597D, Part-Based Recognition p. 1/32 Introduction Many objects are made up of parts It s presumably easier to identify simple
Multi-View Object Class Detection with a 3D Geometric Model
 Multi-View Object Class Detection with a 3D Geometric Model Joerg Liebelt IW-SI, EADS Innovation Works D-81663 Munich, Germany [email protected] Cordelia Schmid LEAR, INRIA Grenoble F-38330 Montbonnot,
Multi-View Object Class Detection with a 3D Geometric Model Joerg Liebelt IW-SI, EADS Innovation Works D-81663 Munich, Germany [email protected] Cordelia Schmid LEAR, INRIA Grenoble F-38330 Montbonnot,
Segmentation & Clustering
 EECS 442 Computer vision Segmentation & Clustering Segmentation in human vision K-mean clustering Mean-shift Graph-cut Reading: Chapters 14 [FP] Some slides of this lectures are courtesy of prof F. Li,
EECS 442 Computer vision Segmentation & Clustering Segmentation in human vision K-mean clustering Mean-shift Graph-cut Reading: Chapters 14 [FP] Some slides of this lectures are courtesy of prof F. Li,
Automatic Labeling of Lane Markings for Autonomous Vehicles
 Automatic Labeling of Lane Markings for Autonomous Vehicles Jeffrey Kiske Stanford University 450 Serra Mall, Stanford, CA 94305 [email protected] 1. Introduction As autonomous vehicles become more popular,
Automatic Labeling of Lane Markings for Autonomous Vehicles Jeffrey Kiske Stanford University 450 Serra Mall, Stanford, CA 94305 [email protected] 1. Introduction As autonomous vehicles become more popular,
Mean-Shift Tracking with Random Sampling
 1 Mean-Shift Tracking with Random Sampling Alex Po Leung, Shaogang Gong Department of Computer Science Queen Mary, University of London, London, E1 4NS Abstract In this work, boosting the efficiency of
1 Mean-Shift Tracking with Random Sampling Alex Po Leung, Shaogang Gong Department of Computer Science Queen Mary, University of London, London, E1 4NS Abstract In this work, boosting the efficiency of
Class-specific Sparse Coding for Learning of Object Representations
 Class-specific Sparse Coding for Learning of Object Representations Stephan Hasler, Heiko Wersing, and Edgar Körner Honda Research Institute Europe GmbH Carl-Legien-Str. 30, 63073 Offenbach am Main, Germany
Class-specific Sparse Coding for Learning of Object Representations Stephan Hasler, Heiko Wersing, and Edgar Körner Honda Research Institute Europe GmbH Carl-Legien-Str. 30, 63073 Offenbach am Main, Germany
Learning Mid-Level Features For Recognition
 Learning Mid-Level Features For Recognition Y-Lan Boureau 1,3,4 Francis Bach 1,4 Yann LeCun 3 Jean Ponce 2,4 1 INRIA 2 Ecole Normale Supérieure 3 Courant Institute, New York University Abstract Many successful
Learning Mid-Level Features For Recognition Y-Lan Boureau 1,3,4 Francis Bach 1,4 Yann LeCun 3 Jean Ponce 2,4 1 INRIA 2 Ecole Normale Supérieure 3 Courant Institute, New York University Abstract Many successful
Segmentation as Selective Search for Object Recognition
 Segmentation as Selective Search for Object Recognition Koen E. A. van de Sande Jasper R. R. Uijlings Theo Gevers Arnold W. M. Smeulders University of Amsterdam University of Trento Amsterdam, The Netherlands
Segmentation as Selective Search for Object Recognition Koen E. A. van de Sande Jasper R. R. Uijlings Theo Gevers Arnold W. M. Smeulders University of Amsterdam University of Trento Amsterdam, The Netherlands
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches
 Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Convolutional Feature Maps
 Convolutional Feature Maps Elements of efficient (and accurate) CNN-based object detection Kaiming He Microsoft Research Asia (MSRA) ICCV 2015 Tutorial on Tools for Efficient Object Detection Overview
Convolutional Feature Maps Elements of efficient (and accurate) CNN-based object detection Kaiming He Microsoft Research Asia (MSRA) ICCV 2015 Tutorial on Tools for Efficient Object Detection Overview
An Energy-Based Vehicle Tracking System using Principal Component Analysis and Unsupervised ART Network
 Proceedings of the 8th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING & DATA BASES (AIKED '9) ISSN: 179-519 435 ISBN: 978-96-474-51-2 An Energy-Based Vehicle Tracking System using Principal
Proceedings of the 8th WSEAS Int. Conf. on ARTIFICIAL INTELLIGENCE, KNOWLEDGE ENGINEERING & DATA BASES (AIKED '9) ISSN: 179-519 435 ISBN: 978-96-474-51-2 An Energy-Based Vehicle Tracking System using Principal
Face Recognition in Low-resolution Images by Using Local Zernike Moments
 Proceedings of the International Conference on Machine Vision and Machine Learning Prague, Czech Republic, August14-15, 014 Paper No. 15 Face Recognition in Low-resolution Images by Using Local Zernie
Proceedings of the International Conference on Machine Vision and Machine Learning Prague, Czech Republic, August14-15, 014 Paper No. 15 Face Recognition in Low-resolution Images by Using Local Zernie
Predict Influencers in the Social Network
 Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, [email protected] Department of Electrical Engineering, Stanford University Abstract Given two persons
Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, [email protected] Department of Electrical Engineering, Stanford University Abstract Given two persons
MVA ENS Cachan. Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos [email protected]
 Machine Learning for Computer Vision 1 MVA ENS Cachan Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos [email protected] Department of Applied Mathematics Ecole Centrale Paris Galen
Machine Learning for Computer Vision 1 MVA ENS Cachan Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos [email protected] Department of Applied Mathematics Ecole Centrale Paris Galen
An Analysis of Single-Layer Networks in Unsupervised Feature Learning
 An Analysis of Single-Layer Networks in Unsupervised Feature Learning Adam Coates 1, Honglak Lee 2, Andrew Y. Ng 1 1 Computer Science Department, Stanford University {acoates,ang}@cs.stanford.edu 2 Computer
An Analysis of Single-Layer Networks in Unsupervised Feature Learning Adam Coates 1, Honglak Lee 2, Andrew Y. Ng 1 1 Computer Science Department, Stanford University {acoates,ang}@cs.stanford.edu 2 Computer
High Level Describable Attributes for Predicting Aesthetics and Interestingness
 High Level Describable Attributes for Predicting Aesthetics and Interestingness Sagnik Dhar Vicente Ordonez Tamara L Berg Stony Brook University Stony Brook, NY 11794, USA [email protected] Abstract
High Level Describable Attributes for Predicting Aesthetics and Interestingness Sagnik Dhar Vicente Ordonez Tamara L Berg Stony Brook University Stony Brook, NY 11794, USA [email protected] Abstract
Segmentation of building models from dense 3D point-clouds
 Segmentation of building models from dense 3D point-clouds Joachim Bauer, Konrad Karner, Konrad Schindler, Andreas Klaus, Christopher Zach VRVis Research Center for Virtual Reality and Visualization, Institute
Segmentation of building models from dense 3D point-clouds Joachim Bauer, Konrad Karner, Konrad Schindler, Andreas Klaus, Christopher Zach VRVis Research Center for Virtual Reality and Visualization, Institute
Group Sparse Coding. Fernando Pereira Google Mountain View, CA [email protected]. Dennis Strelow Google Mountain View, CA strelow@google.
 Group Sparse Coding Samy Bengio Google Mountain View, CA [email protected] Fernando Pereira Google Mountain View, CA [email protected] Yoram Singer Google Mountain View, CA [email protected] Dennis Strelow
Group Sparse Coding Samy Bengio Google Mountain View, CA [email protected] Fernando Pereira Google Mountain View, CA [email protected] Yoram Singer Google Mountain View, CA [email protected] Dennis Strelow
Removing Moving Objects from Point Cloud Scenes
 1 Removing Moving Objects from Point Cloud Scenes Krystof Litomisky [email protected] Abstract. Three-dimensional simultaneous localization and mapping is a topic of significant interest in the research
1 Removing Moving Objects from Point Cloud Scenes Krystof Litomisky [email protected] Abstract. Three-dimensional simultaneous localization and mapping is a topic of significant interest in the research
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Neural Network based Vehicle Classification for Intelligent Traffic Control
 Neural Network based Vehicle Classification for Intelligent Traffic Control Saeid Fazli 1, Shahram Mohammadi 2, Morteza Rahmani 3 1,2,3 Electrical Engineering Department, Zanjan University, Zanjan, IRAN
Neural Network based Vehicle Classification for Intelligent Traffic Control Saeid Fazli 1, Shahram Mohammadi 2, Morteza Rahmani 3 1,2,3 Electrical Engineering Department, Zanjan University, Zanjan, IRAN
Optical Flow. Shenlong Wang CSC2541 Course Presentation Feb 2, 2016
 Optical Flow Shenlong Wang CSC2541 Course Presentation Feb 2, 2016 Outline Introduction Variation Models Feature Matching Methods End-to-end Learning based Methods Discussion Optical Flow Goal: Pixel motion
Optical Flow Shenlong Wang CSC2541 Course Presentation Feb 2, 2016 Outline Introduction Variation Models Feature Matching Methods End-to-end Learning based Methods Discussion Optical Flow Goal: Pixel motion
Transform-based Domain Adaptation for Big Data
 Transform-based Domain Adaptation for Big Data Erik Rodner University of Jena Judy Hoffman Jeff Donahue Trevor Darrell Kate Saenko UMass Lowell Abstract Images seen during test time are often not from
Transform-based Domain Adaptation for Big Data Erik Rodner University of Jena Judy Hoffman Jeff Donahue Trevor Darrell Kate Saenko UMass Lowell Abstract Images seen during test time are often not from
Practical Tour of Visual tracking. David Fleet and Allan Jepson January, 2006
 Practical Tour of Visual tracking David Fleet and Allan Jepson January, 2006 Designing a Visual Tracker: What is the state? pose and motion (position, velocity, acceleration, ) shape (size, deformation,
Practical Tour of Visual tracking David Fleet and Allan Jepson January, 2006 Designing a Visual Tracker: What is the state? pose and motion (position, velocity, acceleration, ) shape (size, deformation,
Privacy Preserving Automatic Fall Detection for Elderly Using RGBD Cameras
 Privacy Preserving Automatic Fall Detection for Elderly Using RGBD Cameras Chenyang Zhang 1, Yingli Tian 1, and Elizabeth Capezuti 2 1 Media Lab, The City University of New York (CUNY), City College New
Privacy Preserving Automatic Fall Detection for Elderly Using RGBD Cameras Chenyang Zhang 1, Yingli Tian 1, and Elizabeth Capezuti 2 1 Media Lab, The City University of New York (CUNY), City College New
Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection
 CSED703R: Deep Learning for Visual Recognition (206S) Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection Bohyung Han Computer Vision Lab. [email protected] 2 3 Object detection
CSED703R: Deep Learning for Visual Recognition (206S) Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection Bohyung Han Computer Vision Lab. [email protected] 2 3 Object detection
Machine Learning for Data Science (CS4786) Lecture 1
 Lecture 1") Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
The KITTI-ROAD Evaluation Benchmark. for Road Detection Algorithms
 The KITTI-ROAD Evaluation Benchmark for Road Detection Algorithms 08.06.2014 Jannik Fritsch Honda Research Institute Europe, Offenbach, Germany Presented material created together with Tobias Kuehnl Research
The KITTI-ROAD Evaluation Benchmark for Road Detection Algorithms 08.06.2014 Jannik Fritsch Honda Research Institute Europe, Offenbach, Germany Presented material created together with Tobias Kuehnl Research
Speed Performance Improvement of Vehicle Blob Tracking System
 Speed Performance Improvement of Vehicle Blob Tracking System Sung Chun Lee and Ram Nevatia University of Southern California, Los Angeles, CA 90089, USA [email protected], [email protected] Abstract. A speed
Speed Performance Improvement of Vehicle Blob Tracking System Sung Chun Lee and Ram Nevatia University of Southern California, Los Angeles, CA 90089, USA [email protected], [email protected] Abstract. A speed
How To Model The Labeling Problem In A Conditional Random Field (Crf) Model
 Model") A Dynamic Conditional Random Field Model for Joint Labeling of Object and Scene Classes Christian Wojek and Bernt Schiele {wojek, schiele}@cs.tu-darmstadt.de Computer Science Department TU Darmstadt Abstract.
A Dynamic Conditional Random Field Model for Joint Labeling of Object and Scene Classes Christian Wojek and Bernt Schiele {wojek, schiele}@cs.tu-darmstadt.de Computer Science Department TU Darmstadt Abstract.
Unsupervised Discovery of Mid-Level Discriminative Patches
 Unsupervised Discovery of Mid-Level Discriminative Patches Saurabh Singh, Abhinav Gupta, and Alexei A. Efros Carnegie Mellon University, Pittsburgh, PA 15213, USA http://graphics.cs.cmu.edu/projects/discriminativepatches/
Unsupervised Discovery of Mid-Level Discriminative Patches Saurabh Singh, Abhinav Gupta, and Alexei A. Efros Carnegie Mellon University, Pittsburgh, PA 15213, USA http://graphics.cs.cmu.edu/projects/discriminativepatches/
Learning Motion Categories using both Semantic and Structural Information
 Learning Motion Categories using both Semantic and Structural Information Shu-Fai Wong, Tae-Kyun Kim and Roberto Cipolla Department of Engineering, University of Cambridge, Cambridge, CB2 1PZ, UK {sfw26,
Learning Motion Categories using both Semantic and Structural Information Shu-Fai Wong, Tae-Kyun Kim and Roberto Cipolla Department of Engineering, University of Cambridge, Cambridge, CB2 1PZ, UK {sfw26,
Decomposing a Scene into Geometric and Semantically Consistent Regions
 Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould Dept. of Electrical Engineering Stanford University [email protected] Richard Fulton Dept. of Computer Science Stanford
Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould Dept. of Electrical Engineering Stanford University [email protected] Richard Fulton Dept. of Computer Science Stanford
Classifying Manipulation Primitives from Visual Data
 Classifying Manipulation Primitives from Visual Data Sandy Huang and Dylan Hadfield-Menell Abstract One approach to learning from demonstrations in robotics is to make use of a classifier to predict if
Classifying Manipulation Primitives from Visual Data Sandy Huang and Dylan Hadfield-Menell Abstract One approach to learning from demonstrations in robotics is to make use of a classifier to predict if
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j
 Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
ACCURACY ASSESSMENT OF BUILDING POINT CLOUDS AUTOMATICALLY GENERATED FROM IPHONE IMAGES
 ACCURACY ASSESSMENT OF BUILDING POINT CLOUDS AUTOMATICALLY GENERATED FROM IPHONE IMAGES B. Sirmacek, R. Lindenbergh Delft University of Technology, Department of Geoscience and Remote Sensing, Stevinweg
ACCURACY ASSESSMENT OF BUILDING POINT CLOUDS AUTOMATICALLY GENERATED FROM IPHONE IMAGES B. Sirmacek, R. Lindenbergh Delft University of Technology, Department of Geoscience and Remote Sensing, Stevinweg
Learning Spatial Context: Using Stuff to Find Things
 Learning Spatial Context: Using Stuff to Find Things Geremy Heitz Daphne Koller Department of Computer Science, Stanford University {gaheitz,koller}@cs.stanford.edu Abstract. The sliding window approach
Learning Spatial Context: Using Stuff to Find Things Geremy Heitz Daphne Koller Department of Computer Science, Stanford University {gaheitz,koller}@cs.stanford.edu Abstract. The sliding window approach
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
W6.B.1. FAQs CS535 BIG DATA W6.B.3. 4. If the distance of the point is additionally less than the tight distance T 2, remove it from the original set
 http://wwwcscolostateedu/~cs535 W6B W6B2 CS535 BIG DAA FAQs Please prepare for the last minute rush Store your output files safely Partial score will be given for the output from less than 50GB input Computer
http://wwwcscolostateedu/~cs535 W6B W6B2 CS535 BIG DAA FAQs Please prepare for the last minute rush Store your output files safely Partial score will be given for the output from less than 50GB input Computer
VEHICLE LOCALISATION AND CLASSIFICATION IN URBAN CCTV STREAMS
 VEHICLE LOCALISATION AND CLASSIFICATION IN URBAN CCTV STREAMS Norbert Buch 1, Mark Cracknell 2, James Orwell 1 and Sergio A. Velastin 1 1. Kingston University, Penrhyn Road, Kingston upon Thames, KT1 2EE,
VEHICLE LOCALISATION AND CLASSIFICATION IN URBAN CCTV STREAMS Norbert Buch 1, Mark Cracknell 2, James Orwell 1 and Sergio A. Velastin 1 1. Kingston University, Penrhyn Road, Kingston upon Thames, KT1 2EE,
COPYRIGHTED MATERIAL. Contents. List of Figures. Acknowledgments
 Contents List of Figures Foreword Preface xxv xxiii xv Acknowledgments xxix Chapter 1 Fraud: Detection, Prevention, and Analytics! 1 Introduction 2 Fraud! 2 Fraud Detection and Prevention 10 Big Data for
Contents List of Figures Foreword Preface xxv xxiii xv Acknowledgments xxix Chapter 1 Fraud: Detection, Prevention, and Analytics! 1 Introduction 2 Fraud! 2 Fraud Detection and Prevention 10 Big Data for
Epipolar Geometry. Readings: See Sections 10.1 and 15.6 of Forsyth and Ponce. Right Image. Left Image. e(p ) Epipolar Lines. e(q ) q R.
 Epipolar Lines. e(q ) q R.") Epipolar Geometry We consider two perspective images of a scene as taken from a stereo pair of cameras (or equivalently, assume the scene is rigid and imaged with a single camera from two different locations).
Epipolar Geometry We consider two perspective images of a scene as taken from a stereo pair of cameras (or equivalently, assume the scene is rigid and imaged with a single camera from two different locations).
ASSESSMENT OF VISUALIZATION SOFTWARE FOR SUPPORT OF CONSTRUCTION SITE INSPECTION TASKS USING DATA COLLECTED FROM REALITY CAPTURE TECHNOLOGIES
 ASSESSMENT OF VISUALIZATION SOFTWARE FOR SUPPORT OF CONSTRUCTION SITE INSPECTION TASKS USING DATA COLLECTED FROM REALITY CAPTURE TECHNOLOGIES ABSTRACT Chris Gordon 1, Burcu Akinci 2, Frank Boukamp 3, and
ASSESSMENT OF VISUALIZATION SOFTWARE FOR SUPPORT OF CONSTRUCTION SITE INSPECTION TASKS USING DATA COLLECTED FROM REALITY CAPTURE TECHNOLOGIES ABSTRACT Chris Gordon 1, Burcu Akinci 2, Frank Boukamp 3, and
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! [email protected]! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! [email protected]! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
Spatio-Temporally Coherent 3D Animation Reconstruction from Multi-view RGB-D Images using Landmark Sampling
 , March 13-15, 2013, Hong Kong Spatio-Temporally Coherent 3D Animation Reconstruction from Multi-view RGB-D Images using Landmark Sampling Naveed Ahmed Abstract We present a system for spatio-temporally
, March 13-15, 2013, Hong Kong Spatio-Temporally Coherent 3D Animation Reconstruction from Multi-view RGB-D Images using Landmark Sampling Naveed Ahmed Abstract We present a system for spatio-temporally
Computer Animation and Visualisation. Lecture 1. Introduction
 Computer Animation and Visualisation Lecture 1 Introduction 1 Today s topics Overview of the lecture Introduction to Computer Animation Introduction to Visualisation 2 Introduction (PhD in Tokyo, 2000,
Computer Animation and Visualisation Lecture 1 Introduction 1 Today s topics Overview of the lecture Introduction to Computer Animation Introduction to Visualisation 2 Introduction (PhD in Tokyo, 2000,
Lecture 6: Classification & Localization. boris. [email protected]
 Lecture 6: Classification & Localization boris. [email protected] 1 Agenda ILSVRC 2014 Overfeat: integrated classification, localization, and detection Classification with Localization Detection. 2 ILSVRC-2014
Lecture 6: Classification & Localization boris. [email protected] 1 Agenda ILSVRC 2014 Overfeat: integrated classification, localization, and detection Classification with Localization Detection. 2 ILSVRC-2014
Lecture 2: The SVM classifier
 Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
Categorical Data Visualization and Clustering Using Subjective Factors
 Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Automatic parameter regulation for a tracking system with an auto-critical function
 Automatic parameter regulation for a tracking system with an auto-critical function Daniela Hall INRIA Rhône-Alpes, St. Ismier, France Email: [email protected] Abstract In this article we propose
Automatic parameter regulation for a tracking system with an auto-critical function Daniela Hall INRIA Rhône-Alpes, St. Ismier, France Email: [email protected] Abstract In this article we propose
Distributed forests for MapReduce-based machine learning
 Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Document Image Retrieval using Signatures as Queries
 Document Image Retrieval using Signatures as Queries Sargur N. Srihari, Shravya Shetty, Siyuan Chen, Harish Srinivasan, Chen Huang CEDAR, University at Buffalo(SUNY) Amherst, New York 14228 Gady Agam and
Document Image Retrieval using Signatures as Queries Sargur N. Srihari, Shravya Shetty, Siyuan Chen, Harish Srinivasan, Chen Huang CEDAR, University at Buffalo(SUNY) Amherst, New York 14228 Gady Agam and
Knowledge Discovery from patents using KMX Text Analytics
 Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs [email protected] Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs [email protected] Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Localizing 3D cuboids in single-view images
 Localizing 3D cuboids in single-view images Jianxiong Xiao Bryan C. Russell Antonio Torralba Massachusetts Institute of Technology University of Washington Abstract In this paper we seek to detect rectangular
Localizing 3D cuboids in single-view images Jianxiong Xiao Bryan C. Russell Antonio Torralba Massachusetts Institute of Technology University of Washington Abstract In this paper we seek to detect rectangular
Professor, D.Sc. (Tech.) Eugene Kovshov MSTU «STANKIN», Moscow, Russia
 Eugene Kovshov MSTU «STANKIN», Moscow, Russia") Professor, D.Sc. (Tech.) Eugene Kovshov MSTU «STANKIN», Moscow, Russia As of today, the issue of Big Data processing is still of high importance. Data flow is increasingly growing. Processing methods
Professor, D.Sc. (Tech.) Eugene Kovshov MSTU «STANKIN», Moscow, Russia As of today, the issue of Big Data processing is still of high importance. Data flow is increasingly growing. Processing methods
Blocks that Shout: Distinctive Parts for Scene Classification
 Blocks that Shout: Distinctive Parts for Scene Classification Mayank Juneja 1 Andrea Vedaldi 2 C. V. Jawahar 1 Andrew Zisserman 2 1 Center for Visual Information Technology, International Institute of
Blocks that Shout: Distinctive Parts for Scene Classification Mayank Juneja 1 Andrea Vedaldi 2 C. V. Jawahar 1 Andrew Zisserman 2 1 Center for Visual Information Technology, International Institute of
Machine Learning Logistic Regression
 Machine Learning Logistic Regression Jeff Howbert Introduction to Machine Learning Winter 2012 1 Logistic regression Name is somewhat misleading. Really a technique for classification, not regression.
Machine Learning Logistic Regression Jeff Howbert Introduction to Machine Learning Winter 2012 1 Logistic regression Name is somewhat misleading. Really a technique for classification, not regression.
Algebra 1 2008. Academic Content Standards Grade Eight and Grade Nine Ohio. Grade Eight. Number, Number Sense and Operations Standard
 Academic Content Standards Grade Eight and Grade Nine Ohio Algebra 1 2008 Grade Eight STANDARDS Number, Number Sense and Operations Standard Number and Number Systems 1. Use scientific notation to express
Academic Content Standards Grade Eight and Grade Nine Ohio Algebra 1 2008 Grade Eight STANDARDS Number, Number Sense and Operations Standard Number and Number Systems 1. Use scientific notation to express
Deformable Part Models with CNN Features
 Deformable Part Models with CNN Features Pierre-André Savalle 1, Stavros Tsogkas 1,2, George Papandreou 3, Iasonas Kokkinos 1,2 1 Ecole Centrale Paris, 2 INRIA, 3 TTI-Chicago Abstract. In this work we
Deformable Part Models with CNN Features Pierre-André Savalle 1, Stavros Tsogkas 1,2, George Papandreou 3, Iasonas Kokkinos 1,2 1 Ecole Centrale Paris, 2 INRIA, 3 TTI-Chicago Abstract. In this work we
Tracking and Recognition in Sports Videos
 Tracking and Recognition in Sports Videos Mustafa Teke a, Masoud Sattari b a Graduate School of Informatics, Middle East Technical University, Ankara, Turkey [email protected] b Department of Computer
Tracking and Recognition in Sports Videos Mustafa Teke a, Masoud Sattari b a Graduate School of Informatics, Middle East Technical University, Ankara, Turkey [email protected] b Department of Computer
Tracking of Small Unmanned Aerial Vehicles
 Tracking of Small Unmanned Aerial Vehicles Steven Krukowski Adrien Perkins Aeronautics and Astronautics Stanford University Stanford, CA 94305 Email: [email protected] Aeronautics and Astronautics Stanford
Tracking of Small Unmanned Aerial Vehicles Steven Krukowski Adrien Perkins Aeronautics and Astronautics Stanford University Stanford, CA 94305 Email: [email protected] Aeronautics and Astronautics Stanford
Image Segmentation and Registration
 Image Segmentation and Registration Dr. Christine Tanner ([email protected]) Computer Vision Laboratory, ETH Zürich Dr. Verena Kaynig, Machine Learning Laboratory, ETH Zürich Outline Segmentation
Image Segmentation and Registration Dr. Christine Tanner ([email protected]) Computer Vision Laboratory, ETH Zürich Dr. Verena Kaynig, Machine Learning Laboratory, ETH Zürich Outline Segmentation