OpenDataPlane Introduction and Overview
|
|
|
- Job Moody
- 10 years ago
- Views:
Transcription
1 Introduction and Overview Linaro Networking Group (LNG) Initial Release 0.1.0, January 2014 Executive Summary OpenDataPlane (ODP) is an open source project that provides an application programming environment for data plane applications that is easy to use, high performance, and portable across networking SoCs of various instruction sets and architectures. The environment consists of common APIs, configuration files, services, and utilities on top of an implementation optimized for the underlying hardware. ODP cleanly separates the API from the underlying implementation and is designed to support implementations ranging from pure software to those that deeply exploit underlying hardware co processing and acceleration features present in most modern networking Systems on Chip (SoCs). The goal of ODP is to create a truly cross platform framework for data plane applications. This document provides an introduction and overview of the initial ODP release and discusses the motivation and philosophy behind it, while presenting how it will evolve to achieve its goals. Also under development is a formal ODP Architecture document which describes the overall design and structure of ODP, a Programmer s Guide that presents the ODP Architecture from a programmer s perspective and is aimed at application developers who wish to use ODP to write portable data plane applications, and an Implementer s Guide aimed at platform vendors and those who wish to create conforming ODP implementations on new platforms. These will be released as they become available in Executive Summary Problem Statement ODP Design Principles Separating Data Plane Application Design from Implementation Design Layering Packets Flows Traffic Classes Raising the Level of Abstraction A Foundation for Growth ODP Staging 1

2 Schemas Reference Implementations Linux Generic Implementation Implementation Limits ODP Overview Definitions Terminology ODP API ODP Application ODP implementation Run to Completion Linux APIs Bare metal SDK Fast path Scope Networking data plane applications Development environment Application environment Abstraction level Programming language CPU architecture Coding style Prefixes Licensing Open source Versioning ODP Application Design and Programming Resource Management APIs Memory Management APIs Thread Management APIs Event Management APIs Packet Management APIs Flow Management APIs Traffic Class Management APIs SoC introduction SoC logical view Design Principles Multicore Hardware acceleration Run to completion 2

3 Software only Virtualization Existing APIs Linux features ODP and Linux Direct hardware access Linux scheduler Kernel interference Real time Preemption Power efficiency Execution Model Load Balancing and Packet Distribution ODP Components and APIs Resources and Resource Management APIs Common mechanism Memory and Memory Management APIs Shared Memory Buffer Pools Thread Management APIs Event and Queue Management APIs Packet I/O Management APIs Application Design Principles and Models Problem Statement To meet the performance, capacity, and scalability needs of modern networks, many vendors provide networking SoCs that incorporate innovative hardware solutions to common networking problems, enabling packet processing at up to 100Gb/s speeds. To enable application software to exploit the capability of these platforms, vendors supply Software Development Kits (SDKs) for each platform. While these SDKs enable applications to exploit the capabilities of each platform, they also make it difficult for applications to be truly portable across different platforms. From an SoC customer standpoint, the proliferation of differing solutions to common problems means it is difficult to manage large scale deployments of networking applications in a consistent manner. What is needed is a open standard framework for data plane applications that supports development of portable applications while simultaneously allowing innovation in how these applications are implemented to achieve various price/performance goals. OpenDataPlane is an effort to separate the development of data plane applications from how the various services used to by these applications are implemented on different networking SoCs. 3

4 As such it is inspired by earlier industry precedents like OpenGL, which at the time of introduction sought to provide a similar commonality for the then fragmented world of graphics processing. ODP Design Principles ODP is motivated by several driving forces. While significant strides have been made in implementing data plane applications on general purpose processors, the leading edge of networking has always required some degree of hardware acceleration and offload. Starting with simple functions such as checksum calculation and verification, which are now virtually universal, networking application design has always been a balance between hardware and software implementation choices. When general purpose processors could handle line rate processing of network flows operating at 1Gb/s speeds, 10Gb/s networks began to arrive which required more sophisticated hardware assists. Today, as general purpose processors are beginning to be able to handle 10Gb/s line rates, 100Gb/s networks are beginning to be deployed. This trend is expected to continue with the climb towards Terabit Ethernet. Separating Data Plane Application Design from Implementation Design Increasing network speeds pose several scaling issues, the most obvious being that the rate of increase in networking speeds outstrips the rate of increase in processing speeds. Multi core processing fills this gap to a certain extent, but this also introduces its own challenges in scheduling, flow order preservation, and overall Quality of Service (QoS) management. In addition, as link capacity increases, converged networking becomes an imperative, with disparate traffic classes sharing high speed links while having very different throughput and latency requirements, all of which are difficult to manage purely in software. Beyond this, as network speeds increase the effect of packet loss on overall system performance becomes greatly magnified. Historically this required that data plane applications be completely redesigned to cope with changes in network speed and capacity because applications needed ever closer integration with specialized offload hardware to achieve acceptable performance levels at higher scale. The key to achieving true network agility is to eliminate this need to redesign and reimplement these applications as network technology evolves by cleanly separating application design from the functional implementation of that design. This is the key aim of ODP. Layering The success and ubiquity of networking application in general is due in large part to the strength of the ISO layered model for networking, which cleanly separates networking into seven distinct layers. This means that innovation at lower layers of the network does not affect the operation of applications running on upper layers. However in the data plane (predominantly Layers 2 and 3 of the ISO model) applications are more fully exposed to the rapid changes in the underlying technologies driving networking. This is what results in the need to redesign and rework data 4

5 plane applications to keep pace with this evolution. However, within the data plane there are identifiable processing layers which can be separated and abstracted usefully. Among these are packets, flows, and traffic classes. Packets A packet is the basic unit of data processing in the data plane. Since data plane applications may need to process tens of millions of packets per second, features such as receive and transmit, buffer management, header parsing and assembly, encapsulation and decapsulation, and similar such offloads are common features of many networking SoCs. ODP provides APIs to abstract these features so that data plane applications may assume that these common features are available regardless of how they are realized in a given ODP implementation. Flows A flow is a related sequence of packets for which order must be preserved and which may share state information (if stateful processing is being performed for the flow). Since most modern networking SoCs provide significant hardware innovation in the management of flows, ODP APIs provide abstractions for flows, enabling data plane applications to take advantage of hardware classification, scheduling, flow ordering, and context management services, which may be available in the implementation. Traffic Classes A traffic class is a set of flows that share a common administrative policy. At the highest level, the data plane is charged with implementing control plane policies with regard to traffic classes. This is especially true in converged networks where storage traffic is mixed with voice/video and similar flows with strict latency/jitter requirements, as well as with general Ethernet traffic. ODP provides APIs for identifying traffic classes to hardware or software rate limiter and other traffic classification and shaping features of the implementation. Raising the Level of Abstraction The idea behind ODP is to provide the data plane application with an abstraction of a modern network SoC for which all common (and many advanced) hardware offload features may be assumed, and then allow the implementation to map these application assumptions to whatever hardware and/or software resources are available on the host SoC to realize these functions. Thus rather than having a least common denominator approach to processing, or else having multiple applications for the same networking function which differ only in their environmental assumptions, the application is free to focus on the function it is designed to achieve and rely on the specific ODP implementation to help it realize that function in the most efficient manner possible for a given platform. This is done not by adding overhead but rather by factoring out implementation details into the ODP implementation layer to permit well designed implementations to leverage the inherent capabilities of the platform. At the same time, network SoC vendors are free to create highly optimized solutions for their platforms which can be easily leveraged across a wide array of ODP applications running on that implementation. 5

6 A Foundation for Growth Similar to the evolution of OpenGL, we expect ODP to evolve and grow both in response to continued innovation in technology and business opportunity as well as a result of the many contributions of the open source community. This will be the true key to the success of this effort and the measure of its worth to the industry. ODP Staging Given the ambitious scope of ODP and the fact that its development is being conducted in a fully open manner, it will take some time to realize its goals fully. One of the challenges in providing cross platform APIs that are both portable and yet exhibit near native performance levels on widely differing SoCs is that it is not obvious in advance how to best structure the fine details of ODP APIs to achieve these goals. Rather than take an Olympian view where a master architecture is first defined and promulgated and then force fit to various implementations, with perhaps very uneven results, ODP intends to follow a more organic path where multiple efficient implementations of ODPs on different SoCs help refine the common high level ODP APIs. Thus, while this document presents an overview of ODP as currently envisioned, it should be kept in mind that the formal ODP architecture is still very much a work in progress and is expected to evolve and change, perhaps significantly, as ODP implementations inform the direction of its evolution. ODP uses a standard three level release naming convention (major.minor.revision) and this first public preview release is designated As such it contains a minimal set of APIs and features needed to give a flavor of ODP and to illustrate the basic programming model ODP will support. Hence not all of the features described here will be found in the initial code. These will follow in subsequent releases both in response to ongoing development as well as feedback and contributions from the open source community at large. Schemas Different networking SoCs offer a wide variety of hardware acceleration and offload features that enable significant variability in how packets are processed by the device. Borrowing from database concepts, we use the term schema to refer to this overarching packet flow architecture embodied by an implementation that is independent of the specific data plane application using it. For example, in many SoCs, packets can be routed and processed to different hardware engines without explicit software involvement. A schema would be the description of this flow architecture and would be expressed in a formal domain specific language (DSL) for this purpose. Some SoCs (typically ASICs) support a single hard wired schema while others permit different schemas to be configured either statically or dynamically. Similar concepts are to be found in the graphics world. For example, GStreamer provides a framework for constructing graphs of media handling components. 6

7 ODP intends to address these capabilities in future architectural revisions, however such extensions are not part of the initial ODP release as described here. Instead, the architecture of the initial ODP release may be thought of as a default schema in which all packet processing flows are under explicit software control and direction. Reference Implementations As noted previously, ODP consists of a common set of APIs that articulate a packet processing schema, coupled to an implementation of those APIs tailored to a specific platform. This is what permits ODP application portability across different platforms. Over time there will be many such implementations of the ODP API for different SoCs and platforms. In this initial release of ODP a single reference implementation is offered named linux generic. Linux-Generic Implementation The linux generic implementation is intended to be a reference ODP implementation that is platform neutral and relies only on the Linux kernel itself. Thus, linux generic can run on any SoC or platform that has a Linux implementation. Linux generic serves as a vehicle both for defining and expressing the core ODP API set as well as a means of rapidly porting ODP applications to any platform in advance of it having a native ODP reference implementation. While not intended as a performance target, the performance of linux generic can be improved by making use of Linux kernel features like NO_HZ_FULL that seek to minimize kernel disruption of threads executing on dedicated cores. The scope of linux generic in the preview release is quite modest and covers only the most essential APIs needed to illustrate basic packet processing in the default software centric schema. A fuller implementation of linux generic will parallel the development of SoC specific reference implementations as ODP development progresses. This will include adding additional general performance improvements as they become available. Implementation Limits While ODP itself does not specify limits on functions or features, as a practical matter each ODP implementation will define appropriate limits for itself. For example, while the ODP architecture does not impose an upper limit on the number of queues that may be created, an implementation may impose such a limit to match the number of physical queues supported by hardware. Similarly, ODP threads are assumed to map uniquely to cores but the number of cores are not unlimited and each implementation may restrict the number of ODP threads to the number of physical/logical cores available, etc. ODP API calls use standard error return codes to indicate whether a given function is either unavailable or if an implementation limit has been exceeded for a given call. It is up to the 7


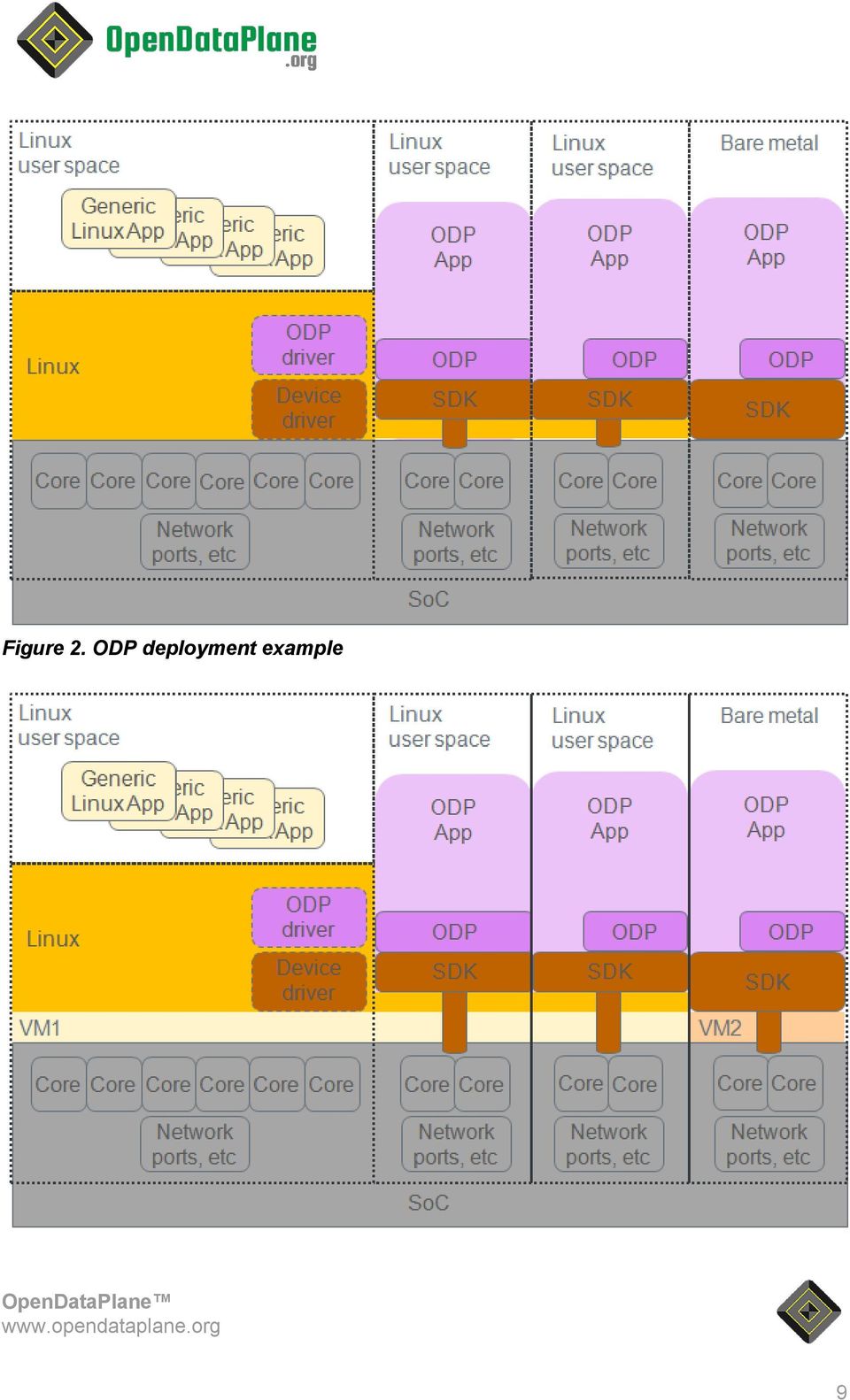
8 application to decide how to structure itself to work with the limits imposed by any given ODP implementation it runs with. ODP Overview Definitions Figure 1 shows ODP and related interfaces at a high level. Figure 1. ODP interfaces An ODP application runs as a Linux user space process but makes very limited calls to Linux APIs. Instead it uses ODP APIs (and possibly SDK APIs) to enable accelerated support of underlying hardware features without incurring kernel overhead. Note that while ODP does not preclude an application from using platform specific SDK calls directly, such use would typically involve a loss of full source level portability across platforms, and would be an application design decision. As a framework for supporting data plane applications, ODP applications can run in parallel with full Linux user processes that implement control and/or management plane functions as these typically do not have the critical performance and latency requirements of the data plane and can more fully benefit from the full Linux API feature set. Figures 2 and 3 demonstrate possible ODP deployments on a multicore SoC. The first deployment has three ODP applications running the first two in separate (sets of) Linux processes in user space and a third one outside Linux in bare metal environment. Linux user space supports direct hardware access from ODP applications (through an SoC specific SDK). The second deployment (in Figure 3) has the same setup, but runs Linux and bare metal in separate virtual machines. ODP is designed to coexist with all standard Virtual Machine Monitors (VMMs) and virtualization hardware to enable data plane applications to run as virtualized containers in support of initiatives like Network Functions Virtualization (NFV). 8


9 Figure 2. ODP deployment example 9
10 Figure 3. ODP deployment example with virtualization Terminology Common terminology used throughout this document includes: ODP API The common data plane application programming interface, as described here and supported by conforming ODP implementations. ODP Application An ODP application is a data plane application using the ODP API. Typically it processes pieces of work (e.g., packets) in a run to completion loop. It may consist of multiple Linux user space processes/threads or bare metal cores. ODP implementation An ODP implementation provides the ODP API for use by ODP applications on a given platform. Run to Completion A programming model in which tasks execute non preemptively and process work requests for as long as progress can be made. This may complete the work in a single dispatch or in stages under application control if the application needs to queue the work for asynchronous processing to an offload function. Linux APIs An ODP application may be a Linux program and thus may use regular Linux/POSIX APIs. Bare metal Bare metal environment does not contain an operating system. Application configures and uses hardware directly, usually through an SDK. SDK A Software Development Kit (SDK) consists of hardware specific APIs and tools. It offers efficient interface towards hardware features, but provides portability only within a family of SoCs. Fast path The part of an ODP application that does majority of the work. It is the part that is optimised for maximum packet rate, data throughput and minimum (real time) latency. Scope Networking data plane applications An ODP application implements a networking function (such as IP router, firewall, mobile network gateway or base station, etc.), which consist of various standard (IETF, 3GPP, IEEE) 10

11 and proprietary networking protocols, and features. The value of the application is in providing an efficient, scalable, feature rich, and innovative implementation of the networking function. Its support of protocols, features, performance, and/or robustness requirements typically exceed those provided by a general purpose Linux IP stack. Development environment ODP applications are expected to be developed under Linux and the libraries and makefiles are distributed in source form designed for compilation using Linux tools and commands. Development may be on Linux systems running natively on the target platform or using cross compilation for other target platforms. The latter model is most convenient when the development target is running an OpenEmbedded (OE) Linux kernel. Application environment The majority of ODP applications are expected to run in Linux user space. However, there will also be applications running in bare metal environments, or a combination of the two. So applications may run entirely in user space, or may be divided between user space and bare metal, or run entirely on bare metal. In general, the Linux kernel (or kernel modules) is not considered an application execution environment for ODP, but may support or implement some ODP services or APIs (e.g., configuration/control). The ODP API itself does not dictate the application execution environment (user space, bare metal, or kernel). Hence, ODP APIs do not contain types, structs or definitions from Linux/Posix headers or a build system. Software on programmable engines (i.e., firmware) is considered part of the hardware implementation and does not use ODP APIs. Abstraction level The goal of ODP is to provide full cross platform source compatibility for ODP applications. Applications using complex hardware acceleration or that are highly tuned to particular hardware may need more porting work than just a recompile. This is an area of ODP development that will be carefully considered as multiple SoC implementations are created and in turn help drive the evolution of the ODP APIs. The goal is to retain full cross platform source portability for applications sharing the same schema, however since applications are generally schema aware it is expected that compatibility across schemas may require more than a simple recompile to achieve portability. Programming language The ODP API and reference implementations are written in the C programming language (C99). Applications or implementations may use also C11 or C++. ODP C++ support is limited to 11

12 providing appropriate extern C clauses in headers to enable usage by C++ routines. ODP itself does not define classes or other object oriented structures as these have limited use in the embedded space. CPU architecture ODP is agnostic to the underlying CPU architecture and is designed to work well on various ISAs, including both 32 and 64 bit versions. As a result, various CPU features (e.g., cache line size) are treated as implementation configurations rather than assumed quantities. For now these are implemented statically as #definesin implementation headers. Other implementations (e.g., those for NUMA architectures) may take into account locality issues such as varying cache line sizes based on the target memory being referenced. ODP is designed to work in both big and little endian modes of a CPU. When referring to networking data types (like IP address) the endianess is documented. By default, all parameters in the API are use an endian native to the implementation s ISA. Packets on the wire use network byte order (big endian). Coding style The Linux kernel coding style is used for API and reference implementations. There are some exceptions, for example in the use of typedefs, as these provide greater levels of abstraction since the implementation of types may vary widely between ODP implementations. Prefixes All ODP APIs are prefixed with odp_ in their names. Licensing The ODP API is provided with 3 clause BSD license. The API cannot have a GPL license since ODP applications and ODP implementations may be proprietary to the companies using the API. Open source The ODP API and reference implementations (including test applications and documentation) are open source. ODP implementations are encouraged to follow this model as well, but ODP does not dictate this. Versioning The ODP API is versioned with major and minor versions. Versions under the same major version (beginning with the version 1.0 release) are fully backward compatible. The version 0.x releases may not be fully backward compatible as they are preview releases. ODP Application Design and Programming ODP APIs are grouped into several component categories: 12

13 Resource Management APIs These APIs enable ODP applications to interrogate the environment to discover resources (cores, I/O interfaces, special purpose offload functions, etc.) and to allocate/configure them for application use. Memory Management APIs These APIs enable ODP applications to allocate and manage memory areas, including shared memory areas used for communication as well as buffer pools used in support of packet processing and other interfaces. Thread Management APIs These APIs enable ODP applications to create and manage logical threads. While ODP itself does not specify a threading model, it does assume that an application can divide itself into multiple threads of control and provides basic APIs for this purpose. In most ODP implementations it is assumed that there is a one to one mapping between threads and processing cores to minimize scheduling overhead and interference. Event Management APIs These APIs enable ODP applications to create and configure event queues to allow threads of control to receive and process events and to queue asynchronous processing requests to other event handlers. Packet Management APIs These APIs enable ODP applications to receive and transmit packets from input interfaces, to manipulate them for processing, and to transmit them on output interfaces. Flow Management APIs These APIs enable ODP applications to configure and manage classification rules that enable packets to be grouped into flows. Traffic Class Management APIs These APIs enable ODP applications to define and implement policies relating to traffic classes for Quality of Service (QoS) or other purposes. SoC introduction SoC logical view All packet processing or data plane applications need a set of basic functionality to manage the packets. Figure 4 illustrates a logical function split (with optional acceleration) that is also easy to map to a networking SoC. 13


14 Figure 4. Logical view on networking SoCs Packet input abstracts physical ingress packet ports Pre processing works at line rate and provides a coarse grained packet classification for buffer pool selection (VM etc) and first level congestion control. It allocates memory for the incoming packets and transfers content to the buffer memory Input classification is a fine grained parsing and classification function that separates traffic flows into the configured queues and adds metadata like packet parsing results Ingress queueing provides queues (FIFOs) of descriptors (meta data for the actual payload). Descriptors to queues may arrive directly from HW devices or from SW Delivery/Scheduling is an important block. It provides a synchronized SW/HW interface, work scheduling and load balancing functionality for all cores with a single receive point. Scheduler makes the decision based on per queue priority settings, queue status and CPU status. Optionally CPUs can bypass the scheduling function and access a queue directly. Accelerators can provide special purpose processing like cryptography or compression with an asynchronous queue based interface. Output from an accelerator typically goes to a queue. The job complete descriptor can then be scheduled towards SW or chained to another accelerator. 14

15 Co processors are like accelerators, but have a synchronous interface towards SW (special opcode, CPU register or dedicated mapped address), execute the operation quickly and are typically per CPU. Output from a co processor is typically synchronous, but could optionally be a descriptor to a queue. Egress queueing provides shared synchronized interface towards egress ports. Each queue is mapped towards a logical port and optionally scheduled/shaped with the configured QoS. A logical port is then mapped towards a physical port with attributes (e.g. QoS, VLAN etc). Post processing schedules packets towards egress ports and frees the packet buffers as the packet leaves the device. It may also provide inline acceleration like adding packet checksums. Packet output provides interface to the physical egress ports While all this could be implemented in software, many of the blocks can benefit from hardware implementation. This is especially true for functions that include very high packet/bit rates (e.g., packet classification), SoC level synchronisation (scheduling, buffer management) or wide data operations (crypto). All of these are good candidates for hardware implementation and are found in many networking SoCs. Design Principles Performance Attention to maximum performance and multi core scaling is needed to achieve high throughput, packet rate and processing efficiency. Design decisions must be evaluated against performance impact on various SoCs. An ODP application should be able to use SoC features at near to native performance and not face significant overheads due to multiple layers of abstraction. While specific performance targets and measurements have yet to be established, for planning purposes the goal of near native is with 5%. Some numeric examples: An ODP application on a SoC may have to sustain ~100 Gbps and ~100 Mpps packet throughput, which could result in a total cycle budget ~500 CPU cycles per packet (32 cores at 1.5GHz). Another application and SoC may have to sustain 10 Gbps or 15 Mpps with just a few Watt power budget (e.g. max four 1.5 GHz CPU cores), which would then result to total cycle budget of ~400 CPU cycles per packet. Multicore Single core solutions are almost non existent nowadays. The power price performance ratio of a system is optimized by selecting a SoC with right hardware features, core count and frequency. The same application code may cover a large range of products and performance targets. When using ODP, the application would be easy to port and scale from small to large SoCs, whichever 15

16 would be the optimal selection for a given power/price budget. As the core count gets higher, it s important to maximize parallelism in applications with minimal performance overhead and programming complexity. These can be achieved with support of hardware synchronisation features (scheduling, mutual exclusion) and an application framework which uses these hardware features. Hardware acceleration Special purpose hardware enables very high throughput, performance and power efficiency when properly used. ODP provides an abstraction of common SoC hardware acceleration features, which can be used on multiple SoCs at near native performance levels. ODP aims not to abstract all hardware features of all SoCs, but rather a set of the most commonly used and provided features. Run-to-completion For maximum performance, ODP avoids per packet interrupts, system calls and CPU context switches. All of these cost additional instructions and potential stall cycles (due to cache, TLB, and branch prediction misses). When the total CPU cycle budget per packet may be from hundreds to couple of thousand cycles, even a single CPU context switch per packet can create an unacceptably large overhead. Most of these overheads can be avoided/minimized by running a single software thread per core (or hardware thread) in a run to completion loop, This thread handles one packet (task/event) at a time to completion, before it starts to process the next packet. This model integrates well to global work scheduling and load balancing of the cores. Software only ODP enables running networking applications also in data centres or customer private clouds. The same ODP application (source code) may need to support both data centers based on general purpose CPUs (with modest hardware acceleration) and utility boxes built from special purpose SoCs. The first would provide savings to customers through high volume hardware (including maintenance) and other benefits, such as flexibility to test new features quickly, but it may not be the most optimized solution. The second would provide customers the most performance price power optimized solution for highly loaded applications. ODP APIs support both software only and hardware accelerated implementations. Typically, a software only implementation would have higher CPU overhead (more instructions) per operation and may not scale as well as with core count as a hardware accelerated implementation. Still, the ODP architecture and the API aims to provide best in class software only performance. 16

17 Virtualization Full virtualization of networking SoCs will become common as core counts increase, hardware features expand and cloud deployments require it. ODP is designed to perform well with virtualization. The performance difference between native and virtualized implementations should be negligible (as long as SoC hardware supports it). Existing APIs ODP implementations may use or depend on existing platform (SDK) APIs when possible. ODP itself does not specify how an implementation may implement the ODP API set. Linux features ODP and Linux ODP considers Linux the default operating system for SoCs running ODP applications. However, ODP API and specifications do not rely on Linux or POSIX definitions. ODP can be very well implemented and used with some other OSes, RTOSes or bare metal environments. The following part refers to Linux features, but same applies to other operating systems. Direct hardware access ODP application performance depends on hardware accelerator performance and application overhead on accessing those accelerators. Many times direct access from application to hardware accelerator registers/interfaces is needed to guarantee high performance. System calls (including context switch) and data copies are avoided at least on the interfaces used by application fast path. Linux scheduler Typically, an ODP application pins a single thread per core. It does not rely on Linux scheduler to schedule threads or work when doing the fast path processing. Application (work) scheduling is based on the SoC level hardware (or a specialised software) scheduler, which is optimised to efficiently load balance and synchronise work between the cores. Normal Linux threads and scheduling is used for running slow path/control plane part of the application. Sometimes the slow and fast path core allocation may overlap, in which case some slow path threads (for debugging, etc.) may be running in the background of the fast path ODP threads. The main reason why this would occur would be in low end systems with limited numbers of cores that preclude full dedication. Kernel interference ODP implementations minimize Linux kernel interference, preferably to zero, on the cores running ODP application fast path logic. When a single thread runs on a core, the kernel should 17

18 not interfere the application (thread) in any way as long as the application does not call system calls or otherwise raise/cause exceptions or interrupts. If or when an ODP application invokes the kernel (system call, exception, etc.), the kernel takes control to process the event, after which it returns to zero interference mode. Since such kernel processing is only done by specific application request, presumably the application has accounted for this overhead in its overall design. For example, Linux system calls during application initialization, termination, or special exception/error path processing for things like device recovery, link up/down, etc., would normally not be a performance concern. The Linux kernel s NO_HZ_FULL configuration option can be used in conjunction with some additional features to achieve the effect of eliminating kernel interrupts on cores to be dedicated to ODP threads. Details of this will be forthcoming. Real-time Although ODP fast path processing generally executes a single thread per core and avoids interrupt processing on those cores, sometimes this cannot be avoided, e.g., due to low core count or other reasons. When a core is shared between fast path and other (interrupt or background) processing, it is important that context switches have relatively low maximum latency in both directions. First, interrupt processing may need fast reaction time, while bulk of the (interrupt) processing can be message based and scheduled with an appropriate priority. Second, pre emptions to fast path processing should be short and relatively constant, otherwise it may not be able to meet deadlines or will suffer from increased packet latency and jitter. Third, fast path processing must be resumed quickly from background processing to meet real time processing deadlines and guarantee maximum system performance. The worst case interrupt or context switch latency should be in order of microseconds, far less than a millisecond. Linux kernel RT patch improves kernel s response time and will help to achieve the real time requirements described above. An ODP implementation should work with or without the RT patch, and leave it to the user to decide if the RT patch is applied or not. Preemption As mentioned, preemption is generally avoided in ODP fast path processing. If a fast path thread is preempted, it should happen only for a short while and preferably with co operation with the thread via an explicit yield (for example, before it starts processing a new packet). In addition to latency issues, preemption may cause core and SoC level performance issues. On core level, pre empting code may suffer from cache misses and cause cache thrashing. Performance degradation may be more severe on SoC level. If the preempted thread is holding 18


19 software or hardware locks (such as for maintaining packet order), it may cause all other fast path threads (cores) to wait and limit severely SoC level throughput. Power efficiency When ODP application core utilization is low, it may be appropriate for some cores to save power. Moves between different power save states may need Linux support, at least in the deeper states. Core idle and power save can be implemented in on several levels. For example: Save automatically core dynamic power whenever there s no work from the SoC level scheduler. In some SoCs this may be a special instruction that blocks waiting on a hardware scheduler and stops the core clocking for the waiting period. The period would be roughly from nanoseconds to seconds. Application initiated context switch to a deeper power save states (e.g., through Linux idle), when the application notices that there s (likely) a longer period of low activity ahead. Implementation needs actions from application control plane and Linux such as re configuring scheduling and classification rules, unpinning the thread, moving the core into a sleep state, etc. Application initiated power down of a core. The application would remove the core (and associated thread) from ODP processing pool and command Linux to power down the core. Execution Model Figure 5 shows the logical view of packet processing using ODP. Figure 5. ODP Packet Processing 19


20 Packets arrive on one or more ingress interfaces and are processed into flows via a classifier function that assigns them to queues. Work is processed from the queues via a scheduler to one or more application threads and/or offload function accelerators and then are routed via queues and another scheduler/shaper instance to one or more egress interfaces. Not every ODP application will follow this model but it is expected to be typical of a large class of them. Load Balancing and Packet Distribution A key design element of ODP is scale out support via multi core processing such that increased workloads can be processed by adding cores without fundamentally changing application design. Figures 6 and 7 show two approaches to scale out using, respectively, push mode and pull mode scheduling Figure 6. ODP Pull Model 20


21 Figure 7. ODP Push Model The difference between push and pull models is the position of the scheduling function. In the pull model the scheduler dispatches items from queues to worker threads while in the push model queues are associated directly with worker threads and are serviced individually by them. Again the choice of which model to use is up to the application as ODP APIs exist to support both. ODP Components and APIs As noted, ODP APIs cover several broad component areas. These are introduced and discussed in the following sections. Resources and Resource Management APIs Hardware resources are more complex and diverse on SoCs, than on general purpose servers due to the variety of advanced hardware accelerators present. A hardware accelerator may serve multiple cores, VMs, kernels and application processes/threads. Also hardware accelerators may be interconnected, which adds complexity to the configuration, For example, typically a packet output port can free packet buffers back to hardware managed buffer pools after transmitting a packet.. Examples of SoC resources CPUs (or hardware threads) Main memory 21
22 Shared memory regions Huge page mappings (how many, what sizes) Physical and virtual input ports / interfaces Packet classification rules Scheduler (core groups, algorithms, ordering) Hardware queues Crypto (sessions, autonomous protocol termination) Timers Buffer management (pools, buffer sizes, buffer counts) Physical and virtual output ports / interfaces Output traffic management and hardware Quality of Service (QoS) support. Deep packet inspection The first four of these are common resources and can use standard (Linux) mechanisms. Others have networking SoC specific features and need special attention. Common mechanism Applications need a common mechanism to find and reserve hardware resources regardless of execution environment (user space, bare metal, with/without virtualization) or resource usage of other applications or kernels. The common ODP resource management (RM) should be dynamic, so that hardware resource allocation and configuration can be changed in a live system. Application would most likely access RM during startup/initialisation/termination phases, but potentially also when processing live traffic. Application level resource allocation and configuration must not be based on static mechanisms like re compiling images or (SoC or VM) rebooting. The RM must work correctly also when ODP application share resources with other applications or kernel (e.g., share a network interface with related packet classification and buffer management). The intent is that the Linux kernel itself provide the bulk of these services since managing shared resources is one of the primary functions of an operating system. Normally the control/management plane will interact with the OS to provision resources for the data plane and the data plane will simply make use of the resources identified to it. Specific ODP APIs to help in this are currently limited to simple functions such as enumerating the number of cores available to an ODP application. Additional functions will be added as needed as ODP evolves. Fast path processing Software threading An ODP application consists of multiple threads running concurrently on multiple cores. These 22
23 threads may be Linux processes, pthreads, or main threads on bare metal. Threads running control plane or slow path processing normally use Linux SMP scheduling, while fast path threads are pinned to separate cores and process packets in a run to completion loop (not using Linux SMP scheduling). Typically there should be only one fast path thread per core (or hardware thread). There may be also some low priority, background threads (e.g., for house keeping, etc.) running on fast path cores, especially in lower end configurations with limited numbers of cores. ODP does not specify how threads are implemented, only that implementations provide some conforming thread semantics. ODP implementations are thus free to support any threading options (OS processes, threads and bare metal) most relevant to that implementation. Linux processes provide better protection by default, while data sharing is easier with pthreads or bare metal. The threads provided by the linux generic reference implementation use pthreads. Main loop The ODP application is in control of its main loop. ODP does not force any particular main loop structure, but offers different options for application developers. For example, an application may just run its framework while(errors == 0) { work = get_work() dispatch(work) } or integrate other software into the framework while(errors == 0) { work = get_work() update_profile_stats() if(work == packet_in) { packet_classifier(work) continue } else if(work == framework) { dispatch(work) continue } 23
24 else if(work == tick) { timer(work) continue } else if(work == packet_out) { packet_output(work) continue } else { error_log(work) errors = 1; } } or poll individual resources while(errors == 0) { packets_out = dequeue(output_done_queues); timeouts = dequeue(timer_queues) packets_in = dequeue(input_queues) if(packets_out) { process_output_done(packets_out) } if(timeouts) { process_timeouts(timeouts) } if(packets_in) { packets_fwd = process_packets(packets_in) enqueue(packets_fwd, output_queues) } 24
25 } Queues Definition Queues are multicore safe, First In First Out (FIFO) structures that can hold packet descriptors / messages / events to be processed by the receiving entity. Both hardware and software entities can enqueue (send) items to queues, and dequeue (receive) items from queues. Queues are the main method to transfer data between various (hardware or software) entities on a SoC. Software may receive items from queues directly or through a scheduler. Typically, high end SoCs have hardware acceleration that supports many of these SoC level queues. Hardware implementation varies from all queues being physical to only logical queue IDs mapped on top of a small set of physical queues. When there is no hardware queue support, the implementation must done in software using optimized, multicore safe queue or ring structures. Ideally all queues on an SoC are equal, so that any entity can en /dequeue on any of the queues. In practice, some sets of queues may have been reserved for specific usage and may not be accessible for all the entities. For example, there can be queues dedicated for a hardware accelerator that cores or the scheduler cannot dequeue from (but cores can send to). Queues and queue IDs are visible in many of the ODP APIs, e.g., as a destination for asynchronous messages or data flows. A queue may represent, for example, a VLAN interface, an IPsec tunnel, a port in a messaging protocol, an end user data flow, a crypto accelerator session, or a packet output interface with specific traffic shaping parameters. The specific queue types and configuration vary based on the application design and structure. Operations The main operations on queues are enqueue and dequeue. A scheduler can perform dequeue operations on behalf of the user software on cores, which is often the default option. Software and schedulers should not dequeue from the same set of queues. Typically hardware acceleration does not allow software to walk queues, remove items in the middle of a queue or empty a queue. Also, queue length may not be known. Some queue implementations support batching, where multiple items can be en /dequeued with a single operation. This typically lowers average queue operation overhead to software and this batching is normally transparent to software. Software only In addition to SoC level queues, ODP offers optimized multicore safe queues for application use. 25
26 These are not connected to a scheduler or other hardware accelerators, but can be used internally to the application. Packet descriptor Many ODP API functions handle packets. A common packet descriptor format is needed for portability and interwork between APIs. ODP defines a common data type and a basic set of metadata that the descriptor can carry. Descriptor fields are left implementation specific and are not accessed directly, but through access macros and/or inline functions. This way the implementation can use SoC specific descriptor formats and avoid data copies and abstraction overhead. If a SoC does not provide all specified metadata in hardware, the missing features are supported in software by its ODP implementation. Buffer descriptor In addition to packet descriptors, ODP defines a common buffer descriptor, which includes features common to all different descriptor formats (packet, software messages, etc.). These support batch processing and scatter gather lists. Common descriptors enable the building of standardized software interfaces and can carry metadata between software blocks. Possible metadata in packet descriptor include: Buffer addresses (virtual and physical), including scatter gather support Total buffer length Current offset Offsets to L2/L3/L4 protocol headers Flags for L2/L3/L4 protocols (errors, multicast, etc.) Reference count Owner Scheduling ODP applications are very dependent on the global scheduling function, which controls their throughput, QoS, queue synchronisation, load balance and multi core scaling. In the run to completion model the global packet/task scheduler replaces the operating system thread scheduler in driving application task priority scheduling and load balancing. It controls the fast path execution, whereas the OS thread scheduler may be used for running background threads (or idle / deep power save modes) on the same cores. Typically high end SoCs have a hardware accelerator for packet scheduling and it is well integrated to the cores (e.g., can prefetch data to core caches). However, ODP implementations for low end SoCs or general purpose CPUs (or emulation/simulation environments) will normally implement the scheduler in software. The linux generic reference implementation uses such a software scheduler since it does not assume the availability of any specific set of hardware 26
27 scheduling features. Features The SoC level queues are inputs to the scheduler. The scheduler can either push scheduled packets/events/work to shallow core specific queues or wait for cores to pull work from it. Supported queue depth is an implementation decision. Scheduling decisions are based on queue priority, core grouping and queue synchronization status. The priority based scheduling algorithm is implementation specific, but typically has some strict priority and/or some weighted round robin levels. Core grouping determines the set of cores the scheduler can target from a specific queue. The scheduler forces queue synchronization between cores, e.g., by having only single outstanding item per queue. Queue synchronization The queue synchronization features are important for avoiding software locking in application code and thus provide effective means to write well scalable applications. The scheduler supports three types of queue synchronization: Parallel queues do not have extra synchronization features. Any number of items can be processed in parallel from a queue, and possible synchronization / ordering issues are handled in application software. An atomic queue can have only one core processing its outstanding items at a time. When a core holds item(s) from an atomic queue, it can be sure that there are no other cores accessing other items or context data of the queue concurrently. Thus it does not need to use software locks on those resources. Ordered queues can have multiple outstanding items processed concurrently by multiple cores, and still the original queue order will be restored after processing (before sending those to another queue). Performance The above scheduling features are required with high packet rate and low latency. Each incoming packet targeted to software will transit at least once through the scheduler, and may transit multiple times depending on the software structure. The result is that SoC level total scheduling decision rates may range from millions to hundreds of millions per second. API interface types ODP supports both synchronous and asynchronous APIs. Synchronous Synchronous APIs complete their requested operation prior to returning to the caller. They thus behave like instructions. The return code indicates the success or failure of the requested operation. 27
28 Synchronous interfaces are used for operations that have short and finite execution time, have a core local implementation, or have real time response requirement. Examples: read cpu cycle count, set timeout, queue enqueue/dequeue. Asynchronous Asynchronous interfaces are prefered when requested operations will take long (hundreds of cycles or more) or undetermined time to finish. Requests may be generated with function calls (rather than with explicit messages), but the replies arrive as messages back to the application through queues and scheduling. Messages can be abstracted using common access functions or standard message formats. Accelerator data I/O interfaces are commonly asynchronous. Queue based interfaces give flexibility to implement acceleration functions in various levels in a SoC (SoC level hardware block, coprocessor, special instructions, plain software, or even an external offload device). Also, core cycles can be used for other useful work (controlled by the scheduler) while waiting for a reply from an asynchronous interface such as an accelerator. On the other hand, application context saves/restores add overhead (compared to synchronous waiting) and may cause side effects like cache misses/thrashing. The latter can be minimized by (hardware assisted) context data prefetching. In general, function calls are prefered over explicit messages, since functions are more portable and can hide underlying access methods. The function interface also makes it possible to combine synchronous and asynchronous modes of an operation into a single API since a return code can indicate either completion or successful initiation of a requested operation that will then be completed asynchronously via message notification. Replies from operations are usually defined as abstract messages with a set of access functions. Sometimes user defined messages are possible (e.g., a user allocated/filled message to a user defined queue). Call back functions and interrupts are avoided as application level reply mechanisms as these are inconsistent with the ODP execution model and in general not easily portable across different SoC hardware implementation models. Software components A standard software component interface will be defined and implemented for ODP applications for easier software reusability and 3rd party software integration. This interface will be synchronous and will enable applications to push or pull packet (or buffer) descriptors through a chain of interconnected software components (similarly to the Click Modular Router project). These chains may be integrated into the application run to completion main loop. Packet input and output Packet I/O configuration can be divided into interface and flow levels. An ODP application must first enable an interface level configuration before it can start sending or receiving any packets. 28
29 The configuration includes: Interface enumeration (physical and virtual interfaces) Interface initialization and default configuration buffer pools and buffer management modes default receive and send queues Link layer addresses (Ethernet MAC) Link status (up, down) and speed After interface level configuration, the application can send/receive packets through default queues. Only one entity (application or kernel) can control the physical functions of an interface, others use only virtual functions. Applications adapt to their role (defined by the resource management) when using an interface. Packet classification Hardware classification capabilities vary between SoCs. Most are able to classify few lower level protocols (ethernet, VLAN, etc.) in hardware, which could form the basic level of ODP classification support. More advanced classification capabilities are diverse, so a flexible method is needed to describe those. Missing or dissimilar hardware features can be complemented with additional classification in software. Integration of additional software classification should be implemented with low overhead. Depending on implementation additional passes through queues and scheduling could be avoided. Another, less portable option is to let application find out hardware capabilities and integrate missing hardware features as additional/modified application (front end) software. Similarly to physical packet I/O interfaces, classification hardware is likely to be shared between other applications or the kernel. Thus common coordination is needed when applications need to change classification rules, so that changes to the classification rules are validated and modified without disturbing other traffic on the SoC. Classification enables definition of target queues for incoming packet flows. A packet flow can be defined with: Physical interface Ethernet type Destination MAC, VLAN or MPLS label Source and destination IP addresses Transport layer source and destination ports Packet priority (VLAN, IP, MPLS) User defined fields relative to L2/L3/L4 layer headers Combinations/tunnels of the above 29
30 Buffer management Buffer management hardware of SoCs typically support a number of buffer pools, each holding a number of fixed size buffers. Buffer allocation and free operations are accelerated, and both hardware accelerators and software can operate on the same pools and buffers. Shared pools enable data sharing without copies. Used buffers can be returned directly back to the pool, regardless of the allocator (hardware or software). Applications may reserve some pools for internal use, but as SoCs often have limited RAM storage relative to general purpose servers this must be done with knowledge of resource limits. Buffer management includes Pool configuration and management Pool information Buffer allocation and free Timers ODP applications use timers frequently and for various purposes. Networking protocols specify many of these. For example, a single user flow may include timers for packet re transmissions, user inactivity, jitter buffering and packet shaping / scheduling. So there can be millions of timers running concurrently on an SoC. Some types of timers almost never expire, but are cancelled or reset in most cases. Others may expire often or periodically (e.g., every 1ms). The aggregate rate of timer operations may reach millions per second. Requested timeout range is wide, from microseconds to hours. Similarly the required resolution varies, starting from the microsecond level. ODP timer operations include timer configuration, timeout requests and cancels. Timeouts are delivered as asynchronous messages through SoC queueing and scheduling. There is an option to use user defined messages and destination queues. This way timeouts and packet data can share the same flow context without extra locking. Crypto The same crypto operations may be provided by an SoC level or external accelerator, accelerated instructions or generic software. Crypto operation latency is relatively high even when hardware accelerators are used since it depends directly on the buffer length. Typically, short buffers are processed more efficiently on CPU cores than on SoC level accelerators due to access latency/overhead. Large buffers fit accelerators better than CPUs, due to higher throughput and lower CPU processing jitter for software on the same cores. ODP provides APIs for both synchronous (inline on the core) and asynchronous crypto processing operations. The application can obtain operational capabilities via the Resource 30
31 Manager. Management of various crypto operation parameters is session based. The application first creates a session with parameters, and later on requests operations with references to the session as well as source and destination buffers. Selection between asynchronous/synchronous operations is on a per session and per packet basis. A crypto session may include:. Crypto algorithm and mode selection Operation chaining (e.g., crypto + authentication) Keys Initialization vector (if session based) Binding to selected implementation(s) Helper library Many small helper functions and definitions are needed to enable ODP applications to be hardware optimized but not tied to a particular hardware or execution environment. These are typically implemented with inline functions, preprocessor macros, or compiler built in features. Thus API definitions are normally inline when possible. The list of envisioned helper features include: Core enumeration Application or middleware need to handle physical and/or logical core IDs, core counts and core masks quite often. Core enumeration has to remain consistent even when core deployment may change during application execution (e.g., due to adaptation to changing traffic profile, etc). Memory alignments For optimal performance and scalability (e.g., to avoid false sharing and cache line aliasing), some application data structures need to be aligned to cache (cache line) and/or memory subsystem (page, DRAM burst) alignments. NUMA systems also support location awareness and potentially different cache line sizes on a per memory basis. Static memory allocation Serves application needs for portable definitions for global and core/thread local data. Compiler hints The compiler and linker can do better optimizations if code includes hints on expected application behavior. Examples of these are classification of branches with likely/unlikely hints, or marking code with hot (optimize for speed) or cold (optimize for size) tags. Prefetching Prefetching data into core caches before using it improves cache hit rate and thus performance. Optimal number of and places for prefetches are hardware dependent, but prefetching in most 31
32 obvious places should increase rather than decrease performance. Atomic operations Modern ISAs offers various atomic instructions to access/manipulate data concurrently from multiple cores. Well scalable multicore software is possible only through correct usage (and combination) of hardware acceleration and atomic instructions. Applications use atomic operations to update global statistics, sequence counters, quotas, etc., and to build concurrent data structures. Memory synchronization barriers Application (or middleware) needs a portable way to synchronize data modifications into main memory before messaging other cores or hardware acceleration about the changes. The nature of the synchronization needs are cache coherence protocol specific. Execution barriers and spinlocks Although software locking should be avoided (especially in fast path code), at times there is no practical way to synchronize cores other than using execution barriers or spinlocks. For example, the application initialization phase typically is not performance critical and may be much simpler with synchronous interfaces and locking. Profiling and debugging Although there are (external) tools for profiling and debugging, some level of application code instrumentation is typically needed (e.g., for on field debug/profiling). Typically an SoC supports CPU level (e.g., cycle count, cache misses, branch prediction misses) and SoC level (system cache misses, interconnect/dram utilization) performance counters. SoC Hardware info The application may be interested in generic performance characteristics of the SoC it is running on to have optimal adaption to the system. APIs for reading this information are thus provided. Data manipulation There are some data manipulation operations that are typical to networking applications. Examples of these are byte order swap for big/little endian conversion, various checksum algorithms, and bit shuffling/shifting. Optimized standard library functions Some commonly used standard C library functions may be supplemented with versions that are specialized, performance optimized and have bounded execution times. For example there could be multiple versions of memcpy / memmove / memset functions with different fixed alignments and possibly even lengths. Memory allocation functions (alloc, etc.) could have versions using huge page mapped memory and optimised for performance rather than memory consumption. Also functions like printfcould have more fast path friendly versions (bounded execution time). 32
33 Data and control plane communication A SoC level communication mechanism is needed between data and control plane software (generic Linux application). Typically those do not share memory and are programmed on (various) different frameworks. The mechanism must be based on message passing through queues/scheduling on data plane side. The same mechanism can be used also for messaging between different data plane applications and processes/threads of an application. Control plane side implementation can be based on any generic message passing framework, such as sockets or signals. Message rate may be high also on this interface, e.g., when all control plane traffic goes through data plane (filtering / forwarding) or when it is used for data plane to data plane communication. Thus hardware acceleration is normally used for buffer management, queues and data copying (with DMA or packet interface loopback) between memory spaces. Output queuing When an SoC is connected to a network that supports QoS or has bottlenecks, some outgoing packet flows may need additional scheduling and shaping. Hardware capabilities vary, but typically first few scheduling/shaping levels (few queues, high throughput per queue) can be done in hardware and higher levels (many queues, low throughput per queue) must be done in software. Output queuing configuration may include: connect queues, scheduler, shaper, output ports into a hierarchy scheduling/shaping parameters back pressure method Deep Packet inspection Deep Packet Inspection (DPI) is typically used to help accelerate intrusion detection, suspicious payload (virus) identification, and as input to higher level traffic classification algorithms. DPI implementation may be in any combination of hardware, software, or external device. ODP applications interact with DPI services via queues or inline packet flows. Memory and Memory Management APIs ODP provides a basic set of APIs to create and manage shared memory areas and buffer pools. Shared Memory Shared memory areas are used both internally in ODP implementations as well as in ODP applications to store information that is globally accessible to application threads. Shared memory areas have three attributes: a name, used as a key for referencing the area, a size, and 33
34 an alignment requirement. Implementations may impose a maximum length for a shared memory area name via the ODP_SHM_NAME_LEN configuration. Applications may create and delete shared memory areas as well as look them up by name. A shared memory area is considered a block of storage and suballocation functions for managing storage within a shared area are not defined by ODP. Buffer Pools Buffer pools are special memory areas that support multiple instances of fixed sized memory areas useful in packet or other processing where frequent allocations and deallocations occur. APIs are provided to create and lookup buffer pools as well as to allocate and free buffers within them. Buffer pools have an associated name, total size, buffer (element) size, and alignment. For implementations making use of hardware buffer managers, buffer allocation and free processing may be implicit and automatic. Thread Management APIs Although ODP does not specify a threading model, it does assume the need for threads and provides a basic set of APIs for creating and identifying threads. In the linux generic implementation these are front ends to the Linux pthreads library. Event and Queue Management APIs ODP provides APIs used to create and manage event queues. Packet I/O Management APIs ODP provides APIs to perform packet I/O on interfaces. Standard open/close/recv/send APIs enable packets to be received and transmitted on interfaces. Note that these functions would normally be used by a scheduler rather than directly by worker threads. They are provided as low level functions mainly as building blocks for other ODP APIs but may be used directly by applications as needed as well. Summary ODP applications are organized into threads that divide work into separate execution units. Threads each have local storage and may share storage with each other via shared memory and may communicate with each other via queue based message passing. The intent is to provide a set of basic APIs that cover the needs of most data plane applications while still permitting efficient implementations of these APIs on a wide variety of networking SoCs. As ODP continues to evolve additional reference implementations will begin to exploit the hardware acceleration features present on their host SoCs. The experience in providing these implementations in turn will help refine both the ODP API set as well as the overall architecture of ODP as ODP evolves towards a stable Release 1.0 later in As an open source project we expect the shape and direction of this evolution to be driven by the contributions of interested 34
35 parties from diverse areas. For additional information on the ODP project and how to become involved and stay informed about its evolution and development, please see the OpenDataPlane.org web site. This site will always be the latest source of current information about the project. 35
Intel DPDK Boosts Server Appliance Performance White Paper
 Intel DPDK Boosts Server Appliance Performance Intel DPDK Boosts Server Appliance Performance Introduction As network speeds increase to 40G and above, both in the enterprise and data center, the bottlenecks
Intel DPDK Boosts Server Appliance Performance Intel DPDK Boosts Server Appliance Performance Introduction As network speeds increase to 40G and above, both in the enterprise and data center, the bottlenecks
The Lagopus SDN Software Switch. 3.1 SDN and OpenFlow. 3. Cloud Computing Technology
 3. The Lagopus SDN Software Switch Here we explain the capabilities of the new Lagopus software switch in detail, starting with the basics of SDN and OpenFlow. 3.1 SDN and OpenFlow Those engaged in network-related
3. The Lagopus SDN Software Switch Here we explain the capabilities of the new Lagopus software switch in detail, starting with the basics of SDN and OpenFlow. 3.1 SDN and OpenFlow Those engaged in network-related
ODP Application proof point: OpenFastPath. ODP mini-summit 2015-11-10
 ODP Application proof point: OpenFastPath ODP mini-summit 2015-11-10 What is Our Intention with OpenFastPath? To enable efficient IP communication Essential in practically all networking use-cases, including
ODP Application proof point: OpenFastPath ODP mini-summit 2015-11-10 What is Our Intention with OpenFastPath? To enable efficient IP communication Essential in practically all networking use-cases, including
White Paper Abstract Disclaimer
 White Paper Synopsis of the Data Streaming Logical Specification (Phase I) Based on: RapidIO Specification Part X: Data Streaming Logical Specification Rev. 1.2, 08/2004 Abstract The Data Streaming specification
White Paper Synopsis of the Data Streaming Logical Specification (Phase I) Based on: RapidIO Specification Part X: Data Streaming Logical Specification Rev. 1.2, 08/2004 Abstract The Data Streaming specification
Scaling Networking Applications to Multiple Cores
 Scaling Networking Applications to Multiple Cores Greg Seibert Sr. Technical Marketing Engineer Cavium Networks Challenges with multi-core application performance Amdahl s Law Evaluates application performance
Scaling Networking Applications to Multiple Cores Greg Seibert Sr. Technical Marketing Engineer Cavium Networks Challenges with multi-core application performance Amdahl s Law Evaluates application performance
An Implementation Of Multiprocessor Linux
 An Implementation Of Multiprocessor Linux This document describes the implementation of a simple SMP Linux kernel extension and how to use this to develop SMP Linux kernels for architectures other than
An Implementation Of Multiprocessor Linux This document describes the implementation of a simple SMP Linux kernel extension and how to use this to develop SMP Linux kernels for architectures other than
Cisco Integrated Services Routers Performance Overview
 Integrated Services Routers Performance Overview What You Will Learn The Integrated Services Routers Generation 2 (ISR G2) provide a robust platform for delivering WAN services, unified communications,
Integrated Services Routers Performance Overview What You Will Learn The Integrated Services Routers Generation 2 (ISR G2) provide a robust platform for delivering WAN services, unified communications,
Network Function Virtualization Using Data Plane Developer s Kit
 Network Function Virtualization Using Enabling 25GbE to 100GbE Virtual Network Functions with QLogic FastLinQ Intelligent Ethernet Adapters DPDK addresses key scalability issues of NFV workloads QLogic
Network Function Virtualization Using Enabling 25GbE to 100GbE Virtual Network Functions with QLogic FastLinQ Intelligent Ethernet Adapters DPDK addresses key scalability issues of NFV workloads QLogic
Multiprocessor Scheduling and Scheduling in Linux Kernel 2.6
 Multiprocessor Scheduling and Scheduling in Linux Kernel 2.6 Winter Term 2008 / 2009 Jun.-Prof. Dr. André Brinkmann [email protected] Universität Paderborn PC² Agenda Multiprocessor and
Multiprocessor Scheduling and Scheduling in Linux Kernel 2.6 Winter Term 2008 / 2009 Jun.-Prof. Dr. André Brinkmann [email protected] Universität Paderborn PC² Agenda Multiprocessor and
Resource Utilization of Middleware Components in Embedded Systems
 Resource Utilization of Middleware Components in Embedded Systems 3 Introduction System memory, CPU, and network resources are critical to the operation and performance of any software system. These system
Resource Utilization of Middleware Components in Embedded Systems 3 Introduction System memory, CPU, and network resources are critical to the operation and performance of any software system. These system
EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications
 ECE6102 Dependable Distribute Systems, Fall2010 EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications Deepal Jayasinghe, Hyojun Kim, Mohammad M. Hossain, Ali Payani
ECE6102 Dependable Distribute Systems, Fall2010 EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications Deepal Jayasinghe, Hyojun Kim, Mohammad M. Hossain, Ali Payani
Real-Time Systems Prof. Dr. Rajib Mall Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 Real-Time Systems Prof. Dr. Rajib Mall Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No. # 26 Real - Time POSIX. (Contd.) Ok Good morning, so let us get
Real-Time Systems Prof. Dr. Rajib Mall Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No. # 26 Real - Time POSIX. (Contd.) Ok Good morning, so let us get
PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions. Outline. Performance oriented design
 PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions Slide 1 Outline Principles for performance oriented design Performance testing Performance tuning General
PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions Slide 1 Outline Principles for performance oriented design Performance testing Performance tuning General
Petascale Software Challenges. Piyush Chaudhary [email protected] High Performance Computing
 Petascale Software Challenges Piyush Chaudhary [email protected] High Performance Computing Fundamental Observations Applications are struggling to realize growth in sustained performance at scale Reasons
Petascale Software Challenges Piyush Chaudhary [email protected] High Performance Computing Fundamental Observations Applications are struggling to realize growth in sustained performance at scale Reasons
Software Datapath Acceleration for Stateless Packet Processing
 June 22, 2010 Software Datapath Acceleration for Stateless Packet Processing FTF-NET-F0817 Ravi Malhotra Software Architect Reg. U.S. Pat. & Tm. Off. BeeKit, BeeStack, CoreNet, the Energy Efficient Solutions
June 22, 2010 Software Datapath Acceleration for Stateless Packet Processing FTF-NET-F0817 Ravi Malhotra Software Architect Reg. U.S. Pat. & Tm. Off. BeeKit, BeeStack, CoreNet, the Energy Efficient Solutions
TCP Servers: Offloading TCP Processing in Internet Servers. Design, Implementation, and Performance
 TCP Servers: Offloading TCP Processing in Internet Servers. Design, Implementation, and Performance M. Rangarajan, A. Bohra, K. Banerjee, E.V. Carrera, R. Bianchini, L. Iftode, W. Zwaenepoel. Presented
TCP Servers: Offloading TCP Processing in Internet Servers. Design, Implementation, and Performance M. Rangarajan, A. Bohra, K. Banerjee, E.V. Carrera, R. Bianchini, L. Iftode, W. Zwaenepoel. Presented
Advanced Core Operating System (ACOS): Experience the Performance
: Experience the Performance") WHITE PAPER Advanced Core Operating System (ACOS): Experience the Performance Table of Contents Trends Affecting Application Networking...3 The Era of Multicore...3 Multicore System Design Challenges...3
WHITE PAPER Advanced Core Operating System (ACOS): Experience the Performance Table of Contents Trends Affecting Application Networking...3 The Era of Multicore...3 Multicore System Design Challenges...3
Frequently Asked Questions
 Frequently Asked Questions 1. Q: What is the Network Data Tunnel? A: Network Data Tunnel (NDT) is a software-based solution that accelerates data transfer in point-to-point or point-to-multipoint network
Frequently Asked Questions 1. Q: What is the Network Data Tunnel? A: Network Data Tunnel (NDT) is a software-based solution that accelerates data transfer in point-to-point or point-to-multipoint network
PCI Express Overview. And, by the way, they need to do it in less time.
 PCI Express Overview Introduction This paper is intended to introduce design engineers, system architects and business managers to the PCI Express protocol and how this interconnect technology fits into
PCI Express Overview Introduction This paper is intended to introduce design engineers, system architects and business managers to the PCI Express protocol and how this interconnect technology fits into
Cloud Networking Disruption with Software Defined Network Virtualization. Ali Khayam
 Cloud Networking Disruption with Software Defined Network Virtualization Ali Khayam In the next one hour Let s discuss two disruptive new paradigms in the world of networking: Network Virtualization Software
Cloud Networking Disruption with Software Defined Network Virtualization Ali Khayam In the next one hour Let s discuss two disruptive new paradigms in the world of networking: Network Virtualization Software
find model parameters, to validate models, and to develop inputs for models. c 1994 Raj Jain 7.1
 Monitors Monitor: A tool used to observe the activities on a system. Usage: A system programmer may use a monitor to improve software performance. Find frequently used segments of the software. A systems
Monitors Monitor: A tool used to observe the activities on a system. Usage: A system programmer may use a monitor to improve software performance. Find frequently used segments of the software. A systems
Where IT perceptions are reality. Test Report. OCe14000 Performance. Featuring Emulex OCe14102 Network Adapters Emulex XE100 Offload Engine
 Where IT perceptions are reality Test Report OCe14000 Performance Featuring Emulex OCe14102 Network Adapters Emulex XE100 Offload Engine Document # TEST2014001 v9, October 2014 Copyright 2014 IT Brand
Where IT perceptions are reality Test Report OCe14000 Performance Featuring Emulex OCe14102 Network Adapters Emulex XE100 Offload Engine Document # TEST2014001 v9, October 2014 Copyright 2014 IT Brand
A Comparative Study on Vega-HTTP & Popular Open-source Web-servers
 A Comparative Study on Vega-HTTP & Popular Open-source Web-servers Happiest People. Happiest Customers Contents Abstract... 3 Introduction... 3 Performance Comparison... 4 Architecture... 5 Diagram...
A Comparative Study on Vega-HTTP & Popular Open-source Web-servers Happiest People. Happiest Customers Contents Abstract... 3 Introduction... 3 Performance Comparison... 4 Architecture... 5 Diagram...
Full and Para Virtualization
 Full and Para Virtualization Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF x86 Hardware Virtualization The x86 architecture offers four levels
Full and Para Virtualization Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF x86 Hardware Virtualization The x86 architecture offers four levels
Intel Ethernet Switch Load Balancing System Design Using Advanced Features in Intel Ethernet Switch Family
 Intel Ethernet Switch Load Balancing System Design Using Advanced Features in Intel Ethernet Switch Family White Paper June, 2008 Legal INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
Intel Ethernet Switch Load Balancing System Design Using Advanced Features in Intel Ethernet Switch Family White Paper June, 2008 Legal INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
VXLAN: Scaling Data Center Capacity. White Paper
 VXLAN: Scaling Data Center Capacity White Paper Virtual Extensible LAN (VXLAN) Overview This document provides an overview of how VXLAN works. It also provides criteria to help determine when and where
VXLAN: Scaling Data Center Capacity White Paper Virtual Extensible LAN (VXLAN) Overview This document provides an overview of how VXLAN works. It also provides criteria to help determine when and where
Operating Systems 4 th Class
 Operating Systems 4 th Class Lecture 1 Operating Systems Operating systems are essential part of any computer system. Therefore, a course in operating systems is an essential part of any computer science
Operating Systems 4 th Class Lecture 1 Operating Systems Operating systems are essential part of any computer system. Therefore, a course in operating systems is an essential part of any computer science
Solving I/O Bottlenecks to Enable Superior Cloud Efficiency
 WHITE PAPER Solving I/O Bottlenecks to Enable Superior Cloud Efficiency Overview...1 Mellanox I/O Virtualization Features and Benefits...2 Summary...6 Overview We already have 8 or even 16 cores on one
WHITE PAPER Solving I/O Bottlenecks to Enable Superior Cloud Efficiency Overview...1 Mellanox I/O Virtualization Features and Benefits...2 Summary...6 Overview We already have 8 or even 16 cores on one
Performance Evaluation of VMXNET3 Virtual Network Device VMware vsphere 4 build 164009
 Performance Study Performance Evaluation of VMXNET3 Virtual Network Device VMware vsphere 4 build 164009 Introduction With more and more mission critical networking intensive workloads being virtualized
Performance Study Performance Evaluation of VMXNET3 Virtual Network Device VMware vsphere 4 build 164009 Introduction With more and more mission critical networking intensive workloads being virtualized
Network Virtualization for Large-Scale Data Centers
 Network Virtualization for Large-Scale Data Centers Tatsuhiro Ando Osamu Shimokuni Katsuhito Asano The growing use of cloud technology by large enterprises to support their business continuity planning
Network Virtualization for Large-Scale Data Centers Tatsuhiro Ando Osamu Shimokuni Katsuhito Asano The growing use of cloud technology by large enterprises to support their business continuity planning
Security Overview of the Integrity Virtual Machines Architecture
 Security Overview of the Integrity Virtual Machines Architecture Introduction... 2 Integrity Virtual Machines Architecture... 2 Virtual Machine Host System... 2 Virtual Machine Control... 2 Scheduling
Security Overview of the Integrity Virtual Machines Architecture Introduction... 2 Integrity Virtual Machines Architecture... 2 Virtual Machine Host System... 2 Virtual Machine Control... 2 Scheduling
Network Simulation Traffic, Paths and Impairment
 Network Simulation Traffic, Paths and Impairment Summary Network simulation software and hardware appliances can emulate networks and network hardware. Wide Area Network (WAN) emulation, by simulating
Network Simulation Traffic, Paths and Impairment Summary Network simulation software and hardware appliances can emulate networks and network hardware. Wide Area Network (WAN) emulation, by simulating
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging
 Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
QoS Parameters. Quality of Service in the Internet. Traffic Shaping: Congestion Control. Keeping the QoS
 Quality of Service in the Internet Problem today: IP is packet switched, therefore no guarantees on a transmission is given (throughput, transmission delay, ): the Internet transmits data Best Effort But:
Quality of Service in the Internet Problem today: IP is packet switched, therefore no guarantees on a transmission is given (throughput, transmission delay, ): the Internet transmits data Best Effort But:
Foundation for High-Performance, Open and Flexible Software and Services in the Carrier Network. Sandeep Shah Director, Systems Architecture EZchip
 Foundation for High-Performance, Open and Flexible Software and Services in the Carrier Network Sandeep Shah Director, Systems Architecture EZchip Linley Carrier Conference June 10, 2015 1 EZchip Overview
Foundation for High-Performance, Open and Flexible Software and Services in the Carrier Network Sandeep Shah Director, Systems Architecture EZchip Linley Carrier Conference June 10, 2015 1 EZchip Overview
Relational Databases in the Cloud
 Contact Information: February 2011 zimory scale White Paper Relational Databases in the Cloud Target audience CIO/CTOs/Architects with medium to large IT installations looking to reduce IT costs by creating
Contact Information: February 2011 zimory scale White Paper Relational Databases in the Cloud Target audience CIO/CTOs/Architects with medium to large IT installations looking to reduce IT costs by creating
How To Make A Vpc More Secure With A Cloud Network Overlay (Network) On A Vlan) On An Openstack Vlan On A Server On A Network On A 2D (Vlan) (Vpn) On Your Vlan
 On A Vlan) On An Openstack Vlan On A Server On A Network On A 2D (Vlan) (Vpn) On Your Vlan") Centec s SDN Switch Built from the Ground Up to Deliver an Optimal Virtual Private Cloud Table of Contents Virtualization Fueling New Possibilities Virtual Private Cloud Offerings... 2 Current Approaches
Centec s SDN Switch Built from the Ground Up to Deliver an Optimal Virtual Private Cloud Table of Contents Virtualization Fueling New Possibilities Virtual Private Cloud Offerings... 2 Current Approaches
I/O Virtualization Using Mellanox InfiniBand And Channel I/O Virtualization (CIOV) Technology
 Technology") I/O Virtualization Using Mellanox InfiniBand And Channel I/O Virtualization (CIOV) Technology Reduce I/O cost and power by 40 50% Reduce I/O real estate needs in blade servers through consolidation Maintain
I/O Virtualization Using Mellanox InfiniBand And Channel I/O Virtualization (CIOV) Technology Reduce I/O cost and power by 40 50% Reduce I/O real estate needs in blade servers through consolidation Maintain
SAN Conceptual and Design Basics
 TECHNICAL NOTE VMware Infrastructure 3 SAN Conceptual and Design Basics VMware ESX Server can be used in conjunction with a SAN (storage area network), a specialized high speed network that connects computer
TECHNICAL NOTE VMware Infrastructure 3 SAN Conceptual and Design Basics VMware ESX Server can be used in conjunction with a SAN (storage area network), a specialized high speed network that connects computer
Definition of a White Box. Benefits of White Boxes
 Smart Network Processing for White Boxes Sandeep Shah Director, Systems Architecture EZchip Technologies [email protected] Linley Carrier Conference June 10-11, 2014 Santa Clara, CA 1 EZchip Overview
Smart Network Processing for White Boxes Sandeep Shah Director, Systems Architecture EZchip Technologies [email protected] Linley Carrier Conference June 10-11, 2014 Santa Clara, CA 1 EZchip Overview
An Oracle Technical White Paper November 2011. Oracle Solaris 11 Network Virtualization and Network Resource Management
 An Oracle Technical White Paper November 2011 Oracle Solaris 11 Network Virtualization and Network Resource Management Executive Overview... 2 Introduction... 2 Network Virtualization... 2 Network Resource
An Oracle Technical White Paper November 2011 Oracle Solaris 11 Network Virtualization and Network Resource Management Executive Overview... 2 Introduction... 2 Network Virtualization... 2 Network Resource
- An Essential Building Block for Stable and Reliable Compute Clusters
 Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
OVERLAYING VIRTUALIZED LAYER 2 NETWORKS OVER LAYER 3 NETWORKS
 OVERLAYING VIRTUALIZED LAYER 2 NETWORKS OVER LAYER 3 NETWORKS Matt Eclavea ([email protected]) Senior Solutions Architect, Brocade Communications Inc. Jim Allen ([email protected]) Senior Architect, Limelight
OVERLAYING VIRTUALIZED LAYER 2 NETWORKS OVER LAYER 3 NETWORKS Matt Eclavea ([email protected]) Senior Solutions Architect, Brocade Communications Inc. Jim Allen ([email protected]) Senior Architect, Limelight
159.735. Final Report. Cluster Scheduling. Submitted by: Priti Lohani 04244354
 159.735 Final Report Cluster Scheduling Submitted by: Priti Lohani 04244354 1 Table of contents: 159.735... 1 Final Report... 1 Cluster Scheduling... 1 Table of contents:... 2 1. Introduction:... 3 1.1
159.735 Final Report Cluster Scheduling Submitted by: Priti Lohani 04244354 1 Table of contents: 159.735... 1 Final Report... 1 Cluster Scheduling... 1 Table of contents:... 2 1. Introduction:... 3 1.1
Programmable Networking with Open vswitch
 Programmable Networking with Open vswitch Jesse Gross LinuxCon September, 2013 2009 VMware Inc. All rights reserved Background: The Evolution of Data Centers Virtualization has created data center workloads
Programmable Networking with Open vswitch Jesse Gross LinuxCon September, 2013 2009 VMware Inc. All rights reserved Background: The Evolution of Data Centers Virtualization has created data center workloads
Performance of Software Switching
 Performance of Software Switching Based on papers in IEEE HPSR 2011 and IFIP/ACM Performance 2011 Nuutti Varis, Jukka Manner Department of Communications and Networking (COMNET) Agenda Motivation Performance
Performance of Software Switching Based on papers in IEEE HPSR 2011 and IFIP/ACM Performance 2011 Nuutti Varis, Jukka Manner Department of Communications and Networking (COMNET) Agenda Motivation Performance
Optimizing Data Center Networks for Cloud Computing
 PRAMAK 1 Optimizing Data Center Networks for Cloud Computing Data Center networks have evolved over time as the nature of computing changed. They evolved to handle the computing models based on main-frames,
PRAMAK 1 Optimizing Data Center Networks for Cloud Computing Data Center networks have evolved over time as the nature of computing changed. They evolved to handle the computing models based on main-frames,
Chapter 6, The Operating System Machine Level
 Chapter 6, The Operating System Machine Level 6.1 Virtual Memory 6.2 Virtual I/O Instructions 6.3 Virtual Instructions For Parallel Processing 6.4 Example Operating Systems 6.5 Summary Virtual Memory General
Chapter 6, The Operating System Machine Level 6.1 Virtual Memory 6.2 Virtual I/O Instructions 6.3 Virtual Instructions For Parallel Processing 6.4 Example Operating Systems 6.5 Summary Virtual Memory General
Quality of Service in the Internet. QoS Parameters. Keeping the QoS. Traffic Shaping: Leaky Bucket Algorithm
 Quality of Service in the Internet Problem today: IP is packet switched, therefore no guarantees on a transmission is given (throughput, transmission delay, ): the Internet transmits data Best Effort But:
Quality of Service in the Internet Problem today: IP is packet switched, therefore no guarantees on a transmission is given (throughput, transmission delay, ): the Internet transmits data Best Effort But:
Accelerating Micro-segmentation
 WHITE PAPER Accelerating Micro-segmentation THE INITIAL CHALLENGE WAS THAT TRADITIONAL SECURITY INFRASTRUCTURES WERE CONCERNED WITH SECURING THE NETWORK BORDER, OR EDGE, WITHOUT BUILDING IN EFFECTIVE SECURITY
WHITE PAPER Accelerating Micro-segmentation THE INITIAL CHALLENGE WAS THAT TRADITIONAL SECURITY INFRASTRUCTURES WERE CONCERNED WITH SECURING THE NETWORK BORDER, OR EDGE, WITHOUT BUILDING IN EFFECTIVE SECURITY
HRG Assessment: Stratus everrun Enterprise
 HRG Assessment: Stratus everrun Enterprise Today IT executive decision makers and their technology recommenders are faced with escalating demands for more effective technology based solutions while at
HRG Assessment: Stratus everrun Enterprise Today IT executive decision makers and their technology recommenders are faced with escalating demands for more effective technology based solutions while at
SiteCelerate white paper
 SiteCelerate white paper Arahe Solutions SITECELERATE OVERVIEW As enterprises increases their investment in Web applications, Portal and websites and as usage of these applications increase, performance
SiteCelerate white paper Arahe Solutions SITECELERATE OVERVIEW As enterprises increases their investment in Web applications, Portal and websites and as usage of these applications increase, performance
White Paper. Real-time Capabilities for Linux SGI REACT Real-Time for Linux
 White Paper Real-time Capabilities for Linux SGI REACT Real-Time for Linux Abstract This white paper describes the real-time capabilities provided by SGI REACT Real-Time for Linux. software. REACT enables
White Paper Real-time Capabilities for Linux SGI REACT Real-Time for Linux Abstract This white paper describes the real-time capabilities provided by SGI REACT Real-Time for Linux. software. REACT enables
CHAPTER 1 INTRODUCTION
 1 CHAPTER 1 INTRODUCTION 1.1 MOTIVATION OF RESEARCH Multicore processors have two or more execution cores (processors) implemented on a single chip having their own set of execution and architectural recourses.
1 CHAPTER 1 INTRODUCTION 1.1 MOTIVATION OF RESEARCH Multicore processors have two or more execution cores (processors) implemented on a single chip having their own set of execution and architectural recourses.
Distributed File Systems
 Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
TRILL Large Layer 2 Network Solution
 TRILL Large Layer 2 Network Solution Contents 1 Network Architecture Requirements of Data Centers in the Cloud Computing Era... 3 2 TRILL Characteristics... 5 3 Huawei TRILL-based Large Layer 2 Network
TRILL Large Layer 2 Network Solution Contents 1 Network Architecture Requirements of Data Centers in the Cloud Computing Era... 3 2 TRILL Characteristics... 5 3 Huawei TRILL-based Large Layer 2 Network
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
CHAPTER 3 PROBLEM STATEMENT AND RESEARCH METHODOLOGY
 51 CHAPTER 3 PROBLEM STATEMENT AND RESEARCH METHODOLOGY Web application operations are a crucial aspect of most organizational operations. Among them business continuity is one of the main concerns. Companies
51 CHAPTER 3 PROBLEM STATEMENT AND RESEARCH METHODOLOGY Web application operations are a crucial aspect of most organizational operations. Among them business continuity is one of the main concerns. Companies
Enhancing Hypervisor and Cloud Solutions Using Embedded Linux Iisko Lappalainen MontaVista
 Enhancing Hypervisor and Cloud Solutions Using Embedded Linux Iisko Lappalainen MontaVista Setting the Stage This presentation will discuss the usage of Linux as a base component of hypervisor components
Enhancing Hypervisor and Cloud Solutions Using Embedded Linux Iisko Lappalainen MontaVista Setting the Stage This presentation will discuss the usage of Linux as a base component of hypervisor components
Computer Network. Interconnected collection of autonomous computers that are able to exchange information
 Introduction Computer Network. Interconnected collection of autonomous computers that are able to exchange information No master/slave relationship between the computers in the network Data Communications.
Introduction Computer Network. Interconnected collection of autonomous computers that are able to exchange information No master/slave relationship between the computers in the network Data Communications.
Datacenter Operating Systems
 Datacenter Operating Systems CSE451 Simon Peter With thanks to Timothy Roscoe (ETH Zurich) Autumn 2015 This Lecture What s a datacenter Why datacenters Types of datacenters Hyperscale datacenters Major
Datacenter Operating Systems CSE451 Simon Peter With thanks to Timothy Roscoe (ETH Zurich) Autumn 2015 This Lecture What s a datacenter Why datacenters Types of datacenters Hyperscale datacenters Major
Quality of Service (QoS) on Netgear switches
 on Netgear switches") Quality of Service (QoS) on Netgear switches Section 1 Principles and Practice of QoS on IP networks Introduction to QoS Why? In a typical modern IT environment, a wide variety of devices are connected
Quality of Service (QoS) on Netgear switches Section 1 Principles and Practice of QoS on IP networks Introduction to QoS Why? In a typical modern IT environment, a wide variety of devices are connected
Making Multicore Work and Measuring its Benefits. Markus Levy, president EEMBC and Multicore Association
 Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Assessing the Performance of Virtualization Technologies for NFV: a Preliminary Benchmarking
 Assessing the Performance of Virtualization Technologies for NFV: a Preliminary Benchmarking Roberto Bonafiglia, Ivano Cerrato, Francesco Ciaccia, Mario Nemirovsky, Fulvio Risso Politecnico di Torino,
Assessing the Performance of Virtualization Technologies for NFV: a Preliminary Benchmarking Roberto Bonafiglia, Ivano Cerrato, Francesco Ciaccia, Mario Nemirovsky, Fulvio Risso Politecnico di Torino,
SYSTEM ecos Embedded Configurable Operating System
 BELONGS TO THE CYGNUS SOLUTIONS founded about 1989 initiative connected with an idea of free software ( commercial support for the free software ). Recently merged with RedHat. CYGNUS was also the original
BELONGS TO THE CYGNUS SOLUTIONS founded about 1989 initiative connected with an idea of free software ( commercial support for the free software ). Recently merged with RedHat. CYGNUS was also the original
Architecture of distributed network processors: specifics of application in information security systems
 Architecture of distributed network processors: specifics of application in information security systems V.Zaborovsky, Politechnical University, Sait-Petersburg, Russia [email protected] 1. Introduction Modern
Architecture of distributed network processors: specifics of application in information security systems V.Zaborovsky, Politechnical University, Sait-Petersburg, Russia [email protected] 1. Introduction Modern
Securing the Intelligent Network
 WHITE PAPER Securing the Intelligent Network Securing the Intelligent Network New Threats Demand New Strategies The network is the door to your organization for both legitimate users and would-be attackers.
WHITE PAPER Securing the Intelligent Network Securing the Intelligent Network New Threats Demand New Strategies The network is the door to your organization for both legitimate users and would-be attackers.
Data and Control Plane Interconnect solutions for SDN & NFV Networks Raghu Kondapalli August 2014
 Data and Control Plane Interconnect solutions for SDN & NFV Networks Raghu Kondapalli August 2014 Title & Abstract Title: Data & Control Plane Interconnect for SDN & NFV networks Abstract: Software defined
Data and Control Plane Interconnect solutions for SDN & NFV Networks Raghu Kondapalli August 2014 Title & Abstract Title: Data & Control Plane Interconnect for SDN & NFV networks Abstract: Software defined
基 於 SDN 與 可 程 式 化 硬 體 架 構 之 雲 端 網 路 系 統 交 換 器
 基 於 SDN 與 可 程 式 化 硬 體 架 構 之 雲 端 網 路 系 統 交 換 器 楊 竹 星 教 授 國 立 成 功 大 學 電 機 工 程 學 系 Outline Introduction OpenFlow NetFPGA OpenFlow Switch on NetFPGA Development Cases Conclusion 2 Introduction With the proposal
基 於 SDN 與 可 程 式 化 硬 體 架 構 之 雲 端 網 路 系 統 交 換 器 楊 竹 星 教 授 國 立 成 功 大 學 電 機 工 程 學 系 Outline Introduction OpenFlow NetFPGA OpenFlow Switch on NetFPGA Development Cases Conclusion 2 Introduction With the proposal
CPU Scheduling Outline
 CPU Scheduling Outline What is scheduling in the OS? What are common scheduling criteria? How to evaluate scheduling algorithms? What are common scheduling algorithms? How is thread scheduling different
CPU Scheduling Outline What is scheduling in the OS? What are common scheduling criteria? How to evaluate scheduling algorithms? What are common scheduling algorithms? How is thread scheduling different
IO Visor: Programmable and Flexible Data Plane for Datacenter s I/O
 IO Visor: Programmable and Flexible Data Plane for Datacenter s I/O LINUX FOUNDATION COLLABORATIVE PROJECTS Introduction Introduction As an industry, we have been building datacenter infrastructure for
IO Visor: Programmable and Flexible Data Plane for Datacenter s I/O LINUX FOUNDATION COLLABORATIVE PROJECTS Introduction Introduction As an industry, we have been building datacenter infrastructure for
Quality of Service Analysis of site to site for IPSec VPNs for realtime multimedia traffic.
 Quality of Service Analysis of site to site for IPSec VPNs for realtime multimedia traffic. A Network and Data Link Layer infrastructure Design to Improve QoS in Voice and video Traffic Jesús Arturo Pérez,
Quality of Service Analysis of site to site for IPSec VPNs for realtime multimedia traffic. A Network and Data Link Layer infrastructure Design to Improve QoS in Voice and video Traffic Jesús Arturo Pérez,
MEASURING WORKLOAD PERFORMANCE IS THE INFRASTRUCTURE A PROBLEM?
 MEASURING WORKLOAD PERFORMANCE IS THE INFRASTRUCTURE A PROBLEM? Ashutosh Shinde Performance Architect [email protected] Validating if the workload generated by the load generating tools is applied
MEASURING WORKLOAD PERFORMANCE IS THE INFRASTRUCTURE A PROBLEM? Ashutosh Shinde Performance Architect [email protected] Validating if the workload generated by the load generating tools is applied
WHITE PAPER. Network Virtualization: A Data Plane Perspective
 WHITE PAPER Network Virtualization: A Data Plane Perspective David Melman Uri Safrai Switching Architecture Marvell May 2015 Abstract Virtualization is the leading technology to provide agile and scalable
WHITE PAPER Network Virtualization: A Data Plane Perspective David Melman Uri Safrai Switching Architecture Marvell May 2015 Abstract Virtualization is the leading technology to provide agile and scalable
Directions for VMware Ready Testing for Application Software
 Directions for VMware Ready Testing for Application Software Introduction To be awarded the VMware ready logo for your product requires a modest amount of engineering work, assuming that the pre-requisites
Directions for VMware Ready Testing for Application Software Introduction To be awarded the VMware ready logo for your product requires a modest amount of engineering work, assuming that the pre-requisites
ConnectX -3 Pro: Solving the NVGRE Performance Challenge
 WHITE PAPER October 2013 ConnectX -3 Pro: Solving the NVGRE Performance Challenge Objective...1 Background: The Need for Virtualized Overlay Networks...1 NVGRE Technology...2 NVGRE s Hidden Challenge...3
WHITE PAPER October 2013 ConnectX -3 Pro: Solving the NVGRE Performance Challenge Objective...1 Background: The Need for Virtualized Overlay Networks...1 NVGRE Technology...2 NVGRE s Hidden Challenge...3
DESIGN AND VERIFICATION OF LSR OF THE MPLS NETWORK USING VHDL
 IJVD: 3(1), 2012, pp. 15-20 DESIGN AND VERIFICATION OF LSR OF THE MPLS NETWORK USING VHDL Suvarna A. Jadhav 1 and U.L. Bombale 2 1,2 Department of Technology Shivaji university, Kolhapur, 1 E-mail: [email protected]
IJVD: 3(1), 2012, pp. 15-20 DESIGN AND VERIFICATION OF LSR OF THE MPLS NETWORK USING VHDL Suvarna A. Jadhav 1 and U.L. Bombale 2 1,2 Department of Technology Shivaji university, Kolhapur, 1 E-mail: [email protected]
OPTIMIZE DMA CONFIGURATION IN ENCRYPTION USE CASE. Guillène Ribière, CEO, System Architect
 OPTIMIZE DMA CONFIGURATION IN ENCRYPTION USE CASE Guillène Ribière, CEO, System Architect Problem Statement Low Performances on Hardware Accelerated Encryption: Max Measured 10MBps Expectations: 90 MBps
OPTIMIZE DMA CONFIGURATION IN ENCRYPTION USE CASE Guillène Ribière, CEO, System Architect Problem Statement Low Performances on Hardware Accelerated Encryption: Max Measured 10MBps Expectations: 90 MBps
Gigabit Ethernet Packet Capture. User s Guide
 Gigabit Ethernet Packet Capture User s Guide Copyrights Copyright 2008 CACE Technologies, Inc. All rights reserved. This document may not, in whole or part, be: copied; photocopied; reproduced; translated;
Gigabit Ethernet Packet Capture User s Guide Copyrights Copyright 2008 CACE Technologies, Inc. All rights reserved. This document may not, in whole or part, be: copied; photocopied; reproduced; translated;
This topic lists the key mechanisms use to implement QoS in an IP network.
 IP QoS Mechanisms QoS Mechanisms This topic lists the key mechanisms use to implement QoS in an IP network. QoS Mechanisms Classification: Each class-oriented QoS mechanism has to support some type of
IP QoS Mechanisms QoS Mechanisms This topic lists the key mechanisms use to implement QoS in an IP network. QoS Mechanisms Classification: Each class-oriented QoS mechanism has to support some type of
Chapter 11 I/O Management and Disk Scheduling
 Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 11 I/O Management and Disk Scheduling Dave Bremer Otago Polytechnic, NZ 2008, Prentice Hall I/O Devices Roadmap Organization
Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 11 I/O Management and Disk Scheduling Dave Bremer Otago Polytechnic, NZ 2008, Prentice Hall I/O Devices Roadmap Organization
hp ProLiant network adapter teaming
 hp networking june 2003 hp ProLiant network adapter teaming technical white paper table of contents introduction 2 executive summary 2 overview of network addressing 2 layer 2 vs. layer 3 addressing 2
hp networking june 2003 hp ProLiant network adapter teaming technical white paper table of contents introduction 2 executive summary 2 overview of network addressing 2 layer 2 vs. layer 3 addressing 2
Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat
 Rik van Riel Sr. Software Engineer, Red Hat") Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat Why Computers Are Getting Slower The traditional approach better performance Why computers are
Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat Why Computers Are Getting Slower The traditional approach better performance Why computers are
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Improving Quality of Service
 Improving Quality of Service Using Dell PowerConnect 6024/6024F Switches Quality of service (QoS) mechanisms classify and prioritize network traffic to improve throughput. This article explains the basic
Improving Quality of Service Using Dell PowerConnect 6024/6024F Switches Quality of service (QoS) mechanisms classify and prioritize network traffic to improve throughput. This article explains the basic
Virtualization: TCP/IP Performance Management in a Virtualized Environment Orlando Share Session 9308
 Virtualization: TCP/IP Performance Management in a Virtualized Environment Orlando Share Session 9308 Laura Knapp WW Business Consultant [email protected] Applied Expert Systems, Inc. 2011 1 Background
Virtualization: TCP/IP Performance Management in a Virtualized Environment Orlando Share Session 9308 Laura Knapp WW Business Consultant [email protected] Applied Expert Systems, Inc. 2011 1 Background
Implementing VoIP support in a VSAT network based on SoftSwitch integration
 Implementing VoIP support in a VSAT network based on SoftSwitch integration Abstract Satellite communications based on geo-synchronous satellites are characterized by a large delay, and high cost of resources.
Implementing VoIP support in a VSAT network based on SoftSwitch integration Abstract Satellite communications based on geo-synchronous satellites are characterized by a large delay, and high cost of resources.
OpenFlow with Intel 82599. Voravit Tanyingyong, Markus Hidell, Peter Sjödin
 OpenFlow with Intel 82599 Voravit Tanyingyong, Markus Hidell, Peter Sjödin Outline Background Goal Design Experiment and Evaluation Conclusion OpenFlow SW HW Open up commercial network hardware for experiment
OpenFlow with Intel 82599 Voravit Tanyingyong, Markus Hidell, Peter Sjödin Outline Background Goal Design Experiment and Evaluation Conclusion OpenFlow SW HW Open up commercial network hardware for experiment
Lustre Networking BY PETER J. BRAAM
 Lustre Networking BY PETER J. BRAAM A WHITE PAPER FROM CLUSTER FILE SYSTEMS, INC. APRIL 2007 Audience Architects of HPC clusters Abstract This paper provides architects of HPC clusters with information
Lustre Networking BY PETER J. BRAAM A WHITE PAPER FROM CLUSTER FILE SYSTEMS, INC. APRIL 2007 Audience Architects of HPC clusters Abstract This paper provides architects of HPC clusters with information
Global Headquarters: 5 Speen Street Framingham, MA 01701 USA P.508.872.8200 F.508.935.4015 www.idc.com
 Global Headquarters: 5 Speen Street Framingham, MA 01701 USA P.508.872.8200 F.508.935.4015 www.idc.com W H I T E P A P E R O r a c l e V i r t u a l N e t w o r k i n g D e l i v e r i n g F a b r i c
Global Headquarters: 5 Speen Street Framingham, MA 01701 USA P.508.872.8200 F.508.935.4015 www.idc.com W H I T E P A P E R O r a c l e V i r t u a l N e t w o r k i n g D e l i v e r i n g F a b r i c
Radware s Attack Mitigation Solution On-line Business Protection
 Radware s Attack Mitigation Solution On-line Business Protection Table of Contents Attack Mitigation Layers of Defense... 3 Network-Based DDoS Protections... 3 Application Based DoS/DDoS Protection...
Radware s Attack Mitigation Solution On-line Business Protection Table of Contents Attack Mitigation Layers of Defense... 3 Network-Based DDoS Protections... 3 Application Based DoS/DDoS Protection...
Embedded Systems. 6. Real-Time Operating Systems
 Embedded Systems 6. Real-Time Operating Systems Lothar Thiele 6-1 Contents of Course 1. Embedded Systems Introduction 2. Software Introduction 7. System Components 10. Models 3. Real-Time Models 4. Periodic/Aperiodic
Embedded Systems 6. Real-Time Operating Systems Lothar Thiele 6-1 Contents of Course 1. Embedded Systems Introduction 2. Software Introduction 7. System Components 10. Models 3. Real-Time Models 4. Periodic/Aperiodic
TIME TO RETHINK REAL-TIME BIG DATA ANALYTICS
 TIME TO RETHINK REAL-TIME BIG DATA ANALYTICS Real-Time Big Data Analytics (RTBDA) has emerged as a new topic in big data discussions. The concepts underpinning RTBDA can be applied in a telecom context,
TIME TO RETHINK REAL-TIME BIG DATA ANALYTICS Real-Time Big Data Analytics (RTBDA) has emerged as a new topic in big data discussions. The concepts underpinning RTBDA can be applied in a telecom context,
Overlapping Data Transfer With Application Execution on Clusters
 Overlapping Data Transfer With Application Execution on Clusters Karen L. Reid and Michael Stumm [email protected] [email protected] Department of Computer Science Department of Electrical and Computer
Overlapping Data Transfer With Application Execution on Clusters Karen L. Reid and Michael Stumm [email protected] [email protected] Department of Computer Science Department of Electrical and Computer
Chapter 5 Cloud Resource Virtualization
 Chapter 5 Cloud Resource Virtualization Contents Virtualization. Layering and virtualization. Virtual machine monitor. Virtual machine. Performance and security isolation. Architectural support for virtualization.
Chapter 5 Cloud Resource Virtualization Contents Virtualization. Layering and virtualization. Virtual machine monitor. Virtual machine. Performance and security isolation. Architectural support for virtualization.
Telecom - The technology behind
 SPEED MATTERS v9.3. All rights reserved. All brand names, trademarks and copyright information cited in this presentation shall remain the property of its registered owners. Telecom - The technology behind
SPEED MATTERS v9.3. All rights reserved. All brand names, trademarks and copyright information cited in this presentation shall remain the property of its registered owners. Telecom - The technology behind
Bivio 7000 Series Network Appliance Platforms
 W H I T E P A P E R Bivio 7000 Series Network Appliance Platforms Uncompromising performance. Unmatched flexibility. Uncompromising performance. Unmatched flexibility. The Bivio 7000 Series Programmable
W H I T E P A P E R Bivio 7000 Series Network Appliance Platforms Uncompromising performance. Unmatched flexibility. Uncompromising performance. Unmatched flexibility. The Bivio 7000 Series Programmable
Bricata Next Generation Intrusion Prevention System A New, Evolved Breed of Threat Mitigation
 Bricata Next Generation Intrusion Prevention System A New, Evolved Breed of Threat Mitigation Iain Davison Chief Technology Officer Bricata, LLC WWW.BRICATA.COM The Need for Multi-Threaded, Multi-Core
Bricata Next Generation Intrusion Prevention System A New, Evolved Breed of Threat Mitigation Iain Davison Chief Technology Officer Bricata, LLC WWW.BRICATA.COM The Need for Multi-Threaded, Multi-Core
10Gb Ethernet: The Foundation for Low-Latency, Real-Time Financial Services Applications and Other, Latency-Sensitive Applications
 10Gb Ethernet: The Foundation for Low-Latency, Real-Time Financial Services Applications and Other, Latency-Sensitive Applications Testing conducted by Solarflare and Arista Networks reveals single-digit
10Gb Ethernet: The Foundation for Low-Latency, Real-Time Financial Services Applications and Other, Latency-Sensitive Applications Testing conducted by Solarflare and Arista Networks reveals single-digit
Virtualization Technologies and Blackboard: The Future of Blackboard Software on Multi-Core Technologies
 Virtualization Technologies and Blackboard: The Future of Blackboard Software on Multi-Core Technologies Kurt Klemperer, Principal System Performance Engineer [email protected] Agenda Session Length:
Virtualization Technologies and Blackboard: The Future of Blackboard Software on Multi-Core Technologies Kurt Klemperer, Principal System Performance Engineer [email protected] Agenda Session Length: