School of Parallel Programming & Parallel Architecture for HPC ICTP October, Hadoop for HPC. Instructor: Ekpe Okorafor
|
|
|
- Hugh Ross
- 10 years ago
- Views:
Transcription
1 School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Hadoop for HPC Instructor: Ekpe Okorafor

2 Outline Hadoop Basics Hadoop Infrastructure HDFS MapReduce Hadoop & HPC

3 Hadoop - Why? Need to process huge datasets on large clusters of computers Very expensive to build reliability into each application Nodes fail every day Failure is expected, rather than exceptional The number of nodes in a cluster is not constant Need a common infrastructure Efficient, reliable, easy to use Open Source, Apache Licence

4 Who uses Hadoop? Amazon/A9 Facebook Google New York Times Veoh Yahoo!. many more

5 Hadoop Infrastructure Original Slides by Ekpe Okorafor, TJ Glazier, Justin Lowe Big Data Academy, Digital Analytics, Accenture

6 Hadoop Infrastructure Overview Clients Master Server Daemons Namenode Secondary Namenode Jobtracker Slave Server Daemons Datanode Tasktracker Makes the requests to the hadoop cluster to store or retrieve files. Sends the job requests to process the data stored in the cluster Masters control the operations that take place in the cluster Namenode tracks all of the block locations of data in the cluster Secondary Namenode does all of the housekeeping for the namenode Jobtrack tracks the mapreduce jobs submitted to the cluster Slaves process and store the data Datanodes are tasked with holding all of the data blocks in hadoop, data is stored nowhere else Tasktrackers run the jobs on the cluster and report back to the Jobtracker 6

7 CLIENTS Submits jobs to the cluster, can also store & retrieve data NAMENODE SECONDARY NAMENODE Tracks all files in HDFS Responsible for data replication Handles Datanode failures JOBTRACKER Runs all jobs on the cluster Handles tasktracker failures Job Queue management DATANODES/TASKTRACKERS Holds the HDFS file system & process all jobs on behalf of the client 7

8 CLIENTS NAMENODE SECONDARY NAMENODE JOBTRACKER JOBTRACKER = FAILS Unable to run jobs until the jobtracker is restored or replaced DATANODES/TASKTRACKERS HDFS is still in-tact! 8



9 CLIENTS NAMENODE SECONDARY NAMENODE JOBTRACKER SECONDARY NAMENODE = FAILS HDFS is addressable however catastrophic failure is imminent as the NAMENODE housekeeping server is down DATANODES/TASKTRACKERS HDFS is still in-tact! 9

10 CLIENTS NAMENODE SECONDARY NAMENODE NAMENODE = FAILS Master file of block metadata lost, extremely high potential for lost data JOBTRACKER DATANODES/TASKTRACKERS HDFS is *NOT* addressable 10

11 Namenode & Secondary Namenode NAMENODE Stores the file metadata of every block in HDFS This information is stored on the LOCAL hard disk of the NAMENODE SECONDARY NAMENODE Does the housekeeping for the NAMENODE Is NOT a backup for the NAMENODE Will periodically retrieve the block location list and build a new image for the NAMENODE 11


12 Hadoop: High Availability SPOF! Single Point Of Failure Hadoop High Availability removes the Single Point of Failure by offloading the block metadata from the local hard drive onto 3 JOURNAL NODES 12

13 Hadoop: High Availability STANDBY JOURNALNODES 13


14 Hadoop: High Availability Zookeeper Failover Daemon JOURNALNODES STANDBY Zookeeper Failover Daemon ZOOKEEPER QUORUM 14


15 HDFS is this easy* 15


16 Client File Write into HDFS 16

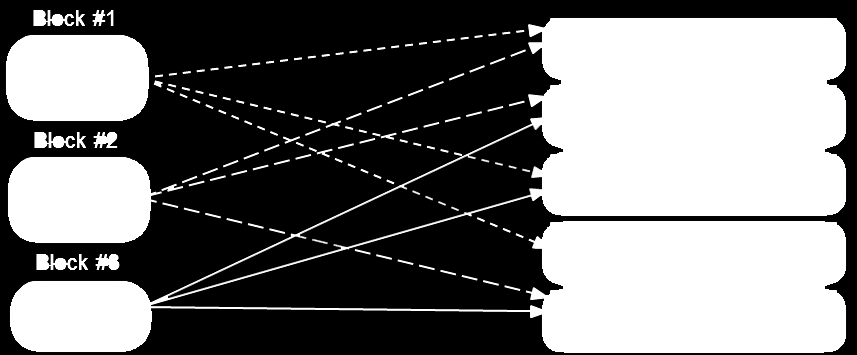
17 17


18 Rack Awareness 18

19 Hadoop Distributed File System (HDFS) Original Slides by Dhruba Borthakur Apache Hadoop Project Management Committee 19

20 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10PB Assumes Commodity Hardware Files are replicated to handle hardware failure Detect failures and recover from them Optimized for Batch Processing Data locations exposed so that computations can move to where data resides Provides very high aggregate bandwidth 20

21 Distributed File System Single Namespace for entire cluster Data Coherency Write-once-read-many access model Client can only append to existing files Files are broken up into blocks Typically 64MB block size Each block replicated on multiple DataNodes Intelligent Client Client can find location of blocks Client accesses data directly from DataNode 21
22 HDFS Architecture 22
23 Functions of a NameNode Manages File System Namespace Maps a file name to a set of blocks Maps a block to the DataNodes where it resides Cluster Configuration Management Replication Engine for Blocks 23
24 NameNode Metadata Metadata in Memory The entire metadata is in main memory No demand paging of metadata Types of metadata List of files List of Blocks for each file List of DataNodes for each block File attributes, e.g. creation time, replication factor A Transaction Log Records file creations, file deletions etc 24
25 DataNode A Block Server Stores data in the local file system (e.g. ext3) Stores metadata of a block (e.g. CRC) Serves data and metadata to Clients Block Report Periodically sends a report of all existing blocks to the NameNode Facilitates Pipelining of Data Forwards data to other specified DataNodes 25
26 Block Placement Current Strategy One replica on local node Second replica on a remote rack Third replica on same remote rack Additional replicas are randomly placed Clients read from nearest replicas Would like to make this policy pluggable 26
27 Heartbeats DataNodes send hearbeat to the NameNode Once every 3 seconds NameNode uses heartbeats to detect DataNode failure 27
28 Replication Engine NameNode detects DataNode failures Chooses new DataNodes for new replicas Balances disk usage Balances communication traffic to DataNodes 28
29 Data Correctness Use Checksums to validate data Use CRC32 File Creation Client computes checksum per 512 bytes DataNode stores the checksum File access Client retrieves the data and checksum from DataNode If Validation fails, Client tries other replicas 29
30 NameNode Failure A single point of failure Transaction Log stored in multiple directories A directory on the local file system A directory on a remote file system (NFS/CIFS) Need to develop a real HA solution 30
31 Data Pipelining Client retrieves a list of DataNodes on which to place replicas of a block Client writes block to the first DataNode The first DataNode forwards the data to the next node in the Pipeline When all replicas are written, the Client moves on to write the next block in file 31
32 Rebalancer Goal: % disk full on DataNodes should be similar Usually run when new DataNodes are added Cluster is online when Rebalancer is active Rebalancer is throttled to avoid network congestion Command line tool 32
33 Secondary NameNode Copies FsImage and Transaction Log from Namenode to a temporary directory Merges FSImage and Transaction Log into a new FSImage in temporary directory Uploads new FSImage to the NameNode Transaction Log on NameNode is purged 33
34 User Interface Commads for HDFS User: hadoop dfs -mkdir /foodir hadoop dfs -cat /foodir/myfile.txt hadoop dfs -rm /foodir/myfile.txt Commands for HDFS Administrator hadoop dfsadmin -report hadoop dfsadmin -decommision datanodename Web Interface 34
35 MapReduce Original Slides by Owen O Malley (Yahoo!) & Christophe Bisciglia, Aaron Kimball & Sierra Michells-Slettvet 35
36 MapReduce - What? MapReduce is a programming model for efficient distributed computing It works like a Unix pipeline cat input grep sort uniq -c cat > output Input Map Shuffle & Sort Reduce Output Efficiency from Streaming through data, reducing seeks Pipelining A good fit for a lot of applications Log processing Web index building 36

37 MapReduce - Dataflow 37
38 MapReduce - Features Fine grained Map and Reduce tasks Improved load balancing Faster recovery from failed tasks Automatic re-execution on failure In a large cluster, some nodes are always slow or flaky Framework re-executes failed tasks Locality optimizations With large data, bandwidth to data is a problem Map-Reduce + HDFS is a very effective solution Map-Reduce queries HDFS for locations of input data Map tasks are scheduled close to the inputs when possible 38
39 Word Count Example Mapper Input: value: lines of text of input Output: key: word, value: 1 Reducer Input: key: word, value: set of counts Output: key: word, value: sum Launching program Defines this job Submits job to cluster 39

40 Word Count Dataflow 40
41 Word Count Mapper public static class Map extends MapReduceBase implements Mapper<LongWritable,Text,Text,IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); public static void map(longwritable key, Text value, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException { String line = value.tostring(); StringTokenizer = new StringTokenizer(line); while(tokenizer.hasnext()) { word.set(tokenizer.nexttoken()); output.collect(word,one); } } } 41
42 Word Count Reducer public static class Reduce extends MapReduceBase implements Reducer<Text,IntWritable,Text,IntWritable> { public static void map(text key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while(values.hasnext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } 42
43 Word Count Example Jobs are controlled by configuring JobConfs JobConfs are maps from attribute names to string values The framework defines attributes to control how the job is executed conf.set( mapred.job.name, MyApp ); Applications can add arbitrary values to the JobConf conf.set( my.string, foo ); conf.set( my.integer, 12); JobConf is available to all tasks
44 Putting it all together Create a launching program for your application The launching program configures: The Mapper and Reducer to use The output key and value types (input types are inferred from the InputFormat) The locations for your input and output The launching program then submits the job and typically waits for it to complete 44
45 Putting it all together JobConf conf = new JobConf(WordCount.class); conf.setjobname( wordcount ); conf.setoutputkeyclass(text.class); conf.setoutputvalueclass(intwritable.class); conf.setmapperclass(map.class); conf.setcombinerclass(reduce.class); conf.setreducer(reduce.class); conf.setinputformat(textinputformat.class); Conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); 45
46 Input and Output Formats A Map/Reduce may specify how it s input is to be read by specifying an InputFormat to be used A Map/Reduce may specify how it s output is to be written by specifying an OutputFormat to be used These default to TextInputFormat and TextOutputFormat, which process line-based text data Another common choice is SequenceFileInputFormat and SequenceFileOutputFormat for binary data These are file-based, but they are not required to be
47 How many Maps and Reduces Maps Usually as many as the number of HDFS blocks being processed, this is the default Else the number of maps can be specified as a hint The number of maps can also be controlled by specifying the minimum split size The actual sizes of the map inputs are computed by: max(min(block_size,data/#maps), min_split_size Reduces Unless the amount of data being processed is small 0.95*num_nodes*mapred.tasktracker.tasks.maximum
48 Finding the Shortest Path A common graph search application is finding the shortest path from a start node to one or more target nodes Commonly done on a single machine with Dijkstra s Algorithm Can we use BFS (breadth first search) to find the shortest path via MapReduce?
49 Finding the Shortest Path: Intuition We can define the solution to this problem inductively DistanceTo(startNode) = 0 For all nodes n directly reachable from startnode, DistanceTo(n) = 1 For all nodes n reachable from some other set of nodes S, DistanceTo(n) = 1 + min(distanceto(m), m S)
50 From Intuition to Algorithm A map task receives a node n as a key, and (D, pointsto) as its value D is the distance to the node from the start points-to is a list of nodes reachable from n p points-to, emit (p, D+1) Reduces task gathers possible distances to a given p and selects the minimum one
51 What This Gives Us This MapReduce task can advance the known frontier by one hop To perform the whole BFS, a non-mapreduce component then feeds the output of this step back into the MapReduce task for another iteration Problem: Where d the points-to list go? Solution: Mapper emits (n, points-to) as well
52 Blow-up and Termination This algorithm starts from one node Subsequent iterations include many more nodes of the graph as the frontier advances Does this ever terminate? Yes! Eventually, routes between nodes will stop being discovered and no better distances will be found. When distance is the same, we stop Mapper should emit (n,d) to ensure that current distance is carried into the reducer
53 Hadoop Related Subprojects Pig High-level language for data analysis HBase Table storage for semi-structured data Zookeeper Coordinating distributed applications Hive SQL-like Query language and Metastore Mahout Machine learning
54 Hadoop & HPC 54
55 Hadoop and HPC PROBLEM: domain scientists/researchers aren't using Hadoop Hadoop is commonly used in the data analytics industry but not so common in domain science academic areas. Java is not always high-performance Hurdles for domain scientists to learn Java, Hadoop tools. SOLUTION: make Hadoop easier for HPC users use existing HPC clusters and software" use Perl/Python/C/C++/Fortran instead of Java" make starting Hadoop as easy as possible 55

56 Compute: Traditional vs. Data-Intensive Traditional HPC CPU-bound problems Solution: OpenMP and MPI-based parallelism Data-Intensive IO-bound problems Solution: Map/reduce based parallelism 56
57 Architecture for Both Workloads PROs High-speed interconnect Complementary object storage Fast CPUs, RAM Less faulty CONs Nodes aren't storage rich Transferring data between HDFS and object storage* unless using Lustre, S3, etc backends 57
58 Hadoop & HPC Add Data Analysis to Existing Compute Infrastructure Physical Compute 58
59 Hadoop & HPC Add Data Analysis to Existing Compute Infrastructure Resource Manager (Torque, SLURM, SGE) Physical Compute 59
60 Hadoop & HPC Add Data Analysis to Existing Compute Infrastructure MPI Job myhadoop MPI Job myhadoop Resource Manager (Torque, SLURM, SGE) Physical Compute 60
61 Hadoop & HPC Add Data Analysis to Existing Compute Infrastructure Hadoop 1.0 Mahout Pig Hbase Hadoop 1.0 Mahout Pig Hbase MPI Job myhadoop MPI Job myhadoop Resource Manager (Torque, SLURM, SGE) Physical Compute 61
62 myhadoop: 3-step Install 1. Download Apache Hadoop 1.x and myhadoop 0.30 $ wget /hadoop bin.tar.gz $ wget tar.gz 2. Unpack both Hadoop and myhadoop! $ tar zxvf hadoop bin.tar.gz $ tar zxvf myhadoop-0.30.tar.gz 3. Apply myhadoop patch to Hadoop! $ cd hadoop-1.2.1/conf $ patch <../myhadoop-0.30/myhadoop patch 62
63 myhadoop: 3-step Install 1. Set a few environment variables # sets HADOOP_HOME, JAVA_HOME, and PATH $ module load hadoop $ export HADOOP_CONF_DIR=$HOME/mycluster.conf 2. Run myhadoop-configure.sh to set up Hadoop $ myhadoop-configure.sh -s /scratch/$user/$pbs_jobid! 3. Start cluster with Hadoop's start-all.sh $ start-all.sh! 63
64 Advanced Features - Useability! System-wide default configurations myhadoop-0.30/conf/myhadoop.conf MH_SCRATCH_DIR specify location of node-local storage for all users" MH_IPOIB_TRANSFORM specify regex to transform node hostnames into IP over InfiniBand hostnames" Users can remain totally ignorant of scratch disks and InfiniBand Literally define HADOOP_CONF_DIR and run myhadoop-configure.sh with no parameters myhadoop figures out everything else 64
65 Advanced Features - Useability! Parallel filesystem support! HDFS on Lustre via myhadoop persistent mode (-p)" Direct Lustre support (IDH)" No performance loss at smaller scales for HDFS on Lustre" Resource managers supported in unified framework: Torque 2.x and 4.x Tested on SDSC Gordon" SLURM 2.6 Tested on TACC Stampede" Grid Engine" Can support LSF, PBSpro, Condor easily (need testbeds) 65
66 Scientific Computing - BioPIG Hadoop based analytic toolkit for large-scale sequence data Built using Apache Hadoop MapReduce and Pig Data Flow language. Benefits reduced development time for parallel bioinformatics apps, good scaling with data size, portability. Run on systems at NERSC (Magellan), Amazon 66
67 Questions? 67
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System. Dhruba Borthakur June, 2007
 Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Data management in the cloud using Hadoop
 UT DALLAS Erik Jonsson School of Engineering & Computer Science Data management in the cloud using Hadoop Murat Kantarcioglu Outline Hadoop - Basics HDFS Goals Architecture Other functions MapReduce Basics
UT DALLAS Erik Jonsson School of Engineering & Computer Science Data management in the cloud using Hadoop Murat Kantarcioglu Outline Hadoop - Basics HDFS Goals Architecture Other functions MapReduce Basics
CS54100: Database Systems
 CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Hadoop: Understanding the Big Data Processing Method
 Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
Hadoop: Understanding the Big Data Processing Method Deepak Chandra Upreti 1, Pawan Sharma 2, Dr. Yaduvir Singh 3 1 PG Student, Department of Computer Science & Engineering, Ideal Institute of Technology
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected]
 Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Istanbul Şehir University Big Data Camp 14. Hadoop Map Reduce. Aslan Bakirov Kevser Nur Çoğalmış
 Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Istanbul Şehir University Big Data Camp 14 Hadoop Map Reduce Aslan Bakirov Kevser Nur Çoğalmış Agenda Map Reduce Concepts System Overview Hadoop MR Hadoop MR Internal Job Execution Workflow Map Side Details
Hadoop WordCount Explained! IT332 Distributed Systems
 Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
NDBI040 Big Data Management and NoSQL Databases Lecture 3. Apache Hadoop Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Apache Hadoop Open-source
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Introduc)on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan [email protected]
on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan sriram@sdsc.edu") Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan [email protected] Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan [email protected] Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
and HDFS for Big Data Applications Serge Blazhievsky Nice Systems
 Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Apache Hadoop FileSystem Internals
 Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
Programming Hadoop Map-Reduce Programming, Tuning & Debugging. Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008
 Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Programming Hadoop Map-Reduce Programming, Tuning & Debugging Arun C Murthy Yahoo! CCDI [email protected] ApacheCon US 2008 Existential angst: Who am I? Yahoo! Grid Team (CCDI) Apache Hadoop Developer
Hadoop Framework. technology basics for data scientists. Spring - 2014. Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN
 Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
Hadoop Framework technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate addi8onal
Programming in Hadoop Programming, Tuning & Debugging
 Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
Programming in Hadoop Programming, Tuning & Debugging Venkatesh. S. Cloud Computing and Data Infrastructure Yahoo! Bangalore (India) Agenda Hadoop MapReduce Programming Distributed File System HoD Provisioning
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
How To Write A Map Reduce In Hadoop Hadooper 2.5.2.2 (Ahemos)
") Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
Processing Data with Map Reduce Allahbaksh Mohammedali Asadullah Infosys Labs, Infosys Technologies 1 Content Map Function Reduce Function Why Hadoop HDFS Map Reduce Hadoop Some Questions 2 What is Map
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Getting to know Apache Hadoop
 Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Data Science in the Wild
 Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Word count example Abdalrahman Alsaedi
 Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Word count example Abdalrahman Alsaedi To run word count in AWS you have two different ways; either use the already exist WordCount program, or to write your own file. First: Using AWS word count program
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Using Hadoop for Webscale Computing. Ajay Anand Yahoo! [email protected] Usenix 2008
 Using Hadoop for Webscale Computing Ajay Anand Yahoo! [email protected] Agenda The Problem Solution Approach / Introduction to Hadoop HDFS File System Map Reduce Programming Pig Hadoop implementation
Using Hadoop for Webscale Computing Ajay Anand Yahoo! [email protected] Agenda The Problem Solution Approach / Introduction to Hadoop HDFS File System Map Reduce Programming Pig Hadoop implementation
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Intro to Map/Reduce a.k.a. Hadoop
 Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Hadoop and its Usage at Facebook. Dhruba Borthakur [email protected], June 22 rd, 2009
 Hadoop and its Usage at Facebook Dhruba Borthakur [email protected], June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Hadoop and its Usage at Facebook Dhruba Borthakur [email protected], June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Hadoop. Dawid Weiss. Institute of Computing Science Poznań University of Technology
 Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
Hadoop Dawid Weiss Institute of Computing Science Poznań University of Technology 2008 Hadoop Programming Summary About Config 1 Open Source Map-Reduce: Hadoop About Cluster Configuration 2 Programming
HowTo Hadoop. Devaraj Das
 HowTo Hadoop Devaraj Das Hadoop http://hadoop.apache.org/core/ Hadoop Distributed File System Fault tolerant, scalable, distributed storage system Designed to reliably store very large files across machines
HowTo Hadoop Devaraj Das Hadoop http://hadoop.apache.org/core/ Hadoop Distributed File System Fault tolerant, scalable, distributed storage system Designed to reliably store very large files across machines
HPCHadoop: MapReduce on Cray X-series
 HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
How To Write A Mapreduce Program In Java.Io 4.4.4 (Orchestra)
") MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
MapReduce framework - Operates exclusively on pairs, - that is, the framework views the input to the job as a set of pairs and produces a set of pairs as the output
Hadoop and Eclipse. Eclipse Hawaii User s Group May 26th, 2009. Seth Ladd http://sethladd.com
 Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Hadoop and Eclipse Eclipse Hawaii User s Group May 26th, 2009 Seth Ladd http://sethladd.com Goal YOU can use the same technologies as The Big Boys Google Yahoo (2000 nodes) Last.FM AOL Facebook (2.5 petabytes
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网. Information Management. Information Management IBM CDL Lab
 IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
IBM CDL Lab Hadoop and ecosystem * 本 文 中 的 言 论 仅 代 表 作 者 个 人 观 点 * 本 文 中 的 一 些 图 例 来 自 于 互 联 网 Information Management 2012 IBM Corporation Agenda Hadoop 技 术 Hadoop 概 述 Hadoop 1.x Hadoop 2.x Hadoop 生 态
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
HADOOP MOCK TEST HADOOP MOCK TEST I
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Petabyte-scale Data with Apache HDFS. Matt Foley Hortonworks, Inc. [email protected]
 Petabyte-scale Data with Apache HDFS Matt Foley Hortonworks, Inc. [email protected] Matt Foley - Background MTS at Hortonworks Inc. HDFS contributor, part of original ~25 in Yahoo! spin-out of Hortonworks
Petabyte-scale Data with Apache HDFS Matt Foley Hortonworks, Inc. [email protected] Matt Foley - Background MTS at Hortonworks Inc. HDFS contributor, part of original ~25 in Yahoo! spin-out of Hortonworks
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Hadoop Architecture and its Usage at Facebook
 Hadoop Architecture and its Usage at Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Microsoft Research, Seattle October 16, 2009 Outline Introduction
Hadoop Architecture and its Usage at Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Microsoft Research, Seattle October 16, 2009 Outline Introduction
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
How To Write A Mapreduce Program On An Ipad Or Ipad (For Free)
") Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Course NDBI040: Big Data Management and NoSQL Databases Practice 01: MapReduce Martin Svoboda Faculty of Mathematics and Physics, Charles University in Prague MapReduce: Overview MapReduce Programming
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
EXPERIMENTATION. HARRISON CARRANZA School of Computer Science and Mathematics
 BIG DATA WITH HADOOP EXPERIMENTATION HARRISON CARRANZA Marist College APARICIO CARRANZA NYC College of Technology CUNY ECC Conference 2016 Poughkeepsie, NY, June 12-14, 2016 Marist College AGENDA Contents
BIG DATA WITH HADOOP EXPERIMENTATION HARRISON CARRANZA Marist College APARICIO CARRANZA NYC College of Technology CUNY ECC Conference 2016 Poughkeepsie, NY, June 12-14, 2016 Marist College AGENDA Contents
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Certified Big Data and Apache Hadoop Developer VS-1221
 Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
5 HDFS - Hadoop Distributed System
 5 HDFS - Hadoop Distributed System 5.1 Definition and Remarks HDFS is a file system designed for storing very large files with streaming data access patterns running on clusters of commoditive hardware.
5 HDFS - Hadoop Distributed System 5.1 Definition and Remarks HDFS is a file system designed for storing very large files with streaming data access patterns running on clusters of commoditive hardware.
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
INTRODUCTION TO HADOOP
 Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
Hadoop & Pig. Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship
 Hadoop & Pig Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship Outline Introduction (Setup) Hadoop, HDFS and MapReduce Pig Introduction What is Hadoop and where did it come from? Big Data
Hadoop & Pig Dr. Karina Hauser Senior Lecturer Management & Entrepreneurship Outline Introduction (Setup) Hadoop, HDFS and MapReduce Pig Introduction What is Hadoop and where did it come from? Big Data
Optimize the execution of local physics analysis workflows using Hadoop
 Optimize the execution of local physics analysis workflows using Hadoop INFN CCR - GARR Workshop 14-17 May Napoli Hassen Riahi Giacinto Donvito Livio Fano Massimiliano Fasi Andrea Valentini INFN-PERUGIA
Optimize the execution of local physics analysis workflows using Hadoop INFN CCR - GARR Workshop 14-17 May Napoli Hassen Riahi Giacinto Donvito Livio Fano Massimiliano Fasi Andrea Valentini INFN-PERUGIA
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Step 4: Configure a new Hadoop server This perspective will add a new snap-in to your bottom pane (along with Problems and Tasks), like so:
, like so:") Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
Hadoop Distributed File System. Jordan Prosch, Matt Kipps
 Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
COSC 6397 Big Data Analytics. Distributed File Systems (II) Edgar Gabriel Spring 2014. HDFS Basics
 Edgar Gabriel Spring 2014. HDFS Basics") COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2014 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
COSC 6397 Big Data Analytics Distributed File Systems (II) Edgar Gabriel Spring 2014 HDFS Basics An open-source implementation of Google File System Assume that node failure rate is high Assumes a small
MapReduce, Hadoop and Amazon AWS
 MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
Introduction to HDFS. Prasanth Kothuri, CERN
 Prasanth Kothuri, CERN 2 What s HDFS HDFS is a distributed file system that is fault tolerant, scalable and extremely easy to expand. HDFS is the primary distributed storage for Hadoop applications. Hadoop
Prasanth Kothuri, CERN 2 What s HDFS HDFS is a distributed file system that is fault tolerant, scalable and extremely easy to expand. HDFS is the primary distributed storage for Hadoop applications. Hadoop
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Hadoop Configuration and First Examples
 Hadoop Configuration and First Examples Big Data 2015 Hadoop Configuration In the bash_profile export all needed environment variables Hadoop Configuration Allow remote login Hadoop Configuration Download
Hadoop Configuration and First Examples Big Data 2015 Hadoop Configuration In the bash_profile export all needed environment variables Hadoop Configuration Allow remote login Hadoop Configuration Download
Distributed File Systems
 Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra