Learning Deep Feature Hierarchies
|
|
|
- Lorraine Spencer
- 7 years ago
- Views:
Transcription
1 Learning Deep Feature Hierarchies Yoshua Bengio, U. Montreal Stanford University, California September 21st, 2009 Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux, Yann LeCun, Guillaume Desjardins, Pascal Lamblin, James Bergstra, Nicolas Le Roux, Max Welling, Myriam Côté, Jérôme Louradour, Ronan Collobert, Jason Weston

2 Interesting Experimental Results with Deep Architectures Beating shallow neural networks on vision and NLP tasks Beating SVMs on visions tasks from pixels (and handling dataset sizes that SVMs cannot handle in NLP) Reaching or beating state-of-the-art performance in NLP Beating deep neural nets without unsupervised component Learn visual features similar to V1 and V2 neurons

3 Deep Motivations Brains have a deep architecture Humans organize their ideas hierarchically, through composition of simpler ideas Unsufficiently deep architectures can be exponentially inefficient Distributed (possibly sparse) representations are necessary to achieve non-local generalization Multiple levels of latent variables allow combinatorial sharing of statistical strength

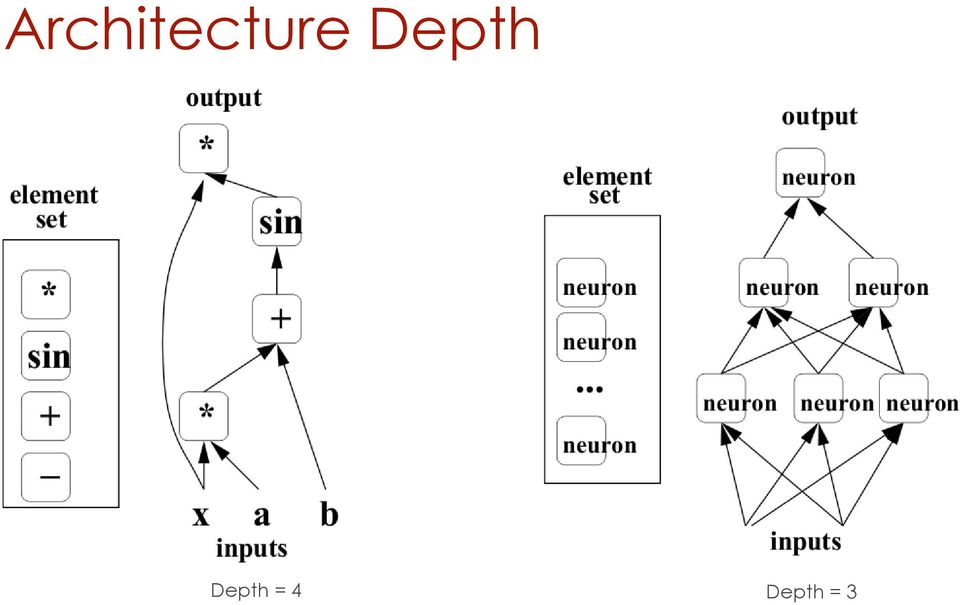
4 Architecture Depth Depth = 4 Depth = 3
5 Deep Architectures are More Expressive Theoretical arguments: 2 layers of Logic gates Formal neurons RBF units = universal approximator Theorems for all 3: (Hastad et al 86 & 91, Bengio et al 2007) Functions compactly represented with k layers may require exponential size with k-1 layers n n

6 Deep Architectures and Sharing Statistical Strength, Multi-Task Learning Generalizing better to new tasks is crucial to approach AI task 1 output y1 task 2 output y2 task 3 output y3 Deep architectures learn good intermediate representations that can be shared across tasks shared intermediate representation h A good representation is one that makes sense for many tasks raw input x

7 Feature and Sub-Feature Sharing Different tasks can share the same high-level feature Different high-level features can be built from the same set of lower-level features More levels = up to exponential gain in representational efficiency task 1 output y1 task N output yn High-level features Low-level features

8 Sharing Components in a Deep Architecture Polynomial expressed with shared components: advantage of depth may grow exponentially

9 The Deep Breakthrough Before 2006, training deep architectures was unsuccessful, except for convolutional neural nets Hinton, Osindero & Teh «A Fast Learning Algorithm for Deep Belief Nets», Neural Computation, 2006 Bengio, Lamblin, Popovici, Larochelle «Greedy Layer-Wise Training of Deep Networks», NIPS 2006 Ranzato, Poultney, Chopra, LeCun «Efficient Learning of Sparse Representations with an Energy-Based Model», NIPS 2006

10 Greedy Layer-Wise Pre-Training Stacking Restricted Boltzmann Machines (RBM) Deep Belief Network (DBN)
 Deep")
11 Greedy Layer-Wise Unsupervised Pre-Training Algorithm Train unsupervised feature extractor (e.g. RBM, auto-encoder) mapping input x to representation h 1, capturing main factors of variation in x (models P(x)) Taking h 1 (x) as an input, train a second unsupervised feature extractor, obtaining representation h 2 of x Etc. to level k gives h k Plug a supervised classifier P(Y h k (x)) on top, taking h k as input Fine-tune parameters of whole system P(Y x) wrt supervised objective

12 Boltzman Machines and MRFs Boltzmann machines: (Hinton 84) Markov Random Fields: More interesting with latent variables!

13 Restricted Boltzman Machine The most popular building block for deep architectures (Smolensky 86, Hinton 2002) hidden Bipartite undirected graphical model h~p(h x), or (P(h i =1 x)) are representations of x observed
, or (P(h i =1 x)) are representations of x")
14 Gibbs Sampling in RBMs h 1 ~ P(h x 1 ) h 2 ~ P(h x 2 ) h 3 ~ P(h x 3 ) x 1 x 2 ~ P(x h 1 ) x 3 ~ P(x h 2 ) P(h x) and P(x h) factorize Easy inference Convenient Gibbs sampling x h x h

15 Problems with Gibbs Sampling In practice, Gibbs sampling does not always mix well RBM trained by CD on MNIST Chains from random state Chains from real digits

16 Boltzmann Machine Gradient Gradient has two components: positive phase negative phase In RBMs, easy to sample or sum over h x Difficult part: sampling from P(x), typically with a Markov chain
, typically with a")
17 Training RBMs Contrastive Divergence: (CD-k) start negative Gibbs chain at observed x, run k Gibbs steps Persistent CD: (PCD) run negative Gibbs chain in background while weights slowly change Fast PCD: two sets of weights, one with a large learning rate only used for negative phase, quickly exploring modes Herding: (see Max Welling s ICML, UAI and ICML workshop talks) Tempered MCMC: use higher temperature to escape modes
 Tempered MCMC: use higher temperature to escape")
18 Contrastive Divergence Contrastive Divergence (CD-k): start negative phase block Gibbs chain at observed x, run k Gibbs steps (Hinton 2002) h ~ P(h x) h ~ P(h x ) Observed x positive phase k = 2 steps Sampled x negative phase Free Energy push down x x push up

19 Persistent CD (PCD) Run negative Gibbs chain in background while weights slowly change (Younes 2000, Tieleman 2008): Guarantees (Younes 89, 2000; Yuille 2004) If learning rate decreases in 1/t, chain mixes before parameters change too much, chain stays converged when parameters change h ~ P(h x) Observed x (positive phase) previous x new x
 Observed x (positive phase)")
20 Persistent CD with Large Step Size Negative phase samples quickly push up the energy of wherever they are and quickly move to another mode FreeEnergy push down x x push up

21 Persistent CD with Large Step Size Negative phase samples quickly push up the energy of wherever they are and quickly move to another mode FreeEnergy push down x x
22 Persistent CD with Large Step Size Negative phase samples quickly push up the energy of wherever they are and quickly move to another mode FreeEnergy push down x x push up
23 Fast Persistent CD and Herding Exploit impressively faster mixing achieved when parameters change quickly (large learning rate) while sampling Fast PCD: two sets of weights, one with a large learning rate only used for negative phase, quickly exploring modes Herding (see Max Welling s ICML, UAI and ICML workshop talks): 0-temperature MRFs and RBMs, only use fast weights
24 Herding MRFs (Welling, ICML 2009) Consider 0-temperature MRF with state s and weights w Fully observed case, observe values s +, dynamical system where s - and W evolve Then statistics of samples s - match the data s statistics, even if approximate max, as long as w remains bounded
25 Herding RBMs (Welling, UAI 2009) Hidden part h of the state s = (x,h) Binomial state variables s i {-1,1} Statistics f s i, s i s j Optimize h given x in positive phase the In practice, greedy maximization works, exploiting RBM structure. Works like 0-temperature PCD.
26 Fast Mixing with Herding FPCD Herding
27 Tempered MCMC Annealing from high-temperature worked well for estimating log-likelihood (AIS) Consider multiple chains at different temperatures and reversible swaps between adjacent chains Higher temperature chains can escape modes Model samples are from T=1 Sample Generation Procedure Training Procedure TMCMC Gibbs (ramdom start) Gibbs (test start) TMCMC ± ± ± 2.8 PCD 44.7 ± ± ± 2.9 CD ± ± ± 6.1
28 Deep Belief Networks Sampling: Sample from top RMB Sample from level k given k+1 Easy approximate inference Training: Variational bound justifies greedy layerwise training of RBMs How to train all levels together? Top-level RBM sampled x h3 h2 h1
29 Deep Convolutional Architectures Mostly from Le Cun s (NYU) and Ng s (Stanford) groups: state-of-the-art on MNIST digits, Caltech-101 objects, faces
30 Convolutional DBNs (Lee et al, ICML 2009)
31 Deep Boltzman Machines (Salakhutdinov et al, AISTATS 2009, Lee et al, ICML 2009) Positive phase: variational approximation (mean-field) Negative phase: persistent chain Can (must) initialize from stacked RBMs Improved performance on MNIST from 1.2% to.95% error h3 h2 h1 Can apply AIS with 2 hidden layers observed x
32 Estimating Log-Likelihood RBMs: requires estimating partition function Reconstruction error provides a cheap proxy Log Z tractable analytically for < 25 binary inputs or hidden Lower-bounded (how well?) with Annealed Importance Sampling (AIS) Deep Belief Networks: Extensions of AIS (Salakhutdinov & Murray, ICML 2008, NIPS 2008) Open question: efficient ways to monitor progress?
33 RBMs and Thin DBNs as Non- Parametric Models As the nb of hidden units increases, RBM capacity increases; with enough hidden units (up to 2 d ), can approximate any discrete distribution on d bits (Le Roux & Bengio, 2008) Similarly, a thin DBN with d+1 units / layer and enough layers (up to 1+2 d /d) can approximate any discrete distribution. Same proof technique also shows universal approximation property of thin deep deterministic neural networks (Le Roux & Bengio, 2009, submitted)
34 Why are Classifiers Obtained from DBNs Working so Well? General principles? Would these principles work for other single-level algorithms? Why does it work?
35 Replacing RBMs by Other Layer- Local Unsupervised Learning Auto-encoders (Bengio et al, NIPS 2006) Sparse auto-encoders (Ranzato et al, NIPS 2006) Kernel PCA (Erhan 2008) Denoising auto-encoders (Vincent et al, ICML 2008) Unsupervised embedding (Weston et al, ICML 2008) Slow features (Mohabi et al, ICML 2009, Bergstra & Bengio NIPS 2009)
36 Stacking Auto-Encoders
37 Auto-Encoders and CD RBM log-likelihood gradient written as converging expansion: CD-k = 2 k terms reconstruction error ~ 1 term (Bengio & Delalleau 2009)
38 Greedy Layerwise Supervised Training Generally worse than unsupervised pre-training but better than ordinary training of a deep neural network (Bengio et al. 2007).
39 Supervised Fine-Tuning is Important Greedy layer-wise unsupervised pre-training phase with RBMs or autoencoders on MNIST Supervised phase with or without unsupervised updates, with or without fine-tuning of hidden layers Can train all RBMs at the same time, same results
40 Sparse Auto-Encoders (Ranzato et al, 2007; Ranzato et al 2008) Sparsity penalty on the intermediate codes Like sparse coding and has explaining away but with efficient runtime encoder (approximate posterior) Sparsity penalty pushes up the free energy of all configurations (proxy for minimizing the partition function) Impressive results in object classification (convolutional nets): MNIST 0.5% error = record-breaking Caltech % correct = state-of-the-art (Jarrett et al, ICCV 2009) Similar results obtained with a convolutional DBN (Lee et al, ICML 2009)
41 Denoising Auto-Encoder (Vincent et al, ICML 2008) Corrupt the input Reconstruct the uncorrupted input Hidden code (representation) KL(reconstruction raw input) Corrupted input Raw input reconstruction
42 Denoising Auto-Encoder Learns a vector field towards higher probability regions Minimizes variational lower bound on a generative model Corrupted input Similar to pseudo-likelihood Corrupted input
43 Stacked Denoising Auto-Encoders No partition function, can measure training criterion Encoder & decoder: any parametrization Performs as well or better than stacking RBMs for usupervised pre-training Infinite MNIST
44 Why is Unsupervised Pre-Training Working So Well? Regularization hypothesis: Unsupervised component forces model close to P(x) Representations good for P(x) are good for P(y x) Optimization hypothesis: Unsupervised initialization near better local minimum of P(y x) Can reach lower local minimum otherwise not achievable by random initialization
45 Learning Trajectories in Function Space Each point a model in function space Color = epoch Top: trajectories w/o pre-training Each trajectory converges in different local min. No overlap of regions with and w/o pre-training
46 Unsupervised Learning as Regularizer Adding extra regularization (reducing # hidden units) hurts more the pre-trained models Pre-trained models have less variance wrt training sample Regularizer = infinite penalty outside of region compatible with unsupervised pre-training
47 Better Optimization of Online Error Both training and online error are smaller with unsupervised pre-training As # samples training err. = online err. = generalization err. Without unsup. pre-training: can t exploit capacity to capture complexity in target function from training data
48 Learning Dynamics of Deep Nets Before fine-tuning After fine-tuning
49 Learning Dynamics of Deep Nets As weights become larger, get trapped in basin of attraction ( quadrant does not change) Initial updates have a crucial influence ( critical period ), explain more of the variance 0 Unsupervised pre-training initializes in basin of attraction with good generalization properties
50 Level-Local Learning is Important Initializing each layer of an unsupervised deep Boltzmann machine helps a lot Initializing each layer of a supervised neural network as an RBM or auto-encoder helps a lot Helps most the layers further away from the target Jointly training all the levels of a deep architecture is difficult
51 Order & Selection of Examples Matters Curriculum learning (Bengio et al, ICML 2009; Krueger & Dayan 2009) Start with easier examples Faster convergence to a better local minimum in deep architectures Also acts like a regularizer with optimization effect? Influencing learning dynamics can make a big difference
52 Take-Home Messages Multiple levels of latent variables: potentially exponential gain in statistical sharing RBMs allow fast inference, stacked RBMs / auto-encoders have fast approximate inference Gibbs sampling in RBMs sometimes does not mix well, but sampling and learning can interact in surprisingly useful ways Unsupervised pre-training of classifiers acts like a strange regularizer with improved optimization of online error At least as important as the model: the inference approximations and the learning dynamics
53 Some Open Problems Why is it difficult to train deep architectures? What is important in the learning dynamics? How to improve joint training of all layers? How to sample better from RBMs and deep generative models? Monitoring unsupervised learning quality in deep nets? Other ways to guide training of intermediate representations? More complex models to handle spatial structure of images, occlusion, temporal structure, etc.
54 Thank you for your attention! Questions? Comments?
Tutorial on Deep Learning and Applications
 NIPS 2010 Workshop on Deep Learning and Unsupervised Feature Learning Tutorial on Deep Learning and Applications Honglak Lee University of Michigan Co-organizers: Yoshua Bengio, Geoff Hinton, Yann LeCun,
NIPS 2010 Workshop on Deep Learning and Unsupervised Feature Learning Tutorial on Deep Learning and Applications Honglak Lee University of Michigan Co-organizers: Yoshua Bengio, Geoff Hinton, Yann LeCun,
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Deep Learning Barnabás Póczos & Aarti Singh Credits Many of the pictures, results, and other materials are taken from: Ruslan Salakhutdinov Joshua Bengio Geoffrey
Introduction to Machine Learning CMU-10701 Deep Learning Barnabás Póczos & Aarti Singh Credits Many of the pictures, results, and other materials are taken from: Ruslan Salakhutdinov Joshua Bengio Geoffrey
Visualizing Higher-Layer Features of a Deep Network
 Visualizing Higher-Layer Features of a Deep Network Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent Dept. IRO, Université de Montréal P.O. Box 6128, Downtown Branch, Montreal, H3C 3J7,
Visualizing Higher-Layer Features of a Deep Network Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent Dept. IRO, Université de Montréal P.O. Box 6128, Downtown Branch, Montreal, H3C 3J7,
arxiv:1312.6062v2 [cs.lg] 9 Apr 2014
![arxiv:1312.6062v2 [cs.lg] 9 Apr 2014](/thumbs/19/374421.jpg "arxiv:1312.6062v2 [cs.lg] 9 Apr 2014") Stopping Criteria in Contrastive Divergence: Alternatives to the Reconstruction Error arxiv:1312.6062v2 [cs.lg] 9 Apr 2014 David Buchaca Prats Departament de Llenguatges i Sistemes Informàtics, Universitat
Stopping Criteria in Contrastive Divergence: Alternatives to the Reconstruction Error arxiv:1312.6062v2 [cs.lg] 9 Apr 2014 David Buchaca Prats Departament de Llenguatges i Sistemes Informàtics, Universitat
Why Does Unsupervised Pre-training Help Deep Learning?
 Journal of Machine Learning Research 11 (2010) 625-660 Submitted 8/09; Published 2/10 Why Does Unsupervised Pre-training Help Deep Learning? Dumitru Erhan Yoshua Bengio Aaron Courville Pierre-Antoine Manzagol
Journal of Machine Learning Research 11 (2010) 625-660 Submitted 8/09; Published 2/10 Why Does Unsupervised Pre-training Help Deep Learning? Dumitru Erhan Yoshua Bengio Aaron Courville Pierre-Antoine Manzagol
LEUKEMIA CLASSIFICATION USING DEEP BELIEF NETWORK
 Proceedings of the IASTED International Conference Artificial Intelligence and Applications (AIA 2013) February 11-13, 2013 Innsbruck, Austria LEUKEMIA CLASSIFICATION USING DEEP BELIEF NETWORK Wannipa
Proceedings of the IASTED International Conference Artificial Intelligence and Applications (AIA 2013) February 11-13, 2013 Innsbruck, Austria LEUKEMIA CLASSIFICATION USING DEEP BELIEF NETWORK Wannipa
A previous version of this paper appeared in Proceedings of the 26th International Conference on Machine Learning (Montreal, Canada, 2009).
.") doi:10.1145/2001269.2001295 Unsupervised Learning of Hierarchical Representations with Convolutional Deep Belief Networks By Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Y. Ng Abstract There
doi:10.1145/2001269.2001295 Unsupervised Learning of Hierarchical Representations with Convolutional Deep Belief Networks By Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Y. Ng Abstract There
Generalized Denoising Auto-Encoders as Generative Models
 Generalized Denoising Auto-Encoders as Generative Models Yoshua Bengio, Li Yao, Guillaume Alain, and Pascal Vincent Département d informatique et recherche opérationnelle, Université de Montréal Abstract
Generalized Denoising Auto-Encoders as Generative Models Yoshua Bengio, Li Yao, Guillaume Alain, and Pascal Vincent Département d informatique et recherche opérationnelle, Université de Montréal Abstract
Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations
 Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations Honglak Lee Roger Grosse Rajesh Ranganath Andrew Y. Ng Computer Science Department, Stanford University,
Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations Honglak Lee Roger Grosse Rajesh Ranganath Andrew Y. Ng Computer Science Department, Stanford University,
Introduction to Deep Learning Variational Inference, Mean Field Theory
 Introduction to Deep Learning Variational Inference, Mean Field Theory 1 Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris Galen Group INRIA-Saclay Lecture 3: recap
Introduction to Deep Learning Variational Inference, Mean Field Theory 1 Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris Galen Group INRIA-Saclay Lecture 3: recap
Supporting Online Material for
 www.sciencemag.org/cgi/content/full/313/5786/504/dc1 Supporting Online Material for Reducing the Dimensionality of Data with Neural Networks G. E. Hinton* and R. R. Salakhutdinov *To whom correspondence
www.sciencemag.org/cgi/content/full/313/5786/504/dc1 Supporting Online Material for Reducing the Dimensionality of Data with Neural Networks G. E. Hinton* and R. R. Salakhutdinov *To whom correspondence
Learning Deep Architectures for AI. Contents
 Foundations and Trends R in Machine Learning Vol. 2, No. 1 (2009) 1 127 c 2009 Y. Bengio DOI: 10.1561/2200000006 Learning Deep Architectures for AI By Yoshua Bengio Contents 1 Introduction 2 1.1 How do
Foundations and Trends R in Machine Learning Vol. 2, No. 1 (2009) 1 127 c 2009 Y. Bengio DOI: 10.1561/2200000006 Learning Deep Architectures for AI By Yoshua Bengio Contents 1 Introduction 2 1.1 How do
Efficient online learning of a non-negative sparse autoencoder
 and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
An Analysis of Single-Layer Networks in Unsupervised Feature Learning
 An Analysis of Single-Layer Networks in Unsupervised Feature Learning Adam Coates 1, Honglak Lee 2, Andrew Y. Ng 1 1 Computer Science Department, Stanford University {acoates,ang}@cs.stanford.edu 2 Computer
An Analysis of Single-Layer Networks in Unsupervised Feature Learning Adam Coates 1, Honglak Lee 2, Andrew Y. Ng 1 1 Computer Science Department, Stanford University {acoates,ang}@cs.stanford.edu 2 Computer
Neural Networks for Machine Learning. Lecture 13a The ups and downs of backpropagation
 Neural Networks for Machine Learning Lecture 13a The ups and downs of backpropagation Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed A brief history of backpropagation
Neural Networks for Machine Learning Lecture 13a The ups and downs of backpropagation Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed A brief history of backpropagation
An Introduction to Deep Learning
 Thought Leadership Paper Predictive Analytics An Introduction to Deep Learning Examining the Advantages of Hierarchical Learning Table of Contents 4 The Emergence of Deep Learning 7 Applying Deep-Learning
Thought Leadership Paper Predictive Analytics An Introduction to Deep Learning Examining the Advantages of Hierarchical Learning Table of Contents 4 The Emergence of Deep Learning 7 Applying Deep-Learning
A Hybrid Neural Network-Latent Topic Model
 Li Wan Leo Zhu Rob Fergus Dept. of Computer Science, Courant institute, New York University {wanli,zhu,fergus}@cs.nyu.edu Abstract This paper introduces a hybrid model that combines a neural network with
Li Wan Leo Zhu Rob Fergus Dept. of Computer Science, Courant institute, New York University {wanli,zhu,fergus}@cs.nyu.edu Abstract This paper introduces a hybrid model that combines a neural network with
Contractive Auto-Encoders: Explicit Invariance During Feature Extraction
 : Explicit Invariance During Feature Extraction Salah Rifai (1) Pascal Vincent (1) Xavier Muller (1) Xavier Glorot (1) Yoshua Bengio (1) (1) Dept. IRO, Université de Montréal. Montréal (QC), H3C 3J7, Canada
: Explicit Invariance During Feature Extraction Salah Rifai (1) Pascal Vincent (1) Xavier Muller (1) Xavier Glorot (1) Yoshua Bengio (1) (1) Dept. IRO, Université de Montréal. Montréal (QC), H3C 3J7, Canada
Transfer Learning for Latin and Chinese Characters with Deep Neural Networks
 Transfer Learning for Latin and Chinese Characters with Deep Neural Networks Dan C. Cireşan IDSIA USI-SUPSI Manno, Switzerland, 6928 Email: dan@idsia.ch Ueli Meier IDSIA USI-SUPSI Manno, Switzerland, 6928
Transfer Learning for Latin and Chinese Characters with Deep Neural Networks Dan C. Cireşan IDSIA USI-SUPSI Manno, Switzerland, 6928 Email: dan@idsia.ch Ueli Meier IDSIA USI-SUPSI Manno, Switzerland, 6928
Unsupervised and Transfer Learning Challenge: a Deep Learning Approach
 JMLR: Workshop and Conference Proceedings 27:97 111, 2012 Workshop on Unsupervised and Transfer Learning Unsupervised and Transfer Learning Challenge: a Deep Learning Approach Grégoire Mesnil 1,2 mesnilgr@iro.umontreal.ca
JMLR: Workshop and Conference Proceedings 27:97 111, 2012 Workshop on Unsupervised and Transfer Learning Unsupervised and Transfer Learning Challenge: a Deep Learning Approach Grégoire Mesnil 1,2 mesnilgr@iro.umontreal.ca
Manifold Learning with Variational Auto-encoder for Medical Image Analysis
 Manifold Learning with Variational Auto-encoder for Medical Image Analysis Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Manifold
Manifold Learning with Variational Auto-encoder for Medical Image Analysis Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Manifold
Forecasting Trade Direction and Size of Future Contracts Using Deep Belief Network
 Forecasting Trade Direction and Size of Future Contracts Using Deep Belief Network Anthony Lai (aslai), MK Li (lilemon), Foon Wang Pong (ppong) Abstract Algorithmic trading, high frequency trading (HFT)
Forecasting Trade Direction and Size of Future Contracts Using Deep Belief Network Anthony Lai (aslai), MK Li (lilemon), Foon Wang Pong (ppong) Abstract Algorithmic trading, high frequency trading (HFT)
Sparse deep belief net model for visual area V2
 Sparse deep belief net model for visual area V2 Honglak Lee Chaitanya Ekanadham Andrew Y. Ng Computer Science Department Stanford University Stanford, CA 9435 {hllee,chaitu,ang}@cs.stanford.edu Abstract
Sparse deep belief net model for visual area V2 Honglak Lee Chaitanya Ekanadham Andrew Y. Ng Computer Science Department Stanford University Stanford, CA 9435 {hllee,chaitu,ang}@cs.stanford.edu Abstract
Representation Learning: A Review and New Perspectives
 1 Representation Learning: A Review and New Perspectives Yoshua Bengio, Aaron Courville, and Pascal Vincent Department of computer science and operations research, U. Montreal also, Canadian Institute
1 Representation Learning: A Review and New Perspectives Yoshua Bengio, Aaron Courville, and Pascal Vincent Department of computer science and operations research, U. Montreal also, Canadian Institute
Deep Belief Nets (An updated and extended version of my 2007 NIPS tutorial)
") UCL Tutorial on: Deep Belief Nets (An updated and extended version of my 2007 NIPS tutorial) Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto
UCL Tutorial on: Deep Belief Nets (An updated and extended version of my 2007 NIPS tutorial) Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto
Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach
 Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach Xavier Glorot (1) glorotxa@iro.montreal.ca Antoine Bordes (2,1) bordesan@hds.utc.fr Yoshua Bengio (1) bengioy@iro.montreal.ca
Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach Xavier Glorot (1) glorotxa@iro.montreal.ca Antoine Bordes (2,1) bordesan@hds.utc.fr Yoshua Bengio (1) bengioy@iro.montreal.ca
Learning to Process Natural Language in Big Data Environment
 CCF ADL 2015 Nanchang Oct 11, 2015 Learning to Process Natural Language in Big Data Environment Hang Li Noah s Ark Lab Huawei Technologies Part 1: Deep Learning - Present and Future Talk Outline Overview
CCF ADL 2015 Nanchang Oct 11, 2015 Learning to Process Natural Language in Big Data Environment Hang Li Noah s Ark Lab Huawei Technologies Part 1: Deep Learning - Present and Future Talk Outline Overview
Modeling Pixel Means and Covariances Using Factorized Third-Order Boltzmann Machines
 Modeling Pixel Means and Covariances Using Factorized Third-Order Boltzmann Machines Marc Aurelio Ranzato Geoffrey E. Hinton Department of Computer Science - University of Toronto 10 King s College Road,
Modeling Pixel Means and Covariances Using Factorized Third-Order Boltzmann Machines Marc Aurelio Ranzato Geoffrey E. Hinton Department of Computer Science - University of Toronto 10 King s College Road,
Deep learning applications and challenges in big data analytics
 Najafabadi et al. Journal of Big Data (2015) 2:1 DOI 10.1186/s40537-014-0007-7 RESEARCH Open Access Deep learning applications and challenges in big data analytics Maryam M Najafabadi 1, Flavio Villanustre
Najafabadi et al. Journal of Big Data (2015) 2:1 DOI 10.1186/s40537-014-0007-7 RESEARCH Open Access Deep learning applications and challenges in big data analytics Maryam M Najafabadi 1, Flavio Villanustre
Improving Deep Neural Network Performance by Reusing Features Trained with Transductive Transference
 Improving Deep Neural Network Performance by Reusing Features Trained with Transductive Transference Chetak Kandaswamy, Luís Silva, Luís Alexandre, Jorge M. Santos, Joaquim Marques de Sá Instituto de Engenharia
Improving Deep Neural Network Performance by Reusing Features Trained with Transductive Transference Chetak Kandaswamy, Luís Silva, Luís Alexandre, Jorge M. Santos, Joaquim Marques de Sá Instituto de Engenharia
Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition
 Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition Marc Aurelio Ranzato, Fu-Jie Huang, Y-Lan Boureau, Yann LeCun Courant Institute of Mathematical Sciences,
Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition Marc Aurelio Ranzato, Fu-Jie Huang, Y-Lan Boureau, Yann LeCun Courant Institute of Mathematical Sciences,
Deep Learning for Big Data
 Deep Learning for Big Data Yoshua Bengio Département d Informa0que et Recherche Opéra0onnelle, U. Montréal 30 May 2013, Journée de la recherche École Polytechnique, Montréal Big Data & Data Science Super-
Deep Learning for Big Data Yoshua Bengio Département d Informa0que et Recherche Opéra0onnelle, U. Montréal 30 May 2013, Journée de la recherche École Polytechnique, Montréal Big Data & Data Science Super-
called Restricted Boltzmann Machines for Collaborative Filtering
 Restricted Boltzmann Machines for Collaborative Filtering Ruslan Salakhutdinov rsalakhu@cs.toronto.edu Andriy Mnih amnih@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu University of Toronto, 6 King
Restricted Boltzmann Machines for Collaborative Filtering Ruslan Salakhutdinov rsalakhu@cs.toronto.edu Andriy Mnih amnih@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu University of Toronto, 6 King
3D Object Recognition using Convolutional Neural Networks with Transfer Learning between Input Channels
 3D Object Recognition using Convolutional Neural Networks with Transfer Learning between Input Channels Luís A. Alexandre Department of Informatics and Instituto de Telecomunicações Univ. Beira Interior,
3D Object Recognition using Convolutional Neural Networks with Transfer Learning between Input Channels Luís A. Alexandre Department of Informatics and Instituto de Telecomunicações Univ. Beira Interior,
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
Selecting Receptive Fields in Deep Networks
 Selecting Receptive Fields in Deep Networks Adam Coates Department of Computer Science Stanford University Stanford, CA 94305 acoates@cs.stanford.edu Andrew Y. Ng Department of Computer Science Stanford
Selecting Receptive Fields in Deep Networks Adam Coates Department of Computer Science Stanford University Stanford, CA 94305 acoates@cs.stanford.edu Andrew Y. Ng Department of Computer Science Stanford
The multilayer sentiment analysis model based on Random forest Wei Liu1, Jie Zhang2
 2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) The multilayer sentiment analysis model based on Random forest Wei Liu1, Jie Zhang2 1 School of
2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) The multilayer sentiment analysis model based on Random forest Wei Liu1, Jie Zhang2 1 School of
Taking Inverse Graphics Seriously
 CSC2535: 2013 Advanced Machine Learning Taking Inverse Graphics Seriously Geoffrey Hinton Department of Computer Science University of Toronto The representation used by the neural nets that work best
CSC2535: 2013 Advanced Machine Learning Taking Inverse Graphics Seriously Geoffrey Hinton Department of Computer Science University of Toronto The representation used by the neural nets that work best
NEURAL NETWORKS A Comprehensive Foundation
 NEURAL NETWORKS A Comprehensive Foundation Second Edition Simon Haykin McMaster University Hamilton, Ontario, Canada Prentice Hall Prentice Hall Upper Saddle River; New Jersey 07458 Preface xii Acknowledgments
NEURAL NETWORKS A Comprehensive Foundation Second Edition Simon Haykin McMaster University Hamilton, Ontario, Canada Prentice Hall Prentice Hall Upper Saddle River; New Jersey 07458 Preface xii Acknowledgments
To Recognize Shapes, First Learn to Generate Images
 Department of Computer Science 6 King s College Rd, Toronto University of Toronto M5S 3G4, Canada http://learning.cs.toronto.edu fax: +1 416 978 1455 Copyright c Geoffrey Hinton 2006. October 26, 2006
Department of Computer Science 6 King s College Rd, Toronto University of Toronto M5S 3G4, Canada http://learning.cs.toronto.edu fax: +1 416 978 1455 Copyright c Geoffrey Hinton 2006. October 26, 2006
Deep Learning using Linear Support Vector Machines
 Yichuan Tang tang@cs.toronto.edu Department of Computer Science, University of Toronto. Toronto, Ontario, Canada. Abstract Recently, fully-connected and convolutional neural networks have been trained
Yichuan Tang tang@cs.toronto.edu Department of Computer Science, University of Toronto. Toronto, Ontario, Canada. Abstract Recently, fully-connected and convolutional neural networks have been trained
Three New Graphical Models for Statistical Language Modelling
 Andriy Mnih Geoffrey Hinton Department of Computer Science, University of Toronto, Canada amnih@cs.toronto.edu hinton@cs.toronto.edu Abstract The supremacy of n-gram models in statistical language modelling
Andriy Mnih Geoffrey Hinton Department of Computer Science, University of Toronto, Canada amnih@cs.toronto.edu hinton@cs.toronto.edu Abstract The supremacy of n-gram models in statistical language modelling
Sense Making in an IOT World: Sensor Data Analysis with Deep Learning
 Sense Making in an IOT World: Sensor Data Analysis with Deep Learning Natalia Vassilieva, PhD Senior Research Manager GTC 2016 Deep learning proof points as of today Vision Speech Text Other Search & information
Sense Making in an IOT World: Sensor Data Analysis with Deep Learning Natalia Vassilieva, PhD Senior Research Manager GTC 2016 Deep learning proof points as of today Vision Speech Text Other Search & information
A Practical Guide to Training Restricted Boltzmann Machines
 Department of Computer Science 6 King s College Rd, Toronto University of Toronto M5S 3G4, Canada http://learning.cs.toronto.edu fax: +1 416 978 1455 Copyright c Geoffrey Hinton 2010. August 2, 2010 UTML
Department of Computer Science 6 King s College Rd, Toronto University of Toronto M5S 3G4, Canada http://learning.cs.toronto.edu fax: +1 416 978 1455 Copyright c Geoffrey Hinton 2010. August 2, 2010 UTML
On Optimization Methods for Deep Learning
 Quoc V. Le quocle@cs.stanford.edu Jiquan Ngiam jngiam@cs.stanford.edu Adam Coates acoates@cs.stanford.edu Abhik Lahiri alahiri@cs.stanford.edu Bobby Prochnow prochnow@cs.stanford.edu Andrew Y. Ng ang@cs.stanford.edu
Quoc V. Le quocle@cs.stanford.edu Jiquan Ngiam jngiam@cs.stanford.edu Adam Coates acoates@cs.stanford.edu Abhik Lahiri alahiri@cs.stanford.edu Bobby Prochnow prochnow@cs.stanford.edu Andrew Y. Ng ang@cs.stanford.edu
Efficient Learning of Sparse Representations with an Energy-Based Model
 Efficient Learning of Sparse Representations with an Energy-Based Model Marc Aurelio Ranzato Christopher Poultney Sumit Chopra Yann LeCun Courant Institute of Mathematical Sciences New York University,
Efficient Learning of Sparse Representations with an Energy-Based Model Marc Aurelio Ranzato Christopher Poultney Sumit Chopra Yann LeCun Courant Institute of Mathematical Sciences New York University,
Generating more realistic images using gated MRF s
 Generating more realistic images using gated MRF s Marc Aurelio Ranzato Volodymyr Mnih Geoffrey E. Hinton Department of Computer Science University of Toronto {ranzato,vmnih,hinton}@cs.toronto.edu Abstract
Generating more realistic images using gated MRF s Marc Aurelio Ranzato Volodymyr Mnih Geoffrey E. Hinton Department of Computer Science University of Toronto {ranzato,vmnih,hinton}@cs.toronto.edu Abstract
Learning a Generative Model of Images by Factoring Appearance and Shape
 ARTICLE Communicated by Kevin Murphy Learning a Generative Model of Images by Factoring Appearance and Shape Nicolas Le Roux nicolas@le-roux.name Microsoft Research Cambridge, Machine Learning and Perception,
ARTICLE Communicated by Kevin Murphy Learning a Generative Model of Images by Factoring Appearance and Shape Nicolas Le Roux nicolas@le-roux.name Microsoft Research Cambridge, Machine Learning and Perception,
Learning multiple layers of representation
 Review TRENDS in Cognitive Sciences Vol.11 No.10 Learning multiple layers of representation Geoffrey E. Hinton Department of Computer Science, University of Toronto, 10 King s College Road, Toronto, M5S
Review TRENDS in Cognitive Sciences Vol.11 No.10 Learning multiple layers of representation Geoffrey E. Hinton Department of Computer Science, University of Toronto, 10 King s College Road, Toronto, M5S
Deep Convolutional Inverse Graphics Network
 Deep Convolutional Inverse Graphics Network Tejas D. Kulkarni* 1, William F. Whitney* 2, Pushmeet Kohli 3, Joshua B. Tenenbaum 4 1,2,4 Massachusetts Institute of Technology, Cambridge, USA 3 Microsoft
Deep Convolutional Inverse Graphics Network Tejas D. Kulkarni* 1, William F. Whitney* 2, Pushmeet Kohli 3, Joshua B. Tenenbaum 4 1,2,4 Massachusetts Institute of Technology, Cambridge, USA 3 Microsoft
Rectified Linear Units Improve Restricted Boltzmann Machines
 Rectified Linear Units Improve Restricted Boltzmann Machines Vinod Nair vnair@cs.toronto.edu Geoffrey E. Hinton hinton@cs.toronto.edu Department of Computer Science, University of Toronto, Toronto, ON
Rectified Linear Units Improve Restricted Boltzmann Machines Vinod Nair vnair@cs.toronto.edu Geoffrey E. Hinton hinton@cs.toronto.edu Department of Computer Science, University of Toronto, Toronto, ON
Marc'Aurelio Ranzato
 Marc'Aurelio Ranzato Facebook Inc. 1 Hacker Way Menlo Park, CA 94025, USA email: ranzato@cs.toronto.edu web: www.cs.toronto.edu/ ranzato RESEARCH INTERESTS My primary research interests are in the area
Marc'Aurelio Ranzato Facebook Inc. 1 Hacker Way Menlo Park, CA 94025, USA email: ranzato@cs.toronto.edu web: www.cs.toronto.edu/ ranzato RESEARCH INTERESTS My primary research interests are in the area
Feature Engineering in Machine Learning
 Research Fellow Faculty of Information Technology, Monash University, Melbourne VIC 3800, Australia August 21, 2015 Outline A Machine Learning Primer Machine Learning and Data Science Bias-Variance Phenomenon
Research Fellow Faculty of Information Technology, Monash University, Melbourne VIC 3800, Australia August 21, 2015 Outline A Machine Learning Primer Machine Learning and Data Science Bias-Variance Phenomenon
Tensor Factorization for Multi-Relational Learning
 Tensor Factorization for Multi-Relational Learning Maximilian Nickel 1 and Volker Tresp 2 1 Ludwig Maximilian University, Oettingenstr. 67, Munich, Germany nickel@dbs.ifi.lmu.de 2 Siemens AG, Corporate
Tensor Factorization for Multi-Relational Learning Maximilian Nickel 1 and Volker Tresp 2 1 Ludwig Maximilian University, Oettingenstr. 67, Munich, Germany nickel@dbs.ifi.lmu.de 2 Siemens AG, Corporate
Deep Learning Methods for Vision (draft)
") 1 CVPR 2012 Tutorial Deep Learning Metods for Vision (draft) Honglak Lee Computer Science and Engineering Division University of Micigan, Ann Arbor pixel 2 Feature representations pixel 1 Input pixel 2
1 CVPR 2012 Tutorial Deep Learning Metods for Vision (draft) Honglak Lee Computer Science and Engineering Division University of Micigan, Ann Arbor pixel 2 Feature representations pixel 1 Input pixel 2
arxiv:1312.6034v2 [cs.cv] 19 Apr 2014
![arxiv:1312.6034v2 [cs.cv] 19 Apr 2014](/thumbs/39/19892728.jpg "arxiv:1312.6034v2 [cs.cv] 19 Apr 2014") Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps arxiv:1312.6034v2 [cs.cv] 19 Apr 2014 Karen Simonyan Andrea Vedaldi Andrew Zisserman Visual Geometry Group,
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps arxiv:1312.6034v2 [cs.cv] 19 Apr 2014 Karen Simonyan Andrea Vedaldi Andrew Zisserman Visual Geometry Group,
Machine learning challenges for big data
 Machine learning challenges for big data Francis Bach SIERRA Project-team, INRIA - Ecole Normale Supérieure Joint work with R. Jenatton, J. Mairal, G. Obozinski, N. Le Roux, M. Schmidt - December 2012
Machine learning challenges for big data Francis Bach SIERRA Project-team, INRIA - Ecole Normale Supérieure Joint work with R. Jenatton, J. Mairal, G. Obozinski, N. Le Roux, M. Schmidt - December 2012
Latent variable and deep modeling with Gaussian processes; application to system identification. Andreas Damianou
 Latent variable and deep modeling with Gaussian processes; application to system identification Andreas Damianou Department of Computer Science, University of Sheffield, UK Brown University, 17 Feb. 2016
Latent variable and deep modeling with Gaussian processes; application to system identification Andreas Damianou Department of Computer Science, University of Sheffield, UK Brown University, 17 Feb. 2016
Recurrent Neural Networks
 Recurrent Neural Networks Neural Computation : Lecture 12 John A. Bullinaria, 2015 1. Recurrent Neural Network Architectures 2. State Space Models and Dynamical Systems 3. Backpropagation Through Time
Recurrent Neural Networks Neural Computation : Lecture 12 John A. Bullinaria, 2015 1. Recurrent Neural Network Architectures 2. State Space Models and Dynamical Systems 3. Backpropagation Through Time
Lecture 6: Classification & Localization. boris. ginzburg@intel.com
 Lecture 6: Classification & Localization boris. ginzburg@intel.com 1 Agenda ILSVRC 2014 Overfeat: integrated classification, localization, and detection Classification with Localization Detection. 2 ILSVRC-2014
Lecture 6: Classification & Localization boris. ginzburg@intel.com 1 Agenda ILSVRC 2014 Overfeat: integrated classification, localization, and detection Classification with Localization Detection. 2 ILSVRC-2014
Research Frontier. Deep Machine Learning A New Frontier in Artificial Intelligence Research
 Itamar Arel, Derek C. Rose, and Thomas P. Karnowski The University of Tennessee, USA Research Frontier Deep Machine Learning A New Frontier in Artificial Intelligence Research Digital Object Identifier
Itamar Arel, Derek C. Rose, and Thomas P. Karnowski The University of Tennessee, USA Research Frontier Deep Machine Learning A New Frontier in Artificial Intelligence Research Digital Object Identifier
Neural Networks and Support Vector Machines
 INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
The Importance of Encoding Versus Training with Sparse Coding and Vector Quantization
 The Importance of Encoding Versus Training with Sparse Coding and Vector Quantization Adam Coates Andrew Y. Ng Stanford University, 353 Serra Mall, Stanford, CA 94305 acoates@cs.stanford.edu ang@cs.stanford.edu
The Importance of Encoding Versus Training with Sparse Coding and Vector Quantization Adam Coates Andrew Y. Ng Stanford University, 353 Serra Mall, Stanford, CA 94305 acoates@cs.stanford.edu ang@cs.stanford.edu
Probabilistic Models for Big Data. Alex Davies and Roger Frigola University of Cambridge 13th February 2014
 Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Optimizing content delivery through machine learning. James Schneider Anton DeFrancesco
 Optimizing content delivery through machine learning James Schneider Anton DeFrancesco Obligatory company slide Our Research Areas Machine learning The problem Prioritize import information in low bandwidth
Optimizing content delivery through machine learning James Schneider Anton DeFrancesco Obligatory company slide Our Research Areas Machine learning The problem Prioritize import information in low bandwidth
Artificial Neural Networks and Support Vector Machines. CS 486/686: Introduction to Artificial Intelligence
 Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Training Methods for Adaptive Boosting of Neural Networks for Character Recognition
 Submission to NIPS*97, Category: Algorithms & Architectures, Preferred: Oral Training Methods for Adaptive Boosting of Neural Networks for Character Recognition Holger Schwenk Dept. IRO Université de Montréal
Submission to NIPS*97, Category: Algorithms & Architectures, Preferred: Oral Training Methods for Adaptive Boosting of Neural Networks for Character Recognition Holger Schwenk Dept. IRO Université de Montréal
Research Article Distributed Data Mining Based on Deep Neural Network for Wireless Sensor Network
 Distributed Sensor Networks Volume 2015, Article ID 157453, 7 pages http://dx.doi.org/10.1155/2015/157453 Research Article Distributed Data Mining Based on Deep Neural Network for Wireless Sensor Network
Distributed Sensor Networks Volume 2015, Article ID 157453, 7 pages http://dx.doi.org/10.1155/2015/157453 Research Article Distributed Data Mining Based on Deep Neural Network for Wireless Sensor Network
Factored 3-Way Restricted Boltzmann Machines For Modeling Natural Images
 For Modeling Natural Images Marc Aurelio Ranzato Alex Krizhevsky Geoffrey E. Hinton Department of Computer Science - University of Toronto Toronto, ON M5S 3G4, CANADA Abstract Deep belief nets have been
For Modeling Natural Images Marc Aurelio Ranzato Alex Krizhevsky Geoffrey E. Hinton Department of Computer Science - University of Toronto Toronto, ON M5S 3G4, CANADA Abstract Deep belief nets have been
Simplified Machine Learning for CUDA. Umar Arshad @arshad_umar Arrayfire @arrayfire
 Simplified Machine Learning for CUDA Umar Arshad @arshad_umar Arrayfire @arrayfire ArrayFire CUDA and OpenCL experts since 2007 Headquartered in Atlanta, GA In search for the best and the brightest Expert
Simplified Machine Learning for CUDA Umar Arshad @arshad_umar Arrayfire @arrayfire ArrayFire CUDA and OpenCL experts since 2007 Headquartered in Atlanta, GA In search for the best and the brightest Expert
Big Data Deep Learning: Challenges and Perspectives
 Big Data Deep Learning: Challenges and Perspectives D.saraswathy Department of computer science and engineering IFET college of engineering Villupuram saraswathidatchinamoorthi@gmail.com Abstract Deep
Big Data Deep Learning: Challenges and Perspectives D.saraswathy Department of computer science and engineering IFET college of engineering Villupuram saraswathidatchinamoorthi@gmail.com Abstract Deep
Module 5. Deep Convnets for Local Recognition Joost van de Weijer 4 April 2016
 Module 5 Deep Convnets for Local Recognition Joost van de Weijer 4 April 2016 Previously, end-to-end.. Dog Slide credit: Jose M 2 Previously, end-to-end.. Dog Learned Representation Slide credit: Jose
Module 5 Deep Convnets for Local Recognition Joost van de Weijer 4 April 2016 Previously, end-to-end.. Dog Slide credit: Jose M 2 Previously, end-to-end.. Dog Learned Representation Slide credit: Jose
Learning Sparse Features with an Auto-Associator
 Learning Sparse Features with an Auto-Associator Sébastien Rebecchi, Hélène Paugam-Moisy, Michèle Sebag To cite this version: Sébastien Rebecchi, Hélène Paugam-Moisy, Michèle Sebag. Learning Sparse Features
Learning Sparse Features with an Auto-Associator Sébastien Rebecchi, Hélène Paugam-Moisy, Michèle Sebag To cite this version: Sébastien Rebecchi, Hélène Paugam-Moisy, Michèle Sebag. Learning Sparse Features
A Fast Learning Algorithm for Deep Belief Nets
 LETTER Communicated by Yann Le Cun A Fast Learning Algorithm for Deep Belief Nets Geoffrey E. Hinton hinton@cs.toronto.edu Simon Osindero osindero@cs.toronto.edu Department of Computer Science, University
LETTER Communicated by Yann Le Cun A Fast Learning Algorithm for Deep Belief Nets Geoffrey E. Hinton hinton@cs.toronto.edu Simon Osindero osindero@cs.toronto.edu Department of Computer Science, University
Learning Deep Architectures for AI
 1 Learning Deep Architectures for AI Yoshua Bengio Dept. IRO, Université de Montréal C.P. 6128, Montreal, Qc, H3C 3J7, Canada Yoshua.Bengio@umontreal.ca http://www.iro.umontreal.ca/ bengioy Technical Report
1 Learning Deep Architectures for AI Yoshua Bengio Dept. IRO, Université de Montréal C.P. 6128, Montreal, Qc, H3C 3J7, Canada Yoshua.Bengio@umontreal.ca http://www.iro.umontreal.ca/ bengioy Technical Report
Course: Model, Learning, and Inference: Lecture 5
 Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 yuille@stat.ucla.edu Abstract Probability distributions on structured representation.
Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 yuille@stat.ucla.edu Abstract Probability distributions on structured representation.
Bayesian networks - Time-series models - Apache Spark & Scala
 Bayesian networks - Time-series models - Apache Spark & Scala Dr John Sandiford, CTO Bayes Server Data Science London Meetup - November 2014 1 Contents Introduction Bayesian networks Latent variables Anomaly
Bayesian networks - Time-series models - Apache Spark & Scala Dr John Sandiford, CTO Bayes Server Data Science London Meetup - November 2014 1 Contents Introduction Bayesian networks Latent variables Anomaly
Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection
 CSED703R: Deep Learning for Visual Recognition (206S) Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 3 Object detection
CSED703R: Deep Learning for Visual Recognition (206S) Lecture 6: CNNs for Detection, Tracking, and Segmentation Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 3 Object detection
Deep Learning for Multivariate Financial Time Series. Gilberto Batres-Estrada
 Deep Learning for Multivariate Financial Time Series Gilberto Batres-Estrada June 4, 2015 Abstract Deep learning is a framework for training and modelling neural networks which recently have surpassed
Deep Learning for Multivariate Financial Time Series Gilberto Batres-Estrada June 4, 2015 Abstract Deep learning is a framework for training and modelling neural networks which recently have surpassed
Università degli Studi di Bologna
 Università degli Studi di Bologna DEIS Biometric System Laboratory Incremental Learning by Message Passing in Hierarchical Temporal Memory Davide Maltoni Biometric System Laboratory DEIS - University of
Università degli Studi di Bologna DEIS Biometric System Laboratory Incremental Learning by Message Passing in Hierarchical Temporal Memory Davide Maltoni Biometric System Laboratory DEIS - University of
Simple and efficient online algorithms for real world applications
 Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
HT2015: SC4 Statistical Data Mining and Machine Learning
 HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
A fast learning algorithm for deep belief nets
 A fast learning algorithm for deep belief nets Geoffrey E. Hinton and Simon Osindero Department of Computer Science University of Toronto 10 Kings College Road Toronto, Canada M5S 3G4 {hinton, osindero}@cs.toronto.edu
A fast learning algorithm for deep belief nets Geoffrey E. Hinton and Simon Osindero Department of Computer Science University of Toronto 10 Kings College Road Toronto, Canada M5S 3G4 {hinton, osindero}@cs.toronto.edu
Applying Deep Learning to Enhance Momentum Trading Strategies in Stocks
 This version: December 12, 2013 Applying Deep Learning to Enhance Momentum Trading Strategies in Stocks Lawrence Takeuchi * Yu-Ying (Albert) Lee ltakeuch@stanford.edu yy.albert.lee@gmail.com Abstract We
This version: December 12, 2013 Applying Deep Learning to Enhance Momentum Trading Strategies in Stocks Lawrence Takeuchi * Yu-Ying (Albert) Lee ltakeuch@stanford.edu yy.albert.lee@gmail.com Abstract We
Unsupervised Feature Learning and Deep Learning
 Unsupervised Feature Learning and Deep Learning Thanks to: Adam Coates Quoc Le Honglak Lee Andrew Maas Chris Manning Jiquan Ngiam Andrew Saxe Richard Socher Develop ideas using Computer vision Audio Text
Unsupervised Feature Learning and Deep Learning Thanks to: Adam Coates Quoc Le Honglak Lee Andrew Maas Chris Manning Jiquan Ngiam Andrew Saxe Richard Socher Develop ideas using Computer vision Audio Text
arxiv:1607.00136v1 [cs.ai] 1 Jul 2016
![arxiv:1607.00136v1 [cs.ai] 1 Jul 2016](/thumbs/40/21149575.jpg "arxiv:1607.00136v1 [cs.ai] 1 Jul 2016") Missing Data Estimation in High-Dimensional Datasets: A Swarm Intelligence-Deep Neural Network Approach Collins Leke and Tshilidzi Marwala University of Johannesburg, Johannesburg, South Africa {collinsl,tmarwala}@uj.ac.za
Missing Data Estimation in High-Dimensional Datasets: A Swarm Intelligence-Deep Neural Network Approach Collins Leke and Tshilidzi Marwala University of Johannesburg, Johannesburg, South Africa {collinsl,tmarwala}@uj.ac.za
Learning outcomes. Knowledge and understanding. Competence and skills
 Syllabus Master s Programme in Statistics and Data Mining 120 ECTS Credits Aim The rapid growth of databases provides scientists and business people with vast new resources. This programme meets the challenges
Syllabus Master s Programme in Statistics and Data Mining 120 ECTS Credits Aim The rapid growth of databases provides scientists and business people with vast new resources. This programme meets the challenges
Various applications of restricted Boltzmann machines for bad quality training data
 Wrocław University of Technology Various applications of restricted Boltzmann machines for bad quality training data Maciej Zięba Wroclaw University of Technology 20.06.2014 Motivation Big data - 7 dimensions1
Wrocław University of Technology Various applications of restricted Boltzmann machines for bad quality training data Maciej Zięba Wroclaw University of Technology 20.06.2014 Motivation Big data - 7 dimensions1
PhD in Computer Science and Engineering Bologna, April 2016. Machine Learning. Marco Lippi. marco.lippi3@unibo.it. Marco Lippi Machine Learning 1 / 80
 PhD in Computer Science and Engineering Bologna, April 2016 Machine Learning Marco Lippi marco.lippi3@unibo.it Marco Lippi Machine Learning 1 / 80 Recurrent Neural Networks Marco Lippi Machine Learning
PhD in Computer Science and Engineering Bologna, April 2016 Machine Learning Marco Lippi marco.lippi3@unibo.it Marco Lippi Machine Learning 1 / 80 Recurrent Neural Networks Marco Lippi Machine Learning
Learning compact class codes for fast inference in large multi class classification
 Learning compact class codes for fast inference in large multi class classification M. Cissé, T. Artières, and P. Gallinari Laboratoire d Informatique de Paris 6 (LIP6), Université Pierre et Marie Curie,
Learning compact class codes for fast inference in large multi class classification M. Cissé, T. Artières, and P. Gallinari Laboratoire d Informatique de Paris 6 (LIP6), Université Pierre et Marie Curie,
Basics of Statistical Machine Learning
 CS761 Spring 2013 Advanced Machine Learning Basics of Statistical Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu Modern machine learning is rooted in statistics. You will find many familiar
CS761 Spring 2013 Advanced Machine Learning Basics of Statistical Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu Modern machine learning is rooted in statistics. You will find many familiar
arxiv:1507.02672v2 [cs.ne] 24 Nov 2015
![arxiv:1507.02672v2 [cs.ne] 24 Nov 2015](/thumbs/40/21700864.jpg "arxiv:1507.02672v2 [cs.ne] 24 Nov 2015") Semi-Supervised Learning with Ladder Networks Antti Rasmus The Curious AI Company, Finland Harri Valpola The Curious AI Company, Finland Mikko Honkala Nokia Labs, Finland arxiv:1507.02672v2 [cs.ne] 24
Semi-Supervised Learning with Ladder Networks Antti Rasmus The Curious AI Company, Finland Harri Valpola The Curious AI Company, Finland Mikko Honkala Nokia Labs, Finland arxiv:1507.02672v2 [cs.ne] 24
Pixels Description of scene contents. Rob Fergus (NYU) Antonio Torralba (MIT) Yair Weiss (Hebrew U.) William T. Freeman (MIT) Banksy, 2006
 Antonio Torralba (MIT) Yair Weiss (Hebrew U.) William T. Freeman (MIT) Banksy, 2006") Object Recognition Large Image Databases and Small Codes for Object Recognition Pixels Description of scene contents Rob Fergus (NYU) Antonio Torralba (MIT) Yair Weiss (Hebrew U.) William T. Freeman (MIT)
Object Recognition Large Image Databases and Small Codes for Object Recognition Pixels Description of scene contents Rob Fergus (NYU) Antonio Torralba (MIT) Yair Weiss (Hebrew U.) William T. Freeman (MIT)
Dirichlet Processes A gentle tutorial
 Dirichlet Processes A gentle tutorial SELECT Lab Meeting October 14, 2008 Khalid El-Arini Motivation We are given a data set, and are told that it was generated from a mixture of Gaussian distributions.
Dirichlet Processes A gentle tutorial SELECT Lab Meeting October 14, 2008 Khalid El-Arini Motivation We are given a data set, and are told that it was generated from a mixture of Gaussian distributions.
Deep Learning of Invariant Features via Simulated Fixations in Video
 Deep Learning of Invariant Features via Simulated Fixations in Video Will Y. Zou 1, Shenghuo Zhu 3, Andrew Y. Ng 2, Kai Yu 3 1 Department of Electrical Engineering, Stanford University, CA 2 Department
Deep Learning of Invariant Features via Simulated Fixations in Video Will Y. Zou 1, Shenghuo Zhu 3, Andrew Y. Ng 2, Kai Yu 3 1 Department of Electrical Engineering, Stanford University, CA 2 Department
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Semi-Supervised Support Vector Machines and Application to Spam Filtering
 Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Machine Learning. 01 - Introduction
 Machine Learning 01 - Introduction Machine learning course One lecture (Wednesday, 9:30, 346) and one exercise (Monday, 17:15, 203). Oral exam, 20 minutes, 5 credit points. Some basic mathematical knowledge
Machine Learning 01 - Introduction Machine learning course One lecture (Wednesday, 9:30, 346) and one exercise (Monday, 17:15, 203). Oral exam, 20 minutes, 5 credit points. Some basic mathematical knowledge
An Introduction to Neural Networks
 An Introduction to Vincent Cheung Kevin Cannons Signal & Data Compression Laboratory Electrical & Computer Engineering University of Manitoba Winnipeg, Manitoba, Canada Advisor: Dr. W. Kinsner May 27,
An Introduction to Vincent Cheung Kevin Cannons Signal & Data Compression Laboratory Electrical & Computer Engineering University of Manitoba Winnipeg, Manitoba, Canada Advisor: Dr. W. Kinsner May 27,
CS 1699: Intro to Computer Vision. Deep Learning. Prof. Adriana Kovashka University of Pittsburgh December 1, 2015
 CS 1699: Intro to Computer Vision Deep Learning Prof. Adriana Kovashka University of Pittsburgh December 1, 2015 Today: Deep neural networks Background Architectures and basic operations Applications Visualizing
CS 1699: Intro to Computer Vision Deep Learning Prof. Adriana Kovashka University of Pittsburgh December 1, 2015 Today: Deep neural networks Background Architectures and basic operations Applications Visualizing