What is Multi Core Architecture?
|
|
|
- Peregrine Mills
- 7 years ago
- Views:
Transcription
1 What is Multi Core Architecture? When a processor has more than one core to execute all the necessary functions of a computer, it s processor is known to be a multi core architecture. In other words, a chip with more than one CPU s(central Processing Unit).
2 What is the difference between a single core processor and a multi core processor?
3 Advantages of multi core CPU the largest boost in performance will likely be noticed in improved response-time while running CPUintensive processes, like anti-virus scans, ripping/burning media. assuming that the die can fit into the package, physically, the multi-core CPU designs require much less printed Circuit Board(PCB) space than multi-chip SMP designs. Also, a dual core processor uses slightly less power than two coupled single core processors, principally because of the decreased power required to drive signals external to the chip.

4

5
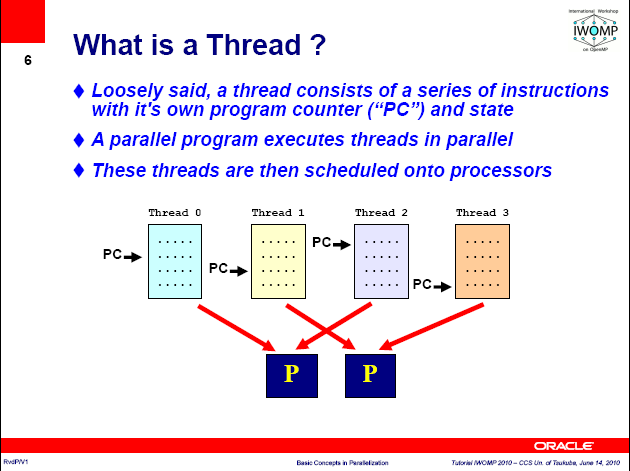
6
7

8

9

10
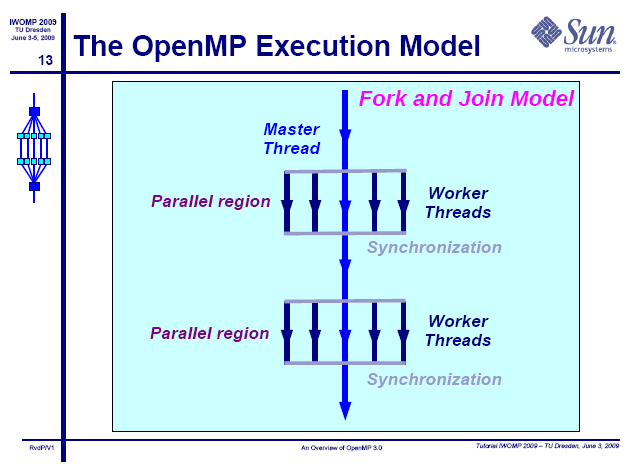
11

12 Bio-grid Cluster
13 How it works!!! DEMO TIME!!!
14 OpenMP example When writing a program in C or C++, you must import the library #include<omp.h> to include the openmp library on your program to allow parallelization during compile time. some sample OpenMP runtime Functions: omp_set_num_threads (Sets number of threads) omp_set_max_active_levels (Sets number of active parallel regions)
15 OpenMP Example Continued.. #include <omp.h> #include <stdio.h> #include <stdlib.h> #define NRA 62 /* number of rows in matrix A */ #define NCA 15 /* number of columns in matrix A */ #define NCB 7 /* number of columns in matrix B */
16 OpenMP Example Continued.. int main (int argc, char *argv[]) { int tid, nthreads, i, j, k, chunk; double a[nra][nca], multiplied */ /* matrix A to be */ b[nca][ncb], /* matrix B to be multiplied c[nra][ncb]; /* result matrix C */ chunk = 10; */ /* set loop iteration chunk size
17 OpenMP Example Continued.. /*** Spawn a parallel region explicitly scoping all variables ***/ #pragma omp parallel shared(a,b,c,nthreads,chunk) private(tid,i,j,k) { tid = omp_get_thread_num(); if (tid == 0) { nthreads = omp_get_num_threads(); printf("starting matrix multiple example with %d threads\n",nthreads); printf("initializing matrices...\n"); printf("hello"); }
18 OpenMP Example Continued.. /*** Initialize matrices ***/ #pragma omp for schedule (static, chunk) for (i=0; i<nra; i++) for (j=0; j<nca; j++) a[i][j]= i+j; #pragma omp for schedule (static, chunk) for (i=0; i<nca; i++) for (j=0; j<ncb; j++) b[i][j]= i*j; #pragma omp for schedule (static, chunk) for (i=0; i<nra; i++) for (j=0; j<ncb; j++) c[i][j]= 0;
19 OpenMP Example Continued.. /*** Do matrix multiply sharing iterations on outer loop ***/ /*** Display who does which iterations for demonstration purposes ***/ printf("thread %d starting matrix multiply...\n",tid); #pragma omp for schedule (static, chunk) for (i=0; i<nra; i++) { printf("thread=%d did row=%d\n",tid,i); for(j=0; j<ncb; j++) for (k=0; k<nca; k++) c[i][j] += a[i][k] * b[k][j]; } } /*** End of parallel region ***/
20 OpenMP Example Continued.. /*** Print results ***/ printf("******************************************************\n"); printf("result Matrix:\n"); for (i=0; i<nra; i++) { for (j=0; j<ncb; j++) printf("%6.2f ", c[i][j]); printf("\n"); } printf("******************************************************\n"); printf ("Done.\n"); }
21 The relevance Using the algorithm derived from solving the Matrix multiplication problem using OpenMP, we can extend this algorithm to solve computational biology problems. Such as developing Algorithms for Identifying Boolean Networks and Related Biological Networks Based on Matrix Multiplication and Fingerprint Function 1
22 The relevance continued By doing so we can analyze gene expression data Understanding matrix multiplication problem and it can be applied to solve cient algorithms for identifying Boolean networks of bounded indegree and related biological networks, where identification of a Boolean network can be formalized as a problem of identifying many Boolean functions simultaneously. 1
23 How to extend my project Add MPI library and functions to send task to different processors Extend this algorithm to solve computational biology problems as stated on previous two slides.
24 Acknowledgements Special thanks to NSF for providing us with this wonderful opportunity to do research under BioGrid Also, Special Acknowledgements to Dr. Chun-His Huang for all his effort, patience and help towards helping me understand and implement the contents of this research! It was a fun summer indeed
25 Source Citation 1. JOURNAL OF COMPUTATIONAL BIOLOGY Volume 7, Numbers 3/4, 2000 Mary Ann Liebert, Inc. Pp Algorithms for Identifying Boolean Networks and Related Biological Networks Based on Matrix Multiplication and Fingerprint Function TATSUYA AKUTSU,1SATORU MIYANO,a nd SATORU KUHARA1 2. wikipedia.org
26 Source Citation sic_concepts_parallelization.pdf
Hybrid Programming with MPI and OpenMP
 Hybrid Programming with and OpenMP Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2015/2016 R. Rocha and F. Silva (DCC-FCUP) Programming
Hybrid Programming with and OpenMP Ricardo Rocha and Fernando Silva Computer Science Department Faculty of Sciences University of Porto Parallel Computing 2015/2016 R. Rocha and F. Silva (DCC-FCUP) Programming
WinBioinfTools: Bioinformatics Tools for Windows Cluster. Done By: Hisham Adel Mohamed
 WinBioinfTools: Bioinformatics Tools for Windows Cluster Done By: Hisham Adel Mohamed Objective Implement and Modify Bioinformatics Tools To run under Windows Cluster Project : Research Project between
WinBioinfTools: Bioinformatics Tools for Windows Cluster Done By: Hisham Adel Mohamed Objective Implement and Modify Bioinformatics Tools To run under Windows Cluster Project : Research Project between
Parallel Algorithm for Dense Matrix Multiplication
 Parallel Algorithm for Dense Matrix Multiplication CSE633 Parallel Algorithms Fall 2012 Ortega, Patricia Outline Problem definition Assumptions Implementation Test Results Future work Conclusions Problem
Parallel Algorithm for Dense Matrix Multiplication CSE633 Parallel Algorithms Fall 2012 Ortega, Patricia Outline Problem definition Assumptions Implementation Test Results Future work Conclusions Problem
Parallel Computing. Parallel shared memory computing with OpenMP
 Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Parallel Computing. Shared memory parallel programming with OpenMP
 Parallel Computing Shared memory parallel programming with OpenMP Thorsten Grahs, 27.04.2015 Table of contents Introduction Directives Scope of data Synchronization 27.04.2015 Thorsten Grahs Parallel Computing
Parallel Computing Shared memory parallel programming with OpenMP Thorsten Grahs, 27.04.2015 Table of contents Introduction Directives Scope of data Synchronization 27.04.2015 Thorsten Grahs Parallel Computing
OpenMP & MPI CISC 879. Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware
 OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
#pragma omp critical x = x + 1; !$OMP CRITICAL X = X + 1!$OMP END CRITICAL. (Very inefficiant) example using critical instead of reduction:
 example using critical instead of reduction:") omp critical The code inside a CRITICAL region is executed by only one thread at a time. The order is not specified. This means that if a thread is currently executing inside a CRITICAL region and another
omp critical The code inside a CRITICAL region is executed by only one thread at a time. The order is not specified. This means that if a thread is currently executing inside a CRITICAL region and another
COMP/CS 605: Introduction to Parallel Computing Lecture 21: Shared Memory Programming with OpenMP
 COMP/CS 605: Introduction to Parallel Computing Lecture 21: Shared Memory Programming with OpenMP Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State
COMP/CS 605: Introduction to Parallel Computing Lecture 21: Shared Memory Programming with OpenMP Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Workshare Process of Thread Programming and MPI Model on Multicore Architecture
 Vol., No. 7, 011 Workshare Process of Thread Programming and MPI Model on Multicore Architecture R. Refianti 1, A.B. Mutiara, D.T Hasta 3 Faculty of Computer Science and Information Technology, Gunadarma
Vol., No. 7, 011 Workshare Process of Thread Programming and MPI Model on Multicore Architecture R. Refianti 1, A.B. Mutiara, D.T Hasta 3 Faculty of Computer Science and Information Technology, Gunadarma
MPI and Hybrid Programming Models. William Gropp www.cs.illinois.edu/~wgropp
 MPI and Hybrid Programming Models William Gropp www.cs.illinois.edu/~wgropp 2 What is a Hybrid Model? Combination of several parallel programming models in the same program May be mixed in the same source
MPI and Hybrid Programming Models William Gropp www.cs.illinois.edu/~wgropp 2 What is a Hybrid Model? Combination of several parallel programming models in the same program May be mixed in the same source
Matrix Multiplication
 Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2016 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2016 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
1.4 Arrays Introduction to Programming in Java: An Interdisciplinary Approach Robert Sedgewick and Kevin Wayne Copyright 2002 2010 2/6/11 12:33 PM!
 1.4 Arrays Introduction to Programming in Java: An Interdisciplinary Approach Robert Sedgewick and Kevin Wayne Copyright 2002 2010 2/6/11 12:33 PM! A Foundation for Programming any program you might want
1.4 Arrays Introduction to Programming in Java: An Interdisciplinary Approach Robert Sedgewick and Kevin Wayne Copyright 2002 2010 2/6/11 12:33 PM! A Foundation for Programming any program you might want
Parallel and Distributed Computing Programming Assignment 1
 Parallel and Distributed Computing Programming Assignment 1 Due Monday, February 7 For programming assignment 1, you should write two C programs. One should provide an estimate of the performance of ping-pong
Parallel and Distributed Computing Programming Assignment 1 Due Monday, February 7 For programming assignment 1, you should write two C programs. One should provide an estimate of the performance of ping-pong
Basic Concepts in Parallelization
 1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
High Performance Computing
 High Performance Computing Oliver Rheinbach oliver.rheinbach@math.tu-freiberg.de http://www.mathe.tu-freiberg.de/nmo/ Vorlesung Introduction to High Performance Computing Hörergruppen Woche Tag Zeit Raum
High Performance Computing Oliver Rheinbach oliver.rheinbach@math.tu-freiberg.de http://www.mathe.tu-freiberg.de/nmo/ Vorlesung Introduction to High Performance Computing Hörergruppen Woche Tag Zeit Raum
Load Balancing. computing a file with grayscales. granularity considerations static work load assignment with MPI
 Load Balancing 1 the Mandelbrot set computing a file with grayscales 2 Static Work Load Assignment granularity considerations static work load assignment with MPI 3 Dynamic Work Load Balancing scheduling
Load Balancing 1 the Mandelbrot set computing a file with grayscales 2 Static Work Load Assignment granularity considerations static work load assignment with MPI 3 Dynamic Work Load Balancing scheduling
Programação pelo modelo partilhada de memória
 Programação pelo modelo partilhada de memória PDP Parallel Programming in C with MPI and OpenMP Michael J. Quinn Introdução OpenMP Ciclos for paralelos Blocos paralelos Variáveis privadas Secções criticas
Programação pelo modelo partilhada de memória PDP Parallel Programming in C with MPI and OpenMP Michael J. Quinn Introdução OpenMP Ciclos for paralelos Blocos paralelos Variáveis privadas Secções criticas
Debugging with TotalView
 Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
www.quilogic.com SQL/XML-IMDBg GPU boosted In-Memory Database for ultra fast data management Harald Frick CEO QuiLogic In-Memory DB Technology
 SQL/XML-IMDBg GPU boosted In-Memory Database for ultra fast data management Harald Frick CEO QuiLogic In-Memory DB Technology The parallel revolution Future computing systems are parallel, but Programmers
SQL/XML-IMDBg GPU boosted In-Memory Database for ultra fast data management Harald Frick CEO QuiLogic In-Memory DB Technology The parallel revolution Future computing systems are parallel, but Programmers
Scalability evaluation of barrier algorithms for OpenMP
 Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
CUDA Programming. Week 4. Shared memory and register
 CUDA Programming Week 4. Shared memory and register Outline Shared memory and bank confliction Memory padding Register allocation Example of matrix-matrix multiplication Homework SHARED MEMORY AND BANK
CUDA Programming Week 4. Shared memory and register Outline Shared memory and bank confliction Memory padding Register allocation Example of matrix-matrix multiplication Homework SHARED MEMORY AND BANK
Big Data and Parallel Work with R
 Big Data and Parallel Work with R What We'll Cover Data Limits in R Optional Data packages Optional Function packages Going parallel Deciding what to do Data Limits in R Big Data? What is big data? More
Big Data and Parallel Work with R What We'll Cover Data Limits in R Optional Data packages Optional Function packages Going parallel Deciding what to do Data Limits in R Big Data? What is big data? More
OpenMP and Performance
 Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Tuning Cycle Performance Tuning aims to improve the runtime of an
Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Tuning Cycle Performance Tuning aims to improve the runtime of an
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
High Performance Cloud: a MapReduce and GPGPU Based Hybrid Approach
 High Performance Cloud: a MapReduce and GPGPU Based Hybrid Approach Beniamino Di Martino, Antonio Esposito and Andrea Barbato Department of Industrial and Information Engineering Second University of Naples
High Performance Cloud: a MapReduce and GPGPU Based Hybrid Approach Beniamino Di Martino, Antonio Esposito and Andrea Barbato Department of Industrial and Information Engineering Second University of Naples
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Introduction. Reading. Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF. CMSC 818Z - S99 (lect 5)
") Introduction Reading Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF 1 Programming Assignment Notes Assume that memory is limited don t replicate the board on all nodes Need to provide load
Introduction Reading Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF 1 Programming Assignment Notes Assume that memory is limited don t replicate the board on all nodes Need to provide load
High Performance Computing. Course Notes 2007-2008. HPC Fundamentals
 High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
Introduction to Programming (in C++) Multi-dimensional vectors. Jordi Cortadella, Ricard Gavaldà, Fernando Orejas Dept. of Computer Science, UPC
 Multi-dimensional vectors. Jordi Cortadella, Ricard Gavaldà, Fernando Orejas Dept. of Computer Science, UPC") Introduction to Programming (in C++) Multi-dimensional vectors Jordi Cortadella, Ricard Gavaldà, Fernando Orejas Dept. of Computer Science, UPC Matrices A matrix can be considered a two-dimensional vector,
Introduction to Programming (in C++) Multi-dimensional vectors Jordi Cortadella, Ricard Gavaldà, Fernando Orejas Dept. of Computer Science, UPC Matrices A matrix can be considered a two-dimensional vector,
Incorporating Multicore Programming in Bachelor of Science in Computer Engineering Program
 Incorporating Multicore Programming in Bachelor of Science in Computer Engineering Program ITESO University Guadalajara, Jalisco México 1 Instituto Tecnológico y de Estudios Superiores de Occidente Jesuit
Incorporating Multicore Programming in Bachelor of Science in Computer Engineering Program ITESO University Guadalajara, Jalisco México 1 Instituto Tecnológico y de Estudios Superiores de Occidente Jesuit
University of Amsterdam - SURFsara. High Performance Computing and Big Data Course
 University of Amsterdam - SURFsara High Performance Computing and Big Data Course Workshop 7: OpenMP and MPI Assignments Clemens Grelck C.Grelck@uva.nl Roy Bakker R.Bakker@uva.nl Adam Belloum A.S.Z.Belloum@uva.nl
University of Amsterdam - SURFsara High Performance Computing and Big Data Course Workshop 7: OpenMP and MPI Assignments Clemens Grelck C.Grelck@uva.nl Roy Bakker R.Bakker@uva.nl Adam Belloum A.S.Z.Belloum@uva.nl
A Pattern-Based Approach to. Automated Application Performance Analysis
 A Pattern-Based Approach to Automated Application Performance Analysis Nikhil Bhatia, Shirley Moore, Felix Wolf, and Jack Dongarra Innovative Computing Laboratory University of Tennessee (bhatia, shirley,
A Pattern-Based Approach to Automated Application Performance Analysis Nikhil Bhatia, Shirley Moore, Felix Wolf, and Jack Dongarra Innovative Computing Laboratory University of Tennessee (bhatia, shirley,
A Comparison Of Shared Memory Parallel Programming Models. Jace A Mogill David Haglin
 A Comparison Of Shared Memory Parallel Programming Models Jace A Mogill David Haglin 1 Parallel Programming Gap Not many innovations... Memory semantics unchanged for over 50 years 2010 Multi-Core x86
A Comparison Of Shared Memory Parallel Programming Models Jace A Mogill David Haglin 1 Parallel Programming Gap Not many innovations... Memory semantics unchanged for over 50 years 2010 Multi-Core x86
A Case Study - Scaling Legacy Code on Next Generation Platforms
 Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Objectives. Overview of OpenMP. Structured blocks. Variable scope, work-sharing. Scheduling, synchronization
 OpenMP Objectives Overview of OpenMP Structured blocks Variable scope, work-sharing Scheduling, synchronization 1 Overview of OpenMP OpenMP is a collection of compiler directives and library functions
OpenMP Objectives Overview of OpenMP Structured blocks Variable scope, work-sharing Scheduling, synchronization 1 Overview of OpenMP OpenMP is a collection of compiler directives and library functions
Architecture Aware Programming on Multi-Core Systems
 Architecture Aware Programming on Multi-Core Systems M.R. Pimple Department of Computer Science & Engg. Visvesvaraya National Institute of Technology, Nagpur 440010 (India) S.R. Sathe Department of Computer
Architecture Aware Programming on Multi-Core Systems M.R. Pimple Department of Computer Science & Engg. Visvesvaraya National Institute of Technology, Nagpur 440010 (India) S.R. Sathe Department of Computer
Rule-Based Program Transformation for Hybrid Architectures CSW Workshop Towards Portable Libraries for Hybrid Systems
 Rule-Based Program Transformation for Hybrid Architectures CSW Workshop Towards Portable Libraries for Hybrid Systems M. Carro 1,2, S. Tamarit 2, G. Vigueras 1, J. Mariño 2 1 IMDEA Software Institute,
Rule-Based Program Transformation for Hybrid Architectures CSW Workshop Towards Portable Libraries for Hybrid Systems M. Carro 1,2, S. Tamarit 2, G. Vigueras 1, J. Mariño 2 1 IMDEA Software Institute,
Optimization on Huygens
 Optimization on Huygens Wim Rijks wimr@sara.nl Contents Introductory Remarks Support team Optimization strategy Amdahls law Compiler options An example Optimization Introductory Remarks Modern day supercomputers
Optimization on Huygens Wim Rijks wimr@sara.nl Contents Introductory Remarks Support team Optimization strategy Amdahls law Compiler options An example Optimization Introductory Remarks Modern day supercomputers
Software Pipelining by Modulo Scheduling. Philip Sweany University of North Texas
 Software Pipelining by Modulo Scheduling Philip Sweany University of North Texas Overview Opportunities for Loop Optimization Software Pipelining Modulo Scheduling Resource and Dependence Constraints Scheduling
Software Pipelining by Modulo Scheduling Philip Sweany University of North Texas Overview Opportunities for Loop Optimization Software Pipelining Modulo Scheduling Resource and Dependence Constraints Scheduling
Software Configuration Management AE6382
 Software Configuration Management Software Configuration Management What is it? Software Configuration Management is the process of tracking changes to software. Why use it? Maintain multiple branches
Software Configuration Management Software Configuration Management What is it? Software Configuration Management is the process of tracking changes to software. Why use it? Maintain multiple branches
Lecture 1 Introduction to Parallel Programming
 Lecture 1 Introduction to Parallel Programming EN 600.320/420 Instructor: Randal Burns 4 September 2008 Department of Computer Science, Johns Hopkins University Pipelined Processor From http://arstechnica.com/articles/paedia/cpu/pipelining-2.ars
Lecture 1 Introduction to Parallel Programming EN 600.320/420 Instructor: Randal Burns 4 September 2008 Department of Computer Science, Johns Hopkins University Pipelined Processor From http://arstechnica.com/articles/paedia/cpu/pipelining-2.ars
Getting OpenMP Up To Speed
 1 Getting OpenMP Up To Speed Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline The
1 Getting OpenMP Up To Speed Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline The
Distributed communication-aware load balancing with TreeMatch in Charm++
 Distributed communication-aware load balancing with TreeMatch in Charm++ The 9th Scheduling for Large Scale Systems Workshop, Lyon, France Emmanuel Jeannot Guillaume Mercier Francois Tessier In collaboration
Distributed communication-aware load balancing with TreeMatch in Charm++ The 9th Scheduling for Large Scale Systems Workshop, Lyon, France Emmanuel Jeannot Guillaume Mercier Francois Tessier In collaboration
Advances in Smart Systems Research : ISSN 2050-8662 : http://nimbusvault.net/publications/koala/assr/ Vol. 3. No. 3 : pp.
 Advances in Smart Systems Research : ISSN 2050-8662 : http://nimbusvault.net/publications/koala/assr/ Vol. 3. No. 3 : pp.49-54 : isrp13-005 Optimized Communications on Cloud Computer Processor by Using
Advances in Smart Systems Research : ISSN 2050-8662 : http://nimbusvault.net/publications/koala/assr/ Vol. 3. No. 3 : pp.49-54 : isrp13-005 Optimized Communications on Cloud Computer Processor by Using
Parallelization of video compressing with FFmpeg and OpenMP in supercomputing environment
 Proceedings of the 9 th International Conference on Applied Informatics Eger, Hungary, January 29 February 1, 2014. Vol. 1. pp. 231 237 doi: 10.14794/ICAI.9.2014.1.231 Parallelization of video compressing
Proceedings of the 9 th International Conference on Applied Informatics Eger, Hungary, January 29 February 1, 2014. Vol. 1. pp. 231 237 doi: 10.14794/ICAI.9.2014.1.231 Parallelization of video compressing
Parallelization: Binary Tree Traversal
 By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
OpenACC Programming on GPUs
 OpenACC Programming on GPUs Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum
OpenACC Programming on GPUs Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum
Using the Intel Inspector XE
 Using the Dirk Schmidl schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Race Condition Data Race: the typical OpenMP programming error, when: two or more threads access the same memory
Using the Dirk Schmidl schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Race Condition Data Race: the typical OpenMP programming error, when: two or more threads access the same memory
Shared Memory Abstractions for Heterogeneous Multicore Processors
 Shared Memory Abstractions for Heterogeneous Multicore Processors Scott Schneider Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment
Shared Memory Abstractions for Heterogeneous Multicore Processors Scott Schneider Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment
Intel Many Integrated Core Architecture: An Overview and Programming Models
 Intel Many Integrated Core Architecture: An Overview and Programming Models Jim Jeffers SW Product Application Engineer Technical Computing Group Agenda An Overview of Intel Many Integrated Core Architecture
Intel Many Integrated Core Architecture: An Overview and Programming Models Jim Jeffers SW Product Application Engineer Technical Computing Group Agenda An Overview of Intel Many Integrated Core Architecture
Load Balancing & DFS Primitives for Efficient Multicore Applications
 Load Balancing & DFS Primitives for Efficient Multicore Applications M. Grammatikakis, A. Papagrigoriou, P. Petrakis, G. Kornaros, I. Christophorakis TEI of Crete This work is implemented through the Operational
Load Balancing & DFS Primitives for Efficient Multicore Applications M. Grammatikakis, A. Papagrigoriou, P. Petrakis, G. Kornaros, I. Christophorakis TEI of Crete This work is implemented through the Operational
aicas Technology Multi Core und Echtzeit Böse Überraschungen vermeiden Dr. Fridtjof Siebert CTO, aicas OOP 2011, 25 th January 2011
 aicas Technology Multi Core und Echtzeit Böse Überraschungen vermeiden Dr. Fridtjof Siebert CTO, aicas OOP 2011, 25 th January 2011 2 aicas Group aicas GmbH founded in 2001 in Karlsruhe Focus: Embedded
aicas Technology Multi Core und Echtzeit Böse Überraschungen vermeiden Dr. Fridtjof Siebert CTO, aicas OOP 2011, 25 th January 2011 2 aicas Group aicas GmbH founded in 2001 in Karlsruhe Focus: Embedded
Scheduling Task Parallelism" on Multi-Socket Multicore Systems"
 Scheduling Task Parallelism" on Multi-Socket Multicore Systems" Stephen Olivier, UNC Chapel Hill Allan Porterfield, RENCI Kyle Wheeler, Sandia National Labs Jan Prins, UNC Chapel Hill Outline" Introduction
Scheduling Task Parallelism" on Multi-Socket Multicore Systems" Stephen Olivier, UNC Chapel Hill Allan Porterfield, RENCI Kyle Wheeler, Sandia National Labs Jan Prins, UNC Chapel Hill Outline" Introduction
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Multi-core Programming System Overview
 Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
An Incomplete C++ Primer. University of Wyoming MA 5310
 An Incomplete C++ Primer University of Wyoming MA 5310 Professor Craig C. Douglas http://www.mgnet.org/~douglas/classes/na-sc/notes/c++primer.pdf C++ is a legacy programming language, as is other languages
An Incomplete C++ Primer University of Wyoming MA 5310 Professor Craig C. Douglas http://www.mgnet.org/~douglas/classes/na-sc/notes/c++primer.pdf C++ is a legacy programming language, as is other languages
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters
 The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
To copy all examples and exercises to your local scratch directory type: /g/public/training/openmp/setup.sh
 OpenMP by Example To copy all examples and exercises to your local scratch directory type: /g/public/training/openmp/setup.sh To build one of the examples, type make (where is the
OpenMP by Example To copy all examples and exercises to your local scratch directory type: /g/public/training/openmp/setup.sh To build one of the examples, type make (where is the
Controlling a Dot Matrix LED Display with a Microcontroller
 Controlling a Dot Matrix LED Display with a Microcontroller By Matt Stabile and programming will be explained in general terms as well to allow for adaptation to any comparable microcontroller or LED matrix.
Controlling a Dot Matrix LED Display with a Microcontroller By Matt Stabile and programming will be explained in general terms as well to allow for adaptation to any comparable microcontroller or LED matrix.
OpenCL for programming shared memory multicore CPUs
 Akhtar Ali, Usman Dastgeer and Christoph Kessler. OpenCL on shared memory multicore CPUs. Proc. MULTIPROG-212 Workshop at HiPEAC-212, Paris, Jan. 212. OpenCL for programming shared memory multicore CPUs
Akhtar Ali, Usman Dastgeer and Christoph Kessler. OpenCL on shared memory multicore CPUs. Proc. MULTIPROG-212 Workshop at HiPEAC-212, Paris, Jan. 212. OpenCL for programming shared memory multicore CPUs
Towards OpenMP Support in LLVM
 Towards OpenMP Support in LLVM Alexey Bataev, Andrey Bokhanko, James Cownie Intel 1 Agenda What is the OpenMP * language? Who Can Benefit from the OpenMP language? OpenMP Language Support Early / Late
Towards OpenMP Support in LLVM Alexey Bataev, Andrey Bokhanko, James Cownie Intel 1 Agenda What is the OpenMP * language? Who Can Benefit from the OpenMP language? OpenMP Language Support Early / Late
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
MAQAO Performance Analysis and Optimization Tool
 MAQAO Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Evaluation Team, University of Versailles S-Q-Y http://www.maqao.org VI-HPS 18 th Grenoble 18/22
MAQAO Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Evaluation Team, University of Versailles S-Q-Y http://www.maqao.org VI-HPS 18 th Grenoble 18/22
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Lecture 3. Optimising OpenCL performance
 Lecture 3 Optimising OpenCL performance Based on material by Benedict Gaster and Lee Howes (AMD), Tim Mattson (Intel) and several others. - Page 1 Agenda Heterogeneous computing and the origins of OpenCL
Lecture 3 Optimising OpenCL performance Based on material by Benedict Gaster and Lee Howes (AMD), Tim Mattson (Intel) and several others. - Page 1 Agenda Heterogeneous computing and the origins of OpenCL
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
The Design and Implementation of Scalable Parallel Haskell
 The Design and Implementation of Scalable Parallel Haskell Malak Aljabri, Phil Trinder,and Hans-Wolfgang Loidl MMnet 13: Language and Runtime Support for Concurrent Systems Heriot Watt University May 8,
The Design and Implementation of Scalable Parallel Haskell Malak Aljabri, Phil Trinder,and Hans-Wolfgang Loidl MMnet 13: Language and Runtime Support for Concurrent Systems Heriot Watt University May 8,
IUmd. Performance Analysis of a Molecular Dynamics Code. Thomas William. Dresden, 5/27/13
 Center for Information Services and High Performance Computing (ZIH) IUmd Performance Analysis of a Molecular Dynamics Code Thomas William Dresden, 5/27/13 Overview IUmd Introduction First Look with Vampir
Center for Information Services and High Performance Computing (ZIH) IUmd Performance Analysis of a Molecular Dynamics Code Thomas William Dresden, 5/27/13 Overview IUmd Introduction First Look with Vampir
Practical Introduction to
 1 Practical Introduction to http://tinyurl.com/cq-intro-openmp-20151006 By: Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@calculquebec.ca, Bart.Oldeman@mcgill.ca Partners and Sponsors 2 3 Outline
1 Practical Introduction to http://tinyurl.com/cq-intro-openmp-20151006 By: Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@calculquebec.ca, Bart.Oldeman@mcgill.ca Partners and Sponsors 2 3 Outline
22S:295 Seminar in Applied Statistics High Performance Computing in Statistics
 22S:295 Seminar in Applied Statistics High Performance Computing in Statistics Luke Tierney Department of Statistics & Actuarial Science University of Iowa August 30, 2007 Luke Tierney (U. of Iowa) HPC
22S:295 Seminar in Applied Statistics High Performance Computing in Statistics Luke Tierney Department of Statistics & Actuarial Science University of Iowa August 30, 2007 Luke Tierney (U. of Iowa) HPC
5x in 5 hours Porting SEISMIC_CPML using the PGI Accelerator Model
 5x in 5 hours Porting SEISMIC_CPML using the PGI Accelerator Model C99, C++, F2003 Compilers Optimizing Vectorizing Parallelizing Graphical parallel tools PGDBG debugger PGPROF profiler Intel, AMD, NVIDIA
5x in 5 hours Porting SEISMIC_CPML using the PGI Accelerator Model C99, C++, F2003 Compilers Optimizing Vectorizing Parallelizing Graphical parallel tools PGDBG debugger PGPROF profiler Intel, AMD, NVIDIA
OpenMP Application Program Interface
 OpenMP Application Program Interface Version.0 - July 01 Copyright 1-01 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
OpenMP Application Program Interface Version.0 - July 01 Copyright 1-01 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
Library (versus Language) Based Parallelism in Factoring: Experiments in MPI. Dr. Michael Alexander Dr. Sonja Sewera.
 Based Parallelism in Factoring: Experiments in MPI. Dr. Michael Alexander Dr. Sonja Sewera.") Library (versus Language) Based Parallelism in Factoring: Experiments in MPI Dr. Michael Alexander Dr. Sonja Sewera Talk 2007-10-19 Slide 1 of 20 Primes Definitions Prime: A whole number n is a prime number
Library (versus Language) Based Parallelism in Factoring: Experiments in MPI Dr. Michael Alexander Dr. Sonja Sewera Talk 2007-10-19 Slide 1 of 20 Primes Definitions Prime: A whole number n is a prime number
Petascale Software Challenges. William Gropp www.cs.illinois.edu/~wgropp
 Petascale Software Challenges William Gropp www.cs.illinois.edu/~wgropp Petascale Software Challenges Why should you care? What are they? Which are different from non-petascale? What has changed since
Petascale Software Challenges William Gropp www.cs.illinois.edu/~wgropp Petascale Software Challenges Why should you care? What are they? Which are different from non-petascale? What has changed since
OpenACC Basics Directive-based GPGPU Programming
 OpenACC Basics Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum (RZ) PPCES,
OpenACC Basics Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum (RZ) PPCES,
Exascale Challenges and General Purpose Processors. Avinash Sodani, Ph.D. Chief Architect, Knights Landing Processor Intel Corporation
 Exascale Challenges and General Purpose Processors Avinash Sodani, Ph.D. Chief Architect, Knights Landing Processor Intel Corporation Jun-93 Aug-94 Oct-95 Dec-96 Feb-98 Apr-99 Jun-00 Aug-01 Oct-02 Dec-03
Exascale Challenges and General Purpose Processors Avinash Sodani, Ph.D. Chief Architect, Knights Landing Processor Intel Corporation Jun-93 Aug-94 Oct-95 Dec-96 Feb-98 Apr-99 Jun-00 Aug-01 Oct-02 Dec-03
Bringing Big Data Modelling into the Hands of Domain Experts
 Bringing Big Data Modelling into the Hands of Domain Experts David Willingham Senior Application Engineer MathWorks david.willingham@mathworks.com.au 2015 The MathWorks, Inc. 1 Data is the sword of the
Bringing Big Data Modelling into the Hands of Domain Experts David Willingham Senior Application Engineer MathWorks david.willingham@mathworks.com.au 2015 The MathWorks, Inc. 1 Data is the sword of the
Lecture 3: Evaluating Computer Architectures. Software & Hardware: The Virtuous Cycle?
 Lecture 3: Evaluating Computer Architectures Announcements - Reminder: Homework 1 due Thursday 2/2 Last Time technology back ground Computer elements Circuits and timing Virtuous cycle of the past and
Lecture 3: Evaluating Computer Architectures Announcements - Reminder: Homework 1 due Thursday 2/2 Last Time technology back ground Computer elements Circuits and timing Virtuous cycle of the past and
OpenMP Application Program Interface
 OpenMP Application Program Interface Version.1 July 0 Copyright 1-0 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
OpenMP Application Program Interface Version.1 July 0 Copyright 1-0 OpenMP Architecture Review Board. Permission to copy without fee all or part of this material is granted, provided the OpenMP Architecture
An Introduction to Parallel Programming with OpenMP
 An Introduction to Parallel Programming with OpenMP by Alina Kiessling E U N I V E R S I H T T Y O H F G R E D I N B U A Pedagogical Seminar April 2009 ii Contents 1 Parallel Programming with OpenMP 1
An Introduction to Parallel Programming with OpenMP by Alina Kiessling E U N I V E R S I H T T Y O H F G R E D I N B U A Pedagogical Seminar April 2009 ii Contents 1 Parallel Programming with OpenMP 1
Designing and Building Applications for Extreme Scale Systems CS598 William Gropp www.cs.illinois.edu/~wgropp
 Designing and Building Applications for Extreme Scale Systems CS598 William Gropp www.cs.illinois.edu/~wgropp Welcome! Who am I? William (Bill) Gropp Professor of Computer Science One of the Creators of
Designing and Building Applications for Extreme Scale Systems CS598 William Gropp www.cs.illinois.edu/~wgropp Welcome! Who am I? William (Bill) Gropp Professor of Computer Science One of the Creators of
Case Study on Productivity and Performance of GPGPUs
 Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Driving force. What future software needs. Potential research topics
 Improving Software Robustness and Efficiency Driving force Processor core clock speed reach practical limit ~4GHz (power issue) Percentage of sustainable # of active transistors decrease; Increase in #
Improving Software Robustness and Efficiency Driving force Processor core clock speed reach practical limit ~4GHz (power issue) Percentage of sustainable # of active transistors decrease; Increase in #
Parallel Computing for Data Science
 Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Universität Karlsruhe (TH)
") Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Working group meeting Software engineering for parallel systems Leipzig, Germany May 11, 2008 Dr. Victor Pankratius http://www.multicore-systems.org/separs
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Working group meeting Software engineering for parallel systems Leipzig, Germany May 11, 2008 Dr. Victor Pankratius http://www.multicore-systems.org/separs
Chapter 6: Programming Languages
 Chapter 6: Programming Languages Computer Science: An Overview Eleventh Edition by J. Glenn Brookshear Copyright 2012 Pearson Education, Inc. Chapter 6: Programming Languages 6.1 Historical Perspective
Chapter 6: Programming Languages Computer Science: An Overview Eleventh Edition by J. Glenn Brookshear Copyright 2012 Pearson Education, Inc. Chapter 6: Programming Languages 6.1 Historical Perspective
An examination of the dual-core capability of the new HP xw4300 Workstation
 An examination of the dual-core capability of the new HP xw4300 Workstation By employing single- and dual-core Intel Pentium processor technology, users have a choice of processing power options in a compact,
An examination of the dual-core capability of the new HP xw4300 Workstation By employing single- and dual-core Intel Pentium processor technology, users have a choice of processing power options in a compact,
Common Mistakes in OpenMP and How To Avoid Them
 Common Mistakes in OpenMP and How To Avoid Them A Collection of Best Practices Michael Süß and Claudia Leopold University of Kassel, Research Group Programming Languages / Methodologies, Wilhelmshöher
Common Mistakes in OpenMP and How To Avoid Them A Collection of Best Practices Michael Süß and Claudia Leopold University of Kassel, Research Group Programming Languages / Methodologies, Wilhelmshöher
OpenMP* 4.0 for HPC in a Nutshell
 OpenMP* 4.0 for HPC in a Nutshell Dr.-Ing. Michael Klemm Senior Application Engineer Software and Services Group (michael.klemm@intel.com) *Other brands and names are the property of their respective owners.
OpenMP* 4.0 for HPC in a Nutshell Dr.-Ing. Michael Klemm Senior Application Engineer Software and Services Group (michael.klemm@intel.com) *Other brands and names are the property of their respective owners.
Introduction to Hybrid Programming
 Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
A Pattern-Based Comparison of OpenACC & OpenMP for Accelerators
 A Pattern-Based Comparison of OpenACC & OpenMP for Accelerators Sandra Wienke 1,2, Christian Terboven 1,2, James C. Beyer 3, Matthias S. Müller 1,2 1 IT Center, RWTH Aachen University 2 JARA-HPC, Aachen
A Pattern-Based Comparison of OpenACC & OpenMP for Accelerators Sandra Wienke 1,2, Christian Terboven 1,2, James C. Beyer 3, Matthias S. Müller 1,2 1 IT Center, RWTH Aachen University 2 JARA-HPC, Aachen
Introduction to Multicore Programming
 Introduction to Multicore Programming Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS 4435 - CS 9624 (Moreno Maza) Introduction to Multicore Programming CS 433 - CS 9624 1 /
Introduction to Multicore Programming Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS 4435 - CS 9624 (Moreno Maza) Introduction to Multicore Programming CS 433 - CS 9624 1 /
LS-DYNA Scalability on Cray Supercomputers. Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp.
 LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
PROACTIVE BOTTLENECK PERFORMANCE ANALYSIS IN PARALLEL COMPUTING USING OPENMP
 PROACTIVE BOTTLENECK PERFORMANCE ANALYSIS IN PARALLEL COMPUTING USING OPENMP Vibha Rajput Computer Science and Engineering M.Tech.2 nd Sem (CSE) Indraprastha Engineering College. M. T.U Noida, U.P., India
PROACTIVE BOTTLENECK PERFORMANCE ANALYSIS IN PARALLEL COMPUTING USING OPENMP Vibha Rajput Computer Science and Engineering M.Tech.2 nd Sem (CSE) Indraprastha Engineering College. M. T.U Noida, U.P., India
Optimizing matrix multiplication Amitabha Banerjee abanerjee@ucdavis.edu
 Optimizing matrix multiplication Amitabha Banerjee abanerjee@ucdavis.edu Present compilers are incapable of fully harnessing the processor architecture complexity. There is a wide gap between the available
Optimizing matrix multiplication Amitabha Banerjee abanerjee@ucdavis.edu Present compilers are incapable of fully harnessing the processor architecture complexity. There is a wide gap between the available