z/os Hybrid Batch Processing and Big Data Session zba07
|
|
|
- Norman McCoy
- 8 years ago
- Views:
Transcription
1 Stephen Goetze Kirk Wolf Dovetailed Technologies, LLC z/os Hybrid Batch Processing and Big Data Session zba07 Wednesday May 14 th, :30AM Technical University/Symposia materials may not be reproduced in whole or in part without the prior written permission of IBM. 9.0

2 Trademarks Co:Z is a registered trademark of Dovetailed Technologies, LLC z/os, DB2, zenterprise and zbx are registered trademarks of IBM Corporation Oracle and Java are registered trademarks of Oracle and/or its affiliates Hadoop, HDFS, Hive, HBase and Pig are either registered trademarks or trademarks of the Apache Software Foundation Linux is a registered trademark of Linus Torvalds 2

3 Agenda Define Hybrid Batch Processing Hello World Example Security Considerations Hybrid Batch Processing and Big Data Processing z/os syslog data with Hive Processing z/os DB2 data with RHadoop Summary / Questions 3

4 zenterprise Hybrid Computing Models Well Known: zbx/zlinux as user-facing edge, web and application servers z/os provides back-end databases and transaction processing zbx as special purpose appliances or optimizers DB2 Analytics Accelerator DataPower Another Model: z/os Hybrid Batch zbx/zlinux/linux/windows integrated with z/os batch 6

5 z/os Hybrid Batch Processing 1. The ability to execute a program or script on a virtual server from a z/os batch job step 2. The target program may already exist and should require little or no modification 3. The target program s input and output are redirected from/to z/os spool files or datasets 4. The target program may easily access other z/os resources: DDs, data sets, POSIX files and programs 5. The target program s exit code is adopted as the z/os job step condition code Data security governed by SAF (RACF/ACF2/TSS) Requires new enablement software 7

6 Co:Z Co-Processing Toolkit Implements z/os Hybrid Batch model Co:Z Launcher starts a program on a target server and automatically redirects the standard streams back to jobstep DDs The target program can use Co:Z DatasetPipes commands to reach back into the active jobstep and access z/os resources: fromdsn/todsn read/write a z/os DD or data set fromfile/tofile read/write a z/os Unix file cozclient run z/os Unix command Free (commercial support licenses are available) Visit for details 8
 Visit")

7 Co:Z Hybrid Batch Processing 9
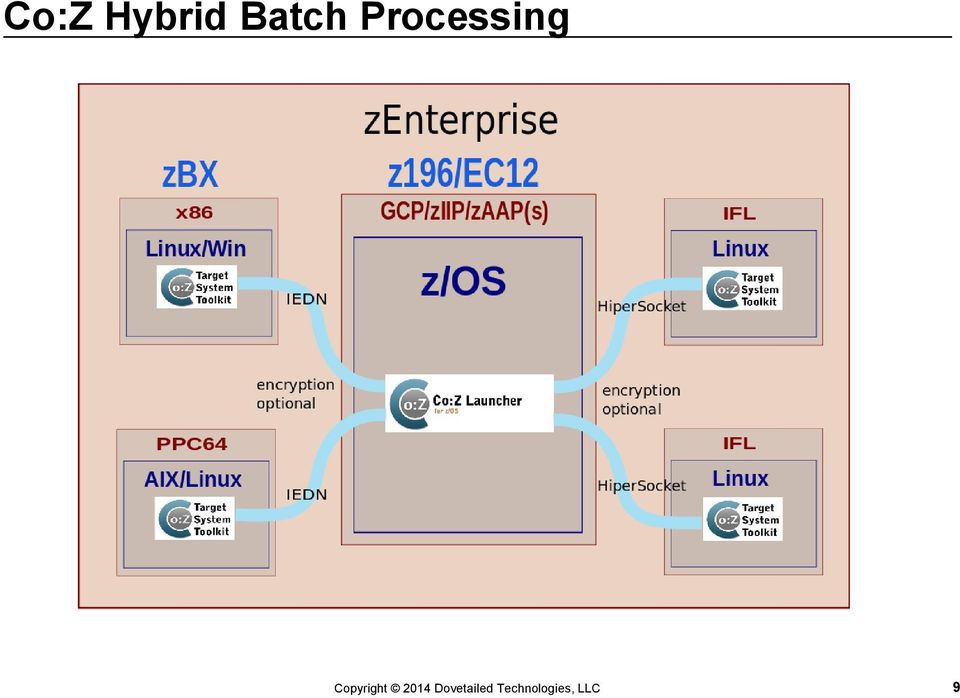

8 Co:Z Hybrid Batch Processing 10

9 Hybrid Batch Hello World Simple example illustrating the principles of Hybrid Batch Processing Launch a process on a remote Linux server Write a message to stdout In a pipeline: Read the contents of a dataset from a jobstep DD Compress the contents using the Linux gzip command Write the compressed data to the z/os Unix file system Exit with a return code that sets the jobstep CC 11

10 Linux echo Hello $(uname)! fromdsn b DD:INPUT 2 gzip c tofile b /tmp/out.gz exit z/os //HYBRIDZ JOB () //RUN EXEC PROC=COZPROC, // ARGS='u@linux' //COZLOG DD SYSOUT=* //STDOUT DD SYSOUT=* //INPUT DD DSN=MY.DATA //STDIN DD * 4 // RC = /tmp/out.gz 13

11 Hello World: Hybrid Batch 1. A script is executed on a virtual server from a z/os batch job step 2. The script uses a program that already exists -- gzip 3. Script output is redirected to z/os spool 4. z/os resources are easily accessed using fromdsn, tofile, etc 5. The script exit code is adopted as the z/os job step CC 14

12 Hello World DD:STDOUT Hello Linux! 15

13 Hello World DD:COZLOG CoZLauncher[N]: version: cozagent[n]: version: fromdsn(dd:stdin)[n]: 5 records/400 bytes read fromdsn(dd:input)[n]: 78 records/6240 bytes read tofile(/tmp/out.gz)[n]: 1419 bytes written todsn(dd:stdout)[n]: 13 bytes written todsn(dd:stderr)[n]: 0 bytes written CoZLauncher[E]: u@linux target ended with RC=4 16
![cozagent[n]: version: 1.](/docs-images/43/9291054/images/page_13.jpg "1.0 2012-03-16 fromdsn(dd:stdin)[n]: 5 records/400 bytes read fromdsn(dd:input)[n]: 78")
14 Hello World DD:JESMSGLG JOB FRIDAY, 7 SEPT JOB01515 IRR010I USERID GOETZE IS ASSIG JOB01515 ICH70001I GOETZE LAST ACCESS AT JOB01515 $HASP373 HYBRIDZ STARTED INIT JOB JOB STEPNAME PROCSTEP RC EXCP JOB RUN COZLNCH JOB HYBRIDZ ENDED. NAME- JOB01515 $HASP395 HYBRIDZ ENDED 17

15 Co:Z Hybrid Batch Network Security is Trusted OpenSSH is used for network security IBM Ported Tools OpenSSH client on z/os OpenSSH sshd on target system By default, data transfer is tunneled (encrypted) over the ssh connection Optionally, data can be transferred over raw sockets (option: sshtunnel=false) This offers very high performance without encryption costs Ideal for a secure network, such as zenterprise HiperSockets or IEDN 18

16 Co:Z Hybrid Batch Data Security is z/os Centric All z/os resource access is through the job step: Controlled by SAF (RACF/ACF2/TSS) Normal user privileges Storing remote user credentials in SAF digital certificates can extend the reach of the z/os security envelope to the target system Shared certificate access enables multiple authorized z/os users to use a single target system id Dataset Pipes streaming technology can be used to reduce data at rest 19

17 Data in Flight Example //APPINT JOB (),'COZ',MSGCLASS=H,NOTIFY=&SYSUID //CUSTDATA EXEC PGM=CUSTCOB //OUTDD DD DSN=&&DATA,DISP=(NEW,PASS), // UNIT=SYSDA,SPACE=(CYL,(20,20)) //COZLOAD EXEC //CUSTCTL DD DSN=HLQ.CUST.CTL,DISP=SHR //CUSTDATA DD DSN=&&DATA,DISP=(OLD,DELETE) //CUSTLOG DD SYSOUT=* //PARMS DD DSN=HLQ.ORACLE.PARMS,DISP=SHR //STDIN DD * sqlldr control=<(fromdsn DD://CUSTCTL), \ data=<(fromdsn DD://CUSTDATA), \ parfile=<(fromdsn DD://PARMS), \ log=>(todsn DD://CUSTLOG) 20
, \ data=<(fromdsn DD://CUSTDATA), \ parfile=<(fromdsn")
18 z/os //APPINT JOB (),'COZ',MSGCLASS=H,NOTIFY=&SYSUID //CUSTDATA EXEC PGM=CUSTCOB //OUTDD DD DSN=&&DATA,DISP=(NEW,PASS), // UNIT=SYSDA,SPACE=(CYL,(20,20)) //COZLOAD EXEC //PARMS DD DSN=HLQ.ORACLE.PARMS,DISP=SHR //CUSTDATA DD DSN=&&DATA,DISP=(OLD,DELETE) //CUSTCTL DD DSN=HLQ.CUST.CTL,DISP=SHR //CUSTLOG DD SYSOUT=* //STDIN DD * Linux on z / zbx sqlldr control=<(fromdsn DD://CUSTCTL), \ data=<(fromdsn DD://CUSTDATA), \ parfile=<(fromdsn DD://PARMS), \ log=>(todsn DD://CUSTLOG) <( ) >( ) -- bash process substitution 21
 //CUSTC")
19 Data In Flight Summary sqlldr exit code seamlessly becomes jobstep CC Concurrent transfer and loading: No data at rest! Facilitated via process substitution High performance Operations can observe real-time job output in the JES spool Credentials are restricted by SAF data set controls 22

20 Big Data and z/os z/os systems often have the Big Data we want to analyze Very large DB2 instances Very large Data sets But, the Hadoop ecosystem is not well suited to z/os Designed for a cluster of many small relatively inexpensive computers Although Hadoop is Java centric, several tools (e.g. R) don t run on z/os z/os compute and storage costs are high Hybrid Batch Processing offers a solution Single SAF profile for a security envelope extending to the BigData environment Exploitation of high speed network links (HiperSockets, IEDN) z/os centric operational control 23
 don t run on z/os z/os compute and storage costs are high Hybrid Batch Processing offers a solution Single SAF profile for a security")
21 Co:Z Toolkit and Big Data The Co:Z Launcher and Dataset Pipes utilities facilitate: Loading HDFS with z/os data DB2 VSAM, Sequential Data sets Unix System Services POSIX files Map Reduce Analysis Drive Hive, Pig, RHadoop, etc with scripts maintained on z/os Monitor progress in the job log Move results to z/os Job spool DB2 Data sets POSIX files 24
22 Processing z/os syslog data with Hive Connect z/os Unix System Services file system syslog data and Hadoop Illustrate hybrid batch use of common Big Data tools: hadoop fs load Hadoop HDFS Hive run Map/Reduce with an SQL like table definition and query 25
23 Processing z/os syslog data with Hive //COZUSERH JOB (), COZ',MSGCLASS=H,NOTIFY=&SYSUID //RUNCOZ EXEC PROC=COZPROC,ARGS='-LI //COZCFG DD * saf-cert=ssh-ring:rsa-cert ssh-tunnel=false //HIVEIN DD DISP=SHR,DSN=COZUSER.HIVE.SCRIPTS(SYSLOG) //STDIN DD * fromfile /var/log/auth.log hadoop fs -put - /logs/auth.log hive -f <(fromdsn DD:HIVEIN) z/os linux /var/log/auth.log fromfile hadoop fs -put HDFS: /logs/auth.log 27
24 Processing z/os syslog data with Hive //COZUSERH JOB (), COZ',MSGCLASS=H,NOTIFY=&SYSUID //RUNCOZ EXEC PROC=COZPROC,ARGS='-LI //COZCFG DD * saf-cert=ssh-ring:rsa-cert ssh-tunnel=false //HIVEIN DD DISP=SHR,DSN=COZUSER.HIVE.SCRIPTS(SYSLOG) //STDIN DD * fromfile /var/log/auth.log hadoop fs -put - /logs/auth.log hive -f <(fromdsn DD:HIVEIN) z/os linux hive f <(fromdsn ) DD:HIVEIN CREATE TABLE 28
25 //HIVEIN DD DISP=SHR,DSN=COZUSER.HIVE.SCRIPTS(SYSLOG) CREATE TABLE IF NOT EXISTS syslogdata ( month STRING, day STRING, time STRING, host STRING, event STRING, msg STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.regexserde' WITH SERDEPROPERTIES ("input.regex" = "(\\w+)\\s+(\\d+)\\s+(\\d+:\\d+:\\d+)\\s+(\\w+\\w*\\w*)\\s+(.*?\\:)\\s+(.*$) ) STORED AS TEXTFILE LOCATION '/logs'; HDFS: /logs Oct 13 21:12:22 S0W1 sshd[65575]: Failed password for invalid user root Oct 13 21:12:21 S0W1 sshd[65575]: subsystem request for sftp Oct 13 21:12:22 S0W1 sshd[65575]: Failed password for invalid user nagios Oct 13 21:12:21 S0W1 sshd[65575]: Accepted publickey for goetze Oct 13 21:12:22 S0W1 sshd[65575]: Port of Entry information retained for 30
26 //HIVEIN DD DISP=SHR,DSN=COZUSER.HIVE.SCRIPTS(SYSLOG) CREATE TABLE IF NOT EXISTS syslogdata ( month STRING, day STRING, time STRING, host STRING, event STRING, msg STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.regexserde' WITH SERDEPROPERTIES ("input.regex" = "(\\w+)\\s+(\\d+)\\s+(\\d+:\\d+:\\d+)\\s+(\\w+\\w*\\w*)\\s+(.*?\\:)\\s+(.*$) ) STORED AS TEXTFILE LOCATION '/logs'; SELECT split(msg, ' ')[5] username, count(*) num FROM syslogdata WHERE msg LIKE 'Failed password for invalid user%' GROUP BY split(msg, ' ')[5] ORDER BY num desc,username; Failed password for invalid user root... Failed password for invalid user nagios
27 Hive Log Output By default, Hive writes its log to the stderr file descriptor on the target system Co:Z automatically redirects back to the job spool DD:STDERR Time taken: seconds Total MapReduce jobs = 2 Launching Job 1 out of 2 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: :33:55,847 Stage-1 map = 0%, reduce = 0% :36:49,447 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 6.89 sec 32
28 Hive Query Output By default, Hive writes its output to the stdout file descriptor on the target system Co:Z automatically redirects back to the job spool DD:STDOUT root admin 1511 www 315 nagios 240 test 226 oracle 191 Easily expands to process large numbers/types of log files incrementally stored in HDFS 33
29 Processing z/os DB2 data with RHadoop z/os DB2 High Performance Unload (HPU) Provides (among other things) rapid unload of table spaces Table space data can be accessed from target system with Co:Z cozclient dataset pipes command inzutilb HPU wrapper Enable data in flight from z/os DB2 to Big Data environments R and Hadoop have a natural affinity RHadoop developed by RevolutionAnalytics Apache 2 License Packages include rmr, rhdfs, rhbase 34
30 Processing z/os DB2 data with RHadoop //CZUSERR JOB (), COZ',MSGCLASS=H,NOTIFY=&SYSUID,CLASS=A //RUNCOZ EXEC PROC=COZPROC,ARGS= //COZCFG DD * saf-cert=ssh-ring:rsa-cert ssh-tunnel=false //STDIN DD * hadoop fs -rmr /user/rhadoop hadoop fs -mkdir /user/rhadoop/in hadoop fs -mkdir /user/rhadoop/out fromdsn //DD:HPUIN cozclient -ib inzutilb.sh 'DBAG,HPU' hadoop fs -put - /user/rhadoop/in/clicks.csv Rscript <(fromdsn DD:RSCRIPT) hadoop fs -cat /user/rhadoop/out/* todsn DD:RRESULT /* //RSCRIPT DD DISP=SHR,DSN=COZUSER.RHADOOP(CLICKS) //RRESULT DD SYSOUT=* //HPUIN DD * 35
31 Dataset Pipes cozclient command and INZUTILB The cozclient command can be used by the target script to run a z/os Unix System Services command Output is piped back the target script fromdsn //DD:HPUIN cozclient -ib inzutilb.sh 'DBAG,HPU' cozclient reads its input from stdin (piped from DD:/HPUIN) inzutilb.sh is a wrapper for the DB2 HPU utility (INZUTILB) Runs authorized on z/os Dynamically allocates HPU DDs SYSIN : stdin SYSREC1 : stdout SYSPRINT : stderr 36
32 DB2 HPU fromdsn //DD:HPUIN cozclient -ib inzutilb.sh 'DBAG,HPU' hadoop fs -put - /user/rhadoop/in/clicks.csv //HPUIN DD * UNLOAD TABLESPACE DB2 FORCE LOCK NO SELECT COUNTRY,TS,COUNT(*) FROM DOVET.CLICKS GROUP BY COUNTRY,TS OUTDDN SYSREC1 FORMAT DELIMITED SEP ',' DELIM '"' EBCDIC ts ip url swid city country state {7A homestead usa fl {6E perth aus wa {92 guaynabo pri na HPU aus", , 2 aus", , 27 38
33 DB2 HPU fromdsn //DD:HPUIN cozclient -ib inzutilb.sh 'DBAG,HPU' hadoop fs -put - /user/rhadoop/in/clicks.csv //HPUIN DD * UNLOAD TABLESPACE DB2 FORCE LOCK NO SELECT COUNTRY,TS,COUNT(*) FROM DOVET.CLICKS GROUP BY COUNTRY,TS OUTDDN SYSREC1 FORMAT DELIMITED SEP ',' DELIM '"' EBCDIC z/os aus", , 2 aus", , 27 piped from z/os linux /user/hadoop/in/clicks 39
34 DB2 HPU Status - DD:COZLOG CoZLauncher[N]: version: cozagent[n]: version: fromdsn(dd:stdin)[n]: 8 records/640 bytes read; 299 bytes written fromdsn(dd:hpuin)[n]: 7 records/560 bytes read; 172 bytes written 1INZU224I IBM DB2 HIGH PERFORMANCE UNLOAD V4.1 INZU219I PTFLEVEL=PM98396-Z499 INZI175I PROCESSING SYSIN AS EBCDIC UNLOAD TABLESPACE DB2 FORCE LOCK NO SELECT COUNTRY, TS, COUNT(*) FROM DOVETAIL.CLICKS GROUP BY COUNTRY, TS OUTDDN SYSREC FORMAT DELIMITED SEP ',' DELIM '"' EBCDIC INZI020I DB2 SUB SYSTEM DBAG DATASHARING GROUP DBAG DB2 VERSION 1010 NFM... 40
35 RHadoop //CZUSERR JOB (), COZ',MSGCLASS=H,NOTIFY=&SYSUID,CLASS=A //RUNCOZ EXEC PROC=COZPROC,ARGS= //STDIN DD * Rscript <(fromdsn DD:RSCRIPT) //RSCRIPT DD DISP=SHR,DSN=COZUSER.RHADOOP(CLICKS) /user/rhadoop/in map reduce (predict) /user/rhadoop/out 41
36 DD:RSCRIPT - Mapper #Modified from Hortonworks example library(rmr2) insertrow <- function(target.dataframe, new.day) { new.row <- c(new.day, 0) target.dataframe <- rbind(target.dataframe,new.row) target.dataframe <- target.dataframe[order(c(1:(nrow(target.dataframe)-1), new.day-0.5)),] row.names(target.dataframe) <- 1:nrow(target.dataframe) return(target.dataframe) } mapper = function(null, line) { keyval(line[[1]], paste(line[[1]],line[[2]],line[[3]],sep=",")) } 42
37 DD:RSCRIPT - Reducer reducer = function(key, val.list) { if( length(val.list) < 10 ) return() list <- list() country <- unlist(strsplit(val.list[[1]], ","))[[1]] for(line in val.list) { l <- unlist(strsplit(line, split=",")) x <- list(as.posixlt(as.date(l[[2]]))$mday, l[[3]]) list[[length(list)+1]] <- x } list <- lapply(list, as.numeric) frame <- do.call(rbind, list) colnames(frame) <- c("day","clickscount") i = 1 while(i < 16) { if(i <= nrow(frame)) curday <- frame[i, "day"] if( curday!= i ) frame <- insertrow(frame, i) i <- i+1 } model <- lm(clickscount ~ day, data=as.data.frame(frame)) p <- predict(model, data.frame(day=16)) keyval(country, p) } 43
38 DD:RSCRIPT - mapreduce mapreduce( input="/user/rhadoop/in", input.format=make.input.format("csv", sep = ","), output="/user/rhadoop/out", output.format="csv", map=mapper, reduce=reducer ) 44
39 DB2 Rhadoop Status - DD:STDERR 14/04/23 13:39:45 INFO mapreduce.job: map 100% reduce 100% 14/04/23 13:39:46 INFO mapreduce.job: Job job_ _0064 completed successfully 14/04/23 13:39:46 INFO mapreduce.job: Counters: 44 File System Counters FILE: Number of bytes read= Job Counters Launched map tasks=2... Map-Reduce Framework Map input records=79... Shuffle Errors BAD_ID=0... rmr reduce calls=21 14/04/23 13:39:46 INFO streaming.streamjob: Output directory: /user/rhadoop/out 45
40 Processing z/os DB2 data with RHadoop //CZUSERR JOB (), COZ',MSGCLASS=H,NOTIFY=&SYSUID,CLASS=A //RUNCOZ EXEC PROC=COZPROC,ARGS= hadoop fs -rmr /user/rhadoop hadoop fs -mkdir /user/rhadoop/in hadoop fs -mkdir /user/rhadoop/out fromdsn //DD:HPUIN cozclient -ib inzutilb.sh 'DBAG,HPU' hadoop fs -put - /user/rhadoop/in/clicks.csv Rscript <(fromdsn DD:RSCRIPT) hadoop fs -cat /user/rhadoop/out/* todsn DD:RRESULT //RRESULT DD SYSOUT=* "usa" " " "pri" " " 46
41 Processing z/os DB2 data with RHadoop Hybrid Batch Principles revisited: 1. R analysis executed on a virtual server from a z/os batch job step 2. Uses existing programs Rscript,hadoop fs 3. Output is redirected to z/os spool 4. DB2 HPU data easily accessed via z/os resources are accessed via cozclient 5. The script exit code is adopted as the z/os job step CC Big Data Opportunities: Incremental growth in Hadoop zbx/puredata systems are relatively inexpensive All processing stays within the z/os security envelope Facilitates R analysis of DB2 data over time Opens up new analysis insights without affecting production systems 47
42 Summary zenterprise / zbx Provides hybrid computing environment Co:Z Launcher and Target System Toolkit Provides framework for hybrid batch processing Co:Z Hybrid Batch enables BigData with z/os High speed data movement SAF security dictates access to z/os resources and can be used to control access to target (BigData) systems z/os retains operational control Website: info@dovetail.com 48

43 Growing your IBM skills a new model for training Global Skills Initiative Meet the authorized IBM Global Training Providers in the Edge Solution Showcase Access to training in more cities local to you, where and when you need it, and in the format you want Use IBM Training Search to locate training classes near to you Demanding a high standard of quality / see the paths to success Learn about the New IBM Training Model and see how IBM is driving quality Check Training Paths and Certifications to find the course that is right for you Academic Initiative works with colleges and universities to introduce real-world technology into the classroom, giving students the hands-on experience valued by employers in today s marketplace 49
z/os Hybrid Batch Processing and Big Data
 z/os Hybrid Batch Processing and Big Data Stephen Goetze Kirk Wolf Dovetailed Technologies, LLC Thursday, August 7, 2014: 1:30 PM-2:30 PM Session 15496 Insert Custom Session QR if Desired. www.dovetail.com
z/os Hybrid Batch Processing and Big Data Stephen Goetze Kirk Wolf Dovetailed Technologies, LLC Thursday, August 7, 2014: 1:30 PM-2:30 PM Session 15496 Insert Custom Session QR if Desired. www.dovetail.com
Using z/os to Access a Public Cloud - Beyond the Hand-Waving
 Using z/os to Access a Public Cloud - Beyond the Hand-Waving Stephen Goetze Kirk Wolf Dovetailed Technologies, LLC Thursday, March 5, 2015: 8:30AM 9:30 AM Session 16785 Trademarks Co:Z is a registered
Using z/os to Access a Public Cloud - Beyond the Hand-Waving Stephen Goetze Kirk Wolf Dovetailed Technologies, LLC Thursday, March 5, 2015: 8:30AM 9:30 AM Session 16785 Trademarks Co:Z is a registered
How To Run A Hybrid Batch Processing Job On An Z/Os V1.13 V1 (V1) V1-R13 (V2) V2.1 (R13) V3.1.1
 V1-R13 (V2) V2.1 (R13) V3.1.1") Co:Z Load Balancer on the zenterprise June 22, 2012 http://dovetail.com info@dovetail.com Copyright 2012 Dovetailed Technologies, LLC Slide 1 Agenda zenterprise Environment Hybrid Batch Processing Overview
Co:Z Load Balancer on the zenterprise June 22, 2012 http://dovetail.com info@dovetail.com Copyright 2012 Dovetailed Technologies, LLC Slide 1 Agenda zenterprise Environment Hybrid Batch Processing Overview
Using SFTP on the z/os Platform
 Using SFTP on the z/os Platform Thursday, December 10 th 2009 Steve Goetze Kirk Wolf http://dovetail.com info@dovetail.com Copyright 2009, Dovetailed Technologies Slide 1 Dovetailed Technologies Our operating
Using SFTP on the z/os Platform Thursday, December 10 th 2009 Steve Goetze Kirk Wolf http://dovetail.com info@dovetail.com Copyright 2009, Dovetailed Technologies Slide 1 Dovetailed Technologies Our operating
RHadoop Installation Guide for Red Hat Enterprise Linux
 RHadoop Installation Guide for Red Hat Enterprise Linux Version 2.0.2 Update 2 Revolution R, Revolution R Enterprise, and Revolution Analytics are trademarks of Revolution Analytics. All other trademarks
RHadoop Installation Guide for Red Hat Enterprise Linux Version 2.0.2 Update 2 Revolution R, Revolution R Enterprise, and Revolution Analytics are trademarks of Revolution Analytics. All other trademarks
Configuring and Tuning SSH/SFTP on z/os
 Configuring and Tuning SSH/SFTP on z/os Kirk Wolf / Steve Goetze Dovetailed Technologies info@dovetail.com dovetail.com Monday, March 10, 2014, 1:30PM Session: 14787 www.share.org Session Info/Eval link
Configuring and Tuning SSH/SFTP on z/os Kirk Wolf / Steve Goetze Dovetailed Technologies info@dovetail.com dovetail.com Monday, March 10, 2014, 1:30PM Session: 14787 www.share.org Session Info/Eval link
Big Data Too Big To Ignore
 Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig
 BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig Contents Acknowledgements... 1 Introduction to Hive and Pig... 2 Setup... 2 Exercise 1 Load Avro data into HDFS... 2 Exercise 2 Define an
BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig Contents Acknowledgements... 1 Introduction to Hive and Pig... 2 Setup... 2 Exercise 1 Load Avro data into HDFS... 2 Exercise 2 Define an
HDFS. Hadoop Distributed File System
 HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
RHadoop and MapR. Accessing Enterprise- Grade Hadoop from R. Version 2.0 (14.March.2014)
") RHadoop and MapR Accessing Enterprise- Grade Hadoop from R Version 2.0 (14.March.2014) Table of Contents Introduction... 3 Environment... 3 R... 3 Special Installation Notes... 4 Install R... 5 Install
RHadoop and MapR Accessing Enterprise- Grade Hadoop from R Version 2.0 (14.March.2014) Table of Contents Introduction... 3 Environment... 3 R... 3 Special Installation Notes... 4 Install R... 5 Install
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Red Hat Enterprise Linux OpenStack Platform 7 OpenStack Data Processing
 Red Hat Enterprise Linux OpenStack Platform 7 OpenStack Data Processing Manually provisioning and scaling Hadoop clusters in Red Hat OpenStack OpenStack Documentation Team Red Hat Enterprise Linux OpenStack
Red Hat Enterprise Linux OpenStack Platform 7 OpenStack Data Processing Manually provisioning and scaling Hadoop clusters in Red Hat OpenStack OpenStack Documentation Team Red Hat Enterprise Linux OpenStack
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS)
") Use Data from a Hadoop Cluster with Oracle Database Hands-On Lab Lab Structure Acronyms: OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS) All files are
Use Data from a Hadoop Cluster with Oracle Database Hands-On Lab Lab Structure Acronyms: OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS) All files are
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
CA Workload Automation Agent for Databases
 CA Workload Automation Agent for Databases Implementation Guide r11.3.4 This Documentation, which includes embedded help systems and electronically distributed materials, (hereinafter referred to as the
CA Workload Automation Agent for Databases Implementation Guide r11.3.4 This Documentation, which includes embedded help systems and electronically distributed materials, (hereinafter referred to as the
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
INTEGRATING R AND HADOOP FOR BIG DATA ANALYSIS
 INTEGRATING R AND HADOOP FOR BIG DATA ANALYSIS Bogdan Oancea "Nicolae Titulescu" University of Bucharest Raluca Mariana Dragoescu The Bucharest University of Economic Studies, BIG DATA The term big data
INTEGRATING R AND HADOOP FOR BIG DATA ANALYSIS Bogdan Oancea "Nicolae Titulescu" University of Bucharest Raluca Mariana Dragoescu The Bucharest University of Economic Studies, BIG DATA The term big data
Using The Hortonworks Virtual Sandbox
 Using The Hortonworks Virtual Sandbox Powered By Apache Hadoop This work by Hortonworks, Inc. is licensed under a Creative Commons Attribution- ShareAlike3.0 Unported License. Legal Notice Copyright 2012
Using The Hortonworks Virtual Sandbox Powered By Apache Hadoop This work by Hortonworks, Inc. is licensed under a Creative Commons Attribution- ShareAlike3.0 Unported License. Legal Notice Copyright 2012
Teradata Connector for Hadoop Tutorial
 Teradata Connector for Hadoop Tutorial Version: 1.0 April 2013 Page 1 Teradata Connector for Hadoop Tutorial v1.0 Copyright 2013 Teradata All rights reserved Table of Contents 1 Introduction... 5 1.1 Overview...
Teradata Connector for Hadoop Tutorial Version: 1.0 April 2013 Page 1 Teradata Connector for Hadoop Tutorial v1.0 Copyright 2013 Teradata All rights reserved Table of Contents 1 Introduction... 5 1.1 Overview...
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Cross Platform Performance Monitoring with RMF XP
 Cross Platform Performance Monitoring with RMF XP Harald Bender bhbe@de.ibm.com 3/14/2012 2012 IBM Corporation IBM Corporation 2007 2007 IBM System z Expo The new Component: RMF XP RMF XP is the solution
Cross Platform Performance Monitoring with RMF XP Harald Bender bhbe@de.ibm.com 3/14/2012 2012 IBM Corporation IBM Corporation 2007 2007 IBM System z Expo The new Component: RMF XP RMF XP is the solution
Leveraging SAP HANA & Hortonworks Data Platform to analyze Wikipedia Page Hit Data
 Leveraging SAP HANA & Hortonworks Data Platform to analyze Wikipedia Page Hit Data 1 Introduction SAP HANA is the leading OLTP and OLAP platform delivering instant access and critical business insight
Leveraging SAP HANA & Hortonworks Data Platform to analyze Wikipedia Page Hit Data 1 Introduction SAP HANA is the leading OLTP and OLAP platform delivering instant access and critical business insight
A Study of Data Management Technology for Handling Big Data
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 9, September 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 9, September 2014,
Co:Z SFTP - User's Guide
 Co:Z Co-Processing Toolkit for z/os Co:Z SFTP - User's Guide V 3.6.3 Edition Published May, 2016 Copyright 2016 Dovetailed Technologies, LLC Table of Contents 1. Introduction... 1 1.1. Features... 1 1.2.
Co:Z Co-Processing Toolkit for z/os Co:Z SFTP - User's Guide V 3.6.3 Edition Published May, 2016 Copyright 2016 Dovetailed Technologies, LLC Table of Contents 1. Introduction... 1 1.1. Features... 1 1.2.
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Constructing a Data Lake: Hadoop and Oracle Database United!
 Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Volume SYSLOG JUNCTION. User s Guide. User s Guide
 Volume 1 SYSLOG JUNCTION User s Guide User s Guide SYSLOG JUNCTION USER S GUIDE Introduction I n simple terms, Syslog junction is a log viewer with graphing capabilities. It can receive syslog messages
Volume 1 SYSLOG JUNCTION User s Guide User s Guide SYSLOG JUNCTION USER S GUIDE Introduction I n simple terms, Syslog junction is a log viewer with graphing capabilities. It can receive syslog messages
SAS 9.4 In-Database Products
 SAS 9.4 In-Database Products Administrator s Guide Fifth Edition SAS Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2015. SAS 9.4 In-Database Products:
SAS 9.4 In-Database Products Administrator s Guide Fifth Edition SAS Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2015. SAS 9.4 In-Database Products:
Data Domain Profiling and Data Masking for Hadoop
 Data Domain Profiling and Data Masking for Hadoop 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or
Data Domain Profiling and Data Masking for Hadoop 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or
Hadoop Hands-On Exercises
 Hadoop Hands-On Exercises Lawrence Berkeley National Lab Oct 2011 We will Training accounts/user Agreement forms Test access to carver HDFS commands Monitoring Run the word count example Simple streaming
Hadoop Hands-On Exercises Lawrence Berkeley National Lab Oct 2011 We will Training accounts/user Agreement forms Test access to carver HDFS commands Monitoring Run the word count example Simple streaming
Java on z/os. Agenda. Java runtime environments on z/os. Java SDK 5 and 6. Java System Resource Integration. Java Backend Integration
 Martina Schmidt martina.schmidt@de.ibm.com Agenda Java runtime environments on z/os Java SDK 5 and 6 Java System Resource Integration Java Backend Integration Java development for z/os 4 1 Java runtime
Martina Schmidt martina.schmidt@de.ibm.com Agenda Java runtime environments on z/os Java SDK 5 and 6 Java System Resource Integration Java Backend Integration Java development for z/os 4 1 Java runtime
MarkLogic Server. MarkLogic Connector for Hadoop Developer s Guide. MarkLogic 8 February, 2015
 MarkLogic Connector for Hadoop Developer s Guide 1 MarkLogic 8 February, 2015 Last Revised: 8.0-3, June, 2015 Copyright 2015 MarkLogic Corporation. All rights reserved. Table of Contents Table of Contents
MarkLogic Connector for Hadoop Developer s Guide 1 MarkLogic 8 February, 2015 Last Revised: 8.0-3, June, 2015 Copyright 2015 MarkLogic Corporation. All rights reserved. Table of Contents Table of Contents
ITG Software Engineering
 Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
BIG DATA HADOOP TRAINING
 BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
TP1: Getting Started with Hadoop
 TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
Extended Attributes and Transparent Encryption in Apache Hadoop
 Extended Attributes and Transparent Encryption in Apache Hadoop Uma Maheswara Rao G Yi Liu ( 刘 轶 ) Who we are? Uma Maheswara Rao G - umamahesh@apache.org - Software Engineer at Intel - PMC/committer, Apache
Extended Attributes and Transparent Encryption in Apache Hadoop Uma Maheswara Rao G Yi Liu ( 刘 轶 ) Who we are? Uma Maheswara Rao G - umamahesh@apache.org - Software Engineer at Intel - PMC/committer, Apache
Control-M for Hadoop. Technical Bulletin. www.bmc.com
 Technical Bulletin Control-M for Hadoop Version 8.0.00 September 30, 2014 Tracking number: PACBD.8.0.00.004 BMC Software is announcing that Control-M for Hadoop now supports the following: Secured Hadoop
Technical Bulletin Control-M for Hadoop Version 8.0.00 September 30, 2014 Tracking number: PACBD.8.0.00.004 BMC Software is announcing that Control-M for Hadoop now supports the following: Secured Hadoop
Using Symantec NetBackup with Symantec Security Information Manager 4.5
 Using Symantec NetBackup with Symantec Security Information Manager 4.5 Using Symantec NetBackup with Symantec Security Information Manager Legal Notice Copyright 2007 Symantec Corporation. All rights
Using Symantec NetBackup with Symantec Security Information Manager 4.5 Using Symantec NetBackup with Symantec Security Information Manager Legal Notice Copyright 2007 Symantec Corporation. All rights
Extreme Computing. Hadoop. Stratis Viglas. School of Informatics University of Edinburgh sviglas@inf.ed.ac.uk. Stratis Viglas Extreme Computing 1
 Extreme Computing Hadoop Stratis Viglas School of Informatics University of Edinburgh sviglas@inf.ed.ac.uk Stratis Viglas Extreme Computing 1 Hadoop Overview Examples Environment Stratis Viglas Extreme
Extreme Computing Hadoop Stratis Viglas School of Informatics University of Edinburgh sviglas@inf.ed.ac.uk Stratis Viglas Extreme Computing 1 Hadoop Overview Examples Environment Stratis Viglas Extreme
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
Hadoop Basics with InfoSphere BigInsights
 An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Part: 1 Exploring Hadoop Distributed File System An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government
An IBM Proof of Technology Hadoop Basics with InfoSphere BigInsights Part: 1 Exploring Hadoop Distributed File System An IBM Proof of Technology Catalog Number Copyright IBM Corporation, 2013 US Government
Important Notice. (c) 2010-2013 Cloudera, Inc. All rights reserved.
 2010-2013 Cloudera, Inc. All rights reserved.") Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Big Data, beating the Skills Gap Using R with Hadoop
 Big Data, beating the Skills Gap Using R with Hadoop Using R with Hadoop There are a number of R packages available that can interact with Hadoop, including: hive - Not to be confused with Apache Hive,
Big Data, beating the Skills Gap Using R with Hadoop Using R with Hadoop There are a number of R packages available that can interact with Hadoop, including: hive - Not to be confused with Apache Hive,
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
COSC 6397 Big Data Analytics. 2 nd homework assignment Pig and Hive. Edgar Gabriel Spring 2015
 COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
Apache Sqoop. A Data Transfer Tool for Hadoop
 Apache Sqoop A Data Transfer Tool for Hadoop Arvind Prabhakar, Cloudera Inc. Sept 21, 2011 What is Sqoop? Allows easy import and export of data from structured data stores: o Relational Database o Enterprise
Apache Sqoop A Data Transfer Tool for Hadoop Arvind Prabhakar, Cloudera Inc. Sept 21, 2011 What is Sqoop? Allows easy import and export of data from structured data stores: o Relational Database o Enterprise
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop for MySQL DBAs. Copyright 2011 Cloudera. All rights reserved. Not to be reproduced without prior written consent.
 Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years sarah@cloudera.com 2 What is Hadoop? An open-source
Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years sarah@cloudera.com 2 What is Hadoop? An open-source
IBM Ported Tools for z/os: OpenSSH - Using Key Rings
 IBM Ported Tools for z/os: OpenSSH - Using Key Rings June 19, 2012 Kirk Wolf Steve Goetze http://dovetail.com info@dovetail.com Note: This webinar is a follow-on to: IBM Ported Tools for z/os: OpenSSH
IBM Ported Tools for z/os: OpenSSH - Using Key Rings June 19, 2012 Kirk Wolf Steve Goetze http://dovetail.com info@dovetail.com Note: This webinar is a follow-on to: IBM Ported Tools for z/os: OpenSSH
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Secure Database Backups with SecureZIP
 Secure Database Backups with SecureZIP A pproved procedures for insuring database recovery in the event of a disaster call for backing up the database and storing a copy of the backup offsite. Given the
Secure Database Backups with SecureZIP A pproved procedures for insuring database recovery in the event of a disaster call for backing up the database and storing a copy of the backup offsite. Given the
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Hadoop Tutorial GridKa School 2011
 Hadoop Tutorial GridKa School 2011 Ahmad Hammad, Ariel García Karlsruhe Institute of Technology September 7, 2011 Abstract This tutorial intends to guide you through the basics of Data Intensive Computing
Hadoop Tutorial GridKa School 2011 Ahmad Hammad, Ariel García Karlsruhe Institute of Technology September 7, 2011 Abstract This tutorial intends to guide you through the basics of Data Intensive Computing
File Transfer Examples. Running commands on other computers and transferring files between computers
 Running commands on other computers and transferring files between computers 1 1 Remote Login Login to remote computer and run programs on that computer Once logged in to remote computer, everything you
Running commands on other computers and transferring files between computers 1 1 Remote Login Login to remote computer and run programs on that computer Once logged in to remote computer, everything you
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh miles@inf.ed.ac.uk October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh miles@inf.ed.ac.uk October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Remote Unix Lab Environment (RULE)
") Remote Unix Lab Environment (RULE) Kris Mitchell krmitchell@swin.edu.au Introducing RULE RULE provides an alternative way to teach Unix! Increase student exposure to Unix! Do it cost effectively http://caia.swin.edu.au
Remote Unix Lab Environment (RULE) Kris Mitchell krmitchell@swin.edu.au Introducing RULE RULE provides an alternative way to teach Unix! Increase student exposure to Unix! Do it cost effectively http://caia.swin.edu.au
Kognitio Technote Kognitio v8.x Hadoop Connector Setup
 Kognitio Technote Kognitio v8.x Hadoop Connector Setup For External Release Kognitio Document No Authors Reviewed By Authorised By Document Version Stuart Watt Date Table Of Contents Document Control...
Kognitio Technote Kognitio v8.x Hadoop Connector Setup For External Release Kognitio Document No Authors Reviewed By Authorised By Document Version Stuart Watt Date Table Of Contents Document Control...
http://glennengstrand.info/analytics/fp
 Functional Programming and Big Data by Glenn Engstrand (September 2014) http://glennengstrand.info/analytics/fp What is Functional Programming? It is a style of programming that emphasizes immutable state,
Functional Programming and Big Data by Glenn Engstrand (September 2014) http://glennengstrand.info/analytics/fp What is Functional Programming? It is a style of programming that emphasizes immutable state,
Quick Deployment Step-by-step instructions to deploy Oracle Big Data Lite Virtual Machine
 Quick Deployment Step-by-step instructions to deploy Oracle Big Data Lite Virtual Machine Version 3.0 Please note: This appliance is for testing and educational purposes only; it is unsupported and not
Quick Deployment Step-by-step instructions to deploy Oracle Big Data Lite Virtual Machine Version 3.0 Please note: This appliance is for testing and educational purposes only; it is unsupported and not
CDH installation & Application Test Report
 CDH installation & Application Test Report He Shouchun (SCUID: 00001008350, Email: she@scu.edu) Chapter 1. Prepare the virtual machine... 2 1.1 Download virtual machine software... 2 1.2 Plan the guest
CDH installation & Application Test Report He Shouchun (SCUID: 00001008350, Email: she@scu.edu) Chapter 1. Prepare the virtual machine... 2 1.1 Download virtual machine software... 2 1.2 Plan the guest
Connection Broker Managing User Connections to Workstations, Blades, VDI, and more. Security Review
 Connection Broker Managing User Connections to Workstations, Blades, VDI, and more Security Review Version 8.1 October 21, 2015 Contacting Leostream Leostream Corporation http://www.leostream.com 465 Waverley
Connection Broker Managing User Connections to Workstations, Blades, VDI, and more Security Review Version 8.1 October 21, 2015 Contacting Leostream Leostream Corporation http://www.leostream.com 465 Waverley
Scheduling in SAS 9.4 Second Edition
 Scheduling in SAS 9.4 Second Edition SAS Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2015. Scheduling in SAS 9.4, Second Edition. Cary, NC: SAS Institute
Scheduling in SAS 9.4 Second Edition SAS Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2015. Scheduling in SAS 9.4, Second Edition. Cary, NC: SAS Institute
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Hadoop Big Data for Processing Data and Performing Workload
 Hadoop Big Data for Processing Data and Performing Workload Girish T B 1, Shadik Mohammed Ghouse 2, Dr. B. R. Prasad Babu 3 1 M Tech Student, 2 Assosiate professor, 3 Professor & Head (PG), of Computer
Hadoop Big Data for Processing Data and Performing Workload Girish T B 1, Shadik Mohammed Ghouse 2, Dr. B. R. Prasad Babu 3 1 M Tech Student, 2 Assosiate professor, 3 Professor & Head (PG), of Computer
Assignment # 1 (Cloud Computing Security)
") Assignment # 1 (Cloud Computing Security) Group Members: Abdullah Abid Zeeshan Qaiser M. Umar Hayat Table of Contents Windows Azure Introduction... 4 Windows Azure Services... 4 1. Compute... 4 a) Virtual
Assignment # 1 (Cloud Computing Security) Group Members: Abdullah Abid Zeeshan Qaiser M. Umar Hayat Table of Contents Windows Azure Introduction... 4 Windows Azure Services... 4 1. Compute... 4 a) Virtual
Building Scalable Big Data Infrastructure Using Open Source Software. Sam William sampd@stumbleupon.
 Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
Exploiting the Web with Tivoli Storage Manager
 Exploiting the Web with Tivoli Storage Manager Oxford University ADSM Symposium 29th Sept. - 1st Oct. 1999 Roland Leins, IBM ITSO Center - San Jose leins@us.ibm.com Agenda The Web Client Concept Tivoli
Exploiting the Web with Tivoli Storage Manager Oxford University ADSM Symposium 29th Sept. - 1st Oct. 1999 Roland Leins, IBM ITSO Center - San Jose leins@us.ibm.com Agenda The Web Client Concept Tivoli
H2O on Hadoop. September 30, 2014. www.0xdata.com
 H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
You should have a working knowledge of the Microsoft Windows platform. A basic knowledge of programming is helpful but not required.
 What is this course about? This course is an overview of Big Data tools and technologies. It establishes a strong working knowledge of the concepts, techniques, and products associated with Big Data. Attendees
What is this course about? This course is an overview of Big Data tools and technologies. It establishes a strong working knowledge of the concepts, techniques, and products associated with Big Data. Attendees
SWsoft Plesk 8.3 for Linux/Unix Backup and Restore Utilities
 SWsoft Plesk 8.3 for Linux/Unix Backup and Restore Utilities Administrator's Guide Revision 1.0 Copyright Notice ISBN: N/A SWsoft. 13755 Sunrise Valley Drive Suite 600 Herndon VA 20171 USA Phone: +1 (703)
SWsoft Plesk 8.3 for Linux/Unix Backup and Restore Utilities Administrator's Guide Revision 1.0 Copyright Notice ISBN: N/A SWsoft. 13755 Sunrise Valley Drive Suite 600 Herndon VA 20171 USA Phone: +1 (703)
I/O Considerations in Big Data Analytics
 Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
Pro Apache Hadoop. Second Edition. Sameer Wadkar. Madhu Siddalingaiah
 Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
How To Integrate Hadoop With R And Data Analysis With Big Data With Hadooper
 Integrating R and Hadoop for Big Data Analysis Bogdan OANCEA (bogdanoancea@univnt.ro) Nicolae Titulescu University of Bucharest Raluca Mariana DRAGOESCU (dragoescuraluca@gmail.com) The Bucharest University
Integrating R and Hadoop for Big Data Analysis Bogdan OANCEA (bogdanoancea@univnt.ro) Nicolae Titulescu University of Bucharest Raluca Mariana DRAGOESCU (dragoescuraluca@gmail.com) The Bucharest University
TIBCO ActiveMatrix BusinessWorks Plug-in for Big Data User s Guide
 TIBCO ActiveMatrix BusinessWorks Plug-in for Big Data User s Guide Software Release 1.0 November 2013 Two-Second Advantage Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE.
TIBCO ActiveMatrix BusinessWorks Plug-in for Big Data User s Guide Software Release 1.0 November 2013 Two-Second Advantage Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE.
Big Business, Big Data, Industrialized Workload
 Big Business, Big Data, Industrialized Workload Big Data Big Data 4 Billion 600TB London - NYC 1 Billion by 2020 100 Million Giga Bytes Copyright 3/20/2014 BMC Software, Inc 2 Copyright 3/20/2014 BMC Software,
Big Business, Big Data, Industrialized Workload Big Data Big Data 4 Billion 600TB London - NYC 1 Billion by 2020 100 Million Giga Bytes Copyright 3/20/2014 BMC Software, Inc 2 Copyright 3/20/2014 BMC Software,
docs.hortonworks.com
 docs.hortonworks.com : Security Administration Tools Guide Copyright 2012-2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform
docs.hortonworks.com : Security Administration Tools Guide Copyright 2012-2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform
IBM BigInsights Has Potential If It Lives Up To Its Promise. InfoSphere BigInsights A Closer Look
 IBM BigInsights Has Potential If It Lives Up To Its Promise By Prakash Sukumar, Principal Consultant at iolap, Inc. IBM released Hadoop-based InfoSphere BigInsights in May 2013. There are already Hadoop-based
IBM BigInsights Has Potential If It Lives Up To Its Promise By Prakash Sukumar, Principal Consultant at iolap, Inc. IBM released Hadoop-based InfoSphere BigInsights in May 2013. There are already Hadoop-based
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
SWsoft Plesk 8.2 for Linux/Unix Backup and Restore Utilities. Administrator's Guide
 SWsoft Plesk 8.2 for Linux/Unix Backup and Restore Utilities Administrator's Guide 2 Copyright Notice ISBN: N/A SWsoft. 13755 Sunrise Valley Drive Suite 325 Herndon VA 20171 USA Phone: +1 (703) 815 5670
SWsoft Plesk 8.2 for Linux/Unix Backup and Restore Utilities Administrator's Guide 2 Copyright Notice ISBN: N/A SWsoft. 13755 Sunrise Valley Drive Suite 325 Herndon VA 20171 USA Phone: +1 (703) 815 5670
Integrating VoltDB with Hadoop
 The NewSQL database you ll never outgrow Integrating with Hadoop Hadoop is an open source framework for managing and manipulating massive volumes of data. is an database for handling high velocity data.
The NewSQL database you ll never outgrow Integrating with Hadoop Hadoop is an open source framework for managing and manipulating massive volumes of data. is an database for handling high velocity data.
SOA Software API Gateway Appliance 7.1.x Administration Guide
 SOA Software API Gateway Appliance 7.1.x Administration Guide Trademarks SOA Software and the SOA Software logo are either trademarks or registered trademarks of SOA Software, Inc. Other product names,
SOA Software API Gateway Appliance 7.1.x Administration Guide Trademarks SOA Software and the SOA Software logo are either trademarks or registered trademarks of SOA Software, Inc. Other product names,
How To Use A Data Center With A Data Farm On A Microsoft Server On A Linux Server On An Ipad Or Ipad (Ortero) On A Cheap Computer (Orropera) On An Uniden (Orran)
 On A Cheap Computer (Orropera) On An Uniden (Orran)") Day with Development Master Class Big Data Management System DW & Big Data Global Leaders Program Jean-Pierre Dijcks Big Data Product Management Server Technologies Part 1 Part 2 Foundation and Architecture
Day with Development Master Class Big Data Management System DW & Big Data Global Leaders Program Jean-Pierre Dijcks Big Data Product Management Server Technologies Part 1 Part 2 Foundation and Architecture
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Lucid Key Server v2 Installation Documentation. www.lucidcentral.org
 Lucid Key Server v2 Installation Documentation Contents System Requirements...2 Web Server...3 Database Server...3 Java...3 Tomcat...3 Installation files...3 Creating the Database...3 Step 1: Create the
Lucid Key Server v2 Installation Documentation Contents System Requirements...2 Web Server...3 Database Server...3 Java...3 Tomcat...3 Installation files...3 Creating the Database...3 Step 1: Create the
E6893 Big Data Analytics: Demo Session for HW I. Ruichi Yu, Shuguan Yang, Jen-Chieh Huang Meng-Yi Hsu, Weizhen Wang, Lin Haung.
 E6893 Big Data Analytics: Demo Session for HW I Ruichi Yu, Shuguan Yang, Jen-Chieh Huang Meng-Yi Hsu, Weizhen Wang, Lin Haung 1 Oct 2, 2014 2 Part I: Pig installation and Demo Pig is a platform for analyzing
E6893 Big Data Analytics: Demo Session for HW I Ruichi Yu, Shuguan Yang, Jen-Chieh Huang Meng-Yi Hsu, Weizhen Wang, Lin Haung 1 Oct 2, 2014 2 Part I: Pig installation and Demo Pig is a platform for analyzing
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
Driving New Value from Big Data Investments
 An Introduction to Using R with Hadoop Jeffrey Breen Principal, Think Big Academy jeffrey.breen@thinkbiganalytics.com http://www.thinkbigacademy.com/ Greater Boston user Group Cambridge, MA February 20,
An Introduction to Using R with Hadoop Jeffrey Breen Principal, Think Big Academy jeffrey.breen@thinkbiganalytics.com http://www.thinkbigacademy.com/ Greater Boston user Group Cambridge, MA February 20,
Building Recommenda/on Pla1orm with Hadoop. Jayant Shekhar
 Building Recommenda/on Pla1orm with Hadoop Jayant Shekhar 1 Agenda Why Big Data Recommenda/on Pla1orm? Architecture Design & Implementa/on Common Recommenda/on PaEerns 2 Recommendations is one of the commonly
Building Recommenda/on Pla1orm with Hadoop Jayant Shekhar 1 Agenda Why Big Data Recommenda/on Pla1orm? Architecture Design & Implementa/on Common Recommenda/on PaEerns 2 Recommendations is one of the commonly
CA Workload Automation EE r11.3 Report Server. Fred Brisard
 CA Workload Automation EE r11.3 Report Server Fred Brisard Terms of This Presentation This presentation was based on current information and resource allocations as of October 2009 and is subject to change
CA Workload Automation EE r11.3 Report Server Fred Brisard Terms of This Presentation This presentation was based on current information and resource allocations as of October 2009 and is subject to change
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1
 How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce