Workload Management for Big Data Analytics
|
|
|
- Andra Marjory Jones
- 8 years ago
- Views:
Transcription
1 Workload Management for Big Data Analytics Ashraf Aboulnaga University of Waterloo Shivnath Babu Duke University

2 Database Workloads On-line Batch Transactional Airline Reservation Payroll This seminar Analytical OLAP BI Report Generation Different tuning for different workloads Different systems support different workloads Trend towards mixed workloads Trend towards real time (i.e., more on-line) 1
 1")
3 Big Data Analytics Complex analysis (on-line or batch) on Large relational data warehouses + Web site access and search logs + Text corpora + Web data + Sensor data + etc. Supported by (focus of this seminar) Parallel database systems MapReduce Other systems also exist SCOPE, Pregel, Spark, GraphLab, R, etc. 2
 Parallel database systems MapReduce")
4 Workload Management Workload 1 Workload 2 Workload N Workloads include all queries/jobs and updates Workloads can also include administrative utilities Multiple users and applications Different requirements Development vs. production Priorities 3

5 Workload Management Manage the execution of multiple workloads to meet explicit or implicit service level objectives Look beyond the performance of an individual request to the performance of an entire workload 4

6 Problems Addressed by WLM Workload isolation Important for multi-tenant systems Priorities How to interpret them? Admission control and scheduling Execution control Kill, suspend, resume Resource allocation Including sharing and throttling Monitoring and prediction Query characterization and classification Service level agreements 5

7 Optimizing Cost and SLOs When optimizing workload-level performance metrics, balancing cost (dollars) and SLOs is always part of the process, whether implicitly or explicitly Also need to account for the effects of failures Run each workload on an independent overprovisioned system (Cost is not an issue) Run all workloads together on the smallest possible shared system (No SLOs) Example: A dedicated business intelligence system with a hot standby 6
 Example: A dedicated business intelligence system with a hot")
8 Recap Workload 1 Workload 2 Workload N Workload management is about controlling the execution of different workloads so that they achieve their SLOs while minimizing cost (dollars) 7

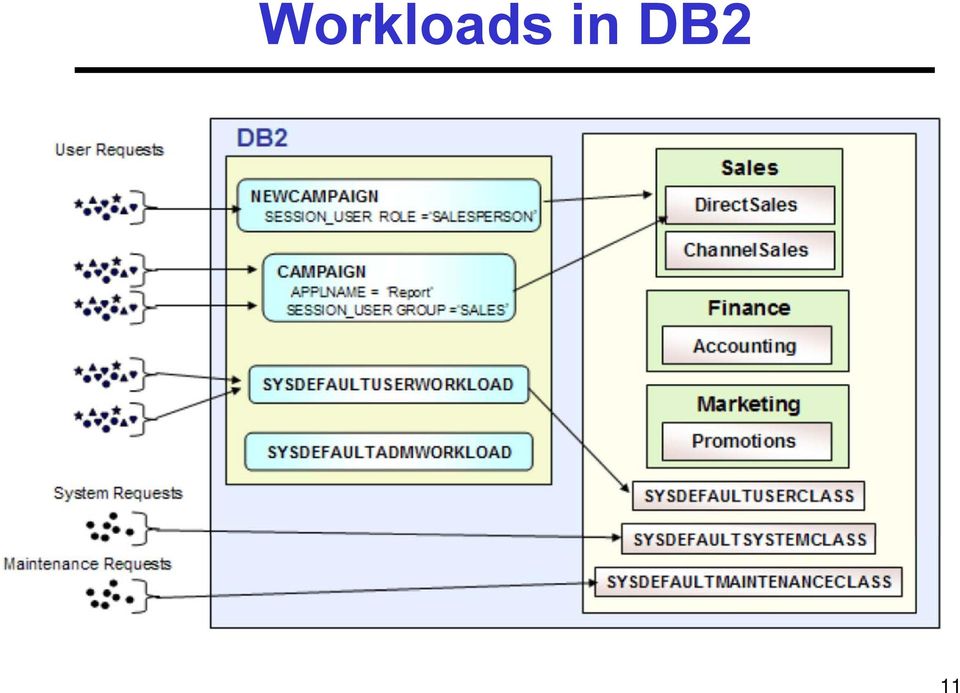
9 Defining Workloads Which workload? Q? Resources Suspend Priority Admission Queues System Specification (by administrator) Define workloads by connection/user/application Classification (by system) Long running vs. short Resource intensive vs. not Just started vs. almost done 8
 Long running vs.")
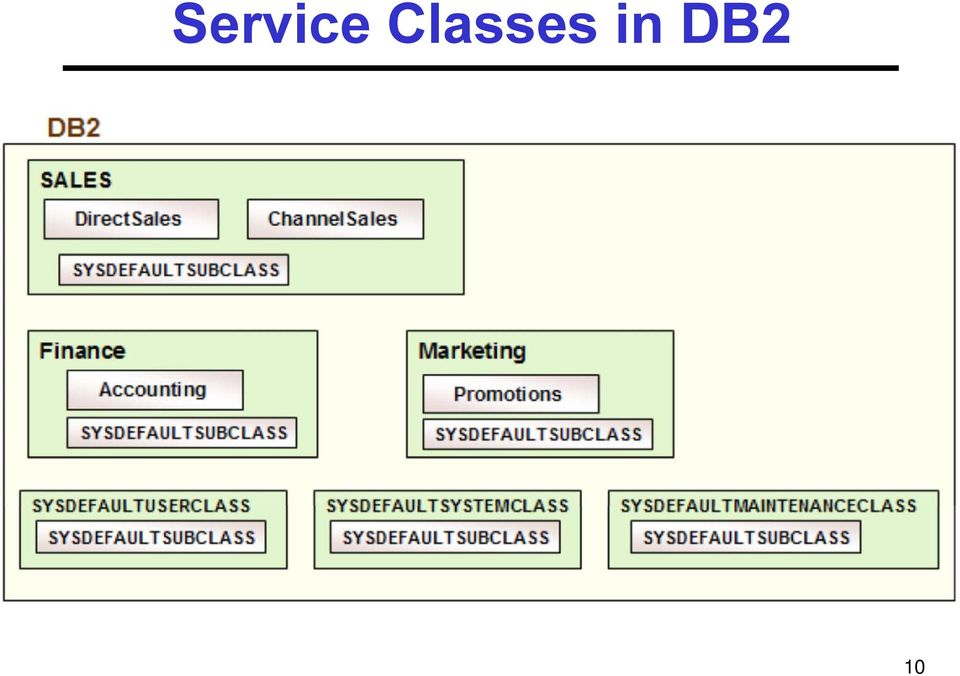
10 DB2 Workload Specifictaion Whei-Jen Chen, Bill Comeau, Tomoko Ichikawa, S Sadish Kumar, Marcia Miskimen, H T Morgan, Larry Pay, Tapio Väättänen. DB2 Workload Manager for Linux, UNIX, and Windows. IBM Redbook, Create service classes Identify workloads by connection Assign workloads to service classes Set thresholds for service classes Specify action when a threshold is crossed Stop execution Collect data 9

11 Service Classes in DB2 10
12 Workloads in DB2 11
13 Thresholds in DB2 Many mechanisms available to the DBA to specify workloads. Need guidance (policy) on how to use these mechanisms. 12
 on how to")
14 MR Workload Classification Yanpei Chen, Sara Alspaugh, Randy Katz. Interactive Analytical Processing in Big Data Systems: A Cross-Industry Study of MapReduce Workloads. VLDB, MapReduce workloads from Cloudera customers and Facebook 13

15 Variation Over Time Workloads are bursty High variance in intensity Cannot rely on daily or weekly patterns Need on-line techniques 14

16 Job Names A considerable fraction is Pig Latin and Hive A handful of job types makes up the majority of jobs Common computation types 15

17 Job Behavior (k-means) Diverse job behaviors Workloads amenable to classification 16

18 Recap Which workload? Q? Resources Suspend Priority Admission Queues System Can specify workloads by connection/user/application. Mechanisms exist for controlling workload execution. Can classify queries/jobs by behavior. Diverse behaviors, but classification still useful. 17

19 Seminar Outline Introduction Workload-level decisions in database systems Physical design Progress monitoring Managing long running queries Performance prediction Progress Monitoring Inter workload interactions Outlook and Open Problems 18

20 Workload-level Decisions in Database Systems 19

21 Physical Database Design Surajit Chaudhuri, Vivek Narasayya. Self-Tuning Database Systems: A Decade of Progress. VLDB, A workload-level decision Estimating benefit relies on query optimizer 20
22 On-line Physical Design Adapts the physical design as the behavior of the workload changes 21
23 Progress Monitoring Can be viewed as continuous on-line self-adjusting performance prediction Useful for workload monitoring and for making workload management decisions Starting point: query optimizer cost estimates 22
24 Solution Overview First attempt at a solution : Query optimizer estimates the number of tuples flowing through each operator in a plan. Progress of a query = Total number of tuples that have flowed through different operators / Total number of tuples that will flow through all operators Refining the solution: Take blocking behavior into account by dividing plan into independent pipelines More sophisticated estimate of the speed of pipelines Refine estimated remaining time based on actual progress 23
25 Speed-independent Pipelines Jiexing Li, Rimma V. Nehme, Jeffrey Naughton. GSLPI: a Costbased Query Progress Indicator. ICDE, Pipelines delimited by blocking or semi-blocking operators Every pipeline has a set of driver nodes Pipeline execution follows a partial order 24
26 Estimating Progress Total time required by a pipeline Wall-clock query cost: maximum amount of nonoverlapping CPU and I/O Based on query optimizer estimates Critical path Pipeline speed: tuples processed per second for the last T seconds Used to estimate remaining time for a pipeline Estimates of cardinality, CPU cost, and I/O cost refined as the query executes 25
27 Accuracy of Estimation Can use statistical models to choose the best progress indicator for a query Arnd Christian Konig, Bolin Ding, Surajit Chaudhuri, Vivek Narasayya. A Statistical Approach Towards Robust Progress Estimation. VLDB,
28 Application to MapReduce Kristi Morton, Magdalena Balazinska, Dan Grossman. ParaTimer: A Progress Indicator for MapReduce DAGs. SIGMOD, Focuses on DAGs of MapReduce jobs produced from Pig Latin queries 27
29 MapReduce Pipelines Pipelines corresponding to the phases of execution of MapReduce jobs Assumes the existence of cardinality estimates for pipeline inputs Use observed per-tuple execution cost for estimating pipeline speed 28
30 Progress Estimation Simulates the scheduling of Map and Reduce tasks to estimate progress Also provides an estimate of progress if failure were to happen during execution Find the task whose failure would have the worst effect on progress, and report remaining time if this task fails (pessimistic) Adjust progress estimates if failures actually happen 29
31 Progress of Interacting Queries Gang Luo, Jeffrey F. Naughton, Philip S. Yu. Multi-query SQL Progress Indicators. EDBT, Estimates the progress of multiple queries in the presence of query interactions The speed of a query is proportional to its weight Weight derived from query priority and available resources When a query in the current query mix finishes, there are more resources available so the weights of remaining queries can be increased 30
32 Accuracy of Estimation Can observe query admission queue to extend visibility into the future 31
33 Relationship to WLM Can use the multi-query progress indicator to answer workload management questions such as Which queries to block in order to speed up the execution of an important query? Which queries to abort and which queries to wait for when we want to quiesce the system for maintenance? 32
34 Long-Running Queries Stefan Krompass, Harumi Kuno, Janet L. Wiener, Kevin Wilkinson, Umeshwar Dayal, Alfons Kemper. Managing Long-Running Queries. EDBT, A close look at the effectiveness of using admission control, scheduling, and execution control to manage long-running queries 33
35 Classification of Queries Estimated resource shares and execution time based on query optimizer cost estimates 34
36 Workload Management Actions Admission control Reject, hold, or warn if estimated cost > threshold Scheduling Two FIFO queues, one for queries whose estimated cost < threshold, and one for all other queries Schedule from the queue of short-running queries first Execution control Actions: Lower query priority, stop and return results so far, kill and return error, kill and resubmit, suspend and resume later Supported by many commercial database systems Take action if observed cost > threshold Threshold can be absolute or relative to estimated cost (e.g., 1.2*estimated cost) 35
37 Surprise Queries Experiments based on simulation show that workload management actions achieve desired objectives except if there are surprise-heavy or surprise-hog queries Why are there surprise queries? Need Inaccurate accurate cost estimates prediction of execution time and resource consumption Bottleneck resource not modeled System overload 36
38 Seminar Outline Introduction Workload-level decisions in database systems Physical design Progress monitoring Managing long running queries Performance prediction Progress Monitoring Inter workload interactions Outlook and Open Problems 37
39 Performance Prediction 38
40 Performance Prediction Query optimizer estimates of query/operator cost and resource consumption are OK for choosing a good query execution plan These estimates do not correlate well with actual cost and resource consumption But they can still be useful Build statistical / machine learning models for performance prediction Which features? Can derive from query optimizer plan. Which model? How to collect training data? 39
41 Query Optimizer vs. Actual Mert Akdere, Ugur Cetintemel, Matteo Riondato, Eli Upfal, Stanley B. Zdonik. Learning-based Query Performance Modeling and Prediction. ICDE, GB TPC-H queries on PostgreSQL 40
42 Prediction Using KCCA Archana Ganapathi, Harumi Kuno, Umeshwar Dayal, Janet L. Wiener, Armando Fox, Michael Jordan, David Patterson. Predicting Multiple Metrics for Queries: Better Decisions Enabled by Machine Learning. ICDE, Optimizer vs. actual: TPC-DS on Neoview 41
43 Aggregated Plan-level Features 42
44 Training a KCCA Model Principal Component Analysis -> Canonical Correlation Analysis -> Kernel Canonical Correlation Analysis KCCA finds correlated pairs of clusters in the query vector space and performance vector space 43
45 Using the KCCA Model Keep all projected query plan vectors and performance vectors Prediction based on nearest neighbor query 44
46 Results: The Good News Can also predict records used, I/O, messages 45
47 Results: The Bad News Aggregate plan-level features cannot generalize to different schema and database 46
48 Operator-level Modeling Jiexing Li, Arnd Christian Konig, Vivek Narasayya, Surajit Chaudhuri. Robust Estimation of Resource Consumption for SQL Queries using Statistical Techniques. VLDB, Optimizer vs. actual CPU With accurate cardinality estimates 47
49 Lack of Generalization 48
50 Operator-level Modeling One model for each type of query processing operator, based on features specific to that operator 49
51 Operator-specific Features Global Features (for all operator types) Operator-specific Features 50
52 Model Training Use regression tree models No need for dividing feature values into distinct ranges No need for normalizing features (e.g, zero mean unit variance) Different functions at different leaves, so can handle discontinuity (e.g., single-pass -> multi-pas sort) 51
53 Scaling for Outlier Features If feature F is much larger than all values seen in training, estimate resources consumed per unit F and scale using some feature- and operator-specific scaling function Example: Normal CPU estimation If CIN too large 52
54 Accuracy Without Scaling 53
55 Accuracy With Scaling 54
56 Modeling Query Interactions Mumtaz Ahmad, Songyun Duan, Ashraf Aboulnaga, Shivnath Babu. Predicting Completion Times of Batch Query Workloads Using Interaction-aware Models and Simulation. EDBT, A database workload consists of a sequence of mixes of interacting queries Interactions can be significant, so their effects should be modeled Features = query types (no query plan features from the optimizer) A mix m = <N 1, N 2,, N T >, where N i is the number of queries of type i in the mix 55
57 Impact of Query Interactions 5.4 hours 3.3 hours Two workloads on a scale factor 10 TPC-H database on DB2 W1 and W2: exactly the same set of 60 instances of TPC-H queries Arrival order is different so mixes are different Workload isolation is important! 56
58 Sampling Query Mixes Query interactions complicate collecting a representative yet small set of training data Number of possible query mixes is exponential How judiciously use the available sampling budget Interaction-level aware Latin Hypercube Sampling Can be done incrementally Mix Q 1 Q 7 Q 9 Q 18 N i A i N i A i N i A i N i A i N2 m N1 m Interaction levels: m1=4, m2=2 57
59 Modeling and Prediction Training data used to build Gaussian Process Models for different query type Model: CompletionTime (QueryType) = f(querymix) Models used in a simulation of workload execution to predict workload completion time 58
60 Prediction Accuracy Accuracy on 120 different TPC-H workloads on DB2 59
61 Buffer Access Latency Jennie Duggan, Ugur Cetintemel, Olga Papaemmanouil, Eli Upfal. Performance Prediction for Concurrent Database Workloads. SIGMOD, Also aims to model the effects of query interactions Feature used: Buffer Access Latency (BAL) The average time for a logical I/O for a query type Focus on sampling and modeling pairwise interactions since they capture most of the effects of interaction 60
62 Solution Overview 61
63 Prediction for MapReduce Herodotos Herodotou, Shivnath Babu. Profiling, What-if Analysis, and Cost-based Optimization of MapReduce Programs. VLDB, Focus: Tuning MapReduce job parameters in Hadoop 190+ parameters that significantly affect performance 62
64 Starfish What-if Engine Combines per-job measurement with whitebox modeling to get accurate what-if models of MapReduce job behavior under different parameter settings Measured White-box Models 63
65 Recap Statistical / machine learning models can be used for accurate prediction of workload performance metrics Query optimizer can provide features for these models Of the shelf models typically sufficient, but may require work to use them properly Judicious sampling to collect training data is important 64
66 Seminar Outline Introduction Workload-level decisions in database systems Physical design Progress monitoring Managing long running queries Performance prediction Progress Monitoring Inter workload interactions Outlook and Open Problems 65
67 Inter-workload Interactions 66
68 Inter Workload Interactions Workload 1 Workload 2 Workload N Positive Negative 67
69 Negative Workload Interactions Workloads W1 and W2 cannot use resource R concurrently CPU, Memory, I/O bandwidth, network bandwidth Read-Write issues and the need for transactional guarantees Locking Lack of end-to-end control on resource allocation and scheduling for workloads Variation / unpredictability in performance Motivates Workload Isolation 68
70 Positive Workload Interactions Cross-workload optimizations Multi-query optimizations Scan sharing Caching Materialized views (in-memory) Motivates Shared Execution of Workloads 69
71 Inter Workload Interactions Workload 1 Workload 2 Workload N Research on workload management is heavily biased towards understanding and controlling negative inter-workload Interactions Balancing the two types of interactions is an open problem 70
72 Multiclass Workloads W1 W2 Wn Kurt P. Brown, Manish Mehta, Michael J. Carey, Miron Livny: Towards Automated Performance Tuning for Complex Workloads, VLDB 1994 Workload: Multiple user-defined classes. Each class Wi defined by a target average response time No-goal class. Best effort performance Goal: DBMS should pick <MPL,memory> allocation for each class Wi such that Wi s target is met while leaving the maximum resources possible for the no goal class Assumption: Fixed MPL for no goal class to 1 71
73 Multiclass Workloads W1 W2 Wn Workload Interdependence: perf(wi) = F([MPL],[MEM]) Assumption: Enough resources available to satisfy requirements of all workload classes Thus, system never forced to sacrifice needs of one class in order to satisfy needs of another They model relationship between MPL and Memory allocation for a workload Shared Memory Pool per Workload = Heap + Buffer Pool Same performance can be given by multiple <MPL,Mem> choices 72
74 Multiclass Workloads Heuristic-based per-workload feedback-driven algorithm M&M algorithm Insight: Best return on consumption of allocated heap memory is when a query is allocated either its maximum or its minimum need [Yu and Cornell, 1993] M&M boils down to setting three knobs per workload class: maxmpl: queries allowed to run at max heap memory minmpl: queries allowed to run at min heap memory Memory pool size: Heap + Buffer pool 73
75 Real-time Multiclass Workloads W1 W2 Wn HweeHwa Pang, Michael J. Carey, Miron Livny: Multiclass Query Scheduling in Real-Time Database Systems. IEEE TKDE 1995 Workload: Multiple user-defined classes Queries come with deadlines, and each class Wi is defined by a miss ratio (% of queries that miss their deadlines) DBA specifies miss distribution: how misses should be distributed among the classes 74
76 Real-time Multiclass Workloads Feedback-driven algorithm called Priority Adaptation Query Resource Scheduling MPL and Memory allocation strategies are similar in spirit to the M&M algorithm Queries in each class are divided into two Priority Groups: Regular and Reserve Queries in Regular group are assigned a priority based on their deadlines (Earliest Deadline First) Queries in Reserve group are assigned a lower priority than those in Regular group Miss ratio distribution is controlled by adjusting size of regular group across workload classes 75
77 Throttling System Utilities W1 W2 Wn Sujay S. Parekh, Kevin Rose, Joseph L. Hellerstein, Sam Lightstone, Matthew Huras, Victor Chang: Managing the Performance Impact of Administrative Utilities. DSOM 2003 Workload: Regular DBMS processing Vs. DBMS system utilities like backups, index rebuilds, etc. 76
78 Throttling System Utilities DBA should be able to say: have no more than x% performance degradation of the production work as a result of running system utilities 77
79 Throttling System Utilities Control theoretic approach to make utilities sleep Proportional-Integral controller from linear control theory 78
80 Impact of Long-Running Queries Stefan Krompass, Harumi Kuno, Janet L. Wiener, Kevin Wilkinson, Umeshwar Dayal, Alfons Kemper. Managing Long-Running Queries. EDBT, Heavy Vs. Hog Overload and Starving 79
81 Impact of Long-Running Queries Commercial DBMSs give rule-based languages for the DBAs to specify the actions to take to deal with problem queries However, implementing good solutions is an art How to quantify progress? How to attribute resource usage to queries? How to distinguish an overloaded scenario from a poorly-tuned scenario? How to connect workload management actions with business importance? 80
82 Utility Functions W1 W2 Wn Baoning Niu, Patrick Martin, Wendy Powley, Paul Bird, Randy Horman: Adapting Mixed Workloads to Meet SLOs in Autonomic DBMSs, SMDB 2007 Workload: Multiple user-defined classes. Each class has: Performance target(s) Business importance Designs utility functions that quantify the utility obtained from allocating more resources to each class Gives an optimization objective Implemented over IBM DB2 s Query Patroller 81
83 Seminar Outline Introduction Workload-level decisions in database systems Physical design Progress monitoring Managing long running queries Performance prediction Progress Monitoring Inter workload interactions Outlook and Open Problems 82
84 On to MapReduce systems 83
85 DBMS Vs. MapReduce (MR) Stack ETL Reports Text Proc.Graph Proc. Narrow waist of the MR stack Workload mgmt. done at the level of MR jobs Pig Hive Oozie / Azkaban Mahout Java / R / Python MapReduce Jobs Hadoop MR Exec. Engine Distributed FS On-premise or Cloud (Elastic MapReduce) 84
86 MapReduce Workload Mgmt. Resource management policy: Fair sharing Unidimensional fair sharing Hadoop s Fair scheduler Dryad s Quincy scheduler Multi-dimensional fair sharing Resource management frameworks Mesos Next Generation MapReduce (YARN) Serengeti 85
87 What is Fair Sharing? 100% CPU 33% n users want to share a resource (e.g., CPU) Solution: Allocate each 1/n of the resource 50% 0% 33% 33% Generalized by max-min fairness Handles if a user wants less than her fair share E.g., user 1 wants no more than 20% Generalized by weighted max-min fairness Give weights to users according to importance User 1 gets weight 1, user 2 weight 2 100% 50% 0% 100% 50% 20% 40 % 40 % 33% 66% 0%
88 Why Care about Fairness? Desirable properties of max-min fairness Isolation policy: A user gets her fair share irrespective of the demands of other users Users cannot affect others beyond their fair share Flexibility separates mechanism from policy: Proportional sharing, priority, reservation,... Many schedulers use max-min fairness Datacenters: Hadoop s Fair Scheduler, Hadoop s Capacity Scheduler, Dryad s Quincy OS: rr, prop sharing, lottery, linux cfs,... Networking: wfq, wf2q, sfq, drr, csfq,...
89 Example: Facebook Data Pipeline Web Servers Scribe Servers Network Storage Analysts Oracle RAC Hadoop Cluster MySQL
90 Example: Facebook Job Types Production jobs: load data, compute statistics, detect spam, etc. Long experiments: machine learning, etc. Small ad-hoc queries: Hive jobs, sampling GOAL: Provide fast response times for small jobs and guaranteed service levels for production jobs
91 Task Slots in Hadoop Map slots Reduce slots TaskTracker Adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed Computing Seminar, 2007 (licensed under Creation Commons Attribution 3.0 License) 90
92 Example: Hierarchical Fair Sharing Cluster Share Policy Spam Dept. 30% Ads Dept. 20% 70% User 1 User 2 Facebook.com 100% Cluster Utilization 80% 60% 40% 20% 0% Time Curr Time 80% Curr Time Curr Time 100% 20% Spam 100% 20% 6% 30% 14% 70% User 1 User 2 Job 1 Job 2 Job 4 80% Ads Job 3 91
93 Hadoop s Fair Scheduler M. Zaharia, D. Borthakur, J. Sen Sarma, K. Elmeleegy, S. Shenker, and I. Stoica, Job Scheduling for Multi- User MapReduce Clusters, UC Berkeley Technical Report UCB/EECS , April 2009 Group jobs into pools each with a guaranteed minimum share Divide each pool s minimum share among its jobs Divide excess capacity among all pools When a task slot needs to be assigned: If there is any pool below its min share, schedule a task from it Else pick as task from the pool we have been most unfair to
94 Quincy: Dryad s Fair Scheduler Michael Isard, Vijayan Prabhakaran, Jon Currey, Udi Wieder, Kunal Talwar, Andrew Goldberg: Quincy: fair scheduling for distributed computing clusters. SOSP 2009
95 Goals in Quincy Fairness: If a job takes t time when run alone, and J jobs are running, then the job should take no more time than Jt Sharing: Fine-grained sharing of the cluster, minimize idle resources (maximize throughput) Maximize data locality
96 Data Locality Data transfer costs depend on where data is located 95
97 Goals in Quincy Fairness: If a job takes t time when run alone, and J jobs are running, then the job should take no more time than Jt Sharing: Fine-grained sharing of the cluster, minimize idle resources (maximize throughput) Maximize data locality Admission control to limit to K concurrent jobs choice trades off fairness wrt locality and avoiding idle resources Assumes fixed task slots per machine Task slots Local Data
98 Queue-based Vs. Graph-based Scheduling Cluster Architecture
99 Queue-based Vs. Graph-based Scheduling Queues
100 Queue-Based Scheduling Greedy (G): Locality-based preferences Does not consider fairness Simple Greedy Fairness (GF): block any job that has its fair allocation of resources Schedule tasks only from unblocked jobs Fairness with preemption (GFP): The over-quota tasks will be killed, with shorter-lived ones killed first Other policies
101 Graph-based Scheduling Encode cluster structure, jobs, and tasks as a flow network Captures entire state of system at any point of time Edge costs encode policy cost of waiting (not being scheduled yet) cost of data transfers Solving the min-cost flow problem gives a scheduling assignment
102 Single resource example 1 resource: CPU However User 1 wants <1 CPU> per task User 2 wants <3 CPU> per task Multi-resource example 2 resources: CPUs & memory User 1 wants <1 CPU, 4 GB> per task User 2 wants <3 CPU, 1 GB> per task What is a fair allocation? 100% 50% 100% 0% 50% 0%? CPU 50 % 50 % CPU? mem
103 Heterogeneous Resource Demands Some tasks are CPU-intensive Most tasks need ~ <2 CPU, 2 GB RAM> Some tasks are memory-intensive 2000-node Hadoop Cluster at Facebook (Oct 2010)
104 Problem Definition How to fairly share multiple resources when users/tasks have heterogeneous resource demands?
105 Model Users have tasks according to a demand vector e.g., <2, 3, 1> user s tasks need 2 R 1, 3 R 2, 1 R 3 How to get the demand vectors is an interesting question Assume divisible resources
106 A Simple Solution: Asset Fairness Asset Fairness Equalize each user s sum of resource shares Problem: User U1 has < 50% of both CPUs and RAM Better off U 1 in needs a separate <2 CPU, cluster 2 GB with RAM> 50% per of the task resources U 2 needs <1 CPU, 2 GB RAM> per task Cluster with 70 CPUs, 70 GB RAM Asset fairness yields U 1 : 15 tasks: 30 CPUs, 30 GB ( =60) U 2 : 20 tasks: 20 CPUs, 40 GB ( =60) 100 % 50 % 0% U1 43% 28% CPU U2 43% 57% RAM
107 Share Guarantee Intuitively: You shouldn t be worse off than if you ran your own cluster with 1/n of the resources Otherwise, no incentive to share resources into a common pool Each user should get at least 1/n of at least one resource (share guarantee)
108 Dominant Resource Fairness A user s dominant resource is the resource for which she has the biggest demand Example: Total resources: <10 CPU, 4 GB> User 1 s task requires: <2 CPU, 1 GB> Dominant resource is memory as 1/4 > 2/10 (1/5) A user s dominant share is the fraction of the dominant resource she is allocated
109 Dominant Resource Fairness (2) Equalize the dominant share of the users Example: Total resources: User 1 demand: User 2 demand: 100% 3 CPUs 50% 66% 6 CPUs 0% CPU (9 total) <9 CPU, 18 GB> <1 CPU, 4 GB> dominant res: mem <3 CPU, 1 GB> dominant res: CPU 12 GB 66% 2 GB mem (18 total) User 1 User 2
110 DRF is Fair and Much More DRF satisfies the share guarantee DRF is strategy-proof DRF allocations are envy-free
111 Cheating the Scheduler Some users will game the system to get more resources Real-life examples A cloud provider had quotas on map and reduce slots Some users found out that the map quota was low Users implemented maps in the reduce slots! A search company provided dedicated machines to users that could ensure certain level of utilization (e.g. 80%) Users used busy-loops to inflate utilization
112 Seminar Outline Introduction Workload-level decisions in database systems Physical design Progress monitoring Managing long running queries Performance prediction Progress Monitoring Inter workload interactions Outlook and Open Problems 111
113 Outlook 112
114 Resource Management Frameworks Rapid innovation in cluster computing frameworks CIEL Pregel Pig Dryad Percolator
115 Resource Management Frameworks Rapid innovation in cluster computing frameworks No single framework optimal for all applications Want to run multiple frameworks in a single cluster to maximize utilization to share data between frameworks
116 Where We Want to Go Today: static partitioning Need: dynamic sharing Hadoop Pregel MPI Shared cluster
117 Resource Management Frameworks Hadoop Pregel Hadoop Pregel Resource Mgmt Layer Node Node Node Node Node Node Node Node Mesos, YARN, Serengeti Also: run multiple instances of the same framework Isolate production and experimental jobs Run multiple versions of the framework concurrently Lots of challenges!
118 Challenges (1/2) Integrating the notion of a workload in traditional systems Query optimization Scheduling Managing workload interactions Better workload isolation Inducing more positive interactions Multi-tenancy and cloud More workloads to interact with each other Opportunities for shared optimizations Heterogeneous infrastructure Elastic infrastructure Scale 117
119 Challenges (2/2) Better performance modeling Especially for MapReduce Rich yet simple definition of SLOs Dollar cost Failure Fuzzy penalties Scale 118
120 References (1/3) Mumtaz Ahmad, Songyun Duan, Ashraf Aboulnaga, Shivnath Babu. Predicting Completion Times of Batch Query Workloads Using Interaction-aware Models and Simulation. EDBT Mert Akdere, Ugur Cetintemel, Matteo Riondato, Eli Upfal, Stanley B. Zdonik. Learning-based Query Performance Modeling and Prediction. ICDE Kurt P. Brown, Manish Mehta, Michael J. Carey, Miron Livny. Towards Automated Performance Tuning for Complex Workloads. VLDB Surajit Chaudhuri, Vivek Narasayya. Self-Tuning Database Systems: A Decade of Progress. VLDB Whei-Jen Chen, Bill Comeau, Tomoko Ichikawa, S Sadish Kumar, Marcia Miskimen, H T Morgan, Larry Pay, Tapio Väättänen. DB2 Workload Manager for Linux, UNIX, and Windows. IBM Redbook Yanpei Chen, Sara Alspaugh, Randy Katz. Interactive Analytical Processing in Big Data Systems: A Cross-Industry Study of MapReduce Workloads. VLDB Jennie Duggan, Ugur Cetintemel, Olga Papaemmanouil, Eli Upfal. Performance Prediction for Concurrent Database Workloads. SIGMOD
121 References (2/3) Archana Ganapathi, Harumi Kuno, Umeshwar Dayal, Janet L. Wiener, Armando Fox, Michael Jordan, David Patterson. Predicting Multiple Metrics for Queries: Better Decisions Enabled by Machine Learning. ICDE A. Ghodsi, M. Zaharia, B. Hindman, A. Konwinski, S. Shenker, I. Stoica. Dominant Resource Fairness: Fair Allocation of Multiple Resources Types. NSDI Herodotos Herodotou, Shivnath Babu. Profiling, What-if Analysis, and Costbased Optimization of MapReduce Programs. VLDB B. Hindman, A. Konwinski, M. Zaharia, A. Ghodsi, A.D. Joseph, R. Katz, S. Shenker, I. Stoica. Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center. NSDI Michael Isard, Vijayan Prabhakaran, Jon Currey, Udi Wieder, Kunal Talwar, Andrew Goldberg. Quincy: fair scheduling for distributed computing clusters. SOSP Arnd Christian Konig, Bolin Ding, Surajit Chaudhuri, Vivek Narasayya. A Statistical Approach Towards Robust Progress Estimation. VLDB Stefan Krompass, Harumi Kuno, Janet L. Wiener, Kevin Wilkinson, Umeshwar Dayal, Alfons Kemper. Managing Long-Running Queries. EDBT
Workload Management for Big Data Analytics
 Workload Management for Big Data Analytics Ashraf Aboulnaga University of Waterloo + Qatar Computing Research Institute Shivnath Babu Duke University Database Workloads On-line Batch Transactional Airline
Workload Management for Big Data Analytics Ashraf Aboulnaga University of Waterloo + Qatar Computing Research Institute Shivnath Babu Duke University Database Workloads On-line Batch Transactional Airline
INFO5011. Cloud Computing Semester 2, 2011 Lecture 11, Cloud Scheduling
 INFO5011 Cloud Computing Semester 2, 2011 Lecture 11, Cloud Scheduling COMMONWEALTH OF Copyright Regulations 1969 WARNING This material has been reproduced and communicated to you by or on behalf of the
INFO5011 Cloud Computing Semester 2, 2011 Lecture 11, Cloud Scheduling COMMONWEALTH OF Copyright Regulations 1969 WARNING This material has been reproduced and communicated to you by or on behalf of the
A Hybrid Scheduling Approach for Scalable Heterogeneous Hadoop Systems
 A Hybrid Scheduling Approach for Scalable Heterogeneous Hadoop Systems Aysan Rasooli Department of Computing and Software McMaster University Hamilton, Canada Email: rasooa@mcmaster.ca Douglas G. Down
A Hybrid Scheduling Approach for Scalable Heterogeneous Hadoop Systems Aysan Rasooli Department of Computing and Software McMaster University Hamilton, Canada Email: rasooa@mcmaster.ca Douglas G. Down
Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II)
") UC BERKELEY Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II) Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter
UC BERKELEY Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II) Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter
Guidelines for Selecting Hadoop Schedulers based on System Heterogeneity
 Noname manuscript No. (will be inserted by the editor) Guidelines for Selecting Hadoop Schedulers based on System Heterogeneity Aysan Rasooli Douglas G. Down Received: date / Accepted: date Abstract Hadoop
Noname manuscript No. (will be inserted by the editor) Guidelines for Selecting Hadoop Schedulers based on System Heterogeneity Aysan Rasooli Douglas G. Down Received: date / Accepted: date Abstract Hadoop
Deploying Database Appliances in the Cloud
 Deploying Database Appliances in the Cloud Ashraf Aboulnaga Kenneth Salem Ahmed A. Soror Umar Farooq Minhas Peter Kokosielis Sunil Kamath University of Waterloo IBM Toronto Lab Abstract Cloud computing
Deploying Database Appliances in the Cloud Ashraf Aboulnaga Kenneth Salem Ahmed A. Soror Umar Farooq Minhas Peter Kokosielis Sunil Kamath University of Waterloo IBM Toronto Lab Abstract Cloud computing
Duke University http://www.cs.duke.edu/starfish
 Herodotos Herodotou, Harold Lim, Fei Dong, Shivnath Babu Duke University http://www.cs.duke.edu/starfish Practitioners of Big Data Analytics Google Yahoo! Facebook ebay Physicists Biologists Economists
Herodotos Herodotou, Harold Lim, Fei Dong, Shivnath Babu Duke University http://www.cs.duke.edu/starfish Practitioners of Big Data Analytics Google Yahoo! Facebook ebay Physicists Biologists Economists
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE
 IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
Characterizing Task Usage Shapes in Google s Compute Clusters
 Characterizing Task Usage Shapes in Google s Compute Clusters Qi Zhang 1, Joseph L. Hellerstein 2, Raouf Boutaba 1 1 University of Waterloo, 2 Google Inc. Introduction Cloud computing is becoming a key
Characterizing Task Usage Shapes in Google s Compute Clusters Qi Zhang 1, Joseph L. Hellerstein 2, Raouf Boutaba 1 1 University of Waterloo, 2 Google Inc. Introduction Cloud computing is becoming a key
Delay Scheduling. A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling
 Delay Scheduling A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Khaled Elmeleegy +, Scott Shenker, Ion Stoica UC Berkeley,
Delay Scheduling A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Khaled Elmeleegy +, Scott Shenker, Ion Stoica UC Berkeley,
Dominant Resource Fairness: Fair Allocation of Multiple Resource Types
 Dominant Resource Fairness: Fair Allocation of Multiple Resource Types Ali Ghodsi Matei Zaharia Benjamin Hindman Andrew Konwinski Scott Shenker Ion Stoica Electrical Engineering and Computer Sciences University
Dominant Resource Fairness: Fair Allocation of Multiple Resource Types Ali Ghodsi Matei Zaharia Benjamin Hindman Andrew Konwinski Scott Shenker Ion Stoica Electrical Engineering and Computer Sciences University
Predicting Multiple Metrics for Queries: Better Decisions Enabled by Machine Learning
 Predicting Multiple Metrics for Queries: Better Decisions Enabled by Machine Learning Archana Ganapathi, Harumi Kuno, Umeshwar Dayal, Janet L. Wiener, Armando Fox, Michael Jordan, David Patterson Computer
Predicting Multiple Metrics for Queries: Better Decisions Enabled by Machine Learning Archana Ganapathi, Harumi Kuno, Umeshwar Dayal, Janet L. Wiener, Armando Fox, Michael Jordan, David Patterson Computer
A Generic Auto-Provisioning Framework for Cloud Databases
 A Generic Auto-Provisioning Framework for Cloud Databases Jennie Rogers 1, Olga Papaemmanouil 2 and Ugur Cetintemel 1 1 Brown University, 2 Brandeis University Instance Type Introduction Use Infrastructure-as-a-Service
A Generic Auto-Provisioning Framework for Cloud Databases Jennie Rogers 1, Olga Papaemmanouil 2 and Ugur Cetintemel 1 1 Brown University, 2 Brandeis University Instance Type Introduction Use Infrastructure-as-a-Service
The Berkeley AMPLab - Collaborative Big Data Research
 The Berkeley AMPLab - Collaborative Big Data Research UC BERKELEY Anthony D. Joseph LASER Summer School September 2013 About Me Education: MIT SB, MS, PhD Joined Univ. of California, Berkeley in 1998 Current
The Berkeley AMPLab - Collaborative Big Data Research UC BERKELEY Anthony D. Joseph LASER Summer School September 2013 About Me Education: MIT SB, MS, PhD Joined Univ. of California, Berkeley in 1998 Current
Application of Predictive Analytics for Better Alignment of Business and IT
 Application of Predictive Analytics for Better Alignment of Business and IT Boris Zibitsker, PhD bzibitsker@beznext.com July 25, 2014 Big Data Summit - Riga, Latvia About the Presenter Boris Zibitsker
Application of Predictive Analytics for Better Alignment of Business and IT Boris Zibitsker, PhD bzibitsker@beznext.com July 25, 2014 Big Data Summit - Riga, Latvia About the Presenter Boris Zibitsker
Automating Workload Management for Enterprise-Scale Business Intelligence Systems: Old Problems Just Won t Go Away
 Automating Workload Management for Enterprise-Scale Business Intelligence Systems: Old Problems Just Won t Go Away Umeshwar Dayal umeshwar.dayal@hp.com Harumi Kuno, Janet Weiner, Kevin Wilkinson, Abhay
Automating Workload Management for Enterprise-Scale Business Intelligence Systems: Old Problems Just Won t Go Away Umeshwar Dayal umeshwar.dayal@hp.com Harumi Kuno, Janet Weiner, Kevin Wilkinson, Abhay
PEPPERDATA IN MULTI-TENANT ENVIRONMENTS
 ..................................... PEPPERDATA IN MULTI-TENANT ENVIRONMENTS technical whitepaper June 2015 SUMMARY OF WHAT S WRITTEN IN THIS DOCUMENT If you are short on time and don t want to read the
..................................... PEPPERDATA IN MULTI-TENANT ENVIRONMENTS technical whitepaper June 2015 SUMMARY OF WHAT S WRITTEN IN THIS DOCUMENT If you are short on time and don t want to read the
Statistics-Driven Workload Modeling for the Cloud
 Statistics-Driven Workload Modeling for the Cloud Archana Ganapathi, Yanpei Chen, Armando Fox, Randy Katz, David Patterson Computer Science Division, University of California at Berkeley {archanag, ychen2,
Statistics-Driven Workload Modeling for the Cloud Archana Ganapathi, Yanpei Chen, Armando Fox, Randy Katz, David Patterson Computer Science Division, University of California at Berkeley {archanag, ychen2,
Where We Are. References. Cloud Computing. Levels of Service. Cloud Computing History. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 25: DBMS-as-a-service and NoSQL We learned quite a bit about data management see course calendar Three topics left: DBMS-as-a-service and NoSQL
Where We Are Introduction to Data Management CSE 344 Lecture 25: DBMS-as-a-service and NoSQL We learned quite a bit about data management see course calendar Three topics left: DBMS-as-a-service and NoSQL
Heterogeneity-Aware Resource Allocation and Scheduling in the Cloud
 Heterogeneity-Aware Resource Allocation and Scheduling in the Cloud Gunho Lee, Byung-Gon Chun, Randy H. Katz University of California, Berkeley, Yahoo! Research Abstract Data analytics are key applications
Heterogeneity-Aware Resource Allocation and Scheduling in the Cloud Gunho Lee, Byung-Gon Chun, Randy H. Katz University of California, Berkeley, Yahoo! Research Abstract Data analytics are key applications
Performance Modeling of MapReduce Jobs in Heterogeneous Cloud Environments Zhuoyao Zhang University of Pennsylvania zhuoyao@seas.upenn.
 Performance Modeling of MapReduce Jobs in Heterogeneous Cloud Environments Zhuoyao Zhang University of Pennsylvania zhuoyao@seas.upenn.edu Ludmila Cherkasova Hewlett-Packard Labs lucy.cherkasova@hp.com
Performance Modeling of MapReduce Jobs in Heterogeneous Cloud Environments Zhuoyao Zhang University of Pennsylvania zhuoyao@seas.upenn.edu Ludmila Cherkasova Hewlett-Packard Labs lucy.cherkasova@hp.com
Herodotos Herodotou Shivnath Babu. Duke University
 Herodotos Herodotou Shivnath Babu Duke University Analysis in the Big Data Era Popular option Hadoop software stack Java / C++ / R / Python Pig Hive Jaql Oozie Elastic MapReduce Hadoop HBase MapReduce
Herodotos Herodotou Shivnath Babu Duke University Analysis in the Big Data Era Popular option Hadoop software stack Java / C++ / R / Python Pig Hive Jaql Oozie Elastic MapReduce Hadoop HBase MapReduce
Introduction to Apache YARN Schedulers & Queues
 Introduction to Apache YARN Schedulers & Queues In a nutshell, YARN was designed to address the many limitations (performance/scalability) embedded into Hadoop version 1 (MapReduce & HDFS). Some of the
Introduction to Apache YARN Schedulers & Queues In a nutshell, YARN was designed to address the many limitations (performance/scalability) embedded into Hadoop version 1 (MapReduce & HDFS). Some of the
Database Virtualization: A New Frontier for Database Tuning and Physical Design
 Database Virtualization: A New Frontier for Database Tuning and Physical Design Ahmed A. Soror Ashraf Aboulnaga Kenneth Salem David R. Cheriton School of Computer Science University of Waterloo {aakssoro,
Database Virtualization: A New Frontier for Database Tuning and Physical Design Ahmed A. Soror Ashraf Aboulnaga Kenneth Salem David R. Cheriton School of Computer Science University of Waterloo {aakssoro,
Cloud Based Dynamic Workload Management
 International Journal of scientific research and management (IJSRM) Volume 2 Issue 6 Pages 940-945 2014 Website: www.ijsrm.in ISSN (e): 2321-3418 Cloud Based Dynamic Workload Management Ms. Betsy M Babykutty
International Journal of scientific research and management (IJSRM) Volume 2 Issue 6 Pages 940-945 2014 Website: www.ijsrm.in ISSN (e): 2321-3418 Cloud Based Dynamic Workload Management Ms. Betsy M Babykutty
Survey on SQL Query Progress Indicator
 Survey on Query Prof. Patil L.V. Mane Urmila P. SKNCOE, Pune. SKNCOE,Pune. Abstract Nowadays, widely used Business Intelligence(BI) and Data Warehousing(DW) technologies are mostly based on long-running
Survey on Query Prof. Patil L.V. Mane Urmila P. SKNCOE, Pune. SKNCOE,Pune. Abstract Nowadays, widely used Business Intelligence(BI) and Data Warehousing(DW) technologies are mostly based on long-running
Managing large clusters resources
 Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Computing at Scale: Resource Scheduling Architectural Evolution and Introduction to Fuxi System
 Computing at Scale: Resource Scheduling Architectural Evolution and Introduction to Fuxi System Renyu Yang( 杨 任 宇 ) Supervised by Prof. Jie Xu Ph.D. student@ Beihang University Research Intern @ Alibaba
Computing at Scale: Resource Scheduling Architectural Evolution and Introduction to Fuxi System Renyu Yang( 杨 任 宇 ) Supervised by Prof. Jie Xu Ph.D. student@ Beihang University Research Intern @ Alibaba
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Research on Job Scheduling Algorithm in Hadoop
 Journal of Computational Information Systems 7: 6 () 5769-5775 Available at http://www.jofcis.com Research on Job Scheduling Algorithm in Hadoop Yang XIA, Lei WANG, Qiang ZHAO, Gongxuan ZHANG School of
Journal of Computational Information Systems 7: 6 () 5769-5775 Available at http://www.jofcis.com Research on Job Scheduling Algorithm in Hadoop Yang XIA, Lei WANG, Qiang ZHAO, Gongxuan ZHANG School of
Spark: Cluster Computing with Working Sets
 Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Autonomic Buffer Pool Configuration in PostgreSQL
 Autonomic Buffer Pool Configuration in PostgreSQL Wendy Powley, Pat Martin, Nailah Ogeer and Wenhu Tian School of Computing Queen s University Kingston, ON, Canada {wendy, martin, ogeer, tian}@cs.queensu.ca
Autonomic Buffer Pool Configuration in PostgreSQL Wendy Powley, Pat Martin, Nailah Ogeer and Wenhu Tian School of Computing Queen s University Kingston, ON, Canada {wendy, martin, ogeer, tian}@cs.queensu.ca
Capacity Management for Oracle Database Machine Exadata v2
 Capacity Management for Oracle Database Machine Exadata v2 Dr. Boris Zibitsker, BEZ Systems NOCOUG 21 Boris Zibitsker Predictive Analytics for IT 1 About Author Dr. Boris Zibitsker, Chairman, CTO, BEZ
Capacity Management for Oracle Database Machine Exadata v2 Dr. Boris Zibitsker, BEZ Systems NOCOUG 21 Boris Zibitsker Predictive Analytics for IT 1 About Author Dr. Boris Zibitsker, Chairman, CTO, BEZ
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Rackspace Cloud Databases and Container-based Virtualization
 Rackspace Cloud Databases and Container-based Virtualization August 2012 J.R. Arredondo @jrarredondo Page 1 of 6 INTRODUCTION When Rackspace set out to build the Cloud Databases product, we asked many
Rackspace Cloud Databases and Container-based Virtualization August 2012 J.R. Arredondo @jrarredondo Page 1 of 6 INTRODUCTION When Rackspace set out to build the Cloud Databases product, we asked many
Non-intrusive Slot Layering in Hadoop
 213 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing Non-intrusive Layering in Hadoop Peng Lu, Young Choon Lee, Albert Y. Zomaya Center for Distributed and High Performance Computing,
213 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing Non-intrusive Layering in Hadoop Peng Lu, Young Choon Lee, Albert Y. Zomaya Center for Distributed and High Performance Computing,
Job Scheduling for MapReduce
 UC Berkeley Job Scheduling for MapReduce Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Scott Shenker, Ion Stoica RAD Lab, * Facebook Inc 1 Motivation Hadoop was designed for large batch jobs
UC Berkeley Job Scheduling for MapReduce Matei Zaharia, Dhruba Borthakur *, Joydeep Sen Sarma *, Scott Shenker, Ion Stoica RAD Lab, * Facebook Inc 1 Motivation Hadoop was designed for large batch jobs
Key Attributes for Analytics in an IBM i environment
 Key Attributes for Analytics in an IBM i environment Companies worldwide invest millions of dollars in operational applications to improve the way they conduct business. While these systems provide significant
Key Attributes for Analytics in an IBM i environment Companies worldwide invest millions of dollars in operational applications to improve the way they conduct business. While these systems provide significant
Scheduling Data Intensive Workloads through Virtualization on MapReduce based Clouds
 ABSTRACT Scheduling Data Intensive Workloads through Virtualization on MapReduce based Clouds 1 B.Thirumala Rao, 2 L.S.S.Reddy Department of Computer Science and Engineering, Lakireddy Bali Reddy College
ABSTRACT Scheduling Data Intensive Workloads through Virtualization on MapReduce based Clouds 1 B.Thirumala Rao, 2 L.S.S.Reddy Department of Computer Science and Engineering, Lakireddy Bali Reddy College
SWISSBOX REVISITING THE DATA PROCESSING SOFTWARE STACK
 3/2/2011 SWISSBOX REVISITING THE DATA PROCESSING SOFTWARE STACK Systems Group Dept. of Computer Science ETH Zürich, Switzerland SwissBox Humboldt University Dec. 2010 Systems Group = www.systems.ethz.ch
3/2/2011 SWISSBOX REVISITING THE DATA PROCESSING SOFTWARE STACK Systems Group Dept. of Computer Science ETH Zürich, Switzerland SwissBox Humboldt University Dec. 2010 Systems Group = www.systems.ethz.ch
Integrating Apache Spark with an Enterprise Data Warehouse
 Integrating Apache Spark with an Enterprise Warehouse Dr. Michael Wurst, IBM Corporation Architect Spark/R/Python base Integration, In-base Analytics Dr. Toni Bollinger, IBM Corporation Senior Software
Integrating Apache Spark with an Enterprise Warehouse Dr. Michael Wurst, IBM Corporation Architect Spark/R/Python base Integration, In-base Analytics Dr. Toni Bollinger, IBM Corporation Senior Software
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Towards Improving MapReduce Task Scheduling Using Online Simulation Based Predictions
 Towards Improving MapReduce Task Scheduling Using Online Simulation Based s Guanying Wang, Aleksandr Khasymski, Krish K. R., Ali R. Butt Department of Computer Science, Virginia Tech Email: {wanggy, khasymskia,
Towards Improving MapReduce Task Scheduling Using Online Simulation Based s Guanying Wang, Aleksandr Khasymski, Krish K. R., Ali R. Butt Department of Computer Science, Virginia Tech Email: {wanggy, khasymskia,
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
6.S897 Large-Scale Systems
 6.S897 Large-Scale Systems Instructor: Matei Zaharia" Fall 2015, TR 2:30-4, 34-301 bit.ly/6-s897 Outline What this course is about" " Logistics" " Datacenter environment What this Course is About Large-scale
6.S897 Large-Scale Systems Instructor: Matei Zaharia" Fall 2015, TR 2:30-4, 34-301 bit.ly/6-s897 Outline What this course is about" " Logistics" " Datacenter environment What this Course is About Large-scale
Nexus: A Common Substrate for Cluster Computing
 Nexus: A Common Substrate for Cluster Computing Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Scott Shenker, Ion Stoica University of California, Berkeley {benh,andyk,matei,alig,adj,shenker,stoica}@cs.berkeley.edu
Nexus: A Common Substrate for Cluster Computing Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Scott Shenker, Ion Stoica University of California, Berkeley {benh,andyk,matei,alig,adj,shenker,stoica}@cs.berkeley.edu
A Berkeley View of Big Data
 A Berkeley View of Big Data Ion Stoica UC Berkeley BEARS February 17, 2011 Big Data is Massive Facebook: 130TB/day: user logs 200-400TB/day: 83 million pictures Google: > 25 PB/day processed data Data
A Berkeley View of Big Data Ion Stoica UC Berkeley BEARS February 17, 2011 Big Data is Massive Facebook: 130TB/day: user logs 200-400TB/day: 83 million pictures Google: > 25 PB/day processed data Data
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center
 : A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, Ion Stoica University of California,
: A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, Ion Stoica University of California,
Universities of Leeds, Sheffield and York http://eprints.whiterose.ac.uk/
 promoting access to White Rose research papers Universities of Leeds, Sheffield and York http://eprints.whiterose.ac.uk/ This is the published version of a Proceedings Paper presented at the 213 IEEE International
promoting access to White Rose research papers Universities of Leeds, Sheffield and York http://eprints.whiterose.ac.uk/ This is the published version of a Proceedings Paper presented at the 213 IEEE International
Database Performance Monitoring and Tuning Using Intelligent Agent Assistants
 Database Performance Monitoring and Tuning Using Intelligent Agent Assistants Sherif Elfayoumy and Jigisha Patel School of Computing, University of North Florida, Jacksonville, FL,USA Abstract - Fast databases
Database Performance Monitoring and Tuning Using Intelligent Agent Assistants Sherif Elfayoumy and Jigisha Patel School of Computing, University of North Florida, Jacksonville, FL,USA Abstract - Fast databases
Improving MapReduce Performance in Heterogeneous Environments
 UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
Quincy: Fair Scheduling for Distributed Computing Clusters
 Quincy: Fair Scheduling for Distributed Computing Clusters Michael Isard, Vijayan Prabhakaran, Jon Currey, Udi Wieder, Kunal Talwar and Andrew Goldberg Microsoft Research, Silicon Valley Mountain View,
Quincy: Fair Scheduling for Distributed Computing Clusters Michael Isard, Vijayan Prabhakaran, Jon Currey, Udi Wieder, Kunal Talwar and Andrew Goldberg Microsoft Research, Silicon Valley Mountain View,
Apache Flink Next-gen data analysis. Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems
 An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems Aysan Rasooli, Douglas G. Down Department of Computing and Software McMaster University {rasooa, downd}@mcmaster.ca Abstract The
An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems Aysan Rasooli, Douglas G. Down Department of Computing and Software McMaster University {rasooa, downd}@mcmaster.ca Abstract The
Big Data Analysis and Its Scheduling Policy Hadoop
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 1, Ver. IV (Jan Feb. 2015), PP 36-40 www.iosrjournals.org Big Data Analysis and Its Scheduling Policy
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 1, Ver. IV (Jan Feb. 2015), PP 36-40 www.iosrjournals.org Big Data Analysis and Its Scheduling Policy
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
How To Make A Cluster Of Workable, Efficient, And Efficient With A Distributed Scheduler
 : A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, Ion Stoica University of California,
: A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, Ion Stoica University of California,
Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center
 Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, Ion Stoica University of
Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center Benjamin Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, Anthony D. Joseph, Randy Katz, Scott Shenker, Ion Stoica University of
MANAGING RESOURCES IN A BIG DATA CLUSTER.
 MANAGING RESOURCES IN A BIG DATA CLUSTER. Gautier Berthou (SICS) EMDC Summer Event 2015 www.hops.io @hopshadoop We are producing lot of data Where does they Come From? On-line services : PBs per day Scientific
MANAGING RESOURCES IN A BIG DATA CLUSTER. Gautier Berthou (SICS) EMDC Summer Event 2015 www.hops.io @hopshadoop We are producing lot of data Where does they Come From? On-line services : PBs per day Scientific
Data Lake In Action: Real-time, Closed Looped Analytics On Hadoop
 1 Data Lake In Action: Real-time, Closed Looped Analytics On Hadoop 2 Pivotal s Full Approach It s More Than Just Hadoop Pivotal Data Labs 3 Why Pivotal Exists First Movers Solve the Big Data Utility Gap
1 Data Lake In Action: Real-time, Closed Looped Analytics On Hadoop 2 Pivotal s Full Approach It s More Than Just Hadoop Pivotal Data Labs 3 Why Pivotal Exists First Movers Solve the Big Data Utility Gap
Affordable, Scalable, Reliable OLTP in a Cloud and Big Data World: IBM DB2 purescale
 WHITE PAPER Affordable, Scalable, Reliable OLTP in a Cloud and Big Data World: IBM DB2 purescale Sponsored by: IBM Carl W. Olofson December 2014 IN THIS WHITE PAPER This white paper discusses the concept
WHITE PAPER Affordable, Scalable, Reliable OLTP in a Cloud and Big Data World: IBM DB2 purescale Sponsored by: IBM Carl W. Olofson December 2014 IN THIS WHITE PAPER This white paper discusses the concept
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP. Eva Andreasson Cloudera
 PROBLEMS USING HADOOP. Eva Andreasson Cloudera") SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
Query Progress Indicator for Open Source Database
 Query Progress Indicator for Open Source Database Urmila Mane 1, Prof. L. V. Patil 2, Dr. S. D. Joshi 3 Department of Information Technology, SKN College of Engineering, Pune, India Abstract: Nowadays
Query Progress Indicator for Open Source Database Urmila Mane 1, Prof. L. V. Patil 2, Dr. S. D. Joshi 3 Department of Information Technology, SKN College of Engineering, Pune, India Abstract: Nowadays
<Insert Picture Here> Best Practices for Extreme Performance with Data Warehousing on Oracle Database
 1 Best Practices for Extreme Performance with Data Warehousing on Oracle Database Rekha Balwada Principal Product Manager Agenda Parallel Execution Workload Management on Data Warehouse
1 Best Practices for Extreme Performance with Data Warehousing on Oracle Database Rekha Balwada Principal Product Manager Agenda Parallel Execution Workload Management on Data Warehouse
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
From GWS to MapReduce: Google s Cloud Technology in the Early Days
 Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu lingu@ieee.org MapReduce/Hadoop
Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu lingu@ieee.org MapReduce/Hadoop
Oracle Database 10g. Page # The Self-Managing Database. Agenda. Benoit Dageville Oracle Corporation benoit.dageville@oracle.com
 Oracle Database 10g The Self-Managing Database Benoit Dageville Oracle Corporation benoit.dageville@oracle.com Agenda Oracle10g: Oracle s first generation of self-managing database Oracle s Approach to
Oracle Database 10g The Self-Managing Database Benoit Dageville Oracle Corporation benoit.dageville@oracle.com Agenda Oracle10g: Oracle s first generation of self-managing database Oracle s Approach to
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Characterizing Task Usage Shapes in Google s Compute Clusters
 Characterizing Task Usage Shapes in Google s Compute Clusters Qi Zhang University of Waterloo qzhang@uwaterloo.ca Joseph L. Hellerstein Google Inc. jlh@google.com Raouf Boutaba University of Waterloo rboutaba@uwaterloo.ca
Characterizing Task Usage Shapes in Google s Compute Clusters Qi Zhang University of Waterloo qzhang@uwaterloo.ca Joseph L. Hellerstein Google Inc. jlh@google.com Raouf Boutaba University of Waterloo rboutaba@uwaterloo.ca
Big Data Analytics Platform @ Nokia
 Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Evaluating Task Scheduling in Hadoop-based Cloud Systems
 2013 IEEE International Conference on Big Data Evaluating Task Scheduling in Hadoop-based Cloud Systems Shengyuan Liu, Jungang Xu College of Computer and Control Engineering University of Chinese Academy
2013 IEEE International Conference on Big Data Evaluating Task Scheduling in Hadoop-based Cloud Systems Shengyuan Liu, Jungang Xu College of Computer and Control Engineering University of Chinese Academy
A Framework for Automated Database TuningUsing Dynamic SGA Parameters and Basic Operating System Utilities
 Database Systems Journal vol. III, no. 4/2012 25 A Framework for Automated Database TuningUsing Dynamic SGA Parameters and Basic Operating System Utilities Hitesh KUMAR SHARMA1, Aditya SHASTRI2, Ranjit
Database Systems Journal vol. III, no. 4/2012 25 A Framework for Automated Database TuningUsing Dynamic SGA Parameters and Basic Operating System Utilities Hitesh KUMAR SHARMA1, Aditya SHASTRI2, Ranjit
Preemptive ReduceTask Scheduling for Fair and Fast Job Completion
 Preemptive ReduceTask Scheduling for Fair and Fast Job Completion Yandong Wang Jian Tan Weikuan Yu Li Zhang Xiaoqiao Meng Auburn University IBM T.J Watson Research {wangyd,wkyu}@auburn.edu {tanji,zhangli,xmeng}@us.ibm.com
Preemptive ReduceTask Scheduling for Fair and Fast Job Completion Yandong Wang Jian Tan Weikuan Yu Li Zhang Xiaoqiao Meng Auburn University IBM T.J Watson Research {wangyd,wkyu}@auburn.edu {tanji,zhangli,xmeng}@us.ibm.com
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
The Improved Job Scheduling Algorithm of Hadoop Platform
 The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: wulinzhi1001@163.com
The Improved Job Scheduling Algorithm of Hadoop Platform Yingjie Guo a, Linzhi Wu b, Wei Yu c, Bin Wu d, Xiaotian Wang e a,b,c,d,e University of Chinese Academy of Sciences 100408, China b Email: wulinzhi1001@163.com
Task Scheduling in Hadoop
 Task Scheduling in Hadoop Sagar Mamdapure Munira Ginwala Neha Papat SAE,Kondhwa SAE,Kondhwa SAE,Kondhwa Abstract Hadoop is widely used for storing large datasets and processing them efficiently under distributed
Task Scheduling in Hadoop Sagar Mamdapure Munira Ginwala Neha Papat SAE,Kondhwa SAE,Kondhwa SAE,Kondhwa Abstract Hadoop is widely used for storing large datasets and processing them efficiently under distributed
Cost-Effective Business Intelligence with Red Hat and Open Source
 Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
What s next for the Berkeley Data Analytics Stack?
 What s next for the Berkeley Data Analytics Stack? Michael Franklin June 30th 2014 Spark Summit San Francisco UC BERKELEY AMPLab: Collaborative Big Data Research 60+ Students, Postdocs, Faculty and Staff
What s next for the Berkeley Data Analytics Stack? Michael Franklin June 30th 2014 Spark Summit San Francisco UC BERKELEY AMPLab: Collaborative Big Data Research 60+ Students, Postdocs, Faculty and Staff
How To Handle Big Data With A Data Scientist
 III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
A Hadoop MapReduce Performance Prediction Method
 A Hadoop MapReduce Performance Prediction Method Ge Song, Zide Meng, Fabrice Huet, Frederic Magoules, Lei Yu and Xuelian Lin University of Nice Sophia Antipolis, CNRS, I3S, UMR 7271, France Ecole Centrale
A Hadoop MapReduce Performance Prediction Method Ge Song, Zide Meng, Fabrice Huet, Frederic Magoules, Lei Yu and Xuelian Lin University of Nice Sophia Antipolis, CNRS, I3S, UMR 7271, France Ecole Centrale
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
Scheduling. Yücel Saygın. These slides are based on your text book and on the slides prepared by Andrew S. Tanenbaum
 Scheduling Yücel Saygın These slides are based on your text book and on the slides prepared by Andrew S. Tanenbaum 1 Scheduling Introduction to Scheduling (1) Bursts of CPU usage alternate with periods
Scheduling Yücel Saygın These slides are based on your text book and on the slides prepared by Andrew S. Tanenbaum 1 Scheduling Introduction to Scheduling (1) Bursts of CPU usage alternate with periods
since 2009. His interests include cloud computing, distributed computing, and microeconomic applications in computer science. alig@cs.berkeley.
 PROGRAMMING Mesos Flexible Resource Sharing for the Cloud BENJAMIN HINDMAN, ANDY KONWINSKI, MATEI ZAHARIA, ALI GHODSI, ANTHONY D. JOSEPH, RANDY H. KATZ, SCOTT SHENKER, AND ION STOICA Benjamin Hindman is
PROGRAMMING Mesos Flexible Resource Sharing for the Cloud BENJAMIN HINDMAN, ANDY KONWINSKI, MATEI ZAHARIA, ALI GHODSI, ANTHONY D. JOSEPH, RANDY H. KATZ, SCOTT SHENKER, AND ION STOICA Benjamin Hindman is
A Framework for Performance Analysis and Tuning in Hadoop Based Clusters
 A Framework for Performance Analysis and Tuning in Hadoop Based Clusters Garvit Bansal Anshul Gupta Utkarsh Pyne LNMIIT, Jaipur, India Email: [garvit.bansal anshul.gupta utkarsh.pyne] @lnmiit.ac.in Manish
A Framework for Performance Analysis and Tuning in Hadoop Based Clusters Garvit Bansal Anshul Gupta Utkarsh Pyne LNMIIT, Jaipur, India Email: [garvit.bansal anshul.gupta utkarsh.pyne] @lnmiit.ac.in Manish
HP Vertica Concurrency and Workload Management
 Technical white paper HP Vertica Concurrency and Workload Management Version 2.0 HP Big Data Platform Presales January, 2015 Table of Contents 1. Introduction... 2 2. Concurrency... 2 2.1 Concurrency vs.
Technical white paper HP Vertica Concurrency and Workload Management Version 2.0 HP Big Data Platform Presales January, 2015 Table of Contents 1. Introduction... 2 2. Concurrency... 2 2.1 Concurrency vs.
Cloud computing The cloud as a pool of shared hadrware and software resources
 Cloud computing The cloud as a pool of shared hadrware and software resources cloud Towards SLA-oriented Cloud Computing middleware layers (e.g. application servers) operating systems, virtual machines
Cloud computing The cloud as a pool of shared hadrware and software resources cloud Towards SLA-oriented Cloud Computing middleware layers (e.g. application servers) operating systems, virtual machines
GraySort on Apache Spark by Databricks
 GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
IJRIT International Journal of Research in Information Technology, Volume 2, Issue 4, April 2014, Pg: 697-701 STARFISH
 International Journal of Research in Information Technology (IJRIT) www.ijrit.com ISSN 2001-5569 A Self-Tuning System for Big Data Analytics - STARFISH Y. Sai Pramoda 1, C. Mary Sindhura 2, T. Hareesha
International Journal of Research in Information Technology (IJRIT) www.ijrit.com ISSN 2001-5569 A Self-Tuning System for Big Data Analytics - STARFISH Y. Sai Pramoda 1, C. Mary Sindhura 2, T. Hareesha
Fast Data in the Era of Big Data: Twitter s Real-
 Fast Data in the Era of Big Data: Twitter s Real- Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Presented by: Rania Ibrahim 1 AGENDA Motivation
Fast Data in the Era of Big Data: Twitter s Real- Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Presented by: Rania Ibrahim 1 AGENDA Motivation
System Behavior Analysis by Machine Learning
 CSC456 OS Survey Yuncheng Li raingomm@gmail.com December 6, 2012 Table of contents 1 Motivation Background 2 3 4 Table of Contents Motivation Background 1 Motivation Background 2 3 4 Scenarios Motivation
CSC456 OS Survey Yuncheng Li raingomm@gmail.com December 6, 2012 Table of contents 1 Motivation Background 2 3 4 Table of Contents Motivation Background 1 Motivation Background 2 3 4 Scenarios Motivation
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open