Performance Optimization Techniques and Tools for Data-Intensive Computation Platforms
|
|
|
- Margaret Garrison
- 8 years ago
- Views:
Transcription
1 Performance Optimization Techniques and Tools for Data-Intensive Computation Platforms Licentiate Seminar Presentation June 11, KTH Kista, Sweden Vasiliki Kalavri

2 Outline 1. Introduction & Research Objectives 2. Background 3. Contributions State-of-the-Art Survey on MapReduce Integration of Pig and Stratosphere Approximate Results in MapReduce Results Materialization and Reuse Asymmetry in Large-Scale Graph Analysis 4. Conclusions & Future Work

3 Introduction

4 The Big Data Era " information that can't be processed or analyzed using traditional processes or tools " Understanding Big Data, Book by IBM Research, 2012 " data whose size forces us to look beyond the tried-and-true methods that are prevalent at that time " The Pathologies of Big Data, Adam Jacobs, Communications of the ACM 4


5 Big Data Use-Cases 5

6 The 3 Vs of Big Data Volume: Facebook reports 15TB of raw compressed data per day (in 2010!) Variety: Relational data, xml, json, clicks, social interactions, purchase logs, raw text etc. Velocity: 100 hours of video are uploaded to YouTube every minute; 58 million tweets per day 6

7 Big Data processing is *slow* MapReduce-like batch processing can be 10x or more slower than RDBMS Jobs may take several hours before they return a result original comic at: 7

8 Research Objective To make data-intensive computation platforms faster, by reducing: the dataset sizes the amount of computation Avoid redundancy in data and computation 8

9 Research Questions Can we improve performance while: maintaining application transparency? being system-independent? keeping user involvement to the minimum? What are the trade-offs? 9

10 Background

11 Common design choices Shared-nothing clusters of commodity machines Programming models that express dataparallelism and abstract communication Fault-tolerant distributed storage Incentive to maximize data locality 11

12 Typical Big Data Architecture 12

13 MapReduce/Hadoop A programming abstraction and open-source implementation that transparently handles parallelization data distribution fault-tolerance Inspired by the functional map and reduce primitives Operates on key-value pairs 13


14 MR Programming Model 14
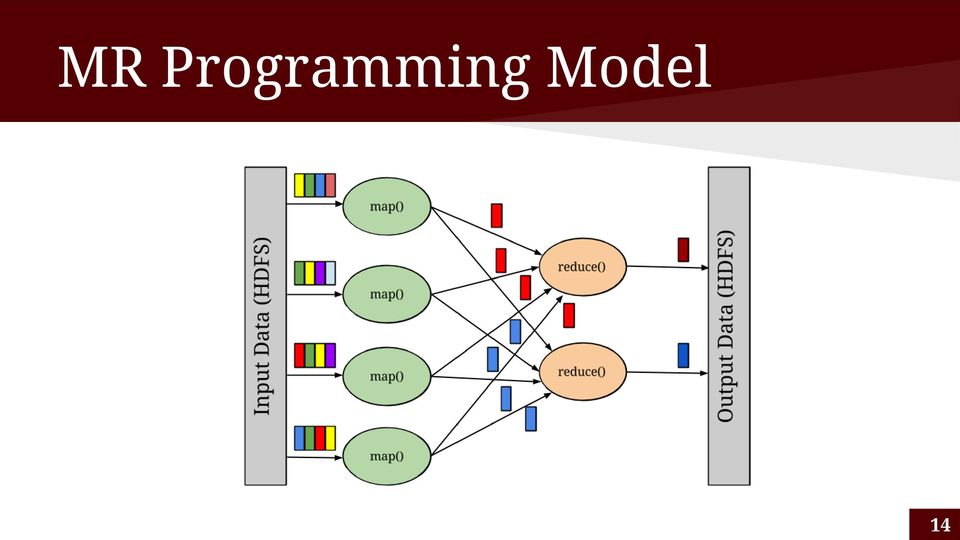
15 Apache Pig A high-level dataflow system A high-level language: Pig Latin A set of compilers that generate MapReduce jobs Pig Latin Program Parser Logical Optimizer MR Compiler Hadoop Job Manager 15

16 Why Pig? Simple language: Pig Latin easy for users familiar with SQL/scripting lower cost to write and maintain Common Operators already provided JOIN, GROUP, FILTER, SORT Scalability and Fault-tolerance of Hadoop 16


17 Plan Compilation Logical Plan Physical Plan MapReduce Plan 17

18 MapReduce Online Input Record map function mapper Output Record Input Record Local Disk HTTP request reducer map function Output Record TCP- push/pull mapper reducer In original MR, a reducer task cannot fetch the output of a map task which hasn't committed its output to disk 18

19 MROnline Advantages Better performance through pipelining avoid frequent materialization improve reducers response times Supports online aggregation return partial results Improves utilization reduce tasks do not block waiting for mappers to finish (in the same job) 19

20 Stratosphere A distributed data processing system Directed Acyclic Graphs (DAGs) of sources, sinks and operators Abstracts data partitioning, parallelism, communication Input Source 1 Input Source 2 map filter reduce join Output Sink 20


21 The Stratosphere Stack 21
22 Contributions
23 Thesis Contributions State-of-the-Art Survey on MapReduce Integration of Pig and Stratosphere Approximate Results in MapReduce Results Materialization and Reuse Asymmetry in Large-Scale Graph Analysis 23
24 The 11th IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA 13) MapReduce: Limitations, Optimizations and Open Issues Vasiliki Kalavri, Vladimir Vlassov 17 July 2013, Melbourne, Australia
25 Motivation Numerous Hadoop variations and enhancements over the past few years each branching out from vanilla Hadoop hard to choose the appropriate tool no categorization / classification exists In our survey overview existing variations classify the optimizations identify trends and open issues 25
26 MapReduce Limitations Performance initialization, scheduling, coordination data materialization - intensive disk I/O Programming Model single-input operators fixed processing pipeline - job chaining no support for iterations Configuration and Automation sensitive to configuration parameters complicated tuning 26
27 Systems Summary System Open-Source, Available? Major Contribution Transparent MR Online Pipelining, Online aggregation yes yes EARL Fast approximate results yes no Hadoop++, HAIL Improve relational operations no yes / no MRShare Concurrent work sharing no no ReStore Reuse of previous computations no yes SkewTune Automatic skew mitigation no yes CoHadoop Data colocation no no HaLoop Iterations support yes no Incoop Incremental processing no no Starfish Dynamic self-tuning no yes Sailfish I/O minimization, automatic tuning no yes Manimal Automatic data-aware optimizations no yes 27
28 Open Issues No standard benchmark No "typical" MapReduce workload Each system is evaluated using different datasets applications deployments impossible to compare or only compare with vanilla Hadoop Application transparency 28
29 19th International European Conference on Parallel and Distributed Computing (Euro-Par 2013) PonIC: Using Stratosphere to Speed Up Pig Analytics Vasiliki Kalavri1, Vladimir Vlassov1, Per Brand2 1 KTH, 2SICS 30 August 2013, Aachen, Germany

30 Motivation single input operators The limitations and inflexibility of Hadoop are still present in the backend... materialization Replace the execution engine! fixed pipeline 30
31 PonIC: Pig on Input Contracts Pig Latin on Stratosphere translates Pig Logical Plans to Stratosphere DAGs benefits from Stratosphere s flexibility and efficiency benefits from the optimizer and the automatic physical selection strategies application transparent 31
32 Plan Optimization in PonIC Simpler translation process Simpler final plans No need for load-store glue between jobs 2 levels of plan optimization 32
33 PonIC vs. Pig/MapReduce 33
34 Conclusions Hadoop s 2-stage fixed pipeline and frequent materialization harm Pig s performance Pig can run on another execution engine without loss of expressiveness with possible performance gains Integration with a different backend is possible after the Logical Plan layer 34
35 5th IEEE International Conference on Cloud Computing Technology and Science (CloudCom 2013) Block Sampling: Efficient Accurate Online Aggregation in MapReduce Vasiliki Kalavri, Vaidas Brundza, Vladimir Vlassov 3 December 2013, Bristol, UK


36 Problem and Motivation Big data processing is usually very timeconsuming... but many applications require results really fast or can only use results for a limited window of time Luckily, in many cases results can be useful even before job completion tolerate some inaccuracy benefit from faster answers 36
37 Online Aggregation Apply the reduce function to the data seen so far Use % of input processed to estimate accuracy 37
38 Sampling Challenges Data in HDFS 5 Disk access is terribly slow Random disk access for sampling is even slower Unstructured Data Sample based on what? We don t know the query, we don t know the key or the value! 38
39 The Block Sampling Technique Sample on the block-level, before the data reach the mapper tasks In-memory shuffling for better performance 39
40 Performance - Overhead snapshot freq = 10% 40
41 MapReduce Online vs. Block Sampling Average Temperature Estimation on Weather Data Each dot corresponds to one year (10 in total) MapReduce Online has 100% error (no estimation at all) for some years provides an estimate for all 10 years, after processing 40% of the data 41
42 Conclusions Useful results even before job completion Disk random access is prohibitively expensive efficiently emulate sampling using in-memory shuffling Higher sampling rate improves accuracy but also increases communication costs 42
43 2nd International Conference on Big Data Science and Engineering (BDSE 2013) m2r2: A Framework for Results Materialization and Reuse in High-Level Dataflow Systems for Big Data Vasiliki Kalavri, Hui Shang, Vladimir Vlassov 4 December 2013, Sydney, Australia
44 Motivation Avoid computational redundancies filter out bad records, spam data representation transformations Microsoft has found a 30%-60% similarity in queries submitted for execution A Berkeley MapReduce workload characterization study shows a big need for caching job results 44
45 m2r2: materialize - match - rewrite - reuse A language-independent framework for storing managing and using previous job and sub-job results Operates on the logical plan level, in order to support different languages and backend execution engines 45

46 m2r2 Implementation Prototype on top of Pig/Hadoop Results Cache: HDFS Repository: MySQL Cluster in-memory, highly-available and faulttolerant Garbage Collection: separate module policy on reuse frequency and last access time 46
47 Performance Materialization Overhead Execution time without reuse Speedup re-using sub-jobs 47
48 Conclusions The logical plan is the proper layer to build a language-independent reuse framework When there exists reuse opportunity, query execution time can be immensely reduced 65% on average in our experiments The materialization overhead is rather small and I/O dominant 48
49 2nd International Workshop on Graph Data Management Experiences and Systems (GRADES 2014) Asymmetry in Large-Scale Graph Analysis, Explained Vasiliki Kalavri1, Stephan Ewen2, Kostas Tzoumas2, Vladimir Vlassov1, Volker Markl2, Seif Haridi1 1 KTH, 2TU Berlin
50 Motivation Many of large-scale data processing applications include fixed point iterations social network analysis web graph analysis machine learning 50

51 Asymmetrical Convergence Often, in fixed point iterations, some elements converge faster than others Not all elements require an update in every iteration 51
52 Can we detect the elements that require recomputation and avoid redundant computations? 52
53 Contributions A categorization of optimizations for fixed point iterative graph processing Necessary conditions under which, it is safe to apply optimizations A mapping of existing techniques to graph processing abstractions An implementation of template execution plans Optimized algorithms yield order of magnitude gains! 53
54 Asymmetry in Connected Components 54

55 Iterative Plans - Bulk In each iteration, all elements are computed 55
 of the")
56 Iterative Plans - Dependency In each iteration, only elements whose - at least one - neighbor has changed, are recomputed in each iteration, only changed elements are emitted in W before executing the update function, we need to gather the rest of the dependencies (neighbors values) of the candidates 56

57 Iterative Plans - Incremental In each iteration, only changed elements are recomputed, using only the changed neighbors 57

58 Iterative Plans - Delta In each iteration, only changed elements are recomputed, using only the deltas of changed neighbors 58
59 Iteration Techniques Equivalence Iteration Technique Equivalent to Bulk? Vertex Activation Vertex Update n/a always using values of all inneighbors always if any in-neighbor is updated using values of all inneighbors Incremental step function idempotent and weakly monotonic if any in-neighbor is updated using values of changed in-neighbors Delta step function linear over composition operator if any in-neighbor is updated Bulk Dependency using values of changed in-neighbors 59
60 Iteration Techniques Support in Graph Processing Systems Bulk Dependency Incremental Delta Pregel X X X X GraphLab X X X X GraphX X X X X Powergraph X X X X Stratosphere X X X X System X X X : provided by default : can be easily implemented : possible, but non-intuitive 60
61 Performance - Connected Components 61
62 Performance - PageRank 62
63 Conclusions Graph-processing algorithms can be efficiently implemented using common relational operators Asymmetrical convergence can be detected and if exploited, can lead to order of magnitude performance gains A cost model is needed to choose the most efficient execution plan 63
64 Conclusions & Future Work
65 Conclusions In a data-intensive computation framework the amount of data and computation can be reduced by using more efficient backends sampling caching and reuse detecting inactive parts of the computation flow 65
66 Revisiting Research Questions (1) Can we improve performance while: maintaining application transparency? yes, when re-using the upper layers of the frameworks challenging because most systems are tightly coupled with their backend engines 66
67 Revisiting Research Questions (2) Can we improve performance while: being system-independent? most of the time yes, as systems are very frequently designed based on similar primitives challenging to find the correct level of abstraction 67
68 Revisiting Research Questions (3) Can we improve performance while: keeping user involvement to the minimum? yes, especially when working with high-level systems challenging to automate configuration parameters depending on specific workloads 68
69 Revisiting Research Questions (4) What are the trade-offs? when using an alternative backend translation and compilation overheads, data transformations when sampling results accuracy vs. response time when caching materialization, storage and garbage collection overheads matching and query re-writing when detecting inactive parts tracking dependencies 69
70 Future Work Extend m2r2 to other high-level systems, such as Hive and Shark Design and implement a cost model for fixed point iterative algorithms choose the most efficient plan at runtime Explore optimization opportunities in other frameworks and application domains asynchronous execution, real-time graph processing 70
71 Acknowledgement Erasmus Mundus Joint Doctorate in Distributed Computing (emjd-dc) E2E Clouds Research Project My advisor, Vladimir Vlassov My secondary advisors, Christian Schulte and Peter Van Roy (UCL) Anne Hakansson My co-authors My colleagues at KTH and UCL Anonymous reviwers 71
72 Performance Optimization Techniques and Tools for Data-Intensive Computation Platforms Licentiate Seminar Presentation June 11, KTH Kista, Sweden Vasiliki Kalavri
How To Optimize Data Processing In A Distributed System
 Performance Optimization Techniques and Tools for Data-Intensive Computation Platforms An Overview of Performance Limitations in Big Data Systems and Proposed Optimizations VASILIKI KALAVRI Licentiate
Performance Optimization Techniques and Tools for Data-Intensive Computation Platforms An Overview of Performance Limitations in Big Data Systems and Proposed Optimizations VASILIKI KALAVRI Licentiate
Apache Flink Next-gen data analysis. Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
The Stratosphere Big Data Analytics Platform
 The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science amir@sics.se June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science amir@sics.se June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect
 Matteo Migliavacca (mm53@kent) School of Computing Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect Simple past - Traditional
Matteo Migliavacca (mm53@kent) School of Computing Conjugating data mood and tenses: Simple past, infinite present, fast continuous, simpler imperative, conditional future perfect Simple past - Traditional
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Accelerating Hadoop MapReduce Using an In-Memory Data Grid
 Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: bdg@qburst.com Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Exploring the Efficiency of Big Data Processing with Hadoop MapReduce
 Exploring the Efficiency of Big Data Processing with Hadoop MapReduce Brian Ye, Anders Ye School of Computer Science and Communication (CSC), Royal Institute of Technology KTH, Stockholm, Sweden Abstract.
Exploring the Efficiency of Big Data Processing with Hadoop MapReduce Brian Ye, Anders Ye School of Computer Science and Communication (CSC), Royal Institute of Technology KTH, Stockholm, Sweden Abstract.
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Unified Big Data Analytics Pipeline. 连 城 lian@databricks.com
 Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
From GWS to MapReduce: Google s Cloud Technology in the Early Days
 Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu lingu@ieee.org MapReduce/Hadoop
Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu lingu@ieee.org MapReduce/Hadoop
A Survey of Large-Scale Analytical Query Processing in MapReduce
 The VLDB Journal manuscript No. (will be inserted by the editor) A Survey of Large-Scale Analytical Query Processing in MapReduce Christos Doulkeridis Kjetil Nørvåg Received: date / Accepted: date Abstract
The VLDB Journal manuscript No. (will be inserted by the editor) A Survey of Large-Scale Analytical Query Processing in MapReduce Christos Doulkeridis Kjetil Nørvåg Received: date / Accepted: date Abstract
Constructing a Data Lake: Hadoop and Oracle Database United!
 Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
How To Handle Big Data With A Data Scientist
 III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
Lecture 10 - Functional programming: Hadoop and MapReduce
 Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
SQL + NOSQL + NEWSQL + REALTIME FOR INVESTMENT BANKS
 Enterprise Data Problems in Investment Banks BigData History and Trend Driven by Google CAP Theorem for Distributed Computer System Open Source Building Blocks: Hadoop, Solr, Storm.. 3548 Hypothetical
Enterprise Data Problems in Investment Banks BigData History and Trend Driven by Google CAP Theorem for Distributed Computer System Open Source Building Blocks: Hadoop, Solr, Storm.. 3548 Hypothetical
Big Data Analysis and HADOOP
 Big Data Analysis and HADOOP B.Jegatheswari and M.Muthulakshmi III year MCA AVC College of engineering, Mayiladuthurai. Email ID: jjega.cool@gmail.com Mobile: 8220380693 Abstract: - Digital universe with
Big Data Analysis and HADOOP B.Jegatheswari and M.Muthulakshmi III year MCA AVC College of engineering, Mayiladuthurai. Email ID: jjega.cool@gmail.com Mobile: 8220380693 Abstract: - Digital universe with
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM
 Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
ISSN: 2320-1363 CONTEXTUAL ADVERTISEMENT MINING BASED ON BIG DATA ANALYTICS
 CONTEXTUAL ADVERTISEMENT MINING BASED ON BIG DATA ANALYTICS A.Divya *1, A.M.Saravanan *2, I. Anette Regina *3 MPhil, Research Scholar, Muthurangam Govt. Arts College, Vellore, Tamilnadu, India Assistant
CONTEXTUAL ADVERTISEMENT MINING BASED ON BIG DATA ANALYTICS A.Divya *1, A.M.Saravanan *2, I. Anette Regina *3 MPhil, Research Scholar, Muthurangam Govt. Arts College, Vellore, Tamilnadu, India Assistant
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Manifest for Big Data Pig, Hive & Jaql
 Manifest for Big Data Pig, Hive & Jaql Ajay Chotrani, Priyanka Punjabi, Prachi Ratnani, Rupali Hande Final Year Student, Dept. of Computer Engineering, V.E.S.I.T, Mumbai, India Faculty, Computer Engineering,
Manifest for Big Data Pig, Hive & Jaql Ajay Chotrani, Priyanka Punjabi, Prachi Ratnani, Rupali Hande Final Year Student, Dept. of Computer Engineering, V.E.S.I.T, Mumbai, India Faculty, Computer Engineering,
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Apache Hadoop Ecosystem
 Apache Hadoop Ecosystem Rim Moussa ZENITH Team Inria Sophia Antipolis DataScale project rim.moussa@inria.fr Context *large scale systems Response time (RIUD ops: one hit, OLTP) Time Processing (analytics:
Apache Hadoop Ecosystem Rim Moussa ZENITH Team Inria Sophia Antipolis DataScale project rim.moussa@inria.fr Context *large scale systems Response time (RIUD ops: one hit, OLTP) Time Processing (analytics:
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Machine Learning over Big Data
 Machine Learning over Big Presented by Fuhao Zou fuhao@hust.edu.cn Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Machine Learning over Big Presented by Fuhao Zou fuhao@hust.edu.cn Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Big Data. White Paper. Big Data Executive Overview WP-BD-10312014-01. Jafar Shunnar & Dan Raver. Page 1 Last Updated 11-10-2014
 White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
GraySort on Apache Spark by Databricks
 GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
MapReduce and Hadoop Distributed File System V I J A Y R A O
 MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
Duke University http://www.cs.duke.edu/starfish
 Herodotos Herodotou, Harold Lim, Fei Dong, Shivnath Babu Duke University http://www.cs.duke.edu/starfish Practitioners of Big Data Analytics Google Yahoo! Facebook ebay Physicists Biologists Economists
Herodotos Herodotou, Harold Lim, Fei Dong, Shivnath Babu Duke University http://www.cs.duke.edu/starfish Practitioners of Big Data Analytics Google Yahoo! Facebook ebay Physicists Biologists Economists
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Machine- Learning Summer School - 2015
 Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
Play with Big Data on the Shoulders of Open Source
 OW2 Open Source Corporate Network Meeting Play with Big Data on the Shoulders of Open Source Liu Jie Technology Center of Software Engineering Institute of Software, Chinese Academy of Sciences 2012-10-19
OW2 Open Source Corporate Network Meeting Play with Big Data on the Shoulders of Open Source Liu Jie Technology Center of Software Engineering Institute of Software, Chinese Academy of Sciences 2012-10-19
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Towards an Optimized Big Data Processing System
 Towards an Optimized Big Data Processing System The Doctoral Symposium of the IEEE/ACM CCGrid 2013 Delft, The Netherlands Bogdan Ghiţ, Alexandru Iosup, and Dick Epema Parallel and Distributed Systems Group
Towards an Optimized Big Data Processing System The Doctoral Symposium of the IEEE/ACM CCGrid 2013 Delft, The Netherlands Bogdan Ghiţ, Alexandru Iosup, and Dick Epema Parallel and Distributed Systems Group
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
W H I T E P A P E R. Deriving Intelligence from Large Data Using Hadoop and Applying Analytics. Abstract
 W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
What s next for the Berkeley Data Analytics Stack?
 What s next for the Berkeley Data Analytics Stack? Michael Franklin June 30th 2014 Spark Summit San Francisco UC BERKELEY AMPLab: Collaborative Big Data Research 60+ Students, Postdocs, Faculty and Staff
What s next for the Berkeley Data Analytics Stack? Michael Franklin June 30th 2014 Spark Summit San Francisco UC BERKELEY AMPLab: Collaborative Big Data Research 60+ Students, Postdocs, Faculty and Staff
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Ali Ghodsi Head of PM and Engineering Databricks
 Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Juwei Shi, Yunjie Qiu, Umar Farooq Minhas, Limei Jiao, Chen Wang, Berthold Reinwald, and Fatma Özcan IBM Research China IBM Almaden
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Juwei Shi, Yunjie Qiu, Umar Farooq Minhas, Limei Jiao, Chen Wang, Berthold Reinwald, and Fatma Özcan IBM Research China IBM Almaden
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing
 A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics
 Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at spoozhikala@stratapps.com.
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at spoozhikala@stratapps.com.
FOUNDATIONS OF A CROSS- DISCIPLINARY PEDAGOGY FOR BIG DATA
 FOUNDATIONS OF A CROSSDISCIPLINARY PEDAGOGY FOR BIG DATA Joshua Eckroth Stetson University DeLand, Florida 3867402519 jeckroth@stetson.edu ABSTRACT The increasing awareness of big data is transforming
FOUNDATIONS OF A CROSSDISCIPLINARY PEDAGOGY FOR BIG DATA Joshua Eckroth Stetson University DeLand, Florida 3867402519 jeckroth@stetson.edu ABSTRACT The increasing awareness of big data is transforming
The Big Data Ecosystem at LinkedIn. Presented by Zhongfang Zhuang
 The Big Data Ecosystem at LinkedIn Presented by Zhongfang Zhuang Based on the paper The Big Data Ecosystem at LinkedIn, written by Roshan Sumbaly, Jay Kreps, and Sam Shah. The Ecosystems Hadoop Ecosystem
The Big Data Ecosystem at LinkedIn Presented by Zhongfang Zhuang Based on the paper The Big Data Ecosystem at LinkedIn, written by Roshan Sumbaly, Jay Kreps, and Sam Shah. The Ecosystems Hadoop Ecosystem
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
CitusDB Architecture for Real-Time Big Data
 CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
Big Data Too Big To Ignore
 Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Introduction to NoSQL Databases and MapReduce. Tore Risch Information Technology Uppsala University 2014-05-12
 Introduction to NoSQL Databases and MapReduce Tore Risch Information Technology Uppsala University 2014-05-12 What is a NoSQL Database? 1. A key/value store Basic index manager, no complete query language
Introduction to NoSQL Databases and MapReduce Tore Risch Information Technology Uppsala University 2014-05-12 What is a NoSQL Database? 1. A key/value store Basic index manager, no complete query language
Interactive Analytical Processing in Big Data Systems,BDGS: AMay Scalable 23, 2014 Big Data1 Generat / 20
 Interactive Analytical Processing in Big Data Systems,BDGS: A Scalable Big Data Generator Suite in Big Data Benchmarking,Study about DataSet May 23, 2014 Interactive Analytical Processing in Big Data Systems,BDGS:
Interactive Analytical Processing in Big Data Systems,BDGS: A Scalable Big Data Generator Suite in Big Data Benchmarking,Study about DataSet May 23, 2014 Interactive Analytical Processing in Big Data Systems,BDGS:
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Analytics in the Cloud. Peter Sirota, GM Elastic MapReduce
 Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Analyzing Big Data at. Web 2.0 Expo, 2010 Kevin Weil @kevinweil
 Analyzing Big Data at Web 2.0 Expo, 2010 Kevin Weil @kevinweil Three Challenges Collecting Data Large-Scale Storage and Analysis Rapid Learning over Big Data My Background Studied Mathematics and Physics
Analyzing Big Data at Web 2.0 Expo, 2010 Kevin Weil @kevinweil Three Challenges Collecting Data Large-Scale Storage and Analysis Rapid Learning over Big Data My Background Studied Mathematics and Physics
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Big Data looks Tiny from the Stratosphere
 Volker Markl http://www.user.tu-berlin.de/marklv volker.markl@tu-berlin.de Big Data looks Tiny from the Stratosphere Data and analyses are becoming increasingly complex! Size Freshness Format/Media Type
Volker Markl http://www.user.tu-berlin.de/marklv volker.markl@tu-berlin.de Big Data looks Tiny from the Stratosphere Data and analyses are becoming increasingly complex! Size Freshness Format/Media Type
Data Management in the Cloud
 Data Management in the Cloud Ryan Stern stern@cs.colostate.edu : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
Data Management in the Cloud Ryan Stern stern@cs.colostate.edu : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
Managing large clusters resources
 Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Large-Scale Data Processing
 Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Adapting scientific computing problems to cloud computing frameworks Ph.D. Thesis. Pelle Jakovits
 Adapting scientific computing problems to cloud computing frameworks Ph.D. Thesis Pelle Jakovits Outline Problem statement State of the art Approach Solutions and contributions Current work Conclusions
Adapting scientific computing problems to cloud computing frameworks Ph.D. Thesis Pelle Jakovits Outline Problem statement State of the art Approach Solutions and contributions Current work Conclusions
Report: Declarative Machine Learning on MapReduce (SystemML)
") Report: Declarative Machine Learning on MapReduce (SystemML) Jessica Falk ETH-ID 11-947-512 May 28, 2014 1 Introduction SystemML is a system used to execute machine learning (ML) algorithms in HaDoop,
Report: Declarative Machine Learning on MapReduce (SystemML) Jessica Falk ETH-ID 11-947-512 May 28, 2014 1 Introduction SystemML is a system used to execute machine learning (ML) algorithms in HaDoop,
Large-Scale Data Sets Clustering Based on MapReduce and Hadoop
 Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Aligning Your Strategic Initiatives with a Realistic Big Data Analytics Roadmap
 Aligning Your Strategic Initiatives with a Realistic Big Data Analytics Roadmap 3 key strategic advantages, and a realistic roadmap for what you really need, and when 2012, Cognizant Topics to be discussed
Aligning Your Strategic Initiatives with a Realistic Big Data Analytics Roadmap 3 key strategic advantages, and a realistic roadmap for what you really need, and when 2012, Cognizant Topics to be discussed
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS
 A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum