Gestão e Tratamento da Informação
|
|
|
- Miles Frank Mitchell
- 10 years ago
- Views:
Transcription
1 Web Data Extraction: Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Slides baseados nos slides oficiais do livro Web Data Mining c Bing Liu, Springer, December, 2006.

2 Outline 1 Introduction 2 3

3 Outline 1 Introduction 2 3

4 Introduction A large amount of information on the Web is contained in regularly structured data objects often data records retrieved from databases Such Web data records are important: lists of products and services; Applications: e.g., comparative shopping, meta-search, meta-query, etc. To process this data implies extracting it from semi-structured web pages and converting it to structured information This is done by using wrappers

5 Wrappers Wrappers are small applications or scripts capable of extracting information from semi-structured sources, such as HTML Wrappers can be built manually E.g., using regular expressions, XSLT,... Or automatically Using machine learning techniques

6 Web Data Pages There are two types of data rich pages: List pages Each such page contains one or more lists of data records Each list in a specific region in the page Two types of data records: flat and nested Detail pages Each such page focuses on a single object But can have a lot of related and unrelated information

7 A List Page

8 A Detail Page
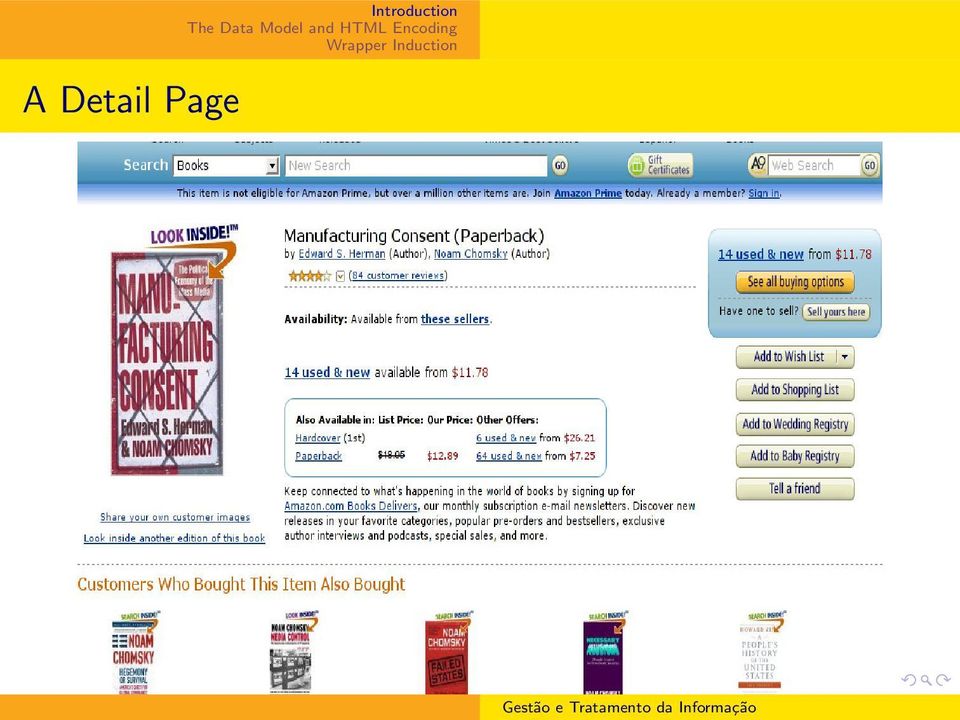
9 Extraction Results Chomsky On Anarchism Noam Chomsky,... $ Manufacturing Consent Edward S. Herman,... $ de septiembre... Noam Chomsky $ Imperial Grand Strategy... Noam Chomsky $

10 Outline 1 Introduction 2 3

11 The Data Model Most Web data can be modeled as nested relations typed objects allowing nested sets and tuples An instance of a type T is simply an element of the domain of T Definition Let B = {B 1, B 2,...,B k } be a set of basic types Each B i is atomic and of domain dom(b i ) If T 1, T 2,...,T n are types, then [T 1, T 2,...,T n ] is a tuple type of domain dom([t 1, T 2,...,T n ]) = {[v 1, v 2,...,v n ] v i dom(t i )} If T is a tuple type, then {T } is a set type with domain dom({t }) = 2 dom(t)
 = {[v 1, v 2,.")
12 An Example Nested Tuple Classic flat relations are of un-nested or flat set types Nested relations are of arbitrary set types An example type tuple book (title: string; author: set (name: string); prices: set (use: string; price: number;)) An example tuple [ Manufacturing Consent, { Edward S. Herman, Noam Chomsky }, {[ used, 4.78], [ new, 8.95]}]

13 Type Trees Definition A basic type B i is a leaf A tuple type [T 1, T 2,...,T n ] is a tree rooted at a tuple node with n sub-trees, one for each T i A set type {T } is a tree rooted at a set node with one sub-tree We introduce a labeling of a type tree, which is defined recursively: If a set node is labeled Φ, then its child is labeled Φ.0 If a tuple node is labeled Φ, then its n children are labeled Φ.1,...,Φ.n

14 An Example Type Tree tuple (book) string (title) set (author) set (prices) string (name) tuple (price) string (use) number (price) Note: attribute names are not part of the type tree.
 Note: attribute names are not part of")
15 Instance Trees Definition An instance (constant) of a basic type is a leaf A tuple instance [v 1, v 2,...,v n ] forms a tree rooted at a tuple node with n children or sub-trees representing attribute values v 1, v 2,...,v n A set instance {e 1, e 2,...,e n } forms a set node with n children or sub-trees representing the set elements e 1, e 2,...,e n Note: A tuple instance is usually called a data record

16 An Example Instance Tree tuple Manufacturing Consent set set Edward S. Herman Noam Chomsky tuple tuple used 4.78 new 8.95

17 HTML Encoding of Data There are no designated tags for each type HTML was not designed as a data encoding language Any HTML tag can be used for any type For a tuple type, values (also called data items) of different attributes are usually encoded differently to distinguish them and to highlight important items A tuple may be partitioned into several groups or sub-tuples Each group covers a disjoint subset of attributes and may be encoded differently

18 HTML Encoding and Type Trees Definition For leaf node of a basic type Φ, an instance c is encoded with enc(φ : c) = OPEN-TAGS c CLOSE-TAGS where OPEN-TAGS is a sequence of open HTML tags and CLOSE-TAGS is a sequence of HTML close tags

19 HTML Encoding and Type Trees (cont.) A tuple node of type [Φ.1, Φ.2,...,Φ.n] is partitioned into h groups: Φ.1,...,Φ.e, Φ.(e + 1),...,Φ.g,..., Φ.(k + 1),...,Φ.n An instance [v 1, v 2,...,v n ] is encoded with: enc(φ : [v.1, v.2,...,v.n]) = OPEN-TAGS 1 enc(v 1 ) enc(v e ) CLOSE-TAGS 1 OPEN-TAGS 2 enc(v e+1 ) enc(v g ) CLOSE-TAGS 2 OPEN-TAGS h enc(v k+1 ) enc(v n ) CLOSE-TAGS h
![..,v n ] is encoded with: enc(φ : [v.1, v.2,...,v.n]) = OPEN-TAGS 1 enc(v 1 ) enc(v e )](/docs-images/58/4467287/images/page_19.jpg "CLOSE-TAGS 1 OPEN-TAGS 2 enc(v e+1 ) enc(v g ) CLOSE-TAGS 2 OPEN-TAGS h enc(v k+1 ) enc(v n )")
20 HTML Encoding and Type Trees (cont.) For a set node labeled Φ, a non-empty set instance {e 1, e 2,...,e n } is encoded with: enc(φ : {e 1, e 2,...,e n }) = OPEN-TAGS enc(e 1 ), enc(e 2 ),...,enc(e n ) CLOSE-TAGS

21 An Example <p> <h3>manufacturing Consent</h3> <ul> <li>edward S. Herman</li> <li>noam Chomsky</li> </ul> <ul> <li> <strong>used</strong> <it>4.78</it> </li> <li> <strong>new</strong> <it>8.95</it> </li> </ul> </p>
22 Limitations Clearly, this mark-up encoding does not cover all cases in Web pages In fact, each group of a tuple type can be further divided In an actual Web page the encoding may not be done by HTML tags alone Words and punctuation marks can be used
23 Outline 1 Introduction 2 3
24 Wrappers are generated by using machine learning to generate extraction rules The user marks the target items in a few training pages The system learns extraction rules from these pages The rules are applied to extract items from other pages There are many wrapper induction systems WIEN (Kushmerick et al, IJCAI-97) Softmealy (Hsu and Dung, 1998) BWI (Freitag and Kushmerick, AAAI-00) WL2 (Cohen et al. WWW-02) We will focus on Stalker (Muslea et al. Agents-99)
25 Stalker: A Hierarchical System Hierarchical wrapper learning Extraction is isolated at different levels of hierarchy This is suitable for nested data records Each item is extracted independently of others The extraction is done using a tree structure called the EC tree (embedded catalog tree) The EC tree is based on the type tree of the data To extract each target item (a node), the wrapper needs a rule that extracts the item from its parent
26 Extraction Rules Each extraction is done using two rules a start rule and an end rule The start rule identifies the beginning of the node and the end rule identifies the end of the node. This strategy is applicable to both leaf nodes (which represent data items) and list nodes For a list node, list iteration rules are needed to break the list into individual data records (tuple instances)
27 Landmarks The extraction rules are based on the idea of landmarks A landmark is a sequence of consecutive tokens Landmarks are used to locate the beginning and the end of a target item Rules use landmarks to extract the items
28 An Example <p>seller Name:<b>Good Books Inc.</b><br><br> <li>321 Red Street, <i>mullen</i>, Phone 0-<i>485</i> </li> <li>62 Blue Street, <i>finner</i>, Phone (621) </li> <li>543 Yellow Street, <i>pitsher</i>, Phone 0-<i>788</i> </li> <li>321 Orange Street, <i>kingston</i>, Phone: (333) </li></p> To extract the seller name, rule R1 can identify the beginning: R1: SkipTo(<b>) This rule means that the system should start from the beginning of the page and skip all the tokens until it sees the first <b> tag. <b> is a landmark Similarly, to identify the end of the seller name, we use: R2: SkipTo(</b>)
29 An Example (cont.) A rule may not be unique. For example, we can also use the following rules to identify the beginning of the name: or R3: SkiptTo(Name Punctuation HtmlTag ) R4: SkiptTo(Name) SkipTo(<b>) R3 means that we skip everything till the word Name followed by a punctuation symbol and then a HTML tag. In this case, Name Punctuation HtmlTag together is a landmark Punctuation and HtmlTag are wildcards
30 Learning Extraction Rules Stalker uses sequential covering to learn extraction rules for each target item In each iteration, it learns a perfect rule that covers as many positive examples as possible without covering any negative example Once a positive example is covered by a rule, it is removed The algorithm ends when all the positive examples are covered. The result is an ordered list of all learned rules
31 The Stalker Algorithm Algorithm LearnRules(examples) 1 rule 2 while examples do 1 disjunct LearnDisjunt(examples) 2 remove all items in examples covered by disjunct 3 add disjunct to rule 3 return rule
32 The Stalker Algorithm (cont.) Algorithm LearnDisjunct(examples) 1 seed the shortest example 2 candidates GetInitialCandidates(seed) 3 while candidates do 1 D BestDisjunct(candidates) 2 if D is a perfect disjunct then 1 return D 3 remove D from candidates 4 candidates candidates Refine(D, seed) 4 return D
33 The Stalker Algorithm (cont.) GetInitialCandidates(seed) Return tokens t that immediately precede the example or wildcards that match t BestDisjunct(candidates) Return candidates that have more correct matches fewer false positives fewer wildcards longer landmarks Refine(D, seed) Specialize D by adding more terminals
34 An Example: Extracting Area Codes E1:<li>321 Red Street, <i>mullen</i>, Ph 0-<i> 485 </i> </li> E2:<li>62 Blue Street, <i>finner</i>, Ph ( 621 ) </li> E3:<li>543 Yellow Street, <i>pitsher</i>, Ph 0-<i> 788 </i> </li> E4:<li>321 Orange Street, <i>kingston</i>, Ph: ( 333 ) </li></p> The following candidate disjuncts are generated: D1: SkipTo(() D2: SkipTo( Punctuation ) D1 is selected by BestDisjunct D1 is a perfect disjunct The first iteration of LearnRule() ends E2 and E4 are removed
35 An Example (cont.) E1:<li>321 Red Street, <i>mullen</i>, Ph 0-<i> 485 </i> </li> E3:<li>543 Yellow Street, <i>pitsher</i>, Ph 0-<i> 788 </i> </li> LearnDisjunct() will select E1 as the seed Two candidates are then generated: D3: SkipTo(<i>) D4: SkipTo( HtmlTag ) Both candidates match early in the uncovered examples, E1 and E3. Thus, they cannot uniquely locate the positive items Refinement is needed
36 Refinement To specialize a disjunct by adding more terminals to it A terminal means a token or one of its matching wildcards We hope the refined version will be able to uniquely identify the positive items in some examples without matching any negative item in any example Two types of refinement: Landmark refinement Topology refinement
37 Landmark Refinement Landmark refinement: increase the size of a landmark by concatenating a terminal E1:<li>321 Red Street, <i>mullen</i>, Ph 0-<i> 485 </i> </li> E3:<li>543 Yellow Street, <i>pitsher</i>, Ph 0-<i> 788 </i> </li> D5: SkipTo(-<i>) D6: SkipTo( Punctuation <i>)
38 Topology Refinement Topology refinement: Increase the number of landmarks by adding 1-terminal landmarks E1:<li>321 Red Street, <i>mullen</i>, Ph 0-<i> 485 </i> </li> E3:<li>543 Yellow Street, <i>pitsher</i>, Ph 0-<i> 788 </i> </li> D7 SkipTo(321)SkipTo(<i>) D8 SkipTo(Red)SkipTo(<i>) D9 SkipTo(Street)SkipTo(<i>) D10 SkipTo(,)SkipTo(<i>) D11 SkipTo(<i>)SkipTo(<i>)... D19 SkipTo( Numeric )SkipTo(<i>) D20 SkipTo( Punctuation )SkipTo(<i>)
39 Final Results E1:<li>321 Red Street, <i>mullen</i>, Ph 0-<i> 485 </i> </li> E2:<li>62 Blue Street, <i>finner</i>, Ph ( 621 ) </li> E3:<li>543 Yellow Street, <i>pitsher</i>, Ph 0-<i> 788 </i> </li> E4:<li>321 Orange Street, <i>kingston</i>, Ph: ( 333 ) </li></p> Using BestDisjunct, D5 is selected as the final solution as it has longest last landmark D5: SkipTo(-<i>) Since all the examples are covered, LearnRule() returns the disjunctive (start) rule: either D1 or D5 R7: either SkipTo(() or SkipTo(-<i>)
40 Wrapper Maintenance Wrapper verification: if the site changes, does the wrapper know the change? Wrapper repair: if the change is correctly detected, how to automatically repair the wrapper? One way to deal with both problems is to learn the characteristic patterns of the target items These patterns are then used to monitor the extraction to check whether the extracted items are correct These tasks are extremely difficult often needs contextual and semantic information to detect changes and to find the new locations of the target items Wrapper maintenance is still an active research area
41 Questions?
Web Data Extraction: 1 o Semestre 2007/2008
 Web Data : Given Slides baseados nos slides oficiais do livro Web Data Mining c Bing Liu, Springer, December, 2006. Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008
Web Data : Given Slides baseados nos slides oficiais do livro Web Data Mining c Bing Liu, Springer, December, 2006. Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008
Database System Concepts
 s Design Chapter 1: Introduction Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
s Design Chapter 1: Introduction Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Content Mining and NLP. Bing Liu Department of Computer Science University of Illinois at Chicago [email protected] http://www.cs.uic.
 Web Content Mining and NLP Bing Liu Department of Computer Science University of Illinois at Chicago [email protected] http://www.cs.uic.edu/~liub Introduction The Web is perhaps the single largest and distributed
Web Content Mining and NLP Bing Liu Department of Computer Science University of Illinois at Chicago [email protected] http://www.cs.uic.edu/~liub Introduction The Web is perhaps the single largest and distributed
From Web Content Mining to Natural Language Processing
 ACL-2007 Tutorial, Prague, June 24, 2007 From Web Content Mining to Natural Language Processing Bing Liu Department of Computer Science University of Illinois at Chicago http://www.cs.uic.edu/~liub Introduction
ACL-2007 Tutorial, Prague, June 24, 2007 From Web Content Mining to Natural Language Processing Bing Liu Department of Computer Science University of Illinois at Chicago http://www.cs.uic.edu/~liub Introduction
Experiments in Web Page Classification for Semantic Web
 Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
Mining Templates from Search Result Records of Search Engines
 Mining Templates from Search Result Records of Search Engines Hongkun Zhao, Weiyi Meng State University of New York at Binghamton Binghamton, NY 13902, USA {hkzhao, meng}@cs.binghamton.edu Clement Yu University
Mining Templates from Search Result Records of Search Engines Hongkun Zhao, Weiyi Meng State University of New York at Binghamton Binghamton, NY 13902, USA {hkzhao, meng}@cs.binghamton.edu Clement Yu University
Quiz! Database Indexes. Index. Quiz! Disc and main memory. Quiz! How costly is this operation (naive solution)?
?") Database Indexes How costly is this operation (naive solution)? course per weekday hour room TDA356 2 VR Monday 13:15 TDA356 2 VR Thursday 08:00 TDA356 4 HB1 Tuesday 08:00 TDA356 4 HB1 Friday 13:15 TIN090
Database Indexes How costly is this operation (naive solution)? course per weekday hour room TDA356 2 VR Monday 13:15 TDA356 2 VR Thursday 08:00 TDA356 4 HB1 Tuesday 08:00 TDA356 4 HB1 Friday 13:15 TIN090
Data Mining with R. Decision Trees and Random Forests. Hugh Murrell
 Data Mining with R Decision Trees and Random Forests Hugh Murrell reference books These slides are based on a book by Graham Williams: Data Mining with Rattle and R, The Art of Excavating Data for Knowledge
Data Mining with R Decision Trees and Random Forests Hugh Murrell reference books These slides are based on a book by Graham Williams: Data Mining with Rattle and R, The Art of Excavating Data for Knowledge
Web Data Extraction, Applications and Techniques: A Survey
 Web Data Extraction, Applications and Techniques: A Survey Emilio Ferrara a,, Pasquale De Meo b, Giacomo Fiumara c, Robert Baumgartner d a Center for Complex Networks and Systems Research, Indiana University,
Web Data Extraction, Applications and Techniques: A Survey Emilio Ferrara a,, Pasquale De Meo b, Giacomo Fiumara c, Robert Baumgartner d a Center for Complex Networks and Systems Research, Indiana University,
Data Integration through XML/XSLT. Presenter: Xin Gu
 Data Integration through XML/XSLT Presenter: Xin Gu q7.jar op.xsl goalmodel.q7 goalmodel.xml q7.xsl help, hurt GUI +, -, ++, -- goalmodel.op.xml merge.xsl goalmodel.input.xml profile.xml Goal model configurator
Data Integration through XML/XSLT Presenter: Xin Gu q7.jar op.xsl goalmodel.q7 goalmodel.xml q7.xsl help, hurt GUI +, -, ++, -- goalmodel.op.xml merge.xsl goalmodel.input.xml profile.xml Goal model configurator
A Workbench for Prototyping XML Data Exchange (extended abstract)
") A Workbench for Prototyping XML Data Exchange (extended abstract) Renzo Orsini and Augusto Celentano Università Ca Foscari di Venezia, Dipartimento di Informatica via Torino 155, 30172 Mestre (VE), Italy
A Workbench for Prototyping XML Data Exchange (extended abstract) Renzo Orsini and Augusto Celentano Università Ca Foscari di Venezia, Dipartimento di Informatica via Torino 155, 30172 Mestre (VE), Italy
Algorithms and Data Structures
 Algorithms and Data Structures Part 2: Data Structures PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering (CiE) Summer Term 2016 Overview general linked lists stacks queues trees 2 2
Algorithms and Data Structures Part 2: Data Structures PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering (CiE) Summer Term 2016 Overview general linked lists stacks queues trees 2 2
Chapter 1: Introduction
 Chapter 1: Introduction Database System Concepts, 5th Ed. See www.db book.com for conditions on re use Chapter 1: Introduction Purpose of Database Systems View of Data Database Languages Relational Databases
Chapter 1: Introduction Database System Concepts, 5th Ed. See www.db book.com for conditions on re use Chapter 1: Introduction Purpose of Database Systems View of Data Database Languages Relational Databases
Full and Complete Binary Trees
 Full and Complete Binary Trees Binary Tree Theorems 1 Here are two important types of binary trees. Note that the definitions, while similar, are logically independent. Definition: a binary tree T is full
Full and Complete Binary Trees Binary Tree Theorems 1 Here are two important types of binary trees. Note that the definitions, while similar, are logically independent. Definition: a binary tree T is full
Mining Text Data: An Introduction
 Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Modeling System Calls for Intrusion Detection with Dynamic Window Sizes
 Modeling System Calls for Intrusion Detection with Dynamic Window Sizes Eleazar Eskin Computer Science Department Columbia University 5 West 2th Street, New York, NY 27 [email protected] Salvatore
Modeling System Calls for Intrusion Detection with Dynamic Window Sizes Eleazar Eskin Computer Science Department Columbia University 5 West 2th Street, New York, NY 27 [email protected] Salvatore
Building a Question Classifier for a TREC-Style Question Answering System
 Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. ~ Spring~r
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Chapter 13: Query Processing. Basic Steps in Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Big Data and Scripting. Part 4: Memory Hierarchies
 1, Big Data and Scripting Part 4: Memory Hierarchies 2, Model and Definitions memory size: M machine words total storage (on disk) of N elements (N is very large) disk size unlimited (for our considerations)
1, Big Data and Scripting Part 4: Memory Hierarchies 2, Model and Definitions memory size: M machine words total storage (on disk) of N elements (N is very large) disk size unlimited (for our considerations)
Using Trace Clustering for Configurable Process Discovery Explained by Event Log Data
 Master of Business Information Systems, Department of Mathematics and Computer Science Using Trace Clustering for Configurable Process Discovery Explained by Event Log Data Master Thesis Author: ing. Y.P.J.M.
Master of Business Information Systems, Department of Mathematics and Computer Science Using Trace Clustering for Configurable Process Discovery Explained by Event Log Data Master Thesis Author: ing. Y.P.J.M.
Binary Search Trees. Data in each node. Larger than the data in its left child Smaller than the data in its right child
 Binary Search Trees Data in each node Larger than the data in its left child Smaller than the data in its right child FIGURE 11-6 Arbitrary binary tree FIGURE 11-7 Binary search tree Data Structures Using
Binary Search Trees Data in each node Larger than the data in its left child Smaller than the data in its right child FIGURE 11-6 Arbitrary binary tree FIGURE 11-7 Binary search tree Data Structures Using
Process Mining by Measuring Process Block Similarity
 Process Mining by Measuring Process Block Similarity Joonsoo Bae, James Caverlee 2, Ling Liu 2, Bill Rouse 2, Hua Yan 2 Dept of Industrial & Sys Eng, Chonbuk National Univ, South Korea jsbae@chonbukackr
Process Mining by Measuring Process Block Similarity Joonsoo Bae, James Caverlee 2, Ling Liu 2, Bill Rouse 2, Hua Yan 2 Dept of Industrial & Sys Eng, Chonbuk National Univ, South Korea jsbae@chonbukackr
Email Spam Detection Using Customized SimHash Function
 International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 1, Issue 8, December 2014, PP 35-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Email
International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 1, Issue 8, December 2014, PP 35-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Email
XML Data Integration
 XML Data Integration Lucja Kot Cornell University 11 November 2010 Lucja Kot (Cornell University) XML Data Integration 11 November 2010 1 / 42 Introduction Data Integration and Query Answering A data integration
XML Data Integration Lucja Kot Cornell University 11 November 2010 Lucja Kot (Cornell University) XML Data Integration 11 November 2010 1 / 42 Introduction Data Integration and Query Answering A data integration
Search Result Optimization using Annotators
 Search Result Optimization using Annotators Vishal A. Kamble 1, Amit B. Chougule 2 1 Department of Computer Science and Engineering, D Y Patil College of engineering, Kolhapur, Maharashtra, India 2 Professor,
Search Result Optimization using Annotators Vishal A. Kamble 1, Amit B. Chougule 2 1 Department of Computer Science and Engineering, D Y Patil College of engineering, Kolhapur, Maharashtra, India 2 Professor,
GRAPH THEORY LECTURE 4: TREES
 GRAPH THEORY LECTURE 4: TREES Abstract. 3.1 presents some standard characterizations and properties of trees. 3.2 presents several different types of trees. 3.7 develops a counting method based on a bijection
GRAPH THEORY LECTURE 4: TREES Abstract. 3.1 presents some standard characterizations and properties of trees. 3.2 presents several different types of trees. 3.7 develops a counting method based on a bijection
Lexical Analysis and Scanning. Honors Compilers Feb 5 th 2001 Robert Dewar
 Lexical Analysis and Scanning Honors Compilers Feb 5 th 2001 Robert Dewar The Input Read string input Might be sequence of characters (Unix) Might be sequence of lines (VMS) Character set ASCII ISO Latin-1
Lexical Analysis and Scanning Honors Compilers Feb 5 th 2001 Robert Dewar The Input Read string input Might be sequence of characters (Unix) Might be sequence of lines (VMS) Character set ASCII ISO Latin-1
Naming. Name Service. Why Name Services? Mappings. and related concepts
 Service Processes and Threads: execution of applications or services Communication: information exchange for coordination of processes But: how can client processes (or human users) find the right server
Service Processes and Threads: execution of applications or services Communication: information exchange for coordination of processes But: how can client processes (or human users) find the right server
Finite Automata. Reading: Chapter 2
 Finite Automata Reading: Chapter 2 1 Finite Automaton (FA) Informally, a state diagram that comprehensively captures all possible states and transitions that a machine can take while responding to a stream
Finite Automata Reading: Chapter 2 1 Finite Automaton (FA) Informally, a state diagram that comprehensively captures all possible states and transitions that a machine can take while responding to a stream
Naming in Distributed Systems
 Naming in Distributed Systems Distributed Systems Sistemi Distribuiti Andrea Omicini [email protected] Dipartimento di Informatica Scienza e Ingegneria (DISI) Alma Mater Studiorum Università di Bologna
Naming in Distributed Systems Distributed Systems Sistemi Distribuiti Andrea Omicini [email protected] Dipartimento di Informatica Scienza e Ingegneria (DISI) Alma Mater Studiorum Università di Bologna
Analysis of Algorithms I: Binary Search Trees
 Analysis of Algorithms I: Binary Search Trees Xi Chen Columbia University Hash table: A data structure that maintains a subset of keys from a universe set U = {0, 1,..., p 1} and supports all three dictionary
Analysis of Algorithms I: Binary Search Trees Xi Chen Columbia University Hash table: A data structure that maintains a subset of keys from a universe set U = {0, 1,..., p 1} and supports all three dictionary
A LANGUAGE INDEPENDENT WEB DATA EXTRACTION USING VISION BASED PAGE SEGMENTATION ALGORITHM
 A LANGUAGE INDEPENDENT WEB DATA EXTRACTION USING VISION BASED PAGE SEGMENTATION ALGORITHM 1 P YesuRaju, 2 P KiranSree 1 PG Student, 2 Professorr, Department of Computer Science, B.V.C.E.College, Odalarevu,
A LANGUAGE INDEPENDENT WEB DATA EXTRACTION USING VISION BASED PAGE SEGMENTATION ALGORITHM 1 P YesuRaju, 2 P KiranSree 1 PG Student, 2 Professorr, Department of Computer Science, B.V.C.E.College, Odalarevu,
WEB SITE OPTIMIZATION THROUGH MINING USER NAVIGATIONAL PATTERNS
 WEB SITE OPTIMIZATION THROUGH MINING USER NAVIGATIONAL PATTERNS Biswajit Biswal Oracle Corporation [email protected] ABSTRACT With the World Wide Web (www) s ubiquity increase and the rapid development
WEB SITE OPTIMIZATION THROUGH MINING USER NAVIGATIONAL PATTERNS Biswajit Biswal Oracle Corporation [email protected] ABSTRACT With the World Wide Web (www) s ubiquity increase and the rapid development
Self Organizing Maps for Visualization of Categories
 Self Organizing Maps for Visualization of Categories Julian Szymański 1 and Włodzisław Duch 2,3 1 Department of Computer Systems Architecture, Gdańsk University of Technology, Poland, [email protected]
Self Organizing Maps for Visualization of Categories Julian Szymański 1 and Włodzisław Duch 2,3 1 Department of Computer Systems Architecture, Gdańsk University of Technology, Poland, [email protected]
Scheduling Shop Scheduling. Tim Nieberg
 Scheduling Shop Scheduling Tim Nieberg Shop models: General Introduction Remark: Consider non preemptive problems with regular objectives Notation Shop Problems: m machines, n jobs 1,..., n operations
Scheduling Shop Scheduling Tim Nieberg Shop models: General Introduction Remark: Consider non preemptive problems with regular objectives Notation Shop Problems: m machines, n jobs 1,..., n operations
Lesson 8: Introduction to Databases E-R Data Modeling
 Lesson 8: Introduction to Databases E-R Data Modeling Contents Introduction to Databases Abstraction, Schemas, and Views Data Models Database Management System (DBMS) Components Entity Relationship Data
Lesson 8: Introduction to Databases E-R Data Modeling Contents Introduction to Databases Abstraction, Schemas, and Views Data Models Database Management System (DBMS) Components Entity Relationship Data
Professor Anita Wasilewska. Classification Lecture Notes
 Professor Anita Wasilewska Classification Lecture Notes Classification (Data Mining Book Chapters 5 and 7) PART ONE: Supervised learning and Classification Data format: training and test data Concept,
Professor Anita Wasilewska Classification Lecture Notes Classification (Data Mining Book Chapters 5 and 7) PART ONE: Supervised learning and Classification Data format: training and test data Concept,
Decision Trees and Networks
 Lecture 21: Uncertainty 6 Today s Lecture Victor R. Lesser CMPSCI 683 Fall 2010 Decision Trees and Networks Decision Trees A decision tree is an explicit representation of all the possible scenarios from
Lecture 21: Uncertainty 6 Today s Lecture Victor R. Lesser CMPSCI 683 Fall 2010 Decision Trees and Networks Decision Trees A decision tree is an explicit representation of all the possible scenarios from
1. Domain Name System
 1.1 Domain Name System (DNS) 1. Domain Name System To identify an entity, the Internet uses the IP address, which uniquely identifies the connection of a host to the Internet. However, people prefer to
1.1 Domain Name System (DNS) 1. Domain Name System To identify an entity, the Internet uses the IP address, which uniquely identifies the connection of a host to the Internet. However, people prefer to
Design and Implementation of Firewall Policy Advisor Tools
 Design and Implementation of Firewall Policy Advisor Tools Ehab S. Al-Shaer and Hazem H. Hamed Multimedia Networking Research Laboratory School of Computer Science, Telecommunications and Information Systems
Design and Implementation of Firewall Policy Advisor Tools Ehab S. Al-Shaer and Hazem H. Hamed Multimedia Networking Research Laboratory School of Computer Science, Telecommunications and Information Systems
Test Case Design by Means of the CTE XL
 Test Case Design by Means of the CTE XL Eckard Lehmann and Joachim Wegener DaimlerChrysler AG Research and Technology Alt-Moabit 96 a D-10559 Berlin [email protected] [email protected]
Test Case Design by Means of the CTE XL Eckard Lehmann and Joachim Wegener DaimlerChrysler AG Research and Technology Alt-Moabit 96 a D-10559 Berlin [email protected] [email protected]
Triangulation by Ear Clipping
 Triangulation by Ear Clipping David Eberly Geometric Tools, LLC http://www.geometrictools.com/ Copyright c 1998-2016. All Rights Reserved. Created: November 18, 2002 Last Modified: August 16, 2015 Contents
Triangulation by Ear Clipping David Eberly Geometric Tools, LLC http://www.geometrictools.com/ Copyright c 1998-2016. All Rights Reserved. Created: November 18, 2002 Last Modified: August 16, 2015 Contents
Application of XML Tools for Enterprise-Wide RBAC Implementation Tasks
 Application of XML Tools for Enterprise-Wide RBAC Implementation Tasks Ramaswamy Chandramouli National Institute of Standards and Technology Gaithersburg, MD 20899,USA 001-301-975-5013 [email protected]
Application of XML Tools for Enterprise-Wide RBAC Implementation Tasks Ramaswamy Chandramouli National Institute of Standards and Technology Gaithersburg, MD 20899,USA 001-301-975-5013 [email protected]
Physical Data Organization
 Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10
![131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10](/thumbs/25/4963058.jpg "131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10") 1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
Classification and Prediction
 Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Fast nondeterministic recognition of context-free languages using two queues
 Fast nondeterministic recognition of context-free languages using two queues Burton Rosenberg University of Miami Abstract We show how to accept a context-free language nondeterministically in O( n log
Fast nondeterministic recognition of context-free languages using two queues Burton Rosenberg University of Miami Abstract We show how to accept a context-free language nondeterministically in O( n log
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
PLANET: Massively Parallel Learning of Tree Ensembles with MapReduce. Authors: B. Panda, J. S. Herbach, S. Basu, R. J. Bayardo.
 PLANET: Massively Parallel Learning of Tree Ensembles with MapReduce Authors: B. Panda, J. S. Herbach, S. Basu, R. J. Bayardo. VLDB 2009 CS 422 Decision Trees: Main Components Find Best Split Choose split
PLANET: Massively Parallel Learning of Tree Ensembles with MapReduce Authors: B. Panda, J. S. Herbach, S. Basu, R. J. Bayardo. VLDB 2009 CS 422 Decision Trees: Main Components Find Best Split Choose split
DATA MINING TECHNIQUES AND APPLICATIONS
 DATA MINING TECHNIQUES AND APPLICATIONS Mrs. Bharati M. Ramageri, Lecturer Modern Institute of Information Technology and Research, Department of Computer Application, Yamunanagar, Nigdi Pune, Maharashtra,
DATA MINING TECHNIQUES AND APPLICATIONS Mrs. Bharati M. Ramageri, Lecturer Modern Institute of Information Technology and Research, Department of Computer Application, Yamunanagar, Nigdi Pune, Maharashtra,
Blog Post Extraction Using Title Finding
 Blog Post Extraction Using Title Finding Linhai Song 1, 2, Xueqi Cheng 1, Yan Guo 1, Bo Wu 1, 2, Yu Wang 1, 2 1 Institute of Computing Technology, Chinese Academy of Sciences, Beijing 2 Graduate School
Blog Post Extraction Using Title Finding Linhai Song 1, 2, Xueqi Cheng 1, Yan Guo 1, Bo Wu 1, 2, Yu Wang 1, 2 1 Institute of Computing Technology, Chinese Academy of Sciences, Beijing 2 Graduate School
The Halting Problem is Undecidable
 185 Corollary G = { M, w w L(M) } is not Turing-recognizable. Proof. = ERR, where ERR is the easy to decide language: ERR = { x { 0, 1 }* x does not have a prefix that is a valid code for a Turing machine
185 Corollary G = { M, w w L(M) } is not Turing-recognizable. Proof. = ERR, where ERR is the easy to decide language: ERR = { x { 0, 1 }* x does not have a prefix that is a valid code for a Turing machine
Sorting Hierarchical Data in External Memory for Archiving
 Sorting Hierarchical Data in External Memory for Archiving Ioannis Koltsidas School of Informatics University of Edinburgh [email protected] Heiko Müller School of Informatics University of Edinburgh
Sorting Hierarchical Data in External Memory for Archiving Ioannis Koltsidas School of Informatics University of Edinburgh [email protected] Heiko Müller School of Informatics University of Edinburgh
Introduction. Compiler Design CSE 504. Overview. Programming problems are easier to solve in high-level languages
 Introduction Compiler esign CSE 504 1 Overview 2 3 Phases of Translation ast modifled: Mon Jan 28 2013 at 17:19:57 EST Version: 1.5 23:45:54 2013/01/28 Compiled at 11:48 on 2015/01/28 Compiler esign Introduction
Introduction Compiler esign CSE 504 1 Overview 2 3 Phases of Translation ast modifled: Mon Jan 28 2013 at 17:19:57 EST Version: 1.5 23:45:54 2013/01/28 Compiled at 11:48 on 2015/01/28 Compiler esign Introduction
Database Design Patterns. Winter 2006-2007 Lecture 24
 Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
KEYWORD SEARCH IN RELATIONAL DATABASES
 KEYWORD SEARCH IN RELATIONAL DATABASES N.Divya Bharathi 1 1 PG Scholar, Department of Computer Science and Engineering, ABSTRACT Adhiyamaan College of Engineering, Hosur, (India). Data mining refers to
KEYWORD SEARCH IN RELATIONAL DATABASES N.Divya Bharathi 1 1 PG Scholar, Department of Computer Science and Engineering, ABSTRACT Adhiyamaan College of Engineering, Hosur, (India). Data mining refers to
Structured vs. unstructured data. Motivation for self describing data. Enter semistructured data. Databases are highly structured
 Structured vs. unstructured data 2 Databases are highly structured Semistructured data, XML, DTDs Well known data format: relations and tuples Every tuple conforms to a known schema Data independence?
Structured vs. unstructured data 2 Databases are highly structured Semistructured data, XML, DTDs Well known data format: relations and tuples Every tuple conforms to a known schema Data independence?
A Study of Detecting Credit Card Delinquencies with Data Mining using Decision Tree Model
 A Study of Detecting Credit Card Delinquencies with Data Mining using Decision Tree Model ABSTRACT Mrs. Arpana Bharani* Mrs. Mohini Rao** Consumer credit is one of the necessary processes but lending bears
A Study of Detecting Credit Card Delinquencies with Data Mining using Decision Tree Model ABSTRACT Mrs. Arpana Bharani* Mrs. Mohini Rao** Consumer credit is one of the necessary processes but lending bears
How To Improve Performance In A Database
 Some issues on Conceptual Modeling and NoSQL/Big Data Tok Wang Ling National University of Singapore 1 Database Models File system - field, record, fixed length record Hierarchical Model (IMS) - fixed
Some issues on Conceptual Modeling and NoSQL/Big Data Tok Wang Ling National University of Singapore 1 Database Models File system - field, record, fixed length record Hierarchical Model (IMS) - fixed
Chapter 8 The Enhanced Entity- Relationship (EER) Model
 Model") Chapter 8 The Enhanced Entity- Relationship (EER) Model Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 8 Outline Subclasses, Superclasses, and Inheritance Specialization
Chapter 8 The Enhanced Entity- Relationship (EER) Model Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 8 Outline Subclasses, Superclasses, and Inheritance Specialization
Classification On The Clouds Using MapReduce
 Classification On The Clouds Using MapReduce Simão Martins Instituto Superior Técnico Lisbon, Portugal [email protected] Cláudia Antunes Instituto Superior Técnico Lisbon, Portugal [email protected]
Classification On The Clouds Using MapReduce Simão Martins Instituto Superior Técnico Lisbon, Portugal [email protected] Cláudia Antunes Instituto Superior Técnico Lisbon, Portugal [email protected]
I. INTRODUCTION NOESIS ONTOLOGIES SEMANTICS AND ANNOTATION
 Noesis: A Semantic Search Engine and Resource Aggregator for Atmospheric Science Sunil Movva, Rahul Ramachandran, Xiang Li, Phani Cherukuri, Sara Graves Information Technology and Systems Center University
Noesis: A Semantic Search Engine and Resource Aggregator for Atmospheric Science Sunil Movva, Rahul Ramachandran, Xiang Li, Phani Cherukuri, Sara Graves Information Technology and Systems Center University
Merkle Hash Trees for Distributed Audit Logs
 Merkle Hash Trees for Distributed Audit Logs Subject proposed by Karthikeyan Bhargavan [email protected] April 7, 2015 Modern distributed systems spread their databases across a large number
Merkle Hash Trees for Distributed Audit Logs Subject proposed by Karthikeyan Bhargavan [email protected] April 7, 2015 Modern distributed systems spread their databases across a large number
not possible or was possible at a high cost for collecting the data.
 Data Mining and Knowledge Discovery Generating knowledge from data Knowledge Discovery Data Mining White Paper Organizations collect a vast amount of data in the process of carrying out their day-to-day
Data Mining and Knowledge Discovery Generating knowledge from data Knowledge Discovery Data Mining White Paper Organizations collect a vast amount of data in the process of carrying out their day-to-day
Artificial Intelligence
 Artificial Intelligence ICS461 Fall 2010 1 Lecture #12B More Representations Outline Logics Rules Frames Nancy E. Reed [email protected] 2 Representation Agents deal with knowledge (data) Facts (believe
Artificial Intelligence ICS461 Fall 2010 1 Lecture #12B More Representations Outline Logics Rules Frames Nancy E. Reed [email protected] 2 Representation Agents deal with knowledge (data) Facts (believe
Distance Degree Sequences for Network Analysis
 Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
Outline. Definition. Name spaces Name resolution Example: The Domain Name System Example: X.500, LDAP. Names, Identifiers and Addresses
 Outline Definition Names, Identifiers and Addresses Name spaces Name resolution Example: The Domain Name System Example: X.500, LDAP CS550: Advanced Operating Systems 2 A name in a distributed system is
Outline Definition Names, Identifiers and Addresses Name spaces Name resolution Example: The Domain Name System Example: X.500, LDAP CS550: Advanced Operating Systems 2 A name in a distributed system is
CS510 Software Engineering
 CS510 Software Engineering Propositional Logic Asst. Prof. Mathias Payer Department of Computer Science Purdue University TA: Scott A. Carr Slides inspired by Xiangyu Zhang http://nebelwelt.net/teaching/15-cs510-se
CS510 Software Engineering Propositional Logic Asst. Prof. Mathias Payer Department of Computer Science Purdue University TA: Scott A. Carr Slides inspired by Xiangyu Zhang http://nebelwelt.net/teaching/15-cs510-se
XML: extensible Markup Language. Anabel Fraga
 XML: extensible Markup Language Anabel Fraga Table of Contents Historic Introduction XML vs. HTML XML Characteristics HTML Document XML Document XML General Rules Well Formed and Valid Documents Elements
XML: extensible Markup Language Anabel Fraga Table of Contents Historic Introduction XML vs. HTML XML Characteristics HTML Document XML Document XML General Rules Well Formed and Valid Documents Elements
Secret Communication through Web Pages Using Special Space Codes in HTML Files
 International Journal of Applied Science and Engineering 2008. 6, 2: 141-149 Secret Communication through Web Pages Using Special Space Codes in HTML Files I-Shi Lee a, c and Wen-Hsiang Tsai a, b, * a
International Journal of Applied Science and Engineering 2008. 6, 2: 141-149 Secret Communication through Web Pages Using Special Space Codes in HTML Files I-Shi Lee a, c and Wen-Hsiang Tsai a, b, * a
Information Extraction
 Information Extraction Definition (after Grishman 1997, Eikvil 1999): "The identificiation and extraction of instances of a particular class of events or relationships in a natural language text and their
Information Extraction Definition (after Grishman 1997, Eikvil 1999): "The identificiation and extraction of instances of a particular class of events or relationships in a natural language text and their
Clustering & Visualization
 Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Introduction to Learning & Decision Trees
 Artificial Intelligence: Representation and Problem Solving 5-38 April 0, 2007 Introduction to Learning & Decision Trees Learning and Decision Trees to learning What is learning? - more than just memorizing
Artificial Intelligence: Representation and Problem Solving 5-38 April 0, 2007 Introduction to Learning & Decision Trees Learning and Decision Trees to learning What is learning? - more than just memorizing
Mathematical Induction. Lecture 10-11
 Mathematical Induction Lecture 10-11 Menu Mathematical Induction Strong Induction Recursive Definitions Structural Induction Climbing an Infinite Ladder Suppose we have an infinite ladder: 1. We can reach
Mathematical Induction Lecture 10-11 Menu Mathematical Induction Strong Induction Recursive Definitions Structural Induction Climbing an Infinite Ladder Suppose we have an infinite ladder: 1. We can reach
Multiple electronic signatures on multiple documents
 Multiple electronic signatures on multiple documents Antonio Lioy and Gianluca Ramunno Politecnico di Torino Dip. di Automatica e Informatica Torino (Italy) e-mail: [email protected], [email protected] web
Multiple electronic signatures on multiple documents Antonio Lioy and Gianluca Ramunno Politecnico di Torino Dip. di Automatica e Informatica Torino (Italy) e-mail: [email protected], [email protected] web
Cassandra. References:
 Cassandra References: Becker, Moritz; Sewell, Peter. Cassandra: Flexible Trust Management, Applied to Electronic Health Records. 2004. Li, Ninghui; Mitchell, John. Datalog with Constraints: A Foundation
Cassandra References: Becker, Moritz; Sewell, Peter. Cassandra: Flexible Trust Management, Applied to Electronic Health Records. 2004. Li, Ninghui; Mitchell, John. Datalog with Constraints: A Foundation
Naming in Distributed Systems
 Naming in Distributed Systems Distributed Systems L-A Sistemi Distribuiti L-A Andrea Omicini [email protected] Ingegneria Due Alma Mater Studiorum Università di Bologna a Cesena Academic Year 2009/2010
Naming in Distributed Systems Distributed Systems L-A Sistemi Distribuiti L-A Andrea Omicini [email protected] Ingegneria Due Alma Mater Studiorum Università di Bologna a Cesena Academic Year 2009/2010
Lecture 10: Regression Trees
 Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Motivation. Korpus-Abfrage: Werkzeuge und Sprachen. Overview. Languages of Corpus Query. SARA Query Possibilities 1
 Korpus-Abfrage: Werkzeuge und Sprachen Gastreferat zur Vorlesung Korpuslinguistik mit und für Computerlinguistik Charlotte Merz 3. Dezember 2002 Motivation Lizentiatsarbeit: A Corpus Query Tool for Automatically
Korpus-Abfrage: Werkzeuge und Sprachen Gastreferat zur Vorlesung Korpuslinguistik mit und für Computerlinguistik Charlotte Merz 3. Dezember 2002 Motivation Lizentiatsarbeit: A Corpus Query Tool for Automatically