Introduction to Information Retrieval
|
|
|
- June Gilmore
- 7 years ago
- Views:
Transcription
1 Introduction to Information Retrieval IIR 1: Boolean Retrieval Hinrich Schütze Center for Information and Language Processing, University of Munich /60
2 Take-away Boolean Retrieval: Design and data structures of a simple information retrieval system What topics will be covered in this class? 2/60
3 Outline 1 Introduction 2 Inverted index 3 Processing Boolean queries 4 Query optimization 5 Course overview 3/60
4 Definition of information retrieval Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers). 4/60
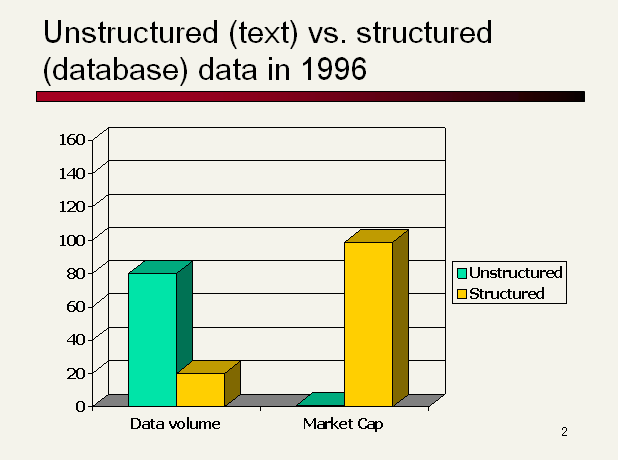
5
6
7 Boolean retrieval The Boolean model is arguably the simplest model to base an information retrieval system on. Queries are Boolean expressions, e.g., Caesar and Brutus The seach engine returns all documents that satisfy the Boolean expression. Does Google use the Boolean model? 7/60
8 Does Google use the Boolean model? On Google, the default interpretation of a query [w 1 w 2...w n ] is w 1 AND w 2 AND...AND w n Cases where you get hits that do not contain one of the w i : anchor text page contains variant of w i (morphology, spelling correction, synonym) long queries (n large) boolean expression generates very few hits Simple Boolean vs. Ranking of result set Simple Boolean retrieval returns matching documents in no particular order. Google (and most well designed Boolean engines) rank the result set they rank good hits (according to some estimator of relevance) higher than bad hits. 8/60
9 Outline 1 Introduction 2 Inverted index 3 Processing Boolean queries 4 Query optimization 5 Course overview 9/60
10 Unstructured data in 1650: Shakespeare 10/60
11 Unstructured data in 1650 Which plays of Shakespeare contain the words Brutus and Caesar, but not Calpurnia? One could grep all of Shakespeare s plays for Brutus and Caesar, then strip out lines containing Calpurnia. Why is grep not the solution? Slow (for large collections) grep is line-oriented, IR is document-oriented not Calpurnia is non-trivial Other operations (e.g., find the word Romans near countryman) not feasible 11/60
12 Term-document incidence matrix Anthony Julius The Hamlet Othello Macbeth... and Caesar Tempest Cleopatra Anthony Brutus Caesar Calpurnia Cleopatra mercy worser Entry is 1 if term occurs. Example: Calpurnia occurs in Julius Caesar. Entry is 0 if term doesn t occur. Example: Calpurnia doesn t occur in The tempest. 12/60
13 Incidence vectors So we have a 0/1 vector for each term. To answer the query Brutus and Caesar and not Calpurnia: Take the vectors for Brutus, Caesar, and Calpurnia Complement the vector of Calpurnia Do a (bitwise) and on the three vectors and and = /60
14 0/1 vectors and result of bitwise operations Anthony Julius The Hamlet Othello Macbeth... and Caesar Tempest Cleopatra Anthony Brutus Caesar Calpurnia Cleopatra mercy worser result: /60
15 Answers to query Anthony and Cleopatra, Act III, Scene ii Agrippa [Aside to Domitius Enobarbus]: Why, Enobarbus, When Antony found Julius Caesar dead, He cried almost to roaring; and he wept When at Philippi he found Brutus slain. Hamlet, Act III, Scene ii Lord Polonius: I did enact Julius Caesar: I was killed i the Capitol; Brutus killed me. 15/60
16 Bigger collections Consider N = 10 6 documents, each with about 1000 tokens total of 10 9 tokens On average 6 bytes per token, including spaces and punctuation size of document collection is about = 6 GB Assume there are M = 500,000 distinct terms in the collection (Notice that we are making a term/token distinction.) 16/60
17 Can t build the incidence matrix M = 500, = half a trillion 0s and 1s. But the matrix has no more than one billion 1s. Matrix is extremely sparse. What is a better representations? We only record the 1s. 17/60
18 Inverted Index For each term t, we store a list of all documents that contain t. Brutus Caesar Calpurnia }{{} } {{ } dictionary postings 18/60
19 Inverted index construction 1 Collect the documents to be indexed: Friends, Romans, countrymen. So let it be with Caesar... 2 Tokenize the text, turning each document into a list of tokens: Friends Romans countrymen So... 3 Do linguistic preprocessing, producing a list of normalized tokens, which are the indexing terms: friend roman countryman so... 4 Index the documents that each term occurs in by creating an inverted index, consisting of a dictionary and postings. 19/60
20 Tokenization and preprocessing Doc 1. I did enact Julius Caesar: I was killed i the Capitol; Brutus killed me. Doc 2. SoletitbewithCaesar. The noble Brutus hath told you Caesar was ambitious: = Doc 1. i did enact julius caesar i was killed i the capitol brutus killed me Doc 2. so let it be with caesar the noble brutus hath told you caesar was ambitious 20/60
21 Generate postings Doc 1. i did enact juliuscaesar i was killed i the capitol brutus killed me Doc 2. so let it be with caesar the noble brutus hath told you caesar was ambitious = term docid i 1 did 1 enact 1 julius 1 caesar 1 i 1 was 1 killed 1 i 1 the 1 capitol 1 brutus 1 killed 1 me 1 so 2 let 2 it 2 be 2 with 2 caesar 2 the 2 noble 2 brutus 2 hath 2 told 2 you 2 caesar 2 was 2 ambitious 2 21/60
22 Sort postings term docid i 1 did 1 enact 1 julius 1 caesar 1 i 1 was 1 killed 1 i 1 the 1 capitol 1 brutus 1 killed 1 me 1 = so 2 let 2 it 2 be 2 with 2 caesar 2 the 2 noble 2 brutus 2 hath 2 told 2 you 2 caesar 2 was 2 ambitious 2 term docid ambitious 2 be 2 brutus 1 brutus 2 capitol 1 caesar 1 caesar 2 caesar 2 did 1 enact 1 hath 1 i 1 i 1 i 1 it 2 julius 1 killed 1 killed 1 let 2 me 1 noble 2 so 2 the 1 the 2 told 2 you 2 was 1 was 2 with 2 22/60
23 Create postings lists, determine document frequency term docid ambitious 2 be 2 brutus 1 brutus 2 capitol 1 caesar 1 caesar 2 caesar 2 did 1 enact 1 hath 1 i 1 i 1 i 1 = it 2 julius 1 killed 1 killed 1 let 2 me 1 noble 2 so 2 the 1 the 2 told 2 you 2 was 1 was 2 with 2 term doc. freq. postings lists ambitious 1 2 be 1 2 brutus capitol 1 1 caesar did 1 1 enact 1 1 hath 1 2 i 1 1 i 1 1 it 1 2 julius 1 1 killed 1 1 let 1 2 me 1 1 noble 1 2 so 1 2 the told 1 2 you 1 2 was with /60
24 Split the result into dictionary and postings file Brutus Caesar Calpurnia }{{} } {{ } dictionary postings file 24/60
25 Later in this course Index construction: how can we create inverted indexes for large collections? How much space do we need for dictionary and index? Index compression: how can we efficiently store and process indexes for large collections? Ranked retrieval: what does the inverted index look like when we want the best answer? 25/60
26 Outline 1 Introduction 2 Inverted index 3 Processing Boolean queries 4 Query optimization 5 Course overview 26/60
27 Simple conjunctive query (two terms) Consider the query: Brutus AND Calpurnia To find all matching documents using inverted index: 1 Locate Brutus in the dictionary 2 Retrieve its postings list from the postings file 3 Locate Calpurnia in the dictionary 4 Retrieve its postings list from the postings file 5 Intersect the two postings lists 6 Return intersection to user 27/60
28 Intersecting two postings lists Brutus Calpurnia Intersection = 2 31 This is linear in the length of the postings lists. Note: This only works if postings lists are sorted. 28/60
29 Intersecting two postings lists Intersect(p 1,p 2 ) 1 answer 2 while p 1 nil and p 2 nil 3 do if docid(p 1 ) = docid(p 2 ) 4 then Add(answer,docID(p 1 )) 5 p 1 next(p 1 ) 6 p 2 next(p 2 ) 7 else if docid(p 1 ) < docid(p 2 ) 8 then p 1 next(p 1 ) 9 else p 2 next(p 2 ) 10 return answer 29/60
30 Query processing: Exercise france paris lear Compute hit list for ((paris AND NOT france) OR lear) 30/60
31 Boolean retrieval model: Assessment The Boolean retrieval model can answer any query that is a Boolean expression. Boolean queries are queries that use and, or and not to join query terms. Views each document as a set of terms. Is precise: Document matches condition or not. Primary commercial retrieval tool for 3 decades Many professional searchers (e.g., lawyers) still like Boolean queries. You know exactly what you are getting. Many search systems you use are also Boolean: spotlight, , intranet etc. 31/60
32 Commercially successful Boolean retrieval: Westlaw Largest commercial legal search service in terms of the number of paying subscribers Over half a million subscribers performing millions of searches a day over tens of terabytes of text data The service was started in In 2005, Boolean search (called Terms and Connectors by Westlaw) was still the default, and used by a large percentage of users although ranked retrieval has been available since /60
33 Westlaw: Example queries Information need: Information on the legal theories involved in preventing the disclosure of trade secrets by employees formerly employed by a competing company Query: trade secret /s disclos! /s prevent /s employe! Information need: Requirements for disabled people to be able to access a workplace Query: disab! /p access! /s work-site work-place (employment /3 place) Information need: Cases about a host s responsibility for drunk guests Query: host! /p (responsib! liab!) /p (intoxicat! drunk!) /p guest 33/60
34 Westlaw: Comments Proximity operators: /3 = within 3 words, /s = within a sentence, /p = within a paragraph Space is disjunction, not conjunction! (This was the default in search pre-google.) Long, precise queries: incrementally developed, not like web search Why professional searchers often like Boolean search: precision, transparency, control When are Boolean queries the best way of searching? Depends on: information need, searcher, document collection,... 34/60
35 Outline 1 Introduction 2 Inverted index 3 Processing Boolean queries 4 Query optimization 5 Course overview 35/60
36 Query optimization Consider a query that is an and of n terms, n > 2 For each of the terms, get its postings list, then and them together Example query: Brutus AND Calpurnia AND Caesar What is the best order for processing this query? 36/60
37 Query optimization Example query: Brutus AND Calpurnia AND Caesar Simple and effective optimization: Process in order of increasing frequency Start with the shortest postings list, then keep cutting further In this example, first Caesar, then Calpurnia, then Brutus Brutus Calpurnia Caesar /60
38 Optimized intersection algorithm for conjunctive queries Intersect( t 1,...,t n ) 1 terms SortByIncreasingFrequency( t 1,...,t n ) 2 result postings(first(terms)) 3 terms rest(terms) 4 while terms nil and result nil 5 do result Intersect(result, postings(first(terms))) 6 terms rest(terms) 7 return result 38/60
39 More general optimization Example query: (madding or crowd) and (ignoble or strife) Get frequencies for all terms Estimate the size of each or by the sum of its frequencies (conservative) Process in increasing order of or sizes 39/60
40 Outline 1 Introduction 2 Inverted index 3 Processing Boolean queries 4 Query optimization 5 Course overview 40/60
41 Course overview We are done with Chapter 1 of IIR (IIR 01). Plan for the rest of the semester: of the 21 chapters of IIR In what follows: teasers for most chapters to give you a sense of what will be covered. 41/60
42 IIR 02: The term vocabulary and postings lists Phrase queries: Stanford University Proximity queries: Gates near Microsoft We need an index that captures position information for phrase queries and proximity queries. 42/60
43 IIR 03: Dictionaries and tolerant retrieval bo aboard about boardroom border or border lord morbid sordid rd aboard ardent boardroom border 43/60
44 IIR 04: Index construction splits assign master assign postings parser a-f g-p q-z inverter a-f parser a-f g-p q-z inverter g-p parser a-f g-p q-z inverter q-z map phase segment files reduce phase 44/60
45 IIR 05: Index compression log10 cf log10 rank 7 Zipf s law 45/60
46 IIR 06: Scoring, term weighting and the vector space model Ranking search results Boolean queries only give inclusion or exclusion of documents. For ranked retrieval, we measure the proximity between the query and each document. One formalism for doing this: the vector space model Key challenge in ranked retrieval: evidence accumulation for a term in a document 1 vs. 0 occurence of a query term in the document 3 vs. 2 occurences of a query term in the document Usually: more is better But by how much? Need a scoring function that translates frequency into score or weight 46/60
47 IIR 07: Scoring in a complete search system Documents Parsing Linguistics user query Free text query parser Results page Document cache Indexers Spell correction Scoring and ranking Metadata in zone and field indexes Inexact Tiered inverted top K positional index retrieval Indexes k-gram Scoring parameters MLR training set 47/60
48 IIR 08: Evaluation and dynamic summaries 48/60
49 IIR 09: Relevance feedback & query expansion 49/60
50 IIR 12: Language models q 1 w P(w q 1 ) w P(w q 1 ) STOP 0.2 toad 0.01 the 0.2 said 0.03 a 0.1 likes 0.02 frog 0.01 that This is a one-state probabilistic finite-state automaton a unigram language model and the state emission distribution for its one state q 1. STOP is not a word, but a special symbol indicating that the automaton stops. frog said that toad likes frog STOP P(string) = = /60
51 IIR 13: Text classification & Naive Bayes Text classification = assigning documents automatically to predefined classes Examples: Language (English vs. French) Adult content Region 51/60
52 IIR 14: Vector classification X X X X X X X X X X X 52/60
53 IIR 15: Support vector machines 53/60
54 IIR 16: Flat clustering 54/60
55 IIR 17: Hierarchical clustering 55/60
56 IIR 18: Latent Semantic Indexing 56/60
57 IIR 19: The web and its challenges Unusual and diverse documents Unusual and diverse users and information needs Beyond terms and text: exploit link analysis, user data How do web search engines work? How can we make them better? 57/60
58 IIR 21: Link analysis / PageRank 58/60
59 Take-away Boolean Retrieval: Design and data structures of a simple information retrieval system What topics will be covered in this class? 59/60
60 Resources Chapter 1 of IIR course schedule information retrieval links Shakespeare search engine 60/60
Lecture 1: Introduction and the Boolean Model
 Lecture 1: Introduction and the Boolean Model Information Retrieval Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group Simone.Teufel@cl.cam.ac.uk 1 Overview
Lecture 1: Introduction and the Boolean Model Information Retrieval Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group Simone.Teufel@cl.cam.ac.uk 1 Overview
1 Boolean retrieval. Online edition (c)2009 Cambridge UP
2009 Cambridge UP") DRAFT! April 1, 2009 Cambridge University Press. Feedback welcome. 1 1 Boolean retrieval INFORMATION RETRIEVAL The meaning of the term information retrieval can be very broad. Just getting a credit card
DRAFT! April 1, 2009 Cambridge University Press. Feedback welcome. 1 1 Boolean retrieval INFORMATION RETRIEVAL The meaning of the term information retrieval can be very broad. Just getting a credit card
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling
 EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project proposals due
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project proposals due
Introduction to Information Retrieval http://informationretrieval.org
 Introduction to Information Retrieval http://informationretrieval.org IIR 7: Scores in a Complete Search System Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-05-07
Introduction to Information Retrieval http://informationretrieval.org IIR 7: Scores in a Complete Search System Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-05-07
Introduction to Information Retrieval http://informationretrieval.org
 Introduction to Information Retrieval http://informationretrieval.org IIR 6&7: Vector Space Model Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-08-29 Schütze:
Introduction to Information Retrieval http://informationretrieval.org IIR 6&7: Vector Space Model Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-08-29 Schütze:
Search and Information Retrieval
 Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
This lecture. Introduction to information retrieval. Making money with information retrieval. Some technical basics. Link analysis.
 This lecture Introduction to information retrieval. Making money with information retrieval. Some technical basics. Link analysis. CSC401/2511 Spring 2015 2 Information retrieval systems Information retrieval
This lecture Introduction to information retrieval. Making money with information retrieval. Some technical basics. Link analysis. CSC401/2511 Spring 2015 2 Information retrieval systems Information retrieval
types of information systems computer-based information systems
 topics: what is information systems? what is information? knowledge representation information retrieval cis20.2 design and implementation of software applications II spring 2008 session # II.1 information
topics: what is information systems? what is information? knowledge representation information retrieval cis20.2 design and implementation of software applications II spring 2008 session # II.1 information
CSCI 5417 Information Retrieval Systems Jim Martin!
 CSCI 5417 Information Retrieval Systems Jim Martin! Lecture 9 9/20/2011 Today 9/20 Where we are MapReduce/Hadoop Probabilistic IR Language models LM for ad hoc retrieval 1 Where we are... Basics of ad
CSCI 5417 Information Retrieval Systems Jim Martin! Lecture 9 9/20/2011 Today 9/20 Where we are MapReduce/Hadoop Probabilistic IR Language models LM for ad hoc retrieval 1 Where we are... Basics of ad
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
TF-IDF. David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt
 TF-IDF David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt Administrative Homework 3 available soon Assignment 2 available soon Popular media article
TF-IDF David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt Administrative Homework 3 available soon Assignment 2 available soon Popular media article
Search Engines. Stephen Shaw <stesh@netsoc.tcd.ie> 18th of February, 2014. Netsoc
 Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. ~ Spring~r
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Clustering Connectionist and Statistical Language Processing
 Clustering Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Clustering Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Similarity Search in a Very Large Scale Using Hadoop and HBase
 Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information
 Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
ifinder ENTERPRISE SEARCH
 DATA SHEET ifinder ENTERPRISE SEARCH ifinder - the Enterprise Search solution for company-wide information search, information logistics and text mining. CUSTOMER QUOTE IntraFind stands for high quality
DATA SHEET ifinder ENTERPRISE SEARCH ifinder - the Enterprise Search solution for company-wide information search, information logistics and text mining. CUSTOMER QUOTE IntraFind stands for high quality
Introduction to IR Systems: Supporting Boolean Text Search. Information Retrieval. IR vs. DBMS. Chapter 27, Part A
 Introduction to IR Systems: Supporting Boolean Text Search Chapter 27, Part A Database Management Systems, R. Ramakrishnan 1 Information Retrieval A research field traditionally separate from Databases
Introduction to IR Systems: Supporting Boolean Text Search Chapter 27, Part A Database Management Systems, R. Ramakrishnan 1 Information Retrieval A research field traditionally separate from Databases
Chapter 2 The Information Retrieval Process
 Chapter 2 The Information Retrieval Process Abstract What does an information retrieval system look like from a bird s eye perspective? How can a set of documents be processed by a system to make sense
Chapter 2 The Information Retrieval Process Abstract What does an information retrieval system look like from a bird s eye perspective? How can a set of documents be processed by a system to make sense
Technical challenges in web advertising
 Technical challenges in web advertising Andrei Broder Yahoo! Research 1 Disclaimer This talk presents the opinions of the author. It does not necessarily reflect the views of Yahoo! Inc. 2 Advertising
Technical challenges in web advertising Andrei Broder Yahoo! Research 1 Disclaimer This talk presents the opinions of the author. It does not necessarily reflect the views of Yahoo! Inc. 2 Advertising
Web Mining. Margherita Berardi LACAM. Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it
 Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
An Overview of a Role of Natural Language Processing in An Intelligent Information Retrieval System
 An Overview of a Role of Natural Language Processing in An Intelligent Information Retrieval System Asanee Kawtrakul ABSTRACT In information-age society, advanced retrieval technique and the automatic
An Overview of a Role of Natural Language Processing in An Intelligent Information Retrieval System Asanee Kawtrakul ABSTRACT In information-age society, advanced retrieval technique and the automatic
1 o Semestre 2007/2008
 Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Julius Caesar: Act I Reading and Study Guide
 Julius Caesar: Act I Reading and Study Guide Name Pd. I. VOCABULARY: Be able to define the following words and understand them when they appear in the play. wherefore exeunt ( k s - nt, - nt ) vulgar What
Julius Caesar: Act I Reading and Study Guide Name Pd. I. VOCABULARY: Be able to define the following words and understand them when they appear in the play. wherefore exeunt ( k s - nt, - nt ) vulgar What
Search and Data Mining: Techniques. Text Mining Anya Yarygina Boris Novikov
 Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Basic indexing pipeline
 Information Retrieval Document Parsing Basic indexing pipeline Documents to be indexed. Friends, Romans, countrymen. Tokenizer Token stream. Friends Romans Countrymen Linguistic modules Modified tokens.
Information Retrieval Document Parsing Basic indexing pipeline Documents to be indexed. Friends, Romans, countrymen. Tokenizer Token stream. Friends Romans Countrymen Linguistic modules Modified tokens.
W. Heath Rushing Adsurgo LLC. Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare. Session H-1 JTCC: October 23, 2015
 W. Heath Rushing Adsurgo LLC Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare Session H-1 JTCC: October 23, 2015 Outline Demonstration: Recent article on cnn.com Introduction
W. Heath Rushing Adsurgo LLC Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare Session H-1 JTCC: October 23, 2015 Outline Demonstration: Recent article on cnn.com Introduction
Natural Language to Relational Query by Using Parsing Compiler
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 3, March 2015,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 3, March 2015,
Large-Scale Test Mining
 Large-Scale Test Mining SIAM Conference on Data Mining Text Mining 2010 Alan Ratner Northrop Grumman Information Systems NORTHROP GRUMMAN PRIVATE / PROPRIETARY LEVEL I Aim Identify topic and language/script/coding
Large-Scale Test Mining SIAM Conference on Data Mining Text Mining 2010 Alan Ratner Northrop Grumman Information Systems NORTHROP GRUMMAN PRIVATE / PROPRIETARY LEVEL I Aim Identify topic and language/script/coding
Comparison of Standard and Zipf-Based Document Retrieval Heuristics
 Comparison of Standard and Zipf-Based Document Retrieval Heuristics Benjamin Hoffmann Universität Stuttgart, Institut für Formale Methoden der Informatik Universitätsstr. 38, D-70569 Stuttgart, Germany
Comparison of Standard and Zipf-Based Document Retrieval Heuristics Benjamin Hoffmann Universität Stuttgart, Institut für Formale Methoden der Informatik Universitätsstr. 38, D-70569 Stuttgart, Germany
An Introduction to Data Mining
 An Introduction to Intel Beijing wei.heng@intel.com January 17, 2014 Outline 1 DW Overview What is Notable Application of Conference, Software and Applications Major Process in 2 Major Tasks in Detail
An Introduction to Intel Beijing wei.heng@intel.com January 17, 2014 Outline 1 DW Overview What is Notable Application of Conference, Software and Applications Major Process in 2 Major Tasks in Detail
Information Retrieval System Assigning Context to Documents by Relevance Feedback
 Information Retrieval System Assigning Context to Documents by Relevance Feedback Narina Thakur Department of CSE Bharati Vidyapeeth College Of Engineering New Delhi, India Deepti Mehrotra ASCS Amity University,
Information Retrieval System Assigning Context to Documents by Relevance Feedback Narina Thakur Department of CSE Bharati Vidyapeeth College Of Engineering New Delhi, India Deepti Mehrotra ASCS Amity University,
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Text mining & Information Retrieval Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Text mining & Information Retrieval Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki
RRSS - Rating Reviews Support System purpose built for movies recommendation
 RRSS - Rating Reviews Support System purpose built for movies recommendation Grzegorz Dziczkowski 1,2 and Katarzyna Wegrzyn-Wolska 1 1 Ecole Superieur d Ingenieurs en Informatique et Genie des Telecommunicatiom
RRSS - Rating Reviews Support System purpose built for movies recommendation Grzegorz Dziczkowski 1,2 and Katarzyna Wegrzyn-Wolska 1 1 Ecole Superieur d Ingenieurs en Informatique et Genie des Telecommunicatiom
Information Retrieval Systems in XML Based Database A review
 Information Retrieval Systems in XML Based Database A review Preeti Pandey 1, L.S.Maurya 2 Research Scholar, IT Department, SRMSCET, Bareilly, India 1 Associate Professor, IT Department, SRMSCET, Bareilly,
Information Retrieval Systems in XML Based Database A review Preeti Pandey 1, L.S.Maurya 2 Research Scholar, IT Department, SRMSCET, Bareilly, India 1 Associate Professor, IT Department, SRMSCET, Bareilly,
STUDY GUIDE. Julius Caesar WILLIAM SHAKESPEARE
 STUDY GUIDE Julius Caesar WILLIAM SHAKESPEARE Hamlet Julius Caesar Macbeth The Merchant of Venice A Midsummer Night s Dream Othello Romeo and Juliet The Tempest Development and Production: Laurel Associates,
STUDY GUIDE Julius Caesar WILLIAM SHAKESPEARE Hamlet Julius Caesar Macbeth The Merchant of Venice A Midsummer Night s Dream Othello Romeo and Juliet The Tempest Development and Production: Laurel Associates,
Recognition. Sanja Fidler CSC420: Intro to Image Understanding 1 / 28
 Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Dublin City University at CLEF 2004: Experiments with the ImageCLEF St Andrew s Collection
 Dublin City University at CLEF 2004: Experiments with the ImageCLEF St Andrew s Collection Gareth J. F. Jones, Declan Groves, Anna Khasin, Adenike Lam-Adesina, Bart Mellebeek. Andy Way School of Computing,
Dublin City University at CLEF 2004: Experiments with the ImageCLEF St Andrew s Collection Gareth J. F. Jones, Declan Groves, Anna Khasin, Adenike Lam-Adesina, Bart Mellebeek. Andy Way School of Computing,
Large-scale Data Mining: MapReduce and Beyond Part 2: Algorithms. Spiros Papadimitriou, IBM Research Jimeng Sun, IBM Research Rong Yan, Facebook
 Large-scale Data Mining: MapReduce and Beyond Part 2: Algorithms Spiros Papadimitriou, IBM Research Jimeng Sun, IBM Research Rong Yan, Facebook Part 2:Mining using MapReduce Mining algorithms using MapReduce
Large-scale Data Mining: MapReduce and Beyond Part 2: Algorithms Spiros Papadimitriou, IBM Research Jimeng Sun, IBM Research Rong Yan, Facebook Part 2:Mining using MapReduce Mining algorithms using MapReduce
dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING
 dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING ABSTRACT In most CRM (Customer Relationship Management) systems, information on
dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING ABSTRACT In most CRM (Customer Relationship Management) systems, information on
Mining Text Data: An Introduction
 Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words
 , pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
, pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Search Engine Design understanding how algorithms behind search engines are established
 Search Engine Design understanding how algorithms behind search engines are established An article written by Koulutus- and Konsultointipalvelu KK Mediat Web: http://www.2kmediat.com/kkmediat/eng/ Last
Search Engine Design understanding how algorithms behind search engines are established An article written by Koulutus- and Konsultointipalvelu KK Mediat Web: http://www.2kmediat.com/kkmediat/eng/ Last
Legal Informatics Final Paper Submission Creating a Legal-Focused Search Engine I. BACKGROUND II. PROBLEM AND SOLUTION
 Brian Lao - bjlao Karthik Jagadeesh - kjag Legal Informatics Final Paper Submission Creating a Legal-Focused Search Engine I. BACKGROUND There is a large need for improved access to legal help. For example,
Brian Lao - bjlao Karthik Jagadeesh - kjag Legal Informatics Final Paper Submission Creating a Legal-Focused Search Engine I. BACKGROUND There is a large need for improved access to legal help. For example,
Journée Thématique Big Data 13/03/2015
 Journée Thématique Big Data 13/03/2015 1 Agenda About Flaminem What Do We Want To Predict? What Is The Machine Learning Theory Behind It? How Does It Work In Practice? What Is Happening When Data Gets
Journée Thématique Big Data 13/03/2015 1 Agenda About Flaminem What Do We Want To Predict? What Is The Machine Learning Theory Behind It? How Does It Work In Practice? What Is Happening When Data Gets
Exam in course TDT4215 Web Intelligence - Solutions and guidelines -
 English Student no:... Page 1 of 12 Contact during the exam: Geir Solskinnsbakk Phone: 94218 Exam in course TDT4215 Web Intelligence - Solutions and guidelines - Friday May 21, 2010 Time: 0900-1300 Allowed
English Student no:... Page 1 of 12 Contact during the exam: Geir Solskinnsbakk Phone: 94218 Exam in course TDT4215 Web Intelligence - Solutions and guidelines - Friday May 21, 2010 Time: 0900-1300 Allowed
Rolling the Dice on Big Data. Ilse Ipsen Department of Mathematics
 Rolling the Dice on Big Data Ilse Ipsen Department of Mathematics The Economist, 27 February 2010 Science, 11 February 2011 McKinsey Global Institute, May 2011 Rolling the Dice on Big Data What is Big?
Rolling the Dice on Big Data Ilse Ipsen Department of Mathematics The Economist, 27 February 2010 Science, 11 February 2011 McKinsey Global Institute, May 2011 Rolling the Dice on Big Data What is Big?
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 10 th, 2013 Wolf-Tilo Balke and Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 10 th, 2013 Wolf-Tilo Balke and Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig
Analysis of Web Archives. Vinay Goel Senior Data Engineer
 Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
Text Analytics Illustrated with a Simple Data Set
 CSC 594 Text Mining More on SAS Enterprise Miner Text Analytics Illustrated with a Simple Data Set This demonstration illustrates some text analytic results using a simple data set that is designed to
CSC 594 Text Mining More on SAS Enterprise Miner Text Analytics Illustrated with a Simple Data Set This demonstration illustrates some text analytic results using a simple data set that is designed to
Clustering Big Data. Anil K. Jain. (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012
 Department of Computer Science Michigan State University November 29, 2012") Clustering Big Data Anil K. Jain (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012 Outline Big Data How to extract information? Data clustering
Clustering Big Data Anil K. Jain (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012 Outline Big Data How to extract information? Data clustering
SEO for Web 2.0 Enterprise Search Summit West September 2008
 SEO for Web 2.0 Enterprise Search Summit West September 2008 Agenda Search 0.0 Search 1.0 Web 2.0 Search 2.0 Data the next Intel inside Harnessing the Collective Intelligence Rich User Experience Software
SEO for Web 2.0 Enterprise Search Summit West September 2008 Agenda Search 0.0 Search 1.0 Web 2.0 Search 2.0 Data the next Intel inside Harnessing the Collective Intelligence Rich User Experience Software
Identifying Focus, Techniques and Domain of Scientific Papers
 Identifying Focus, Techniques and Domain of Scientific Papers Sonal Gupta Department of Computer Science Stanford University Stanford, CA 94305 sonal@cs.stanford.edu Christopher D. Manning Department of
Identifying Focus, Techniques and Domain of Scientific Papers Sonal Gupta Department of Computer Science Stanford University Stanford, CA 94305 sonal@cs.stanford.edu Christopher D. Manning Department of
Wikipedia and Web document based Query Translation and Expansion for Cross-language IR
 Wikipedia and Web document based Query Translation and Expansion for Cross-language IR Ling-Xiang Tang 1, Andrew Trotman 2, Shlomo Geva 1, Yue Xu 1 1Faculty of Science and Technology, Queensland University
Wikipedia and Web document based Query Translation and Expansion for Cross-language IR Ling-Xiang Tang 1, Andrew Trotman 2, Shlomo Geva 1, Yue Xu 1 1Faculty of Science and Technology, Queensland University
Questions to be responded to by the firm submitting the application
 Questions to be responded to by the firm submitting the application Why do you think this project should receive an award? How does it demonstrate: innovation, quality, and professional excellence transparency
Questions to be responded to by the firm submitting the application Why do you think this project should receive an award? How does it demonstrate: innovation, quality, and professional excellence transparency
Note: These activities are suitable for students who don t know a lot (possibly nothing at all) about Shakespeare s writing.
 about Shakespeare s writing.") Shakespeare Teacher s notes Level: Topic: Subject(s): Time (approx): Preparation: Lower Intermediate (and above) Shakespeare Literature and History Activity 1: 15-20 minutes Activity 2: 10 minutes Activity
Shakespeare Teacher s notes Level: Topic: Subject(s): Time (approx): Preparation: Lower Intermediate (and above) Shakespeare Literature and History Activity 1: 15-20 minutes Activity 2: 10 minutes Activity
Word Completion and Prediction in Hebrew
 Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
MapReduce Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Google Field Trip Map Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Distributed Indexing - Architecture
Google Field Trip Map Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Distributed Indexing - Architecture
Search engine ranking
 Proceedings of the 7 th International Conference on Applied Informatics Eger, Hungary, January 28 31, 2007. Vol. 2. pp. 417 422. Search engine ranking Mária Princz Faculty of Technical Engineering, University
Proceedings of the 7 th International Conference on Applied Informatics Eger, Hungary, January 28 31, 2007. Vol. 2. pp. 417 422. Search engine ranking Mária Princz Faculty of Technical Engineering, University
CS54100: Database Systems
 CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
Anotaciones semánticas: unidades de busqueda del futuro?
 Anotaciones semánticas: unidades de busqueda del futuro? Hugo Zaragoza, Yahoo! Research, Barcelona Jornadas MAVIR Madrid, Nov.07 Document Understanding Cartoon our work! Complexity of Document Understanding
Anotaciones semánticas: unidades de busqueda del futuro? Hugo Zaragoza, Yahoo! Research, Barcelona Jornadas MAVIR Madrid, Nov.07 Document Understanding Cartoon our work! Complexity of Document Understanding
Homework 2. Page 154: Exercise 8.10. Page 145: Exercise 8.3 Page 150: Exercise 8.9
 Homework 2 Page 110: Exercise 6.10; Exercise 6.12 Page 116: Exercise 6.15; Exercise 6.17 Page 121: Exercise 6.19 Page 122: Exercise 6.20; Exercise 6.23; Exercise 6.24 Page 131: Exercise 7.3; Exercise 7.5;
Homework 2 Page 110: Exercise 6.10; Exercise 6.12 Page 116: Exercise 6.15; Exercise 6.17 Page 121: Exercise 6.19 Page 122: Exercise 6.20; Exercise 6.23; Exercise 6.24 Page 131: Exercise 7.3; Exercise 7.5;
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
SWIFT: A Text-mining Workbench for Systematic Review
 SWIFT: A Text-mining Workbench for Systematic Review Ruchir Shah, PhD Sciome LLC NTP Board of Scientific Counselors Meeting June 16, 2015 Large Literature Corpus: An Ever Increasing Challenge Systematic
SWIFT: A Text-mining Workbench for Systematic Review Ruchir Shah, PhD Sciome LLC NTP Board of Scientific Counselors Meeting June 16, 2015 Large Literature Corpus: An Ever Increasing Challenge Systematic
Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework
 Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework Usha Nandini D 1, Anish Gracias J 2 1 ushaduraisamy@yahoo.co.in 2 anishgracias@gmail.com Abstract A vast amount of assorted
Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework Usha Nandini D 1, Anish Gracias J 2 1 ushaduraisamy@yahoo.co.in 2 anishgracias@gmail.com Abstract A vast amount of assorted
Text Mining and Analysis
 Text Mining and Analysis Practical Methods, Examples, and Case Studies Using SAS Goutam Chakraborty, Murali Pagolu, Satish Garla From Text Mining and Analysis. Full book available for purchase here. Contents
Text Mining and Analysis Practical Methods, Examples, and Case Studies Using SAS Goutam Chakraborty, Murali Pagolu, Satish Garla From Text Mining and Analysis. Full book available for purchase here. Contents
The Seven Practice Areas of Text Analytics
 Excerpt from: Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications G. Miner, D. Delen, J. Elder, A. Fast, T. Hill, and R. Nisbet, Elsevier, January 2012 Available now:
Excerpt from: Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications G. Miner, D. Delen, J. Elder, A. Fast, T. Hill, and R. Nisbet, Elsevier, January 2012 Available now:
Data, Data Everywhere
 Dr. Willa Pickering Lockheed Martin enior Fellow March 2012 Data, Data Everywhere Big Data what is it Protecting Data in Cloud how do we handle it Data Analysis are we prepared to use it Willa Pickering
Dr. Willa Pickering Lockheed Martin enior Fellow March 2012 Data, Data Everywhere Big Data what is it Protecting Data in Cloud how do we handle it Data Analysis are we prepared to use it Willa Pickering
PSG College of Technology, Coimbatore-641 004 Department of Computer & Information Sciences BSc (CT) G1 & G2 Sixth Semester PROJECT DETAILS.
 G1 & G2 Sixth Semester PROJECT DETAILS.") PSG College of Technology, Coimbatore-641 004 Department of Computer & Information Sciences BSc (CT) G1 & G2 Sixth Semester PROJECT DETAILS Project Project Title Area of Abstract No Specialization 1. Software
PSG College of Technology, Coimbatore-641 004 Department of Computer & Information Sciences BSc (CT) G1 & G2 Sixth Semester PROJECT DETAILS Project Project Title Area of Abstract No Specialization 1. Software
Microsoft Azure Machine learning Algorithms
 Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql Tomaz.kastrun@gmail.com http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql Tomaz.kastrun@gmail.com http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
The PageRank Citation Ranking: Bring Order to the Web
 The PageRank Citation Ranking: Bring Order to the Web presented by: Xiaoxi Pang 25.Nov 2010 1 / 20 Outline Introduction A ranking for every page on the Web Implementation Convergence Properties Personalized
The PageRank Citation Ranking: Bring Order to the Web presented by: Xiaoxi Pang 25.Nov 2010 1 / 20 Outline Introduction A ranking for every page on the Web Implementation Convergence Properties Personalized
Electronic Document Management Using Inverted Files System
 EPJ Web of Conferences 68, 0 00 04 (2014) DOI: 10.1051/ epjconf/ 20146800004 C Owned by the authors, published by EDP Sciences, 2014 Electronic Document Management Using Inverted Files System Derwin Suhartono,
EPJ Web of Conferences 68, 0 00 04 (2014) DOI: 10.1051/ epjconf/ 20146800004 C Owned by the authors, published by EDP Sciences, 2014 Electronic Document Management Using Inverted Files System Derwin Suhartono,
Challenges in Running a Commercial Web Search Engine. Amit Singhal
 Challenges in Running a Commercial Web Search Engine Amit Singhal Overview Introduction/History Search Engine Spam Evaluation Challenge Google Introduction Crawling Follow links to find information Indexing
Challenges in Running a Commercial Web Search Engine Amit Singhal Overview Introduction/History Search Engine Spam Evaluation Challenge Google Introduction Crawling Follow links to find information Indexing
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks
 A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
CSE454 Project Part4: Dealer s Choice Assigned: Monday, November 28, 2005 Due: 10:30 AM, Thursday, December 15, 2005
 CSE454 Project Part4: Dealer s Choice Assigned: Monday, November 28, 2005 Due: 10:30 AM, Thursday, December 15, 2005 1 Project Description For the last part of your project, you should choose what to do.
CSE454 Project Part4: Dealer s Choice Assigned: Monday, November 28, 2005 Due: 10:30 AM, Thursday, December 15, 2005 1 Project Description For the last part of your project, you should choose what to do.
Search Result Optimization using Annotators
 Search Result Optimization using Annotators Vishal A. Kamble 1, Amit B. Chougule 2 1 Department of Computer Science and Engineering, D Y Patil College of engineering, Kolhapur, Maharashtra, India 2 Professor,
Search Result Optimization using Annotators Vishal A. Kamble 1, Amit B. Chougule 2 1 Department of Computer Science and Engineering, D Y Patil College of engineering, Kolhapur, Maharashtra, India 2 Professor,
Language and Computation
 Language and Computation week 13, Thursday, April 24 Tamás Biró Yale University tamas.biro@yale.edu http://www.birot.hu/courses/2014-lc/ Tamás Biró, Yale U., Language and Computation p. 1 Practical matters
Language and Computation week 13, Thursday, April 24 Tamás Biró Yale University tamas.biro@yale.edu http://www.birot.hu/courses/2014-lc/ Tamás Biró, Yale U., Language and Computation p. 1 Practical matters
Outline. for Making Online Advertising Decisions. The first banner ad in 1994. Online Advertising. Online Advertising.
 Modeling Consumer Search for Making Online Advertising Decisions i Alan Montgomery Associate Professor Carnegie Mellon University Tepper School of Business Online Advertising Background Search Advertising
Modeling Consumer Search for Making Online Advertising Decisions i Alan Montgomery Associate Professor Carnegie Mellon University Tepper School of Business Online Advertising Background Search Advertising
Indexing and Compression of Text
 Compressing the Digital Library Timothy C. Bell 1, Alistair Moffat 2, and Ian H. Witten 3 1 Department of Computer Science, University of Canterbury, New Zealand, tim@cosc.canterbury.ac.nz 2 Department
Compressing the Digital Library Timothy C. Bell 1, Alistair Moffat 2, and Ian H. Witten 3 1 Department of Computer Science, University of Canterbury, New Zealand, tim@cosc.canterbury.ac.nz 2 Department
Hadoop Usage At Yahoo! Milind Bhandarkar (milindb@yahoo-inc.com)
") Hadoop Usage At Yahoo! Milind Bhandarkar (milindb@yahoo-inc.com) About Me Parallel Programming since 1989 High-Performance Scientific Computing 1989-2005, Data-Intensive Computing 2005 -... Hadoop Solutions
Hadoop Usage At Yahoo! Milind Bhandarkar (milindb@yahoo-inc.com) About Me Parallel Programming since 1989 High-Performance Scientific Computing 1989-2005, Data-Intensive Computing 2005 -... Hadoop Solutions
Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata
 Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata Alessandra Giordani and Alessandro Moschitti Department of Computer Science and Engineering University of Trento Via Sommarive
Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata Alessandra Giordani and Alessandro Moschitti Department of Computer Science and Engineering University of Trento Via Sommarive
Where Text Analytics is at Today
 Where Text Analytics is at Today Robert Dale Centre for Language Technology www.clt.mq.edu.au Sydney Data Miners 2008-07-29 Robert Dale 1 The Aim of This Talk To give you an idea of where the commercial
Where Text Analytics is at Today Robert Dale Centre for Language Technology www.clt.mq.edu.au Sydney Data Miners 2008-07-29 Robert Dale 1 The Aim of This Talk To give you an idea of where the commercial
Flattening Enterprise Knowledge
 Flattening Enterprise Knowledge Do you Control Your Content or Does Your Content Control You? 1 Executive Summary: Enterprise Content Management (ECM) is a common buzz term and every IT manager knows it
Flattening Enterprise Knowledge Do you Control Your Content or Does Your Content Control You? 1 Executive Summary: Enterprise Content Management (ECM) is a common buzz term and every IT manager knows it
An Information Retrieval using weighted Index Terms in Natural Language document collections
 Internet and Information Technology in Modern Organizations: Challenges & Answers 635 An Information Retrieval using weighted Index Terms in Natural Language document collections Ahmed A. A. Radwan, Minia
Internet and Information Technology in Modern Organizations: Challenges & Answers 635 An Information Retrieval using weighted Index Terms in Natural Language document collections Ahmed A. A. Radwan, Minia
Building a Question Classifier for a TREC-Style Question Answering System
 Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
LexisNexis TotalPatent. Training Manual
 LexisNexis TotalPatent Training Manual March, 2013 Table of Contents 1 GETTING STARTED Signing On / Off Setting Preferences and Project IDs Online Help and Feedback 2 SEARCHING FUNDAMENTALS Overview of
LexisNexis TotalPatent Training Manual March, 2013 Table of Contents 1 GETTING STARTED Signing On / Off Setting Preferences and Project IDs Online Help and Feedback 2 SEARCHING FUNDAMENTALS Overview of
Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project
 Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project Ahmet Suerdem Istanbul Bilgi University; LSE Methodology Dept. Science in the media project is funded
Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project Ahmet Suerdem Istanbul Bilgi University; LSE Methodology Dept. Science in the media project is funded
Supervised Learning Evaluation (via Sentiment Analysis)!
!") Supervised Learning Evaluation (via Sentiment Analysis)! Why Analyze Sentiment? Sentiment Analysis (Opinion Mining) Automatically label documents with their sentiment Toward a topic Aggregated over documents
Supervised Learning Evaluation (via Sentiment Analysis)! Why Analyze Sentiment? Sentiment Analysis (Opinion Mining) Automatically label documents with their sentiment Toward a topic Aggregated over documents
Chapter 7. Language models. Statistical Machine Translation
 Chapter 7 Language models Statistical Machine Translation Language models Language models answer the question: How likely is a string of English words good English? Help with reordering p lm (the house
Chapter 7 Language models Statistical Machine Translation Language models Language models answer the question: How likely is a string of English words good English? Help with reordering p lm (the house
OPINION MINING IN PRODUCT REVIEW SYSTEM USING BIG DATA TECHNOLOGY HADOOP
 OPINION MINING IN PRODUCT REVIEW SYSTEM USING BIG DATA TECHNOLOGY HADOOP 1 KALYANKUMAR B WADDAR, 2 K SRINIVASA 1 P G Student, S.I.T Tumkur, 2 Assistant Professor S.I.T Tumkur Abstract- Product Review System
OPINION MINING IN PRODUCT REVIEW SYSTEM USING BIG DATA TECHNOLOGY HADOOP 1 KALYANKUMAR B WADDAR, 2 K SRINIVASA 1 P G Student, S.I.T Tumkur, 2 Assistant Professor S.I.T Tumkur Abstract- Product Review System
Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study
 Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study Aron Henriksson 1, Martin Hassel 1, and Maria Kvist 1,2 1 Department of Computer and System Sciences
Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study Aron Henriksson 1, Martin Hassel 1, and Maria Kvist 1,2 1 Department of Computer and System Sciences
Information Retrieval. Lecture 8 - Relevance feedback and query expansion. Introduction. Overview. About Relevance Feedback. Wintersemester 2007
 Information Retrieval Lecture 8 - Relevance feedback and query expansion Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 32 Introduction An information
Information Retrieval Lecture 8 - Relevance feedback and query expansion Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 32 Introduction An information
Data Mining & Knowledge Discovery: Personalization and Profiling Technologies
 Data Mining & Knowledge Discovery: Personalization and Profiling Technologies 1 Predictive Modeling and Knowledge Discovery via Data Mining v A black box that makes predictions about the future based on
Data Mining & Knowledge Discovery: Personalization and Profiling Technologies 1 Predictive Modeling and Knowledge Discovery via Data Mining v A black box that makes predictions about the future based on