How To Create A Specimen Database
|
|
|
- Harry King
- 3 years ago
- Views:
Transcription
1 from the Natural History Domain Computational Linguistics Saarland University 11 October 2007

2 Background The MITCH project Mining for Information in Texts from the Cultural Heritage joint research project between Tilburg University and Naturalis (Dutch National Museum of Natural History) text mining and information extraction for natural history data part of the CATCH programme (10 projects, funded by NWO)

3 Naturalis

4 Naturalis more than 10 million specimens: 5,250,000 insects 2,290,000 invertebrates 1,000,000 vertebrates 1,160,000 fossils 440,000 stones and minerals 150,000 species 10% of the Earth s biodiversity

5 Naturalis
6 Data and Meta-Data

7 Data and Meta-Data

8 Data and Meta-Data

9 Data and Meta-Data

10 Data and Meta-Data

11 Data and Meta-Data

12 Data and Meta-Data

13 Data and Meta-Data

14 Data Sources and Tasks Two main data sources... Tasks... (handwritten) fieldbooks (digitised and externally transcribed) specimen databases (manually created by curators, incomplete) converting transcribed field books into structured records data cleaning for specimen databases (error detection, data completion)
 converting transcribed")

15 Digitisation of Fieldbooks
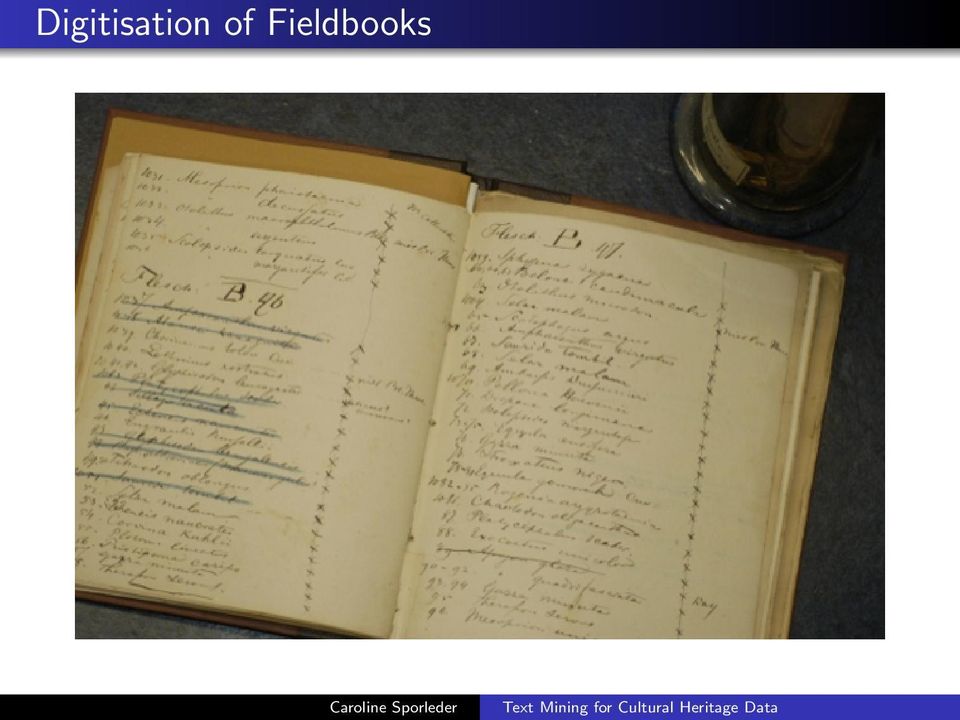
16 Transcription of Fieldbooks all fieldbooks relating to Reptiles and Amphibians Collection 15,000 handwritten pages manually transcribed by typists at Combiwerk simple guidelines on how to deal with non-ascii characters text written in the margins illegible passages etc. transcriptions completed in around 8 months

17 Specimen Databases manually compiled from field books designed by biologists not by database experts maintained by several people rows in the database correspond to fieldbook entries usually one specimen per row columns give information about specimen and circumstances of their collection (when, where, by whom etc.) columns in a variety of formats: numbers (e.g., collection date, registration number) short text (e.g., collector, genus) free text (e.g., biotope, place, remarks)
 columns in a variety of formats: numbers (e.g., collection date, registration number) short text (e.g., collector, genus) free text (e.")
18 Example Columns place: 10 km. N. of Lucie Base Bivuac near De Kock Mountain weg van Lozoya naar Navarradonda location: h. on small tree in deciduous tropical forest (now in full leaf), 150 cm. above ground, Dewlap orange with red around rim. kwakend op grashalm in poel lang weg biotope: under stone on moist, calcareous loam 275 m, forest floor among leaf litter, near Arroyo special remarks: aangereden (nog niet dood) according to information from R. Heyer, Smithsonian, Washington, this is likely to be L. knudseni, considering the short dorso-lateral folds and chest spines ( to J. W. Arntzen January 2004)
 according to information from R. Heyer, Smithsonian, Washington, this is likely to be L.")
19 Task 1: Converting Fieldbooks into Structured Records

20 Structure of Fieldbook Entries Number 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij P. femoralis. Gonyocephalus auritus Meyer, 3 ex. (1 juv.), Misool. Hoedt RMNH Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr. Marowijne, Suriname, 19-VIII-1975, onder stuk hout, 610m, l [plus] d M. S. Hoogmoed.
, Misool. Hoedt 1867. RMNH 17656 Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr.")
21 Structure of Fieldbook Entries Number 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij P. femoralis. Gonyocephalus auritus Meyer, 3 ex. (1 juv.), Misool. Hoedt RMNH Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr. Marowijne, Suriname, 19-VIII-1975, onder stuk hout, 610m, l [plus] d M. S. Hoogmoed.
22 Structure of Fieldbook Entries Number, Genus 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij P. femoralis. Gonyocephalus auritus Meyer, 3 ex. (1 juv.), Misool. Hoedt RMNH Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr. Marowijne, Suriname, 19-VIII-1975, onder stuk hout, 610m, l [plus] d M. S. Hoogmoed.
23 Structure of Fieldbook Entries Number, Genus, Species 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij P. femoralis. Gonyocephalus auritus Meyer, 3 ex. (1 juv.), Misool. Hoedt RMNH Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr. Marowijne, Suriname, 19-VIII-1975, onder stuk hout, 610m, l [plus] d M. S. Hoogmoed.
24 Structure of Fieldbook Entries Number, Genus, Species, Biotope 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij P. femoralis. Gonyocephalus auritus Meyer, 3 ex. (1 juv.), Misool. Hoedt RMNH Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr. Marowijne, Suriname, 19-VIII-1975, onder stuk hout, 610m, l [plus] d M. S. Hoogmoed.
25 Structure of Fieldbook Entries Number, Genus, Species, Biotope, Collection Time 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij P. femoralis. Gonyocephalus auritus Meyer, 3 ex. (1 juv.), Misool. Hoedt RMNH Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr. Marowijne, Suriname, 19-VIII-1975, onder stuk hout, 610m, l [plus] d M. S. Hoogmoed.
26 Structure of Fieldbook Entries Number, Genus, Species, Biotope, Collection Time, Reg. Num. 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij P. femoralis. Gonyocephalus auritus Meyer, 3 ex. (1 juv.), Misool. Hoedt RMNH Eleutherodactylus zeuctotylus 1 [vrouw] Lelygebergte, 4 km N.O. van airstrip, distr. Marowijne, Suriname, 19-VIII-1975, onder stuk hout, 610m, l [plus] d M. S. Hoogmoed.
27 Converting Fieldbook Entries into Structured Records Aim make inherent structure of entry explicit (i.e., find segments conveying different types of information) Motivation Enable more sophisticated search raw data only allows keyword search enriched data allows querying of specific types of information
28 Example Aim: find all specimens of Phyllobates femoralis Query: Fieldbook entry contains string Pyllobates femoralis Result: Phyllobates femoralis, post Conini, Coeroenirivier, bosgrond, 25-IV-1968, 8:30-13:30 u. RMNH Lithodytes lineatus, Brownsberg, aan voet, onder stuk rot hout, , 8.45 u., RMNH Dorsolateraal strepen heldergeel, tekening op dijen vuurrood, veel feller als bij Phyllobates femoralis.
29 Modelled as Sequence Labelling 1 ex. Leptodactylus wagneri At base of tree on small island, primary forest, u. RMNH 23865
30 Modelled as Sequence Labelling 1/num ex./num Leptodactylus/genus wagneri/species At/bio base/bio of/bio tree/bio on/bio small/bio island/bio,/bio primary/bio forest/bio,/o 20/time./time 45/time -/time 22/time./time 00/time u/time./time RMNH/reg num 23865/reg num
31 Supervised Machine Learning... could use supervised learner: Hidden Markov Models, Conditional Random Fields etc. However: requires manual annotation of data (by domain experts) annotation needs to be re-done for each new domain (e.g., archaeological field reports)... or even sub-domain (reptiles vs. crustaceans)
32 Bootstrapping from Existing Resources Specimen databases readily available database entry = fieldbook entry database column labels = fieldbook segment labels Caveat: databases are only derived from fieldbooks some information in fieldbooks not in database and vice versa re-writings, systematic differences (format of dates, cue words (e.g., RMNH for registration number) etc.) segment sequence probabilities are lost in databases (joint work with Sander Canisius)
33 Converting Fieldbooks into Structured Records Three approaches... database look-up supervised ML trained on data automatically created from database HMMs plus language modelling trained on database
34 Database Look-Up (a) assign each token its most frequent column label in the database (unigram look-up) (b) assign each token the most frequent column label of the trigram centred on it, backing off to bi- and unigrams (trigram look-up) (c) assign labels to trigrams in a sliding window (each token receives 3 labels) and vote over them (trigram look-up plus voting) (d) check field book entries for substrings which are exact matched of database cells (exact match)
35 Training on Automatically Created Data Training Data concatenation of (contents of) database fields: (a) with uniform probabilities (random) (b) with probabilities that were taken from 10 manually labelled field book entries (biased) Machine Learning Set-Up memory-based learner (TiMBL) training data: 18,000 database entries test data: 150 field book entries 107 features: sliding window of 5 tokens typographic features tfidf similarities between n-grams and database column labels (in a window of 3 tokens around focus token)
36 HMM plus Language Modelling Segmentation look for bigrams which are unlikely within a field language modelling (based on database) plus Viterbi to find most likely segmentation Labelling HMM applied to segmented data initial and transition probabilities estimated in unsupervised fashion (Baum-Welch algorithm) emission probabilities based on language model of database... plus a few domain-independent rules to deal with systematic differences between databases and fieldbook
37 Results Token Segment Acc. Prec. Rec. F β=1 ExactB UniB TriB TriB+Vote MBL rand MBL bias HMM
38 Results Token Segment Acc. Prec. Rec. F β=1 ExactB UniB TriB TriB+Vote MBL rand MBL bias HMM
39 Results Token Segment Acc. Prec. Rec. F β=1 ExactB UniB TriB TriB+Vote MBL rand MBL bias HMM
40 Results Token Segment Acc. Prec. Rec. F β=1 ExactB UniB TriB TriB+Vote MBL rand MBL bias HMM
41 Task 2: Cleaning Textual Databases
42 Automatic Database Cleaning Errors and Missing Values unavoidable, even in well-maintained databases negatively affect information retrieval manual error correction extremely time consuming Traditional Data Clean-Up Methods not geared towards text databases treat fields as atoms but tokens within text string can provide valuable cues e.g. km frequent in location column but may indicate error in other columns
43 Errors in Specimen Databases Error types typos: 1% content errors (information is wrong, e.g. Surinam instead of Indonesia): 5.4% disprefered synonyms: 6.2% wrong-column errors (information is correct but should be in a different column, e.g., location instead of special remarks): 3.5% missing values: up to 90% of a given column
44 Semi-Automatic Database Cleaning Subtasks predict missing values detect and correct wrong values (typos, content errors, disprefered synonyms) detect and correct wrong-column errors Semi-Automatic set-up tools search the database to predict missing values detect potential errors and find possible corrections new value/potential error and correction are flagged to domain expert
45 Predicting Missing Values Method exploit interdependencies between different fields location: Tafel Mountain & country: South Africa train classifier to predict the value of a field given the values of the other fields
46 Predicting Missing Values Set-Up one classifier per column training data automatically generated from database split data into 80% training, 20% testing
47 Predicting Missing Values Set-Up one classifier per column training data automatically generated from database split data into 80% training, 20% testing Features Label Author Determinator Family Genus Country Location (Daudin, 1802) (Schlegel) Schneider G. vd. Boog M.S. Hoogmoed Bataguridae Colubridae Anolis Geophis Bufo Cambodia Indonesia Suriname B. Hoeksema s garden near airfield
48 Predicting Missing Values Set-Up one classifier per column training data automatically generated from database split data into 80% training, 20% testing Features Label (Daudin, 1802) Bataguridae Anolis Cambodia Author Determinator Family Genus Country Location (Daudin, 1802) (Schlegel) Schneider G. vd. Boog M.S. Hoogmoed Bataguridae Colubridae Anolis Geophis Bufo Cambodia Indonesia Suriname B. Hoeksema s garden near airfield
49 Predicting Missing Values Set-Up one classifier per column training data automatically generated from database split data into 80% training, 20% testing Features Label (Daudin, 1802) Bataguridae Anolis Cambodia (Schlegel) G. vd. Boog Colubridae Geophis B. Hoeksema s garden Indonesia Author Determinator Family Genus Country Location (Daudin, 1802) (Schlegel) Schneider G. vd. Boog M.S. Hoogmoed Bataguridae Colubridae Anolis Geophis Bufo Cambodia Indonesia Suriname B. Hoeksema s garden near airfield
50 Predicting Missing Values Set-Up one classifier per column training data automatically generated from database split data into 80% training, 20% testing Features Label (Daudin, 1802) Bataguridae Anolis Cambodia (Schlegel) G. vd. Boog Colubridae Geophis B. Hoeksema s garden Indonesia Schneider M.S. Hoogmoed Bufo near airfield Suriname Author Determinator Family Genus Country Location (Daudin, 1802) (Schlegel) Schneider G. vd. Boog M.S. Hoogmoed Bataguridae Colubridae Anolis Geophis Bufo Cambodia Indonesia Suriname B. Hoeksema s garden near airfield
51 Results Generally... fairly high prediction accuracies, even for free-text fields well above baselines (random (rnd) and majority value (maj)) Accuracies for different columns Accuracy column # values (types) ML maj rnd family % 18.59% 1.92% genus % 10.13% 0.35% species 1, % 6.18% 0.07% collector 1, % 30.44% 0.09% special remarks 2, % 4.07% 0.03% location % 22.46% 0.15% biotope % 4.63% 0.14%
52 More Sophisticated Approach simple approach treats values of fields as atoms not ideal for free text fields Example: Predict value of country from place Venezuela co-occurs with 56 distinct values in place 30 of those contain the string El Dorado, e.g.: La Escalera, Z. van El Dorado, weg El Dorado - Sta El Dorado, Estado Bolivar Las Claritas, 85 km Z. van El Dorado El Dorado, Estado Bolivar, 4 km N van El Dorado
53 More Sophisticated Approach Alternative feature representations instead of representing fields as atomic strings: (a) represent only named entities (e.g., binary features indicating presence of various NEs) (b) represent fields by the unigram with the highest tfidf (c) represent fields by the unigram for which the mutual information with the values in the target column is highest Pilot study indicates that (c) works best: full string NEs (binary features) max. tfidf max. MI Acc % 83.13% 82.41% 84.30%
54 Detecting Content Errors Apply Value Prediction to filled fields... Actual Value: Geophis Predicted Value: Rhabdophis Author Determinator Family Genus Country Conservation (Daudin, 1802) (Schlegel) Schneider (Horst, 1883) G. vd. Boog M.S. Hoogmoed Tyler, M.J. Bataguridae Colubridae Hylidae Anolis Geophis Bufo Litoria Cambodia Indonesia Suriname (shell, dry) alcohol
55 Detecting Content Errors Apply Value Prediction to filled fields... Actual Value: Geophis Predicted Value: Rhabdophis Author Determinator Family Genus Country Conservation (Daudin, 1802) (Schlegel) Schneider (Horst, 1883) G. vd. Boog M.S. Hoogmoed Tyler, M.J. Bataguridae Colubridae Hylidae Anolis Geophis Bufo Litoria Cambodia Indonesia Suriname (shell, dry) alcohol
56 Detecting Content Errors Apply Value Prediction to filled fields... Actual Value: Geophis Predicted Value: Rhabdophis Author Determinator Family Genus Country Conservation (Daudin, 1802) (Schlegel) Schneider (Horst, 1883) G. vd. Boog M.S. Hoogmoed Tyler, M.J. Bataguridae Colubridae Hylidae Anolis? Bufo Litoria Cambodia Indonesia Suriname (shell, dry) alcohol
57 Detecting Content Errors Apply Value Prediction to filled fields... Actual Value: Geophis Predicted Value: Rhabdophis Author Determinator Family Genus Country Conservation (Daudin, 1802) (Schlegel) Schneider (Horst, 1883) G. vd. Boog M.S. Hoogmoed Tyler, M.J. Bataguridae Colubridae Hylidae Anolis? Bufo Litoria Cambodia Indonesia Suriname (shell, dry) alcohol
58 Detecting Content Errors Apply Value Prediction to filled fields... Actual Value: Geophis Predicted Value: Rhabdophis Author Determinator Family Genus Country Conservation (Daudin, 1802) (Schlegel) Schneider (Horst, 1883) G. vd. Boog M.S. Hoogmoed Tyler, M.J. Bataguridae Colubridae Hylidae Anolis? Bufo Litoria Cambodia Indonesia Suriname (shell, dry) alcohol
59 Detecting Content Errors Experimental Set-Up test on taxonomic fields potential errors can be checked by non-expert against gold standard taxonomy (correction) precision calculated by manual checking (detection) recall estimated on artificial errors
60 Detecting Content Errors Detection Recall (estimated) column recall class 95.56% order 96.82% family 96.15% genus 93.09% Correction Precision precision column items flagged incl. synonyms excl. synonyms class % 50.00% order % 38.00% family % 9.09% genus % 5.93%
61 Detecting Wrong Column Errors Aim detect information that was entered in the wrong column: e.g., died in captivity is in location but should be in special remarks Method recast as a text classification problem train classifier to predict column of a text string apply to cell contents signal potential error if: predicted column actual column
62 Detection Wrong-Column Errors Training Data generated automatically from database Features typographical (number of tokens, capitalisation, punctuation, numbers, units of measurement etc.) similarity with each column (i.e., tfidf weighted token overlap)
63 Detecting Wrong-Column Errors Training Set Creation Features Label Daudin, 1802 Author Author Determinator Family Place Genus Province Daudin, 1802 (Peters, 1867) (Schlegel) M. S. Hoogmoed Polychrotidae Bigisanti beach Anolis A. H. Bol, 1972/73 Agamidae Gonocephalus M Java, Wonosobo Elaphe Ned. Nieuw Guinea
64 Detecting Wrong-Column Errors Training Set Creation Features Label Daudin, 1802 M. S. Hoogmoed Author Determinator Author Determinator Family Place Genus Province Daudin, 1802 (Peters, 1867) (Schlegel) M. S. Hoogmoed Polychrotidae Bigisanti beach Anolis A. H. Bol, 1972/73 Agamidae Gonocephalus M Java, Wonosobo Elaphe Ned. Nieuw Guinea
65 Detecting Wrong-Column Errors Training Set Creation Features Label Daudin, 1802 M. S. Hoogmoed Polychrotidae Author Determinator Family Author Determinator Family Place Genus Province Daudin, 1802 (Peters, 1867) (Schlegel) M. S. Hoogmoed Polychrotidae Bigisanti beach Anolis A. H. Bol, 1972/73 Agamidae Gonocephalus M Java, Wonosobo Elaphe Ned. Nieuw Guinea
66 Detecting Wrong-Column Errors Actual Value: Geophis Predicted Value: Rhabdophis Conservation Location Biotope Special Remarks alcohol alcohol Huys te Linschoten roadside bordering secondary forest in roadside pool Bodemvallen Parkbos aanplant Eik died in captivity alcohol bosbivak Zanderij in betonnen met water biotoop: zwampig terrein gevulde bak met zandboden on base of tree along trail in terra firme forest geen verdere gegevens bekend alcohol 12 km NE of Elmali clay soil with reed vegetation Tank 8 alcohol in field near roadside injured before capture by observers
67 Detecting Wrong-Column Errors Actual Value: Geophis Predicted Value: Rhabdophis Conservation Location Biotope Special Remarks alcohol alcohol Huys te Linschoten roadside bordering secondary forest in roadside pool Bodemvallen Parkbos aanplant Eik died in captivity alcohol bosbivak Zanderij in betonnen met water biotoop: zwampig terrein gevulde bak met zandboden on base of tree along trail in terra firme forest geen verdere gegevens bekend alcohol 12 km NE of Elmali clay soil with reed vegetation Tank 8 alcohol in field near roadside injured before capture by observers
68 Detecting Wrong-Column Errors Actual Value: Location Predicted Value: Rhabdophis Conservation? Biotope Special Remarks alcohol alcohol Huys te Linschoten roadside bordering secondary forest in roadside pool Bodemvallen Parkbos aanplant Eik died in captivity alcohol bosbivak Zanderij in betonnen met water biotoop: zwampig terrein gevulde bak met zandboden on base of tree along trail in terra firme forest geen verdere gegevens bekend alcohol 12 km NE of Elmali clay soil with reed vegetation Tank 8 alcohol in field near roadside injured before capture by observers
69 Detecting Wrong-Column Errors Actual Value: Location Predicted Value: Biotope Conservation? Biotope Special Remarks alcohol alcohol Huys te Linschoten roadside bordering secondary forest in roadside pool Bodemvallen Parkbos aanplant Eik died in captivity alcohol bosbivak Zanderij in betonnen met water biotoop: zwampig terrein gevulde bak met zandboden on base of tree along trail in terra firme forest geen verdere gegevens bekend alcohol 12 km NE of Elmali clay soil with reed vegetation Tank 8 alcohol in field near roadside injured before capture by observers
70 Detecting Wrong-Column Errors Experimental Set-Up leave-one-out testing manual annotation for 4 free-text columns: biotope, location, publication, special remarks Results items detection correction column flagged recall precision accuracy biotope % 24.4% 91.2% location % 18.2% 51.9% publication % 6.9% 25.0% special remarks % 20.1% 61.7%
71 Detecting Wrong-Column Errors, Examples Good corrections: string original column predicted column on a tree 2.5 m above ground special remarks biotope 25 km N.N.W Antalya special remarks location 1700 m biotope altitude died in captivity location special remarks roadside bordering secondary forest location biotope Suriname Exp collection number collector Not so good: string original column predicted column (Kikkervisje) special remarks author N.W. van Meknes location collector
72 Conclusions Summary for the cultural heritage domain, manual annotation of training data is usually not feasible but it is possible to go a long way by exploiting existing resources exploit existing databases to bootstrap a fieldbook segmenter exploit redundancy and interdependencies to detect database errors Software Error Detection Demo ( Timpute: a TiMBL wrapper for semi-automatic error detection in databases to be released soon
73 Collaborators Antal van den Bosch, Sander Canisius, Marieke van Erp, Steve Hunt, Tijn Porcelijn Links Error Detection Demo MITCH project CATCH programme Museum Naturalis
Vorbespechung/Introductory Meeting: Text Mining for Historical Documents
 Vorbespechung/Introductory Meeting: Computational Linguistics Universität des Saarlandes Wintersemester 2011/12 17.01.2012 Organisational Stuff What is it? Project Seminar a theoretical part (class presentations)
Vorbespechung/Introductory Meeting: Computational Linguistics Universität des Saarlandes Wintersemester 2011/12 17.01.2012 Organisational Stuff What is it? Project Seminar a theoretical part (class presentations)
Mining for Information in Texts from the Cultural Heritage. Marieke van Erp http://ticc.uvt.nl/mitch
 Mining for Information in Texts from the Cultural Heritage Marieke van Erp http://ticc.uvt.nl/mitch Piroska Lendvai Steve Hunt Marieke van Erp 16,870 records describing characteristics and history of
Mining for Information in Texts from the Cultural Heritage Marieke van Erp http://ticc.uvt.nl/mitch Piroska Lendvai Steve Hunt Marieke van Erp 16,870 records describing characteristics and history of
From Field Notes Towards a Knowledge Base
 From Field Notes Towards a Knowledge Base Piroska Lendvai, Steve Hunt Department of Communication and Information Science Tilburg University, The Netherlands {p.lendvai,s.j.hunt}@uvt.nl Abstract We describe
From Field Notes Towards a Knowledge Base Piroska Lendvai, Steve Hunt Department of Communication and Information Science Tilburg University, The Netherlands {p.lendvai,s.j.hunt}@uvt.nl Abstract We describe
Web-Scale Extraction of Structured Data Michael J. Cafarella, Jayant Madhavan & Alon Halevy
 The Deep Web: Surfacing Hidden Value Michael K. Bergman Web-Scale Extraction of Structured Data Michael J. Cafarella, Jayant Madhavan & Alon Halevy Presented by Mat Kelly CS895 Web-based Information Retrieval
The Deep Web: Surfacing Hidden Value Michael K. Bergman Web-Scale Extraction of Structured Data Michael J. Cafarella, Jayant Madhavan & Alon Halevy Presented by Mat Kelly CS895 Web-based Information Retrieval
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
POS Tagging 1. POS Tagging. Rule-based taggers Statistical taggers Hybrid approaches
 POS Tagging 1 POS Tagging Rule-based taggers Statistical taggers Hybrid approaches POS Tagging 1 POS Tagging 2 Words taken isolatedly are ambiguous regarding its POS Yo bajo con el hombre bajo a PP AQ
POS Tagging 1 POS Tagging Rule-based taggers Statistical taggers Hybrid approaches POS Tagging 1 POS Tagging 2 Words taken isolatedly are ambiguous regarding its POS Yo bajo con el hombre bajo a PP AQ
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Project 2: Term Clouds (HOF) Implementation Report. Members: Nicole Sparks (project leader), Charlie Greenbacker
 Implementation Report. Members: Nicole Sparks (project leader), Charlie Greenbacker") CS-889 Spring 2011 Project 2: Term Clouds (HOF) Implementation Report Members: Nicole Sparks (project leader), Charlie Greenbacker Abstract: This report describes the methods used in our implementation
CS-889 Spring 2011 Project 2: Term Clouds (HOF) Implementation Report Members: Nicole Sparks (project leader), Charlie Greenbacker Abstract: This report describes the methods used in our implementation
The University of Amsterdam s Question Answering System at QA@CLEF 2007
 The University of Amsterdam s Question Answering System at QA@CLEF 2007 Valentin Jijkoun, Katja Hofmann, David Ahn, Mahboob Alam Khalid, Joris van Rantwijk, Maarten de Rijke, and Erik Tjong Kim Sang ISLA,
The University of Amsterdam s Question Answering System at QA@CLEF 2007 Valentin Jijkoun, Katja Hofmann, David Ahn, Mahboob Alam Khalid, Joris van Rantwijk, Maarten de Rijke, and Erik Tjong Kim Sang ISLA,
CI6227: Data Mining. Lesson 11b: Ensemble Learning. Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore.
 CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
HELP DESK SYSTEMS. Using CaseBased Reasoning
 HELP DESK SYSTEMS Using CaseBased Reasoning Topics Covered Today What is Help-Desk? Components of HelpDesk Systems Types Of HelpDesk Systems Used Need for CBR in HelpDesk Systems GE Helpdesk using ReMind
HELP DESK SYSTEMS Using CaseBased Reasoning Topics Covered Today What is Help-Desk? Components of HelpDesk Systems Types Of HelpDesk Systems Used Need for CBR in HelpDesk Systems GE Helpdesk using ReMind
Mining the Software Change Repository of a Legacy Telephony System
 Mining the Software Change Repository of a Legacy Telephony System Jelber Sayyad Shirabad, Timothy C. Lethbridge, Stan Matwin School of Information Technology and Engineering University of Ottawa, Ottawa,
Mining the Software Change Repository of a Legacy Telephony System Jelber Sayyad Shirabad, Timothy C. Lethbridge, Stan Matwin School of Information Technology and Engineering University of Ottawa, Ottawa,
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
2015 Workshops for Professors
 SAS Education Grow with us Offered by the SAS Global Academic Program Supporting teaching, learning and research in higher education 2015 Workshops for Professors 1 Workshops for Professors As the market
SAS Education Grow with us Offered by the SAS Global Academic Program Supporting teaching, learning and research in higher education 2015 Workshops for Professors 1 Workshops for Professors As the market
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Offline Recognition of Unconstrained Handwritten Texts Using HMMs and Statistical Language Models. Alessandro Vinciarelli, Samy Bengio and Horst Bunke
 1 Offline Recognition of Unconstrained Handwritten Texts Using HMMs and Statistical Language Models Alessandro Vinciarelli, Samy Bengio and Horst Bunke Abstract This paper presents a system for the offline
1 Offline Recognition of Unconstrained Handwritten Texts Using HMMs and Statistical Language Models Alessandro Vinciarelli, Samy Bengio and Horst Bunke Abstract This paper presents a system for the offline
Experiments in Web Page Classification for Semantic Web
 Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
Experiments in Web Page Classification for Semantic Web Asad Satti, Nick Cercone, Vlado Kešelj Faculty of Computer Science, Dalhousie University E-mail: {rashid,nick,vlado}@cs.dal.ca Abstract We address
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks
 A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
Chapter 6. The stacking ensemble approach
 82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
Micro blogs Oriented Word Segmentation System
 Micro blogs Oriented Word Segmentation System Yijia Liu, Meishan Zhang, Wanxiang Che, Ting Liu, Yihe Deng Research Center for Social Computing and Information Retrieval Harbin Institute of Technology,
Micro blogs Oriented Word Segmentation System Yijia Liu, Meishan Zhang, Wanxiang Che, Ting Liu, Yihe Deng Research Center for Social Computing and Information Retrieval Harbin Institute of Technology,
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
PICCL: Philosophical Integrator of Computational and Corpus Libraries
 1 PICCL: Philosophical Integrator of Computational and Corpus Libraries Martin Reynaert 12, Maarten van Gompel 1, Ko van der Sloot 1 and Antal van den Bosch 1 Center for Language Studies - Radboud University
1 PICCL: Philosophical Integrator of Computational and Corpus Libraries Martin Reynaert 12, Maarten van Gompel 1, Ko van der Sloot 1 and Antal van den Bosch 1 Center for Language Studies - Radboud University
Gwen Landburg December 2012. Anton de Kom University of Suriname
 Gwen Landburg December 2012 Anton de Kom University of Suriname Short term impacts of selective logging loss of habitat drier conditions Result: only species with a broad physiological range and species
Gwen Landburg December 2012 Anton de Kom University of Suriname Short term impacts of selective logging loss of habitat drier conditions Result: only species with a broad physiological range and species
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Overview. Evaluation Connectionist and Statistical Language Processing. Test and Validation Set. Training and Test Set
 Overview Evaluation Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes training set, validation set, test set holdout, stratification
Overview Evaluation Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes training set, validation set, test set holdout, stratification
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Resolving Common Analytical Tasks in Text Databases
 Resolving Common Analytical Tasks in Text Databases The work is funded by the Federal Ministry of Economic Affairs and Energy (BMWi) under grant agreement 01MD15010B. Database Systems and Text-based Information
Resolving Common Analytical Tasks in Text Databases The work is funded by the Federal Ministry of Economic Affairs and Energy (BMWi) under grant agreement 01MD15010B. Database Systems and Text-based Information
Transformation of Free-text Electronic Health Records for Efficient Information Retrieval and Support of Knowledge Discovery
 Transformation of Free-text Electronic Health Records for Efficient Information Retrieval and Support of Knowledge Discovery Jan Paralic, Peter Smatana Technical University of Kosice, Slovakia Center for
Transformation of Free-text Electronic Health Records for Efficient Information Retrieval and Support of Knowledge Discovery Jan Paralic, Peter Smatana Technical University of Kosice, Slovakia Center for
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Cell Phone based Activity Detection using Markov Logic Network
 Cell Phone based Activity Detection using Markov Logic Network Somdeb Sarkhel sxs104721@utdallas.edu 1 Introduction Mobile devices are becoming increasingly sophisticated and the latest generation of smart
Cell Phone based Activity Detection using Markov Logic Network Somdeb Sarkhel sxs104721@utdallas.edu 1 Introduction Mobile devices are becoming increasingly sophisticated and the latest generation of smart
Automated Content Analysis of Discussion Transcripts
 Automated Content Analysis of Discussion Transcripts Vitomir Kovanović v.kovanovic@ed.ac.uk Dragan Gašević dgasevic@acm.org School of Informatics, University of Edinburgh Edinburgh, United Kingdom v.kovanovic@ed.ac.uk
Automated Content Analysis of Discussion Transcripts Vitomir Kovanović v.kovanovic@ed.ac.uk Dragan Gašević dgasevic@acm.org School of Informatics, University of Edinburgh Edinburgh, United Kingdom v.kovanovic@ed.ac.uk
!"!!"#$$%&'()*+$(,%!"#$%$&'()*""%(+,'-*&./#-$&'(-&(0*".$#-$1"(2&."3$'45"
*+$(,%!#$%$&'()*%(+,'-*&./#-$&'(-&(0*.$#-$1(2&.3$'45") !"!!"#$$%&'()*+$(,%!"#$%$&'()*""%(+,'-*&./#-$&'(-&(0*".$#-$1"(2&."3$'45"!"#"$%&#'()*+',$$-.&#',/"-0%.12'32./4'5,5'6/%&)$).2&'7./&)8'5,5'9/2%.%3%&8':")08';:
!"!!"#$$%&'()*+$(,%!"#$%$&'()*""%(+,'-*&./#-$&'(-&(0*".$#-$1"(2&."3$'45"!"#"$%&#'()*+',$$-.&#',/"-0%.12'32./4'5,5'6/%&)$).2&'7./&)8'5,5'9/2%.%3%&8':")08';:
131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10
![131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10](/thumbs/25/4963058.jpg "131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10") 1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
Machine Learning and Statistics: What s the Connection?
 Machine Learning and Statistics: What s the Connection? Institute for Adaptive and Neural Computation School of Informatics, University of Edinburgh, UK August 2006 Outline The roots of machine learning
Machine Learning and Statistics: What s the Connection? Institute for Adaptive and Neural Computation School of Informatics, University of Edinburgh, UK August 2006 Outline The roots of machine learning
Term extraction for user profiling: evaluation by the user
 Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
Specimen Labels v. 09/2002
 Division of Arthropods Museum of Southwestern Biology The University of New Mexico Specimen Labels v. 09/2002 All arthropod museum specimens must be properly labeled as to geographic collection locality,
Division of Arthropods Museum of Southwestern Biology The University of New Mexico Specimen Labels v. 09/2002 All arthropod museum specimens must be properly labeled as to geographic collection locality,
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R
 Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Open Domain Information Extraction. Günter Neumann, DFKI, 2012
 Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
Word Completion and Prediction in Hebrew
 Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
II. RELATED WORK. Sentiment Mining
 Sentiment Mining Using Ensemble Classification Models Matthew Whitehead and Larry Yaeger Indiana University School of Informatics 901 E. 10th St. Bloomington, IN 47408 {mewhiteh, larryy}@indiana.edu Abstract
Sentiment Mining Using Ensemble Classification Models Matthew Whitehead and Larry Yaeger Indiana University School of Informatics 901 E. 10th St. Bloomington, IN 47408 {mewhiteh, larryy}@indiana.edu Abstract
Visualization methods for patent data
 Visualization methods for patent data Treparel 2013 Dr. Anton Heijs (CTO & Founder) Delft, The Netherlands Introduction Treparel can provide advanced visualizations for patent data. This document describes
Visualization methods for patent data Treparel 2013 Dr. Anton Heijs (CTO & Founder) Delft, The Netherlands Introduction Treparel can provide advanced visualizations for patent data. This document describes
CS570 Data Mining Classification: Ensemble Methods
 CS570 Data Mining Classification: Ensemble Methods Cengiz Günay Dept. Math & CS, Emory University Fall 2013 Some slides courtesy of Han-Kamber-Pei, Tan et al., and Li Xiong Günay (Emory) Classification:
CS570 Data Mining Classification: Ensemble Methods Cengiz Günay Dept. Math & CS, Emory University Fall 2013 Some slides courtesy of Han-Kamber-Pei, Tan et al., and Li Xiong Günay (Emory) Classification:
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
ToxiCat: Hybrid Named Entity Recognition services to support curation of the Comparative Toxicogenomic Database
 ToxiCat: Hybrid Named Entity Recognition services to support curation of the Comparative Toxicogenomic Database Dina Vishnyakova 1,2, 4, *, Julien Gobeill 1,3,4, Emilie Pasche 1,2,3,4 and Patrick Ruch
ToxiCat: Hybrid Named Entity Recognition services to support curation of the Comparative Toxicogenomic Database Dina Vishnyakova 1,2, 4, *, Julien Gobeill 1,3,4, Emilie Pasche 1,2,3,4 and Patrick Ruch
ALIAS: A Tool for Disambiguating Authors in Microsoft Academic Search
 Project for Michael Pitts Course TCSS 702A University of Washington Tacoma Institute of Technology ALIAS: A Tool for Disambiguating Authors in Microsoft Academic Search Under supervision of : Dr. Senjuti
Project for Michael Pitts Course TCSS 702A University of Washington Tacoma Institute of Technology ALIAS: A Tool for Disambiguating Authors in Microsoft Academic Search Under supervision of : Dr. Senjuti
Learning is a very general term denoting the way in which agents:
 What is learning? Learning is a very general term denoting the way in which agents: Acquire and organize knowledge (by building, modifying and organizing internal representations of some external reality);
What is learning? Learning is a very general term denoting the way in which agents: Acquire and organize knowledge (by building, modifying and organizing internal representations of some external reality);
The Delicate Art of Flower Classification
 The Delicate Art of Flower Classification Paul Vicol Simon Fraser University University Burnaby, BC pvicol@sfu.ca Note: The following is my contribution to a group project for a graduate machine learning
The Delicate Art of Flower Classification Paul Vicol Simon Fraser University University Burnaby, BC pvicol@sfu.ca Note: The following is my contribution to a group project for a graduate machine learning
Search and Information Retrieval
 Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Data, Measurements, Features
 Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Enhanced Boosted Trees Technique for Customer Churn Prediction Model
 IOSR Journal of Engineering (IOSRJEN) ISSN (e): 2250-3021, ISSN (p): 2278-8719 Vol. 04, Issue 03 (March. 2014), V5 PP 41-45 www.iosrjen.org Enhanced Boosted Trees Technique for Customer Churn Prediction
IOSR Journal of Engineering (IOSRJEN) ISSN (e): 2250-3021, ISSN (p): 2278-8719 Vol. 04, Issue 03 (March. 2014), V5 PP 41-45 www.iosrjen.org Enhanced Boosted Trees Technique for Customer Churn Prediction
Introduction to Machine Learning and Data Mining. Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk
 Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
Nature Values Screening Using Object-Based Image Analysis of Very High Resolution Remote Sensing Data
 Nature Values Screening Using Object-Based Image Analysis of Very High Resolution Remote Sensing Data Aleksi Räsänen*, Anssi Lensu, Markku Kuitunen Environmental Science and Technology Dept. of Biological
Nature Values Screening Using Object-Based Image Analysis of Very High Resolution Remote Sensing Data Aleksi Räsänen*, Anssi Lensu, Markku Kuitunen Environmental Science and Technology Dept. of Biological
CYBER SCIENCE 2015 AN ANALYSIS OF NETWORK TRAFFIC CLASSIFICATION FOR BOTNET DETECTION
 CYBER SCIENCE 2015 AN ANALYSIS OF NETWORK TRAFFIC CLASSIFICATION FOR BOTNET DETECTION MATIJA STEVANOVIC PhD Student JENS MYRUP PEDERSEN Associate Professor Department of Electronic Systems Aalborg University,
CYBER SCIENCE 2015 AN ANALYSIS OF NETWORK TRAFFIC CLASSIFICATION FOR BOTNET DETECTION MATIJA STEVANOVIC PhD Student JENS MYRUP PEDERSEN Associate Professor Department of Electronic Systems Aalborg University,
Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis
 Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis Yue Dai, Ernest Arendarenko, Tuomo Kakkonen, Ding Liao School of Computing University of Eastern Finland {yvedai,
Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis Yue Dai, Ernest Arendarenko, Tuomo Kakkonen, Ding Liao School of Computing University of Eastern Finland {yvedai,
Technical Report. The KNIME Text Processing Feature:
 Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
On Discovering Deterministic Relationships in Multi-Label Learning via Linked Open Data
 On Discovering Deterministic Relationships in Multi-Label Learning via Linked Open Data Eirini Papagiannopoulou, Grigorios Tsoumakas, and Nick Bassiliades Department of Informatics, Aristotle University
On Discovering Deterministic Relationships in Multi-Label Learning via Linked Open Data Eirini Papagiannopoulou, Grigorios Tsoumakas, and Nick Bassiliades Department of Informatics, Aristotle University
ATLAS.ti for Mac OS X Getting Started
 ATLAS.ti for Mac OS X Getting Started 2 ATLAS.ti for Mac OS X Getting Started Copyright 2014 by ATLAS.ti Scientific Software Development GmbH, Berlin. All rights reserved. Manual Version: 5.20140918. Updated
ATLAS.ti for Mac OS X Getting Started 2 ATLAS.ti for Mac OS X Getting Started Copyright 2014 by ATLAS.ti Scientific Software Development GmbH, Berlin. All rights reserved. Manual Version: 5.20140918. Updated
Introduction to Data Mining
 Introduction to Data Mining Jay Urbain Credits: Nazli Goharian & David Grossman @ IIT Outline Introduction Data Pre-processing Data Mining Algorithms Naïve Bayes Decision Tree Neural Network Association
Introduction to Data Mining Jay Urbain Credits: Nazli Goharian & David Grossman @ IIT Outline Introduction Data Pre-processing Data Mining Algorithms Naïve Bayes Decision Tree Neural Network Association
Inner Classification of Clusters for Online News
 Inner Classification of Clusters for Online News Harmandeep Kaur 1, Sheenam Malhotra 2 1 (Computer Science and Engineering Department, Shri Guru Granth Sahib World University Fatehgarh Sahib) 2 (Assistant
Inner Classification of Clusters for Online News Harmandeep Kaur 1, Sheenam Malhotra 2 1 (Computer Science and Engineering Department, Shri Guru Granth Sahib World University Fatehgarh Sahib) 2 (Assistant
PoliticalMashup. Make implicit structure and information explicit. Content
 1 2 Content Connecting promises and actions of politicians and how the society reacts on them Maarten Marx Universiteit van Amsterdam Overview project Zooming in on one cultural heritage dataset A few
1 2 Content Connecting promises and actions of politicians and how the society reacts on them Maarten Marx Universiteit van Amsterdam Overview project Zooming in on one cultural heritage dataset A few
Data Mining. Knowledge Discovery, Data Warehousing and Machine Learning Final remarks. Lecturer: JERZY STEFANOWSKI
 Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Clustering Connectionist and Statistical Language Processing
 Clustering Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Clustering Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Data Mining Algorithms Part 1. Dejan Sarka
 Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Chapter 8. Final Results on Dutch Senseval-2 Test Data
 Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
Using Data Mining for Mobile Communication Clustering and Characterization
 Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
<is web> Information Systems & Semantic Web University of Koblenz Landau, Germany
 Information Systems University of Koblenz Landau, Germany Exploiting Spatial Context in Images Using Fuzzy Constraint Reasoning Carsten Saathoff & Agenda Semantic Web: Our Context Knowledge Annotation
Information Systems University of Koblenz Landau, Germany Exploiting Spatial Context in Images Using Fuzzy Constraint Reasoning Carsten Saathoff & Agenda Semantic Web: Our Context Knowledge Annotation
1. Classification problems
 Neural and Evolutionary Computing. Lab 1: Classification problems Machine Learning test data repository Weka data mining platform Introduction Scilab 1. Classification problems The main aim of a classification
Neural and Evolutionary Computing. Lab 1: Classification problems Machine Learning test data repository Weka data mining platform Introduction Scilab 1. Classification problems The main aim of a classification
The Role of Metadata for Effective Data Warehouse
 ISSN: 1991-8941 The Role of Metadata for Effective Data Warehouse Murtadha M. Hamad Alaa Abdulqahar Jihad University of Anbar - College of computer Abstract: Metadata efficient method for managing Data
ISSN: 1991-8941 The Role of Metadata for Effective Data Warehouse Murtadha M. Hamad Alaa Abdulqahar Jihad University of Anbar - College of computer Abstract: Metadata efficient method for managing Data
Interactive Information Visualization in the Digital Flora of Texas
 Interactive Information Visualization in the Digital Flora of Texas Teong Joo Ong 1, John J. Leggett 1, Hugh D. Wilson 2, Stephan L. Hatch 3, Monique D. Reed 2 1 Center for the Study of Digital Libraries,
Interactive Information Visualization in the Digital Flora of Texas Teong Joo Ong 1, John J. Leggett 1, Hugh D. Wilson 2, Stephan L. Hatch 3, Monique D. Reed 2 1 Center for the Study of Digital Libraries,
Big Data: Rethinking Text Visualization
 Big Data: Rethinking Text Visualization Dr. Anton Heijs anton.heijs@treparel.com Treparel April 8, 2013 Abstract In this white paper we discuss text visualization approaches and how these are important
Big Data: Rethinking Text Visualization Dr. Anton Heijs anton.heijs@treparel.com Treparel April 8, 2013 Abstract In this white paper we discuss text visualization approaches and how these are important
Framing Business Problems as Data Mining Problems
 Framing Business Problems as Data Mining Problems Asoka Diggs Data Scientist, Intel IT January 21, 2016 Legal Notices This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS
Framing Business Problems as Data Mining Problems Asoka Diggs Data Scientist, Intel IT January 21, 2016 Legal Notices This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS
Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata
 Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata Alessandra Giordani and Alessandro Moschitti Department of Computer Science and Engineering University of Trento Via Sommarive
Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata Alessandra Giordani and Alessandro Moschitti Department of Computer Science and Engineering University of Trento Via Sommarive
Information Leakage in Encrypted Network Traffic
 Information Leakage in Encrypted Network Traffic Attacks and Countermeasures Scott Coull RedJack Joint work with: Charles Wright (MIT LL) Lucas Ballard (Google) Fabian Monrose (UNC) Gerald Masson (JHU)
Information Leakage in Encrypted Network Traffic Attacks and Countermeasures Scott Coull RedJack Joint work with: Charles Wright (MIT LL) Lucas Ballard (Google) Fabian Monrose (UNC) Gerald Masson (JHU)
SVM Based Learning System For Information Extraction
 SVM Based Learning System For Information Extraction Yaoyong Li, Kalina Bontcheva, and Hamish Cunningham Department of Computer Science, The University of Sheffield, Sheffield, S1 4DP, UK {yaoyong,kalina,hamish}@dcs.shef.ac.uk
SVM Based Learning System For Information Extraction Yaoyong Li, Kalina Bontcheva, and Hamish Cunningham Department of Computer Science, The University of Sheffield, Sheffield, S1 4DP, UK {yaoyong,kalina,hamish}@dcs.shef.ac.uk
Text Mining for Health Care and Medicine. Sophia Ananiadou Director National Centre for Text Mining www.nactem.ac.uk
 Text Mining for Health Care and Medicine Sophia Ananiadou Director National Centre for Text Mining www.nactem.ac.uk The Need for Text Mining MEDLINE 2005: ~14M 2009: ~18M Overwhelming information in textual,
Text Mining for Health Care and Medicine Sophia Ananiadou Director National Centre for Text Mining www.nactem.ac.uk The Need for Text Mining MEDLINE 2005: ~14M 2009: ~18M Overwhelming information in textual,
Cross-Validation. Synonyms Rotation estimation
 Comp. by: BVijayalakshmiGalleys0000875816 Date:6/11/08 Time:19:52:53 Stage:First Proof C PAYAM REFAEILZADEH, LEI TANG, HUAN LIU Arizona State University Synonyms Rotation estimation Definition is a statistical
Comp. by: BVijayalakshmiGalleys0000875816 Date:6/11/08 Time:19:52:53 Stage:First Proof C PAYAM REFAEILZADEH, LEI TANG, HUAN LIU Arizona State University Synonyms Rotation estimation Definition is a statistical
University of Glasgow Terrier Team / Project Abacá at RepLab 2014: Reputation Dimensions Task
 University of Glasgow Terrier Team / Project Abacá at RepLab 2014: Reputation Dimensions Task Graham McDonald, Romain Deveaud, Richard McCreadie, Timothy Gollins, Craig Macdonald and Iadh Ounis School
University of Glasgow Terrier Team / Project Abacá at RepLab 2014: Reputation Dimensions Task Graham McDonald, Romain Deveaud, Richard McCreadie, Timothy Gollins, Craig Macdonald and Iadh Ounis School
It Takes a Village to Raise a Machine Learning Model. Lucian Lita @datariver
 It Takes a Village to Raise a Machine Learning Model Lucian Lita It Takes a Village to Raise a Machine Learning Model Lucian Lita Algorithms Data Big Data Sheep @bigdatasheep n 5yr more data is better
It Takes a Village to Raise a Machine Learning Model Lucian Lita It Takes a Village to Raise a Machine Learning Model Lucian Lita Algorithms Data Big Data Sheep @bigdatasheep n 5yr more data is better
Gerry Hobbs, Department of Statistics, West Virginia University
 Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
How to use Big Data in Industry 4.0 implementations. LAURI ILISON, PhD Head of Big Data and Machine Learning
 How to use Big Data in Industry 4.0 implementations LAURI ILISON, PhD Head of Big Data and Machine Learning Big Data definition? Big Data is about structured vs unstructured data Big Data is about Volume
How to use Big Data in Industry 4.0 implementations LAURI ILISON, PhD Head of Big Data and Machine Learning Big Data definition? Big Data is about structured vs unstructured data Big Data is about Volume
Improving Data Driven Part-of-Speech Tagging by Morphologic Knowledge Induction
 Improving Data Driven Part-of-Speech Tagging by Morphologic Knowledge Induction Uwe D. Reichel Department of Phonetics and Speech Communication University of Munich reichelu@phonetik.uni-muenchen.de Abstract
Improving Data Driven Part-of-Speech Tagging by Morphologic Knowledge Induction Uwe D. Reichel Department of Phonetics and Speech Communication University of Munich reichelu@phonetik.uni-muenchen.de Abstract
Sentiment analysis: towards a tool for analysing real-time students feedback
 Sentiment analysis: towards a tool for analysing real-time students feedback Nabeela Altrabsheh Email: nabeela.altrabsheh@port.ac.uk Mihaela Cocea Email: mihaela.cocea@port.ac.uk Sanaz Fallahkhair Email:
Sentiment analysis: towards a tool for analysing real-time students feedback Nabeela Altrabsheh Email: nabeela.altrabsheh@port.ac.uk Mihaela Cocea Email: mihaela.cocea@port.ac.uk Sanaz Fallahkhair Email:
Efficient database auditing
 Topicus Fincare Efficient database auditing And entity reversion Dennis Windhouwer Supervised by: Pim van den Broek, Jasper Laagland and Johan te Winkel 9 April 2014 SUMMARY Topicus wants their current
Topicus Fincare Efficient database auditing And entity reversion Dennis Windhouwer Supervised by: Pim van den Broek, Jasper Laagland and Johan te Winkel 9 April 2014 SUMMARY Topicus wants their current
Big Data & Scripting Part II Streaming Algorithms
 Big Data & Scripting Part II Streaming Algorithms 1, Counting Distinct Elements 2, 3, counting distinct elements problem formalization input: stream of elements o from some universe U e.g. ids from a set
Big Data & Scripting Part II Streaming Algorithms 1, Counting Distinct Elements 2, 3, counting distinct elements problem formalization input: stream of elements o from some universe U e.g. ids from a set
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 10 Sajjad Haider Fall 2012 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 10 Sajjad Haider Fall 2012 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Assisting bug Triage in Large Open Source Projects Using Approximate String Matching
 Assisting bug Triage in Large Open Source Projects Using Approximate String Matching Amir H. Moin and Günter Neumann Language Technology (LT) Lab. German Research Center for Artificial Intelligence (DFKI)
Assisting bug Triage in Large Open Source Projects Using Approximate String Matching Amir H. Moin and Günter Neumann Language Technology (LT) Lab. German Research Center for Artificial Intelligence (DFKI)
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 5 ISSN 2229-5518
 International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 5 INTELLIGENT MULTIDIMENSIONAL DATABASE INTERFACE Mona Gharib Mohamed Reda Zahraa E. Mohamed Faculty of Science,
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 5 INTELLIGENT MULTIDIMENSIONAL DATABASE INTERFACE Mona Gharib Mohamed Reda Zahraa E. Mohamed Faculty of Science,
Guide for Bioinformatics Project Module 3
 Structure- Based Evidence and Multiple Sequence Alignment In this module we will revisit some topics we started to look at while performing our BLAST search and looking at the CDD database in the first
Structure- Based Evidence and Multiple Sequence Alignment In this module we will revisit some topics we started to look at while performing our BLAST search and looking at the CDD database in the first
Sentiment analysis on tweets in a financial domain
 Sentiment analysis on tweets in a financial domain Jasmina Smailović 1,2, Miha Grčar 1, Martin Žnidaršič 1 1 Dept of Knowledge Technologies, Jožef Stefan Institute, Ljubljana, Slovenia 2 Jožef Stefan International
Sentiment analysis on tweets in a financial domain Jasmina Smailović 1,2, Miha Grčar 1, Martin Žnidaršič 1 1 Dept of Knowledge Technologies, Jožef Stefan Institute, Ljubljana, Slovenia 2 Jožef Stefan International
Segmentation and Classification of Online Chats
 Segmentation and Classification of Online Chats Justin Weisz Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 jweisz@cs.cmu.edu Abstract One method for analyzing textual chat
Segmentation and Classification of Online Chats Justin Weisz Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 jweisz@cs.cmu.edu Abstract One method for analyzing textual chat
COURSE RECOMMENDER SYSTEM IN E-LEARNING
 International Journal of Computer Science and Communication Vol. 3, No. 1, January-June 2012, pp. 159-164 COURSE RECOMMENDER SYSTEM IN E-LEARNING Sunita B Aher 1, Lobo L.M.R.J. 2 1 M.E. (CSE)-II, Walchand
International Journal of Computer Science and Communication Vol. 3, No. 1, January-June 2012, pp. 159-164 COURSE RECOMMENDER SYSTEM IN E-LEARNING Sunita B Aher 1, Lobo L.M.R.J. 2 1 M.E. (CSE)-II, Walchand
Blog Post Extraction Using Title Finding
 Blog Post Extraction Using Title Finding Linhai Song 1, 2, Xueqi Cheng 1, Yan Guo 1, Bo Wu 1, 2, Yu Wang 1, 2 1 Institute of Computing Technology, Chinese Academy of Sciences, Beijing 2 Graduate School
Blog Post Extraction Using Title Finding Linhai Song 1, 2, Xueqi Cheng 1, Yan Guo 1, Bo Wu 1, 2, Yu Wang 1, 2 1 Institute of Computing Technology, Chinese Academy of Sciences, Beijing 2 Graduate School
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Develop and Implement a Pilot Status and Trend Monitoring Program for Salmonids and their Habitat in the Wenatchee and Grande Ronde River Basins.
 Project ID: 35019 Title: Develop and Implement a Pilot Status and Trend Monitoring Program for Salmonids and their Habitat in the Wenatchee and Grande Ronde River Basins. Response to ISRP Comments A. This
Project ID: 35019 Title: Develop and Implement a Pilot Status and Trend Monitoring Program for Salmonids and their Habitat in the Wenatchee and Grande Ronde River Basins. Response to ISRP Comments A. This
3.1 Measuring Biodiversity
 3.1 Measuring Biodiversity Every year, a news headline reads, New species discovered in. For example, in 2006, scientists discovered 36 new species of fish, corals, and shrimp in the warm ocean waters
3.1 Measuring Biodiversity Every year, a news headline reads, New species discovered in. For example, in 2006, scientists discovered 36 new species of fish, corals, and shrimp in the warm ocean waters
Introduction to Pattern Recognition
 Introduction to Pattern Recognition Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Introduction to Pattern Recognition Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
6.2.8 Neural networks for data mining
 6.2.8 Neural networks for data mining Walter Kosters 1 In many application areas neural networks are known to be valuable tools. This also holds for data mining. In this chapter we discuss the use of neural
6.2.8 Neural networks for data mining Walter Kosters 1 In many application areas neural networks are known to be valuable tools. This also holds for data mining. In this chapter we discuss the use of neural
Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study
 Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study Aron Henriksson 1, Martin Hassel 1, and Maria Kvist 1,2 1 Department of Computer and System Sciences
Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study Aron Henriksson 1, Martin Hassel 1, and Maria Kvist 1,2 1 Department of Computer and System Sciences