CS570 Data Mining Classification: Ensemble Methods
|
|
|
- Warren Hensley
- 8 years ago
- Views:
Transcription
1 CS570 Data Mining Classification: Ensemble Methods Cengiz Günay Dept. Math & CS, Emory University Fall 2013 Some slides courtesy of Han-Kamber-Pei, Tan et al., and Li Xiong Günay (Emory) Classification: Ensemble Methods Fall / 6

2 Today Due today midnight: Homework #2 Frequent itemsets Given today: Homework #3 Classification Today s menu: Classification: Ensemble Methods Günay (Emory) Classification: Ensemble Methods Fall / 6
 Classification: Ensemble Methods Fall")
3 Ensemble Methods Given a data set, generate multiple models and combine the results Bagging Random Forests Boosting PAC learning significance

4 General Idea
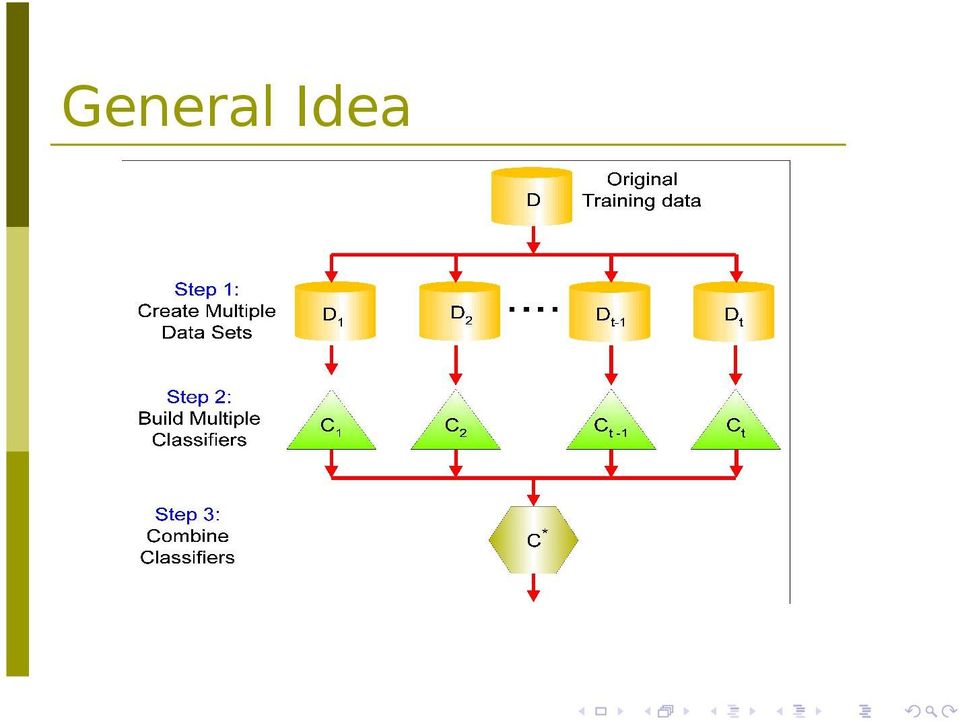
5 Why does it work? Suppose there are 25 base classifiers Each classifier has error rate, ε = 0.35 Assume classifiers are independent Probability that the ensemble classifier makes a wrong prediction: 25 ( 25i ) εi (1 ε )25 i =0. 06 i=13

6 Types of Ensemble Methods Can be obtained by manipulating: 1 Training set: Bagging Boosting Günay (Emory) Classification: Ensemble Methods Fall / 6

7 Types of Ensemble Methods Can be obtained by manipulating: 1 Training set: Bagging Boosting 2 Input features: Random forests Multi-objective evolutionary algorithms Forward/backward elimination? Günay (Emory) Classification: Ensemble Methods Fall / 6

8 Types of Ensemble Methods Can be obtained by manipulating: 1 Training set: Bagging Boosting 2 Input features: Random forests Multi-objective evolutionary algorithms Forward/backward elimination? 3 Class labels: Multi-classes Active learning Günay (Emory) Classification: Ensemble Methods Fall / 6
 Classification:")
9 Types of Ensemble Methods Can be obtained by manipulating: 1 Training set: Bagging Boosting 2 Input features: Random forests Multi-objective evolutionary algorithms Forward/backward elimination? 3 Class labels: Multi-classes Active learning Learning algorithm: ANNs Decision trees Günay (Emory) Classification: Ensemble Methods Fall / 6

10 Bagging Create a data set by sampling data points with replacement Create model based on the data set Generate more data sets and models Predict by combining votes Classification: majority vote Prediction: average

11 Bagging Sampling with replacement Original Data Bagging (Round 1) Bagging (Round 2) Bagging (Round 3) Build classifier on each bootstrap sample Each sample has probability (1 1/n)n of being selected
n of being")
12 Bagging Advantages: Less overfitting Helps when classifier is unstable (has high variance) Disadvantages: Not useful when classifier is stable and has large bias Günay (Emory) Classification: Ensemble Methods Fall 2013 / 6
 Classification: Ensemble")
13 PAC learning Model defining learning with given accuracy and confidence using polynomial sample complexity References: L. Valiant. A theory of the learnable. D. Haussler. Overview of the Probably Approximately Correct (PAC) Learning Framework
 Learning Framework")
14 Boosting Use weak learners and combine to form strong learner in PAC learning sense Learn using a weak learner Boost the accuracy by reweighting the examples misclassified by previous weak learner and forcing the next weak learner to focus on the hard examples Predict by using a weighted combination of the weak learners Weight is determined by their accuracy

15 Boosting An iterative procedure to adaptively change distribution of training data by focusing more on previously misclassified records Initially, all N records are assigned equal weights Unlike bagging, weights may change at the end of boosting round

16 Boosting Records that are wrongly classified will have their weights increased Records that are classified correctly will have their weights decreased Original Data Boosting (Round 1) Boosting (Round 2) Boosting (Round 3) Example is hard to classify Its weight is increased, therefore it is more likely to be chosen again in subsequent rounds

17 Boosting Advantages: Focuses on samples that are hard to classify Sample weights can be used for: Adaboost: 1 Sampling probability 2 Used by classifier to value them more Calculates classifier importance instead of voting Exponential weight update rules But, susceptible to overfitting Günay (Emory) Classification: Ensemble Methods Fall / 6
 Classification: Ensemble Methods Fall")
18 Example: AdaBoost Base classifiers: C1, C2,, CT Error rate: 1 εi = N N w j δ ( C i ( x j ) y j ) j=1 Importance of a classifier: 1 ε i 1 α i= ln 2 εi ( )

19 Example: AdaBoost Weight update: ( j) wi ( j+ 1) wi = Zj { α j if C j ( xi )=y i αj if C j ( xi ) y i exp exp } where Z j is the normalization factor If any intermediate rounds produce error rate higher than 50%, the weights are reverted back to 1/n and the resampling procedure is repeated Classification: C * ( x ) = arg max α jδ ( C j ( x ) = y ) T y j =1
 = arg max α jδ ( C j ( x ) = y")
20 Illustrating AdaBoost Initial weights for each data point (C) Vipin Kumar, Parallel Issues in Data Mining, V Data points for training 11

21 Illustrating AdaBoost (C) Vipin Kumar, Parallel Issues in Data Mining, V 12
22 Random Forests Sample a data set with replacement Select m variables at random from p variables Create a tree Similarly create more trees Combine the results Reference: Hastie, Tibshirani, Friedman, The Elements of Statistical Learning, Chapter 15
23 Random Forests Advantages: Only for decision trees Lowers generalization error Uses randomization in tree construction: #features= log 2 d + 1 Equivalent accuracy to Adaboost, but faster See table in Tan et al p. 29 for comparison of ensemble methods. Günay (Emory) Classification: Ensemble Methods Fall / 6
CI6227: Data Mining. Lesson 11b: Ensemble Learning. Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore.
 CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Introduction to Machine Learning and Data Mining. Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk
 Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
Chapter 11 Boosting. Xiaogang Su Department of Statistics University of Central Florida - 1 -
 Chapter 11 Boosting Xiaogang Su Department of Statistics University of Central Florida - 1 - Perturb and Combine (P&C) Methods have been devised to take advantage of the instability of trees to create
Chapter 11 Boosting Xiaogang Su Department of Statistics University of Central Florida - 1 - Perturb and Combine (P&C) Methods have been devised to take advantage of the instability of trees to create
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Model Combination. 24 Novembre 2009
 Model Combination 24 Novembre 2009 Datamining 1 2009-2010 Plan 1 Principles of model combination 2 Resampling methods Bagging Random Forests Boosting 3 Hybrid methods Stacking Generic algorithm for mulistrategy
Model Combination 24 Novembre 2009 Datamining 1 2009-2010 Plan 1 Principles of model combination 2 Resampling methods Bagging Random Forests Boosting 3 Hybrid methods Stacking Generic algorithm for mulistrategy
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier
 A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 10 Sajjad Haider Fall 2012 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 10 Sajjad Haider Fall 2012 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Boosting. riedmiller@informatik.uni-freiburg.de
 . Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Using multiple models: Bagging, Boosting, Ensembles, Forests
 Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Chapter 6. The stacking ensemble approach
 82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Why Ensembles Win Data Mining Competitions
 Why Ensembles Win Data Mining Competitions A Predictive Analytics Center of Excellence (PACE) Tech Talk November 14, 2012 Dean Abbott Abbott Analytics, Inc. Blog: http://abbottanalytics.blogspot.com URL:
Why Ensembles Win Data Mining Competitions A Predictive Analytics Center of Excellence (PACE) Tech Talk November 14, 2012 Dean Abbott Abbott Analytics, Inc. Blog: http://abbottanalytics.blogspot.com URL:
FilterBoost: Regression and Classification on Large Datasets
 FilterBoost: Regression and Classification on Large Datasets Joseph K. Bradley Machine Learning Department Carnegie Mellon University Pittsburgh, PA 523 jkbradle@cs.cmu.edu Robert E. Schapire Department
FilterBoost: Regression and Classification on Large Datasets Joseph K. Bradley Machine Learning Department Carnegie Mellon University Pittsburgh, PA 523 jkbradle@cs.cmu.edu Robert E. Schapire Department
Ensemble Methods. Adapted from slides by Todd Holloway h8p://abeau<fulwww.com/2007/11/23/ ensemble- machine- learning- tutorial/
 Ensemble Methods Adapted from slides by Todd Holloway h8p://abeau
Ensemble Methods Adapted from slides by Todd Holloway h8p://abeau
L25: Ensemble learning
 L25: Ensemble learning Introduction Methods for constructing ensembles Combination strategies Stacked generalization Mixtures of experts Bagging Boosting CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna
L25: Ensemble learning Introduction Methods for constructing ensembles Combination strategies Stacked generalization Mixtures of experts Bagging Boosting CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna
REVIEW OF ENSEMBLE CLASSIFICATION
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IJCSMC, Vol. 2, Issue.
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IJCSMC, Vol. 2, Issue.
Ensemble Approach for the Classification of Imbalanced Data
 Ensemble Approach for the Classification of Imbalanced Data Vladimir Nikulin 1, Geoffrey J. McLachlan 1, and Shu Kay Ng 2 1 Department of Mathematics, University of Queensland v.nikulin@uq.edu.au, gjm@maths.uq.edu.au
Ensemble Approach for the Classification of Imbalanced Data Vladimir Nikulin 1, Geoffrey J. McLachlan 1, and Shu Kay Ng 2 1 Department of Mathematics, University of Queensland v.nikulin@uq.edu.au, gjm@maths.uq.edu.au
Ensemble Data Mining Methods
 Ensemble Data Mining Methods Nikunj C. Oza, Ph.D., NASA Ames Research Center, USA INTRODUCTION Ensemble Data Mining Methods, also known as Committee Methods or Model Combiners, are machine learning methods
Ensemble Data Mining Methods Nikunj C. Oza, Ph.D., NASA Ames Research Center, USA INTRODUCTION Ensemble Data Mining Methods, also known as Committee Methods or Model Combiners, are machine learning methods
Leveraging Ensemble Models in SAS Enterprise Miner
 ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
Generalizing Random Forests Principles to other Methods: Random MultiNomial Logit, Random Naive Bayes, Anita Prinzie & Dirk Van den Poel
 Generalizing Random Forests Principles to other Methods: Random MultiNomial Logit, Random Naive Bayes, Anita Prinzie & Dirk Van den Poel Copyright 2008 All rights reserved. Random Forests Forest of decision
Generalizing Random Forests Principles to other Methods: Random MultiNomial Logit, Random Naive Bayes, Anita Prinzie & Dirk Van den Poel Copyright 2008 All rights reserved. Random Forests Forest of decision
Source. The Boosting Approach. Example: Spam Filtering. The Boosting Approach to Machine Learning
 Source The Boosting Approach to Machine Learning Notes adapted from Rob Schapire www.cs.princeton.edu/~schapire CS 536: Machine Learning Littman (Wu, TA) Example: Spam Filtering problem: filter out spam
Source The Boosting Approach to Machine Learning Notes adapted from Rob Schapire www.cs.princeton.edu/~schapire CS 536: Machine Learning Littman (Wu, TA) Example: Spam Filtering problem: filter out spam
Data Mining Methods: Applications for Institutional Research
 Data Mining Methods: Applications for Institutional Research Nora Galambos, PhD Office of Institutional Research, Planning & Effectiveness Stony Brook University NEAIR Annual Conference Philadelphia 2014
Data Mining Methods: Applications for Institutional Research Nora Galambos, PhD Office of Institutional Research, Planning & Effectiveness Stony Brook University NEAIR Annual Conference Philadelphia 2014
Ensemble of Classifiers Based on Association Rule Mining
 Ensemble of Classifiers Based on Association Rule Mining Divya Ramani, Dept. of Computer Engineering, LDRP, KSV, Gandhinagar, Gujarat, 9426786960. Harshita Kanani, Assistant Professor, Dept. of Computer
Ensemble of Classifiers Based on Association Rule Mining Divya Ramani, Dept. of Computer Engineering, LDRP, KSV, Gandhinagar, Gujarat, 9426786960. Harshita Kanani, Assistant Professor, Dept. of Computer
Data Analytics and Business Intelligence (8696/8697)
") http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/36 Data Analytics and Business Intelligence (8696/8697) Ensemble Decision Trees Graham.Williams@togaware.com Data Scientist Australian
http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/36 Data Analytics and Business Intelligence (8696/8697) Ensemble Decision Trees Graham.Williams@togaware.com Data Scientist Australian
Comparison of Data Mining Techniques used for Financial Data Analysis
 Comparison of Data Mining Techniques used for Financial Data Analysis Abhijit A. Sawant 1, P. M. Chawan 2 1 Student, 2 Associate Professor, Department of Computer Technology, VJTI, Mumbai, INDIA Abstract
Comparison of Data Mining Techniques used for Financial Data Analysis Abhijit A. Sawant 1, P. M. Chawan 2 1 Student, 2 Associate Professor, Department of Computer Technology, VJTI, Mumbai, INDIA Abstract
Knowledge Discovery and Data Mining. Bootstrap review. Bagging Important Concepts. Notes. Lecture 19 - Bagging. Tom Kelsey. Notes
 Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-19-B &
Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-19-B &
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL
 The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
Distributed forests for MapReduce-based machine learning
 Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Journal of Asian Scientific Research COMPARISON OF THREE CLASSIFICATION ALGORITHMS FOR PREDICTING PM2.5 IN HONG KONG RURAL AREA.
 Journal of Asian Scientific Research journal homepage: http://aesswebcom/journal-detailphp?id=5003 COMPARISON OF THREE CLASSIFICATION ALGORITHMS FOR PREDICTING PM25 IN HONG KONG RURAL AREA Yin Zhao School
Journal of Asian Scientific Research journal homepage: http://aesswebcom/journal-detailphp?id=5003 COMPARISON OF THREE CLASSIFICATION ALGORITHMS FOR PREDICTING PM25 IN HONG KONG RURAL AREA Yin Zhao School
DECISION TREE INDUCTION FOR FINANCIAL FRAUD DETECTION USING ENSEMBLE LEARNING TECHNIQUES
 DECISION TREE INDUCTION FOR FINANCIAL FRAUD DETECTION USING ENSEMBLE LEARNING TECHNIQUES Vijayalakshmi Mahanra Rao 1, Yashwant Prasad Singh 2 Multimedia University, Cyberjaya, MALAYSIA 1 lakshmi.mahanra@gmail.com
DECISION TREE INDUCTION FOR FINANCIAL FRAUD DETECTION USING ENSEMBLE LEARNING TECHNIQUES Vijayalakshmi Mahanra Rao 1, Yashwant Prasad Singh 2 Multimedia University, Cyberjaya, MALAYSIA 1 lakshmi.mahanra@gmail.com
Case Study Report: Building and analyzing SVM ensembles with Bagging and AdaBoost on big data sets
 Case Study Report: Building and analyzing SVM ensembles with Bagging and AdaBoost on big data sets Ricardo Ramos Guerra Jörg Stork Master in Automation and IT Faculty of Computer Science and Engineering
Case Study Report: Building and analyzing SVM ensembles with Bagging and AdaBoost on big data sets Ricardo Ramos Guerra Jörg Stork Master in Automation and IT Faculty of Computer Science and Engineering
Monday Morning Data Mining
 Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik
Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik
Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods
 Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods Jerzy B laszczyński 1, Krzysztof Dembczyński 1, Wojciech Kot lowski 1, and Mariusz Paw lowski 2 1 Institute of Computing
Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods Jerzy B laszczyński 1, Krzysztof Dembczyński 1, Wojciech Kot lowski 1, and Mariusz Paw lowski 2 1 Institute of Computing
Ensemble Learning Better Predictions Through Diversity. Todd Holloway ETech 2008
 Ensemble Learning Better Predictions Through Diversity Todd Holloway ETech 2008 Outline Building a classifier (a tutorial example) Neighbor method Major ideas and challenges in classification Ensembles
Ensemble Learning Better Predictions Through Diversity Todd Holloway ETech 2008 Outline Building a classifier (a tutorial example) Neighbor method Major ideas and challenges in classification Ensembles
How To Solve The Class Imbalance Problem In Data Mining
 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS 1 A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches Mikel Galar,
IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS 1 A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches Mikel Galar,
Decompose Error Rate into components, some of which can be measured on unlabeled data
 Bias-Variance Theory Decompose Error Rate into components, some of which can be measured on unlabeled data Bias-Variance Decomposition for Regression Bias-Variance Decomposition for Classification Bias-Variance
Bias-Variance Theory Decompose Error Rate into components, some of which can be measured on unlabeled data Bias-Variance Decomposition for Regression Bias-Variance Decomposition for Classification Bias-Variance
On the effect of data set size on bias and variance in classification learning
 On the effect of data set size on bias and variance in classification learning Abstract Damien Brain Geoffrey I Webb School of Computing and Mathematics Deakin University Geelong Vic 3217 With the advent
On the effect of data set size on bias and variance in classification learning Abstract Damien Brain Geoffrey I Webb School of Computing and Mathematics Deakin University Geelong Vic 3217 With the advent
Ensembles and PMML in KNIME
 Ensembles and PMML in KNIME Alexander Fillbrunn 1, Iris Adä 1, Thomas R. Gabriel 2 and Michael R. Berthold 1,2 1 Department of Computer and Information Science Universität Konstanz Konstanz, Germany First.Last@Uni-Konstanz.De
Ensembles and PMML in KNIME Alexander Fillbrunn 1, Iris Adä 1, Thomas R. Gabriel 2 and Michael R. Berthold 1,2 1 Department of Computer and Information Science Universität Konstanz Konstanz, Germany First.Last@Uni-Konstanz.De
Local classification and local likelihoods
 Local classification and local likelihoods November 18 k-nearest neighbors The idea of local regression can be extended to classification as well The simplest way of doing so is called nearest neighbor
Local classification and local likelihoods November 18 k-nearest neighbors The idea of local regression can be extended to classification as well The simplest way of doing so is called nearest neighbor
Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms
 Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms Yin Zhao School of Mathematical Sciences Universiti Sains Malaysia (USM) Penang, Malaysia Yahya
Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms Yin Zhao School of Mathematical Sciences Universiti Sains Malaysia (USM) Penang, Malaysia Yahya
MHI3000 Big Data Analytics for Health Care Final Project Report
 MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
Online Algorithms: Learning & Optimization with No Regret.
 Online Algorithms: Learning & Optimization with No Regret. Daniel Golovin 1 The Setup Optimization: Model the problem (objective, constraints) Pick best decision from a feasible set. Learning: Model the
Online Algorithms: Learning & Optimization with No Regret. Daniel Golovin 1 The Setup Optimization: Model the problem (objective, constraints) Pick best decision from a feasible set. Learning: Model the
Government of Russian Federation. Faculty of Computer Science School of Data Analysis and Artificial Intelligence
 Government of Russian Federation Federal State Autonomous Educational Institution of High Professional Education National Research University «Higher School of Economics» Faculty of Computer Science School
Government of Russian Federation Federal State Autonomous Educational Institution of High Professional Education National Research University «Higher School of Economics» Faculty of Computer Science School
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
( ) = ( ) = {,,, } β ( ), < 1 ( ) + ( ) = ( ) + ( )
 = ( ) = {,,, } β ( ), < 1 ( ) + ( ) = ( ) + ( )") { } ( ) = ( ) = {,,, } ( ) β ( ), < 1 ( ) + ( ) = ( ) + ( ) max, ( ) [ ( )] + ( ) [ ( )], [ ( )] [ ( )] = =, ( ) = ( ) = 0 ( ) = ( ) ( ) ( ) =, ( ), ( ) =, ( ), ( ). ln ( ) = ln ( ). + 1 ( ) = ( ) Ω[ (
{ } ( ) = ( ) = {,,, } ( ) β ( ), < 1 ( ) + ( ) = ( ) + ( ) max, ( ) [ ( )] + ( ) [ ( )], [ ( )] [ ( )] = =, ( ) = ( ) = 0 ( ) = ( ) ( ) ( ) =, ( ), ( ) =, ( ), ( ). ln ( ) = ln ( ). + 1 ( ) = ( ) Ω[ (
A Novel Classification Approach for C2C E-Commerce Fraud Detection
 A Novel Classification Approach for C2C E-Commerce Fraud Detection *1 Haitao Xiong, 2 Yufeng Ren, 2 Pan Jia *1 School of Computer and Information Engineering, Beijing Technology and Business University,
A Novel Classification Approach for C2C E-Commerce Fraud Detection *1 Haitao Xiong, 2 Yufeng Ren, 2 Pan Jia *1 School of Computer and Information Engineering, Beijing Technology and Business University,
Boosting Applied to Classification of Mass Spectral Data
 Journal of Data Science 1(2003), 391-404 Boosting Applied to Classification of Mass Spectral Data K. Varmuza 1,PingHe 2,3 and Kai-Tai Fang 2 1 Vienna University of Technology, 2 Hong Kong Baptist University
Journal of Data Science 1(2003), 391-404 Boosting Applied to Classification of Mass Spectral Data K. Varmuza 1,PingHe 2,3 and Kai-Tai Fang 2 1 Vienna University of Technology, 2 Hong Kong Baptist University
Welcome. Data Mining: Updates in Technologies. Xindong Wu. Colorado School of Mines Golden, Colorado 80401, USA
 Welcome Xindong Wu Data Mining: Updates in Technologies Dept of Math and Computer Science Colorado School of Mines Golden, Colorado 80401, USA Email: xwu@ mines.edu Home Page: http://kais.mines.edu/~xwu/
Welcome Xindong Wu Data Mining: Updates in Technologies Dept of Math and Computer Science Colorado School of Mines Golden, Colorado 80401, USA Email: xwu@ mines.edu Home Page: http://kais.mines.edu/~xwu/
Random forest algorithm in big data environment
 Random forest algorithm in big data environment Yingchun Liu * School of Economics and Management, Beihang University, Beijing 100191, China Received 1 September 2014, www.cmnt.lv Abstract Random forest
Random forest algorithm in big data environment Yingchun Liu * School of Economics and Management, Beihang University, Beijing 100191, China Received 1 September 2014, www.cmnt.lv Abstract Random forest
Chapter 12 Bagging and Random Forests
 Chapter 12 Bagging and Random Forests Xiaogang Su Department of Statistics and Actuarial Science University of Central Florida - 1 - Outline A brief introduction to the bootstrap Bagging: basic concepts
Chapter 12 Bagging and Random Forests Xiaogang Su Department of Statistics and Actuarial Science University of Central Florida - 1 - Outline A brief introduction to the bootstrap Bagging: basic concepts
A Learning Algorithm For Neural Network Ensembles
 A Learning Algorithm For Neural Network Ensembles H. D. Navone, P. M. Granitto, P. F. Verdes and H. A. Ceccatto Instituto de Física Rosario (CONICET-UNR) Blvd. 27 de Febrero 210 Bis, 2000 Rosario. República
A Learning Algorithm For Neural Network Ensembles H. D. Navone, P. M. Granitto, P. F. Verdes and H. A. Ceccatto Instituto de Física Rosario (CONICET-UNR) Blvd. 27 de Febrero 210 Bis, 2000 Rosario. República
Lecture/Recitation Topic SMA 5303 L1 Sampling and statistical distributions
 SMA 50: Statistical Learning and Data Mining in Bioinformatics (also listed as 5.077: Statistical Learning and Data Mining ()) Spring Term (Feb May 200) Faculty: Professor Roy Welsch Wed 0 Feb 7:00-8:0
SMA 50: Statistical Learning and Data Mining in Bioinformatics (also listed as 5.077: Statistical Learning and Data Mining ()) Spring Term (Feb May 200) Faculty: Professor Roy Welsch Wed 0 Feb 7:00-8:0
Internet Traffic Prediction by W-Boost: Classification and Regression
 Internet Traffic Prediction by W-Boost: Classification and Regression Hanghang Tong 1, Chongrong Li 2, Jingrui He 1, and Yang Chen 1 1 Department of Automation, Tsinghua University, Beijing 100084, China
Internet Traffic Prediction by W-Boost: Classification and Regression Hanghang Tong 1, Chongrong Li 2, Jingrui He 1, and Yang Chen 1 1 Department of Automation, Tsinghua University, Beijing 100084, China
Training Methods for Adaptive Boosting of Neural Networks for Character Recognition
 Submission to NIPS*97, Category: Algorithms & Architectures, Preferred: Oral Training Methods for Adaptive Boosting of Neural Networks for Character Recognition Holger Schwenk Dept. IRO Université de Montréal
Submission to NIPS*97, Category: Algorithms & Architectures, Preferred: Oral Training Methods for Adaptive Boosting of Neural Networks for Character Recognition Holger Schwenk Dept. IRO Université de Montréal
Homework Assignment 7
 Homework Assignment 7 36-350, Data Mining Solutions 1. Base rates (10 points) (a) What fraction of the e-mails are actually spam? Answer: 39%. > sum(spam$spam=="spam") [1] 1813 > 1813/nrow(spam) [1] 0.3940448
Homework Assignment 7 36-350, Data Mining Solutions 1. Base rates (10 points) (a) What fraction of the e-mails are actually spam? Answer: 39%. > sum(spam$spam=="spam") [1] 1813 > 1813/nrow(spam) [1] 0.3940448
Active Learning with Boosting for Spam Detection
 Active Learning with Boosting for Spam Detection Nikhila Arkalgud Last update: March 22, 2008 Active Learning with Boosting for Spam Detection Last update: March 22, 2008 1 / 38 Outline 1 Spam Filters
Active Learning with Boosting for Spam Detection Nikhila Arkalgud Last update: March 22, 2008 Active Learning with Boosting for Spam Detection Last update: March 22, 2008 1 / 38 Outline 1 Spam Filters
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
How To Perform An Ensemble Analysis
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
Solving Regression Problems Using Competitive Ensemble Models
 Solving Regression Problems Using Competitive Ensemble Models Yakov Frayman, Bernard F. Rolfe, and Geoffrey I. Webb School of Information Technology Deakin University Geelong, VIC, Australia {yfraym,brolfe,webb}@deakin.edu.au
Solving Regression Problems Using Competitive Ensemble Models Yakov Frayman, Bernard F. Rolfe, and Geoffrey I. Webb School of Information Technology Deakin University Geelong, VIC, Australia {yfraym,brolfe,webb}@deakin.edu.au
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Ensembles of data-reduction-based classifiers for distributed learning from very large data sets
 Ensembles of data-reduction-based classifiers for distributed learning from very large data sets R. A. Mollineda, J. M. Sotoca, J. S. Sánchez Dept. de Lenguajes y Sistemas Informáticos Universidad Jaume
Ensembles of data-reduction-based classifiers for distributed learning from very large data sets R. A. Mollineda, J. M. Sotoca, J. S. Sánchez Dept. de Lenguajes y Sistemas Informáticos Universidad Jaume
On the application of multi-class classification in physical therapy recommendation
 RESEARCH Open Access On the application of multi-class classification in physical therapy recommendation Jing Zhang 1,PengCao 1,DouglasPGross 2 and Osmar R Zaiane 1* Abstract Recommending optimal rehabilitation
RESEARCH Open Access On the application of multi-class classification in physical therapy recommendation Jing Zhang 1,PengCao 1,DouglasPGross 2 and Osmar R Zaiane 1* Abstract Recommending optimal rehabilitation
Applied Multivariate Analysis - Big data analytics
 Applied Multivariate Analysis - Big data analytics Nathalie Villa-Vialaneix nathalie.villa@toulouse.inra.fr http://www.nathalievilla.org M1 in Economics and Economics and Statistics Toulouse School of
Applied Multivariate Analysis - Big data analytics Nathalie Villa-Vialaneix nathalie.villa@toulouse.inra.fr http://www.nathalievilla.org M1 in Economics and Economics and Statistics Toulouse School of
An Experimental Study on Ensemble of Decision Tree Classifiers
 An Experimental Study on Ensemble of Decision Tree Classifiers G. Sujatha 1, Dr. K. Usha Rani 2 1 Assistant Professor, Dept. of Master of Computer Applications Rao & Naidu Engineering College, Ongole 2
An Experimental Study on Ensemble of Decision Tree Classifiers G. Sujatha 1, Dr. K. Usha Rani 2 1 Assistant Professor, Dept. of Master of Computer Applications Rao & Naidu Engineering College, Ongole 2
Gerry Hobbs, Department of Statistics, West Virginia University
 Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams
 Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams Pramod D. Patil Research Scholar Department of Computer Engineering College of Engg. Pune, University of Pune Parag
Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams Pramod D. Patil Research Scholar Department of Computer Engineering College of Engg. Pune, University of Pune Parag
Combining Multiple Models Across Algorithms and Samples for Improved Results
 Combining Multiple Models Across Algorithms and Samples for Improved Results Haleh Vafaie, PhD. Federal Data Corporation Bethesda, MD Hvafaie@feddata.com Dean Abbott Abbott Consulting San Diego, CA dean@abbottconsulting.com
Combining Multiple Models Across Algorithms and Samples for Improved Results Haleh Vafaie, PhD. Federal Data Corporation Bethesda, MD Hvafaie@feddata.com Dean Abbott Abbott Consulting San Diego, CA dean@abbottconsulting.com
When Efficient Model Averaging Out-Performs Boosting and Bagging
 When Efficient Model Averaging Out-Performs Boosting and Bagging Ian Davidson 1 and Wei Fan 2 1 Department of Computer Science, University at Albany - State University of New York, Albany, NY 12222. Email:
When Efficient Model Averaging Out-Performs Boosting and Bagging Ian Davidson 1 and Wei Fan 2 1 Department of Computer Science, University at Albany - State University of New York, Albany, NY 12222. Email:
II. RELATED WORK. Sentiment Mining
 Sentiment Mining Using Ensemble Classification Models Matthew Whitehead and Larry Yaeger Indiana University School of Informatics 901 E. 10th St. Bloomington, IN 47408 {mewhiteh, larryy}@indiana.edu Abstract
Sentiment Mining Using Ensemble Classification Models Matthew Whitehead and Larry Yaeger Indiana University School of Informatics 901 E. 10th St. Bloomington, IN 47408 {mewhiteh, larryy}@indiana.edu Abstract
Introduction to Machine Learning Lecture 1. Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu
 Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
ICPSR Summer Program
 ICPSR Summer Program Data Mining Tools for Exploring Big Data Department of Statistics Wharton School, University of Pennsylvania www-stat.wharton.upenn.edu/~stine Modern data mining combines familiar
ICPSR Summer Program Data Mining Tools for Exploring Big Data Department of Statistics Wharton School, University of Pennsylvania www-stat.wharton.upenn.edu/~stine Modern data mining combines familiar
Beating the NCAA Football Point Spread
 Beating the NCAA Football Point Spread Brian Liu Mathematical & Computational Sciences Stanford University Patrick Lai Computer Science Department Stanford University December 10, 2010 1 Introduction Over
Beating the NCAA Football Point Spread Brian Liu Mathematical & Computational Sciences Stanford University Patrick Lai Computer Science Department Stanford University December 10, 2010 1 Introduction Over
How To Solve The Kd Cup 2010 Challenge
 A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
CLASS imbalance learning refers to a type of classification
 IEEE TRANSACTIONS ON SYSTEMS, MAN AND CYBERNETICS, PART B Multi-Class Imbalance Problems: Analysis and Potential Solutions Shuo Wang, Member, IEEE, and Xin Yao, Fellow, IEEE Abstract Class imbalance problems
IEEE TRANSACTIONS ON SYSTEMS, MAN AND CYBERNETICS, PART B Multi-Class Imbalance Problems: Analysis and Potential Solutions Shuo Wang, Member, IEEE, and Xin Yao, Fellow, IEEE Abstract Class imbalance problems
SVM Ensemble Model for Investment Prediction
 19 SVM Ensemble Model for Investment Prediction Chandra J, Assistant Professor, Department of Computer Science, Christ University, Bangalore Siji T. Mathew, Research Scholar, Christ University, Dept of
19 SVM Ensemble Model for Investment Prediction Chandra J, Assistant Professor, Department of Computer Science, Christ University, Bangalore Siji T. Mathew, Research Scholar, Christ University, Dept of
BALANCE LEARNING TO RANK IN BIG DATA. Guanqun Cao, Iftikhar Ahmad, Honglei Zhang, Weiyi Xie, Moncef Gabbouj. Tampere University of Technology, Finland
 BALANCE LEARNING TO RANK IN BIG DATA Guanqun Cao, Iftikhar Ahmad, Honglei Zhang, Weiyi Xie, Moncef Gabbouj Tampere University of Technology, Finland {name.surname}@tut.fi ABSTRACT We propose a distributed
BALANCE LEARNING TO RANK IN BIG DATA Guanqun Cao, Iftikhar Ahmad, Honglei Zhang, Weiyi Xie, Moncef Gabbouj Tampere University of Technology, Finland {name.surname}@tut.fi ABSTRACT We propose a distributed
Machine Learning for Medical Image Analysis. A. Criminisi & the InnerEye team @ MSRC
 Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
How Boosting the Margin Can Also Boost Classifier Complexity
 Lev Reyzin lev.reyzin@yale.edu Yale University, Department of Computer Science, 51 Prospect Street, New Haven, CT 652, USA Robert E. Schapire schapire@cs.princeton.edu Princeton University, Department
Lev Reyzin lev.reyzin@yale.edu Yale University, Department of Computer Science, 51 Prospect Street, New Haven, CT 652, USA Robert E. Schapire schapire@cs.princeton.edu Princeton University, Department
Chapter 13 Introduction to Nonlinear Regression( 非 線 性 迴 歸 )
") Chapter 13 Introduction to Nonlinear Regression( 非 線 性 迴 歸 ) and Neural Networks( 類 神 經 網 路 ) 許 湘 伶 Applied Linear Regression Models (Kutner, Nachtsheim, Neter, Li) hsuhl (NUK) LR Chap 10 1 / 35 13 Examples
Chapter 13 Introduction to Nonlinear Regression( 非 線 性 迴 歸 ) and Neural Networks( 類 神 經 網 路 ) 許 湘 伶 Applied Linear Regression Models (Kutner, Nachtsheim, Neter, Li) hsuhl (NUK) LR Chap 10 1 / 35 13 Examples
Incremental SampleBoost for Efficient Learning from Multi-Class Data Sets
 Incremental SampleBoost for Efficient Learning from Multi-Class Data Sets Mohamed Abouelenien Xiaohui Yuan Abstract Ensemble methods have been used for incremental learning. Yet, there are several issues
Incremental SampleBoost for Efficient Learning from Multi-Class Data Sets Mohamed Abouelenien Xiaohui Yuan Abstract Ensemble methods have been used for incremental learning. Yet, there are several issues
Metalearning for Dynamic Integration in Ensemble Methods
 Metalearning for Dynamic Integration in Ensemble Methods Fábio Pinto 12 July 2013 Faculdade de Engenharia da Universidade do Porto Ph.D. in Informatics Engineering Supervisor: Doutor Carlos Soares Co-supervisor:
Metalearning for Dynamic Integration in Ensemble Methods Fábio Pinto 12 July 2013 Faculdade de Engenharia da Universidade do Porto Ph.D. in Informatics Engineering Supervisor: Doutor Carlos Soares Co-supervisor:
Data Mining in Direct Marketing with Purchasing Decisions Data.
 Data Mining in Direct Marketing with Purchasing Decisions Data. Randy Collica Sr. Business Analyst Database Mgmt. & Compaq Computer Corp. Database Mgmt. & Overview! Business Problem to Solve.! Data Layout
Data Mining in Direct Marketing with Purchasing Decisions Data. Randy Collica Sr. Business Analyst Database Mgmt. & Compaq Computer Corp. Database Mgmt. & Overview! Business Problem to Solve.! Data Layout
BIOINF 585 Fall 2015 Machine Learning for Systems Biology & Clinical Informatics http://www.ccmb.med.umich.edu/node/1376
 Course Director: Dr. Kayvan Najarian (DCM&B, kayvan@umich.edu) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
Course Director: Dr. Kayvan Najarian (DCM&B, kayvan@umich.edu) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
Data Mining Introduction
 Data Mining Introduction Bob Stine Dept of Statistics, School University of Pennsylvania www-stat.wharton.upenn.edu/~stine What is data mining? An insult? Predictive modeling Large, wide data sets, often
Data Mining Introduction Bob Stine Dept of Statistics, School University of Pennsylvania www-stat.wharton.upenn.edu/~stine What is data mining? An insult? Predictive modeling Large, wide data sets, often
Classification tree analysis using TARGET
 Computational Statistics & Data Analysis 52 (2008) 1362 1372 www.elsevier.com/locate/csda Classification tree analysis using TARGET J. Brian Gray a,, Guangzhe Fan b a Department of Information Systems,
Computational Statistics & Data Analysis 52 (2008) 1362 1372 www.elsevier.com/locate/csda Classification tree analysis using TARGET J. Brian Gray a,, Guangzhe Fan b a Department of Information Systems,
Using Random Forest to Learn Imbalanced Data
 Using Random Forest to Learn Imbalanced Data Chao Chen, chenchao@stat.berkeley.edu Department of Statistics,UC Berkeley Andy Liaw, andy liaw@merck.com Biometrics Research,Merck Research Labs Leo Breiman,
Using Random Forest to Learn Imbalanced Data Chao Chen, chenchao@stat.berkeley.edu Department of Statistics,UC Berkeley Andy Liaw, andy liaw@merck.com Biometrics Research,Merck Research Labs Leo Breiman,
Online Forecasting of Stock Market Movement Direction Using the Improved Incremental Algorithm
 Online Forecasting of Stock Market Movement Direction Using the Improved Incremental Algorithm Dalton Lunga and Tshilidzi Marwala University of the Witwatersrand School of Electrical and Information Engineering
Online Forecasting of Stock Market Movement Direction Using the Improved Incremental Algorithm Dalton Lunga and Tshilidzi Marwala University of the Witwatersrand School of Electrical and Information Engineering
Ensemble Approaches for Regression: A Survey
 Ensemble Approaches for Regression: A Survey JOÃO MENDES-MOREIRA, LIAAD-INESC TEC, FEUP, Universidade do Porto CARLOS SOARES, INESC TEC, FEP, Universidade do Porto ALíPIO MÁRIO JORGE, LIAAD-INESC TEC,
Ensemble Approaches for Regression: A Survey JOÃO MENDES-MOREIRA, LIAAD-INESC TEC, FEUP, Universidade do Porto CARLOS SOARES, INESC TEC, FEP, Universidade do Porto ALíPIO MÁRIO JORGE, LIAAD-INESC TEC,
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R
 Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
AdaBoost. Jiri Matas and Jan Šochman. Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz
 AdaBoost Jiri Matas and Jan Šochman Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Presentation Outline: AdaBoost algorithm Why is of interest? How it works? Why
AdaBoost Jiri Matas and Jan Šochman Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Presentation Outline: AdaBoost algorithm Why is of interest? How it works? Why
Reference Books. Data Mining. Supervised vs. Unsupervised Learning. Classification: Definition. Classification k-nearest neighbors
 Classification k-nearest neighbors Data Mining Dr. Engin YILDIZTEPE Reference Books Han, J., Kamber, M., Pei, J., (2011). Data Mining: Concepts and Techniques. Third edition. San Francisco: Morgan Kaufmann
Classification k-nearest neighbors Data Mining Dr. Engin YILDIZTEPE Reference Books Han, J., Kamber, M., Pei, J., (2011). Data Mining: Concepts and Techniques. Third edition. San Francisco: Morgan Kaufmann
Class Imbalance Learning in Software Defect Prediction
 Class Imbalance Learning in Software Defect Prediction Dr. Shuo Wang s.wang@cs.bham.ac.uk University of Birmingham Research keywords: ensemble learning, class imbalance learning, online learning Shuo Wang
Class Imbalance Learning in Software Defect Prediction Dr. Shuo Wang s.wang@cs.bham.ac.uk University of Birmingham Research keywords: ensemble learning, class imbalance learning, online learning Shuo Wang
Data Mining and Visualization
 Appears in the National Academy of Engineering (NAE) US Frontiers of Engineering 2000 Data Mining and Visualization Ron Kohavi Blue Martini Software 2600 Campus Drive San Mateo, CA, 94403, USA URQQ\N#EOXHPDUWLQLFRP
Appears in the National Academy of Engineering (NAE) US Frontiers of Engineering 2000 Data Mining and Visualization Ron Kohavi Blue Martini Software 2600 Campus Drive San Mateo, CA, 94403, USA URQQ\N#EOXHPDUWLQLFRP
Advanced Ensemble Strategies for Polynomial Models
 Advanced Ensemble Strategies for Polynomial Models Pavel Kordík 1, Jan Černý 2 1 Dept. of Computer Science, Faculty of Information Technology, Czech Technical University in Prague, 2 Dept. of Computer
Advanced Ensemble Strategies for Polynomial Models Pavel Kordík 1, Jan Černý 2 1 Dept. of Computer Science, Faculty of Information Technology, Czech Technical University in Prague, 2 Dept. of Computer