Data Deduplication. Hao Wen
|
|
|
- Preston O’Brien’
- 10 years ago
- Views:
Transcription
1 Data Deduplication Hao Wen
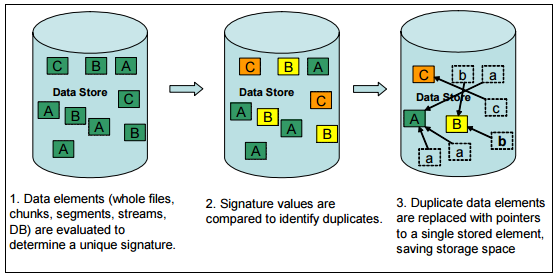
2 What Data Deduplication is
3 What Data Deduplication is Dedup vs Compression Compression: identifying redundancy within a file. High processor overhead. Low memory resource requirement. Deduplication: The comparable range is now across all the files (in fact segments of those files) in the environment. More memory intensive-> data on disks Caching technique to move data in and out of DRAM Traditionally not cache friendly (not in FIFO)
4 Evaluation Dedup ratio Throughput Throughput refers to the rate at which data can be transferred in and out of the system. High throughput is particularly important because it can enable fast backups, minimizing the length of a backup window. Scalability the ability to support large amounts of raw storage with consistent performance.
5 Classification Dedup location Source: When the deduplication occurs close to where data is created, it is often referred to as "source deduplication" Target: When it occurs near where the data is stored, it is commonly called "target deduplication".
6 Classification When to dedup Post: With post-process deduplication, new data is first stored on the storage device and then a process at a later time will analyze the data looking for duplication. Inline: This is the process where the deduplication hash calculations are created on the target device as the data enters the device in real time. If the device spots a block that it already stored on the system it does not store the new block, just references to the existing block.
7 Scenario Backup Dedup Deduplication in backup and archival systems was introduced by Microsoft SIS in 2000 and Venti in 2002 Write once Primary Dedup Performance sensitive Not write once and expect modification: Copy on write to prevent updates on aliased data. Chunk references change quickly
8 Scenario

9 Methods Hash based each chunk of data is assigned an identification calculated by the software The assumption is made that if the identification is identical, the data is identical
10 Methods Hash based Fix size chunking Pros: fast, simple, minimum CPU Cons: A little modification -> Change in all subsequent chunks original: aaa aaa aaa new: aaa baa aaa a
11 Methods Hash based Variable size chunking Content-defined chunking (CDC)
12 Methods Hash based Exp_chunk_size: 8KB chunk_mask: 0x1fff, the last 13bits Magic_value: 0x = 8k

13 Methods Content aware
14 Overview Of CBC Approach Sliding window Byte stream asfdgegsacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg abcdega Stream beginning
15 Overview Of CBC Approach abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg Compute Rabin s rabin s fingerprint H( abcdega )= 726
16 Overview Of CBC Approach abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg Rabin s fingerprint H( abcdega ) = mod 128 0
17 Overview Of CBC Approach Move forward abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg Rabin s fingerprint H( bcdegaa ) = mod 128 0
18 Overview Of CBC Approach Move forward abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg Rabin s fingerprint H( cdegaac ) = mod 128 0
19 Overview Of CBC Approach Move forward abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr Rabin s fingerprint H( cdegaac ) = mod 128 0
20 Overview Of CBC Approach Move forward abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr Rabin s fingerprint H( acgdgyr ) = mod 128 0
21 Overview Of CBC Approach Set boundary abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr SHA1( abcdegaacgdyr ) = 0x bits Chunk id
22 Overview Of CBC Approach abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr SHA1( abcdegaacgdyr ) =0x Lookup SHA1 0x in index table Chk id Chk freq Chk ptr NULL NULL NULL Table Initially NULL NULL NULL Empty NULL NULL NULL NULL NULL NULL NULL NULL NULL Chunk container
23 Overview Of CBC Approach abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr SHA1( abcdegaacgdyr ) =0x Lookup SHA1 0x in index table Chk id Chk freq Chk ptr NULL NULL NULL 0x not NULL NULL NULL Exist in the table! NULL NULL NULL NULL NULL NULL NULL NULL NULL Chunk container
24 Overview Of CBC Approach abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr SHA1( abcdegaacgdyr ) =0x Lookup SHA1 0x in index table Chk id Chk freq Chk ptr NULL NULL NULL It s a new chunk, need to transmit NULL NULL NULL it to the container & NULL NULL NULL Update the chunk index NULL NULL NULL table NULL NULL NULL Chunk container
25 Overview Of CBC Approach abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr Update the SHA1( abcdegaacgdyr ) =0x Index table Chk id Chk freq Chk ptr NULL NULL NULL Lookup SHA1 0x in index table 0x NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL Chunk container
26 Overview Of CBC Approach transmit the chunk to The chunk container abcdegaacgdyr Network Chunk container
27 Overview Of CBC Approach abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg acgdgyr SHA1( abcdegaacgdyr ) =0x Lookup SHA1 0x in index table Chk id Chk freq Chk ptr NULL NULL NULL 0x NULL NULL NULL NULL NULL NULL Insert chunk addr In chk-ptr field 0xf3 ea1 NULL NULL NULL Chunk container abcdegaacgdyr
28 Overview Of CBC Approach Move forward, start a new chunk Abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfgcgdgyrg Rabin s fingerprint H( cgdgyrg ) = mod 128 0
29 Overview Of CBC Approach Move forward Abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg Omit the repeated Rabin s Fingerprinting check & chunk generations
30 Overview Of CBC Approach Move forward abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg casdfeg Rabin s fingerprint H( casdfeg ) = mod 128 0
31 Overview Of CBC Approach Set boundary abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg casdfeg SHA1( gfdhchjsdfhjrchcsaaabgdvcasdfeg ) = 0x bits
32 Overview Of CBC Approach Set boundary abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg casdfeg SHA1( gfdhchjsdfhjrchcsaaabgdvcasdfeg ) = 0x Lookup SHA1 if 0x in index table Chk id Chk freq Chk ptr NULL NULL NULL 0x xff ab1 NULL 1 NULL NULL NULL NULL 0xfff fff 300 0x Chunk container
33 Overview Of CBC Approach Set boundary abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg casdfeg SHA1( gfdhchjsdfhjrchcsaaabgdvcasdfeg ) = 0x Lookup SHA1 if 0x in index table Chk id Chk freq Chk ptr NULL NULL NULL No need to store Sliding Chunk window exists! Continue to move forward 0x xff ab1 NULL NULL NULL 0xfff fff 300 0x Chunk container
34 Overview Of CBC Approach Move forward abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg asdfegg Rabin s fingerprint H( asdfegg ) = mod 128 0
35 Overview Of CBC Approach Move forward abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg asdfegg Continue this process till the end of the stream 75 mod 128 0
36 Overview Of CBC Approach File Retrieval Process: retrieve foo.txt Step I: get the index file from chunk container Get index file Foo.txt id x id y id z Chunk container
37 Overview Of CBC Approach File Retrieval Process Step II: lookup chunk index table for corresponding chunks Foo.txt abcdegaacgdgyrgfdhchjsdfhjrchcsaaabgdvcasdfegggasdvghhyuufhjjfg Foo.txt id x id y id z Index file Chk id Chk freq Chk ptr 0x xa1 0x x11 NULL NULL NULL 0x xfe NULL NULL NULL 0xfff fff 300 Chk 3 Chk 2 Chunk container Chk 1
38 Overview Of CBC Approach File Retrieval Process Step III: send addresses of requested chunk to the chunk container And concatenate receive chunks Foo.txt Get chunks Foo.txt id id id Chk Chk 3 2 Chk 1 Chk id Chk freq Chk ptr 0x xa1 0x x11 0x NULL 1NULL 0xfe NULL 0x xfe 0xfff fff NULL 300 NULL 0xef NULL 0xfff fff 300 Chunk container
39 Overview of CBC Approach It chooses anchors uniformly at random as boundaries. Number of anchors v.s anchor frequency follows Zipf like distribution, meaning the major portion of anchors has low frequency. It can mitigate boundary shifting problem Its performance degrades significantly when changes sprinkle over the data stream Large sampling rate (smaller modulo N) results in smaller chunk size and larger metadata overhead, hence the dedup benefit may not be maximized
40 Performance Issue Dedup ratio vs. performance Fine-grained chunking Big index tables a) large overhead to look up table b) RAM cannot fit. Partially stored on disk. Disk overhead cache for indexes

41 Performance Issue Dedup ratio vs. performance Avoiding the Disk Bottleneck in the Data Domain Deduplication File System - In-memory Bloom Filter and caching index fragments reduce the number of times that the system goes to disk to look for a duplicate segment only to find that none exists - In backup applications, chunks tend to reappear in the same of very similar sequences with other chunks Dedicates containers to hold chunks for a single stream in their logical order. - Cache. if a chunk is a duplicate, the base chunk is highly likely cached already. Descriptors of all chunks in a container are added or removed from the chunk cache at once.
42 Performance Issue Dedup ratio vs. performance Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality - If two pieces of backup streams share any chunks, they are likely to share many chunks. - Based on segments. A segment is a sequence of chunks. We say that two segments are similar if they share a number of chunks. - Identify among all the segments in the store some that are most similar to the incoming segment. Deduplicate against those segments by finding the chunks they share with the incoming segment
43 Performance Issue Inline vs. post deduplication should be performed as soon as data enters the storage system to maximize its benefits. Consume CPU and memory. Impact latency. If in background, 100% additional storage space needed in worst case.

44 Performance Issue Dedup fragmentation
45 Performance Issue Dedup fragmentation Improving restore speed for backup systems that use inline chunk based deduplication Forward Assembly Area
46 Performance Issue Dedup fragmentation Improving restore speed for backup systems that use inline chunk based deduplication Container capping
47 Scalability Issue Dedup in large-scale storage system As the scale increases, it s harder to find matches. A centralized index solution is likely to become itself very large and its manipulation a bottleneck on deduplication throughput. Mitigate by (1) Isolated nodes. Exploiting data locality (routing similar files to the same nodes) (2) Distributed hash table (DHT) as the index
48 Reliability and Security Issue Reliability Deduplication vs. Redundancy for reliability Both for metadata and data Security Deduplication vs. Encryption Convergent Encryption (1) Brute-force attack (2) Large key space overheads and single-point-of-failure
49 SNIA. Understanding data deduplication ratios. Kaczmarczyk M, Barczynski M, Kilian W, et al. Reducing impact of data fragmentation caused by in-line deduplication[c]//proceedings of the 5th Annual International Systems and Storage Conference. ACM, 2012: 15. Guo, Fanglu, and Petros Efstathopoulos. "Building a High-performance Deduplication System." USENIX Annual Technical Conference Lu, Guanlin, Yu Jin, and David HC Du. "Frequency based chunking for data de-duplication." Modeling, Analysis & Simulation of Computer and Telecommunication Systems (MASCOTS), 2010 IEEE International Symposium on. IEEE, Bobbarjung, Deepak R., Suresh Jagannathan, and Cezary Dubnicki. "Improving duplicate elimination in storage systems." ACM Transactions on Storage (TOS) 2.4 (2006): Babette H, Alessio B, Michael B, Rik F, Abbe W. Guide to Data De-duplication: The IBM System Storage TS7650G ProtecTIER Deduplication Gateway. Meyer, Dutch T., and William J. Bolosky. "A study of practical deduplication." ACM Transactions on Storage (TOS) 7.4 (2012): 14. Pibytes. Deduplication Internals Hash based deduplication : Part-2. Paulo, J., & Pereira, J. (2014). A survey and classification of storage deduplication systems. ACM Computing Surveys (CSUR), 47(1), 11. Lillibridge, Mark, Kave Eshghi, and Deepavali Bhagwat. "Improving restore speed for backup systems that use inline chunk-based deduplication."fast Zhu, Benjamin, Kai Li, and R. Hugo Patterson. "Avoiding the Disk Bottleneck in the Data Domain Deduplication File System." Fast. Vol Lillibridge, Mark, et al. "Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality." Fast. Vol
50 Prepared for DISC-meeting, 02/24/2011 Deduplication Research Update Read Performance & Reliability Young Jin Nam, Guanlin Lu, Nohhyun Park, Weijun Xiao, David Du
51 Talk Outline 1. Overview of Dedupe Storage Designs 2. Dedupe Read Performance Problem 3. Dedupe Reliability Problem (briefly) 51
52 Data Deduplication Process Dividing data(object) into (variable/fixed-sized) small chunks & computing hash (SHA-1) for each chunk For each chunk hash, decide if it has a copy by looking up an index (a set of hash) If yes, store the address of the copy, Otherwise, (LZ-compress it &) store the new (unique) chunks in the data store 52
53 Data Dedupe Design Options [Dubnicki09] Granularity of dedupe whole files, partial files, fixed or variable-sized chunks Time to dedupe inline during write or post storage server Precision of duplicate identification finding all duplicates or approximate (for performance) Verification of equality betw. duplicate & its copy hash comparison or full data comparison Scope of the dedupe global dedupe(entire system) or local dedupe(limited, specific node) 53

54 Data Dedupe Design Options Post process In-line 54
55 Current Dedupe Design It mainly highlights maximizing the duplicate detection and efficiency (chunking, index optimization/caching, bloom filtering) improving write I/O performance (LZ-compression, log-structured + largewrite containers) [Efstathopoulos10] HotStorage 10 [Dong11]-FAST 11 EMC deduplication storage architecture 55
56 Current Dedupe Design It didn t pay much attention to 1) Read I/O performance(*) Data domain [Zhu08] mentioned its importance data is read occasionally from the dedupe storage (200MB/s 140MB/s, 30% ) The more dedupe chunks, The more RD perf. degradation (esp. with different data streams) (each successive version of a given backup stream) 56
![Current Dedupe Design It didn t pay much attention to 2) Dedupe & Reliability issue(*) HPL [Li10] paper presented](/docs-images/27/11900892/images/57-0.png "in HotMetrics 10 dedupe & reliability are considered separately Higher severity of data loss Dedupe & Make copies!")
57 Current Dedupe Design It didn t pay much attention to 2) Dedupe & Reliability issue(*) HPL [Li10] paper presented in HotMetrics 10 dedupe & reliability are considered separately Higher severity of data loss Dedupe & Make copies! 57
58 Current Dedupe Design It didn t pay much attention to 3) Scalability (clustering) issue EMC [Dong11] -FAST 11, Symantec [Efst10]-HotStorage 10 single dedupe storage(1.5gb/s in-line t-put) is not good enough 58
59 Talk Outline 1. Overview of Dedupe Storage Designs 2. Dedupe Read Performance Problem 3. Dedupe Reliability Problem 59
60 Problem in Read Performance As deduped ratio increases, read performance decreases (200MB/s 140MB/s, 30% ) [Zhu08] original write sequence(sequential write) will be fragmented by eliminating the duplicate chunks 60
61 Problem in Read Performance Read t-put variations of single backup & 4 backup streams [Zhu08] (200MB/s 140MB/s, 30% ) (*) Note : Synthetic workloads (each successive version of a given backup stream) 61
62 Why Read Performance Matters? Traditionally, with Secondary Storage Rebuild Performance in Secondary Storage critical with the secondary storage [Zhu08] recovery window time & system availability with evergrowing data Arguing that it s occasionally happening! 62
63 Why Read Performance Matters? Recently, with Secondary Storage Long-Term Digital Preservation Requirements SNIA DPCO(snia.org/forums/dpco) LTDP Reference Model ( ) motivation: repository needs to have effective mechanisms to detect bit corruption or loss one solution: running a back-end process to reconstitute on the fly for audit purposes: hash, verify, recover if they test bad) 63
64 Why Read Performance Matters? Dedupe & Primary Storage Dedupe gets used for Primary Storage read IOs will be as many as write IOs eg: storing VM(virtual machine) images 64
65 Dedupe vs. Primary Storage VME in Primary Storage [Das10]-ATC 10 Migrating VM image of an idle desktop onto a (dedupeenabled) network storage for energy saving 65
66 Guanlin s Comment about why read performance is also important The dedupe box size is limited and once a while the backed data stored in the dedupe box has to be staged to archive storage, say tapes. This requires stream reconstruction because tape operations are stream based. In fact, this staging frequency is remarkably higher than the user triggered data retrieval frequency and hence the read performance is also important. 66
67 Defining Our Problem Dedupe Environment Dedupe Abstraction Data Store Multiple Data streams, where a data stream a series of (compressed/plain) files (for backup), or memory/disk/process-status image (for VM) after Chunking/Removing duplicates a series of unique chunks Storing Chunks into Storage, a pool of unique chunks store data stream chunks of data stream B unique pool of unique chunks B A Chunking b1 a1 b0 a0 Removing Dup a1 b0 a0 Storing Chunks b0 a1 a0 chunks of data stream A Storage 67
68 Defining Our Problem Dedupe Environment Dedupe Abstraction Read Reconstructing data streams a data stream consists of a series of chunks, but its chunks are physically dispersed due to dedupe read data stream caching, buffering, prefetching? dispersed chunks b0 b1 B A Chunking b1 a1 b0 a0 Removing Dup a1 b0 a0 Storing Chunks b0 a1 a0 chunks of data stream A Storage 68
69 Defining Our Problem Improvement of Read I/O Performance Our Research Topics How to effectively contain chunk data? How to effectively read chunk(stream) data? read data stream caching, buffering, prefetching? dispersed chunks b0 b1 B A Chunking b1 a1 b0 a0 Removing Dup a1 b0 a0 Storing Chunks b0 a1 a0 chunks of data stream A Storage 69
70 Our Research Topics Improvement of Read I/O Performance Effective Chunk Data Containing Understand chunk fragmentation with dedupe & how much read performance is degraded! (**) How effectively/initially place chunks into storage? read/reconstruction-aware chunk placements How adaptively replace/duplicate chunks to assure a demanded stream read performance? B A Chunking b1 a1 b0 a0 Removing Dup a1 b0 a0 Storing Chunks b0 a1 a0 chunks of data stream A Storage 70
71 Our Research Topics Improvement of Read I/O Performance Effective Chunk Data Reading How effectively prefetch the chunk data? How effectively cache the (deduped) chunks? read data stream caching, buffering, prefetching? dispersed chunks b0 b1 How effectively handle the concurrent reads of multiple chunk data streams? (prefetch & cache) b0 a1 a0 Storage 71 71
72 Our Research Topics Effective Chunk Data Containing Any Existing Solutions? No solutions are published yet to the best of our knowledge! Data Domain said in [Zhu08] they have investigated mechanisms to reduce fragmentation and sustain high write/read throughput but, no published literatures yet 72
73 Our Research Topics Effective Chunk Data Containing Any Existing Solutions? I/O De-duplication [Koller10] Increase in the # of duplicates for popular content on the disk can create greater opportunities for read I/O optimization ( solution with a single disk) content-based cache (filters the I/O stream based on hits in a content-addressed cache) dynamic replica retriever (optionally redirects on the disk to use the best access latencies to requests) selective duplicator (kernel: create a candidate list of content for replication; user: populate replica content in scratch space distributed across the entire disk) 73
 D_A data stream A0 A1 A2 A3 A0 A1 A2 A3 do a LARGE write a series of unique chunks from D_A logged into a container container (fixed size, as large as RAID stripe size)")
74 Our Research Topics Effective Chunk Data Containing Understanding Chunk Fragmentation Very initially, all unique chunks are grouped into a container to preserve a spatial locality (read sequence is the same as write; sequential) D_A data stream A0 A1 A2 A3 A0 A1 A2 A3 do a LARGE write a series of unique chunks from D_A logged into a container container (fixed size, as large as RAID stripe size) Container 74
75 Our Research Topics Effective Chunk Data Containing Understanding Chunk Fragmentation Chunks fragmentation chunks of a stream get distributed in a more # of containers read from ONE container D_A read from TWO containers D_A A1 is deduped A0 A1 A2 A0 A1 A2 A3 pointing A0 A1 A2 A3 Container 3 A0 A2 Container 7 75
76 Our Research Topics Understanding Chunk Fragmentation New Metric for Chunk Fragmentation Assumptions & notations CS : fixed container size (B) data stream, DS = {c i 0 i n-1}, c i is the i-th chunk chunk size, s i is the size of c i Optimal chunk fragmentation(ocf) ceiling of [sum of s i (0 i n-1) / CS] Current chunk fragmentation(ccf) # of containers where {c i 0 i n-1} are dispersed Chunk Fragmentation Level(CFL) = OCF / CCF overuse ratio of containers w.r.t. OCF 76
77 Our Research Topics Understanding Chunk Fragmentation CFL vs. Read Performance CFL good indicator for read performance degradation with deduped data stream Under optimal conditions (CFL=1, CCF=OCF), to read the entire data stream, approximately, there will be (OCF-1) short seeks (betw. different containers) Under non-optimal conditions (CFL < 1, CCF > OCF), there will (OCF-1) short seeks + (CCF-OCF) long seeks Long seeks contribute to the read perf. degradation 77
78 Our Research Topics Understanding Chunk Fragmentation Theoretical Model with CFL Expected Read performance(resp. time) Response time under optimal conditions(cfl=1) to read the entire data stream RT opt = (OCF-1)*S, S is a short-seek time Response time under non-optimal conditions(cfl>1) RT non = (OCF-1)*S+(CCF-OCF)*L, L is a long-seek time RT non / RT opt = 1 + (1/CFL 1)*, where =L/S 78
 RT non / RT opt = 1 + (1/CFL 1)*, where =L/S Variation of RT with decrease of CFL, =1,2,4,8 80 70 60 RT non / RT opt =8 50 40 30 20 10 0 1 0.9 0.8 0.7 0.6 0.5 0.")
79 Our Research Topics Understanding Chunk Fragmentation Theoretical Model with CFL Expected Read performance(resp. time) RT non / RT opt = 1 + (1/CFL 1)*, where =L/S Variation of RT with decrease of CFL, =1,2,4, RT non / RT opt = CFL (Chunk Fragmentation Level) =4 =2 =1 79
80 Our Research Topics Understanding Chunk Fragmentation Chunk Fragmentation Patterns Chunk in its own stream or one of other streams Current version(backup number or generation) or one of previous versions Four different cases : Case 1: current version of its own stream Case 2: one of previous versions of its own stream Case 3: current version of one of other streams Case 4: one of previous versions of one of other streams 80
81 Our Research Topics Understanding Chunk Fragmentation Case 1 & 2 Looks fine? Deduped from its own stream (self-dedupe) Giving little impact on read performance? relatively short seek times? D_A C1 is deduped D_A A0 A1 A2 A3 A0 A1 A2 partially sequential read (w/ fragment) fully sequential read pointing (self-dedupe) A0 A2 A0 A1 A2 A3 Container 7 Container 3 81
82 Our Research Topics Understanding Chunk Fragmentation Case 1 & 2 Looks fine? Read performance remains constant in [Zhu08] (*) Note : Synthetic workloads (each successive version of a given backup stream) 82
83 Our Research Topics Understanding Chunk Fragmentation Case 3 & 4 Looks bad? Deduped from other streams(b2) Giving considerable impact on read perf? more randomly distributed (long seek times)? D_A C1 is deduped D_B B0 B1 B2 B3 A0 B1 A2 partially sequential read (w/ fragment) pointing (dedupe from others) A0 A2 B0 B1 B2 B3 Container 7 Container 3 83
84 Our Research Topics Understanding Chunk Fragmentation Case 3 & 4 Looks bad? Read performance is degraded in [Zhu08] (200MB/s 140MB/s, 30% ) (*) Note : Synthetic workloads (each successive version of a given backup stream) 84
85 Guanlin s Comments How to verify our guess that there are (CCF-OCF) # of long seeks and OCF # of short seeks? From the result at slide #34 we could conclude: Case (1) if dedupe write process always packs chunks of one or multiple generations of a single stream into containers and never put chunks from different streams into a single container, then the read performance is roughly the same for any given generation (maybe this indicates that access penalty for any generation is almost the same, e.g., read a generation [i] requires read container [0] plus container [i] (i >0) but read container [0] and [i] could be long distanced Case (2) if dedupe write process allows packing chunks of multiple streams into a single container (mix-mode, which is true in real system where it has to handle a large number of concurrent streams with limited number of open containers in RAM), it has much more random seeks than case (1). 85
86 Our Research Topics Understanding Chunk Fragmentation Simulations/Experiments CFL variation w/ increase of backup number (successive versions of streams) Read perf. variation w/ increase of CFL (should be matched with its theoretical model) 86
87 Our Research Topics Understanding Chunk Fragmentation Paper Work(HotStorage 11) Main Contributions will be Address read performance degradation w/ dedupe 2. Introduce the CFL indicator for read perf. degradation w/ dedupe & its theoretical read performance model 3. Examine the CFL variations vs. backup number with multiple real traced workloads 4. Validate the read performance vs. CFL make sure it s matching with its theoretical model) 87
88 Future Work(1/2) Our Research Topics Effective Chunk Data Containing 1. How adaptively replace/duplicate chunks to assure a demanded stream read performance? idea 1: selective migration approach with case 1, 2, 4 whenever index cache misses (don t remove the original one while its container is not reclaimed) idea 2: replication approach whenever index cache misses 2. How effectively/initially place chunks into storage? 1. read/reconstruction-aware chunk placements 88
89 Future Work(2/2) Our Research Topics Effective Chunk Data Reading 1. How effectively prefetch the chunk data? 2. How effectively cache the unique(deduped) chunks? 3. How effectively handle the concurrent reads of multiple chunk data streams? (prefetch & cache) 89
90 Talk Outline 1. Overview of Dedupe Storage Designs 2. Dedupe Read Performance Problem 3. Dedupe Reliability Problem (briefly) 90
91 Data Reliability vs. Data Dedupe Some data(file) requires a level of reliability, mostly creating data duplication(raid1) or using more storage spaces for parity(raid5/6, erasure codes) This is a conflicting direction that the data deduplication is pursuing! 91
92 Typical Steps to provide Data Reliability for Deduped Storage 1. Perform data deduplication process (s chunks) 2. Aggregate chunks into a large fixed-sized container 3. Reliably store the container over a fixed # of disks by using erasure coding(or RAID) schemes 92
93 Example with Typical Steps 1. Storing two data(a,b) : reliability 1-out-of unique chunks (container size = 2 chunks) Data A : 1-out-of-3 D_A Data B : 1-out-of-3 D_B a1 a2 a3 b2 Disk 1 Disk 2 Disk Par of 3 Disk 4 Disk 5 Disk Par of 6 a1 a2 a3 x a1,2 a3,x disk1 disk2 disk3 disk4 disk5 disk6 93
94 Existing Reliability Metric 1. Data loss probability(probabilistic combinatorics) 2. Each chunk will survive in face of a disk failure (Dlp w/ dedupe is the same as dlp w/o dedupe) D_A D_B D_A, D_B : 1-out-of-3 a1 a2 a3 b2 Disk 1 Disk 2 Disk Par of a1 a2 3 Disk a3 4 Disk x 5 Disk Par of 6 a1,2 a3,x disk1 disk2 disk3 disk4 disk5 disk6 94
95 Severity in Data Loss How many data will be lost when a chunk is lost? 1) without dedupe : only 1 2) with dedupe : more than 1 D_A without dedupe D_B a1 a2 a3 a2 a3 b2 D_A with dedupe D_B a1 a2 a3 b2 95
96 Our Research Topics Defining Our Problem Data Reliability with Dedupe How to nicely represent the data loss severity? How to assure the given data loss prob & data loss severity with dedupe storage? reliable chunk(container) placement chunk(container) migration when a newly dedupe chunk demands higher data reliability 96
97 Questions & Answering! DEDUPLICATION RESEARCH UPDATE READ PERFORMANCE & RELIABILITY Young Jin Nam, Guanlin Lu, Nohhyun Park, Weijun Xiao, David Du
98 SNIA. Understanding data deduplication ratios. Kaczmarczyk M, Barczynski M, Kilian W, et al. Reducing impact of data fragmentation caused by in-line deduplication[c]//proceedings of the 5th Annual International Systems and Storage Conference. ACM, 2012: 15. Guo, Fanglu, and Petros Efstathopoulos. "Building a High-performance Deduplication System." USENIX Annual Technical Conference Lu, Guanlin, Yu Jin, and David HC Du. "Frequency based chunking for data de-duplication." Modeling, Analysis & Simulation of Computer and Telecommunication Systems (MASCOTS), 2010 IEEE International Symposium on. IEEE, Bobbarjung, Deepak R., Suresh Jagannathan, and Cezary Dubnicki. "Improving duplicate elimination in storage systems." ACM Transactions on Storage (TOS) 2.4 (2006): Babette H, Alessio B, Michael B, Rik F, Abbe W. Guide to Data De-duplication: The IBM System Storage TS7650G ProtecTIER De-duplication Gateway. Meyer, Dutch T., and William J. Bolosky. "A study of practical deduplication." ACM Transactions on Storage (TOS) 7.4 (2012): 14. Pibytes. Deduplication Internals Hash based deduplication : Part-2. Paulo, J., & Pereira, J. (2014). A survey and classification of storage deduplication systems. ACM Computing Surveys (CSUR), 47(1), 11.
99 Assuring Demand Read Performance of Data Deduplication Storage with Backup Datasets, Proc. of IEEE MASCOTS 2012 (Youngjin Nam, Dongchul Park and David Du) "Chunk Fragmentation Level: An Effective Indicator for Read Performance Degradation in Deduplication Storage," IEEE International Symposium of Advances on High Performance Computing and Networking (HPCC/AHPCN), September 2011 (Youngjin Nam, Guanlin Lu, Nohhyun Park, Weijun Xiao and David Du) "Reliability-Aware Deduplication Storage: Assuring Chunk Reliability and Chunk Loss Severity," The First International Workshop on Energy Consumption and Reliability of Storage Systems (IGCC/ERSS), July 2011 (Youngjin Nam, Guanlin Lu and David Du) ADMAD: Application-Driven Metadata Aware De-duplication Archival Storage System, Proc. of SNAPI08 Workshop on Storage Network Architecture and Parallel I/Os, Oct. 2008, Baltimore, Maryland (with Chuanyi Liu, Yingping Lu, Guanlin Lu, Dong-Sheng Wang, and David Du)
Assuring Demanded Read Performance of Data Deduplication Storage with Backup Datasets
 Assuring Demanded Read Performance of Data Deduplication Storage with Backup Datasets Young Jin Nam School of Computer and Information Technology Daegu University Gyeongsan, Gyeongbuk, KOREA 7-7 Email:
Assuring Demanded Read Performance of Data Deduplication Storage with Backup Datasets Young Jin Nam School of Computer and Information Technology Daegu University Gyeongsan, Gyeongbuk, KOREA 7-7 Email:
RevDedup: A Reverse Deduplication Storage System Optimized for Reads to Latest Backups
 RevDedup: A Reverse Deduplication Storage System Optimized for Reads to Latest Backups Chun-Ho Ng and Patrick P. C. Lee Department of Computer Science and Engineering The Chinese University of Hong Kong,
RevDedup: A Reverse Deduplication Storage System Optimized for Reads to Latest Backups Chun-Ho Ng and Patrick P. C. Lee Department of Computer Science and Engineering The Chinese University of Hong Kong,
A Novel Way of Deduplication Approach for Cloud Backup Services Using Block Index Caching Technique
 A Novel Way of Deduplication Approach for Cloud Backup Services Using Block Index Caching Technique Jyoti Malhotra 1,Priya Ghyare 2 Associate Professor, Dept. of Information Technology, MIT College of
A Novel Way of Deduplication Approach for Cloud Backup Services Using Block Index Caching Technique Jyoti Malhotra 1,Priya Ghyare 2 Associate Professor, Dept. of Information Technology, MIT College of
A Deduplication File System & Course Review
 A Deduplication File System & Course Review Kai Li 12/13/12 Topics A Deduplication File System Review 12/13/12 2 Traditional Data Center Storage Hierarchy Clients Network Server SAN Storage Remote mirror
A Deduplication File System & Course Review Kai Li 12/13/12 Topics A Deduplication File System Review 12/13/12 2 Traditional Data Center Storage Hierarchy Clients Network Server SAN Storage Remote mirror
Fragmentation in in-line. deduplication backup systems
 Fragmentation in in-line 5/6/2013 deduplication backup systems 1. Reducing Impact of Data Fragmentation Caused By In-Line Deduplication. Michal Kaczmarczyk, Marcin Barczynski, Wojciech Kilian, Cezary Dubnicki.
Fragmentation in in-line 5/6/2013 deduplication backup systems 1. Reducing Impact of Data Fragmentation Caused By In-Line Deduplication. Michal Kaczmarczyk, Marcin Barczynski, Wojciech Kilian, Cezary Dubnicki.
A Novel Deduplication Avoiding Chunk Index in RAM
 A Novel Deduplication Avoiding Chunk Index in RAM 1 Zhike Zhang, 2 Zejun Jiang, 3 Xiaobin Cai, 4 Chengzhang Peng 1, First Author Northwestern Polytehnical University, 127 Youyixilu, Xi an, Shaanxi, P.R.
A Novel Deduplication Avoiding Chunk Index in RAM 1 Zhike Zhang, 2 Zejun Jiang, 3 Xiaobin Cai, 4 Chengzhang Peng 1, First Author Northwestern Polytehnical University, 127 Youyixilu, Xi an, Shaanxi, P.R.
Read Performance Enhancement In Data Deduplication For Secondary Storage
 Read Performance Enhancement In Data Deduplication For Secondary Storage A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY Pradeep Ganesan IN PARTIAL FULFILLMENT
Read Performance Enhancement In Data Deduplication For Secondary Storage A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY Pradeep Ganesan IN PARTIAL FULFILLMENT
Data Backup and Archiving with Enterprise Storage Systems
 Data Backup and Archiving with Enterprise Storage Systems Slavjan Ivanov 1, Igor Mishkovski 1 1 Faculty of Computer Science and Engineering Ss. Cyril and Methodius University Skopje, Macedonia [email protected],
Data Backup and Archiving with Enterprise Storage Systems Slavjan Ivanov 1, Igor Mishkovski 1 1 Faculty of Computer Science and Engineering Ss. Cyril and Methodius University Skopje, Macedonia [email protected],
IDENTIFYING AND OPTIMIZING DATA DUPLICATION BY EFFICIENT MEMORY ALLOCATION IN REPOSITORY BY SINGLE INSTANCE STORAGE
 IDENTIFYING AND OPTIMIZING DATA DUPLICATION BY EFFICIENT MEMORY ALLOCATION IN REPOSITORY BY SINGLE INSTANCE STORAGE 1 M.PRADEEP RAJA, 2 R.C SANTHOSH KUMAR, 3 P.KIRUTHIGA, 4 V. LOGESHWARI 1,2,3 Student,
IDENTIFYING AND OPTIMIZING DATA DUPLICATION BY EFFICIENT MEMORY ALLOCATION IN REPOSITORY BY SINGLE INSTANCE STORAGE 1 M.PRADEEP RAJA, 2 R.C SANTHOSH KUMAR, 3 P.KIRUTHIGA, 4 V. LOGESHWARI 1,2,3 Student,
Speeding Up Cloud/Server Applications Using Flash Memory
 Speeding Up Cloud/Server Applications Using Flash Memory Sudipta Sengupta Microsoft Research, Redmond, WA, USA Contains work that is joint with B. Debnath (Univ. of Minnesota) and J. Li (Microsoft Research,
Speeding Up Cloud/Server Applications Using Flash Memory Sudipta Sengupta Microsoft Research, Redmond, WA, USA Contains work that is joint with B. Debnath (Univ. of Minnesota) and J. Li (Microsoft Research,
Building a High Performance Deduplication System Fanglu Guo and Petros Efstathopoulos
 Building a High Performance Deduplication System Fanglu Guo and Petros Efstathopoulos Symantec Research Labs Symantec FY 2013 (4/1/2012 to 3/31/2013) Revenue: $ 6.9 billion Segment Revenue Example Business
Building a High Performance Deduplication System Fanglu Guo and Petros Efstathopoulos Symantec Research Labs Symantec FY 2013 (4/1/2012 to 3/31/2013) Revenue: $ 6.9 billion Segment Revenue Example Business
DEXT3: Block Level Inline Deduplication for EXT3 File System
 DEXT3: Block Level Inline Deduplication for EXT3 File System Amar More M.A.E. Alandi, Pune, India [email protected] Zishan Shaikh M.A.E. Alandi, Pune, India [email protected] Vishal Salve
DEXT3: Block Level Inline Deduplication for EXT3 File System Amar More M.A.E. Alandi, Pune, India [email protected] Zishan Shaikh M.A.E. Alandi, Pune, India [email protected] Vishal Salve
A Deduplication-based Data Archiving System
 2012 International Conference on Image, Vision and Computing (ICIVC 2012) IPCSIT vol. 50 (2012) (2012) IACSIT Press, Singapore DOI: 10.7763/IPCSIT.2012.V50.20 A Deduplication-based Data Archiving System
2012 International Conference on Image, Vision and Computing (ICIVC 2012) IPCSIT vol. 50 (2012) (2012) IACSIT Press, Singapore DOI: 10.7763/IPCSIT.2012.V50.20 A Deduplication-based Data Archiving System
Theoretical Aspects of Storage Systems Autumn 2009
 Theoretical Aspects of Storage Systems Autumn 2009 Chapter 3: Data Deduplication André Brinkmann News Outline Data Deduplication Compare-by-hash strategies Delta-encoding based strategies Measurements
Theoretical Aspects of Storage Systems Autumn 2009 Chapter 3: Data Deduplication André Brinkmann News Outline Data Deduplication Compare-by-hash strategies Delta-encoding based strategies Measurements
A Survey on Aware of Local-Global Cloud Backup Storage for Personal Purpose
 A Survey on Aware of Local-Global Cloud Backup Storage for Personal Purpose Abhirupa Chatterjee 1, Divya. R. Krishnan 2, P. Kalamani 3 1,2 UG Scholar, Sri Sairam College Of Engineering, Bangalore. India
A Survey on Aware of Local-Global Cloud Backup Storage for Personal Purpose Abhirupa Chatterjee 1, Divya. R. Krishnan 2, P. Kalamani 3 1,2 UG Scholar, Sri Sairam College Of Engineering, Bangalore. India
Low-Cost Data Deduplication for Virtual Machine Backup in Cloud Storage
 Low-Cost Data Deduplication for Virtual Machine Backup in Cloud Storage Wei Zhang, Tao Yang, Gautham Narayanasamy, and Hong Tang University of California at Santa Barbara, Alibaba Inc. Abstract In a virtualized
Low-Cost Data Deduplication for Virtual Machine Backup in Cloud Storage Wei Zhang, Tao Yang, Gautham Narayanasamy, and Hong Tang University of California at Santa Barbara, Alibaba Inc. Abstract In a virtualized
Inline Deduplication
 Inline Deduplication [email protected] 1.1 Inline Vs Post-process Deduplication In target based deduplication, the deduplication engine can either process data for duplicates in real time (i.e.
Inline Deduplication [email protected] 1.1 Inline Vs Post-process Deduplication In target based deduplication, the deduplication engine can either process data for duplicates in real time (i.e.
Data Deduplication and Tivoli Storage Manager
 Data Deduplication and Tivoli Storage Manager Dave Cannon Tivoli Storage Manager rchitect Oxford University TSM Symposium September 2007 Disclaimer This presentation describes potential future enhancements
Data Deduplication and Tivoli Storage Manager Dave Cannon Tivoli Storage Manager rchitect Oxford University TSM Symposium September 2007 Disclaimer This presentation describes potential future enhancements
MAD2: A Scalable High-Throughput Exact Deduplication Approach for Network Backup Services
 MAD2: A Scalable High-Throughput Exact Deduplication Approach for Network Backup Services Jiansheng Wei, Hong Jiang, Ke Zhou, Dan Feng School of Computer, Huazhong University of Science and Technology,
MAD2: A Scalable High-Throughput Exact Deduplication Approach for Network Backup Services Jiansheng Wei, Hong Jiang, Ke Zhou, Dan Feng School of Computer, Huazhong University of Science and Technology,
Top Ten Questions. to Ask Your Primary Storage Provider About Their Data Efficiency. May 2014. Copyright 2014 Permabit Technology Corporation
 Top Ten Questions to Ask Your Primary Storage Provider About Their Data Efficiency May 2014 Copyright 2014 Permabit Technology Corporation Introduction The value of data efficiency technologies, namely
Top Ten Questions to Ask Your Primary Storage Provider About Their Data Efficiency May 2014 Copyright 2014 Permabit Technology Corporation Introduction The value of data efficiency technologies, namely
Deploying De-Duplication on Ext4 File System
 Deploying De-Duplication on Ext4 File System Usha A. Joglekar 1, Bhushan M. Jagtap 2, Koninika B. Patil 3, 1. Asst. Prof., 2, 3 Students Department of Computer Engineering Smt. Kashibai Navale College
Deploying De-Duplication on Ext4 File System Usha A. Joglekar 1, Bhushan M. Jagtap 2, Koninika B. Patil 3, 1. Asst. Prof., 2, 3 Students Department of Computer Engineering Smt. Kashibai Navale College
INTENSIVE FIXED CHUNKING (IFC) DE-DUPLICATION FOR SPACE OPTIMIZATION IN PRIVATE CLOUD STORAGE BACKUP
 DE-DUPLICATION FOR SPACE OPTIMIZATION IN PRIVATE CLOUD STORAGE BACKUP") INTENSIVE FIXED CHUNKING (IFC) DE-DUPLICATION FOR SPACE OPTIMIZATION IN PRIVATE CLOUD STORAGE BACKUP 1 M.SHYAMALA DEVI, 2 V.VIMAL KHANNA, 3 M.SHAHEEN SHAH 1 Assistant Professor, Department of CSE, R.M.D.
INTENSIVE FIXED CHUNKING (IFC) DE-DUPLICATION FOR SPACE OPTIMIZATION IN PRIVATE CLOUD STORAGE BACKUP 1 M.SHYAMALA DEVI, 2 V.VIMAL KHANNA, 3 M.SHAHEEN SHAH 1 Assistant Professor, Department of CSE, R.M.D.
Trends in Enterprise Backup Deduplication
 Trends in Enterprise Backup Deduplication Shankar Balasubramanian Architect, EMC 1 Outline Protection Storage Deduplication Basics CPU-centric Deduplication: SISL (Stream-Informed Segment Layout) Data
Trends in Enterprise Backup Deduplication Shankar Balasubramanian Architect, EMC 1 Outline Protection Storage Deduplication Basics CPU-centric Deduplication: SISL (Stream-Informed Segment Layout) Data
IMPLEMENTATION OF SOURCE DEDUPLICATION FOR CLOUD BACKUP SERVICES BY EXPLOITING APPLICATION AWARENESS
 IMPLEMENTATION OF SOURCE DEDUPLICATION FOR CLOUD BACKUP SERVICES BY EXPLOITING APPLICATION AWARENESS Nehal Markandeya 1, Sandip Khillare 2, Rekha Bagate 3, Sayali Badave 4 Vaishali Barkade 5 12 3 4 5 (Department
IMPLEMENTATION OF SOURCE DEDUPLICATION FOR CLOUD BACKUP SERVICES BY EXPLOITING APPLICATION AWARENESS Nehal Markandeya 1, Sandip Khillare 2, Rekha Bagate 3, Sayali Badave 4 Vaishali Barkade 5 12 3 4 5 (Department
Tradeoffs in Scalable Data Routing for Deduplication Clusters
 Tradeoffs in Scalable Data Routing for Deduplication Clusters Wei Dong Princeton University Fred Douglis EMC Kai Li Princeton University and EMC Hugo Patterson EMC Sazzala Reddy EMC Philip Shilane EMC
Tradeoffs in Scalable Data Routing for Deduplication Clusters Wei Dong Princeton University Fred Douglis EMC Kai Li Princeton University and EMC Hugo Patterson EMC Sazzala Reddy EMC Philip Shilane EMC
A Survey on Deduplication Strategies and Storage Systems
 A Survey on Deduplication Strategies and Storage Systems Guljar Shaikh ((Information Technology,B.V.C.O.E.P/ B.V.C.O.E.P, INDIA) Abstract : Now a day there is raising demands for systems which provide
A Survey on Deduplication Strategies and Storage Systems Guljar Shaikh ((Information Technology,B.V.C.O.E.P/ B.V.C.O.E.P, INDIA) Abstract : Now a day there is raising demands for systems which provide
Avoiding the Disk Bottleneck in the Data Domain Deduplication File System
 Avoiding the Disk Bottleneck in the Data Domain Deduplication File System Benjamin Zhu Data Domain, Inc. Kai Li Data Domain, Inc. and Princeton University Hugo Patterson Data Domain, Inc. Abstract Disk-based
Avoiding the Disk Bottleneck in the Data Domain Deduplication File System Benjamin Zhu Data Domain, Inc. Kai Li Data Domain, Inc. and Princeton University Hugo Patterson Data Domain, Inc. Abstract Disk-based
FAST 11. Yongseok Oh <[email protected]> University of Seoul. Mobile Embedded System Laboratory
 CAFTL: A Content-Aware Flash Translation Layer Enhancing the Lifespan of flash Memory based Solid State Drives FAST 11 Yongseok Oh University of Seoul Mobile Embedded System Laboratory
CAFTL: A Content-Aware Flash Translation Layer Enhancing the Lifespan of flash Memory based Solid State Drives FAST 11 Yongseok Oh University of Seoul Mobile Embedded System Laboratory
Physical Data Organization
 Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Deduplication Demystified: How to determine the right approach for your business
 Deduplication Demystified: How to determine the right approach for your business Presented by Charles Keiper Senior Product Manager, Data Protection Quest Software Session Objective: To answer burning
Deduplication Demystified: How to determine the right approach for your business Presented by Charles Keiper Senior Product Manager, Data Protection Quest Software Session Objective: To answer burning
A Method of Deduplication for Data Remote Backup
 A Method of Deduplication for Data Remote Backup Jingyu Liu 1,2, Yu-an Tan 1, Yuanzhang Li 1, Xuelan Zhang 1, Zexiang Zhou 3 1 School of Computer Science and Technology, Beijing Institute of Technology,
A Method of Deduplication for Data Remote Backup Jingyu Liu 1,2, Yu-an Tan 1, Yuanzhang Li 1, Xuelan Zhang 1, Zexiang Zhou 3 1 School of Computer Science and Technology, Beijing Institute of Technology,
Data Deduplication in Tivoli Storage Manager. Andrzej Bugowski 19-05-2011 Spała
 Data Deduplication in Tivoli Storage Manager Andrzej Bugowski 19-05-2011 Spała Agenda Tivoli Storage, IBM Software Group Deduplication concepts Data deduplication in TSM 6.1 Planning for data deduplication
Data Deduplication in Tivoli Storage Manager Andrzej Bugowski 19-05-2011 Spała Agenda Tivoli Storage, IBM Software Group Deduplication concepts Data deduplication in TSM 6.1 Planning for data deduplication
The assignment of chunk size according to the target data characteristics in deduplication backup system
 The assignment of chunk size according to the target data characteristics in deduplication backup system Mikito Ogata Norihisa Komoda Hitachi Information and Telecommunication Engineering, Ltd. 781 Sakai,
The assignment of chunk size according to the target data characteristics in deduplication backup system Mikito Ogata Norihisa Komoda Hitachi Information and Telecommunication Engineering, Ltd. 781 Sakai,
WAN Optimized Replication of Backup Datasets Using Stream-Informed Delta Compression
 WAN Optimized Replication of Backup Datasets Using Stream-Informed Delta Compression Philip Shilane, Mark Huang, Grant Wallace, and Windsor Hsu Backup Recovery Systems Division EMC Corporation Abstract
WAN Optimized Replication of Backup Datasets Using Stream-Informed Delta Compression Philip Shilane, Mark Huang, Grant Wallace, and Windsor Hsu Backup Recovery Systems Division EMC Corporation Abstract
A Method of Deduplication for Data Remote Backup
 A Method of Deduplication for Data Remote Backup Jingyu Liu 1,2, Yu-an Tan 1, Yuanzhang Li 1, Xuelan Zhang 1, and Zexiang Zhou 3 1 School of Computer Science and Technology, Beijing Institute of Technology,
A Method of Deduplication for Data Remote Backup Jingyu Liu 1,2, Yu-an Tan 1, Yuanzhang Li 1, Xuelan Zhang 1, and Zexiang Zhou 3 1 School of Computer Science and Technology, Beijing Institute of Technology,
Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality
 Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality Mark Lillibridge, Kave Eshghi, Deepavali Bhagwat, Vinay Deolalikar, Greg Trezise, and Peter Camble HP Labs UC Santa Cruz HP
Sparse Indexing: Large Scale, Inline Deduplication Using Sampling and Locality Mark Lillibridge, Kave Eshghi, Deepavali Bhagwat, Vinay Deolalikar, Greg Trezise, and Peter Camble HP Labs UC Santa Cruz HP
3Gen Data Deduplication Technical
 3Gen Data Deduplication Technical Discussion NOTICE: This White Paper may contain proprietary information protected by copyright. Information in this White Paper is subject to change without notice and
3Gen Data Deduplication Technical Discussion NOTICE: This White Paper may contain proprietary information protected by copyright. Information in this White Paper is subject to change without notice and
Understanding EMC Avamar with EMC Data Protection Advisor
 Understanding EMC Avamar with EMC Data Protection Advisor Applied Technology Abstract EMC Data Protection Advisor provides a comprehensive set of features to reduce the complexity of managing data protection
Understanding EMC Avamar with EMC Data Protection Advisor Applied Technology Abstract EMC Data Protection Advisor provides a comprehensive set of features to reduce the complexity of managing data protection
Reducing Replication Bandwidth for Distributed Document Databases
 Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu 1, Andy Pavlo 1, Sudipta Sengupta 2 Jin Li 2, Greg Ganger 1 Carnegie Mellon University 1, Microsoft Research 2 #1 You can
Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu 1, Andy Pavlo 1, Sudipta Sengupta 2 Jin Li 2, Greg Ganger 1 Carnegie Mellon University 1, Microsoft Research 2 #1 You can
UNDERSTANDING DATA DEDUPLICATION. Tom Sas Hewlett-Packard
 UNDERSTANDING DATA DEDUPLICATION Tom Sas Hewlett-Packard SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individual members may use this material
UNDERSTANDING DATA DEDUPLICATION Tom Sas Hewlett-Packard SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individual members may use this material
Cloud Storage. Parallels. Performance Benchmark Results. White Paper. www.parallels.com
 Parallels Cloud Storage White Paper Performance Benchmark Results www.parallels.com Table of Contents Executive Summary... 3 Architecture Overview... 3 Key Features... 4 No Special Hardware Requirements...
Parallels Cloud Storage White Paper Performance Benchmark Results www.parallels.com Table of Contents Executive Summary... 3 Architecture Overview... 3 Key Features... 4 No Special Hardware Requirements...
Understanding Disk Storage in Tivoli Storage Manager
 Understanding Disk Storage in Tivoli Storage Manager Dave Cannon Tivoli Storage Manager Architect Oxford University TSM Symposium September 2005 Disclaimer Unless otherwise noted, functions and behavior
Understanding Disk Storage in Tivoli Storage Manager Dave Cannon Tivoli Storage Manager Architect Oxford University TSM Symposium September 2005 Disclaimer Unless otherwise noted, functions and behavior
PARALLELS CLOUD STORAGE
 PARALLELS CLOUD STORAGE Performance Benchmark Results 1 Table of Contents Executive Summary... Error! Bookmark not defined. Architecture Overview... 3 Key Features... 5 No Special Hardware Requirements...
PARALLELS CLOUD STORAGE Performance Benchmark Results 1 Table of Contents Executive Summary... Error! Bookmark not defined. Architecture Overview... 3 Key Features... 5 No Special Hardware Requirements...
A Data De-duplication Access Framework for Solid State Drives
 JOURNAL OF INFORMATION SCIENCE AND ENGINEERING 28, 941-954 (2012) A Data De-duplication Access Framework for Solid State Drives Department of Electronic Engineering National Taiwan University of Science
JOURNAL OF INFORMATION SCIENCE AND ENGINEERING 28, 941-954 (2012) A Data De-duplication Access Framework for Solid State Drives Department of Electronic Engineering National Taiwan University of Science
Protecting Information in a Smarter Data Center with the Performance of Flash
 89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com 212.367.7400 Protecting Information in a Smarter Data Center with the Performance of Flash IBM FlashSystem and IBM ProtecTIER Printed in
89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com 212.367.7400 Protecting Information in a Smarter Data Center with the Performance of Flash IBM FlashSystem and IBM ProtecTIER Printed in
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
DEDUPLICATION has become a key component in modern
 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 27, NO. 3, MARCH 2016 855 Reducing Fragmentation for In-line Deduplication Backup Storage via Exploiting Backup History and Cache Knowledge Min
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 27, NO. 3, MARCH 2016 855 Reducing Fragmentation for In-line Deduplication Backup Storage via Exploiting Backup History and Cache Knowledge Min
UNDERSTANDING DATA DEDUPLICATION. Thomas Rivera SEPATON
 UNDERSTANDING DATA DEDUPLICATION Thomas Rivera SEPATON SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individual members may use this material
UNDERSTANDING DATA DEDUPLICATION Thomas Rivera SEPATON SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individual members may use this material
The Curious Case of Database Deduplication. PRESENTATION TITLE GOES HERE Gurmeet Goindi Oracle
 The Curious Case of Database Deduplication PRESENTATION TITLE GOES HERE Gurmeet Goindi Oracle Agenda Introduction Deduplication Databases and Deduplication All Flash Arrays and Deduplication 2 Quick Show
The Curious Case of Database Deduplication PRESENTATION TITLE GOES HERE Gurmeet Goindi Oracle Agenda Introduction Deduplication Databases and Deduplication All Flash Arrays and Deduplication 2 Quick Show
Chapter 13 File and Database Systems
 Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems
 Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Demystifying Deduplication for Backup with the Dell DR4000
 Demystifying Deduplication for Backup with the Dell DR4000 This Dell Technical White Paper explains how deduplication with the DR4000 can help your organization save time, space, and money. John Bassett
Demystifying Deduplication for Backup with the Dell DR4000 This Dell Technical White Paper explains how deduplication with the DR4000 can help your organization save time, space, and money. John Bassett
Data Deduplication and Tivoli Storage Manager
 Data Deduplication and Tivoli Storage Manager Dave annon Tivoli Storage Manager rchitect March 2009 Topics Tivoli Storage, IM Software Group Deduplication technology Data reduction and deduplication in
Data Deduplication and Tivoli Storage Manager Dave annon Tivoli Storage Manager rchitect March 2009 Topics Tivoli Storage, IM Software Group Deduplication technology Data reduction and deduplication in
Alternatives to Big Backup
 Alternatives to Big Backup Life Cycle Management, Object- Based Storage, and Self- Protecting Storage Systems Presented by: Chris Robertson Solution Architect Cambridge Computer Copyright 2010-2011, Cambridge
Alternatives to Big Backup Life Cycle Management, Object- Based Storage, and Self- Protecting Storage Systems Presented by: Chris Robertson Solution Architect Cambridge Computer Copyright 2010-2011, Cambridge
Data Storage - II: Efficient Usage & Errors
 Data Storage - II: Efficient Usage & Errors Week 10, Spring 2005 Updated by M. Naci Akkøk, 27.02.2004, 03.03.2005 based upon slides by Pål Halvorsen, 12.3.2002. Contains slides from: Hector Garcia-Molina
Data Storage - II: Efficient Usage & Errors Week 10, Spring 2005 Updated by M. Naci Akkøk, 27.02.2004, 03.03.2005 based upon slides by Pål Halvorsen, 12.3.2002. Contains slides from: Hector Garcia-Molina
09'Linux Plumbers Conference
 09'Linux Plumbers Conference Data de duplication Mingming Cao IBM Linux Technology Center [email protected] 2009 09 25 Current storage challenges Our world is facing data explosion. Data is growing in a amazing
09'Linux Plumbers Conference Data de duplication Mingming Cao IBM Linux Technology Center [email protected] 2009 09 25 Current storage challenges Our world is facing data explosion. Data is growing in a amazing
UNDERSTANDING DATA DEDUPLICATION. Jiří Král, ředitel pro technický rozvoj STORYFLEX a.s.
 UNDERSTANDING DATA DEDUPLICATION Jiří Král, ředitel pro technický rozvoj STORYFLEX a.s. SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individual
UNDERSTANDING DATA DEDUPLICATION Jiří Král, ředitel pro technický rozvoj STORYFLEX a.s. SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individual
File System & Device Drive. Overview of Mass Storage Structure. Moving head Disk Mechanism. HDD Pictures 11/13/2014. CS341: Operating System
 CS341: Operating System Lect 36: 1 st Nov 2014 Dr. A. Sahu Dept of Comp. Sc. & Engg. Indian Institute of Technology Guwahati File System & Device Drive Mass Storage Disk Structure Disk Arm Scheduling RAID
CS341: Operating System Lect 36: 1 st Nov 2014 Dr. A. Sahu Dept of Comp. Sc. & Engg. Indian Institute of Technology Guwahati File System & Device Drive Mass Storage Disk Structure Disk Arm Scheduling RAID
FAWN - a Fast Array of Wimpy Nodes
 University of Warsaw January 12, 2011 Outline Introduction 1 Introduction 2 3 4 5 Key issues Introduction Growing CPU vs. I/O gap Contemporary systems must serve millions of users Electricity consumed
University of Warsaw January 12, 2011 Outline Introduction 1 Introduction 2 3 4 5 Key issues Introduction Growing CPU vs. I/O gap Contemporary systems must serve millions of users Electricity consumed
Reducing impact of data fragmentation caused by in-line deduplication
 Reducing impact of data fragmentation caused by in-line deduplication Michal Kaczmarczyk, Marcin Barczynski, Wojciech Kilian, and Cezary Dubnicki 9LivesData, LLC {kaczmarczyk, barczynski, wkilian, dubnicki}@9livesdata.com
Reducing impact of data fragmentation caused by in-line deduplication Michal Kaczmarczyk, Marcin Barczynski, Wojciech Kilian, and Cezary Dubnicki 9LivesData, LLC {kaczmarczyk, barczynski, wkilian, dubnicki}@9livesdata.com
How To Make A Backup System More Efficient
 Identifying the Hidden Risk of Data De-duplication: How the HYDRAstor Solution Proactively Solves the Problem October, 2006 Introduction Data de-duplication has recently gained significant industry attention,
Identifying the Hidden Risk of Data De-duplication: How the HYDRAstor Solution Proactively Solves the Problem October, 2006 Introduction Data de-duplication has recently gained significant industry attention,
Online Remote Data Backup for iscsi-based Storage Systems
 Online Remote Data Backup for iscsi-based Storage Systems Dan Zhou, Li Ou, Xubin (Ben) He Department of Electrical and Computer Engineering Tennessee Technological University Cookeville, TN 38505, USA
Online Remote Data Backup for iscsi-based Storage Systems Dan Zhou, Li Ou, Xubin (Ben) He Department of Electrical and Computer Engineering Tennessee Technological University Cookeville, TN 38505, USA
Availability Digest. www.availabilitydigest.com. Data Deduplication February 2011
 the Availability Digest Data Deduplication February 2011 What is Data Deduplication? Data deduplication is a technology that can reduce disk storage-capacity requirements and replication bandwidth requirements
the Availability Digest Data Deduplication February 2011 What is Data Deduplication? Data deduplication is a technology that can reduce disk storage-capacity requirements and replication bandwidth requirements
Hardware Configuration Guide
 Hardware Configuration Guide Contents Contents... 1 Annotation... 1 Factors to consider... 2 Machine Count... 2 Data Size... 2 Data Size Total... 2 Daily Backup Data Size... 2 Unique Data Percentage...
Hardware Configuration Guide Contents Contents... 1 Annotation... 1 Factors to consider... 2 Machine Count... 2 Data Size... 2 Data Size Total... 2 Daily Backup Data Size... 2 Unique Data Percentage...
STORAGE. Buying Guide: TARGET DATA DEDUPLICATION BACKUP SYSTEMS. inside
 Managing the information that drives the enterprise STORAGE Buying Guide: DEDUPLICATION inside What you need to know about target data deduplication Special factors to consider One key difference among
Managing the information that drives the enterprise STORAGE Buying Guide: DEDUPLICATION inside What you need to know about target data deduplication Special factors to consider One key difference among
The Classical Architecture. Storage 1 / 36
 1 / 36 The Problem Application Data? Filesystem Logical Drive Physical Drive 2 / 36 Requirements There are different classes of requirements: Data Independence application is shielded from physical storage
1 / 36 The Problem Application Data? Filesystem Logical Drive Physical Drive 2 / 36 Requirements There are different classes of requirements: Data Independence application is shielded from physical storage
Metadata Feedback and Utilization for Data Deduplication Across WAN
 Zhou B, Wen JT. Metadata feedback and utilization for data deduplication across WAN. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 31(3): 604 623 May 2016. DOI 10.1007/s11390-016-1650-6 Metadata Feedback
Zhou B, Wen JT. Metadata feedback and utilization for data deduplication across WAN. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 31(3): 604 623 May 2016. DOI 10.1007/s11390-016-1650-6 Metadata Feedback
Cumulus: filesystem backup to the Cloud
 Michael Vrable, Stefan Savage, a n d G e o f f r e y M. V o e l k e r Cumulus: filesystem backup to the Cloud Michael Vrable is pursuing a Ph.D. in computer science at the University of California, San
Michael Vrable, Stefan Savage, a n d G e o f f r e y M. V o e l k e r Cumulus: filesystem backup to the Cloud Michael Vrable is pursuing a Ph.D. in computer science at the University of California, San
Cluster Computing. ! Fault tolerance. ! Stateless. ! Throughput. ! Stateful. ! Response time. Architectures. Stateless vs. Stateful.
 Architectures Cluster Computing Job Parallelism Request Parallelism 2 2010 VMware Inc. All rights reserved Replication Stateless vs. Stateful! Fault tolerance High availability despite failures If one
Architectures Cluster Computing Job Parallelism Request Parallelism 2 2010 VMware Inc. All rights reserved Replication Stateless vs. Stateful! Fault tolerance High availability despite failures If one
Managing Storage Space in a Flash and Disk Hybrid Storage System
 Managing Storage Space in a Flash and Disk Hybrid Storage System Xiaojian Wu, and A. L. Narasimha Reddy Dept. of Electrical and Computer Engineering Texas A&M University IEEE International Symposium on
Managing Storage Space in a Flash and Disk Hybrid Storage System Xiaojian Wu, and A. L. Narasimha Reddy Dept. of Electrical and Computer Engineering Texas A&M University IEEE International Symposium on
Backup Software Data Deduplication: What you need to know. Presented by W. Curtis Preston Executive Editor & Independent Backup Expert
 Backup Software Data Deduplication: What you need to know Presented by W. Curtis Preston Executive Editor & Independent Backup Expert When I was in the IT Department When I started as backup guy at $35B
Backup Software Data Deduplication: What you need to know Presented by W. Curtis Preston Executive Editor & Independent Backup Expert When I was in the IT Department When I started as backup guy at $35B
SQL Server 2014 New Features/In- Memory Store. Juergen Thomas Microsoft Corporation
 SQL Server 2014 New Features/In- Memory Store Juergen Thomas Microsoft Corporation AGENDA 1. SQL Server 2014 what and when 2. SQL Server 2014 In-Memory 3. SQL Server 2014 in IaaS scenarios 2 SQL Server
SQL Server 2014 New Features/In- Memory Store Juergen Thomas Microsoft Corporation AGENDA 1. SQL Server 2014 what and when 2. SQL Server 2014 In-Memory 3. SQL Server 2014 in IaaS scenarios 2 SQL Server
Online De-duplication in a Log-Structured File System for Primary Storage
 Online De-duplication in a Log-Structured File System for Primary Storage Technical Report UCSC-SSRC-11-03 May 2011 Stephanie N. Jones [email protected] Storage Systems Research Center Baskin School
Online De-duplication in a Log-Structured File System for Primary Storage Technical Report UCSC-SSRC-11-03 May 2011 Stephanie N. Jones [email protected] Storage Systems Research Center Baskin School
M710 - Max 960 Drive, 8Gb/16Gb FC, Max 48 ports, Max 192GB Cache Memory
 SFD6 NEC *Gideon Senderov NEC $1.4B/yr in R & D Over 55 years in servers and storage (1958) SDN, Servers, Storage, Software M-Series and HYDRAstor *Chauncey Schwartz MX10-Series New models are M110, M310,
SFD6 NEC *Gideon Senderov NEC $1.4B/yr in R & D Over 55 years in servers and storage (1958) SDN, Servers, Storage, Software M-Series and HYDRAstor *Chauncey Schwartz MX10-Series New models are M110, M310,
An Efficient Deduplication File System for Virtual Machine in Cloud
 An Efficient Deduplication File System for Virtual Machine in Cloud Bhuvaneshwari D M.E. computer science and engineering IndraGanesan college of Engineering,Trichy. Abstract Virtualization is widely deployed
An Efficient Deduplication File System for Virtual Machine in Cloud Bhuvaneshwari D M.E. computer science and engineering IndraGanesan college of Engineering,Trichy. Abstract Virtualization is widely deployed
An Authorized Duplicate Check Scheme for Removing Duplicate Copies of Repeating Data in The Cloud Environment to Reduce Amount of Storage Space
 An Authorized Duplicate Check Scheme for Removing Duplicate Copies of Repeating Data in The Cloud Environment to Reduce Amount of Storage Space Jannu.Prasanna Krishna M.Tech Student, Department of CSE,
An Authorized Duplicate Check Scheme for Removing Duplicate Copies of Repeating Data in The Cloud Environment to Reduce Amount of Storage Space Jannu.Prasanna Krishna M.Tech Student, Department of CSE,
Byte-index Chunking Algorithm for Data Deduplication System
 , pp.415-424 http://dx.doi.org/10.14257/ijsia.2013.7.5.38 Byte-index Chunking Algorithm for Data Deduplication System Ider Lkhagvasuren 1, Jung Min So 1, Jeong Gun Lee 1, Chuck Yoo 2 and Young Woong Ko
, pp.415-424 http://dx.doi.org/10.14257/ijsia.2013.7.5.38 Byte-index Chunking Algorithm for Data Deduplication System Ider Lkhagvasuren 1, Jung Min So 1, Jeong Gun Lee 1, Chuck Yoo 2 and Young Woong Ko
Overview of RD Virtualization Host
 RD Virtualization Host Page 1 Overview of RD Virtualization Host Remote Desktop Virtualization Host (RD Virtualization Host) is a Remote Desktop Services role service included with Windows Server 2008
RD Virtualization Host Page 1 Overview of RD Virtualization Host Remote Desktop Virtualization Host (RD Virtualization Host) is a Remote Desktop Services role service included with Windows Server 2008
Data Reduction: Deduplication and Compression. Danny Harnik IBM Haifa Research Labs
 Data Reduction: Deduplication and Compression Danny Harnik IBM Haifa Research Labs Motivation Reducing the amount of data is a desirable goal Data reduction: an attempt to compress the huge amounts of
Data Reduction: Deduplication and Compression Danny Harnik IBM Haifa Research Labs Motivation Reducing the amount of data is a desirable goal Data reduction: an attempt to compress the huge amounts of
Quanqing XU [email protected]. YuruBackup: A Highly Scalable and Space-Efficient Incremental Backup System in the Cloud
 Quanqing XU [email protected] YuruBackup: A Highly Scalable and Space-Efficient Incremental Backup System in the Cloud Outline Motivation YuruBackup s Architecture Backup Client File Scan, Data
Quanqing XU [email protected] YuruBackup: A Highly Scalable and Space-Efficient Incremental Backup System in the Cloud Outline Motivation YuruBackup s Architecture Backup Client File Scan, Data
Multi-level Metadata Management Scheme for Cloud Storage System
 , pp.231-240 http://dx.doi.org/10.14257/ijmue.2014.9.1.22 Multi-level Metadata Management Scheme for Cloud Storage System Jin San Kong 1, Min Ja Kim 2, Wan Yeon Lee 3, Chuck Yoo 2 and Young Woong Ko 1
, pp.231-240 http://dx.doi.org/10.14257/ijmue.2014.9.1.22 Multi-level Metadata Management Scheme for Cloud Storage System Jin San Kong 1, Min Ja Kim 2, Wan Yeon Lee 3, Chuck Yoo 2 and Young Woong Ko 1
Google File System. Web and scalability
 Google File System Web and scalability The web: - How big is the Web right now? No one knows. - Number of pages that are crawled: o 100,000 pages in 1994 o 8 million pages in 2005 - Crawlable pages might
Google File System Web and scalability The web: - How big is the Web right now? No one knows. - Number of pages that are crawled: o 100,000 pages in 1994 o 8 million pages in 2005 - Crawlable pages might
Improving Restore Speed for Backup Systems that Use Inline Chunk-Based Deduplication
 Improving Restore Speed for Backup Systems that Use Inline Chunk-Based Deduplication Mark Lillibridge, Kave Eshghi, and Deepavali Bhagwat HP Labs HP Storage [email protected] Abstract Slow restoration
Improving Restore Speed for Backup Systems that Use Inline Chunk-Based Deduplication Mark Lillibridge, Kave Eshghi, and Deepavali Bhagwat HP Labs HP Storage [email protected] Abstract Slow restoration
IBM TSM DISASTER RECOVERY BEST PRACTICES WITH EMC DATA DOMAIN DEDUPLICATION STORAGE
 White Paper IBM TSM DISASTER RECOVERY BEST PRACTICES WITH EMC DATA DOMAIN DEDUPLICATION STORAGE Abstract This white paper focuses on recovery of an IBM Tivoli Storage Manager (TSM) server and explores
White Paper IBM TSM DISASTER RECOVERY BEST PRACTICES WITH EMC DATA DOMAIN DEDUPLICATION STORAGE Abstract This white paper focuses on recovery of an IBM Tivoli Storage Manager (TSM) server and explores
Cloud De-duplication Cost Model THESIS
 Cloud De-duplication Cost Model THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Christopher Scott Hocker
Cloud De-duplication Cost Model THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Christopher Scott Hocker
VM-Centric Snapshot Deduplication for Cloud Data Backup
 -Centric Snapshot Deduplication for Cloud Data Backup Wei Zhang, Daniel Agun, Tao Yang, Rich Wolski, Hong Tang University of California at Santa Barbara Pure Storage Inc. Alibaba Inc. Email: [email protected],
-Centric Snapshot Deduplication for Cloud Data Backup Wei Zhang, Daniel Agun, Tao Yang, Rich Wolski, Hong Tang University of California at Santa Barbara Pure Storage Inc. Alibaba Inc. Email: [email protected],