APACHE HADOOP JERRIN JOSEPH CSU ID#
|
|
|
- Joseph Thompson
- 8 years ago
- Views:
Transcription
1 APACHE HADOOP JERRIN JOSEPH CSU ID#

2 CONTENTS Hadoop Hadoop Distributed File System (HDFS) Hadoop MapReduce Introduction Architecture Operations Conclusion References

3 ABSTRACT Hadoop is an efficient Big data handling tool. Reduced the data processing time from days to hours. Hadoop Distributed File System(HDFS) is the data storage unit of Hadoop. Hadoop MapReduce is the data processing unit which works on distributed processing principle.

4 INTRODUCTION What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to transmit 1TB of data through 4 channels : 43 Minutes. What if 500 TB??

5 HADOOP The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models [1] Core Components : HDFS: large data sets across clusters of computers. Hadoop MapReduce: the distributed processing using simple programming models
![simple programming models [1] Core Components : HDFS: large data sets across](/docs-images/45/7098121/images/page_5.jpg "clusters of computers.")
6 HADOOP : KEY FEATURES High Scalability Highly Tolerant to Software & Hardware Failures High Throughput Best for larger files with less in number Performs fast and parallel execution of Jobs Provides Streaming access to data Can be built out of commodity hardware

7 HADOOP: DRAWBACKS Not good for Low-latency data access Not good for Small files with large in number Not good for Multiple write files Do not encryption at storage level or network level Have a high complexity security model Hadoop is not a Database: Hence cannot alter a file.

8 HADOOP ARCHITECTURE

9 HADOOP DISTRIBUTED FILE SYSTEM (HDFS)

10 HADOOP DISTRIBUTED FILE SYSTEM (HDFS) Storage unit of Hadoop Relies on principles of Distributed File System. HDFS have a Master-Slave architecture Main Components: Name Node : Master Data Node : Slave 3+ replicas for each block Default Block Size : 64MB

11 HDFS: KEY FEATURES Highly fault tolerant. (automatic failure recovery system) High throughput Designed to work with systems with vary large file (files with size in TB) and few in number. Provides streaming access to file system data. It is specifically good for write once read many kind of files (for example Log files). Can be built out of commodity hardware. HDFS doesn't need highly expensive storage devices.
.")
12 HDFS ARCHITECTURE

13 NAME NODE Master of HDFS Maintains and Manages data on Data Nodes High reliability Machine (can be even RAID) Expensive Hardware Stores NO data; Just holds Metadata! Secondary Name Node: Reads from RAM of Name Node and stores it to hard disks periodically. Active & Passive Name Nodes from Gen2 Hadoop

14 DATA NODES Slaves in HDFS Provides Data Storage Deployed on independent machines Responsible for serving Read/Write requests from Client. The data processing is done on Data Nodes.

15 HDFS OPERATION

16 HDFS OPERATION Client makes a Write request to Name Node Name Node responds with the information about on available data nodes and where data to be written. Client write the data to the addressed Data Node. Replicas for all blocks are automatically created by Data Pipeline. If Write fails, Data Node will notify the Client and get new location to write. If Write Completed Successfully, Acknowledgement is given to Client Non-Posted Write by Hadoop

17 HDFS: FILE WRITE

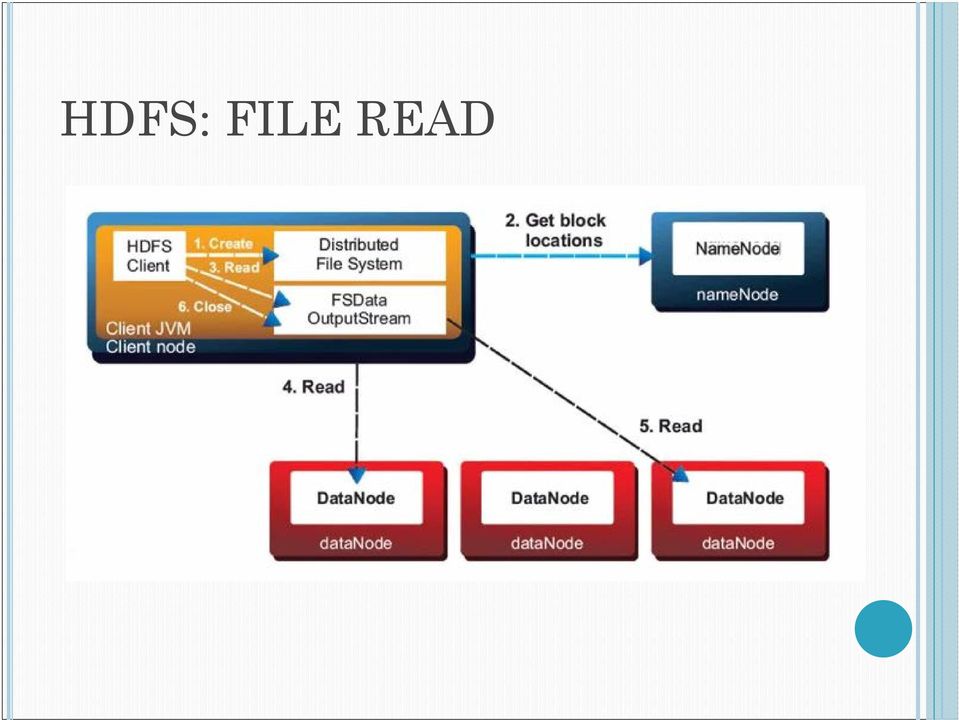
18 HDFS: FILE READ
19 HADOOP MAPREDUCE

20 HADOOP MAPREDUCE Simple programming model Hadoop Processing Unit MapReduce also have Master-Slave architecture Main Components: Job Tracker : Master Task Tracker : Slave From Google s MapReduce Do not fetch data to Master Node; Processed data at Slave Node and returns output to Master

21 HADOOP MAPREDUCE Implemented using Maps and Reduces Split by FileInputFormat Maps Inheriting Mapper Class Produces (key, value) pair as intermediate result from data. Reduces Inheriting Reducer Class Produces required output from intermediate result produced by Maps.
22 JOB TRACKER Master in MapReduce Receives the job request from Client Governs execution of jobs Makes the task scheduling decision TASK TRACKER Slave in MapReduce Governs execution of Tasks Periodically reports the progress of tasks
23 MAPREDUCE ARCHITECTURE
24 MAPREDUCE OPERATIONS
25 MAPREDUCE OPERATIONS
26 MAPREDUCE OPERATIONS
27 MAPREDUCE OPERATIONS
28 APACHE HIVE
29 HIVE Built on top of Hadoop Supports SQL like Query Language : Hive-QL Data in Hive is organized into tables Provides structure for unstructured Big Data Work with data inside HDFS Tables Data : File or Group of Files in HDFS Schema : In the form of metadata stored in Relational Database Have a corresponding HDFS directory Data in a table is Serialized Supports Primitive Column Types and Nestable Collection Types (Array and Map)
30 HIVE QUERY LANGUAGE SQL like language DDL : to create tables with specific serialization formats DML : to load data from external sources and insert query results into Hive tables Do not support updating and deleting rows in existing tables Supports Multi-Table insert Supports custom map-reduce scripts written in any language Can be extended with custom functions (UDFs) User Defined Transformation Function(UDTF) User Defined Aggregation Function (UDAF)
31 HIVE ARCHITECTURE External Interfaces: Web UI : Management Hive CLI : Run Queries, Browse Tables, etc API : JDBC, ODBC Metastore : System catalog which contains metadata about Hive tables Driver : manages the life cycle of a Hive-QL statement during compilation, optimization and execution Compiler : translates Hive-QL statement into a plan which consists of a DAG of map-reduce jobs
32 HIVE ARCHITECTURE
33 HIVE ACHIEVEMENTS & FUTURE PLANS First step to provide warehousing layer for Hadoop(Web-based Map-Reduce data processing system) Accepts only sub-set of SQL: Working to subsume SQL syntax Working on Rule-based optimizer : Plans to build Cost-based optimizer Enhancing JDBC and ODBC drivers for making the interactions with commercial BI tools. Working on making it perform better
34 APACHE HBASE
35 H-BASE Distributed Column-oriented database on top of Hadoop/HDFS Provides low-latency access to single rows from billions of records Column oriented: OLAP Best for aggregation High compression rate: Few distinct values Do not have a Schema or data type Built for Wide tables : Millions of columns Billions of rows Denormalized data Master-Slave architecture
36 H-BASE ARCHITECTURE
37 HMASTER SERVER Like Name Node in HDFS Manages and Monitors HBase Cluster Operations Assign Region to Region Servers Handling Load-balancing and Splitting REGION SERVER Like Data Node in HDFS Highly Scalable Handle Read/ Write Requests Direct communication with Clients
38 INTERNAL ARCHITECTURE Tables Regions Store MemStore FileStore Blocks Column Families
39 APACHE ZOOKEEPER
40 ZOOKEEPER What is ZooKeeper? Distributed coordination service for distributed applications Like a Centralized Repository Challenges for Distributed Applications ZooKeeper Goals
41 ZOOKEEPER ARCHITECTURE
42 ZOOKEEPER ARCHITECTURE Always Odd number of nodes. Leader is elected by voting. Leader and Follower can get connected to Clients and Perform Read Operations Write Operation is done only by the Leader. Observer nodes to address scaling problems
43 ZOOKEEPER DATA MODEL
44 ZOOKEEPER DATA MODEL Z Nodes: Similar to Directory in File system Container for data and other nodes Stores Statistical information and User data up to 1MB Used to store and share configuration information between applications Z Node Types Persistent Nodes Ephemeral Nodes Sequential Nodes Watch : Event system for client notification
45 PROJECTS & TOOLS ON HADOOP HBase Hive Pig Jaql ZooKeeper AVRO UIMA Sqoop
46 CONCLUSION Hadoop is a successful solution for Big Data Handling Hadoop expanded from a simple project to the level of a platform The projects and tools on Hadoop are proof for the successfulness of Hadoop.
47 REFERENCES [1] "Apache Hadoop", [2] Apache Hive, [3] Apache HBase, [4] Apache ZooKeeper, [5] Jason Venner, "Pro Hadoop", Apress Books, 2009 [6] "Hadoop Wiki", [7] Jiong Xie, Shu Yin, Xiaojun Ruan, Zhiyang Ding, Yun Tian, James Majors, Adam Manzanares, Xiao Qin, " Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters", 19th International Heterogeneity in Computing Workshop, Atlanta, Georgia, April 2010
48 REFERENCES [8] Dhruba Borthakur, The Hadoop Distributed File System: Architecture and Design, The Apache Software Foundation [9] "Apache Hadoop", [10] "Hadoop Overview", [11] Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, The Hadoop Distributed File System, Yahoo!, Sunnyvale, California USA, Published in: Mass Storage Systems and Technologies (MSST), 2010 IEEE 26th Symposium.
49 REFERENCES [12] Vinod Kumar Vavilapalli, Arun C Murthy, Chris Douglas, Sharad Agarwal, Mahadev Konar, Robert Evans, Thomas Graves, Jason Lowe, Hitesh Shah, Siddharth Seth, Bikas Saha, Carlo Curino, Owen O Malley, Sanjay Radia, Benjamin Reed, Eric Baldeschwieler, Apache Hadoop YARN: Yet Another Resource Negotiator, ACM Symposium on Cloud Computing 2013, Santa Clara, California. [13] Raja Appuswamy, Christos Gkantsidis, Dushyanth Narayanan, Orion Hodson, and Antony Rowstron, Scale-up vs Scale-out for Hadoop: Time to rethink?, Microsoft Research, ACM Symposium on Cloud Computing 2013, Santa Clara, California.
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
ITG Software Engineering
 Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Qsoft Inc www.qsoft-inc.com
 Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Hadoop Big Data for Processing Data and Performing Workload
 Hadoop Big Data for Processing Data and Performing Workload Girish T B 1, Shadik Mohammed Ghouse 2, Dr. B. R. Prasad Babu 3 1 M Tech Student, 2 Assosiate professor, 3 Professor & Head (PG), of Computer
Hadoop Big Data for Processing Data and Performing Workload Girish T B 1, Shadik Mohammed Ghouse 2, Dr. B. R. Prasad Babu 3 1 M Tech Student, 2 Assosiate professor, 3 Professor & Head (PG), of Computer
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop
 Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Certified Big Data and Apache Hadoop Developer VS-1221
 Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Survey Paper on Big Data Processing and Hadoop Components
 Survey Paper on Big Data Processing and Hadoop Components Poonam S. Patil 1, Rajesh. N. Phursule 2 Department of Computer Engineering JSPM s Imperial College of Engineering and Research, Pune, India Abstract:
Survey Paper on Big Data Processing and Hadoop Components Poonam S. Patil 1, Rajesh. N. Phursule 2 Department of Computer Engineering JSPM s Imperial College of Engineering and Research, Pune, India Abstract:
Processing of Hadoop using Highly Available NameNode
 Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
Constructing a Data Lake: Hadoop and Oracle Database United!
 Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
Apache Hadoop: Past, Present, and Future
 The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
Spring,2015. Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE
 Spring,2015 Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE Contents: Briefly About Big Data Management What is hive? Hive Architecture Working
Spring,2015 Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE Contents: Briefly About Big Data Management What is hive? Hive Architecture Working
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Inverted Indexing In Big Data Using Hadoop Multiple Node Cluster
 Inverted Indexing In Big Data Using Hadoop Multiple Node Cluster Kaushik Velusamy Nivetha Vijayaraju Deepthi Venkitaramanan Greeshma Suresh Divya Madhu Dept. of IT Amrita University Abstract Inverted Indexing
Inverted Indexing In Big Data Using Hadoop Multiple Node Cluster Kaushik Velusamy Nivetha Vijayaraju Deepthi Venkitaramanan Greeshma Suresh Divya Madhu Dept. of IT Amrita University Abstract Inverted Indexing
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Realtime Apache Hadoop at Facebook. Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens
 Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
ISSN: 2321-7782 (Online) Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies
 Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
ISSN: 2321-7782 (Online) Volume 3, Issue 4, April 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
MySQL and Hadoop. Percona Live 2014 Chris Schneider
 MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Highly Available Hadoop Name Node Architecture-Using Replicas of Name Node with Time Synchronization among Replicas
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 3, Ver. II (May-Jun. 2014), PP 58-62 Highly Available Hadoop Name Node Architecture-Using Replicas
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 3, Ver. II (May-Jun. 2014), PP 58-62 Highly Available Hadoop Name Node Architecture-Using Replicas
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,dhruba@facebook.com Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Big Data: Tools and Technologies in Big Data
 Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data and Hadoop. Module 1: Introduction to Big Data and Hadoop. Module 2: Hadoop Distributed File System. Module 3: MapReduce
 Big Data and Hadoop Module 1: Introduction to Big Data and Hadoop Learn about Big Data and the shortcomings of the prevailing solutions for Big Data issues. You will also get to know, how Hadoop eradicates
Big Data and Hadoop Module 1: Introduction to Big Data and Hadoop Learn about Big Data and the shortcomings of the prevailing solutions for Big Data issues. You will also get to know, how Hadoop eradicates
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Apache Hadoop: The Pla/orm for Big Data. Amr Awadallah CTO, Founder, Cloudera, Inc. aaa@cloudera.com, twicer: @awadallah
 Apache Hadoop: The Pla/orm for Big Data Amr Awadallah CTO, Founder, Cloudera, Inc. aaa@cloudera.com, twicer: @awadallah 1 The Problems with Current Data Systems BI Reports + Interac7ve Apps RDBMS (aggregated
Apache Hadoop: The Pla/orm for Big Data Amr Awadallah CTO, Founder, Cloudera, Inc. aaa@cloudera.com, twicer: @awadallah 1 The Problems with Current Data Systems BI Reports + Interac7ve Apps RDBMS (aggregated
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop Introduction. Olivier Renault Solution Engineer - Hortonworks
 Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Storage and Retrieval of Data for Smart City using Hadoop
 Storage and Retrieval of Data for Smart City using Hadoop Ravi Gehlot Department of Computer Science Poornima Institute of Engineering and Technology Jaipur, India Abstract Smart cities are equipped with
Storage and Retrieval of Data for Smart City using Hadoop Ravi Gehlot Department of Computer Science Poornima Institute of Engineering and Technology Jaipur, India Abstract Smart cities are equipped with
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Pro Apache Hadoop. Second Edition. Sameer Wadkar. Madhu Siddalingaiah
 Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Entering the Zettabyte Age Jeffrey Krone
 Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Second Credit Seminar Presentation on Big Data Analytics Platforms: A Survey
 Second Credit Seminar Presentation on Big Data Analytics Platforms: A Survey By, Mr. Brijesh B. Mehta Admission No.: D14CO002 Supervised By, Dr. Udai Pratap Rao Computer Engineering Department S. V. National
Second Credit Seminar Presentation on Big Data Analytics Platforms: A Survey By, Mr. Brijesh B. Mehta Admission No.: D14CO002 Supervised By, Dr. Udai Pratap Rao Computer Engineering Department S. V. National
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
Hadoop: The Definitive Guide
 FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
BIG DATA HADOOP TRAINING
 BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
Alternatives to HIVE SQL in Hadoop File Structure
 Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop and Hive Development at Facebook. Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009
 Hadoop and Hive Development at Facebook Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009 Hadoop @ Facebook Who generates this data? Lots of data
Hadoop and Hive Development at Facebook Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009 Hadoop @ Facebook Who generates this data? Lots of data
Mr. Apichon Witayangkurn apichon@iis.u-tokyo.ac.jp Department of Civil Engineering The University of Tokyo
 Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn apichon@iis.u-tokyo.ac.jp Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn apichon@iis.u-tokyo.ac.jp Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network