Pepper: An Elastic Web Server Farm for Cloud based on Hadoop. Subramaniam Krishnan, Jean Christophe Counio Yahoo! Inc. MAPRED 1 st December 2010
|
|
|
- Shawn McDonald
- 8 years ago
- Views:
Transcription
1 Pepper: An Elastic Web Server Farm for Cloud based on Hadoop Subramaniam Krishnan, Jean Christophe Counio. MAPRED 1 st December 2010

2 Agenda Motivation Design Features Applications Evaluation Conclusion Future Work 1

3 Motivation 2

4 What s in a Name Wave 1: Grid-ification Crunch s of GBs of data in hours Large data like wikipedia Hosted, multitenant platform Grid workflow management system (PacMan) Wave 2: Content Freshness Process 100s of feeds/sec, size in KBs in seconds Web feeds like breaking news, tweets, finance quotes Scalable, high throughput & low latency platform Pepper elastic web server farm on grid Motivation 3

5 Requirements Elastic: handle intra/inter application load variance Multi-tenant: provide process/memory isolation Sub-second platform overhead Simple API Execute user code in platform context Reliability: transparent fault tolerance Motivation 4

6 Design 5

7 Deployment Flow Web application deployed as WAR onto HDFS Job Manager Embedded Jetty server runs in Map task, registers with ZooKeeper 1 Hadoop job = 1 Map task = 1 Web Server = 1 Web application Design 6

8 Processing Flow Proxy Router receives incoming requests, looks up ZooKeeper & redirects to appropriate Web Server Design 7

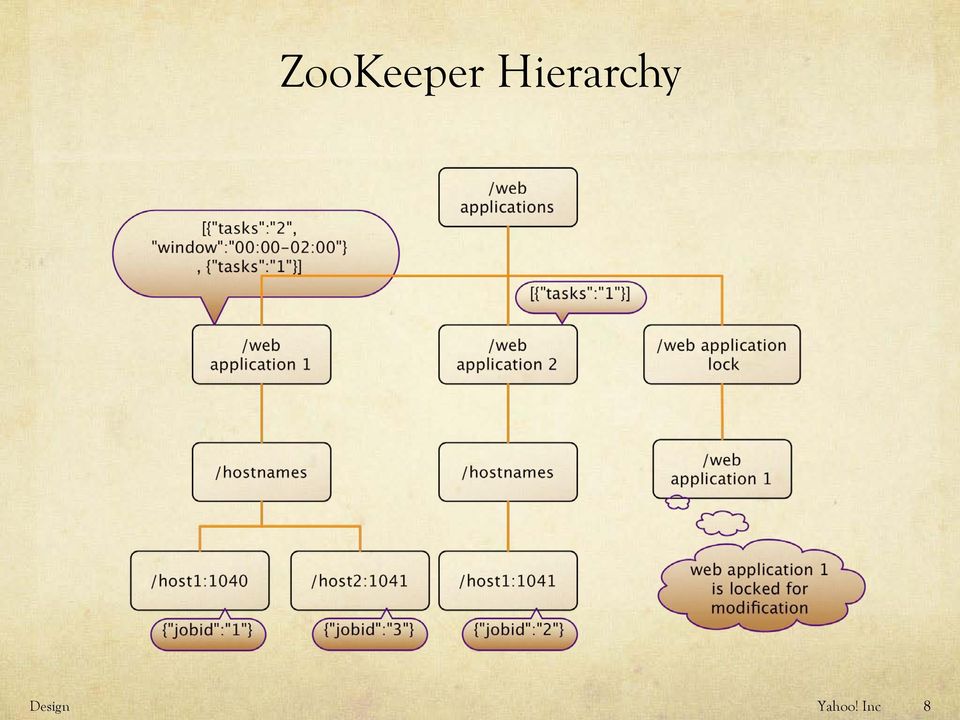
9 ZooKeeper Hierarchy Design 8
10 Features 9

11 Features Scalability: Web application can scale by configuring more instances (Elasticity), system can scale with addition of Hadoop nodes Performance: High throughput by ensuring that all the heavy lifting is done during deployment High Availability/Self-healing: Redundant server instances. Health check piggybacked on TaskTracker heartbeat Isolation: Hadoop map provides process isolation Ease of Development: Standard Servlet API & WAR packaging Reuse of Grid Infrastructure: The system runs on a Grid that can be shared across several applications Features 10

12 Applications 11

13 Applications Web Feeds Processing: Configure workflow orchestration engine to run in-memory, 1 workflow = 1 web-application. Benefits: Scalability Isolation Avoids Hadoop job bootstrap latency and HDFS small files bottleneck. Online Clustering: Extracts features and assigns incoming feeds to clusters predetermined by offline clustering. Performed online for Yahoo! News to identify hot news clusters during ingestion of articles. Applications 12

14 Evaluation 13

15 Setup Hardware: Intel Xeon L GHz with 8GB DDR2 RAM Software: 64-bit SUN JDK 1.6 update 18 on RHEL AS 4 U8, Linux ELsmp x86_64 Configuration: 8 map slots/node with 512MB heap, 25 threads/jetty server Number of Computing Hadoop nodes: 3 Evaluation 14

16 Linear Scaling for Predefined Capacity Throughput: number of requests handled successfully per second for a specified number of tasks Evaluation 15

17 Elastic Scaling for Dynamic Capacity Rejection: failure to execute within predefined timeout Load is increased and additional map task allocated at points A and B based on predefined schedule Failure rate of < 0.001% observed in Production Evaluation 16

18 Pepper Performance Numbers System Burst Rate (request/mi n) Throughput (requests/da y) Platform Latency (Avg.) Response Time (Avg.) Pepper 2,000 3 million 75 ms 4s PacMan 50 10,000 90s 120s Dataset is Yahoo! News feeds with sizes < 1MB Processing is typically computation intensive like processing and enriching web feeds that involves validation, normalization, geo tagging, persistence in service stores, etc Evaluation 17

19 Conclusion 18

20 Conclusion Pepper marries the benefits of traditional server farms i.e. low latency and high throughput with those of cloud i.e. elasticity and isolation In production within Yahoo! from December 2009 Current Y! properties - Newspaper Consortium, Finance & News. Sports & Entertainment are in pipeline System scales linearly with addition of more Hadoop computing nodes Conclusion 19

21 Future Work 20
22 Future Work On demand allocation of servers Experimenting with async NIO between Proxy Router & Map Web Engine to increase scalability Improving distribution of requests across web servers Integrate into Hadoop (?) Future Work 21
23 References Hadoop, Web Page J. Dean and S. Ghemawat, MapReduce: Simplified Data Processing on Large Cluster, 6th Symposium on Operating Systems Design and Implementation (OSDI 04), San Francisco, CA, December 2004, pp P. Hunt, M. Konar, F.P. Junqueira, and B. Reed, ZooKeeper: Wait-free coordination for Internet-scale systems, Proceedings of the 2010 USENIX Conference on USENIX Annual Technical Conference, Boston, MA, June 2010, pp Oozie (successor to PacMan), Web Page oozie/ 22
24 Questions? 23
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
BookKeeper. Flavio Junqueira Yahoo! Research, Barcelona. Hadoop in China 2011
 BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Extending Hadoop beyond MapReduce
 Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Architecting for the next generation of Big Data Hortonworks HDP 2.0 on Red Hat Enterprise Linux 6 with OpenJDK 7
 Architecting for the next generation of Big Data Hortonworks HDP 2.0 on Red Hat Enterprise Linux 6 with OpenJDK 7 Yan Fisher Senior Principal Product Marketing Manager, Red Hat Rohit Bakhshi Product Manager,
Architecting for the next generation of Big Data Hortonworks HDP 2.0 on Red Hat Enterprise Linux 6 with OpenJDK 7 Yan Fisher Senior Principal Product Marketing Manager, Red Hat Rohit Bakhshi Product Manager,
DESIGN ARCHITECTURE-BASED ON WEB SERVER AND APPLICATION CLUSTER IN CLOUD ENVIRONMENT
 DESIGN ARCHITECTURE-BASED ON WEB SERVER AND APPLICATION CLUSTER IN CLOUD ENVIRONMENT Gita Shah 1, Annappa 2 and K. C. Shet 3 1,2,3 Department of Computer Science & Engineering, National Institute of Technology,
DESIGN ARCHITECTURE-BASED ON WEB SERVER AND APPLICATION CLUSTER IN CLOUD ENVIRONMENT Gita Shah 1, Annappa 2 and K. C. Shet 3 1,2,3 Department of Computer Science & Engineering, National Institute of Technology,
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Mobile Cloud Computing for Data-Intensive Applications
 Mobile Cloud Computing for Data-Intensive Applications Senior Thesis Final Report Vincent Teo, vct@andrew.cmu.edu Advisor: Professor Priya Narasimhan, priya@cs.cmu.edu Abstract The computational and storage
Mobile Cloud Computing for Data-Intensive Applications Senior Thesis Final Report Vincent Teo, vct@andrew.cmu.edu Advisor: Professor Priya Narasimhan, priya@cs.cmu.edu Abstract The computational and storage
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
Research Article Hadoop-Based Distributed Sensor Node Management System
 Distributed Networks, Article ID 61868, 7 pages http://dx.doi.org/1.1155/214/61868 Research Article Hadoop-Based Distributed Node Management System In-Yong Jung, Ki-Hyun Kim, Byong-John Han, and Chang-Sung
Distributed Networks, Article ID 61868, 7 pages http://dx.doi.org/1.1155/214/61868 Research Article Hadoop-Based Distributed Node Management System In-Yong Jung, Ki-Hyun Kim, Byong-John Han, and Chang-Sung
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Open Cloud System. (Integration of Eucalyptus, Hadoop and AppScale into deployment of University Private Cloud)
") Open Cloud System (Integration of Eucalyptus, Hadoop and into deployment of University Private Cloud) Thinn Thu Naing University of Computer Studies, Yangon 25 th October 2011 Open Cloud System University
Open Cloud System (Integration of Eucalyptus, Hadoop and into deployment of University Private Cloud) Thinn Thu Naing University of Computer Studies, Yangon 25 th October 2011 Open Cloud System University
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000
 Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Efficient Data Replication Scheme based on Hadoop Distributed File System
 , pp. 177-186 http://dx.doi.org/10.14257/ijseia.2015.9.12.16 Efficient Data Replication Scheme based on Hadoop Distributed File System Jungha Lee 1, Jaehwa Chung 2 and Daewon Lee 3* 1 Division of Supercomputing,
, pp. 177-186 http://dx.doi.org/10.14257/ijseia.2015.9.12.16 Efficient Data Replication Scheme based on Hadoop Distributed File System Jungha Lee 1, Jaehwa Chung 2 and Daewon Lee 3* 1 Division of Supercomputing,
Evaluating HDFS I/O Performance on Virtualized Systems
 Evaluating HDFS I/O Performance on Virtualized Systems Xin Tang xtang@cs.wisc.edu University of Wisconsin-Madison Department of Computer Sciences Abstract Hadoop as a Service (HaaS) has received increasing
Evaluating HDFS I/O Performance on Virtualized Systems Xin Tang xtang@cs.wisc.edu University of Wisconsin-Madison Department of Computer Sciences Abstract Hadoop as a Service (HaaS) has received increasing
Energy-Saving Cloud Computing Platform Based On Micro-Embedded System
 Energy-Saving Cloud Computing Platform Based On Micro-Embedded System Wen-Hsu HSIEH *, San-Peng KAO **, Kuang-Hung TAN **, Jiann-Liang CHEN ** * Department of Computer and Communication, De Lin Institute
Energy-Saving Cloud Computing Platform Based On Micro-Embedded System Wen-Hsu HSIEH *, San-Peng KAO **, Kuang-Hung TAN **, Jiann-Liang CHEN ** * Department of Computer and Communication, De Lin Institute
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
HDFS Space Consolidation
 HDFS Space Consolidation Aastha Mehta*,1,2, Deepti Banka*,1,2, Kartheek Muthyala*,1,2, Priya Sehgal 1, Ajay Bakre 1 *Student Authors 1 Advanced Technology Group, NetApp Inc., Bangalore, India 2 Birla Institute
HDFS Space Consolidation Aastha Mehta*,1,2, Deepti Banka*,1,2, Kartheek Muthyala*,1,2, Priya Sehgal 1, Ajay Bakre 1 *Student Authors 1 Advanced Technology Group, NetApp Inc., Bangalore, India 2 Birla Institute
Cisco Unified Data Center Solutions for MapR: Deliver Automated, High-Performance Hadoop Workloads
 Solution Overview Cisco Unified Data Center Solutions for MapR: Deliver Automated, High-Performance Hadoop Workloads What You Will Learn MapR Hadoop clusters on Cisco Unified Computing System (Cisco UCS
Solution Overview Cisco Unified Data Center Solutions for MapR: Deliver Automated, High-Performance Hadoop Workloads What You Will Learn MapR Hadoop clusters on Cisco Unified Computing System (Cisco UCS
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source
 - In- Memory Data Fabric Fast Data Meets Open Source") Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org #apacheignite Agenda Apache Ignite (tm) In- Memory
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org #apacheignite Agenda Apache Ignite (tm) In- Memory
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Hadoop on OpenStack Cloud. Dmitry Mescheryakov Software Engineer, @MirantisIT
 Hadoop on OpenStack Cloud Dmitry Mescheryakov Software Engineer, @MirantisIT Agenda OpenStack Sahara Demo Hadoop Performance on Cloud Conclusion OpenStack Open source cloud computing platform 17,209 commits
Hadoop on OpenStack Cloud Dmitry Mescheryakov Software Engineer, @MirantisIT Agenda OpenStack Sahara Demo Hadoop Performance on Cloud Conclusion OpenStack Open source cloud computing platform 17,209 commits
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
How Cisco IT Built Big Data Platform to Transform Data Management
 Cisco IT Case Study August 2013 Big Data Analytics How Cisco IT Built Big Data Platform to Transform Data Management EXECUTIVE SUMMARY CHALLENGE Unlock the business value of large data sets, including
Cisco IT Case Study August 2013 Big Data Analytics How Cisco IT Built Big Data Platform to Transform Data Management EXECUTIVE SUMMARY CHALLENGE Unlock the business value of large data sets, including
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
In Memory Accelerator for MongoDB
 In Memory Accelerator for MongoDB Yakov Zhdanov, Director R&D GridGain Systems GridGain: In Memory Computing Leader 5 years in production 100s of customers & users Starts every 10 secs worldwide Over 15,000,000
In Memory Accelerator for MongoDB Yakov Zhdanov, Director R&D GridGain Systems GridGain: In Memory Computing Leader 5 years in production 100s of customers & users Starts every 10 secs worldwide Over 15,000,000
CDH AND BUSINESS CONTINUITY:
 WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Cost-Effective Business Intelligence with Red Hat and Open Source
 Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
Viswanath Nandigam Sriram Krishnan Chaitan Baru
 Viswanath Nandigam Sriram Krishnan Chaitan Baru Traditional Database Implementations for large-scale spatial data Data Partitioning Spatial Extensions Pros and Cons Cloud Computing Introduction Relevance
Viswanath Nandigam Sriram Krishnan Chaitan Baru Traditional Database Implementations for large-scale spatial data Data Partitioning Spatial Extensions Pros and Cons Cloud Computing Introduction Relevance
How In-Memory Data Grids Can Analyze Fast-Changing Data in Real Time
 SCALEOUT SOFTWARE How In-Memory Data Grids Can Analyze Fast-Changing Data in Real Time by Dr. William Bain and Dr. Mikhail Sobolev, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T wenty-first
SCALEOUT SOFTWARE How In-Memory Data Grids Can Analyze Fast-Changing Data in Real Time by Dr. William Bain and Dr. Mikhail Sobolev, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T wenty-first
Fast Data in the Era of Big Data: Tiwtter s Real-Time Related Query Suggestion Architecture
 Fast Data in the Era of Big Data: Tiwtter s Real-Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Adeniyi Abdul 2522715 Agenda Abstract Introduction
Fast Data in the Era of Big Data: Tiwtter s Real-Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Adeniyi Abdul 2522715 Agenda Abstract Introduction
Snapshots in Hadoop Distributed File System
 Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Beyond Sampling: Fast, Whole- Dataset Analytics for Big Data on Hadoop
 Josh Poduska, Sr. Business Analytics Consultant, Actian Corporation Beyond Sampling: Fast, Whole- Dataset Analytics for Big Data on Hadoop October 2013 KNIME Day Boston Agenda The Age of Data Scaling Gap
Josh Poduska, Sr. Business Analytics Consultant, Actian Corporation Beyond Sampling: Fast, Whole- Dataset Analytics for Big Data on Hadoop October 2013 KNIME Day Boston Agenda The Age of Data Scaling Gap
ESPRESSO: An Encryption as a Service for Cloud Storage Systems
 8th International Conference on Autonomous Infrastructure, Management and Security ESPRESSO: An Encryption as a Service for Cloud Storage Systems Kang Seungmin 30 th Jun., 2014 Outline Introduction and
8th International Conference on Autonomous Infrastructure, Management and Security ESPRESSO: An Encryption as a Service for Cloud Storage Systems Kang Seungmin 30 th Jun., 2014 Outline Introduction and
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
DESIGN AN EFFICIENT BIG DATA ANALYTIC ARCHITECTURE FOR RETRIEVAL OF DATA BASED ON
 DESIGN AN EFFICIENT BIG DATA ANALYTIC ARCHITECTURE FOR RETRIEVAL OF DATA BASED ON WEB SERVER IN CLOUD ENVIRONMENT Gita Shah 1, Annappa 2 and K. C. Shet 3 1,2,3 Department of Computer Science & Engineering,
DESIGN AN EFFICIENT BIG DATA ANALYTIC ARCHITECTURE FOR RETRIEVAL OF DATA BASED ON WEB SERVER IN CLOUD ENVIRONMENT Gita Shah 1, Annappa 2 and K. C. Shet 3 1,2,3 Department of Computer Science & Engineering,
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Oracle Database Scalability in VMware ESX VMware ESX 3.5
 Performance Study Oracle Database Scalability in VMware ESX VMware ESX 3.5 Database applications running on individual physical servers represent a large consolidation opportunity. However enterprises
Performance Study Oracle Database Scalability in VMware ESX VMware ESX 3.5 Database applications running on individual physical servers represent a large consolidation opportunity. However enterprises
Accelerating Hadoop MapReduce Using an In-Memory Data Grid
 Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
The Performance Characteristics of MapReduce Applications on Scalable Clusters
 The Performance Characteristics of MapReduce Applications on Scalable Clusters Kenneth Wottrich Denison University Granville, OH 43023 wottri_k1@denison.edu ABSTRACT Many cluster owners and operators have
The Performance Characteristics of MapReduce Applications on Scalable Clusters Kenneth Wottrich Denison University Granville, OH 43023 wottri_k1@denison.edu ABSTRACT Many cluster owners and operators have
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
What is Big Data? Concepts, Ideas and Principles. Hitesh Dharamdasani
 What is Big Data? Concepts, Ideas and Principles Hitesh Dharamdasani # whoami Security Researcher, Malware Reversing Engineer, Developer GIT > George Mason > UC Berkeley > FireEye > On Stage Building Data-driven
What is Big Data? Concepts, Ideas and Principles Hitesh Dharamdasani # whoami Security Researcher, Malware Reversing Engineer, Developer GIT > George Mason > UC Berkeley > FireEye > On Stage Building Data-driven
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Virtual Machine Based Resource Allocation For Cloud Computing Environment
 Virtual Machine Based Resource Allocation For Cloud Computing Environment D.Udaya Sree M.Tech (CSE) Department Of CSE SVCET,Chittoor. Andra Pradesh, India Dr.J.Janet Head of Department Department of CSE
Virtual Machine Based Resource Allocation For Cloud Computing Environment D.Udaya Sree M.Tech (CSE) Department Of CSE SVCET,Chittoor. Andra Pradesh, India Dr.J.Janet Head of Department Department of CSE
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Data Pipeline with Kafka
 Data Pipeline with Kafka Peerapat Asoktummarungsri AGODA Senior Software Engineer Agoda.com Contributor Thai Java User Group (THJUG.com) Contributor Agile66 AGENDA Big Data & Data Pipeline Kafka Introduction
Data Pipeline with Kafka Peerapat Asoktummarungsri AGODA Senior Software Engineer Agoda.com Contributor Thai Java User Group (THJUG.com) Contributor Agile66 AGENDA Big Data & Data Pipeline Kafka Introduction
Big Data - Infrastructure Considerations
 April 2014, HAPPIEST MINDS TECHNOLOGIES Big Data - Infrastructure Considerations Author Anand Veeramani / Deepak Shivamurthy SHARING. MINDFUL. INTEGRITY. LEARNING. EXCELLENCE. SOCIAL RESPONSIBILITY. Copyright
April 2014, HAPPIEST MINDS TECHNOLOGIES Big Data - Infrastructure Considerations Author Anand Veeramani / Deepak Shivamurthy SHARING. MINDFUL. INTEGRITY. LEARNING. EXCELLENCE. SOCIAL RESPONSIBILITY. Copyright
A Cost-Evaluation of MapReduce Applications in the Cloud
 1/23 A Cost-Evaluation of MapReduce Applications in the Cloud Diana Moise, Alexandra Carpen-Amarie Gabriel Antoniu, Luc Bougé KerData team 2/23 1 MapReduce applications - case study 2 3 4 5 3/23 MapReduce
1/23 A Cost-Evaluation of MapReduce Applications in the Cloud Diana Moise, Alexandra Carpen-Amarie Gabriel Antoniu, Luc Bougé KerData team 2/23 1 MapReduce applications - case study 2 3 4 5 3/23 MapReduce
HDP Hadoop From concept to deployment.
 HDP Hadoop From concept to deployment. Ankur Gupta Senior Solutions Engineer Rackspace: Page 41 27 th Jan 2015 Where are you in your Hadoop Journey? A. Researching our options B. Currently evaluating some
HDP Hadoop From concept to deployment. Ankur Gupta Senior Solutions Engineer Rackspace: Page 41 27 th Jan 2015 Where are you in your Hadoop Journey? A. Researching our options B. Currently evaluating some
Elasticsearch on Cisco Unified Computing System: Optimizing your UCS infrastructure for Elasticsearch s analytics software stack
 Elasticsearch on Cisco Unified Computing System: Optimizing your UCS infrastructure for Elasticsearch s analytics software stack HIGHLIGHTS Real-Time Results Elasticsearch on Cisco UCS enables a deeper
Elasticsearch on Cisco Unified Computing System: Optimizing your UCS infrastructure for Elasticsearch s analytics software stack HIGHLIGHTS Real-Time Results Elasticsearch on Cisco UCS enables a deeper
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Ground up Introduction to In-Memory Data (Grids)
") Ground up Introduction to In-Memory Data (Grids) QCON 2015 NEW YORK, NY 2014 Hazelcast Inc. Why you here? 2014 Hazelcast Inc. Java Developer on a quest for scalability frameworks Architect on low-latency
Ground up Introduction to In-Memory Data (Grids) QCON 2015 NEW YORK, NY 2014 Hazelcast Inc. Why you here? 2014 Hazelcast Inc. Java Developer on a quest for scalability frameworks Architect on low-latency
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
How To Run Apa Hadoop 1.0 On Vsphere Tmt On A Hyperconverged Network On A Virtualized Cluster On A Vspplace Tmter (Vmware) Vspheon Tm (
 Vspheon Tm (") Apache Hadoop 1.0 High Availability Solution on VMware vsphere TM Reference Architecture TECHNICAL WHITE PAPER v 1.0 June 2012 Table of Contents Executive Summary... 3 Introduction... 3 Terminology...
Apache Hadoop 1.0 High Availability Solution on VMware vsphere TM Reference Architecture TECHNICAL WHITE PAPER v 1.0 June 2012 Table of Contents Executive Summary... 3 Introduction... 3 Terminology...
Scaling Hadoop for Multi-Core and Highly Threaded Systems
 Scaling Hadoop for Multi-Core and Highly Threaded Systems Jangwoo Kim, Zoran Radovic Performance Architects Architecture Technology Group Sun Microsystems Inc. Project Overview Hadoop Updates CMT Hadoop
Scaling Hadoop for Multi-Core and Highly Threaded Systems Jangwoo Kim, Zoran Radovic Performance Architects Architecture Technology Group Sun Microsystems Inc. Project Overview Hadoop Updates CMT Hadoop
Designing a Cloud Storage System
 Designing a Cloud Storage System End to End Cloud Storage When designing a cloud storage system, there is value in decoupling the system s archival capacity (its ability to persistently store large volumes
Designing a Cloud Storage System End to End Cloud Storage When designing a cloud storage system, there is value in decoupling the system s archival capacity (its ability to persistently store large volumes
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: bdg@qburst.com Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM
 Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Big Data Use Case. How Rackspace is using Private Cloud for Big Data. Bryan Thompson. May 8th, 2013
 Big Data Use Case How Rackspace is using Private Cloud for Big Data Bryan Thompson May 8th, 2013 Our Big Data Problem Consolidate all monitoring data for reporting and analytical purposes. Every device
Big Data Use Case How Rackspace is using Private Cloud for Big Data Bryan Thompson May 8th, 2013 Our Big Data Problem Consolidate all monitoring data for reporting and analytical purposes. Every device
HDFS Federation. Sanjay Radia Founder and Architect @ Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Enhancing Dataset Processing in Hadoop YARN Performance for Big Data Applications
 Enhancing Dataset Processing in Hadoop YARN Performance for Big Data Applications Ahmed Abdulhakim Al-Absi, Dae-Ki Kang and Myong-Jong Kim Abstract In Hadoop MapReduce distributed file system, as the input
Enhancing Dataset Processing in Hadoop YARN Performance for Big Data Applications Ahmed Abdulhakim Al-Absi, Dae-Ki Kang and Myong-Jong Kim Abstract In Hadoop MapReduce distributed file system, as the input
OSG Hadoop is packaged into rpms for SL4, SL5 by Caltech BeStMan, gridftp backend
 Hadoop on HEPiX storage test bed at FZK Artem Trunov Karlsruhe Institute of Technology Karlsruhe, Germany KIT The cooperation of Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) www.kit.edu
Hadoop on HEPiX storage test bed at FZK Artem Trunov Karlsruhe Institute of Technology Karlsruhe, Germany KIT The cooperation of Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) www.kit.edu
Ignify ecommerce. Item Requirements Notes
 wwwignifycom Tel (888) IGNIFY5 sales@ignifycom Fax (408) 516-9006 Ignify ecommerce Server Configuration 1 Hardware Requirement (Minimum configuration) Item Requirements Notes Operating System Processor
wwwignifycom Tel (888) IGNIFY5 sales@ignifycom Fax (408) 516-9006 Ignify ecommerce Server Configuration 1 Hardware Requirement (Minimum configuration) Item Requirements Notes Operating System Processor
Distributed Storage Systems
 Distributed Storage Systems John Leach john@brightbox.com twitter @johnleach Brightbox Cloud http://brightbox.com Our requirements Bright box has multiple zones (data centres) Should tolerate a zone failure
Distributed Storage Systems John Leach john@brightbox.com twitter @johnleach Brightbox Cloud http://brightbox.com Our requirements Bright box has multiple zones (data centres) Should tolerate a zone failure
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Processing Large Amounts of Images on Hadoop with OpenCV
 Processing Large Amounts of Images on Hadoop with OpenCV Timofei Epanchintsev 1,2 and Andrey Sozykin 1,2 1 IMM UB RAS, Yekaterinburg, Russia, 2 Ural Federal University, Yekaterinburg, Russia {eti,avs}@imm.uran.ru
Processing Large Amounts of Images on Hadoop with OpenCV Timofei Epanchintsev 1,2 and Andrey Sozykin 1,2 1 IMM UB RAS, Yekaterinburg, Russia, 2 Ural Federal University, Yekaterinburg, Russia {eti,avs}@imm.uran.ru
Entering the Zettabyte Age Jeffrey Krone
 Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications
 ECE6102 Dependable Distribute Systems, Fall2010 EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications Deepal Jayasinghe, Hyojun Kim, Mohammad M. Hossain, Ali Payani
ECE6102 Dependable Distribute Systems, Fall2010 EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications Deepal Jayasinghe, Hyojun Kim, Mohammad M. Hossain, Ali Payani
Cloud Computing and Advanced Relationship Analytics
 Cloud Computing and Advanced Relationship Analytics Using Objectivity/DB to Discover the Relationships in your Data By Brian Clark Vice President, Product Management Objectivity, Inc. 408 992 7136 brian.clark@objectivity.com
Cloud Computing and Advanced Relationship Analytics Using Objectivity/DB to Discover the Relationships in your Data By Brian Clark Vice President, Product Management Objectivity, Inc. 408 992 7136 brian.clark@objectivity.com
Liferay Portal Performance. Benchmark Study of Liferay Portal Enterprise Edition
 Liferay Portal Performance Benchmark Study of Liferay Portal Enterprise Edition Table of Contents Executive Summary... 3 Test Scenarios... 4 Benchmark Configuration and Methodology... 5 Environment Configuration...
Liferay Portal Performance Benchmark Study of Liferay Portal Enterprise Edition Table of Contents Executive Summary... 3 Test Scenarios... 4 Benchmark Configuration and Methodology... 5 Environment Configuration...
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
6. How MapReduce Works. Jari-Pekka Voutilainen
 6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
6. How MapReduce Works Jari-Pekka Voutilainen MapReduce Implementations Apache Hadoop has 2 implementations of MapReduce: Classic MapReduce (MapReduce 1) YARN (MapReduce 2) Classic MapReduce The Client
CLOUDDMSS: CLOUD-BASED DISTRIBUTED MULTIMEDIA STREAMING SERVICE SYSTEM FOR HETEROGENEOUS DEVICES
 CLOUDDMSS: CLOUD-BASED DISTRIBUTED MULTIMEDIA STREAMING SERVICE SYSTEM FOR HETEROGENEOUS DEVICES 1 MYOUNGJIN KIM, 2 CUI YUN, 3 SEUNGHO HAN, 4 HANKU LEE 1,2,3,4 Department of Internet & Multimedia Engineering,
CLOUDDMSS: CLOUD-BASED DISTRIBUTED MULTIMEDIA STREAMING SERVICE SYSTEM FOR HETEROGENEOUS DEVICES 1 MYOUNGJIN KIM, 2 CUI YUN, 3 SEUNGHO HAN, 4 HANKU LEE 1,2,3,4 Department of Internet & Multimedia Engineering,
Michael Thomas, Dorian Kcira California Institute of Technology. CMS Offline & Computing Week
 Michael Thomas, Dorian Kcira California Institute of Technology CMS Offline & Computing Week San Diego, April 20-24 th 2009 Map-Reduce plus the HDFS filesystem implemented in java Map-Reduce is a highly
Michael Thomas, Dorian Kcira California Institute of Technology CMS Offline & Computing Week San Diego, April 20-24 th 2009 Map-Reduce plus the HDFS filesystem implemented in java Map-Reduce is a highly
ENABLING GLOBAL HADOOP WITH EMC ELASTIC CLOUD STORAGE
 ENABLING GLOBAL HADOOP WITH EMC ELASTIC CLOUD STORAGE Hadoop Storage-as-a-Service ABSTRACT This White Paper illustrates how EMC Elastic Cloud Storage (ECS ) can be used to streamline the Hadoop data analytics
ENABLING GLOBAL HADOOP WITH EMC ELASTIC CLOUD STORAGE Hadoop Storage-as-a-Service ABSTRACT This White Paper illustrates how EMC Elastic Cloud Storage (ECS ) can be used to streamline the Hadoop data analytics
Parallel Computing. Benson Muite. benson.muite@ut.ee http://math.ut.ee/ benson. https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage
 Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
IncidentMonitor Server Specification Datasheet
 IncidentMonitor Server Specification Datasheet Prepared by Monitor 24-7 Inc October 1, 2015 Contact details: sales@monitor24-7.com North America: +1 416 410.2716 / +1 866 364.2757 Europe: +31 088 008.4600
IncidentMonitor Server Specification Datasheet Prepared by Monitor 24-7 Inc October 1, 2015 Contact details: sales@monitor24-7.com North America: +1 416 410.2716 / +1 866 364.2757 Europe: +31 088 008.4600
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source
 - In- Memory Data Fabric Fast Data Meets Open Source") Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Network-Aware Scheduling of MapReduce Framework on Distributed Clusters over High Speed Networks
 Network-Aware Scheduling of MapReduce Framework on Distributed Clusters over High Speed Networks Praveenkumar Kondikoppa, Chui-Hui Chiu, Cheng Cui, Lin Xue and Seung-Jong Park Department of Computer Science,
Network-Aware Scheduling of MapReduce Framework on Distributed Clusters over High Speed Networks Praveenkumar Kondikoppa, Chui-Hui Chiu, Cheng Cui, Lin Xue and Seung-Jong Park Department of Computer Science,
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
Big Data and Natural Language: Extracting Insight From Text
 An Oracle White Paper October 2012 Big Data and Natural Language: Extracting Insight From Text Table of Contents Executive Overview... 3 Introduction... 3 Oracle Big Data Appliance... 4 Synthesys... 5
An Oracle White Paper October 2012 Big Data and Natural Language: Extracting Insight From Text Table of Contents Executive Overview... 3 Introduction... 3 Oracle Big Data Appliance... 4 Synthesys... 5
Improving Grid Processing Efficiency through Compute-Data Confluence
 Solution Brief GemFire* Symphony* Intel Xeon processor Improving Grid Processing Efficiency through Compute-Data Confluence A benchmark report featuring GemStone Systems, Intel Corporation and Platform
Solution Brief GemFire* Symphony* Intel Xeon processor Improving Grid Processing Efficiency through Compute-Data Confluence A benchmark report featuring GemStone Systems, Intel Corporation and Platform
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
PLATFORA INTERACTIVE, IN-MEMORY BUSINESS INTELLIGENCE FOR HADOOP
 PLATFORA INTERACTIVE, IN-MEMORY BUSINESS INTELLIGENCE FOR HADOOP Your business is swimming in data, and your business analysts want to use it to answer the questions of today and tomorrow. YOU LOOK TO
PLATFORA INTERACTIVE, IN-MEMORY BUSINESS INTELLIGENCE FOR HADOOP Your business is swimming in data, and your business analysts want to use it to answer the questions of today and tomorrow. YOU LOOK TO
Purpose-Built Load Balancing The Advantages of Coyote Point Equalizer over Software-based Solutions
 Purpose-Built Load Balancing The Advantages of Coyote Point Equalizer over Software-based Solutions Abstract Coyote Point Equalizer appliances deliver traffic management solutions that provide high availability,
Purpose-Built Load Balancing The Advantages of Coyote Point Equalizer over Software-based Solutions Abstract Coyote Point Equalizer appliances deliver traffic management solutions that provide high availability,
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Oracle s Big Data solutions. Roger Wullschleger. <Insert Picture Here>
 s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
Maximum performance, minimal risk for data warehousing
 SYSTEM X SERVERS SOLUTION BRIEF Maximum performance, minimal risk for data warehousing Microsoft Data Warehouse Fast Track for SQL Server 2014 on System x3850 X6 (95TB) The rapid growth of technology has
SYSTEM X SERVERS SOLUTION BRIEF Maximum performance, minimal risk for data warehousing Microsoft Data Warehouse Fast Track for SQL Server 2014 on System x3850 X6 (95TB) The rapid growth of technology has