Lexical Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT.
|
|
|
- Steven Gilmore
- 7 years ago
- Views:
Transcription
1 Lexical Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu
2 Q: What s meaning? Compositional semantics answer:
3 Q: What s meaning? We now answer from a lexical semantics perspective i.e. let s think about the meaning of words
4 Today Word senses & word relations WordNet Word Sense Disambiguation Supervised Semi-supervised
5 WORD SENSES & WORD RELATIONS
6 Where can we look up the meaning of words? Dictionary?
7 Word Senses Word sense = distinct meaning of a word Same word, different senses Homonyms (homonymy): unrelated senses; identical orthographic form is coincidental Polysemes (polysemy): related, but distinct senses Metonyms (metonymy): stand in, technically, a subcase of polysemy Different word, same sense Synonyms (synonymy)
8 Just to confuse you Homophones: same pronunciation, different orthography, different meaning Examples: would/wood, to/too/two Homographs: distinct senses, same orthographic form, different pronunciation Examples: bass (fish) vs. bass (instrument)
9 Relationship Between Senses IS-A relationships From specific to general (up): hypernym (hypernymy) From general to specific (down): hyponym (hyponymy) Part-Whole relationships wheel is a meronym of car (meronymy) car is a holonym of wheel (holonymy)
10 WordNet: a lexical database for English Includes most English nouns, verbs, adjectives, adverbs Electronic format makes it amenable to automatic manipulation: used in many NLP applications WordNets generically refers to similar resources in other languages
11 WordNet: History Research in artificial intelligence: How do humans store and access knowledge about concept? Hypothesis: concepts are interconnected via meaningful relations Useful for reasoning The WordNet project started in 1986 Can most (all?) of the words in a language be represented as a semantic network where words are interlinked by meaning? If so, the result would be a large semantic network
12 Synonymy in WordNet WordNet is organized in terms of synsets Unordered set of (roughly) synonymous words (or multi-word phrases) Each synset expresses a distinct meaning/concept
13 WordNet: Example Noun {pipe, tobacco pipe} (a tube with a small bowl at one end; used for smoking tobacco) {pipe, pipage, piping} (a long tube made of metal or plastic that is used to carry water or oil or gas etc.) {pipe, tube} (a hollow cylindrical shape) {pipe} (a tubular wind instrument) {organ pipe, pipe, pipework} (the flues and stops on a pipe organ) Verb {shriek, shrill, pipe up, pipe} (utter a shrill cry) {pipe} (transport by pipeline) pipe oil, water, and gas into the desert {pipe} (play on a pipe) pipe a tune {pipe} (trim with piping) pipe the skirt What do you think of the sense granularity?
14 The Net Part of WordNet {conveyance; transport} hyperonym {vehicle} hyperonym {bumper} {motor vehicle; automotivevehicle} meronym hyperonym {car dor} {car window} {car; auto; automobile; machine; motorcar} {armrest} meronym hyperonym hyperonym {cruiser; squadcar; patrol car; policecar; prowl car} {cab; taxi; hack; taxicab; } {car miror} meronym meronym {hinge; flexiblejoint} {dorlock}
15 WordNet: Size Part of speech Word form Synsets Noun 117,798 82,115 Verb 11,529 13,767 Adjective 21,479 18,156 Adverb 4,481 3,621 Total 155, ,659
16 Word Sense From WordNet: Noun {pipe, tobacco pipe} (a tube with a small bowl at one end; used for smoking tobacco) {pipe, pipage, piping} (a long tube made of metal or plastic that is used to carry water or oil or gas etc.) {pipe, tube} (a hollow cylindrical shape) {pipe} (a tubular wind instrument) {organ pipe, pipe, pipework} (the flues and stops on a pipe organ) Verb {shriek, shrill, pipe up, pipe} (utter a shrill cry) {pipe} (transport by pipeline) pipe oil, water, and gas into the desert {pipe} (play on a pipe) pipe a tune {pipe} (trim with piping) pipe the skirt
17 WORD SENSE DISAMBIGUATION
18 Word Sense Disambiguation Task: automatically select the correct sense of a word Lexical sample All-words Motivated by many applications: Semantic similarity Information retrieval Machine translation But gains in performance have been elusive.
19 How big is the problem? Most words in English have only one sense 62% in Longman s Dictionary of Contemporary English 79% in WordNet But the others tend to have several senses Average of 3.83 in LDOCE Average of 2.96 in WordNet Ambiguous words are more frequently used In the British National Corpus, 84% of instances have more than one sense Some senses are more frequent than others
20 Ground Truth Which sense inventory do we use? Issues there? Application specificity?
21 Existing Corpora Lexical sample line-hard-serve corpus (4k sense-tagged examples) interest corpus (2,369 sense-tagged examples) All-words SemCor (234k words, subset of Brown Corpus) Senseval/SemEval (2081 tagged content words from 5k total words)
22 Evaluation Intrinsic Measure accuracy of sense selection wrt ground truth Extrinsic Integrate WSD as part of a bigger end-to-end system, e.g., machine translation or information retrieval Compare WSD
23 Baseline Performance Baseline: most frequent sense Equivalent to take first sense in WordNet Does surprisingly well! 62% accuracy in this case!
24 Upper Bound Performance Upper bound Fine-grained WordNet sense: 75-80% human agreement Coarser-grained inventories: 90% human agreement possible
25 WSD Approaches Depending on use of manually created knowledge sources Knowledge-lean Knowledge-rich Depending on use of labeled data Supervised Semi- or minimally supervised Unsupervised
26 Simplest WSD algorithm: Lesk s Algorithm Intuition: note word overlap between context and dictionary entries Unsupervised, but knowledge rich The bank can guarantee deposits will eventually cover future tuition costs because it invests in adjustable-rate mortgage securities. WordNet
27 Lesk s Algorithm Simplest implementation: Count overlapping content words between glosses and context Lots of variants: Include the examples in dictionary definitions Include hypernyms and hyponyms Give more weight to larger overlaps (e.g., bigrams) Give extra weight to infrequent words (e.g., idf weighting)
28 Another approach: Supervised WSD How would you frame WSD as a supervised classification task?
29 Supervised Classification Training Testing training data? unlabeled document label 1 label 2 label 3 label 4 supervised machine learning algorithm Representation Function Classifier label 1? label 2? label 3? label 4?
30 Features Possible features POS and surface form of the word itself Surrounding words and POS tag Positional information of surrounding words and POS tags Same as above, but with n-grams Grammatical information Richness of the features? Richer features = ML algorithm does less of the work More impoverished features = ML algorithm does more of the work
31 Classifiers Once we cast the WSD problem as supervised classification, any multiclass classifer can be used: Perceptron Support Vector Machines
32 WSD Accuracy Generally Supervised approaches yield ~70-80% accuracy However depends on actual word, sense inventory, amount of training data, number of features, etc.
33 WORD SENSE DISAMBIGUATION: MINIMIZING SUPERVISION
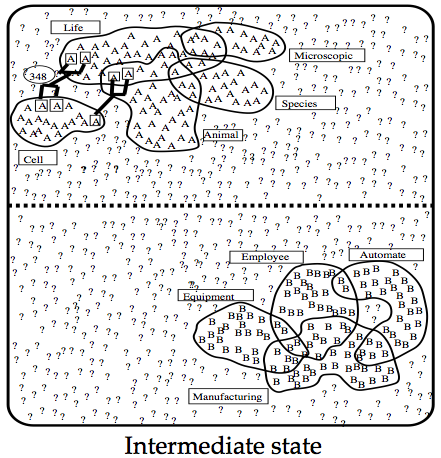
34 Minimally Supervised WSD Problem: annotations are expensive! Solution 1: Bootstrapping or co-training (Yarowsky 1995) Start with (small) seed, learn classifier Use classifier to label rest of corpus Retain confident labels, treat as annotated data to learn new classifier Repeat Heuristics (derived from observation): One sense per discourse One sense per collocation
35 One Sense per Discourse A word tends to preserve its meaning across all its occurrences in a given discourse Evaluation: 8 words with two-way ambiguity, e.g. plant, crane, etc. 98% of the two-word occurrences in the same discourse carry the same meaning the grain of salt: accuracy depends on granularity Performance of one sense per discourse measured on SemCor is approximately 70%
36 One Sense per Collocation A word tends to preserve its meaning when used in the same collocation Strong for adjacent collocations Weaker as the distance between words increases Evaluation: 97% precision on words with two-way ambiguity Again, accuracy depends on granularity: 70% precision on SemCor words
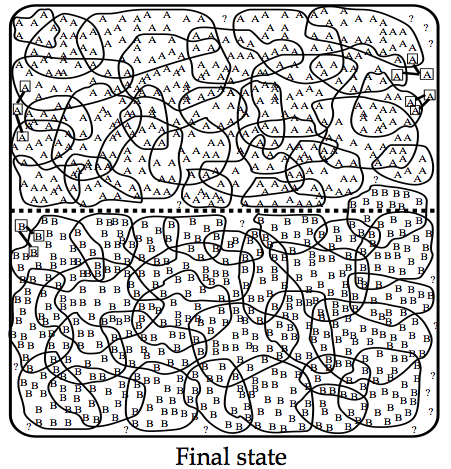
37 Yarowsky s Method: Example Disambiguating plant: industrial sense vs. living thing sense Think of seed features for each sense Industrial sense: co-occurring with manufacturing Living thing sense: co-occurring with life Use one sense per collocation to build initial decision list classifier Treat results as annotated data, train new decision list classifier, iterate
 and bass")
38 Decision List Ordered list of tests (equivalent to case statement): Example decision list, discriminating between bass (fish) and bass (music) :
39 Building Decision Lists Simple algorithm: Compute how discriminative each feature is: log P( S P( S 1 2 ) ) Create ordered list of tests from these values f f i i
40

41
42
43
44 Yarowsky s Method: Stopping Stop when: Error on training data is less than a threshold No more training data is covered Use final decision list for WSD
45 Yarowsky s Method: Discussion Advantages: Accuracy is about as good as a supervised algorithm Bootstrapping: far less manual effort Disadvantages: Seeds may be tricky to construct Works only for coarse-grained sense distinctions Snowballing error with co-training
46 WSD with Parallel Text Problems: annotations are expensive! What s the proper sense inventory? How fine or coarse grained? Application specific? Observation: multiple senses translate to different words in other languages! Use the foreign language as the sense inventory! Added bonus: annotations for free! (Byproduct of word-alignment process in machine translation)
47 Today Word senses & word relations WordNet Word Sense Disambiguation Lesk Algorithm Supervised classification Semi-supervised approaches Co-training: combine 2 views of data Use parallel text Next: semantic similarity & more unsupervised learning
Natural Language Processing. Part 4: lexical semantics
 Natural Language Processing Part 4: lexical semantics 2 Lexical semantics A lexicon generally has a highly structured form It stores the meanings and uses of each word It encodes the relations between
Natural Language Processing Part 4: lexical semantics 2 Lexical semantics A lexicon generally has a highly structured form It stores the meanings and uses of each word It encodes the relations between
Building a Question Classifier for a TREC-Style Question Answering System
 Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
ANALYSIS OF LEXICO-SYNTACTIC PATTERNS FOR ANTONYM PAIR EXTRACTION FROM A TURKISH CORPUS
 ANALYSIS OF LEXICO-SYNTACTIC PATTERNS FOR ANTONYM PAIR EXTRACTION FROM A TURKISH CORPUS Gürkan Şahin 1, Banu Diri 1 and Tuğba Yıldız 2 1 Faculty of Electrical-Electronic, Department of Computer Engineering
ANALYSIS OF LEXICO-SYNTACTIC PATTERNS FOR ANTONYM PAIR EXTRACTION FROM A TURKISH CORPUS Gürkan Şahin 1, Banu Diri 1 and Tuğba Yıldız 2 1 Faculty of Electrical-Electronic, Department of Computer Engineering
Comparing methods for automatic acquisition of Topic Signatures
 Comparing methods for automatic acquisition of Topic Signatures Montse Cuadros, Lluis Padro TALP Research Center Universitat Politecnica de Catalunya C/Jordi Girona, Omega S107 08034 Barcelona {cuadros,
Comparing methods for automatic acquisition of Topic Signatures Montse Cuadros, Lluis Padro TALP Research Center Universitat Politecnica de Catalunya C/Jordi Girona, Omega S107 08034 Barcelona {cuadros,
Clever Search: A WordNet Based Wrapper for Internet Search Engines
 Clever Search: A WordNet Based Wrapper for Internet Search Engines Peter M. Kruse, André Naujoks, Dietmar Rösner, Manuela Kunze Otto-von-Guericke-Universität Magdeburg, Institut für Wissens- und Sprachverarbeitung,
Clever Search: A WordNet Based Wrapper for Internet Search Engines Peter M. Kruse, André Naujoks, Dietmar Rösner, Manuela Kunze Otto-von-Guericke-Universität Magdeburg, Institut für Wissens- und Sprachverarbeitung,
Combining Contextual Features for Word Sense Disambiguation
 Proceedings of the SIGLEX/SENSEVAL Workshop on Word Sense Disambiguation: Recent Successes and Future Directions, Philadelphia, July 2002, pp. 88-94. Association for Computational Linguistics. Combining
Proceedings of the SIGLEX/SENSEVAL Workshop on Word Sense Disambiguation: Recent Successes and Future Directions, Philadelphia, July 2002, pp. 88-94. Association for Computational Linguistics. Combining
Automatic assignment of Wikipedia encyclopedic entries to WordNet synsets
 Automatic assignment of Wikipedia encyclopedic entries to WordNet synsets Maria Ruiz-Casado, Enrique Alfonseca and Pablo Castells Computer Science Dep., Universidad Autonoma de Madrid, 28049 Madrid, Spain
Automatic assignment of Wikipedia encyclopedic entries to WordNet synsets Maria Ruiz-Casado, Enrique Alfonseca and Pablo Castells Computer Science Dep., Universidad Autonoma de Madrid, 28049 Madrid, Spain
Sense-Tagging Verbs in English and Chinese. Hoa Trang Dang
 Sense-Tagging Verbs in English and Chinese Hoa Trang Dang Department of Computer and Information Sciences University of Pennsylvania htd@linc.cis.upenn.edu October 30, 2003 Outline English sense-tagging
Sense-Tagging Verbs in English and Chinese Hoa Trang Dang Department of Computer and Information Sciences University of Pennsylvania htd@linc.cis.upenn.edu October 30, 2003 Outline English sense-tagging
Knowledge-Based WSD on Specific Domains: Performing Better than Generic Supervised WSD
 Knowledge-Based WSD on Specific Domains: Performing Better than Generic Supervised WSD Eneko Agirre and Oier Lopez de Lacalle and Aitor Soroa Informatika Fakultatea, University of the Basque Country 20018,
Knowledge-Based WSD on Specific Domains: Performing Better than Generic Supervised WSD Eneko Agirre and Oier Lopez de Lacalle and Aitor Soroa Informatika Fakultatea, University of the Basque Country 20018,
An Integrated Approach to Automatic Synonym Detection in Turkish Corpus
 An Integrated Approach to Automatic Synonym Detection in Turkish Corpus Dr. Tuğba YILDIZ Assist. Prof. Dr. Savaş YILDIRIM Assoc. Prof. Dr. Banu DİRİ İSTANBUL BİLGİ UNIVERSITY YILDIZ TECHNICAL UNIVERSITY
An Integrated Approach to Automatic Synonym Detection in Turkish Corpus Dr. Tuğba YILDIZ Assist. Prof. Dr. Savaş YILDIRIM Assoc. Prof. Dr. Banu DİRİ İSTANBUL BİLGİ UNIVERSITY YILDIZ TECHNICAL UNIVERSITY
Intro to Linguistics Semantics
 Intro to Linguistics Semantics Jarmila Panevová & Jirka Hana January 5, 2011 Overview of topics What is Semantics The Meaning of Words The Meaning of Sentences Other things about semantics What to remember
Intro to Linguistics Semantics Jarmila Panevová & Jirka Hana January 5, 2011 Overview of topics What is Semantics The Meaning of Words The Meaning of Sentences Other things about semantics What to remember
Comparing Ontology-based and Corpusbased Domain Annotations in WordNet.
 Comparing Ontology-based and Corpusbased Domain Annotations in WordNet. A paper by: Bernardo Magnini Carlo Strapparava Giovanni Pezzulo Alfio Glozzo Presented by: rabee ali alshemali Motive. Domain information
Comparing Ontology-based and Corpusbased Domain Annotations in WordNet. A paper by: Bernardo Magnini Carlo Strapparava Giovanni Pezzulo Alfio Glozzo Presented by: rabee ali alshemali Motive. Domain information
AN APPROACH TO WORD SENSE DISAMBIGUATION COMBINING MODIFIED LESK AND BAG-OF-WORDS
 AN APPROACH TO WORD SENSE DISAMBIGUATION COMBINING MODIFIED LESK AND BAG-OF-WORDS Alok Ranjan Pal 1, 3, Anirban Kundu 2, 3, Abhay Singh 1, Raj Shekhar 1, Kunal Sinha 1 1 College of Engineering and Management,
AN APPROACH TO WORD SENSE DISAMBIGUATION COMBINING MODIFIED LESK AND BAG-OF-WORDS Alok Ranjan Pal 1, 3, Anirban Kundu 2, 3, Abhay Singh 1, Raj Shekhar 1, Kunal Sinha 1 1 College of Engineering and Management,
Chapter 8. Final Results on Dutch Senseval-2 Test Data
 Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
Identifying Focus, Techniques and Domain of Scientific Papers
 Identifying Focus, Techniques and Domain of Scientific Papers Sonal Gupta Department of Computer Science Stanford University Stanford, CA 94305 sonal@cs.stanford.edu Christopher D. Manning Department of
Identifying Focus, Techniques and Domain of Scientific Papers Sonal Gupta Department of Computer Science Stanford University Stanford, CA 94305 sonal@cs.stanford.edu Christopher D. Manning Department of
Search and Data Mining: Techniques. Text Mining Anya Yarygina Boris Novikov
 Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Word Sense Disambiguation for Text Mining
 Word Sense Disambiguation for Text Mining Daniel I. MORARIU, Radu G. CREŢULESCU, Macarie BREAZU Lucian Blaga University of Sibiu, Engineering Faculty, Computer and Electrical Engineering Department Abstract:
Word Sense Disambiguation for Text Mining Daniel I. MORARIU, Radu G. CREŢULESCU, Macarie BREAZU Lucian Blaga University of Sibiu, Engineering Faculty, Computer and Electrical Engineering Department Abstract:
A Sentiment Analysis Model Integrating Multiple Algorithms and Diverse. Features. Thesis
 A Sentiment Analysis Model Integrating Multiple Algorithms and Diverse Features Thesis Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The
A Sentiment Analysis Model Integrating Multiple Algorithms and Diverse Features Thesis Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The
Analyzing survey text: a brief overview
 IBM SPSS Text Analytics for Surveys Analyzing survey text: a brief overview Learn how gives you greater insight Contents 1 Introduction 2 The role of text in survey research 2 Approaches to text mining
IBM SPSS Text Analytics for Surveys Analyzing survey text: a brief overview Learn how gives you greater insight Contents 1 Introduction 2 The role of text in survey research 2 Approaches to text mining
TERMINOGRAPHY and LEXICOGRAPHY What is the difference? Summary. Anja Drame TermNet
 TERMINOGRAPHY and LEXICOGRAPHY What is the difference? Summary Anja Drame TermNet Summary/ Conclusion Variety of language (GPL = general purpose SPL = special purpose) Lexicography GPL SPL (special-purpose
TERMINOGRAPHY and LEXICOGRAPHY What is the difference? Summary Anja Drame TermNet Summary/ Conclusion Variety of language (GPL = general purpose SPL = special purpose) Lexicography GPL SPL (special-purpose
DISA at ImageCLEF 2014: The search-based solution for scalable image annotation
 DISA at ImageCLEF 2014: The search-based solution for scalable image annotation Petra Budikova, Jan Botorek, Michal Batko, and Pavel Zezula Masaryk University, Brno, Czech Republic {budikova,botorek,batko,zezula}@fi.muni.cz
DISA at ImageCLEF 2014: The search-based solution for scalable image annotation Petra Budikova, Jan Botorek, Michal Batko, and Pavel Zezula Masaryk University, Brno, Czech Republic {budikova,botorek,batko,zezula}@fi.muni.cz
Clustering Connectionist and Statistical Language Processing
 Clustering Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Clustering Connectionist and Statistical Language Processing Frank Keller keller@coli.uni-sb.de Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
An Efficient Database Design for IndoWordNet Development Using Hybrid Approach
 An Efficient Database Design for IndoWordNet Development Using Hybrid Approach Venkatesh P rabhu 2 Shilpa Desai 1 Hanumant Redkar 1 N eha P rabhugaonkar 1 Apur va N agvenkar 1 Ramdas Karmali 1 (1) GOA
An Efficient Database Design for IndoWordNet Development Using Hybrid Approach Venkatesh P rabhu 2 Shilpa Desai 1 Hanumant Redkar 1 N eha P rabhugaonkar 1 Apur va N agvenkar 1 Ramdas Karmali 1 (1) GOA
The study of words. Word Meaning. Lexical semantics. Synonymy. LING 130 Fall 2005 James Pustejovsky. ! What does a word mean?
 Word Meaning LING 130 Fall 2005 James Pustejovsky The study of words! What does a word mean?! To what extent is it a linguistic matter?! To what extent is it a matter of world knowledge? Thanks to Richard
Word Meaning LING 130 Fall 2005 James Pustejovsky The study of words! What does a word mean?! To what extent is it a linguistic matter?! To what extent is it a matter of world knowledge? Thanks to Richard
Word Sense Disambiguation as an Integer Linear Programming Problem
 Word Sense Disambiguation as an Integer Linear Programming Problem Vicky Panagiotopoulou 1, Iraklis Varlamis 2, Ion Androutsopoulos 1, and George Tsatsaronis 3 1 Department of Informatics, Athens University
Word Sense Disambiguation as an Integer Linear Programming Problem Vicky Panagiotopoulou 1, Iraklis Varlamis 2, Ion Androutsopoulos 1, and George Tsatsaronis 3 1 Department of Informatics, Athens University
Exploiting Comparable Corpora and Bilingual Dictionaries. the Cross Language Text Categorization
 Exploiting Comparable Corpora and Bilingual Dictionaries for Cross-Language Text Categorization Alfio Gliozzo and Carlo Strapparava ITC-Irst via Sommarive, I-38050, Trento, ITALY {gliozzo,strappa}@itc.it
Exploiting Comparable Corpora and Bilingual Dictionaries for Cross-Language Text Categorization Alfio Gliozzo and Carlo Strapparava ITC-Irst via Sommarive, I-38050, Trento, ITALY {gliozzo,strappa}@itc.it
A Method for Automatic De-identification of Medical Records
 A Method for Automatic De-identification of Medical Records Arya Tafvizi MIT CSAIL Cambridge, MA 0239, USA tafvizi@csail.mit.edu Maciej Pacula MIT CSAIL Cambridge, MA 0239, USA mpacula@csail.mit.edu Abstract
A Method for Automatic De-identification of Medical Records Arya Tafvizi MIT CSAIL Cambridge, MA 0239, USA tafvizi@csail.mit.edu Maciej Pacula MIT CSAIL Cambridge, MA 0239, USA mpacula@csail.mit.edu Abstract
Semantic Clustering in Dutch
 t.van.de.cruys@rug.nl Alfa-informatica, Rijksuniversiteit Groningen Computational Linguistics in the Netherlands December 16, 2005 Outline 1 2 Clustering Additional remarks 3 Examples 4 Research carried
t.van.de.cruys@rug.nl Alfa-informatica, Rijksuniversiteit Groningen Computational Linguistics in the Netherlands December 16, 2005 Outline 1 2 Clustering Additional remarks 3 Examples 4 Research carried
Optimizing the relevancy of Predictions using Machine Learning and NLP of Search Query
 International Journal of Scientific and Research Publications, Volume 4, Issue 8, August 2014 1 Optimizing the relevancy of Predictions using Machine Learning and NLP of Search Query Kilari Murali krishna
International Journal of Scientific and Research Publications, Volume 4, Issue 8, August 2014 1 Optimizing the relevancy of Predictions using Machine Learning and NLP of Search Query Kilari Murali krishna
Cross-lingual Synonymy Overlap
 Cross-lingual Synonymy Overlap Anca Dinu 1, Liviu P. Dinu 2, Ana Sabina Uban 2 1 Faculty of Foreign Languages and Literatures, University of Bucharest 2 Faculty of Mathematics and Computer Science, University
Cross-lingual Synonymy Overlap Anca Dinu 1, Liviu P. Dinu 2, Ana Sabina Uban 2 1 Faculty of Foreign Languages and Literatures, University of Bucharest 2 Faculty of Mathematics and Computer Science, University
Module Catalogue for the Bachelor Program in Computational Linguistics at the University of Heidelberg
 Module Catalogue for the Bachelor Program in Computational Linguistics at the University of Heidelberg March 1, 2007 The catalogue is organized into sections of (1) obligatory modules ( Basismodule ) that
Module Catalogue for the Bachelor Program in Computational Linguistics at the University of Heidelberg March 1, 2007 The catalogue is organized into sections of (1) obligatory modules ( Basismodule ) that
SEMANTIC RESOURCES AND THEIR APPLICATIONS IN HUNGARIAN NATURAL LANGUAGE PROCESSING
 SEMANTIC RESOURCES AND THEIR APPLICATIONS IN HUNGARIAN NATURAL LANGUAGE PROCESSING Doctor of Philosophy Dissertation Márton Miháltz Supervisor: Gábor Prószéky, D.Sc. Multidisciplinary Technical Sciences
SEMANTIC RESOURCES AND THEIR APPLICATIONS IN HUNGARIAN NATURAL LANGUAGE PROCESSING Doctor of Philosophy Dissertation Márton Miháltz Supervisor: Gábor Prószéky, D.Sc. Multidisciplinary Technical Sciences
Using Knowledge Extraction and Maintenance Techniques To Enhance Analytical Performance
 Using Knowledge Extraction and Maintenance Techniques To Enhance Analytical Performance David Bixler, Dan Moldovan and Abraham Fowler Language Computer Corporation 1701 N. Collins Blvd #2000 Richardson,
Using Knowledge Extraction and Maintenance Techniques To Enhance Analytical Performance David Bixler, Dan Moldovan and Abraham Fowler Language Computer Corporation 1701 N. Collins Blvd #2000 Richardson,
Machine Learning Approach To Augmenting News Headline Generation
 Machine Learning Approach To Augmenting News Headline Generation Ruichao Wang Dept. of Computer Science University College Dublin Ireland rachel@ucd.ie John Dunnion Dept. of Computer Science University
Machine Learning Approach To Augmenting News Headline Generation Ruichao Wang Dept. of Computer Science University College Dublin Ireland rachel@ucd.ie John Dunnion Dept. of Computer Science University
Applying Co-Training Methods to Statistical Parsing. Anoop Sarkar http://www.cis.upenn.edu/ anoop/ anoop@linc.cis.upenn.edu
 Applying Co-Training Methods to Statistical Parsing Anoop Sarkar http://www.cis.upenn.edu/ anoop/ anoop@linc.cis.upenn.edu 1 Statistical Parsing: the company s clinical trials of both its animal and human-based
Applying Co-Training Methods to Statistical Parsing Anoop Sarkar http://www.cis.upenn.edu/ anoop/ anoop@linc.cis.upenn.edu 1 Statistical Parsing: the company s clinical trials of both its animal and human-based
Chapter ML:XI (continued)
") Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Textual Data Analysis tools for Word Sense Disambiguation
 Textual Data Analysis tools for Word Sense Disambiguation Simona Balbi 1, Agnieszka Stawinoga 2 Università FedericoII di Napoli 1 simona.balbi@unina.it, 2 agnieszka.stawinoga@unina.it Abstract The ambiguity
Textual Data Analysis tools for Word Sense Disambiguation Simona Balbi 1, Agnieszka Stawinoga 2 Università FedericoII di Napoli 1 simona.balbi@unina.it, 2 agnieszka.stawinoga@unina.it Abstract The ambiguity
Simple Features for Chinese Word Sense Disambiguation
 Simple Features for Chinese Word Sense Disambiguation Hoa Trang Dang, Ching-yi Chia, Martha Palmer, and Fu-Dong Chiou Department of Computer and Information Science University of Pennsylvania htd,chingyc,mpalmer,chioufd
Simple Features for Chinese Word Sense Disambiguation Hoa Trang Dang, Ching-yi Chia, Martha Palmer, and Fu-Dong Chiou Department of Computer and Information Science University of Pennsylvania htd,chingyc,mpalmer,chioufd
Package wordnet. January 6, 2016
 Title WordNet Interface Version 0.1-11 Package wordnet January 6, 2016 An interface to WordNet using the Jawbone Java API to WordNet. WordNet () is a large lexical database
Title WordNet Interface Version 0.1-11 Package wordnet January 6, 2016 An interface to WordNet using the Jawbone Java API to WordNet. WordNet () is a large lexical database
Testing Data-Driven Learning Algorithms for PoS Tagging of Icelandic
 Testing Data-Driven Learning Algorithms for PoS Tagging of Icelandic by Sigrún Helgadóttir Abstract This paper gives the results of an experiment concerned with training three different taggers on tagged
Testing Data-Driven Learning Algorithms for PoS Tagging of Icelandic by Sigrún Helgadóttir Abstract This paper gives the results of an experiment concerned with training three different taggers on tagged
2. SEMANTIC RELATIONS
 2. SEMANTIC RELATIONS 2.0 Review: meaning, sense, reference A word has meaning by having both sense and reference. Sense: Word meaning: = concept Sentence meaning: = proposition (1) a. The man kissed the
2. SEMANTIC RELATIONS 2.0 Review: meaning, sense, reference A word has meaning by having both sense and reference. Sense: Word meaning: = concept Sentence meaning: = proposition (1) a. The man kissed the
Clustering of Polysemic Words
 Clustering of Polysemic Words Laurent Cicurel 1, Stephan Bloehdorn 2, and Philipp Cimiano 2 1 isoco S.A., ES-28006 Madrid, Spain lcicurel@isoco.com 2 Institute AIFB, University of Karlsruhe, D-76128 Karlsruhe,
Clustering of Polysemic Words Laurent Cicurel 1, Stephan Bloehdorn 2, and Philipp Cimiano 2 1 isoco S.A., ES-28006 Madrid, Spain lcicurel@isoco.com 2 Institute AIFB, University of Karlsruhe, D-76128 Karlsruhe,
DanNet Teaching and Research Perspectives at CST
 DanNet Teaching and Research Perspectives at CST Patrizia Paggio Centre for Language Technology University of Copenhagen paggio@hum.ku.dk Dias 1 Outline Previous and current research: Concept-based search:
DanNet Teaching and Research Perspectives at CST Patrizia Paggio Centre for Language Technology University of Copenhagen paggio@hum.ku.dk Dias 1 Outline Previous and current research: Concept-based search:
3 Paraphrase Acquisition. 3.1 Overview. 2 Prior Work
 Unsupervised Paraphrase Acquisition via Relation Discovery Takaaki Hasegawa Cyberspace Laboratories Nippon Telegraph and Telephone Corporation 1-1 Hikarinooka, Yokosuka, Kanagawa 239-0847, Japan hasegawa.takaaki@lab.ntt.co.jp
Unsupervised Paraphrase Acquisition via Relation Discovery Takaaki Hasegawa Cyberspace Laboratories Nippon Telegraph and Telephone Corporation 1-1 Hikarinooka, Yokosuka, Kanagawa 239-0847, Japan hasegawa.takaaki@lab.ntt.co.jp
Towards Robust High Performance Word Sense Disambiguation of English Verbs Using Rich Linguistic Features
 Towards Robust High Performance Word Sense Disambiguation of English Verbs Using Rich Linguistic Features Jinying Chen and Martha Palmer Department of Computer and Information Science, University of Pennsylvania,
Towards Robust High Performance Word Sense Disambiguation of English Verbs Using Rich Linguistic Features Jinying Chen and Martha Palmer Department of Computer and Information Science, University of Pennsylvania,
Exploiting Strong Syntactic Heuristics and Co-Training to Learn Semantic Lexicons
 Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Philadelphia, July 2002, pp. 125-132. Association for Computational Linguistics. Exploiting Strong Syntactic Heuristics
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Philadelphia, July 2002, pp. 125-132. Association for Computational Linguistics. Exploiting Strong Syntactic Heuristics
Chapter 2 The Information Retrieval Process
 Chapter 2 The Information Retrieval Process Abstract What does an information retrieval system look like from a bird s eye perspective? How can a set of documents be processed by a system to make sense
Chapter 2 The Information Retrieval Process Abstract What does an information retrieval system look like from a bird s eye perspective? How can a set of documents be processed by a system to make sense
Sentiment Analysis of Movie Reviews and Twitter Statuses. Introduction
 Sentiment Analysis of Movie Reviews and Twitter Statuses Introduction Sentiment analysis is the task of identifying whether the opinion expressed in a text is positive or negative in general, or about
Sentiment Analysis of Movie Reviews and Twitter Statuses Introduction Sentiment analysis is the task of identifying whether the opinion expressed in a text is positive or negative in general, or about
Word sense disambiguation through associative dictionaries
 INSTITUTO POLITÉCNICO NACIONAL CENTRO DE INVESTIGACIÓN EN COMPUTACIÓN LABORATORIO DE LENGUAJE NATURAL Y PROCESAMIENTO DE TEXTO Word sense disambiguation through associative dictionaries TESIS QUE PRESENTA
INSTITUTO POLITÉCNICO NACIONAL CENTRO DE INVESTIGACIÓN EN COMPUTACIÓN LABORATORIO DE LENGUAJE NATURAL Y PROCESAMIENTO DE TEXTO Word sense disambiguation through associative dictionaries TESIS QUE PRESENTA
C o p yr i g ht 2015, S A S I nstitute Inc. A l l r i g hts r eser v ed. INTRODUCTION TO SAS TEXT MINER
 INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
A clustering-based Approach for Unsupervised Word Sense Disambiguation
 Procesamiento del Lenguaje Natural, Revista nº 49 septiembre de 2012, pp 49-56 recibido 04-05-12 revisado 04-06-12 aceptado 07-06-12 A clustering-based Approach for Unsupervised Word Sense Disambiguation
Procesamiento del Lenguaje Natural, Revista nº 49 septiembre de 2012, pp 49-56 recibido 04-05-12 revisado 04-06-12 aceptado 07-06-12 A clustering-based Approach for Unsupervised Word Sense Disambiguation
Building the Multilingual Web of Data: A Hands-on tutorial (ISWC 2014, Riva del Garda - Italy)
") Building the Multilingual Web of Data: A Hands-on tutorial (ISWC 2014, Riva del Garda - Italy) Multilingual Word Sense Disambiguation and Entity Linking on the Web based on BabelNet Roberto Navigli, Tiziano
Building the Multilingual Web of Data: A Hands-on tutorial (ISWC 2014, Riva del Garda - Italy) Multilingual Word Sense Disambiguation and Entity Linking on the Web based on BabelNet Roberto Navigli, Tiziano
A Mixed Trigrams Approach for Context Sensitive Spell Checking
 A Mixed Trigrams Approach for Context Sensitive Spell Checking Davide Fossati and Barbara Di Eugenio Department of Computer Science University of Illinois at Chicago Chicago, IL, USA dfossa1@uic.edu, bdieugen@cs.uic.edu
A Mixed Trigrams Approach for Context Sensitive Spell Checking Davide Fossati and Barbara Di Eugenio Department of Computer Science University of Illinois at Chicago Chicago, IL, USA dfossa1@uic.edu, bdieugen@cs.uic.edu
Context Sensitive Paraphrasing with a Single Unsupervised Classifier
 Appeared in ECML 07 Context Sensitive Paraphrasing with a Single Unsupervised Classifier Michael Connor and Dan Roth Department of Computer Science University of Illinois at Urbana-Champaign connor2@uiuc.edu
Appeared in ECML 07 Context Sensitive Paraphrasing with a Single Unsupervised Classifier Michael Connor and Dan Roth Department of Computer Science University of Illinois at Urbana-Champaign connor2@uiuc.edu
Semi-Supervised Learning for Blog Classification
 Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008) Semi-Supervised Learning for Blog Classification Daisuke Ikeda Department of Computational Intelligence and Systems Science,
Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008) Semi-Supervised Learning for Blog Classification Daisuke Ikeda Department of Computational Intelligence and Systems Science,
An empirical study of semantic similarity in WordNet and Word2Vec. A Thesis
 An empirical study of semantic similarity in WordNet and Word2Vec A Thesis Submitted to the Graduate Faculty of the University of New Orleans in partial fulfillment of the requirements for the degree of
An empirical study of semantic similarity in WordNet and Word2Vec A Thesis Submitted to the Graduate Faculty of the University of New Orleans in partial fulfillment of the requirements for the degree of
How the Computer Translates. Svetlana Sokolova President and CEO of PROMT, PhD.
 Svetlana Sokolova President and CEO of PROMT, PhD. How the Computer Translates Machine translation is a special field of computer application where almost everyone believes that he/she is a specialist.
Svetlana Sokolova President and CEO of PROMT, PhD. How the Computer Translates Machine translation is a special field of computer application where almost everyone believes that he/she is a specialist.
Comparing Topiary-Style Approaches to Headline Generation
 Comparing Topiary-Style Approaches to Headline Generation Ruichao Wang 1, Nicola Stokes 1, William P. Doran 1, Eamonn Newman 1, Joe Carthy 1, John Dunnion 1. 1 Intelligent Information Retrieval Group,
Comparing Topiary-Style Approaches to Headline Generation Ruichao Wang 1, Nicola Stokes 1, William P. Doran 1, Eamonn Newman 1, Joe Carthy 1, John Dunnion 1. 1 Intelligent Information Retrieval Group,
Resolving Common Analytical Tasks in Text Databases
 Resolving Common Analytical Tasks in Text Databases The work is funded by the Federal Ministry of Economic Affairs and Energy (BMWi) under grant agreement 01MD15010B. Database Systems and Text-based Information
Resolving Common Analytical Tasks in Text Databases The work is funded by the Federal Ministry of Economic Affairs and Energy (BMWi) under grant agreement 01MD15010B. Database Systems and Text-based Information
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information
 Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Applications of Named Entity Recognition in Customer Relationship Management Systems
 Applications of Named Entity Recognition in Customer Relationship Management Systems Farbod Saraf Jadidian September 2014 Dissertation submitted in partial fulfilment for the degree of Master of Science
Applications of Named Entity Recognition in Customer Relationship Management Systems Farbod Saraf Jadidian September 2014 Dissertation submitted in partial fulfilment for the degree of Master of Science
Semantic analysis of text and speech
 Semantic analysis of text and speech SGN-9206 Signal processing graduate seminar II, Fall 2007 Anssi Klapuri Institute of Signal Processing, Tampere University of Technology, Finland Outline What is semantic
Semantic analysis of text and speech SGN-9206 Signal processing graduate seminar II, Fall 2007 Anssi Klapuri Institute of Signal Processing, Tampere University of Technology, Finland Outline What is semantic
What Is This, Anyway: Automatic Hypernym Discovery
 What Is This, Anyway: Automatic Hypernym Discovery Alan Ritter and Stephen Soderland and Oren Etzioni Turing Center Department of Computer Science and Engineering University of Washington Box 352350 Seattle,
What Is This, Anyway: Automatic Hypernym Discovery Alan Ritter and Stephen Soderland and Oren Etzioni Turing Center Department of Computer Science and Engineering University of Washington Box 352350 Seattle,
Introduction to Machine Learning Lecture 1. Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu
 Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words
 , pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
, pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
Learning Domain Ontologies from Document Warehouses and Dedicated Web Sites
 Learning Domain Ontologies from Document Warehouses and Dedicated Web Sites Roberto Navigli Università di Roma La Sapienza Paola Velardi Università di Roma La Sapienza We present a method and a tool, OntoLearn,
Learning Domain Ontologies from Document Warehouses and Dedicated Web Sites Roberto Navigli Università di Roma La Sapienza Paola Velardi Università di Roma La Sapienza We present a method and a tool, OntoLearn,
Sentiment analysis on news articles using Natural Language Processing and Machine Learning Approach.
 Sentiment analysis on news articles using Natural Language Processing and Machine Learning Approach. Pranali Chilekar 1, Swati Ubale 2, Pragati Sonkambale 3, Reema Panarkar 4, Gopal Upadhye 5 1 2 3 4 5
Sentiment analysis on news articles using Natural Language Processing and Machine Learning Approach. Pranali Chilekar 1, Swati Ubale 2, Pragati Sonkambale 3, Reema Panarkar 4, Gopal Upadhye 5 1 2 3 4 5
Taxonomies for Auto-Tagging Unstructured Content. Heather Hedden Hedden Information Management Text Analytics World, Boston, MA October 1, 2013
 Taxonomies for Auto-Tagging Unstructured Content Heather Hedden Hedden Information Management Text Analytics World, Boston, MA October 1, 2013 About Heather Hedden Independent taxonomy consultant, Hedden
Taxonomies for Auto-Tagging Unstructured Content Heather Hedden Hedden Information Management Text Analytics World, Boston, MA October 1, 2013 About Heather Hedden Independent taxonomy consultant, Hedden
PoS-tagging Italian texts with CORISTagger
 PoS-tagging Italian texts with CORISTagger Fabio Tamburini DSLO, University of Bologna, Italy fabio.tamburini@unibo.it Abstract. This paper presents an evolution of CORISTagger [1], an high-performance
PoS-tagging Italian texts with CORISTagger Fabio Tamburini DSLO, University of Bologna, Italy fabio.tamburini@unibo.it Abstract. This paper presents an evolution of CORISTagger [1], an high-performance
Report on the embedding and evaluation of the second MT pilot
 Report on the embedding and evaluation of the second MT pilot quality translation by deep language engineering approaches DELIVERABLE D3.10 VERSION 1.6 2015-11-02 P2 QTLeap Machine translation is a computational
Report on the embedding and evaluation of the second MT pilot quality translation by deep language engineering approaches DELIVERABLE D3.10 VERSION 1.6 2015-11-02 P2 QTLeap Machine translation is a computational
Semi-Supervised and Unsupervised Machine Learning. Novel Strategies
 Brochure More information from http://www.researchandmarkets.com/reports/2179190/ Semi-Supervised and Unsupervised Machine Learning. Novel Strategies Description: This book provides a detailed and up to
Brochure More information from http://www.researchandmarkets.com/reports/2179190/ Semi-Supervised and Unsupervised Machine Learning. Novel Strategies Description: This book provides a detailed and up to
Semi-Supervised Maximum Entropy Based Approach to Acronym and Abbreviation Normalization in Medical Texts
 Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, July 2002, pp. 160-167. Semi-Supervised Maximum Entropy Based Approach to Acronym and Abbreviation
Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, July 2002, pp. 160-167. Semi-Supervised Maximum Entropy Based Approach to Acronym and Abbreviation
Stock Market Prediction Using Data Mining
 Stock Market Prediction Using Data Mining 1 Ruchi Desai, 2 Prof.Snehal Gandhi 1 M.E., 2 M.Tech. 1 Computer Department 1 Sarvajanik College of Engineering and Technology, Surat, Gujarat, India Abstract
Stock Market Prediction Using Data Mining 1 Ruchi Desai, 2 Prof.Snehal Gandhi 1 M.E., 2 M.Tech. 1 Computer Department 1 Sarvajanik College of Engineering and Technology, Surat, Gujarat, India Abstract
Finding Negative Key Phrases for Internet Advertising Campaigns using Wikipedia
 Finding Negative Key Phrases for Internet Advertising Campaigns using Wikipedia Martin Scaiano University of Ottawa mscai056@uottawa.ca Diana Inkpen University of Ottawa diana@site.uottawa.com Abstract
Finding Negative Key Phrases for Internet Advertising Campaigns using Wikipedia Martin Scaiano University of Ottawa mscai056@uottawa.ca Diana Inkpen University of Ottawa diana@site.uottawa.com Abstract
Machine Learning: Overview
 Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
TextRank: Bringing Order into Texts
 TextRank: Bringing Order into Texts Rada Mihalcea and Paul Tarau Department of Computer Science University of North Texas rada,tarau @cs.unt.edu Abstract In this paper, we introduce TextRank a graph-based
TextRank: Bringing Order into Texts Rada Mihalcea and Paul Tarau Department of Computer Science University of North Texas rada,tarau @cs.unt.edu Abstract In this paper, we introduce TextRank a graph-based
Doctoral Dissertation. Graph-Theoretic Approaches to Minimally-Supervised Natural Language Learning. Mamoru Komachi
 NAIST-IS-DD0761015 Doctoral Dissertation Graph-Theoretic Approaches to Minimally-Supervised Natural Language Learning Mamoru Komachi March 17, 2010 Department of Information Processing Graduate School
NAIST-IS-DD0761015 Doctoral Dissertation Graph-Theoretic Approaches to Minimally-Supervised Natural Language Learning Mamoru Komachi March 17, 2010 Department of Information Processing Graduate School
Extraction of Hypernymy Information from Text
 Extraction of Hypernymy Information from Text Erik Tjong Kim Sang, Katja Hofmann and Maarten de Rijke Abstract We present the results of three different studies in extracting hypernymy information from
Extraction of Hypernymy Information from Text Erik Tjong Kim Sang, Katja Hofmann and Maarten de Rijke Abstract We present the results of three different studies in extracting hypernymy information from
Free Construction of a Free Swedish Dictionary of Synonyms
 Free Construction of a Free Swedish Dictionary of Synonyms Viggo Kann and Magnus Rosell KTH Nada SE-1 44 Stockholm Sweden {viggo, rosell}@nada.kth.se Abstract Building a large dictionary of synonyms for
Free Construction of a Free Swedish Dictionary of Synonyms Viggo Kann and Magnus Rosell KTH Nada SE-1 44 Stockholm Sweden {viggo, rosell}@nada.kth.se Abstract Building a large dictionary of synonyms for
Open Domain Information Extraction. Günter Neumann, DFKI, 2012
 Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
Overview of MT techniques. Malek Boualem (FT)
") Overview of MT techniques Malek Boualem (FT) This section presents an standard overview of general aspects related to machine translation with a description of different techniques: bilingual, transfer,
Overview of MT techniques Malek Boualem (FT) This section presents an standard overview of general aspects related to machine translation with a description of different techniques: bilingual, transfer,
Presented to The Federal Big Data Working Group Meetup On 07 June 2014 By Chuck Rehberg, CTO Semantic Insights a Division of Trigent Software
 Semantic Research using Natural Language Processing at Scale; A continued look behind the scenes of Semantic Insights Research Assistant and Research Librarian Presented to The Federal Big Data Working
Semantic Research using Natural Language Processing at Scale; A continued look behind the scenes of Semantic Insights Research Assistant and Research Librarian Presented to The Federal Big Data Working
COLLOCATION TOOLS FOR L2 WRITERS 1
 COLLOCATION TOOLS FOR L2 WRITERS 1 An Evaluation of Collocation Tools for Second Language Writers Ulugbek Nurmukhamedov Northern Arizona University COLLOCATION TOOLS FOR L2 WRITERS 2 Abstract Second language
COLLOCATION TOOLS FOR L2 WRITERS 1 An Evaluation of Collocation Tools for Second Language Writers Ulugbek Nurmukhamedov Northern Arizona University COLLOCATION TOOLS FOR L2 WRITERS 2 Abstract Second language
Benefits of HPC for NLP besides big data
 Benefits of HPC for NLP besides big data Barbara Plank Center for Sprogteknologie (CST) University of Copenhagen, Denmark http://cst.dk/bplank Web-Scale Natural Language Processing in Northern Europe Oslo,
Benefits of HPC for NLP besides big data Barbara Plank Center for Sprogteknologie (CST) University of Copenhagen, Denmark http://cst.dk/bplank Web-Scale Natural Language Processing in Northern Europe Oslo,
Machine Translation. Agenda
 Agenda Introduction to Machine Translation Data-driven statistical machine translation Translation models Parallel corpora Document-, sentence-, word-alignment Phrase-based translation MT decoding algorithm
Agenda Introduction to Machine Translation Data-driven statistical machine translation Translation models Parallel corpora Document-, sentence-, word-alignment Phrase-based translation MT decoding algorithm
Construction of Thai WordNet Lexical Database from Machine Readable Dictionaries
 Construction of Thai WordNet Lexical Database from Machine Readable Dictionaries Patanakul Sathapornrungkij Department of Computer Science Faculty of Science, Mahidol University Rama6 Road, Ratchathewi
Construction of Thai WordNet Lexical Database from Machine Readable Dictionaries Patanakul Sathapornrungkij Department of Computer Science Faculty of Science, Mahidol University Rama6 Road, Ratchathewi
Hybrid Strategies. for better products and shorter time-to-market
 Hybrid Strategies for better products and shorter time-to-market Background Manufacturer of language technology software & services Spin-off of the research center of Germany/Heidelberg Founded in 1999,
Hybrid Strategies for better products and shorter time-to-market Background Manufacturer of language technology software & services Spin-off of the research center of Germany/Heidelberg Founded in 1999,
Network Machine Learning Research Group. Intended status: Informational October 19, 2015 Expires: April 21, 2016
 Network Machine Learning Research Group S. Jiang Internet-Draft Huawei Technologies Co., Ltd Intended status: Informational October 19, 2015 Expires: April 21, 2016 Abstract Network Machine Learning draft-jiang-nmlrg-network-machine-learning-00
Network Machine Learning Research Group S. Jiang Internet-Draft Huawei Technologies Co., Ltd Intended status: Informational October 19, 2015 Expires: April 21, 2016 Abstract Network Machine Learning draft-jiang-nmlrg-network-machine-learning-00
Mining Text Data: An Introduction
 Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Word Completion and Prediction in Hebrew
 Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Clustering Technique in Data Mining for Text Documents
 Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Transaction-Typed Points TTPoints
 Transaction-Typed Points TTPoints version: 1.0 Technical Report RA-8/2011 Mirosław Ochodek Institute of Computing Science Poznan University of Technology Project operated within the Foundation for Polish
Transaction-Typed Points TTPoints version: 1.0 Technical Report RA-8/2011 Mirosław Ochodek Institute of Computing Science Poznan University of Technology Project operated within the Foundation for Polish
Semantic Relatedness Metric for Wikipedia Concepts Based on Link Analysis and its Application to Word Sense Disambiguation
 Semantic Relatedness Metric for Wikipedia Concepts Based on Link Analysis and its Application to Word Sense Disambiguation Denis Turdakov, Pavel Velikhov ISP RAS turdakov@ispras.ru, pvelikhov@yahoo.com
Semantic Relatedness Metric for Wikipedia Concepts Based on Link Analysis and its Application to Word Sense Disambiguation Denis Turdakov, Pavel Velikhov ISP RAS turdakov@ispras.ru, pvelikhov@yahoo.com
Refining the most frequent sense baseline
 Refining the most frequent sense baseline Judita Preiss Department of Linguistics The Ohio State University judita@ling.ohio-state.edu Josh King Computer Science and Engineering The Ohio State University
Refining the most frequent sense baseline Judita Preiss Department of Linguistics The Ohio State University judita@ling.ohio-state.edu Josh King Computer Science and Engineering The Ohio State University
SENTIMENT ANALYSIS: A STUDY ON PRODUCT FEATURES
 University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Dissertations and Theses from the College of Business Administration Business Administration, College of 4-1-2012 SENTIMENT
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Dissertations and Theses from the College of Business Administration Business Administration, College of 4-1-2012 SENTIMENT
Exploiting Redundancy in Natural Language to Penetrate Bayesian Spam Filters
 Exploiting Redundancy in Natural Language to Penetrate Bayesian Spam Filters Christoph Karlberger, Günther Bayler, Christopher Kruegel, and Engin Kirda Secure Systems Lab Technical University Vienna {christoph,gmb,chris,ek}@seclab.tuwien.ac.at
Exploiting Redundancy in Natural Language to Penetrate Bayesian Spam Filters Christoph Karlberger, Günther Bayler, Christopher Kruegel, and Engin Kirda Secure Systems Lab Technical University Vienna {christoph,gmb,chris,ek}@seclab.tuwien.ac.at
The Open University s repository of research publications and other research outputs. PowerAqua: fishing the semantic web
 Open Research Online The Open University s repository of research publications and other research outputs PowerAqua: fishing the semantic web Conference Item How to cite: Lopez, Vanessa; Motta, Enrico
Open Research Online The Open University s repository of research publications and other research outputs PowerAqua: fishing the semantic web Conference Item How to cite: Lopez, Vanessa; Motta, Enrico
Taxonomy learning factoring the structure of a taxonomy into a semantic classification decision
 Taxonomy learning factoring the structure of a taxonomy into a semantic classification decision Viktor PEKAR Bashkir State University Ufa, Russia, 450000 vpekar@ufanet.ru Steffen STAAB Institute AIFB,
Taxonomy learning factoring the structure of a taxonomy into a semantic classification decision Viktor PEKAR Bashkir State University Ufa, Russia, 450000 vpekar@ufanet.ru Steffen STAAB Institute AIFB,
Although the IT community widely acknowledges the usefulness of domain ontologies,
 N a t u r a l L a n g u a g e P r o c e s s i n g Ontology Learning and Its Application to Automated Terminology Translation Roberto Navigli and Paola Velardi Università di Roma La Sapienza Aldo Gangemi
N a t u r a l L a n g u a g e P r o c e s s i n g Ontology Learning and Its Application to Automated Terminology Translation Roberto Navigli and Paola Velardi Università di Roma La Sapienza Aldo Gangemi
Tibetan-Chinese Bilingual Sentences Alignment Method based on Multiple Features
 , pp.273-280 http://dx.doi.org/10.14257/ijdta.2015.8.4.27 Tibetan-Chinese Bilingual Sentences Alignment Method based on Multiple Features Lirong Qiu School of Information Engineering, MinzuUniversity of
, pp.273-280 http://dx.doi.org/10.14257/ijdta.2015.8.4.27 Tibetan-Chinese Bilingual Sentences Alignment Method based on Multiple Features Lirong Qiu School of Information Engineering, MinzuUniversity of