Learning to Recognize Talkers from Natural, Sinewave, and Reversed Speech Samples
|
|
|
- Marvin Baldwin
- 7 years ago
- Views:
Transcription
1 Learning to Recognize Talkers from Natural, Sinewave, and Reversed Speech Samples Presented by: Pankaj Rajan Graduate Student, Department of Computer Sciences. Texas A&M University, College Station
2 Agenda Introduction Background Experiments Discussion
3 What the paper is about? How a listener recognizes the unfamiliar talker? Different talker specific properties of the speech signal to perceptual learning
4 Traditional View: Word and Talker Recognition Features for Speech perception and Talker recognition are different. As per Traditional View: : Vocal quality of Individual is represented by Features that are linguistically irrelevant. Melodic patterns Roughness Smoothness Fundamental Frequency Glottal Features Style/Accent For perception talker specific attributes are separated from phonetic representation.
5 Alternative to Traditional view Experiments have revealed relation between Linguistic and Indexical perception. Evidence!!! Experiments show that Listeners recognize phonemes and words faster and accurate when spoken by same speaker. Talker attributes cannot be ignored. Linguistic perception preserve talker specific attributes which become part of long term memory. Experiments by Nygaard In which he found that the listeners familiar with the talker were able to transcribe the sentences more easily
6 Conclusions of Alternative view Talker properties and the linguistic form are associated with same single memory system. Linguistic and Indexical attributes are transmitted in parallel
7 Remez Experiment AIM: To test hypothesis that phonetic representations represent both talker characteristics and words. Listener familiar with the talker were presented the Sinewave representation of the natural speech for individual recognition. Listeners were able to recognize the talker and hence demonstrated that perception of talker characteristics is present in talker specific phoneme utterances. Sine Waves: Acoustic structure of the original utterance that lack fine grained acoustic details of natural speech but evoke: 1. impression of segmental phonetic attributes and 2. Vocal quality like Fundamental frequency, broadband resonances, harmonic structure.
8 Spectrogram Representation
9 Present Work To establish if learners can perceive speaker in absence of acoustic vocal quality parameters. To know about the feature structure of the talker that develops during perceptual training To know the extent to which the attributes of the talker are transferred to the type of signal.
10 5 Experiments: Experiment 1 and 2 Aimed to investigate if listener would recognize a talker from samples featuring phonetic segmental properties at the cost of qualitative aspects. Experiment 3, 4,5 Experiment 3, 4,5 Aimed to explore how listeners would categorize unfamiliar talker when presented with qualitative aspects at the cost of segmental phonetic and lexical properties
11 Experiment 1 and 2
12 Experiments: Both Sinewave and the natural speech samples were used to train the listeners. Sentences were recorded in an audiotape in a soundproof booth and were low passed filtered at 4.5 khz and sampled at 10 khz. Subjects were trained to extent of 70 % accuracy to identify the talker and training was conducted for several days. Subjects were encouraged to pay attention to the talker attributes rather than content of message.
13 Continued.. There was a familiarization phase, to reinstate correspondence between sine wave tokens and talkers name. It was followed by the Generalization test
14 Experiment1learning to identify talkers with Sinewave Sentences Training: Listeners were trained in a quite room to identify 10 speakers of Sinewave utterances Analysis: Listeners were able to identify speakers and accuracy increases day by day. One way ANOVA revealed significant effect of talker identity on recognition performance Generalization Performance/Test: Half of the subjects were first presented with natural speeches to be identified before Sinewave and other half was presented in reversed order. Results: Talker specific knowledge acquired during Sinewave training generalized to novel natural and Sinewave sentences
15 Continued Listener can identify talker with the phonetic attributes present in the Sinewave in absence of traditional qualitative attributes of vocal sound production. It is perceptual discriminability of talker in the set that is source of differences in identification. Interesting Observation Individual listener differed in their ability to identify the talkers. However, reason was not known. Conclusion: Individual attributes are carried by the segmental phonetic properties in addition to vocal timber. Linguistic and individual attributes can be represented by common representation code.
16 Training

17 Last day of Training Experiment 1
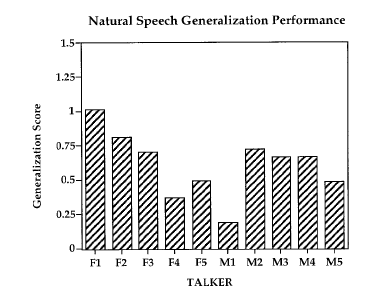
18 Generalized test
19 Experiment2Learning to identify talkers from natural speech Aim: To find if similar generalization as observed in previous experiment can be obtained using natural speech training Training: Subjects were trained on the natural sentences Similar to training in the Experiment 1. Analysis Listeners were able to learn from natural speech very fast. It indicates that natural speech provides listeners with salient sample of each talker s indexical attributes.
20 Continued. Generalized performance: Similar to the first Experiment. Results: Listener s ability to understand the speech was 88% for natural speech generalization test but 27% for Sinewave generalization test. Conclusions Indexical knowledge acquired during the training with the natural speech doesn't generalized to Sinewave utterances.

21 Last day Training Results- Exp:2

22 Generalization Test
23 Experiment 3, 4, 5
24 Experiment 3 Recognizing an unintelligible talker AIM: To test hypothesis that subjects use glottal source quality rather than fine grained phonetic properties during natural speech training. Training: Listeners were trained using natural speech. Generalization Performance: Generalization test samples were reversed natural speech and sinewave samples. Analysis: Subjects were able to identify talker from reversed speech samples Performance on the Sinewave samples was far poorer
25 Continued.. Results Qualitative attributes are prominent perceptual attributes during training with natural speech samples. Though results were poorer on Sinewave samples, correlation analysis shows that listeners do encoded some fine grained phonetic attributes for the recognition. Conclusion Under Normal circumstances listeners naturally encode talkers using mixture of different properties, relying more on qualitative characteristics while also using the phonetic details
26 Generalization test: Exp:3
27 Experiment 4 Getting to know unintelligible talker Aim: To test the sufficiency of qualitative aspects of speech in relative absence of many phonetic and lexical impressions. Ability to learn from reversed samples is tested. Training Training material were reversed speech samples. Generalization Process The generalized material are reversed speech samples and sine wave speeches sentences. Analysis Listener learned to identify the individuals from reversed speech samples. Rate was intermediate between training with natural speech and with sine wave replica.
28 Continued.. Results Reveres speech training was highly correlated with reverse speech talker identification. No correlation between training and Sinewave talker identification. Conclusion The features with which listeners become familiar during training did not correspond to indexical attributes available in Sinewave replica.
29 Last day Training Performance
30 Generalization test Exp:4
31 Experiment5 Robustness of Qualitative Indexical attributes Aim Training To test that the qualitative attributes available in reversed speech samples match those of natural speech. Reversed natural speech samples. Generalized performance Analysis Results Generalized test material were natural speech samples and Sinewave replicas. Results were identical with the previous experiment. Similar to the previous experiment. Weak Correlation between reversed speech training and Sinewave generalization.
32 Generalization test Exp:5
33 Discussion: The listeners exploit various cues to perceive the talker. In some circumstances global qualitative attributes are used to perceive talker while in some circumstances, phonetic attributes alone can be used.
Speech Signal Processing: An Overview
 Speech Signal Processing: An Overview S. R. M. Prasanna Department of Electronics and Electrical Engineering Indian Institute of Technology Guwahati December, 2012 Prasanna (EMST Lab, EEE, IITG) Speech
Speech Signal Processing: An Overview S. R. M. Prasanna Department of Electronics and Electrical Engineering Indian Institute of Technology Guwahati December, 2012 Prasanna (EMST Lab, EEE, IITG) Speech
L2 EXPERIENCE MODULATES LEARNERS USE OF CUES IN THE PERCEPTION OF L3 TONES
 L2 EXPERIENCE MODULATES LEARNERS USE OF CUES IN THE PERCEPTION OF L3 TONES Zhen Qin, Allard Jongman Department of Linguistics, University of Kansas, United States qinzhenquentin2@ku.edu, ajongman@ku.edu
L2 EXPERIENCE MODULATES LEARNERS USE OF CUES IN THE PERCEPTION OF L3 TONES Zhen Qin, Allard Jongman Department of Linguistics, University of Kansas, United States qinzhenquentin2@ku.edu, ajongman@ku.edu
Turkish Radiology Dictation System
 Turkish Radiology Dictation System Ebru Arısoy, Levent M. Arslan Boaziçi University, Electrical and Electronic Engineering Department, 34342, Bebek, stanbul, Turkey arisoyeb@boun.edu.tr, arslanle@boun.edu.tr
Turkish Radiology Dictation System Ebru Arısoy, Levent M. Arslan Boaziçi University, Electrical and Electronic Engineering Department, 34342, Bebek, stanbul, Turkey arisoyeb@boun.edu.tr, arslanle@boun.edu.tr
Program curriculum for graduate studies in Speech and Music Communication
 Program curriculum for graduate studies in Speech and Music Communication School of Computer Science and Communication, KTH (Translated version, November 2009) Common guidelines for graduate-level studies
Program curriculum for graduate studies in Speech and Music Communication School of Computer Science and Communication, KTH (Translated version, November 2009) Common guidelines for graduate-level studies
Perceptual experiments sir-skur-spur-stir
 Perceptual experiments sir-skur-spur-stir Amy Beeston & Guy Brown 19 May 21 1 Introduction 2 Experiment 1: cutoff Set up Results 3 Experiment 2: reverse Set up Results 4 Discussion Introduction introduction
Perceptual experiments sir-skur-spur-stir Amy Beeston & Guy Brown 19 May 21 1 Introduction 2 Experiment 1: cutoff Set up Results 3 Experiment 2: reverse Set up Results 4 Discussion Introduction introduction
Workshop Perceptual Effects of Filtering and Masking Introduction to Filtering and Masking
 Workshop Perceptual Effects of Filtering and Masking Introduction to Filtering and Masking The perception and correct identification of speech sounds as phonemes depends on the listener extracting various
Workshop Perceptual Effects of Filtering and Masking Introduction to Filtering and Masking The perception and correct identification of speech sounds as phonemes depends on the listener extracting various
Things to remember when transcribing speech
 Notes and discussion Things to remember when transcribing speech David Crystal University of Reading Until the day comes when this journal is available in an audio or video format, we shall have to rely
Notes and discussion Things to remember when transcribing speech David Crystal University of Reading Until the day comes when this journal is available in an audio or video format, we shall have to rely
DRA2 Word Analysis. correlated to. Virginia Learning Standards Grade 1
 DRA2 Word Analysis correlated to Virginia Learning Standards Grade 1 Quickly identify and generate words that rhyme with given words. Quickly identify and generate words that begin with the same sound.
DRA2 Word Analysis correlated to Virginia Learning Standards Grade 1 Quickly identify and generate words that rhyme with given words. Quickly identify and generate words that begin with the same sound.
L9: Cepstral analysis
 L9: Cepstral analysis The cepstrum Homomorphic filtering The cepstrum and voicing/pitch detection Linear prediction cepstral coefficients Mel frequency cepstral coefficients This lecture is based on [Taylor,
L9: Cepstral analysis The cepstrum Homomorphic filtering The cepstrum and voicing/pitch detection Linear prediction cepstral coefficients Mel frequency cepstral coefficients This lecture is based on [Taylor,
Lecture 12: An Overview of Speech Recognition
 Lecture : An Overview of peech Recognition. Introduction We can classify speech recognition tasks and systems along a set of dimensions that produce various tradeoffs in applicability and robustness. Isolated
Lecture : An Overview of peech Recognition. Introduction We can classify speech recognition tasks and systems along a set of dimensions that produce various tradeoffs in applicability and robustness. Isolated
THE VOICE OF LOVE. Trisha Belanger, Caroline Menezes, Claire Barboa, Mofida Helo, Kimia Shirazifard
 THE VOICE OF LOVE Trisha Belanger, Caroline Menezes, Claire Barboa, Mofida Helo, Kimia Shirazifard University of Toledo, United States tbelanger@rockets.utoledo.edu, Caroline.Menezes@utoledo.edu, Claire.Barbao@rockets.utoledo.edu,
THE VOICE OF LOVE Trisha Belanger, Caroline Menezes, Claire Barboa, Mofida Helo, Kimia Shirazifard University of Toledo, United States tbelanger@rockets.utoledo.edu, Caroline.Menezes@utoledo.edu, Claire.Barbao@rockets.utoledo.edu,
. Niparko, J. K. (2006). Speech Recognition at 1-Year Follow-Up in the Childhood
. Speech Recognition at 1-Year Follow-Up in the Childhood") Psychology 230: Research Methods Lab A Katie Berg, Brandon Geary, Gina Scharenbroch, Haley Schmidt, & Elizabeth Stevens Introduction: Overview: A training program, under the lead of Professor Jeremy Loebach,
Psychology 230: Research Methods Lab A Katie Berg, Brandon Geary, Gina Scharenbroch, Haley Schmidt, & Elizabeth Stevens Introduction: Overview: A training program, under the lead of Professor Jeremy Loebach,
How Can Teachers Teach Listening?
 3 How Can Teachers Teach Listening? The research findings discussed in the previous chapter have several important implications for teachers. Although many aspects of the traditional listening classroom
3 How Can Teachers Teach Listening? The research findings discussed in the previous chapter have several important implications for teachers. Although many aspects of the traditional listening classroom
Application Note. Using PESQ to Test a VoIP Network. Prepared by: Psytechnics Limited. 23 Museum Street Ipswich, Suffolk United Kingdom IP1 1HN
 Using PESQ to Test a VoIP Network Application Note Prepared by: Psytechnics Limited 23 Museum Street Ipswich, Suffolk United Kingdom IP1 1HN t: +44 (0) 1473 261 800 f: +44 (0) 1473 261 880 e: info@psytechnics.com
Using PESQ to Test a VoIP Network Application Note Prepared by: Psytechnics Limited 23 Museum Street Ipswich, Suffolk United Kingdom IP1 1HN t: +44 (0) 1473 261 800 f: +44 (0) 1473 261 880 e: info@psytechnics.com
Quarterly Progress and Status Report. An ontogenetic study of infant speech perception
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report An ontogenetic study of infant speech perception Lacerda, F. and Aurelius, G. and Landberg,. and Roug-Hellichius, L-L. journal:
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report An ontogenetic study of infant speech perception Lacerda, F. and Aurelius, G. and Landberg,. and Roug-Hellichius, L-L. journal:
Analog Representations of Sound
 Analog Representations of Sound Magnified phonograph grooves, viewed from above: The shape of the grooves encodes the continuously varying audio signal. Analog to Digital Recording Chain ADC Microphone
Analog Representations of Sound Magnified phonograph grooves, viewed from above: The shape of the grooves encodes the continuously varying audio signal. Analog to Digital Recording Chain ADC Microphone
Bachelors of Science Program in Communication Disorders and Sciences:
 Bachelors of Science Program in Communication Disorders and Sciences: Mission: The SIUC CDS program is committed to multiple complimentary missions. We provide support for, and align with, the university,
Bachelors of Science Program in Communication Disorders and Sciences: Mission: The SIUC CDS program is committed to multiple complimentary missions. We provide support for, and align with, the university,
have more skill and perform more complex
 Speech Recognition Smartphone UI Speech Recognition Technology and Applications for Improving Terminal Functionality and Service Usability User interfaces that utilize voice input on compact devices such
Speech Recognition Smartphone UI Speech Recognition Technology and Applications for Improving Terminal Functionality and Service Usability User interfaces that utilize voice input on compact devices such
Text-To-Speech Technologies for Mobile Telephony Services
 Text-To-Speech Technologies for Mobile Telephony Services Paulseph-John Farrugia Department of Computer Science and AI, University of Malta Abstract. Text-To-Speech (TTS) systems aim to transform arbitrary
Text-To-Speech Technologies for Mobile Telephony Services Paulseph-John Farrugia Department of Computer Science and AI, University of Malta Abstract. Text-To-Speech (TTS) systems aim to transform arbitrary
PERCENTAGE ARTICULATION LOSS OF CONSONANTS IN THE ELEMENTARY SCHOOL CLASSROOMS
 The 21 st International Congress on Sound and Vibration 13-17 July, 2014, Beijing/China PERCENTAGE ARTICULATION LOSS OF CONSONANTS IN THE ELEMENTARY SCHOOL CLASSROOMS Dan Wang, Nanjie Yan and Jianxin Peng*
The 21 st International Congress on Sound and Vibration 13-17 July, 2014, Beijing/China PERCENTAGE ARTICULATION LOSS OF CONSONANTS IN THE ELEMENTARY SCHOOL CLASSROOMS Dan Wang, Nanjie Yan and Jianxin Peng*
Creating voices for the Festival speech synthesis system.
 M. Hood Supervised by A. Lobb and S. Bangay G01H0708 Creating voices for the Festival speech synthesis system. Abstract This project focuses primarily on the process of creating a voice for a concatenative
M. Hood Supervised by A. Lobb and S. Bangay G01H0708 Creating voices for the Festival speech synthesis system. Abstract This project focuses primarily on the process of creating a voice for a concatenative
An Arabic Text-To-Speech System Based on Artificial Neural Networks
 Journal of Computer Science 5 (3): 207-213, 2009 ISSN 1549-3636 2009 Science Publications An Arabic Text-To-Speech System Based on Artificial Neural Networks Ghadeer Al-Said and Moussa Abdallah Department
Journal of Computer Science 5 (3): 207-213, 2009 ISSN 1549-3636 2009 Science Publications An Arabic Text-To-Speech System Based on Artificial Neural Networks Ghadeer Al-Said and Moussa Abdallah Department
Functional Auditory Performance Indicators (FAPI)
") Functional Performance Indicators (FAPI) An Integrated Approach to Skill FAPI Overview The Functional (FAPI) assesses the functional auditory skills of children with hearing loss. It can be used by parents,
Functional Performance Indicators (FAPI) An Integrated Approach to Skill FAPI Overview The Functional (FAPI) assesses the functional auditory skills of children with hearing loss. It can be used by parents,
Acoustics for Musicians
 Unit 1: Acoustics for Musicians Unit code: QCF Level 3: Credit value: 10 Guided learning hours: 60 Aim and purpose J/600/6878 BTEC National The aim of this unit is to establish knowledge of acoustic principles
Unit 1: Acoustics for Musicians Unit code: QCF Level 3: Credit value: 10 Guided learning hours: 60 Aim and purpose J/600/6878 BTEC National The aim of this unit is to establish knowledge of acoustic principles
Formant Bandwidth and Resilience of Speech to Noise
 Formant Bandwidth and Resilience of Speech to Noise Master Thesis Leny Vinceslas August 5, 211 Internship for the ATIAM Master s degree ENS - Laboratoire Psychologie de la Perception - Hearing Group Supervised
Formant Bandwidth and Resilience of Speech to Noise Master Thesis Leny Vinceslas August 5, 211 Internship for the ATIAM Master s degree ENS - Laboratoire Psychologie de la Perception - Hearing Group Supervised
Regionalized Text-to-Speech Systems: Persona Design and Application Scenarios
 Regionalized Text-to-Speech Systems: Persona Design and Application Scenarios Michael Pucher, Gudrun Schuchmann, and Peter Fröhlich ftw., Telecommunications Research Center, Donau-City-Strasse 1, 1220
Regionalized Text-to-Speech Systems: Persona Design and Application Scenarios Michael Pucher, Gudrun Schuchmann, and Peter Fröhlich ftw., Telecommunications Research Center, Donau-City-Strasse 1, 1220
Intonation difficulties in non-native languages.
 Intonation difficulties in non-native languages. Irma Rusadze Akaki Tsereteli State University, Assistant Professor, Kutaisi, Georgia Sopio Kipiani Akaki Tsereteli State University, Assistant Professor,
Intonation difficulties in non-native languages. Irma Rusadze Akaki Tsereteli State University, Assistant Professor, Kutaisi, Georgia Sopio Kipiani Akaki Tsereteli State University, Assistant Professor,
Robust Methods for Automatic Transcription and Alignment of Speech Signals
 Robust Methods for Automatic Transcription and Alignment of Speech Signals Leif Grönqvist (lgr@msi.vxu.se) Course in Speech Recognition January 2. 2004 Contents Contents 1 1 Introduction 2 2 Background
Robust Methods for Automatic Transcription and Alignment of Speech Signals Leif Grönqvist (lgr@msi.vxu.se) Course in Speech Recognition January 2. 2004 Contents Contents 1 1 Introduction 2 2 Background
SPEAKER IDENTIFICATION FROM YOUTUBE OBTAINED DATA
 SPEAKER IDENTIFICATION FROM YOUTUBE OBTAINED DATA Nitesh Kumar Chaudhary 1 and Shraddha Srivastav 2 1 Department of Electronics & Communication Engineering, LNMIIT, Jaipur, India 2 Bharti School Of Telecommunication,
SPEAKER IDENTIFICATION FROM YOUTUBE OBTAINED DATA Nitesh Kumar Chaudhary 1 and Shraddha Srivastav 2 1 Department of Electronics & Communication Engineering, LNMIIT, Jaipur, India 2 Bharti School Of Telecommunication,
The effect of mismatched recording conditions on human and automatic speaker recognition in forensic applications
 Forensic Science International 146S (2004) S95 S99 www.elsevier.com/locate/forsciint The effect of mismatched recording conditions on human and automatic speaker recognition in forensic applications A.
Forensic Science International 146S (2004) S95 S99 www.elsevier.com/locate/forsciint The effect of mismatched recording conditions on human and automatic speaker recognition in forensic applications A.
Lecture 1-10: Spectrograms
 Lecture 1-10: Spectrograms Overview 1. Spectra of dynamic signals: like many real world signals, speech changes in quality with time. But so far the only spectral analysis we have performed has assumed
Lecture 1-10: Spectrograms Overview 1. Spectra of dynamic signals: like many real world signals, speech changes in quality with time. But so far the only spectral analysis we have performed has assumed
MICHIGAN TEST FOR TEACHER CERTIFICATION (MTTC) TEST OBJECTIVES FIELD 062: HEARING IMPAIRED
 TEST OBJECTIVES FIELD 062: HEARING IMPAIRED") MICHIGAN TEST FOR TEACHER CERTIFICATION (MTTC) TEST OBJECTIVES Subarea Human Development and Students with Special Educational Needs Hearing Impairments Assessment Program Development and Intervention
MICHIGAN TEST FOR TEACHER CERTIFICATION (MTTC) TEST OBJECTIVES Subarea Human Development and Students with Special Educational Needs Hearing Impairments Assessment Program Development and Intervention
Carla Simões, t-carlas@microsoft.com. Speech Analysis and Transcription Software
 Carla Simões, t-carlas@microsoft.com Speech Analysis and Transcription Software 1 Overview Methods for Speech Acoustic Analysis Why Speech Acoustic Analysis? Annotation Segmentation Alignment Speech Analysis
Carla Simões, t-carlas@microsoft.com Speech Analysis and Transcription Software 1 Overview Methods for Speech Acoustic Analysis Why Speech Acoustic Analysis? Annotation Segmentation Alignment Speech Analysis
The Pronunciation of the Aspirated Consonants P, T, and K in English by Native Speakers of Spanish and French
 144 The Pronunciation of the Aspirated Consonants P, T, and K in English by Native Speakers of Spanish and French Philip Suarez Florida International University, USA Abstract: This study examines whether
144 The Pronunciation of the Aspirated Consonants P, T, and K in English by Native Speakers of Spanish and French Philip Suarez Florida International University, USA Abstract: This study examines whether
62 Hearing Impaired MI-SG-FLD062-02
 62 Hearing Impaired MI-SG-FLD062-02 TABLE OF CONTENTS PART 1: General Information About the MTTC Program and Test Preparation OVERVIEW OF THE TESTING PROGRAM... 1-1 Contact Information Test Development
62 Hearing Impaired MI-SG-FLD062-02 TABLE OF CONTENTS PART 1: General Information About the MTTC Program and Test Preparation OVERVIEW OF THE TESTING PROGRAM... 1-1 Contact Information Test Development
This document is downloaded from DR-NTU, Nanyang Technological University Library, Singapore.
 This document is downloaded from DR-NTU, Nanyang Technological University Library, Singapore. Title Transcription of polyphonic signals using fast filter bank( Accepted version ) Author(s) Foo, Say Wei;
This document is downloaded from DR-NTU, Nanyang Technological University Library, Singapore. Title Transcription of polyphonic signals using fast filter bank( Accepted version ) Author(s) Foo, Say Wei;
CHARTES D'ANGLAIS SOMMAIRE. CHARTE NIVEAU A1 Pages 2-4. CHARTE NIVEAU A2 Pages 5-7. CHARTE NIVEAU B1 Pages 8-10. CHARTE NIVEAU B2 Pages 11-14
 CHARTES D'ANGLAIS SOMMAIRE CHARTE NIVEAU A1 Pages 2-4 CHARTE NIVEAU A2 Pages 5-7 CHARTE NIVEAU B1 Pages 8-10 CHARTE NIVEAU B2 Pages 11-14 CHARTE NIVEAU C1 Pages 15-17 MAJ, le 11 juin 2014 A1 Skills-based
CHARTES D'ANGLAIS SOMMAIRE CHARTE NIVEAU A1 Pages 2-4 CHARTE NIVEAU A2 Pages 5-7 CHARTE NIVEAU B1 Pages 8-10 CHARTE NIVEAU B2 Pages 11-14 CHARTE NIVEAU C1 Pages 15-17 MAJ, le 11 juin 2014 A1 Skills-based
Thirukkural - A Text-to-Speech Synthesis System
 Thirukkural - A Text-to-Speech Synthesis System G. L. Jayavardhana Rama, A. G. Ramakrishnan, M Vijay Venkatesh, R. Murali Shankar Department of Electrical Engg, Indian Institute of Science, Bangalore 560012,
Thirukkural - A Text-to-Speech Synthesis System G. L. Jayavardhana Rama, A. G. Ramakrishnan, M Vijay Venkatesh, R. Murali Shankar Department of Electrical Engg, Indian Institute of Science, Bangalore 560012,
Audio Engineering Society. Convention Paper. Presented at the 129th Convention 2010 November 4 7 San Francisco, CA, USA
 Audio Engineering Society Convention Paper Presented at the 129th Convention 2010 November 4 7 San Francisco, CA, USA The papers at this Convention have been selected on the basis of a submitted abstract
Audio Engineering Society Convention Paper Presented at the 129th Convention 2010 November 4 7 San Francisco, CA, USA The papers at this Convention have been selected on the basis of a submitted abstract
The Minor Third Communicates Sadness in Speech, Mirroring Its Use in Music
 Emotion 2010 American Psychological Association 2010, Vol. 10, No. 3, 335 348 1528-3542/10/$12.00 DOI: 10.1037/a0017928 The Minor Third Communicates Sadness in Speech, Mirroring Its Use in Music Meagan
Emotion 2010 American Psychological Association 2010, Vol. 10, No. 3, 335 348 1528-3542/10/$12.00 DOI: 10.1037/a0017928 The Minor Third Communicates Sadness in Speech, Mirroring Its Use in Music Meagan
Computer Networks and Internets, 5e Chapter 6 Information Sources and Signals. Introduction
 Computer Networks and Internets, 5e Chapter 6 Information Sources and Signals Modified from the lecture slides of Lami Kaya (LKaya@ieee.org) for use CECS 474, Fall 2008. 2009 Pearson Education Inc., Upper
Computer Networks and Internets, 5e Chapter 6 Information Sources and Signals Modified from the lecture slides of Lami Kaya (LKaya@ieee.org) for use CECS 474, Fall 2008. 2009 Pearson Education Inc., Upper
Active Monitoring of Voice over IP Services with Malden
 Active Monitoring of Voice over IP Services with Malden Introduction Active Monitoring describes the process of evaluating telecommunications system performance with intrusive tests. It differs from passive
Active Monitoring of Voice over IP Services with Malden Introduction Active Monitoring describes the process of evaluating telecommunications system performance with intrusive tests. It differs from passive
A Comparison of Speech Coding Algorithms ADPCM vs CELP. Shannon Wichman
 A Comparison of Speech Coding Algorithms ADPCM vs CELP Shannon Wichman Department of Electrical Engineering The University of Texas at Dallas Fall 1999 December 8, 1999 1 Abstract Factors serving as constraints
A Comparison of Speech Coding Algorithms ADPCM vs CELP Shannon Wichman Department of Electrical Engineering The University of Texas at Dallas Fall 1999 December 8, 1999 1 Abstract Factors serving as constraints
Grade 1 LA. 1. 1. 1. 1. Subject Grade Strand Standard Benchmark. Florida K-12 Reading and Language Arts Standards 27
 Grade 1 LA. 1. 1. 1. 1 Subject Grade Strand Standard Benchmark Florida K-12 Reading and Language Arts Standards 27 Grade 1: Reading Process Concepts of Print Standard: The student demonstrates knowledge
Grade 1 LA. 1. 1. 1. 1 Subject Grade Strand Standard Benchmark Florida K-12 Reading and Language Arts Standards 27 Grade 1: Reading Process Concepts of Print Standard: The student demonstrates knowledge
Prelinguistic vocal behaviors. Stage 1 (birth-1 month) Stage 2 (2-3 months) Stage 4 (7-9 months) Stage 3 (4-6 months)
 Stage 2 (2-3 months) Stage 4 (7-9 months) Stage 3 (4-6 months)") 3 stages of phonological development 1. Prelinguistic vocal behaviors 2. Phonology of the first 50 words 3. Emergence of rules Prelinguistic vocal behaviors Reflexive/vegetative sounds (birth-1 month)
3 stages of phonological development 1. Prelinguistic vocal behaviors 2. Phonology of the first 50 words 3. Emergence of rules Prelinguistic vocal behaviors Reflexive/vegetative sounds (birth-1 month)
Formant frequencies of British English vowels produced by native speakers of Farsi
 Formant frequencies of British English vowels produced by native speakers of Farsi Gordon HUNTER, Hanna Kebede To cite this version: Gordon HUNTER, Hanna Kebede. Formant frequencies of British English
Formant frequencies of British English vowels produced by native speakers of Farsi Gordon HUNTER, Hanna Kebede To cite this version: Gordon HUNTER, Hanna Kebede. Formant frequencies of British English
BLIND SOURCE SEPARATION OF SPEECH AND BACKGROUND MUSIC FOR IMPROVED SPEECH RECOGNITION
 BLIND SOURCE SEPARATION OF SPEECH AND BACKGROUND MUSIC FOR IMPROVED SPEECH RECOGNITION P. Vanroose Katholieke Universiteit Leuven, div. ESAT/PSI Kasteelpark Arenberg 10, B 3001 Heverlee, Belgium Peter.Vanroose@esat.kuleuven.ac.be
BLIND SOURCE SEPARATION OF SPEECH AND BACKGROUND MUSIC FOR IMPROVED SPEECH RECOGNITION P. Vanroose Katholieke Universiteit Leuven, div. ESAT/PSI Kasteelpark Arenberg 10, B 3001 Heverlee, Belgium Peter.Vanroose@esat.kuleuven.ac.be
Implementing an In-Service, Non- Intrusive Measurement Device in Telecommunication Networks Using the TMS320C31
 Disclaimer: This document was part of the First European DSP Education and Research Conference. It may have been written by someone whose native language is not English. TI assumes no liability for the
Disclaimer: This document was part of the First European DSP Education and Research Conference. It may have been written by someone whose native language is not English. TI assumes no liability for the
INCREASE YOUR PRODUCTIVITY WITH CELF 4 SOFTWARE! SAMPLE REPORTS. To order, call 1-800-211-8378, or visit our Web site at www.pearsonassess.
 INCREASE YOUR PRODUCTIVITY WITH CELF 4 SOFTWARE! Report Assistant SAMPLE REPORTS To order, call 1-800-211-8378, or visit our Web site at www.pearsonassess.com In Canada, call 1-800-387-7278 In United Kingdom,
INCREASE YOUR PRODUCTIVITY WITH CELF 4 SOFTWARE! Report Assistant SAMPLE REPORTS To order, call 1-800-211-8378, or visit our Web site at www.pearsonassess.com In Canada, call 1-800-387-7278 In United Kingdom,
Music technology. Draft GCE A level and AS subject content
 Music technology Draft GCE A level and AS subject content July 2015 Contents The content for music technology AS and A level 3 Introduction 3 Aims and objectives 3 Subject content 4 Recording and production
Music technology Draft GCE A level and AS subject content July 2015 Contents The content for music technology AS and A level 3 Introduction 3 Aims and objectives 3 Subject content 4 Recording and production
Develop Software that Speaks and Listens
 Develop Software that Speaks and Listens Copyright 2011 Chant Inc. All rights reserved. Chant, SpeechKit, Getting the World Talking with Technology, talking man, and headset are trademarks or registered
Develop Software that Speaks and Listens Copyright 2011 Chant Inc. All rights reserved. Chant, SpeechKit, Getting the World Talking with Technology, talking man, and headset are trademarks or registered
Convention Paper Presented at the 118th Convention 2005 May 28 31 Barcelona, Spain
 Audio Engineering Society Convention Paper Presented at the 118th Convention 25 May 28 31 Barcelona, Spain 6431 This convention paper has been reproduced from the author s advance manuscript, without editing,
Audio Engineering Society Convention Paper Presented at the 118th Convention 25 May 28 31 Barcelona, Spain 6431 This convention paper has been reproduced from the author s advance manuscript, without editing,
Acoustic design according to room shape
 Acoustic design according to room shape The shape of the room defines the movement of the sound waves within the room. Placement of acoustic materials should be determined by the way the sound moves in
Acoustic design according to room shape The shape of the room defines the movement of the sound waves within the room. Placement of acoustic materials should be determined by the way the sound moves in
Common European Framework of Reference for Languages: learning, teaching, assessment. Table 1. Common Reference Levels: global scale
 Common European Framework of Reference for Languages: learning, teaching, assessment Table 1. Common Reference Levels: global scale C2 Can understand with ease virtually everything heard or read. Can summarise
Common European Framework of Reference for Languages: learning, teaching, assessment Table 1. Common Reference Levels: global scale C2 Can understand with ease virtually everything heard or read. Can summarise
Phonemic Awareness. Section III
 Section III Phonemic Awareness Rationale Without knowledge of the separate sounds that make up words, it is difficult for children to hear separate sounds, recognize the sound s position in a word, and
Section III Phonemic Awareness Rationale Without knowledge of the separate sounds that make up words, it is difficult for children to hear separate sounds, recognize the sound s position in a word, and
Voice Communication Package v7.0 of front-end voice processing software technologies General description and technical specification
 Voice Communication Package v7.0 of front-end voice processing software technologies General description and technical specification (Revision 1.0, May 2012) General VCP information Voice Communication
Voice Communication Package v7.0 of front-end voice processing software technologies General description and technical specification (Revision 1.0, May 2012) General VCP information Voice Communication
What is the Sapir-Whorf hypothesis?
 What is the Sapir-Whorf hypothesis? Paul Kay & Willett Kempton (1984) Based on a powerpoint presentation by NT Rusiyanadi Outline Introduction Sapir-Whorf hypothesis Study done by Kay & Kempton Conclusions
What is the Sapir-Whorf hypothesis? Paul Kay & Willett Kempton (1984) Based on a powerpoint presentation by NT Rusiyanadi Outline Introduction Sapir-Whorf hypothesis Study done by Kay & Kempton Conclusions
What makes a language attractive its sound, national identity or familiarity?
 LÍNGUA INGLESA What makes a language attractive its sound, national identity or familiarity? The allure of a language may have more to do with perceptions of that country's status and social values than
LÍNGUA INGLESA What makes a language attractive its sound, national identity or familiarity? The allure of a language may have more to do with perceptions of that country's status and social values than
Open-Source, Cross-Platform Java Tools Working Together on a Dialogue System
 Open-Source, Cross-Platform Java Tools Working Together on a Dialogue System Oana NICOLAE Faculty of Mathematics and Computer Science, Department of Computer Science, University of Craiova, Romania oananicolae1981@yahoo.com
Open-Source, Cross-Platform Java Tools Working Together on a Dialogue System Oana NICOLAE Faculty of Mathematics and Computer Science, Department of Computer Science, University of Craiova, Romania oananicolae1981@yahoo.com
Reading Competencies
 Reading Competencies The Third Grade Reading Guarantee legislation within Senate Bill 21 requires reading competencies to be adopted by the State Board no later than January 31, 2014. Reading competencies
Reading Competencies The Third Grade Reading Guarantee legislation within Senate Bill 21 requires reading competencies to be adopted by the State Board no later than January 31, 2014. Reading competencies
The Lexicon. The Lexicon. The Lexicon. The Significance of the Lexicon. Australian? The Significance of the Lexicon 澳 大 利 亚 奥 地 利
 The significance of the lexicon Lexical knowledge Lexical skills 2 The significance of the lexicon Lexical knowledge The Significance of the Lexicon Lexical errors lead to misunderstanding. There s that
The significance of the lexicon Lexical knowledge Lexical skills 2 The significance of the lexicon Lexical knowledge The Significance of the Lexicon Lexical errors lead to misunderstanding. There s that
Acoustics for the Speech and Hearing Sciences SPH 267 Fall 2003
 Acoustics for the Speech and Hearing Sciences SPH 267 Fall 2003 Title of Course: Acoustics for the Speech and Hearing Sciences Room & Time: 205 SPH, MWF 11:00 11:50 Instructor: Brad Story, Ph.D. Office
Acoustics for the Speech and Hearing Sciences SPH 267 Fall 2003 Title of Course: Acoustics for the Speech and Hearing Sciences Room & Time: 205 SPH, MWF 11:00 11:50 Instructor: Brad Story, Ph.D. Office
Chinese Proficiency Test (HSK)
") Chinese Proficiency Test (HSK) The new HSK test was launched by Hanban in an effort to better serve Chinese language learners. The test is the result of coordinated efforts by experts from different disciplines
Chinese Proficiency Test (HSK) The new HSK test was launched by Hanban in an effort to better serve Chinese language learners. The test is the result of coordinated efforts by experts from different disciplines
Curriculum Vitae. Alison M. Trude December 2014. Website: https://sites.google.com/site/alisontrude/ Department of Psychology, University of Chicago
 Curriculum Vitae Alison M. Trude December 2014 Dept. of Psychology University of Chicago 5848 S. University Ave. Chicago, IL 60637 Email: trude@uchicago.edu Website: https://sites.google.com/site/alisontrude/
Curriculum Vitae Alison M. Trude December 2014 Dept. of Psychology University of Chicago 5848 S. University Ave. Chicago, IL 60637 Email: trude@uchicago.edu Website: https://sites.google.com/site/alisontrude/
HEARING. With Your Brain
 HEARING With Your Brain Better Hearing with Both Ears Experience A NEW FREEDOM Your brain is responsible for processing everything you hear and needs accurate sound information from both ears. When you
HEARING With Your Brain Better Hearing with Both Ears Experience A NEW FREEDOM Your brain is responsible for processing everything you hear and needs accurate sound information from both ears. When you
Speech Analytics. Whitepaper
 Speech Analytics Whitepaper This document is property of ASC telecom AG. All rights reserved. Distribution or copying of this document is forbidden without permission of ASC. 1 Introduction Hearing the
Speech Analytics Whitepaper This document is property of ASC telecom AG. All rights reserved. Distribution or copying of this document is forbidden without permission of ASC. 1 Introduction Hearing the
Timing Errors and Jitter
 Timing Errors and Jitter Background Mike Story In a sampled (digital) system, samples have to be accurate in level and time. The digital system uses the two bits of information the signal was this big
Timing Errors and Jitter Background Mike Story In a sampled (digital) system, samples have to be accurate in level and time. The digital system uses the two bits of information the signal was this big
How Children Acquire Language: A New Answer by Dr. Laura Ann Petitto
 How Children Acquire Language: A New Answer by Dr. Laura Ann Petitto How do babies acquire language? What do babies know when they start to speak? Prevailing views about the biological foundations of language
How Children Acquire Language: A New Answer by Dr. Laura Ann Petitto How do babies acquire language? What do babies know when they start to speak? Prevailing views about the biological foundations of language
Prosodic Characteristics of Emotional Speech: Measurements of Fundamental Frequency Movements
 Prosodic Characteristics of Emotional Speech: Measurements of Fundamental Frequency Movements Authors: A. Paeschke, W. F. Sendlmeier Technical University Berlin, Germany ABSTRACT Recent data on prosodic
Prosodic Characteristics of Emotional Speech: Measurements of Fundamental Frequency Movements Authors: A. Paeschke, W. F. Sendlmeier Technical University Berlin, Germany ABSTRACT Recent data on prosodic
ETS Automated Scoring and NLP Technologies
 ETS Automated Scoring and NLP Technologies Using natural language processing (NLP) and psychometric methods to develop innovative scoring technologies The growth of the use of constructed-response tasks
ETS Automated Scoring and NLP Technologies Using natural language processing (NLP) and psychometric methods to develop innovative scoring technologies The growth of the use of constructed-response tasks
Establishing the Uniqueness of the Human Voice for Security Applications
 Proceedings of Student/Faculty Research Day, CSIS, Pace University, May 7th, 2004 Establishing the Uniqueness of the Human Voice for Security Applications Naresh P. Trilok, Sung-Hyuk Cha, and Charles C.
Proceedings of Student/Faculty Research Day, CSIS, Pace University, May 7th, 2004 Establishing the Uniqueness of the Human Voice for Security Applications Naresh P. Trilok, Sung-Hyuk Cha, and Charles C.
Unit 2 Title: Word Work Grade Level: 1 st Grade Timeframe: 6 Weeks
 Unit 2 Title: Grade Level: 1 st Grade Timeframe: 6 Weeks Unit Overview: This unit of word work will focus on the student s ability to identify and pronounce the initial, medial vowel, and final sounds.
Unit 2 Title: Grade Level: 1 st Grade Timeframe: 6 Weeks Unit Overview: This unit of word work will focus on the student s ability to identify and pronounce the initial, medial vowel, and final sounds.
Speech Production 2. Paper 9: Foundations of Speech Communication Lent Term: Week 4. Katharine Barden
 Speech Production 2 Paper 9: Foundations of Speech Communication Lent Term: Week 4 Katharine Barden Today s lecture Prosodic-segmental interdependencies Models of speech production Articulatory phonology
Speech Production 2 Paper 9: Foundations of Speech Communication Lent Term: Week 4 Katharine Barden Today s lecture Prosodic-segmental interdependencies Models of speech production Articulatory phonology
There are many reasons why reading can be hard. This handout describes
 Understand the problems a child may be having with reading, and target what you can do to help! Look inside for practical, research-based information for parents and teachers about: Phonological and Phonemic
Understand the problems a child may be having with reading, and target what you can do to help! Look inside for practical, research-based information for parents and teachers about: Phonological and Phonemic
The 3 Best Individual Strength Patterns. Thomas Yeomans
 The 3 Best Individual Strength Patterns. Thomas Yeomans Hi. I am the creator of the Forex trading tool often called the Currency Strength Meter. Nowadays it is a chart. It all began eight years ago and
The 3 Best Individual Strength Patterns. Thomas Yeomans Hi. I am the creator of the Forex trading tool often called the Currency Strength Meter. Nowadays it is a chart. It all began eight years ago and
The Effects of Speaking Rate on Mandarin Tones. C2008 Yun H. Stockton
 The Effects of Speaking Rate on Mandarin Tones BY C2008 Yun H. Stockton Submitted to the graduate degree program in Linguistics and the Graduate Faculty of the University of Kansas in partial fulfillment
The Effects of Speaking Rate on Mandarin Tones BY C2008 Yun H. Stockton Submitted to the graduate degree program in Linguistics and the Graduate Faculty of the University of Kansas in partial fulfillment

Rotating Machinery Diagnostics & Instrumentation Solutions for Maintenance That Matters www.mbesi.com
 13 Aberdeen Way Elgin, SC 29045 Cell (803) 427-0791 VFD Fundamentals & Troubleshooting 19-Feb-2010 By: Timothy S. Irwin, P.E. Sr. Engineer tsi@mbesi.com Rotating Machinery Diagnostics & Instrumentation
13 Aberdeen Way Elgin, SC 29045 Cell (803) 427-0791 VFD Fundamentals & Troubleshooting 19-Feb-2010 By: Timothy S. Irwin, P.E. Sr. Engineer tsi@mbesi.com Rotating Machinery Diagnostics & Instrumentation
Oral language is the foundation on which reading and writing are
 If children come to school with welld eveloped oral language, it must be expanded. If children come to school with underdeve l o p e d oral language, it must be developed. Foundations for Learning to Read
If children come to school with welld eveloped oral language, it must be expanded. If children come to school with underdeve l o p e d oral language, it must be developed. Foundations for Learning to Read
Pronunciation in English
 The Electronic Journal for English as a Second Language Pronunciation in English March 2013 Volume 16, Number 4 Title Level Publisher Type of product Minimum Hardware Requirements Software Requirements
The Electronic Journal for English as a Second Language Pronunciation in English March 2013 Volume 16, Number 4 Title Level Publisher Type of product Minimum Hardware Requirements Software Requirements
Automatic Speech Recognition and Hybrid Machine Translation for High-Quality Closed-Captioning and Subtitling for Video Broadcast
 Automatic Speech Recognition and Hybrid Machine Translation for High-Quality Closed-Captioning and Subtitling for Video Broadcast Hassan Sawaf Science Applications International Corporation (SAIC) 7990
Automatic Speech Recognition and Hybrid Machine Translation for High-Quality Closed-Captioning and Subtitling for Video Broadcast Hassan Sawaf Science Applications International Corporation (SAIC) 7990
Artificial Neural Network for Speech Recognition
 Artificial Neural Network for Speech Recognition Austin Marshall March 3, 2005 2nd Annual Student Research Showcase Overview Presenting an Artificial Neural Network to recognize and classify speech Spoken
Artificial Neural Network for Speech Recognition Austin Marshall March 3, 2005 2nd Annual Student Research Showcase Overview Presenting an Artificial Neural Network to recognize and classify speech Spoken
Areas of Processing Deficit and Their Link to Areas of Academic Achievement
 Areas of Processing Deficit and Their Link to Areas of Academic Achievement Phonological Processing Model Wagner, R.K., Torgesen, J.K., & Rashotte, C.A. (1999). Comprehensive Test of Phonological Processing.
Areas of Processing Deficit and Their Link to Areas of Academic Achievement Phonological Processing Model Wagner, R.K., Torgesen, J.K., & Rashotte, C.A. (1999). Comprehensive Test of Phonological Processing.
Analog-to-Digital Voice Encoding
 Analog-to-Digital Voice Encoding Basic Voice Encoding: Converting Analog to Digital This topic describes the process of converting analog signals to digital signals. Digitizing Analog Signals 1. Sample
Analog-to-Digital Voice Encoding Basic Voice Encoding: Converting Analog to Digital This topic describes the process of converting analog signals to digital signals. Digitizing Analog Signals 1. Sample
Introduction to Digital Audio
 Introduction to Digital Audio Before the development of high-speed, low-cost digital computers and analog-to-digital conversion circuits, all recording and manipulation of sound was done using analog techniques.
Introduction to Digital Audio Before the development of high-speed, low-cost digital computers and analog-to-digital conversion circuits, all recording and manipulation of sound was done using analog techniques.
A Computer Program for Pronunciation Training and Assessment in Japanese Language Classrooms Experimental Use of Pronunciation Check
 A Computer Program for Pronunciation Training and Assessment in Japanese Language Classrooms Experimental Use of Pronunciation Check 5 CHIHARU TSURUTANI, Griffith University, Australia 10 E-learning is
A Computer Program for Pronunciation Training and Assessment in Japanese Language Classrooms Experimental Use of Pronunciation Check 5 CHIHARU TSURUTANI, Griffith University, Australia 10 E-learning is
CBS RECORDS PROFESSIONAL SERIES CBS RECORDS CD-1 STANDARD TEST DISC
 CBS RECORDS PROFESSIONAL SERIES CBS RECORDS CD-1 STANDARD TEST DISC 1. INTRODUCTION The CBS Records CD-1 Test Disc is a highly accurate signal source specifically designed for those interested in making
CBS RECORDS PROFESSIONAL SERIES CBS RECORDS CD-1 STANDARD TEST DISC 1. INTRODUCTION The CBS Records CD-1 Test Disc is a highly accurate signal source specifically designed for those interested in making
Teaching and Learning Mandarin Tones. 19 th May 2012 Rob Neal
 Teaching and Learning Mandarin Tones 19 th May 2012 Rob Neal Aims of the presentation Reflect on why tones are so challenging for Anglophone learners Review several empirical studies which have examined
Teaching and Learning Mandarin Tones 19 th May 2012 Rob Neal Aims of the presentation Reflect on why tones are so challenging for Anglophone learners Review several empirical studies which have examined
Objective Intelligibility Assessment of Text-to-Speech Systems Through Utterance Verification
 Objective Intelligibility Assessment of Text-to-Speech Systems Through Utterance Verification Raphael Ullmann 1,2, Ramya Rasipuram 1, Mathew Magimai.-Doss 1, and Hervé Bourlard 1,2 1 Idiap Research Institute,
Objective Intelligibility Assessment of Text-to-Speech Systems Through Utterance Verification Raphael Ullmann 1,2, Ramya Rasipuram 1, Mathew Magimai.-Doss 1, and Hervé Bourlard 1,2 1 Idiap Research Institute,
Chinese Tests Chinese Proficiency Test (HSK)
") Chinese Tests To help evaluate the Chinese levels of non-native Chinese speakers across the world, Hanban has developed three exams, HSK (Hanyu Shuiping Kaoshi), YCT (youth learner test) and BCT (business
Chinese Tests To help evaluate the Chinese levels of non-native Chinese speakers across the world, Hanban has developed three exams, HSK (Hanyu Shuiping Kaoshi), YCT (youth learner test) and BCT (business
Programme 6: International Business Economics (IBE) 2nd year
 2nd year") Programme 6: International Business Economics (IBE) 2nd year Maximum number of students: 10 English: equivalent to IELTS 6.0 the student s major should be business related The student should have successfully
Programme 6: International Business Economics (IBE) 2nd year Maximum number of students: 10 English: equivalent to IELTS 6.0 the student s major should be business related The student should have successfully
Speech Recognition on Cell Broadband Engine UCRL-PRES-223890
 Speech Recognition on Cell Broadband Engine UCRL-PRES-223890 Yang Liu, Holger Jones, John Johnson, Sheila Vaidya (Lawrence Livermore National Laboratory) Michael Perrone, Borivoj Tydlitat, Ashwini Nanda
Speech Recognition on Cell Broadband Engine UCRL-PRES-223890 Yang Liu, Holger Jones, John Johnson, Sheila Vaidya (Lawrence Livermore National Laboratory) Michael Perrone, Borivoj Tydlitat, Ashwini Nanda
Application Note. Introduction to. Page 1 / 10
 Application Note Introduction to RAPID-TEST Page 1 / 10 ABSTRACT With the RAPID-TEST instruments, NTI offers a series of powerful multitone analyzers for an extremely fast, yet precise audio performance
Application Note Introduction to RAPID-TEST Page 1 / 10 ABSTRACT With the RAPID-TEST instruments, NTI offers a series of powerful multitone analyzers for an extremely fast, yet precise audio performance
ELPS TELPAS. Proficiency Level Descriptors
 ELPS TELPAS Proficiency Level Descriptors Permission to copy the ELPS TELPAS Proficiency Level Descriptors is hereby extended to Texas school officials and their agents for their exclusive use in determining
ELPS TELPAS Proficiency Level Descriptors Permission to copy the ELPS TELPAS Proficiency Level Descriptors is hereby extended to Texas school officials and their agents for their exclusive use in determining
The Transmission Model of Communication
 The Transmission Model of Communication In a theoretical way it may help to use the model of communication developed by Shannon and Weaver (1949). To have a closer look on our infographics using a transmissive
The Transmission Model of Communication In a theoretical way it may help to use the model of communication developed by Shannon and Weaver (1949). To have a closer look on our infographics using a transmissive
Membering T M : A Conference Call Service with Speaker-Independent Name Dialing on AIN
 PAGE 30 Membering T M : A Conference Call Service with Speaker-Independent Name Dialing on AIN Sung-Joon Park, Kyung-Ae Jang, Jae-In Kim, Myoung-Wan Koo, Chu-Shik Jhon Service Development Laboratory, KT,
PAGE 30 Membering T M : A Conference Call Service with Speaker-Independent Name Dialing on AIN Sung-Joon Park, Kyung-Ae Jang, Jae-In Kim, Myoung-Wan Koo, Chu-Shik Jhon Service Development Laboratory, KT,
Spot me if you can: Uncovering spoken phrases in encrypted VoIP conversations
 Spot me if you can: Uncovering spoken phrases in encrypted VoIP conversations C. Wright, L. Ballard, S. Coull, F. Monrose, G. Masson Talk held by Goran Doychev Selected Topics in Information Security and
Spot me if you can: Uncovering spoken phrases in encrypted VoIP conversations C. Wright, L. Ballard, S. Coull, F. Monrose, G. Masson Talk held by Goran Doychev Selected Topics in Information Security and
PCM Encoding and Decoding:
 PCM Encoding and Decoding: Aim: Introduction to PCM encoding and decoding. Introduction: PCM Encoding: The input to the PCM ENCODER module is an analog message. This must be constrained to a defined bandwidth
PCM Encoding and Decoding: Aim: Introduction to PCM encoding and decoding. Introduction: PCM Encoding: The input to the PCM ENCODER module is an analog message. This must be constrained to a defined bandwidth
Effects of hearing words, imaging hearing words, and reading on auditory implicit and explicit memory tests
 Memory & Cognition 2000, 28 (8), 1406-1418 Effects of hearing words, imaging hearing words, and reading on auditory implicit and explicit memory tests MAURA PILOTTI, DAVID A. GALLO, and HENRY L. ROEDIGER
Memory & Cognition 2000, 28 (8), 1406-1418 Effects of hearing words, imaging hearing words, and reading on auditory implicit and explicit memory tests MAURA PILOTTI, DAVID A. GALLO, and HENRY L. ROEDIGER